
Abstract
Dynamic scheduling is one of the most important key technologies in production and flexible job shop is widespread. Therefore, this paper considers a dynamic flexible job shop scheduling problem considering setup time and random job arrival. To solve this problem, a dynamic scheduling framework based on the improved gene expression programming algorithm is proposed to construct scheduling rules. In this framework, the variable neighborhood search using four efficient neighborhood structures is combined with gene expression programming algorithm. And, an adaptive method adjusting recombination rate and transposition rate in the evolutionary progress is proposed. The test results on 24 groups of instances with different scales show that the improved gene expression programming performs better than the standard gene expression programming, genetic programming, and scheduling rules.
Keywords
Introduction
Production manufacturing process is vital to a manufacturing company’s survival and growth, where scheduling plays a key role in determining the overall efficiency and productivity. Scheduling has attracted lots of research attention, but much of traditional research focused on static scheduling, where system state is known in advance and not subject to change throughout the scheduling process. However, actual production environment often encounters dynamic and unexpected events. For example, new jobs may arrive randomly, job processing times may vary, and machines may break down during the production process. All these dynamic events negatively affect the manufacturing process, often rendering the static scheduling solution infeasible and thus resulting in reduced production efficiency and sapped revenue. Therefore, it is more realistic to consider dynamic events in the scheduling, and dynamic flexible job shop scheduling problem (DFJSP) emerges as a promising problem, which has received increasing research attention in the past years.1,2
Since the work of Jackson 3 that introduced the dynamic scheduling problem in the 1950s for the first time, the dynamic scheduling problem has gained enormous popularity in the scheduling research community, and fruitful results have been reported in the literature, which can be classified into three main categories, namely, rescheduling,4–10 robust scheduling,11–14 and online scheduling.15–18
Rescheduling is also known as pre-reaction scheduling, which implies to schedule again when new events occur. It consists of two stages, the first stage, the pre-scheduling stage, aims to generate a scheduling plan to be followed by actual production; and the second stage, also named as the rescheduling stage, adjusts some or all the original scheduling plans to accommodate the dynamic events happening at a certain moment during production. Usually, some algorithms are used for rescheduling and need some computation time. The rescheduling methods maybe not suitable for some real-time scheduling problems.
Robust scheduling takes into account the system robustness during the scheduling process, strives to anticipate possible future events based on the current manufacturing condition, and generates a pre-schedule that encompasses various dynamic events, which is to ensure that the performance of the scheduling system will not deteriorate when dynamic events occur. However, since the dynamic events will happen uncertainly, the robust scheduling may make the scheduling plan less effective if the dynamic events do not happen.
Online scheduling is also known as real-time scheduling, fully reactive scheduling, and so on. Unlike the above-mentioned two scheduling types, it is a real-time scheduling strategy that does not generate a schedule in advance and is usually used after dynamic events occur, where a certain strategy is used to make a decision for scheduling. In an environment where dynamic events occur frequently, online scheduling can improve system stability and is therefore widely used in actual production.
Aside from limited research on multi-agent technology, 14 online scheduling research mainly focuses on designing scheduling rules, also named as heuristic rules or dispatching rules. They are used to select jobs for machines or assign machines to jobs. There exist some well-recognized scheduling rules in the literature, including SPT (shortest processing time) rules, EDD (earliest due date) rules, and FCFS (first come first served) rules. It is observed that a particular rule may perform superior to other rules regarding a specific criterion. However, dynamic scheduling problems often involve multiple criteria, a rule suitable for a certain criterion can hardly dominate other criteria. To address this problem, a hybridization of multiple scheduling rules is more appealing to produce better scheduling results. Initial attempts have been made to produce hybrid rules manually, which is often time-consuming and not adaptive. In recent years, promising strides have been made to generate hybrid rules using artificial intelligence algorithms such as genetic programming, 19 gene expression programming (GEP),20,21 and other data mining algorithms.
GEP22,23 was proposed by Ferreira in 2001. It is a machine learning algorithm that combines the advantages of genetic algorithm (GA) and genetic programming (GP). GEP has been widely used in function discovery, rule construction, and prediction. Zhou et al. 24 proposed a new algorithm based on simulated annealing and GEP, and used it to solve the traveling salesman problem (TSP). Guo et al. 25 adopted the principle of gene silencing from biology to tackle the symbolic regression problem, and proposed an improved GEP based on the gene silencing mechanism. Zhang and Liu 26 combined the tabu search with GEP for the prediction of relations between leaching rate of rare earth mineral and the density of its mother liquid. In terms of workshop schedule, Nie et al.20,21 applied the basic GEP for dynamic job shop scheduling problems and DFJSPs with job release date. Liao 27 combined GEP with biogeography-based optimization, proposed a hybrid biogeography-based gene expression programming algorithm, and constructed a corresponding framework for scheduling rule discovery.
Therefore, the GEP provides a viable approach for solving scheduling problems through extracting useful empirical knowledge and constructing effective scheduling rules. To the best of the authors’ knowledge, Nie et al. 21 is the only attempt in the literature to use GEP for flexible job shop dynamic scheduling problems. However, the traditional GEP suffers from disadvantages such as inferior local search capability and poor population diversity. This paper intends to overcome the disadvantages and proposes an improved GEP algorithm for the DFJSP.
In the following sections, the description and mathematical formulation of DFJSP are first introduced. Then, the improved GEP for flexible job shop scheduling problem (FJSP) is presented in detail, followed by the description of the variable neighborhood search algorithm that is used to improve the local search capability of GEP, and the transposition operators used for promoting population diversity. We also explain the framework proposed for solving dynamic scheduling problems based on the improved GEP. Testing instances are then presented and computational results are given. The final section summarizes our work.
DFJSP
Problem description
In a typical dynamic flexible job shop, there are m available machines and n jobs to be processed. The arrival times for these n jobs to the workshop are uncertain. Each operation of a job can be processed on multiple machines. It is necessary to determine the processing machine for each operation and the processing sequence of the operations on each machine so as to obtain the optimal scheduling solution. In a production workshop, before each operation of a job is processed, some preparation work will be done on the corresponding machine, such as adjustment and clamping. This period is usually called the setup time. 28 In the traditional scheduling problem research, the setup time is usually ignored or used as a part of the processing time. However, in the actual processing, the switch between different processes will lead to different setup times, so the makespan of the job will be affected as well. Therefore, it is necessary to separate the setup time from the processing time in the DFJSP.
Some basic assumptions are listed as follows:
No order constraints exist among jobs;
A job can only be processed on one machine at a time;
A machine can only process one job at a time;
Machine preemption and interruption are not allowed;
The processing order among the operations of a job is fixed;
An operation can be assigned to multiple candidate machines for processing;
Machines are available at the initial moment, regardless of machine failure.
Mathematical model
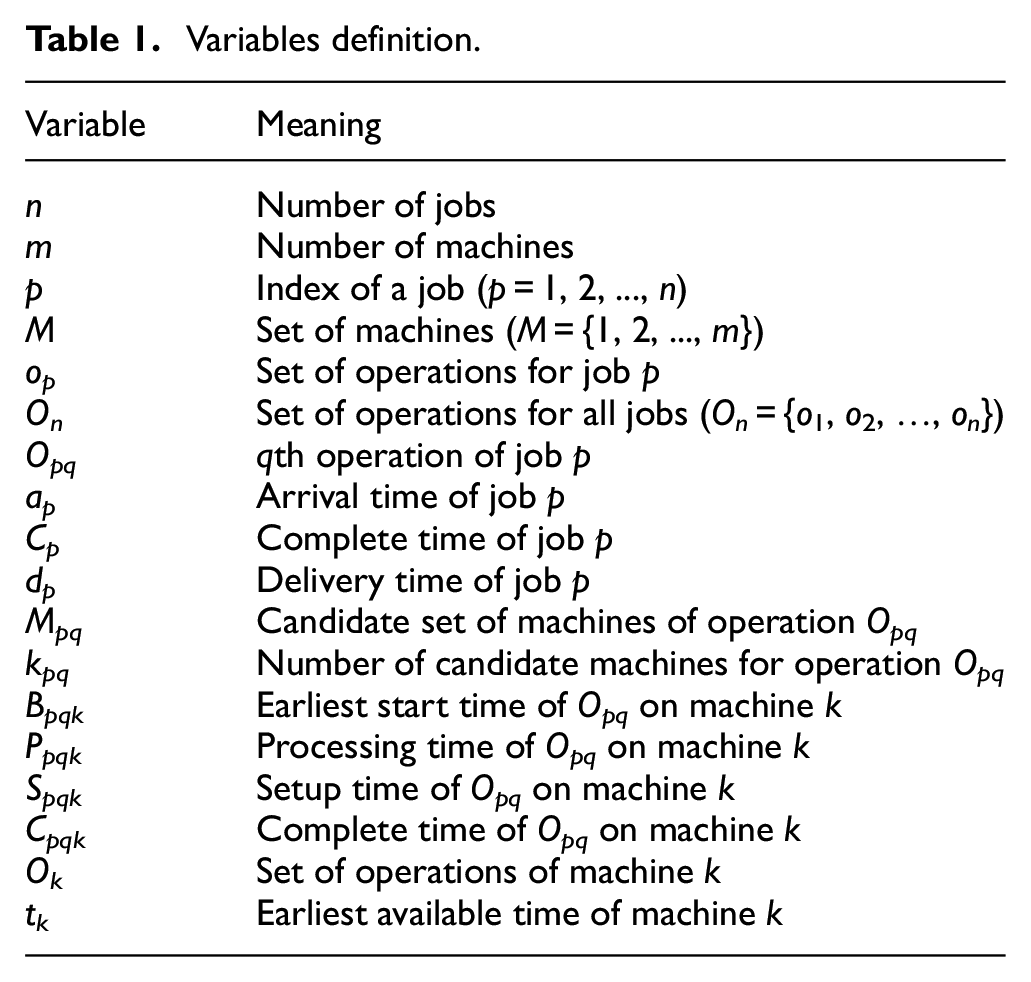
The mathematical model of the DFJSP considering separate setup time is given. The variables used in the model are listed in Table 1.
Variables definition.
All constraints are presented as follows

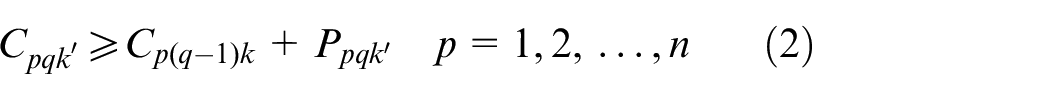
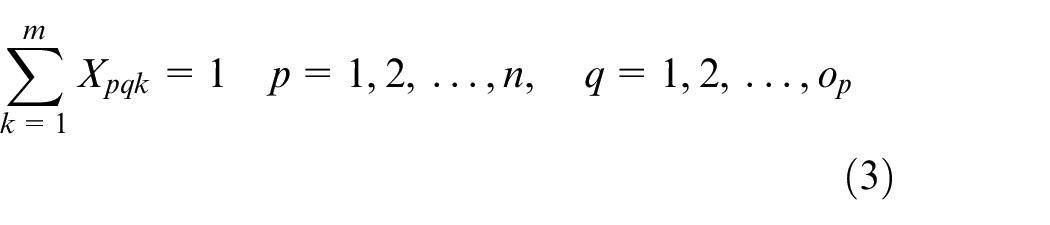
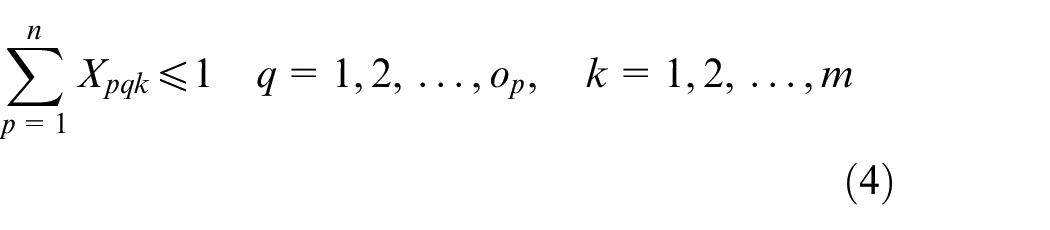
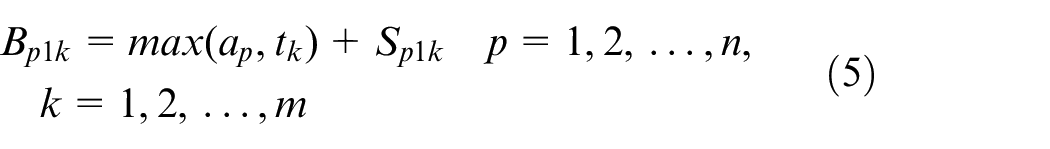
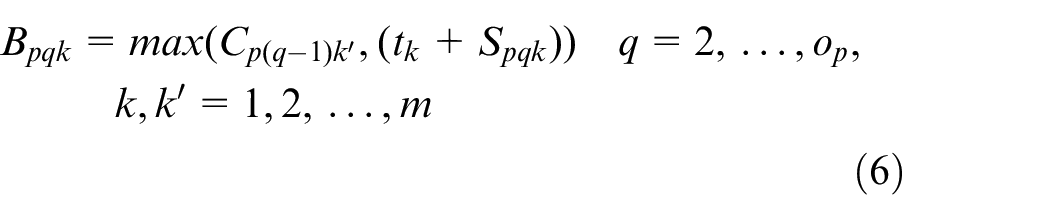

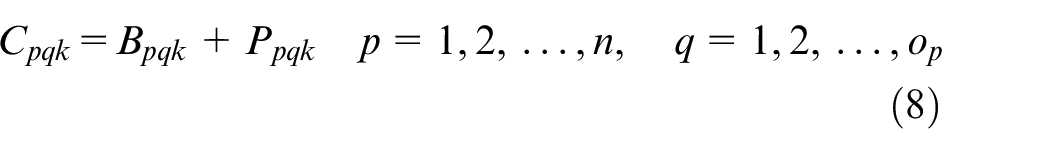
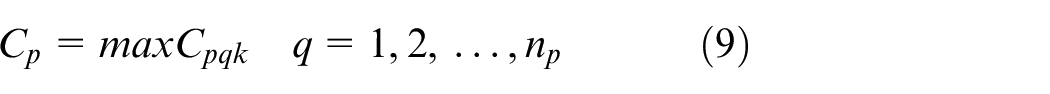
Xpqk is the decision variable

Constraint (1) ensures that the processing time for each operation is positive. Constraint (2) shows the complete time constraint between two adjacent operations. The constraint that a job can only be processed on one machine at a time is given in equation (3), and the constraint that a machine can only process one job at a time is presented in equation (4). The start time of the first operation for each job is calculated by equation (5). Since the arrival time cannot be known in advance, the start time of the first operation can be known after the job arrivals. The start time for other operations except the first operation is obtained by equation (6). Constraint (7) indicates that the operation on a machine cannot start only after the last operation on the machine and the setup is finished. The complete time for each operation is calculated by equation (8), and the complete time for a job is the complete time of its last operation, which is shown in equation (9). The objective function is to minimize the makespan tms shown in equation (11)
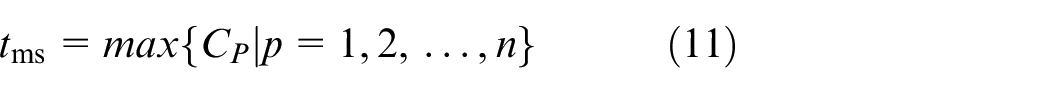
Improved GEP for DFJSP
The original GEP
Basic steps
GEP is a variant from combining GA and GP, and its basic steps are similar to GA:
Step 1. Set the parameters and initialize the population.
Step 2. Calculate the fitness value for individuals in the population and check the termination condition. If the termination condition is satisfied, output the best solution found. Otherwise, go to step 3.
Step 3. Select individuals by the roulette wheel selection.
Step 4. Perform genetic operators for the selected individuals.
Step 5. Generate a new population, and go to step 2.
Encoding and decoding
In the GEP, a gene is composed of a fixed-length string, which can be divided into two parts, the head and the tail, which are important components of the whole gene. The relationship between the tail length t and the head length h is shown in equation (12), where s is the number of all parameters in the predefined function set (FS) in GEP. The element in the head of the gene can be selected from FS and terminal set (TS), while the element in the tail can only be selected from TS. Chromosomes in GEP may be composed of more than one gene
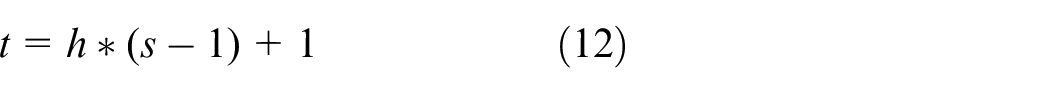
The encoding of GEP adopts the “head + tail” way. After the expression tree is obtained, the depth-first traversal method can be used to traverse the expression tree to obtain the final desired expression. Conversely, using a depth-first approach can also decode strings into expression trees.
Genetic operators
Genetic operators include selection, recombination, transposition, and mutation. These operators are introduced briefly as follows:
Selection: the roulette wheel selection with elitism is adopted in the original GEP.
Recombination: GEP usually uses one-point recombination, two-point recombination, and gene recombination.
Transposition: transpositions are unique operators in GEP. There are three kinds of transpositions including IS (insertion sequence elements) transposition, RIS (root IS elements) transposition, and gene transposition. IS transposition means that a gene fragment is first randomly selected and then inserted into other elements except for the first element at the head of the gene. At the same time, the gene segment with the same length as the insert is deleted at the end of the head, keeping the head and tail of the entire gene to ensure the whole length unchanged. The difference between root insertion sequence elements transposition and IS transposition is that the selected inserted gene segment can only start with an element of the head, and the insertion position is only at the top of the gene head. Gene transposition is only used in multi-gene chromosomes. Firstly, a gene is randomly selected and then moved to the head of the entire chromosome and the original gene is deleted.
Mutation: GEP used one-point mutation which is the same as GA.
Improved GEP
GEP inherits the strong global search ability from GA, but its local search ability is limited. The variable neighborhood search 29 (VNS) searches by constructing different neighborhood structures and constantly searches for new and better local optimal solutions by changing the neighborhood structure near the current local optimal solution. Because of its strong local search ability, VNS has been used to solve various combinatorial optimization problems. Embedding the VNS in GEP can greatly improve the local search capability of GEP. At the same time, in order to overcome the shortcomings of poor population diversity in the late evolution, an adaptive genetic operator is used to guide the search process of the algorithm, and part of the population is updated after evolving over a certain number of generations.
VNS
According to the characteristics of the shop scheduling problem, four neighborhood structures are constructed in the VNS:
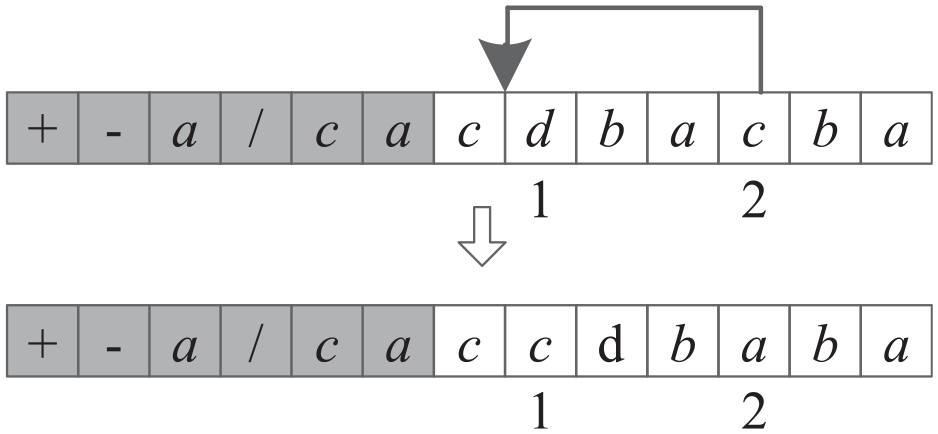
Insert neighborhood: randomly select two elements from the tail of the gene and insert the element in the latter position before the one in the previous position, as shown in Figure 1.
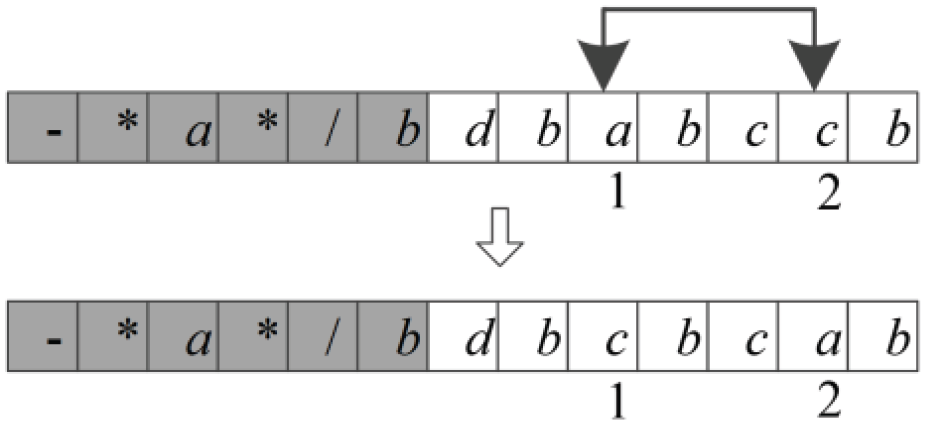
Swap neighborhood: two elements are randomly selected in the tail of the gene, and the elements at the two positions are swapped with each other, as shown in Figure 2.
Rearrangement neighborhood: randomly select four elements from the tail of the chromosome, and shuffle their positions as shown in Figure 3.
Inverse neighborhood: randomly select two positions in the tail of the chromosome, then arrange the elements between the two positions in reverse order, as shown in Figure 4.
Insert neighborhood.
Swap neighborhood.
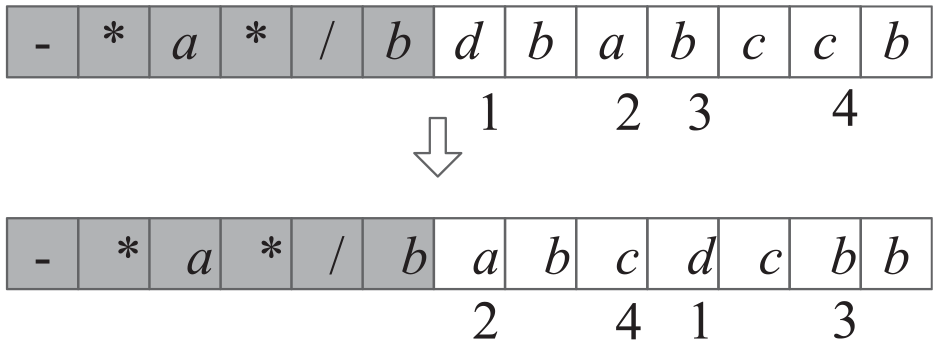
Random rearrangement neighborhood.
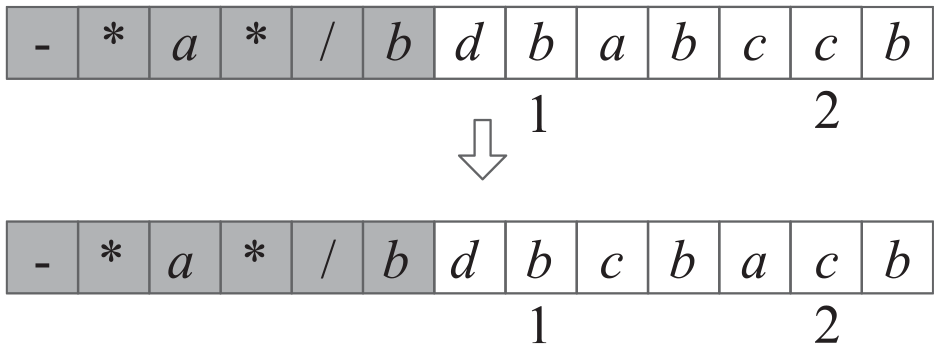
Inverse neighborhood.
In the GEP, the population evolves by the guidance of the genetic operators, and then, some individuals are selected for executing the VNS; the steps are described as follows:
Rank all the individuals in the population according to their corresponding fitness values in decreasing order.
Select the individuals ranking on the top as the elite solutions, denoted as population M.
Half of the solutions selected randomly from M, and the other half selected randomly from the other solutions are executed VNS.
Adaptive genetic operator rate
Parameters such as recombination rate and transposition rate play important roles in GEP. However, using fixed parameters throughout the whole evolutionary process is not conducive to the convergence of the algorithm. An adaptive genetic operator is proposed to autonomously adjust the parameters during the evolutionary process. The new recombination rate and transposition rate in GEP are shown in equations (13) and (14), respectively.
In equation (13), pr is the recombination rate, prmin is the minimum recombination rate, prmax is the maximum recombination rate, fi is the fitness value of individual i, x is a weighting factor between 0 and 1, n is the number of successive iterations that the population is not improved, and nm is the maximum number of successive iterations that the population is not improved. This formula shows that as the iteration progresses, the fitness value of the individual and the current number of unimproved iterations both affect the recombination rate.
In equation (14), pm is the transposition rate, pmmin is the minimum transposition rate, pmmax is the maximum transposition rate, and the others are the same as in equation (13).
In the early stages of population evolution, poor individuals are given a higher recombination rate and transposition rate, which may accelerate the evolution of the individuals. The individuals with better fitness values are given a lower recombination rate and transposition rate, so as to protect the good individuals. In the late stage of population evolution, there is still a certain probability for poor individuals to update to prevent the algorithm from the premature convergence. This adaptive setting method for the two genetic rates can balance the convergence and the diversity of the population
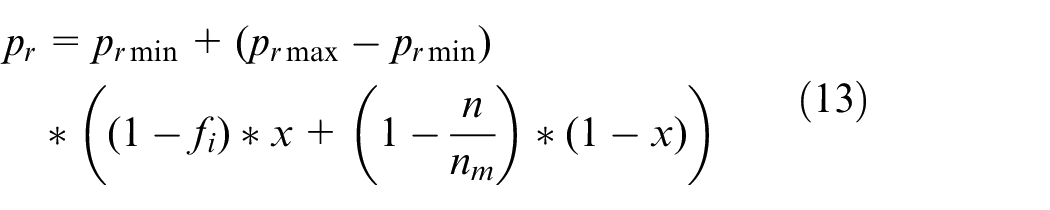
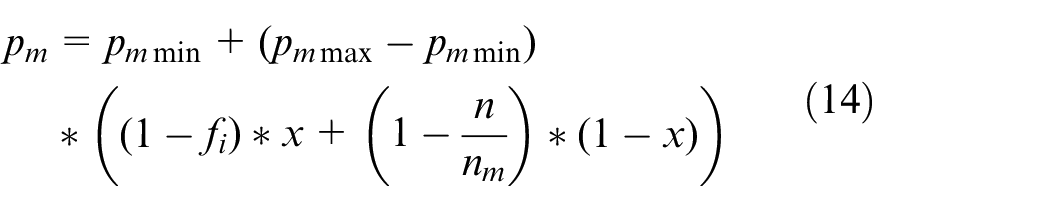
Improved GEP for shop dynamic scheduling
Fitness value
When using GEP to solve the dynamic scheduling problem, the fitness function is shown in equation (15), where Fi represents the fitness value of the ith chromosome, n is the population size, Si represents the objective function value corresponding to the scheduling rule represented by the ith chromosome, Smax represents the maximum value of the objective function, and Smin represents the minimum value of the objective function
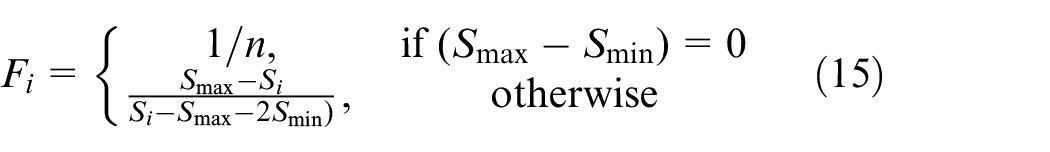
FS and TS
Scheduling rules can be composed of a combination of parameters of jobs, machines, and so on in the workshop scheduling. Therefore, some parameters of jobs and machines are used as the element source of the TS, and the relationship between these parameters can be used to construct the FS:
FS.
The elements of the FS for the improved GEP include “+, -, *, /.” When the divisor is 0, 1 will be obtained by the element “/.”
TS.
The constructed elements of the TS are shown in Table 2, where JTS (job terminal set) and MTS (machine terminal set) represent the TS for job allocation and machine selection, respectively.
Elements in the terminal set.
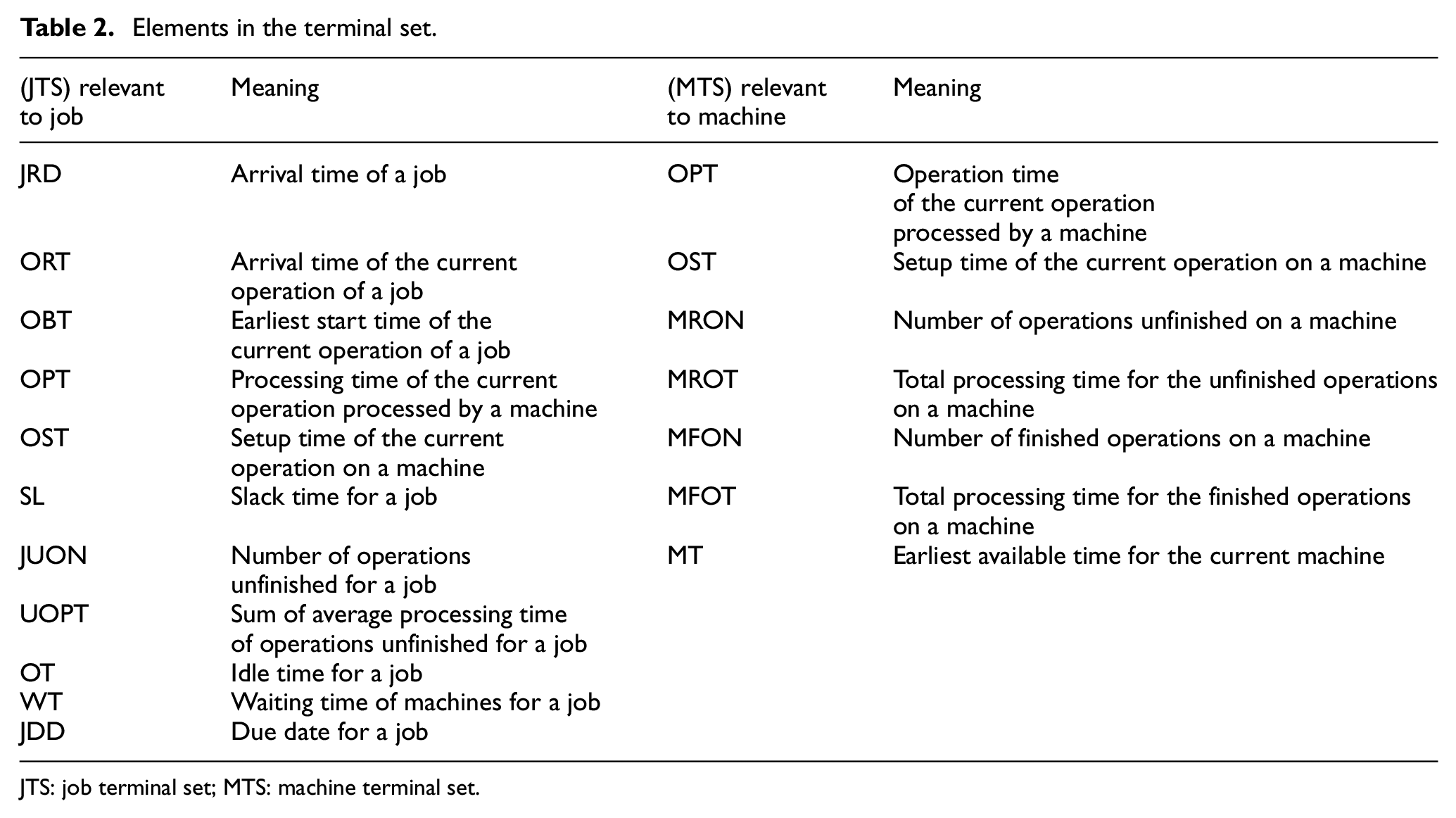
JTS: job terminal set; MTS: machine terminal set.
The average processing time

In Table 2, the arrival time of the current operation is the finish time of its last operation. The earliest start time of the current operation is shown in equation (17), where MT is the earliest available time of the assigned machine. The slack time SL is shown in equation (18), where CT is the current time. The idle time of a job is presented in equation (19), and the waiting time of a machine is shown in equation (20)

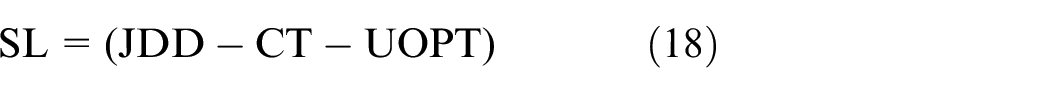


Since terminal elements include JTS and MTS, there are two parts about job and machine in the chromosome. The elements for operation assignment come from JTS and FS. The elements for machine selection are from MTS and FS. Figure 5 shows a multiple-gene chromosome constructed by the above encoding method, where one gene is used for job assignment and the other one for machine selection. The head parts are shown in shadow and other parts are the tail parts. The decoding method takes a depth-first approach.
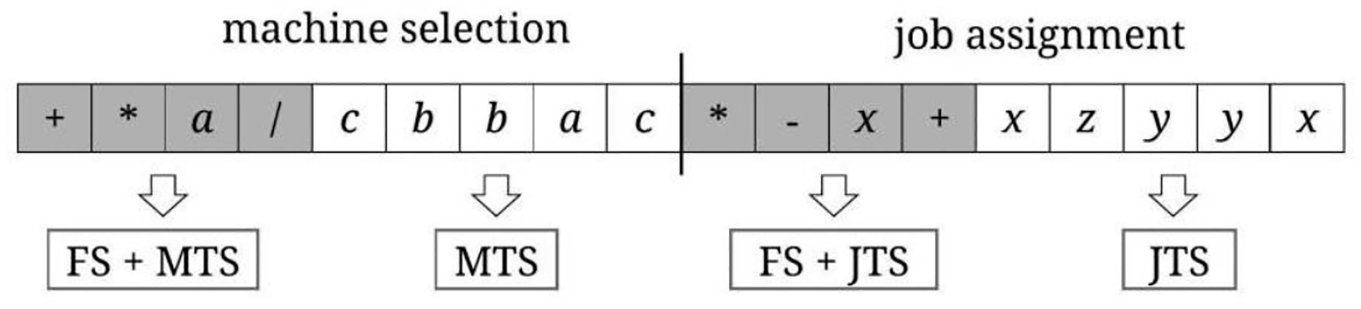
Multi-gene chromosome.
Framework and steps
A dynamic shop scheduling framework based on the improved GEP is proposed, as shown in Figure 6. In the framework, the evaluation module is the core module. Since there is no pre-determined data set and no evaluation criteria for dynamic scheduling, a simulation evaluation system is constructed based on the parameters related to jobs and machines in the shop and applied to evaluate the constructed scheduling rules. In the rule construction module, the scheduling rules generated by the population initialization are passed to the evaluation module. The evaluation module evaluates the scheduling rules according to some required performance indicators and performs a series of genetic operations on the population according to the evaluation results to form a new population. The new population is passed into the evaluation module for evaluation. The process is repeated until the termination condition is met. The final output is the scheduling rule.
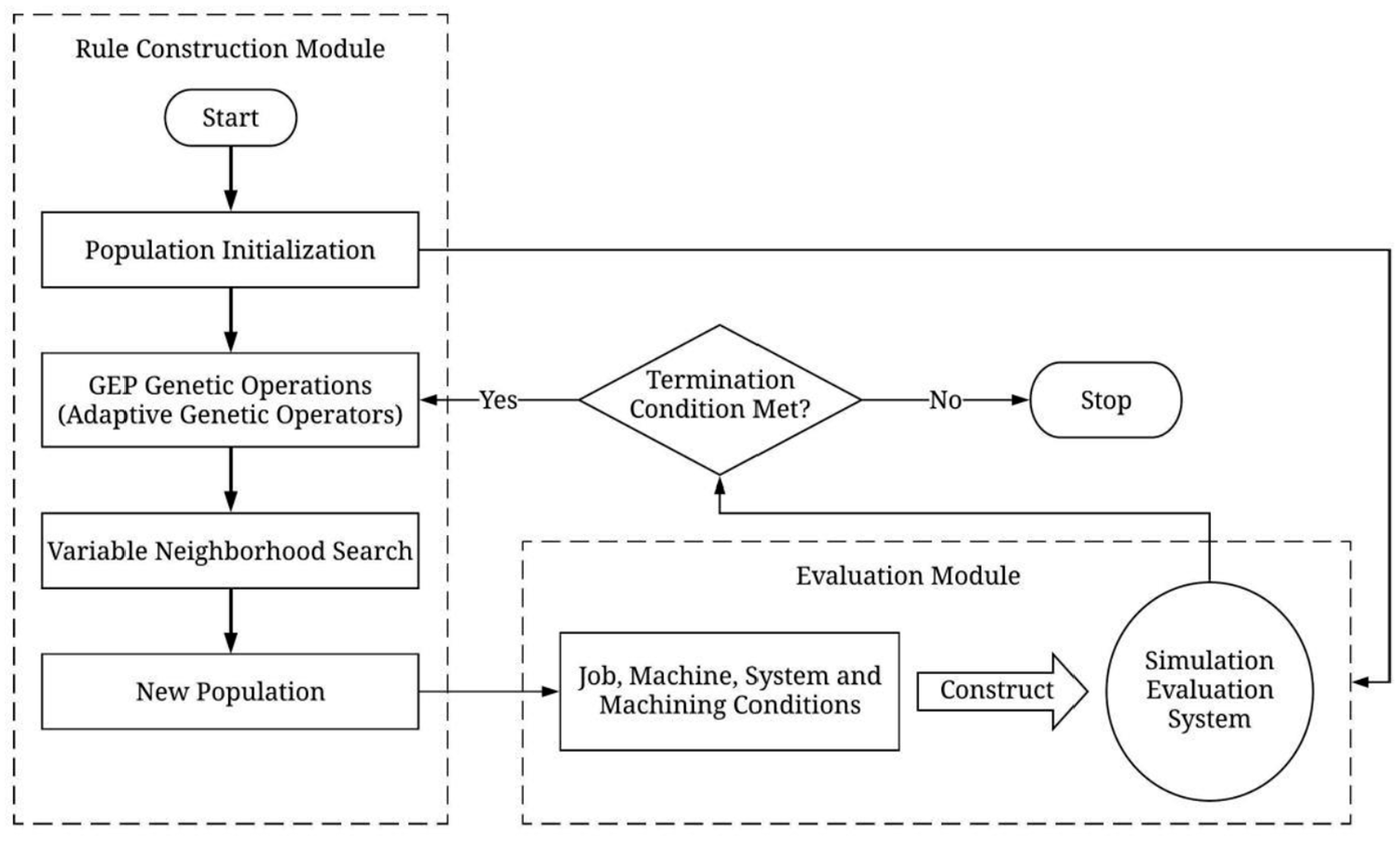
Framework of dynamic shop scheduling based on improved GEP.
The specific steps are as follows:
Step 1. Algorithm parameters setting, including population size, termination condition, genetic operator rate, number of neighborhoods, and so on.
Step 2. Random initialization of the population, according to the constructed FS and TS, initialize the machine selection and job allocation parts, respectively.
Step 3. Calculate the fitness value of the individuals and check whether the termination condition is met. If it is met, the algorithm stops and outputs the result, otherwise, go to step 4;
Step 4. Use the roulette wheel with elite reservation to perform the selection operation. The selected individuals are reorganized and shifted according to the adaptive recombination rate and transposition rate. At the same time, each individual in the population is mutated according to the given mutation rate.
Step 5. Sort the fitness value of the population after the above operations, select individuals for VNS, and perform VNS for them.
Step 6. Check whether the number of iterations where the optimal solution has not updated does reach the preset value. If so, randomly generate some individuals to replace the worst individuals in the current population. Otherwise, go to step 7.
Step 7. Generate a new population through the above operations and evaluate the individuals in the population.
Step 8. Repeat steps 3–7 until the termination condition is met, and output the result. Here, the termination condition is that the current iteration number reaches to the maximum iteration number.
Experiment and analysis
Experiment setting
A numerical experiment is designed to verify the effectiveness of the proposed algorithm for the DFJSP where the jobs arrive randomly. There are no benchmark problems for the problem, and test cases need to be generated according to the problem characteristics. Table 3 shows the parameter settings for the experiment and improved GEP.
Parameter setting for the experiment and improved GEP.
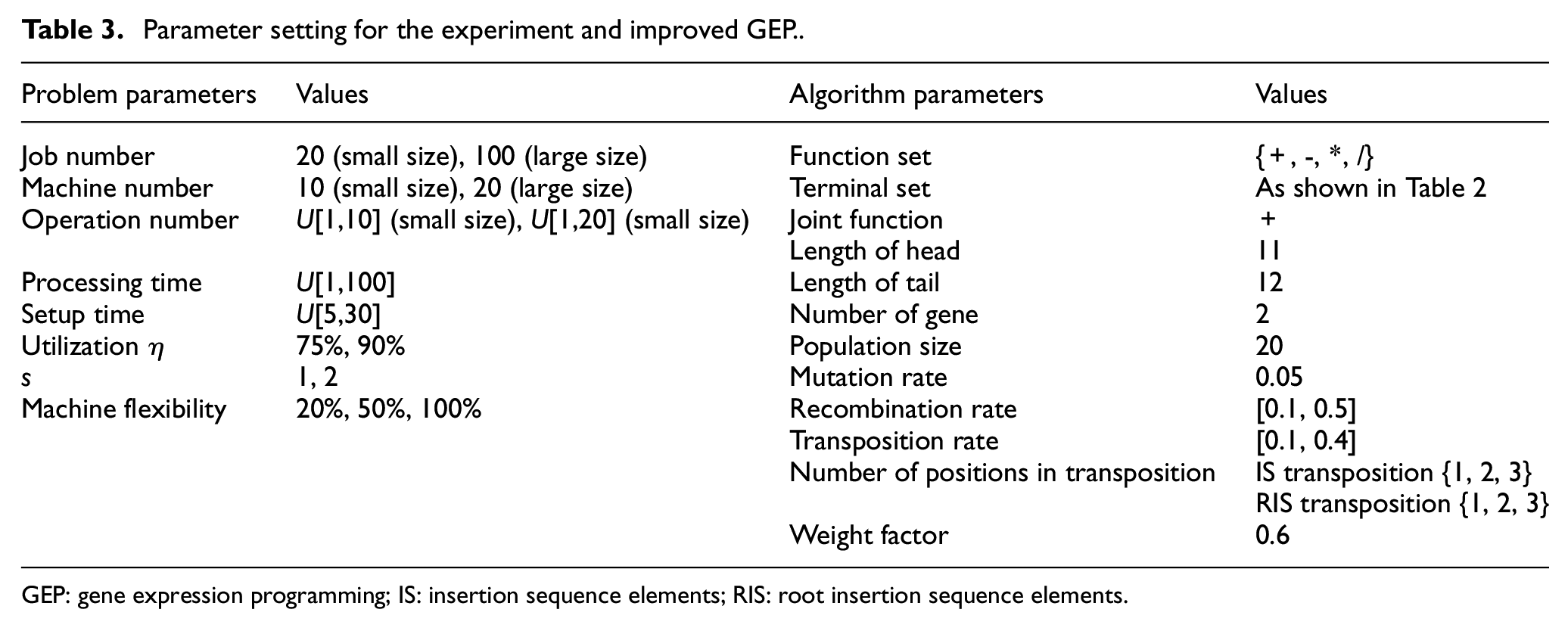
GEP: gene expression programming; IS: insertion sequence elements; RIS: root insertion sequence elements.
Parameter setting for the experiment
Two kinds of test instances with small and large scales are generated in the experiment. The number of jobs is 10 in the instances with a small scale, while 100 for large-scale instances. The number of machines in the two kinds of instances is 10 and 20, respectively. The number of operations for a job obeys uniform discrete distributions within [1,10] and [1,20]. The processing time of each job follows the uniform distribution of [1,100], and the setup time follows the uniform distribution of [5,30]. The parameter s defines the urgency level of a job. The flexibility of the machine indicates the number of machines that can be selected for an operation in the FJSP, and the values are 20%, 50% and 100%, which can be seen in Table 3. Two kinds of scales, three types of machine flexibility, two types of workshop utilization levels, and two types of tension factors together lead to a total of 24 groups of instances, where each group contains 40 random instances and 20 instances are used for training to get dispatch rules and the others for testing.
Assuming the job arrival is a Poisson process, their interval of arrival follows an exponential distribution whose mean interval is shown as (21)
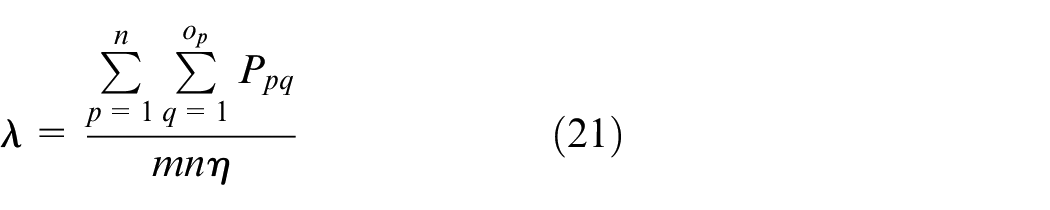
In equation (21), λ is the mean interval, Ppq is the processing time of operation Opq, op is the number of operations for job p, m is the number of machines, n is the number of jobs, and η is the utilization of machines.
Parameter setting for the improved GEP
The parameters in the improved GEP are also listed in Table 3. The parameters for standard GEP and GP are listed in Tables 4 and 5. All programs for the three algorithms are coded by C++. All experiments are run on a personal computer with Intel core i5-3470 (3.20 GHz) and 4 GB RAM, and the operating system is Windows 7.
Parameters for the GEP.
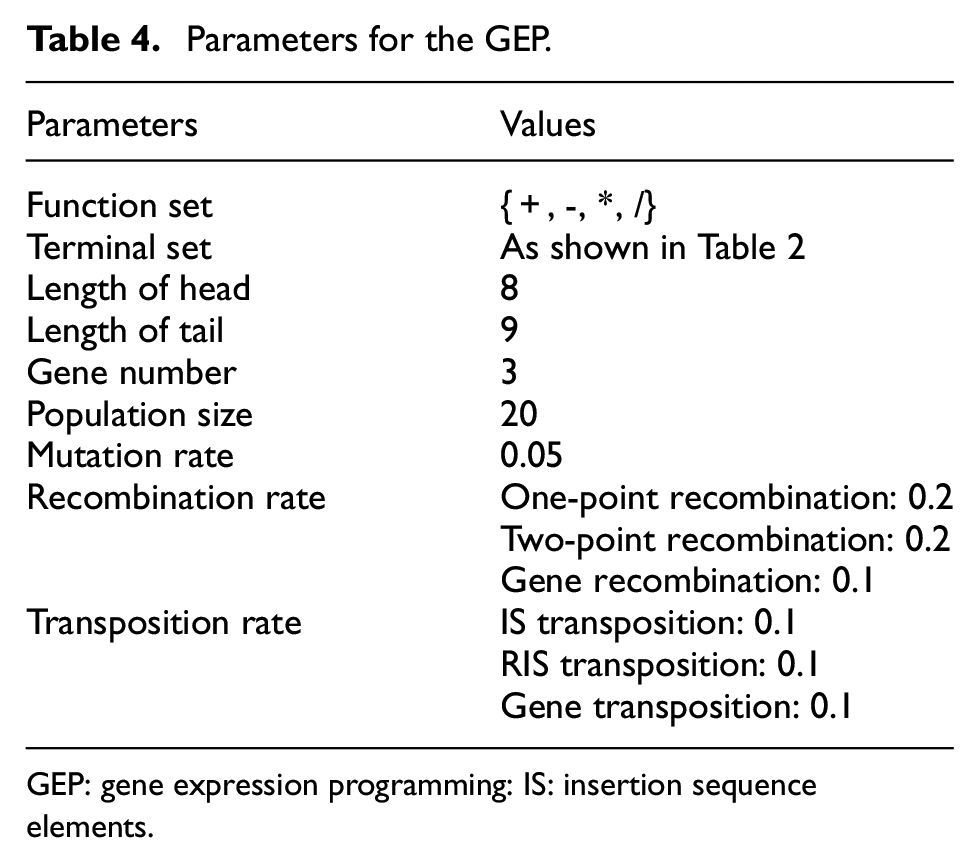
GEP: gene expression programming: IS: insertion sequence elements.
Parameters for the GP.

GP: genetic programming.
Since there are two subproblems (machine selection and job assignment) in FJSP, the following methods are used to verify the efficiency of the proposed GEP. The common rule for machine selection is LMT (least waiting time). The rule will select the machine with the least total processing time of the operations waiting for processing. The rules for job assignment generated by the standard GEP and GP and some classic dispatch rules are used for comparison. The above combinations of rules are presented as “LMT/GEP,”“LMT/GP,”“LMT/SPT,”“LMT/EDD,” and “LMT/(SL + SPT).” Some involved dispatch rules are introduced as follows:
SPT: the rule will select operation with the shortest processing time and it can be represented by OPT.
EDD (earliest delivery date): the rule will select operation with the earliest delivery date and it can be expressed by JDD.
SL + SPT: it is a hybrid rule. SL is the slack time of a job, and it can be represented by SL = JDD − CT − UOPT, where CT is the current time.
The delivery date is calculated as equation (22)
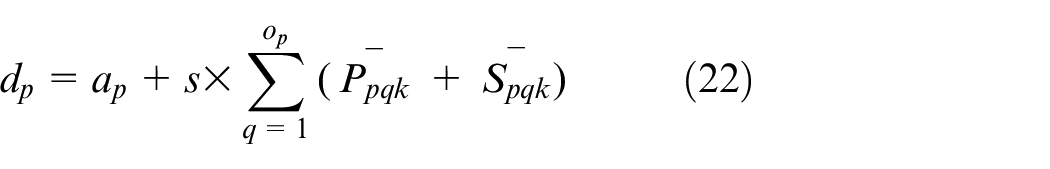
where dp is the delivery date of job p; ap is the arrival time of job p;
Each algorithm runs five times, and the average values are used for comparison and the maximum iteration for the improved GEP, GEP, and GP is 1000.
Result analysis
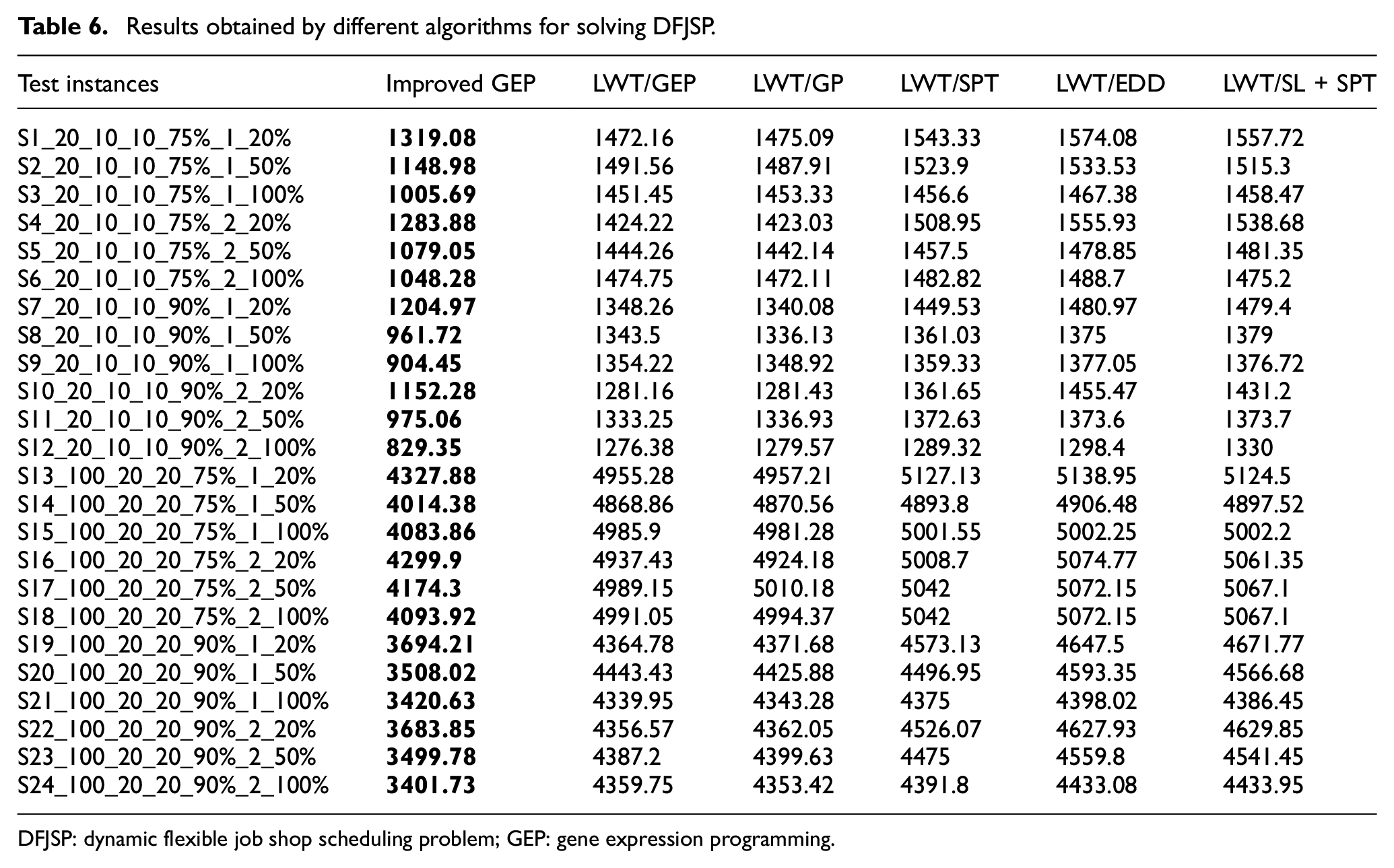
The comparison results for the three algorithms are presented in Table 6, where the values in bold are the best ones among the three algorithms. Take “S1_20_10_10_75%_1_20%” as an example to explain the name of the instance set. “S1” represents the first test set; “20” means the job number is 20; The first value “10” represents the machine number is 10 and the second value “10” means the operation number obeys uniform discrete distributions within [1,10]; “75%” is the machine utilization and the value “1” is the s value in (22); The last value “20%” is the machine flexibility.
Results obtained by different algorithms for solving DFJSP.
DFJSP: dynamic flexible job shop scheduling problem; GEP: gene expression programming.
Taking the instances S2_20_10_10_75%_1_50% and S3_20_10_10_75%_1_100% as an example, the scheduling rules obtained by the improved GEP, which can get the best makespan among the five runs, are shown in equations (22) and (23), respectively. The upper part in each formula is the rule for machine selection and the lower part is the rule for job assignment. The meaning of the variables is shown in Table 2. For the rules of machine selection, when the objective function is the makespan tms, the processing time OPT on the machine is an important parameter except for the MROT which is the only parameter MROT in LWT. Compared with the corresponding instance for equation (24), the instance for equation (23) has lower machine flexibility and the suitable machine for a job is harder to be found, so the rule for machine selection in equation (23) is more complex than the rule in equation (24). The rule includes the parameters MROT, MFON, OST, and so on, except OPT. For the machine where the total processing time for the unfinished operations is less, the number of finished operations and the setup time of the current operation is less, having higher priority in the machine selection
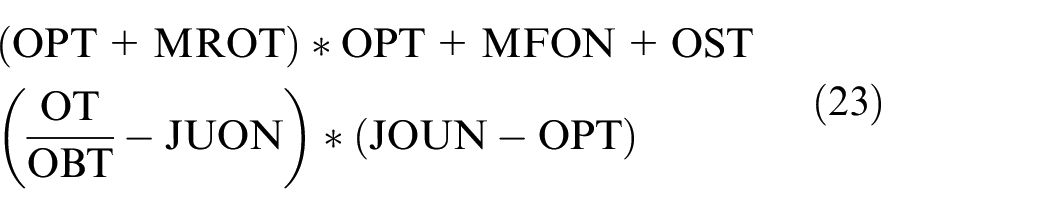
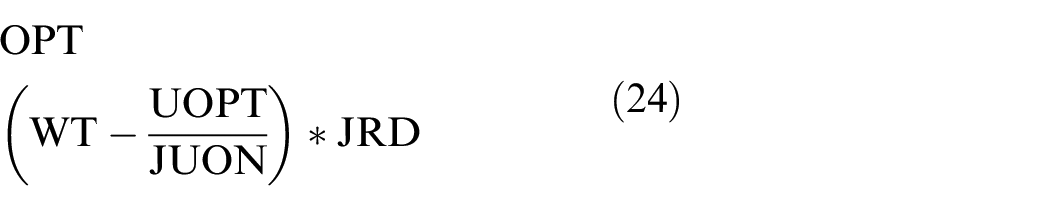
It can be observed from Table 6 that the average makespan under the rules obtained by the improved GEP is much better than that under the classical scheduling rules and the rules obtained by the other two algorithms both on small-scale and large-scale problems. The makespan under the rules obtained by the improved GEP is smallest on all the instances and the efficiency of the improved GEP is verified. Meanwhile, when the rule for machine selection is LWT, the rule for job assignment obtained based on GEP and GP can get smaller makespan for most instances than the other classical scheduling rules. The classical scheduling rule SPT is better than EDD and the compound rule “SL + SPT.” The rule EDD and the compound rule “SL + SPT” show similar performance, which indicates that a compound rule is not always better than a single rule.
Conclusion and future work
An improved GEP-based dynamic scheduling method was proposed for solving the DFJSP considering setup time and random job arrival. The variable neighborhood search is embedded into the GEP, and multiple neighborhood structures are designed for improving the local search ability. Meanwhile, a method for adaptively setting the genetic operator rate is introduced to alleviate the premature convergence problem. Some worse individuals are replaced in the latter search process to improve the diversity of the population. A framework based on the improved GEP is proposed. Twenty-four groups of test instances are generated, and the improved GEP is compared with standard GEP, GP, and other classical scheduling rules. The comparison results demonstrate the efficiency of the improved GEP.
The most critical point when using GEP to construct scheduling rules is the selection of FS and TS elements. At the same time, the constructed scheduling rules are sometimes complicated and difficult to understand. How to design the TS to ensure that the resulting scheduling rules are efficient and easy to understand is a major focus of future research. This work only focuses on the random arrival of jobs. In the future, dynamic events such as machine failures, insertion orders, and change of delivery time can also be considered. At the same time, other objectives such as energy efficiency30,31 can also be considered in the future.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research work was supported, in part, by the National Key R&D Program of China under grant no. 2019YFB1704603 and the National Natural Science Foundation of China under grant nos 51905199, 51775216, and 51705177.