
Abstract
Systems fail. Period. No matter how much planning and fault analysis is performed, it is impossible to create a perfectly reliable machine. The existing approach to improving reliability invariably involves advances in fault prediction and detection to include specific mechanisms to overcome a particular failure or mitigate its effect. While this has gone a long way in increasing the operational life of a machine, the overall complexity of systems has improved sharply, and it is becoming more and more difficult to predict and account for all possible failure modes. What is discussed here is a possible shift in approach from specific repair strategies to autonomous self-repair. Rather than focusing on mitigating or reducing the probability of failure, the focus is instead on what can be done to correct a failure that will invariably occur at some point during operation. By taking this approach, it is not just expected failure that can be designed for, unexpected failure modes are also inherently compensated for, extending the potential life of a system and reducing the need for through-life servicing.
I. Introduction
It is impossible to discuss the concepts of self-healing and self-repair without having some notion about their meanings. There are currently no universally accepted definitions of these terms, but instead, intuitive notions about the concepts involved. It is not the purpose of this article to suggest a new taxonomy, but instead to look at what the overall aims are of this emerging field and perhaps reflect on what is achievable now. To make these issues more awkward, there are currently many terms for the similar ideas, and conversely, many distinctly different ideas that are referred to by the same name. Furthermore, different fields of research such as electronics or mechanical design can have vastly different interpretations and objectives. A good example of this is modular or physical1–3 redundancy in electronics—these concepts could perhaps be thought of as inefficient if the same principles are applied to a purely mechanical system that contains more material or elements than are strictly necessary for an optimized design.
In layman’s terms, perhaps what we are looking in self-repair are systems that are able to maintain some degree of functionality after a failure has occurred. This might be a controversial interpretation, however, as it can be argued that certain self-preservation or preemptive actions, such as prognostics or mitigation through fault tolerance, are an intrinsic element of self-healing, and hence, we should not focus solely on what happens after the event of a failure.
The above definition is similar to the general or biological definition of “resilience,” which is commonly interpreted as the ability to recover from adversity. 4 Hence, fault-tolerant approaches might better fall under this general umbrella of “resilience” rather than self-healing.
Fundamentally, one crucial distinction is the difference between a reactive or proactive system. In fault tolerance, where the system is able to absorb a finite number of fault events without explicit repair or reconfiguration, it is assumed that failure can to a certain extent be prevented. For the purpose of this discussion, however, we will assume that failure can and does occur.
II. Achieving Self-Repair
To achieve a self-repairing system, it is clear that the system must have an element of self-awareness. Amor-Segan et al. 5 state that the ultimate aim is to develop a system with “the ability to autonomously predict or detect and diagnose failure conditions, confirm any given diagnosis, and perform appropriate corrective intervention(s).” Following this logic, Figure 1 offers a proposed approach that can theoretically be applied to any system. By breaking the process down into a number of finite steps, we can better assess the current progress toward achieving an idealized self-repairing system.
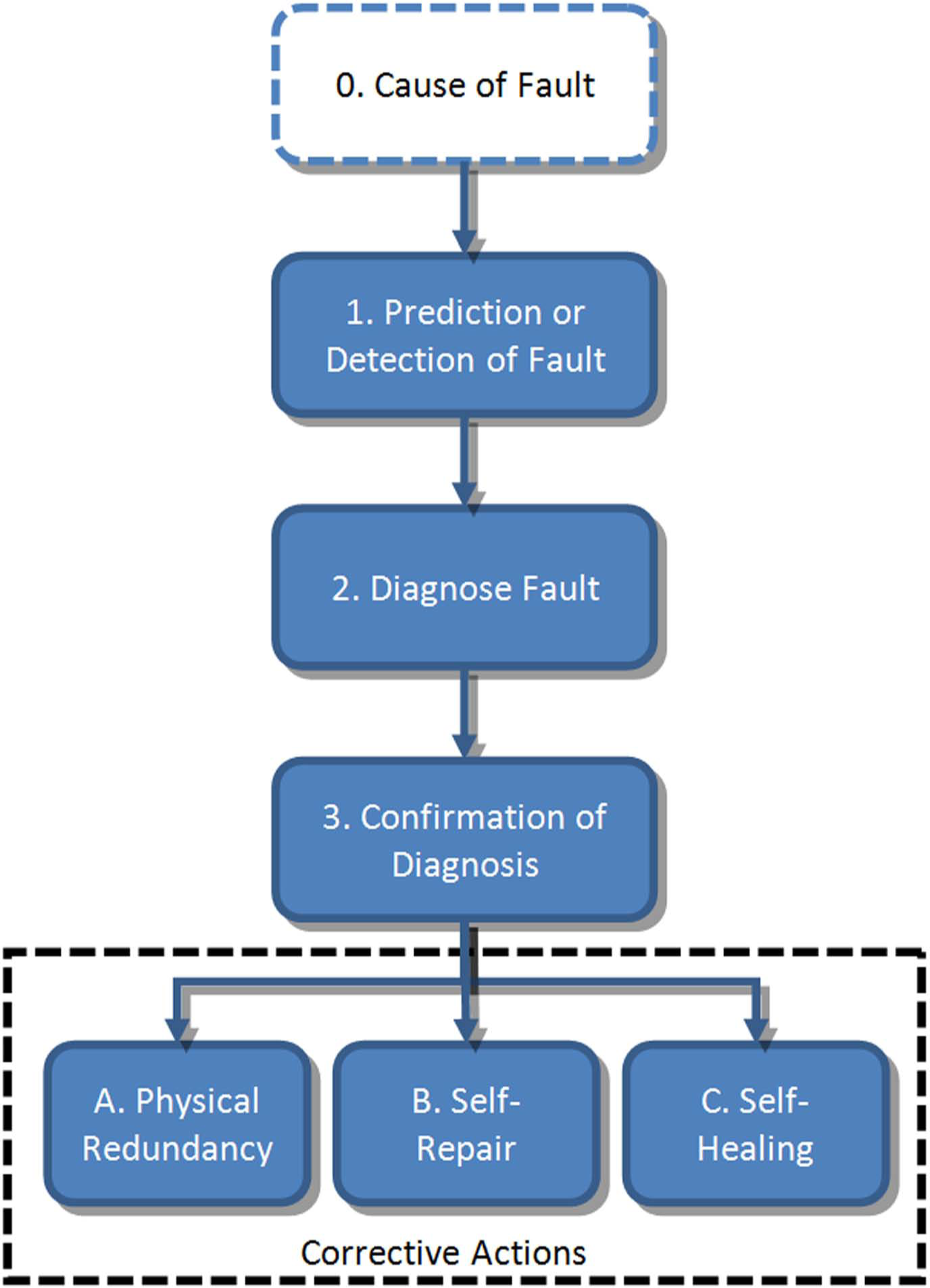
Proposed approach to self-correcting systems
Perhaps the first point that can be drawn from this proposed process is that the underlying cause of fault is not considered crucial. There is a whole research sector dedicated to function-based failure analysis,6–8 and while there will invariably be some degree of crossover between the disciplines, here, it is better to focus instead on what happens after failure has occurred.
III. Detection and Diagnosis
Any critical fault will almost invariably lead to a fundamental change in the behavior of the system. This could perhaps be most easily interpreted as a deviation from the prescribed behavior, utilizing either internal or external telemetric data. One of the difficulties with this complex system is in defining “expected behavior”; however, this problem is not insurmountable, and a great deal of progress has been made in this research area. 9
Conversely, the diagnosis of a fault is perhaps a more difficult proposition. This is partly due the difficulty in validating large, complex system models because of the vast number of possible system states. 5 Furthermore, there is the issue of confidence in diagnosis, that is, how much certainty must be present to initiate repair? Because of this, an additional step is proposed in which the diagnosis must be confirmed, to avoid undesirable events such as “good” components being unnecessarily removed or routed around. Several methods are currently available for this:
Model-based abductive reasoning. Compare observation with predicted observation—if “X” is expected but “Y” is obtained, then “Y” must be corrected to get it to match;
Bayesian belief networks. Probabilistic graphical model is a type of statistical model that represents a set of random variables and their conditional dependencies—if “X” and “Y” happen, it is likely a failure with “Z”;
Case-based reasoning methods. Anecdotal evidence—if “X” happens, do “Y”—it accounts for expected failure only.
Currently, there has been some progress in these areas in electronics with built-in self-testing (BIST). Silicon electronic devices are susceptible to a variety of upset events, including transitory events (e.g. random single upset events caused by radiation) and permanent fault conditions that can be triggered by a vast variety of events. Rather than eliminating the underlying cause, BIST has been developed for computer dynamic random access memory (DRAM), where special structures are included in the memory chips that are activated when attached to production test machine. This enables rapid and reliable allocation of redundant memory cells to replace faulty cells that are commonly found in high-density memory. Perhaps what we now seek is a shift from this external detection to in-system detection and correction, such as self-contained BIST logic that can operate independently of the (expensive) production test machine during the operational life time of the memory chip. Data error detection and repair are particularly pervasive in electronic systems; it protects critical memory areas such as on-chip cache, which cannot tolerate transient upset errors.
IV. Corrective Actions
Perhaps of most interest in self-repairing systems is the corrective action itself. If it were possible to fully automate this process, then there are huge potential savings in maintenance, repair, and operations (MRO) costs. The precise methodology employed will almost invariably have to be application specific; however, a number of possible approaches are available:
Physical redundancy. An alternative load path or system is available should the primary system fail:
Currently, this is the easiest approach to include and is already implemented on mission-critical systems; At a very basic level, this can simply be a complete facsimile of the primary system (modular redundancy) that can take over if failure occurs; Its relative efficiency can perhaps be measured by how much of the primary system has to be physically replicated to provide the backup.
Self-repair. The system, as a whole, has the ability to partially or fully fix a given fault to continue operation:
This is the approach that is perhaps most achievable in the immediate future; One approach is to extend the concept of redundancy to the use of degenerate modules that have the ability to perform the same function or yield the same output even if they are structurally different;
10
Using this approach rather than having individual backups for each module, a single spare module can be reconfigured to provide cover for any defective module; Alternatively, this concept of self-repair through self-reconfiguration does not necessarily require additional materials, instead performance can be sacrificed to ensure continued functionality utilizing only the currently available resources.
Self-healing. The system is able to physically bring itself back to its initial state of operation after a fault has occurred:
True self-healing systems are currently prohibitively expensive and infeasible for all but the most basic of systems or limited to exotic materials; An idealized example couple would be the ability to automatically re-straighten a mechanical element (through a chemical process) after it has been bent, or physically fix thermal damage in an electronic component; An alternative approach would be to have entirely adaptable systems, such as “smart dust,”
11
where there is a finer level of granularity and near infinite possibilities for reconfiguration.
To better emphasize the distinction between the corrective actions, Tables 1 shows a simple example of the repair of a car-tire puncture and how this compares to biological approaches.
One salient point that becomes apparent when looking at biological parallels is that each of the corrective actions does not necessarily have to occur in isolation. Indeed, in the broken skin example, it is common for self-repair and self-healing to occur sequentially to produce a coupled-whole system. Indeed, this is normally preceded by assisted repair in which the wound is externally bandaged.
Biological inspiration for self-healing

V. Current Progress
The electronics domain is perhaps leading the way with regard to self-repairing systems. An evolution from external testing to self-contained testing is already underway with the next proposed approach built-in self-repair (BISR). Electronic Data Capture (EDC) methods offer BISR functionality via special hardware structures. A limitation here is that permanent faults cannot generally be handled by EDC, and system failure will result. Permanent faults can be protected by introducing system redundancy such as Triple Modular Redundancy (TMR), which was first proposed more than 50 years ago; 12 however, one must assume that the voting logic itself is trustworthy or else can also be replicated.
A less popular approach is that of fine-grained fault tolerance employing interconnect interleaving and quadded logic, 13 which requires additional logic and signal routing hardware but which is able to “absorb” certain permanent fault events without loss of functionality. The basic principles at work here are the fine granularity of the underlying transistor and interconnecting structure that offers many possibilities for reconfiguration and fault tolerance. Beyond this, there is significant interest in new bio-inspired approaches that use cellular based architectures. Inspired by the early observations of Von Neumann on the intrinsic fault-tolerant properties of biological systems, 4 this offers the possibility of electronics systems whose operation is governed by localized interactions between electronic “cells,” that is, circuits not requiring global coordination, and hence, BIST and BISR can be executed at the cellular level.14,15
VI. Conclusion
Looking at the overall concept of product reliability, if viewed from the perspective of the user, a system with an integral resilience-mechanism would appear to be more “reliable”—it is able to maintain operation for a longer period of time than would otherwise have been possible. However, from a design approach, systems with additional procedures built-in are invariably more complex, and hence, the primary system becomes intrinsically less “reliable,” even though it is able to bring itself back to a normal operating condition. Getting the balance right between this intrinsic reliability and apparent reliability is important to ensure that self-healing technologies are accepted by the end user.
Despite vast improvements in system modeling and prediction, most machines still fail in the face of unexpected damage, 16 and one of the long-standing challenges of creating a reliable system is achieving robust performance under uncertainty. 17 Self-repairing techniques inherently must be designed to compensate for a wide variety of failure modes, thus overcoming some of the problems associated with uncertainty. Although specific solutions have not been suggested, proposed methodologies for developing self-repairing strategies should not focus on a finite number of underlying causes. Instead, the focus should be on how these causes manifest, how they can be detected, and ultimately how they can be corrected autonomously.
Footnotes
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.