
Abstract
Power allocation plays an important and challenging role in fuel cell and supercapacitor hybrid electric vehicle because it influences the fuel economy significantly. We present a novel Q-learning strategy with deterministic rule for real-time hybrid electric vehicle energy management between the fuel cell and the supercapacitor. The Q-learning controller (agent) observes the state of charge of the supercapacitor, provides the energy split coefficient satisfying the power demand, and obtains the corresponding rewards of these actions. By processing the accumulated experience, the agent learns an optimal energy control policy by iterative learning and maintains the best Q-table with minimal fuel consumption. To enhance the adaptability to different driving cycles, the deterministic rule is utilized as a complement to the control policy so that the hybrid electric vehicle can achieve better real-time power allocation. Simulation experiments have been carried out using MATLAB and Advanced Vehicle Simulator, and the results prove that the proposed method minimizes the fuel consumption while ensuring less and current fluctuations of the fuel cell.
Introduction
Energy shortage, air pollution, and global warming have pushed the development of fuel cell (FC)-driven vehicles to replace pure fuel–driven vehicles.1–4 However, possessing quick dynamic response and load-following ability is difficult for current FC. 5 Furthermore, rapid load variation has bad effects on the lifetime of FC. 6 Thus, pure FC vehicles are still in their early development stages, which will probably last for the next decade. A hybrid propulsion, such as the supercapacitor (SC), with fast charge/discharge attributes, long life cycles, and high power density seems to be the most economical and feasible solution so far. Hybrid electric vehicles (HEVs) composed of the FC and the SC may be a good choice. When HEV is in braking, climbing, or acceleration condition, SC can be used as a power buffer,7–9 and the combination of FC and SC as the hybrid propulsion is an efficient way to overcome the slow dynamic response and rapid load variation while achieving braking energy recovery.10,11 How to control the energy flow between the hybrid FC/SC has been the core issue.
Literature review
The conventional energy management method can be generally classified into the following two trends: rule-based and optimization-based. 12 The former strategy can be subdivided into deterministic and fuzzy rule–based methods, while the latter can be subdivided into off-line global and real-time optimization–based methods. The deterministic rule methods are the most direct and widely used strategy with easy implementation and low calculation burden. Jalil et al. 13 proposed a rule-based strategy in which the power demand is allocated between the engine and the battery, by which those power sources can be used efficiently. The proposed rules ensure efficient operation of the engine and battery at any situation, but it is applicable only in series hybrid structure because of its simplicity. In the study by Phillips, 14 a type of state machine was utilized to supervise the control of a more general parallel HEV; however, in terms of achieving the goals of fuel economy and emission reduction, it has not gained good performance optimization. To further realize improvement of the performances of energy management system (EMS) for HEV, literally, fuzzy logic and their modified variants, instead of using deterministic rules, seem to be the most effective way to solve the problem of robustness and adaptability,15–17 because they are not only tolerable to fuzzy measurement but also easy to adapt, if necessary. Multi-objective optimization strategies based on fuel economy, FC lifetime and so on are also researched widely and have obtained good simulation results.18–20 These rule-based control strategies are optimized by minimization of a loss function generally representing the control objectives under a fixed driving cycle, which means a prior knowledge of a predefined driving cycle is used. Obviously, they cannot be directly used in real-time energy management. Recently, several optimization-based methods, such as real-time control based on equivalent fuel consumption, were proposed to develop a loss function in instantaneous optimization.21–23 Model predictive control 24 and dynamic programming25,26 have also been widely used to develop the advanced on-line EMS. Furthermore, to obtain a prior knowledge of driving cycle, we 27 proposed a driving pattern recognition–based EMS using neural network, which also achieved real-time control while accomplishing less current fluctuation and fuel consumption. Intelligent algorithms have developed rapidly in recent years, and the learning-based energy management method has been considered as a viable solution to apply decision and control problems in electric power system. 28 A learning-based EMS aims to take appropriate actions automatically according to the states, not relying on any manual predefined rules, and converges to an optimal policy without any optimization algorithms. In addition, the learning-based EMS has shown its self-learning ability to adapt to different driving conditions.29–31 Statistical learning method is a significant way to optimization approach, and related studies may help to improve the robustness of the EMSs.32–34
Motivation and innovation
The main goal of this study was to propose a novel Q-learning strategy with deterministic rule (QLDR) for real-time HEV energy management that satisfies the driver’s demand for traction power while achieving decreased fuel consumption and load fluctuation. In particular, we focus on improving the Q-learning (QL)-driven agent’s adaptation to different driving cycles. The main contributions of this paper are as follows. (1) To reduce the load fluctuation of the FC, we innovatively propose two optional sets of the maximum FC power output, which will be selected by the deterministic rule. The smaller set is for the general driving conditions that are frequently used. And the alternative set is provided for extreme driving conditions like continuous high power demand, which will only be used when these extreme situations occur. (2) The deterministic rule is combined with the QL policy to further improve the adaptation to different driving conditions. (3) To realize less fuel consumption, we manage to keep the best Q-table with minimal fuel consumption and maintain the state of charge
Organization of this paper
The structure of this paper is as follows. Section “HEV energy system” describes the power-train of the HEV system and the modeling of the FC and SC. Then the HEV energy optimization problem is formulated. Section “QL-based HEV energy optimization” describes the key concepts of QL in HEV energy management control. Then the proposed QLDR algorithm is designed and the real-time energy management strategy is provided. The evaluation results of the proposed method are shown in section “Simulation results,” and section “Conclusion” concludes the paper.
HEV energy system
In this section, we first describe the power-train of the HEV system. Then the modeling of the FC and SC is achieved. Finally, we present how the HEV energy optimization problem formulates.
Power-train description
The power-train of the HEV energy system is shown in Figure 1, where the black and red arrows represent the control signals and the direction of power flow, respectively. The power demand of the HEV can be satisfied by controlling the direction of the power flow between the FC stack and the SC storage. By means of the proposed QLDR, the power supply required is derived, which is packed as signals sent to the corresponding energy source. Among the energy components, the FC is used as the primary power source. The SC, with the characteristics of fast charge and discharge, is equipped as a power buffer for leveling the peak power during cold start and hard acceleration and for recovering the braking energy. The
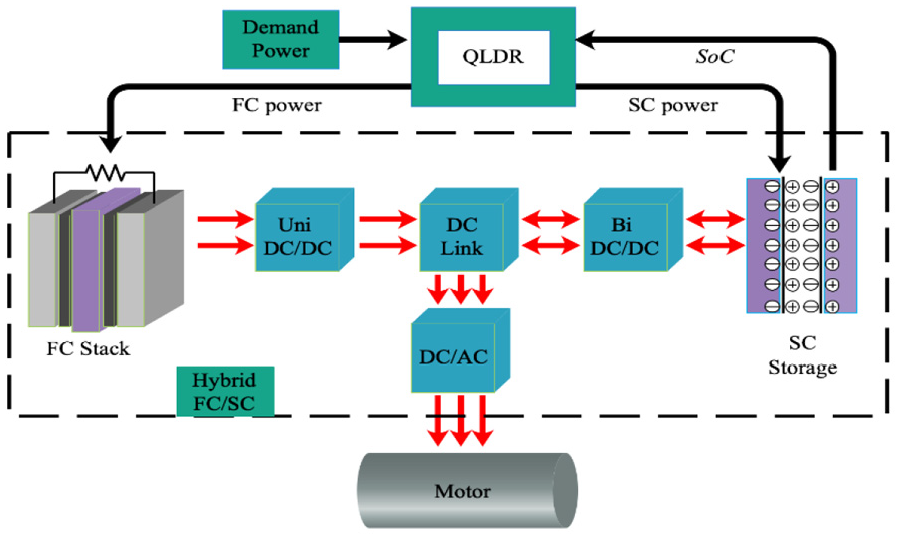
The power-train of the HEV energy system.
The modeling of the FC and the SC
1. FC model: To calculate the output power of the FC, we need to obtain the output voltage of the FC
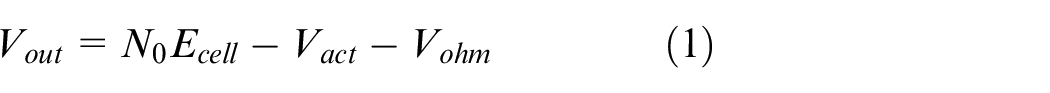

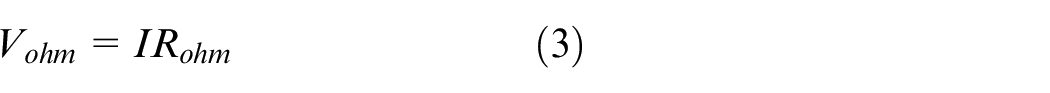
where
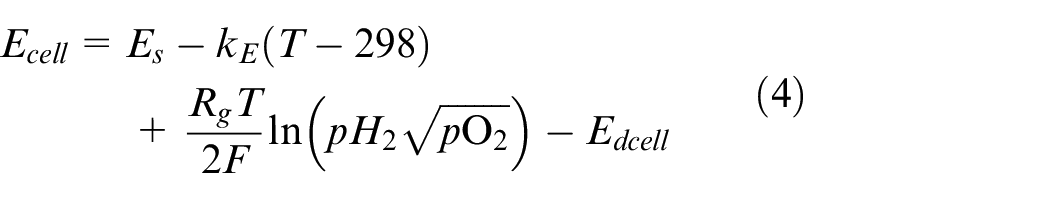
where

where

where
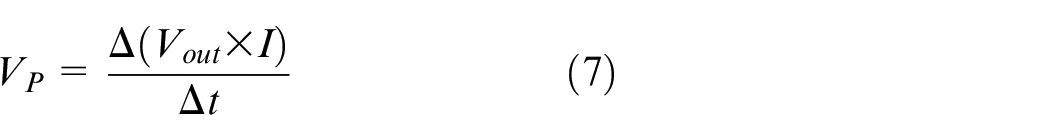

2. SC model: We use the resistor–capacitor circuit model to emulate the internal part of the SC, which is described in Figure 2.
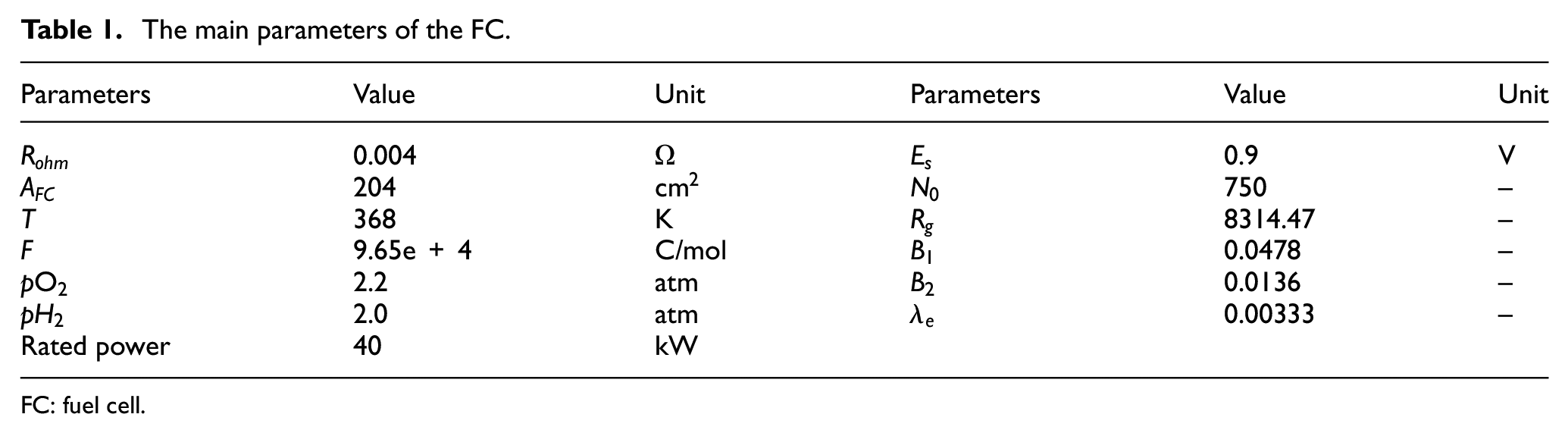
The main parameters of the FC.
FC: fuel cell.
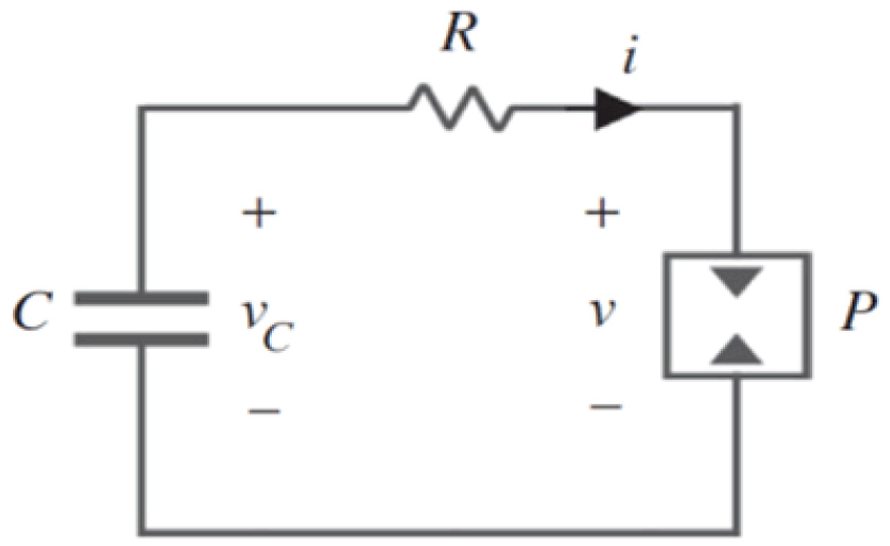
SC internal model.
In Figure 2,
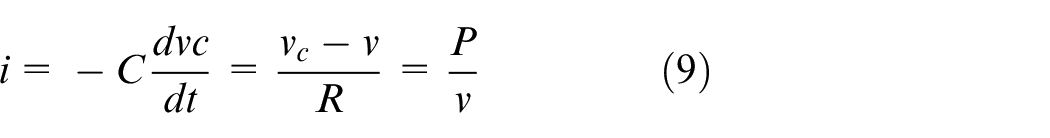
Provided that the impedance matching is satisfied in this model, the SC is capable of supplying maximum power, which is derived by:
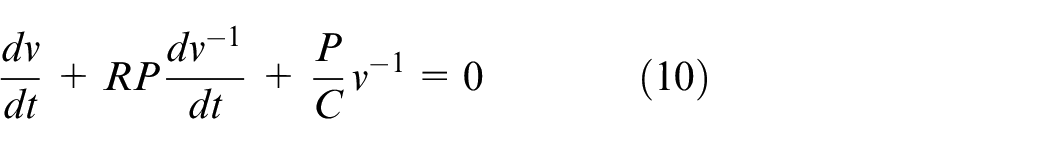
Ignoring the negligible impact of the internal resistor, the
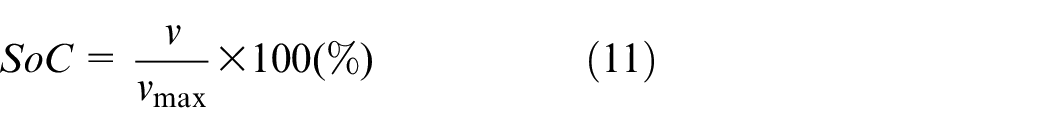
where
The main parameters of the SC per cell.

SC: supercapacitor.
Problem formulation
The HEV energy optimization problems are formulated in four perspectives. First, unlike the pure fuel–driven vehicle, the power shortage phenomenon of HEV may occur in accelerated or heavy load condition because of the slow response of the FC. Second, the fuel economy is an essential optimizing goal which is reflected on the effectiveness of regenerating braking energy. Third, the
To sum up, our essential goal is to meet the power demand of the HEV and minimize the H2 fuel consumption. At the same time, we ought to reduce the current fluctuation of the FC to prolong its lifetime. The essential solution to these goals is to manage the power flow between FC and SC in real time. This is elaborated in the following sections.
QL-based HEV energy optimization
Reinforcement learning is introduced as the theoretical foundation of the proposed QLDR strategy. We first describe the key concepts of QL in HEV energy control. Then, a deterministic rule is designed and combined in the QL controller. Finally, the proposed QLDR real-time energy management strategy is given in this section.
QL in HEV energy control
Given an episode under the defined driving cycle, that is, the time-continuous sequence of the power demand from the HEV, the goal of the proposed algorithm is to complete the power allocation by satisfying the power demand while keeping the SoC of SC in the safe range and saving the H2 fuel consumption. To accomplish this, QL is introduced as the baseline to carry out energy management. QL belongs to the reinforcement learning family that learns by interacting with the environment. During the learning process, the QL-driven controller observes the state of the power system, such as the power demand and SoC of SC; then performs the action of power split between FC and SC; and calculates the reward value by assessing the safety range of SoC of SC. Finally, the value function that accumulates the total rewards over time is updated. When the value function converges, the learning process ends and the control policy is obtained. Using this connection can produce a lot of information about causality, behavioral consequences, and what should be done for higher rewards and achieving goals. To further explicate the QL in HEV energy control, the key concepts applied in the proposed QLDR are formulated.
Policy
A policy assigns how learned agents behave in a given state. In other words, the state of the environment is perceived first, and then the strategy is mapped to the actions to be taken in these states. The policy is generated from the Q-table, that is, a lookup table filled with value functions. Specifically, the Q-table is represented by a simple two-dimensional array that contains the SoC of SC and split coefficient of power demand to FC. When the agent is in one of these states, by checking the maximum value function of the state in the Q-table, the corresponding action is selected and performed.
State space definition
The instantaneous
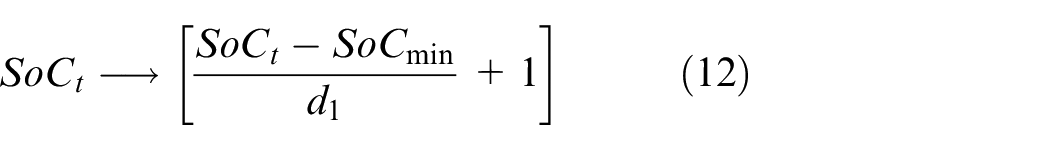

where
Action space definition
We choose the output power of the FC,
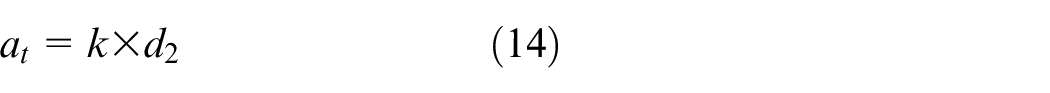
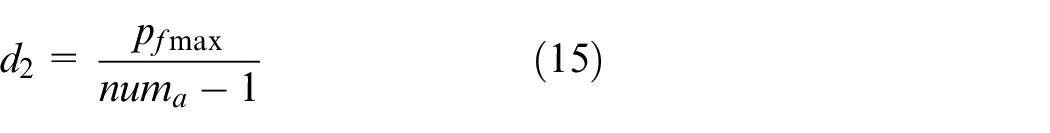
where
Reward definition
Immediate reward evaluates the effect of the action at the current state. The control objectives of the HEV are to satisfy the power demand and minimize the fuel consumption, which can be summarized as maintaining the
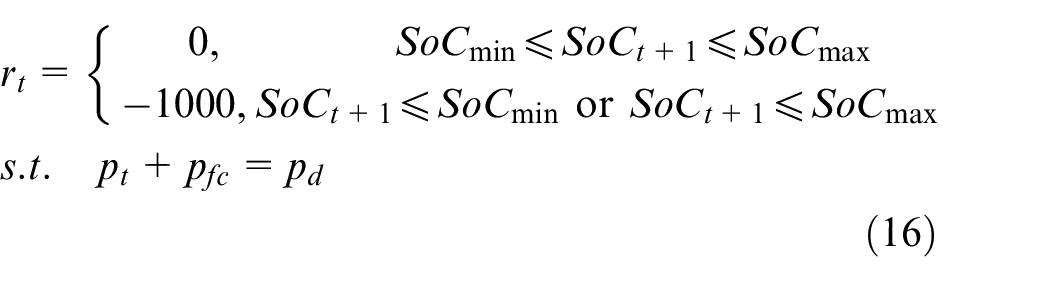
where pd is the power demand, pt is the output power provided by the SC, and pfc is the output power of the FC.
Value function
Value function is an estimation of future total rewards at state
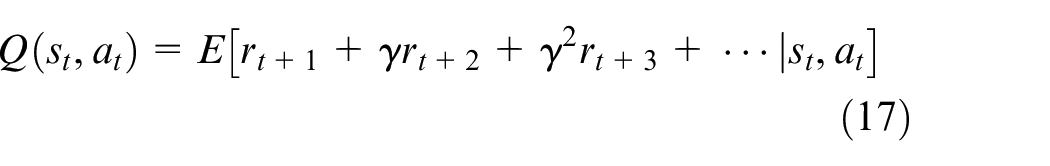
where
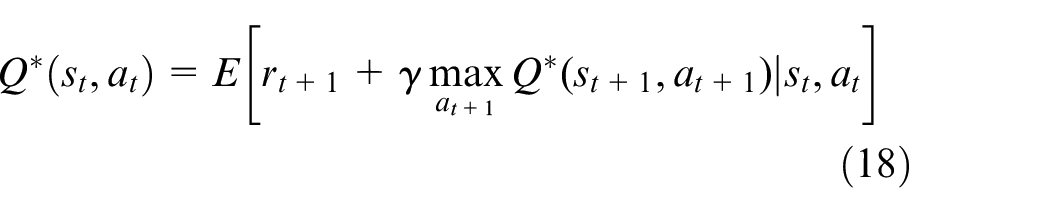
where the first part is the immediate reward
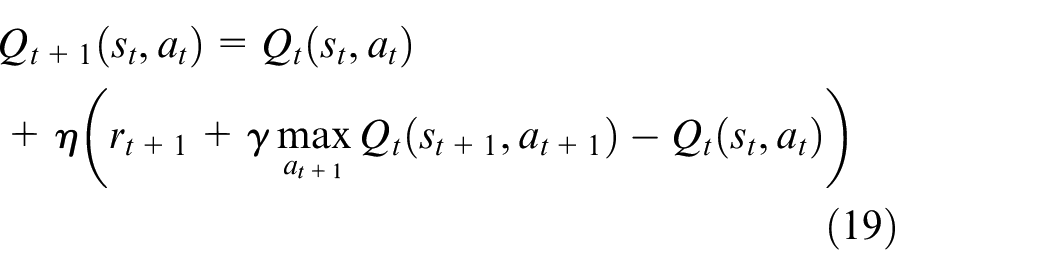
Algorithm design
The proposed QLDR for HEV energy management is presented in Algorithm 1. The Q-table is initialized by 0, which means the power demand is provided by the FC in default, and the learning process maximizes the reward function by tuning the action of SC. The outer loop represents the number of training epochs to update the value function, while the inner loop describes energy management policy at each step within the episode duration. The maximum number of the training epochs is set as

Real-time energy management
The proposed QLDR for HEV energy management in section “Algorithm design” is implemented off-line, which means the agent is trained under the specific driving cycle. However, because of applying the deterministic rule, the converged agent is adaptive under different driving cycles for real-time EMS. For example, the agent is trained under the urban dynamometer driving schedule (UDDS) episode and then applied directly in the highway fuel economy certification test (HWFET) episode. Unlike the traditional driving cycle recognition–based algorithms, the proposed HEV energy management algorithm is a lightweight and high real-time method that does not depend on the driving pattern recognition. We aim at controlling the
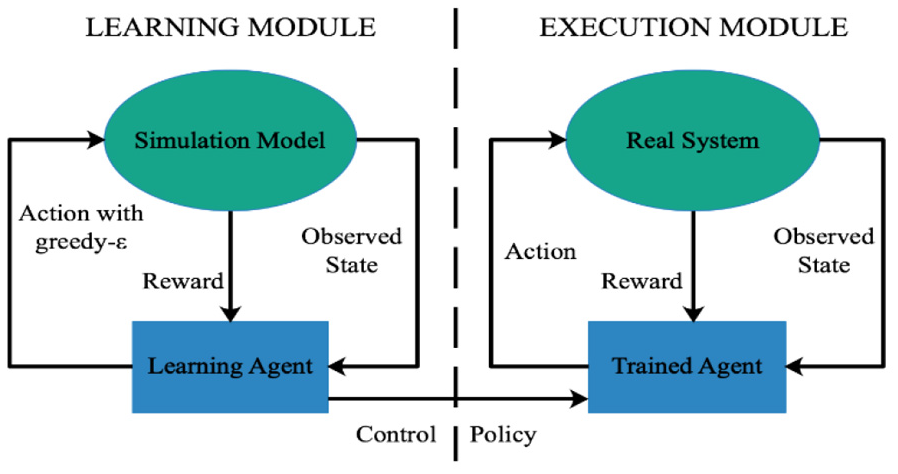
Framework for power system decision and control in QLDR.
As we can see, there is a little difference between the learning module and the execution module. In the simulation environment, the agent tries to explore more information by action with the
Simulation results
Off-line training
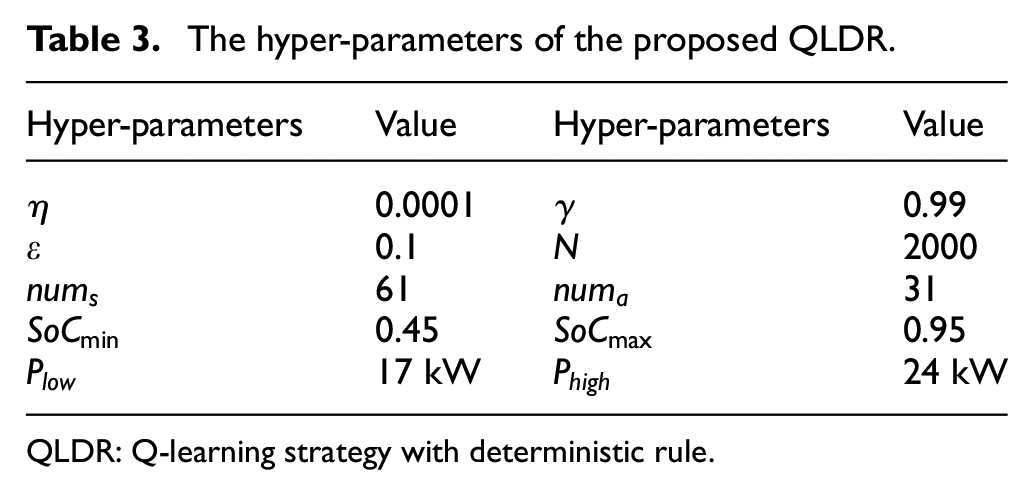
To verify and evaluate the effectiveness of the proposed QLDR algorithm, this study uses the joint simulation environment of MATLAB and Advanced Vehicle Simulator (ADVISOR) to carry out simulation experiments. The main hyper-parameters of the QLDR algorithm involved in the simulation are summarized in Table 3. The specific values of the hyper-parameters are obtained by trial and error—especially the number of states and actions, which should be set carefully by trial and error because if the number is too small, the controller accuracy is too low; on the contrary, the calculation complexity is too high. In addition, it is worth mentioning that the value of
The hyper-parameters of the proposed QLDR.
QLDR: Q-learning strategy with deterministic rule.
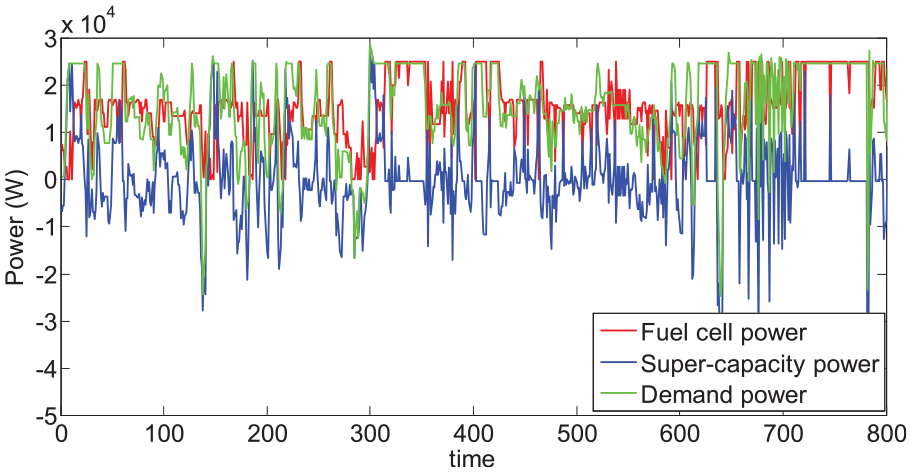
Power allocation of the power demand off-line.
The error distribution between the power demand and the hybrid FC/SC output power is shown in Figure 5. It is obvious that the QL-based controller acts well to satisfy the power demand with slight deviation. The
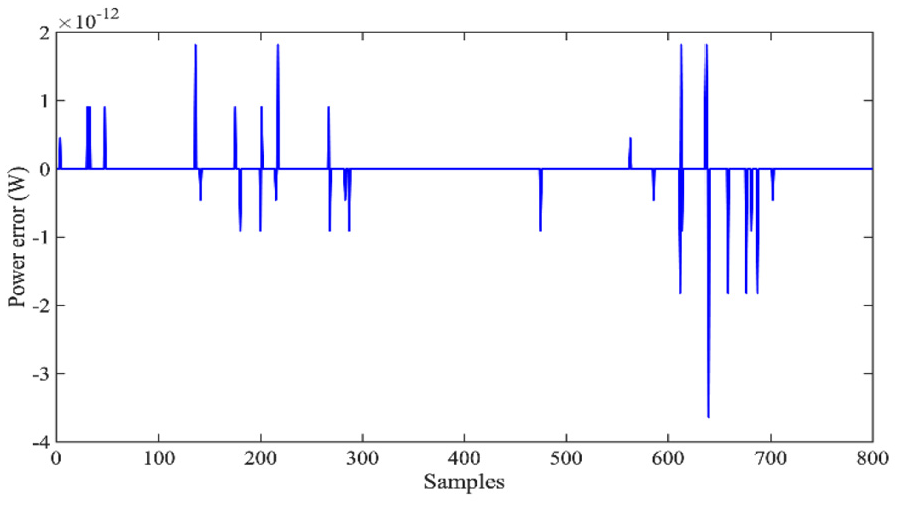
The power error distribution off-line.
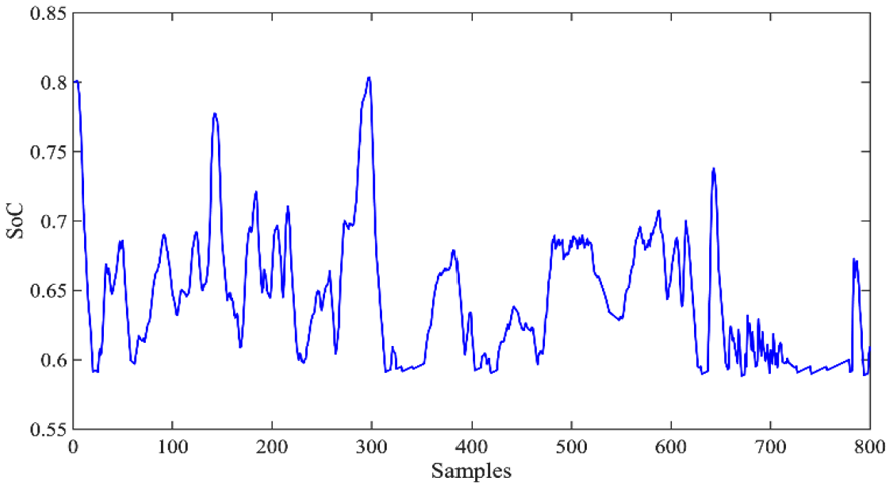
The SoC of the SC off-line.
Real-time application
In the real-time application, the trained agent under HWFET was directly tested under the four typical driving cycles mentioned by the Environmental Protection Agency (EPA). They are congested urban roads, flowing urban roads, and subway and highway, which are represented by Manhattan bus drive cycle (MBDC), EPA urban dynamometer driving schedule (UDDS), West Virginia suburban driving schedule (WVUSUB), and HWFET, correspondingly. The characteristics of each driving cycle are described in Table 4.
Four typical driving cycles.

MBDC: Manhattan bus drive cycle; UDDS: urban dynamometer driving schedule; WVUSUB: West Virginia suburban driving schedule; HWFET: highway fuel economy certification test.
The simulation results under the four combined driving cycles are provided in the following figures. Figure 7 gives the real-time power allocation of the power demand. The error distribution between the power demand and the hybrid FC/SC output power is shown in Figure 8. It can be seen that the error is within [−4 × 10−12, 4 × 10−12], which means that the proposed QL-based controller performs well on-line to satisfy the power demand with the slight deviation.
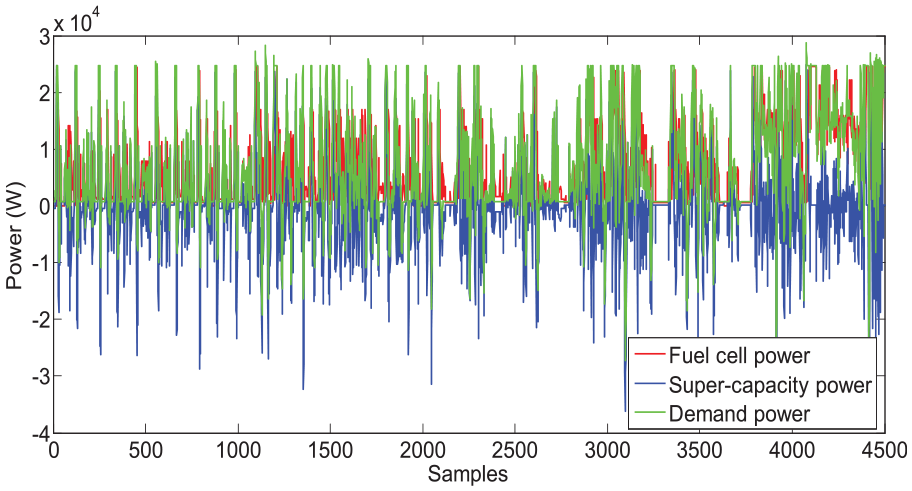
Power allocation of the power demand on-line.
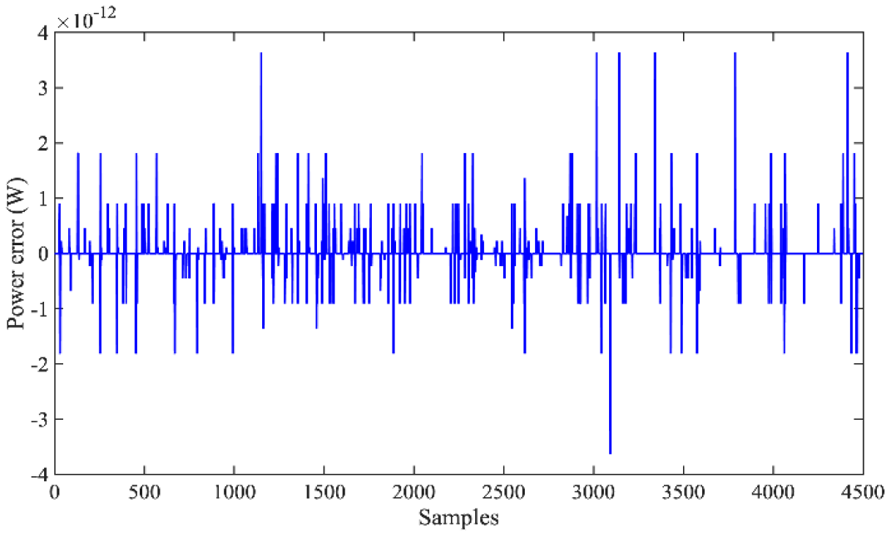
The power error distribution on-line.
Figure 9 shows the real-time
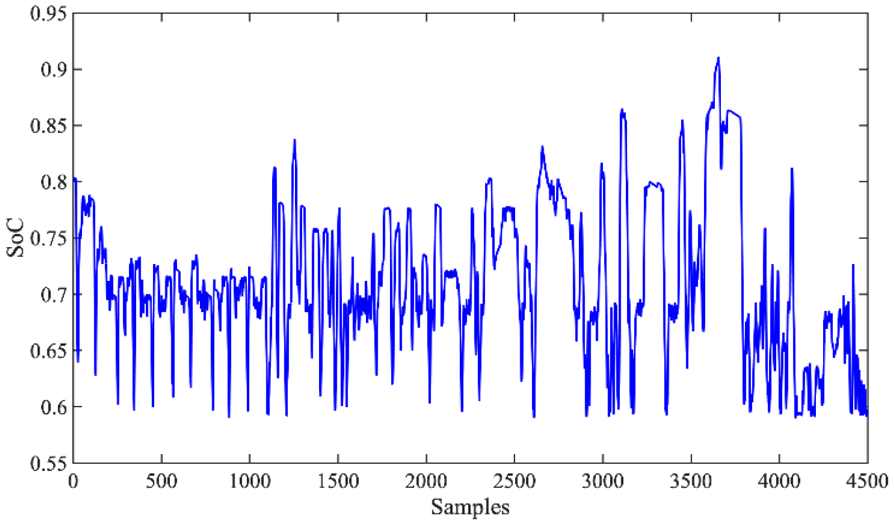
The SoC of the SC on-line.
Performance comparison
To evaluate the superiority of the proposed QLDR, the adaptive fuzzy-based algorithm in EMS
27
and the pure QL-based control strategy have been selected for comparison. For effective comparison, the maximum power output of the FC in the pure QL algorithm is set as either 17 kW, that is, 17 kW QL or 24 W, that is, 24 kW QL, as the deterministic rule defines. Two aspects of the simulation are taken into consideration, including the adaptation to the complex driving cycles and the optimization of the FC’s load and current fluctuation. First, as we can see in Figure 10, the
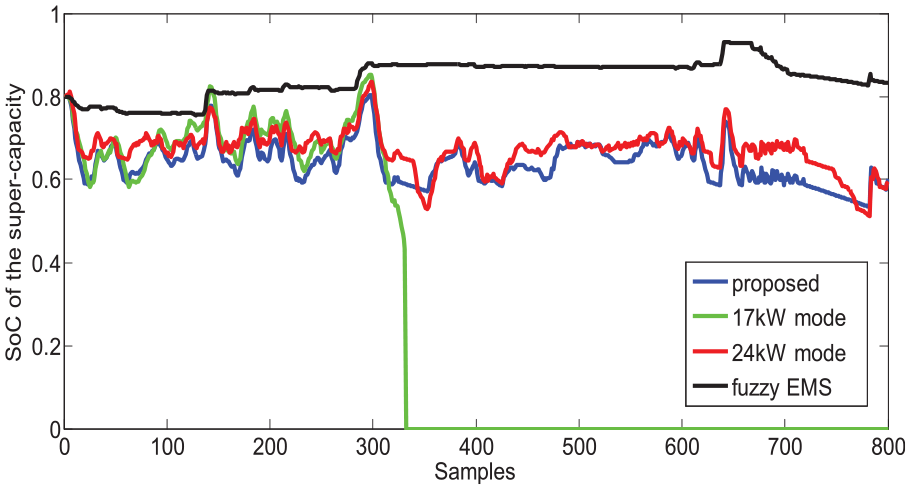
SoC of the SC.
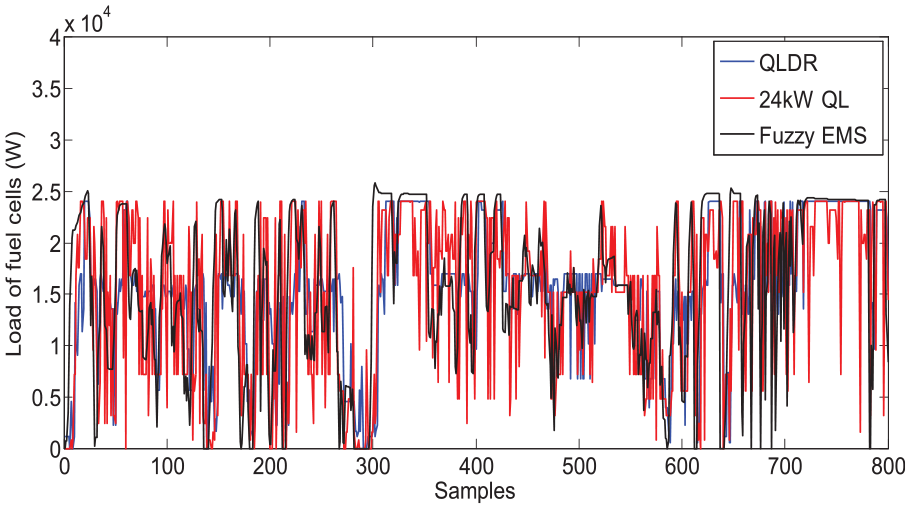
Load of the FC.
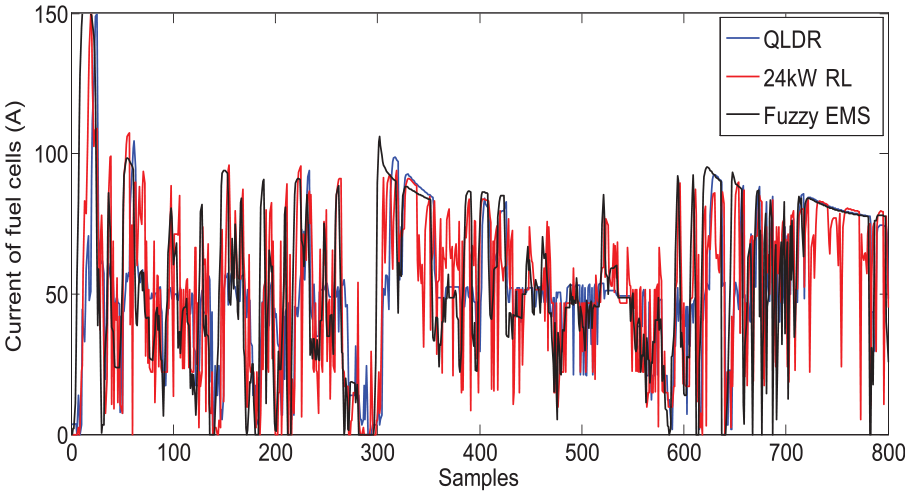
Current of the FC.
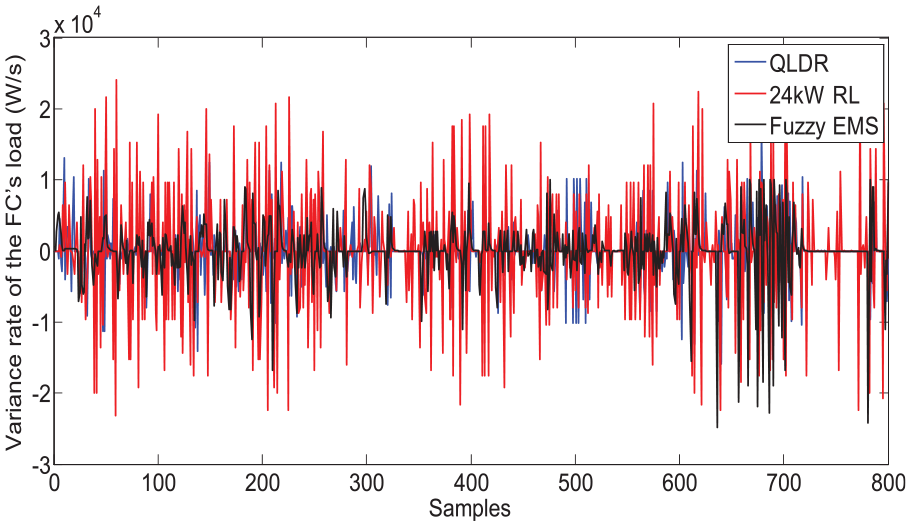
Variance rate of the FC’s load.
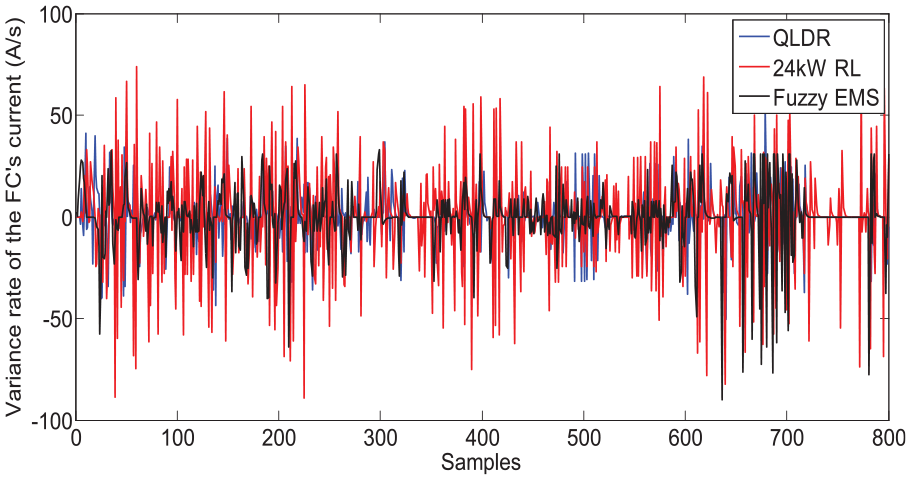
Variance rate of the FC’s current.
The RMS of the variance rate in the FC’s load and current for three methods.

RMS: root mean square; FC: fuel cell; QLDR: Q-learning strategy with deterministic rule; QL: Q-learning; EMS: energy management system.
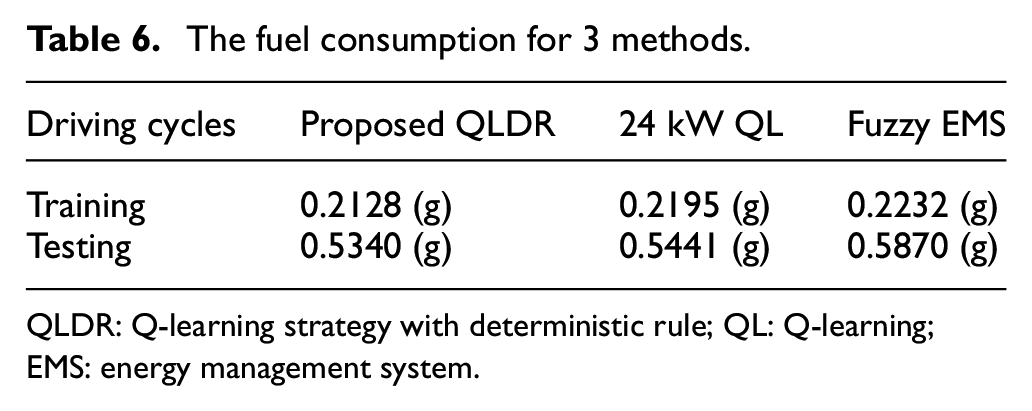
In addition, comparisons have also been performed by the three methods by taking into consideration the fuel economy. The contrastive experiments are carried out on the share dataset, that is, HWFET driving cycle for the training and combined driving cycles for the testing. The results are described in Table 6, where we can find that a small progress in the fuel consumption has been achieved by the proposed method compared to the 24 kW QL, but 9.03% of the fuel consumption is saved when compared to the fuzzy EMS, which further proves the effectiveness of the deterministic rule to QL and the superiority of the proposed method to the fuzzy EMS.
The fuel consumption for 3 methods.
QLDR: Q-learning strategy with deterministic rule; QL: Q-learning; EMS: energy management system.
Conclusion
In this work, a novel QL method with deterministic rule is proposed for the real-time HEV energy management. To enhance the adaptation to different driving cycles, especially the extreme conditions, the deterministic rule is applied to the conventional QL algorithm as a complement to the policy. What’s more, by employing two optional sets of the maximum FC output power, which is determined by the deterministic rule, less load and current fluctuation of the FC are achieved because the smaller set of maximum output power will limit the fluctuation. The proposed algorithm is trained under the HWFET driving cycle and tested under four typical combined driving cycles. Simulation results illustrate that compared with the driving pattern–based fuzzy logic controller, the proposed QL-driven controller is more lightweight and effective. More importantly, 9.03% reduction of the fuel consumption and less load and current fluctuation of the FC have been achieved, which help to improve the fuel economy and prolong the lifetime of the FC. In addition, to prove the superiority of the proposed QLDR to the conventional QL algorithm, simulation has been conducted for performance comparison. The results show that there is small difference in the fuel consumption, but the load and current fluctuation of the FC have been greatly reduced by applying the deterministic rule. In the future, to face the open environment, instead of taking the power demand of the HEV as the only factor, information on more driving conditions including driver’s behavior will be taken into consideration to make the EMS perform well under more complex driving conditions. Moreover, the uncertainties in the system, such as the difference between the training model and the real model, will be researched in depth.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the National Natural Science Foundation of China under Grant 61603337 and the Zhejiang Province Natural Science Fund under Grant LY19F030009, Ningbo Science, and Technology Innovation 2025 Major Projects (2019B10109, 2019B10116).