
Abstract
The purpose of the article is to design data-driven attitude controllers for a 3-degree-of-freedom experimental helicopter under multiple constraints. Controllers were updated by utilizing the reinforcement learning technique. The 3-degree-of-freedom helicopter platform is an approximation to a practical helicopter attitude control system, which includes realistic features such as complicated dynamics, coupling and uncertainties. The method in this paper first describes the training environment, which consists of user-defined constraints and performance expectations by using a reward function module. Then, actor–critic-based controllers were designed for helicopter elevation and pitch axis. Next, the policy gradient method, which is an important branch of the reinforcement learning algorithms, is utilized to train the networks and optimize controllers. Finally, from experimental results acquired by the 3-degree-of-freedom helicopter platform, the advantages of the proposed method are illustrated by satisfying multiple control constraints.
Keywords
Introduction
In the unmanned aerial system field, the helicopter control problems have attracted much attention because of their wide applications and scientific significance. Difficulties in designing controllers for helicopters are due to their particular features, such as external disturbance forces, model uncertainties, nonlinear dynamic conditions and coupling axis problems. In the past few decades, abundant papers have been reported about the controller design for the helicopter, see for example, sliding mode controllers,1,2 robust controller,
In order to avoid the difficulties of the practical helicopter experiments, we aim to find a simplified model to corroborate the theoretical application. The helicopter platform in the study by Zheng and Zhong 6 provided a simplified model, which consisted of strong coupling characteristic and complicated, nonlinear dynamics. Also, this model utilized the Simulink for controller design, and then it compiled the codes for the practical experiments. Based on this model, a large amount of research papers have been published so far. Rios et al. 7 utilized the sliding-mode observation method. The robust controller design methods were brought out by Liu et al. 8 Also, Kutay et al. 9 used the adaptive method to design the pitch axis output feedback controller within this platform. Rosales dealt in three axes the set-point regulation problem. Li et al. 10 brought out robust nonlinear controller, which is based on the robust integral of the error, to solve the attitude track problems, both set-point tracking and sine-signal tracking. But, all these controllers are designed by manually adjusting parameters. Also, seldom controllers can deal with control problems under multiple constraints. In this paper, authors want to design controllers for the helicopter platform under multiple constraints only with its input data and output data, which also means model-free controllers.
Among the machine learning method, reinforcement learning (RL) performs well when dealing with serial decision-making problems and control strategies. Sutton and Barto
11
based on the past decade research introduced the RL in their study. One of the fundamental theories is the Bellman equation, which is utilized to optimize value function iterations or policy iterations. Inspired by this, the researchers in control theory field improved the adaptive dynamic programming (ADP) by RL. By using the reward in “Linear Quadratic Regulator (LQR)” form, they used the Hamilton–Jacobi–Bellman (HJB) equation to deal with controller design problems for linear systems,12–16 discrete nonlinear system,17–20 complex-valued nonlinear systems,
21
nonlinear switched systems,
22
multiagent systems23–25 and so on. Also, according to ADP, Kiumarsi et al.,
26
Luo et al.,
27
and Modares et al.
28
brought out
Methods such as ADP and Q-learning are the value-based learning methods. These algorithms alternate actions by estimating the value function or Q-function and then improve the policy. Another type of RL algorithm is the PG method. It improves the policy by an estimator of the gradient of the cost function, which is calculated through the data. Abundant research studies about PG methods have been reported so far, see for example the studies by Peters and Schaal 32 and Luo et al. 33 But, few of them behaved well in practical plants, 34 because it is difficult for us to choose an appropriate step size. Too short means slow learning rates and too long results in divergence. Schulman et al. 35 solved this problem by giving a limitation for the choice of the step size.
The aim of the article is to design RL-based controllers for the helicopter under multiple constraints. In the practical systems, there exist many constraints, such as the limiting control inputs. Also, researchers want to add some constraints for the performance such as no overshoot. In this article, we use the reward functions to describe these constraints and construct the learning environment. An actor–critic-based controller is brought out for the helicopter experiment plant, and we utilize one type of the PG methods to optimize the controllers. Finally, the table-mount helicopter platform is used to prove the efficiency of the proposed algorithm under different constraint conditions.
Problem formulation
The helicopter model used in this article is the table-mount helicopter, which is shown in Figure 1. The helicopter consists of two parts: a rectangular body frame and two propeller assemblies. The arm in this model allows the elevation and the travel motions of the helicopter with the utilization of a 2-degree-of-freedom (DOF) instrumented joint. The helicopter will elevate when motors are both driven with two positive voltages. If the voltage on the front motor is greater than that on the back motor, the positive pitch movement is generated. The thrust vectors of the body pitches can result in the travel motion. Angle position information can be directly measured by encoders mounted through the middle part.
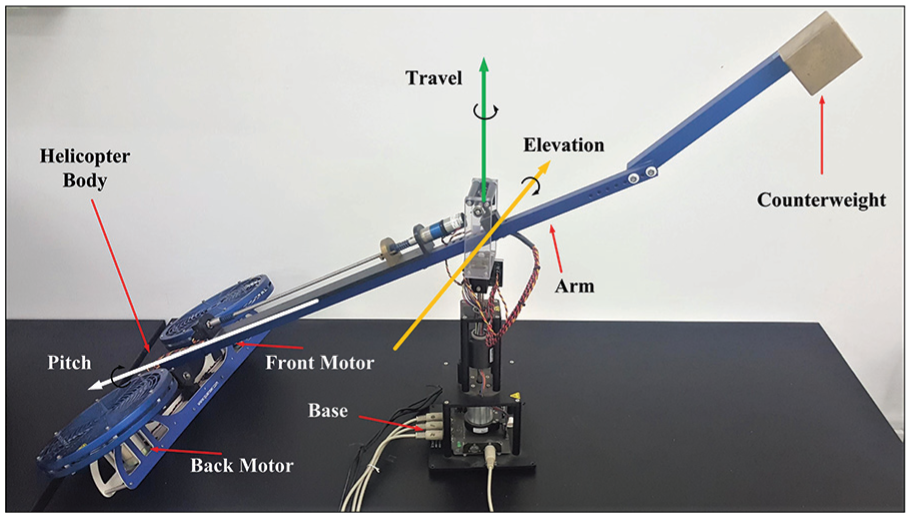
Quanser table-mount helicopter platform.
Based on the abovementioned simplified structure of the helicopter model, the control method designed in the article aims to track the reference signals of elevation and pitch axes. Then, we can formulate elevation and pitch motions of the helicopter as follows.
Elevation motion
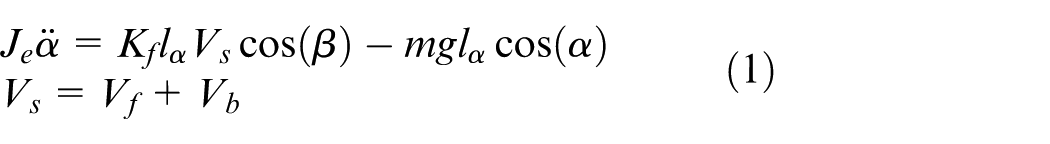
Pitch motion
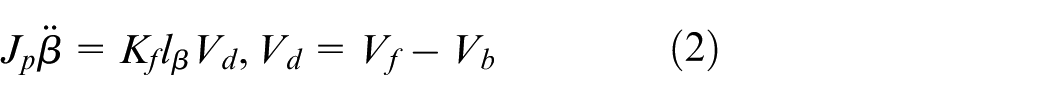
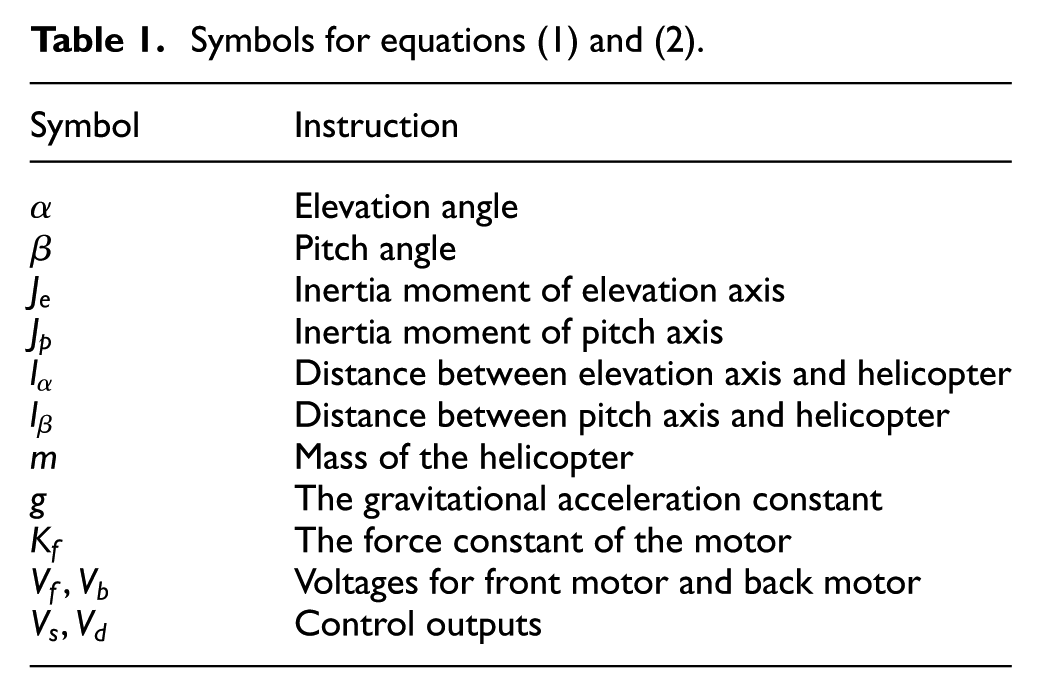
where parameter symbols are listed in Table 1.
Symbols for equations (1) and (2).
Define
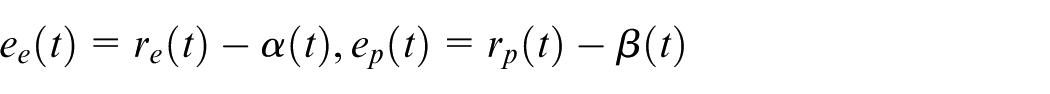
where
The aim of this paper is to design a controller that can track the signal and satisfy multiple performance constraints. Then, we define these special constraints as
Remark 1
Here, we present some examples for the special constraints
In conclusion, our control objective is to design two model-free controllers for elevation axis and pitch axis such that
Preliminary on RL
Policy iteration is an important part of the RL. It is widely known that the Q-function in RL is described as follows
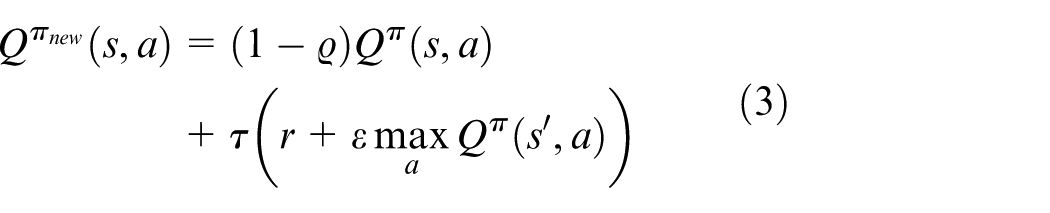
where

This type of Q-function brings many shortcomings when it is applied to solve the continuous system problem. The action bound and the action amount will be noted as infinity. Then, it is difficult to make a choice, which can bring maximal reward. However, another branch, PG method, can solve such problems.
PG method
In the PG method,
32
we directly parameterize policy
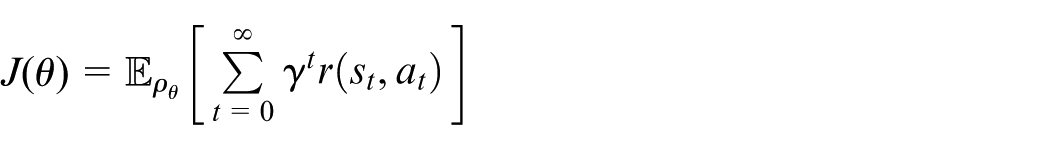
where
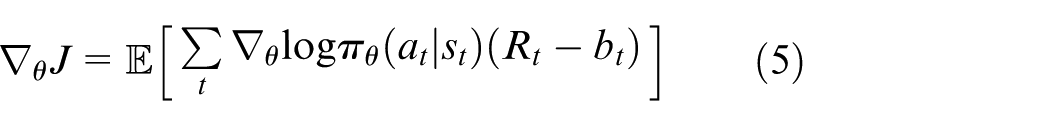
where
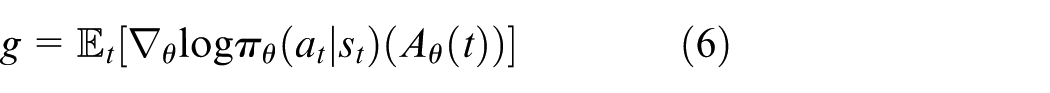
Then, we can optimize the policy by a stochastic gradient descent optimizer to obtain a policy, which can maximize the sum of the reward.
Trust region policy optimization
When we apply the PG method into the practical utilization, it is hard to choose the step size for the optimization. The policy will not converge when our step size is quite large. Also, the optimization process is exceedingly time-consuming when it has small step size.
Schulman et al.
35
brought out the TRPO method to solve this problem by defining a trust region for the step size. In each iteration, TRPO transfers the current parameters
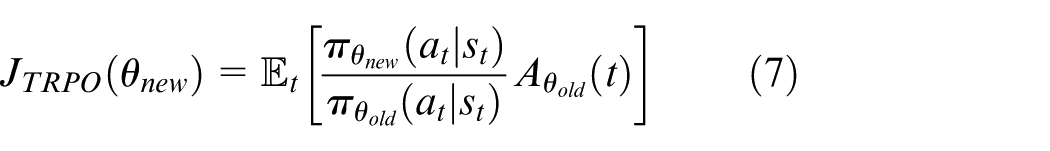
TRPO sets a constraint for the step size of the policy update. By using Kullback–Leibler (KL) divergence, the constraint can be expressed as
Main result
In this section, we will introduce the structure of the table-mount helicopter control system and the controller design method with the consideration under multiple constraints.
The structure of the controllers and the physical plant is shown in Figure 2. From the figure we have two main modules, reward function module and RL controller. Reward function module provides reward for the controller according to multiple constraints. The algorithm updates controllers with the utilization of reward and state signals based on RL. After optimization, the controllers can efficiently track the reference signal and satisfy multiple constraints.
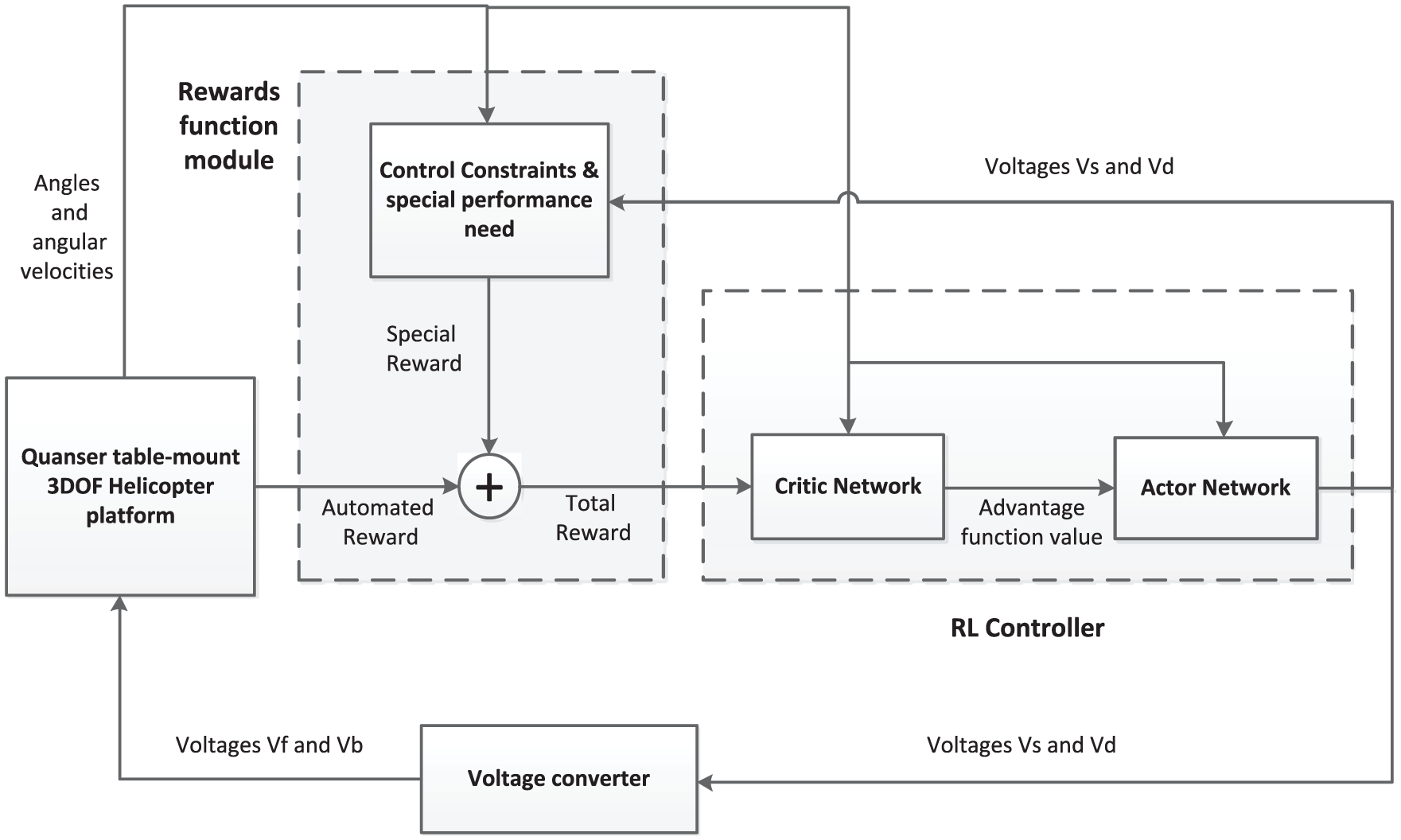
Helicopter control system.
Reward function module
In the history of the RL, reward plays an important role as one of four basic elements. We set reward rules for the problem and with the algorithm, the agent obtains more and more rewards after each episode. In other words, we utilize reward functions to construct the performance environment, which helps us train the policy. In this paper, the reward we use is continuous with states varying.
From Figure 2, one can see that the total reward
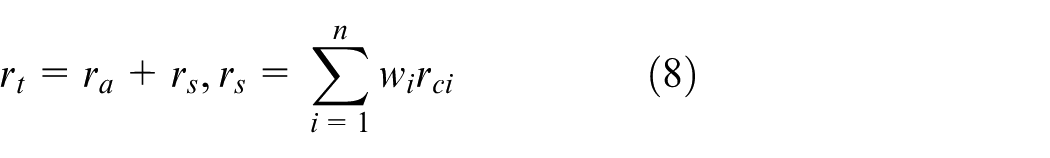
where

where
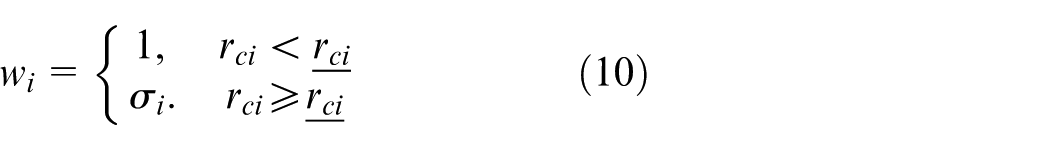
where
Remark 2
Compared with main target, constraint
The
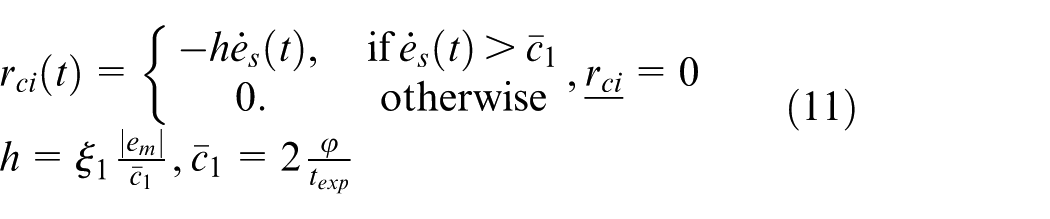
where

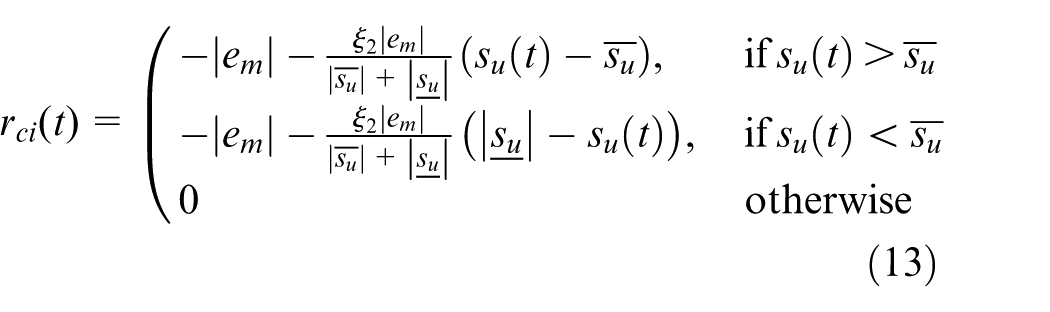
where
Based on the above introduction, we can assume that we utilize rewards
Remark 3
Here, the reward we give for such three types of constraints is efficient in our simulation. We suggest that in similar constraints, the reward can follow similar structures and hyperparameters
Remark 4
In previous studies,12–14,17–19,21–23 the authors utilized the ADP method to design controllers and the reward they use can be described as
Optimization method
From section “Preliminary on RL,” we denote the expected discounted cost under a stochastic policy

where
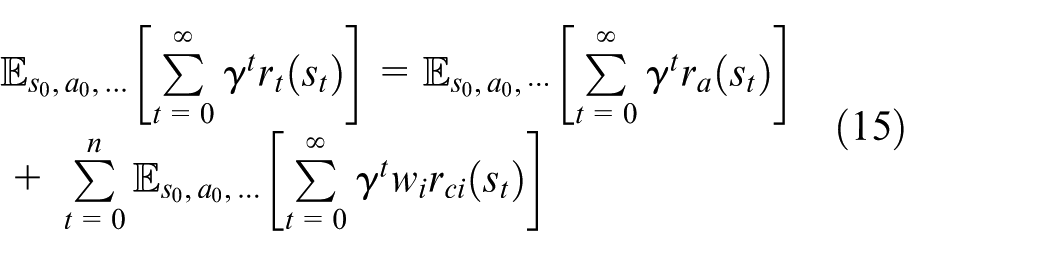
According to equation (10), in the tolerable range,
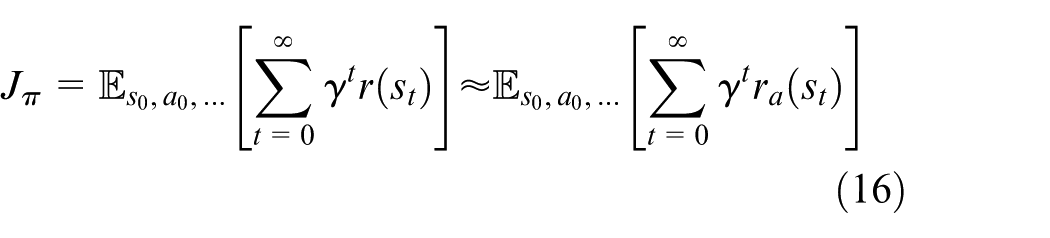
In our following method, we set
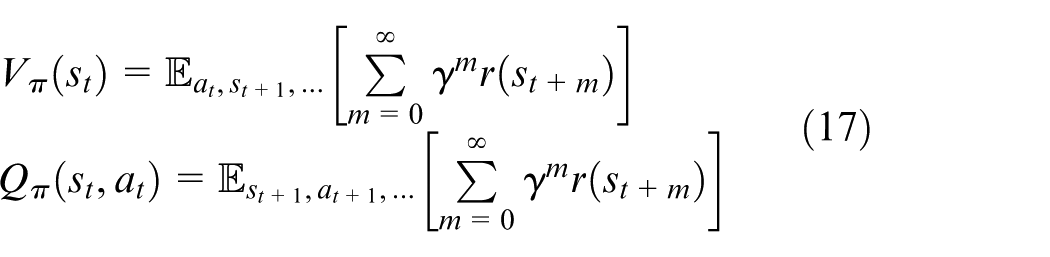
Then, we define the advantage function
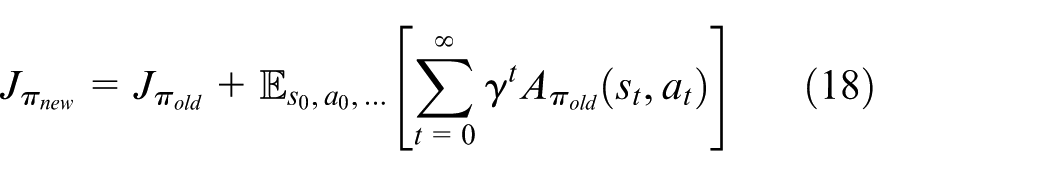
where
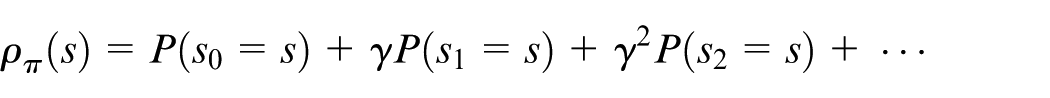
Then, equation (11) can be reformulated as
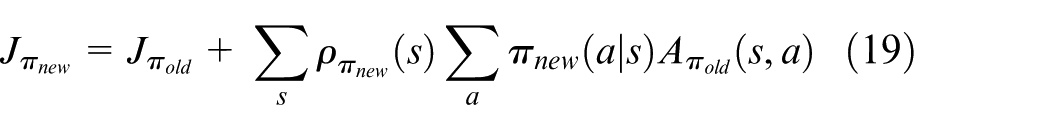
One can see that from equation (19), we can obtain that if
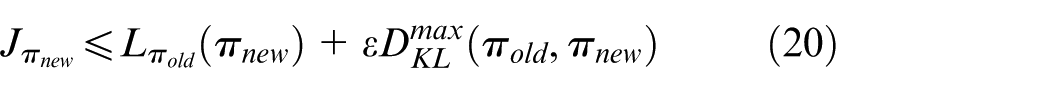
where
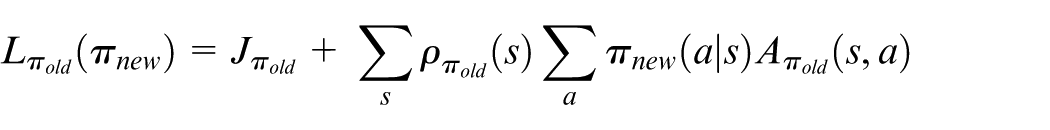
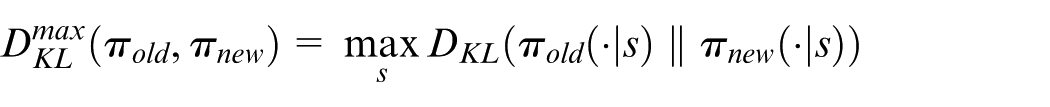
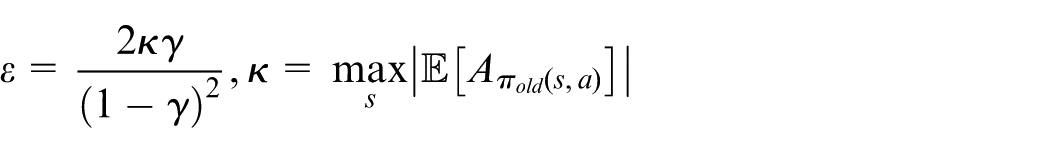
where
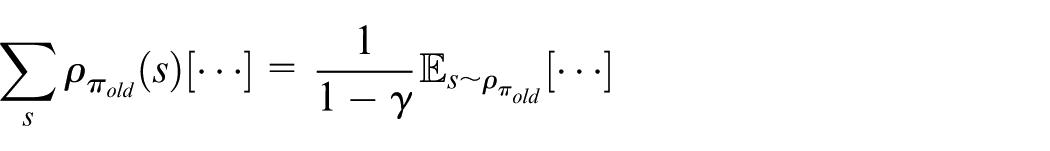
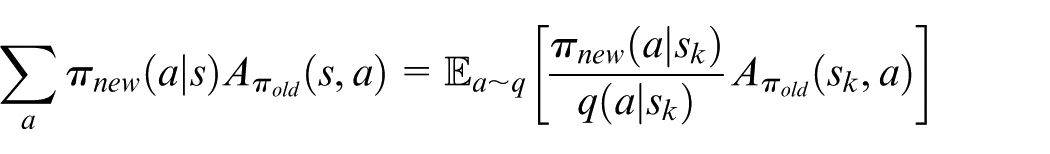
In the estimation procedure, we simulate the plants with policy
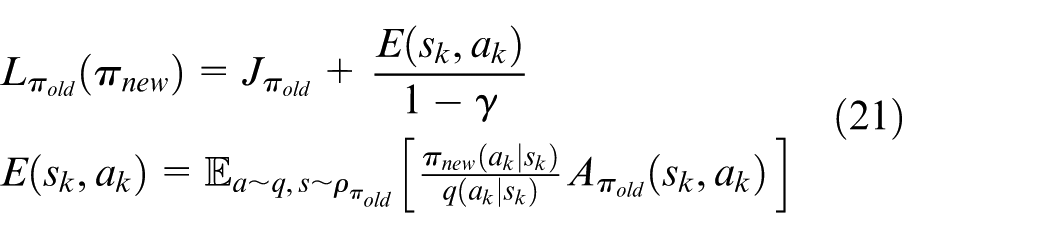
From equation (13), we can find that the penalty parameter
In this study, we usually choose the reward
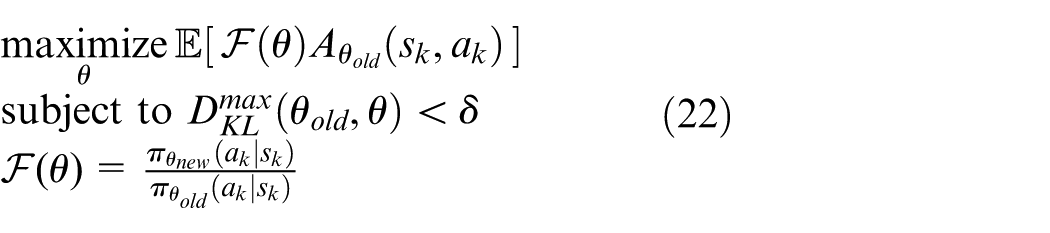
From equation (22), we can find that in the optimization of each episode, the algorithm first obtain the second derivative of the constraint and then optimize through conjugate gradient. The process is time-consuming, and then we utilize a method, which only requires the first derivative during the optimization. Set
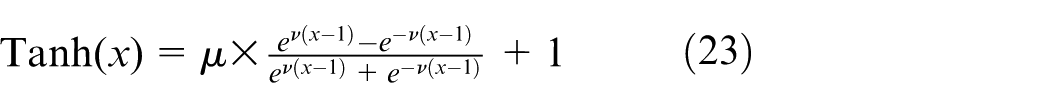
where
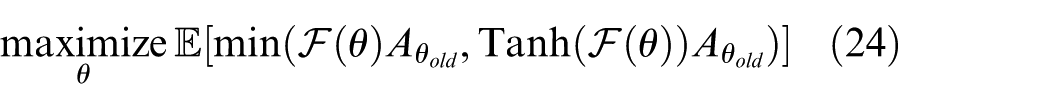
Compared with equation (22), equation (24) only have upper bound with the variation of
Remark 5
In the TRPO algorithm, the policy is optimized through conjugate gradient algorithm and before that TRPO will obtain the second derivative of the constraint, which is time-consuming. However, algorithm in this paper is based on the TRPO abandon using the constraint, which means the algorithm will optimize policy only with first-order derivative. In other words, without constraints, maximization of the objective will lead to an excessively large policy update. When
Controller implement
In this section, we introduce the implement of the critic–actor-based controller and conclude the algorithm.
From Figure 2, we have that the RL-based controller utilizes reward, state signals to update and output voltages. Reward obtained by reward function module guarantees the controller satisfy multiple constraints. Back propagation neural networks (NNs) are employed to implement the controller. For the critic part, we use a three-layer network with definition as follows
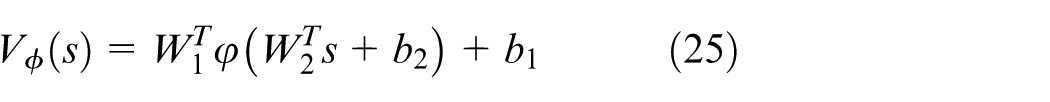
where
For the critic part, our aim is to minimize the advantage function
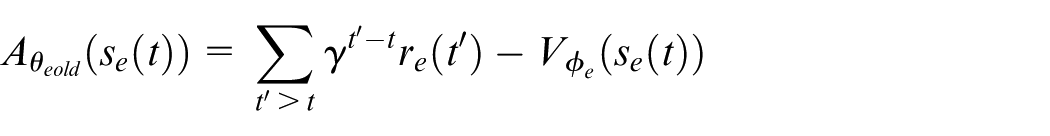
With minibatch
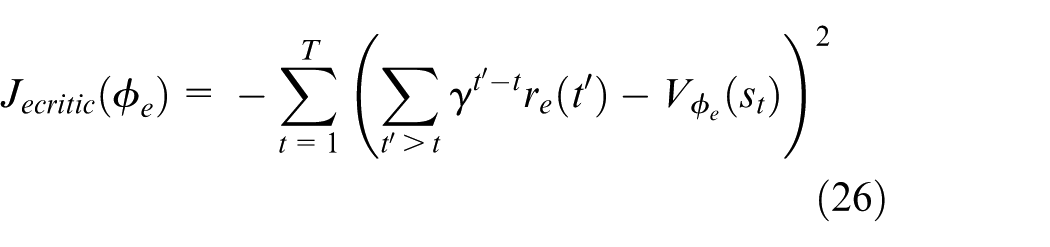
We can update the critic parameters
For the actor network, we optimize the actor network by using the advantage function value obtained from the critic part. In this paper, actor network structure is similar to critic network, but it has two outputs. The inputs for the network are
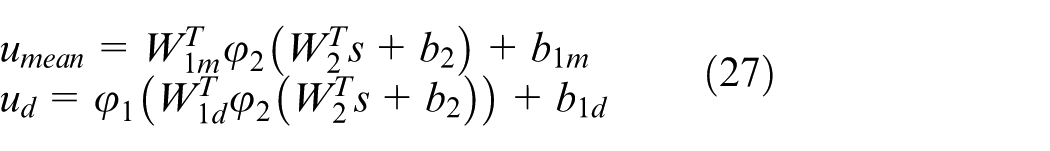
where
In this part, our aim is to optimize the actor policy as fast as possible according to equation (24). For elevation axis, we define
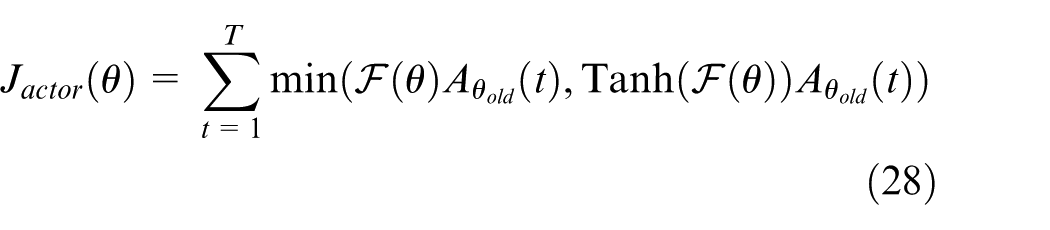
We can obtain
The technique used in the article is a gradient descent method. It is well known that optimizer is important in dealing with the gradient descent problem. In this paper, we utilize a momentum optimizer, Adam optimizer, which was brought out by Kingma and Ba. 37 It has lower variance than the Stochastic gradient descent (SGD) optimizer when the optimization converges.
Based on the abovementioned statement, we have our controller design algorithm described in the following steps:

Example
In this section, we will use the experiments on the table-mount helicopter platform to illustrate the applicability of the proposed algorithm.
The equipment is shown in Figure 1, and the control system model is shown in Figure 2. The sampling time for the experiments is 5 ms. The parameters of the helicopter are shown in Table 2. The hidden layers of both critic network and actor network have 20 neurons. The minibatch for the training technique is 64. The learning rates for critic net and actor net are 0.0001 and 0.0002, respectively. The discounted rate
Parameters of the Quanser helicopter.

Experiment with constrained control input
In this experiment, we test the applicability of our controllers with strict limitation constraint. In the table-mount helicopter plant, the initial position of the helicopter is −27° elevation axis and initial pitch angle is 0°. The targets of elevation axis and pitch axis are both 0°. In the traditional method, we cannot control the maximum of the control input and we adjust the parameters of the controller in practice. In this experiment, we provide a LQR controller with little parameter adjustments for comparison. The controller parameters are shown in equation (29). Assume there are strong limitations for DC motor such that voltages
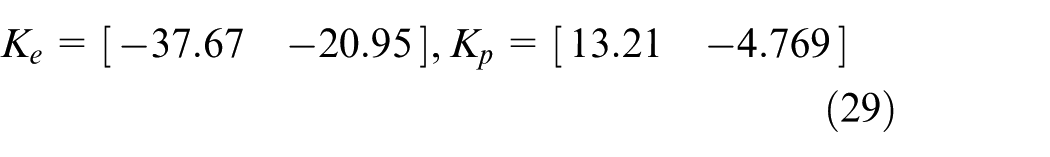
According to the algorithm, we first establish the reward function module with
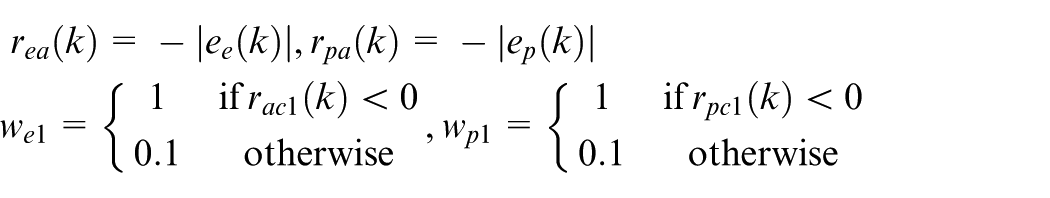
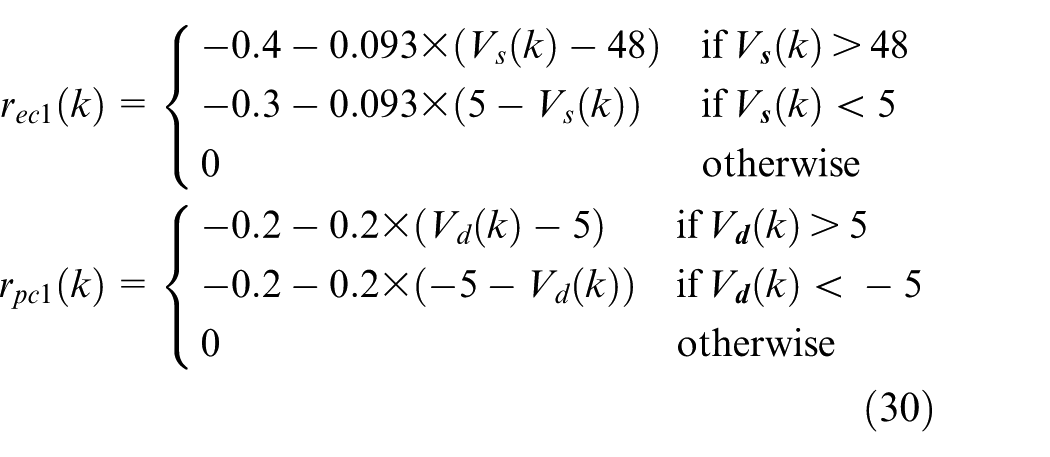
For elevation axis, the reward at state
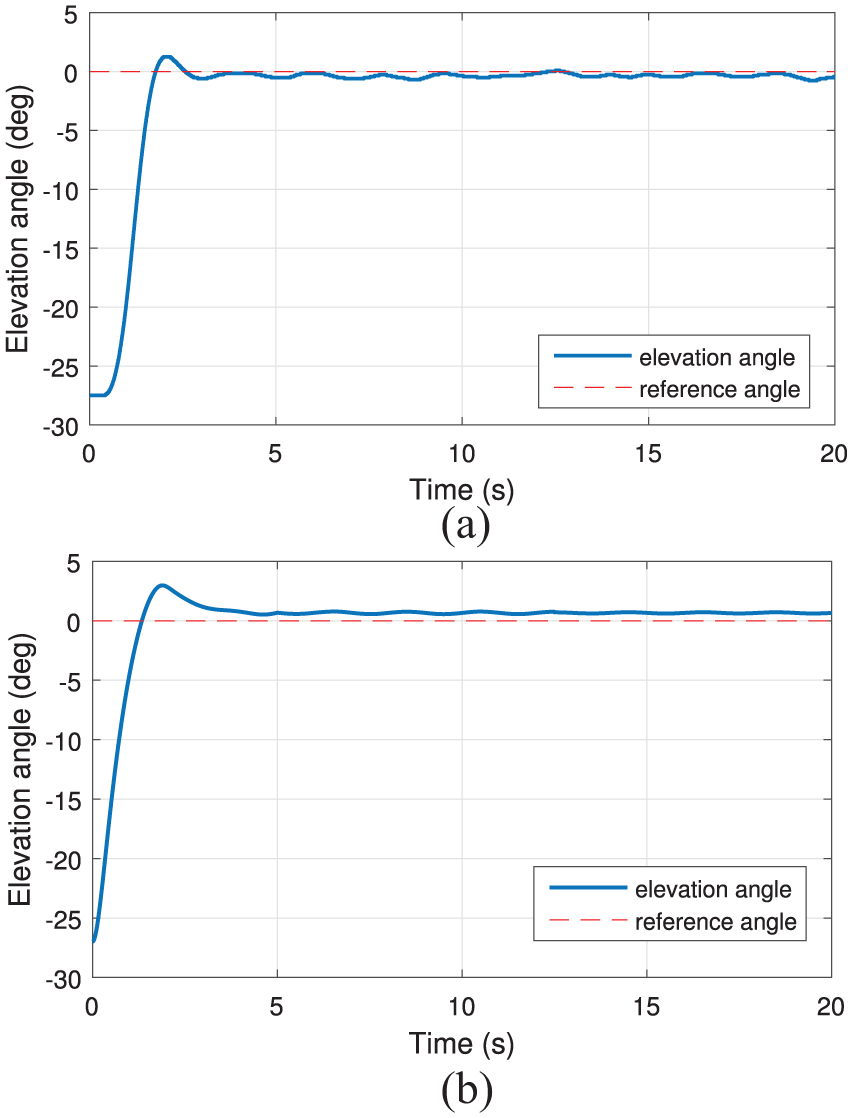
Comparison of elevation axis tracking response for (a) reinforcement learning-based controllers and (b) traditional LQR controller with small parameter adjustment.
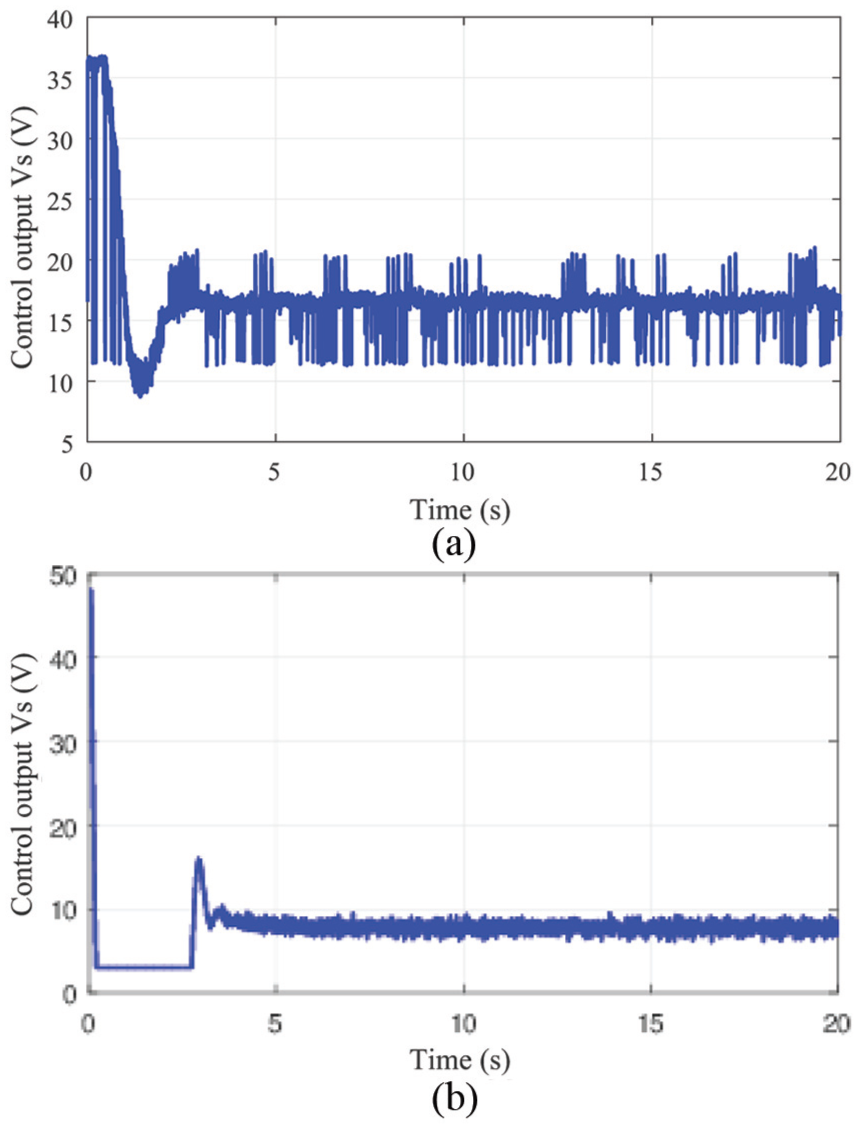
Comparison of control output
From Figure 3, compared with the LQR controller, the controller design in our RL-based algorithm has a shorter settling time, less overshoot and less steady-state error. At the same time, our controllers are model-free, which means they can learn to optimize themselves without any parameter adjustments. Also, from Figure 4(a), we can find that under this reward environment, controllers learn to adapt this penalty environment, which satisfies limitation.
Experiment with multiple constraints
During this experiment, we will illustrate that the proposed controllers can guarantee the special performance need. Similar to the abovementioned experiment, the initial positions for elevation axis and pitch axis are −27° and 0°. The targets of two axes are both 0°. In this experiment, we want the helicopter to have such a performance that there is no overshoot in the step response. We add the special reward as follows with
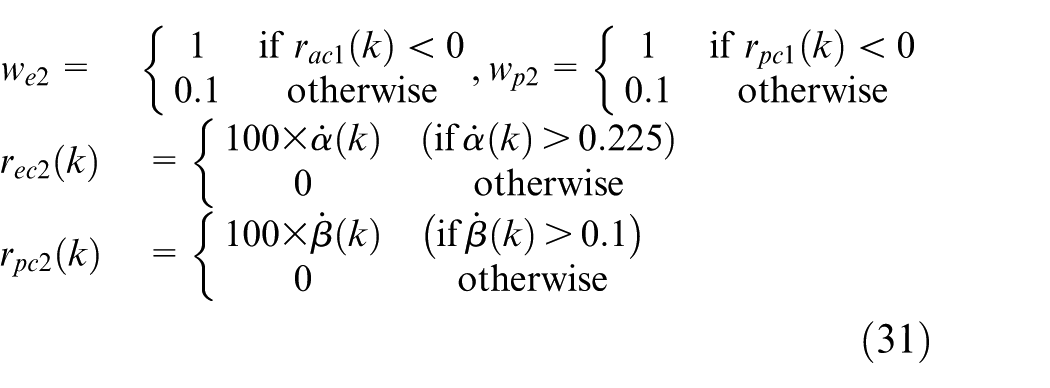
According to equations (30) and (31), we can have the reward for elevation axis as
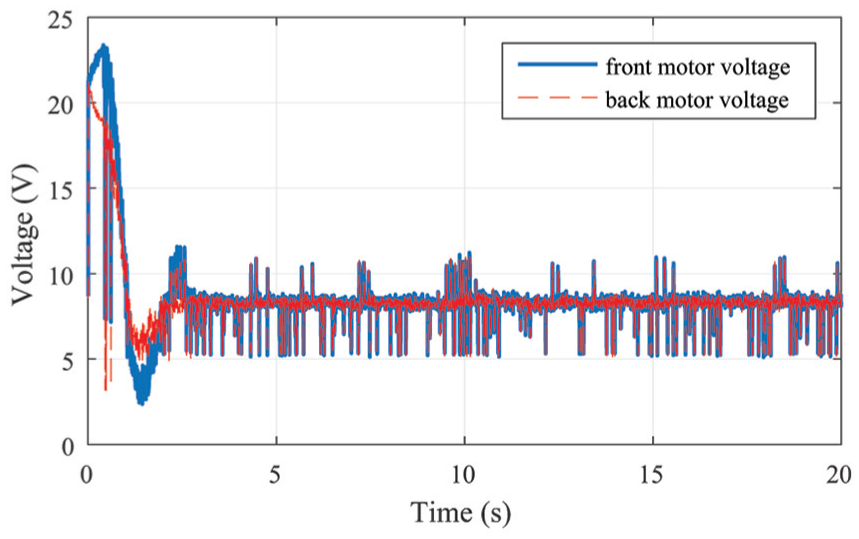
Front motor and back motor voltages of the step response for elevation axis.
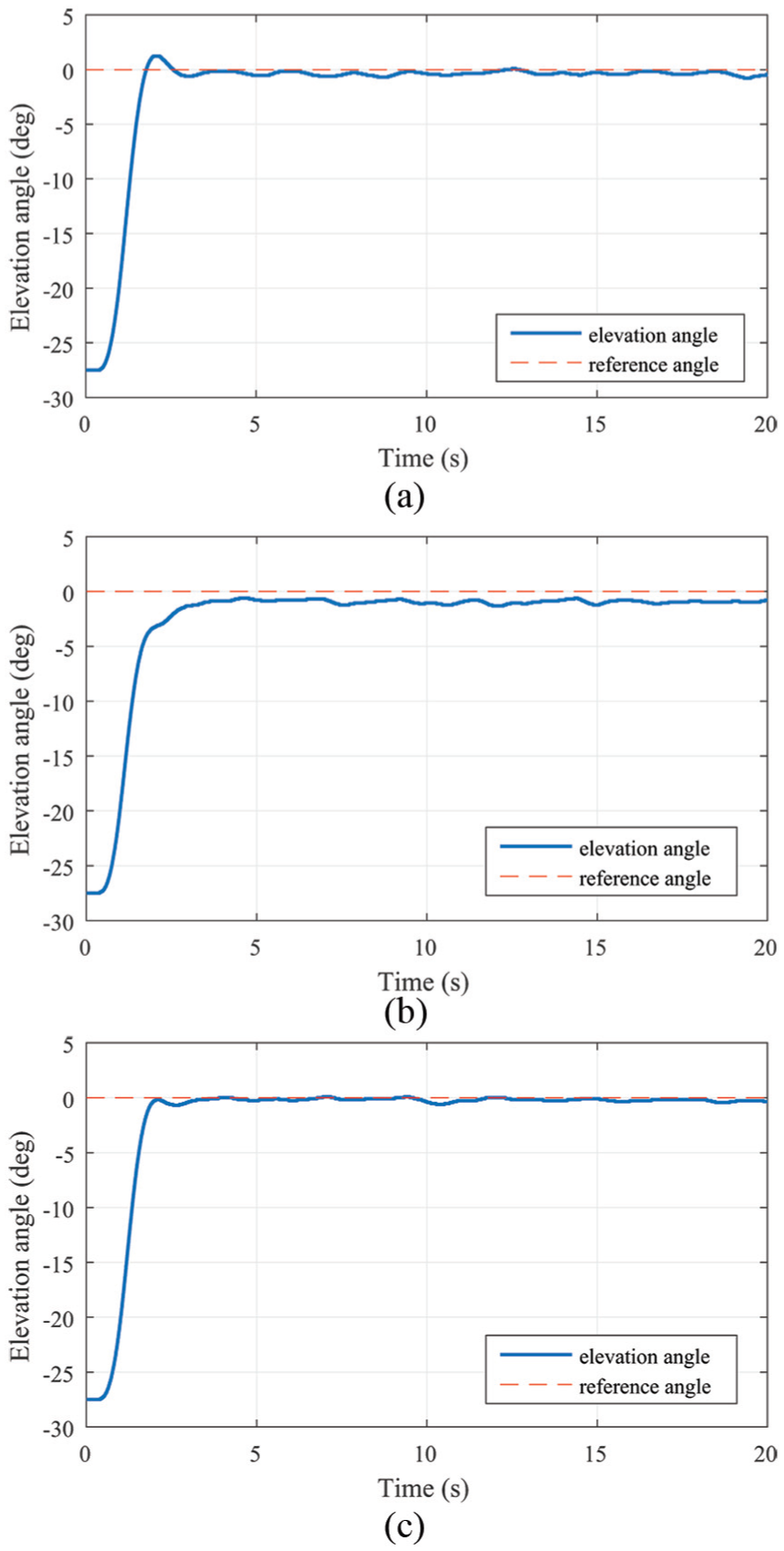
Step response for the elevation axis: (a) before training, (b) during the training and (c) after training.
Figure 6 shows the tracking response for the elevation axis before, during and after training. The controller before training we used is the controller in the experiment 1, which is trained in the reward environment (30). The settling time is around 2 s, the overshot is 4.5% and the tracking error is about 0.34°. The tracking response (Figure 6(b)) we got utilizes the controller, which we trained in the reward environments (30) and (31) after 500 iterations. The settling time is 2.9 s, and it has no overshot but −0.8° tracking error. After the complete training, we obtain the tracking response in Figure 6(c), whose settling time is 2.5 s and tracking error is 0.16°. Surely, the response has no overshoot.
Figure 5 shows the front motor voltage and back motor voltage of the tracking response after training. Both voltages are in the interval (0, 24), which satisfies the reward constraints
Experiment with step signal tracking
In this part, we illustrate that our two-axis controllers can successfully track the step signals. The initial position of the helicopter is −27° for elevation axis and 0° for pitch axis. We will carry out four experiments, and the target pitch angle we set remains 20°. For elevation axis, the helicopter will carry out four experiments separately, and the four target elevation angles are −22°, −17°, −12° and −7°. The reward function module we utilized in this part is that
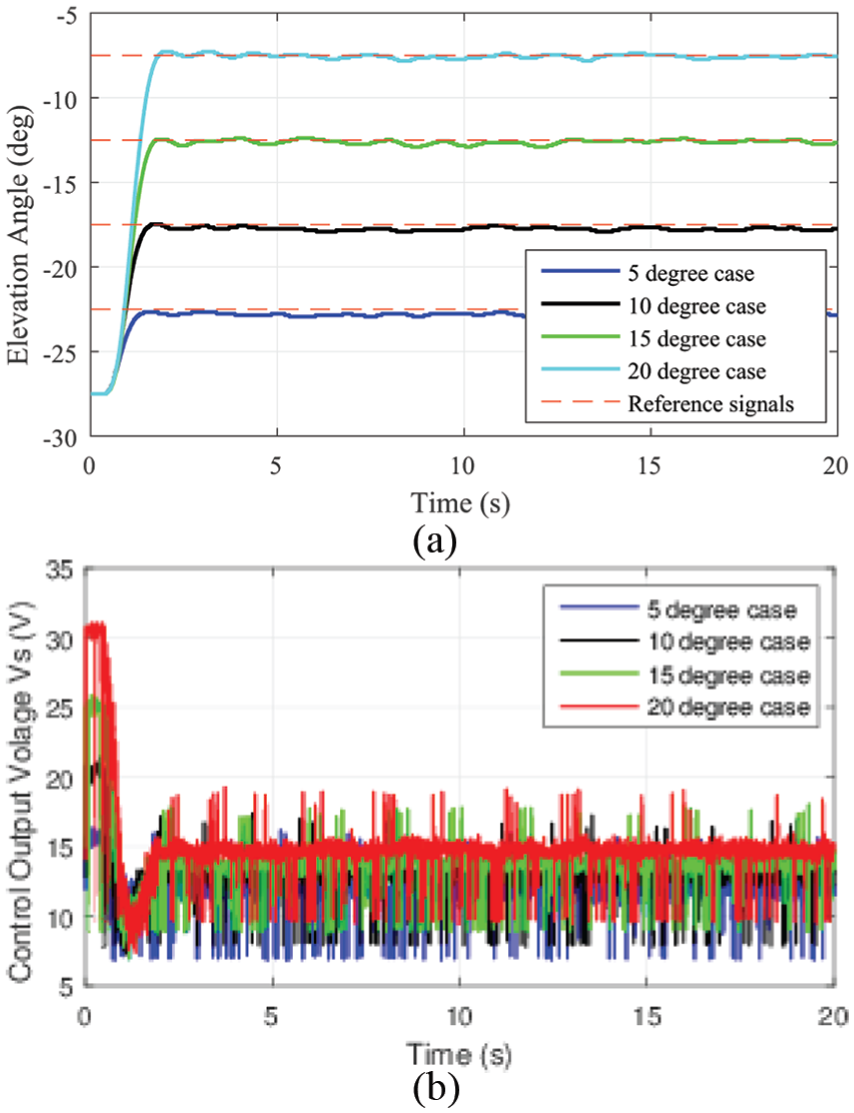
(a) Elevation axis tracking responses for four cases and (b) elevation axis control output
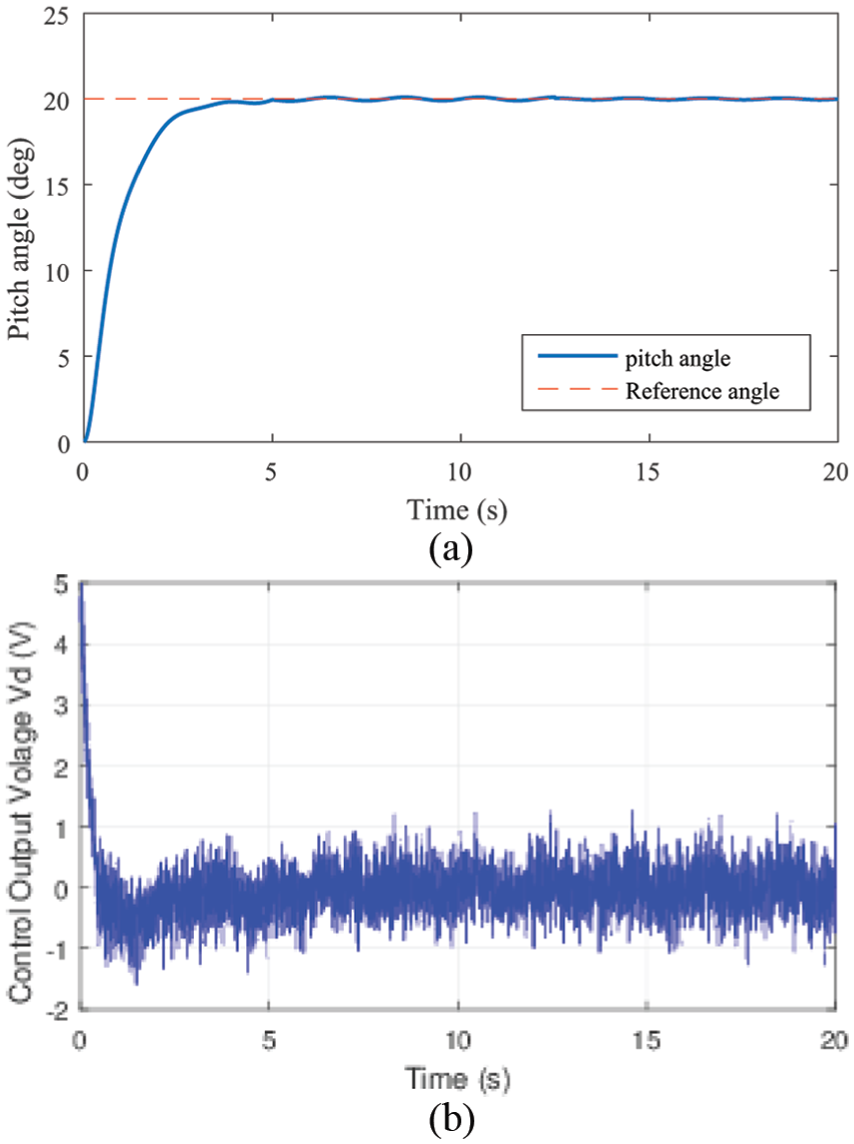
(a) Tracking responses for pitch axis from 0° to 20° and (b) control output
As shown in Figure 7(a), the controllers we design can successfully help the helicopter track the signals in different step cases. Figure 7(b) shows the control output
Conclusion
In this paper, we propose an RL-based controller to address the controller problem for a 3-DOF helicopter with multiple constraints. By choosing a special reward function module, the critic controller can successfully learn the reward environment and actor controller can update policy quickly. There are two advantages of this algorithm. One is that the controller we design is model-free controller, which means the controller is trained only according to the control inputs and system states. This point results in that the controllers will update by themselves by using real-time data. Another advantage is that we can design controllers according to our demand through reward function module. The platform experiment results show that the proposed controllers can successfully satisfy the constraints, special performance and step signal tracking performance.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
This research was supported by State Key Laboratory of Robotics and System (HIT) (grant no.: SKLRS-2018-KF-12), the National Natural Science Foundation of China (grant no: 61603113), China Postdoctoral Science Foundation (grant no.: 2018T110309) and the 111 Project (grant no.: B16014).