
Abstract
Workpiece quality prediction is very important in modern manufacturing industry. However, traditional machine learning methods are very sensitive to their hyperparameters, making the tuning of the machine learning methods essential to improve the prediction performance. Hyperparameter optimization (HPO) approaches are applied attempting to tune hyperparameters, such as grid search and random search. However, the hyperparameters space for workpiece quality prediction model is high dimension and it consists with continuous, combinational and conditional types of hyperparameters, which is difficult to be tuned. In this article, a new automatic machine learning based HPO, named adaptive Tree Pazen Estimator (ATPE), is proposed for workpiece quality prediction in high dimension. In the proposed method, it can iteratively search the best combination of hyperparameters in the automatic way. During the warm-up process for ATPE, it can adaptively adjust the hyperparameter interval to guide the search. The proposed ATPE is tested on sparse stack autoencoder based MNIST and XGBoost based WorkpieceQuality dataset, and the results show that ATPE provides the state-of-the-art performances in high-dimensional space and can search the hyperparameters in reasonable range by comparing with Tree Pazen Estimator, annealing, and random search, showing its potential in the field of workpiece quality prediction.
Keywords
Introduction
Workpiece quality prediction is very important in manufacturing industry since defects not only have negative impacts on the products quality but also could reduce the sales volume and even cause irreparable losses to the enterprises. 1 With the development of smart manufacturing, the automatic prediction of workpiece quality has been vital, and many machine learning (ML) methods have been applied effectively on the prediction of workpiece quality. 2
However, though most ML methods have been successfully applied in manufacturing industry, their performance heavily relies on the hyperparameters. 3 Since default hyperparameters cannot guarantee the performance of ML models, 4 tuning the hyperparameters becomes the essential process for ML methods. Various tuning approaches, such as trial and error, manual search, are developed to obtain the best configuration of hyperparameters. But they still face the following barriers: (1) Tuning hyperparameters is mostly dependent on experts’ experience and tedious episodes of trial and error, making it very time-consuming and labor-intensive. (2) The tuning process has to be repeated when applied to a new dataset; it is hard to decide the tuning range of the hyperparameters. (3) The combinations of hyperparameters are innumerable in high dimension, which is hard to find its best combination. So the tuning process is very time-consumption and labor-intensive, and the results of tuning process is easy to converge to the suboptimal hyperparameters configuration.
To overcome above drawbacks, some approaches are investigated to tune the hyperparameters in the automatic way, and they are denoted as the hyperparameter optimization (HPO). The most prominent HPO approaches are grid search, random search, and Bayesian optimization, and HPO has been applied into many fields. Shi et al. 5 applied grid search for few hyperparameters tuning in order to improve accuracy of monitoring tilt angle. Hao et al. 6 used Random Search to optimize serval control hyperparameters for efficiency. McParland et al. optimized hyperparameters for improvement of prediction of tool wear rates by Bayesian optimization. 7 Compared with trial and error and manual search, HPO methods are easy to use and also can achieve the state-of-the-art results in some tasks. HPO methods are effective and efficient, but they also need to be further improved when the hyperparameter spaces are complex, such as the hyperparameters space for workpiece quality prediction model is high dimension with continuous, combinational, and conditional types of hyperparameters, which is difficult to be tuned.
In this research, a new automatic machine learning (AutoML) based HPO is proposed for workpiece quality prediction, named adaptive Tree Pazen Estimator (ATPE). First, it models the tuning process to the sequential model-based optimization (SMBO), and it iteratively searches the promoting hyperparameter combination in the automatic way. Second, ATPE updates the width of search interval based on the historical information of HPO, and improves the warm-up process of Tree Pazen Estimator (TPE).
The main contribution of this article is proposing an adaptive warm-up process for TPE, named ATPE, which can automatically tune hyperparameters for workpiece quality prediction in high dimension. The proposed ATPE is tested on two datasets, MNIST and workpiece quality prediction dataset. The results show that ATPE can provide the state-of-the-art performance for HPO in high dimension by comparing with RS, annealing, and TPE.
The rest of this article is organized as follows. Section “Literature review” discusses the literature review. The next section introduces the “HPO based on AutoML.” Section “The proposed ATPE for HPO in high dimension” gives the methodologies of the proposed ATPE. Section “Case studies and results” shows the experimental results of ATPE on two datasets. Section “Conclusion and future researches” presents the conclusion and future researches.
Literature review
This section introduces the literature review about ML applications on quality prediction and AutoML based HPO.
ML applications on quality prediction
Automatic process monitoring methods have raised great concern in recent years because hand-crafted quality identification is tedious, time-consuming, laborious, and prone to errors and omissions. Many ML methods have been applied on the quality prediction in various fields. Scime and Beuth 8 used Decision Tree, Support Vector Machine for additive manufacturing quality identification; El Mazgualdi et al. 9 applied Random Forest, XGBoost, and Deep Learning for prediction of efficiency in manufacturing industry; Li et al. 10 and Zhang et al. 11 applied and showed that data-driven algorithms are highly effective tool for automatic feature extraction and quality monitoring performance.
However, even though there are a number of ML methods applications on workpiece quality identification and prediction,12,13 the performances of ML depend on its hyperparameters heavily. Since the models for workpiece quality prediction have complex hyperparameter space, the tuning process for workpiece quality prediction is challengeable, and it is promising to develop the automatic hyperparameters tuning process for workpiece quality prediction models.
HPO in AutoML
AutoML aims at using ML methods in a data-driven and automated way. In some cases, AutoMLs surpass human experts in some tasks. 14 HPO is the most popular task in AutoML, and the results have shown that the performances of ML can be improved by HPO.3,4
If the ML algorithm A has N hyperparameters to be optimized, the domain of the n-th hyperparameter denoted by
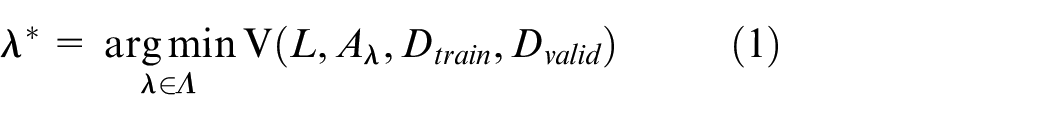
Many HPO methods have been investigated in the field, such as grid search, random search, evolutionary algorithms, and Bayesian optimization.
HPO methods are effective and efficient, but they also need to be further improved when the hyperparameter spaces are complex and high dimension in the applications on manufacturing industry. In this article, a new AutoML based HPO is conducted for workpiece quality prediction.
HPO based on AutoML
This section presents the workflow of HPO based on AutoML, introduces TPE, and explains the procedure to generate next promising point.
Workflow of HPO based on AutoML
The most promising framework for expensive black-box function optimization in AutoML is BO. It is an iterative algorithm and consists of two critical components, the probabilistic surrogate model and acquisition function. The workflow of HPO is presented in Figure 1.
Step 1: Initialize. Sample serval points from the configuration space and evaluate them.
Step 2: Fit data. Use the probabilistic surrogate model TPE (see in section “Tree pazen estimator”) to establish prior distribution and posterior distribution based on data D.
Step 3: Generate the next point. Obtain the next promising point
Step 4: Evaluate. Evaluate the chosen point by computing its objective function to get
Step 5: Update. Update the data D.
Step 6: Repeat step2∼step5 until sampling the required number of points n.
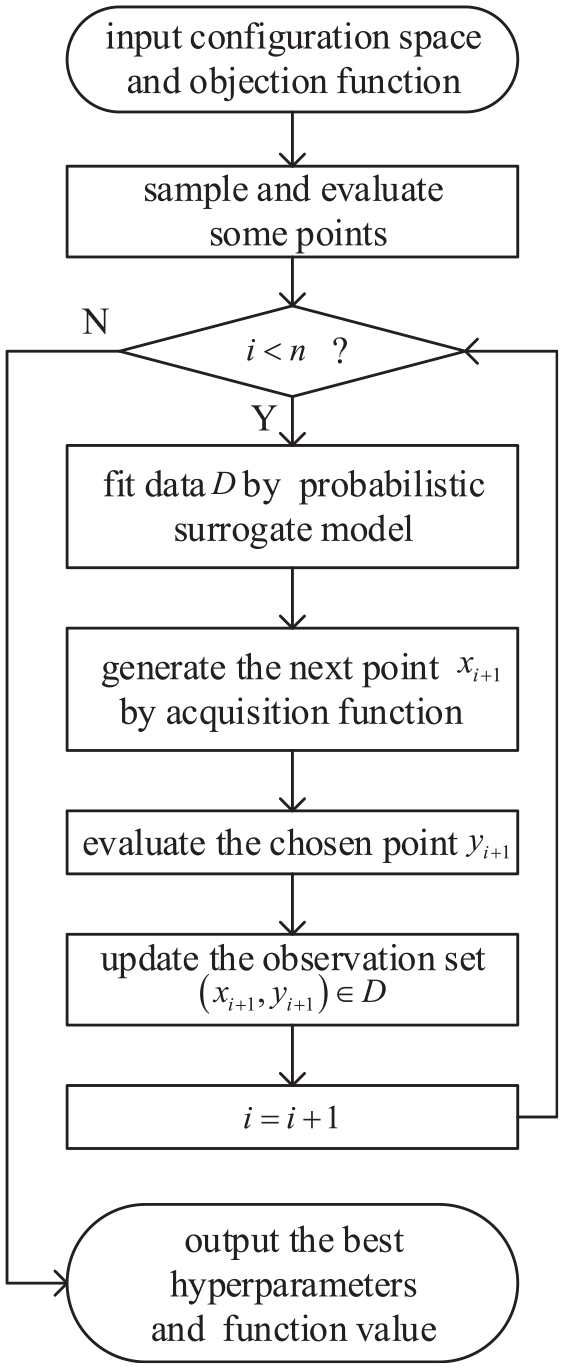
The workflow of HPO.
The probabilistic surrogate model and acquisition function are shown in Figure 2. The probabilistic surrogate model is used to model the target function by fitting all current observations. Acquisition function describes the trade-off strategy between exploration and exploration, the next sampling point is generated by maximizing it. In Figure 2(a), the highest acquisition value always occurs where the posterior mean is low and the posterior uncertainty is high. The chosen point will be evaluated to update the observation. In Figure 2(b), when enough points are sampled, the probabilistic surrogate model is almost as accurate as the objection function.
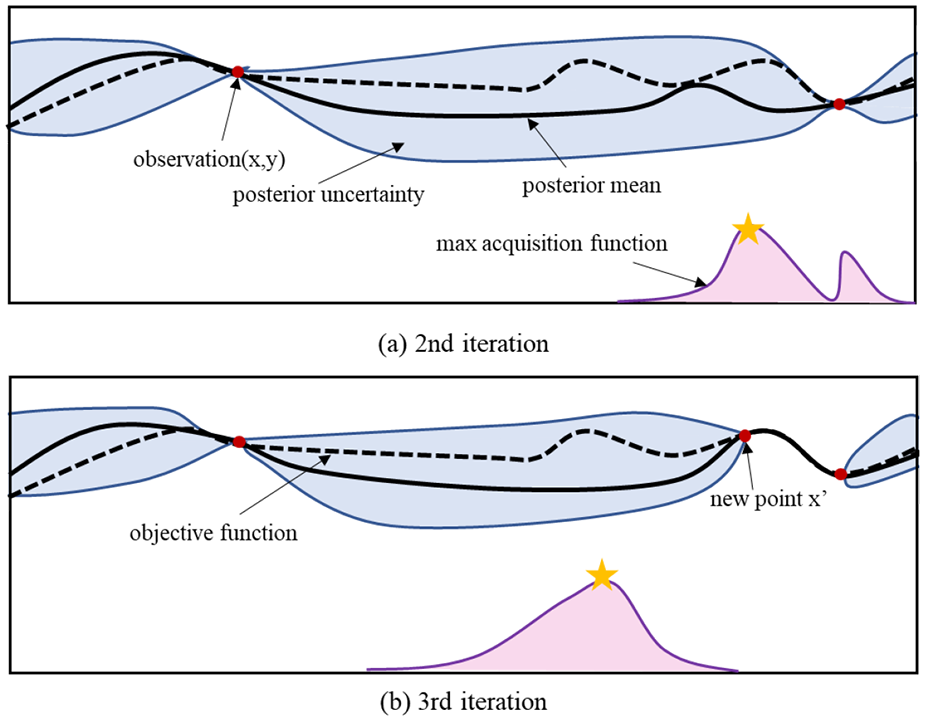
The probabilistic surrogate model and acquisition function in HPO.
Tree pazen estimator
TPE is proposed by Bergstra et al.
25
It reduces computation by modeling

where
The establishment process of
Generally,
Procedure to generate next promising point
The acquisition function trades off exploration and exploitation to select the most promising point, which makes the targets better. This means that a point sampled needs to meet the condition:
1. Probability of improvement
The formulation of PI is presented by equation (3). It considers the probability of improving but ignores the increasement.
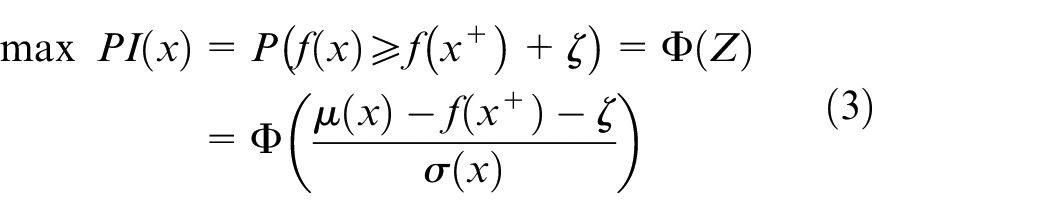
2. Upper confidence bound
UCB uses a tunable k to balance exploitation against exploration, as shown in equation (4)
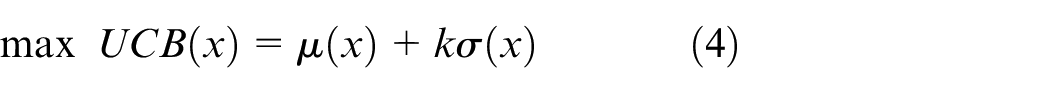
3. Expected improvement
EI is the most frequently used function since it considers both the probability and increasement of a point. As shown in equation (5),
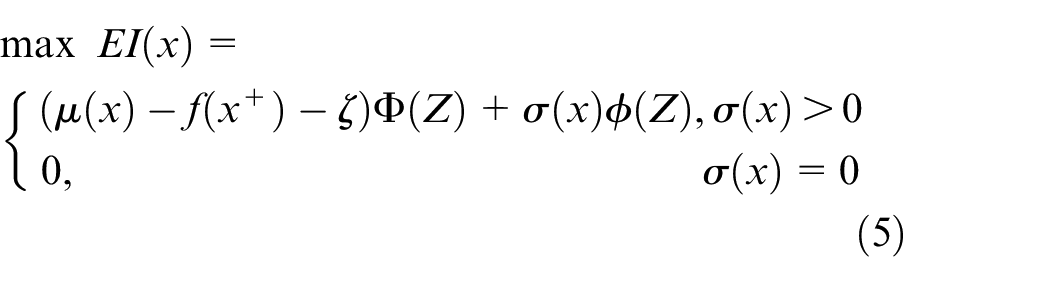
Maximizing EI is equivalent to maximizing the ratio
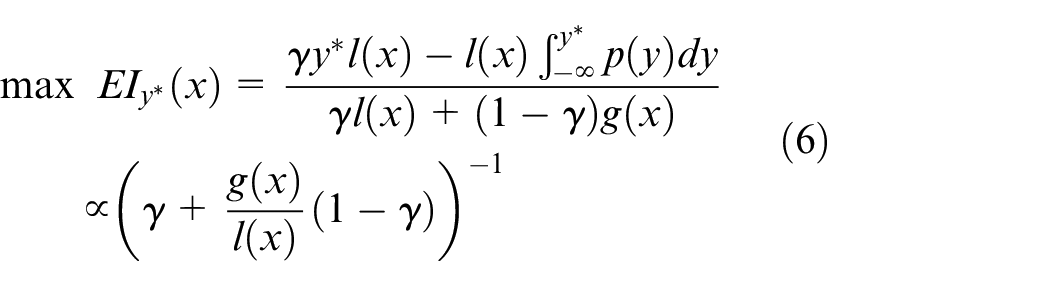
The proposed ATPE for HPO in high dimension
This section presents the workflow of the proposed ATPE, and the details of the adaptive warm-up process for TPE.
Workflow of ATPE
The workflow of ATPE is shown in Figure 4. There are total three modules in ATPE: adaptive warm-up process, TPE, and EI. In ATPE, the method first generates and evaluates some observations (it set to be 20 points in this research) by adaptive warm-up process. Then ATPE builds the PDF separately by TPE to fit the observations from warm-up process. Finally, ATPE uses EI to generate the next point. This process will continue until reaching the max evaluation n.
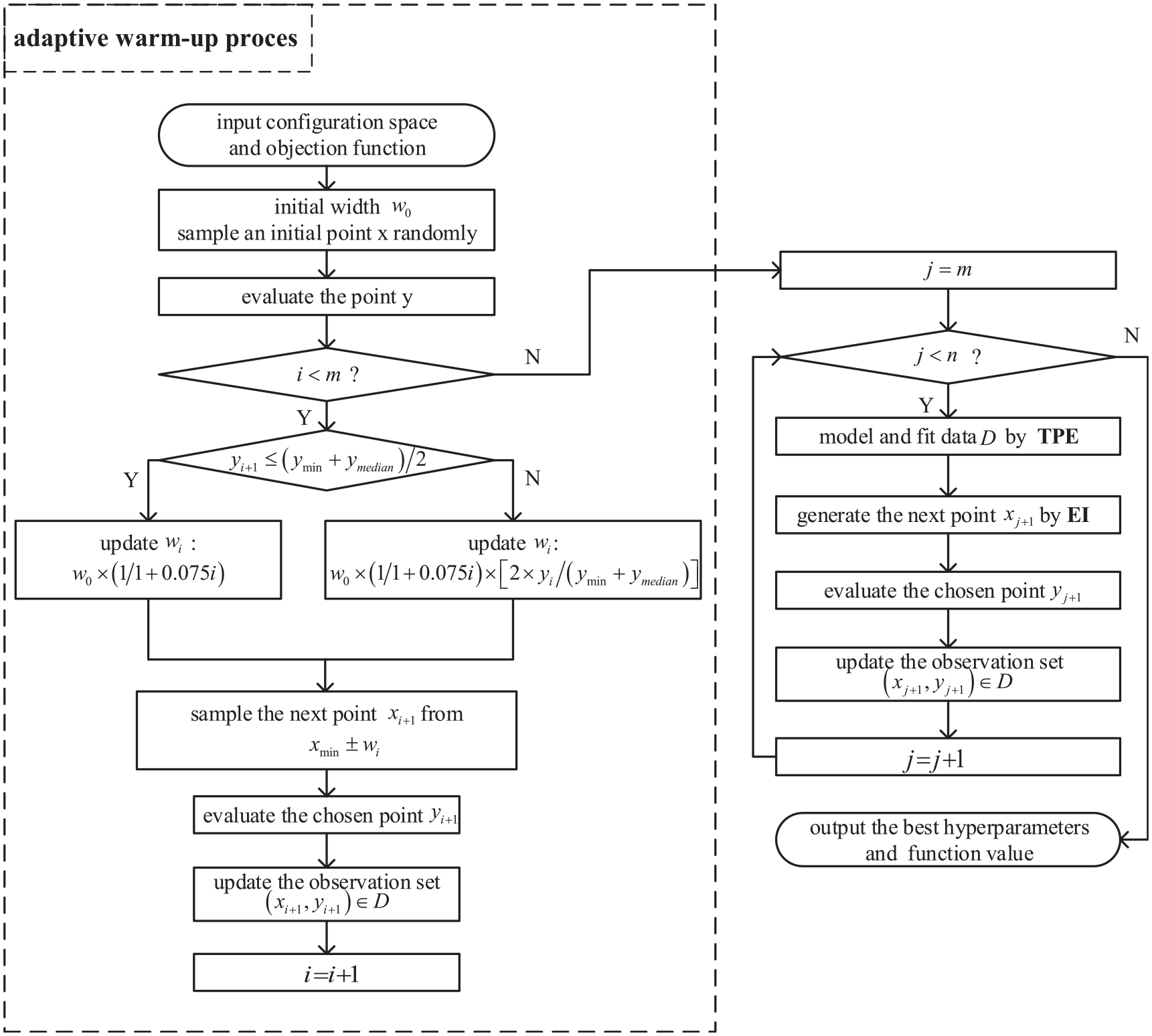
The workflow of ATPE.
The adaptive warm-up process
The configuration space has various kinds of hyperparameter such as continuous, discrete, categorical, and conditional and they are described by the distribution and the interval; the width of interval is one term in the objective function. The width of the interval is inversely proportional to the number of iterations n to obtain stable and good results within several evaluations, as shown in Figure 5. If the point sampled from the interval is better, the interval will shrink naturally, just as displayed in Figure 5(a). Otherwise, the interval will speed up the reduction to avoid falling into this bad area again as shown in Figure 5(b).
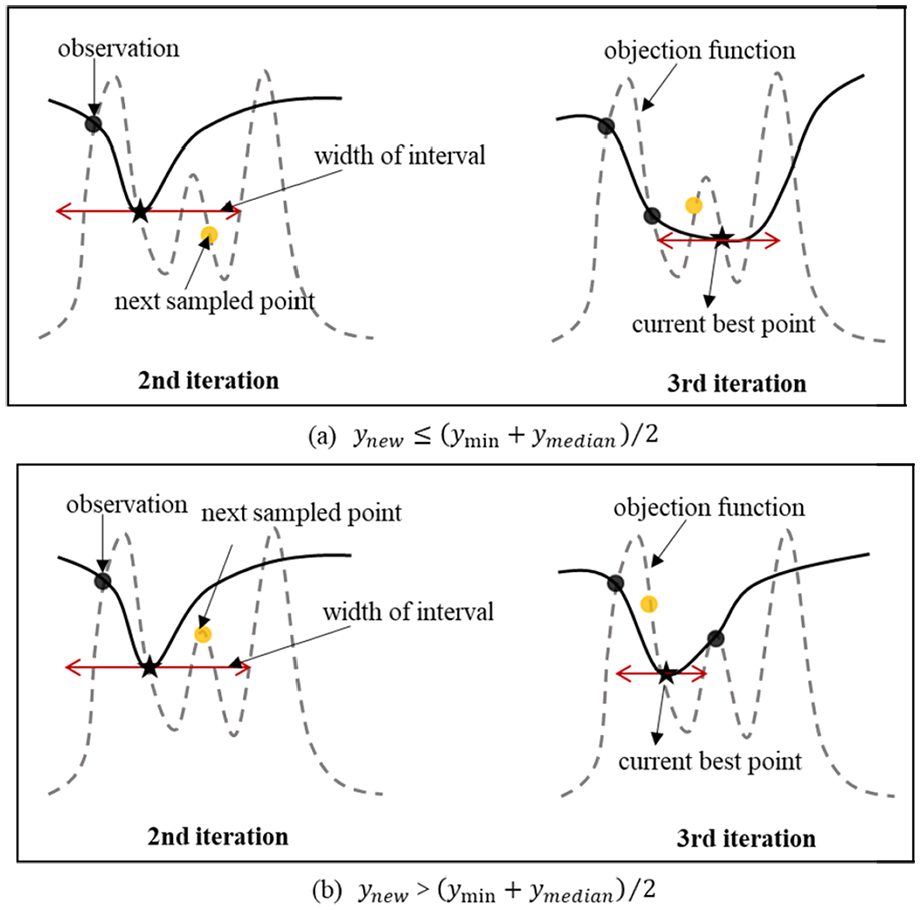
Illustration of adaptive warm-up process.
Let
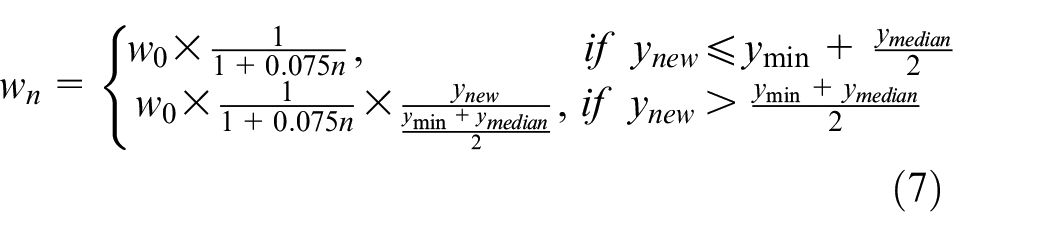
The proposed adaptive warm-up process for TPE is shown in Algorithm 1. It should be noted that minimizing the objective function is assumed.

The proposed ATPE can automatically tune hyperparameters of ML models during training process avoiding repetitive and tedious manual search especially in high dimension, and in this research, it is applied to the workpiece quality prediction to tune eight different hyperparameters.
Case studies and results
In order to validate the effectiveness and efficiency of the ATPE, the case studies on the mnist dataset and workpiece quality dataset are conducted. The proposed method is implemented by Tensorflow and Hyperopt from Python and runs on Ubuntu 16.04 with RTX 2080Ti GPU.
Cross validation is a popular technique in ML to obtain the stable and reliable prediction of workpiece quality. Hence, the proposed ATPE uses fivefold cross validation for fair comparison. There are 50 evaluations in each run. All experimental results are tested with ten independent runs.
Case 1: MNIST dataset
The MNIST database of handwritten digits, a typical dataset of computer vision, has 60k training and 10k testing samples. It has ten handwritten digits (0–9) with a size of 28 × 28 pixels. The Sparse Stack Autoencoder (SSAE) is often seen in industrial image recognition applications due to its efficient feature extraction and simple implementation. The hyperparameters influence its performance heavily, so it is important to apply HPO to SSAE. In this case study, SSAE is applied and the proposed ATPE is used for the HPO of SSAE.
The parameters of SSAE are: epoch is 30 and AdamOptimizer is applied to minimize the function
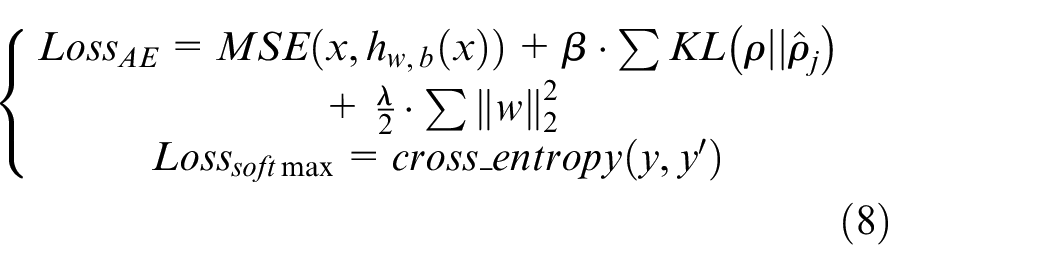
The hyperparameters of SSAE are as follows: (i) the number of stack AEs; (ii) the number of hidden units for the first autoencoder; (iii) learning rate; (iv) sparse coefficient; (v) weight balance coefficients; (vi) sparsity balance factor; (vii) batch size, and (viii) sparse coefficient. Table 1 provides more details about these parameters. Symbol U means uniform, qU stands for discrete uniform, drawn by round (uniform (low, high)/q) * q. The sampling method is random. Note that the hidden layer units can be formulated as equation (9). The units of first layer indicate the number of units in each hidden layer decreased by an equal difference after that
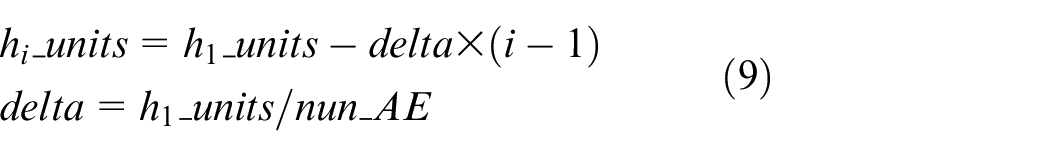
Hyperparameters that need to be optimized of SSAE on MNIST.
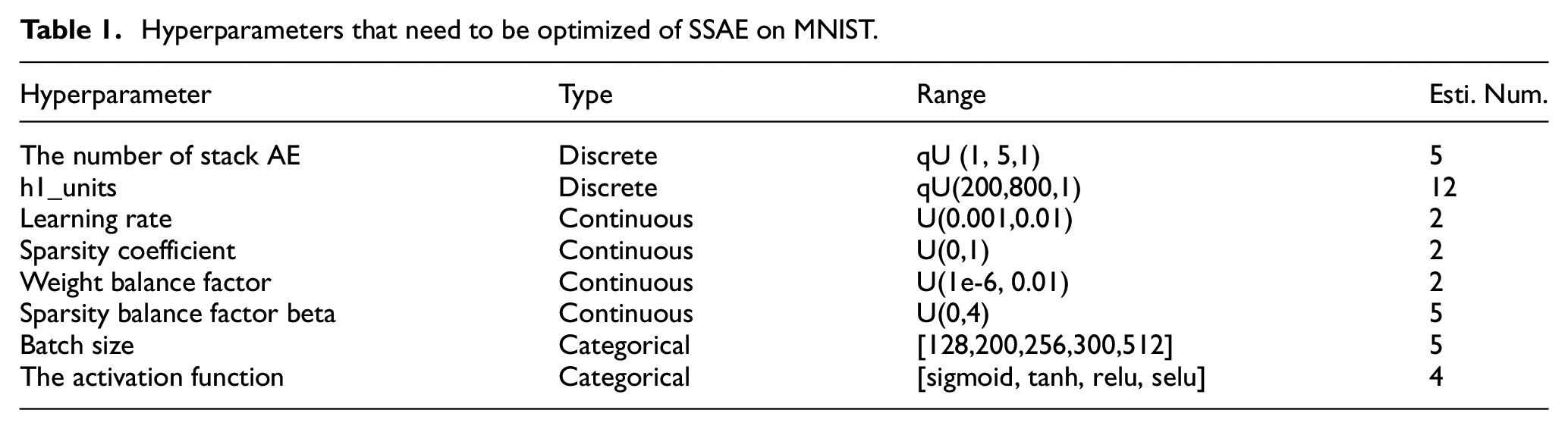
It has eight dimensions and can be estimated that there are almost 4,800 combinations of hyperparameters in Table 1. Esti. Num. means estimated number of feasible values. The combinations estimation are as follows: (1) The number of hidden units has a large range and is usually taken values at equal intervals (set 50) in human-design, meaning there are 12 values. (2) The sparsity coefficient is the core of SSAE, therefore give it five choices. (3) Except for categorical and discrete hyperparameters, the others can be considered at least two values for each. So the total combinations are calculated by
Results on accuracy and convergence
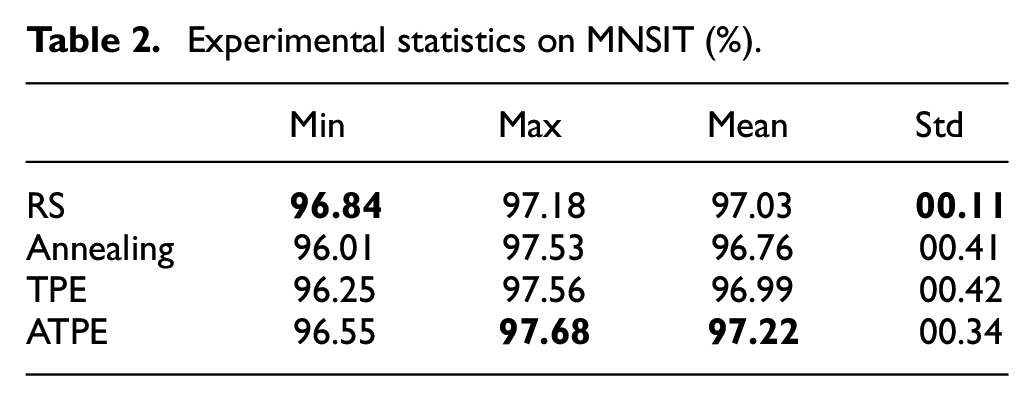
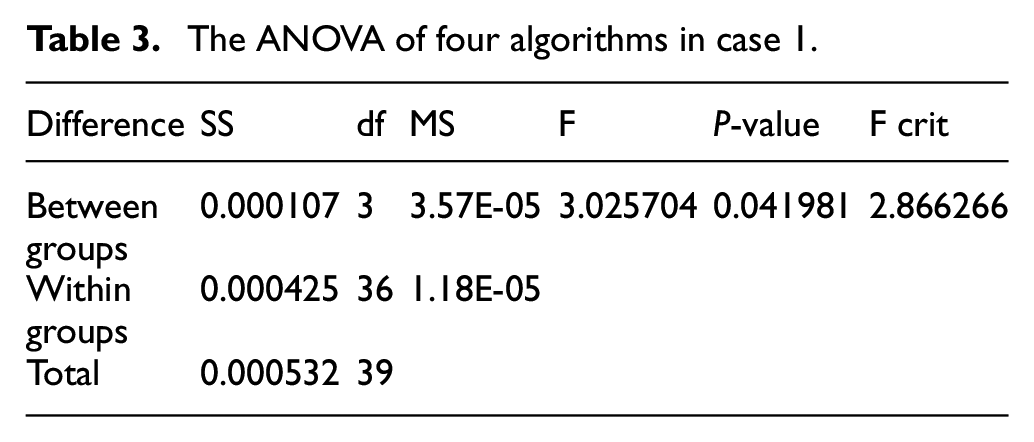
In this case study, both accuracy and time are taken into consideration for evaluation. Table 2 and Figure 6 show the experimental results of 10 runs, including the min, max, mean, std of accuracy. From these results, it can be concluded that compared with RS, annealing, and TPE, the proposed algorithm shows superior performance in high-dimensional space: It has achieved comparative results, the best max value 97.68% and the best mean value 97.22%. Table 3 gives the ANOVA analysis of these four methods, and the results show the stability and optimization ability of ATPE are better, and the result of ATPE is significantly better than other three methods since the
Experimental statistics on MNSIT (%).
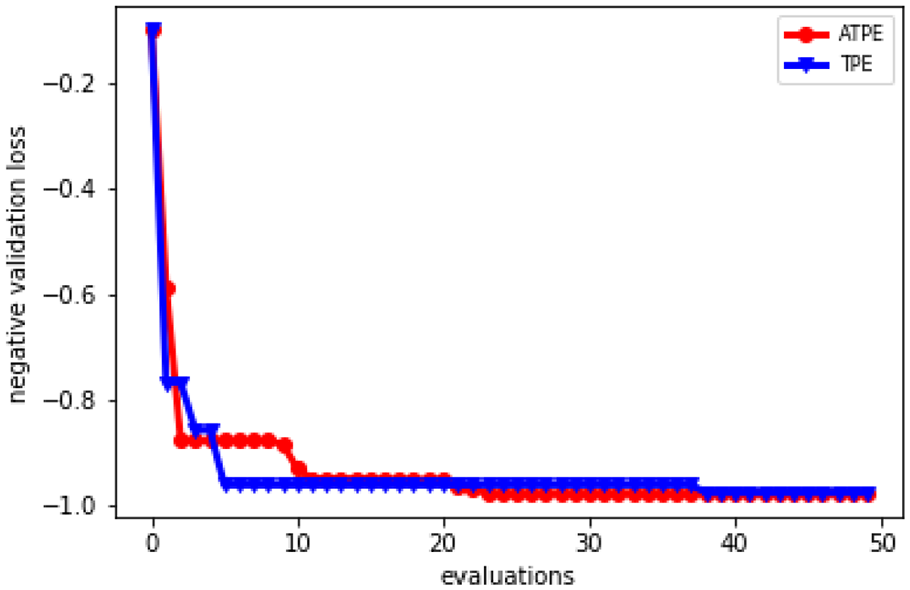
The best result convergence curves of ATPE and TPE in case 1.
The ANOVA of four algorithms in case 1.
The best result convergence curves of ATPE and TPE are shown in Figure 6; the first 20 iterations are warm-up process. ATPE performs as better as TPE without human interfere, but it finds the best result more quickly.
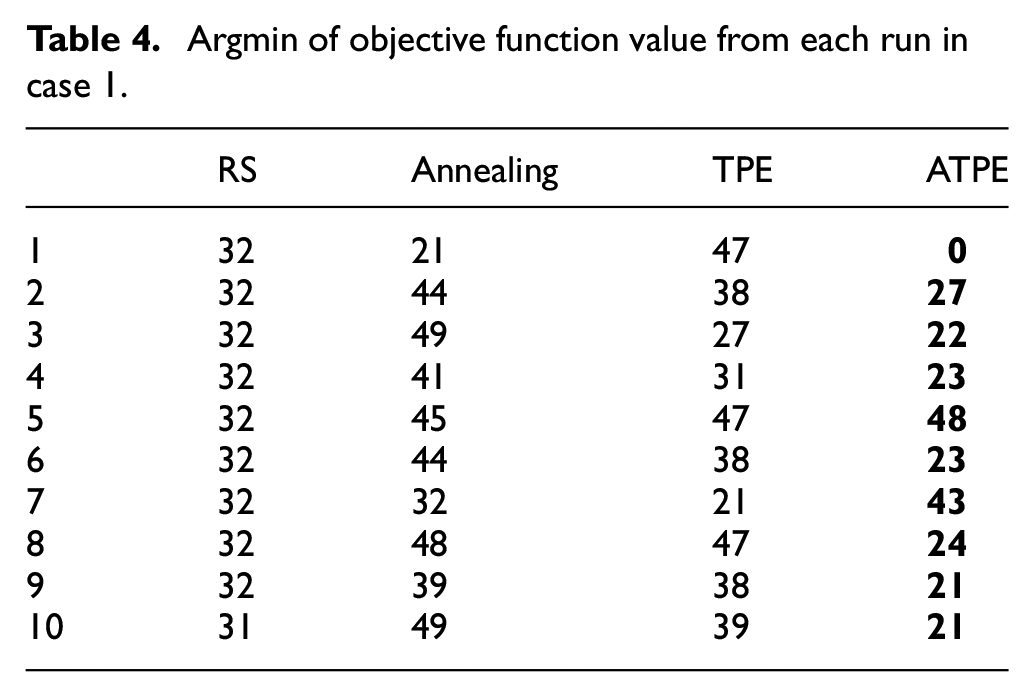
In order to conduct the further study on efficiency of algorithms, the best index of each run is figured out. As described in Table 4, ATPE has 80% probability to find the optimal value in the first 30 iterations, while TPE and annealing need more evaluations. This result indicates that the adaptive warm-up process could raise speed of convergence for TPE in high-dimensional space, when it was applied to SSAE.
Argmin of objective function value from each run in case 1.
The convergence of hyperparameters
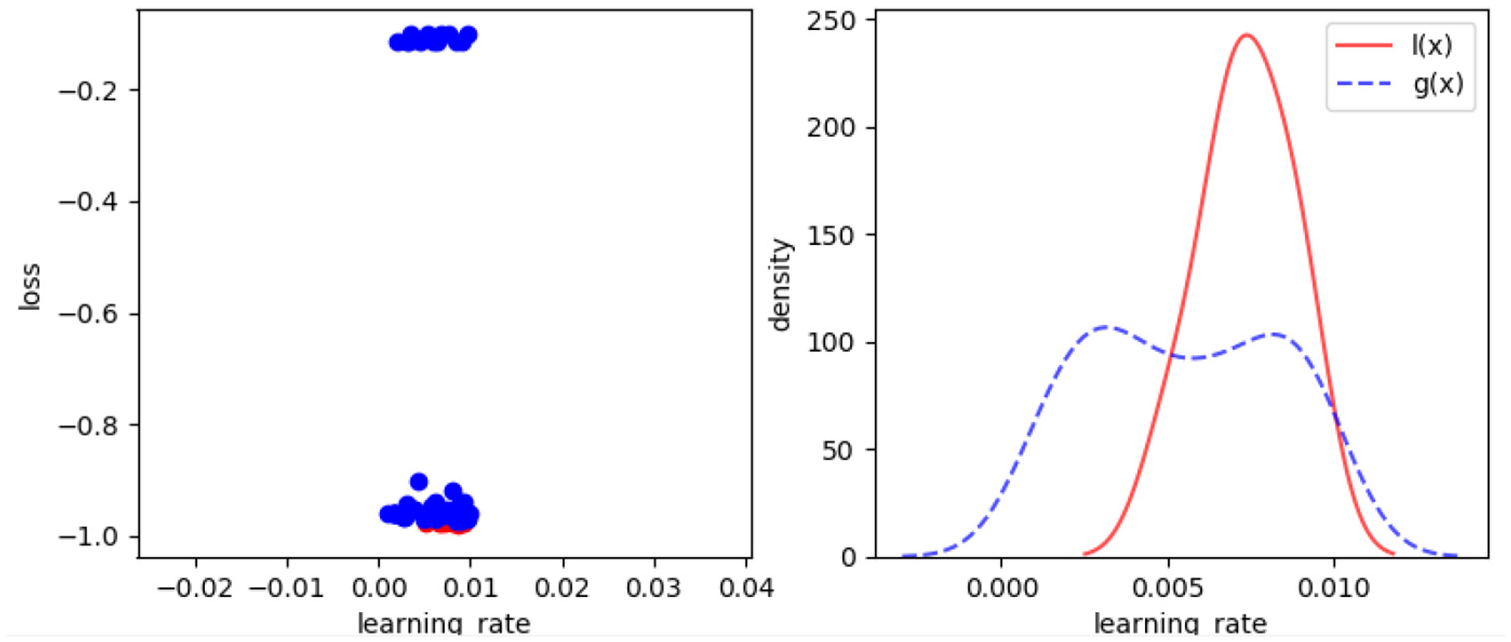
The convergence of hyperparameters in ATPE is also presented in this study. Taking the fourth run of ATPE as an example as shown in Figure 7, the objective function values are sorted in descending order and divided by 1/4 quartile; the first 1/4 quartile is better and the rest is worse. The histogram is drawn for discrete hyperparameters, and the density function based on Gaussian kernel is drawn for continuous ones.
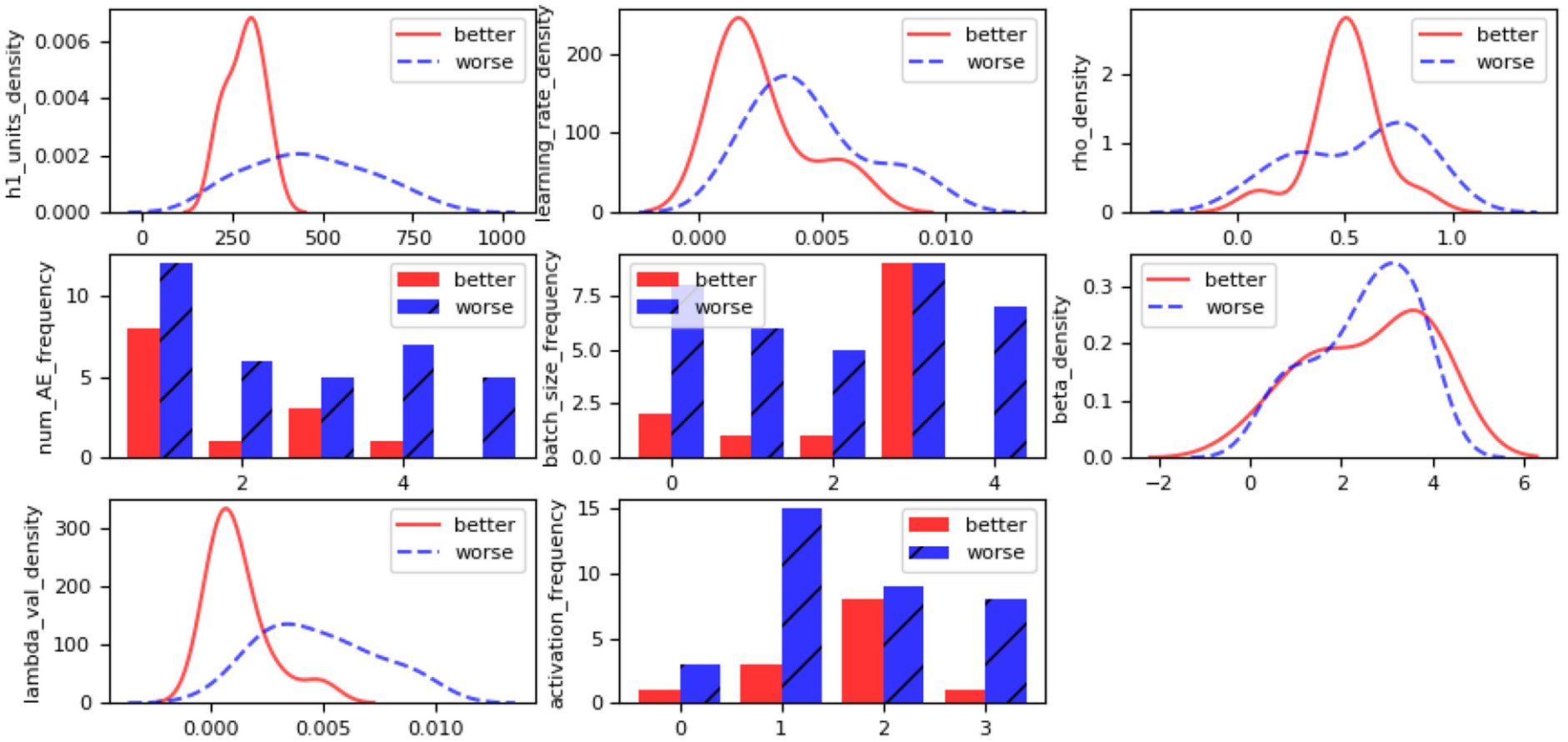
Sampling space of SSAE in ATPE.
As shown in Figure 7, sparsity coefficient
Based on results, it experimentally shows that the ATPE automatically improves the performance of hyperparameters of SSAE in high dimensions and finds the regions with larger probability to generate good solution in this case study.
Case 2: workpiece quality dataset
The workpiece quality dataset is from the competition “prediction of quality conformity rate of typical workpieces in discrete manufacturing process,” which is held by China Computer Federation. It comes from the real data collected by a factory and has been desensitized. This dataset will be referred to as workpiece quality dataset for the rest of this article. This dataset includes two types of features: (1) 10 classes of equipment processing parameters, referred to as P; (2) 10 attributes of quality index, referred to as A. The quality level is divided into four categories: excellent, good, pass, and fail. The denotation of “Fail-0” denotes that the category fail is used as 0 when training. There are 12,934 pieces of training data and 6000 pieces of test data.
The dataset is unbalanced, which can be seen from Table 5. Therefore, stratified K-fold cross validation (with K = 5) is applied. Through descriptive statistics and polynomial construction, 45 kinds of features are constructed finally, including statistical features (e.g. mean, std, frequency).
The number of categories.

XGBoost has greatly improved the training speed and prediction accuracy of the model. Because of its excellent performance and low computational complexity, it has been widely used in industry. 27 The hyperparameters have great impact on its accuracy, so it is realistic to study the HPO of XGBoost. In this research, the XGBoost method is implemented from XGBoost package and its hyperparameters to be optimized are described in Table 6. In this hyperparameters, the subsample denotes the fraction of observations to be randomly samples for each tree and colsample_by_tree denotes the fraction of columns to be randomly samples for each tree; both of them reflect randomness of XGBoost.
Hyperparameters that need to be optimized of XGBoost.

The hyperparameter in this case study has 8 dimensions and there are 6400 combinations of hyperparameters in Table 6. Esti. Num. means estimated number of feasible values. The combinations estimation are as follows: (1) The number of n_estimators takes values at equal intervals (set 100) in human-design, so there are 5 values. (2) Subsample mainly reflects the randomness and accuracy of XGBoost, therefore give it 5 choices. (3) Except for categorical and discrete hyperparameters, the others can be considered as at least 2 values. So the total combination are calculated by
Results on accuracy and convergence
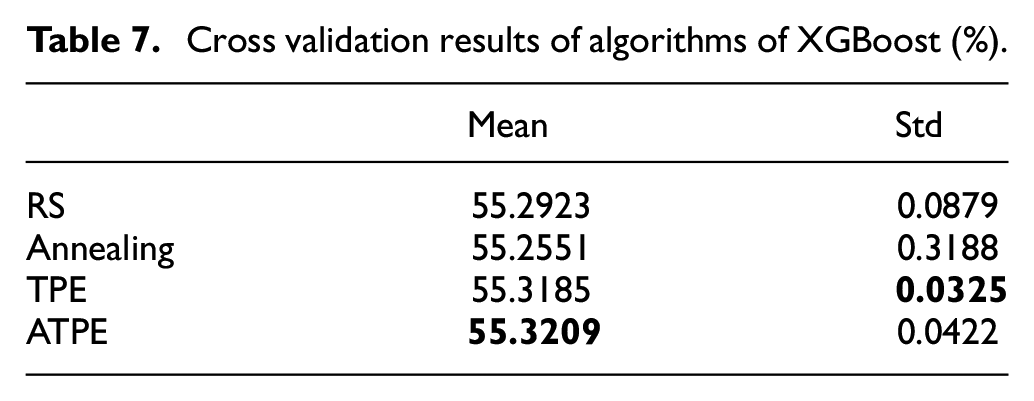
The results of ATPE are also compared with other algorithms, as shown in Table 7. The average accuracy of ATPE achieves 55.3209% over 10 independent runs, which is better than TPE, annealing, and RS.
Cross validation results of algorithms of XGBoost (%).
The best result convergence curves of ATPE and TPE are shown in Figure 8. The first 20 iterations are warm-up process; there is obvious improvement in TPE after applying adaptive algorithm, during which ATPE performs better than TPE without human interfere.
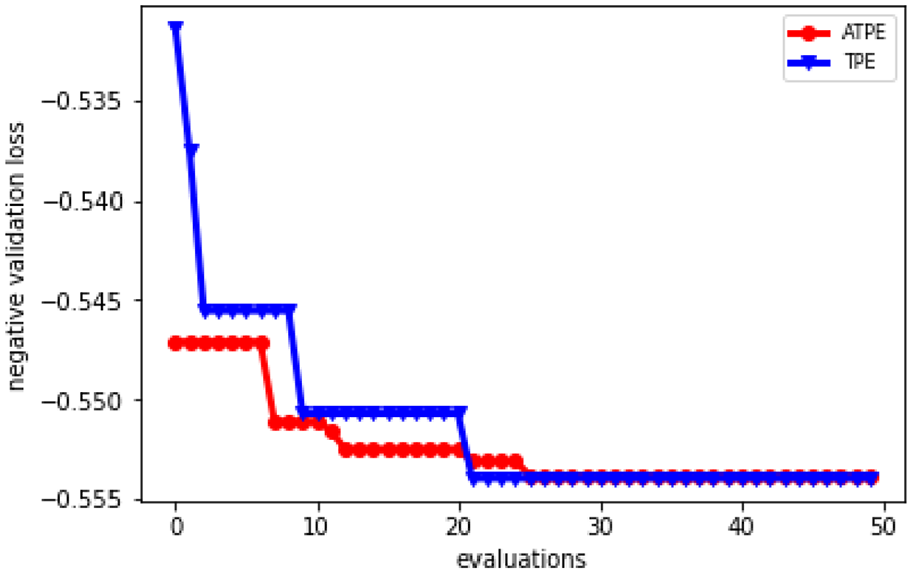
The best result convergence curves of ATPE and TPE in case 2.
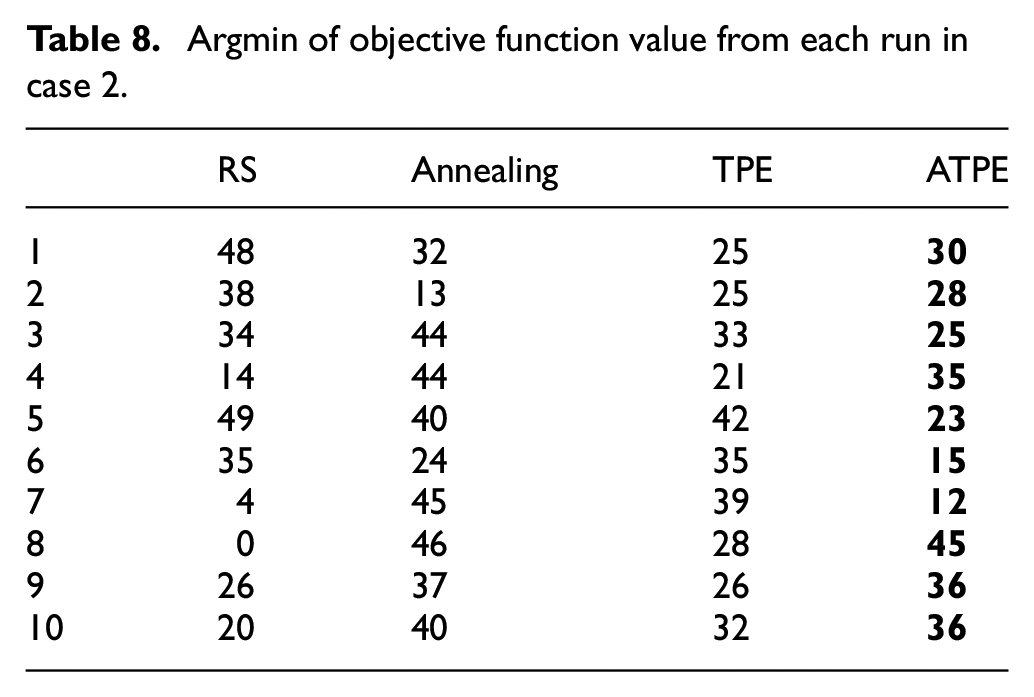
The best index of each run is figured out in Table 8; both ATPE and TPE has 90% probability to find the optimal value in the first 40 iterations, while ATPE has the smallest median, value at 29. This case experimentally proves that in high dimensions, the adaptive warm-up process has a faster convergence for TPE when it applied to XGBoost.
Argmin of objective function value from each run in case 2.
The convergence of hyperparameters
Hyperparameters in this case are eight dimensions. Take the best run of ATPE as an example and results display that during the training process, ATPE is also able to automatically optimize and schedule hyperparameters well even in high-dimensional space, as shown in Figure 9.
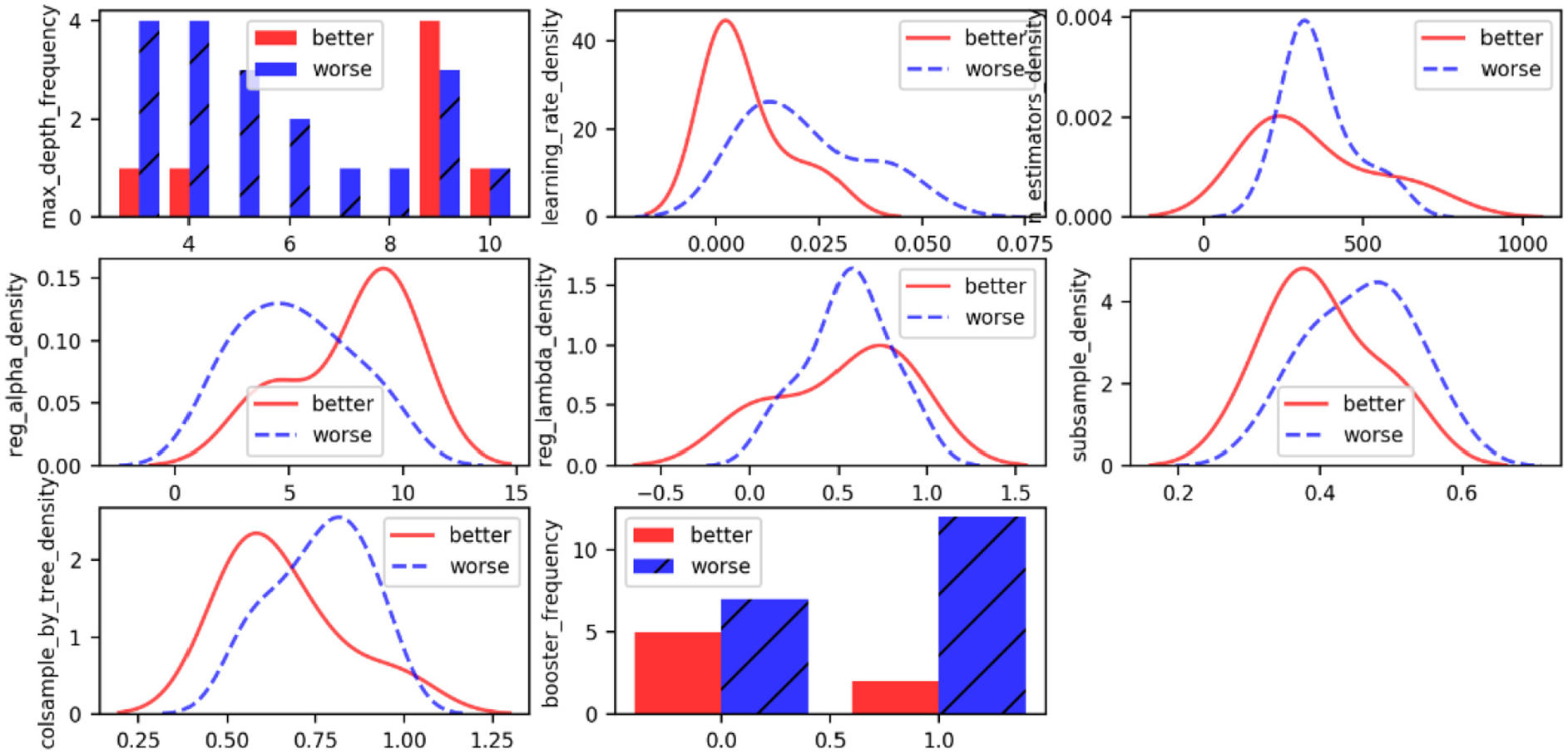
Sampling space of XGBoost in ATPE.
In this case study, max_depth performs well when getting value 9, and it is consistent with human-design. The relatively less estimators are more likely to have greater performance due to the dataset being small, revising the common sense that more estimators would get better prediction. Even the configuration space is described by uniform, most hyperparameters (e.g. learning_rate, reg_alpha, subsample, colsample) are scheduled at small range where the probability of generation better results is larger than the worse during the automatic iterations.
Conclusion and future researches
This article presents a new AutoML based HPO of workpiece quality prediction, named ATPE. The main contribution is as follows: ATPE provides an adaptive warm-up process for TPE and it can automatically tune hyperparameters in high dimension. The proposed algorithm is tested on SSAE based MNIST and XGBoost based workpiece quality dataset. The results show that it accelerates convergence of eight hyperparameters without human interference and outperforms RS, annealing, and TPE. The results show that ATPE not only eases tuning hyperparameters process but also achieves state-of-the-art performance, validating its potential on the workpiece quality prediction.
The limitation of the proposed algorithm requires hyperparameters to remain unchanged during each evaluation. That means it is unable to handle those changeable ones during training process. Therefore, the future research can introduce reinforcement learning to tune these hyperparameters.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is supported by National Key R&D Program of China (Grant No. 2019YFB1704600), National Natural Science Foundation of China (Grant No. 51805192, 51825502) and the State Key Laboratory of Digital Manufacturing Equipment and Technology (DMET) of Huazhong University of Science and Technology (HUST) under Grant No. DMETKF2020029.