
Abstract
Effective and efficient incipient fault diagnosis is vital to the maintenance and safe application of large-scale key mechanical system. Variable predictive model–based class discrimination is a recently developed multiclass discrimination method and has been proved to be potential tool for multi-fault detection. However, the vibration signals from dynamic mechanical system always present non-normal distribution so that the original variable predictive model–based class discrimination might produce the inaccurate outcomes. An improved variable predictive model–based class discrimination method is introduced at first in this work. At the same time, variable predictive model–based class discrimination will suffer computation difficulty in the case of high-dimension input features. Therefore, a novel feature selection method based on similarity-fuzzy entropy is presented to boost the performance of the variable predictive model–based class discrimination classifier. In this method, the ideal feature vectors are optimized to acquire more accurate similarity-fuzzy entropies for the input features. And, the one with the largest similarity-fuzzy entropy value is removed to refine input feature subset. Moreover, the optimal input features are repeatedly evaluated using the improved variable predictive model–based class discrimination classifier until the expected results are achieved. Finally, the incipient multi-fault diagnosis model for a hydraulic piston pump is established and verified by experimental test. Some comparisons with commonly used methods were made, and the results indicate that the proposed method is more effective and efficient.
Keywords
Introduction
The sudden failure of key engineering equipment, such as wind turbine and construction machine, will likely lead to unexpected break down and even casualties resulting in huge financial loss. Therefore, it will be plausible if any fault in them can be detected automatically as soon as possible. However, the reliable and real-time intelligent condition monitor and fault diagnosis is still a challenge due to the complex structure and work mechanism with harsh working environment and heavy working load for these key engineering equipments.1,2
Generally speaking, intelligent fault diagnosis is essentially pattern recognition 3 which includes feature extraction, feature selection, and pattern recognition. 4 So far, many data-driven intelligent fault diagnosis techniques have been developed.5–12 Many powerful signal processing techniques, such as time-domain statistic analysis, wavelet transform, 13 and empirical mode decomposition (EMD) and its extension methods,14,15 have been employed to extract sensitive fault features from different domains. Subsequently, to achieve accurate results, a feature selection technique is used to reduce the dimension of features before applying various pattern recognition techniques to indentify different situations.16–23 Manifold learning has been combined with Shannon wavelet support vector machine (SW-SVM) to fulfill the fault diagnosis for a wind turbine transmission system. 24 The hierarchical symbol dynamic entropy was extracted to quantify the complexity of signals caused by early faults of rolling bearings, and the binary tree support vector machine (BT-SVM) served as intelligent recognition approach. 25 But, the widely used pattern recognition methods, such as artifical neural network (ANN) and support vector machine (SVM), have their individual shortcomings. For example, the ANN method needs plenty of samples and has low speed due to complex iterating computation; SVM is a binary classifier and requires rigid parameter tuning so that it is complicate to solve the multicalss problem. Variable predictive model–based class discrimination (VPMCD) is a novel multiclass discrimination method.26–28 The VPMCD can make full use of interactions among the features to establish mathematical models—variable predictive models (VPMs)—for each class so as to identify the classes without complex iterating nor strict parameters adjustment.3,29–31 Recently, many works have shown that the VPMCD classifiers have much better performance and are a potential tool for multiclass fault diagnosis.29,32,33 However, the original VPMCD method cannot always adapt the non-normal distribution characteristics of features collected from vibration signals in dynamic mechanical system. Hence, the improved VPMCD technique is introduced in this paper. The details can be found in section “VPMCD principle and improvement strategy.”
Moreover, it is found that the computation expense of the improved VPMCD classifiers will greatly increase when the feature dimension is larger to acquire the richer information, which would limit its efficiency for multiclass discrimination. If some irrelevant features are removed using a feature selection technique, then the information which is sensitive to fault type and fault degree for effective classification is presented with fewer features, then the improved VPMCD classifier would have less time cost and higher accuracy. In general, feature selection algorithms include filter models, wrapper models, and embedded models.19,20,22,23,34,35 Filter models evaluate the general characteristics of the training data to select a feature subset without employing any learning algorithm; thus, it has less computation cost. 23 Nevertheless, it might obtain the feature subsets irrelevant to classes. Recently, Tang et al. 19 proposed a feature selection method and applied it to bearing fault identification to improve the VPMCD performance, but the procedure is very complicated and difficult to be applied in practice. The wrapper models assess the performance of the feature subset selected using a pre-determined classification algorithm so that the classifiers can usually achieve more accuracy, but they are usually slower than filter models. 23 Fuzzy entropy based on similarity measure can indicate the relevance of features and classes and has been used to successfully complete the wrapper feature selection with similarity classifier.22,35 However, the similarity measure was usually computed by the mean value, likely leading to inaccurate results. Simutanously, the similarity classifier is complicated for the paremeters adjustment. A novel wrapper feature selection technique integrating similarity-fuzzy entropy with the improved VPMCD was proposed to refine input features so as to boost the identification efficiency in the intelligent multi-fault diagnosis in this work. And, the proposed method was applied to establish the incipient intelligent multi-fault diagnosis model including three types of single-fault and two types of multi-fault for a hydraulic piston pump in a construction machine. The experimental results show that the intelligent multi-fault model with the novel feature selection technique and the improved VPMCD is more effective and efficient.
The rest of the paper is written as follows. The VPMCD method and its improved technique are introduced in section “VPMCD principle and improvement strategy.” A novel wrapper feature selection technique which integrated the improved similarity-fuzzy entropy and the improved VPMCD is developed in section “A novel feature selection method.” Considering that piston pumps play great role in hydraulic system of some key large-scale equipments, the proposed technique is applied to incipient intelligent multi-fault diagnosis and verified in section “Application to incipient intelligent multi-fault diagnosis for piston pumps” and the conclusions are drawn in section “Conclusion.”
VPMCD principle and improvement strategy
Basic VPMCD method
The feature variables extracted from the original signals and their intrinsic relationship can always quantify the natural characteristics of the dynamic system. Based on this hypothesis, a new multiclass discrimination method, called variable prediction model class discrimination (VPMCD), has been proposed and applied to medicine signal analysis.26–28 The VPMCD can establish mathematical variable prediction models (VPMs) to discover the intrinsic and quantitative interactions among these feature variables and utilize these VPMs to identify the classes of unknown test samples. The VPMCD is implemented in the following two steps described as Figure 1.
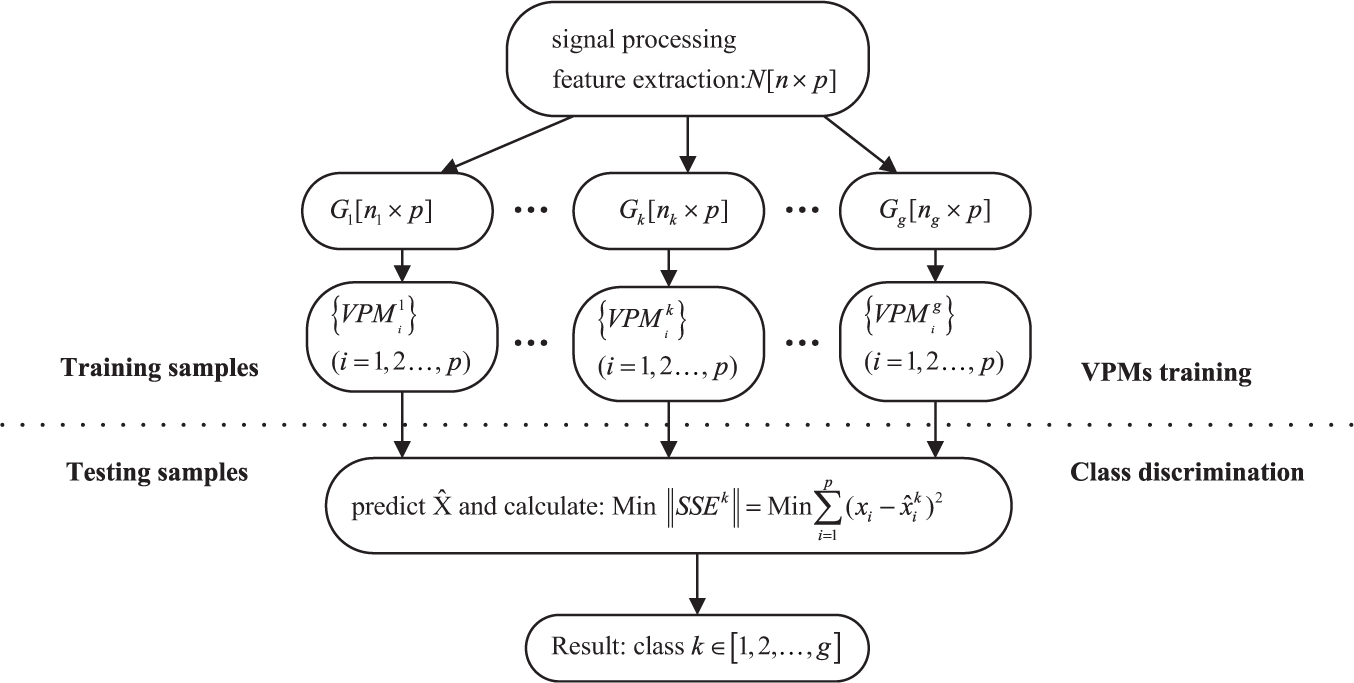
Flowchart of the VPMCD algorithm.
Step 1: VPM training
Suppose we collected
Linear (L) VPM
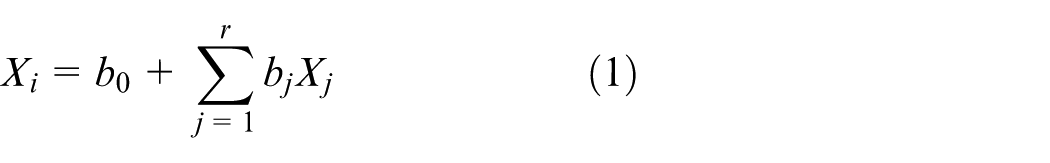
Linear + Interaction (LI) VPM
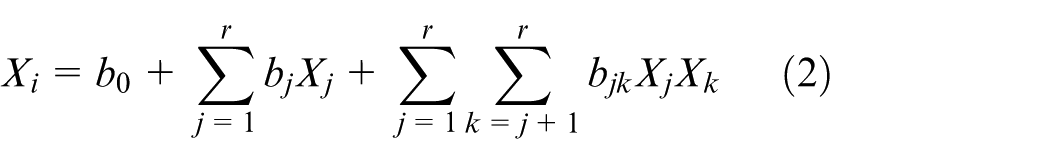
Pure Quadratic (PQ) VPM
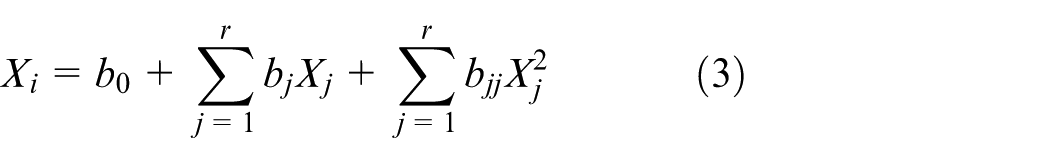
Quadratic + Interaction (QI) VPM
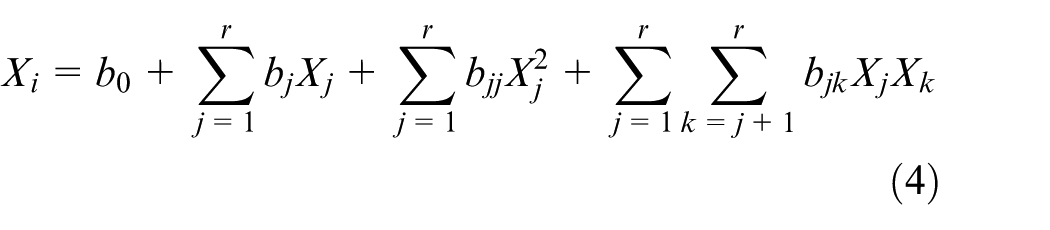
Supposed there are
In particular, the
Details on design matrix and number of parameters.

L: linear; LI: linear + interaction; QI: quadratic + interaction; Q: quadratic.
Once the coefficients are estimated, the set of best predictive models
It is worthwhile pointing out that after choosing the model type and its order
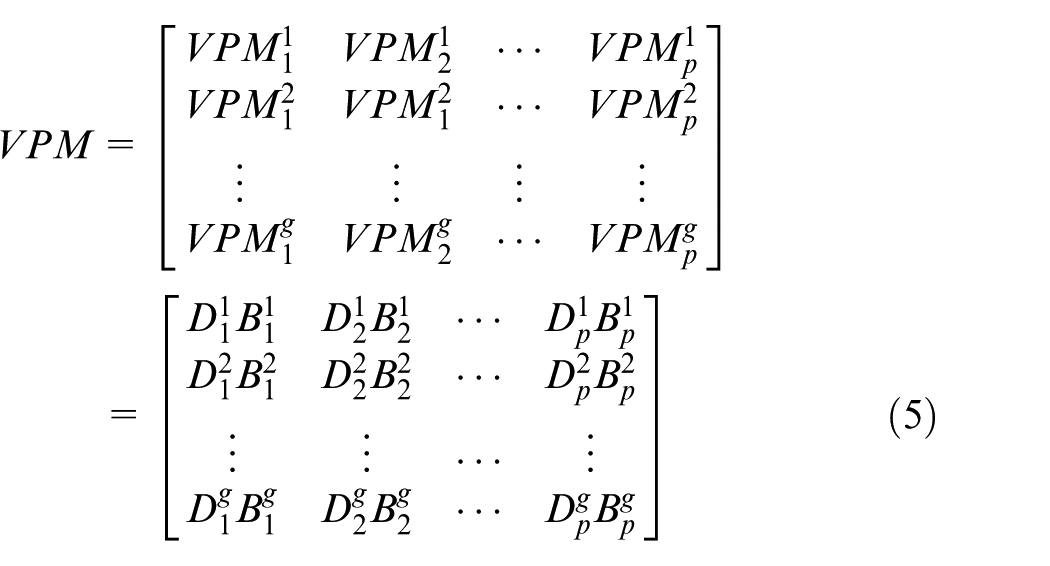
Step 2: class discrimination
As dedicated above, each
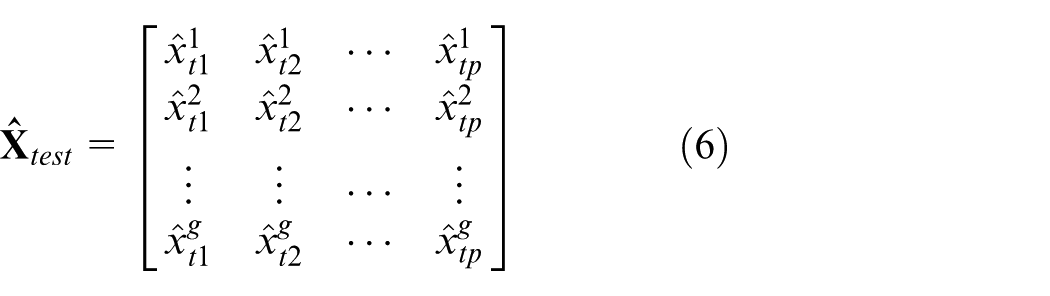
Moreover, the sum

Therefore, the error square sum vector
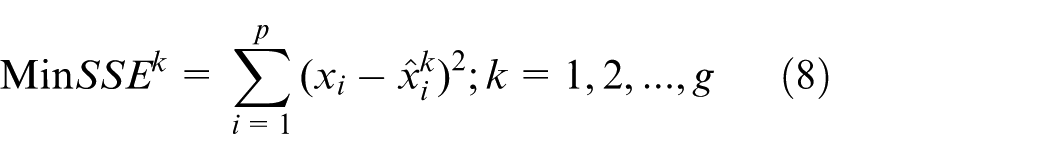
In summary, the multivariate interactions expressed by the VPMs can be mathematically established, and these mathematical models will show distinct dissimilarities among the classes. Moreover, the distinct relations in the VPMs are specific to each class so that they can be directly used as class discrimination models. As a model-based multiclass discrimination approach, the VPMCD technique has advantages of robustness with less computational effort and is greatly useful to multiclass problem.
Improved VPMCD
As mentioned above, the coefficient vector
One aspect of improvement is that the weighted least square (WLS) algorithm is utilized to compute the coefficient vector of VPMs instead of the normal least square technique. The training process for VPMs in the VPMCD method is actually a linear or nonlinear regression procedure, and the estimation method of the model parameters is extremely significant for the accuracy and stability of the VPMCD method. In the basic VPMCD method, the least square algorithm is used to solve the issue. As we all know, the premise of the least squares method is that the variables are independent and subject to a normal distribution. However, in the practice of mechanical fault diagnosis, the error of measurement data tends to be non-normal distribution. With least squares estimation, the regular equation will be ill-conditioned, and the effective parameter estimation value may not be obtained. Moreover, when using the least squares method, in order to improve the stability of the parameter estimation, the sample capacity is often required to be high, and the general requirement is greater than 30 or greater than five to eight times the number of variables. But, it is difficult to meet the requirement since fault samples are often not easily acquired resulting in rare fault samples in mechanical fault diagnosis. Therefore, the WLS algorithm is used to obtain more reliable and accurate parameters for VPMs in the VPMCD method.
Unlike the general least square algorithm, the WLS algorithm computes the regression coefficient by taking the minimum of the weighted squared error of the fitting as the objective function, which is expressed as
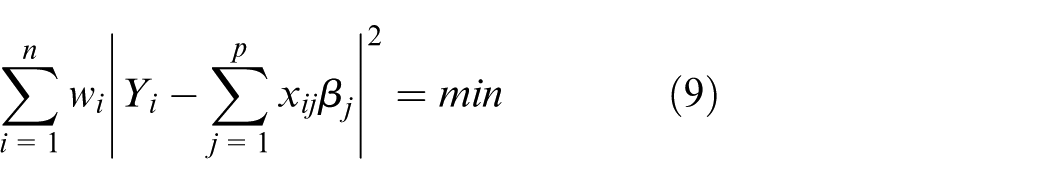
where
The other aspect of improvement is an ensemble VPMCD strategy. Since the basic VPMCD has to decide the model type and its order
First, for a feature variable
In summary, the VPMCD would be flexible to the data distribution of features extracted from the nonlinear and non-stationary vibration signals of mechanical dynamic system after improvement. However, the number of the possible VPMs equals to
A novel feature selection method
Fuzzy entropy brief
The basic principle in similarity classifier is calculating the similarity measure between the observations and an ideal vector
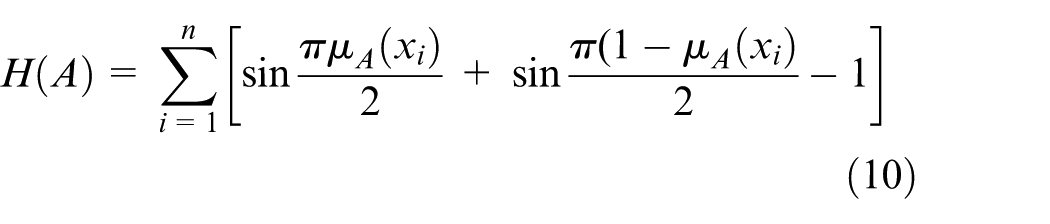
where
Feature selection based on similarity-fuzzy entropy with the improved VPMCD
Similarity measure indicates the similar degree between the sample
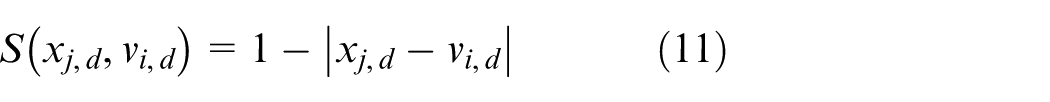
The similarity can be acquired for each training sample
1. Divide the collection samples set into the training sample subset and the test sample subset randomly, and use the FCM to compute the cluster centers


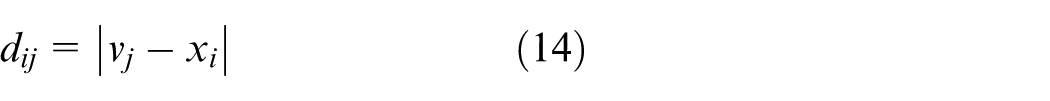
FCM optimizes the objective function to obtain the optimal cluster centers. Its objective function is provided by
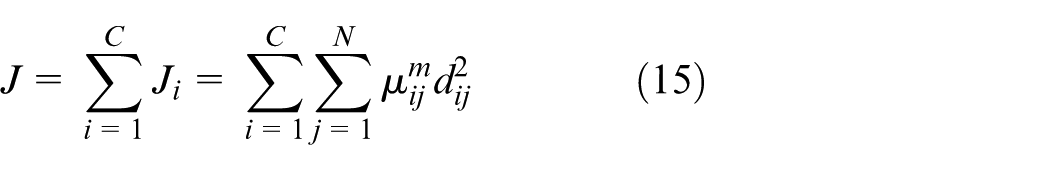
where
2. Calculate the similarity

Then, the similarity measures with scale factor can be calculated as

3. Calculate the fuzzy entropy measures and remove the less relevant features to fulfill feature selection. The fuzzy entropy can be acquired using the similarity measures
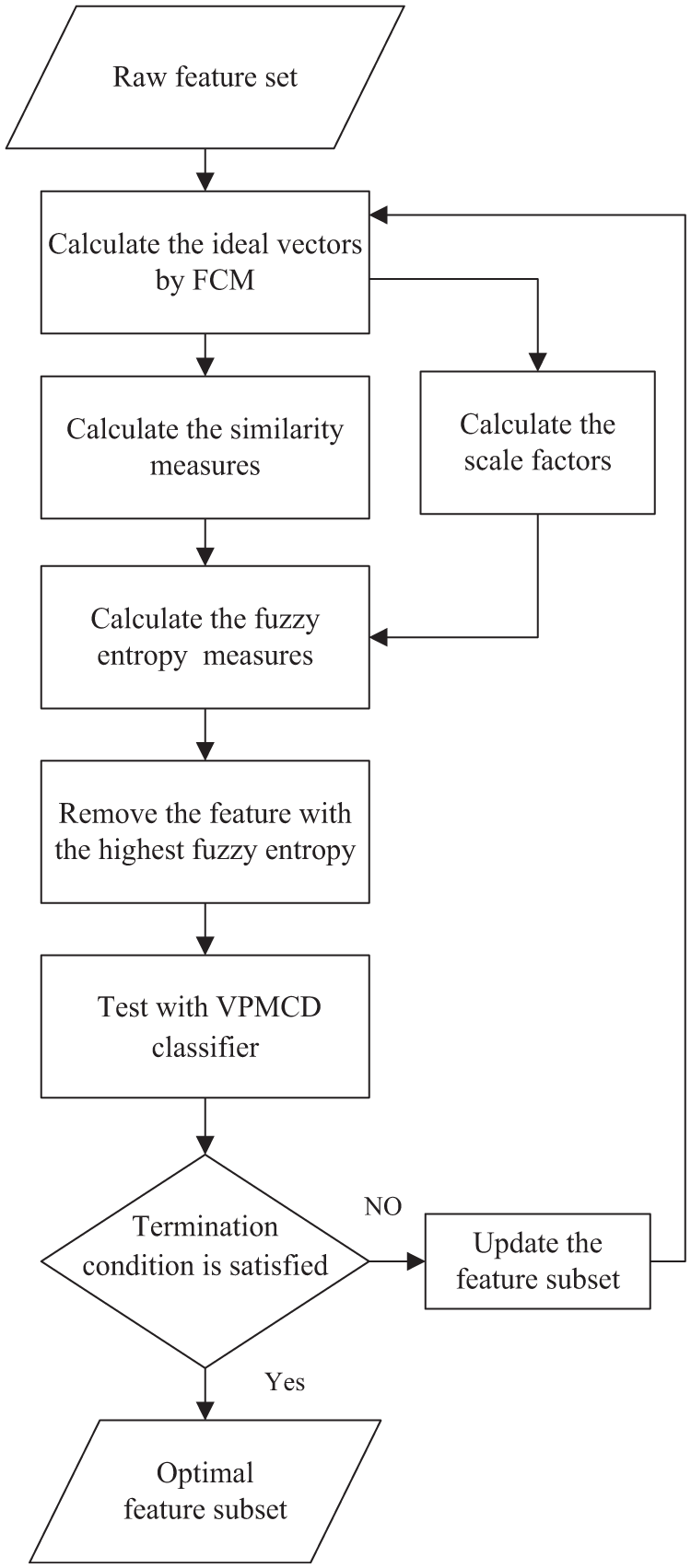
Flowchart of the proposed feature selection method.
Application to incipient intelligent multi-fault diagnosis for piston pumps
Piston pumps play important role for a hydraulic system in aircraft, construction machine, and so on. The major parts of a piston pump include in cylinder block, driving shaft, piston, swash plate, valve plate, and slipper and have three most crucial frictional pairs: piston and cylinder bore, swash plate and slipper, and valve plate and cylinder block. When a piston pump is running, due to load fluctuation and impact excitation, the frictional pairs are easy to wear out, which will lead to incipient abrasion failures. Therefore, efficient real-time incipient fault diagnosis for piston pumps is essential to guarantee high reliability and safety.16,37–40 In this section, an incipient fault diagnosis model for piston pumps was developed and applied using the proposed feature selection method with the improved VPMCD.
Data set collection
The experimental vibration signals were collected from axial piston pump experiment rig. The experimental rig and the relevant details are shown in Figure 3. The axial piston pump used is A11VLO190 with nine pistons. The parts were obtained from the fault part library. The speed of driving shaft was 1600 r/min, and the pressure of the main hydraulic circuit was kept at 10 MPa. The accelerometer was installed to the axial piston pump with magnetic base to collect the vibration signals using NI9233 data acquisition card with a sampling frequency of 10 kHz. The piston pump was tested under six different conditions. They are noted as class 1–class 6: class 1—normal condition, class 2—one piston abrasion, class 3—swash pate abrasion, class 4—valve plate abrasion, class 5—both swash pate and valve plate abrasion, and class 6—counter-position pistons abrasion. There were obviously three types of single-fault and two types of multi-fault. The vibration signals under different conditions and their fast Fourier transformation (FFT) spectrum are given in Figures 4 and 5, respectively. We collected 60 raw vibration signals under each condition and 360 raw vibration signals in total. The time of each sample was 0.25 s.

Experiment rig of hydraulic pump and the major parts of the axial piston pump: (a) experiment test rig, (b) axial piston pump, (c) single piston, (d) swash plate, (e) valve plate, and (f) counter-position pistons.
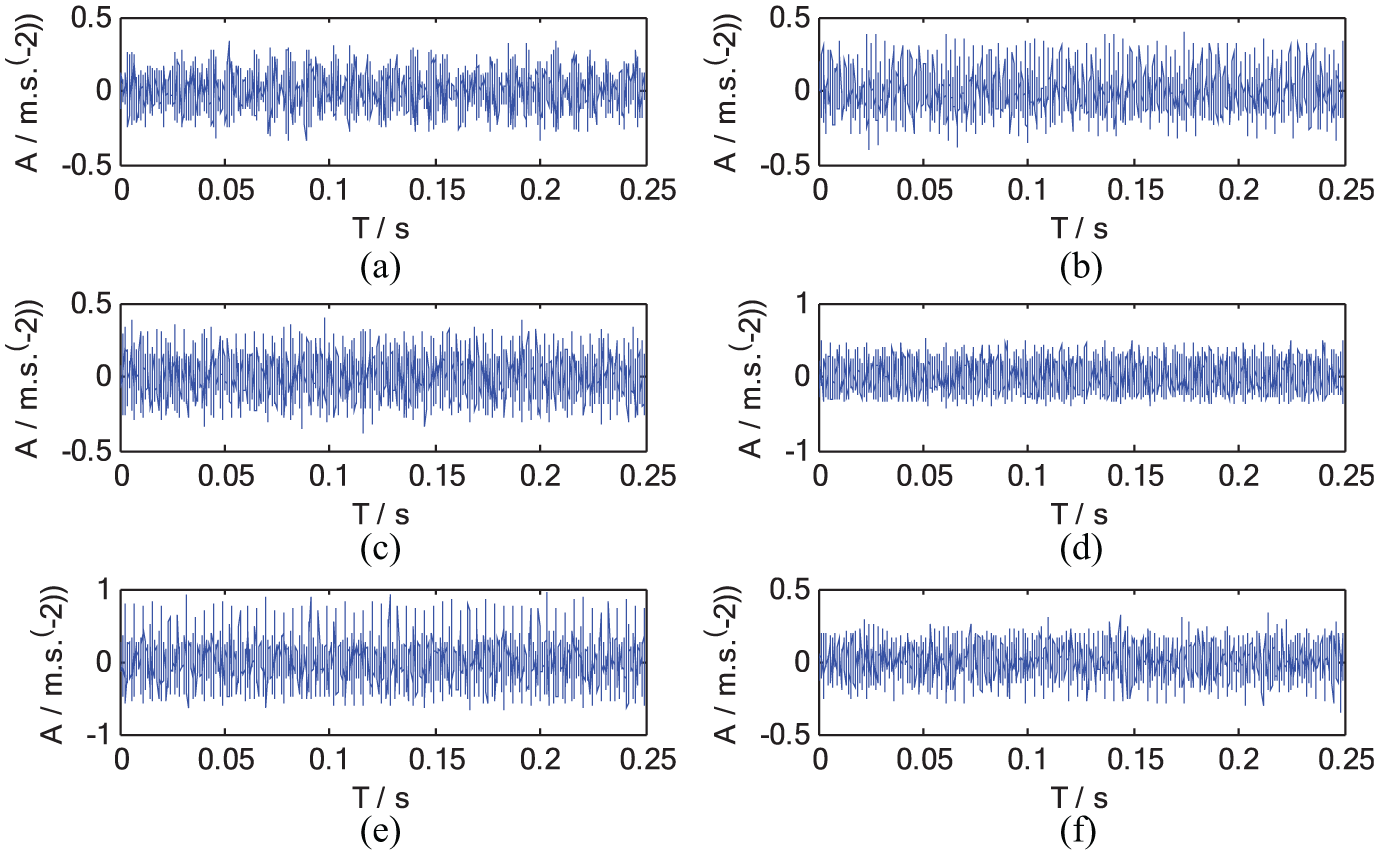
Time-domain waveform: (a) normal condition, (b) one piston abrasion, (c) swash pate abrasion, (d) valve plate abrasion, (e) both swash pate and valve plate abrasion, and (f) counter-position pistons abrasion.
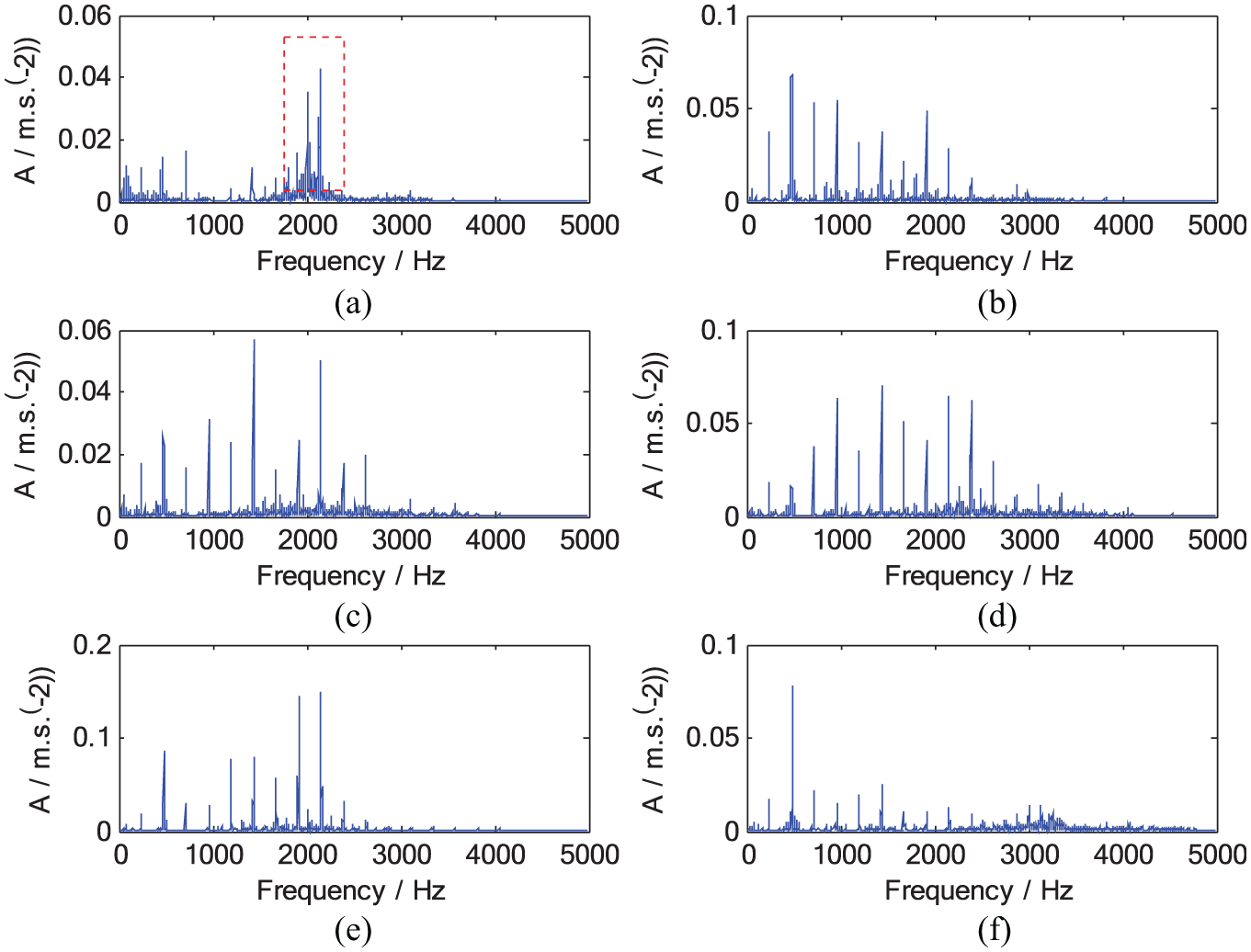
FFT spectrum: (a) normal condition, (b) one piston abrasion, (c) swash pate abrasion, (d) valve plate abrasion, (e) both swash pate and valve plate abrasion, and (f) counter-position pistons abrasion.
Feature extraction
From Figures 4 and 5, it was found that the vibration signals collected under different conditions had no distinct difference in structure from each other. But, compared with normal condition, the vibration intensity of the signals under various abnormal conditions increases to different degrees; meanwhile, both the distribution of frequency components and energy change greatly. In other words, the signals show different complexities in structure. In order to realize intelligent fault diagnosis, the raw data sets were processed and some features were extracted for characterizing the signals from different domains. Here, 15 features were obtained using some useful techniques such as time-domain statistic, singular value decomposition (SVD), 41 and local characteristic-scale decomposition (LCD). 42 The first 10 ones were widely used time-domain statistic indexes, they are listed as follows: (1) peak, (2) mean square value, (3) variance, (4) standard deviation, (5) root mean square (RMS), (6) waveform metric, (7) peak metric, (8) pulse metric, (9) skewness, and (10) kurtosis. Then, the special five features from different viewpoints were extracted shown as follows.
From Figure 5, it was observed that when the running condition of the piston pump was normal, the frequency region of the vibration energy ranged from 1900 to 2200 Hz, and when faults happened, the vibration energy moved toward the lower frequency region. So, the 11th and the 12th features to indicate the change for energy distribution with running conditions were designed as follows:
11. The ratio of the vibration in the frequency region 43 (1900 Hz, 2200 Hz)

where
12. The ratio of the vibration in the frequency region 43 (1 Hz, 1900 Hz)

13. Singular spectrum entropy,
SVD using matrix reconstruction is an important analytical method for time series.41,44 However, the reconstruction parameters greatly influence the result of SVD method, so that it is difficult to determine them. 44 Hence, a special skill was used to deal with the issue as follows. First, we used LCD to transform the collected signal into the set of intrinsic scale components (ISCs) 42

where
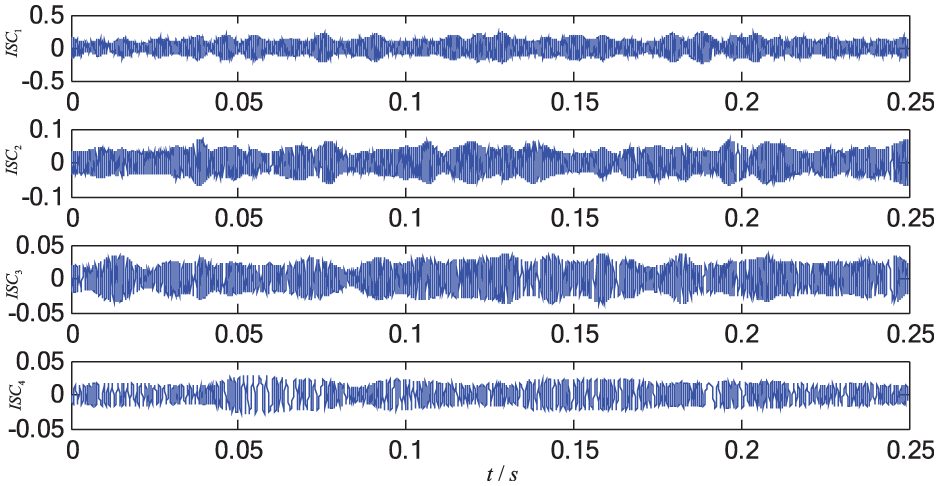
LCD results of the signal under normal condition.
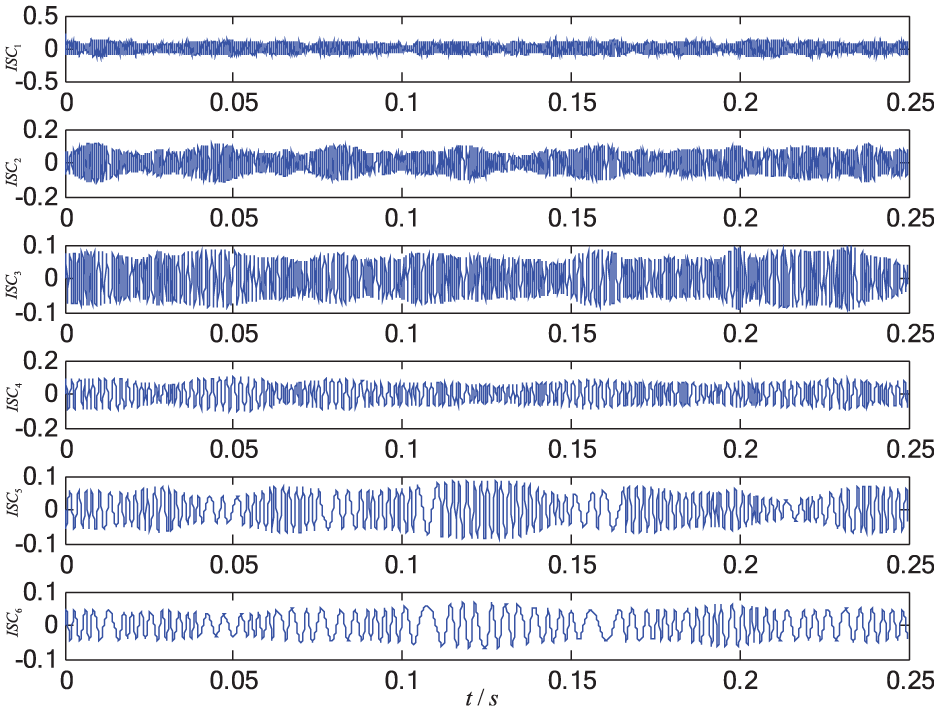
LCD results of the signal under one piston abrasion.
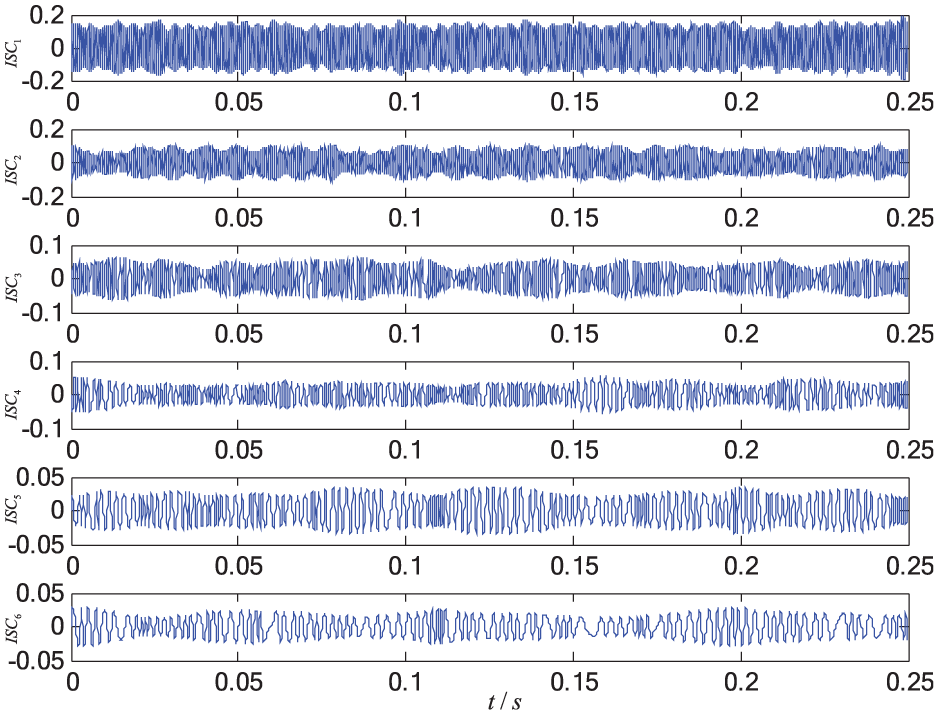
LCD results of the signal under swash plate abrasion.
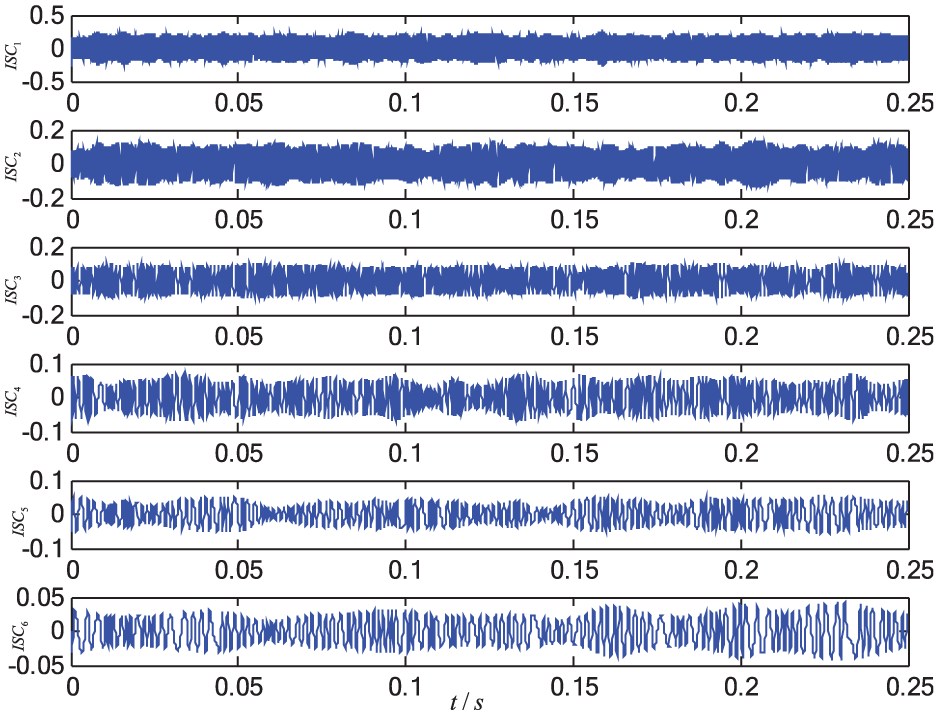
LCD results of the signal under valve plate abrasion.
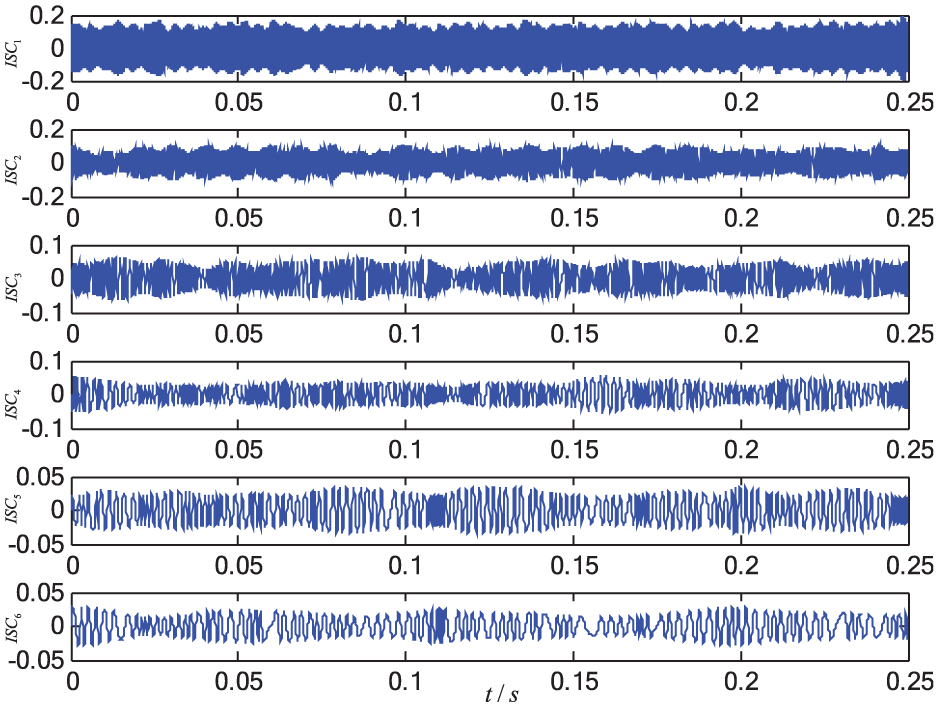
LCD results of the signal under both swash pate and valve plate abrasion.
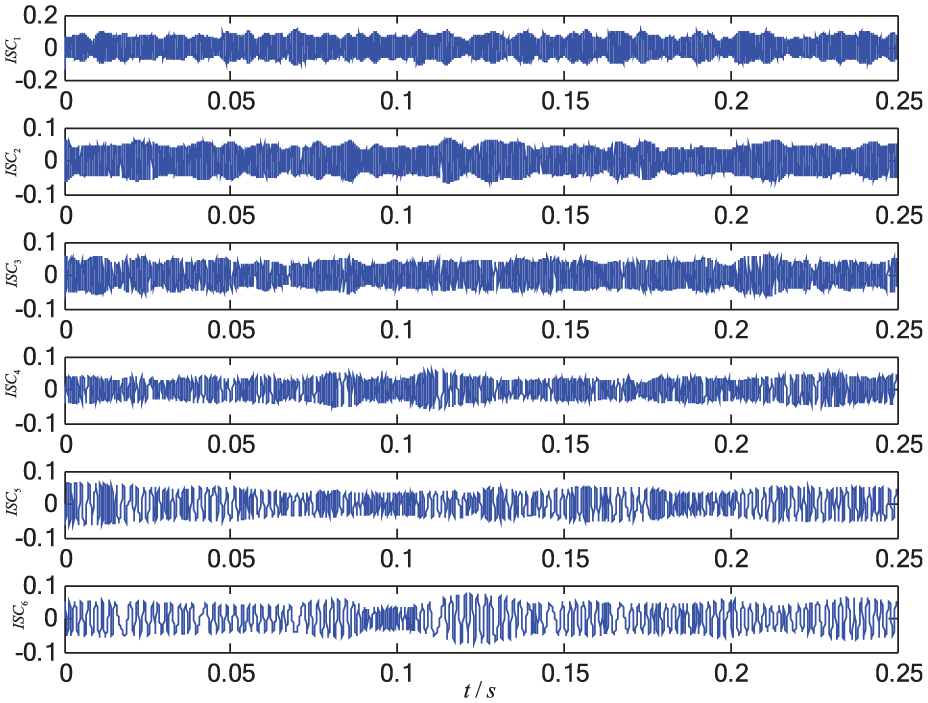
LCD results of the signal under counter-position pistons abrasion.
Recently, related researches have indicated that entropy-based measures are powerful information extraction tool for analyzing complex time series from nonlinear dynamic system.11,25,45 According to the definition of information entropy, the singular spectrum entropy using all of the ISCs from the original signal were extracted as features, which is given as
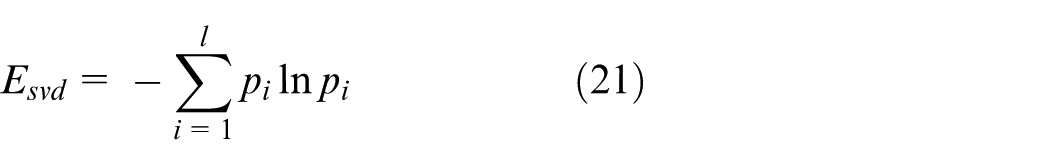
where
Simultaneously, it was found that the high-frequency ISCs were more informative. Therefore, the inherent fuzzy entropy values of the first two ISCs to quantify the fault-sensitive information as the 14th and 15th features:
14. The inherent fuzzy entropy value
15. The inherent fuzzy entropy value
In the end, 15 features were acquired. The flowchart of feature extraction is given in Figure 12. And, the description of features is shown in Table 2.
Flowchart of feature extraction technique.
Description of features.

Fault diagnosis results and comparison
Three kinds of feature selection techniques and three kinds of classifiers were utilized to built fault diagnosis model and make a comparison. The flowchart of multi-fault diagnosis is shown in Figure 13. To begin with, 15 raw features were served as input vector and three different types of classification algorithms—Multi-SVM classifier, backpropagation neural network (BP-NN) classifier, and the improved predictive model–based class discrimination (PMCD) classifier—were employed, respectively. Different number of samples from each class were used as training samples to acquire the classifiers’ model. The remaining samples were employed to test the intelligent fault diagnosis model. Because the parameters of BP-NN can greatly affect the classification results, a BP-NN with three-layer structure of 15-8-6 was employed after analysis. The input of the network was raw vector which included 15 elements, and the output of the network was classification results responding to classes of the axial piston pump. The activation functions of input layer and output layer were “logsig” function and “line purelin” function, respectively. The training function was “traingdx” function. The training precise was set as 0.005 and the learning rate 0.001. As we all know, SVM is able to show consistent success rates, but SVM algorithm is binary (separating only two classes at a time) in nature, and the extension to multiclass problems requires iterative or combinatorial analysis using multiple classifiers and intensive optimization routines. Here, a Multi-SVM program was used with the linear kernel function pre-selected based on prior knowledge.
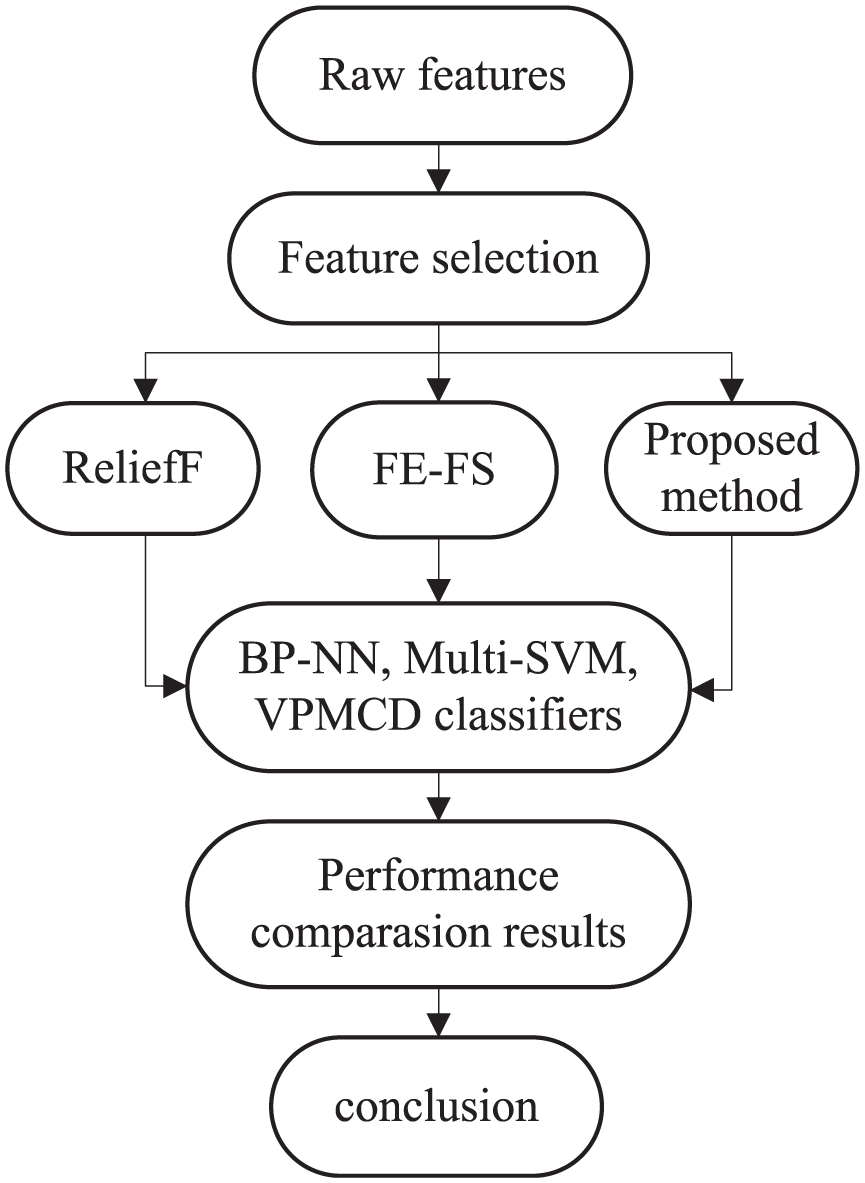
Comparisons flowchart for multi-fault diagnosis of piston pump.
The test was done for 1000 times, and some results when using different training samples are presented in Table 3. When the number of training samples is less (such as 6), the mean accuracy of BP-NN model can get 82.24%, and it sounds promising, but minimum is 49.69% and the standard deviation is 10.19%, which is the highest in three methods. This shows that BP-NN model has poor robust. Although the mean and minimum accuracy of the VPMCD classifier seem weaker than the Multi-SVM model, VPMCD has higher stability. In addition, the VPMCD classifier costs much less time. When the number of training samples added up to 10, overall, all the three models do well. But BP-NN model was not stable enough; it had the standard deviation at 4.95%, which was more than the one of the two other models. When the number of training samples was 14, the situation was roughly the same as above. When the number of training samples rises up to 20, the time consumption of Multi-SVM model was as long as 34.94 s. The minimum accuracy of BP-NN model cut down as low as 45.42%. On the contrary, the VPMCD classifier outperforms Multi-SVM at high accuracy, small standard deviation, and the lowest time consumption due to its clear mathematic expression and no iterative operation iteration. However, better performance of the VPMCD classifier is expected in engineering. Through analysis, it is found if the higher relevant features are selected to establish the mathematic model, the diagnosis performance can be improved.
Comparison results when different training samples and different classification techniques.
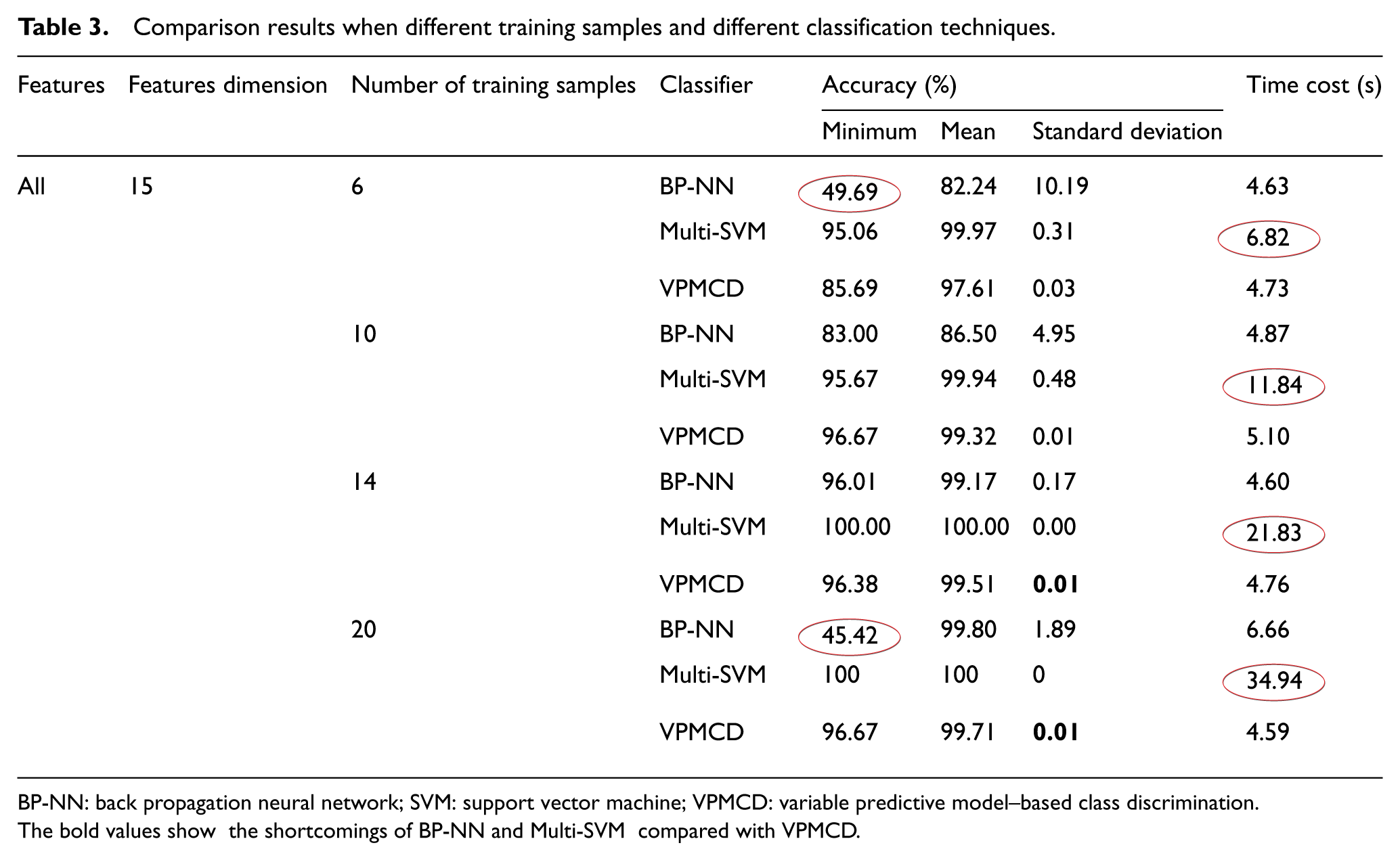
BP-NN: back propagation neural network; SVM: support vector machine; VPMCD: variable predictive model–based class discrimination.The bold values show the shortcomings of BP-NN and Multi-SVM compared with VPMCD.
As shown above that BP-NN classifier had weak stability, only multi-SVM and the improved VPMCD were used as class recognition methods to make a comparison between different feature selection techniques. First, the ReliefF approach served to accomplish the feature selection which ranked the features according to their importance weights,46,47 shown in Figure 14. From Figure 14, it can be seen that feature importance weights of number 2, 7, 8, and 14 features (four features in total below the dash line in Figure 14) were lower than 0.1 s; so, these features (below the dash line) were removed from the raw feature set. The results using Multi-SVM and VPMCD were illustrated in the first and the second rows in Table 4, respectively. Note that the results were attained when 10 training samples were used, and there was the same situation below. Second, the fuzzy entropy–based feature selection (FE-FS) approach22,35 was used to the same data sets to reduce the feature dimension, and the fuzzy entropy values calculated are visualized in Figure 15. Here, half selection strategy was taken to select approximately 50% of the features in the domain, so the number 2, 7, 8, 10, 11, 12, and 15 features (seven features above the dash line in Figure 15) were removed. The results using Multi-SVM and VPMCD were illustrated in the third and fourth rows in Table 4, respectively. The first four rows of Table 4 indicated that no matter which classification model was used, both the ReliefF and FE-FS can achieve better results and shortened time cost. Through further analysis for the first four rows, it can be shown that the improved VPMCD classifier outweighed Multi-SVM: faster classification speed and more robustness, which are vital for fault diagnosis in engineering practice.
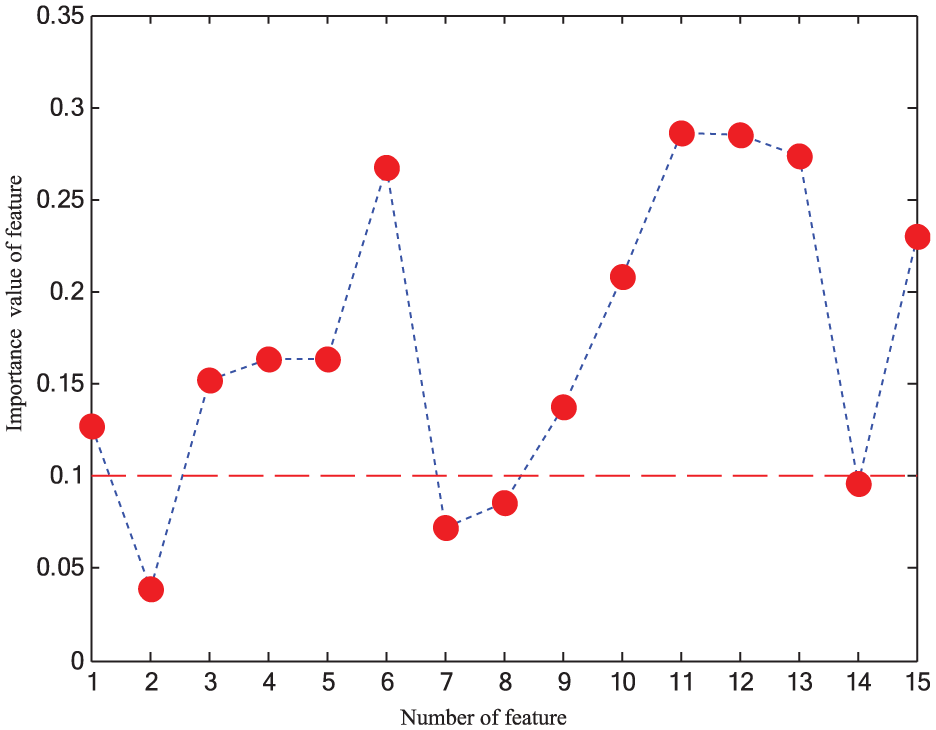
Importance value of features via ReliefF approach.
Comparison results of fault diagnosis of different strategies for the axial piston pump.

FE-FS: fuzzy entropy–based feature selection; SVM: support vector machine; VPMCD: variable predictive model–based class discrimination.The bold values show the superiority of VPMCD.
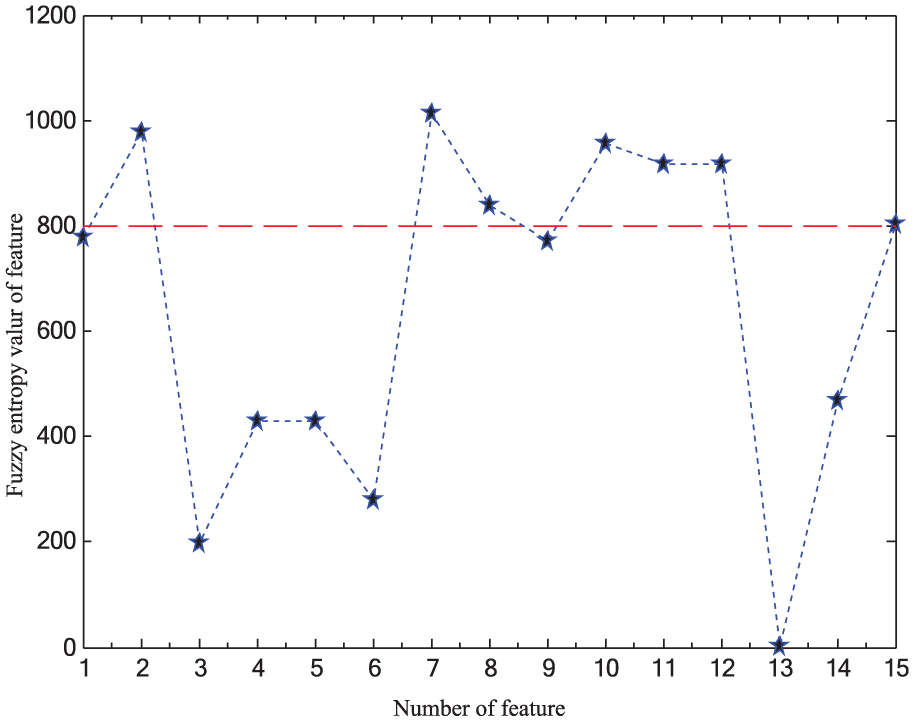
Fuzzy entropy values of features.
Finally, the proposed feature selection method was utilized to select the optimal feature variables to diagnose the faults for the axial piston pump. Five optimal feature variables and the optimal
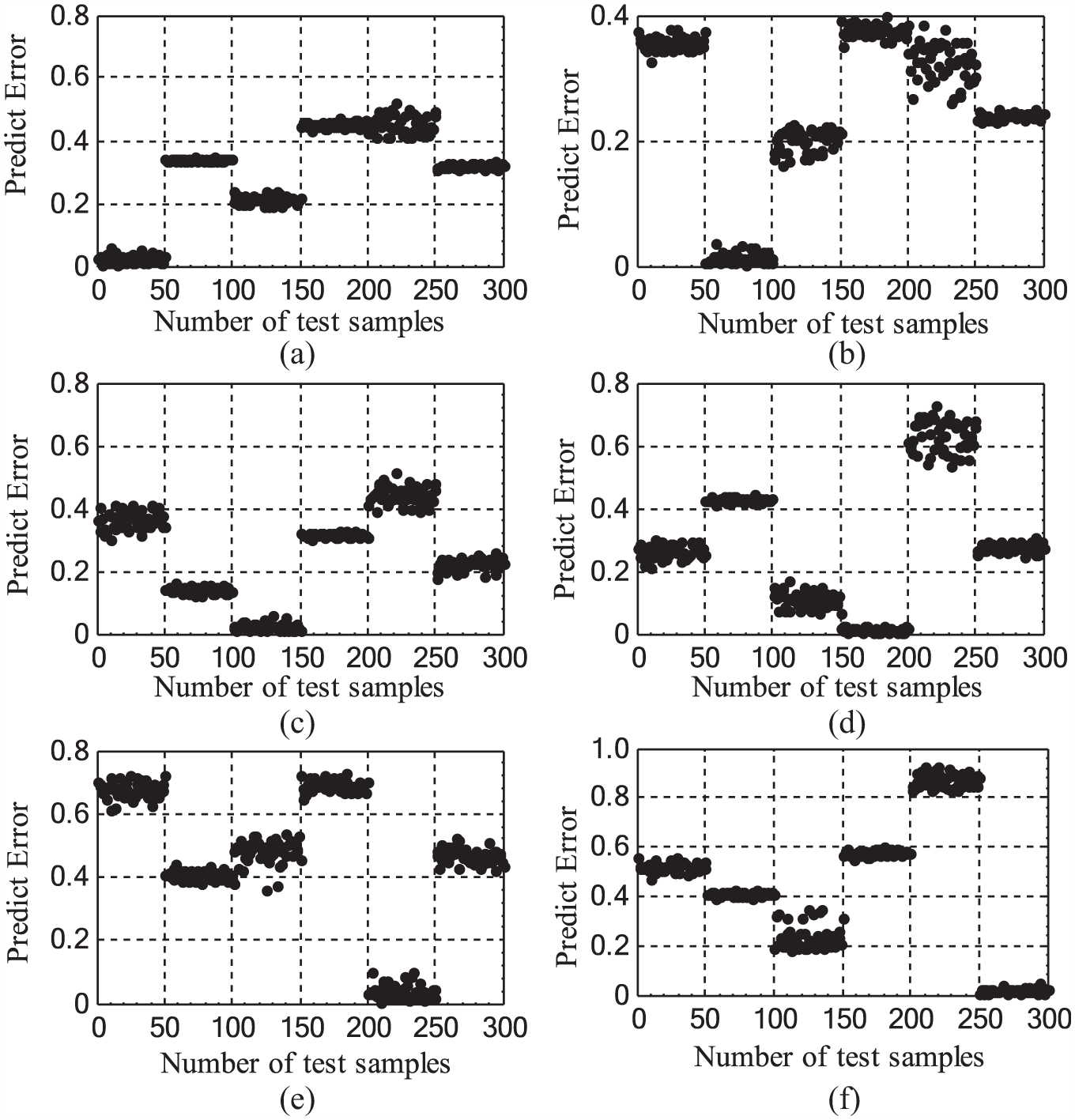
Predict errors of test samples using the VPMs: (a) for class 1, (b) for class 2, (c) for class 3, (d) class 4, (e) for class 5, and (f) for class 6.
Simultaneously, Multi-SVM was used to make a comparison. The results are given in the fifth and the sixth rows in Table 4. It can be shown that the Multi-SVM would take longer time due to intense computation though it can also achieve 100% accuracy and get excellent stability after using the proposed feature selection method. Whereas, the improved VPMCD can achieve the optimal diagnosis performance: the highest accuracy, the least time consumption (just 0.08 s), and the best robustness, which is vital for the condition monitoring and fault diagnosis online for key large-scale mechanical system.
Conclusion
First, an improve VPMCD algorithm was proposed to adapt the non-normal distribution characteristics of features. Besides, a novel feature selection technique has been developed by integrating the similarity-fuzzy entropy and the improved VPMCD method. The proposed feature selection technique can find the ideal feature vector using FCM approach for the similarity measures estimation and obtain more accurate fuzzy entropy values, so the dimension of input feature variables can be effectively reduced to boost the performance during the VPM training and test procedure of the VPMCD classifiers, At last, the proposed method was applied to establish incipient intelligent multi-fault diagnosis model for the axial piston pump, which includes three types of single-fault and two types of multi-fault. The results demonstrate that the proposed technique can sort out the most relevant features as optimal features which are more sensitive to fault type and more adaptive. The improved VPMCD classifiers with the optimal features have achieved higher accuracy, less computational cost, and best robustness. But, it should be noted that the VPMCD classifiers need to pre-determine the type of VPMs, which likely leads to unstability of classification results when different models are used. Although this weakness has been considered in this paper, further research should be done in the future.
Footnotes
Acknowledgements
The authors greatly appreciate the support from Cooperative Innovation Center for the Construction and Development of Dongting Lake Ecological Economic Zone, and China Scholarship Council.
Data availability
All data included in this study are available upon request by contacting the corresponding author.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Natural Science Foundation of Hunan Province (2018JJ2275, 2019JJ6002), Scientific Research Foundation of Hunan Provincial Education Department (17A147), Doctoral Scientific Research Start-up Foundation of Hunan University of Arts and Science (16BSQD22), and National Natural Science Foundation of China (11402036).