
Abstract
Inline inspection tools that are used to scan the interior defects of gas and oil pipelines tend to suffer from measuring error due to their sizing accuracy. This error often causes an over- or under-estimation of the operating conditions of the pipeline, which might lead to a system failure. While parametric calibration models provide a simple method to reduce the measuring error, it is limited to datasets that follow the normal distribution only. Thus, in this paper, a non-parametric calibration model based on k-nearest neighbor interpolation was proposed to improve the measurements recorded by the scanning tools. Corrosion data collected using an ultrasonic scan device and the magnetic flux leakage intelligent pig are considered in the research. The k-nearest neighbor interpolation is studied based on the effect of using six kernel functions with two different positioning approaches on the interpolation behavior. The results have shown enhancement in the accuracy of the readings obtained from the intelligent pig from ±20% of the pipeline wall thickness to only ±8%. This enhancement in the sizing accuracy is meant to prevent a possible system failure for using the corroded part of the studied pipeline for an extra 4.6 years instead of replacing it.
Introduction
Pipelines fulfilled the daily demand for oil and gas to the markets efficiently since 1879 when the first oil pipeline was built in Pennsylvania. Nowadays, pipelines are considered the fastest, safest, and most economical means to transport oil and gas. There are more than 3.5 million kilometers of oil pipeline crossing 120 countries around the world through networks that sometimes exceed 2000 km in length.1–3 A periodical integrity assessment of the operational pipelines should be applied constantly to prevent the consequences of any system failure. Through its service time, aging pipelines are subjected to various corrosion mechanisms. These mechanisms are considered to be the defying factors affecting the integrity of the transfer system that may lead to failure. 4 Since corrosion deteriorates the pipeline walls both internally and externally, the early and accurate detection of the actual remaining wall thickness of the operational pipeline through thorough inspection could potentially save the production circle from any halts. Inline inspection (ILI) tools, also known as non-destructive testing (NDT), are widely used to scan the interior of oil and gas pipeline for corrosion. 5 Smart/intelligent pigs equipped with magnetic flux leakage (MFL-IP) sensors and ultrasonic scan devices are the two main types of metal-loss inspection techniques.6,7 Both technologies scan the remaining pipeline wall thickness to decide the remaining operating lifetime of a pipeline. Some of the intelligent pigs used these days are supported with both MFL and ultrasonic testing (UT) sensors to do the scanning using both the technologies at the same time.8–10 Each individual technology suffers from a different sizing accuracy and bears different properties. MFL-IP is used much often for corrosion and internal pipeline defect inspection. However, it has a lower sizing accuracy compared with other high-resolution scan devices and gives corrosion readings as relative measurements. On the other hand, the UT tool has a higher sizing accuracy and has the ability to give an actual measure for the remaining wall thickness making it a more accurate tool. The accuracy of corrosion measurements scanned using ILI tools is affected directly by its sizing accuracy. Table 1 shows the differences in the sizing accuracy for both devices11,12 (t stands for pipeline nominal wall thickness).
Sizing accuracy of MFL and UT tools.

MFL-IP: magnetic flux leakage intelligent pig; UT: ultrasonic testing.
As shown in Table 1, the standard MLP-IP has a sizing accuracy of ±20%t with 80% confidence level. Although this error margin is significantly high, yet this standard resolution tool is preferred by most operators due to its comparatively low cost when compared to higher resolution techniques. This implies that the error in the measurements of the MFL-IP tool may cause an under- or over-estimation of the actual condition of the pipeline. This may result in operating a faulty pipeline or replacing a good one.
Different studies have been carried out to handle the error in ILI measurements. Yet, the majority of the suggested methods were parametric-based models. The simple least square regression (LSR) line was suggested by Hallen et al. 11 to calibrate the measurements of an ILI tool with some real field measurements. McNealy et al. 13 proposed the API 1163 model for calibrating the error in corrosion measurements scanned with ILI tool with the field measurements. The assumption about corrosion measurements being normally distributed is required to apply such calibration. Average for tolerance calibration model was applied by Din et al. 14 to estimate the calibrated corrosion rate of a certain pipeline using the corrosion data of three previous scans from different years. Caleyo et al. 15 developed a statistical calibration method based on parametric regression estimators to calibrate the measurements of an MFL pig tools using the ultrasonic ILI-reported data and corresponding field measurements. The calibration process was based on comparing the growth of the pipeline defects using the readings of different tools as done by Salama et al. 16 Others used the corrosion data from different scans at different times as done by Din et al. 14 Abdolrazaghi et al. 17 proposed the calibration of MFL-IP with the data of UT scan tool using the linear regression model. The calibration was done based on the readings of three runs of both MFL-IP and UT device. The error in ILI measurements was assumed to follow the normal distribution in order to perform the aforementioned calibration method.
Most calibration models used in the literature are of parametric nature. Parametric calibration models have a big limitation related to the normality assumption of the dataset. Although it is convenient for most researchers to use parametric models, it cannot cover all distributions of the measurement data. Non-parametric models, however, do not require the assumption of normality, thus, it can overcome the limitation of parametric estimators. Based on the previous discussion, this paper presents a non-parametric calibration procedure to reduce the error in the MFL-IP measurements using the UT readings. The procedure proposed in this paper was based on applying a weighted k-nearest neighbor (KNN) interpolation as a calibration tool. A new positioning approach was suggested to reduce the bias in the resulted measurements. The process was followed by a comparison of the effect of using various kernel functions and different positioning techniques on the measurements in order to get the closest, unbiased, and enhanced MFL corrosion measurements. The next section in this paper will present the statistical background behind the suggested method.
Statistical background
Interpolation can be defined as the prediction of an unknown or a missing value relative to a function or simply a sample point. The prediction is done by making use of the neighboring points that are known. Many different techniques can be applied, and some of these techniques are interpolators such as KNN interpolation, multivariate interpolation, bilinear interpolation, polynomial interpolation, quadratic interpolation, B-spline interpolation, bicubic spline interpolation, Gaussian interpolation, Lagrange interpolation, inverse distance weighting (IDW) interpolation and many others.18–21 KNN interpolation has been used for time-series forecasting in several applications, such as coal-mill-related variables, 22 electricity price predictions, 23 hydrologic time series, 24 in addition to image processing, 18 data mining, 25 and big data classification. 26 In this paper, KNN interpolators were chosen to use the neighbor grid of the UT tool measurements in calibrating corrosion metrics of the MFL intelligent pig.
KNN interpolation can be defined as a statistical test conducted to determine a point significance in terms of its nearest neighbor contiguity. This is done to calculate the amount of deviation from the norm.19,27 An estimation of the contiguity may be done using a weight function (also known as a kernel function), which is simply a function measuring the effect of every single neighbor point on the interpolated one. Simply, the value estimated of the required or missing point is the neighbor’s weighted average value. 28 The weight function must gain its maximum value at zero distance from the interpolated point, and as the distance increases, the function should decrease respectively. 29 The simplest weight function is described in Equation (1)28,30
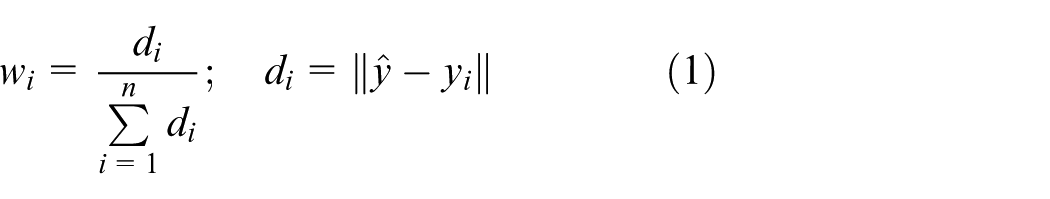
where
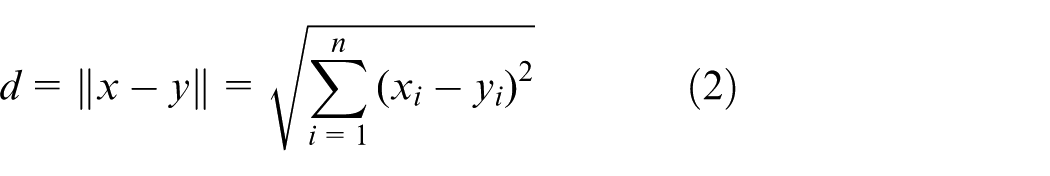
where
Various types of kernels can be found in the literature. The KNN weighted function was first introduced by Loftsgaarden and Quesenberry
30
in the field of density estimation. Similarly, Cover and Hart
33
introduced it for classification purposes. Hinton and Roweis
34
defined a stochastic neighborhood embedding algorithm used to visualize a given dataset by learning a low-dimensional embedding in two or three dimensions, based on the Gaussian kernel, Equation (3), introduced by Atkeson et al.
29
Wolberg used the inverse distance kernel to deal with a case of noisy data; the kernel is shown in Equation (4). In psychological models, exponential kernel, Equation (5), is used to give the weighted average for the model.
29
Fan and Hall
35
used the quadratic kernel introduced by Epanechnikov
36
as given in Equation (6). Wang
39
used the tricube kernel given in Equation (7). Gou et al.
37
combined the ratio between the query point and its farthest neighbor to the nearest neighbor distance. This ratio was made to introduce the kernel in Equation (8). Franke and Nielson
38
used a classic form of weight function as seen in Equation (9). Dumitru
19
used a modified version of the weight function used by Franke and Nielson for superior results as shown in Equation (10). Table 2 shows the aforementioned kernels with their parameters of interest, where
Various types of kernel functions.

The KNN algorithm interpolates the query point using Equation (11)
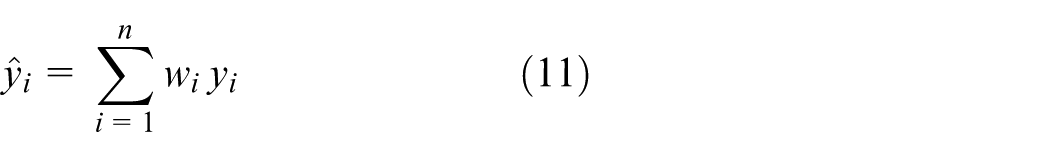
where
In this work, six kernels were used for calibrating MFL-IP corrosion measurements with the measurements of the UT device. The prediction behavior for the studied kernels was tested using two positioning approaches. The ordinary positioning practice (center position) assumes that the predicted point is located at the center of the neighbor grid (surrounded by the neighbor points as a rectangle or a circle). In the case of big neighbor grid, there is a possibility of overfitted prediction. Hence, a new positioning approach (moving position) was suggested. It is now assumed that the location of the predicted point is either next to the largest or the smallest point in the grid. The decision about the query point location depends on whether the value of the MFL-IP point is greater or less than the UT point.
Methodology
The corrosion data collected using two different devices have almost identical properties but may have a different design. For instance, the measurements that are collected using a UT scan device are given as a full grid of actual remaining wall thickness of the pipeline, respectively, to its length and circumference. However, the MFL-IP provides only corroded points in their exact positions along the length of the pipeline respective to their circumferential orientation. Hence, a mapping procedure is applied to join each point from the MFL-IP with its equivalent measure from the UT device, thus forming a pair.
Given the better sizing accuracy of the UT device compared to the MFL-IP, the UT device measurements were assumed to be the goal metrics and used for the calibration of the MFL-IP measurements. The KNN interpolation will be the basis of this calibration. Eight UT points are selected to set up a neighbor grid for the point that needs calibration. Figure 1 illustrates the position of the UT goal point with respect to the neighbors. The fifth element in the grid (
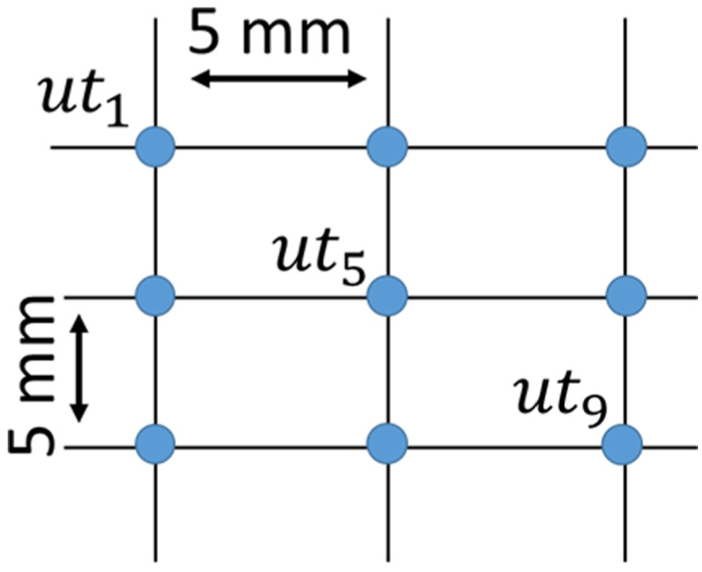
UT neighbor grid.
The UT neighbor grid was expanded by inserting the MFL-IP measurements. Accordingly, the grid now consists of 10 elements instead of 9. Hence, the neighbors for the query point became 9 instead of 8. This number will be labeled as K, the number of neighbors in the model. The expansion was made using two approaches. The first approach is called the center position approach. This approach plants the MFL-IP measurements as the sixth element in each neighbor grid. The IP point was placed at a distance very near to the center of the grid, such that it is almost at the same position. Let
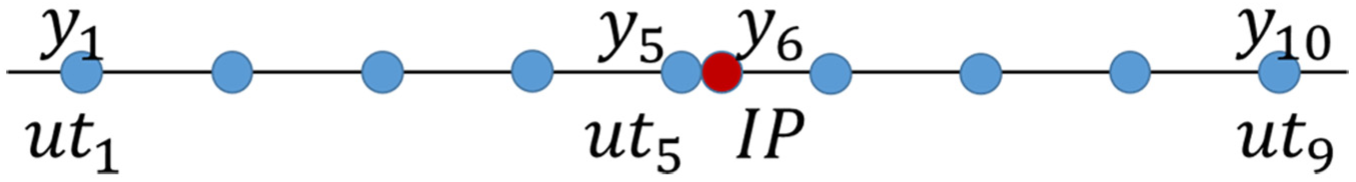
Remaining wall thickness expanded vector.
Since the IP point was placed as the nearest neighbor to the goal point, there will be a possibility of over-fitting or a biased estimation. In order to avoid this possibility a new positioning approach is proposed for the expansion. The proposed moving position approach takes into consideration the relationship between the original IP and UT measurements to avoid the possibility of over-fitting. An IP measurement is placed closest to the maximum point in the grid if it is greater than the UT measurement as shown in Figure 3(a).
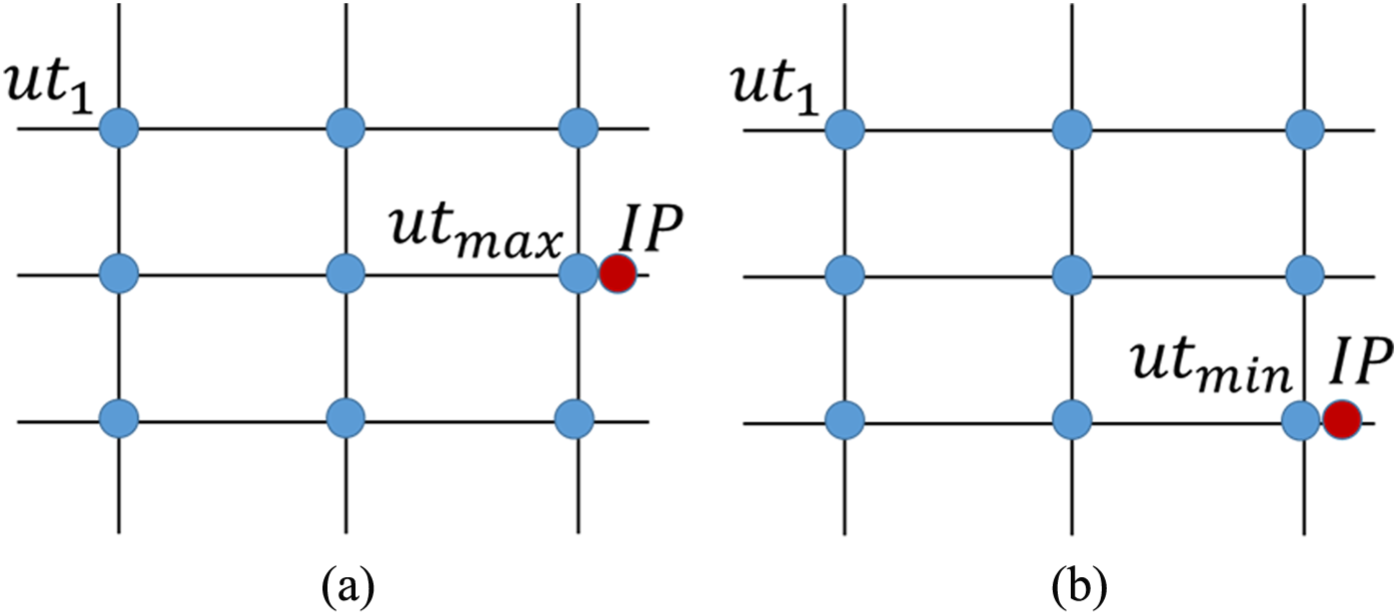
Expanded neighbor grid: (a) IP > UT; (b) IP < UT.
On the contrary, if MFL-IP measurement is smaller than the UT measurement, then the position of the point that requires calibration will be assumed to be the closest to the position of the minimum value point in the neighborhood, as shown in Figure 3(b). This position will assure that the calibrated point will be relatively close to the original MFL-IP measurement rather than the goal measurement (
The distance vector between the planted IP point and the other neighbors in the grid is generated using the Euclidean distance function expressed in Equation (2).
For the expanded vector, a weight sequence was calculated using the weight functions given in Table 2. The kernel function will concentrate on the closest neighbor to the IP point as it has the biggest effect on the estimation.
KNN interpolation (with k = 9 neighbors) is applied on the expanded vector. Equation (11) is used to replace the IP value with the weighted average calculated by the KNN interpolation. The result is labeled as the new enhanced MFL-IP corrosion measurements.
Mean square error (MSE) is used to evaluate the model’s performance and to point out the effect of using different kernels on the interpolation procedure for both approaches

This was followed by applying the median absolute percentage error (MdAPE) index to determine the preference of a certain kernel on the others. The usage of the median for the evaluation will increase the chance to find the superiority of one interpolator over the rest considering its ability in eliminating the effect of the extreme values (outliers) in the dataset 40
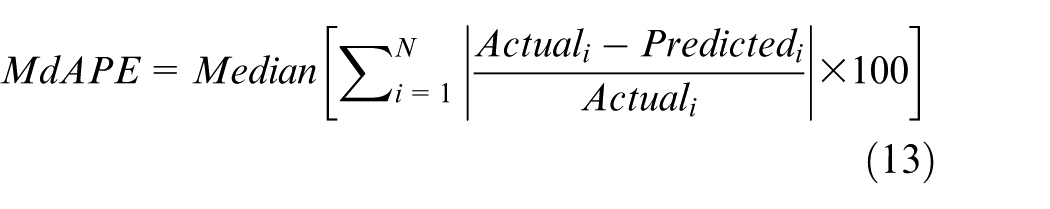
The bias of the model was measured by comparing the error in the estimated value from the original IP metrics using Equation (14) to ensure that the prediction model that depends on both suggested approaches is not over-estimating the measurements

where
Case study
This framework is applied to a set of corrosion data collected from oil pipeline used in Malaysia. It is about 20 years old and has a length of 3.9 km, a diameter of 25.4 cm, and an internal wall thickness of 12.7 mm. The data (depth, length, and width) of corrosion geometry parameters were collected using two ILI tools. An MFL-IP with a sizing accuracy of ±20% and UT scan device with a sizing accuracy of ±5%. Both suggested methodologies were applied to a section of the aforementioned pipeline that contained 273 corroded points.
Results and discussion
The results of applying the proposed methodology were illustrated at a single segment of the studied pipeline which contains 38 defected points. The calibration technique suggested in this paper show a remarkable enhancement in corrosion measurements for some of the used weight functions and a weak effort in others. The evaluation of the proposed interpolators was done by comparing the MSE and the MdAPE index for the first six of the suggested kernels as given in Table 2. The Franke–Nielson and Dumitru kernels contain a distance parameter at the denominator. Since the suggested methodology calculates zero distance between the center of the neighbor grid and the predicted point, both the abovementioned kernels will be resulted as infinity, making them inapplicable in this study due to the case of indetermination. The error evaluation was followed by a comparison of the difference between the original IP measures, the goal UT measures, and the interpolated measures. The measurement of the point with the thinnest wall thickness in the pipeline was compared between three cases: the actual metrics collected by UT device, the original metrics collected by MFL-IP device, and the enhanced metrics approximated using the proposed techniques.
Table 3 shows the error in the interpolated corrosion metrics using both the suggested methods for each one of the six kernels mentioned in Equations (3)–(8), indexed from A to F.
Mean square error (MSE) for interpolators.

Based on the MSE values shown in Table 3, kernels A, B, C, and D have almost the same interpolating behavior when using the center position approach. Hence, the MdAPE index is calculated to determine the best among them as shown in Table 4.
Median absolute percentage error (MdAPE) for interpolators.

From the MdAPE index shown in Table 4, kernel B shows the best interpolating behavior with a MdAPE value of 1.61%, outperforming the accuracy of kernel A with 1.68%. Kernels C and D have almost the same interpolation abilities, while kernel F is seen to have the weakest effect between the studied kernels. This can be attributed to its unique definition that neglects the effect of the neighbors, given that the distance between the neighbor points in the grid when applying the center position approach is constant. However, when applying the moving position approach, kernels D and E show less accurate predictions (with errors of 0.288 and 0.265 mm, respectively) when compared to kernels A, B, and C with MSE values of 0.145, 0.124, and 0.151 mm, respectively. In the case of moving position approach, kernel B shows a much accurate prediction with 1.99% MdAPE index, followed by kernels A and C. Kernel E has a slightly better approximation when compared to kernel D with an MdAPE index of 3.06% and 3.23%, respectively. Kernel F has the minimal prediction accuracy compared to other kernels based on both MSE and MdAPE index.
Figure 4 presents a comparison between the original IP, goal UT, predicted center position approach, and predicted moving position approach line chart for all the studied kernels.
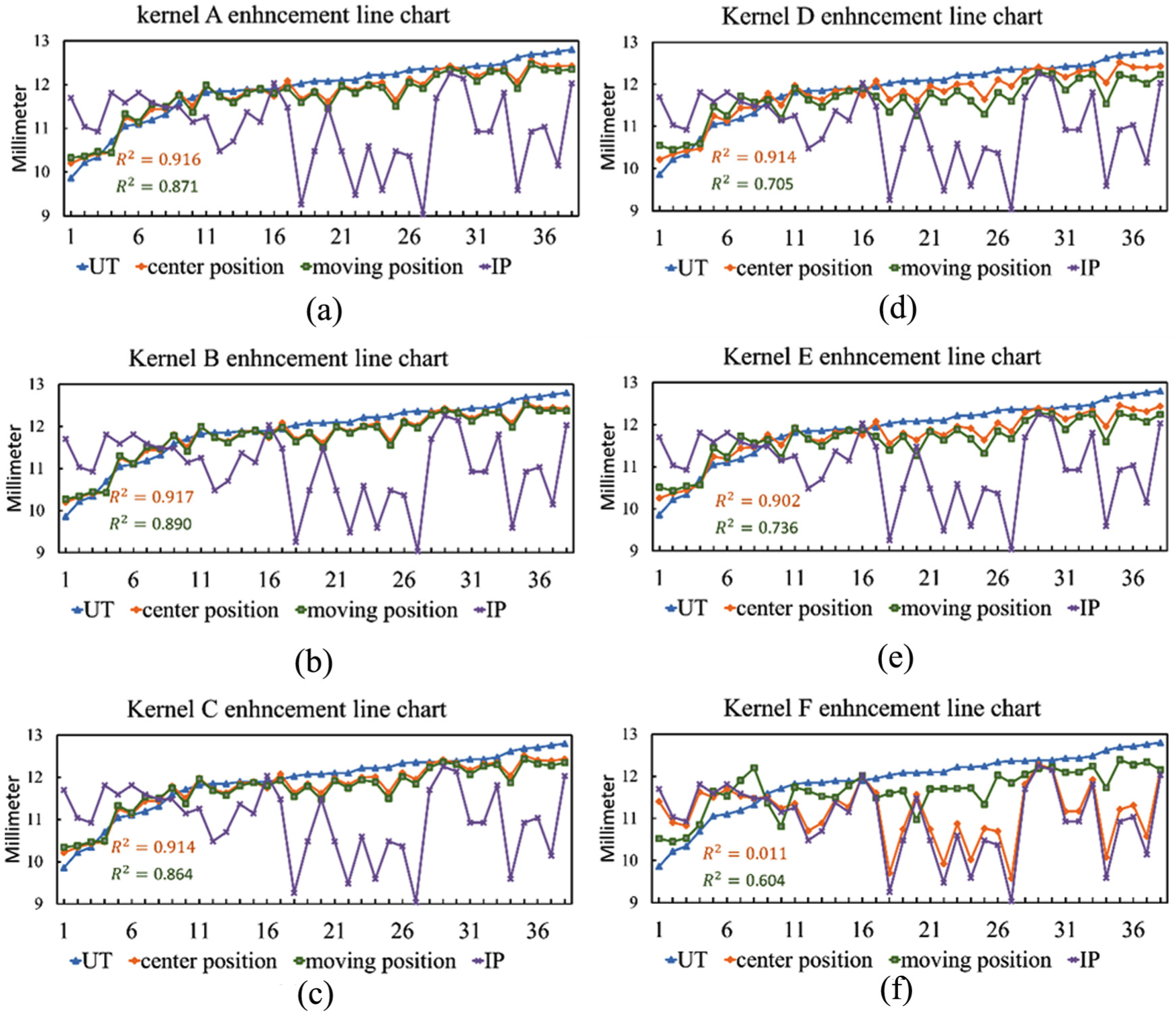
Comparison between original IP and goal UT for interpolators with different kernels.
It is clear from Figure 4 that kernels A, B, and C have prediction lines that are close to the goal UT measurements, which explains their small prediction error. It is also shown that the three kernels have very small differences as their line charts have almost the same alignment toward the UT line.
Table 5 shows the bias test for the studied kernels for both approaches. The error between the predicted and the original IP measurements was calculated using Equation (12) in order to study the bias of the predictors.
Bias of interpolators.

The method that has a smaller error when compared with the original IP measurements was considered less biased to the goal UT line. Hence, it is clear from Table 5 that the proposed moving position approach has a less biased interpolation behavior for all the kernels when compared to the center position approach. Thus, it is highly recommended to use the predicted measurements using this technique.
The economic benefit of such research can be clearly explained by analyzing the thinnest remaining wall thickness in the corroded pipeline. The point with the thinnest wall thickness in the pipeline is usually used in the extreme value analysis to determine the probability of system failure. Hence, the weakest part of the studied section was approximated using the suggested approaches to evaluate the calibration method as given in Table 6.
Thinnest wall thickness (mm) in the studied segment.

IP: intelligent pig; UT: ultrasonic testing; CP: center position approach; MP: moving position approach.
The MFL-IP operator reported that the thinnest part of the studied segment had a remaining wall thickness of 11.70 mm, while the reading of the UT tool showed that it should be 9.86 mm. This 1.84 mm difference between the two readings means that depending on the MFL-IP report, the pipeline can operate for an extra period of 4.6 years when compared to the reading of the UT tool, given that the average growth rate of the corrosion per year according to the NACE (National Association of Corrosion Engineers) is reported to be 0.4 mm. 41 This under-estimation of the pipeline operating condition may lead to an unexpected system failure within the time frame given by the MFL-IP device. The enhanced measurements of the remaining wall thickness for the thinnest part of the segment were found to be as shown in Table 6.
Both approaches show a better approximation for the actual condition of the remaining wall thickness with an error that does not exceed 3% of the actual wall thickness recorded by the UT scan device. Considering the original sizing accuracy of the UT scan device, this means that the error in the estimated measurements is not more than 8% of the pipeline wall thickness. This result indicates a significant increment in the sizing accuracy of the corrosion metrics of the MFL-IP as the error was to be reduced from ±20%t to only ±8%t. Relative to pipeline operating lifetime, the enhancement in the MFL-IP metrics error will help to prevent a possible system failure for over operating the pipeline for 4.6 extra years.
As discussed earlier, most calibration methods used in the literature were of parametric nature. Hence, a comparison between the enhancement of the suggested approaches and the LSR line was done. The MSE of the LSR line was found to be 0.87 mm, which is way larger than the MSE for the KNN approach which was almost 0.1 mm when using kernel B for both positioning approaches. The enhancement of the thinnest recorded wall thickness using the LSR was found to be 10.93 mm, as shown in Table 7, but it was reduced to 10.19 and 10.27 mm using KNN approaches. There is almost 0.8 mm difference between the LSR and the KNN calibration methods, which means a difference of two extra operating years for the studied pipeline.
Thinnest wall thickness (mm): LSR vs KNN.

LSR: least square regression; KNN: k-nearest neighbor; IP: intelligent pig; UT: ultrasonic testing; CP: center position approach; MP: moving position approach.
Conclusion
The proposed KNN interpolation method in this paper presented an effective calibration technique to enhance the sizing accuracy of the corrosion measurements collected by the IP tool. It has been shown that using the moving position approach will result in a less biased estimation when compared to the center position approach. The proposed technique enhanced the measurements of the IP tool to have an error that is not more than 8% of the pipeline’s wall thickness. This result is much reliable than the 20% affecting the IP device. It was concluded that using different kernels affects the KNN interpolation process differently. The inverse distance kernel showed the best interpolation behavior among the other studied kernels. However, the moving position approach showed a less biased estimation when compared to the center position approach with almost the same accuracy. The calibration of the thinnest wall thickness in the studied segment showed an under-estimation of 4.6 operating years, which can cause an unexpected system failure. The results indicate the potential of the proposed techniques in enhancing the corrosion measurements of pipeline corrosion NDT tools. Besides, the suggested KNN calibration showed a better enhancement behavior compared to LSR.
Footnotes
Acknowledgements
The authors would like to acknowledge the Universiti Teknologi PETRONAS for the financial assistance provided to conduct this research.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.