
Abstract
This paper is a discussion of the nature of systematic failures in Safety Instrumented Systems and the way that they can be managed. It identifies the upper bound to the probability of failure due to systematic failures as a function of demand rate and a systematic test interval. It discusses how the functional safety standards address systematic failures through systematic capability defences and how these considerations may be addressed when identifying a ‘Prior-use’ case for assessing fitness-for-purpose of system elements.
I. Introduction
In IEC 61508:2010 1 Part 4, systematic failure is defined as ‘failure, related in a deterministic way to a certain cause, which can only be eliminated by a modification of the design or of the manufacturing process, operational procedures, documentation or other relevant factors’. The standard distinguishes these from random hardware failures which it identifies as more susceptible to statistical analysis. Probability of Failure on Demand (PFD) calculations are routinely performed using estimates of undetected dangerous random hardware failure rates, but this assumes the systematic failure possibilities have been addressed by other means. It might be argued that some systematic failures are susceptible to assessment using statistical techniques in the same way as random hardware failures, and in an earlier article, 2 the case was made for assuming an additional failure rate associated with the specifics of the equipment deployment (rather than inherent to the equipment itself).
Although much is made of PFD calculations and supporting equipment certification, the rigour with which these concerns is often pursued may be of questionable value when considered in the wider context including the systematic failure possibilities. The SINTEF reliability data handbook 3 makes the point that ‘vendor estimates of dangerous undetected failure rate are often an order of magnitude (or even lower) than that reported in generic data handbooks’. In their estimates of failure rate, they identify a parameter r as the fraction of dangerous undetected failure rate arising from random hardware failures. Values of r for field equipment (sensors and final elements) typically vary between 30% and 50%. It can be seen that systematic failures may be very significant and may well dominate. Even equipment that has been certified as Safety Integrity Level (SIL) capable and installed, operated and maintained in accordance with safety manual stipulations may be found to remain susceptible to systematic failures. This article considers how these concerns may be addressed.
II. Types of Systematic Failures
We may identify different types of systematic failures, for example:
Hardware issues that are ‘engineered in’ as part of the design or installation;
Software issues that are ‘engineered in’ as part of the design;
Those that develop progressively, for example, impulse line blockage;
Those that arise under certain operating or environmental conditions;
Those that arise from human error, for example, erroneous modification/adjustment.
Of these, types 1 and 2 should be mostly captured during function verification and validation. Types 3 through 5 are potentially more difficult to address but may be captured by appropriate testing techniques.
We may further categorise systematic failures as ‘persistent’ or ‘transient’: Persistent failures will remain until rectified and will therefore be discovered by effective testing techniques. Transient failures would only be present whilst certain conditions exist; when the conditions change the failure will ‘repair’ itself. These are much the most difficult to capture.
Although the relationship between testing and random hardware failure rate is well understood, the usefulness of testing in capturing systematic failures is often overlooked – reliance is placed instead on employing equipment which has an appropriate ‘systematic capability’, that is, possessing appropriate defences against systematic failures.
III. Probability of Coincidence
Although we typically cannot assign a failure rate to systematic failures and cannot therefore calculate a corresponding PFD in the conventional manner, we can identify an upper bound to the probability of the coincidence of a trip demand with a persisting systematic failure, as a function of the demand rate (D) and a systematic failure test interval (TS): Consider a demand arising once per year; if we test 10 times a year, then we would expect to discover (and eliminate) any persisting systematic failure that arises within 0.1 of a year. The probability of a demand arising within a given test interval is 0.1 and on average would be half way through an interval, and so we may assess that the probability of coincidence (Pc) of a demand with a persisting systematic failure must be less than 0.1/2 = 0.05. Generally
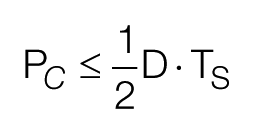
Demand rate here corresponds with the frequency with which the hazard would be realised without the safety instrumented function. That is, with other provisions such as conditional modifiers or mechanical relief accounted for (the ‘intermediate likelihood frequency’ that is identified in Layer of Protection Analysis) and in the process sector will typically be very much less than 1/year.
IV. Systematic Failure Testing
The systematic failure test interval identified above is that associated with a completely comprehensive test, that is, one that would identify any systematic failures. Note that normal proof testing, which is predicated on random hardware failure rate and as typically undertaken during process shutdowns, will not usually provide complete coverage of the systematic failure possibilities. Note in particular that some obscure failure mechanisms may present under normal operating conditions that may not be apparent with proof test performed during plant shutdown. Examples are as follows:
A valve that strokes satisfactorily during plant shutdown may not be effective in stopping full flow when pipework is stressed under operating pressure and temperature.
A test button on a tuning fork would not identify whether the wrong length probe had been installed in the top of a vessel.
A workshop calibration check on a pressure transmitter would not reveal problems with the field power supply or impulse line.
Signal injection would not reveal a ranging error on a transmitter.
Line vibration may interfere with no/low flow detection by a vortex meter.
For systematic failure testing, the best testing approach is to drive the process to the trip point, but this may be impracticable or potentially hazardous. If it is a practicable option, critical consideration must be given to the possibility that the function fails and the process may be driven to a potentially unsafe state; appropriate procedures and back stop provisions must be in place.
Other than driving the process to the trip point, coverage can typically be enhanced by in situ testing with minimal disturbance to the installation and with elements exercised during plant operation (rather than at shutdown). It may be possible to corroborate measurements through cross checks while the plant is operating. The better practice is to avoid interrupting power supplies since this would cause equipment to reinitialise and possibly ‘repair’ systematic software failures that would otherwise be revealed.
Note that real trip events constitute the best possible test; if the necessary data can be captured to demonstrate that a trip performed satisfactorily, then this would allow the next systematic failure test to be deferred. Note that this is not simply a matter of observing that the plant did shutdown safely; you would need to demonstrate that all the function elements performed as per design. For example, did the flow stop because the emergency shutdown valve closed on command from the safety instrumented system or was it because the control valve closed on command from the basic process control system? Note also that elements that are employed by multiple functions do not need to be tested for each function; recognition of this can massively reduce the testing burden.
One possible response to these considerations would be to specifically test for systematic failures frequently enough so that the PC contribution is suitably constrained. It may be that this is not a practicable option for many functions, but the approach may be worthy of consideration.
V. Assessing Systematic Capability
The approach prescribed in IEC 61508 for establishing defences against systematic failures is qualitative rather than quantitative, and there are numerous tables listing techniques and measures that may be employed in supporting claims of systematic capability (Part 2 Annexes A and B). These techniques and measures are called upon to be employed in a variety of combinations (some measures are held to be replaceable by alternatives), with differing degrees of effectiveness (High/Medium/Low) and differing degrees of recommendation (Mandatory/Highly Recommended/Recommended) depending on the SIL to be supported. Although not explicitly declared, the notion is that the measures and their effectiveness can be suitably weighted to allow an evaluation of their aggregate contribution. This is a somewhat convoluted approach in which the apparent ‘rigour’ is largely illusory; for example, ‘The effort required for medium effectiveness lies somewhere between that specified for low and high effectiveness’. In practice, it would be difficult for an end user to assess an element against the requirements for techniques and measures; more typically, this would be for the manufacturer.
VI. Prior-Use Assessment
Although not currently an explicit requirement in IEC 61511, 4 the requirement for systematic capability is implicit in the requirements for ‘prior-use’ evaluations. These include ‘evidence of suitability’, which includes the following:
Consideration of the manufacturer’s quality, management and configuration management systems;
Adequate identification and specification of the components and subsystems;
Demonstration of the performance of the components and subsystems in similar operating profiles and physical environments;
The volume of the operating experience.
The maturity of products is critical to the assessment, it being through feedback from experience that confidence in deployment can be gained. It may well be that manufacturer’s experience leads to modifications, particularly to firmware, and it is critical that these modifications are managed with appropriate quality assurance (QA) measures. The following questions are suggested as an appropriate outline for an assessment of systematic capability of an identified element type and build; appropriate thresholds could be identified against which the level of systematic capability might be nominated or disallowed. In assessing a product, it then becomes a question of the duty holder satisfying himself in regard to these characteristics and placing the assessment on record:
For how long has the element been manufactured? (Relates to manufacturer’s experience)
For how long has the manufacturer been established in the process sector? (Does the manufacturer have an established reputation to protect?)
Is the element series type manufactured in volume? (If not, manufacturer’s confidence from customer feedback will be limited.)
Has the manufacturer operated an accredited QA scheme covering manufacture and development of the element, including any software?
Are there known issues with reliability? (Would immediately disqualify a product unless the issues can be eliminated by specific deployment measures)
What type of software language is employed: Fixed Program, Limited Variability, Full Variability? (Refer IEC 61511 Section 11.5)
Can any programmable capability be secured?
Are comprehensive installation and operating instructions available?
Are comprehensive specifications available? (Functional, Operating and Storage Conditions, Performance, Physical, Electrical, etc.)
This assessment is to be performed by a responsible and competent engineer and held as an archive record in support of the judgement of the systematic capability of the element.
VII. Legacy Installations
This is all well and good when procuring a NEW element on the basis of an existing element (perhaps to add a similar function or to replace an existing element with the current version of the same model), but would be problematical if looking to make an assessment of an EXISTING (legacy) in-service element to substantiate its continuing deployment in fulfilment of a retrospectively nominated SIL. Difficulties would likely arise in acquiring supporting QA information (particularly if the in-service model has been superseded) since we would need to consider the history of the manufacturing systems BEFORE original procurement, rather than their current status. It might also be the case that the manufacturing history prior to original procurement is not extensive; an element may have been in service for 10 years and manufactured for little more than this period. However, if the user experience gives no reason to doubt the suitability of the legacy equipment, it would be perverse to insist on its replacement with something that is not proven on that particular duty. We might, then, accept extensive and satisfactory experience (with a record of time in service and details of the specific duty, environment and service) in lieu of ‘consideration of the manufacturer’s quality, management and configuration management systems’.
Since our concern here is with defences against systematic failure, we do not need to identify the performance of a large population for the purposes of our legacy assessment; an assessment might be made against a single instance. (The performance of an identified population would pertain rather to the random hardware failure rate assumed.) We would, however, need to consider the in-service performance of the element in question and consider whether there have been any unresolved issues with reliability due to systematic concerns. The longer an element has been in service, the more opportunity there will have been for any systematic weakness to manifest itself and the greater our confidence will be that an element has adequate defences against systematic failures. It would be necessary to be satisfied that the element has responded to a real demand or has in some other manner been comprehensively tested for systematic failures. It would otherwise be conceivable that the element may have suffered an unrevealed systematic failure. It should be understood that this assessment would only be valid for that specific legacy duty.
This assessment process would establish the Systematic Capability of an element for the identified duties; it would remain to compile a full safety specification for the element to allow evaluation of requirements in respect of hardware fault tolerance, failure rate and stipulations for installation, configuration, maintenance and operation. This may be prepared by consideration of the element nature and design and references to the manufacturer’s product specifications and manuals, together with estimates of failure rates from manufacturer’s data, generic databases or experience with identified populations with circumstances of deployment suitably close to that proposed. 5
VIII. Conclusion
It should be recognised that absolute guarantees of fitness-for-purpose are simply not available; we seek rather a degree of confidence. A responsible and critical (but relatively straightforward) examination of the provenance and in-service history of elements may provide this confidence. We should recognise also that the ultimate safety performance of elements is often governed by the specifics of the equipment deployment and the maintenance management provisions rather than the intrinsic characteristics of the equipment itself.
Footnotes
Funding
This research received no specific grant from any funding agency in the public, commercial or not-for-profit sectors.