
Abstract
In this article, a novel continuous-time optimal tracking controller is proposed for the single-input-single-output linear system with completely unknown dynamics. Unlike those existing solutions to the optimal tracking control problem, the proposed controller introduces an integral compensation to reduce the steady-state error and regulates the feedforward part simultaneously with the feedback part. An augmented system composed of the integral compensation, error dynamics, and desired trajectory is established to formulate the optimal tracking control problem. The input energy and tracking error of the optimal controller are minimized according to the objective function in the infinite horizon. With the application of reinforcement learning techniques, the proposed controller does not require any prior knowledge of the system drift or input dynamics. The integral reinforcement learning method is employed to approximate the Q-function and update the critic network on-line. And the actor network is updated with the deterministic learning method. The Lyapunov stability is proved under the persistence of excitation condition. A case study on a hydraulic loading system has shown the effectiveness of the proposed controller by simulation and experiment.
Keywords
Introduction
Accurate tracking control has drawn great research interests in a number of application fields.1–3 Optimal control deals with problems of minimizing the prescribed objective function in the infinite or finite horizon. Traditional optimal control for linear system solves the algebraic Riccati equation (ARE) off-line.4,5 The optimal control policy is regulated as a state feedback according to the gradient of the value function. 6 However, this kind of controller may suffer from steady-state error because of the disturbance in the system. 7 And the design of the feedforward part is separate from the optimal regulation.
In this study, the integral compensation and feedforward part are introduced in the optimal controller. The integral term is necessary to maintain the system state around the equilibrium points and reduce the steady-state error. Inspired by the adaptive robust control, a discontinuous projection for the integral compensation is applied to ensure the robustness.8,9 While the feedforward part can remarkably improve the responses of the control system, 10 which is necessary for high-accuracy control problems. So, an augmented system with the integral compensation, error dynamics, and desired trajectory is established in this study. And the optimal tracking control problem (OTCP) of the augmented system is formulated for minimizing the performance function in the infinite horizon.
However, the introduction of the integral compensation and feedforward brings difficulties to the optimal controller design. The optimal control policy for the augmented system can hardly be obtained by solving the Hamilton–Jacobi–Bellman (HJB) equation directly. And the completely unknown system dynamics are also challenges for the controller design. In this study, a new optimal controller with reinforcement learning techniques is proposed to deal with the problems mentioned above.11–14 Different from many state-of-the-art continuous-time optimal controllers, the proposed controller is built up with a Q-function-based actor–critic architecture. 15 The critic is updated by the Q-function approximation, and the actor is optimized by the deterministic learning method.
The implementation of Q-function approximation in the continuous-time domain is inspired by the integral reinforcement learning (IRL) method.16,17 An integral of the linear quadratic function is calculated to obtain the Bellman error and update the critic weights. The optimal control policy is obtained by the method of deterministic learning.18,19 Different from those off-line deterministic policy gradient (DPG) methods, the deterministic learning method in this study enables an on-line policy update.20,21
In this article, we developed an adaptive optimal controller based on the deterministic learning technique. The contribution of this article is as follows. First, the integral compensation and feedforward are added in the control input, so that the control performance can be improved. Second, the OTCP of the system can be solved on-line with completely unknown dynamics, by employing Q-function approximation and deterministic learning method. Third, the convergence and Lyapunov stability of the proposed controller are proved. And the effectiveness of the controller is validated by simulation and experiment.
The rest of this article is organized as follows. Section “Optimal tracking problem formulation” presents the OTCP for the augmented system. Section “Optimal controller design” presents the design of the optimal controller. Section “Stability analysis” presents the Lyapunov stability of the proposed controller. Section “Case study” presents a case study on a hydraulic loading system. Section “Conclusion” presents the conclusion.
Optimal tracking problem formulation
Linear control system with integral compensation
Consider the single-input-single-output (SISO) affine continuous-time linear system described as

where
Assumption 1
The system state
Assumption 2
The system with A and B is controllable. The vector
Assumption 3
Assume that the desired trajectory of the system
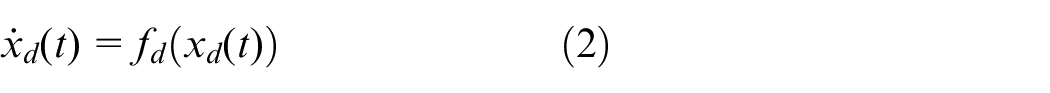
The tracking error

The control input

where
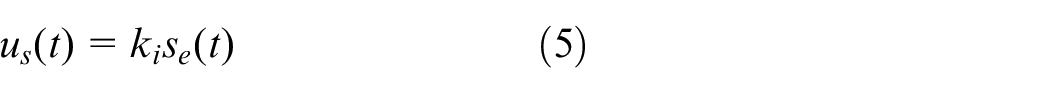
where
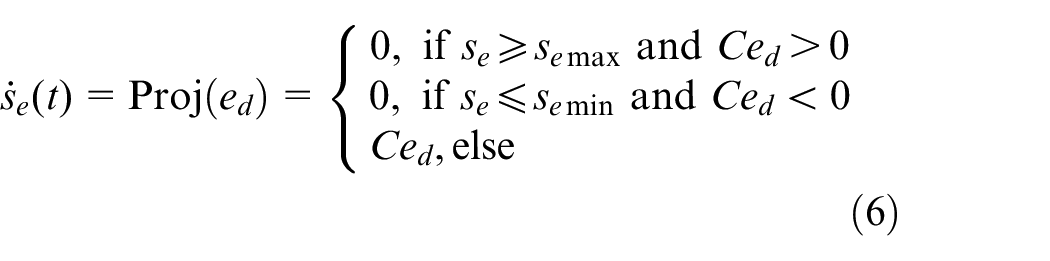
where
Remark 1
The traditional optimal regulation method obtains a proportional–derivative (PD)-type controller with feedback only, which may cause steady-state error under uncertain dynamics. In this study, an integral compensation is introduced to eliminate the steady-state error.
Augmented system and performance function
Define the augmented system state
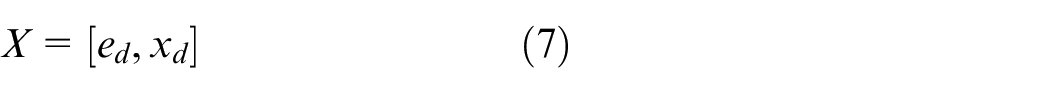
The augmented state vector is composed of the tracking error and desired trajectory.
Then, the dynamics of the augmented system can be written as

where the drift dynamics
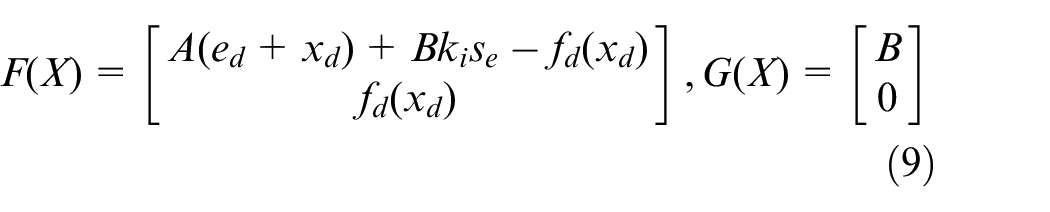
Remark 2
Because
Remark 3
The coefficient of the integral compensation is set as a constant in this study. Only the feedforward and feedback parts
The objective of the OTCP is to minimize the performance function of the augmented system
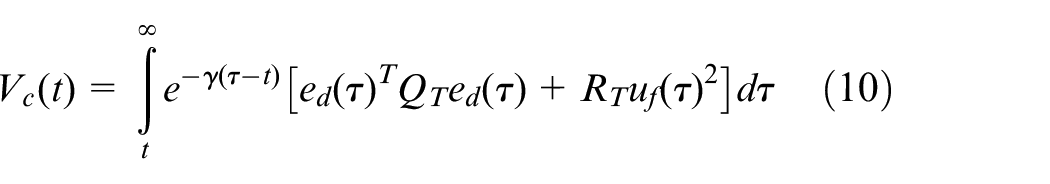
The optimal control policy for
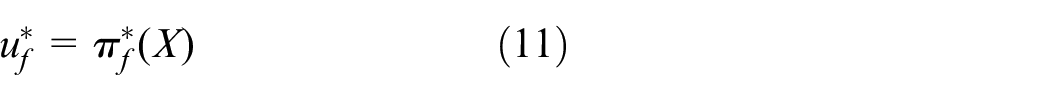
According to Leibniz’s rule, the derivative of
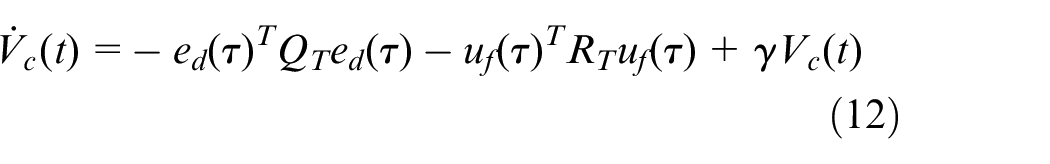
And the tracking HJB equation can be written as
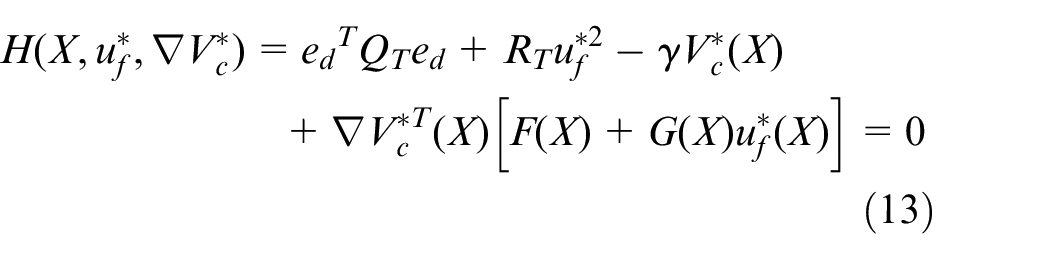
Remark 4
The system dynamics
Optimal controller design
For systems with completely unknown dynamics, the HJB function can hardly be solved. In this section, an optimal controller is proposed with the actor-critic architecture. The structure of the controller is shown in Figure 1. The Q-value approximation is employed to evaluate the performance function. And the optimal control policy is updated on-line by the deterministic learning technique. The feedback and feedforward parts of the control input can be obtained simultaneously.

Structure of the proposed optimal controller.
Critic network and Q-function approximation
The state vector is pre-processed by a normalization while considering the difference of scale between the desired trajectory
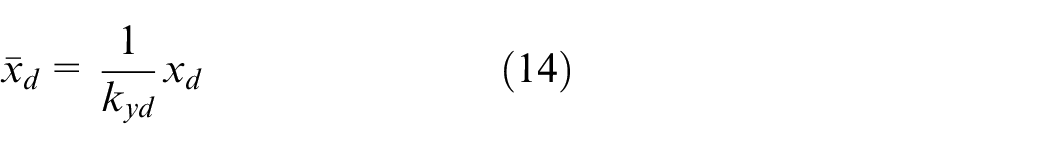
The state vector is transformed as

The value function

where
Remark 5
During the on-line learning process, a probing noise is added on
Because the amplitude of probing noise is relatively low, the approximation error
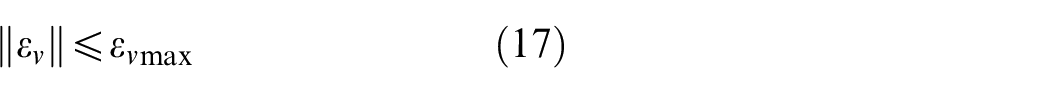
The Q-function can be obtained by a linear approximation
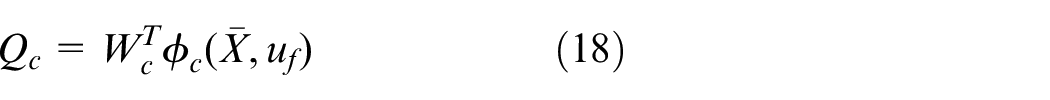
where
The Bellman equation can be obtained from equation (10), which is written as
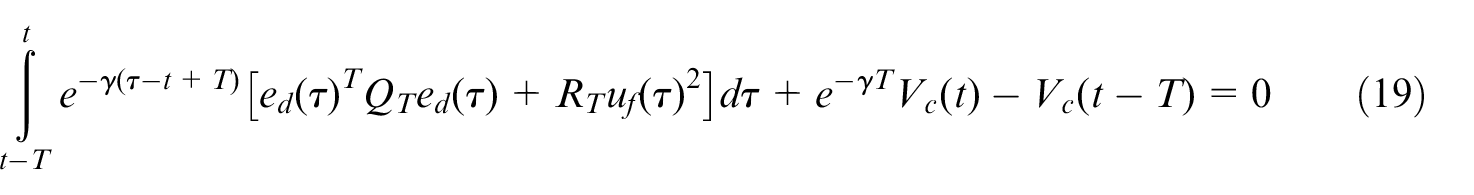
According to equations (16) and (19), the tracking Bellman error can be written as
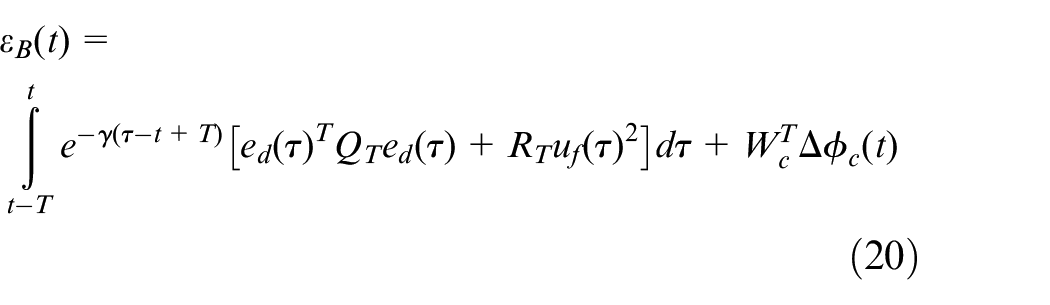
where
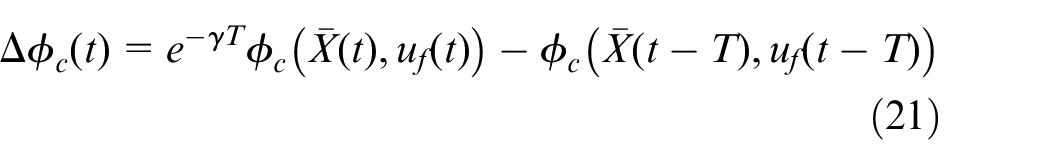
According to equations (16) and (18), the tracking Bellman equation error
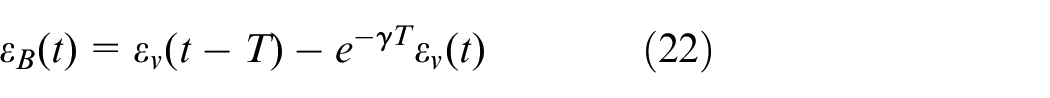
So,
The Q-value is estimated by the critic network
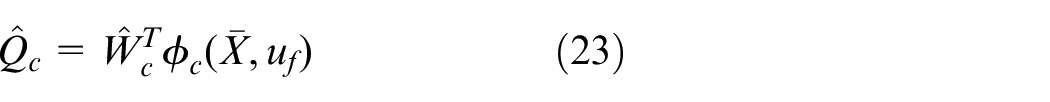
According to equation (20), the Bellman error with respect to the weights of the critic network
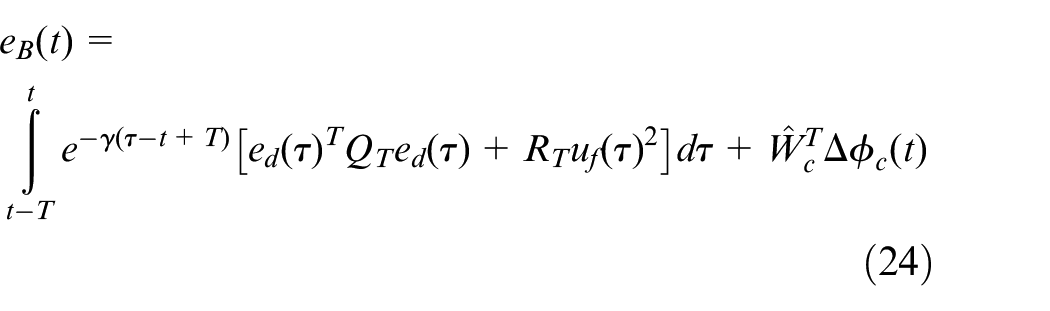
In this study, the policy iteration method is employed to minimize the Bellman error. The objective function of the critic network can be written as

The update rate of
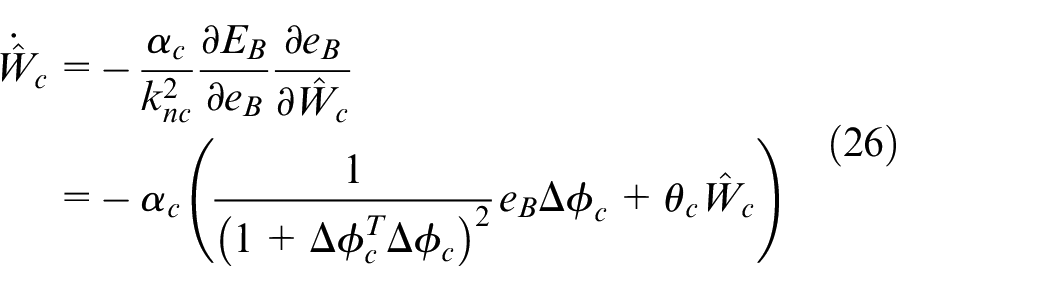
where
The normalization term is applied to limit the update rate of the network weights.
Define the estimation error of the critic network as
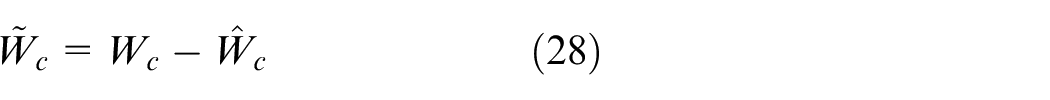
According to equations (20) and (28), the Bellman error
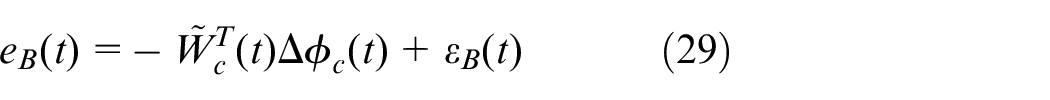
So, the critic neural network (NN) estimation error dynamics becomes
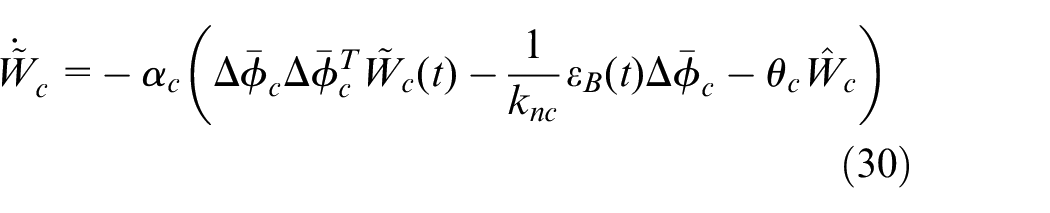
where
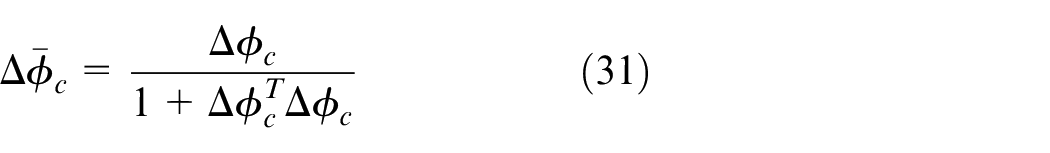
Actor network and deterministic learning technique
The control policy is improved by the actor network. The deterministic learning technique is applied to update the actor network weights on-line.
The optimal control policy

The optimal control input
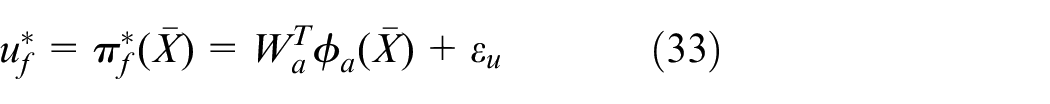
where
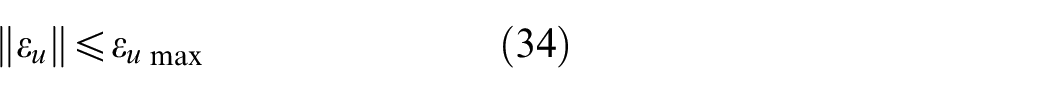

The deterministic learning method is employed to update the weights
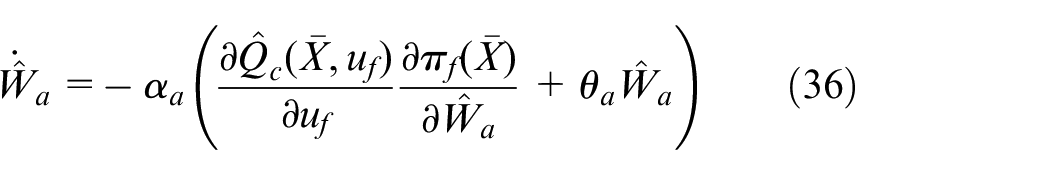
where
The term

So, the update rate
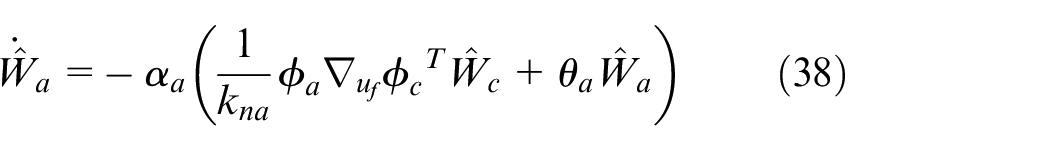
where
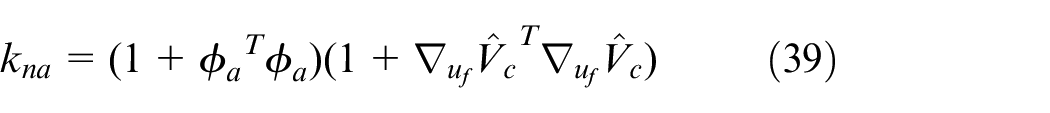
Remark 6
The initial weights of the actor network
The estimation error

Then, the estimation error dynamics of weights
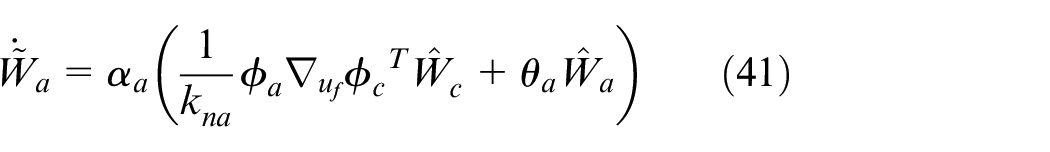
Persistently exciting condition
According to equation (26), the convergence of the weights
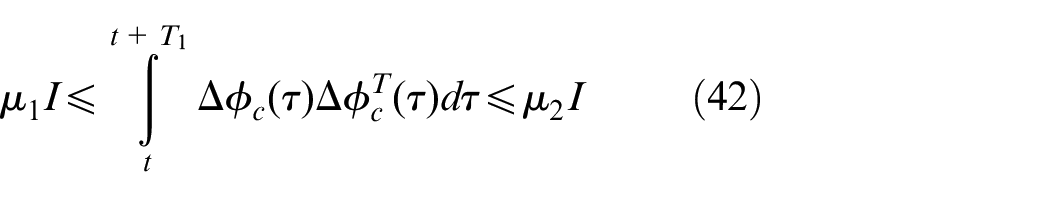
According to equation (38), the term
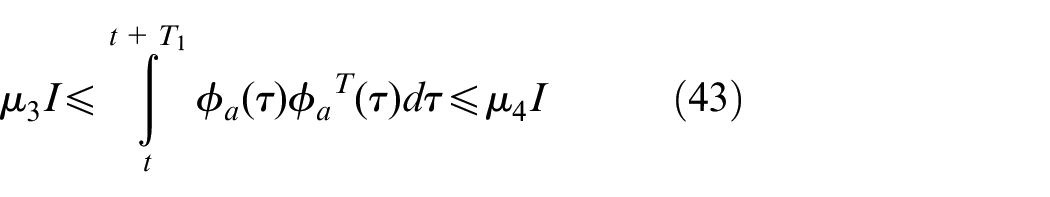
However, the PE condition can hardly be verified on-line.23,24 So, in this study, a probing noise is added on the control input
Stability analysis
In this section, the stability of the proposed method is proved in the Lyapunov sense.
The Lyapunov function is defined as
The derivative of the Lyapunov function is given by
According to equations (12) and (18),
Note that
The first term in equation (46) can be written as

So, the derivative
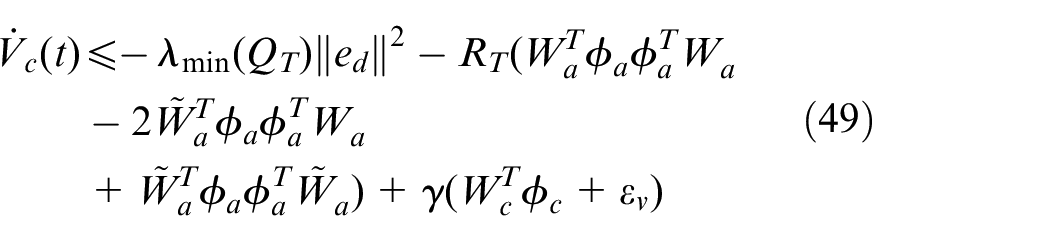
According to equation (30), the second term in equation (45) can be written as
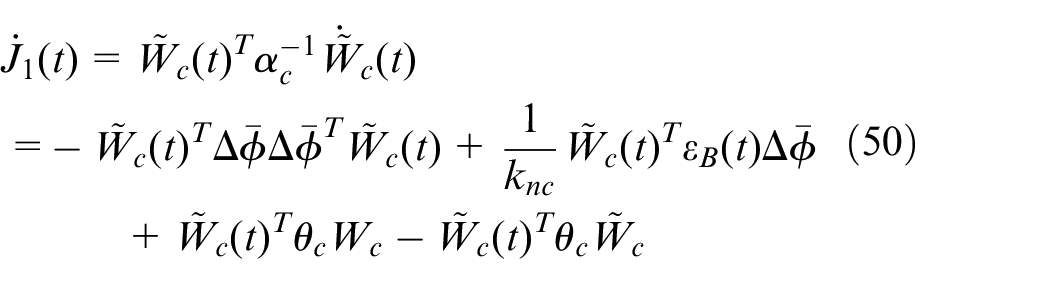
Using equation (41), the third term in equation (45) can be written as
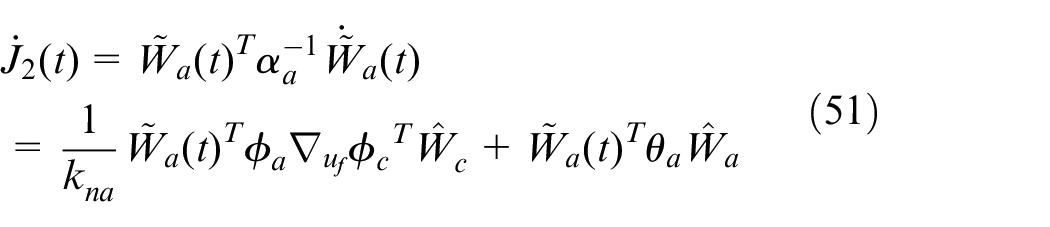
According to equations (23) and (38),
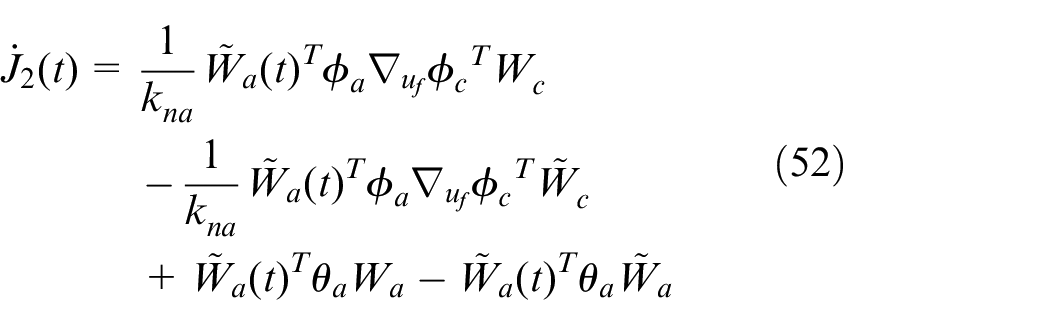
According to the basic inequality, the second term in equation (52) can be written as
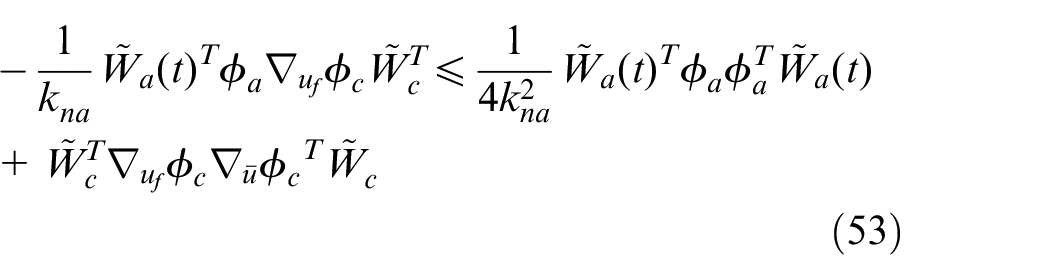
Therefore
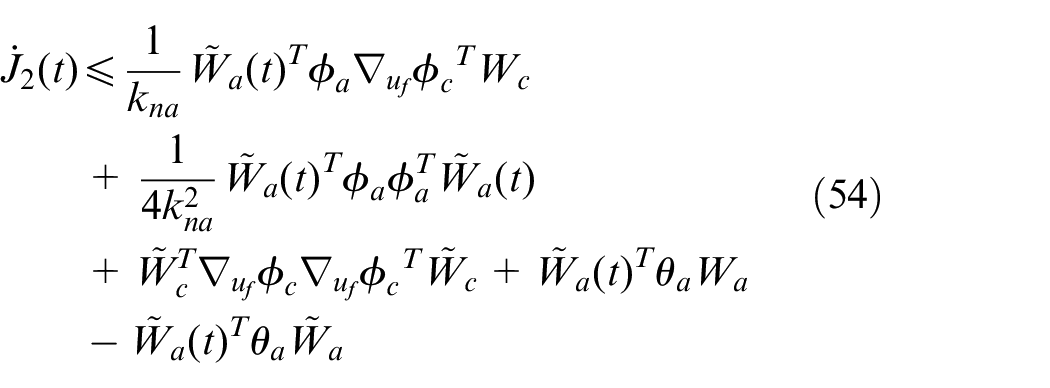
Using equations (49), (50), and (54),
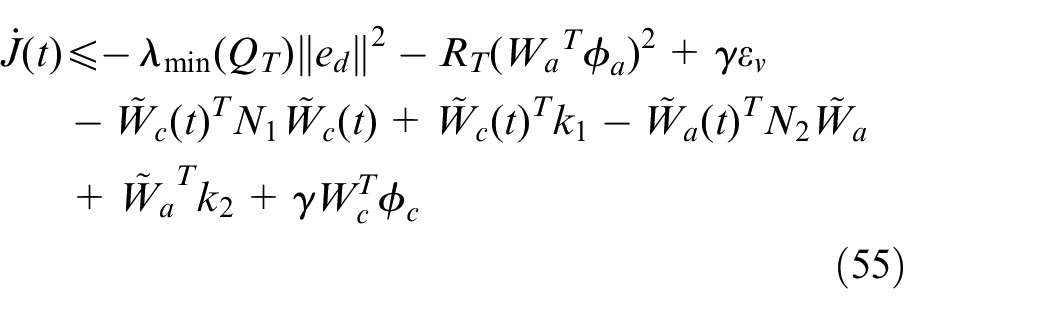
where

and
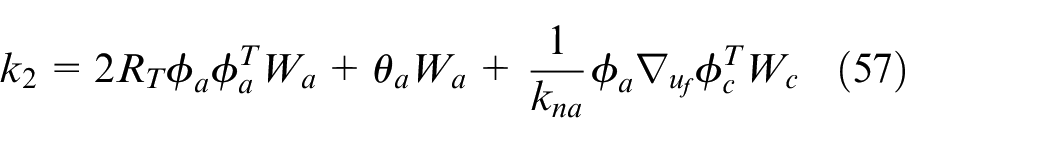
According to the range of
And
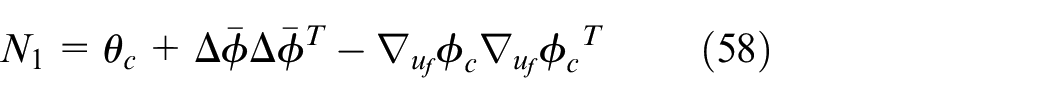
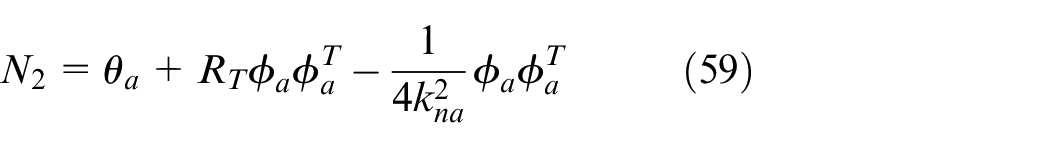
The regularization coefficients

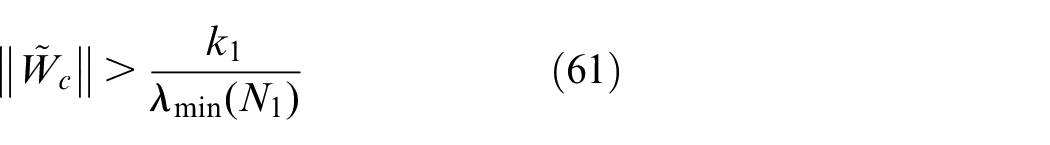
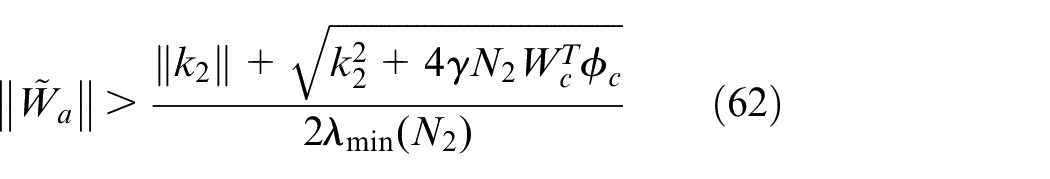
Case study
In this section, the tracking control of a hydraulic loading system for hydraulic motors is taken as a case study. 25 The hydraulic loading system utilizes energy regeneration technique to improve efficiency.26–28 The photograph of the experimental setup is shown in Figure 2. Simulation and experiment results are given to verify the effectiveness of the proposed controller. The objective is to achieve high-accuracy pressure control, which can be defined as an OTCP.

Experimental setup of the hydraulic loading system with energy regeneration.
OTCP of the hydraulic loading system
The simplified schematic of the hydraulic loading system with energy regeneration is shown in Figure 3. The hydraulic loading system is used to test the hydraulic motor (Rexroth A2FM63) mounted on the transmission shaft. The system is driven by a variable frequency induction motor (ABB QABP 355L2A). The variable displacement loading pump (Rexroth A6V2F63) regenerates the mechanical energy and adjusts the system pressure. Two flow meters (KRACHT VC12) and pressure sensors (KELLER PA-33X/600BAR) are mounted at two outlets of the tested motor. A personal computer (PC) receives all the sensor signals and sends the control signal by an I/O card (ADVANTECH USB4716). The objective of the OTCP is to obtain the optimal displacement input of the loading pump so that the performance function (10) can be minimized.
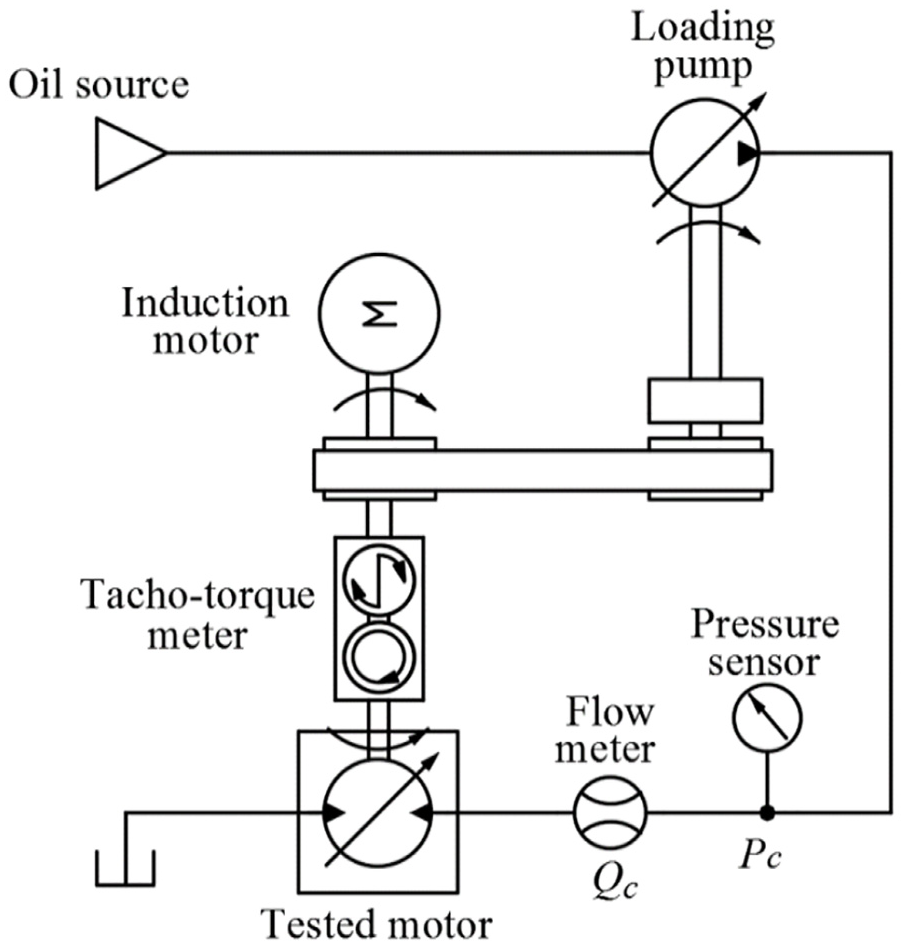
Simplified schematic of the hydraulic loading system.
The dynamics of the loading pump can be simplified as a first-order system
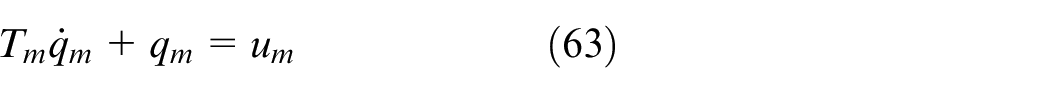
where
The system pressure dynamics can be described as

where

Define the system state and output as
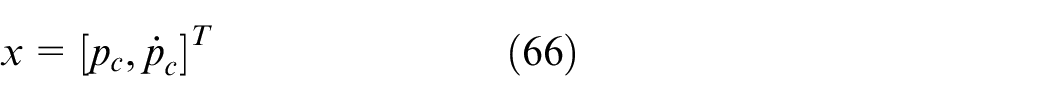
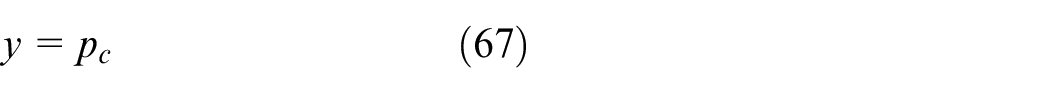
According to equations (63) and (64), the hydraulic loading system can be described as a second-order linear system



The control input
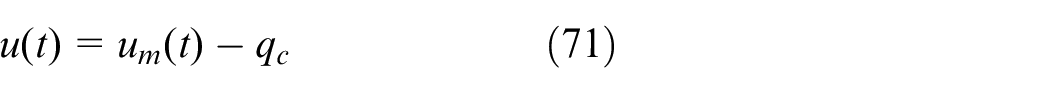
And the range of
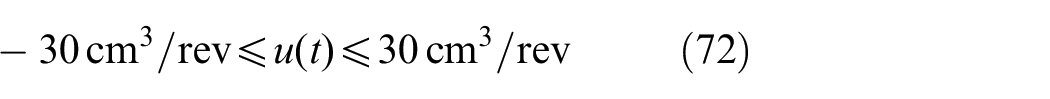
The state vector for the optimal controller is written as
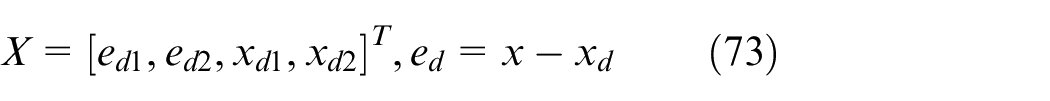
where
The basis function
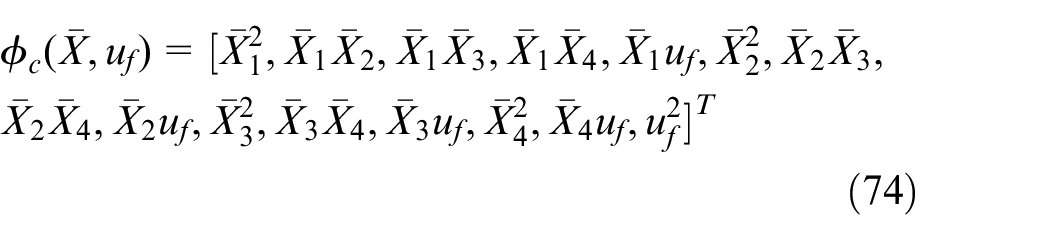
And

The controller is designed with
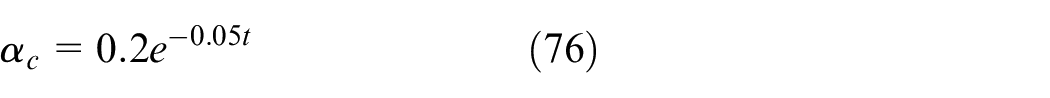
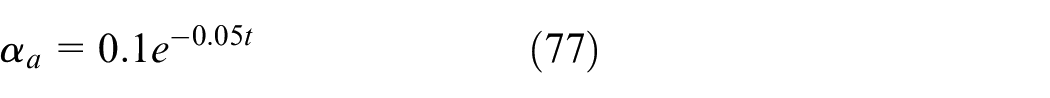
Simulation results
The hydraulic loading system is modeled in Matlab/Simulink with


Notice that the system dynamics
Figure 4 shows the control performance of the proposed controller while tracking a non-periodic signal compared with a proportional–integral–derivative (PID) controller.29,30
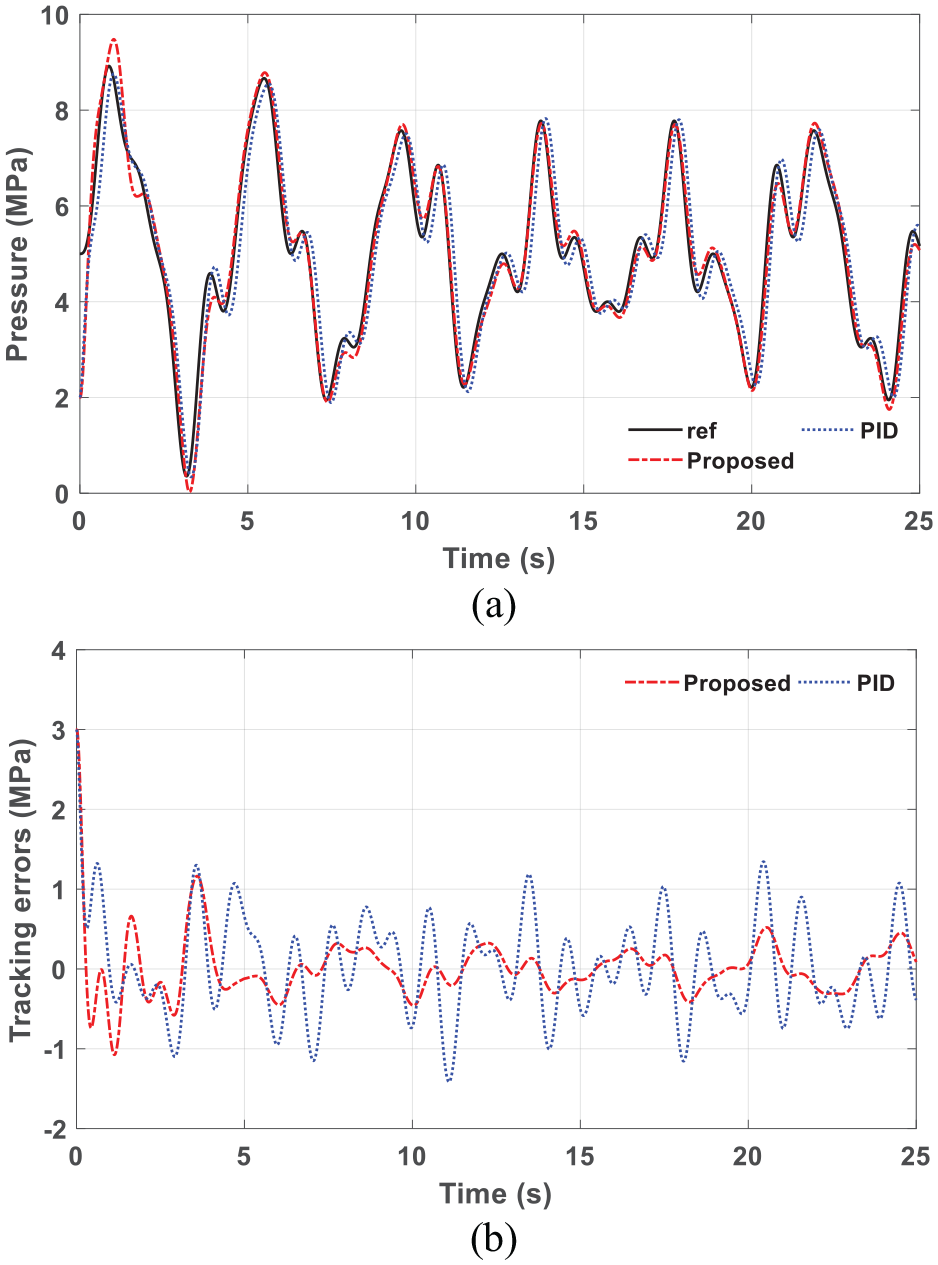
Simulation results of the proposed controller compared with the PID method: (a) system pressure while tracking a non-periodic signal and (b) comparison of the tracking errors.
The feedback gain of the PID controller

It can be seen that the tracking error of the proposed controller can be remarkably reduced after the learning process. With the feedforward term in the output, the proposed controller can outperform the PID controller, which is shown in Figure 4(b).
Figure 5 shows the system state
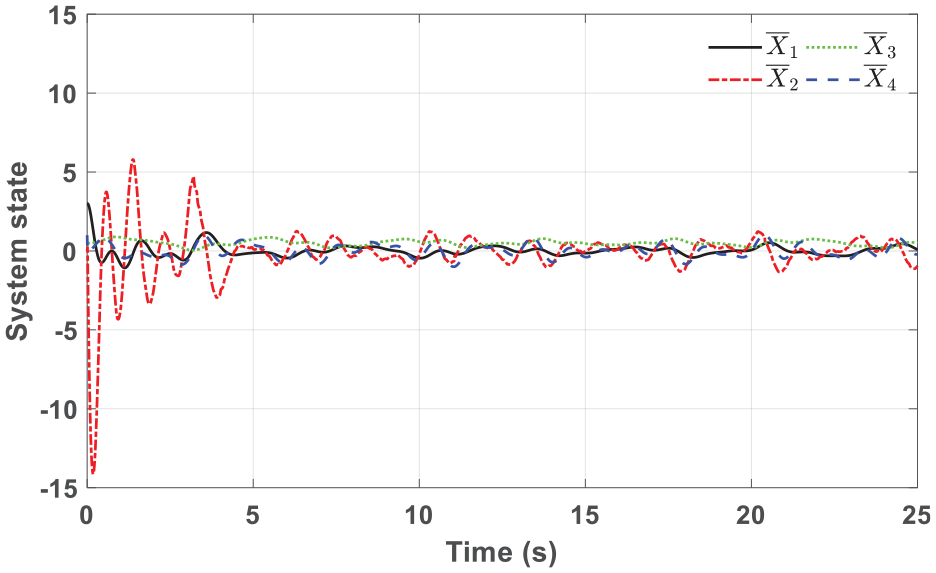
System state with normalization in simulation.
The gradient
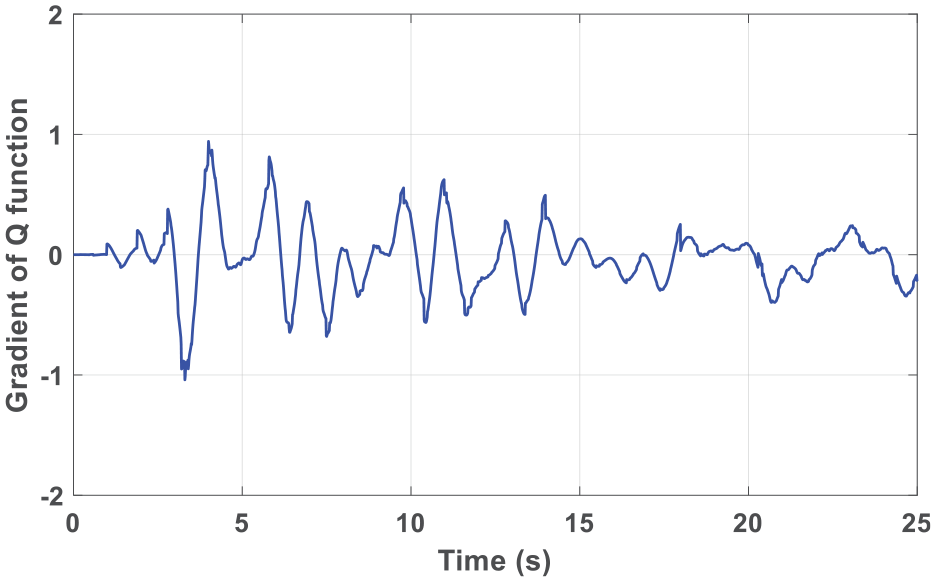
Gradient of the Q-function
The convergence during the learning process is shown in Figure 7. The Bellman error keeps bounded and converges to zero gradually. In Figure 7(b), the critic weights vector finally converge to
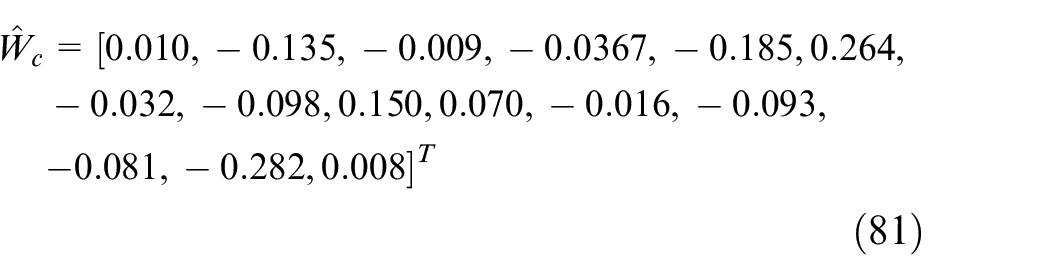
The initial weights of actor network are set to be
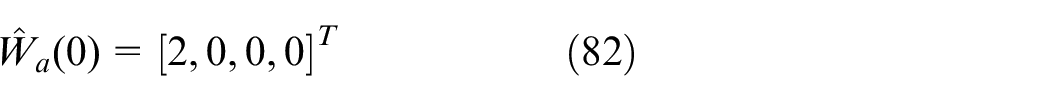
In Figure 7(c), it can be seen that the weights
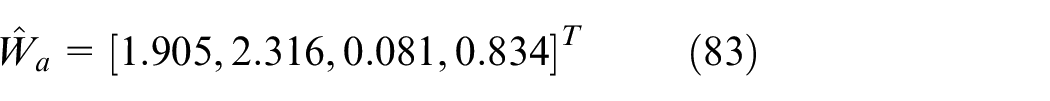
The feedback and feedforward parts are learned simultaneously.
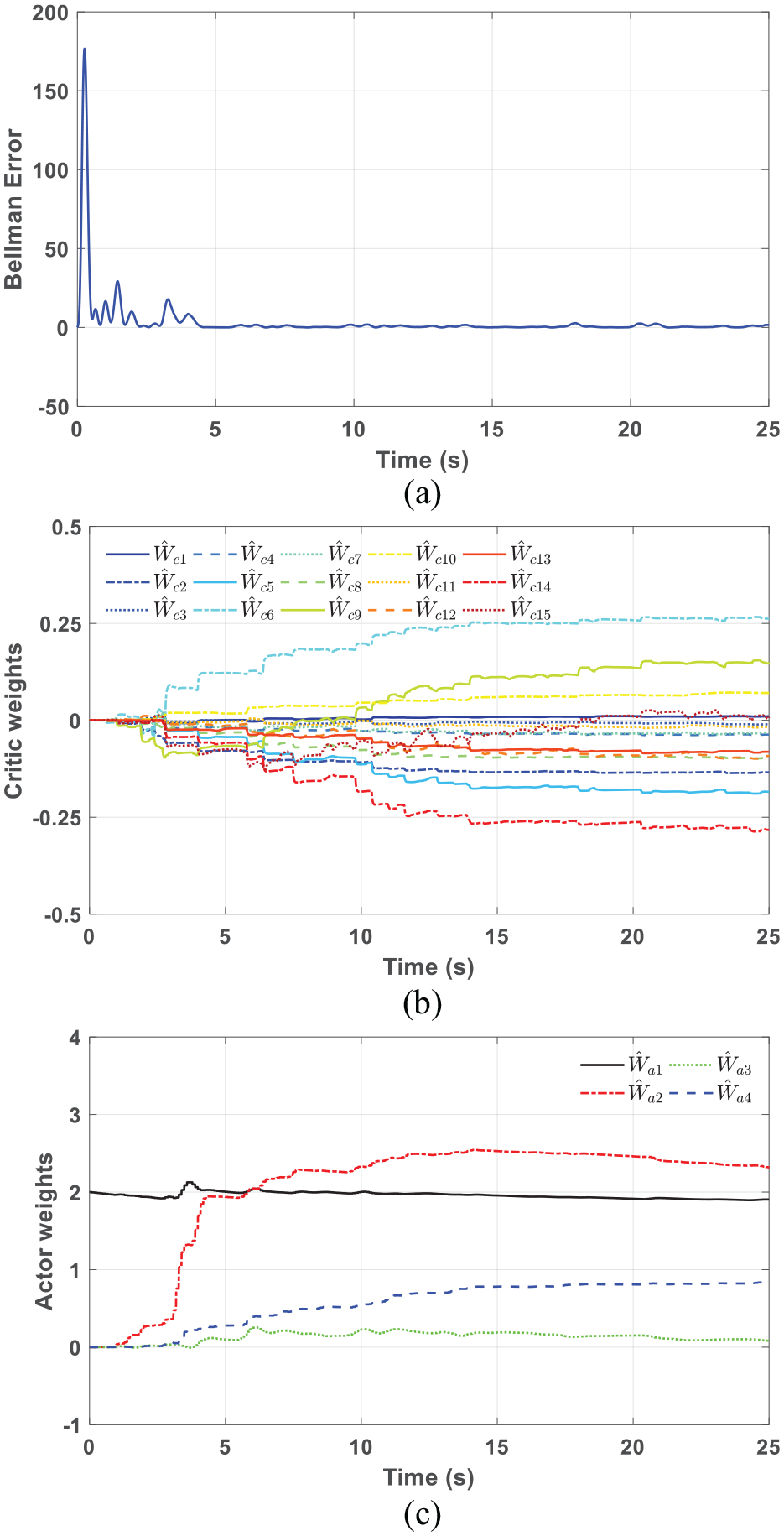
Convergence of the proposed controller in simulation: (a) Bellman error, (b) critic network weights, and (c) actor network weights.
Experiment results
Figure 8 shows the experiment results of the proposed optimal controller while tracking a non-periodic signal. The performance of the proposed controller is also compared with a PID controller. It can be seen that the difference of tracking errors between the two controllers is relatively small at the beginning. After several seconds for learning, the tracking error of the proposed controller is remarkably reduced.
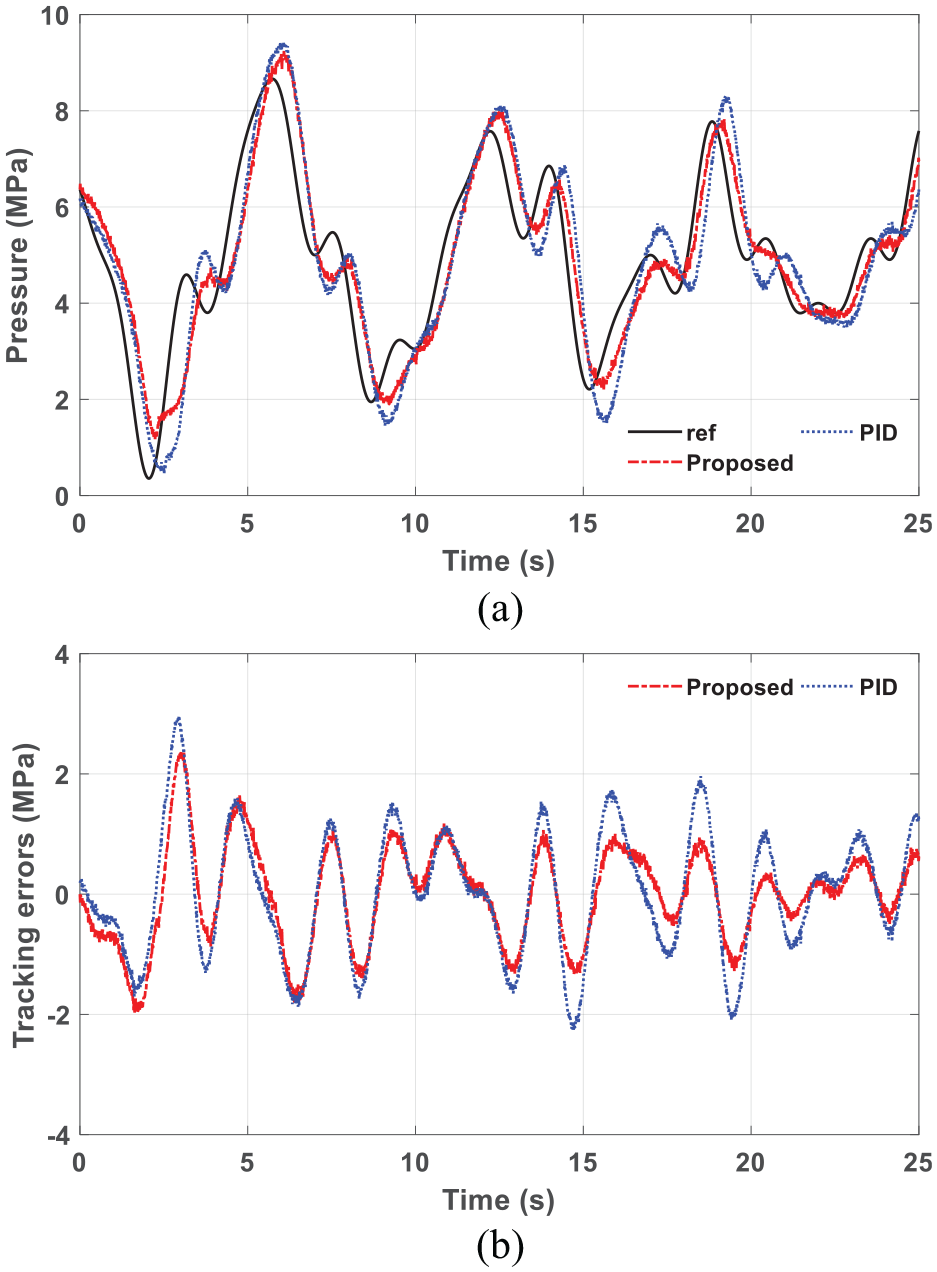
Experiment results of the proposed controller on the hydraulic loading system: (a) system pressure while tracking a non-periodic signal and (b) tracking error compared with the PID method.
Figure 9 shows the convergence of the proposed controller. It can be seen that the Bellman error keeps bounded under the experimental circumstances. The weights of the critic
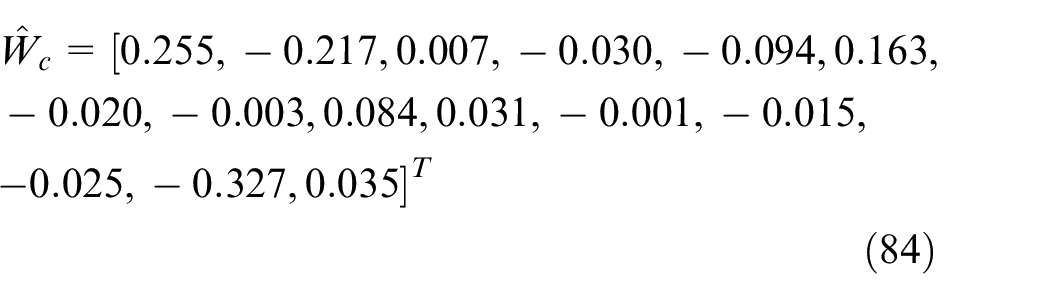
And
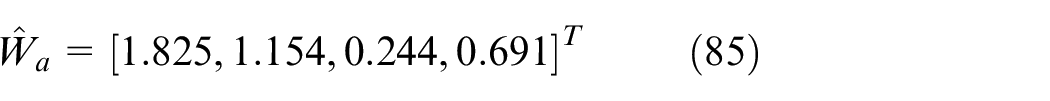
So, the convergences of
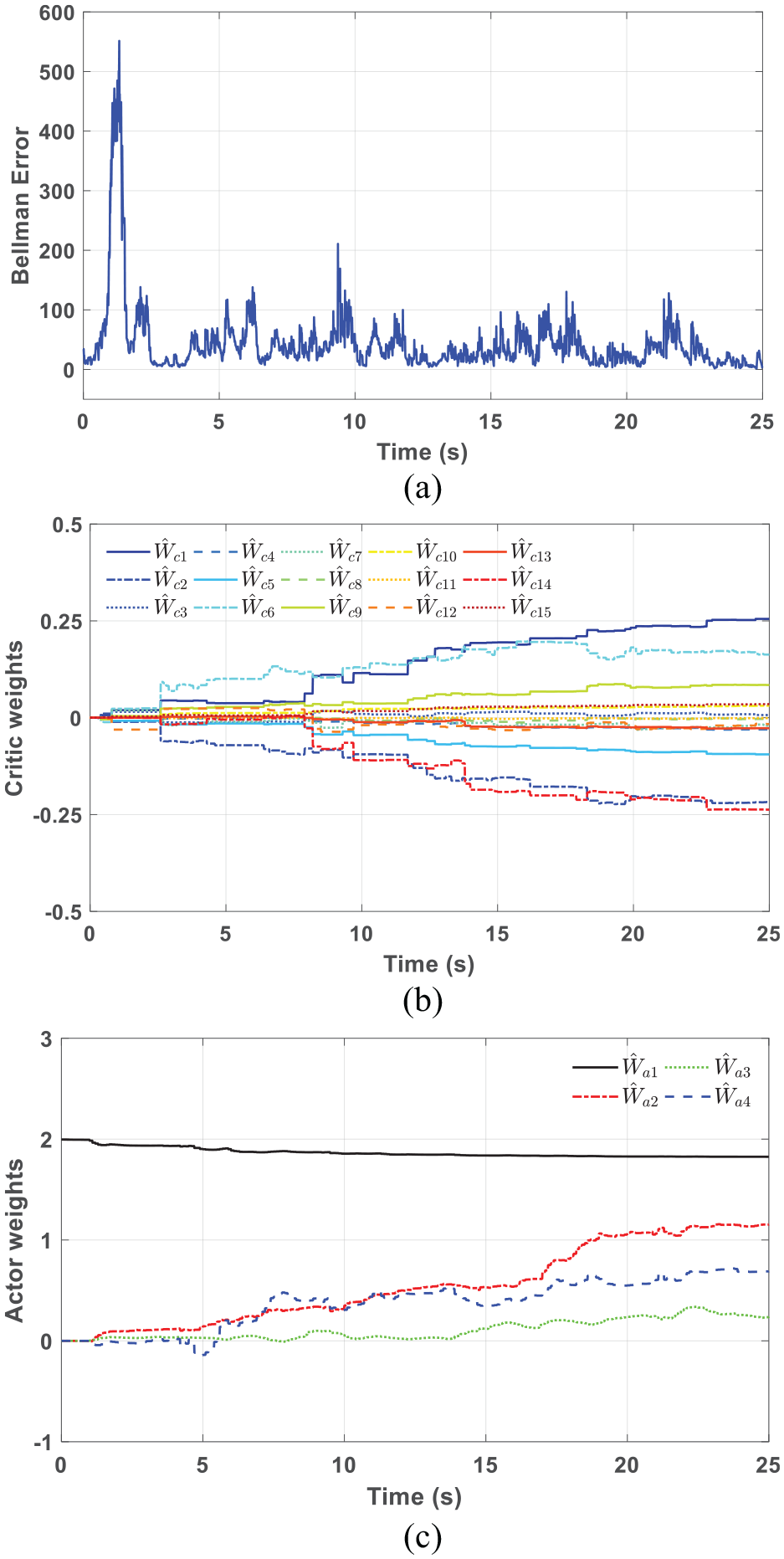
The learning process of the proposed controller in experiment: (a) Bellman error, (b) critic network weights, and (c) actor network weights.
Conclusion
In this article, an SISO continuous-time optimal tracking controller is proposed for linear systems with completely unknown dynamics. The proposed controller is different from those conventional proportional-deviation-type optimal controllers in two aspects. First, the integral compensation and the feedforward part are introduced into the controller, so the control performance can be improved. Second, the reinforcement learning techniques are applied in the controller design, and the optimal control policy can be obtained on-line without the prior knowledge of system dynamics. The Lyapunov stability and the convergence of the system have been proved. A case study on a hydraulic loading system with energy regeneration is given to validate the control performance. The simulation and experiment results have shown the effectiveness of the proposed controller.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research is supported by the National Natural Science Foundation of China (51475414 and 51875504), as well as the Foundation for Innovative Research Groups of the National Natural Science Foundation of China (51821093).