
Abstract
The operator of a power block must prove its safety to the state authority. This article deals with the modeling of safety systems using the fault tree analysis method, powered by RiskSpectrum software. Based on real data, the importance analysis of several safety functions is shown. As a result of a quantitative analysis, the influence of several safety system components on the total availability of the protection system is described. The statistics of a number of components that influence 90% of the unavailability of the safety system and the component with the greatest importance measure from each safety function is also shown.
I. Highlights
We modeled 37 power plant safety functions.
We evaluated the unavailability of each safety function.
The importance measures of each component of the safety system were calculated.
Recommendations were introduced to increase the safety function quality.
II. Motivation
This contribution deals with the importance measures of each component of the safety system providing watch-keeping of power plant safety. It introduces examples of safety functions based on actual coal power plant situations, but due to the fact that some information is part of the plants’ business secrets, all of the information will be transformed into a percentual expression. The influence of each safety system component on the overall unavailability of the safety function is calculated as a percentual expression of the component’s influence on the safety function. Safety functions were analyzed using the fault tree analysis (FTA), and all calculations were made with the globally approved RiskSpectrum software tool, which was developed to support the FTA. The importance of the component is affected by the logical structure of the safety function and by the connection between the analyzed component and the safety function from the dependability point of view. The achieved results should lead to an improvement in the dependability of safety systems and a simplification of the decision-making of power plant operators, and which components should be redesigned because of their greater importance. In other words, this means where the investments would bring the greatest benefit. Or, and this is very understandable for managers, how to achieve the requested unavailability of safety systems (safety integrity level (SIL)) at the lowest cost while realizing the requirements for power plant operation. 1
III. Modeling of Safety Functions
The operator of the power block must prove its safety. This can be done in several ways. It is currently increasingly popular to prove safety by meeting the requirements given by the so-called SIL. 2
This text shows the principles of SIL computing for the new projected power source. The authors calculated the unavailability of safety-related systems—securing the boiler and hydrogenous system. Calculations were made using the FTA of safety functions. 3 RiskSpectrum software was used to support data computing, which is globally accepted software for modeling nuclear power plant safety-related systems and functions.
For the purpose of power source safety system modeling, only those safety functions that prove the level of their (un)availability were chosen. Each safety function has a defined SIL on a scale from 1 to 4. The quantitative expression of that scale and its transformation to parameters commonly used in dependability theory, as an unavailability or failure rate, is shown in Table 1 .
Failure rates and unavailabilities related to SILs
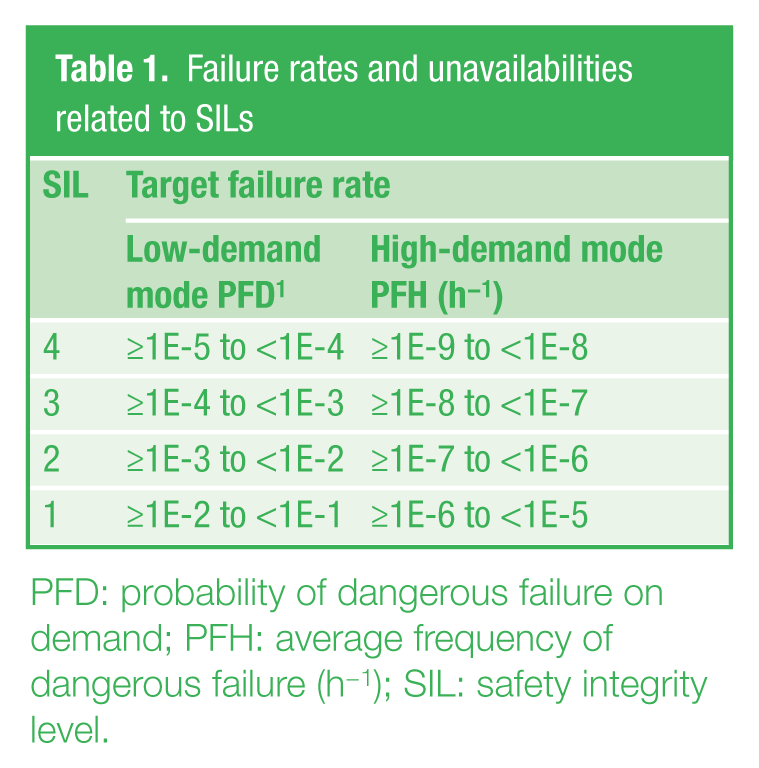
PFD: probability of dangerous failure on demand; PFH: average frequency of dangerous failure (h−1); SIL: safety integrity level.
As this text is about safety-related function modeling, where we suppose the correct reaction to a dangerous event (solution to unwanted situation), it is evident that the frequency of occurrence of the safety system action will be lower than once per year. Thus, the safety system works in the low-demand mode and the object of our interest is its probability of dangerous failure on demand (PFD), also called unavailability.Conversion of SIL to PFD will be done by the left low-demand mode column in Table 1 .
The unavailability of an object, respectively, the unavailability of the function, depends on two basic characteristics. The first is mean time between failures (MTBF), respectively, its reciprocal value—failure rate λ. The second is mean time to restoration (MTTR) or its reciprocal repair rate µ value. Due to the fact that there is no sufficiently accurate data about the failures and maintenance of safety-related systems, we had to take into account some simplifications and presumptions. The first presumption was the estimation of MTTR. A repair itself does not take so much time as it is mainly performed in the replacement of a faulty component, but to the MTTR we must also add the time the component was in an unknown faulty state, that is, the so-called latent failure or latent fault state. This presumption is based on the fact that safety-related systems do not work continuously, and many failures occur only upon a demand for its function, or better still, during preventive maintenance or periodical testing. For the purpose of this contribution, 100% successful testing, meaning all latent failures will be revealed during the test, is supposed. Such testing was executed once a year, but its contribution shows how the overall unavailability of the safety function moves as a result of changing test periods.
The next limitation was the inaccessibility of data about the dependability of a few components. In some cases, the producer only sent a certificate showing that said components meet the requirements of SIL. But that could not be confused with whole SIL safety functions. In that case, we conservatively supposed the value of unavailability of such components as the highest value in the relevant SIL interval (the worst possible value).
An important factor influencing the unavailability of the safety function is the possible occurrence of the so-called common cause failure (CCF). These failures affect all CCF group components under the same failure cause (e.g. loss of electric power causes the loss of function of all pumps in the pumping station). Unfortunately, in this case the data were also incomplete, so for the purpose of the analysis, the probability of CCF was set at 10% of the component failure rate.
These simplifications and presumptions lead to conservative results. This means that the calculated unavailability will in all cases be higher than the reality, and if such a result will meet the required SIL, it is obvious that the real safety function will also meet it. It is now possible to transform the FTA safety functions and to calculate the unavailability of the model.
IV. Choosing of the Analysis Type
The dependability theory includes many types of analysis. Basically, there are two types of approach—inductive and deductive. Based on our experiences, the inductive approach is commonly used. The representative of such an analysis is failure mode, effects and criticality analysis (FMECA), reliability block diagram (RBD), what-if analysis, hazard and operability study (HAZOP), and so on. The principle of inductive analysis is to define what would happen if some component fails. That means, the analyst has to go through all components of the system and identify effects and consequences of every simple failure. In case of extensive system, this approach is very time-consuming.
The deductive principle of dependability analysis is represented by the FTA. In case of deductive modeling, the analyst first determines the objective of analysis, mainly the well-defined fault of the system. Then, there are identified events (or their combinations) that lead to the failure defined as the so-called top event. The FTA guarantees that all components related to the top event are included into the analysis, but no more items must be examined. The properties described above were the reason why we choose the FTA as the method for the power plant safety system analysis.
V. FTA
Calculations of the unavailability of safety functions for the hydrogen generator and boiler protection system during the analysis of the power plant safety systems were made. That analysis identifies the failure modes and also takes the operating conditions, maintenance support and maintainability of the analyzed equipment into account. The next step saw the logic models of each safety function made using the fault tree models. The top event of each FTA model represents an unwanted event, that is, the failure of a safety system. Basic events of the FTA models represent the failures of every single component dealing with the safety function. The structure of fault trees shows (by using logic gates) possible combinations of basic events (component failures) leading to the top event occurrence. The quantification of developed models is made as the final part of the FTA. The result of that action is the probability of the top event that can be understood as the unavailability of the safety function. This value is often also called PFD. The described procedure was repeated for all safety functions (37 times) of the boiler and hydrogen generator safety system.
The calculation of the PFD safety functions is based on the model quantification through the input values of dependability parameters of basic events. These parameters consist of reliability, failure rate, maintainability, maintenance support, MTTR, and so on. Fortunately, these parameters are interconnected, for example, reliability is characterized by the failure rate λ (h−1) or by the opposite value of the failure rate, called MTBF. Maintainability and maintenance support are characterized by MTTR. It was determined that the greatest influence on the MTTR of safety functions is time to reveal the failure. This is because the safety system failure is usually hidden until such time that the safety function is required. All safety functions are periodically tested. A basic simulation was made for a test interval of 1 year, but we also tried to simulate other test intervals. The time to safety function failure was set at one-half of the test interval. We supposed that 100% of hidden failures will be disclosed during the function test.
Every safety system, as well as protection of the hydrogen generator as the boiler, can fail not only in case of safety function demand but also in case of so-called safe way. Safe failure means that the safety system trips the production process without any external reason. These failures are not dangerous, but they cause economic loss for the plant operator. However, safe failures mostly only lead to economic consequences and as such we did not take them into account in the safety analysis. More information about this problem can be found in Kamenicky. 4
VI. Case Study—Safety Function Modeling
There were 37 safety function models examined during the analysis of one power plant. These modeled functions were, for example, trip of the fuel gas system, trip of the coal belt conveyor, trip of the coal heating system, trip of the air blower, and so on. The case study introduced in this article will represent a boiler protection system from the separator flap including command making and sending. This model was chosen because of its simplicity corresponding with the space possibilities of this text.
The top event of the presented fault tree is dangerous failure (DF), meaning no function of the safety system on demand. The logic of failures’ combination leading to the top event is shown in Figure 1 . How should this picture be read? Starting from the top event, it is evident that safety function is generated by a logic solver followed by three independent measurement channels. Each channel measures the position of the separator flap and the “true” value is chosen from these three measurements by the 2 out of 3 algorithms.5,6 The analyst can see that the top event also occurs during the CCF of the following:
Separator flap position sensors;
Splitters of the signal from each individual measurement channel;
Input units.
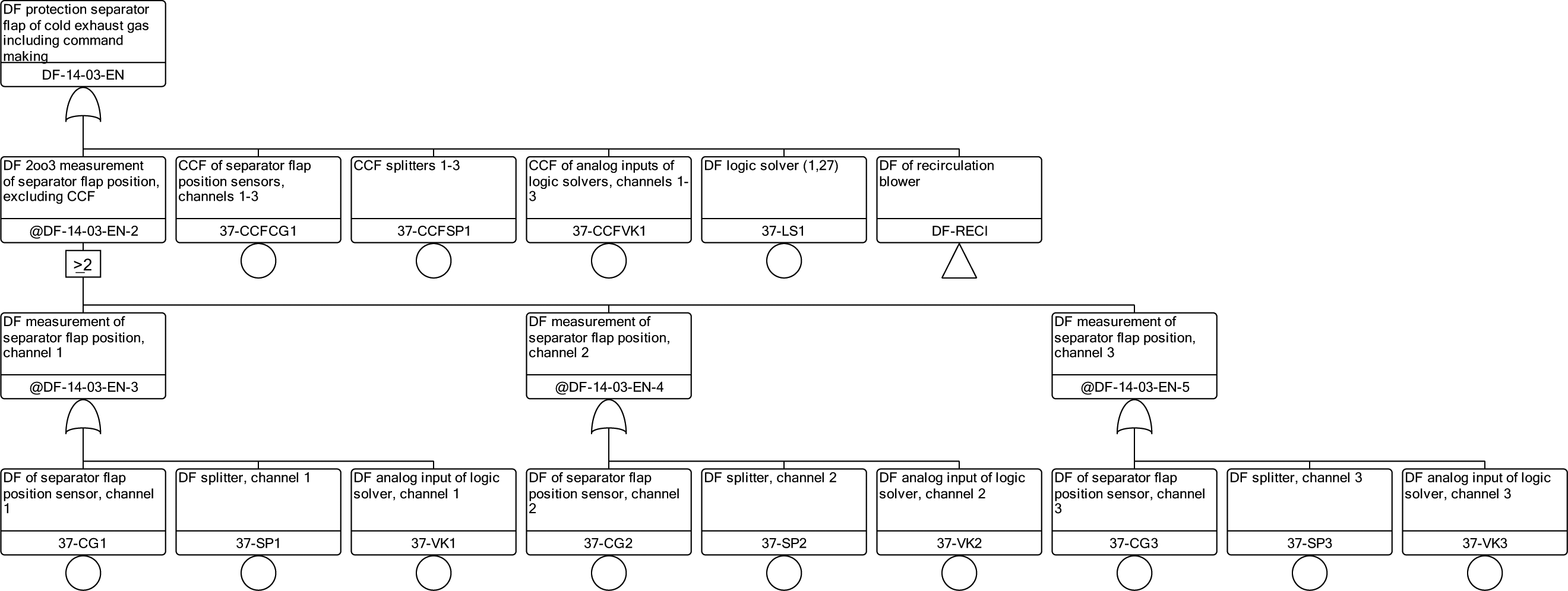
Fault tree of boiler safety system for an unwanted event coming from the cold exhaust gas separator flap
Based on the knowledge of this logic, we can suppose that the greatest influence (importance) on top event unavailability will involve a logic solver failure. The last option to raise the top event (DF of the boiler protection system from the separator flap, including command making) is that the recirculation blower fails dangerously, which is described in the separate fault tree marked as dangerous failure of recirculation blower (DF-RECI). It is a great advantage of fault tree modeling that one failure described in a separate fault tree can be used as an input (or be precisely transferred) to the other fault tree for further analysis.
VII. Importance Analysis
There are many importance measures known in dependability theory. In this article, we mention at least the Birnbaum et al. 7 and Fussell–Vesely8,9 principle of the importance analysis.
The Birnbaum importance can be calculated in two ways—the first way is to compute the whole safety function unavailability with the premise that the analyzed component is the fault and with the premise that the analyzed component is reliable and finds a difference between these two values. This method is expressed in formula (1)
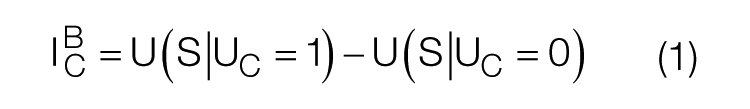
The second option to calculate the Birnbaum importance is to do a partial derivation of the system unavailability by the unavailability of the analyzed component. The mathematical expression of such calculation is given in equation (2)
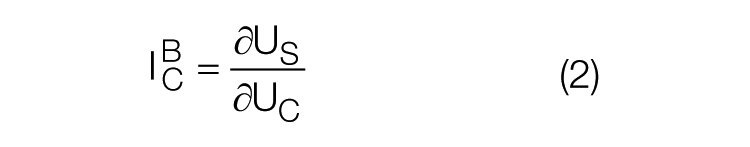
The other point of view of the component importance is given by the Fussell–Vesely importance calculation. In this meaning, the component importance shows the percentual expression of the unavailability of minimal cut sets including the analyzed component on the basis of unavailability of the whole safety function. 10 This can be expressed mathematically as in equation (3)
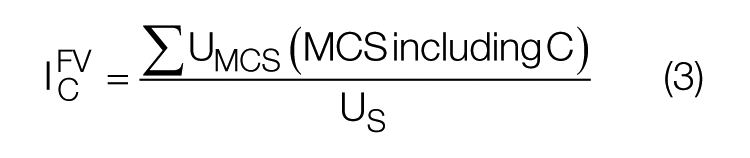
The Fussell–Vesely importance measure is also used by the RiskSpectrum software to evaluate the importance of the basic event, parameter or minimal cut set. Moreover, the RiskSpectrum uses the percentage value of minimal cut sets’ importance. This value tells us what the addition of top event unavailability caused by the analyzed minimal cut set is. We suppose that all analyzed components are independent of each other. This is the actual situation from the field data. In regard to the safety functions, the logic solvers and integrated circuits are also only single purpose.
The safety function mentioned in Figure 1 is just an example: 37 safety-related functions were analyzed. The first step of the analysis was to make a logical model of the function, after which the dependability parameters of each basic event were loaded and the importance measures were calculated. For the mentioned fault tree, the result of the importance analysis is that 97% of the safety function unavailability results from the transfer gate that represents fault tree DF-RECI. This result means that the DF of the separator flap protection system depends on the value of the unavailability of the DF of the recirculation blower.11,12
The analysis of all 37 safety functions was performed in the same way as the importance and sensitivity analysis of the safety system related to the separator flap. The following shows four attributes for each safety function:
The number of components that participate in the safety function;
The importance of the most important component;
The number of components that cause 90% of safety function unavailability;
The percentual expression of the number of components that cause 90% of safety function unavailability.
The concrete descriptions and names of the safety functions are the subject of commercial confidentiality, and we are not allowed to present them, so each safety function will be marked by an “anonymous” identifier only.
VIII. Decision-Making Based on Importance Analysis
Probably, the greatest benefit from the importance analysis could come from the decision-making process, in which managers decide which is the best place to invest money. 13 Table 2 shows the component with the greatest importance and also the percentual expression of the number of components that cause at least 90% of safety function unavailability.
List of safety functions, number of components of each safety function, the greatest importance of one component and number of components that caused 90% of top event unavailability
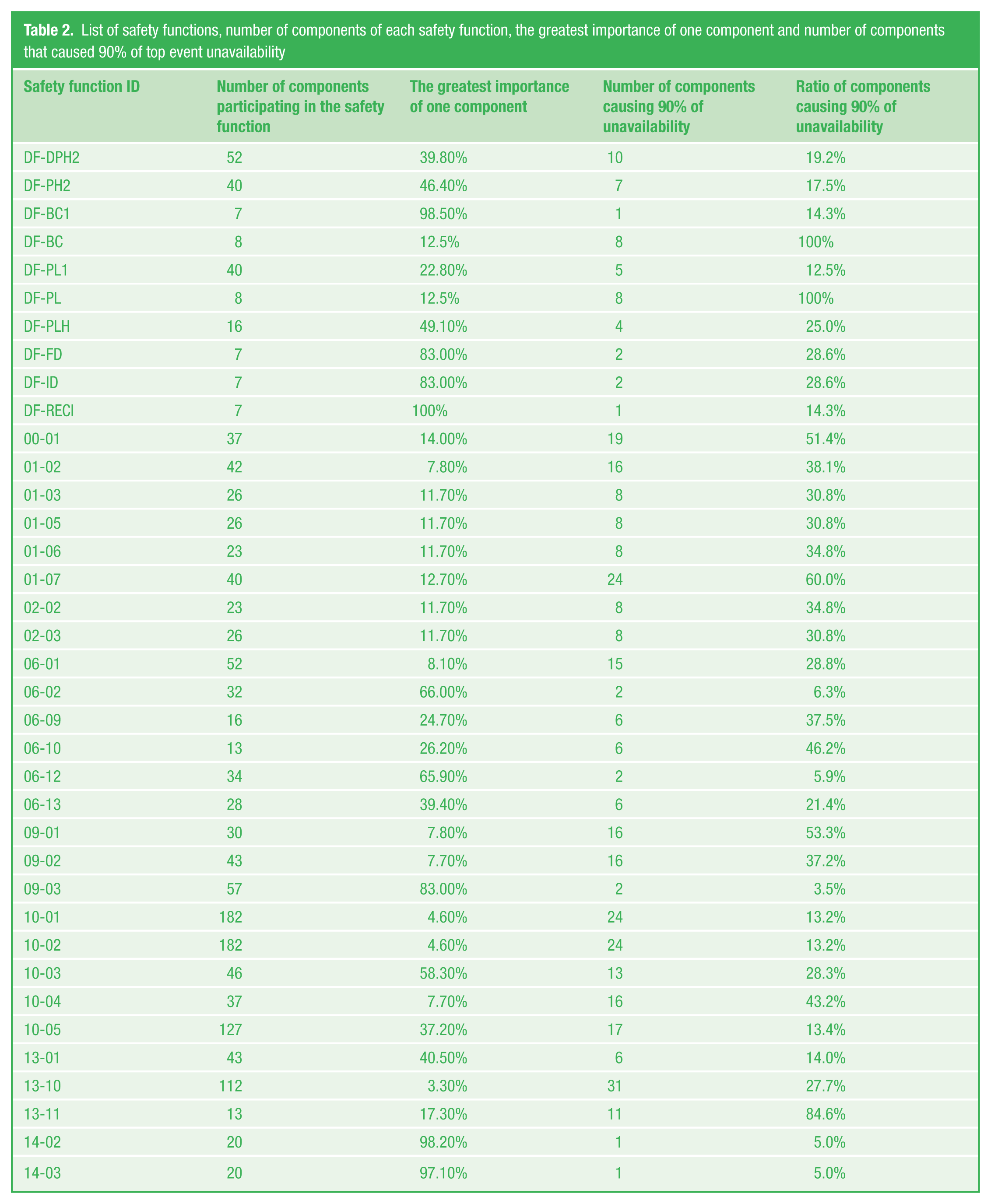
It is evident from the Table 2 that less than one-third of components cause more than 90% of situations where the safety system does not respond as required. Moreover, it is possible to underline those components that have the greatest influence on the unavailability of the safety system and focus our attention on them during modification of the concept or logic of every single component usage in the safety system. There are in fact three options on how to increase the dependability (reliability and/or availability) of the safety system. The first is to increase the MTBF of critical components, for example, by their replacement with more dependable ones. The second option is to change the maintenance process in such a way that the MTTR of components will be lower—this means in fact shortening test intervals to avoid latent DFs of safety system components. And the last but no less important option for increasing dependability is change of the backup system. This means using additional components for processing the same function, but in some voting/averaging system that shall increase the system dependability. To read more about that problem, see Kamenicky 4 and Guo et al. 14
Each option has its pros and cons. Generally, we can say that the component dependability grows more slowly than its price. The only exception could be components that are at the end of their moral technical life, meaning they could be replaced by new and modern components at a similar price level (e.g. analog vs digital sensors). Lowering the test interval is not necessarily possible in all cases because safety systems must work during the whole power block operation, and of course, during preventive maintenance and testing, the safety system is not able to protect the industrial process. The third option, backup increase/implementation, is also not applicable everywhere. There are space limitations for the sensors and cables in the measured area. Moreover, this option brings investment in the dependability growing process, which is always a problem to approve. 15
To be better introduced to the problems of component importance, Fussell–Vesely importance measures of the safety function from Figure 1 will also be shown in Table 3 .
Fussell–Vesely importance measures of safety function components
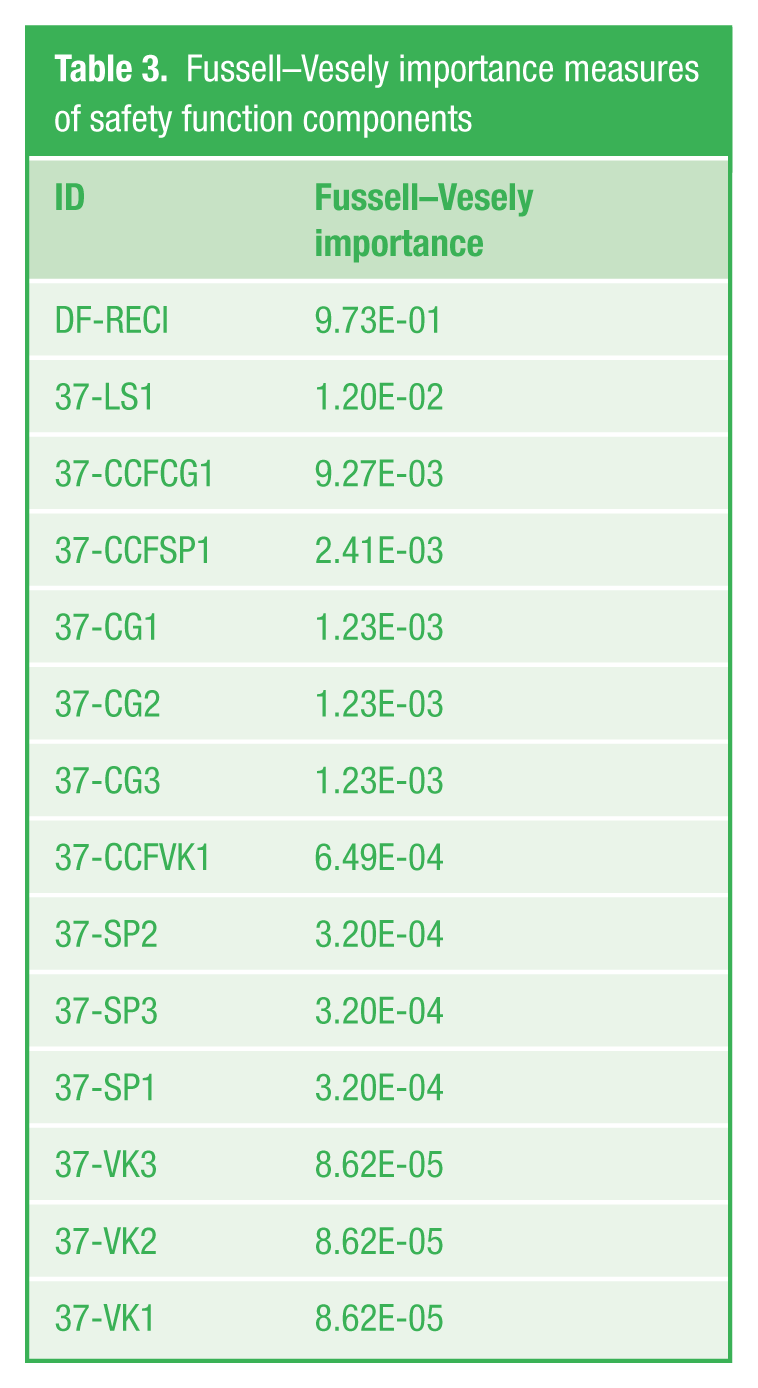
The example shown in Table 3 is interesting because of one of the biggest computed importance measures, where more than 97% of safety system unavailability is caused by only one component. If the operator of the power plant increased dependability of only one component, the safety function unavailability would decrease rapidly. The component with ID DF-RECI is probably the best place to invest money. We tried to simulate placing another DF-RECI in a parallel structure into the modeled safety function and its unavailability fell 35-fold, while the importance measure of the DF-RECI came down from 97% to just 7%. The question is whether it is possible to elaborate such redesign or not. Of course, it is well known that huge economical effect has also wrong action of operators or maintenance staff, who are generally called human factor; 16 but the level of importance of humankind can be hardly calculated and does not influence unavailability of safety function.
Second important finding comes from the importance analysis, and visible in Table 3 is the big importance of the logic solver—component 37-LS1. It is well known that logic solvers are more dependable than sensors or final elements so the importance of logic solver should be lower. One must realize that in the case study, there is the voting mechanism 2oo3 (2 out of 3) joining together triple measurement of the flap position and increasing dependability of the sensor group before this information enters the logic solver. Logic solver itself is in the whole safety function just once, so its dependability is lower in comparison with the backed-up position sensors.
IX. Discussion and Conclusion
Based on the obtained results, it is evident that the overall dependability of the safety function depends on a relatively small number of components that perform the safety function. The results of the importance analysis of 37 safety functions show us that the most important component of each protection system is its logic solver that processes measured information. The level of redundancy seems to be sufficient at the present time, regardless of what measurement to analyze. All measurements (temperature, level, flow, pressure, or their combinations) are redundant enough.
A special group of sensors is the so-called smart sensors, which are able to combine the measurement of more quantities, and based on that comparison, the sensor itself transmits information about its output credibility (validated output). A great disadvantage of these sensors is their technical complexity and of course their price, which is too high for mass usage.
Threats to industrial factories including power plants are failures with a common cause. These failures cause non-functioning of the whole measurement circuit composed of more redundant sensors. Another threat is a safety function logic that could be processed only in a limited number of integrated circuits because of their speed, space, requirements, and so on. The failure of these components causes the non-functioning of the whole protection system and can result in an unwanted trip of the process in the better case and a catastrophic scenario (loss of human life, massive environmental damage, huge economic loss, etc.) in case of dangerous event occurrence and incoming demand on the safety function action. The results published in this article can help power plant operators to manage their investments in safety and dependability. To put it simply, this article could help operators to maximize the effect of the money they spend.
Footnotes
Appendix 1
Funding
This research was supported by the technology agency of the Czech Republic, project no. Te01020036—advanced technologies for heat and electricity production.