
Abstract
When low-resolution face images are used for face recognition, the model accuracy is substantially decreased. How to recover high-resolution face features from low-resolution images precisely and efficiently is an essential subtask in face recognition. In this study, we introduce shuffle block SRGAN, a new image super-resolution network inspired by the SRGAN structure. By replacing the residual blocks with shuffle blocks, we can achieve efficient super-resolution reconstruction. Furthermore, by considering the generated image quality in the loss function, we can obtain more realistic super-resolution images. We train and test SB-SRGAN in three public face image datasets and use transfer learning strategy during the training process. The experimental results show that shuffle block SRGAN can achieve desirable image super-resolution performance with respect to visual effect as well as the peak signal-to-noise ratio and structure similarity index method metrics, compared with the performance attained by the other chosen deep-leaning models.
Introduction
With the development of face recognition techniques, face image collection has become an important task. However, in an application system, some factors may have remarkable impacts on image quality, such as the image capture device, the illumination level of image, the distance between target and lens, the motion of the target, etc. Face image recognition results can be significantly influenced by using low resolution (LR) with unclear face details. Image super-resolution (SR) reconstruction technology, which aims to convert an LR image to a high-resolution (HR) image, is a useful approach to enhance the quality of face images.
There are three main types of image SR methods: interpolation schemes, reconstruction schemes, and learning-based schemes. Early image SR methods are mainly based on interpolation. The most common ones are Nearest Neighbor Interpolation, Bilinear Interpolation, Bicubic Interpolation, nonuniform sampling interpolation, etc.1,2 Interpolation-based methods have been widely used because they are simple to implement. However, the linear characteristics of these models inhibit their ability to reconstruct high-frequency details. Especially when the scaling factor becomes large, the reconstruction effect decreases dramatically. The reconstruction-based method is inspired by image degradation. It acquires nonredundant information in the LR image and builds the correspondence between LR and HR image pairs, which can be used for further modeling. A typical reconstruction-based method is Projection onto Convex Set (POCS). 3 POCS is based on some hypothetical constraints, such as smoothness, support boundedness, energy boundedness, non-negativity, etc. It reconstructs the SR image by solving these constraints. POCS has no unique solution. The final solution depends on the initial estimation of the image and has the disadvantages of slow convergence speed. Moreover, the reconstruction-based method can be significantly affected by the degradation model and noise level, and it is difficult to achieve real-time modeling and reliable robustness. Learning-based schemes, on the contrary, rely on a machine learning algorithm to improve the quality of generated image. Consequently, the learning-based method has gained raising interest among the researchers recently. Yang et al. 4 establish a sparse dictionary between LR and HR through training data, which can be used to generate the SR image patch. The disadvantage of the algorithm is that there is no sparse correlation between HR and LR image blocks. It is difficult to select the appropriate samples, so the running time is relatively long. Wang et al. employ weighted sparse regularization to face reconstruction. They introduce neighborhood embedding (NE) from LR and HR image manifolds to retrieve very LR face images. 5 Rasti et al. introduce an SR scheme for single images. The illumination between adjacent patches can be consistent by taking the minimum distance between the LR patches. 6 The learning-based method breaks the limitation of Nyquist sampling frequency. Even if the sampling rate is less than or equal to 2 times of Nyquist frequency, the original image can still be recovered. However, the computational complexity is high, which is not conducive to practical application. Moreover, when the input image structure does not match the test image structure, the reconstruction quality can be reduced.
As we know, the convolutional neural network (CNN) shows a compelling capability in many computer vision tasks lately. Simultaneously, CNN-based image SR models have gradually demonstrated outstanding performance. Zhang et al. set up a residual dense network, extracting hierarchical features of LR image to learn deep features and reconstruct the SR image. 7 To enhance the SR effect and reduce the training time, Mao et al. introduce an encoder-decoder network with deep residual structure for image SR reconstruction by adding symmetric skip connections between the convolution layers. 8 Luo et al. 9 propose a robust CNN model for the satellite image SR task. To improve the visual effect of SR image, Johnson et al. 10 use perceptual loss function and a pretrained 16-layer Visual Geometry Group model to train a feed-forward network for image transfer and SR tasks. Dong et al. 11 trained an SRCNN to establish an end-to-end mapping between LR and HR images. This method combines the traditional sparse coding with the SR method. Although it shows a better reconstruction effect, SRCNN does not get a better effect while deepening the network layers. Also, it is not suitable for multiscale reconstruction.
CNN-based schemes have been victorious in image SR tasks. However, most of these models are optimized by reducing the mean square error (MSE), which will cause some problems, such as the unclear details and unreal visual perception of the reconstructed image. Generative adversary networks (GANs), on the other hand, is a new framework of unsupervised learning. 12 It uses an adversarial strategy to learn high-level image features, which is proved to be beneficial for high-quality image feature extraction. The SRGAN introduced by Ledig et al. is shown to be the state-of-the-art framework to realize the photorealistic SR image reconstruction performance. 13
In this study, a face image SR reconstruction network is proposed based on adversarial learning. To further reduce the time complexity of SRGAN, our model optimizes the SRGAN architecture by replacing the residual block with shuffle block that consists of multiple shuffle units, each of which contains channel shuffle, pointwise group convolution, and depthwise separable convolution layers. We name this SR model as shuffle block SRGAN (SB-SRGAN). The efficient convolution design can significantly reduce the computational complexity while maintaining extraordinary model ability. Furthermore, the loss function is renewed to improve the SR image quality. We not only consider the content loss and the adversarial loss of the generated image by comparison to the natural HR image but also analyze the clarity of the generated image itself. In addition, to make full use of the comprehended knowledge of images features, we utilize transfer learning during the training process. Weights and bias are initialized from a pretrained model on a small image set and then fine-tuned by other datasets throughout the training process.
Our contribution in this paper is threefold:
First, SB-SRGAN is proposed for face image SR tasks based on the improved SRGAN structure. Instead of using the residual connection, SB-SRGAN uses shuffle unit connection with group convolution layer and depthwise convolution (DWConv) layer to extract more reliable image features and train network effectively.
Second, the content loss in the loss function of SB-SRGAN is upgraded. Content loss focuses on the generated image quality as well as the similarity between the original image and the generated image. In contrast, the adversarial loss focuses on the authenticity of the generated face image.
Third, transfer learning is implemented during the training process. The initial weights and bias trained in a small image set are used for model fine-tuning on a large image set to accelerate model convergence.
This study is arranged as follows. Section “Related work” briefly reviews the model structure and loss function of the traditional GAN. The details of SB-SRGAN for face image SR are specified in section “Proposed method.” Experimental results and evaluations are given and analyzed in section “Experimental results.” Finally, we draw conclusions based on our work in section “Conclusion.”
Related work
The application of GAN
Since Good Fellow and others put forward GAN, researchers have done a lot of work based on it. GAN is proved to be a superior network for learning image feature representations adversarially to generate visually attractive samples. However, GAN is usually challenging to train, which often leads to mode collapse or meaningless output. Since then, how to stably train a GAN model becomes an important issue when implementing GAN. Radford et al. introduced a deep convolution GAN and proposed some guidelines to improve the training stability of GAN. 14 Salimans et al. 15 introduced feature matching, small batch discrimination, and other methods to enhance classification performance through semisupervised learning strategy. Gulajani et al. 16 proposed a training strategy on the basis of the Wasserstein GAN (WGAN). By penalizing the gradient norm of discriminator, the network can generate higher-quality image samples and achieve faster model convergence. 17 Karras et al. 18 proposed a progressive training method, which gradually increased layers in the generator and discriminator as the training progressed, to generate HR images starting from a low resolution. Schlegl et al. 19 conducted unsupervised learning to distinguish irregularities as samples to be marked. Dong et al. proposed an unsupervised method to change images from one domain into another without referring to the original image. 20 Zhong et al. proposed a high-quality SR for face image based on generative adversarial networks. 21 Yuan et al. 22 carried out an image SR reconstruction experiment by using the GAN structure without LR/HR pairs. In this structure, noise and blur input is first mapped to clean LR image space, and then mapped to the intermediate image, which is sampled by the fine-tuning EDSR model. 23 The reconstructed HR image output is obtained. Ledig et al. proposed SRGAN, which can generate natural SR images by using perceptual loss. 13
SR reconstruction model of face image based on GAN
There are two components in GAN structure: generator and discriminator. Generator (abbreviated as
Figure 1 shows the network structure of the face image SR reconstruction model based on traditional GAN. The generator
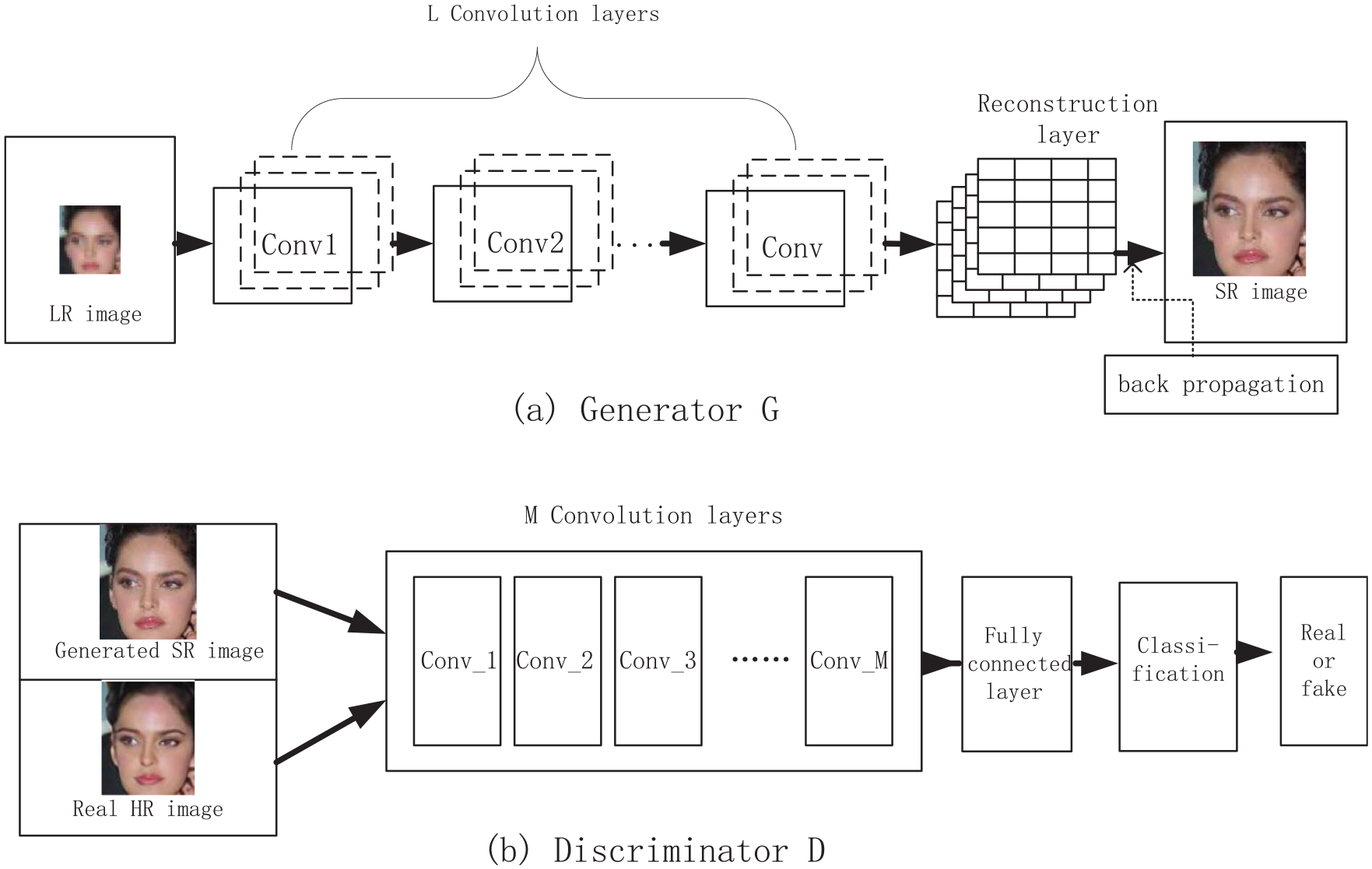
Face image SR reconstruction model based on GAN.
Each training iteration can be separated into two steps. The first one is to train discriminator
The second step is to train generator
The optimization objectives of GAN can be simply summarized in equation (1)
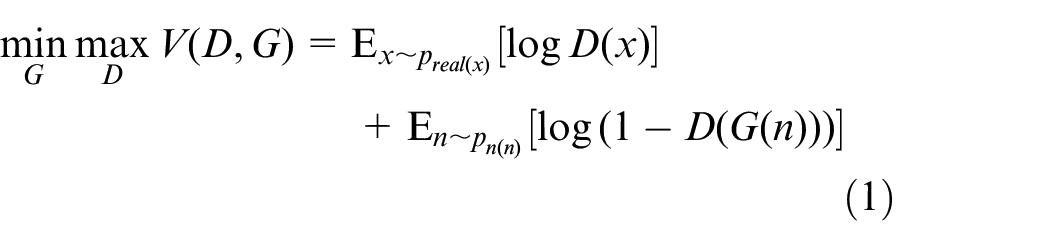
where
Equation (1) shows that the optimal model only can be achieved when the condition

Proposed method
The network structure of SB-SRGAN
The generator
Comparatively, the training purpose of the discriminator is to tell the real HR image from the generated SR one precisely. The proposed SB-SRGAN architecture is illustrated in Figure 2.
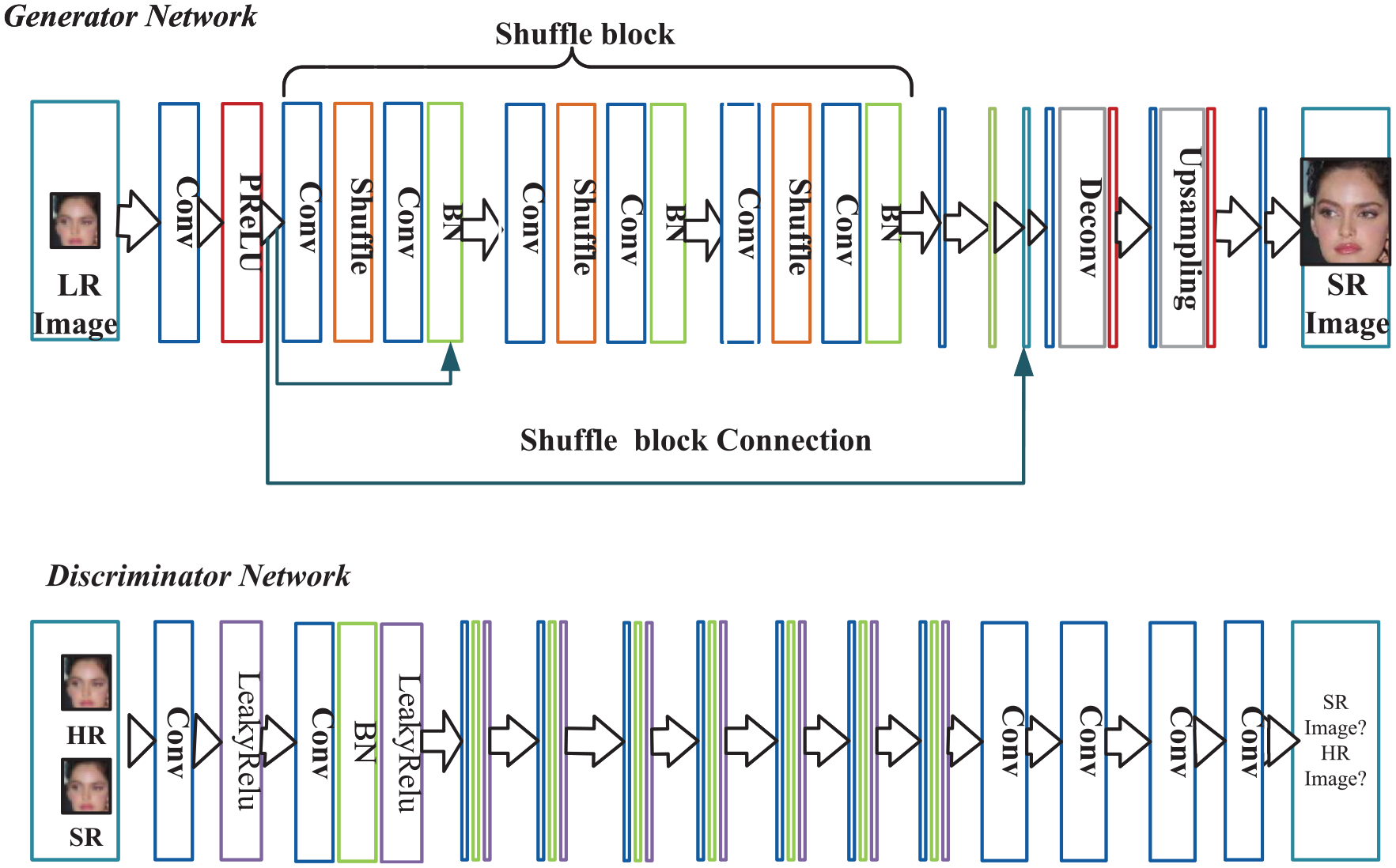
The proposed SB-SRGAN structure for image SR.
As can be seen from Figure 2, the generator
The shuffle unit shown is first proposed and applied in Zhang et al.
24
The shuffle block in this paper is similar to the SRGAN residual block structure and is improved by adding the shuffle unit. The structure of the shuffle unit is shown in Figure 3. This is a residual unit with four layers: first is
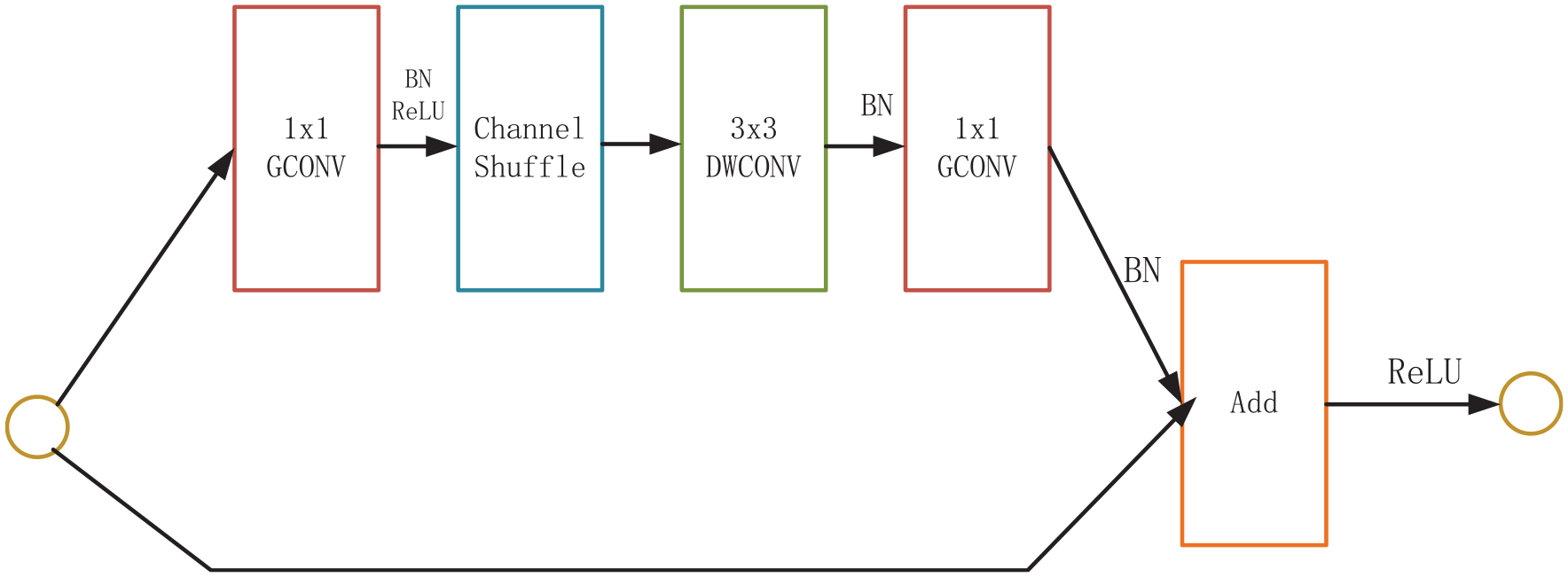
Shuffle unit.
Then, there is a
The discriminator
Loss function
The traditional SR model chooses MSE between pixels as the optimization object defined as
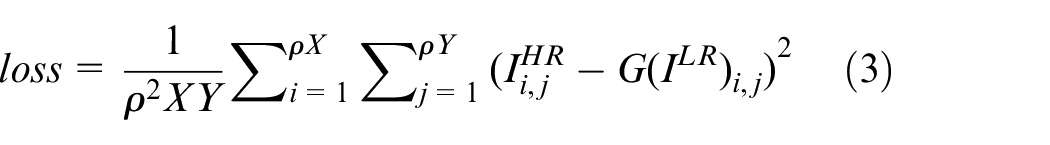
where
Therefore, in this paper, we combine MSE loss between pixels and image quality measurement as the loss function. To summarize, the loss function is defined as the weighted sum of content loss and adversarial loss, as shown below

where
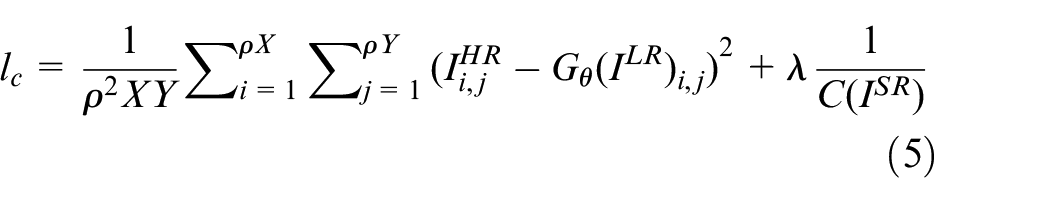
where
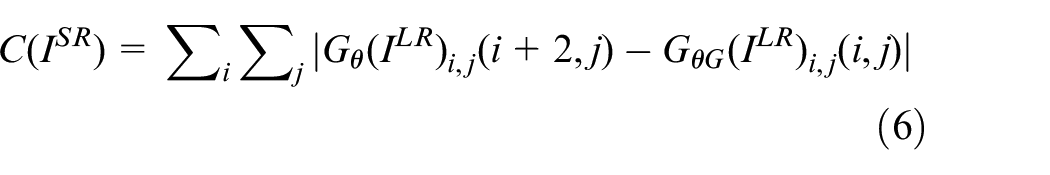
The first part of content loss is based on MSE, while the second part considers the clarity of the SR image
The adversarial loss
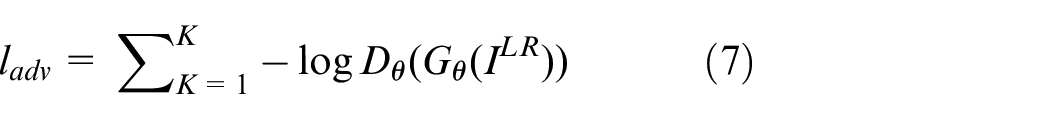
where
Adversarial training
In this paper, we use content loss and adversarial loss to restore image resolution. The discriminator
The purpose of the adversarial training is, on the one hand, to maximize the discriminator’s ability to identify whether the training samples are real or fake during the training process and, on the other hand, to improve the capacity of the generator by generating undistinguishable images. As the training steps go on, the generator enhances the ability to create realistic SR images, while the discriminator develops the strength to identify the generated image and HR image simultaneously.
Experimental results
Face image dataset
The size and type of training set will directly affect the parameters of a model, and then ultimately have some influence on the quality of the reconstructed face image. To investigate the experimental results of SB-SRGAN on different datasets, we use three different face image datasets for training and testing, Wider Face, 25 CelebA, 26 and LFW (Labeled Faces in the Wild (LFW)). 27 All of them are public data sets. Models are trained separately for each face database.
Wide face, including 32,203 images and 393,703 labeled faces. Forty percent of the images are train images with HR, all zoomed to 1024 in width. The minimum annotation face image is
CelebA is a large face attribute dataset provided by the Chinese University of Hong Kong. The dataset contains more than 200,000 celebrity images; each of them has 40 attribute labels. Most of the images have a messy background and carry a variety of human poses. To sum up, CelebA includes 10,177 characters, 202,599 faces, and five human face positions.
The LFW face image dataset is a public benchmark for face verification. It contains 13,233
The number of samples we used in our experiment in the three face image datasets is shown in Table 1. The number of validation images is one-quarter of the number of train images. After a certain number of face images are extracted to form the three different datasets, the images selected should be normalized to make the pixel value to change the range from 0–255 to −1,1.
Number of samples used in different datasets.
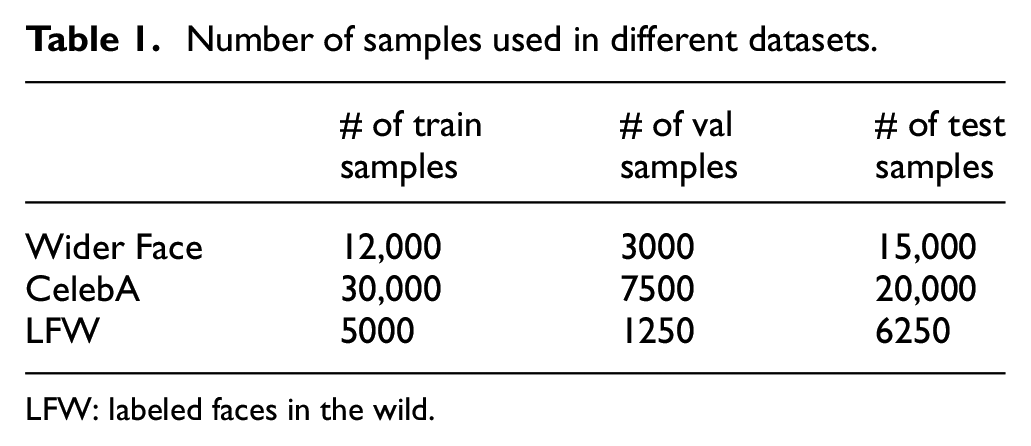
LFW: labeled faces in the wild.
Experiment setup
The platform used in these experiments is based on Windows 10 operating system, with GTX 1060 GPU to accelerate. The algorithm is implemented by Python 3.5 under Tensorflow framework.
To make sure the network can extract better face features, we use a face detection network to locate human face so that the faces can stay in the fixed position of the image and hasten model convergence. MTCNN 28 is a robust face detection algorithm, which can not only detect the face of the image but also automatically achieve face truncation, face alignment, and face size specification.
After preprocessing by MTCNN, we transfer the original images in the face image datasets into HR face images that focus only on the human face. Then, we apply the bicubic algorithm to preprocess the HR face images with a downsample scaling factor of
An example of image preprocessing is displayed in Figure 4. Figure 4(a) is an original HR image from the face image dataset, and Figure 4(a) is the preprocessed HR face images generated by MTCNN. Doing so allows the network to extract facial features better and get a better reconstruction result.

(a) Original HR image. (b) HR image after preprocessing.
The batch size is set to 32.
In the process of model training, the adjustment of weight is realized by the gradient descent algorithm. Adam (Adaptive Moment Estimation) optimizer
29
is used with
SR image quality evaluation metrics
The SR image quality evaluation standard needs to be calculated with a specific mathematical formula to numerically quantify the reconstructed SR image quality. A good evaluation standard must first be consistent with the judgment by the vision of the human eye. In addition, whether the SR image is good should be evaluated by calculating the difference between the HR image and the reconstructed SR image. The peak signal-to-noise ratio (PSNR) and structure similarity index method (SSIM) 30 are two commonly used metrics for evaluating the reconstructed SR image quality.
PSNR quantifies the quality of a reconstructed or corrupt image with reference to the ground-truth. The higher the PSNR, the smaller the distortion after reconstruction. PSNR is generally calculated by MSE. The formula of PSNR (in dB) is shown in equation (8)

where peak is the maximum possible pixel in the image, and its value depends on the sampling interval. If using linear PCM with
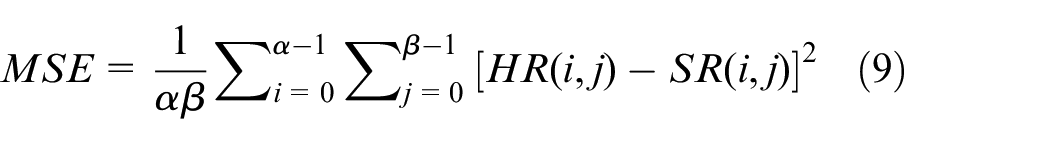
where
PSNR is sensitive to the reconstruction error because its calculation is based on the erroneousness between these corresponding pixels of two images. However, sometimes PSNR is inconsistent with human visual perception. For example, the human eye is more sensitive to the difference in the low-frequency region of the image than in the high-frequency region, and the perception result of the human eye to an area will be influenced by the adjacent region, etc. Accordingly, PSNR often seems inconsistent with human feelings in the image quality aspect.
SSIM is another measure designed to evaluate image quality from a distinct perspective. Because the original HR image has a similar structure with the reconstructed image, the reconstruction result can be evaluated according to the structure similarity. SSIM mainly combines image similarity in the aspect of contrast, brightness, and image structure. SSIM has frequently proved that its performance is much better than MSE and other metrics, and it has gradually become a general standard for evaluating the quality of reconstructed images.
The value of SSIM is between 0 and 1. Larger SSIM indicates better image quality, as well as a higher structural similarity between the target image and the reference image. The calculation formula of SSIM is shown in equation (10)
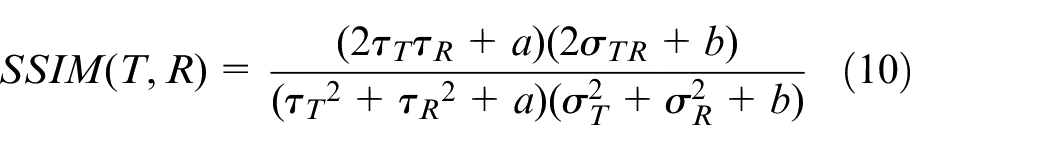
where
The influence of the number of shuffle blocks on the reconstruction performance
ShuffleNet is proposed by Megvii Inc., a company owns the world’s leading AI algorithm, face recognition software, and hardware. ShuffleNet applies a CNN architecture that extremely computation efficient. As a result, it can even be used in mobile devices. One good advantage of ShuffleNet is the pointwise group convolution layer and channel shuffle. This dramatically reduces the calculation of the model while maintaining sharpness. The basic unit is improved on the basis of a residual unit. It manages to obtain lower top-1 error on ImageNet classification and achieves 13 times actual speedup as many as AlexNet while maintaining comparable accuracy.
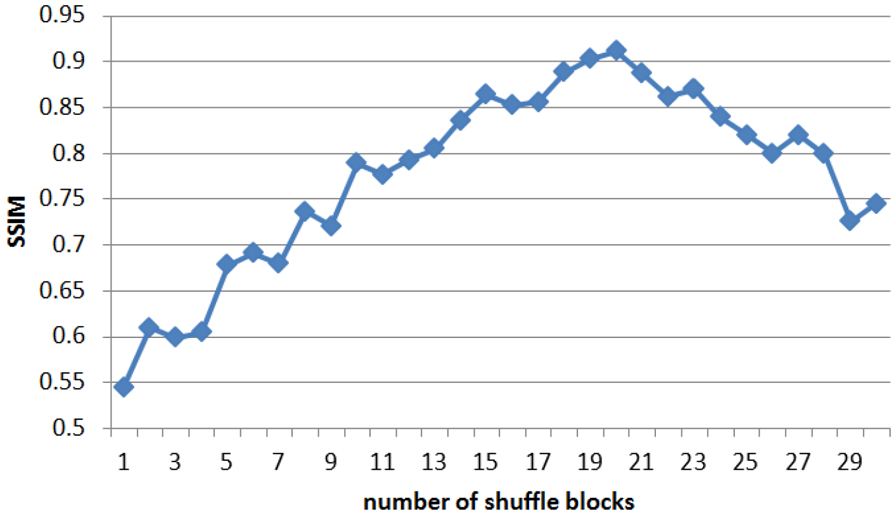
In this section, we carry out experiments to decide how many shuffle blocks should be employed in the SB-SRGAN and to see how does it affect the SR image quality. The number of shuffle blocks is set from 1 to 30, with the structure GConv + channel shuffle + DWConv + GConv + ReLU. The convolution layer and the deconvolution layer before and after the shuffle connection structure both contain 64 convolution kernels with a size of
For the convenience of model training, we set the Adam learning rate to 0.01 and the batch size for each training step to 32. We randomly pick 2000 images from each of the three face datasets to form a mixed dataset with 6000 face images. Then, we divide the mixed dataset into the training set, validation set, and testing set according to the proportions of 50%, 10%, and 40%, respectively. The impact of the number of different shuffle blocks on the PSNR and SSIM of SR images is demonstrated in Figures 5 and 6.
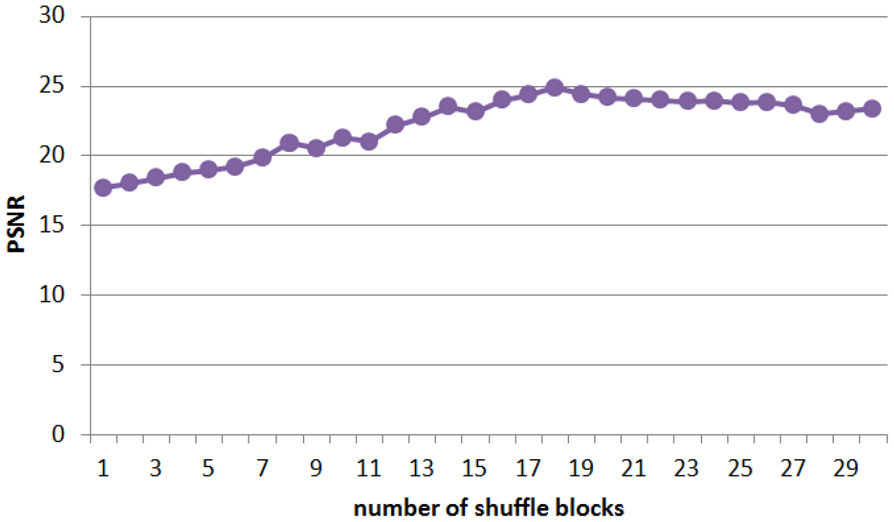
PSNR results affected by the number of shuffle blocks.
SSIM results affected by the number of shuffle blocks.
As can be seen from Figures 5 and 6 that with the growth of the number of shuffle blocks, the values of PSNR and SSIM also change to different degrees. When the number of shuffle blocks is small, the trained SB-SRGAN model is vulnerable. When the number gets too large, the PSNR and SSIM can also decline. It is because when the number of shuffle blocks is too small, the advantages of the model cannot be reflected. While the number is too big, it will lead to an enormous solution space of the model, which means the model is difficult to converge to its optimal.
As the number of shuffle blocks increases, the PSNR and SSIM of the model begin to increase. When the number of shuffle blocks increases to 18, PSNR reaches the maximum. Then, with the increase in the number, PSNR began to decrease slightly. For SSIM, when the number of shuffle blocks reaches 20, the SR reconstruction of face image achieves the best result. However, SSIM under 18 shuffle blocks and 20 shuffle blocks are close. As a result, the block number we choose in our experiment is 18.
The influence of the number of training samples on the reconstruction performance
In this section, to study how the size of the training set affects the performance of SB-SRGAN, experiments are carried out on different training sizes. As shown in Figure 7, when the amount of the training set changes from small to large, the SR reconstruction effect of face image will be enhanced. When the face image data set size reaches a certain degree, the growth rate becomes flat, and the reconstruction curve based on PSRN becomes smooth. From this experiment, we can infer that the increase in the number of training samples can intensify the model ability to a certain extent. Due to the model training time complexity, it is necessary to consider the appropriate training size.
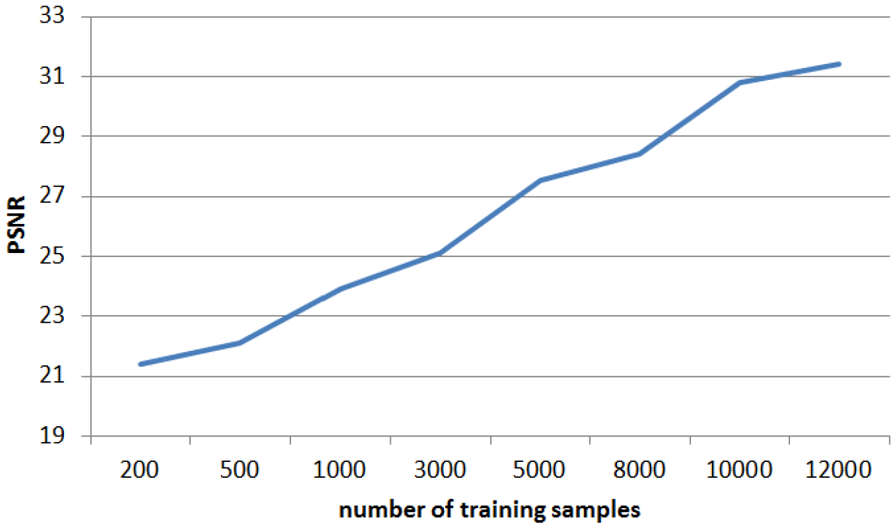
PSNR results based on different training sizes.
Face image SR reconstruction results
To test the performance of the SB-SRGAN, we select three deep learning-based image SR reconstruction models for comparative experiments, the traditional GAN model, SRCNN model, 11 and SRGAN. 13 The four models are trained on the preprocessing images sets from the three face image datasets. The number of images in the training set, testing set, and validation set can be found in Table 1. We choose some examples to show the comparison of the SR reconstruction results, which are shown in Figure 8.

Examples of original HR image, LR image, the generated SR images by traditional GAN, SRCNN, and SB-SRGAN (from left to right).
As it is demonstrated in Figure 8, we pick different types of face images, including those people with covers (wearing hats), with side face, with different facial expressions and skin colors, and with distinct clarity of the original image as well. From the left column to the right, it indicates the original HR image, and the downsampled LR image, SR reconstruction image generated by traditional GAN, SRCNN, and SB-SRGAN. It is apparent to see that the reconstructed face image via SB-SRGAN has a higher image quality with better image resolution and sharp lines and edges in the image. The details of the human face, including the eyebrows, eyes, wrinkles, mouth, hair, and so on, in the face image generated by the SB-SRGAN are more visible than those produced by the other two models. Therefore, SB-SRGAN proposed in this paper is superior to the traditional GAN in terms of visual perception. Also, it is comparable to SRCNN, with more noticeable details.
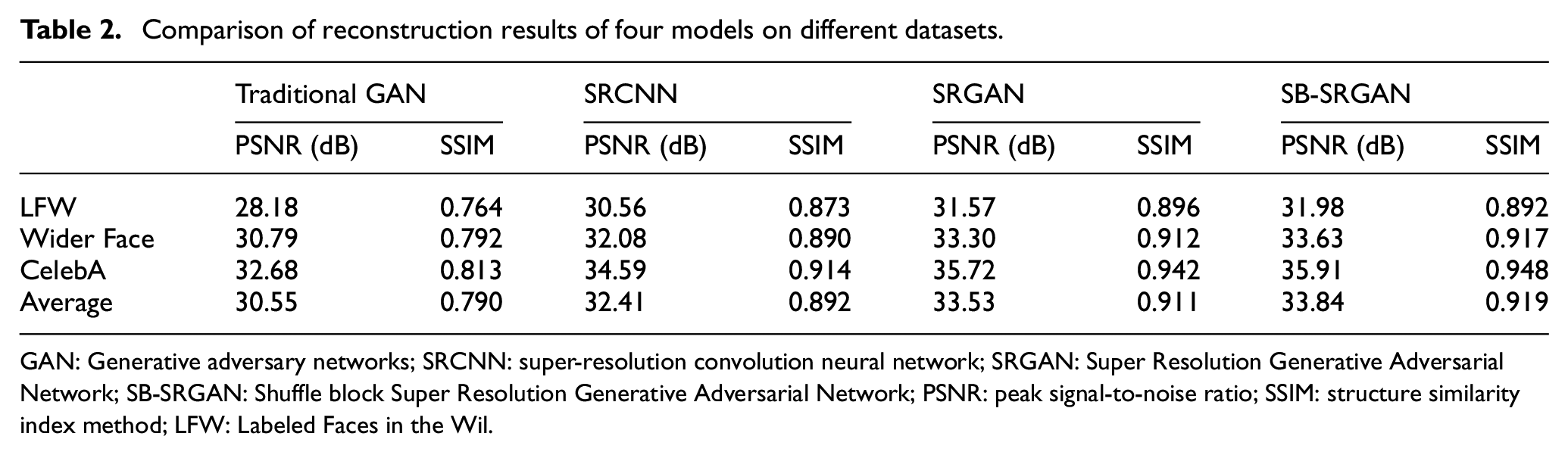
In addition to the subjective perception evaluation, this paper compares the performance of three models in diverse datasets in regard to PSNR and SIMM. To accelerate the convergence speed of the model, we implement the transfer learning strategy during the training processes. First, an initial model is trained using random initialization on LFW data. Then, the initial model is utilized to initialize the parameters of other models trained on Wider Face and CelebA. All the layers except the last three layers are frozen, and training is continued for 100 epochs. Then, all layers are unfrozen and the training process is continued until the model converges. The performance of the four models on different datasets is presented in Table 2.
Comparison of reconstruction results of four models on different datasets.
GAN: Generative adversary networks; SRCNN: super-resolution convolution neural network; SRGAN: Super Resolution Generative Adversarial Network; SB-SRGAN: Shuffle block Super Resolution Generative Adversarial Network; PSNR: peak signal-to-noise ratio; SSIM: structure similarity index method; LFW: Labeled Faces in the Wil.
As shown in Table 2, compared with the traditional GAN, SRCNN improves PSNR by 1.86 dB on average, with an improvement rate of 6%, and improves SSIM by 0.038, with an improvement rate of 12%. Compared with SRCNN, SB-SRGAN improves PSNR by 1.43 dB on average, with a rate of about 4.41%. And it improves SSIM by 0.027 at a rate of about 3.03%. And compared with SRGAN, SB-SRGAN slightly improves PSNR by 0.93% and SSIM by 0.088%. It can be seen from the results that SB-SRGAN proposed in this paper is much better than the traditional GAN and SRCNN in the SR reconstruction of face image and slightly better than SRGAN. From the perspective of different datasets, the LFW database-based model has the worst performance because it has the least training samples and only uses the method of random initialization. From the experimental results on different datasets, it can be seen that transfer learning improves the performance of the model to some extent. For example, when using LFW as a training set, the model is trained without the transfer learning strategy. Therefore, the performance in LFW is the lowest among the three datasets. When applying transfer learning on Wider Face and CelebA datasets, the model converge speed has increased, and the model performance has also been improved. This is because transfer learning makes the features learned in other datasets reused by fine-tuning in the new datasets.
Conclusion
We have introduced shuffle block GAN, namely SB-SRGAN, which makes use of the shuffle blocks to accomplish efficient image SR reconstruction. We changed the content loss function by considering the generated image clarity. We tested our model on three public image face datasets and evaluated it with SSIM and PSNR metrics. Besides, transfer learning has been applied during the training process. We compared our model to three deep-learning-based SR networks. The experimental results have confirmed the advantage of SB-SRGAN.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (No. 61802410), and the Chinese Universities Scientific Fund (2018XD002 & 2018QC024).