
Abstract
The aim of topic detection is to automatically identify the events and hot topics in social networks and continuously track known topics. Applying the traditional methods such as Latent Dirichlet Allocation and Probabilistic Latent Semantic Analysis is difficult given the high dimensionality of massive event texts and the short-text sparsity problems of social networks. The problem also exists of unclear topics caused by the sparse distribution of topics. To solve the above challenge, we propose a novel word embedding topic model by combining the topic model and the continuous bag-of-words mode (Cbow) method in word embedding method, named Cbow Topic Model (CTM), for topic detection and summary in social networks. We conduct similar word clustering of the target social network text dataset by introducing the classic Cbow word vectorization method, which can effectively learn the internal relationship between words and reduce the dimensionality of the input texts. We employ the topic model-to-model short text for effectively weakening the sparsity problem of social network texts. To detect and summarize the topic, we propose a topic detection method by leveraging similarity computing for social networks. We collected a Sina microblog dataset to conduct various experiments. The experimental results demonstrate that the CTM method is superior to the existing topic model method.
Introduction
In recent years, the rapid development of online social networks, such as Twitter, Facebook, Sina Weibo, has greatly affected people’s social and working styles. In social networks, individuals can interact with friends anytime, anywhere, to share their relevant information, to pay attention to interested users, subscribe to information, and view a variety of news. Organizations and official organizations can also use social networks to publish new products and news.1–3 Due to the openness and sharing of social networks, the information that people share or the topics they talk about may spread widely in the network, causing huge social impact. It is necessary to detect the social topics and emergencies, and to identify all kinds of events, so as to purify the network environment and improve the social atmosphere. These approaches can be used to help grasp public sentiment and public opinion, and provide the basis for government decision-making. Therefore, research on social network topic detection and summary has both theoretical research significance and social practical significance.
Topic detection requires a series of processes such as preprocessing, modeling, and similarity calculation. At first, researchers proposed a method based on a vector space model and a statistical language model to implement the event monitoring modeling process. However, these models almost ignored the relevant semantic parts, which in turn affected the effect and performance of event monitoring. In 1999, Hofmann 4 incorporated statistical concepts into the Latent Semantic Analysis (LSA) model and proposed the Probabilistic Latent Semantic Analysis method. This method, based on dual-mode and the co-occurrence data analysis method, became a research hotspot in academia. Subsequently, Blei et al. 5 proposed a classic Latent Dirichlet Allocation (LDA) model, which discovered the topic through the co-occurrence of document-words and achieved outstanding results in the field of event monitoring, greatly influencing both academic and industrial circles. However, social network text is usually short and sparse, resulting in fewer document-words in the event topic. Due to the randomness of the social network posting method, related topic words appear less frequently and lack relevant background information. The above two aspects mean that the traditional event theme model faces many challenges in social network event monitoring.
For the short-text sparsity of social network topics, Cheng et al. 6 proposed the double-word topic model, named a Biterm Topic Model (BTM), which effectively solved the sparsity problem of short-text topics in social networks, and provided new ideas for LDA to solve short-text problems. Zuo et al. 7 proposed a short-text topic model, named Pseudo-document-based Topic Model (PTM), by leveraging text self-aggregation. Mehrotra et al. 8 proposed a hash pool scheme for a Twitter dataset. In the original LDA data preprocessing stage, this method establishes a content pool for Twitter through hashing and implements automatic tagging. The above approaches can overcome the sparsity problem in the social network context by modeling the different features or attributes. However, these methods ignore the importance of relationships between words and require complex heuristic processing.
In the study of mixed methods of topic detection and summary, Cao et al. 9 combined LDA and deep learning methods to propose a topic monitoring framework, which effectively represents documents and words and has good applicability. Based on LDA, Xie et al. 10 proposed a real-time emergency event monitoring algorithm based on the set of simplified graph theme models. The validity of the algorithm was verified using a Twitter dataset. Yang et al. 11 proposed a new hierarchical Bayesian theme model that adopts the potential theme of the N-level conceptual hierarchy and can capture the dependence of words appearing in the local context of a word. Multi-document theme discovery has achieved good results. Xu et al. 12 leveraged the sentiments and topics of a microblog to model short texts for addressing the sparsity problem and detected bursty topics by detecting the burstiness of words. Huang et al. 13 proposed a bursty topic tracking method to discover topics by aligning bursty word detection from a temporal view and calculating topic novelty by designing an optimization problem. However, the above methods require specialized data and extranet post-processing and can easily cause over-fitting.
In this paper, we propose a novel word embedding topic model for topic detection and summary, named CTM. First, we apply the continuous bag-of-words model (Cbow) 14 method of word embedding to learn the internal relationships between words for generating coherent topics. Second, we directly model the aggregated-document instead of the short text to weaken the sparsity problem of short text by leveraging the self-aggregation topic model (SATM). Finally, to effectively detect and summarize topics, we propose a detection and summary topic method by adopting the similarity computing approach in the proposed topic model.
Related work
Research on topic monitoring and summary has attracted considerable attention. The research can be grouped into two main categories: the topic model method and the clustering method.
In the topic model, Li et al. 15 aggregated short text into long documents to indirectly model short text for alleviating the sparsity problem in social networks. Zuo et al. 16 built a word co-occurrence network to model text directly and used LDA to model semantic information, effectively address the problem of lack of word co-occurrence in social network context. Pang et al. 17 used a two-step approach to generate a multi-modal description of an Internet topic from background-removed similarities. By removing background similarities, they generated a coherent and informative multi-media description for a topic. Liu et al. 18 proposed a topic model to sample global and local topics by leveraging the location information for detecting social events. He et al. 19 improved the BTM using the Metropolis-Hastings and alias method to reduce the sampling complexity of BTM without degrading the topic quality. Liang et al. 20 used the preference of users’ followers to model topics to improve the accuracy of topic monitoring. Quan et al. 21 proposed a two-stage SATM to alleviate the sparsity problem in topic monitoring. Yan et al. 22 used the burstiness of words as a priori to incorporate it into the topic model for topic monitoring. Although the above methods weaken the sparsity problem in the process of topic monitoring, it ignores the importance of the internal relationship between social network words for topic detection and summary.
In the clustering method, the documents are usually clustered according to the topic similarity of the corpus. Hasan et al. 23 proposed a topic detection system to provide a low computational cost solution by leveraging the improved inverted indices and an incremental clustering method for detecting real-time social network events. Xu et al. 12 proposed a user sentiment topic modeling method to model users’ sentiments and topics for alleviating the sparsity problem and designed a method to identify bursty topics by clustering the bursty words. Ai et al. 24 proposed a two-stage distributed topic monitoring method by leveraging spark and topic clustering. Li et al. 25 first extended short text in social networks using a word concept network to minimize the sparsity of short text. Then, based on the extended words, a clustering-based method was proposed to implement topic monitoring. Zhao et al. 26 used a hypergraph to model various features of social networks, such as temporal, spatial, and cross-media features, and cluster these features to monitor social network topics. However, these methods require complex preprocessing or post-processing and are prone to over-fitting.
Algorithm introduction and inference
Algorithm framework
Given the above problems, we propose a novel CTM model to solve the above problem. The key idea of the model vectorizes the short text using the Cbow algorithm and assumes that a large amount of short text is generated from a small number of regular-sized aggregated-documents. The topic modeling of short texts is converted into a smaller amount of aggregated-documents topic modeling by learning the topic distribution of aggregated-documents. Through this process, the better performance can be obtained, over-fitting can be prevented, and the problem of social network topic dispersion and short-text sparsity can be effectively solved. Then, the topic can be detected and summarized by leveraging the similarity computing. The algorithm framework is shown in Figure 1.
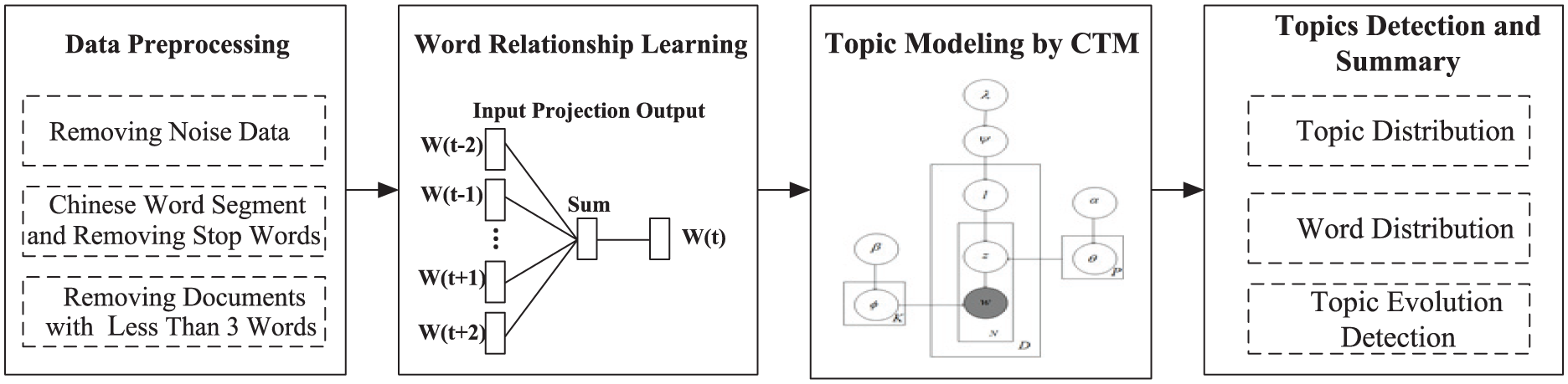
Algorithm framework.
Vector representation of the event text
Cbow is a method based on distributed representation. 14 The basic idea involves mapping the context information of the dataset words into K-dimensional real numbers by training (K is generally a hyperparameter in the model), and to map high-dimensional space. Then, by calculating the distance between words (such as cosine similarity, Euclidean distance, etc.), it is possible to judge their semantic similarity. Specifically, the words in the dataset are mapped to the middle projection layer through the input layer on the left to perform a vector summation operation to produce a dictionary. The specific structure is shown in Figure 2.
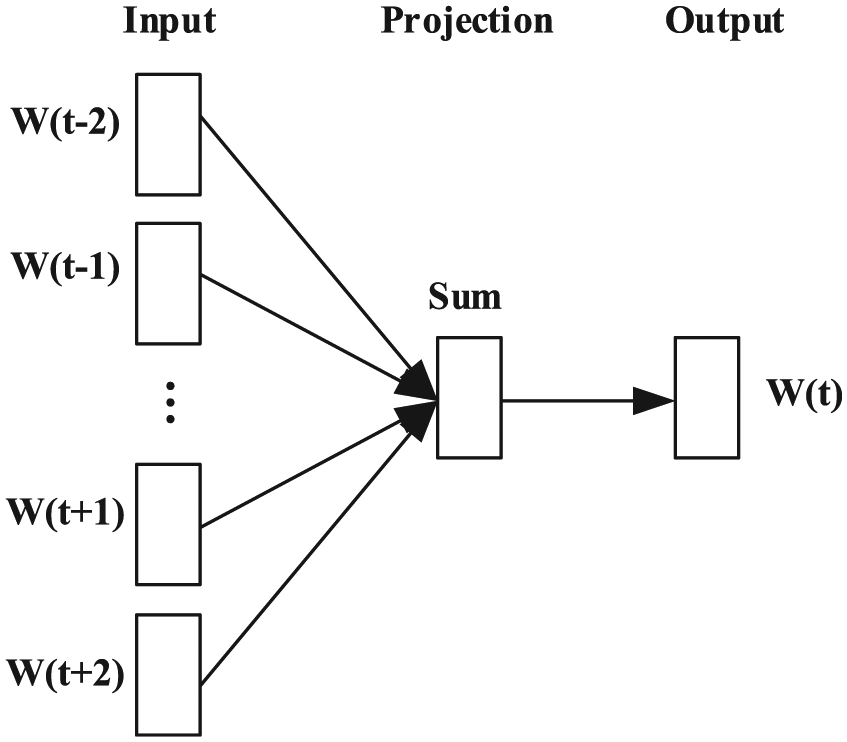
Cbow structure.
Suppose that D words E(d) in event dataset E are projected to the corresponding location W(d). Then, the context information past W(d) is used to predict the specific training process of W(d) as follows:
Input the word vector of the input context, define the context window size of the input layer by the window value k, and read the words in the window, then use the hash table to determine the corresponding position of the projection layer. Obtain a word through the above W(d) process context vocabulary
Based on the projection layer in the middle, use the W(d) context information
Focusing on the output layer structure, the conditional probability expression
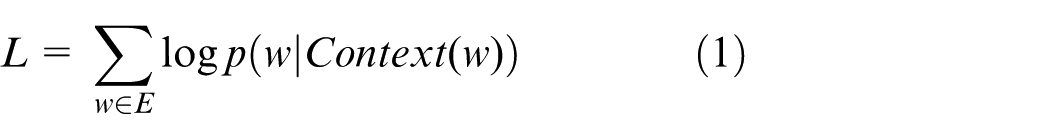
The gradient descent method is used to adjust the input word vector to make the actual path close to the correct path. After training, we obtain the word vector corresponding to each word from the vocabulary. 19 The result obtained is shown in equation (2)
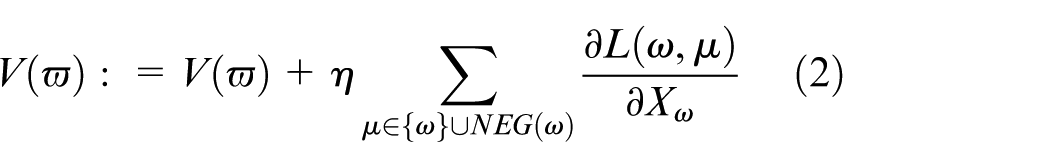
where
CTM model
Inspired by PTM 7 modeling of short-text validity, we propose the CTM to model short and solve the sparsity problem. The CTM algorithm has K topic. Each topic is a multi-distribution with M short texts and C aggregated-documents. Short text is observable, whereas aggregated-documents are hidden variables. It is also assumed that each short text belongs to an aggregated-document. Each word in the short text is generated by sampling the topic Z. The word frequency is different from the LDA input and a topic is directly extracted from the document, so the CTM input is a Cbow vectorized word vector. Short text is converted into the aggregated-document, and the topic is extracted from the aggregated-document. Table 1 lists the variables and notations of the proposed CTM model.
Variables and notations.
The LDA model and CTM model are compared in Figure 3, where Figure 3(a) is the disk pattern of the LDA model and Figure 3(b) is the CTM disk chart. Figure 3(a) shows that LDA is a Bayesian model for learning hidden topics in documents. LDA assumes that there is an implicit topic layer in the visible document layer and word layer. Each document is a polynomial distribution of topics, and each topic is a polynomial distribution of words. Unlike LDA, CTM assumes that a large amount of short text is generated from a relatively small number of latent documents. Here, we refer to potential documents as aggregated-documents. By learning the topic of the aggregate-document instead of learning the topic directly from the short text, CTM avoids the problem caused by a lack of word co-occurrence information in the context of social networks. A reasonable modeling method means that the number of CTM parameters does not increase with the data, which reduces the risk of over-fitting the data, and it ensures the efficiency of the CTM learning algorithm.
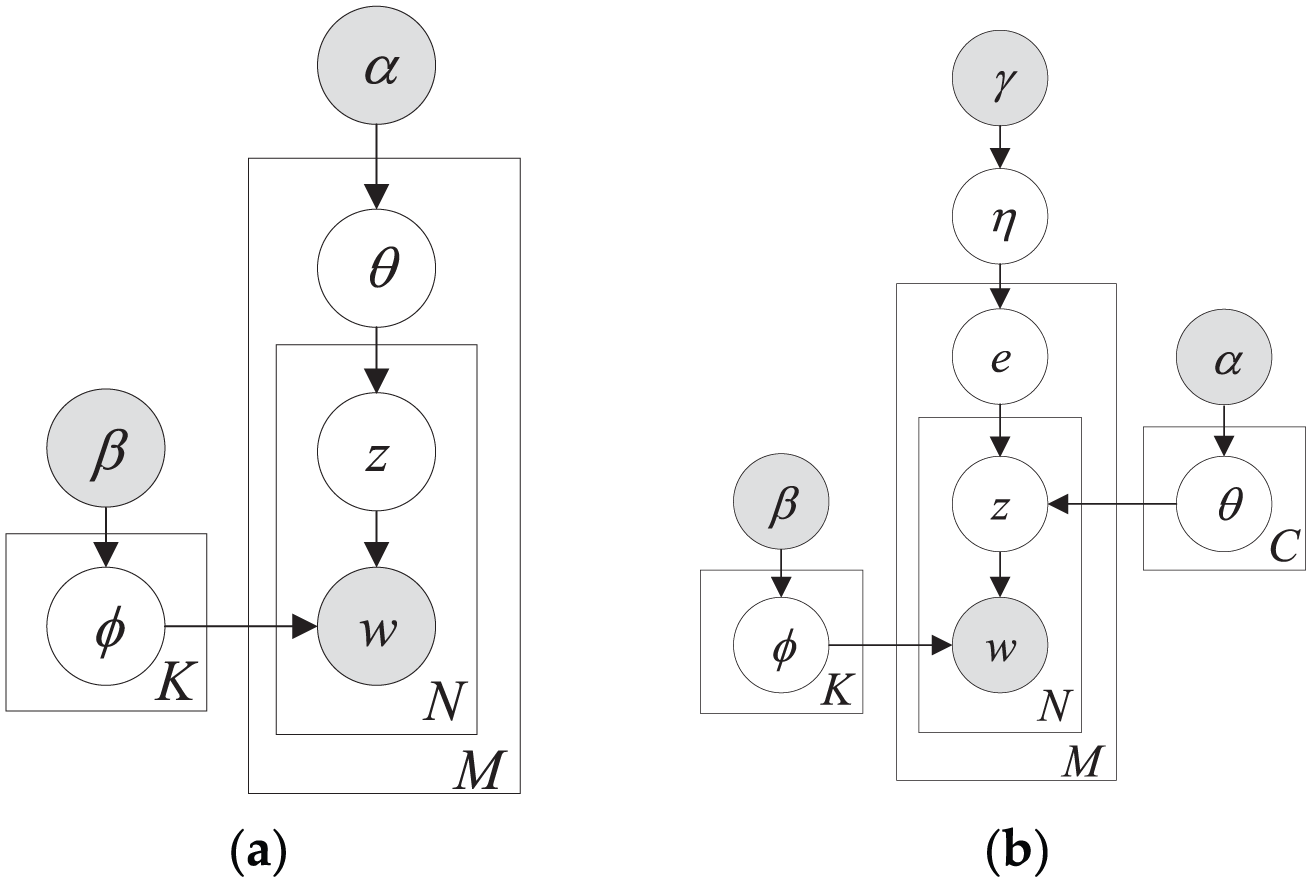
Comparison of LDA model and CTM model: (a) the disk pattern of the LDA model and (b) the disk pattern of the CTM model.
The CTM generation process is as follows:
Step 1. Sampling
Step 2. For each text topic z:
Sampling
Step 3. For each aggregated-document C:
Sampling
Step 4. For each short text S: Sampling aggregated-document, For each word wi in S: Sampling topic Sampling the ith word
The academic community often uses approximate derivation methods to estimate the relevant parameters of the topic model. Commonly used derivation methods include the variational Expectation-Maximization (EM) algorithm and the Gibbs sampling method. However, previous studies found that the approximate effect of Gibbs sampling is better.6,7 Therefore, the Gibbs sampling algorithm 27 is used to derive the relevant parameters. The Gibbs sampling procedure of the proposed CTM is shown in Algorithm 1.

Given the related variables, first, in terms of topic assignment C for sampling aggregated-documents, the calculation method is
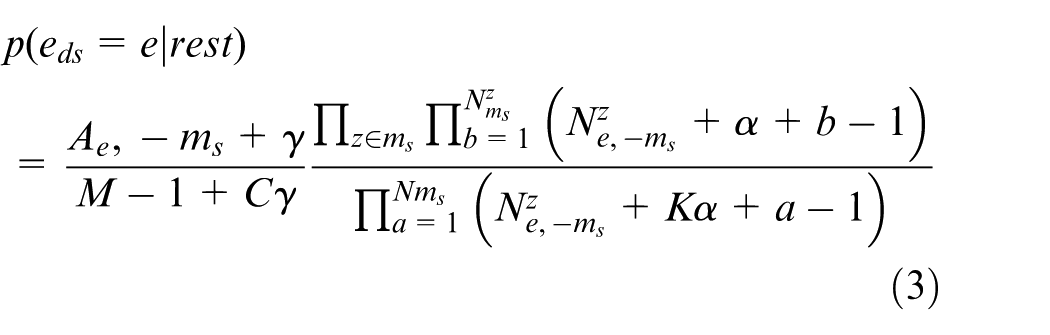
where Ae is the number of short texts belong to the e aggregated-document,
The method of sampling text topic classification z is similar to the hidden Dirichlet distribution method. The difference is that
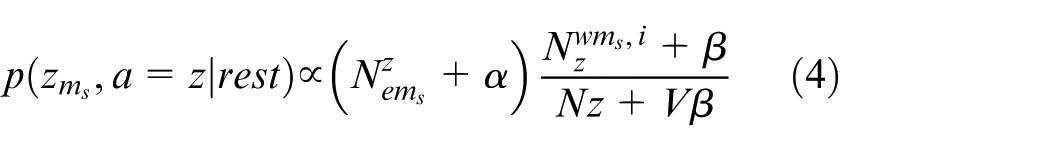
where
After iterating multiple times, the result of sampling tends to be stable, using the learned parameter mean as a parameter estimate. The following five distribution results are obtained using equations (5)–(7)
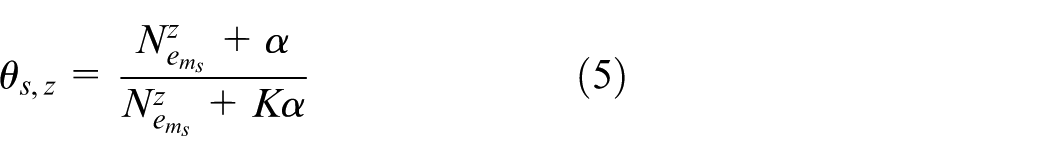
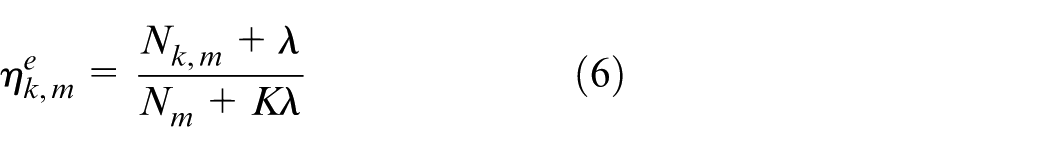
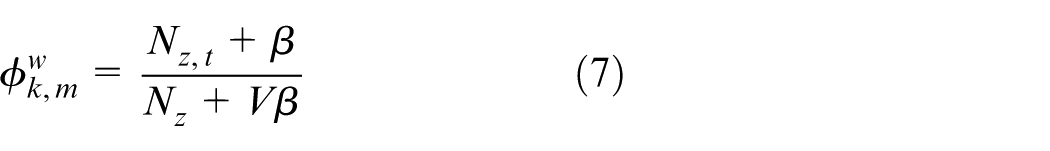
where
For the same event text content, the CTM algorithm performs similarity clustering of word vectors. Essentially, the distribution of document-words input by the topic model is optimized so that the results of the solution sum are updated, and new terms and topic items are obtained.
Topic detection and summary
After the relevant topics and parameters are obtained, the above results are used to monitor and predict the event topics. Given the new microblog text, we first sample the topic assignments of each word from the learned CTM method. When the sampling process is completed, the topic distribution of the new microblogs can be obtained. Therefore, we leverage similarity computing to detect and summarize new topics for a microblog. The method is shown in equations (8) and (9)
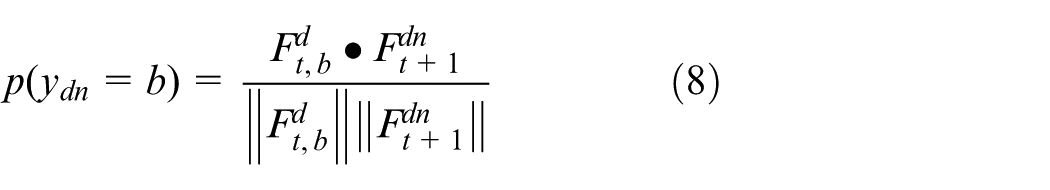
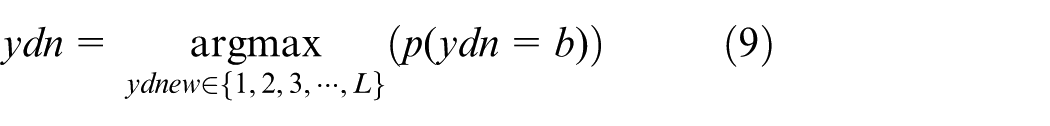
where b represents the topics and
In particular, each topic first needs to be initialized using CTM. Second, many upcoming microblog topics are categorized according to equations (7) and (8). Then, we can determine the classification of Weibo topics and update the CTM method. Finally, we can detect and summarize microblog topics and summarize.
Experiment and result analysis
Dataset
We crawled data from the Sina Weibo (the URL of Sina Weibo: https://weibo.com/), which contains more than 600,000 from August 2015 to September 2015, including several hot topics on Weibo, such as “Explosion Accident in Tianjin Binhai New Area.” The Chinese sentence was processed using the popular deep learning-based word segmentation tool. The tool was trained by the People’s Daily corpus, and the word segment accuracy rate was 97.5%. 28 Then, the noise data, such as stop words and advertisement content, were removed.
Experimental setup
The event dataset is input into the vector program of the CTM model for vectorization, and gradient ascent and negative sampling were used to solve the calculation. The threshold of similarity is set to 0.75. We set
For comparison, we selected comparison methods are the current mainstream topic model methods: LDA, 5 SATM, 21 LTM, 15 and BBTM. 22 The evaluation indicators were cluster purity and average accuracy. In total, 90% of the event data in the dataset were randomly selected to train the model, and the remaining 10% were employed for testing. This was verified in two ways. First, a strict truth comparison was conducted and, second, the topic evaluation was pursued and three random microblogs were selected for manual evaluation, with the first five of each event being evaluated by three human judges. This experiment used two methods because objective evaluation is not sufficiently comprehensive for this issue. Topic evaluation can broaden the evaluation index and produce more realistic results.
Result analysis
Comparison and analysis of topic discovery accuracy
Since the crawled data have no tag information, manual annotation is used to judge the accuracy of topic detection and summary by leveraging hashtags (In Sina Weibo, the hashtags were represented as “#…#”) as auxiliary label. The experiment invited four students from different colleges to mark the results. Search engines and other Internet resources are available as an aid. When more than two students decided that the topic is a sudden topic, we determined it is the correct result. The precision (P@T) corresponding to the number of topics T is calculated as an evaluation index. The experimental results are shown in Table 2.
Accuracy comparison of topic detection.
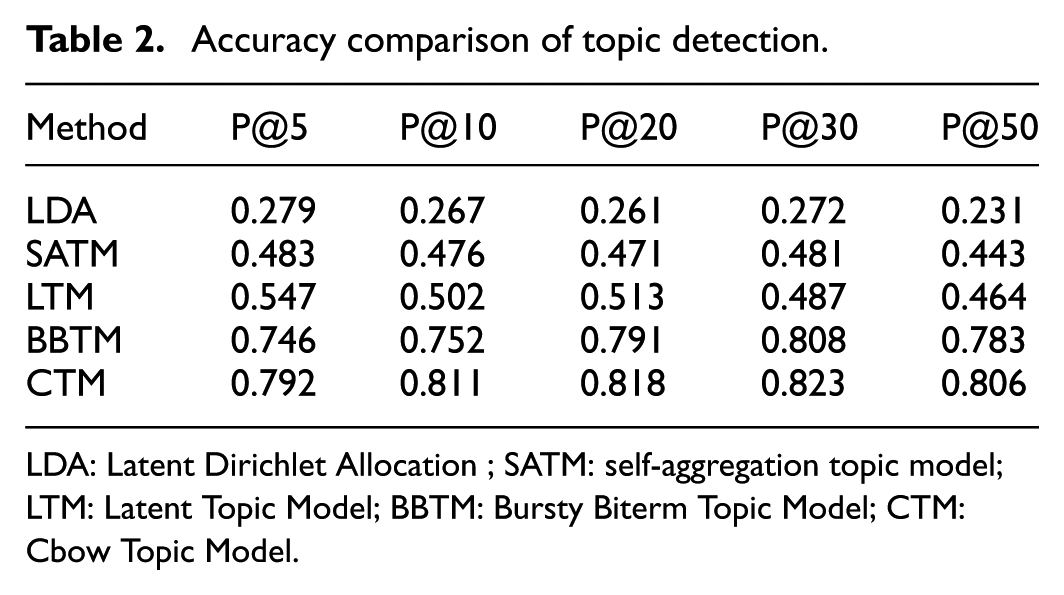
LDA: Latent Dirichlet Allocation ; SATM: self-aggregation topic model; LTM: Latent Topic Model; BBTM: Bursty Biterm Topic Model; CTM: Cbow Topic Model.
The experimental results show that the proposed CTM method was always more accurate than all the comparison methods for different topics, indicating that the proposed CTM can accurately monitor sudden topics. We also found that the performance of CTM is slightly worse when T is 5, which may be due to the small number of topics, which makes the topic more discrete and less focused. The BBTM and LTM outperform SATM and LDA, but they are slightly less effective than CTM. This indicates that CTM can improve the performance of topic monitoring by expressing microblog short texts through Cbow word vectors and self-aggregating short texts by modeling aggregated-documents. LDA’s performance was the worst, mainly because it could not overcome the sparsity problem and did not consider the suddenness of the topic.
Topic coherence
To verify the performance of CTM, pointwise mutual information (PMI), commonly used in topic model research, was used to evaluate the topic consistency of the CTM method. 29 Given a topic E, the average PMI of the top T words with the highest probability in a topic was calculated using the auxiliary corpus. The higher the PMI-score, the more relevant the topic detection results are. The PMI calculation method is shown in equation (10)
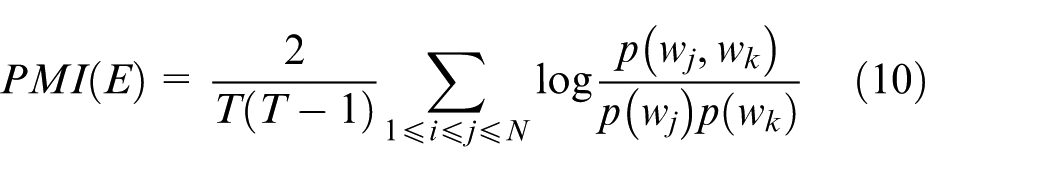
where p(wj, wk) is the joint distribution of the words wj and wk simultaneously appearing in the same time window, and p(wk) represents the edge probability of the word wk.
Using Chinese Wikipedia data as an auxiliary corpus, the experimental results of the topic consistency are shown in Figure 4.
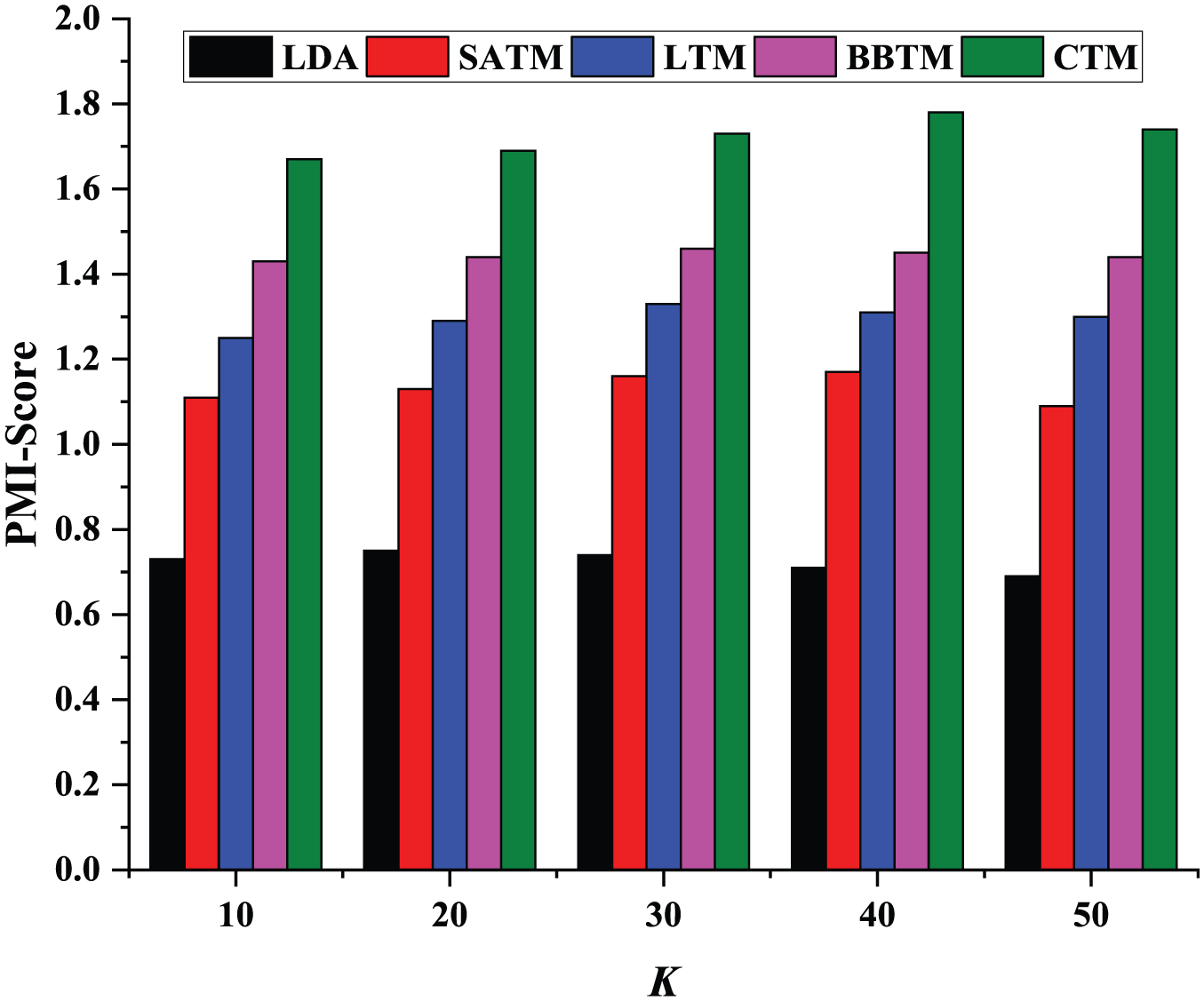
Topic coherence comparison.
Figure 4 shows that the topic consistency result of the proposed CTM method is superior to all comparison methods, and the BBTM method also performed well. This shows that CTM can more consistently learn topics’ representation. The high consistency of the BBTM theme indicates that the modeling word pair can minimize the sparsity of the microblog text to a certain extent. LTM and SATM also performed well, mainly because the two methods weaken the sparsity problem through different perspectives. Among all methods, LDA performed the worst, mainly because it was originally designed to model standard news documents, but in the microblog environment, there is a short-text sparsity problem.
To further verify the effectiveness of our CTM, we qualitatively analyzed the detected and summarized topic. For all baseline methods, we list the top 10 most probable words related to “#天津滨海爆炸事故 (Explosion Accident in Tianjin Binhai New Area) #” that appeared in each topic. Table 3 lists the top 10 words of the topic discovered by each method.
The top 10 most probable words related to “#天津滨海爆炸事故 (Explosion Accident in Tianjin Binhai New Area) #.”
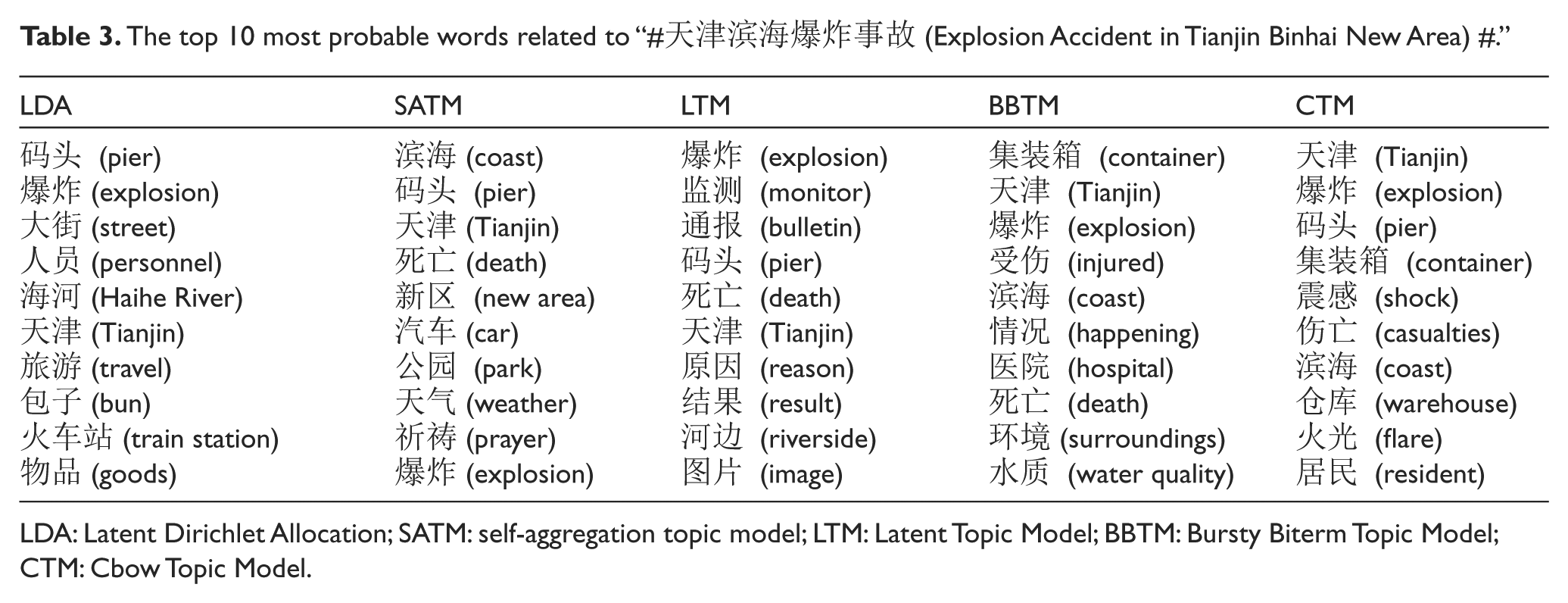
LDA: Latent Dirichlet Allocation; SATM: self-aggregation topic model; LTM: Latent Topic Model; BBTM: Bursty Biterm Topic Model; CTM: Cbow Topic Model.
From Table 3, we can see that (1) the words detected by CTM are most similar to the topic; This is because CTM can learn the relationship between words and solve the sparsity problem; (2) BBTM is also able to obtain better results, but contains some common words, such as “环境 (surroundings)” and “水质 (water quality)”; (3) LTM contains many irrelevant words, such as “结果 (result),” “河边 (riverside)” and “图片 (image).” This indicates that the bursty word clustering is more sensitive to noise; (4) the topics detected by SATM are mixed with the different topic words, and only some of the words are related to “#Explosion Accident in Tianjin Binhai New Area#”; and (5) LDA performed the worst in all methods. This is because LDA cannot address the sparsity problem.
Quality of topic detection and summary
The quality of topic discovery can be verified by clustering indicators. Experiments were conducted using clustering evaluation indicators of cluster purity and clustering entropy. The higher the cluster purity result, the higher the quality of the topic discovery; the smaller the cluster entropy index, the higher the quality of the topic discovery. Since the microblog data have no tags, the hashtags of the microblog are used as the clustering tags. The experimental results are shown in Figures 5 and 6.
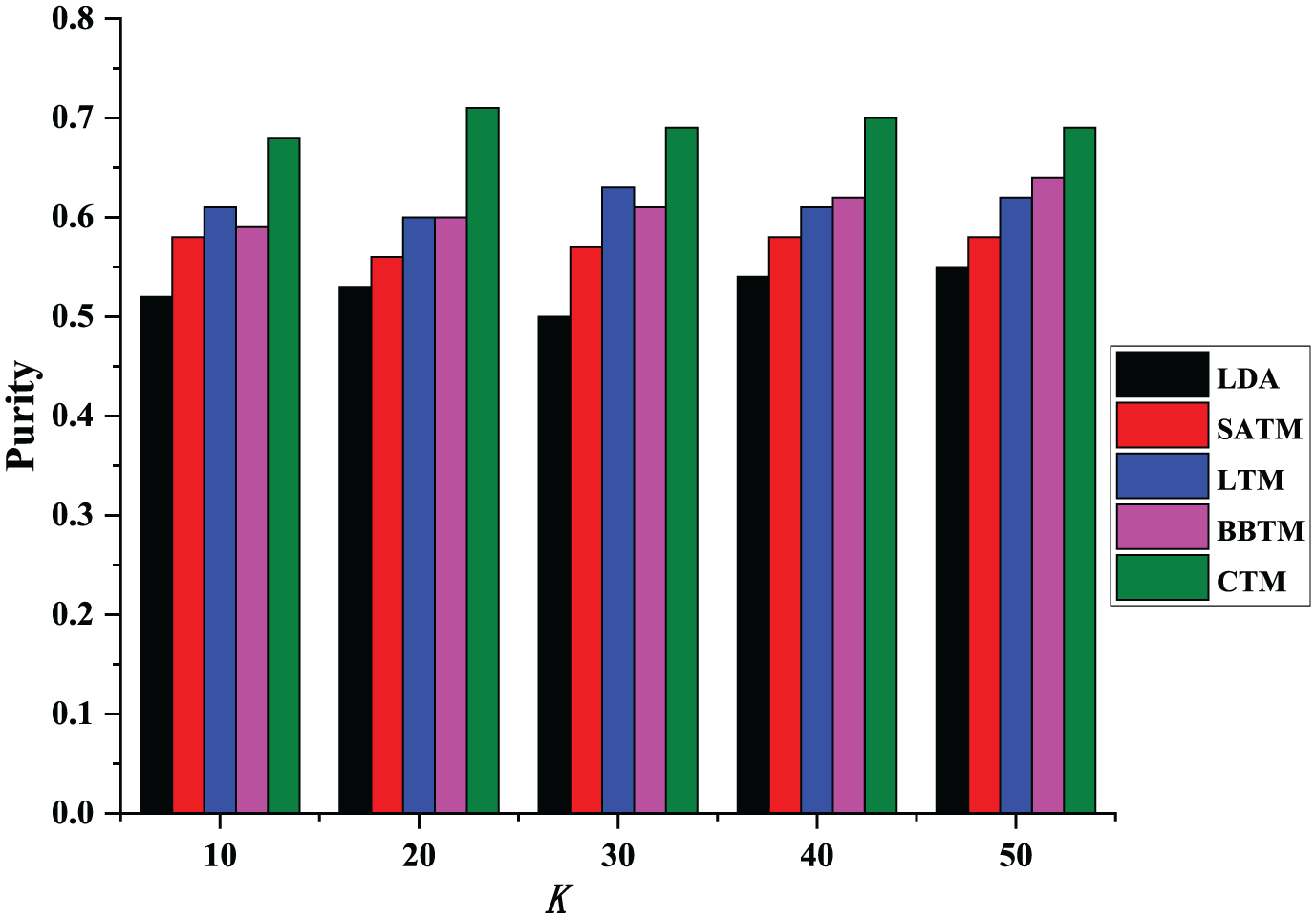
Clustering purity comparison.
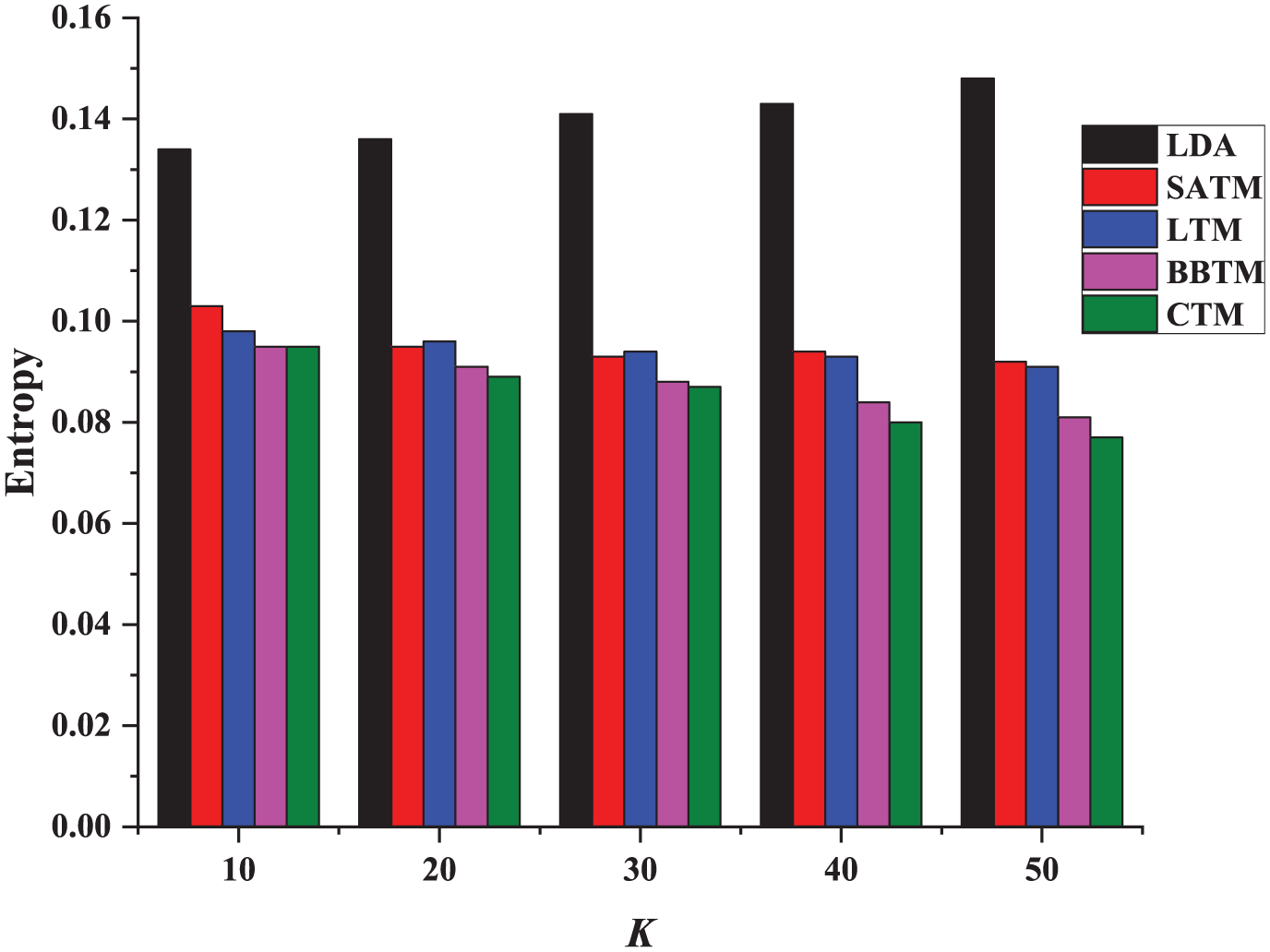
Clustering entropy comparison.
The results show that CTM outperformed all other comparison methods for both clustering indicators. This is because the CTM algorithm vectorizes the text data before the input stage and performs similar word clustering, which can be used to effectively learn the internal relations between words and reduce the dimension of the input text of the model. The CTM topic detection method proposed in this paper considers the high dimensionality of the massive texts in the social network and the sparse characteristics of short texts. Therefore, it is higher than the comparison method in terms of the cluster purity and clustering entropy evaluation index. The original LDA method cannot overcome the short-text sparsity problem, so its performance is the worst in all algorithms. The BBTM method considers the sparseness problem of short texts in social networks but does not consider the high dimensionality of the text and the dispersal of the theme, so the cluster purity is good, but the algorithm proposed in this paper is slightly worse.
Conclusion
In this paper, we propose a novel word embedding topic model for topic detection and a summary method by combining a Cbow event vectorization model and aggregated-document topic model. First, we adopted the Cbow method to cluster similar words and learn the relationship between words. The results learned by Cbow are used as the input of the model. Thus, the dimension of the event topic is reduced and more clearly expressed. Second, we conduct a SATM to address the sparsity problem by aggregating short text into long documents. Finally, to detect and summarize topics, we propose a topic detection method based on the similarity computing approach. We have conducted experiments on the Sina microblog dataset, and the experimental results showed that our CTM outperforms all other baseline methods. However, social networks also contain images, temporal and spatial information, which cannot be modeled by our CTM.
In the future, we will focus on the optimization and expansion of CTM by leveraging social relationships, images, and spatial–temporal information to achieve cross-media retrieval and the bursty event detection. We also plan to extend the CTM method for sentiment analysis and hashtag recommendations.
Footnotes
Acknowledgements
The authors would like to thank all reviewers and editors for their comments and views that improved the quality of this paper.
Author contributions
L.S. and G.C. designed the overall framework and conceived the idea of this paper, L.S. analyzed the data using correlation algorithms, L.S. and G.C. wrote the paper, S.X. help typesetting and revising the paper, G.X. help modify the English grammar and put forward some suggestions for improving the writing of the paper.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by the National Natural Science Foundation of China (no. 41702347), National Key Research and Development Program of China (no. 2018YFC1505104), Natural Science Foundation of Hebei Province of China (no. D2018508107), China Postdoctoral Science Foundation (no. 2019M651786), Hebei IoT Monitoring Engineering Technology Research Center (no. 3142018055), and Scientific Research Projects of Education Department of Hebei Province, China (no. Z2017043).