
Abstract
This study aims to solve the problem involving the high false alarm rate experienced during the detection process when using the traditional multivariate statistical process monitoring method. In addition, the existing model cannot be updated according to the actual situation. This article proposes a novel adaptive neighborhood preserving embedding algorithm as well as an online fault-detection approach based on adaptive neighborhood preserving embedding. This approach combines the approximate linear dependence condition with neighborhood preserving embedding. According to the newly proposed update strategy, the algorithm can achieve an adaptive update model that realizes the online fault detection of processes. The effectiveness and feasibility of the proposed approach are verified by experiments of the Tennessee Eastman process. Theoretical analysis and application experiment of Tennessee Eastman process demonstrate that in this article proposed fault-detection method based on adaptive neighborhood preserving embedding can effectively reduce the false alarm rate and improve the fault-detection performance.
Keywords
Introduction
With the increasing scale and complexity industrial process, the fault detection of the entire process has become the focus of research in the field of process control. Because the use of analytical methods and knowledge-based methods make it difficult to model complex industrial processes directly, and sensors are widely used in the industrial process, a lot of industrial process data can be preserved.1,2 As a result, data-driven methods have received widespread attention and rapid development.1,3–7 Industrial processes possess multiple characteristics, and monitoring these process characteristics independently can lead to false judgments. Therefore, there is a need for multivariate statistical process monitoring (MSPM).8,9
MSPM is widely used in chemical, power, machinery, and others industrial processes based on the interrelationships between multiple sets of measurement data.10,11–13 Process monitoring and fault-detection methods that are based on multivariate statistical projection theory are widely used. 14 In MSPM, key information pertaining to the data is mapped into the low-dimensional space by the data dimension reduction, and the original high-dimensional data feature information is obtained, after which comprehensive statistics are established for the low-dimensional data to realize online monitoring. At present, MSPM methods include principal component analysis (PCA),15,16 canonical correlation analysis (CCA),17,18 independent component analysis (ICA),19,20 Fisher discriminant analysis (FDA),21,22 and partial least squares (PLS).23,24
These methods usually assume that process variables are linearly related and obey the Gaussian distribution. For these problems, many extended methods have been developed, including kernel PCA, 25 dynamic PCA, 26 modified ICA, 27 dynamic ICA, 28 kernel FDA, 29 kernel PLS, 30 and dynamic kernel PLS. 31 Although the above-mentioned methods and extended methods are widely used in fault detection. These methods can only capture the global variability of the process data, the detailed local neighborhood structure on the data manifold, which is proved to be more successful in identifying that the underlying data structures are failed to be discovered. As a result, the dimensionality reduction performance will be greatly degenerated without this crucial information. The global-based method mainly gives a constraint for the far away data points, which can guarantee their corresponding data points still faraway in low-dimensional mapping space. As a result, the intrinsic data structure may be distorted and the data points may be heavily overlapped in the reduced space. Through this point, a desirable projection should be the one that it can represent the local detailed geometry structure while modeling the process data.
Recently, based on the limited understanding of the traditional global linear dimensionality reduction method, the manifold learning method has been developed. Locally linear embedding (LLE), 32 locality preserving projections (LPP), 33 and neighborhood preserving embedding (NPE) 34 are the most widely used manifold learning methods. Most of the manifold learning methods use the local structure information of the data to reduce their dimension. NPE is a well-known manifold learning algorithm that is based on the idea of local data linearity and describes the local characteristics of the data to obtain the overall characteristics of the manifold structure. The algorithm is based on dimension reduction to extract the data characteristics, so low-dimensional spatial data can maximally retain reliable information about the original data. Hence, NPE can reveal the intrinsic geometrical structure of the observed data and find more meaningful low-dimensional information hidden in the high-dimensional observations compared with other methods. NPE has been used by engineers for process monitoring and fault detection. Song et al. 35 proposed a novel process monitoring in the Tennessee Eastman (TE) process via enhanced NPE. Yuan et al. 36 proposed a supervised NPE method for feature extraction and soft sensor modeling to improve the control of debutanizer column. Miao et al. 37 utilized the neighborhood preserving regression embedding (NPRE) method for nonlinear process soft sensor modeling to monitor fermentation process for penicillin production. In addition, Fan et al. 38 first proposed quality-relevant kernel NPE to detect abnormal and failure in the electro-fused magnesia furnace process.
However, the above NPE methods can only detect the process using the model that was initially established, and they cannot update the model according to the actual working condition, while the model lacks adaptability. Therefore, they will inevitably lead to high false alarm rates (FARs) in practice. 39 To solve the above problems, this article proposes an adaptive neighborhood preserving embedding (ANPE) algorithm method that can realize the online updating of the model and reduce FAR of the model. This proposed method combines traditional NPE and approximate linear dependence (ALD)40,41 conditions. By calculating the approximate linear dependency between the new sample and the model, a new sample updating history model that satisfies the condition is selected to realize the adaptive updating of the model, and the online detection of the sampled data is achieved. At the same time, the adaptive update capability of the algorithm can ensure the continuous validity of the method. The proposed ANPE algorithm is verified by experiments of the TE process in this article.
The rest of this article is structured as follows. The concepts of NPE, ALD, and the inference procedure of the ANPE are introduced in section “Fault-detection method based on ANPE.” In section “Experiments using the TE process,” the performance of ANPE in fault detection is compared with that of NPE using the TE process.42–45 Finally, conclusions are made in section “Conclusion.”
Fault-detection method based on ANPE
In this section, the related NPE algorithm and ALD condition were introduced and further described how to build ANPE algorithm and proposed online fault-detection method based on ANPE algorithm.
NPE algorithm
NPE is based on the idea of data local linearity, and its overall manifold structure characteristics are obtained by describing the local features of the data. More details about NPE can be found in He et al. 34
Suppose that the measurement matrix
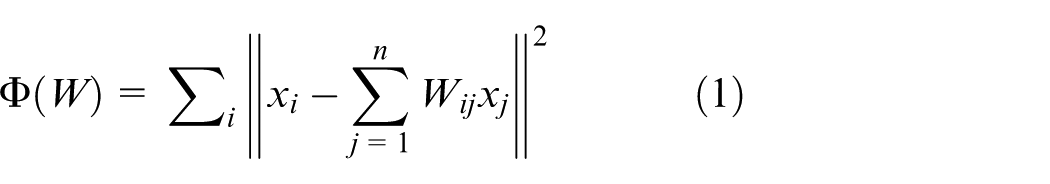
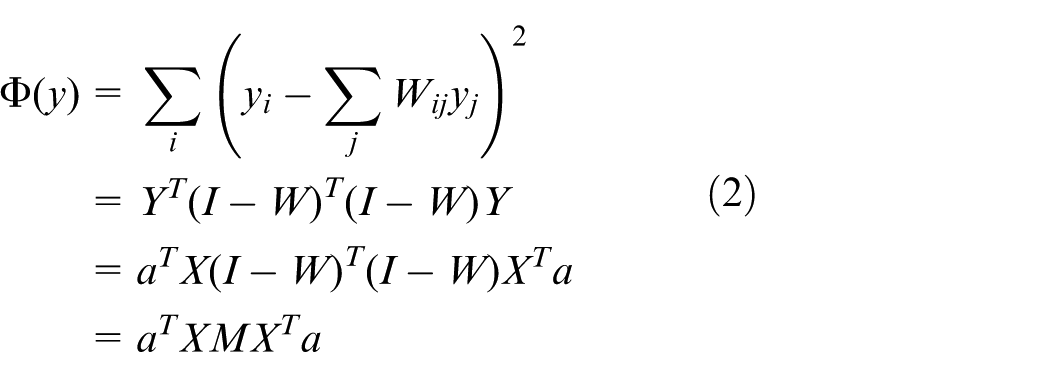
In the formula,

Easy to get,
ALD
The ALD condition can check the linear dependency relationship between the new sample and the modeling sample, and it can effectively reduce the computational load caused by the sample update strategy. It is often used as the update decision condition of the model. More details about ALD can be obtained in Engel et al. 40 and Tang et al. 41
When the historical model selects new samples for model updating, the diversity and independence of these samples should be considered. To ensure the applicability of the model, the independent new sample should be selected for model updating, so this article selects the ALD condition to determine whether the new sample is available for model updates. The ALD update conditions are as follows 39
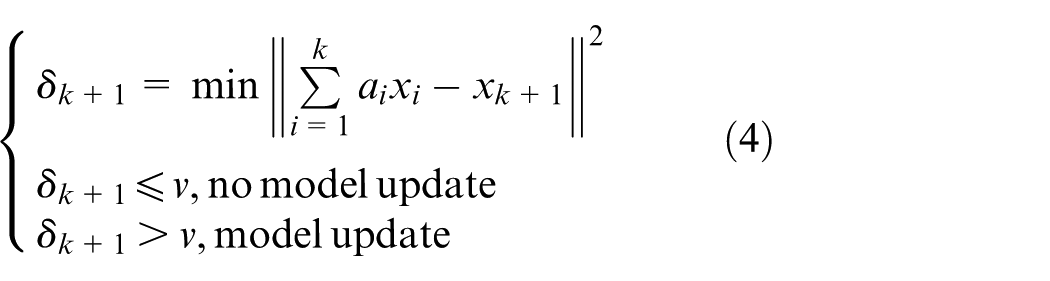
In Equation (4),
To solve Equation (4), Tang et al.
41
give a concrete solution. When the new sample is added, by solving the differential of

In Equation (5),
When the update is determined according to the ALD condition, the selection of the threshold v is not systematic and can only be set by expert experience. While the higher threshold reduces the operating burden of the model, it reduces the accuracy of the model when detecting the fault. Furthermore, while the lower threshold can improve its accuracy, it also increases the computation and updates the time of the model. Therefore, it is very important to choose the right v.

Description of ANPE algorithm
The ANPE algorithm comprises two parts: the offline modeling part based on NPE and the online part. The function of the offline modeling part is obtained by using the NPE algorithm based on the historical off-line data, and it is also the initial model.
The online part contains an online update module and an online fault-detection module. The online update module is used to assess the new sample according to the update strategy. If the new sample satisfies the strategy, then update the offline model with the valuable new sample to make the model adaptable to the actual situation. The role of the online fault-detection module is to monitor the new sample to determine whether a fault has occurred. Eventually, it achieves adaptive online fault detection.
The update strategy involves a comparison of online fault-detection results and ALD conditions. The detailed description of the updating strategy is to determine whether the new sample belongs to the faulty sample according to the online fault-detection module. If it is not a faulty sample, the ALD value of the sample is calculated according to Equation (5) for ALD conditions. When the calculated ALD value is greater than the set threshold v, it indicates that although the new sample is a normal sample, it fluctuates greatly with the training dataset, which meets the updating strategy. The new sample should be used as a training set to update the model.
When updating the model according to the fault-detection results and ALD condition, it is assumed that the point that needs to be updated is
Online fault-detection method based on ANPE
Based on the ANPE algorithm, an online fault-detection method based on ANPE is constructed. Then, the squared prediction error (SPE) statistic is introduced as the output of the model. The SPE is calculated as follows47,48
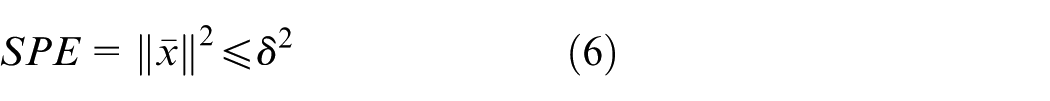
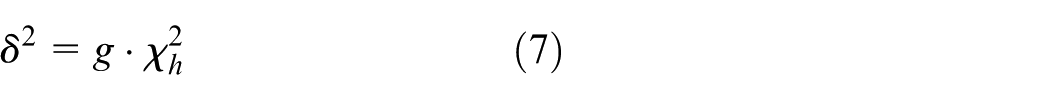
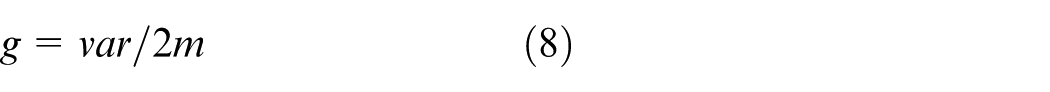
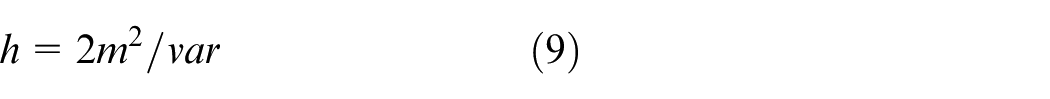
In the above equations,
The online fault-detection method based on ANPE uses the fault-detection rate (FDR) and FAR as performance indexes to measure the detection effect of the proposed method. The FDR and FAR are defined as follows 9
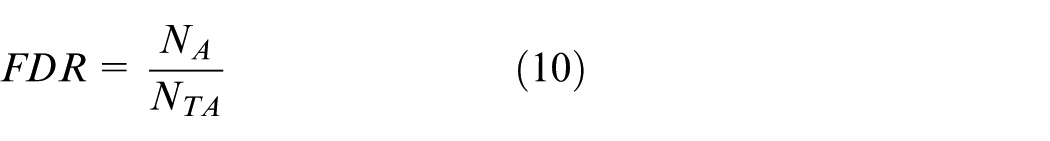
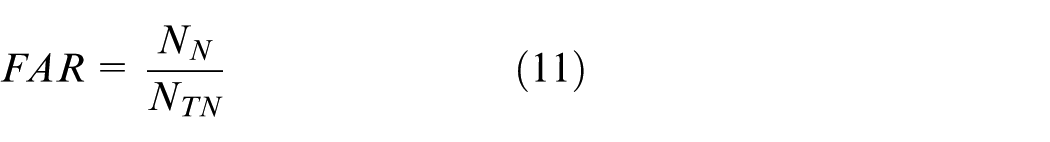
In Equation (10),
Using Equations (7)–(9), when the training sample changes, the SPE statistic limit will change, and the corresponding FAR will change. Figure 1 shows the process of the online fault-detection method based on ANPE.
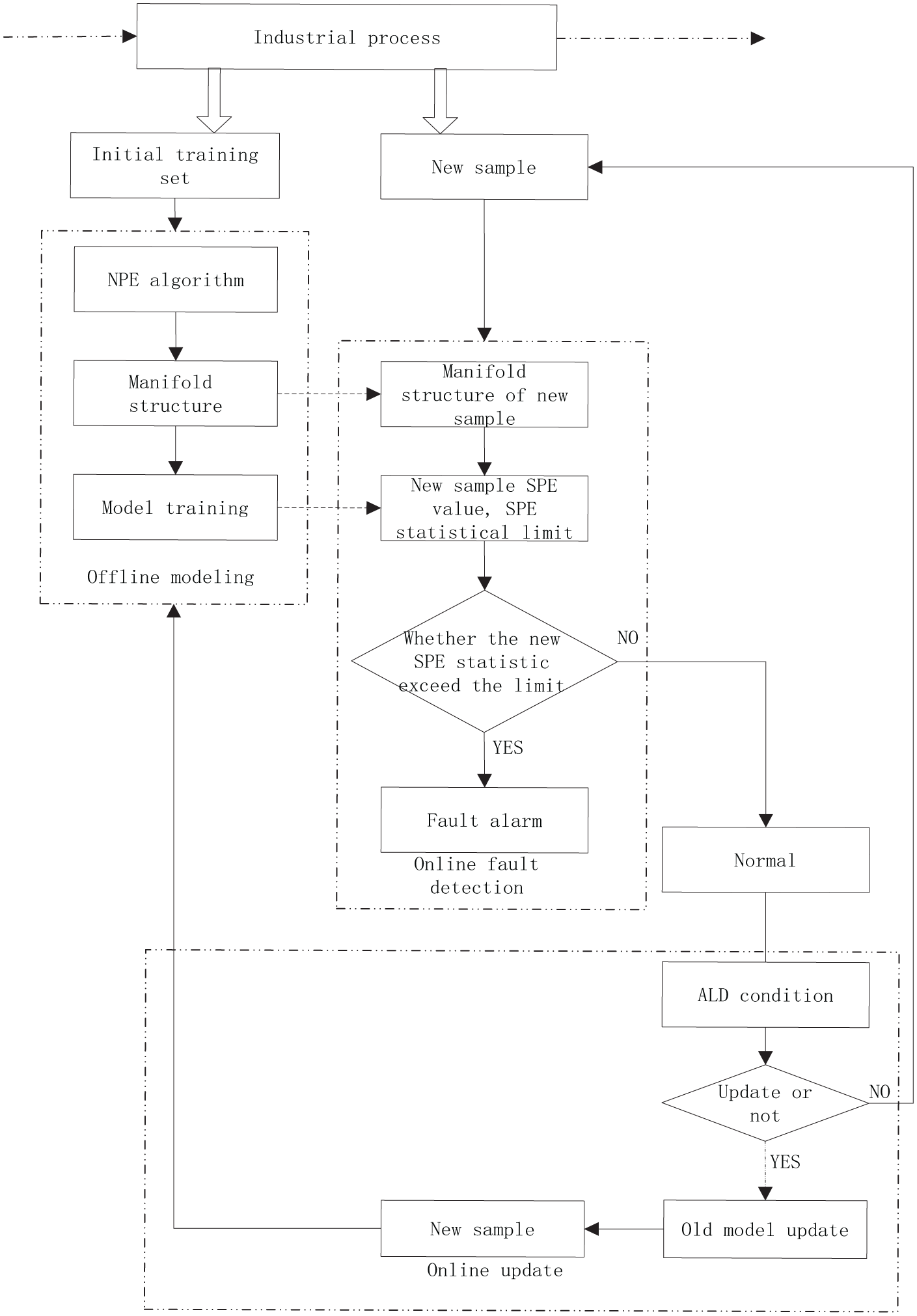
Flow chart of online fault-detection method based on ANPE.
From the flowchart, the working process of the proposed method can be determined as follows. First, the initial model is established by using the NPE algorithm according to the training dataset. Then, the SPE statistic of the new sample is calculated according to the stored old model, and it is then compared with the statistical limit.
Second, the SPE statistic of new samples is calculated and compared with the SPE statistical limit. If the SPE statistic is greater than the statistical limit, it indicates that a fault has occurred, and a fault-alarm signal is triggered; otherwise, it is the normal state.
Then, because the new sample is normal, the new sample’s ALD value needs to be calculated. If the ALD value is less than or equal to the set threshold v, no model update is performed; otherwise, the NPE model is re-trained and the old model is replaced. A new SPE statistical limit was obtained according to the output of NPE model based on new samples. Finally, the method realizes the online fault detection.
Experiments using the TE process
The performance of the proposed algorithm was verified using the TE process simulation. The ANPE algorithm was compared with the traditional NPE algorithm. The SPE statistic selects the control limit according to the 99% confidence level. In this experiment, k is the number of neighbors in the NPE algorithm, and d is the number of eigenvalues in the NPE algorithm. By dividing the neighborhood of the data, the initial data are divided into relatively small unit datasets, and the expected values can better balance the relationship between the local geometric features of the data and their global geometric features. When the selection of k values is relatively small, the data will be divided into many small neighborhoods, so the local geometric features of the process data cannot be effectively depicted. When k is larger, although more spatial information can be excavated, it can guarantee the intersection of neighborhoods. However, it requires extensive computations, and some unrelated data points may be included in the same neighborhood, so the assumption condition of local linearity is not satisfied. As the linear reconstruction reflects the local geometric information of the manifolds, the number of nearest neighbors is set based on the minimized reconstruction error of Equation (1). Considering and comparing several experiments, the nearest-neighbor number k of ANPE and NPE is set as 12. The number of the selected components d for dimensionality reduction in ANPE and NPE are determined according to the cumulative percent variance (CPV) criterion. In these experiments, d is chosen as 5 as the percent of variance accounted for 90% by these five selected factors. In other words, it means that the five selected factors can explain 90% of the original process data.
TE process
The TE process is a standard test platform that was developed by J. J. Downs and E. F. Vogel according to an actual chemical process developed by Eastman Chemical Company, which has become a common test platform for evaluating process control and fault-detection methods.42–45,49 The TE model includes five major unit operations: a reactor, a condenser, a flash separator, a stripper, and a recycle compressor. There are four reactants A, C, D, and E; two products G and H; and one byproduct F. Figure 2 shows a flow chart of the TE process. As a simulation of a real industrial process, it contains 11 measurement variables, 22 continuous process measurements, and 19 manipulated variables. A total of m = 52 variables were recorded for all the manipulation and measurement variables, except for the agitation speed of the reactor’s stirrer. In this case study, all of the 52 variables were monitored. The complete list of variables is given in Table 1.9,50 The TE process has one normal operating condition and 21 faulty operating conditions. 51 The information about these faults is summarized in Table 2. The TE process sampling interval is 3 min, and a normal dataset and 21 fault datasets were acquired from the TE process.
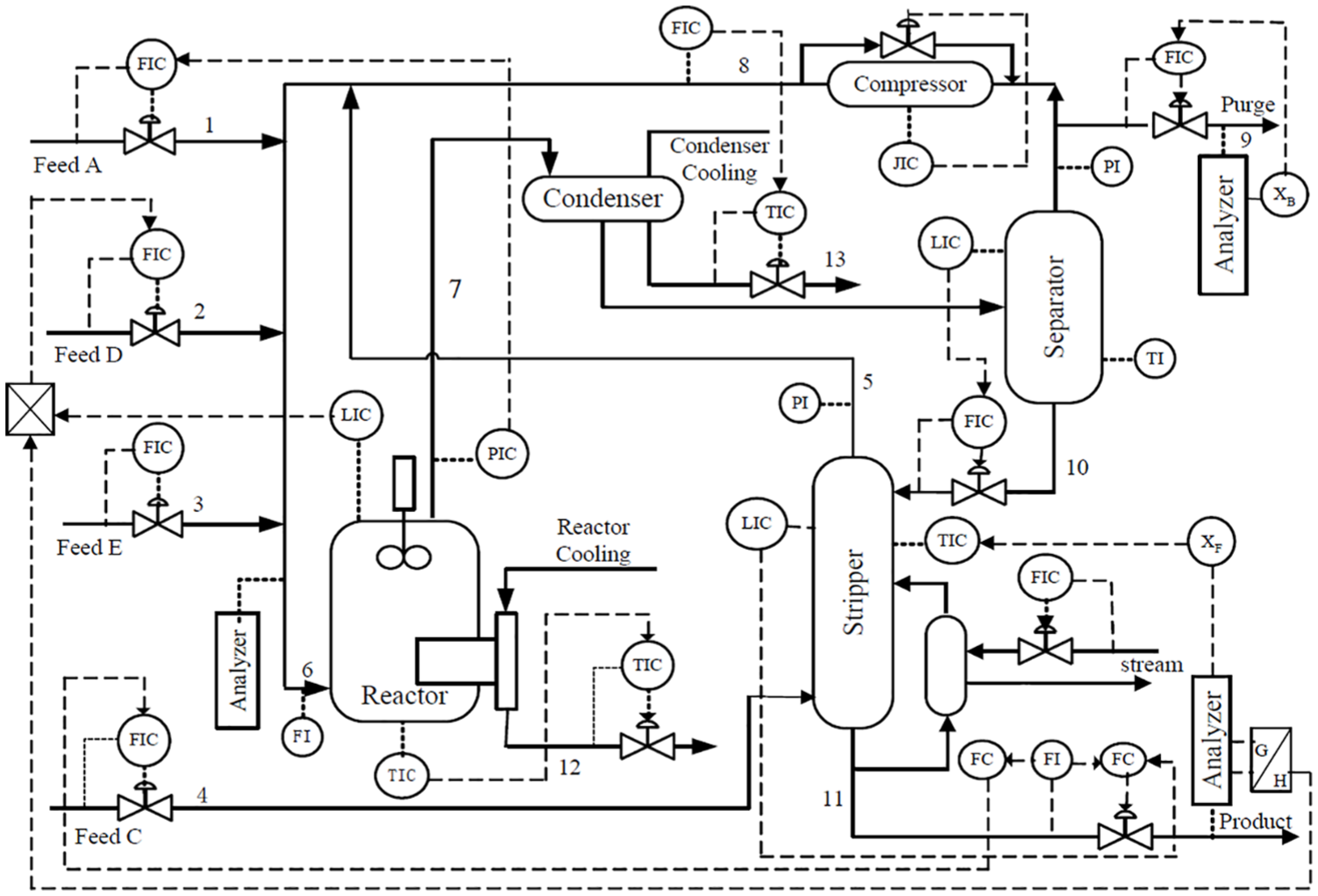
Flow chart of the Tennessee Eastman process.
Monitoring variables in the Tennessee Eastman process.

Process faults for the Tennessee Eastman process.

Case study of the TE process
In this case study, a normal dataset has 960 samples. Each fault dataset consists of 960 samples, and all faults started at the 161st sample. This article compared the ANPE method with the NPE method proposed by He et al. 34 in 2005. The case study included the online monitoring of one normal operating condition and 21 faulty operating conditions.
During the monitoring of normal operating conditions, the duration of the training dataset sampling is 24 h, and the test dataset sampling period is 24 h. The number of training datasets is 480, and there are 480 test datasets. Experiments were performed using the ANPE method and the NPE method, and the FAR of the two methods was obtained under the normal situation according to Equations (10) and (11); the
FAR of normal operating condition for the two methods.

FAR: false alarm rate; NPE: neighborhood preserving embedding; ANPE: adaptive neighborhood preserving embedding.
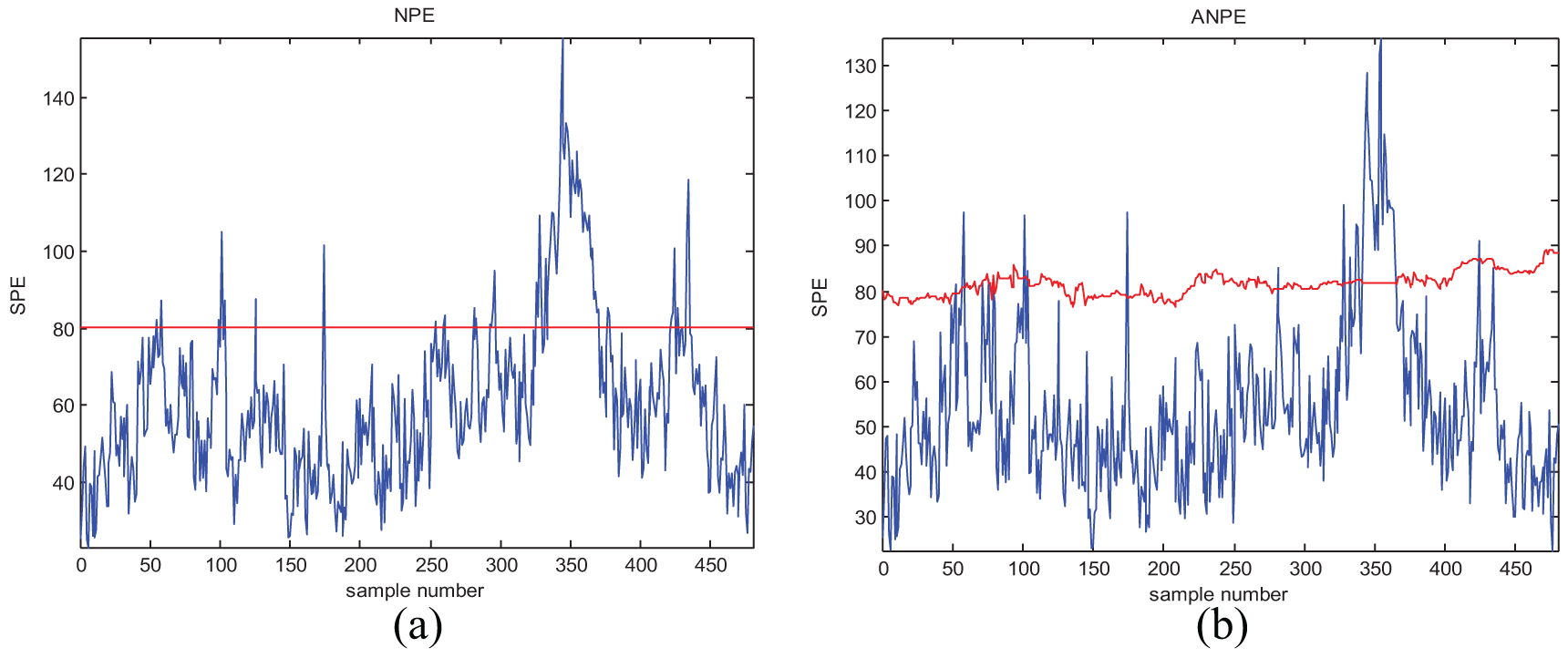
Monitoring results of normal operating condition with (a) NPE and (b) ANPE.
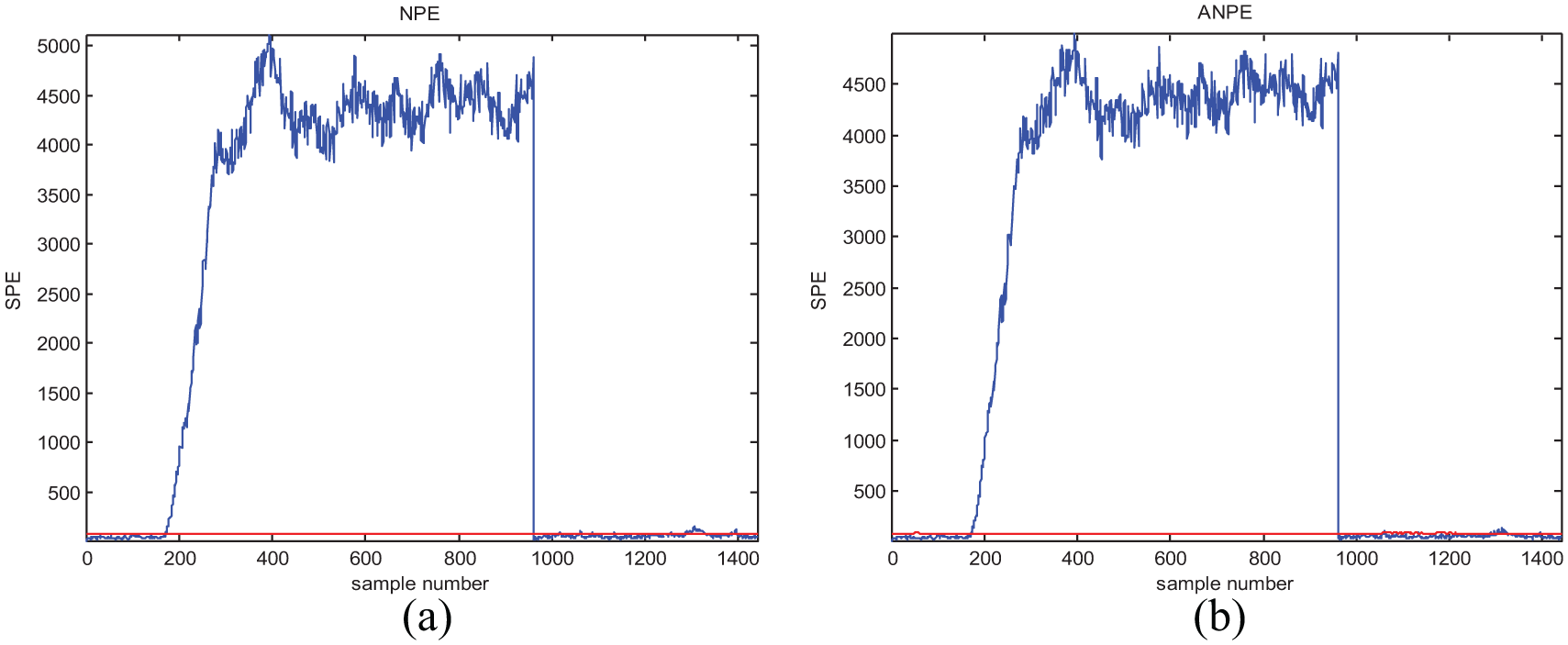
Monitoring results of fault 02 with (a) NPE and (b) ANPE.
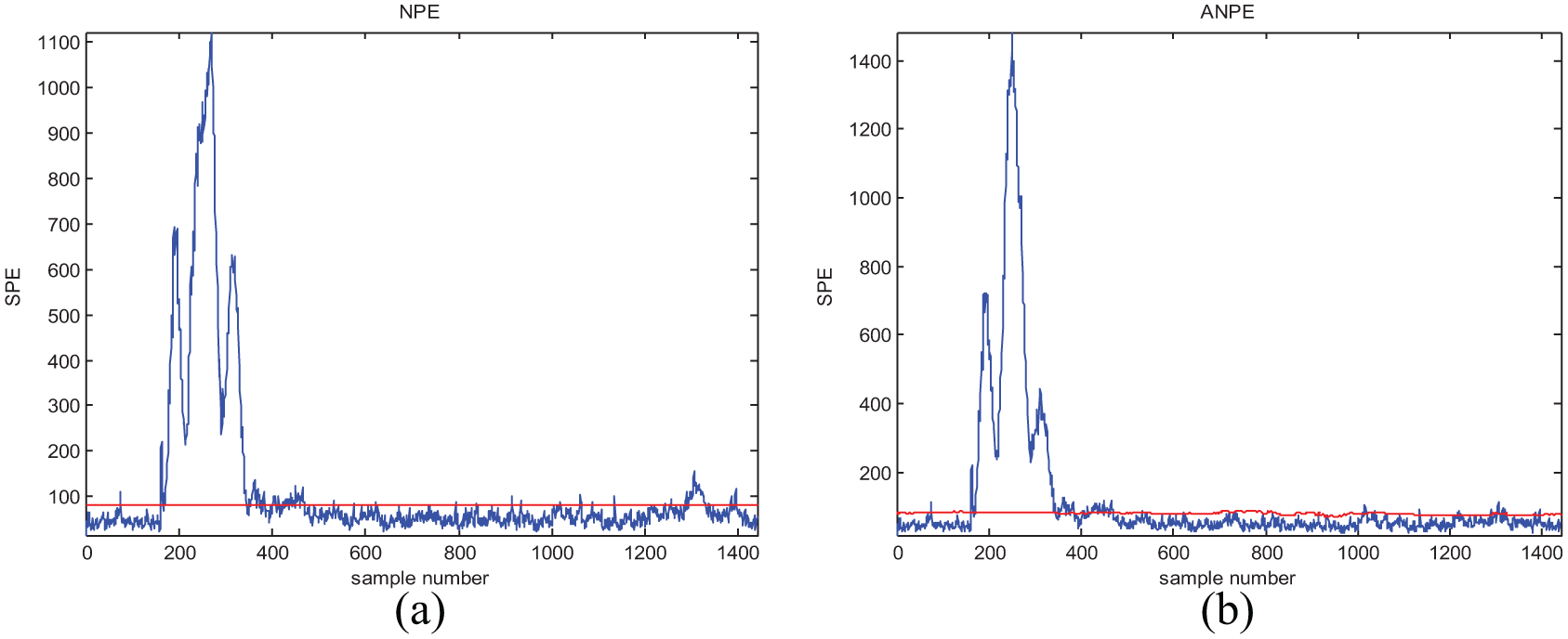
Monitoring results of fault 05 with (a) NPE and (b) ANPE.
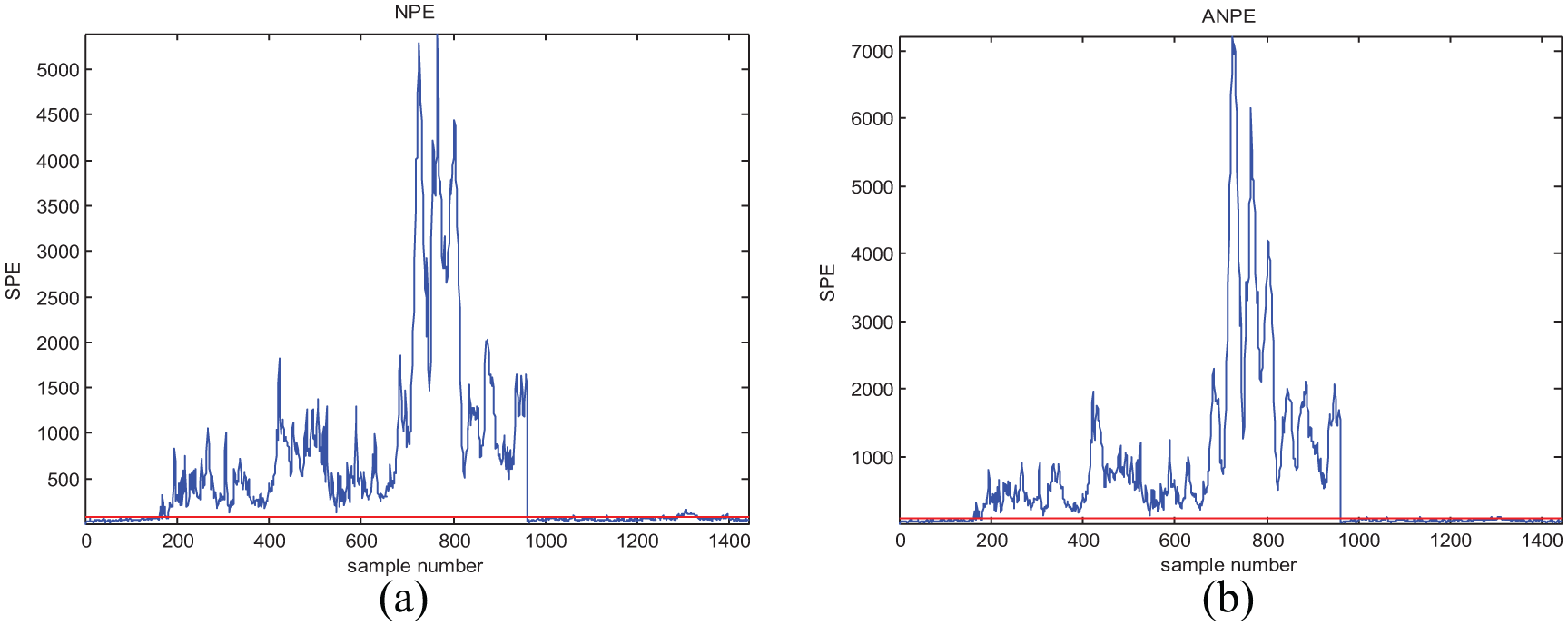
Monitoring results of fault 12 with (a) NPE and (b) ANPE.
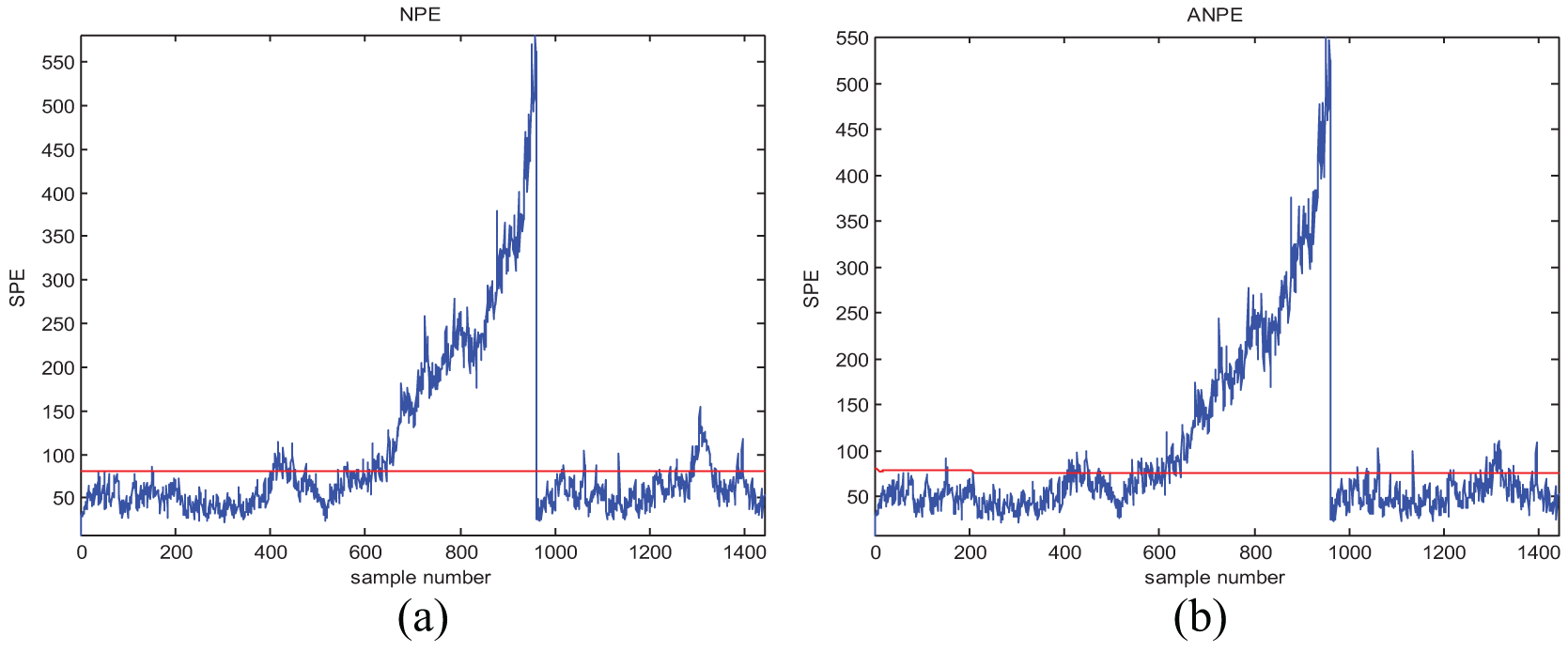
Monitoring results of fault 21 with (a) NPE and (b) ANPE.
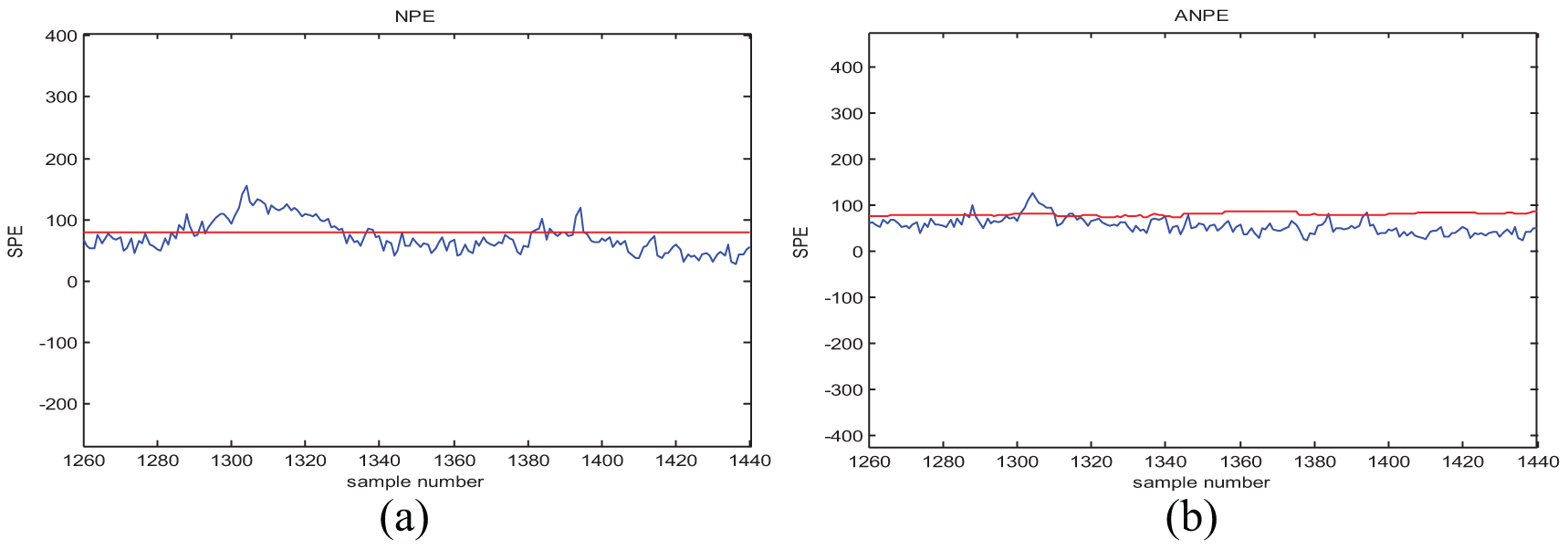
Enlarged view of 12 fault-monitoring results obtained with (a) NPE and (b) ANPE.
In the monitoring of 21 faulty operating conditions, the test dataset consisting of 960 faulty samples and 480 normal operation samples was collected. This article added a set of normal data after each fault dataset to simulate that the system works under normal operation conditions after the fault is repaired. Each training dataset is collected under normal operation conditions, and its sampling duration is 24 h and the number of training samples is 480. The test dataset was sampled for 72 h. The first 8 h is the normal data and the fault time is 40 h; the last 24 h is normal data and the number of test samples is 1440; all faults started at the 161st sample.
This article collected the FDR for the failure data and the FAR for the normal data. The monitoring results for the NPE and ANPE methods are presented in Table 4, and v is a pre-defined positive threshold in the ANPE method; the lower threshold can improve its accuracy, as well as increase the computation and update the time of the model. A larger FDR value indicates an improved detection effect; the lower the FAR value, the better the system performance. Figures 4–8 show the detailed detection results of two methods for fault 02, 05, 12, and 21. Figure 8 gives an enlarged view of fault 12.
Monitoring results of faulty operating conditions for the two methods.
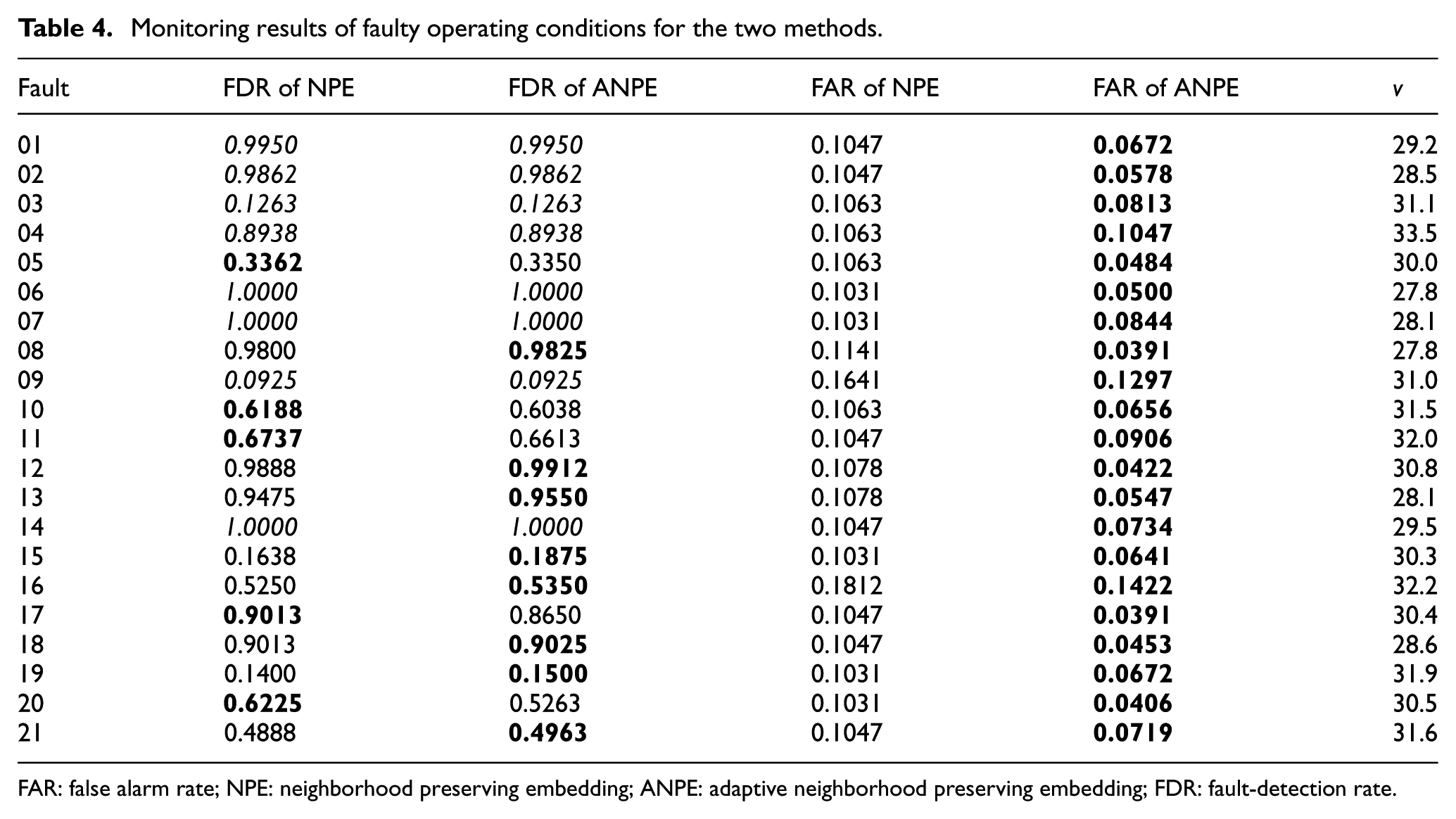
FAR: false alarm rate; NPE: neighborhood preserving embedding; ANPE: adaptive neighborhood preserving embedding; FDR: fault-detection rate.
In Figures 3–8, the red line is the SPE statistical limit, and the blue line is the SPE statistic of the monitoring variables. Table 3 shows that the FAR of the ANPE method for the normal dataset is much lower than that of the NPE method, and the lower the FAR, the better the monitoring effect. Moreover, in Figure 3, because the ANPE method can be updated according to the online model, the SPE statistical limit has changed. According to Equations (7)–(9), you can find that when the training sample changes, the SPE statistic limit will change and the corresponding FAR will change. As the ANPE model was updated with new training samples, the number of samples ranges between 100–150, 200–300, and 400–450; the SPE statistical limit of the ANPE method is shifted upward, which reduces the FAR of the model. Based on the above results, this article further analyze the performance of the algorithm. The ANPE method provides a lower FAR than the NPE method, which verifies the effectiveness of the online monitoring method with adaptive capability.
From Table 4, we can see that for most kinds of process data, the ANPE method performs much better than NPE. In the monitoring of faults 01, 02, 03, 04, 06, 07, 09, and 14, ANPE and NPE obtain the same fault-detection results, but there are fewer false alarms for the ANPE method. In particular, ANPE achieves a better performance for most of the fault cases. During the monitoring process, ANPE not only has fewer false alarms but also performs better with respect to fault detection than NPE for faults 08, 12, 13, 15, 16, 18, 19, and 21. For the faults that are more difficult to detect, that is, faults 03, 09, and 15, both methods give a lower detection rate. This is because the duration of process data deviates from the normal fluctuation after a short fault occurs. In Figures 4(b), 5(b), 6(b), and 7(b), the ANPE method can detect the SPE statistics exceeding the limit, which indicates that the ANPE method can detect faults effectively. The fault-detection performance of the ANPE method depends on the fault type. When a fault occurs, the process data deviate from the normal fluctuations for long term; ANPE has a higher FDR, such as for fault 02 and fault 12. And if the process data deviate from the normal fluctuations for short term, the FDR of ANPE method will be low, like fault 03 and fault 21. However, the ANPE method can detect the occurrence of faults in time, even if the FDR for some fault types is relatively low. The enlarged view of fault 12 in Figure 8 shows that false alarms can be effectively reduced by updating the model online. Because the ANPE method can be updated according to the online model, the SPE statistical limit has changed. For cases where the number of samples ranges between 1280–1340 and 1380–1400, the SPE statistical limit of the ANPE method is shifted upward, which reduces the FAR of the model. According to the real-time data obtained to update the model online, the ANPE method will greatly improve the monitoring performance of the industrial process.
If considering the time delay of algorithm, the ANPE method may cost time more than about 1–2 s compared with the NPE method, and it is due to online updating the model according to ALD condition. In the TE process, the sampling period is 180 s, so a few seconds time delay dose not reduce the application effect of ANPE. But in some applications with high real-time requirement, the disadvantage of ANPE in time cost should be considered.
In summary, the case study verified that the proposed method can effectively reduce the FAR on the basis of guaranteeing the FDR and realizing the online accurate detection of industrial process faults. At the same time, the adaptive update capability of the algorithm ensures the real-time performance of the monitoring process and the continuous validity of the fault detection.
Conclusion
In order to reduce the FAR of fault detection for industrial processes, this article presents a new method based on the ANPE algorithm for fault detection, which is different from the traditional NPE method. The proposed method is based on offline training according to a set update strategy to determine whether the new sample can be used as a training sample to update the model. The model based on this method has the ability to perform adaptive updating and can achieve the online real-time monitoring of industrial processes. By performing simulation experiments involving the TE process, it is proven that the proposed method can reduce the FAR of the model while improving the effect of fault detection, and the effectiveness of the method in fault detection is explained. The method can be used for the online fault detection of industrial processes. In the future work, we plan to improve the algorithm proposed in this article using some optimization method to accommodate more process fault types, so that it can adaptively select thresholds v or others empirical parameters according to fault types and training sample. However, we also plan to present a new method to solve the online updating issue for time neighborhood preserving embedding (TNPE) algorithm. 52
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This work was supported in part by the National Natural Science Foundation of China (NSFC; 61763049), the Science and Technology plan of Applied Basic Research Programs key Foundation of Yunnan province (2018FB112), the Science and Technology plan of Applied Basic Research Programs Foundation of Yunnan province (2017FB096), and the 8th Postgraduate Research and Innovation Project of Yunnan University.
Statement of data availability
Lei Tan and other co-authors allow readers to use any of the data in the manuscript.