
Abstract
Nowadays, user expects image retrieval systems using a large database as an active research area for the investigators. Generally, content-based image retrieval system retrieves the images based on the low-level features, high-level features, or the combination of both. Content-based image retrieval results can be improved by considering various features like directionality, contrast, coarseness, busyness, local binary pattern, and local tetra pattern with modified binary wavelet transform. In this research work, appropriate features are identified, applied and results are validated against existing systems. Modified binary wavelet transform is a modified form of binary wavelet transform and this methodology produced more similar retrieval images. The proposed system also combines the interactive feedback to retrieve the user expected results by addressing the issues of semantic gap. The quantitative evaluations such as average retrieval rate, false image acceptation ratio, and false image rejection ratio are evaluated to ensure the user expected results of the system. In addition to that, precision and recall are evaluated from the proposed system against the existing system results. When compared with the existing content-based image retrieval methods, the proposed approach provides better retrieval accuracy.
Keywords
Introduction
User expects image retrieval as an important and a promising field as it indulges with images for various purposes. Galleries, education, fashion design, medicine, designing, remote sensing, military applications, and so on are the various applications related to user expected image retrieval. It is often necessary to retrieve a user desired images from the image database with accurate and relevant images for further processing. Hence, an effective system for image retrieval with a reduced semantic gap is proposed.
Image retrieval system is accomplished with two different strategies namely text and content of the image. 1 Image annotation and text descriptors are the basis for retrieving images from the database in text-based image retrieval. Normally, two basic problems arise at the time of using manual annotation based on image retrieval methodology. They are the subjective description of image contents by human and mismatches between image annotations and textual queries. Traditionally, search engines retrieve thousands of images based on the user query. The images are ranked on the basis of keywords in the query. The ambiguity of keyword impacts the text-based image search. Due to wrong semantic meanings, the search results are quite different from the user anticipation. The top 10 images for the input query “cheetah” from Google search engine are shown in Figure 1.

Top 10 ranked images from Google search engine.
The resultant images belong to different categories, due to the ambiguity in the keyword “cheetah.” The main fact behind this issue is inadequate knowledge of the user on the textual description of the output image. The second reason is the diversified meanings of the keyword against user expectation. To resolve the ambiguity in searching, additional information is required to extract the relevant images as per the user request.
Google image search has a feature called “Related Search.” This feature allows the users to extend the search similar with the existing results. If the related query keywords are used for image retrieval, then the intention of the user may be diverted from the actual search. Visual contents of an image are the basic source of image retrieval. The main objective of the content based image retrieval (CBIR) system is to extract semantic features from images to enable efficient and meaningful user expected image retrieval.2,3
Image retrieval techniques available in image processing 4 can be widely classified into two categories: (1) based on local features and (2) based on global features. It is not worth to decide whether global features or local features are suitable for image retrieval. 5 Two similar images may be different from each other semantically. For an instance, the fox and the dog have similar texture attribute and appearance, but they are not belonging to the same animal category.
To address this issue, the proposed method uses semantic information features such as directionality, contrast, coarseness, busyness, local binary pattern (LBP), local tetra pattern (LTrP), and modified binary wavelet transform (MBWT). The system captures user desired images from the given image pool with interactive feedback. Machine learning (ML) and deep learning 6 methods for computer vision applications are also the most promising research direction to reduce the semantic gap.
Related work
CBIR 7 uses visual features to evaluate image similarity. Singh et al. 8 had addressed the subject of human visual perception. They apply multiple features related to the high-level and low-level features. Also scale invariant feature transform (SIFT) and moment feature based retrieval address human perception for image retrieval developed a computational measure for a set of textural features. Ma et al. 9 handled latent Dirichlet allocation (LDA) and Gabor feature to describe the texture information and developed a platform for image retrieval. The work of Tamura et al. 10 was based on the co-occurrence matrix and the work of Amadasun et al. 11 was based on neighborhood gray-tone difference matrix (NGTDM).
The results obtained by both of them show good correspondence with human perception. The performance of the model is evaluated with a psychometric method (based on rank correlation) and it is correspondent to human judgments and outperforms related works.2,12 Sanu and Tamase 13 had addressed the region-based representation for each image in the DB, and the final meaningful image was retrieved by means of using the Bayesian classifier and probabilistic approach. Lowe et al. 14 projected scale-invariant feature transform (SIFT) feature-based scale, location invariant, and character image retrieval. Corner points are used as identification features for the character images. SIFT used accumulation and aggregation of local gradients in a local region is described in the previous studies.15–17 Bay et al. 18 handled speeded-up robust feature (SURF). It confers the dominant direction of the image and is divided into 4 × 4 blocks. Haar templates are applied in each block. To generate 64-bit dimensional descriptors, responses for these templates are accumulated. To improve the strength of local description, color, 19 orientation,17,20 and shape 21 features are embedded. A semi-supervised graph-theoretic method using the framework 22 for multi-labeled image retrieval problems is highlighted by Bendita Chaudhuri and Begum Demir. In order to retrieve the target images, positive and negative feedback sample-based different relevance feedback methods have been developed based on different assumptions. A support vector machine (SVM) is considered the positive feedback and ignores the negative feedback which is exposed in Chen et al. 23 The two-class SVM method considered both the positive and negative feedback equally. 24 Pairwise labeled and unlabeled image constraints in relevance feedback (RF) demoralized with discriminative semantic subspace analysis (DSSA) method. Low-level and high-level semantic features are bridged using pairwise RF. 25 Dubey et al. 26 proposed multichannel decoded LPB for image retrieval and utilized the adder and decoder based on the local information of multiple channels. The performance of the proposed method is evaluated and compared with various images of different data sets with an efficient similarity measures and provides better accuracy compared to other methods. Section “Semantic feature–based image retrieval system” describes the proposed semantic feature–based image retrieval system. In section “Experiment results and discussion,” experimental results are presented with comparative studies using various visualization techniques. Section “Conclusion” concludes with future directions.
Semantic feature–based image retrieval system
The proposed system performs the image retrieval task using semantic features and interactive feedback (Figure 2). The semantic features are directionality, contrast, coarseness, busyness, LPB, LTrP, and MBWT. To produce efficient results, a combination of several features for extraction based on interactive feedback methodology is proposed.
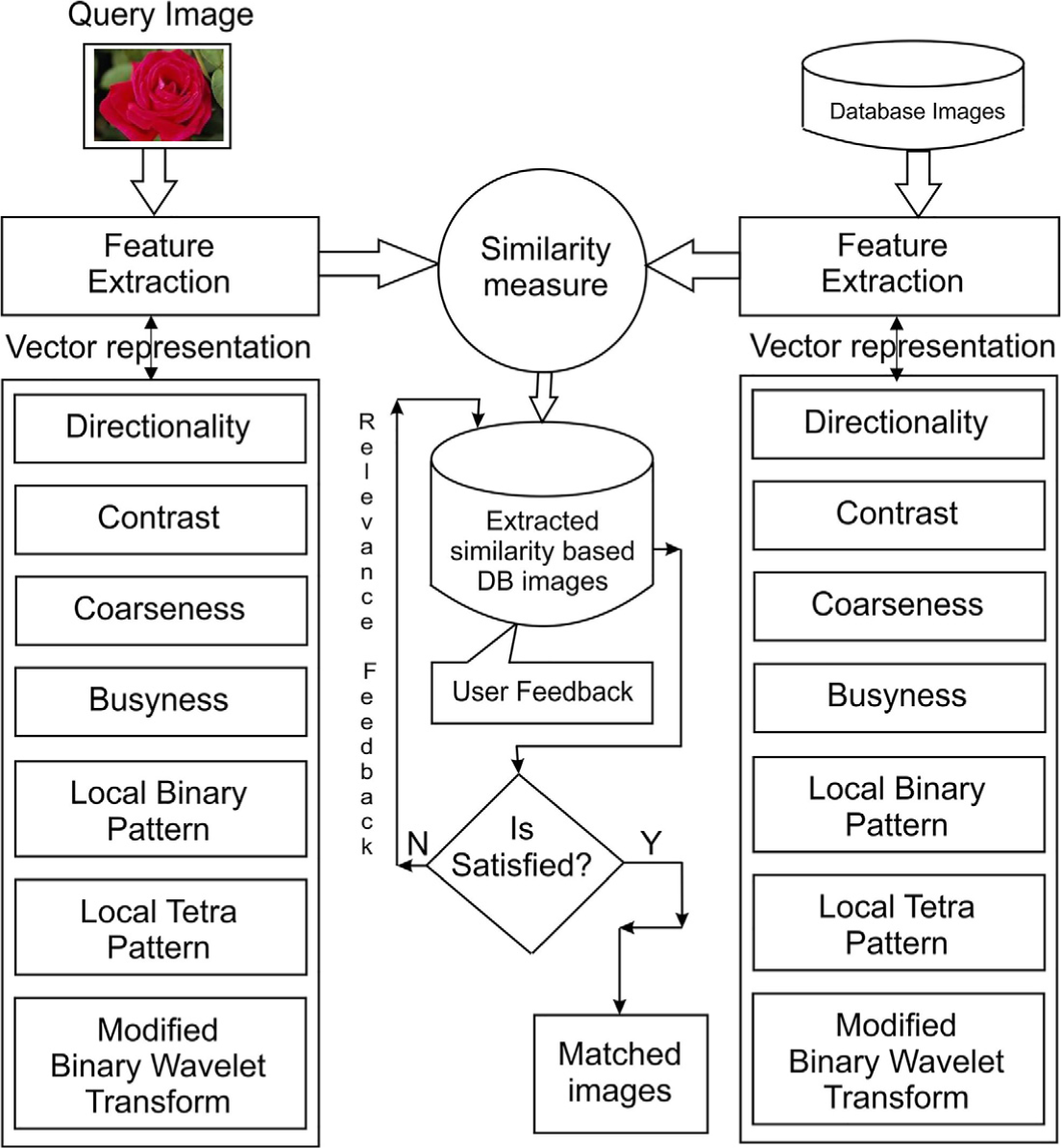
Architectural design of proposed system.
Semantic features
Directionality is one of the global properties of an image. It is represented by the dominant orientation(s).3,7,27 Contrast is used to measures the grade of clarity and differentiate the difference between various primitives of a texture.2,28 Primitives of an image are clearly visible and separable for a complete contrast image. The factors that influence contrast are the gray levels in the image; the proportion of white and black present in the image; and the intensity of gray levels.
A texture constitutes 57 the size of the primitives and it can be measured by coarseness. It also constitutes large primitives characterized by a high degree of local uniformity of gray levels. It is estimated using the auto correlation function.
The variation of intensity from a pixel to its neighborhood is referred in terms of busyness 27 ; a busy texture is defined as the texture in which the intensity changes are fast and rush, but in case of a non-busy texture the variations are slow and gradual. The spatial frequency in an image is related to Busyness. The risks are been invisible for very small changes. Subsequently, the amplitude of the intensity changes has also reflected on busyness. It is well noted that the busyness has a reversible relationship with coarseness.
The mentioned four features are selected based on the literature and relevance to image retrieval task. The features are extracted from the entire image. Added with this, LBP, local ternary pattern (LTP), LTrP, MBWT features from blocks of images are extracted to form a feature vector. LBP is chosen to address illumination variation. 29
The LBP feature vector is calculated as follows:
The image is divided into blocks of size 3 × 3 pixels.
For each pixel presented in a block, the center pixel is compared to each of its eight neighborhood pixels (on its left-top, left-middle, left-bottom, right-top, etc.).
If center pixel’s value is greater than the neighbor’s value, the region is filled by “1.” Otherwise, by “0.” This provides an eight-digit binary number (which is usually converted to decimal for convenience), which is the required feature.
LTP is an extension of the LBP. In LBP, it uses two threshold levels (0 and 1) but in LTP there are three threshold levels (–1, 0, and 1). It consists of one user-specified threshold value T. The LTP is calculated in the pattern using the following equation
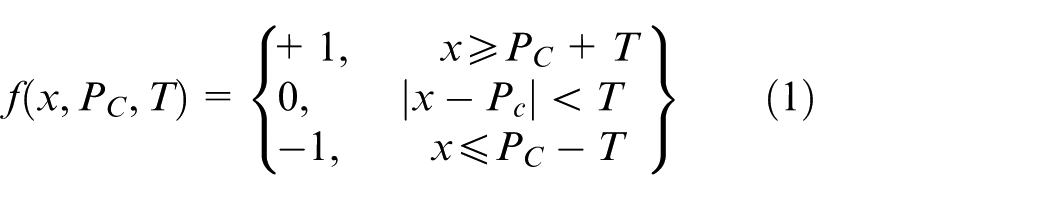
where x is the neighbor pixel value and
LTrP
Horizontal and vertical derivatives are used to calculate second-order LTrP. It is based on the directionality features of the pixels. For the directionality computation of each pixel, this work makes use of 0 and 90 derivatives of local directional pattern (LDP). The LDP encodes 30 the relationship between the nth-order derivatives of the center pixel and its neighbors in 0, 45, 90, and 135 directions separately, whereas the LTrP encodes the relationship based on the direction of the center pixel and its neighbors, which are calculated by combining nth-order derivatives of the 0 and 90 directions. From the obtained results, the LTrP result is analyzed. The LTrP designates the spatial structure of the local texture with the direction of the center gray pixel.

MBWT
Memory space for storing images is reduced since the images can be written in binary formats. 6 Bit planes technique allows logical operations. It is easy to retain grayscale image or color image. The binary image information was divided into three image planes instead of eight image planes recommended in binary wavelet transformations. The division of the least significant bit (LSB) to most significant bit (MSB) information of the binary image and the division of binary image information into three image planes as shown in Figure 3.
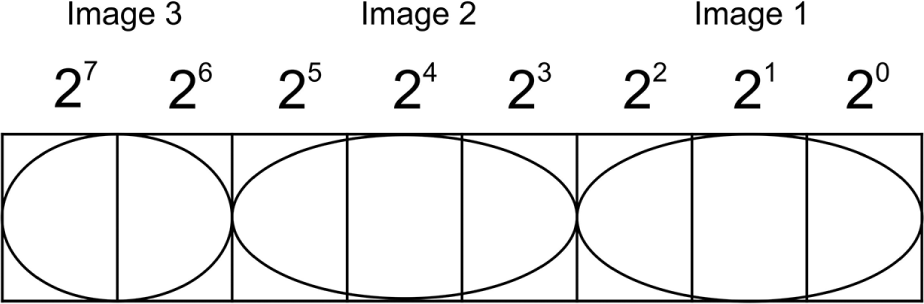
Binary image information and division of binary image into three image planes.
Image plane 1 contains three bits of LSB followed by next three bits of LSB represented in Image plane 2. Finally, the last two bits are represented in Image plane 3. The three image planes are separated using MATLAB left and right shift operations. Then, the binary wavelet transform (BWT) is applied for the image plane groups. BWT in one-dimensional (1D) and two-dimensional (2D) is explained in the following section.
BWT
Law et al. 31 proposed the in-place implementation of BWT. This reduces memory requirement and arithmetic operations. Odd positions values in the 1D signal give the low-pass output while even and odd together with XOR operation give the high-pass or band-pass output. Thus, low-pass output consists only sub-sampling operation while the high-pass output has XOR operation between two neighboring samples. Figure 4 illustrates the process of binary wavelet transform–based histogram (BWTH) for RGB image.
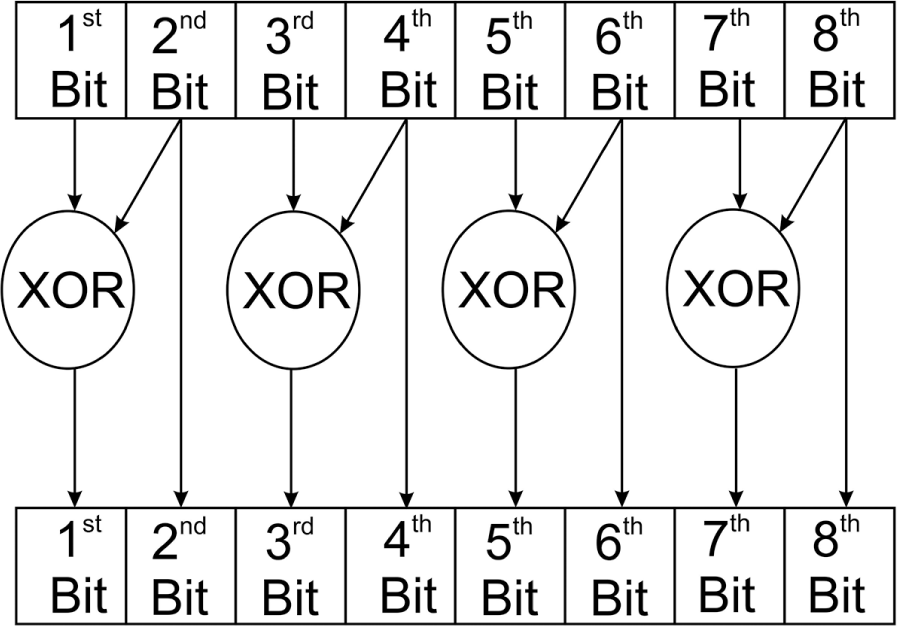
BWT implementation.
Low-pass output does not create any change apart from sampling. A separable 2D BWT32–34 can be efficiently computed in discrete space with the associated 1D filter bank to each column of the image, applying the filter bank to each row of the resultant coefficients. The two-level binary wavelet decomposition of a 2D image is shown in Figure 4. One low-pass sub-image (lower limit (LL)) and other three orientation selective high-pass sub-images (LH, HL, and HH) are established with the first level of decomposition. 35
In Figure 5, the first order low-pass sub-image (LL) is decomposed into one low-pass sub-image (LLLLL) and three high-pass sub-images (LLLH, LLHL, and LLHH) are produced during the second level decomposition. Repetition of the low-pass sub-image process form a higher level of binary wavelet decomposition is made. In other hands, BWT decomposes an image into a pyramid structure of the sub-images with various resolutions, equivalent to the different scales.
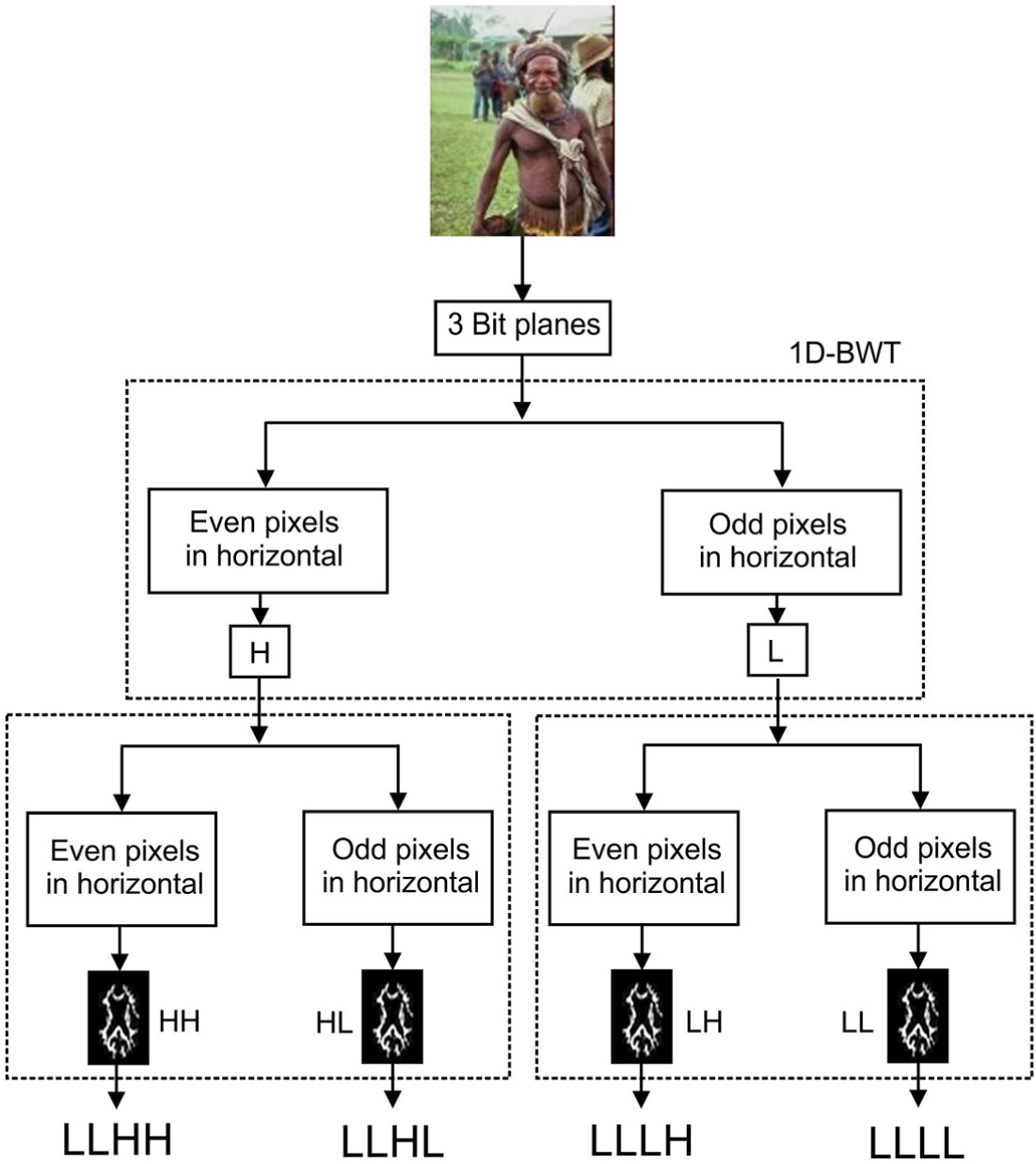
2D BWT.
Thus, three scale BWT decomposition of an image will be created with three low-pass sub-bands and nine (three each in horizontal, vertical, and diagonal directions) high-pass directional sub-band.
Modified binary wavelet transform–based histogram
Image representation using modified binary wavelet transform–based histogram (MBWTH) feature vector is proposed in this paper. Modified binary wavelet transform-based histogram (MBWTH) feature vector used for image representation is proposed in this paper.4,36

Each order or level of images contains 32 features and the whole process contains 96 features.
Interactive RF
The system requires a rational amount of feedback at the end of the iteration when a set of images are retrieved. If the user needs are provided in the feedback for more images after the iteration, they will fatigue and be unsatisfied with the process. After one or two iterations later, the system can produce an acceptable result.
In order to reduce the problems in CBIR such as semantic gap, a wide variety of RF algorithms have been developed to improve the performance of CBIR systems. The belief of “similar” in the mind of the user may change depending on the query. The history of retrievals is observed. The results are designed to be unsatisfactory based on the significant divergence between the opinion of similarity in the user’s mind and the similarity as calculated by the system. This problem has served as the momentum for what is identified as “RF.” RF retrieval system24,37,38 is used to increase the retrieval performance by prompting the user for feedback based on retrieval results.
The subsequent retrievals use this user feedback to obtain the outcome of the interactive RF. A classic user feedback system is works as follows. The system retrieves a fixed number of images against the user input query image to the system. Each retrieved results are validated by the user with respect to usefulness of the result. Various factors are considered for the validation of the images such as “relevant” or “not relevant” or may have better accuracy of relevancy such as “somewhat relevant,”“not sure,” and “somewhat irrelevant.”
The interactive RF algorithm is applied for selecting another image set based on the feedback information. The main objective of the present system is to infer the user desired image in the image database based on the user feedback without the disjoint sets of another system. Similarly, the user can rate such images in the second set with an indefinite iteration process which continues in a closed-loop manner.
Different kinds of design requirements are available in RF retrieval system and its functions perform in an efficient manner with the design requirements. After a retrieval of certain set of images, the system compelled to have reasonable amount of feedback as the iteration completed. Providing additional feedback for various images after the iteration leads to enervate and unsatisfied with process.
The similarity measure is computed between the query image and the images in the database with the extracted features and the semantic images have been retrieved. The retrieval process is stopped after the final result is satisfied by the user and the results are been displayed. Once the user unsatisfied with the output, the query is refined and the RF method is applied till the relevant images is retrieved from the image pool.
Experiment results and discussion
Several experiments were conducted with the extracted different features retrieved from the images to authenticate the proposed approach for the semantic information–based image retrieval. The feature vector is produced for the query image followed by all the images available in the database. Successively, the retrieval system retrieves a set of similar images from the database based on their similarity distance.
The proposed methodology for image retrieval is evaluated when several images are revolved as queries. The databases involved in the systems are on our own database collection with 405 images, Brodatz-1856, Corel-24, Medical DB, and Vistex-640.
Performance evaluation
This section deals with performance evaluation of the proposed method and the previous existing methods. The proposed method retrieves the very meaningful images from the database based on the similarity distance value. Different types of quantitative measures have been used to examine the performance of the proposed system.
Here three important quantitative evaluations are used. They are average retrieval rate (ARR), false image acceptation ratio (FIAR), and false image rejection ratio (FIRR). The proposed method performance is measured with the accuracy using the similarity in distance computation. The retrieved images are sorted and displayed in the ascending order using similarity distance estimation between the input query image and target images in the image database. The first sets of images are considered as a set of retrieved images. The performance of a proposed image retrieval system based on semantic approach is determined by three metrics such as ARR, FIAR, and FIRR.
The ARR defines the ARR P(NR) on retrieving NR retrieved image. The value of P(NR) on retrieving NR retrieved image defines the average recall rate. 39 The formula used for ARR calculation is given as follows
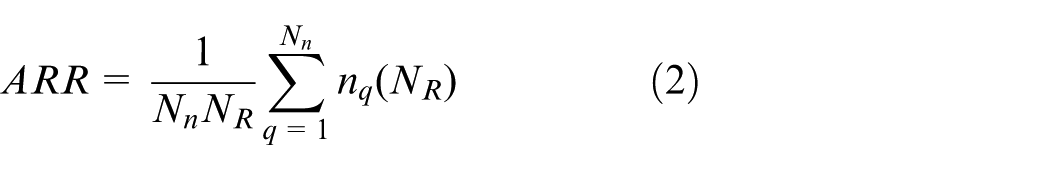
where Nn denotes the number of images available in the image database, q is the query image, and use nq (NR = Q) to retrieve a relevant image Q exactly at L.
A higher value on precision, recall, and ARR indicate the higher retrieval image rate or better retrieval performance. The FIAR and FIRR are two important quantitative evaluations which are used to compute the value for those irrelevant images that are accepted and relevant images that are rejected from the database for every input of the query input image. The formulas for FIAR and FIRR calculations 40 are given as follows
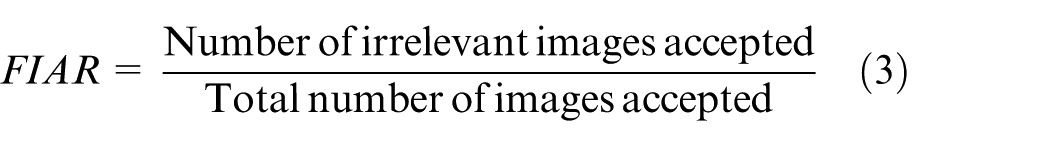
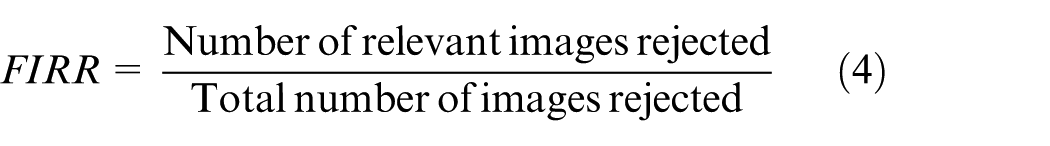
Also, two additional basic metrics such as precision and recall are used to evaluate the performance. The effectiveness of the proposed image retrieval system is measured by these two metrics. Precision and recall metrics are the standard ways to evaluate retrieval results of image retrieval system. Precision41,42 is the proportion of the retrieved images that are relevant to the input query image. Recall signifies the relevant images in the database that retrieves in response to a query. The above two metrics are defined as

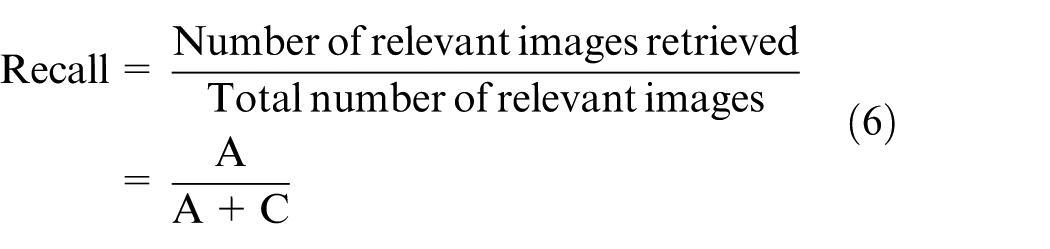
where the numbers of relevant images that are retrieved from the database are indicated by the symbol A, the numbers of irrelevant items are represented by the symbol B, and C indicates the number of relevant images that were not retrieved.
All images are used as query image q in image retrieval system. The performance evaluation is conducted by averaging the values of overall query images. Formally, the average precision P(q) and average recall R(q) measurements for describing the performance of the image retrieval system are defined in Guo and Prasetyo 43 and Lasmar and Berthoumieu 44 and are mentioned as follows


where L, Nn, and NR denote the number of images retrieved, the number of images available in the image and the number of relevant images retrieved on each category, respectively. The symbol nq(L) is used to retrieve a relevant image Q exactly at L.
Experimental setup
Five databases, as organized in Table 1, are experimented in this proposed work to examine the performance of the semantic information-based CBIR system. The database considered for the experimentation contains a combination of various textural and natural images of different color scale, color space, and size.
Outline of image databases.
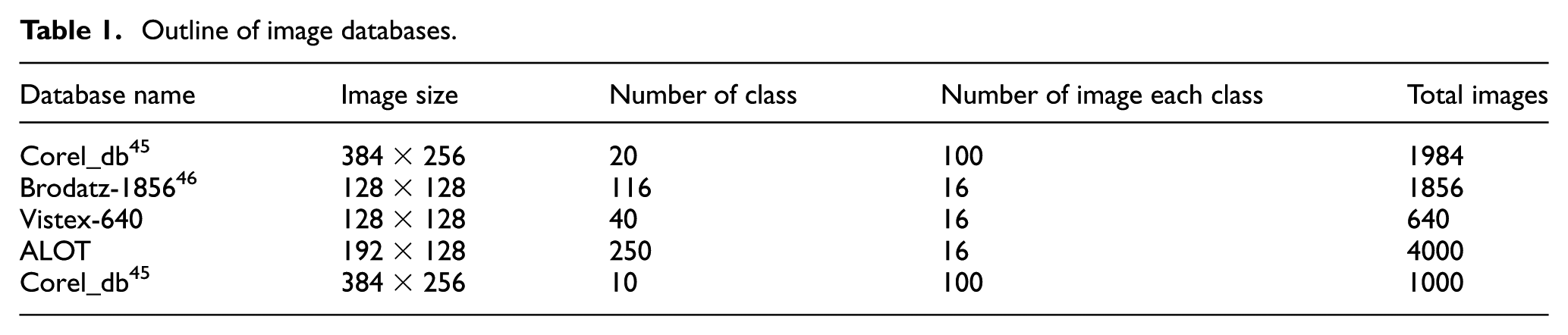
All the image databases listed in Table 1 are categories into several semantic information-based class of image in which all the images under the same semantic categories are considered as similar images. Outline of image databases used in this experiment such as its name, class, number of images of each class, and the total number of images in the databases are listed in Table 1. For example, Corel_DB image database consists of two sets of an image in the databases named as image and image.org. The image.org database consists of 1000 natural images grouped into 10 classes, in which each class contains 100 images. All the images are of size 384 × 256 pixel grouped into several semantic categories such as people, beach, building, buses, dinosaurs, elephants, flowers, horses, mountains, and foods. In Corel image database sample images are rendered in Figure 6. Likewise, all the 10 databases are considered for the experiment setup.

Corel-DB database sample images of each category.
The image retrieval performance of the various image databases is measured in terms of precision and recall rate. At first, the query image from any of the category is selected as an input. The features are extracted from the query image one by one and it is represented in the feature vector. Initially, the applied feature extraction is based on texture features such as directionality, contrast, coarseness, and busyness. Totally, the feature vector consists of 204 features and its dimension is 1 × 940. The feature vector size is clearly listed in Table 2.
Feature vector names and their respective sizes.

Example of the proposed image retrieval system
The usability of the proposed image retrieval system is illustrated in this section. Various examples are provided to show the practicability of the system and check the outcome of the system based on the given query image. In this proposed system, an image is randomly picked from each class of the prescribed Database, which acts as a query image.
Based on the query image, a set of similar images are subsequently retrieved from the database by comparing both the query image and database image feature vector. The returned images are ordered in an ascending manner based on their similarity distance score which is calculated with the help of Euclidean distance measure. The effectiveness of the proposed retrieval system is determined by the poster gesture and its performance measure. Figure 7 shows the resultant images based on individual features of the input query image.

Retrieved images based on modified binary wavelet transform.
The final resultant image clearly demonstrates the satisfaction of user request. The input query image is represented in the first column of each in Figure 7 and subsequent resultant images are listed in row-wise. The proposed system brings the results after executing the GUI-based application. If the user is satisfied with the result retrieved, then the result is retained. Otherwise, the user is allowed to select a set of images which is appropriate for them and the searching process continues. If the result is not satisfied for the user, then the successive iteration continues until the user is satisfied. The same system is applicable to different kinds of images from the different data sets. Figure 8(a) shows the combination of proposed system results without RF and RF after the second iteration results. The same RF is extended to the database Medical DB which contains medical images and results are projected in Figure 8(b).
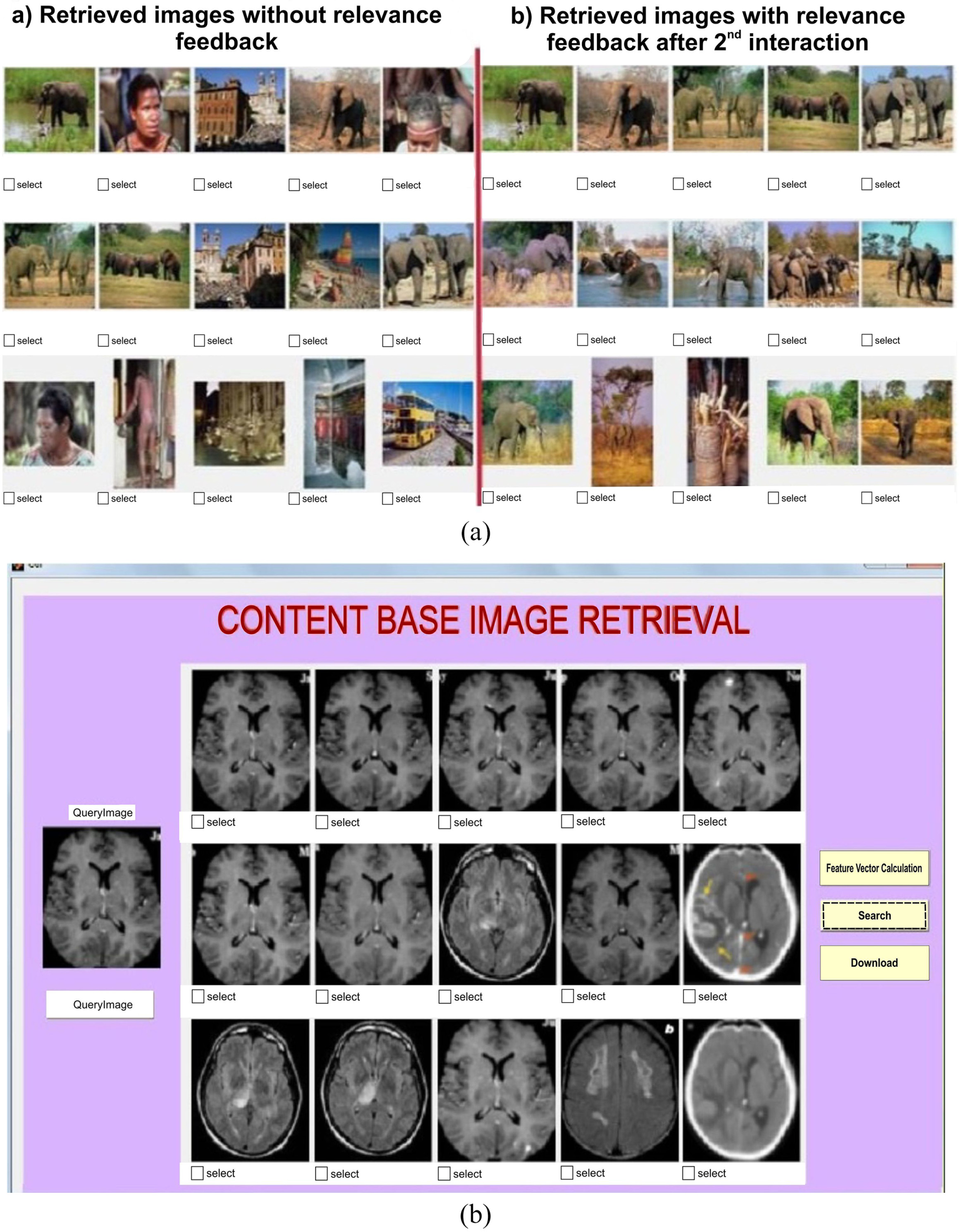
Retrieved image examples for the COREL database using the proposed system: (a) combination of without relevance feedback and with relevance feedback after second iteration results and (b) proposed system results for a Medical image database.
Comparison with earlier schemes
In image retrieval, various research works are carried out and considered for evaluation.34,47–51 Several characteristics are considered for image retrieval in the form of single feature or a combination of more than one. A small change in the feature based on retrieval can be termed as MBWT feature that can be combined with some other features to retrieve the meaningful images. In this experiment, every image in the database is treated as query image.
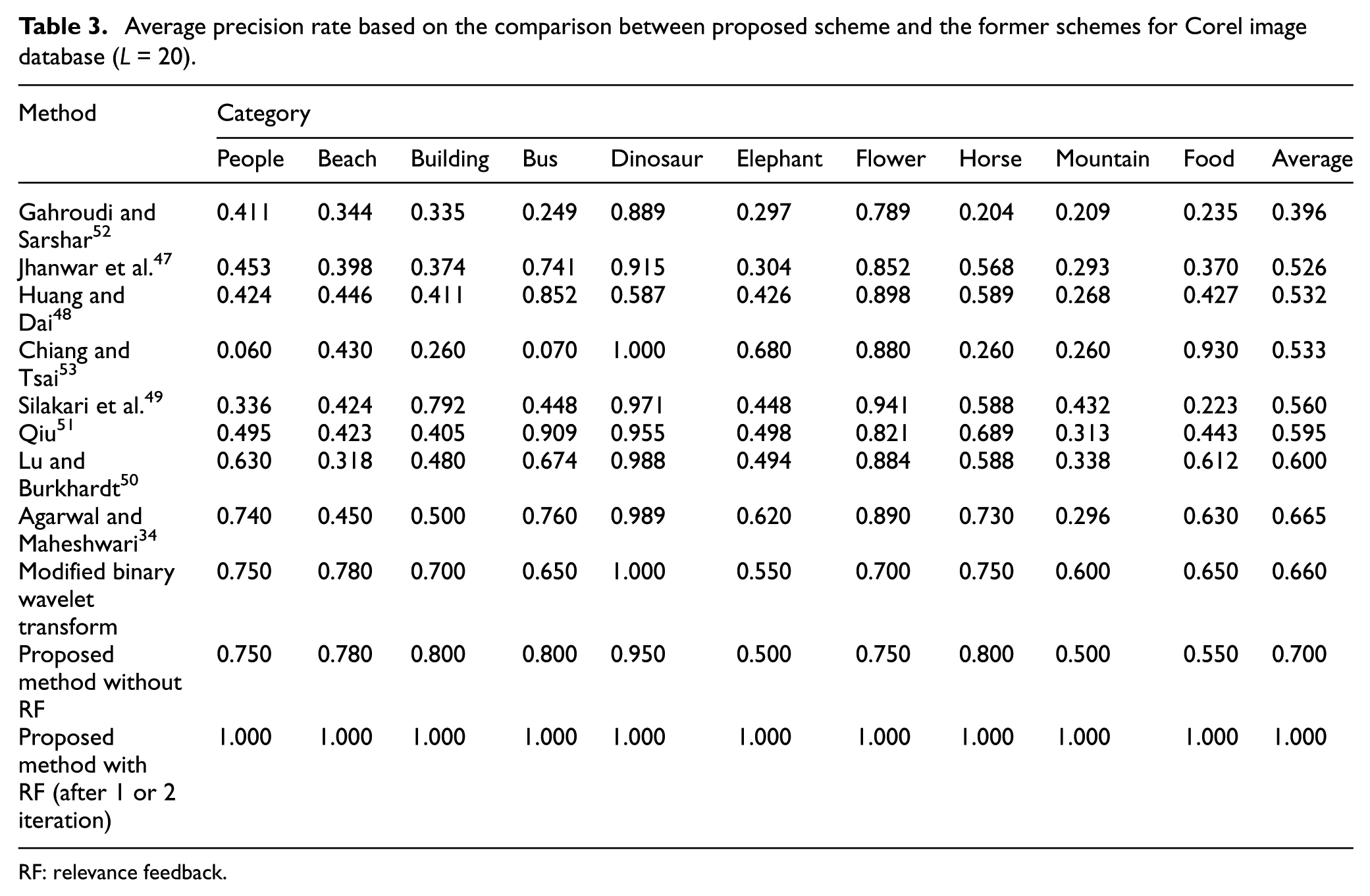
The average precision rate is computed using the formula which is mentioned in Bala and Kaur. 39 Table 3 contains average precision rate and it can be noted that the proposed method does not produce a consistent rate on each image class. However, the proposed method yields a constant average precision rate as indicated in Table 3. Apart from the mentioned points, the proposed method produces the good retrieval accuracy when compared to various existing methods by considering the simple low-level semantic features such as perspective, LBP, LTrP, and MBWT pattern.
Average precision rate based on the comparison between proposed scheme and the former schemes for Corel image database (L = 20).
RF: relevance feedback.
The proposed method performance is analyzed using various textual image databases such as Brodatz-1856, Vistex-640, and ALOT. The ARR analysis is conducted among the proposed image retrieval method with and without interactive feedback and the results are clearly exhibited in Tables 4 and 5. The ARR-based comparison produced better results than the existing schemes.
ARR-based comparison of result among the proposed image retrieval method and the former image retrieval schemes for ALOT image database.
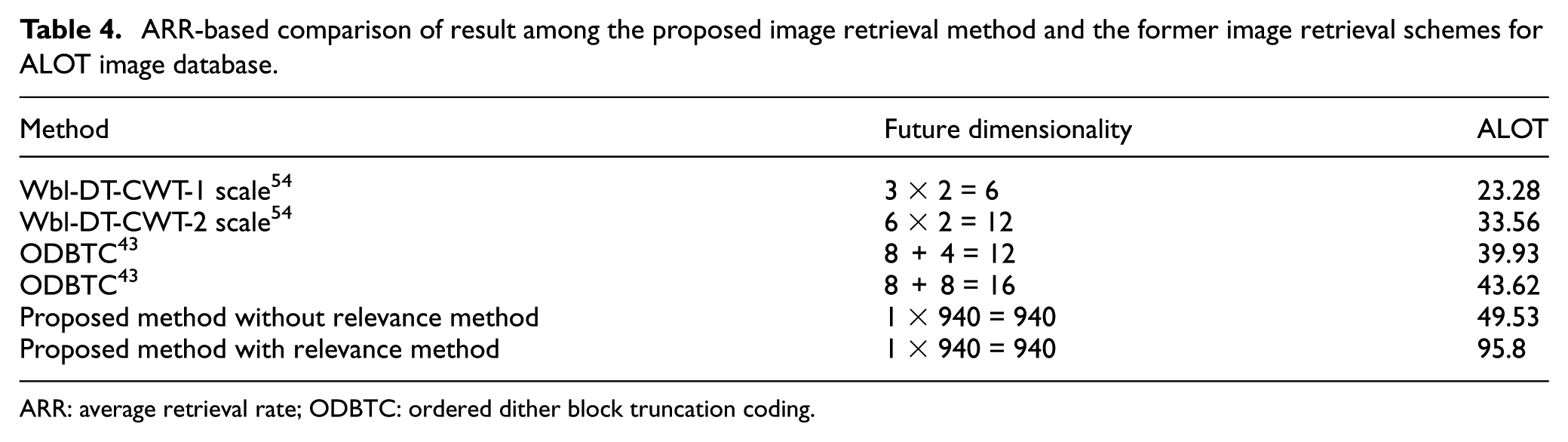
ARR: average retrieval rate; ODBTC: ordered dither block truncation coding.
ARR-based result comparison with the proposed image retrieval method and the former image retrieval schemes for VISTEX-640 image database.
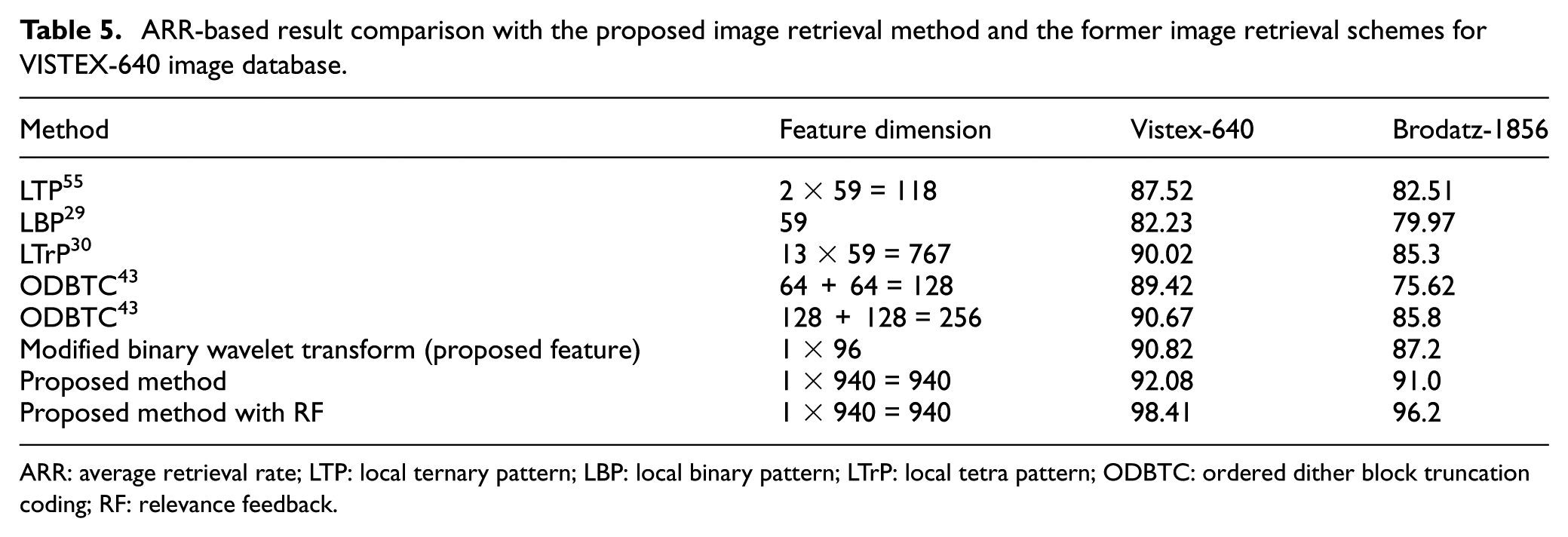
ARR: average retrieval rate; LTP: local ternary pattern; LBP: local binary pattern; LTrP: local tetra pattern; ODBTC: ordered dither block truncation coding; RF: relevance feedback.
The other testing is directed between the former schemes and the proposed schemes in terms of FIAR and FIRR. The FIAR-based comparison between the proposed method and the existing schemes are clearly exhibited in Table 6.
FIAR-based result comparison between proposed method and the former schemes for COREL image database.
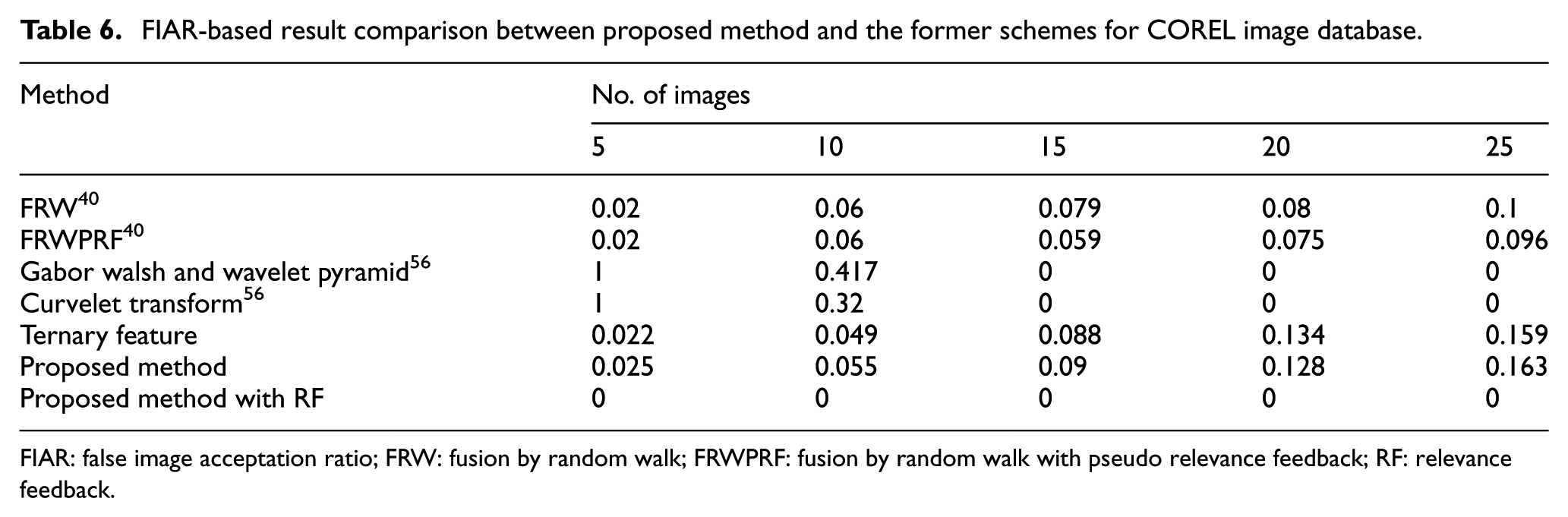
FIAR: false image acceptation ratio; FRW: fusion by random walk; FRWPRF: fusion by random walk with pseudo relevance feedback; RF: relevance feedback.
The accuracy of the proposed image retrieval method is related to various graphical features in CBIR such as fusion by random walk (FRW) 40 and fusion by random walk with pseudo relevance feedback (FRWPRF) method. 40 The analysis is carried out on the basis of number of the retrieved images such as 5, 10, 15, 20, and 25. The proposed method and the former schemes are compared in terms of the FIAR measurements and it is projected in Figure 9. The accuracy measures in terms of performance are better comparing with other existing methodologies.
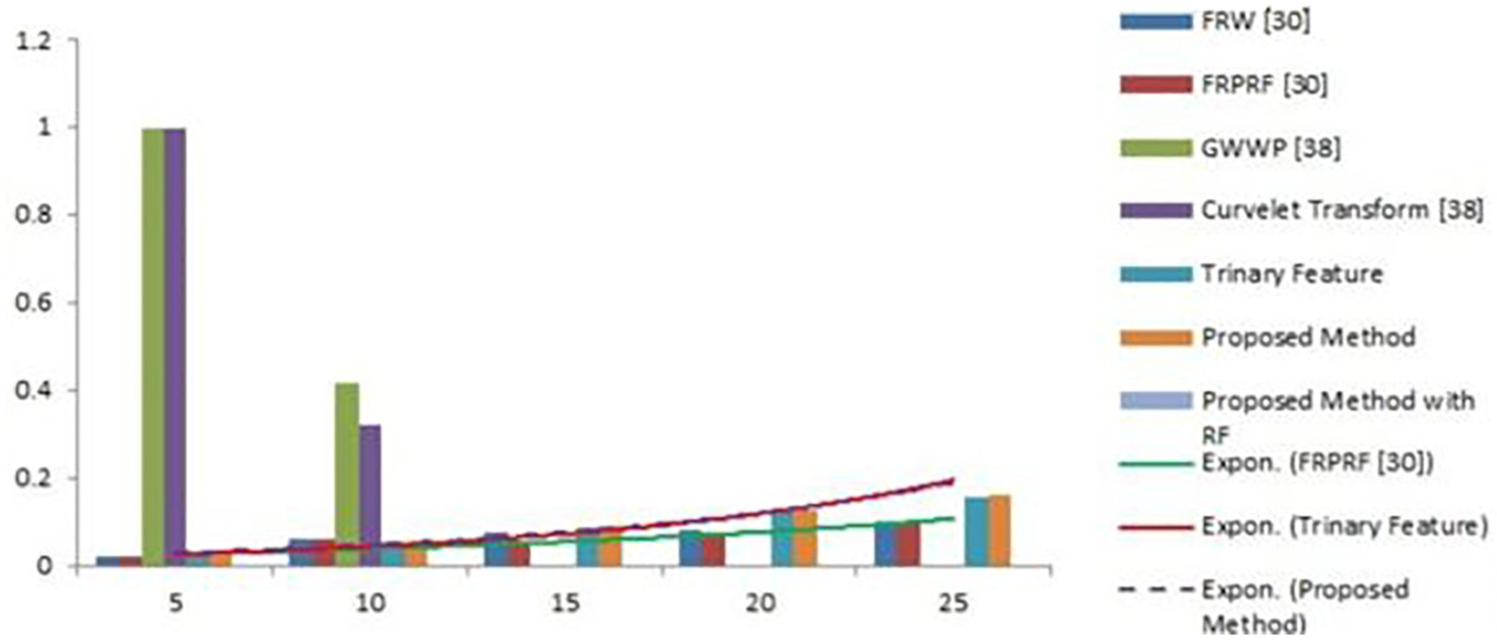
FIAR-based comparison between the existing and proposed methodologies.
Precision and recall
The proposed system performance is validated using precision and recall. In this experiment, all images in the database are treated as query images. The precision and recall measure for all categories of query images are calculated based on increasing the number of images retrieved from the database as 5, 10, 15, 20, and 25(L value) in the first iteration. The same precision and recall calculation are extended after applying MBWT feature and the results are represented in Figure 10(a), and proposed method without the application of RF results are listed in Figure 10(b).
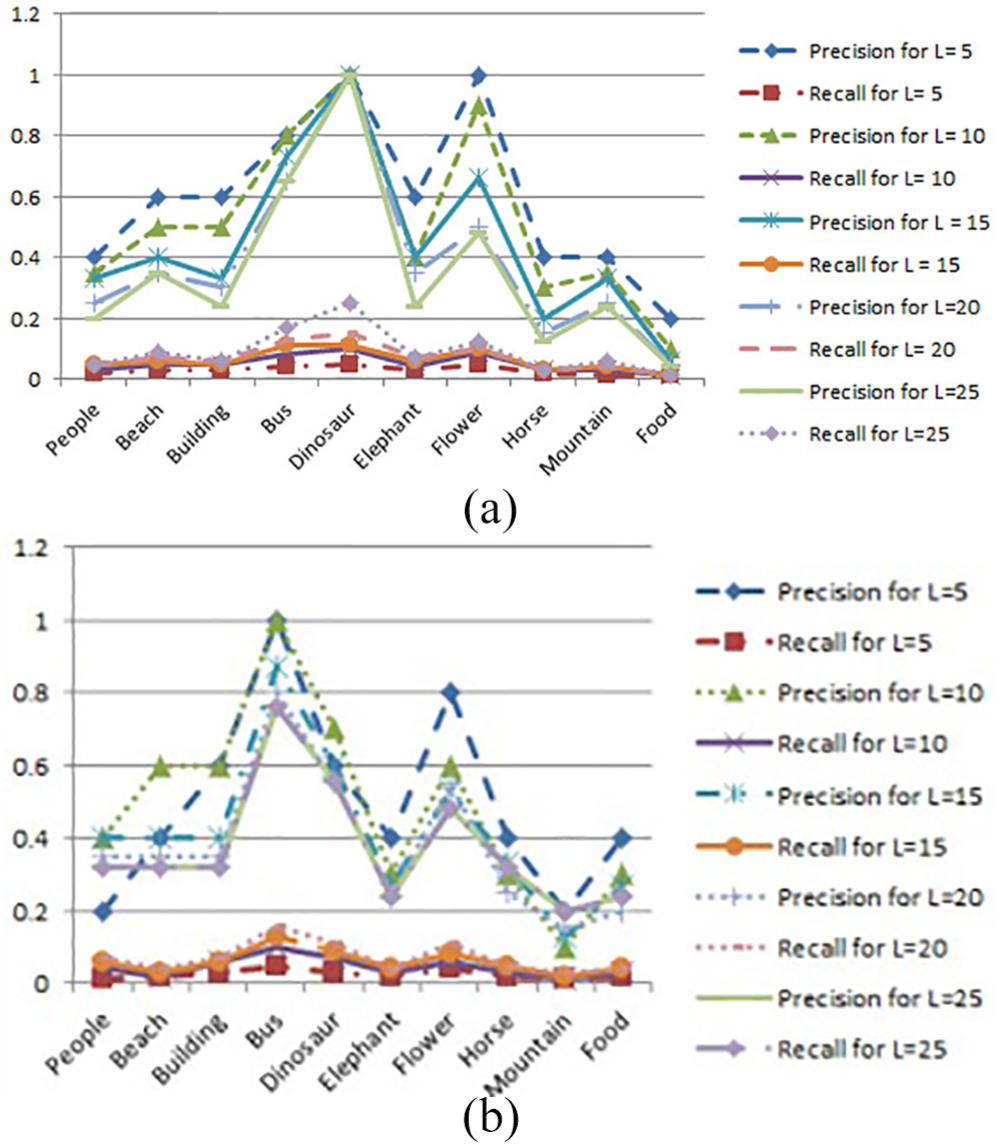
Comparison of performance measures such as precision and recall for COREL image database: (a) precision and recall calculation using modified binary wavelet transform feature and (b) precision and recall calculation using proposed method without the application of relevance feedback.
The proposed image retrieval method improves the precision and recall values and outperforms the existing retrieval methods. It is also understood that the image contains more background information can reduce the accuracy of image retrieval from 100%. This creates a bottleneck to this research, while considering global image database. The system takes more time to produce the feature vector if the database has more number of images. Once the system produces the feature vector, the system retrieves the images quickly as expected by the user. By considering the setbacks, an appropriate number of features can be considered to reduce the semantic gap.
Conclusion
In this work, CBIR methodology is experimented by exploiting the semantic information features such as coarseness, contrast, directionality, MBWT, LPB, LTrP and along with RF mechanism to retrieve the user expected result. Two similar images semantically different are identified using the selected features. To speed up the feature-based image retrieval process, binary wavelet pattern is modified and proposed a new feature. To evaluate the methods, benchmark DataBase is used. Also, a collection of images from the Internet can also be used as a DataBase. Selected features are combined to select the semantic-based image from the DataBase. Furthermore, the research can also be extended to video image retrieval. The system can able to bridge the gap between semantic knowledge, image content, and also the slanted criteria for human-oriented judgment.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.