
Abstract
Violent interaction detection is a hot topic in computer vision. However, the recent research works on violent interaction detection mainly focus on the traditional hand-craft features, and does not make full use of the research results of deep learning in computer vision. In this paper, we propose a new robust violent interaction detection framework based on multi-stream deep learning in surveillance scene. The proposed approach enhances the recognition performance of violent action in video by fusing three different streams: attention-based spatial RGB stream, temporal stream, and local spatial stream. The attention-based spatial RGB stream learns the spatial attention regions of persons that have high probability to be action region through soft-attention mechanism. The temporal stream employs optical flow as input to extract temporal features. The local spatial stream learns spatial local features using block images as input. Experimental results demonstrate the effectiveness and reliability of the proposed method on three violent interactive datasets: hockey fights, movies, violent interaction. We also verify the proposed method on our own elevator surveillance video dataset and the performance of the proposed method is satisfied.
Introduction
In recent years, automatic detection and recognition of activity in real video has become increasingly important for human–computer interaction, video surveillance, and content-based video retrieval applications. Violent interaction detection is a special sub-problem in the field of action recognition. With the development of computer vision, the research on violent interaction detection (VID) has made some big progress. However, due to the low quality of surveillance video, occlusion and large changes in motion scale and illumination, VID is still a challenging task.
The VID is to identify whether a violent action has occurred in a video, such as fighting. The artificially trimmed video of the general related dataset is a fragment containing only action and is labeled as “violent action” and “non-violent action.” In early time, trajectory information and orientation information of a person’s limbs are presented by Datta et al. 1 to detect violent behavior. And some researchers attempted violent behavior detection methods on audio features.2–4 However, it is difficult to include high-quality sound in current datasets and in actual surveillance videos, so we mainly identify visual violence in video based on visual features. In fact, the previous VID method has low detection performance and high false alarm rate. If the accuracy of features extracted to represent violent action is satisfactory enough, the performance will be better. The accuracy of the spatio-temporal hand-craft features, such as motion scale invariant feature transform (MoSIFT), 5 spatio-temporal interest points (STIP), 6 and violent flow (ViF), 7 in-deed increased to an extent, and the violent detection method 8 based on these features performs better. Methods based on optical flow9,10 are also employed for detection task. However, it still cannot meet the requirement of real-time detection in different scenarios.
Recently, with the development of deep learning, action recognition has achieved rapid development. At the same time, there are many methods based on deep learning in the field of VID. Meng et al. 11 obtained better detection performance by fused integration trajectory and deep convolutional neural network (CNN) feature. But it did not consider the temporal feature. Ding et al. 12 uses three-dimensional (3D) ConvNet to model the spatial–temporal feature, but the 3D network has large amounts of parameters and cannot use deeper networks. Multi-stream deep CNNs 13 combine spatial stream, temporal stream, and acceleration stream to achieve good detection performance. However, this method only considers global spatial–temporal information, ignoring the impact of local information.
In this paper, we designed a multi-stream fusion model to address the above issues. Different from multi-stream method proposed by Dong et al., 13 in our method, the multi-stream deep learning framework mainly includes attention-based spatial RGB stream, temporal stream (by optical flow), and local spatial stream (by block-based spatial RGB). For the attention-based spatial RGB stream, we used typical soft-attention to learn attention region on the video frame; the temporal stream is similar to the optical flow mode in the temporal segment networks (TSN) 14 method, which is for action recognition and the local spatial stream divide the frames into different blocks and applies CNN to learn different regional features. Finally, the results from different stream are fused to obtain the final detection results. In addition, most of the previous methods apply a variety of modes fusions, however, it is still confused which mode has the greatest impact on action recognition or VID. In this paper, we compare VID results of different mode fusion, trying to explore the impact of different mode fusion on VID and its real reasons.
In summary, the main contributions of this paper are in the following aspects: (1) A new multi-stream deep learning approach in the VID is proposed to identify whether violence action is included in the video. (2) The effects of multi-mode on the results of VID are discussed and the optimal multi-mode fusion method for VID tasks is presented (Figure 1).
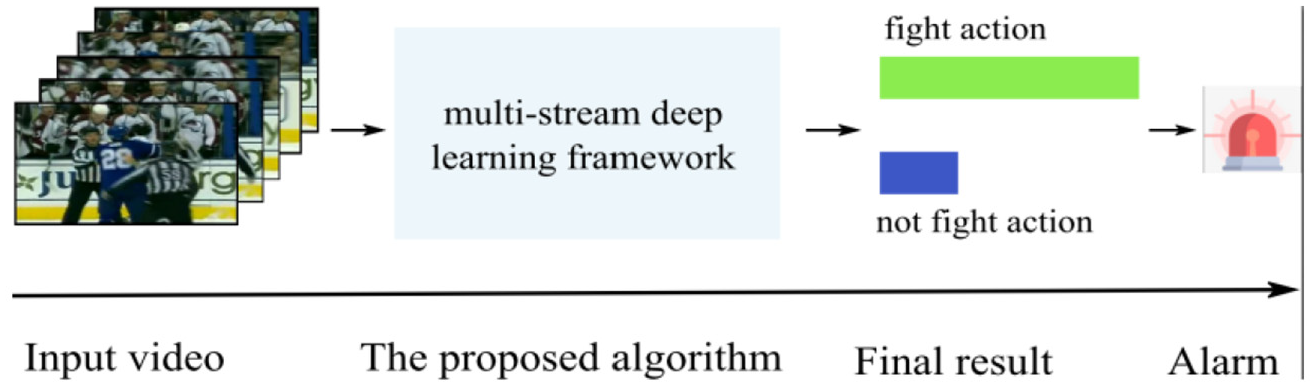
Violent interaction detection using the proposed algorithm.
The remainder of this paper is organized as follows. Section “Related works” describes the related works. Section “Multi-stream deep learning algorithm,” details the proposed multi-stream deep learning approach. Section “Experiments and analysis” reports the implementation details, the experimental results and analysis compared with the baseline and other VID methods and activity recognition methods. At the end of the paper, we conclude the proposed algorithm.
Related works
Action recognition
Action recognition is a fundamental research topic in the field of video analysis and has been extensively researched in the past few years. In the past few years, action recognition algorithms mainly employ hand-crafted features, such as scale invariant feature transform (SIFT), 15 histogram of oriented gradient (HOG), 16 improved dense trajectories (iDT) 17 and the classifier is support vector machine (SVM) or others to obtain the final prediction results. Among all the hand-crafted features, iDT achieves better performance. In recent years, deep learning methods have greatly improved the performance of action recognition. Wang et al. 18 proposed the test-driven development (TDD) algorithm. By replacing the traditional features in the iDT algorithm with the features based on the deep CNN, two normalization methods were designed: spatio-temporal normalization and channel normalization. The two-stream method19,20 applies a single RGB image and flow images as input to CNN and fuse features to achieve simultaneously modeling of spatio-temporal features. TSN method 14 proposes multi-segments method on the basis of two-stream to enhance the expressive ability of the model. Y Zhu et al. 21 by designing the optical flow network to replace the pre-extraction of the optical flow in the video, the optical flow network is added to the optical flow branch of the two-stream model, thereby greatly accelerating the recognition speed based on achieving higher recognition accuracy. Wang et al. 22 designed a non-local block to learn the global information of the original input data.
Based on C3D method, 23 action recognition is directly performed by modeling spatio-temporal features of the input frame sequence and the speed of recognition is greatly improved. D Tran et al. 24 compares the network structure commonly used in the action recognition task, and proves that the performance of 3D convolution is better than the two-dimensional (2D) convolution performance. And since this year’s one-dimensional (1D) convolution in deep learning is widely used in channel changes, the authors proposed the R(2 + 1)D structure. The R(2 + 1)D structure decomposition of the 3D convolution into a 2D spatial convolution and a 1D temporal convolution, thereby increasing the number of nonlinear layers of the network, making the network easier to optimize, and good performance has been achieved on the action recognition dataset. Y Zhao et al. 25 believes that although the decomposition of 3D convolution into 2D spatial convolution and 1D temporal convolution can achieve good recognition performance. However, there is an implicit assumption in 1D convolution: the characteristics of different time steps are aligned, and this assumption can facilitate the 1D convolution to aggregate the features of the same position. This assumption is very disadvantageous for the action recognition task. The author believes that motion in video is a crucial clue and is therefore subject to traditional trajectory-based methods: DT, 26 iDT, 17 TDD. 18 This article presents TrajectoryNet. TrajectoryNet can fully consider the deformation of the motion subject, as well as the content changes caused by the continuation of the motion in the video, allowing the visual features to be aggregated along the path of motion. This method has achieved significant performance improvement on two large-scale datasets by directly replacing the 1D temporal convolutional layer in Separable-3D (S3D) 27 with the trajectory convolutional layer. Efficient convolutional network for online video understanding (ECO) method 28 proposes two stages for recognition: extracting 2D feature of the input frame sequence and stacking the corresponding channels of all 2D feature maps as the input of 3D CNN, and it achieves better performance under the premise of faster speed.
VID
Similar to action recognition, VID is also divided into methods using hand-crafted features and methods based on deep learning. In the method based on hand-crafted features, the iDT 17 feature is a more common one. Serrano Gracia et al. 29 proposed a new feature extracted from the motion trajectory between successive frames to recognition violent action. Similar to two-stream algorithm in action recognition, EY Fu and colleagues30,31 apply optical flow to obtain motion statistics. Y Gao et al. 32 proposed a new feature extraction method for the dynamic amplitude change information of the VID task: oriented violent flows (OViF). At the same time, feature fusion and multi-classifiers achieved good detection performance. Wang and Schmid 33 demonstrates that the Gray Level Co-Occurrence Matrix (GLCM) feature can be used to determine the density of the population, as evidenced by the fact that 34 uses violent crow texture to detect violent action in the population of the input video. Zhou et al. 35 segments the motion regions as the input video according to the distribution of the optical flow field, and employs Bag of words (BoW) 36 to extract two low-level features of the spatial and temporal features of the segmented motion regions. The features are encoded to eliminate redundant information in the feature, and finally SVM is used to classify the final detection result. This method achieves good detection performance on Hockey dataset and the other two related datasets. With the development of hardware platforms and deep learning techniques, feature extraction methods based on deep CNN are becoming more and more popular. Inspired by TSN, 14 acceleration field 37 is designed, and it is merged with the original two modes of TSN. Similarly, Xia et al. 38 design a new frame difference modality to complement the original RGB modal and finally fuse the results. Since this algorithm only uses RGB frames, it can improve recognition speed while ensuring recognition performance. In addition, most of the videos of related datasets are usually cropped from movie clips or web videos, and the video of the real scene is relatively small. Therefore, to cope with this problem, 39 takes advantage of the inherent commonality between humans and animals and the ensemble learning mechanism to propose a new cross-species learning method, which has low computational cost features, thus effectively solving the human fight video limited issue.
Multi-stream deep learning algorithm
We propose a new VID model based on multi-stream deep learning. Our model includes the streams of attention-based spatial RGB stream, temporal stream, and local spatial stream. Finally, the results of the three streams are fused to obtain the final recognition result (Figure 2).
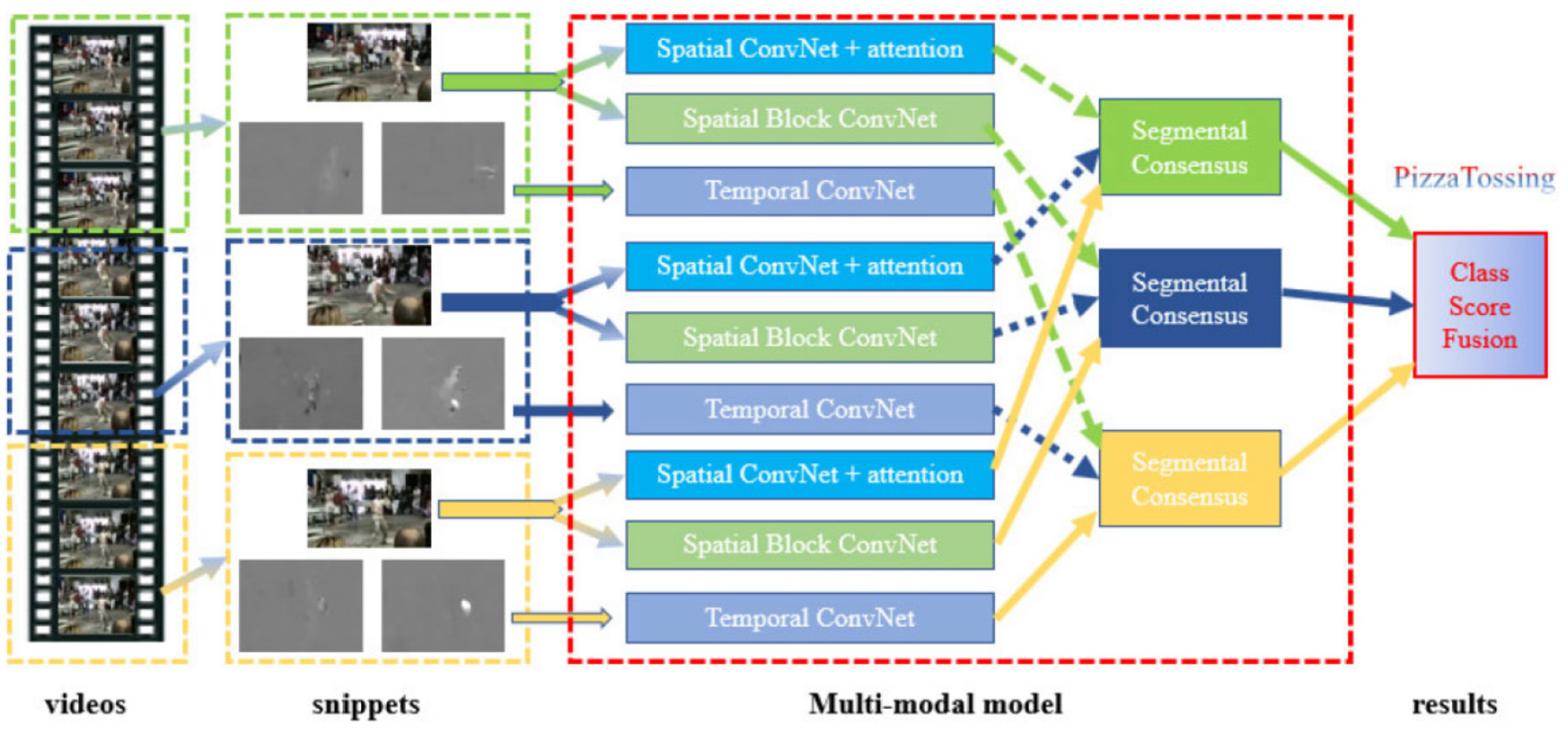
The proposed multi-stream deep learning framework.
Attention-based spatial RGB stream
The details of this stream are shown in Figure 3. This stream first divides each trimmed video into several segments, and then randomly samples one frame from each segment, so that for each input video we can get several frames, and the spatial features of each frame are extracted using batch normalized (BN)-Inception network. Based on the extracted spatial features, we use the attention mechanism to make the stream pay more attention to the main body of the action, improving the performance of the stream.
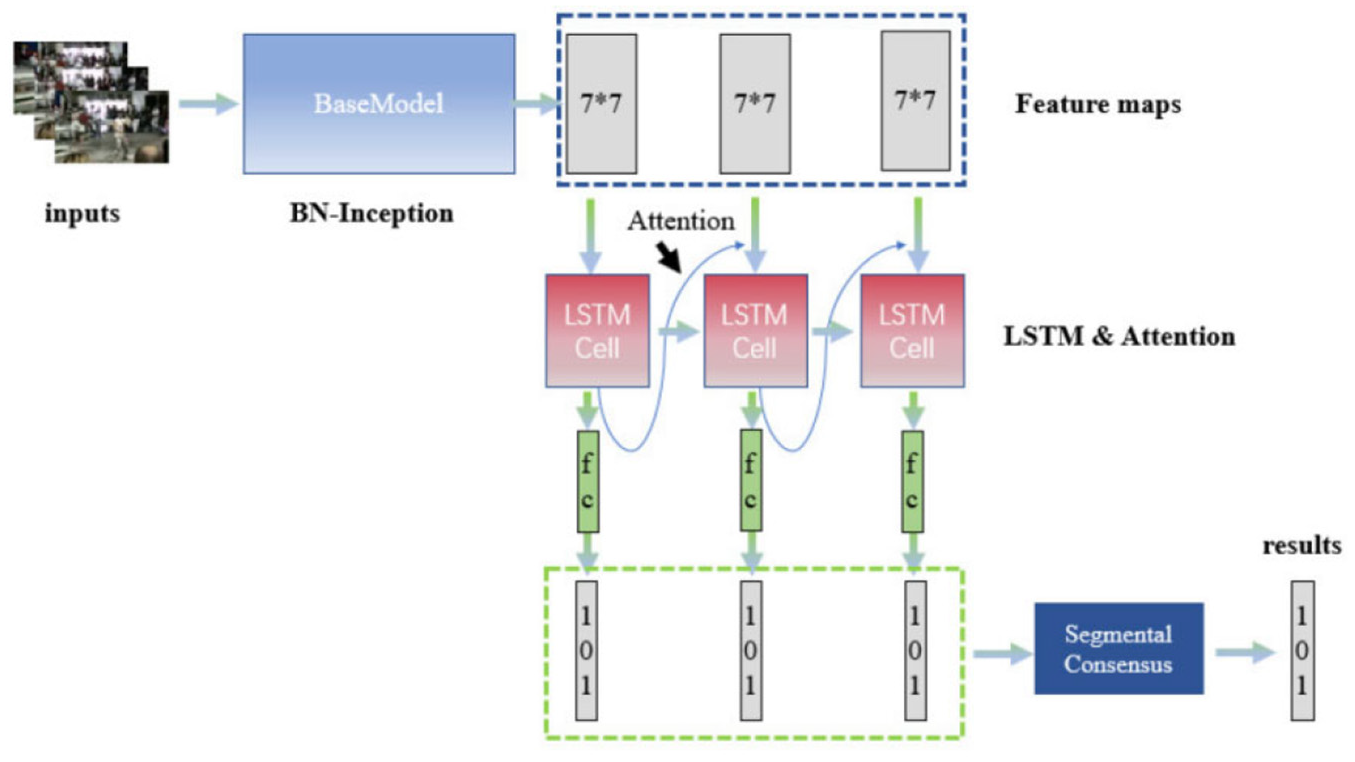
The details of attention-based RGB stream.
Let S denote a video. We divide video S into M segments with the same length,
After extracting feature maps for each image, soft attention is employed to capture a finer representation of the feature, as illustrated in Figure 3. The attention mechanism can generate weights
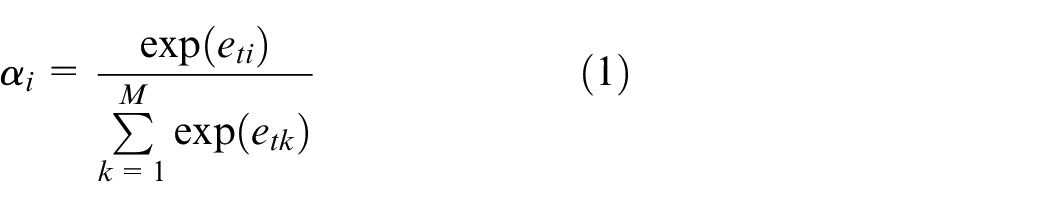
where
Attention can be seen as a series of weights generated from feature maps. The region of the specific violent action on the original feature map will be learned to be closer to one. Attention mechanisms focus on the specific region of the action, and ignore the interference of the surrounding noise on the prediction to achieve the purpose of improving the prediction performance. Accordingly, we employ long short-term memory (LSTM) 40 network and soft attention 41 to learn the regions, such as the human body region that makes the action. And it improves the quality of feature representation extracted by RGB frames. Sigmoid is employed as the activation function to predict the label of each frame. The prediction result of the final attention stream is obtained by combining the prediction results of LSTM cells.
Local spatial stream
Local information has been successful applied in person Re-ID,42,43 which also takes one person as the object of study by the model. They divide the image into blocks to get the local information of human body, and align the output results to get the final detection results. Inspired by this, we propose to extract human local information using block-RGB stream in VID.
Similar to attention-based spatial RGB stream, the video is also divided into segments with the same length. For each segment, the frame corresponding to attention-based spatial RGB stream is divided from top to bottom into three sub-blocks. The inputs of this stream contain a RGB frame and its three sub-blocks. The details of this stream are shown in Figure 4.
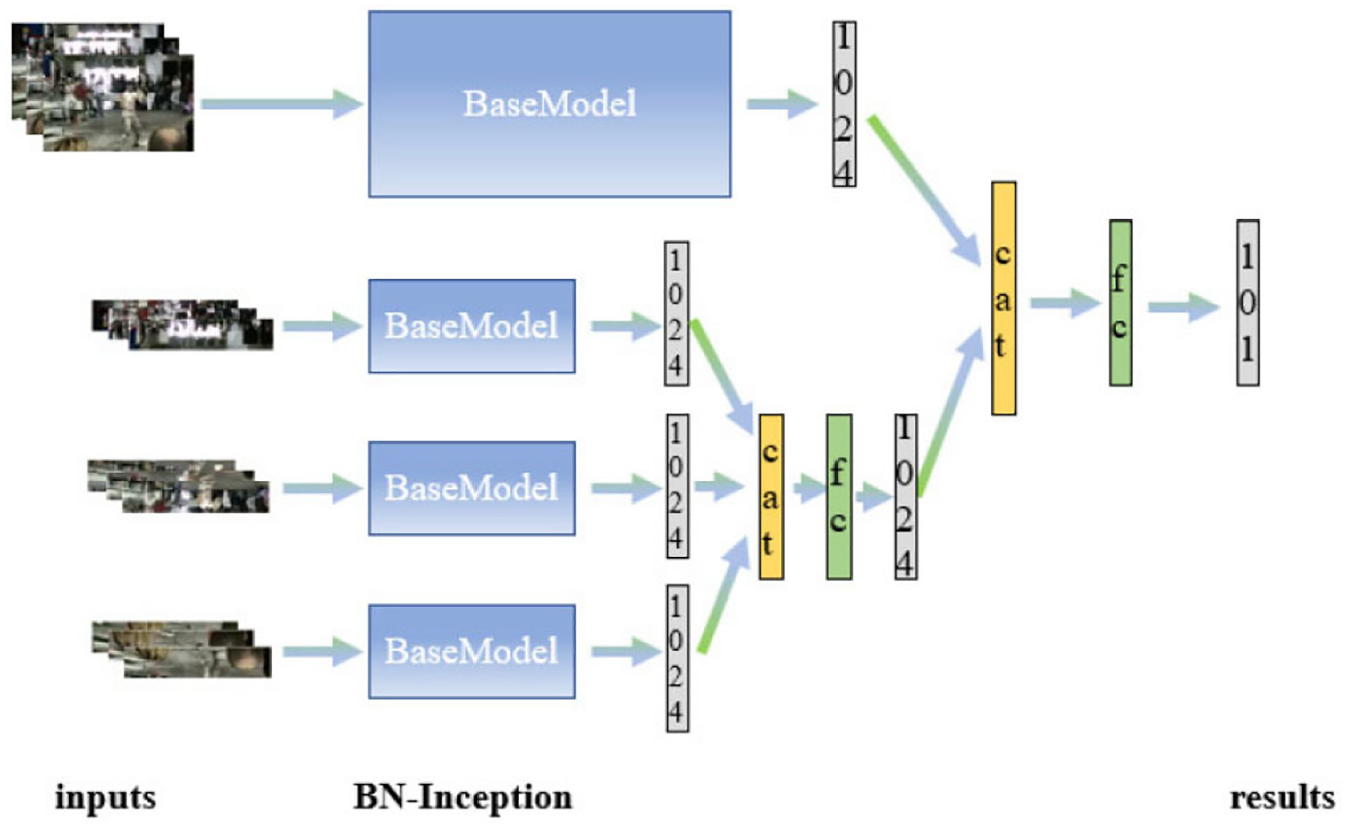
The details of block-based RGB stream.
BN-Inception is used to extract the corresponding local feature representation of the three divided sub-blocks. Although each local feature representation only contains a part of the overall information, it is not affected by the context. For this reason, the divisions can learn stronger local feature representation and the proposed method enhances the local feature representation. However, it does not interact with other information in the frame to determine the specific action in the video. For the sake of interaction of different divided parts, we contact the local information obtained from these three sub-blocks, and set an fully connected (FC) layer for local information interaction. Using the block method proposed above, three sub-blocks of RGB frame are input into the block-based RGB stream, and we can get 1D features to represent them. Finally, we interact the global feature representation extracted by BN-inception from the original size frame with the fused local information representation, and obtain better information representation to improve the performance.
Temporal stream
The details of this stream are shown in Figure 5. Optical flow is calculated from two adjacent frames in the input video.

The details of optical flow stream.
For video data, not only is it necessary to model spatial feature representations, but temporal features are also an important feature representation for describing the type of activity occurring in the video. Temporal features can model the temporal association of actions performed by active subjects in a video to establish a contextual relationship between frames. Therefore, our model uses attention-based spatial RGB stream, local spatial stream to establish the feature representation in each frame of the video, and uses the temporal stream to establish the temporal relationship between frames. The difference in feature representation is large, so it can be fused to each other to obtain better recognition performance similar to the flow module in TSN. 14
For a given video S, we first employ TVL-1 algorithm 44 in OpenCV 45 to extract optical flow of the video. For each pixel in optical flow graph, it can be represented by x and y axes of optical flow
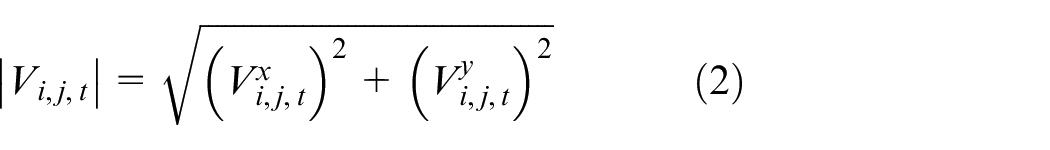
where t represents the tth frame of the input video, and i and j, respectively, represents the positions of the corresponding pixels in the optical flow graph. For each optical flow extracted from the video, we save both its x-axis image and y-axis image for convenience. The optical flow method describes motion of a moving target, a surface or an edge in a video, and it approximates motion information of the object in the video that cannot be directly obtained from the sequence of frame.
Similar to attention-based spatial RGB stream, in temporal stream, the video is also divided into M segments with the same length. For each segment, the optical flow is extracted on the frame corresponding to the attention-based spatial RGB stream. And each frame corresponds to two images: x-axis image and y-axis image, which represent the optical flow graph.
Fusion
For different streams, the model can be used to model spatial feature representations and temporal feature representations simultaneously. For each of our three streams, the probability of the category to which each input video belongs can be obtained from each stream. Therefore, for each video, the probability of three different videos belonging to the category can be obtained. To make these three streams fusion for better recognition performance, we use the last fusion method to fuse the class probabilities of the three stream outputs. So, for an input video, we have the following formula to get its prediction
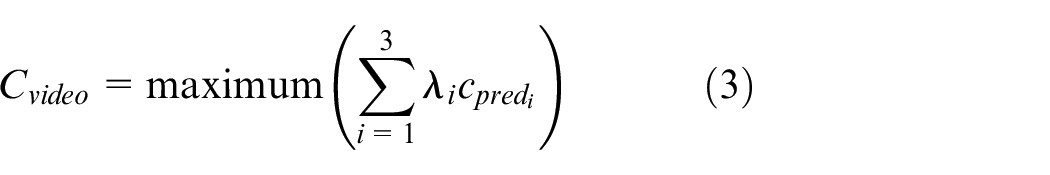
where
Loss function
From the above three streams, the stream of attention-based spatial RGB, local spatial and temporal, we have obtained information from three modes as input to the BN-Inception network, and after the BN-Inception network, features are extracted directly to the classification layer to get the final results. Each stream applies a cross-entropy loss function and stochastic gradient descent (SGD) optimizer. This loss function is expressed as

where C is the number of action classes, yi,c is the true label of sample i, and pi, c is the probability that sample i is the category c.
Experiments and analysis
Datasets
We compared our proposed algorithm with other methods on datasets that related to four violent action detections of hockey fight, 6 movies, 6 VID 37 and our own elevator surveillance video (EsV) dataset.
Hockey fight dataset
The hockey fight dataset contains 1000 video clips extracted from hockey games. Among them, violence occurred in 500 videos, and another 500 is videos of no violence. Each video is about 1–2 s duration. We convert the videos into frames at 25 frames per second (FPS), and each video contains about 40 frames.
Movies dataset
The movies dataset contains 200 trimmed video clips. There are 100 video clips containing violent action extracted from action movies and 100 video clips extracted from other publicly available action recognition datasets that do not contain violent action. The duration of each video clip is around 2 s. We convert the videos into frames at 25 FPS, and each video contains about 40 frames.
VID dataset
The VID dataset is mainly extracted from the four datasets of hockey fights, movies, UCF101, 46 and HMDB51. 47 The video corresponding to the three categories kick, hit, punches extracted from the HMDB51 dataset, and 206 video clips are obtained. The samples corresponding to two categories, punches and Sumo Wrestling, are extracted from UCF101. A total of 271 video clips are obtained; the two datasets, hockey fight and movies, are combined. As a result, VID contains a total of 2314 videos, of which 1077 video clips contain violent action and 1237 video clips that do not contain violent action. The number of videos in VID dataset is much larger than the hockey fight and movies datasets. The larger amount of data can help the deep learning model to fit better, achieving better performance and generalization capabilities.
EsV dataset
Our own dataset adds 25 real elevator surveillance video clips to the VID. These new videos come from clips in our elevator surveillance videos, which are more authentic than the original video in the dataset. Examples of adding videos are shown in Figure 6. It shows two actions happening in the elevator: fighting and falling, and the former is containing violence in this paper and the other is not.

The examples of elevator surveillance video dataset.
Implementation details
All models use BN-inception as the base model, our BN-inception is initialized using the model trained on ImageNet. We employ SGD method to optimize the network, and set the same values for the following parameter: weight decay 5e-4, momentum 0.9, batch size 8, learning rate 0.001. For the sake of increasing efficiency, we set the values of some parameters for different datasets. Because the training data distribution in the four datasets is different and the video content is different, the training difficulty of different datasets is different. For each of the four datasets, each of our models trained different epochs to get the best results, and it is summarized in Table 1.
The number of epochs trained for each stream in each of the four datasets.
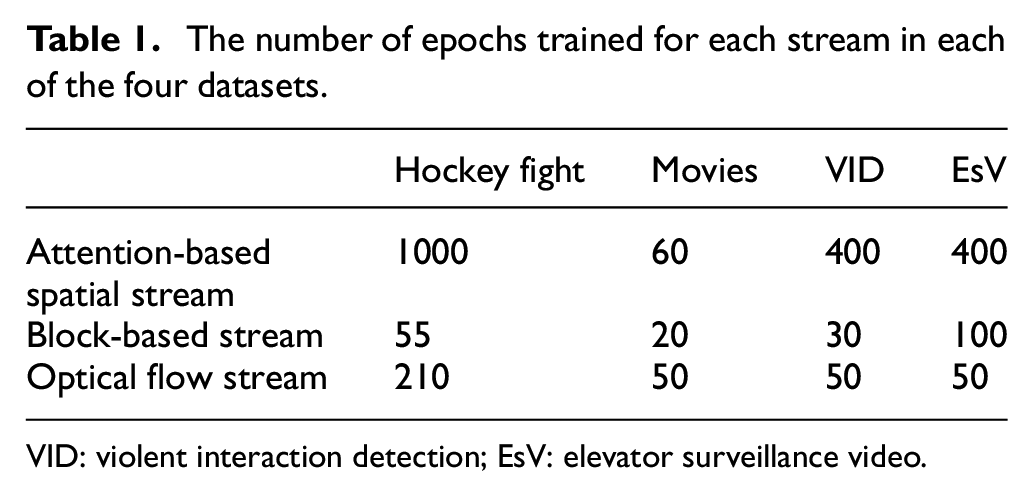
VID: violent interaction detection; EsV: elevator surveillance video.
Multimodal analysis
In this paper, we analyze the role of different modalities in VID tasks. It mainly includes optical flow mode (corresponding to temporal stream), warpped flow mode (corresponding to warpped flow in TSN), 14 RGB mode (corresponding to spatial RGB stream without attention), and RGB with attention (corresponding to attention-based spatial RGB stream). The local spatial stream corresponded to clip mode. The results of different modes fusion are compared to give the optimal multimodal combination method for VID tasks.
As shown in Table 2, the results of two-modal fusion and three-modal fusion are given. RGB, RGB with attention, local spatial three modes mainly perform the VID task by modeling the spatial features of a single frame. Different from the above three modes, the optical flow and warp flow pass the frame in the modeling video. Temporal features between frames for VID.
Exploration of different streams on dataset VID.
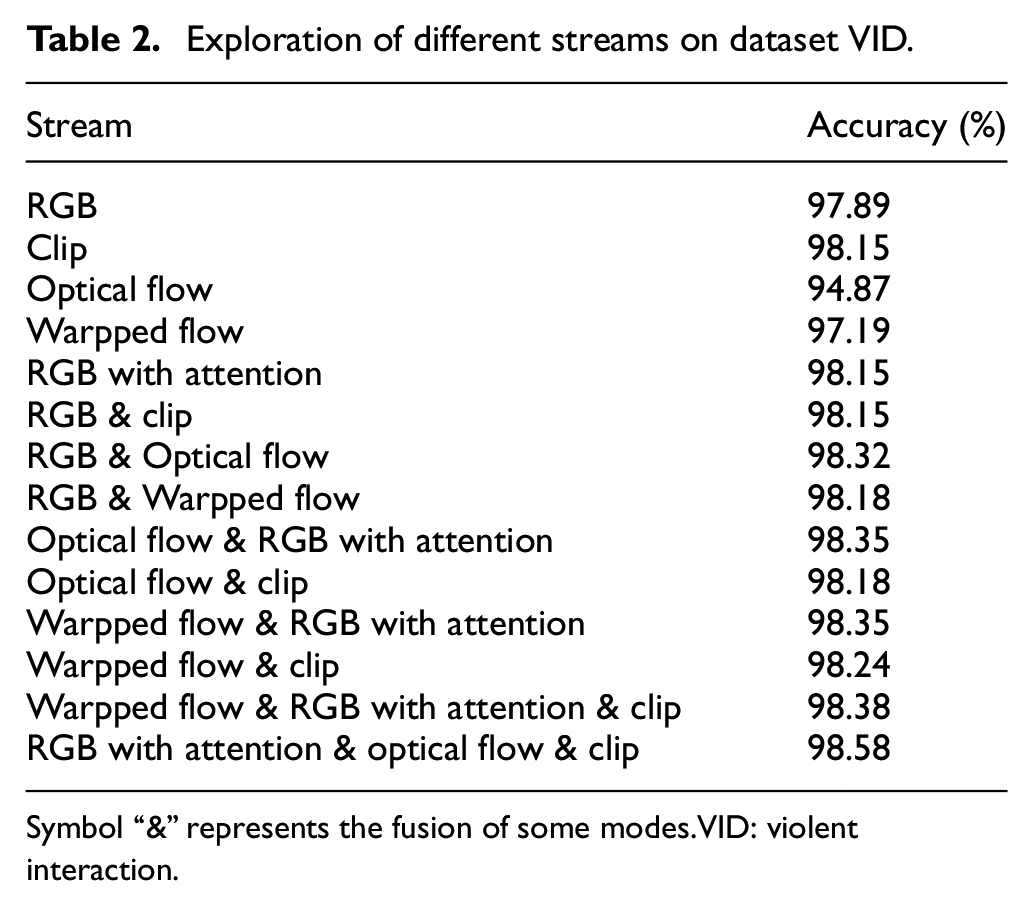
Symbol “&” represents the fusion of some modes.VID: violent interaction.
It can be seen from Table 2 that the spatio-temporal feature representation of the input video can be greatly improved by fusion of the modality of the modeling spatial feature and the modality of the modeling temporal feature. As can be seen from Table 2, we can achieve good performance with a single RGB with attention stream. When fusing two modes, attention-based spatial RGB mode achieves the best performance when fusion with optical flow or warpped flow. Attention-based spatial RGB mode employs attention mechanism and can obtain a better representation of the spatial features, so that the temporal feature representations of the modes associated with the flow can complement each other for better detection performance. Clip mode cannot be combined with optical flow like RGB with attention stream to get a particularly good performance boost. The general reason we guess this phenomenon is that the clip mode does not learn more spatial information than the optical flow difference compared with the RGB with attention stream. However, the clip mode is better able to learn local information. At the same time, for three-modal fusion, the optimal mode can be obtained using optical flow, attention-based spatial RGB, and block-based RGB. Although warpped flow mode can achieve better performance than optical flow mode in single mode, it does not perform as well as optical flow mode in fusion.
Results and analysis
For hockey fight, as shown in Table 3, our model adds new modalities and multi-modal fusion. Not only does the performance of multi-modal fusion exceeds TSN 14 and FightNet, 37 but the performance of each individual modality also exceeds these two.
Results of dataset hockey fight.
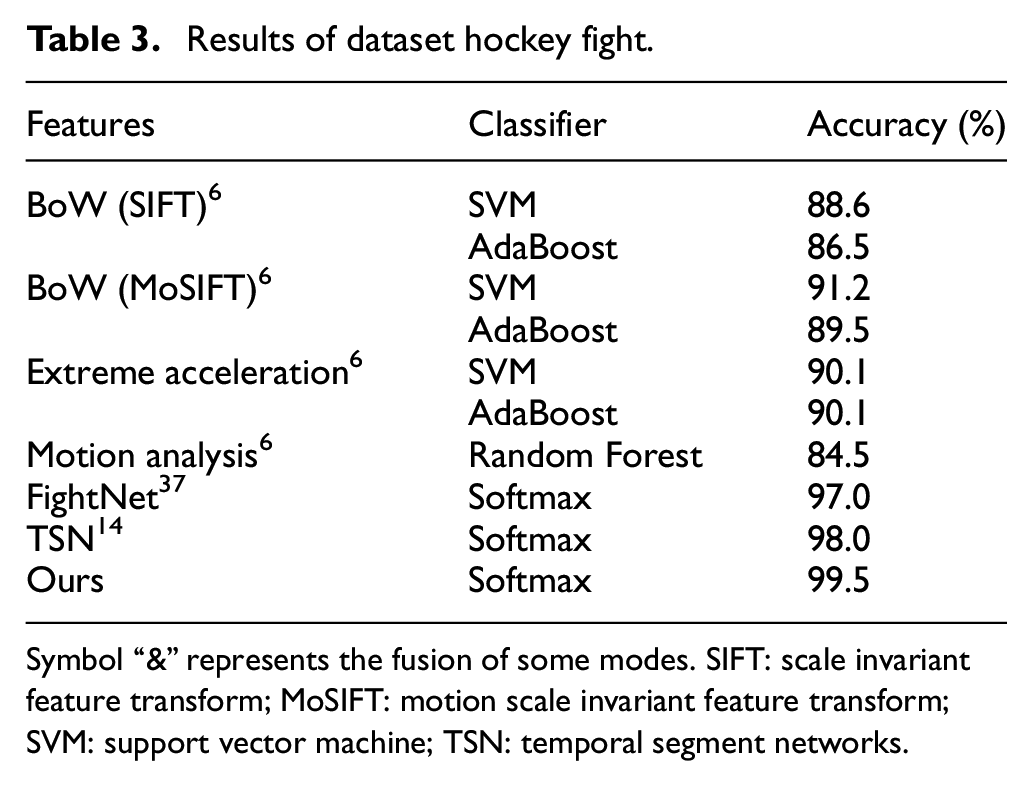
Symbol “&” represents the fusion of some modes. SIFT: scale invariant feature transform; MoSIFT: motion scale invariant feature transform; SVM: support vector machine; TSN: temporal segment networks.
The single-mode performance of the model is shown in Table 3. Through the last fusion, the local information of the attention-based spatial RGB stream and the local spatial stream can be better complemented by the global information of the optical flow stream. We think this is the main source of recognition performance improvement. Because of the number of videos in the movies dataset, our model is able to achieve 100% prediction accuracy on all modalities.
As shown in Table 4, the modalities of our model show good performance on large datasets such as VID. Not only the model, after last fusion, exceeds the FightNet, but also exceeds TSN. Our model has shown the best detection performance on the general three datasets, which can be verified that our proposed multi-stream fusion model has good detection performance and good generalization ability.
Results of dataset VID.
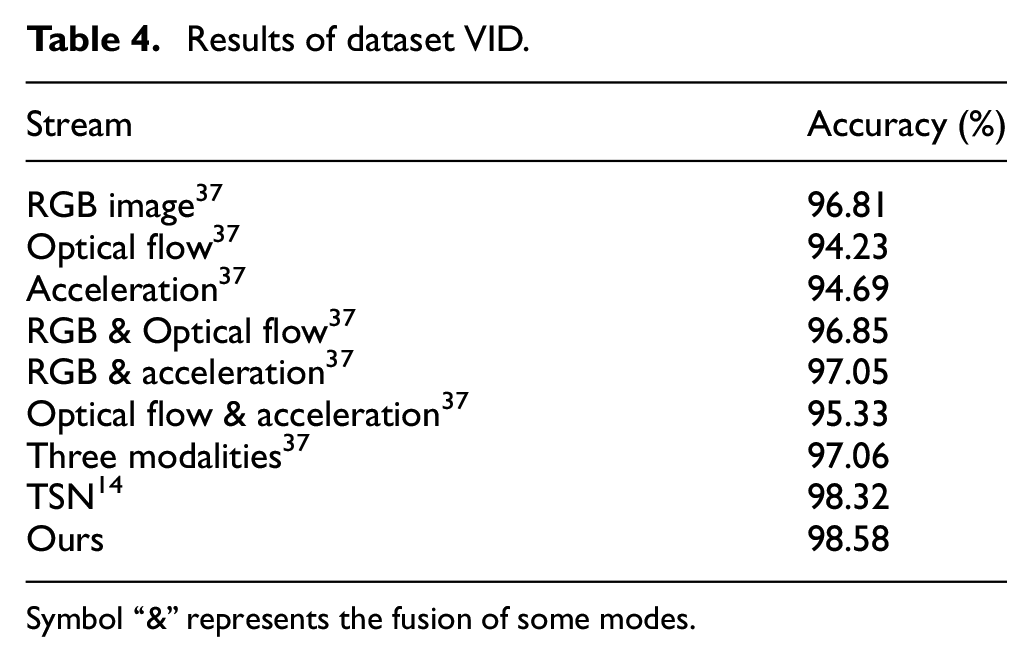
Symbol “&” represents the fusion of some modes.
In Table 5, we list the results of each modality and various modal fusions on our dataset. Since the local features of the input video sequence are better learned, and the local spatial stream itself has a certain global feature learning capability, this stream can simultaneously capture local features as well as global features, so local spatial stream get the best recognition performance in a single model. Although the warpped flow stream can obtain better results than the optical flow stream when the two modes are merged with each other, the optical flow stream can be better merged with more streams. Therefore, the new three-modal fusion model proposed by us has 98.71% performance higher than the 98.13% of the TSN model.
Results of our dataset.
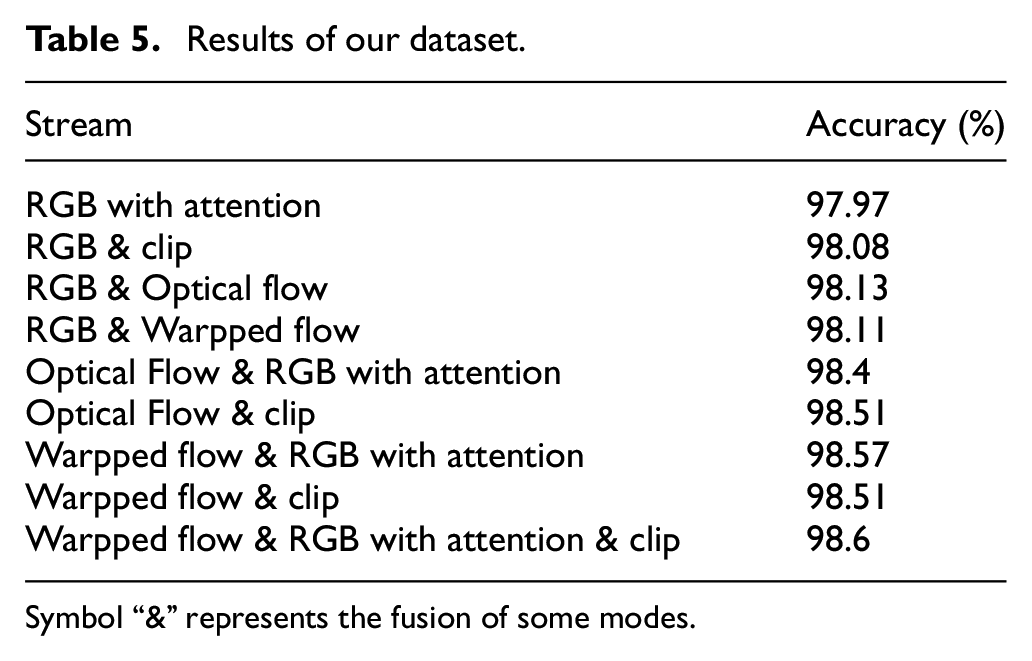
Symbol “&” represents the fusion of some modes.
It can be seen from the experimental results of the above four datasets that the proposed multi-stream model has a larger performance improvement on the four datasets than the other VID models. We think the possible reasons are: first, our attention based with RGB spatial and local spatial stream effectively model the spatial features of the input video, so that a single stream can achieve better detection performance. At the same time, to verify the effectiveness of the attention mechanism we used, we visualized some of the attention results in the test video on the hockey dataset and VID dataset. As can be seen from Figure 7, the whiter regions in the captured visualization indicate that our model has a higher degree of interest in this region of the image. By comparing the original image and the attention image in Figure 7, the following conclusions can be obtained: the attention mechanism we use can effectively capture the body of the behavior object in the video to help the model improve detection performance. Second, the temporal stream we use can effectively model the temporal information in the video data to perform the VID task based on the temporal information. Third, for the spatial features and temporal features modeled by the three streams, we used last fusion to make our model the spatio-temporal features at the same time, thus improving the performance of the detection.

Attention visualization results on test videos of hockey dataset and VID dataset: (a) original image and attention visualization on the hockey dataset test sample and (b) original image and attention visualization on the VID dataset test sample.
Conclusion
In this paper, we propose a new multi-stream deep learning approach for VID. The attention-based spatial RGB stream learns the attention regions through attention mechanism, improving the performance of the global spatial information. The local spatial stream can better learn the local features by simply dividing the frame. The temporal stream achieves a temporal feature representation of the video by employing optical flow method. Through the fusion of the above three streams, we have reached state-of-the-art on hockey fight, movies, VID, and our EsV dataset. Through analyzing the influence of different modalities on detection performance, we find the optimal combination between different modalities. The proposed algorithm is not only limited in the application of VID, it can also be applied to other applications of activity recognition.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.