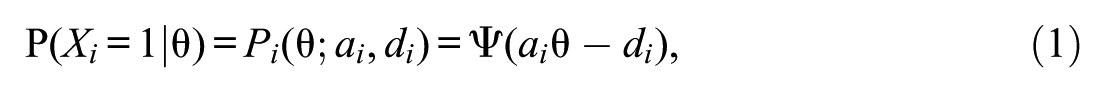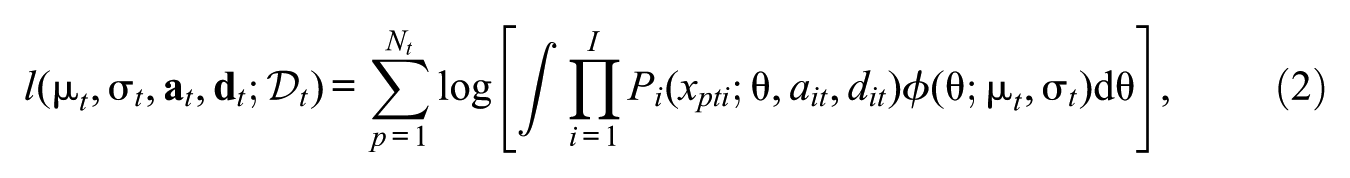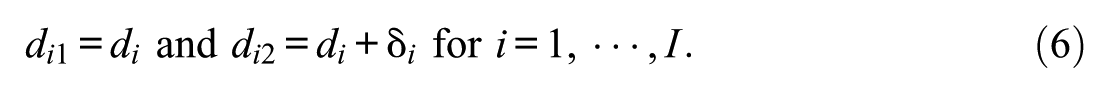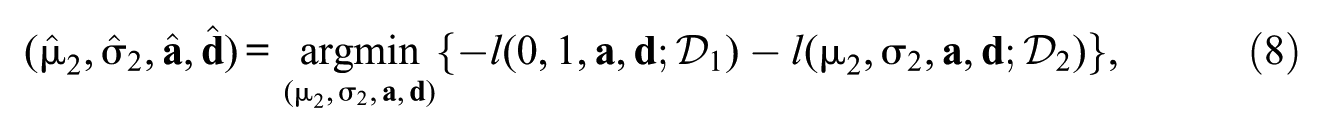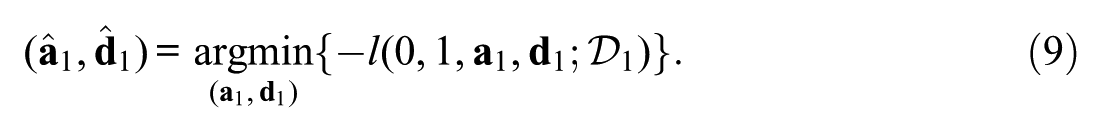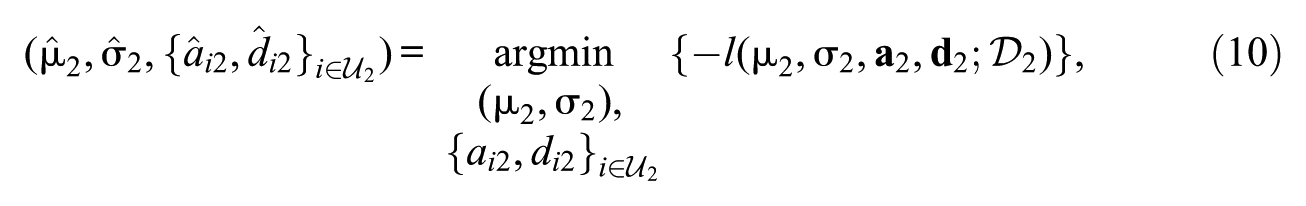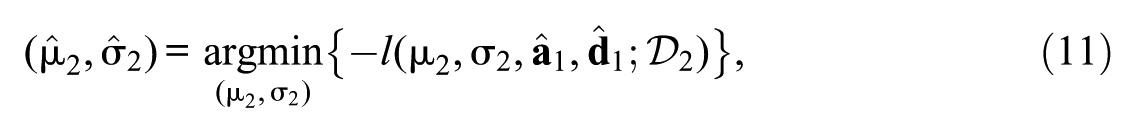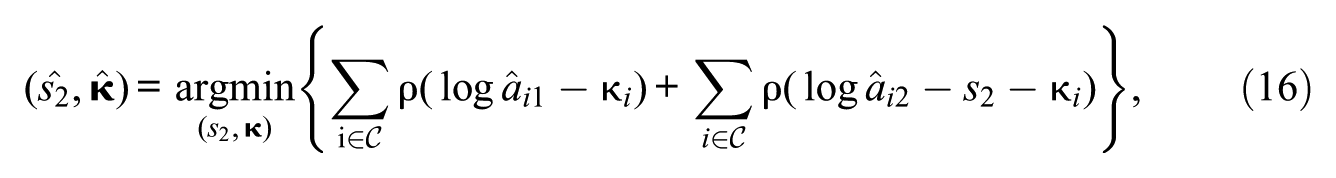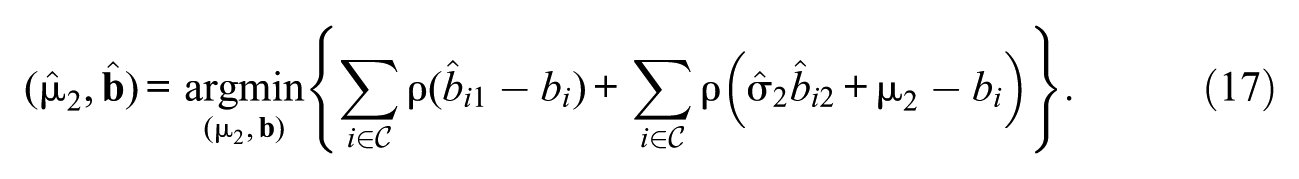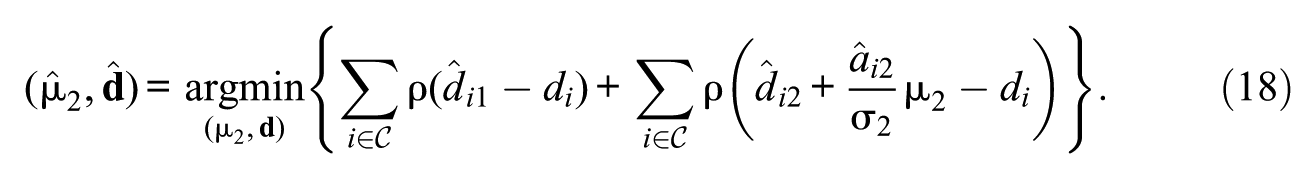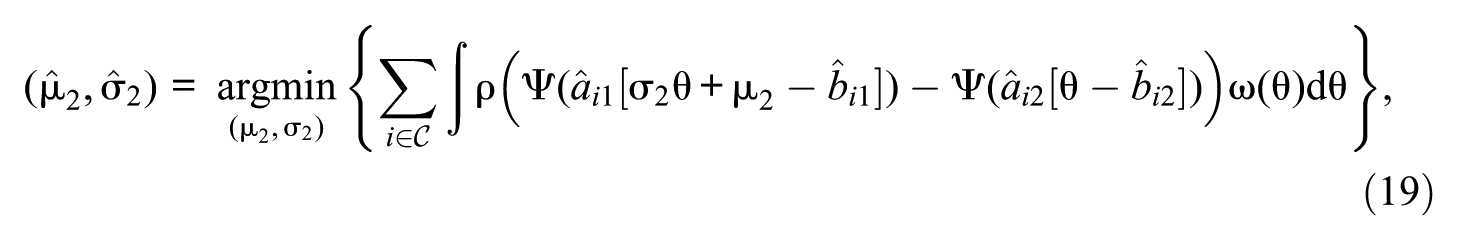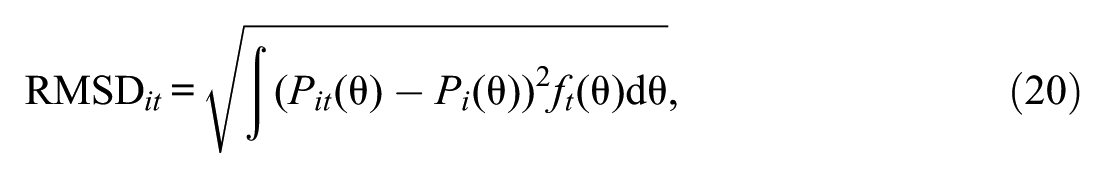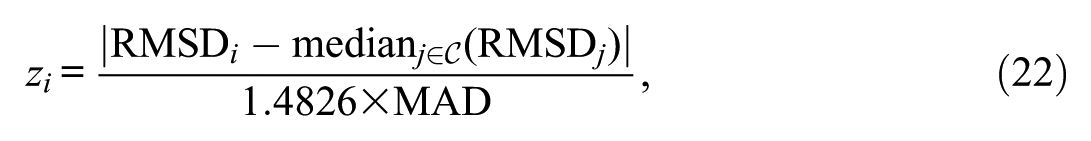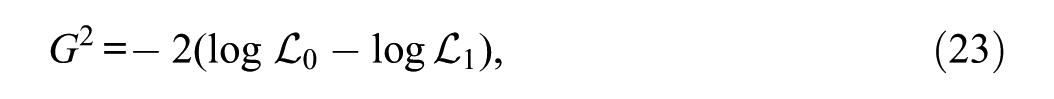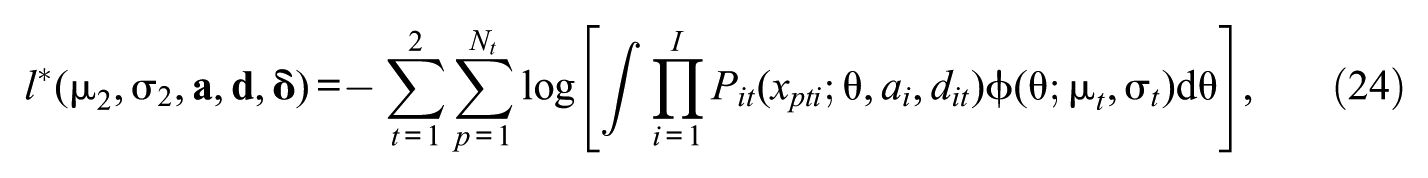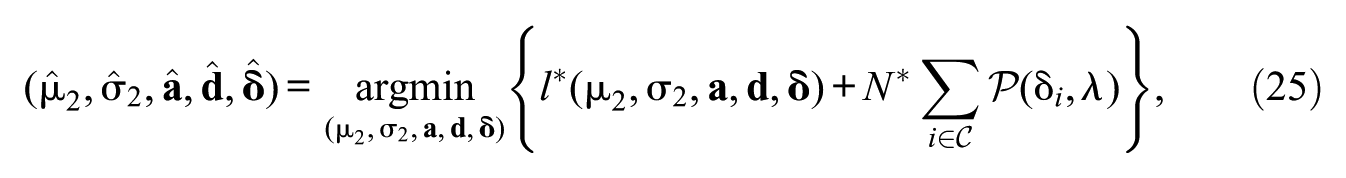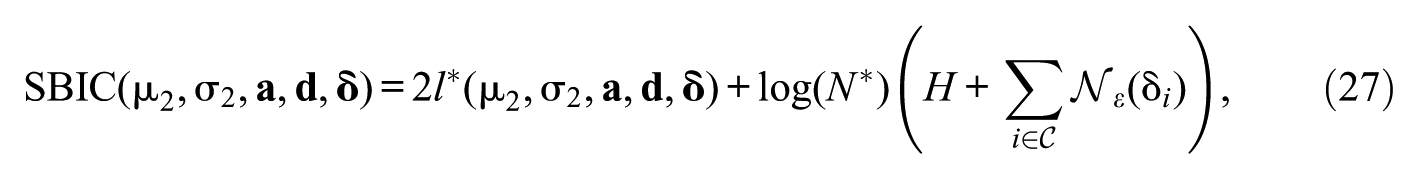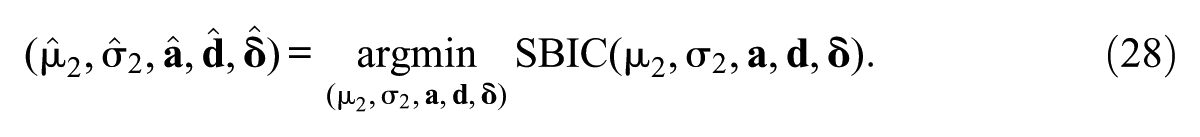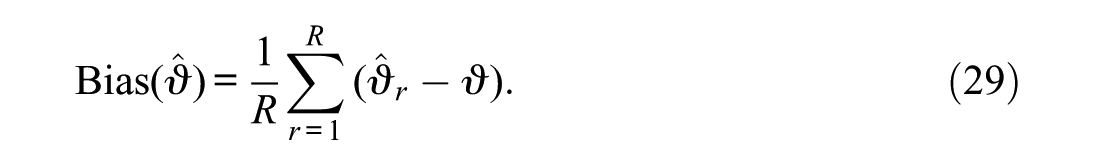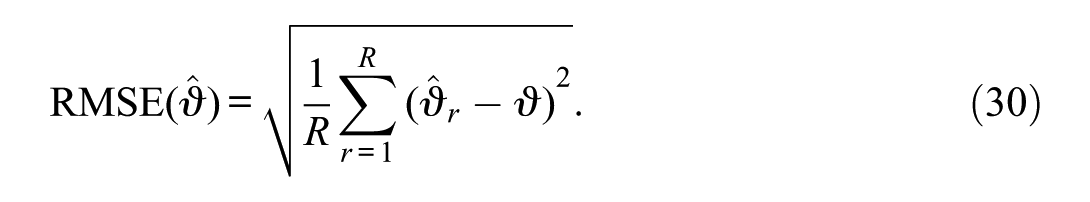In longitudinal assessments, tests are frequently used to estimate trends over time. However, when item parameters lack invariance, time-point comparisons can be distorted, necessitating appropriate statistical methods to achieve accurate estimation. This study compares trend estimates using the two-parameter logistic (2PL) model under item parameter drift (IPD) across five trend-estimation approaches for two time points: First, concurrent calibration, which jointly estimates item parameters across multiple time points. Second, fixed calibration, which estimates item parameters at a single time point and fixes them at the other time point. Third, robust linking with Haberman and Haebara as linking methods with or losses. Fourth, non-invariant items are detected using likelihood-ratio tests or the root mean square deviation statistic with fixed or data-driven cutoffs, and trend estimates are then recomputed using only the detected invariant items under partial invariance. Fifth, regularized estimation under a smooth Bayesian information criterion (SBIC) is applied, shrinking small or null IPD effects toward zero while estimating all others as nonzero. Bias and relative root mean square error (RMSE) were evaluated for the mean and SD at T2. An empirical example using synthetic longitudinal reading data, applying the trend-estimation approaches, is provided. The results indicate that the regularized estimation with SBIC performed best across conditions, maintaining low bias and RMSE, followed by robust linking methods. Specifically, Haberman linking with the loss function showed superior performance under unbalanced IPD, outperforming the partial invariance approaches. Concurrent and fixed calibration showed the poorest trend recovery under unbalanced IPD conditions.
Longitudinal large-scale assessments (LSAs) in educational and psychological sciences are frequently used to estimate trends over time (Rohm et al., 2021; M. von Davier et al., 2011). These assessments typically employ different but overlapping test forms at successive time points. Examples of such assessments include the National Educational Panel Study (NEPS) in Germany, the Early Childhood Longitudinal Program (ECLS) in the United States, and the National Assessment Program-Literacy and Numeracy (NAPLAN) in Australia (Australian Curriculum, Assessment and Reporting Authority, 2023; Blossfeld et al., 2011; Tourangeau et al., 2018). The overlap created by common items links the time-point-specific forms, thereby aligning the test scores on a common scale (Kolen & Brennan, 2014; A. A. von Davier et al., 2004).
In this study, the two-parameter logistic model (2PL; Birnbaum, 1968) is examined exclusively as a special case of a unidimensional item-response theory (IRT) model (van der Linden, 2016). The 2PL model is employed to analyze the relationship between a unidimensional latent trait and dichotomous item responses for . The item-response function (IRF) for the 2PL model is expressed as
where is the logistic distribution function, and and are the item discrimination and (negative) item intercept parameters, respectively. We now present IRT estimation for two time points . Let denote the response vector of person at time point . We define the log-likelihood function for data in time point () as
where denotes the probability density function of the normal distribution with mean and standard deviation (SD) , the vectors of item parameters are defined as and , and is the probability of response given by the IRF defined above. The mean and the SD of at the first time point (T1) are fixed for identification reasons to 0 and 1, respectively.
IPD affecting both discrimination and intercept parameters and is termed nonuniform IPD, while drift affecting only the intercept parameter (with for ) is referred to as uniform IPD (Mellenbergh, 1982). We assume that the 2PL holds for both time points, and that there is uniform IPD, constraining the discrimination parameter to be time-invariant (i.e., ), while allowing the intercept to be time-point-specific
An equivalent parameterization of the model uses item difficulties, , which are related to item intercepts by the identity . The model is then written as
In the presence of IPD, the time-point-specific item intercept can be decomposed as
where represents the time-invariant intercept and represents the IPD effect for item at time . We focus on a two-time-point design (), for which the general expression reduces to
The objective of this study is to compare the performance of different trend-estimation approaches for handling sparse uniform IPD across two time points. To this end, we conduct a comparative analysis encompassing five trend-estimation approaches: First, concurrent calibration (CC), which jointly estimates item parameters across multiple time points (e.g., S.-H. Kim & Cohen, 1998; Kolen & Brennan, 2014). Second, fixed calibration (FC), which estimates item parameters at a single time point and fixes them at the other (e.g., S. Kim, 2006; König et al., 2021). Third, robust linking with Haberman (2009; Robitzsch, 2023a) and Haebara as linking methods (Haebara, 1980; He et al., 2015). Fourth, non-invariant items are detected using likelihood-ratio tests (LRTs; e.g., Finch, 2005; Thissen et al., 1988) or the root mean square deviation (RMSD) statistic with fixed (FIX, e.g., Oliveri & von Davier, 2011) or data-driven (DD) cutoffs (M. von Davier & Bezirhan, 2023), and trend estimates are then recomputed using only the detected invariant items under partial invariance. Fifth, regularized estimation (REG) under an smooth Bayesian information criterion is applied, shrinking small or null IPD effects toward zero while estimating all others as nonzero (O’Neill & Burke, 2023; Robitzsch, 2024b).
While individual trend-estimation approaches have been studied under sparse uniform IPD, comprehensive comparisons remain limited. Cho et al. (2016) compared four approaches for handling DIF under the assumption of known DIF items: deleting DIF items, CC under full and partial invariance, and confirmatory multidimensional modeling. However, they did not examine FC, detection-based methods, robust linking approaches, or REG. Finch (2005) compared the LRT against three alternative DIF detection methods using a single significance level and re-estimation via CC only, but they did not examine FC, robust linking methods, or REG. Robitzsch and Lüdtke (2022) compared CC under full and partial invariance, the latter employing RMSD detection with FIX cutoffs, as well as robust Haberman linking (HAB) and Haebara linking (HAE) methods under balanced and unbalanced DIF conditions. Their study, however, did not examine iterative purification approaches, DD RMSD cutoffs (subsequently developed by M. von Davier and Bezirhan, 2023), LRT, FC, or REG. Robitzsch (2023a) compared regularization with the smoothly clipped absolute deviation (SCAD; Fan & Li, 2001) against robust HAB and HAE and RMSD with DD cutoffs under both balanced and unbalanced DIF; however, this study did not examine FC, the LRT, RMSD with FIX cutoffs, or iterative purification. No prior study has compared all five approaches in the specifications employed in this study under both balanced and unbalanced IPD conditions.
The remainder of this article is organized as follows. We introduce five approaches for trend estimation under sparse uniform IPD in the 2PL model. Next, we describe the simulation study design and present the main results. Two additional analyses examine FIX and DD RMSD cutoffs and LRT significance levels. An empirical example using synthetic data from a longitudinal reading comprehension assessment illustrates the application of trend-estimation approaches. Finally, this article concludes with a discussion of the findings and limitations, directions for future research, and a conclusion.
Approaches for Trend Estimation
In longitudinal assessments with two time points, we distinguish between the following item sets: the set of common items, , which appear at both time points and serve to link the assessments onto a common scale, the set of unique items, , which appear only at time point (where ), the set of anchor items, , which are invariant common items with time-invariant parameters (i.e., for all ), and the set of biased items, , which are non-invariant common items with time-varying parameters (i.e., for and ). Note that with .
Concurrent Calibration (CC)
The CC method (e.g., Hanson & Béguin, 2002) estimates parameters for all items at both time points jointly, in a multiple-group IRT model. This model includes both common items and time-point-specific unique items . Common item discriminations and item intercepts are estimated by minimizing the estimation function
with and being fixed for identification reasons to 0 and 1. The CC method enforces parameter invariance for all common items across time points, effectively assuming that and . Thus, for all for . This assumption is violated when IPD is present, as items that belong to are incorrectly constrained to have at . Unique items at each time point are estimated freely within their respective time points. The CC method has been shown to perform well under correct model assumptions and without DIF or IPD (Jodoin et al., 2003; S.-H. Kim & Cohen, 1998; Kolen & Brennan, 2014). When IPD is present, unbalanced IPD typically introduces more bias in trend estimates than balanced IPD, although even balanced IPD can still lead to slightly biased estimates in the 2PL model, as the presence of any IPD may negatively affect the estimation of common item discriminations (Robitzsch, 2023a). The CC method has been extensively studied in various contexts (e.g., Jodoin et al., 2003; S.-H. Kim & Cohen, 1998; Kolen & Brennan, 2014; Lee & Ban, 2009; Robitzsch & Lüdtke, 2022).
Fixed Calibration (FC)
The FC method (Jodoin et al., 2003; Kang & Petersen, 2012; Keller & Keller, 2011; S. Kim, 2006) is a two-stage procedure. First, item parameters are estimated from the data at the first time point (T1), with the latent trait distribution fixed for identification (). Here, and are the vectors of discrimination and intercept parameters for all items at T1 and are estimated as
Second, the estimated item parameters and at T1 for common items, , are held fixed when fitting the model to data from the second time point (T2). These fixed values serve as equality constraints for the T2 calibration
where and denote the combined parameter vectors, with the constraint that and for all common items , while parameters for unique items are freely estimated. With no unique items present at T2, this simplifies to
where only the distribution parameters () are freely estimated at T2. Like CC, this method assumes that all common items are invariant (, ). FC has been found to perform satisfactorily under no IPD, or under partial invariance when items with detected drift are excluded from the common item set before calibration (Hu et al., 2008; König et al., 2021). In the presence of DIF, FC yields biased estimates of the mean (e.g., Sachse et al., 2016), and there is also evidence for bias in the SD (e.g., Robitzsch, 2024a). The bias in the estimated mean can change sign when ability distributions differ across administrations (Keller & Keller, 2011).
Robust Linking
Robust linking is a two-step process. First, item parameters are calibrated separately for both time points, without invariance constraints, typically with identification constraints and . In the second step, robust linking methods place these separately estimated parameters onto a common scale using the common items . In robust linking methods, the sets and are determined implicitly by down-weighting outlier items. T1 serves as the reference scale, and two linking constants, and , transform T2 to this scale via , such that . The linking constant represents the estimated SD, whereas denotes the estimated mean for T2. Non-robust linking uses the loss function, while robust methods employ loss functions that minimize the influence of items with IPD when determining linking constants, effectively down-weighting biased items. The choice of the loss function is central to the robustness of these methods. This study focuses on the versatile family of loss functions and the related loss function, which are described next.
The loss corresponds to squared loss, while corresponds to median regression (Koenker, 2017; Koenker & Hallock, 2001). For , the function is non-differentiable at . A differentiable approximation of can be used as
The approximation of the loss function has been shown to outperform approximations of other loss functions for small values of (Robitzsch, 2023b). A value of has been shown to perform well in various settings and will be applied in this study for the approximation with (e.g., Robitzsch, 2025b). The approximation will be used with and .
Haberman Linking (HAB)
Haberman (2009) introduced a regression technique that extends the mean-geometric mean (MGM) method for multiple time points. The original Haberman formulation uses the loss. The regression model uses log-transformed item discriminations and item intercepts, where the mean and SD of T1 are set to 0 and 1, respectively, for identification. First, the log-transformed SD of T2, , and the common logarithmized item discriminations , are estimated as
where is the or loss function. The untransformed SD of the T2 is obtained as . Under uniform IPD, where remains invariant across time points, this SD estimation remains unaffected by the drift in intercept parameters. Second, the mean can be estimated based on either item difficulties or item intercepts . The former is the original version proposed by Haberman (2009). The common item difficulties are estimated as
Estimation based on item intercepts is performed as (Robitzsch, 2025a)
The intercept parameterization yields more precise trend estimates due to the lower estimation variance of intercept parameters compared to difficulty parameters (Robitzsch, 2025a). Unlike MGM linking, which directly uses group-specific item parameter estimates, HAB simultaneously estimates joint item parameters across both groups. Empirical evidence from Robitzsch (2025b) indicates modest efficiency gains from this approach in two-group settings, even though it was originally proposed and used for linking multiple groups or time points.
Haebara Linking (HAE)
HAE linking (Haebara, 1980) minimizes the discrepancy between the IRFs based on item parameters obtained from separate calibrations. The linking function, based on the item difficulty parameterization (), is defined as
where is the or loss function, and is a weighting function. The weighting function can be uniform or a normal-density function. Haebara’s original proposal used the empirical frequency of ability estimates as weights, which is closely approximated by a normal-density function (Haebara, 1980; Robitzsch, 2025c). A recent variant, called information-weighted HAE, weights the squared deviations by the sum of the item information functions from both groups to reduce the impact of parameter estimation errors (S. Wang et al., 2024; W. Wang et al., 2022). However, simulations by Robitzsch (2025c) found that, while this approach outperforms HAE with uniform weights, it is inferior to normal-density weights in terms of bias and root mean square error (RMSE). Normal-density weights emphasize the ability scale center, where estimates are more precise, thereby reducing estimation error influence from the tails and decreasing linking constant variance (Robitzsch, 2025c). In contrast to HAB, HAE simultaneously estimates both and by minimizing differences between the IRFs [Equation (19)]. Therefore, uniform IPD affecting item intercepts influences both parameter estimates. The original Haebara method employed an loss (), which is sensitive to outliers. To increase robustness against IPD, variations using an loss () were proposed (He & Cui, 2019; He et al., 2015). Further research demonstrated that even smaller exponents () can reduce bias more effectively in the presence of unbalanced IPD (Robitzsch, 2020). This increased robustness was found to result in only a small loss of statistical efficiency (i.e., a higher RMSE) in scenarios involving no or balanced IPD (Robitzsch, 2020; Robitzsch & Lüdtke, 2022). In addition, it should be noted that the standard HAE procedure is asymmetric, aligning the IRFs from T1 onto those of T2. This asymmetry implies that the direction of linking can influence the results when IPD is present, as the method minimizes deviations in only one direction. For a symmetric HAE method, see S. Kim and Kolen (2007), Arai and Mayekawa (2011), and Weeks (2010).
Partial Invariance Using IPD Statistics
Partial invariance using IPD statistics handles non-invariance in a two-stage procedure. First, items exhibiting IPD are detected using IPD statistics. Then, they are accounted for in a subsequent modeling step (e.g., Penfield & Camilli, 2007; Wu, 2010). This approach partitions the set of common items into sets and . After identifying the biased items, a model under partial invariance is re-estimated. In this model, the item parameters of the items in are estimated freely across time points, while item parameters in the anchor set are constrained to be equal. The trend is then estimated from the final partial invariance model. In this model, the common scale is established by the anchor items (Robitzsch & Lüdtke, 2022).
The detection-based approach faces the circular problem of needing a set of DIF-free items to reliably detect items with DIF or IPD (Angoff, 1982; Doebler, 2019). If the initial anchor set contains biased items, it can distort the detection process and inflate Type I error rates for other items (Shaffer, 1995). While various IPD statistics exist in the literature (see Penfield & Camilli, 2007, for an overview), this study focuses on the significance-based LRT (Thissen et al., 1988) and the effect-size-based RMSD (Tijmstra et al., 2020), using FIX and DD cutoffs (M. von Davier & Bezirhan, 2023).
Re-estimation and Item Purification
A variety of approaches exist for implementing IPD detection methods (e.g., Kopf et al., 2015a). In this study, a one-step (OS) approach and a forward-only iterative (IT) approach are utilized for RMSD (Magis et al., 2010). In this study, we implement both the OS and IT approaches for RMSD. In contrast, the LRT is evaluated using only the OS approach due to computational constraints that require model calibrations per iteration, where is the number of items tested.
In the OS approach, all items in are initially assumed invariant. IPD statistics are computed for each item , and items exceeding the threshold are reassigned from to . The procedure terminates here or continues iteratively. In the IT approach, items that are flagged as non-invariant are not retested in later iterations. Each iteration re-estimates a model under partial invariance, freeing parameters for items in and maintaining equality constraints for items in , and recomputes RMSD statistics only for the items that remain in . Newly flagged items are transferred to , and the cycle repeats until no additional items are flagged or a maximum set of iterations is reached. Similar to the implementation of the difR package (Magis et al., 2010), we set a maximum number of iterations. While the difR authors chose 10 iterations, we opted for 7 iterations.
After IPD detection identifies biased items, the resulting anchor set is used for trend estimation through two approaches: CC under partial invariance, which frees time-point-specific parameters for items in while maintaining equality constraints for , and linking methods applied to the anchor items. For linking, we use the squared loss () for HAB (with item intercepts and item difficulties) and HAE (with uniform and normal densities, with and ).
The IT approach carries inherent risks. As items are removed, remaining anchors bear greater responsibility for scale identification. Type I errors can create a cascade effect where contaminated anchors lead to further misclassifications (e.g., Kopf et al., 2015b). Early false positives cannot be corrected in later iterations.
To ensure model identifiability across LRT and RMSD, a minimum of three common items must remain in the anchor set . Two items would theoretically suffice for identification in the 2PL model; three anchor items provide more stable trend estimation and reduce sensitivity to parameter estimation errors in individual items. If detection procedures flag more items than this constraint allows, only those with the highest values for LRT, or the highest FIX or DD RMSD values, are flagged, up to items. If no items are flagged, the re-estimation proceeds with .
Root Mean Square Deviation (RMSD)
The RMSD for a common item at time point assesses the distance between a time-point-specific IRF and the model-implied IRF under invariance (Thissen et al., 1988). It is calculated as
where represents the IRF under the invariance constraint (using the pooled or constrained parameter estimates across time points as defined earlier), and is the density of at time point . It is important to note that the sample-based RMSD is a biased estimator of its population counterpart. Therefore, it tends to be positively biased in smaller samples due to sampling variability (Köhler et al., 2020). Its value is context-dependent, as item misfit can inflate RMSD values for well-fitting items in the same test (M. von Davier & Bezirhan, 2023). For more details on estimating the RMSD, see Köhler et al. (2020) and Tijmstra et al. (2020).
Fixed Cutoffs
Items are flagged when RMSD exceeds a FIX cutoff. Proposed cutoffs in the literature range from 0.05 (Robitzsch & Lüdtke, 2022) to 0.20 (OECD, 2016). Simulation studies demonstrated that stricter cutoffs (0.05, 0.08) outperform lenient thresholds in controlling bias and identifying biased items (Buchholz & Hartig, 2019; Fährmann et al., 2022; Köhler et al., 2020; Robitzsch & Lüdtke, 2022). Based on this evidence, this study employs a range of strict to moderate cutoffs (0.03, 0.05, and 0.08) to evaluate their effectiveness.
Data-Driven Cutoffs
The DD approach proposed by M. von Davier and Bezirhan (2023) offers an alternative for identifying items with IPD effects using median-based statistics. Unlike FIX cutoffs, which apply predetermined cutoffs regardless of the data distribution, this approach derives cutoffs DD from the observed RMSD distribution itself. First, the median absolute deviation (MAD) of the RMSD values is computed as the median of the absolute deviations from the median RMSD
where denotes the value for item , and the index serves as a running index over all common items when computing the inner median. A robust z-score is then calculated for each common item at time point
where the scaling constant 1.4826 makes the MAD comparable to the SD under normality assumptions (Huber, 1981). We estimated the MAD separately for T1 and T2.
Items are flagged as exhibiting IPD if their robust z-score exceeds a critical value . Since the RMSD has a meaningful lower bound of zero, items are flagged only if their robust z-score exceeds the positive cutoff, effectively making it a one-sided test for large deviations (M. von Davier & Bezirhan, 2023). M. von Davier and Bezirhan (2023) evaluated cutoffs of 2, 2.5, and 3 in their original study. The present study examines two cutoff levels, and , to evaluate detection performance across different stringencies. The value of 2.7 has been employed in subsequent applications (Robitzsch, 2023a) and aligns with robust outlier detection practices in IRT models (Huynh & Meyer, 2010; Liu & Jurich, 2022). The DD approach adapts to the empirical RMSD distribution, making it less sensitive to sample-specific peculiarities than FIX cutoffs. M. von Davier and Bezirhan (2023) found that DD was more sensitive than a relatively lenient FIX cutoff of 0.15. However, stricter FIX cutoffs (e.g., 0.05 and 0.08) have been shown to identify IPD items better and reduce bias in trend estimates (Buchholz & Hartig, 2019; Fährmann et al., 2022; Köhler et al., 2020; Robitzsch & Lüdtke, 2022). Accordingly, the present study compares DD alongside these lower FIX cutoffs.
Likelihood-Ratio Test (LRT)
The LRT for IPD detection (Thissen et al., 1988) compares nested IRT models. This study employs the constrained-baseline model approach, also known as the all-other anchor method, which is common in IRT research (Stark et al., 2006; W.-C. Wang & Yeh, 2003). In this approach, the baseline model (Model 0) constrains all common items to be invariant (, and for all ). To test a specific item for IPD, an alternative model (Model 1) is fitted, in which the item’s parameters are freely estimated across time points. At the same time, the invariance constraints are maintained for all other common items, which serve as the anchor set that establishes the common metric (Cohen et al., 1996; S. H. Kim & Cohen, 1995). The test statistic is computed as
where is the likelihood of the baseline model (Model 0), which constrains the item to be invariant, and is the likelihood of the alternative model (Model 1), where the item’s parameters are freely estimated. The statistic follows a chi-square distribution with for the 2PL model (S. H. Kim & Cohen, 1995). Items are flagged when exceeds the critical value corresponding to the chosen significance level. We apply , α = 0.01, and Bonferroni-corrected , where is the number of items tested (Bonferroni, 1936). The LRT procedure is computationally demanding, requiring separate model calibrations for a test involving items (S. H. Kim & Cohen, 1995).
Under no IPD for the 2PL model, the LRT maintains Type I error rates close to the nominal alpha level (Cohen et al., 1996; S.-H. Kim & Cohen, 1998). While standard alpha levels (e.g., ) can lead to inflated Type I error rates when the anchor set is contaminated (Finch, 2005; González-Betanzos & Abad, 2012; Stark et al., 2006), stricter Bonferroni corrections reduce statistical power with small sample sizes or small IPD effects (Stark et al., 2006). Anchor set quality crucially influences LRT power, with higher-discrimination anchors improving detection rates (Lopez Rivas et al., 2009). Unbalanced IPD poses problems for the constrained-baseline approach by distorting the latent scale (W. Wang et al., 2022).
Regularized Estimation (REG)
Regularization methods handle IPD by addressing the model identification problem directly within the estimation framework. If IPD effects were freely estimated for all items in , the model would be unidentified, as the item-level drift parameters would be perfectly confounded with the overall trend parameters () (Bechger & Maris, 2015; Doebler, 2019). Unlike CC, which enforces full invariance by assuming (all ), or detection methods that explicitly partition into and , regularization treats all items in as potentially having IPD under a sparsity assumption. Therefore, in Equation (5), most items are expected to have , while only a subset have nonzero effects.
The REG approach employs a multiple-group IRT framework, where both time points are estimated simultaneously. For time points , the negative log-likelihood function is
with and fixed for identification, contains the time-invariant discrimination parameters, contains the baseline intercept parameters, and contains the IPD effects. Note that , as defined in Equation (5), where and for the two-time-point case. Compared to Equation (2), the parameter vector now contains . This overidentified model with all potential IPD effects is made identifiable by adding a penalty term to the log-likelihood function, and the REG problem becomes
where is the total sample size across both time points, and is a penalty function with regularization parameter .
While penalty functions such as the least absolute shrinkage and selection operator (LASSO; Tibshirani, 1996) and the SCAD (Fan & Li, 2001) could be applied, these require computationally intensive grid search or cross-validation to select optimal values, making them less efficient for large-scale assessment applications (Robitzsch, 2024b). In addition, the LASSO is known to produce biased estimates for nonzero coefficients and therefore underestimates the magnitude of true IPD effects (Fan & Li, 2001). Previous research has shown that regularization based on a grid search does not always perform convincingly in the pure recovery of population parameters compared to other approaches, such as robust linking (see Robitzsch, 2023a). This study, therefore, employs a more recent regularization estimation approach proposed by O’Neill and Burke (2023), which directly optimizes the smooth Bayesian information criterion (SBIC). This method avoids the computational burden of grid search and has demonstrated the ability to accurately recover population parameters in the context of IRT models under DIF and was found to be the best-performing regularization method for estimating group means in the presence of unbalanced DIF (Robitzsch, 2024b).
The SBIC method modifies the estimation approach based on the Bayesian information criterion (BIC). While the BIC for a regularized model penalizes complexity by counting the number of nonzero parameters using a non-differentiable indicator function, , the SBIC approach replaces this discrete counter with a smooth, differentiable approximation that allows for direct optimization (O’Neill & Burke, 2023; Robitzsch, 2024b)
where is a small tuning parameter. The resulting SBIC to be minimized is
where is the number of non-penalized parameters, and the sum runs over all potentially non-invariant IPD effects. We use three values of the tuning parameter and , while Robitzsch (2024b) found to perform best. The alternative smooth Akaike information criterion (SAIC) was found to have higher Type I error rates. It was outperformed by SBIC in parameter recovery, supporting the use of the SBIC for this application (Robitzsch, 2024b). The final parameter estimate is obtained by
The direct optimization of this criterion performs the estimation of all model parameters and the selection of items with nonzero IPD effects simultaneously. In this integrated process, the IPD effects () of items that are functionally invariant are shrunk toward zero, implicitly defining the set of anchor items within the single estimation step.
Simulation Study
Purpose
This simulation study assesses the performance of five trend-estimation approaches, as described in section “Approaches for Trend Estimation,” in the 2PL model when item parameters are affected by sparse uniform IPD across two time points. The primary goal is to investigate how these trend-estimation approaches perform under varying conditions, particularly the distinction between balanced and unbalanced IPD. The latter is known to challenge methods that assume full invariance or do not employ robust estimation techniques (DeMars, 2019; Robitzsch & Lüdtke, 2022). Therefore, we investigate the extent to which the factors of balanced and unbalanced IPD, the magnitude of IPD effects, the proportion of affected items, sample size, and the number of items influence the accuracy of trend estimates, in terms of bias and root mean square error. We examine contamination scenarios with 10% and 30% affected items, and include a larger mean shift () to assess performance under a larger developmental change.
For balanced IPD conditions, we anticipate that CC, and, to a lesser extent FC, will remain largely unbiased, mitigated by the cancelation effects of symmetric IPD patterns (Chalmers et al., 2015), although slight bias may occur in CC (Hanson & Béguin, 2002; Kolen & Brennan, 2014), and FC is expected to produce biased SD estimates due to model misspecification and the mean shift between T1 and T2 (Robitzsch, 2024a). Robust linking methods with are expected to show reduced bias compared with the loss function (He & Cui, 2019; Robitzsch, 2023a), with HAB based on intercepts being more efficient than HAB based on difficulties (Robitzsch, 2025a). The performance of the detection method will depend critically on correct item identification, with LRT being particularly susceptible to contaminated anchor set effects (Cohen et al., 1996; Stark et al., 2006; W.-C. Wang & Yeh, 2003). REG is expected to maintain unbiased estimation through selective shrinkage of IPD effects (Robitzsch, 2024b). However, the comparative performance of REG versus robust linking methods under balanced IPD with lower IPD item percentages (10% and 30%) remains an open question.
Under unbalanced IPD conditions, we expect the most severe challenges for trend estimation (Chalmers et al., 2015). CC and FC should exhibit unsatisfactory bias that does not diminish with increasing sample size, reflecting fundamental model misspecification (DeMars, 2019; Robitzsch & Lüdtke, 2022). Among robust linking methods, the loss function is expected to minimize bias most effectively, while normal-density weights for HAE are expected to improve precision relative to uniform weights (Robitzsch, 2025b, 2025c). The LRT will face a trade-off between Type I error rates when using the Bonferroni correction and statistical power when using standard significance levels (Finch, 2005; González-Betanzos & Abad, 2012; Stark et al., 2006). For RMSD-based detection, DD cutoffs outperformed a FIX cutoff of 0.15, but it is still uncertain how they compare to lower FIX cutoffs (M. von Davier & Bezirhan, 2023). REG is anticipated to provide strong performance under unbalanced IPD, particularly with the tuning parameter (Robitzsch, 2024b). However, the comparative advantage of REG versus robust linking under unbalanced IPD remains to be seen. Finally, we aim to identify which method specifications yield optimal performance across diverse conditions and, in which IPD conditions, the CC and FC methods, which are misspecified, yield unbiased results.
Method
For the analysis, the ability variable for T1 was assumed to follow a standard normal distribution (i.e., ). For T2, the mean was set to , and the SD was set to . The increased mean represents a larger growth between measurement occasions, while the increased SD reflects the assumption that individual growth trajectories diverge over time. The simulation employed a fixed set of 10 base items, with item discrimination parameters being 1.06, 0.78, 0.91, 1.14, 1.19, 0.89, 0.82, 1.00, 1.00, and 1.00, with values ranging from 0.78 to 1.19 (M = 0.98, SD = 0.12), and item intercept parameters were −0.17, −0.77, 0.36, 1.37, 2.08, −1.56, 0.72, −0.46, −0.46, and −0.46, ranging from −1.56 to 2.08 (M = 0.07, SD = 1.12). The discrimination parameters for IPD-affected items (Items 8, 9, and 10 in each block) were set to to simplify interpretation and ensure comparability with previous studies that used difficulty-based data generation (Robitzsch, 2023a; M. von Davier & Bezirhan, 2023). In addition, using the base item set avoids confounding with simulation factors (e.g., test length). The item parameters can also be found at https://osf.io/q86jz. All items were treated as common items across both time points ( and ).
The simulation design was configured to vary five factors: (a) The sample size () was set at 500, 1,000, and 2,500 for each time point, representing typical sample sizes commonly employed in practice and methodological research (e.g., Berrío et al., 2020; Harwell et al., 1996). (b) The number of items () was set at either 20 or 40, obtained by duplicating or quadruplicating the base set of 10 items (i.e., using two or four 10-item blocks). (c) The IPD effect size () was set to 0, indicating an absence of IPD, 0.5, indicating moderate IPD, or 1.0, indicating large IPD, for the item intercept on designated IPD items. (d) The percentage of common items affected by IPD (%IPD) was 0%, 10%, or 30%. For 10% IPD, Item 10 in each 10-item block exhibited IPD. For 30% IPD, Items 8, 9, and 10 in each 10-item block were affected, all with . (e) The IPD type was balanced, in which positive and negative effects averaged to zero across affected items (half received , and half received ), or unbalanced, in which all affected items received negative effects (), uniformly decreasing the item intercepts at T2. Dichotomous item responses were generated according to a 2PL model for each time point. At T2, uniform sparse IPD effects were applied according to Equation (6) by adding to the base intercept parameter for the specified items. After eliminating redundant conditions in which no IPD would be present (i.e., conditions with either or %IPD = 0%, but not both), the design yielded 54 unique simulation conditions: 3 sample sizes item ([2 IPD effect sizes IPD percentages IPD types] + 1 no-IPD condition). A total of 1,000 replications were conducted for each condition.
The study compared five approaches of trend-estimation methods (described in section “Approaches for Trend Estimation”). For CC, time points T1 and T2 were calibrated simultaneously in a multiple-group 2PL model. FC used the estimated item parameters from T1 as fixed values when calibrating T2. The robust linking methods included the HAB and HAE approaches with loss functions for and , as well as the loss function. The HAB method used item intercepts and item difficulties, whereas the HAE method used four weighting functions: uniform weighting, and normal-density weighting with and . The detection-based methods employed the LRT with , and the Bonferroni correction () with the OS approach. The RMSD was used with FIX cutoffs (0.03, 0.05, and 0.08) and DD cutoffs ( and ) in both the OS and IT approaches. For re-estimation after detection, we applied CC, HAB (with item intercepts or item difficulties), and HAE (with the aforementioned four weighting functions), all with the loss function. An IT approach with a maximum of 7 iterations was implemented for RMSD methods. REG employed SBIC with and . In total, the combinations of all the previously described methods and their specifications resulted in 126 distinct trend estimators.
To present the main findings, we selected the best-performing specification for each approach based on absolute bias in the most challenging condition: unbalanced IPD, 30% IPD, , , and . The sample size was chosen for asymptotic assessment (the largest sample size, ). The complete results for this condition are reported in the Supplement (Table S1). The selected specifications are as follows: We used REG with SBIC (). For robust linking, we chose HAB with item intercepts and HAE with normal-density weighting (). For detection-based estimation, we employed the LRT with a Bonferroni correction (), followed by re-estimation using HAB with item difficulties. Regarding the RMSD, we considered two variants: a FIX cutoff of 0.05 using the IT approach, followed by HAE with normal-density weighting (); and a DD cutoff with using the IT approach, followed by HAE with normal-density weighting (). After reporting the results for these specifications, we present two additional results within the simulation study. The first examines how RMSD FIX cutoffs (0.03, 0.05, and 0.08) and DD cutoffs ( and ), as well as OS versus IT approaches, affect trend recovery. The second set of additional results evaluates how different LRT significance levels influence the re-estimated trends.
The performance of each method was assessed based on the recovery of the two trend parameters of interest: the mean and the SD. For each simulation condition with replications (), the parameter estimate was (either or ). The bias of an estimated parameter was calculated as
The RMSE was estimated by
To enhance comparability across sample sizes, the RMSE was normalized against the REG approach, which was set as the reference method with a value of 100 in each condition. The REG approach was selected as the reference method because it aligns with the data-generating model used in the simulation study. It assumes sparse uniform IPD; therefore, only the item intercepts have IPD effects () at T2, while item discriminations remain invariant across time points. An estimator was considered satisfactory if its relative RMSE was 125 or less, indicating that its RMSE was no more than 25% higher than that of the reference method. Performance for bias was considered satisfactory if the absolute bias was less than 0.015. This threshold was determined based on considerations for two-sample comparisons with . For per group, the standard error of the mean difference is , indicating that a bias below 0.015 represents a negligible fraction of the typical standard errors in large samples.
All analyses were conducted using R (R Core Team, 2024, Version 4.3.3). The sirt package (Robitzsch, 2025d, Version 4.2-114) was employed to estimate IRT models, including the HAB, HAE, CC, and REG implementations. The package was installed from its GitHub repository. Replication material for the simulation study is available at https://osf.io/q86jz.
Results
No IPD
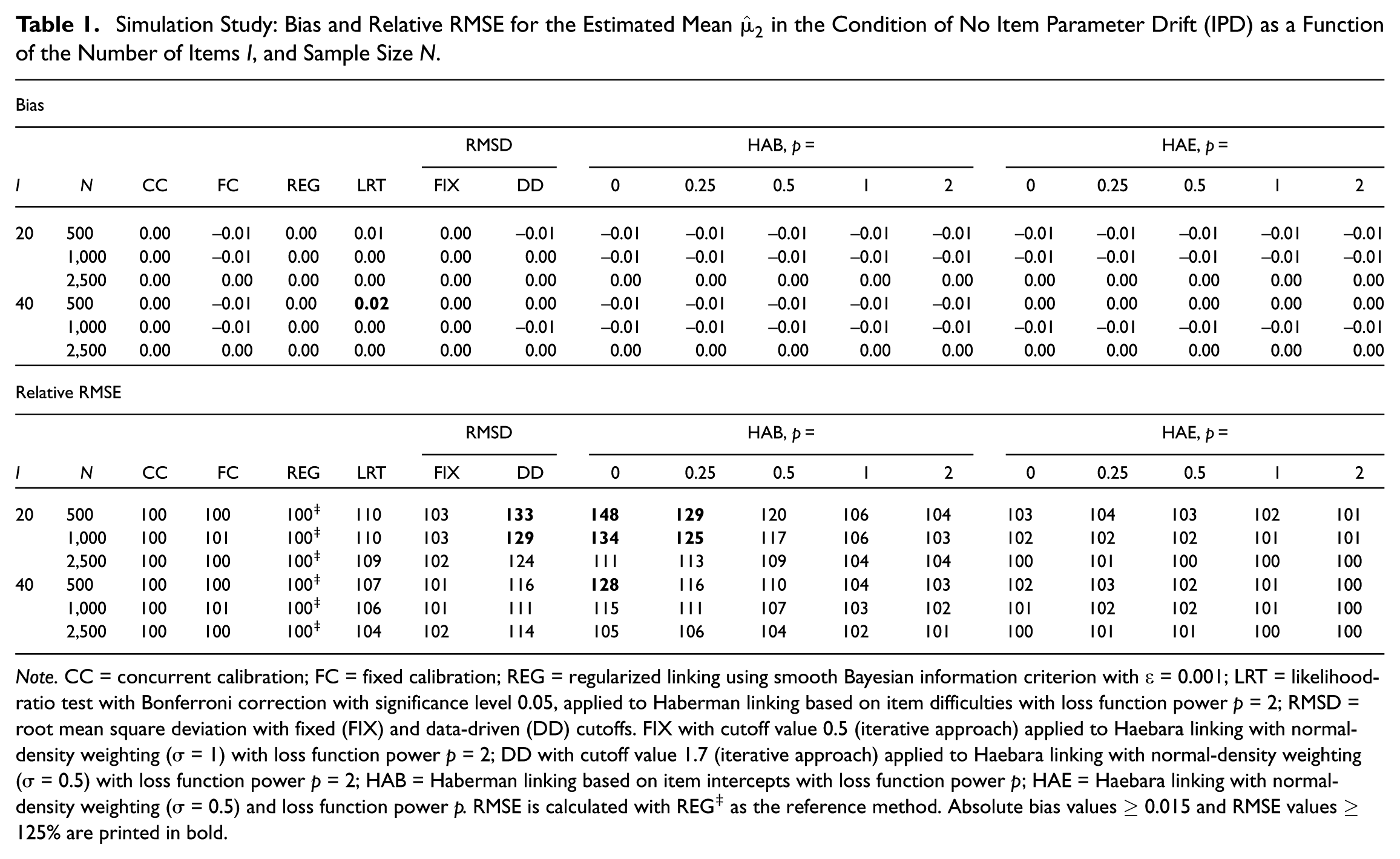
The results for the estimated mean are shown in Table 1, and the results for the SD are shown in Supplementary Table S2 for the condition of no IPD, as a function of the number of items and sample size . Without IPD, all methods produced unbiased estimates for and . The only exception was the LRT method, which showed slight bias above 0.015 for the mean when and . Regarding the RMSE for the mean, CC, FC, and HAE with were approximately as efficient as the reference method, REG. This was followed by LRT, FIX, HAE with , and HAB with , all of which performed satisfactorily. DD and HAB with or crossed the 125 threshold for both parameters in conditions with and . For DD, this loss of efficiency diminished as and increased. For HAB, efficiency improved as and increased, as expected under the absence of IPD. In contrast, HAE showed little change across for the mean and remained close to the reference method, REG. For SD, HAE was less efficient, although it still performed satisfactorily and improved as , , and increased. The methods CC, FC, LRT, and FIX stayed close to the reference method REG for SD.
Simulation Study: Bias and Relative RMSE for the Estimated Mean in the Condition of No Item Parameter Drift (IPD) as a Function of the Number of Items , and Sample Size .
Note. CC = concurrent calibration; FC = fixed calibration; REG = regularized linking using smooth Bayesian information criterion with = 0.001; LRT = likelihood-ratio test with Bonferroni correction with significance level 0.05, applied to Haberman linking based on item difficulties with loss function power = 2; RMSD = root mean square deviation with fixed (FIX) and data-driven (DD) cutoffs. FIX with cutoff value 0.5 (iterative approach) applied to Haebara linking with normal-density weighting ( = 1) with loss function power = 2; DD with cutoff value 1.7 (iterative approach) applied to Haebara linking with normal-density weighting ( = 0.5) with loss function power = 2; HAB = Haberman linking based on item intercepts with loss function power ; HAE = Haebara linking with normal-density weighting ( = 0.5) and loss function power . RMSE is calculated with REG‡ as the reference method. Absolute bias values and RMSE values % are printed in bold.
Balanced IPD
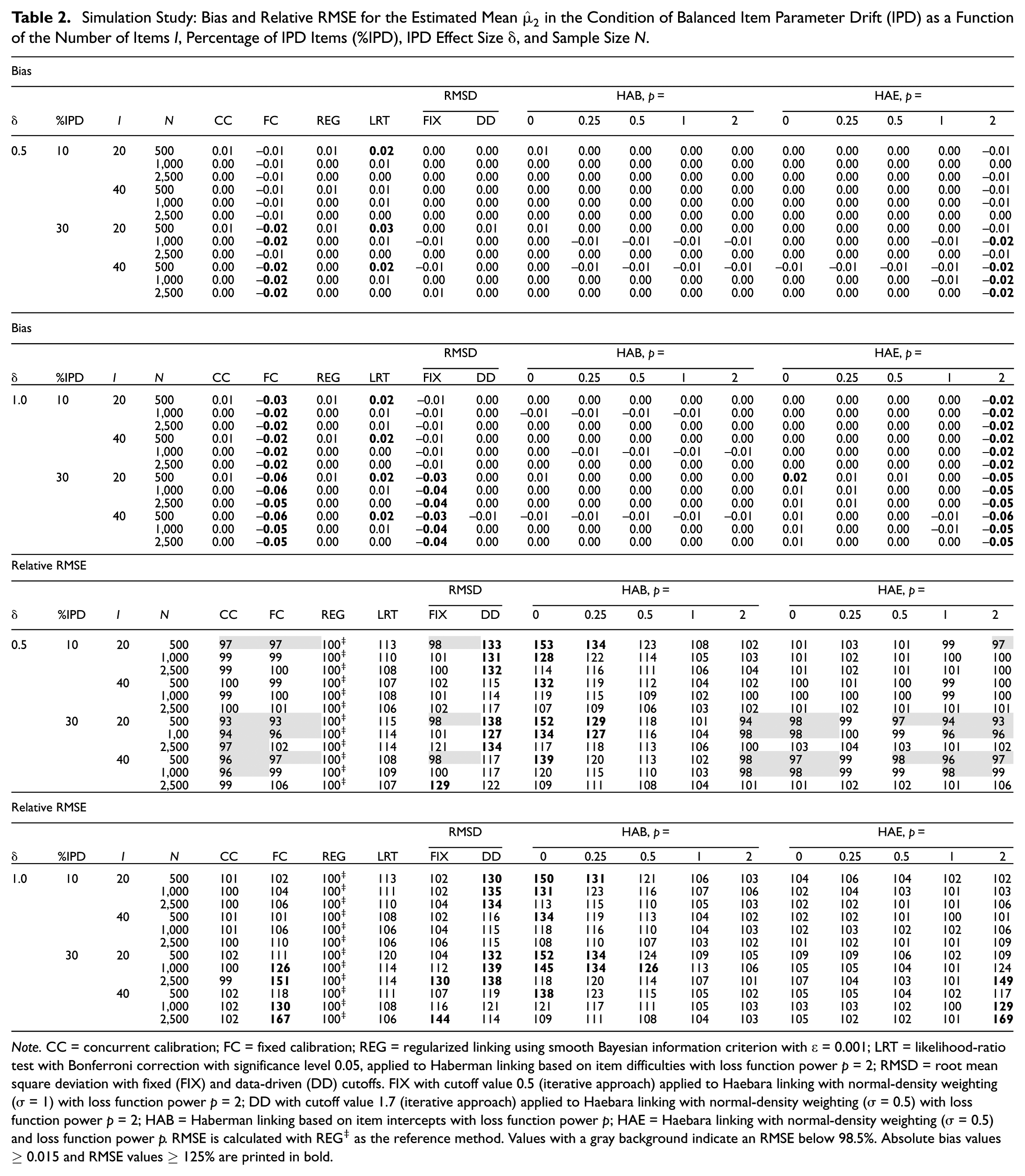
Table 2 presents the results for the estimated mean under balanced IPD as a function of the number of items , the percentage of IPD items, the IPD effect size, and the sample size . For , REG, CC, DD, and HAB performed satisfactorily in terms of bias across these conditions. FC, and HAE, with , exhibited unsatisfactory negative bias primarily at 30% IPD with . LRT showed unsatisfactory bias, mainly at . HAE with was also biased in a single condition (, 30% IPD, , ). For RMSE, in the 30% IPD, conditions, CC, FC, FIX, HAB, with , and HAE, for all , were more efficient than REG, particularly at smaller . In the 30% IPD, conditions, FC, FIX, and HAE with showed unsatisfactory RMSE at larger . For HAB, with , RMSE was generally unsatisfactory at smaller , but improved as or increased. DD was again unsatisfactory in conditions with .
Simulation Study: Bias and Relative RMSE for the Estimated Mean in the Condition of Balanced Item Parameter Drift (IPD) as a Function of the Number of Items , Percentage of IPD Items (%IPD), IPD Effect Size , and Sample Size .
Note. CC = concurrent calibration; FC = fixed calibration; REG = regularized linking using smooth Bayesian information criterion with = 0.001; LRT = likelihood-ratio test with Bonferroni correction with significance level 0.05, applied to Haberman linking based on item difficulties with loss function power = 2; RMSD = root mean square deviation with fixed (FIX) and data-driven (DD) cutoffs. FIX with cutoff value 0.5 (iterative approach) applied to Haebara linking with normal-density weighting ( = 1) with loss function power = 2; DD with cutoff value 1.7 (iterative approach) applied to Haebara linking with normal-density weighting ( = 0.5) with loss function power = 2; HAB = Haberman linking based on item intercepts with loss function power ; HAE = Haebara linking with normal-density weighting ( = 0.5) and loss function power . RMSE is calculated with REG‡ as the reference method. Values with a gray background indicate an RMSE below 98.5%. Absolute bias values and RMSE values % are printed in bold.
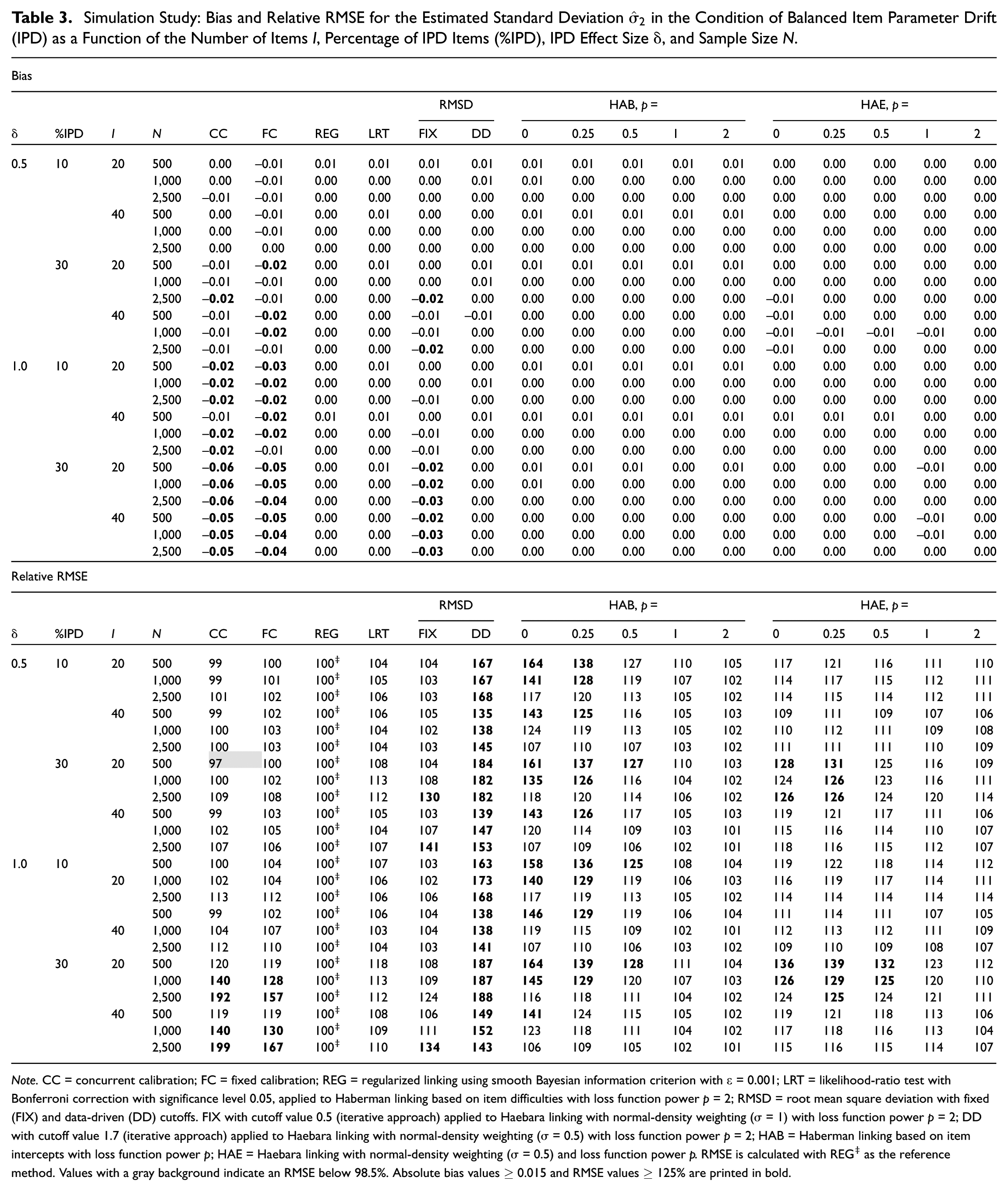
Table 3 presents the results for the estimated SD, , under balanced IPD. REG, LRT, DD, and HAB, for all , remained unbiased, as did HAE, with . CC, FC, and FIX showed unsatisfactory negative bias and elevated RMSE when 30% of items drifted or when . For RMSE, LRT, HAB, and HAE, with , performed satisfactorily across all conditions, whereas DD remained the most inefficient, with the highest RMSE values. HAB, with , was unsatisfactory at , and HAE with was unsatisfactory at and 30% IPD.
Simulation Study: Bias and Relative RMSE for the Estimated Standard Deviation in the Condition of Balanced Item Parameter Drift (IPD) as a Function of the Number of Items , Percentage of IPD Items (%IPD), IPD Effect Size , and Sample Size .
Note. CC = concurrent calibration; FC = fixed calibration; REG = regularized linking using smooth Bayesian information criterion with = 0.001; LRT = likelihood-ratio test with Bonferroni correction with significance level 0.05, applied to Haberman linking based on item difficulties with loss function power = 2; RMSD = root mean square deviation with fixed (FIX) and data-driven (DD) cutoffs. FIX with cutoff value 0.5 (iterative approach) applied to Haebara linking with normal-density weighting ( = 1) with loss function power = 2; DD with cutoff value 1.7 (iterative approach) applied to Haebara linking with normal-density weighting ( = 0.5) with loss function power = 2; HAB = Haberman linking based on item intercepts with loss function power ; HAE = Haebara linking with normal-density weighting ( = 0.5) and loss function power . RMSE is calculated with REG‡ as the reference method. Values with a gray background indicate an RMSE below 98.5%. Absolute bias values and RMSE values % are printed in bold.
Unbalanced IPD
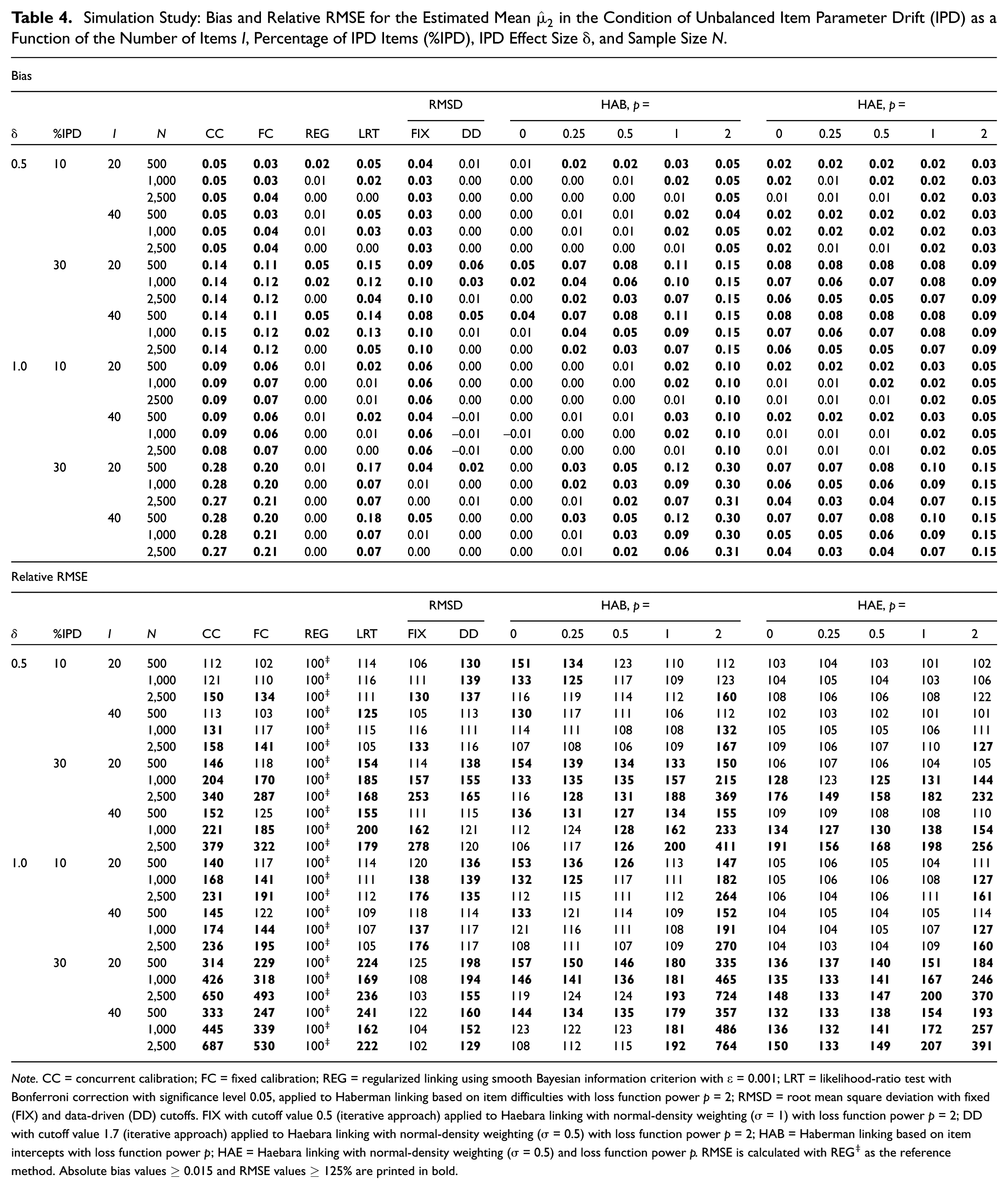
Table 4 displays the results for the estimated mean under unbalanced IPD as a function of the number of items , the percentage of IPD items, the IPD effect size, and sample size . No method was uniformly satisfactory for the mean . Regarding bias, HAB with performed best overall, with only three unsatisfactory values up to 0.05 at and , when 30% of the items drifted and . DD and REG showed satisfactory bias at , with only a few exceptions at . The bias of CC, FC, and LRT increased with %IPD and , reaching values as high as 0.28, 0.21, and 0.18, respectively. For LRT, however, the bias decreased as the sample size increased. For both HAB and HAE, the bias increased as the loss function power increased. Consequently, specifications with were the most biased, with values up to 0.31 for HAB and up to 0.15 for HAE. In terms of RMSE, most methods performed unsatisfactorily whenever 30% of items drifted and/or held. Methods that exhibited the largest biases under the 30% IPD, condition—CC, FC, LRT, and HAB/HAE with —also exhibited high RMSE, often surpassing 300 at . Satisfactory performance relative to REG was largely confined to the 10% IPD, case, where FC, FIX, and most HAE with were adequate. For HAB, this occurred only for and .
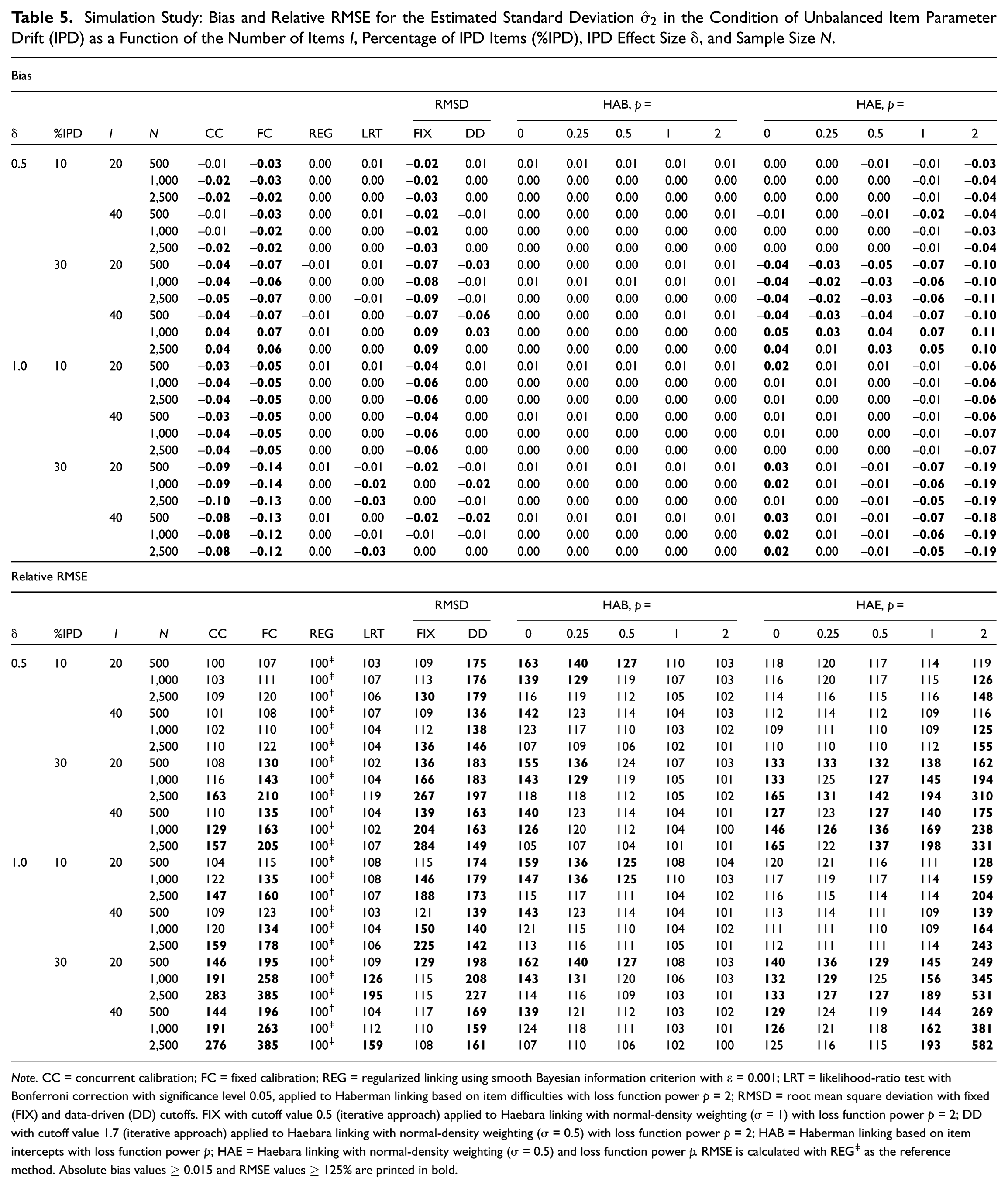
Simulation Study: Bias and Relative RMSE for the Estimated Mean in the Condition of Unbalanced Item Parameter Drift (IPD) as a Function of the Number of Items , Percentage of IPD Items (%IPD), IPD Effect Size , and Sample Size .
Note. CC = concurrent calibration; FC = fixed calibration; REG = regularized linking using smooth Bayesian information criterion with = 0.001; LRT = likelihood-ratio test with Bonferroni correction with significance level 0.05, applied to Haberman linking based on item difficulties with loss function power = 2; RMSD = root mean square deviation with fixed (FIX) and data-driven (DD) cutoffs. FIX with cutoff value 0.5 (iterative approach) applied to Haebara linking with normal-density weighting ( = 1) with loss function power = 2; DD with cutoff value 1.7 (iterative approach) applied to Haebara linking with normal-density weighting ( = 0.5) with loss function power = 2; HAB = Haberman linking based on item intercepts with loss function power ; HAE = Haebara linking with normal-density weighting ( = 0.5) and loss function power . RMSE is calculated with REG‡ as the reference method. Absolute bias values and RMSE values % are printed in bold.
The results for the estimated SD are shown in Table 5 for unbalanced IPD. REG and HAB (across all ) were unbiased. Although HAE performed unsatisfactorily when 30% of the items drifted, it performed its best at , followed by . FC and CC displayed unsatisfactorily negative bias that worsened with the percentage of IPD items and with . FIX bias decreased at 30% IPD and as increased. DD was biased in five of the 12 30% IPD cells. For RMSE, HAB with performed satisfactorily across all conditions. All other non-reference methods became unsatisfactory for at least some when 30% of the items drifted and/or when was applied. FC and HAE exhibited the highest RMSE, particularly at 30% IPD and with . DD was inefficient throughout, with RMSE regularly above 160. No method outperformed REG.
Simulation Study: Bias and Relative RMSE for the Estimated Standard Deviation in the Condition of Unbalanced Item Parameter Drift (IPD) as a Function of the Number of Items , Percentage of IPD Items (%IPD), IPD Effect Size , and Sample Size .
Note. CC = concurrent calibration; FC = fixed calibration; REG = regularized linking using smooth Bayesian information criterion with = 0.001; LRT = likelihood-ratio test with Bonferroni correction with significance level 0.05, applied to Haberman linking based on item difficulties with loss function power = 2; RMSD = root mean square deviation with fixed (FIX) and data-driven (DD) cutoffs. FIX with cutoff value 0.5 (iterative approach) applied to Haebara linking with normal-density weighting ( = 1) with loss function power = 2; DD with cutoff value 1.7 (iterative approach) applied to Haebara linking with normal-density weighting ( = 0.5) with loss function power = 2; HAB = Haberman linking based on item intercepts with loss function power ; HAE = Haebara linking with normal-density weighting ( = 0.5) and loss function power . RMSE is calculated with REG‡ as the reference method. Absolute bias values and RMSE values % are printed in bold.
In summary, methods that assume full invariance (CC and FC) performed optimally without IPD but severely degraded under unbalanced IPD. Robust linking methods with small -values and REG maintained stability across all conditions, although with some loss of efficiency in the no-IPD case. The systematic negative bias in for FC aligns with the findings from Robitzsch (2024a), as the fixed parameters cannot accommodate the increased item-response variability induced by IPD. The negative bias, therefore, leads to an underestimation of the population variance. The superior performance of HAB over HAE for SD estimation under uniform IPD reflects the previously discussed differences in estimation. HAB’s advantage over HAE for SD estimation under uniform IPD stems from its separate estimation of the variance parameter using only discrimination parameters, which remain unaffected by uniform intercept drift. In contrast, HAE’s simultaneous estimation of both trend parameters makes it more vulnerable to bias propagation from drifting intercepts, as detailed by Robitzsch (2025c).
Additional Results: Variation of Fixed and Data-Driven RMSD Cutoffs
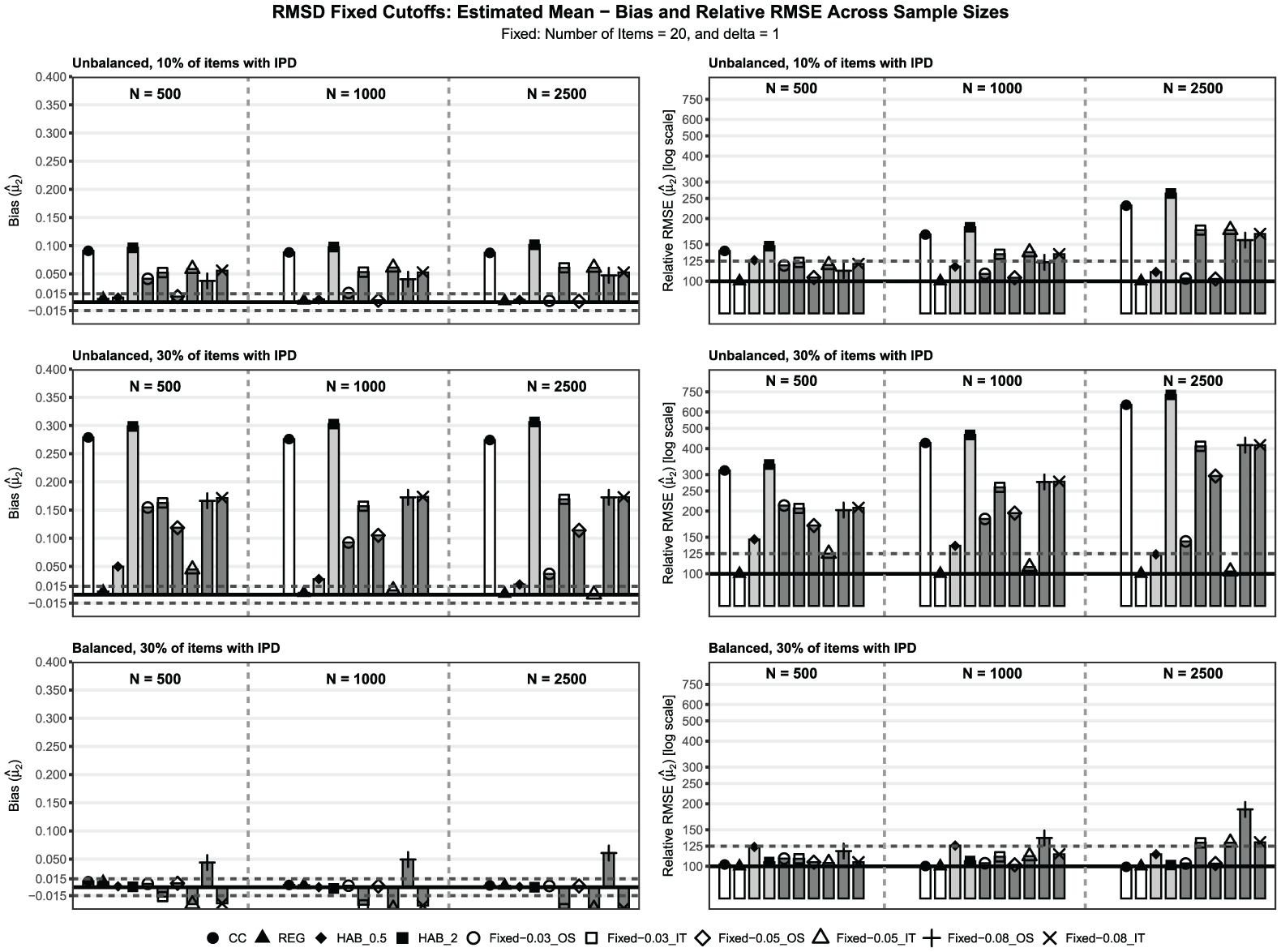
We extend the previous cutoff analysis (FIX , DD ) to include FIX cutoffs and and DD cutoff . Each cutoff uses OS and IT approaches, yielding six combinations. The re-estimation procedure under partial invariance remains constant. After fixed RMSD, trends are re-estimated using HAE with normal-density weights (). After DD RMSD, trends are re-estimated using HAE with normal-density weights (). We compare these results to those of CC, REG, and HAB, based on item intercepts with loss function powers and . Performance is assessed by bias and RMSE for the trend estimates of the mean and the SD at T2. Figures 1 and 2 display the bar plots for the estimated mean () for FIX and DD RMSD cutoffs, respectively, under both OS and IT, showing three key conditions: unbalanced IPD with 10% and 30% of items exhibiting drift; and balanced IPD with 30% drift; all three with and items. Complete tabular results for both and under all conditions are provided in the Supplement (Tables S3 to S14).
Bias and Relative RMSE for the Estimated Mean in the Condition of = 20 Number of Items, and IPD Effect Size = 1 as a Function of IPD Balance (Unbalanced, Balanced), Percentage of IPD Items (%IPD), and Sample Size .
Bias and Relative RMSE for the Estimated Mean in the Condition of = 20 Number of Items, and IPD Effect Size = 1 as a Function of IPD Balance (Unbalanced, Balanced), Percentage of IPD Items (%IPD), and Sample Size .
Fixed RMSD Cutoffs
Without IPD, all six combinations yielded satisfactory bias for and across sample sizes and item counts. All specifications showed satisfactory RMSE, although 0.03 was slightly elevated at versus 0.05 and 0.08. The 0.05 and 0.08 cutoffs were similar to the comparison methods under no IPD.
Under balanced IPD, the bias patterns differed between the two trend parameters. For , the 0.03 and 0.05 cutoffs with the OS approach maintained satisfactory bias across all conditions. However, the 0.03 IT approach, the 0.05 IT approach, and both 0.08 approaches produced unsatisfactory bias (exceeding 0.015) when 30% of the items exhibited IPD with . With 0.08, a sign reversal appeared between the OS approach (positive bias) and the IT approach (negative bias) under these conditions. For , no specification achieved satisfactory performance across all conditions. The 0.03 OS approach exhibited unsatisfactory bias of in two conditions, while the IT approach showed this in four conditions with 30% IPD and . The 0.08 cutoffs produced the largest negative bias values, with the IT approach ranging from to . RMSE became unsatisfactory primarily when bias was elevated, with the 0.08 OS approach performing worst (up to 231). In comparison with the reference methods, for the mean, under the OS approach, with 0.03 and 0.05, the FIX-cutoff estimators were broadly comparable to REG, HAB, and CC; in terms of RMSE, they were weaker than REG and CC, and for the SD, they performed similarly to CC, but below REG and HAB, especially HAB, with .
Under unbalanced IPD, no FIX-cutoff specification provided uniformly satisfactory performance. For , positive bias increased with both the percentage of IPD items and the effect size across all specifications. The 0.05 IT approach uniquely achieved satisfactory bias when 10% of items drifted with in larger samples. The 0.03 OS approach occasionally achieved satisfactory bias at , in selected conditions with . RMSE exceeded the 125 threshold for most specifications when 30% of items drifted, or when . For , all specifications produced unsatisfactory negative bias. The 0.08 approaches showed the most severe bias, reaching with 30% IPD and . The 0.05 IT approach showed the least bias among FIX cutoffs, but remained unsatisfactory in most conditions with 30% IPD. Under unbalanced IPD, FIX cutoffs generally underperformed relative to REG, HAB, and CC in both bias and RMSE for and , with comparability observed only in isolated cases, such as 0.05 with IT for the mean at 10% IPD and , in larger samples.
Overall, the FIX-cutoff approach performed adequately only under no IPD or under limited, balanced IPD conditions. Among the specifications, 0.05 with OS provided the most satisfactory performance across balanced IPD. IT performed better in specific unbalanced IPD scenarios. The 0.08 cutoff was too lenient under balanced IPD with and 30% IPD, in both OS and IT.
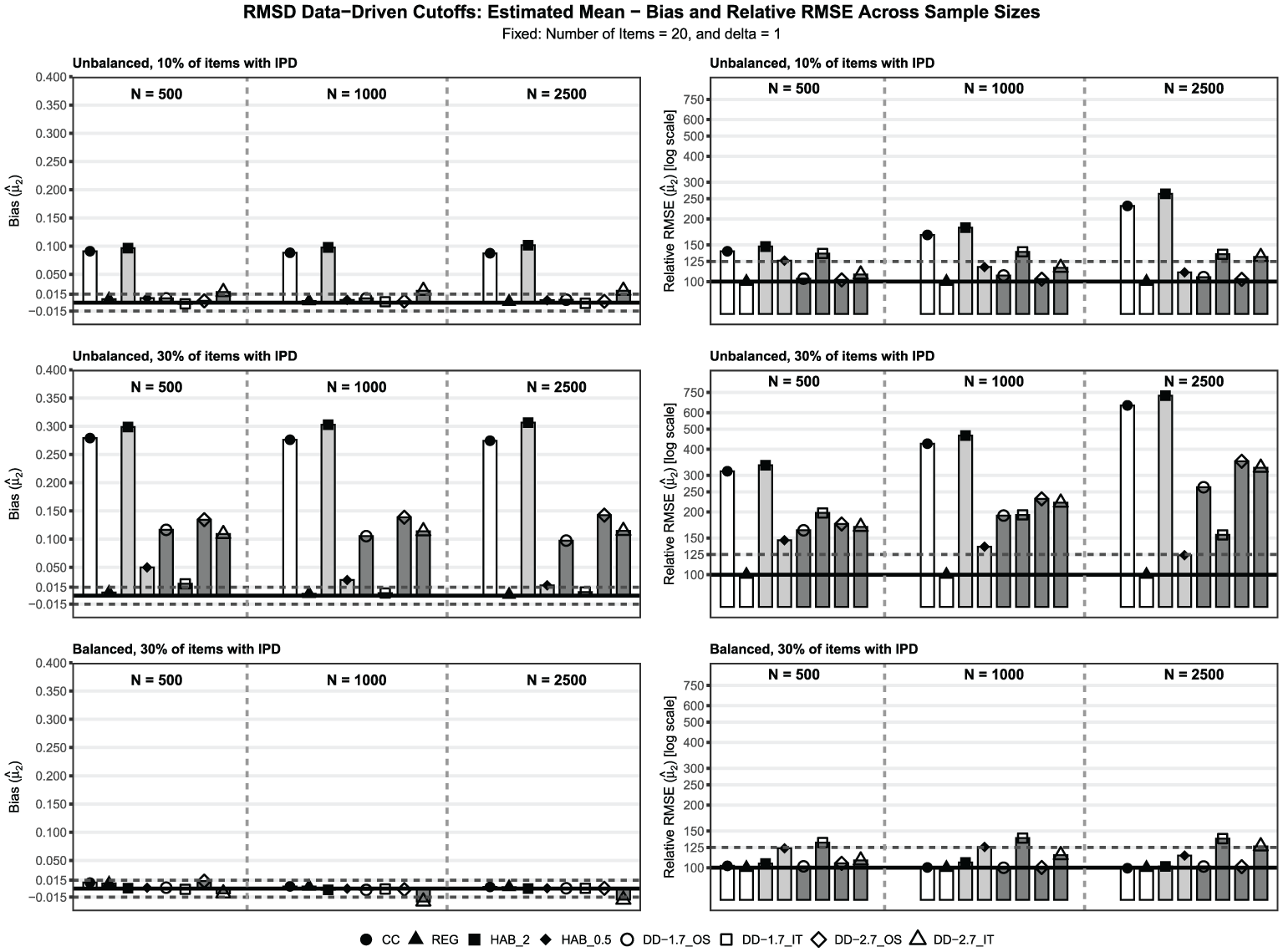
Data-Driven RMSD Cutoffs
Without IPD, all DD specifications maintained satisfactory bias for both trend parameters. RMSE performance varied by cutoff and approach. The specifications were satisfactory across all conditions. The IT specification showed unsatisfactory RMSE for with items (reaching 133 at ) and for in several conditions (up to 169). The OS approach was more efficient than the IT approach. Compared to the reference methods, the bias for and was similar. However, for , the RMSE of all RMSD DD specifications was worse than that of REG and CC. For , all specifications except for the IT approach with achieved a lower RMSE than HAB with and were comparable to HAB with ; however, they remained less efficient than REG and CC.
Under balanced IPD, the DD RMSD cutoffs showed mixed performance. For , the OS specification maintained satisfactory bias across most conditions. The specifications produced unsatisfactory negative bias when 30% of items drifted with . The RMSE was primarily unsatisfactory for the IT specifications, consistently exceeding 125 with items. For , the specifications generally maintained satisfactory bias, whereas the specifications showed unsatisfactory negative bias (up to ) when 30% of the items drifted with and items. The RMSE patterns mirrored those for the mean, with the IT approach showing lower efficiency. For , the OS specification performed similarly to CC, REG, and HAB () in terms of both bias and RMSE. For RMSE, this also held for the OS specification, although its bias lagged behind in the most demanding, balanced condition. For , bias was comparable to CC at OS, but generally lower than REG and HAB, especially at , and RMSE remained lower than REG.
Under unbalanced IPD, the DD specifications did not maintain satisfactory performance in challenging conditions. For , the IT specification achieved satisfactory bias in select conditions with 10% or 30% IPD at larger sample sizes. Across specifications, positive bias increased with the percentage of IPD items and the effect size, . The RMSE was higher for the IT approach; the IT specification reached 410 when 30% of the items drifted with . For , negative bias was pervasive, reaching for the specifications under the severe IPD condition ( and 30% IPD items) for and . The IT specifications were the most variable, occasionally achieving satisfactory bias, although with extremely poor RMSE (up to 540). Compared to the reference methods, CC, REG, and HAB, all DD specifications performed worse in terms of both bias and RMSE for and . One limited exception occurred for , using the OS approach at larger and 10% IPD, where the mean bias was comparable to that of HAB with . However, RMSE still lagged behind REG and CC; with OS yielded better RMSE, but at the cost of larger bias. For , both cutoffs showed more negative bias and higher RMSE than REG, CC, and HAB, especially , including the severe condition (, 30% IPD items).
Overall, DD cutoffs yielded mixed results. Stricter cutoffs () with IT minimized bias in extreme conditions but sacrificed efficiency, particularly for items. The more lenient cutoff () maintained better efficiency, yet it failed to control bias under unbalanced IPD, especially at and with 30% IPD items. These findings suggest that the optimal cutoff and approach choice depend critically on the expected pattern of IPD.
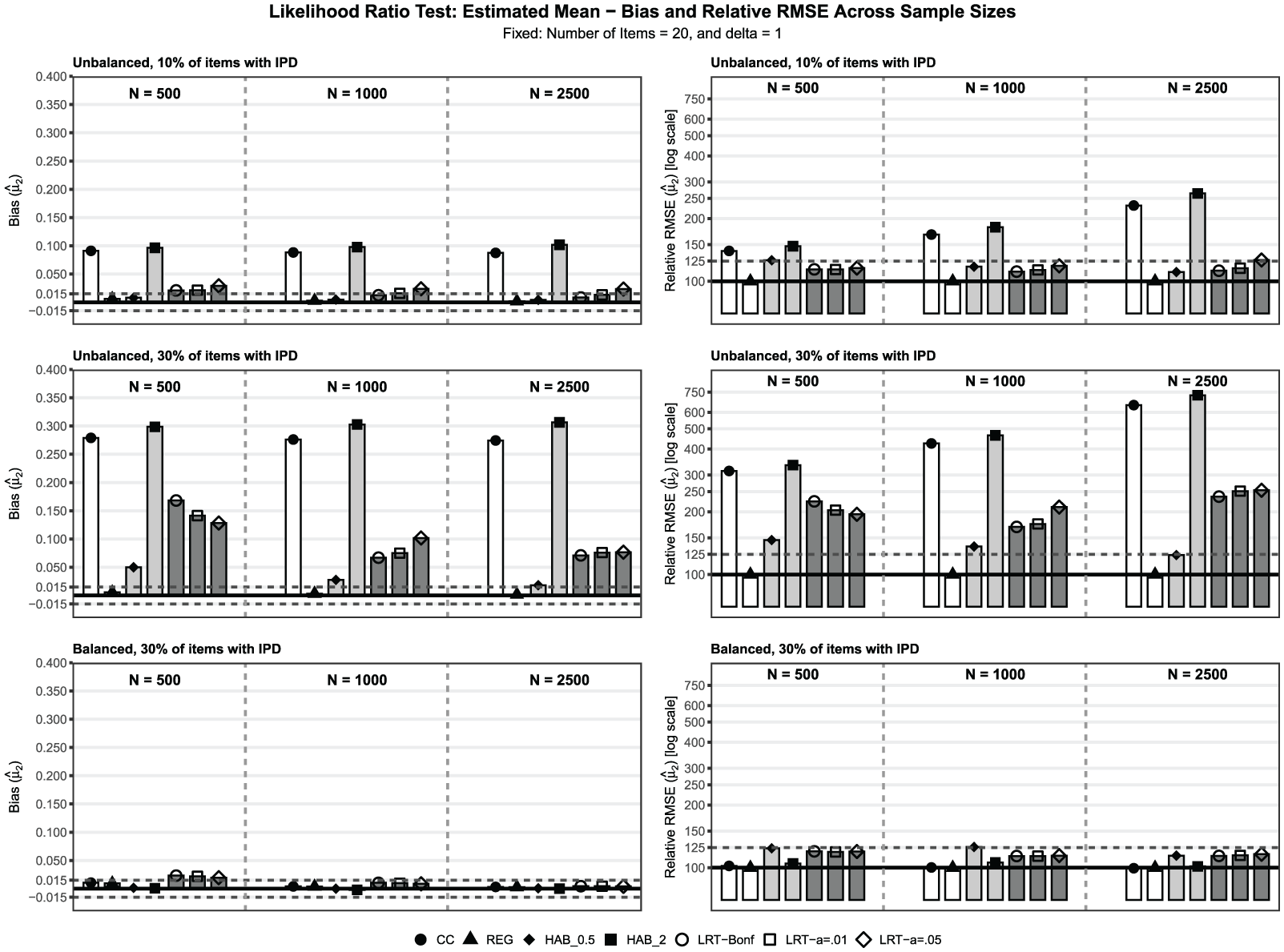
Additional Results: Optimal Configuration of the Likelihood-Ratio Test
Building on the main analysis, where the LRT with Bonferroni correction () was selected in the most challenging condition (unbalanced IPD, 30% IPD, , , ), we examine whether this choice generalizes and how alternative significance levels perform. We consider three LRT specifications that all use the OS approach: , , and Bonferroni-corrected . Re-estimation is kept fixed to HAB, with item difficulties and loss, as in the main analysis. As references, we report again CC, REG, and HAB, based on item intercepts with loss function powers and . Performance is evaluated by bias and RMSE for the trend estimates of the mean and the SD at T2. We show a subset of conditions for the estimated mean in Figure 3 (unbalanced IPD with 10% and 30% drift, and balanced IPD with 30% drift, , ). The complete tabular results for both and are provided in the Supplement (Tables S15 to S20).
Bias and Relative RMSE for the Estimated Mean in the Condition of = 20 Number of Items, and IPD Effect Size = 1 as a Function of IPD Balance (Unbalanced, Balanced), Percentage of IPD Items (%IPD), and Sample Size .
Under no IPD conditions, all LRT specifications maintain satisfactory bias for both trend parameters across most conditions. The Bonferroni correction shows a single instance with bias for , with and . RMSE values remain satisfactory across all specifications, although slightly elevated compared with the REG, particularly for smaller sample sizes.
Under balanced IPD, the LRT specifications show performance that varies with sample size. For , all three significance levels produce unsatisfactory positive bias at across multiple conditions; values do not exceed . As the sample size increases, bias decreases to satisfactory levels for most conditions at , and becomes consistently satisfactory at . RMSE values remain satisfactory in most conditions, with slight elevations at smaller sample sizes (notably at ). For , all LRT specifications maintain satisfactory bias across conditions. RMSE remains satisfactory overall, with slight elevations when 30% of items drift with . Relative to CC, REG, and HAB, RMSE for under balanced IPD was generally higher for the LRT specifications.
Under unbalanced IPD, LRT specifications often fail to control bias adequately. For , positive bias increases with both IPD percentage and effect size across all significance levels. The Bonferroni correction produces the highest bias, reaching when 30% of items drift, with . The and specifications exhibit similar patterns, but with slightly lower maximum bias values ( and , respectively). Bias decreases with increasing sample size, but remains unsatisfactory in most conditions. RMSE values exceed the 125 threshold in nearly all conditions with 30% IPD, reaching values above 300 at . For under unbalanced IPD, negative bias concentrates in the severe condition ( and 30% IPD items) for both and . It is most pronounced for the Bonferroni correction and for at larger sample sizes. For , negative bias appears across all sample sizes in the 30% setting and is also present at with 30% IPD items. RMSE becomes particularly poor when 30% of items drift, exceeding 200 in multiple conditions. Compared with CC, REG, and HAB, the RMSE for under unbalanced IPD was consistently worse for all LRT specifications, especially in the severe condition (, 30% IPD items).
The Bonferroni correction generally achieved the lowest bias and RMSE among LRT variants under moderate unbalanced IPD conditions, although all variants exceeded satisfactory thresholds in severe IPD conditions. The variant showed slightly better RMSE performance at with 30% IPD (137 to 179) compared to the Bonferroni correction (154 to 200). The optimal significance level appears condition-dependent, where stricter corrections perform better under unbalanced IPD, while standard levels suffice for balanced conditions. The sample size dependency of performance demonstrated that the LRT requires large samples to function adequately, which limits its practical applicability, as is well known in the literature.
Empirical Example
We illustrate the trend-estimation approaches using synthetic data derived from the ELFE reading comprehension test (Lenhard & Schneider, 2005), which was used in an earlier study by Robitzsch et al. (2011). We estimate the change from the first wave (T1) to the third wave (T2). The synthetic dataset was created using a data-augmented multiple-imputation approach (Grund et al., 2024; Jiang et al., 2022). This approach preserves the statistical properties of the original data while ensuring participant confidentiality. It combines partial least squares regression for dimension reduction with controlled noise injection (noise factor: ) to generate synthetic observations that retain the original covariance structure and marginal distributions. Specifically, the approach preserves marginal distributions exactly while adding a calibrated amount of unreliability to protect individual responses (Grund et al., 2024; Jiang et al., 2022).
Before synthesis, the first item at T1 was removed because its -value indicated insufficient fit. In addition, items T3I21 to T3I26 at T2 were excluded to prevent them from influencing the linking. Item labels range from I2 to I20, yielding 19 items total, where item 20 refers to label I20 rather than the twentieth sequential position. The dataset contains responses from students to reading comprehension items, administered at two time points: the end of Grade 3 (T1) and the end of Grade 4 (T2). All items are common across both time points. The R code for creating the synthetic data and reproducing this empirical example, along with the synthetic dataset, is available at https://osf.io/q86jz.
We apply the trend-estimation approaches examined in the simulation study and in the additional results to this two-time-point setting, using T1 as the reference scale with and . Although the analysis focuses on two time points, the methods can readily be applied to additional time points via chain linking (e.g., Kolen & Brennan, 2014).
Results
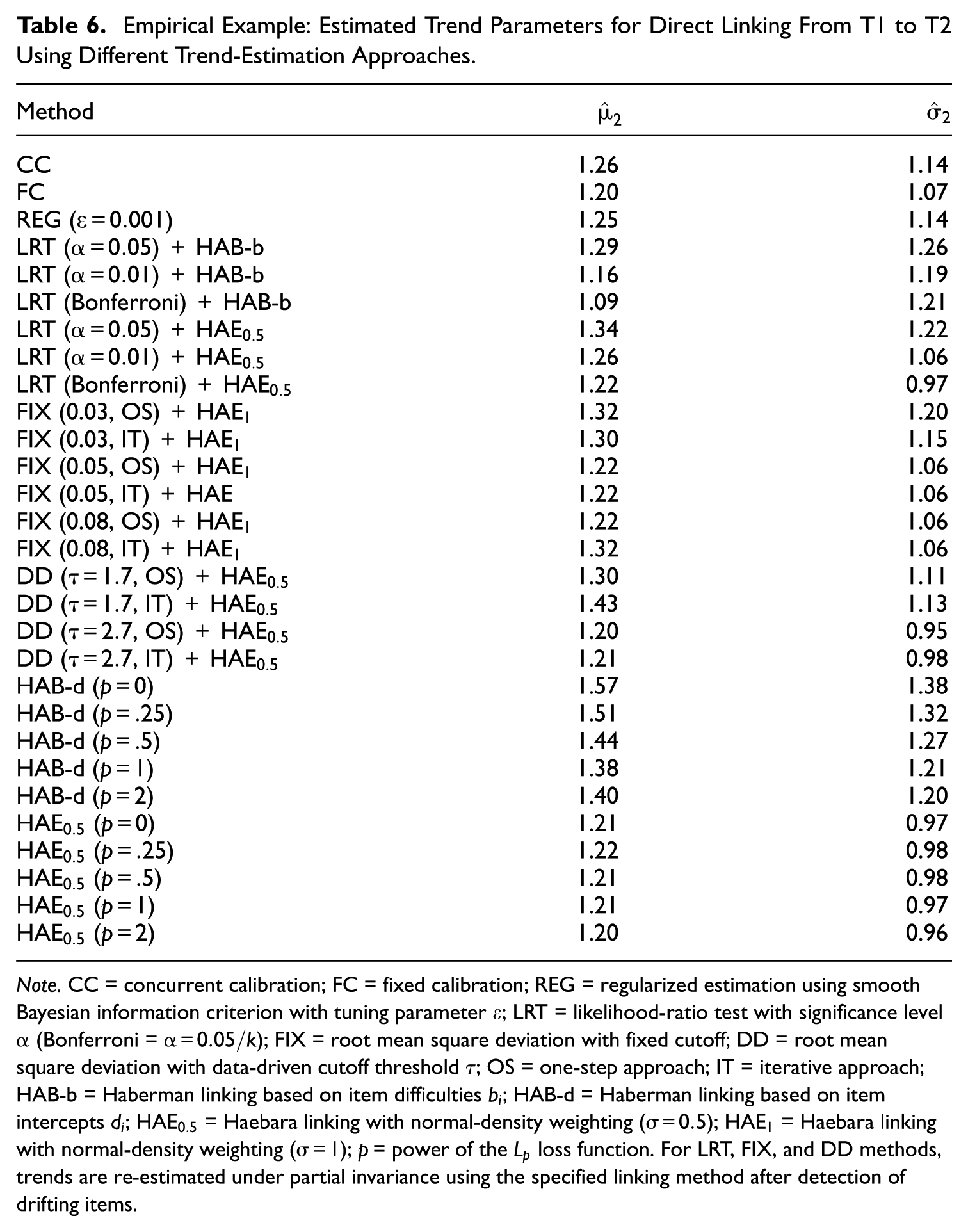
Table 6 presents the estimated distribution parameters for T2 across the trend-estimation approaches considered in the simulation study, as well as the additional results. For the mean at T2, estimates ranged from (LRT with Bonferroni correction and re-estimation with HAB-b) to (HAB-d with p = 0). CC and REG produced estimates of 1.26 and 1.25, respectively, while FC yielded an estimate of 1.20. Among the RMSD detection-based approaches, for FIX cutoffs, the estimates ranged from 1.22 to 1.32, depending on the cutoff and approach (OS vs. IT), while DD estimates ranged from 1.20 to 1.43. The LRT estimates varied with significance level, from 1.09 (Bonferroni) to 1.34 ( with HAE). The robust linking methods showed systematic variation based on the loss function parameter, with HAB-d estimates decreasing from 1.57 () to 1.38 (), and a slight increase to 1.40 at , while HAE estimates remained around 1.20–1.22 across all . SD estimates at T2 ranged from (DD with , IT) to (HAB-d with ). For CC, FC, and REG, the estimates were 1.14, 1.07, and 1.14, respectively. Within the detection-based approaches, RMSD with FIX cutoffs ranged from 1.06 to 1.20, DD from 0.95 to 1.13, and the LRT from 0.97 to 1.26, depending on the specification. The robust linking methods exhibited a decreasing trend with increasing for HAB-d (from 1.38 to 1.20), whereas HAE remained stable between 0.96 and 0.98.
Empirical Example: Estimated Trend Parameters for Direct Linking From T1 to T2 Using Different Trend-Estimation Approaches.
Method
CC
1.26
1.14
FC
1.20
1.07
REG ()
1.25
1.14
LRT () + HAB-b
1.29
1.26
LRT () + HAB-b
1.16
1.19
LRT (Bonferroni) + HAB-b
1.09
1.21
LRT () +
1.34
1.22
LRT () +
1.26
1.06
LRT (Bonferroni) +
1.22
0.97
FIX (0.03, OS) +
1.32
1.20
FIX (0.03, IT) +
1.30
1.15
FIX (0.05, OS) +
1.22
1.06
FIX (0.05, IT) + HAE
1.22
1.06
FIX (0.08, OS) +
1.22
1.06
FIX (0.08, IT) +
1.32
1.06
DD (, OS) +
1.30
1.11
DD (, IT) +
1.43
1.13
DD (, OS) +
1.20
0.95
DD (, IT) +
1.21
0.98
HAB-d ()
1.57
1.38
HAB-d ()
1.51
1.32
HAB-d ()
1.44
1.27
HAB-d ()
1.38
1.21
HAB-d ()
1.40
1.20
()
1.21
0.97
()
1.22
0.98
()
1.21
0.98
()
1.21
0.97
()
1.20
0.96
Note. CC = concurrent calibration; FC = fixed calibration; REG = regularized estimation using smooth Bayesian information criterion with tuning parameter ; LRT = likelihood-ratio test with significance level (Bonferroni = ); FIX = root mean square deviation with fixed cutoff; DD = root mean square deviation with data-driven cutoff threshold ; OS = one-step approach; IT = iterative approach; HAB-b = Haberman linking based on item difficulties ; HAB-d = Haberman linking based on item intercepts ; = Haebara linking with normal-density weighting (); = Haebara linking with normal-density weighting (); = power of the loss function. For LRT, FIX, and DD methods, trends are re-estimated under partial invariance using the specified linking method after detection of drifting items.
The detection-based methods identified varying numbers of items with IPD, resulting in different anchor sets. The LRT approaches flagged between 4 and 12 items depending on the significance level: Bonferroni correction identified Items 5, 9, 14, and 18; identified Items 2, 4, 5, 9, 14, 18, and 20; and identified Items 2–5, 9, 11–14, 18, 19, and 20. The FIX cutoff RMSD method showed varying sensitivity across cutoff values and detection approaches: the 0.03 cutoff, the OS approach flagged 15 (3–14, 18–20), while the IT approach flagged 16 items (2–14, 18–20). In contrast, both the 0.05 and 0.08 cutoffs detected no items under either approach. The DD RMSD method with identified 10 items (2, 7, 10, 11, 15–20) using the OS approach and 11 items (2, 7, 10, 11, 14–20) using the IT approach. The cutoff detected only item 15 with the OS approach, whereas the IT approach identified three items (15, 16, and 20). The regularization approach identified only item 9 as having drift (), with the sum of all IPD effects being nonzero, indicating unbalanced IPD.
The difference of 0.48 between the lowest and highest mean estimates could lead to different conclusions about trends. If the true trend is 1.09, as suggested by LRT with Bonferroni correction, this indicates progress of approximately one SD over the school year. If the true growth is 1.57, as with HAB-d at , this represents a trend exceeding 1.5 SD. The variation in SD estimates (0.95 to 1.38) likewise affects interpretations of variance in student growth.
Discussion
This article investigated trend-estimation approaches across two time points under sparse, uniform IPD in the 2PL model. A comparative analysis was conducted of five approaches for trend estimation: CC, FC, robust linking with HAB and HAE, partial invariance using LRT and RMSD with FIX and DD cutoffs, and REG with the SBIC.
In balanced IPD settings, CC remained unbiased and efficient for . However, this was not the case for , particularly for an IPD effect size , aligning with prior research showing that balanced IPD can still negatively affect SD estimation in the 2PL model (Robitzsch, 2023a; Robitzsch & Lüdtke, 2022). Robust linking with maintained good efficiency (He & Cui, 2019; Robitzsch, 2023a), while small values reduced bias marginally but increased variance in shorter tests. The RMSD with DD cutoffs and other detection-based variants sometimes exhibited efficiency losses for , while achieving acceptable bias control in many balanced conditions. Furthermore, under balanced IPD, HAB performed acceptably with and outperformed the other loss functions. This pattern did not hold for HAE at , which deteriorated under 30% IPD, , with unsatisfactory negative bias and elevated RMSE for both trend parameters. However, it did not vary in its efficiency across loss functions for , unlike HAB.
Under conditions of unbalanced IPD, CC and FC exhibited bias across all conditions, confirming earlier findings that unbalanced IPD introduces substantial bias in methods that assume full invariance (DeMars, 2019; Robitzsch, 2023a). This bias increased with increasing and the percentage of IPD items. The RMSD with DD cutoffs mitigated bias in severe unbalanced settings, but this occurred at the expense of efficiency for the smaller number of items, . Under unbalanced IPD conditions, CC and FC exhibited bias in the estimated mean, with values reaching 0.28 for CC and 0.21 for FC in the most severe conditions. Regarding robust linking, lower loss function powers () effectively controlled bias under unbalanced IPD, with HAB using showing bias in only three conditions. In comparison, higher powers (p= 2) yielded better efficiency under no IPD but severe bias under unbalanced conditions, extending previous findings on the trade-off between robustness and efficiency (Robitzsch, 2020; Robitzsch & Lüdtke, 2022). In addition, a smaller mean shift at T2 () was considered, and the pattern of findings was found to be similar to the main results (see Tables S21–S26 in the Supplement).
Overall, the regularization approach using SBIC proved to be the most consistently effective across conditions, and our findings corroborate Robitzsch (2024b) by demonstrating that REG using SBIC provides satisfactory parameter recovery under no or balanced IPD. Extending the 40% contamination design, we found that regularization maintained acceptable performance at 10% and 30% drift rates across various sample sizes. Under unbalanced IPD, robust HAB with achieved in more conditions a satisfactory bias than regularization for , but with some efficiency loss. Notably, REG remained within acceptable limits at the largest sample size (), suggesting its viability for adequately powered studies. The RMSD with DD cutoffs demonstrated potential, but its inefficiency for was a notable limitation that stemmed from the IT approach.
Limitations and Future Research
As with any simulation, the conclusions are bounded by the particular conditions investigated. We assumed that the scaling model, the 2PL model, was specified correctly. However, it is important to note that data may also be generated by more complex or multidimensional item-response models. Therefore, it is advisable to exercise caution when generalizing to contexts characterized by distinct or as yet unidentified data-generating processes. Evaluating the primary specifications under alternative IRT models, such as the 1PL and 3PL, would provide additional insight, given their practical use (Arce-Ferrer & Bulut, 2017; Fischer et al., 2021; Huggins, 2014). Future research could also investigate the trend-estimation approaches under model misspecification (Bolt et al., 2014; Fischer et al., 2021; Samejima, 2000; Xu et al., 2009), as well as guessing and slipping (Culpepper, 2017; DeMars & Jurich, 2015). Moreover, this study used only dichotomous items. Extending the design to polytomous items or mixed-format data would provide valuable insights (Andersson, 2018; S. Wang et al., 2024; Zhao & Hambleton, 2017). The exploration of nonuniform sparse IPD in item discriminations could be another area for future research. In the current study, which investigated uniform IPD, regularization was specified for the data-generating model, with a penalty term only applied to the item intercept IPD effects. In contrast, HAB applied robust loss functions for both the mean and SD. However, uniform IPD does not affect the estimation of SD under HAB, and LRT tests both intercepts and discriminations. Under uniform IPD, HAB could alternatively be applied with constrained linking, which sets discrimination parameters invariant while allowing non-invariant intercepts (Chen et al., 2023). This approach would likely improve its performance in terms of bias and RMSE, approaching the results achieved by regularization. Under nonuniform IPD conditions, regularization could be enhanced by incorporating a second set of IPD effects for the item discriminations (see Schauberger & Mair, 2020), and the relative performance compared to HAB, as applied here, should be investigated. In addition, the five trend-estimation approaches could be examined under chain and joint linking involving three or more time points, as well as under different longitudinal linking designs (e.g., booklet, consecutive time points with adjacent items, or common items across all time points) (e.g., Battauz, 2013; Engels et al., 2025; Keller & Keller, 2011). Investigating proportions of IPD items greater than 30% (not exceeding 50%, see Halpin, 2024; W. Wang et al., 2022) presents another promising avenue for future inquiry. It is important to note that applications may contain fewer common items than those considered here. Therefore, examining smaller sets, such as or fewer (Robitzsch, 2025b), would be beneficial. Future research should also consider the incorporation of unique items and their effects on various trend-estimation approaches (Engels et al., 2025). In addition, the impact of unequal sample sizes on trend-estimation methods could be addressed in future studies, as this often poses a challenge in longitudinal designs when participants drop out (Cho et al., 2016; DeMars, 2019; Woods, 2008). Unequal group sizes also arise when linking large item banks or multiple measurement occasions, not only in simple two-group comparisons. The forward-only IT approach was chosen for computational feasibility in this study. LRT could also be applied with item purification, and FC could be used as another re-estimation method under partial invariance (González-Betanzos & Abad, 2012; König et al., 2021; W.-C. Wang & Yeh, 2003). A variety of IT approaches have been developed, including approaches that allow the re-evaluation of previously flagged items or the use of different anchor sets, which could be compared with the trend-estimation methods employed in this study in future studies (Kopf et al., 2015b). A small dedicated simulation comparing OS and IT approaches, including computational efficiency considerations, would provide valuable guidance for practitioners.
In instances where unbalanced IPD is suspected, methods that down-weight or shrink IPD, such as HAB with or REG with SBIC, are preferable to approaches that assume full invariance (CC and FC) or to HAE. For large sample sizes (), REG with SBIC proved to be the optimal method across all conditions. The trade-offs associated with partial invariance using IPD statistics should be considered. While these methods can achieve satisfactory outcomes, their efficacy depends on the appropriate selection of cutoffs, which may not be known in practical settings. The choice of cutoffs is not trivial, as different thresholds can lead to different conclusions about the magnitude of the trend. In the context of robust linking, non-robust specifications were most efficient when IPD was absent or balanced. Conversely, smaller values have been shown to enhance robustness under conditions of unbalanced IPD. Given the trade-offs between different loss function powers, when the nature of potential IPD is unknown, intermediate values such as or appear to offer reasonable compromises between efficiency and robustness, as indicated by this study. Due to the superior efficiency of REG with SBIC over HAB and RMSD with DD cutoffs, it can be recommended that practitioners prioritize regularized estimation when computational resources permit and sample sizes are adequate.
Footnotes
Acknowledgements
Not applicable.
Author Contributions
All authors have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Availability of Data and Materials
Replication material can be found at .
References
1.
AnderssonB. (2018). Asymptotic variance of linking coefficient estimators for polytomous IRT models. Applied Psychological Measurement, 42(3), 192–205. https://doi.org/10.1177/0146621617721249
2.
AngoffW. (1982). Use of difficulty and discrimination indices for detecting item bias. In BerkR. (Ed.), Handbook of methods for detecting test bias (pp. 96–116). The Johns Hopkins Press.
3.
AraiS.MayekawaS. (2011). A comparison of equating methods and linking designs for developing an item pool under item response theory. Behaviormetrika, 38(1), 1–16. https://doi.org/10.2333/bhmk.38.1
4.
Arce-FerrerA. J.BulutO. (2017). Investigating separate and concurrent approaches for item parameter drift in 3PL item response theory equating. International Journal of Testing, 17(1), 1–22. https://doi.org/10.1080/15305058.2016.1227825
BerríoA. I.Gómez-BenitoJ.Arias-PatiñoE. M. (2020). Developments and trends in research on methods of detecting differential item functioning. Educational Research Review, 31, Article 100340. https://doi.org/10.1016/j.edurev.2020.100340
10.
BirnbaumA. (1968). Some latent trait models and their use in inferring an examinee’s ability. In LordF. M.NovickM. R. (Eds.), Statistical theories of mental test scores (pp. 397–479). MIT Press.
11.
BlossfeldH.-P.von MauriceJ.SchneiderT. (2011). The National Educational Panel Study: Need, main features, and research potential. Zeitschrift für Erziehungswissenschaft, 14(S2), 5–17. https://doi.org/10.1007/s11618-011-0178-3
12.
BoltD. M.DengS.LeeS. (2014). IRT model misspecification and measurement of growth in vertical scaling. Journal of Educational Measurement, 51(2), 141–162. https://doi.org/10.1111/jedm.12039
13.
BonferroniC. E. (1936). Teoria statistica delle classi e calcolo delle probabilità. Pubblicazioni del r Istituto Superiore di Scienze Economiche e Commerciali di Firenze, 8, 3–62.
14.
BorsboomD.RomeijnJ.-W.WichertsJ. M. (2008). Measurement invariance versus selection invariance: Is fair selection possible?Psychological Methods, 13(2), 75–98. https://doi.org/10.1037/1082-989X.13.2.75
15.
BuchholzJ.HartigJ. (2019). Comparing attitudes across groups: An IRT-based item-fit statistic for the analysis of measurement invariance. Applied Psychological Measurement, 43(3), 241–250. https://doi.org/10.1177/0146621617748323
16.
ByrneB. M.ShavelsonR. J.MuthénB. (1989). Testing for the equivalence of factor covariance and mean structures: The issue of partial measurement invariance. Psychological Bulletin, 105(3), 456–466. https://doi.org/10.1037/0033-2909.105.3.456
17.
CamilliG. (1993). The case against item bias detection techniques based on internal criteria: Do item bias procedures obscure test fairness issues? In HollandP. W.WainerH. (Eds.), Differential item functioning: Theory and practice (pp. 397–417). Lawrence Erlbaum.
18.
ChalmersR. P.CounsellA.FloraD. B. (2015). It might not make a big DIF: Improved differential test functioning statistics that account for sampling variability. Educational and Psychological Measurement, 76(1), 114–140. https://doi.org/10.1177/0013164415584576
ChoS.-J.SuhY.LeeW.-Y. (2016). After differential item functioning is detected: IRT item calibration and scoring in the presence of DIF. Applied Psychological Measurement, 40(8), 573–591. https://doi.org/10.1177/0146621616664304
21.
CohenA. S.KimS.-H.WollackJ. A. (1996). An investigation of the likelihood ratio test for detection of differential item functioning. Applied Psychological Measurement, 20(1), 15–26. https://doi.org/10.1177/014662169602000102
22.
CulpepperS. A. (2017). The prevalence and implications of slipping on low-stakes, large-scale assessments. Journal of Educational and Behavioral Statistics, 42(6), 706–725. https://doi.org/10.3102/1076998617705653
DeMarsC. E. (2019). Alignment as an alternative to anchor purification in DIF analyses. Structural Equation Modeling: A Multidisciplinary Journal, 27(1), 56–72. https://doi.org/10.1080/10705511.2019.1617151
25.
DeMarsC. E.JurichD. P. (2015). The interaction of ability differences and guessing when modeling differential item functioning with the Rasch model: Conventional and tailored calibration. Educational and Psychological Measurement, 75(4), 610–633. https://doi.org/10.1177/0013164414554082
26.
DoeblerA. (2019). Looking at DIF from a new perspective: A structure-based approach acknowledging inherent indefinability. Applied Psychological Measurement, 43(4), 303–321. https://doi.org/10.1177/0146621618795727
27.
El MasriY. H.AndrichD. (2020). The trade-off between model fit, invariance, and validity: The case of PISA science assessments. Applied Measurement in Education, 33(2), 174–188. https://doi.org/10.1080/08957347.2020.1732384
28.
EngelsO.LüdtkeO.RobitzschA. (2025). A comparison of linking methods for longitudinal designs with the 2PL model under item parameter drift. Applied Measurement in Education, 38, 185–216. https://doi.org/10.1080/08957347.2025.2540290
29.
FährmannK.KöhlerC.HartigJ.HeineJ.-H. (2022). Practical significance of item misfit and its manifestations in constructs assessed in large-scale studies. Large-Scale Assessments in Education, 10, Article 7. https://doi.org/10.1186/s40536-022-00124-w
30.
FanJ.LiR. (2001). Variable selection via nonconcave penalized likelihood and its oracle properties. Journal of the American Statistical Association, 96(456), 1348–1360. https://doi.org/10.1198/016214501753382273
31.
FinchH. (2005). The MIMIC model as a method for detecting DIF: Comparison with Mantel-Haenszel, SIBTEST, and the IRT likelihood ratio. Applied Psychological Measurement, 29(4), 278–295. https://doi.org/10.1177/0146621605275728
32.
FischerL.RohmT.CarstensenC. H.GnambsT. (2021). Linking of Rasch-scaled tests: Consequences of limited item pools and model misfit. Frontiers in Psychology, 12, Article 633896. https://doi.org/10.3389/fpsyg.2021.633896
33.
FrederickxS.TuerlinckxF.De BoeckP.MagisD. (2010). RIM: A random item mixture model to detect differential item functioning. Journal of Educational Measurement, 47(4), 432–457. https://doi.org/10.1111/j.1745-3984.2010.00122.x
34.
GoldsteinH. (1983). Measuring changes in educational attainment over time: Problems and possibilities. Journal of Educational Measurement, 20(4), 369–377. https://doi.org/10.1111/j.1745-3984.1983.tb00214.x
35.
González-BetanzosF.AbadF. J. (2012). The effects of purification and the evaluation of differential item functioning with the likelihood ratio test. Methodology, 8(4), 134–145. https://doi.org/10.1027/1614-2241/a000046
36.
GrundS.LüdtkeO.RobitzschA. (2024). Using synthetic data to improve the reproducibility of statistical results in psychological research. Psychological Methods, 29(4), 789–806. https://doi.org/10.1037/met0000526
37.
HabermanS. J. (2009). Linking parameter estimates derived from an item response model through separate calibrations (Research report no. RR-09-40). Education Testing Service. https://doi.org/10.1002/j.2333-8504.2009.tb02197.x
38.
HaebaraT. (1980). Equating logistic ability scales by a weighted least squares method. Japanese Psychological Research, 22(3), 144–149. https://doi.org/10.4992/psycholres1954.22.144
HanK. T.WellsC. S.SireciS. G. (2012). The impact of multidirectional item parameter drift on IRT scaling coefficients and proficiency estimates. Applied Measurement in Education, 25(2), 97–117. https://doi.org/10.1080/08957347.2012.660000
41.
HansonB. A.BéguinA. A. (2002). Obtaining a common scale for item response theory item parameters using separate versus concurrent estimation in the common-item equating design. Applied Psychological Measurement, 26(1), 3–24. https://doi.org/10.1177/0146621602026001001
42.
HarwellM. R.StoneC. A.HsuT.-C.KirisciL. (1996). Monte Carlo studies in item response theory. Applied Psychological Measurement, 20(2), 101–125. https://doi.org/10.1177/014662169602000201
43.
HeY.CuiZ. (2019). Evaluating robust scale transformation methods with multiple outlying common items under IRT true score equating. Applied Psychological Measurement, 44(4), 296–310. https://doi.org/10.1177/0146621619886050
44.
HeY.CuiZ.OsterlindS. J. (2015). New robust scale transformation methods in the presence of outlying common items. Applied Psychological Measurement, 39(8), 613–626. https://doi.org/10.1177/0146621615587003
HuH.RogersW. T.VukmirovicZ. (2008). Investigation of IRT-based equating methods in the presence of outlier common items. Applied Psychological Measurement, 32(4), 311–333. https://doi.org/10.1177/0146621606292215
HugginsA. C. (2014). The effect of differential item functioning in anchor items on population invariance of equating. Educational and Psychological Measurement, 74(4), 627–658. https://doi.org/10.1177/0013164413506222
49.
HuynhH.MeyerP. (2010). Use of robust z in detecting unstable items in item response theory models. Practical Assessment, Research, and Evaluation, 15(1), Article 2. https://doi.org/10.7275/ycx6-e864
50.
JiangB.RafteryA. E.SteeleR. J.WangN. (2022). Balancing inferential integrity and disclosure risk via model targeted masking and multiple imputation. Journal of the American Statistical Association, 117(537), 52–66. https://doi.org/10.1080/01621459.2021.1909597
51.
JodoinM. G.KellerL. A.SwaminathanH. (2003). A comparison of linear, fixed common item, and concurrent parameter estimation equating procedures in capturing academic growth. The Journal of Experimental Education, 71(3), 229–250. https://doi.org/10.1080/00220970309602064
KankarašM.MoorsG. (2014). Analysis of cross-cultural comparability of PISA 2009 scores. Journal of Cross-Cultural Psychology, 45(3), 381–399. https://doi.org/10.1177/0022022113511297
54.
KellerL. A.KellerR. R. (2011). The long-term sustainability of different item response theory scaling methods. Educational and Psychological Measurement, 71(2), 362–379. https://doi.org/10.1177/0013164410375111
KimS.KolenM. J. (2007). Effects on scale linking of different definitions of criterion functions for the IRT characteristic curve methods. Journal of Educational and Behavioral Statistics, 32(4), 371–397. https://doi.org/10.3102/1076998607302632
57.
KimS. H.CohenA. S. (1995). A comparison of Lord’s chi-square, Raju’s area measures, and the likelihood ratio test on detection of differential item functioning. Applied Measurement in Education, 8(4), 291–312. https://doi.org/10.1207/s15324818ame0804_2
58.
KimS.-H.CohenA. S. (1998). A comparison of linking and concurrent calibration under item response theory. Applied Psychological Measurement, 22(2), 131–143. https://doi.org/10.1177/01466216980222003
KöhlerC.RobitzschA.HartigJ. (2020). A bias-corrected RMSD item fit statistic: An evaluation and comparison to alternatives. Journal of Educational and Behavioral Statistics, 45(3), 251–273. https://doi.org/10.3102/1076998619890566
KönigC.KhorramdelL.YamamotoK.FreyA. (2021). The benefits of fixed item parameter calibration for parameter accuracy in small sample situations in large-scale assessments. Educational Measurement: Issues and Practice, 40(1), 17–27. https://doi.org/10.1111/emip.12381
64.
KopfJ.ZeileisA.StroblC. (2015a). Anchor selection strategies for DIF analysis: Review, assessment, and new approaches. Educational and Psychological Measurement, 75(1), 22–56. https://doi.org/10.1177/0013164414529792
65.
KopfJ.ZeileisA.StroblC. (2015b). A framework for anchor methods and an iterative forward approach for DIF detection. Applied Psychological Measurement, 39(2), 83–103. https://doi.org/10.1177/0146621614544195
66.
KreinerS.ChristensenK. B. (2014). Analyses of model fit and robustness: A new look at the PISA scaling model underlying ranking of countries according to reading literacy. Psychometrika, 79(2), 210–231. https://doi.org/10.1007/s11336-013-9347-z
LenhardW.SchneiderW. (2005). ELFE 1–6: Ein Leseverständnistest für Erst-bis Sechstklässler [ELFE 1-6: A reading comprehension test for first to sixth graders] (1st ed.). Hogrefe.
69.
LipovetskyS. (2007). Optimal Lp-metric for minimizing powered deviations in regression. Journal of Modern Applied Statistical Methods, 6(1), 219–227. https://doi.org/10.22237/jmasm/1177993140
70.
LiuC.JurichD. (2022). Outlier detection using t-test in Rasch IRT equating under NEAT design. Applied Psychological Measurement, 47(1), 34–47. https://doi.org/10.1177/01466216221124045
71.
Lopez RivasG. E.StarkS.ChernyshenkoO. S. (2009). The effects of referent item parameters on differential item functioning detection using the free baseline likelihood ratio test. Applied Psychological Measurement, 33(4), 251–265. https://doi.org/10.1177/0146621608321760
72.
MagisD.BélandS.TuerlinckxF.De BoeckP. (2010). A general framework and an R package for the detection of dichotomous differential item functioning. Behavior Research Methods, 42(3), 847–862. https://doi.org/10.3758/BRM.42.3.847
73.
MagisD.De BoeckP. (2011). Identification of differential item functioning in multiple-group settings: A multivariate outlier detection approach. Multivariate Behavioral Research, 46(5), 733–755. https://doi.org/10.1080/00273171.2011.606757
74.
MellenberghG. J. (1982). Contingency table models for assessing item bias. Journal of Educational Statistics, 7(2), 105–118. https://doi.org/10.2307/1164960
MillsapR. E.EversonH. T. (1993). Methodology review: Statistical approaches for assessing measurement bias. Applied Psychological Measurement, 17(4), 297–334. https://doi.org/10.1177/014662169301700401
78.
OelkerM.-R.PößneckerW.TutzG. (2015). Selection and fusion of categorical predictors with L0-type penalties. Statistical Modelling, 15(5), 389–410. https://doi.org/10.1177/1471082X14553366
79.
OelkerM. R.TutzG. (2017). A uniform framework for the combination of penalties in generalized structured models. Advances in Data Analysis and Classification, 11, 97–120. https://doi.org/10.1007/s11634-015-0205-y
80.
OliveriM. E.von DavierM. (2011). Investigation of model fit and score scale comparability in international assessments. Psychological Test and Assessment Modeling, 53(3), 315–333.
81.
OliveriM. E.von DavierM. (2017). Analyzing invariance of item parameters used to estimate trends in international large-scale assessments. In JiaoH.LissitzR. W. (Eds.), Test fairness in the new generation of large-scale assessment (pp. 121–146). Information Age.
82.
O’NeillM.BurkeK. (2023). Variable selection using a smooth information criterion for distributional regression models. Statistics and Computing, 33, 71. https://doi.org/10.1007/s11222-023-10204-8
83.
Organisation for Economic Co-operation and Development. (2016). PISA 2015 results (Volume I): Excellence and equity in education [Technical report]. https://doi.org/10.1787/9789264266490-en
84.
PenfieldR. D.CamilliG. (2007). Differential item functioning and item bias. In RaoC. R.SinharayS. (Eds.), Handbook of statistics: Psychometrics (Vol. 26, pp. 125–167). Elsevier. https://doi.org/10.1016/S0169-7161(06)26005-X.
85.
R Core Team. (2024). R: A language and environment for statistical computing [Computer software manual]. https://www.R-project.org/
86.
RobitzschA. (2020). Robust Haebara linking for many groups: Performance in the case of uniform DIF. Psych, 2(3), 155–173. https://doi.org/10.3390/psych2030014
87.
RobitzschA. (2023a). Comparing robust linking and regularized estimation for linking two groups in the 1PL and 2PL models in the presence of sparse uniform differential item functioning. Stats, 6(1), 192–208. https://doi.org/10.3390/stats6010012
88.
RobitzschA. (2023b). Loss functions in model-robust estimation of structural equation models. Psych, 5(4), 1122–1139. https://doi.org/10.3390/psych5040075
RobitzschA.DörflerT.PfostM.ArteltC. (2011). Die Bedeutung der Itemauswahl und der Modellwahl für die längsschnittliche Erfassung von Kompetenzen [Relevance of item selection and model selection for assessing the development of competencies: The development in reading competence in primary school students]. Zeitschrift für Entwicklungspsychologie und Pädagogische Psychologie, 43(4), 213–227. https://doi.org/10.1026/0049-8637/a000052
96.
RobitzschA.LüdtkeO. (2022). Mean comparisons of many groups in the presence of DIF: An evaluation of linking and concurrent scaling approaches. Journal of Educational and Behavioral Statistics, 47(1), 36–68. https://doi.org/10.3102/10769986211017479
97.
RohmT.CarstensenC. H.FischerL.GnambsT. (2021). The achievement gap in reading competence: The effect of measurement non-invariance across school types. Large-scale Assessments in Education, 9, Article 23. https://doi.org/10.1186/s40536-021-00116-2
98.
SachseK. A.RoppeltA.HaagN. (2016). A comparison of linking methods for estimating national trends in international comparative large-scale assessments in the presence of cross-national DIF. Journal of Educational Measurement, 53(2), 152–171. https://doi.org/10.1111/jedm.12106
99.
SamejimaF. (2000). Logistic positive exponent family of models: Virtue of asymmetric item characteristic curves. Psychometrika, 65(3), 319–335. https://doi.org/10.1007/BF02296149
100.
SchaubergerG.MairP. (2020). A regularization approach for the detection of differential item functioning in generalized partial credit models. Behavior Research Methods, 52, 279–294. https://doi.org/10.3758/s13428-019-01224-2
ShealyR.StoutW. (1993). A model-based standardization approach that separates true bias/DIF from group ability differences and detects test bias/DTF as well as item bias/DIF. Psychometrika, 58(2), 159–194. https://doi.org/10.1007/BF02294572
103.
StarkS.ChernyshenkoO. S.DrasgowF. (2006). Detecting differential item functioning with confirmatory factor analysis and item response theory: Toward a unified strategy. The Journal of Applied Psychology, 91(6), 1292–1306. https://doi.org/10.1037/0021-9010.91.6.1292
104.
SteenkampJ.-B. E. M.BaumgartnerH. (1998). Assessing measurement invariance in cross-national consumer research. Journal of Consumer Research, 25(1), 78–90. https://doi.org/10.1086/209528
105.
ThissenD.SteinbergL.WainerH. (1988). Use of item response theory in the study of group difference in trace lines. In WainerH.BraunH. (Eds.), Test validity (pp. 147–170). Lawrence Erlbaum.
106.
ThissenD.SteinbergL.WainerH. (1993). Detection of differential item functioning using the parameters of item response models. In HollandP. W.WainerH. (Eds.), Differential item functioning (pp. 67–114). Lawrence Erlbaum.
107.
TibshiraniR. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society: Series B (Methodological), 58(1), 267–288. https://doi.org/10.1111/j.2517-6161.1996.tb02080.x
108.
TijmstraJ.BolsinovaM.LiawY.-L.RutkowskiL.RutkowskiD. (2020). Sensitivity of the RMSD for detecting item-level misfit in low-performing countries. Journal of Educational Measurement, 57(4), 566–583. https://doi.org/10.1111/jedm.12263
109.
TourangeauK.NordC.LêT.Wallner-AllenK.Vaden-KiernanN.BlakerL.NajarianM. (2018). Early childhood longitudinal study, kindergarten class of 2010–11 (ECLS-K:2011): User’s manual for the ECLS-K:2011 kindergarten—Fourth grade data file and electronic codebook, public version (Tech. rep. no. NCES 2018-032). National Center for Education Statistics, Institute of Education Sciences, U.S. Department of Education. https://nces.ed.gov/pubsearch/pubsinfo.asp?pubid=2018032
110.
van BorkR.RhemtullaM.SijtsmaK.BorsboomD. (2024). A causal theory of error scores. Psychological Methods, 29(4), 807–826. https://doi.org/10.1037/met0000521
111.
van der LindenW. J. (2016). Unidimensional logistic response models. In van der LindenW. J. (Ed.), Handbook of item response theory: Models (Vol. 1, pp. 11–30). CRC Press. https://doi.org/10.1201/9781315119144.
112.
von DavierA. A.HollandP. W.ThayerD. T. (2004). The chain and post-stratification methods for observed-score equating: Their relationship to population invariance. Journal of Educational Measurement, 41(1), 15–32. https://doi.org/10.1111/j.1745-3984.2004.tb01156.x
113.
von DavierM.BezirhanU. (2023). A robust method for detecting item misfit in large-scale assessments. Educational and Psychological Measurement, 83(4), 740–765. https://doi.org/10.1177/00131644221105819
114.
von DavierM.XuX.CarstensenC. H. (2011). Measuring growth in a longitudinal large-scale assessment with a general latent variable model. Psychometrika, 76(2), 318–336. https://doi.org/10.1007/s11336-011-9202-z
115.
WangS.LeeW.-C.ZhangM.YuanL. (2024). IRT characteristic curve linking methods weighted by information for mixed-format tests. Applied Measurement in Education, 37(4), 377–390. https://doi.org/10.1080/08957347.2024.2424547
116.
WangW.LiuY.LiuH. (2022). Testing differential item functioning without predefined anchor items using robust regression. Journal of Educational and Behavioral Statistics, 47(6), 666–692. https://doi.org/10.3102/10769986221109208
117.
WangW.-C.YehY.-L. (2003). Effects of anchor item methods on differential item functioning detection with the likelihood ratio test. Applied Psychological Measurement, 27(6), 479–498. https://doi.org/10.1177/0146621603259902
118.
WeeksJ. P. (2010). Plink: An R package for linking mixed-format tests using IRT-based methods. Journal of Statistical Software, 35(12), 1–33. https://doi.org/10.18637/jss.v035.i12
119.
WoodsC. M. (2008). Likelihood-ratio DIF testing: Effects of nonnormality. Applied Psychological Measurement, 32(7), 511–526. https://doi.org/10.1177/0146621607310402
120.
WuM. (2010). Measurement, sampling, and equating errors in large-scale assessments. Educational Measurement: Issues and Practice, 29(4), 15–27. https://doi.org/10.1111/j.1745-3992.2010.00190.x
121.
XuX.DouglasJ. A.LeeY. S. (2009). Linking with nonparametric IRT models. In von DavierA. (Ed.), Statistical models for test equating, scaling, and linking (pp. 243–258). https://doi.org/10.1007/978-0-387-98138-3_15
122.
ZhaoY.HambletonR. K. (2017). Practical consequences of item response theory model misfit in the context of test equating with mixed-format test data. Frontiers in Psychology, 8, Article 484. https://doi.org/10.3389/fpsyg.2017.00484