
Abstract
In item response theory modeling, item fit analysis using posterior expectations, otherwise known as pseudocounts, has many advantages. They are readily obtained from the E-step output of the Bock–Aitkin Expectation-Maximization (EM) algorithm and continue to function as a basis of evaluating model fit, even when missing data are present. This paper aimed to improve the interpretability of the root mean squared deviation (RMSD) index based on posterior expectations. In Study 1, we assessed its performance using two approaches. First, we employed the poor person’s posterior predictive model checking (PP-PPMC) to compute their significance levels. The resulting Type I error was generally controlled below the nominal level, but power noticeably declined with smaller sample sizes and shorter test lengths. Second, we used receiver operating characteristic (ROC) curve analysis to empirically determine the reference values (cutoff thresholds) that achieve an optimal balance between false-positive and true-positive rates. Importantly, we identified optimal reference values for each combination of sample size and test length in the simulation conditions. The cutoff threshold approach outperformed the PP-PPMC approach with greater gains in true-positive rates than losses from the inflated false-positive rates. In Study 2, we extended the cutoff threshold approach to conditions with larger sample sizes and longer test lengths. Moreover, we evaluated the performance of the optimized cutoff thresholds under varying levels of data missingness. Finally, we employed response surface analysis to develop a prediction model that generalizes the way the reference values vary with sample size and test length. Overall, this study demonstrates the application of the PP-PPMC for item fit diagnostics and implements a practical frequentist approach to empirically derive reference values. Using our prediction model, practitioners can compute the reference values of RMSD that are tailored to their dataset’s sample size and test length.
Keywords
Introduction
Given the widespread use of item response theory (IRT) models, evaluation of IRT model fit is pivotal to any IRT-based measurement activities. Especially, an item-level evaluation of fit is of great interest to practitioners who desire to identify items that do not sufficiently conform to the fitted model. Evaluation of an item fit, however, is not as straightforward as evaluating an overall model fit. It requires that examinees’ categorical responses to the item (e.g., correct or incorrect, in case of a dichotomously scored item) be rearranged in a way that they can be compared with a model prediction that is represented on a continuous scale of a latent variable
Various item fit evaluation methods have been proposed to address the challenge, among which chi-square type indices are the most common. The indices primarily differ in the ways they sort examinees into subgroups. Examinees were sorted into a fixed or varying number of intervals based on their
An alternative approach is to use posterior expectations, also known as pseudocounts or pseudo-observed frequencies (Donoghue & McClellan, 1999, 2003; Li, 2005; Stone, 2000, 2003). The posterior expectations are represented on quadrature points, a set of discrete values that approximate the continuous scale of
Given rich information and the ease of access, posterior expectations have been widely used to visualize observed probabilities alongside model-implied probabilities (e.g., Allen et al., 1999; Eckerly et al., 2022; van Rijn et al., 2016). This approach is also described as comparing the empirical or observed item response functions (IRFs) or tracelines with their theoretical or expected counterparts. The agreement or disagreement between the two curves is typically assessed through a visual inspection or “eyeballing,” due to the challenge in performing a statistical test for misfit.
The most prominent test quantity that can support—if not replace—the visual inspection is the root mean squared deviation (RMSD) index, which has gained increasing attention in recent years (Köhler et al., 2020; Robitzsch, 2022). The RMSD quantifies the discrepancy between the expected and observed IRFs, weighted by the population density. That is, item fit is assessed by how much the observed IRF deviates from the expected IRF, with greater weight given to regions where the population density is higher. In this way, the RMSD effectively captures the data-model fit in a relevant manner. Note that the RMSD has also appeared in literature as the root integrated squared error (RISE) index that quantifies the discrepancy between parametric and nonparametric IRFs (e.g., Douglas & Cohen, 2001; Lee et al., 2009). The RMSD can be understood as a special case of RISE where the nonparametric IRF is estimated using posterior expectations (e.g., Sueiro & Abad, 2011). In this study, we focus on the RMSD as it does not require additional fitting of the nonparametric IRF.
Despite the ease of computation and the meaningful interpretation offered by the RMSD, its null distribution remains unknown due to the impact of sampling error, estimation error, and the dependencies among the pseudocounts (attributable to each examinee probabilistically contributing to all quadrature points). Moreover, the RMSD is not interpretable as an effect size for misfit (i.e., a consistent measure that informs the magnitude of misfit; Köhler et al., 2021) because its size depends on the characteristics of the data, such as sample size and test length (Köhler et al., 2020;, 2021; Robitzsch, 2022). To address the challenge, a parametric bootstrap method was used to compute significance values for the RMSD (Köhler et al., 2020;, 2021; Sueiro & Abad, 2011), which demonstrated unsatisfactory power under small to moderate sample sizes and shorter test lengths. Other efforts have aimed to analytically derive the asymptotic null distribution (Donoghue & McClellan, 1999, 2003), but the required task of computing the covariance matrix of pseudocounts is computationally intensive and thus has not been widely implemented in practice. Even after the computational burden was alleviated by replacing the full covariance matrix with its observed counterpart (Li, 2005), the approximation was prone to introducing additional sources of error. More fundamentally, the existing methods for computing the significance values rely on the assumption that item parameters are fixed and known, which is highly restrictive in applied settings.
In this study, we demonstrate two approaches to address the limitation. First, we demonstrate the implementation of the poor person’s posterior predictive model checking (PP-PPMC) introduced by Lee et al. (2016) to compute significance values for the RMSD. The PP-PPMC is a frequentist simplification of posterior predictive model checking (PPMC; Gelman et al., 1996; Rubin, 1984), a prominent Bayesian model diagnostic tool. PPMC has a strong theoretical basis and provides graphical and numerical evidence about model fit, while organically accounting for sampling and estimation errors. That is, it no longer relies on the unrealistic assumption that item parameters are fixed and known. Despite the merits, since PPMC requires simulated draws from a posterior predictive distribution, it has almost exclusively been applied to Bayesian IRT contexts (e.g., Joo & Lee, 2022; Levy et al., 2009; Sinharay, 2005, 2006; Sinharay et al., 2006). The PP-PPMC (Lee et al., 2016), however, enabled the PPMC procedure in models estimated using maximum likelihood (ML). It was shown that Bayesian estimation can be bypassed by approximating the posterior distribution with a multivariate normal distribution, using ML estimates as the mean and the corresponding variance–covariance matrix as the covariance. While the original development took place in the context of structural equation modeling, Kuhfeld (2019) applied the PP-PPMC to the context of IRT estimated using full-information ML to test for local independence, where it was once again confirmed that the multivariate normal approximation of the posterior distribution performed well even with small sample sizes. In this study, we extended the application of the PP-PPMC to item fit evaluation using the RMSD. This application enabled us to assess the performance of the RMSD by examining the distribution of its significance levels under null conditions.
Second, we derived reference values (cutoff thresholds) for the RMSD to facilitate its use. We utilized the item fit values generated via simulation study to construct an empirical distribution of the RMSD under null and non-null conditions. Then, we identified the optimal reference values using receiver operating characteristic (ROC) curve analysis (Metz, 1978) and fitted a model by response surface analysis (Box, 1954) to generalize the optimized reference values to conditions beyond those in the simulation study. This procedure verified the performance of the RMSD and made available the reference values that practitioners can readily adopt to interpret their RMSD values. In addition, the performance of the optimized reference values was evaluated in the presence of missing data commonly found in large-scale assessments.
The rest of the paper is structured as follows. We first describe the computation of the RMSD and outline the two approaches in detail, along with their guiding philosophy. Next, we present two simulation studies that implement the methods. In Study 1, we compared the performance of the two approaches: the PP-PPMC method and the application of optimized reference values. In Study 2, we derived the optimized reference values for conditions not covered in Study 1, with greater emphasis on large-scale assessment contexts characterized by larger sample sizes, longer test lengths, and higher levels of data missingness. The simulation studies are followed by an empirical example that illustrates the application of the findings. We conclude with summary and discussions.
Computation of Pseudocounts and RMSD
Suppose there are dichotomously scored items (
Pseudocounts
Donoghue and McClellan (1999, 2003) characterized pseudocounts as compilations across response patterns to items except for the target item. Under the framework, a pseudocount for item
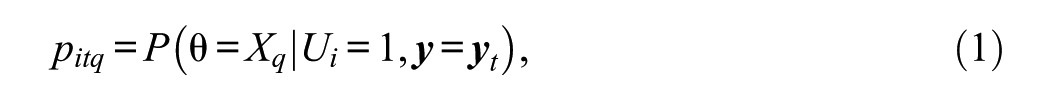
is a posterior probability of
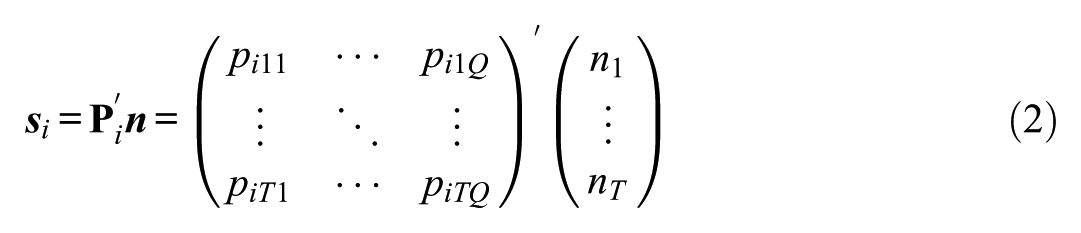
where the frequency vector
Alternatively, Li (2005) reformulated
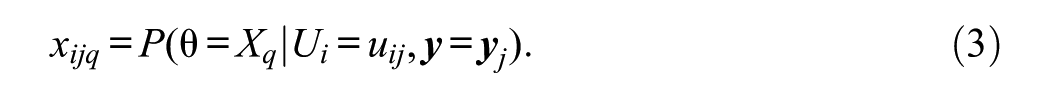
The unit pseudocounts of each person (i.e.,
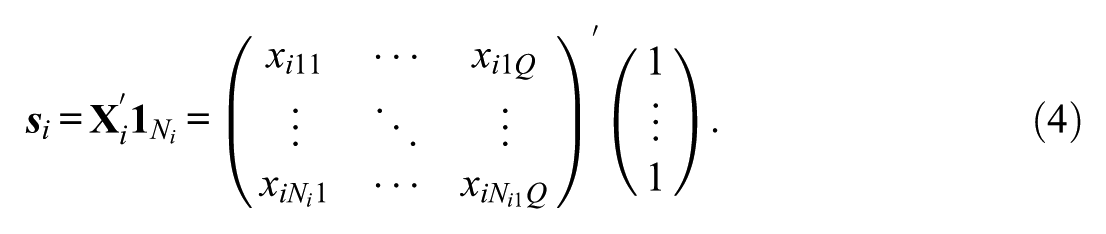
The reformulation has improved computational efficiency by decreasing the size of the matrix from
When a model is estimated using the EM algorithm (Bock & Aitkin, 1981), the pseudocount vector
RMSD Index
An item fit can be quantified as the discrepancy between the observed and expected probabilities correct:
The weight matrix can be an identity matrix
Item Fit Index Development
While the RMSD effectively quantifies the deviations indicative of an item fit or misfit, it lacks interpretability on its own. To make the index meaningful, we require either statistical significance levels (i.e.,
One approach is the use of the PP-PPMC method (Lee et al., 2016) to assess the properties of the RMSD, including the distribution of its significance levels under null conditions, Type I error rate, and power. Here, the focus was to compute the significance level of the index for each dataset. The significance levels represent the plausibility of the observed discrepancies (quantified by the RMSD in our application) relative to the discrepancies found in hypothetical replications after observing each dataset. Thus, as formally introduced later in this section, the replications (
Another approach is to derive optimal reference values by empirically evaluating the diagnostic performance of all possible thresholds. We utilized the observed discrepancies (i.e., the RMSD values) generated via simulation studies to construct an empirical distribution of the RMSD under null and non-null conditions. Here, hypothetical replications were sampled from the predictive distribution that conditions on the model only, before observing any data, that is,
Both of these approaches leverage Monte Carlo frequency simulation to approximate and communicate Bayesian answers, aligning with what has been described as “Bayesianly justifiable and relevant frequency calculations” (Rubin, 1984, p. 1152), an “amalgam of Bayesian and frequentist ideas” (Little, 2006, p. 220), or a “frequentist simplification” (Bayarri & Berger, 2004, p. 71). Moreover, they illustrate how the definition of replications should vary depending on the purpose of model checking (Rubin, 1984). In the PP-PPMC approach, replications were drawn from the posterior predictive distribution that conditions on the model and the observed data. This approach assesses the significance level of the RMSD observed in a given data, and the ultimate goal is to validate whether the RMSD formalizes the model-data discrepancy in “relevant ways” (Rubin, 1984, p. 1166). In the cutoff threshold approach, replications were drawn from the predictive distribution that conditions on the model only, before any data are observed. This approach facilitates the identification of reference values that distinguish the RMSD values observed in correct model specification from those observed under model misspecification. The following subsections elaborate on these approaches in general terms.
PPMC and PP-PPMC
Given a hypothesized model
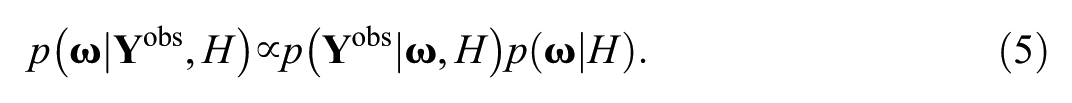
The replicated data are generated from the posterior predictive distribution, which is the conditional distribution of replicated data
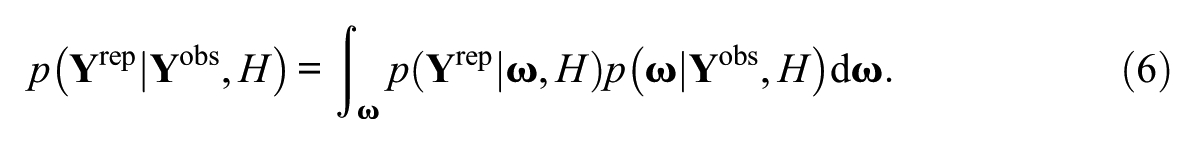
Notice that there are two components determining the posterior predictive distribution. First,
When the posterior distribution of the parameters (Equation [5]) is approximated by a multivariate normal distribution with ML parameter estimates as means and associated variance-covariance matrix as covariances, the procedure is referred to as PP-PPMC (Lee et al., 2016). The approximation relies on the posterior distribution being asymptotically normal, and this strategy can be described as “employing frequentist estimation and treating the answers as Bayesian results” (e.g., Levy & McNeish, 2023). The normal approximation to the posterior distribution has also been used in service of computing Bayes factors (Gu et al., 2019). The accuracy of the normal approximation may be reduced for a small sample size. However, in the context of IRT, Kuhfeld (2019) demonstrated that, even with a sample size as small as 250, the normal approximation to the posterior closely matched the posterior distribution obtained from Bayesian estimation.
To compare observed data with replicated data in terms of the discrepancy measure
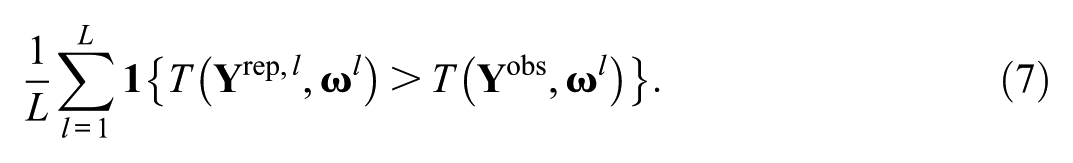
The PPP value indicates the probability that the data-model discrepancy is greater in the replicated data than in the observed data. If the model fits the data well, the PPP value will be near 0.5 (Meng (1994); Sinharay & Stern, 2003). If the PPP value is lower than a nominal significance level
Selection of Optimal Reference Values
In the context of a simulation study, the observed dataset
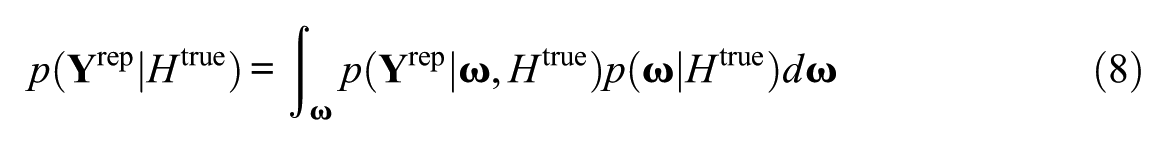
where
Following the data generation, we calibrate the data with a hypothesized model
The diagnostic performance of all possible reference values was evaluated using the ROC curve method. The ROC curve plots the false-positive rate (false alarm rate, or 1 minus specificity) on the
The ROC curve provides the basis for determining an optimal reference value, a cutoff threshold that achieves the best balance between sensitivity and specificity. This approach has been proven valuable when gold standards are not available and cutoff values are needed to distinguish between normal and abnormal conditions (e.g., Beck et al., 2019; Nahm, 2022). The appropriate trade-off between sensitivity and specificity depends on their relative importance or benefit. In the context of item fit diagnostic, it is crucial to maximize the true positives by flagging as many misfitting items as possible, while minimizing the false positives to avoid unnecessary reviews or edits of items which can be time-consuming and costly. Therefore, both sensitivity and specificity often play equally important roles in ensuring an efficient and effective diagnostic process, although their relative importance may depend on the specific purpose of item fit evaluation.
To determine the cutoff value that equally weighs sensitivity (Se) and specificity (Sp), we applied the Youden’s J statistic (Youden, 1950) that identifies the cutoff value by maximizing
Study 1
In Study 1, we implemented the two approaches to interpreting the RMSD values: (a) the PP-PPMC approach to compute their significance values and (b) the cutoff threshold approach to derive reference values for specific data characteristics. Their performances were compared via Type I error rate and power of the PP-PPMC and false-positive and true-positive rates of the reference values.
Simulation Design
A simulation study was designed to examine the performance of the RMSD under different data conditions. We manipulated three factors: (1) sample size (5,000; 1,000; 500), (2) test length (100; 40; and 20), and (3) the proportion of misfitting items (0.05; 0.1; and 0.2), resulting in a total of
It is worth reiterating that the data generated in this simulation are used in both of the approaches discussed in the previous section, but their role and interpretation differ between the two. In the PP-PPMC approach, each of the simulated datasets was treated as observed data that is,
Data Generation
The fitting items were generated under the 2PL model. The parameters were randomly sampled from preset distributions, that is,
The misfitting items were generated using a logistic function of a monotonic polynomial with a lower asymptote (LMPA; Falk & Cai, 2016a, 2016b) that provides a flexible yet monotonic shape of IRF by introducing lower asymptotes and/or plateaus. The probability of a correct response for item
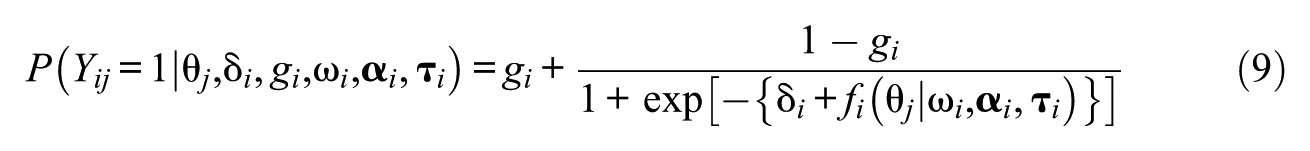
where
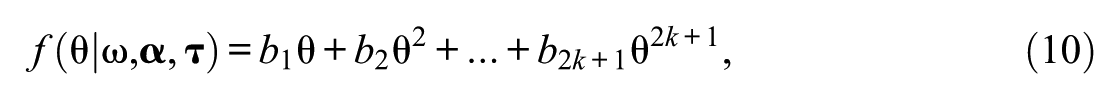
with
To simulate the IRFs of misfitting items, we conducted a preliminary analysis to identify the combinations of parameters in the LMPA that yield non-negligible degrees of item misfit. The order of
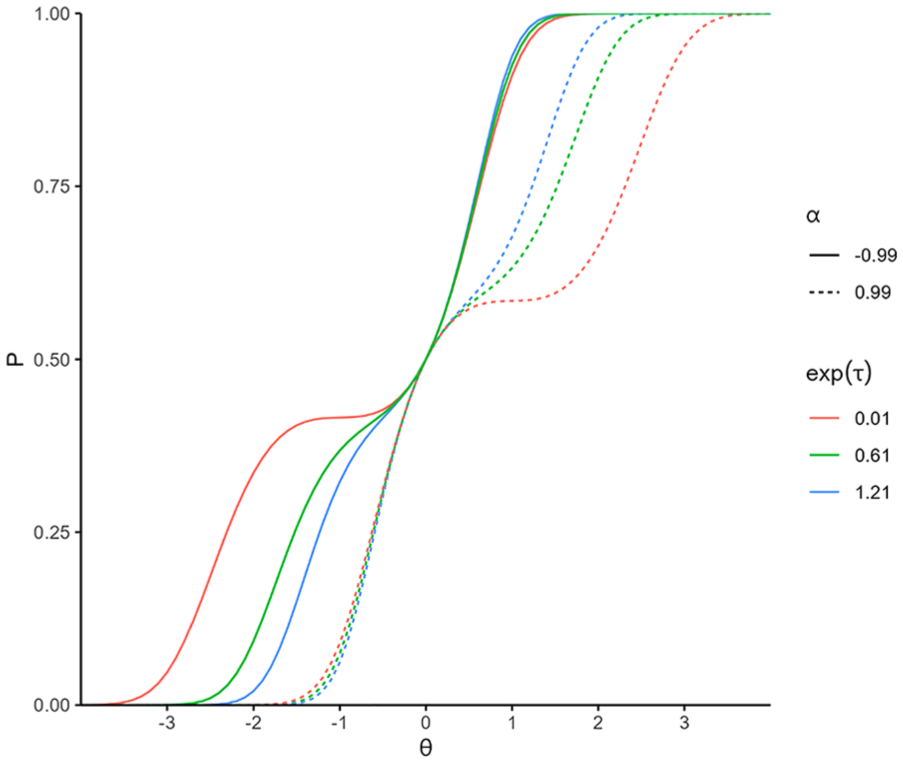
Example of item response functions for misfitting items.
For each of the possible combinations, we compared the true IRF generated by the LMPA with the IRF of the 2PL model that best approximates the true IRF. The approximating 2PL model was obtained by fitting a 2PL model to the true IRF with population density (that is assumed to be a standard normal in this study) as weights. Then, we excluded the cases in which one or more of the parameters of the fitted 2PL model are extreme, that is, beyond the plausible range of item parameters. The fitted parameter was considered extreme if it fell outside two standard deviations from the mean of the distribution (i.e.,
Parameter Estimation
The calibration of 2PL models was conducted using flexMIRT® (Cai, 2024). Item parameters were estimated using the Bock–Aitkin EM algorithm (Bock & Aitkin, 1981), and the covariances of the item parameters were computed by the supplemented EM algorithm (Cai, 2008). Quadrature points used for calibration and item fit analysis were 81 equally spaced points ranging from −4 to 4.
PP-PPMC Implementation
Following the parameter estimation,
Selection of Optimal Reference Values
The magnitude of the RMSD is known to depend heavily on data characteristics such as sample size and test length, while remaining robust to variations in the proportion of misfitting items (Köhler et al., 2020, 2021; Robitzsch, 2022; Sueiro & Abad, 2011). Hence, the ROC curve was generated separately for different combinations of sample size and test length. That is, the distribution of discrepancy measures was conditioned on some fixed features of data (Rubin, 1984). For each combination of sample size and test length (e.g., sample size of 5,000 and test length of 100), the ROC curve was constructed as follows: First, the RMSD values were computed for all of the simulated datasets; second, equally spaced values with a minimal grid size (e.g., 0.001) within the range of observed RMSD values were considered as candidate reference values; third, each of the candidate reference values was applied to the observed RMSD values, and the resulting false-positive and true-positive rates were plotted as points; finally, the points were connected to form a line, that is, the ROC curve.
Based on the ROC curves, the Youden’s J statistic criterion was applied to identify —for each combination of sample size and test length—the reference Value that achieves an optimal balance between sensitivity and specificity. Examples of the optimization procedure are presented in Figure 2. The reference value that maximizes the objective function, indicated by a dot, is selected as the optimal value. Figure 2(a) illustrates the condition with the largest sample size and the longest test length, and Figure 2(b) depicts the condition with the smallest sample size and the shortest test length. The optimized value in Figure 2(a) achieves a near-perfect classification with sensitivity and specificity of ones, while the optimized value in Figure 2(b) achieves less accurate classification. These examples suggest that the diagnostic performance of an optimal reference value is constrained by the amount of information available in the data.
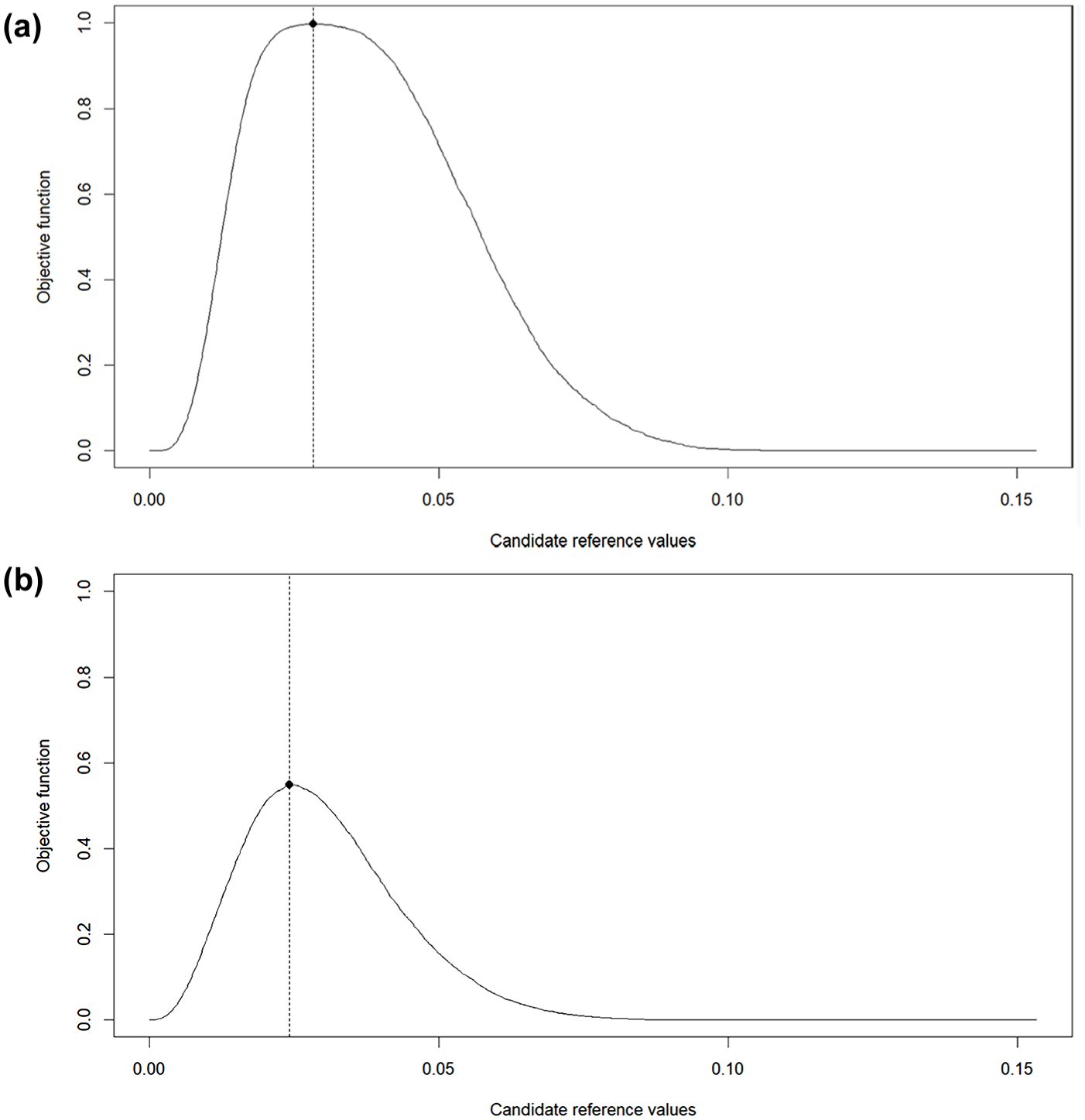
Example of reference value optimization. (a) Sample size = 5,000; test length = 100. (b) Sample size = 500; test length = 20.
Results
The results of implementing the PP-PPMC for statistical testing and the ROC method for establishing reference values are presented in the following.
Type I Error Rate and Power
The performance of the RMSD under null conditions was first examined via the distribution of PPP values for fitting items. Figure 3 presents the distribution of PPP values, with each panel corresponding to a specific combination of sample size and test length. In each panel, separate distributions are shown for different proportions of misfitting items. The median PPP values were consistently around 0.5, except when the proportion of misfitting items was the highest (i.e., 0.2) under the largest sample size (i.e., 5,000) and the longest test length (i.e., 100). The distributions were closest to uniform when the number of items was largest (i.e., 100) and became increasingly concentrated around 0.5 as the number of items decreased. The pattern reflects the tendency of PPP values to have a tighter concentration around 0.5 when less information is available in the data (e.g., Gilbride & Lenk, 2010). Furthermore, when the sample size was largest (i.e., 5,000), as the proportion of misfitting items increased, the PPP values were less concentrated around the center, with more PPP values near zero. Especially when the largest sample size was combined with the longest test length, the highest proportion of misfitting items (i.e., 0.2) resulted in a noticeable peak of PPP values near zero.
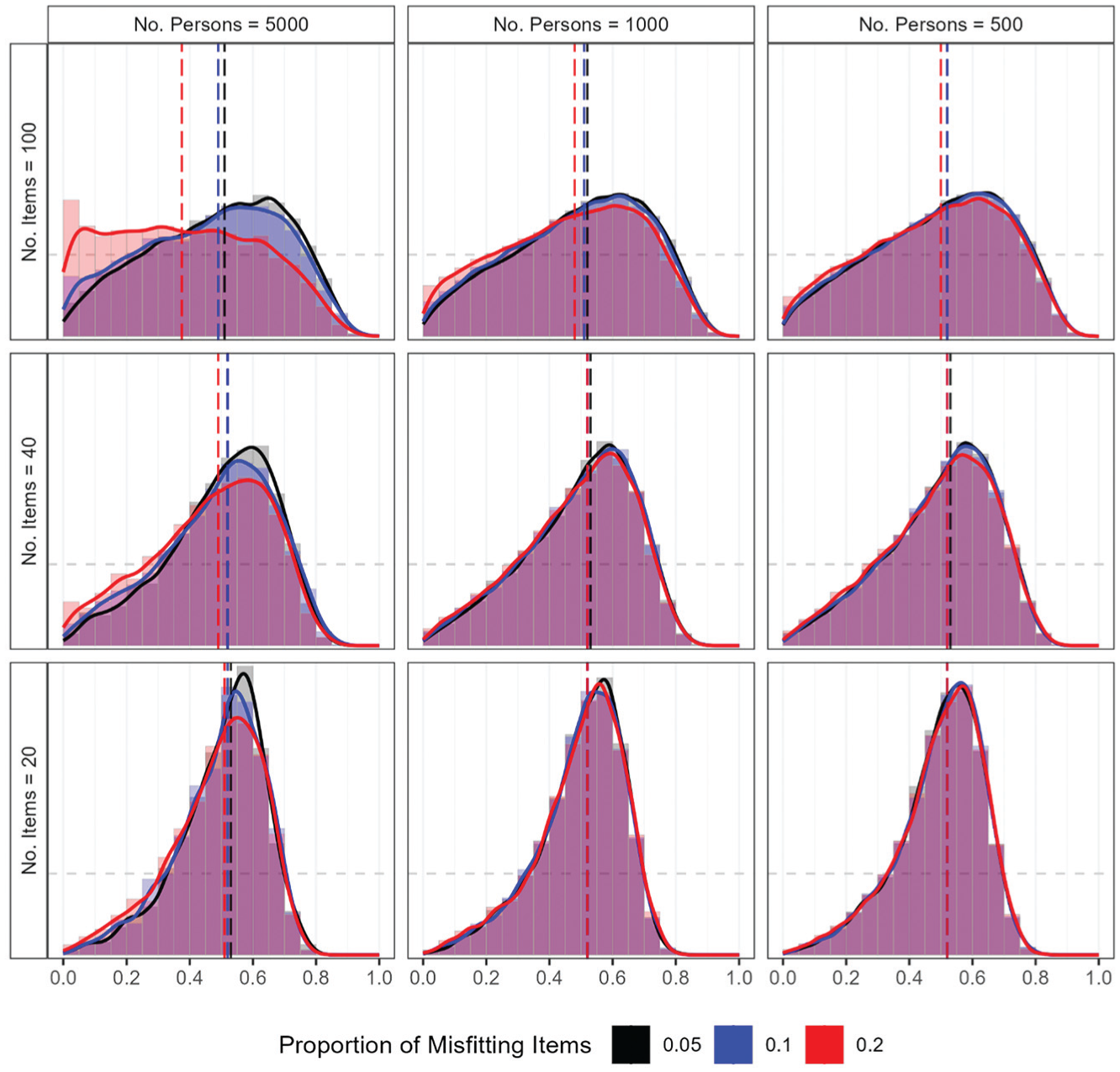
Study 1: Distribution of PPP values under null conditions.
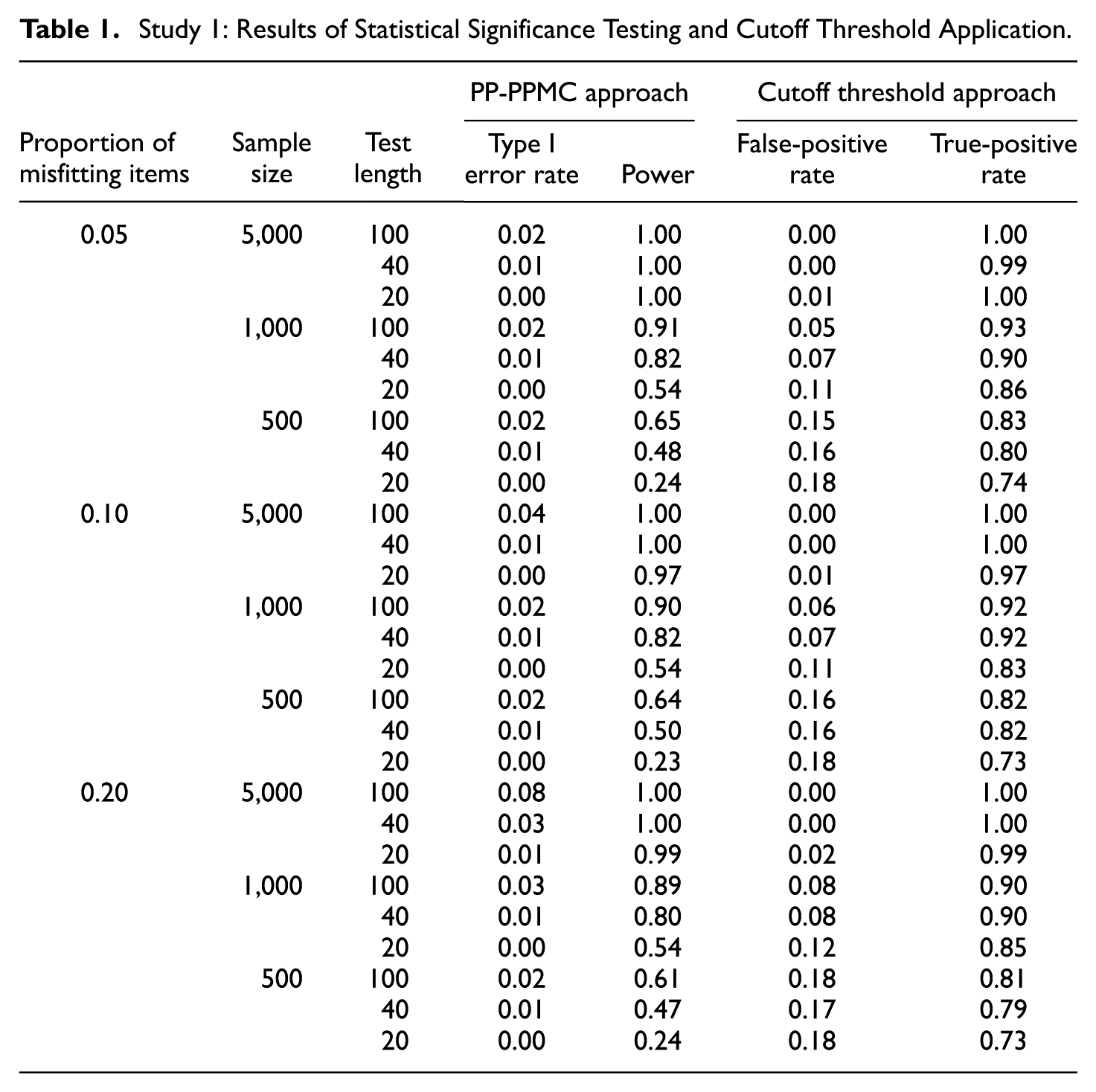
The resulting Type I error rate and power are summarized in Table 1. The Type I error rates were mostly below the nominal level of 0.05, except when the proportion of misfitting items was 0.2 with 5,000 persons and 100 items, where the false alarm rate was mildly inflated to 0.08. The power was nearly one (i.e., all misfitting items were detected) when the sample size was 5,000. For smaller sample sizes, the power decreased as the number of items decreased. Specifically, the power ranged from 0.54 to 0.91 with the sample size of 1,000, and from 0.23 to 0.65 with the sample size of 500. Notably, no systematic differences in power were observed across varying proportions of misfitting items.
Study 1: Results of Statistical Significance Testing and Cutoff Threshold Application.
Optimized Reference Values
The ROC curves that represent the diagnostic performances of the RMSD under different data characteristics are presented in Figure 4. Each point marks the coordinate of the false-positive rate and true-positive rate under the optimal reference value. The condition with the sample size of 5,000 and the test length of 100, illustrated in Figure 2(a), is represented by the red dotted line that lies furthest away from the diagonal and reaches the point of perfect classification (i.e., [0,1]). This indicates that, when sufficient information is available in the data, the distribution of the RMSD values for fitting items show minimal overlap with that for misfitting items, thereby allowing the optimized cutoff value to achieve near-perfect classification. By contrast, the with the sample size of 500 and the test length of 20, illustrated in Figure 2(b), is represented by the green solid line that lies closest to the diagonal. This suggests that, when there is limited amount of information in the data, the distributions of the RMSD values for fitting and misfitting items overlap considerably, thereby limiting the classification performance of the optimized cutoff value.
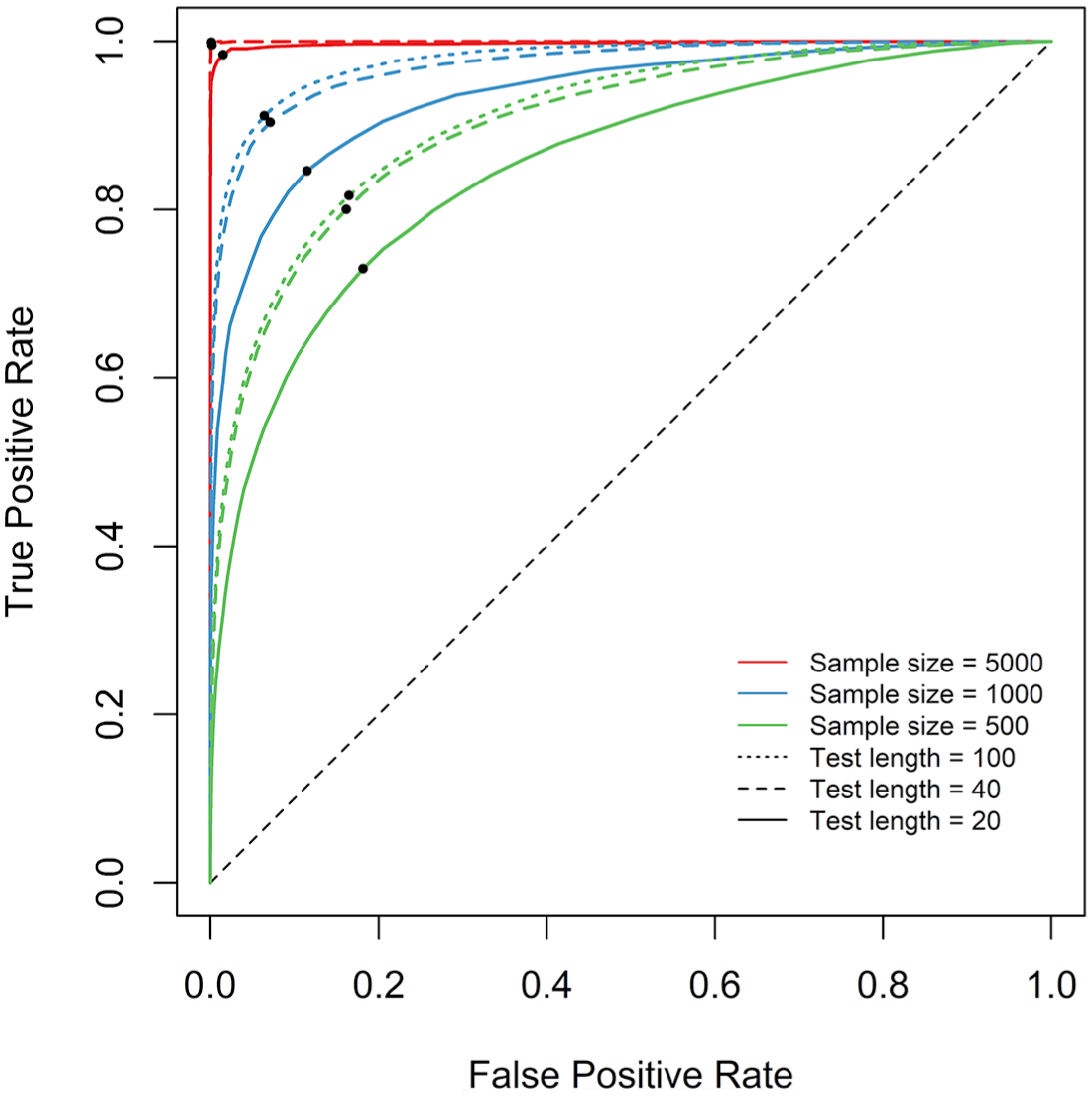
Study 1: ROC curves and optimized reference values.
The optimized reference values are presented in the first three columns of Table 2. They tend to decrease as the test length decreases and as the sample size increases, while this effect of test length decreases as the sample size increases. Such a pattern is in alignment with previous findings on the dependence of the RMSD on test length and sample size (e.g., Köhler et al., 2020, 2021; Sueiro & Abad, 2011). An analytical discussion of the sources of bias in the RMSD attributable to estimation error can be found in Robitzsch (2022).
Optimized Reference Values by Sample Size and Test Length.
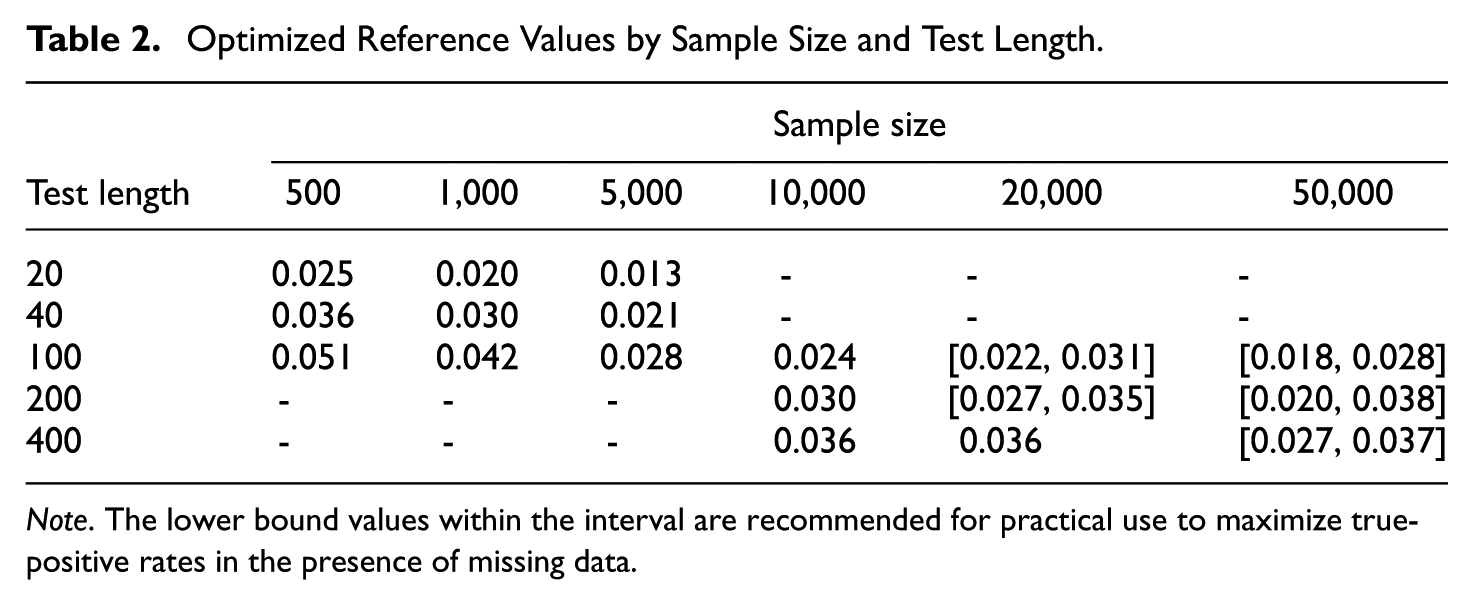
Note. The lower bound values within the interval are recommended for practical use to maximize true-positive rates in the presence of missing data.
The false-positive and true-positive rates of the suggested reference values are summarized in Table 1. Compared to the statistical testing via the PP-PPMC, applying the cutoff thresholds generally resulted in higher false-positive rates but also higher true-positive rates. For instance, under the sample size of 5,000 and test length of 100 or 40, the cutoff threshold approach yielded lower false-positive rates while also maintaining near-perfect true-positive rates. That is, while the PP-PPMC approach resulted in an inflated Type I error rate under a higher proportion of misfitting items, the cutoff thresholds approach consistently yielded a near-zero Type I error rate, regardless of the proportion of misfitting items. In conditions with smaller sample sizes, as the proportion of misfitting items increased, the false-positive rate increased and true-positive rate decreased, but only to a marginal degree. This result is consistent with the previous findings that the magnitude of the RMSD is largely unaffected by the proportion of misfitting items (e.g., Köhler et al., 2020; Sueiro & Abad, 2011). Overall, the cutoff threshold approach outperformed the PP-PPMC approach in that the improvement in the true-positive rates outweighed the increase in the false-positive rates, while exhibiting robustness to varying proportions of misfitting items.
Study 2
We conducted an additional simulation to further generalize the reference values to larger numbers of persons and items. We also examined the performance of the reference values under data missingness which is prevalent in large-scale assessments with a relatively large number of items and persons. The parameter estimation and the selection of optimal reference values followed the same procedure as in Study 1.
Simulation Design
We manipulated four factors: (1) sample size (50,000; 20,000; and 10,000), (2) test length (400; 200; and 100), (3) the proportion of misfitting items (0.05; 0.1; and 0.2), and (4) the proportion of missing responses per person (0; 0.4; and 0.8), resulting in a total of
Data Generation
The fitting and misfitting items were generated using the same procedure as in Study 1. They were generated under 2PL and the LMPA (Falk & Cai, 2016a, 2016b) models, respectively. For conditions with non-zero proportions of data missingness, the assigned proportion of missingness was imposed on each person’s responses to generate random missingness.
Results
The results are summarized in three parts. First, we discuss the impact of the manipulated factors on the magnitude and dispersion of the RMSD values, with special emphasis on the impact of missing data, along with its interaction with other manipulated factors that was not addressed in Study 1. Then, we present the reference values that were optimized for data without missing responses, where we also discuss the impact of missing responses on the performance of the optimized reference values. Finally, we utilize the optimized reference values from both studies (Study 1 and Study 2) to fit a model that can predict optimal reference values for conditions that were not included in the studies.
Descriptive Statistics of RMSD Values
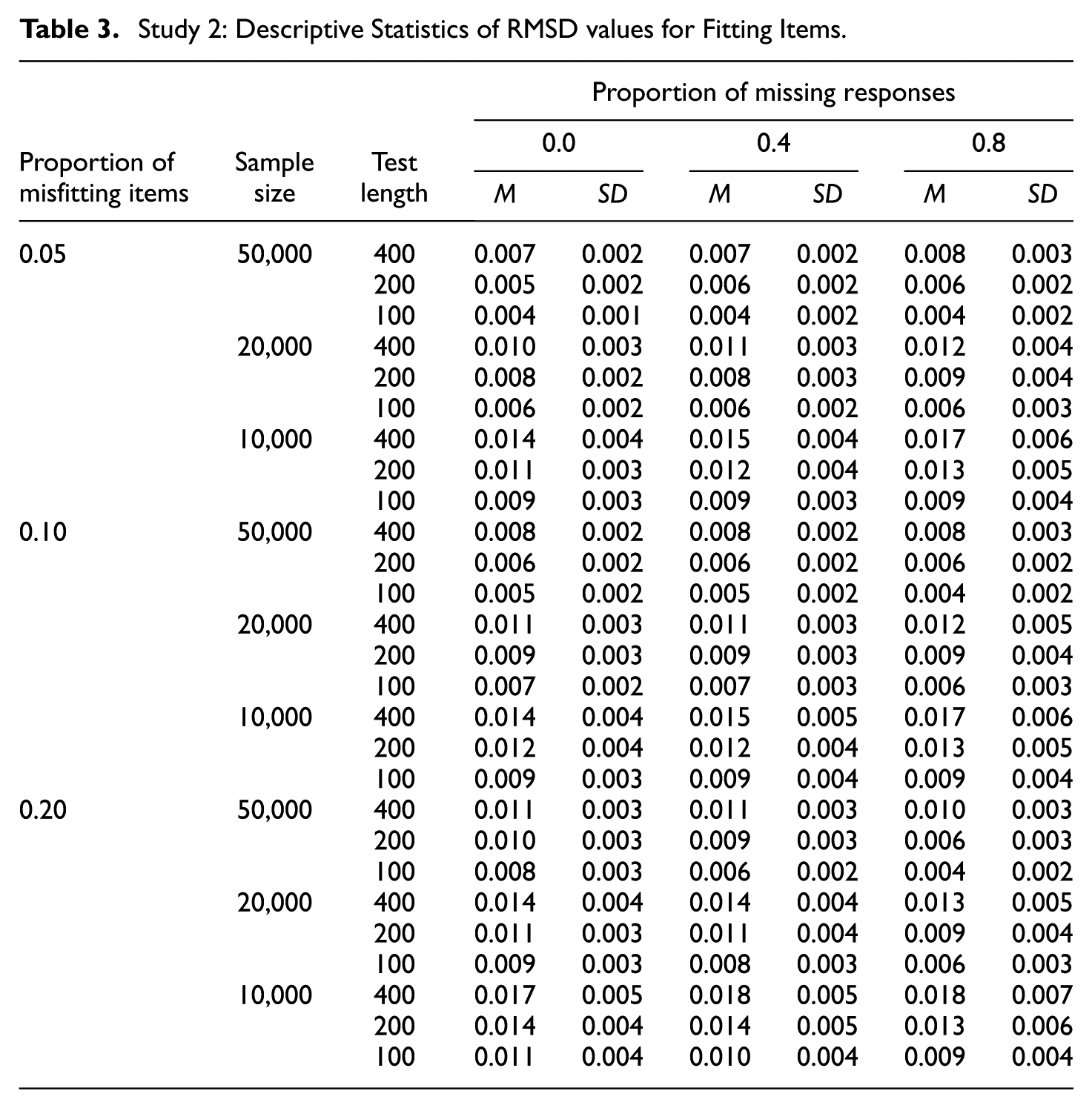
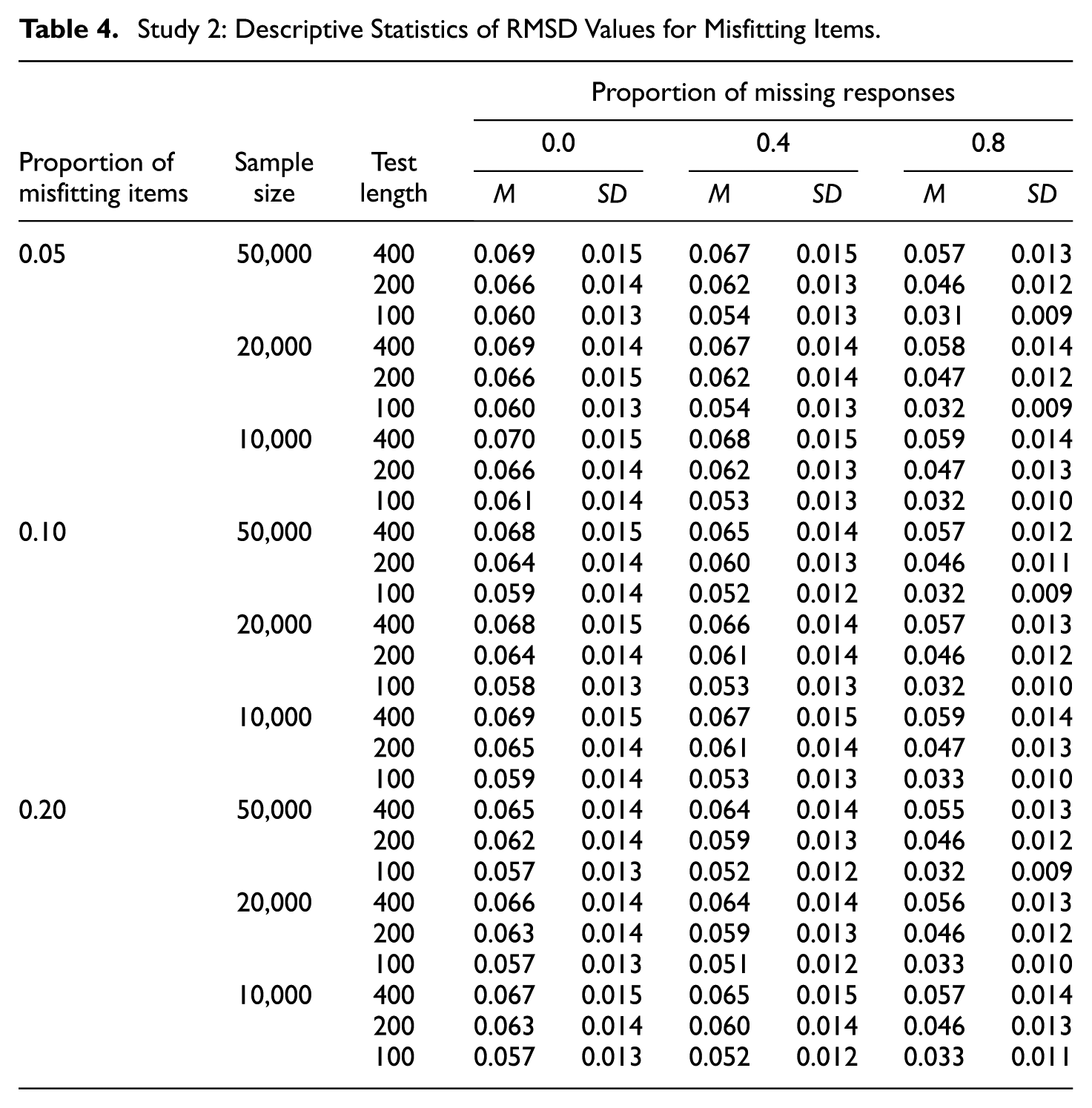
The descriptive statistics of the RMSD values for fitting and misfitting items are presented in Tables 3 and 4, respectively. Figure 5 illustrates the average RMSD values for fitting and misfitting items by condition. The mean and variance of the RMSD values for fitting items were only minimally impacted by the missingness. The nearly flat black lines in Figure 5 highlight that the mean RMSD values remained fairly stable across varying proportions of missing data. The most impacted condition occurred under the combination of the largest sample size, the shortest test length, and the highest proportion of misfitting items (i.e., sample size = 50,000; test length = 100; proportion of misfitting items = 0.2). In this case, the average RMSD value for fitting items was 0.008, 0.006, and 0.004 when the proportion of missing responses was 0, 0.4, and 0.8, respectively. Hence, we concluded that the magnitude for RMSD values for fitting items is negatively affected by data missingness, though by a marginal degree, when the ratio of sample size to test length is large (e.g., 500 or higher) and the proportion of misfitting items is high (e.g., 0.2 or higher). By contrast, the mean and variance of the RMSD values for misfitting items were both negatively impacted by data missingness. That is, as a larger proportion of data was missing, the mean RMSD values decreased—as signified by the declining red lines in Figure 5—and the variance of RMSD values also decreased.
Study 2: Descriptive Statistics of RMSD values for Fitting Items.
Study 2: Descriptive Statistics of RMSD Values for Misfitting Items.
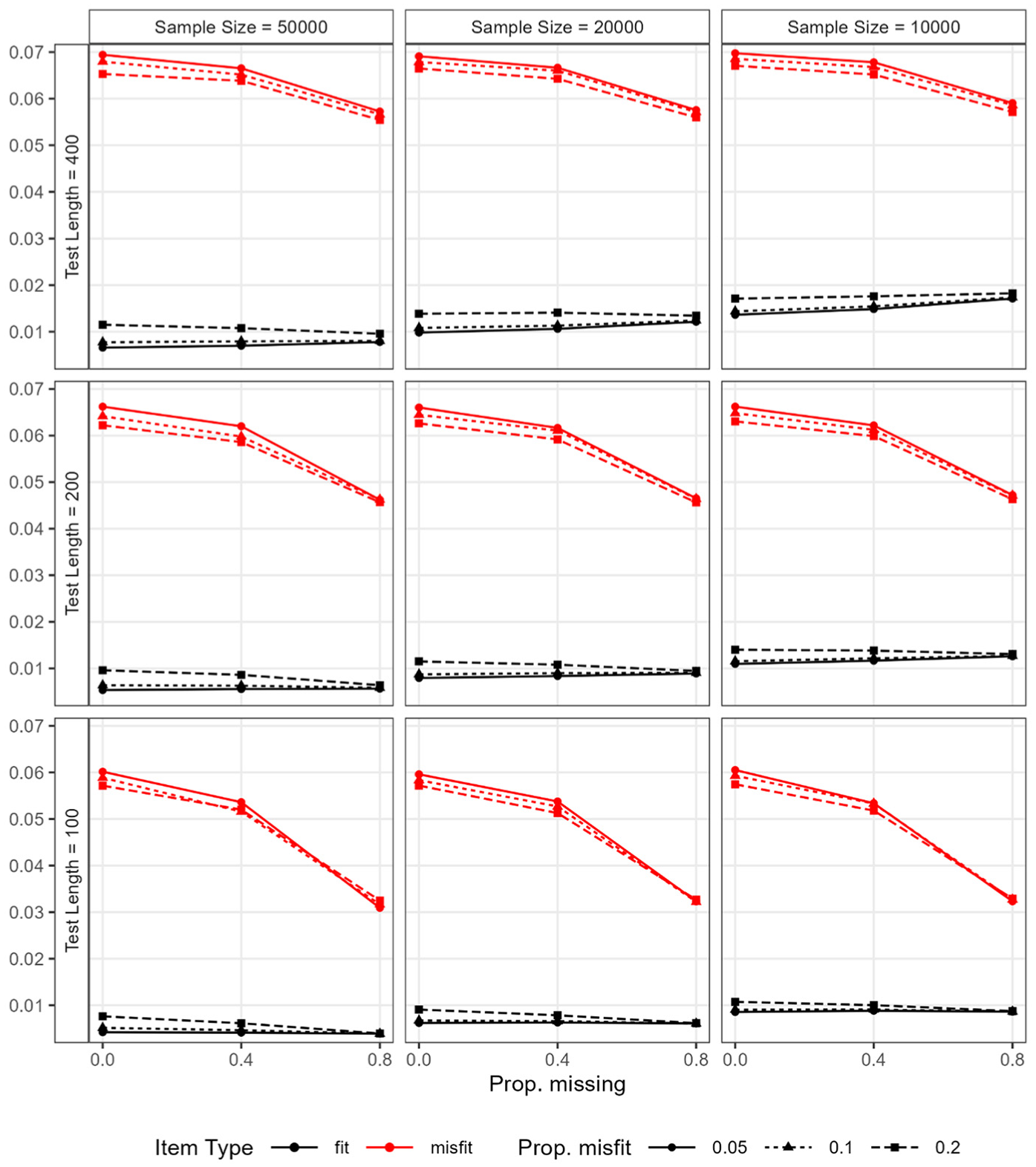
Study 2: Average RMSD values for fitting and misfitting items by condition.
As a result of these changes in the RMSD values, the distance between the average RMSD values for fitting and misfitting items decreased as the level of missingness increased, and this impact of missingness was larger under shorter test lengths (e.g., 100). Moreover, as the proportion of misfitting items increased, the distance between the average RMSD values slightly decreased, although the magnitude of this influence was small and further diminished to near zero as the proportion of missing responses increased. In other words, the impact of the proportion of misfitting items became even more negligible as the proportion of missing responses was larger.
Optimized Reference Values
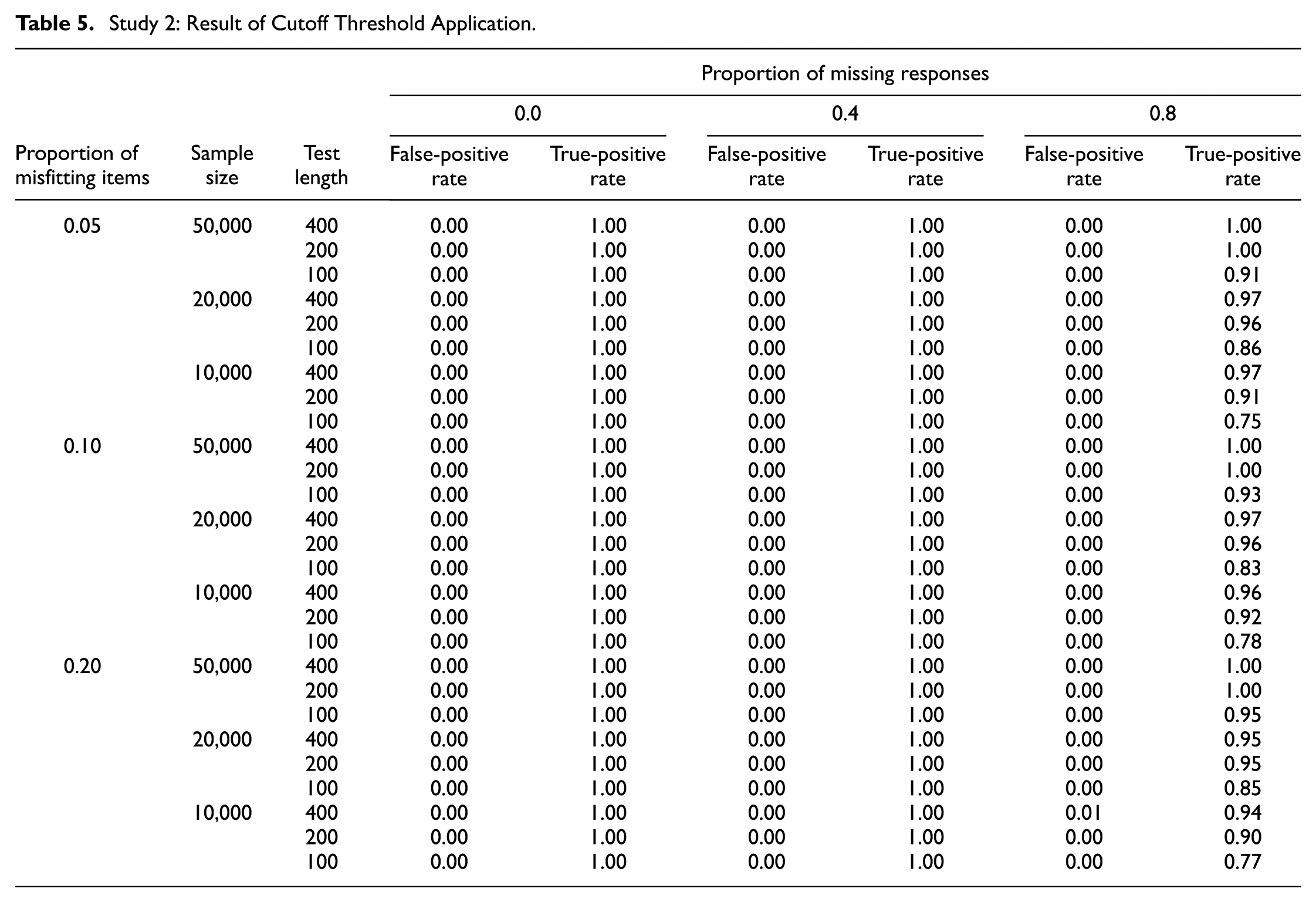
Among the simulated conditions, only those with no missing responses were used to optimize the reference values. This choice was made primarily to maintain consistency with Study 1, where no missing responses were presumed. The same ROC curve analysis as in Study 1 was applied to identify reference values that maximize the sum of specificity and sensitivity, following the Youden’s J criterion. The optimized values are presented in the last three columns of Table 2. They achieved the false-positive and true-positive rates of 0.00 and 1.00, that is, perfect classification, within each combination of sample size and test lengths. It is notable that, when the sample size is large (e.g., 20,000 or larger) and the ratio of sample size to test length is high (e.g., 100 or higher), there were more than one candidate cutoff value that achieved the optimal classification performance. For instance, with a sample size of 50,000 and a test length of 400, the candidate cutoff values ranging from 0.027 to 0.037 all achieved the same classification performance of 0.00 false-positive rate and 1.00 true-positive rate. This result is due to the distributions of the RMSD values for fitting and misfitting items exhibiting minimal overlap when abundant information is available in a dataset (see Figure 5).
When the optimized reference values form an interval rather than a single point estimate, we suggest using the lower bound of the interval. This recommendation accounts for potential presence of data missingness, which is a common scenario in large-scale assessments. As discussed in the previous subsection, the average RMSD values for misfitting items tend to decrease as the proportion of missing responses increases, whereas the average RMSD values for fitting items remain stable. Therefore, adopting the lower bound of the optimal interval helps guard against the loss of power in detecting misfitting items in the presence of missing responses. The result of applying the lower bound of the interval as a cutoff is summarized in Table 5. As noted earlier, the conditions with no missing data were used to optimize the cutoff thresholds, so their false-positive and true-positive rates are zero and one, respectively. When 40% of item responses were missing, the performance of the cutoff thresholds was unaffected in terms of the false-positive and true-positive rates remaining zero and one, respectively. When 80% of item responses were missing, however, the true-positive rates decreased for smaller sample sizes (e.g., 10,000 or 20,000) and shorter test length (e.g., 100), while the false-positive rates remained zero. This result is as expected, as the average RMSD values for fitting items remained stable, while the average RMSD values for misfitting items decreased with data missingness. The most impacted condition occurred under the smallest sample size (i.e., 10,000) and the shortest test length (i.e., 100), where the true-positive rate ranged from 0.75 to 0.78, depending on the proportion of misfitting items. Except for this condition, the true-positive rate was 0.83 or higher, showing that the suggested reference values performed sufficiently well even under severe levels of data missingness.
Study 2: Result of Cutoff Threshold Application.
Generalization of Recommended Reference Values
To further generalize the recommended cutoff values from Study 1 and Study 2 to conditions that were not included in the simulation conditions, we fitted a model to predict them based on sample size and test length. This approach, known as response surface analysis (Box, 1954), involves fitting a polynomial equation to experimental data. Its application can be found in analytical chemistry (e.g., Bezerra et al., 2008) as well as educational psychology (e.g., Zhao et al., 2024). The analysis was performed by regressing the optimal cutoff values on sample size and test length. Let
Table 6 summarizes the predictors included in each model, along with the corresponding variance explained (i.e.,
Explained Variance of Polynomial Regression Models.
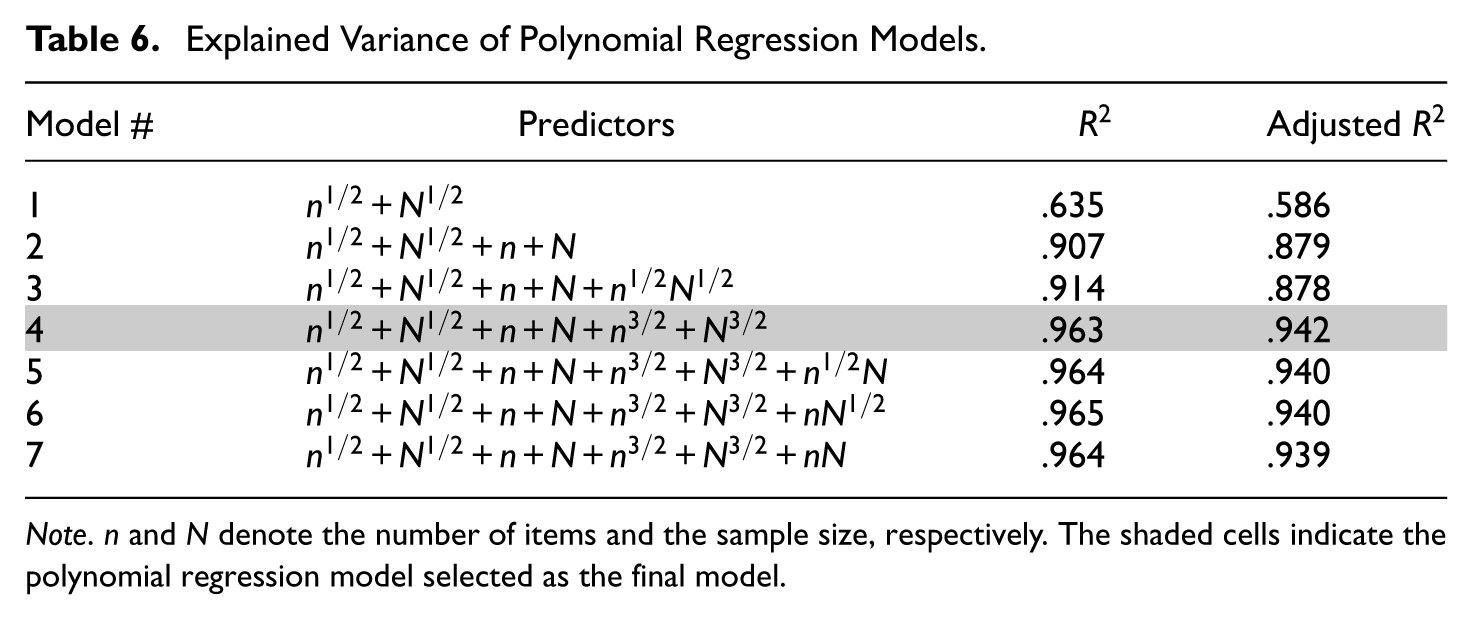
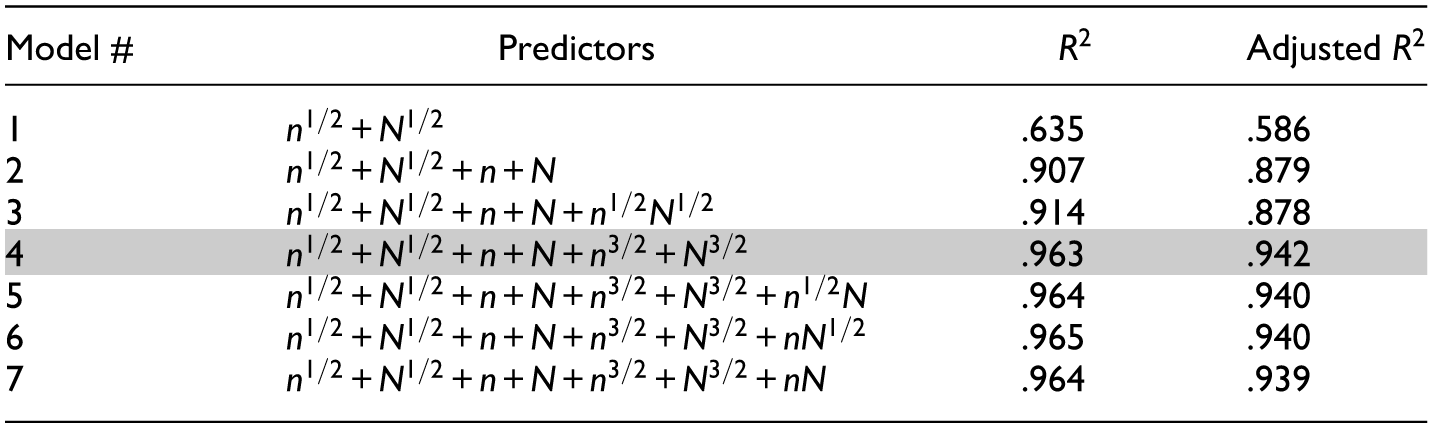
Note. n and N denote the number of items and the sample size, respectively. The shaded cells indicate the polynomial regression model selected as the final model.
In the final model (Model 4), all coefficients for the predictors were statistically significant, as shown in Table 7. In Figure 6, the model-predicted reference values (dashed lines) are overlaid with the observed reference values (solid lines), showing close overlap. Notably, the residuals (observed minus fitted values) are relatively large at the lowest and the highest ends of the observed or predicted values. Specifically, the residual was 0.013 − 0.010 = 0.003 under the condition of 5,000 persons and 20 items, and 0.051 − 0.047 = 0.004 under the condition of 500 persons and 100 items. The two cases, respectively, correspond to the conditions with the highest and lowest ratio of sample size to test length in Study 1. The diagnostic plots in Supplemental Materials also highlight these two cases as influential points. Such patterns were expected as residuals tend to be larger at the extremes of the outcome range, and the absolute magnitude of these residuals remained small. Therefore, we conclud that this model can be used to compute reference values tailored to the specific sample size and test length of the dataset at hand.
Coefficients of the Selected Polynomial Regression Model (Model 4).
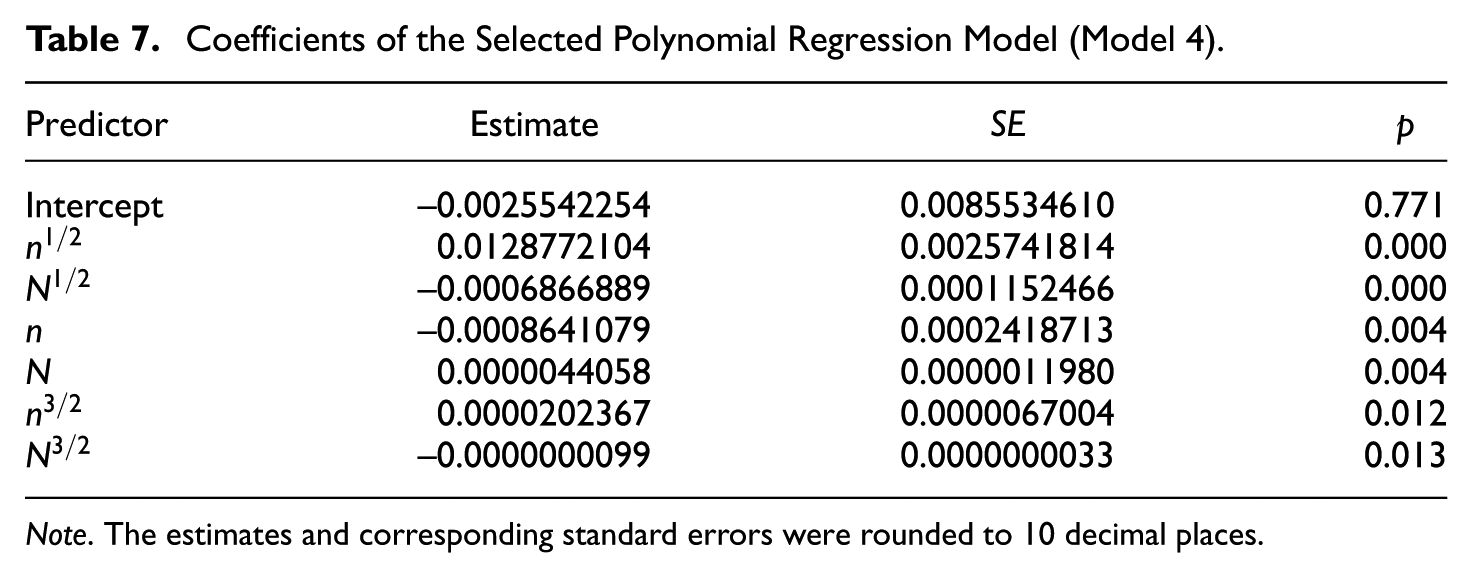
Note. The estimates and corresponding standard errors were rounded to 10 decimal places.
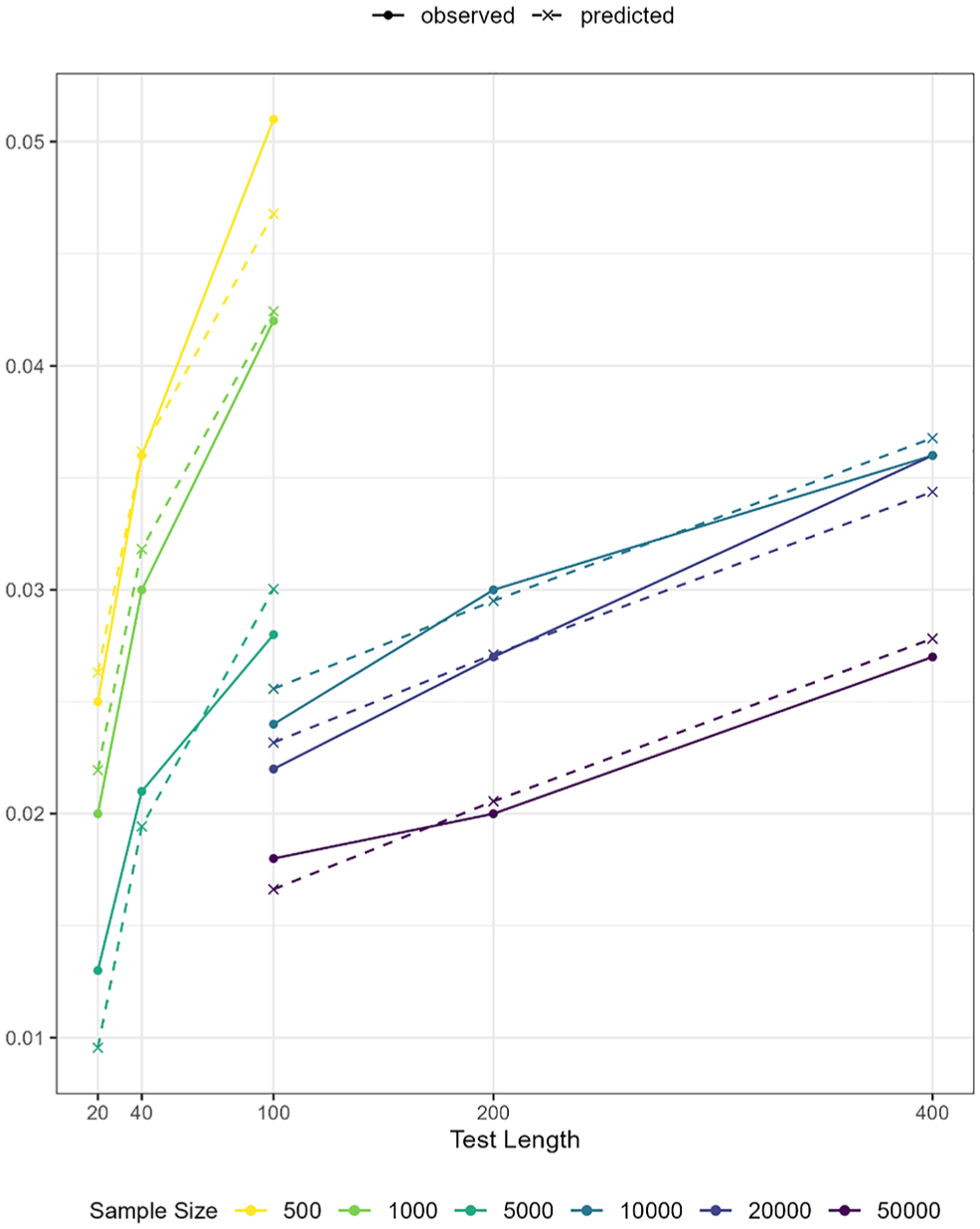
Observed and predicted reference values by sample size and test length.
Empirical Example
In this section, we demonstrate an application of the RMSD using an empirical example collected from a large-scale computer-based assessment on Calculus. The dataset consists of item responses of 13,217 examinees to 132 dichotomously scored items. A 2PL model was hypothesized for all items. The average proportion of missing responses per person was 69%. Based on the model selected in the Generalization of Recommended Reference Values section (Model 4 of which coefficients are presented in Table 7), the suggested reference value tailored for this dataset was 0.026. As a result of applying the cutoff, a total of 41 items were flagged for meaningfully deviating from the hypothesized model.
All misfitting items exhibited patterns that warrant further scrutiny, and their IRFs often exhibited one or more plateaus. As an example, Figure 7 visualizes the discrepancies between observed and expected IRFs found in one of the flagged items. The solid line represents the expected or model-implied response probabilities of correct response, and the points indicate observed probabilities of correct response. The size of each point corresponds to the weight assigned by the standard normal density. This item with the RMSD value of 0.057 exhibited a plateau around
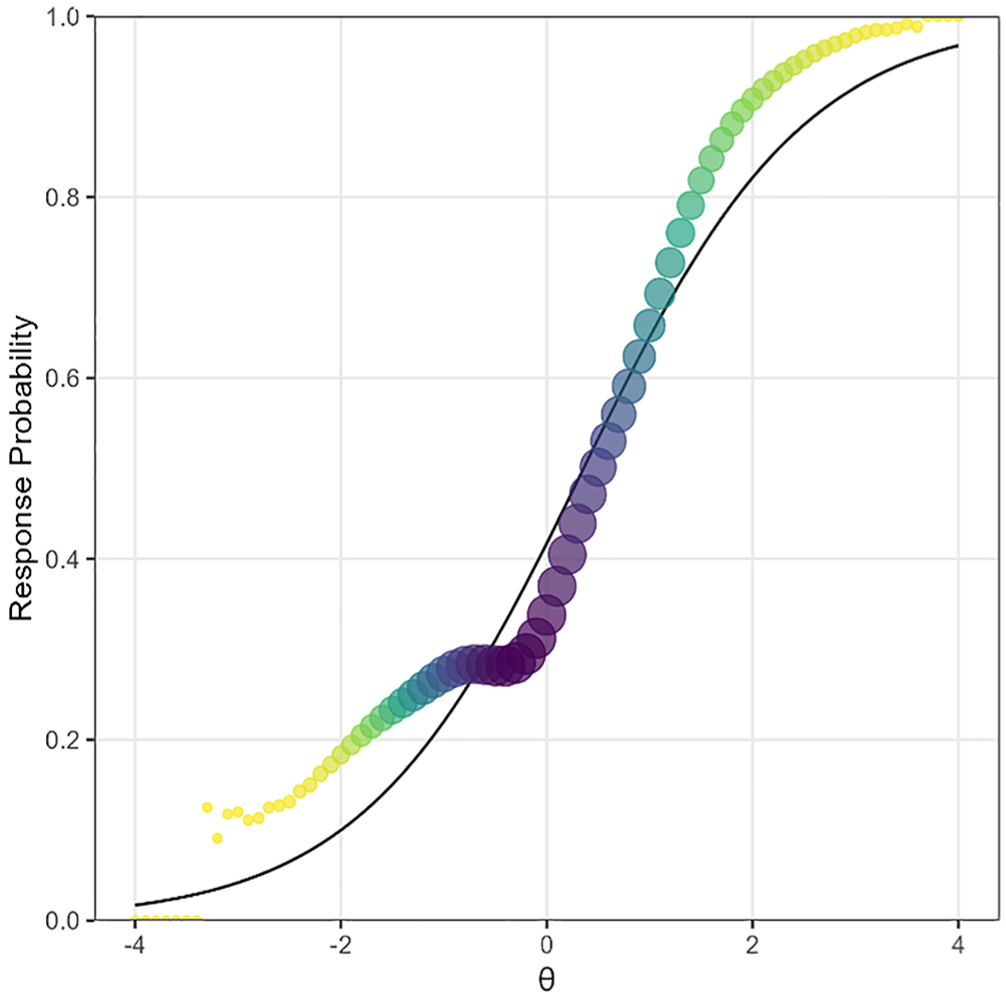
Empirical example of observed and expected item response functions.
Summary and Discussions
Summary
Posterior expectations, otherwise known as pseudocounts, provide a powerful and accessible foundation for item fit analysis. They eliminate the need to categorize examinees into potentially imprecise subgroups, while fully incorporating the uncertainties of the latent variable estimates. Even in small sample sizes or under substantial data missingness, they ensure a smooth distribution of examinees across the continuum. Moreover, they are natural by-products of the Bock–Aitkin EM algorithm, a standard estimation method for IRT models, which makes pseudocount-based item fit indices highly accessible to users of IRT models. Given these advantages, the RMSD based on posterior expectations, along with corresponding visualizations, has been widely adopted. This study enhanced the interpretability of the RMSD by implementing two approaches the statistical significance testing via the PP-PPMC and the optimization of reference values (cutoff thresholds) using the ROC curve analysis.
In Study 1, we showcased that the PP-PPMC (Lee et al., 2016) can be used to compute statistical significance levels for the RMSD. The PP-PPMC inherently accounted for the estimation and sampling errors, which resolved the key obstacles in identifying the null distributions of the RMSD. As a result, the Type I error rates were well-controlled, and the power was moderate to high in most cases. However, in conditions with a small sample size (e.g., 500) and a short test length (e.g., 20), the power considerably declined while the Type I error rate remained below the nominal level. As an alternative approach, we implemented the ROC curve analysis (Metz, 1978) to empirically derive reference values that achieve the best balance of the false-positive and true-positive rates. Applying the optimized reference values resulted in both higher false-positive rates and higher true-positive rates, compared to the PP-PPMC approach, especially under data-limited scenarios with smaller sample sizes and/or shorter test lengths. Overall, the cutoff threshold approach offered significant improvement in the true-positive rates, albeit with a slight increase in the false-positive rates.
In Study 2, we extended the ROC curve analysis to conditions with larger sample sizes and longer test lengths, reflecting scenarios typical of large-scale assessments. The optimized reference values achieved a near-perfect classification under complete datasets. In the presence of missing responses, the true-positive rates moderately declined, while the false-positive rates remained close to zero. To further generalize the suggested reference values beyond the simulated conditions, we employed the response surface analysis (Box, 1954). Specifically, a polynomial regression model was fitted by regressing the suggested reference values from Study 1 and Study 2 on the linear, quadratic, and cubic effects of test length and sample size. The model allows practitioners to compute benchmark values tailored to the characteristics of their datasets.
Key Contributions
This study makes several key contributions. First, we employed the PP-PPMC (Lee et al., 2016) to implement a pseudo-Bayesian model checking approach for item fit diagnostics in a frequentist framework. Second, we used the ROC analysis (Metz, 1978) to empirically derive reference values optimized for specific combinations of test length and sample size—two factors well known for their influence on the magnitude of RMSD. This highlights the necessity of selecting reference values based on data-specific conditions. Recent work by von Davier and Bezirhan (2023) similarly suggested identifying misfitting items by selecting outliers in a dataset-specific distribution of the RMSD values. Condition-specific reference values have been highlighted in other contexts as well (e.g., McNeish & Wolf, 2021). Third, we evaluated the performance of the optimized cutoff thresholds under varying degrees of data missingness. As missing responses are introduced into a dataset, the RMSD values of fitting items largely remained stable, while the RMSD values of misfitting items noticeably decreased, particularly when the test length was shorter. Consequently, applying the optimized cutoffs resulted in moderately reduced true-positive rates while maintaining stable, near-zero false-positive rates. Fourth, we presented a prediction model that predicts the suggested reference values based on test length and sample size, enabling practitioners to compute tailored thresholds for the RMSD with ease. This approach can be extended seamlessly to other item fit measures, such as RMSDs with alternative weights (e.g., Joo et al., 2024) or those incorporating nonparametric or semiparametric methods for computing observed probabilities (e.g., Douglas & Cohen, 2001; Köhler et al., 2021; Lee et al., 2009).
Limitations
This study has limitations that constrain the interpretation of its results and warrant further research. First, it is important to examine whether the RMSD performs similarly under conditions beyond those simulated in this study. Potential factors that may influence the performance of the RMSD include calibration model (e.g., 3PL model), type of items (e.g., items with more than two score categories), type of item misfit (e.g., nonmonotone IRF), systematic missing pattern (i.e., missing not at random), or violation of standard IRT model assumptions (e.g., unidimensionality, local independence, and normal population density). Since the optimality of the recommended reference values is contingent upon the simulated conditions, these reference values may need to be re-evaluated in other contexts.
Second, this study evaluated the performance of the RMSD in the context of testing whether a hypothesized model (e.g., 2PL model) adequately explains the data. That is, the RMSD was used to detect items exhibiting unexpected response probabilities across different levels of the latent variable. However, the RMSD is also widely used in other contexts. For example, it can be used for measurement invariance testing or differential item functioning (DIF) analysis (e.g., Buchholz & Hartig, 2019; Joo et al., 2021, 2024; Tijmstra et al., 2020). The reference values derived in this study are not generalizable to these contexts.
Closing Remark
This study provides two rigorous yet accessible approaches to evaluating item fit using a pseudocount-based RMSD: (1) statistical significance testing using the PP-PPMC where replicated data are drawn from the posterior predictive distribution and (2) empirical derivation of reference values where replicated data are drawn from the predictive distribution. Under a sufficiently large number of examinees (e.g., 1,000 or more) and items (e.g., 40 or more), the two approaches demonstrated comparable power (true-positive rate) and Type I error rate (false-positive rate). Under data-limited scenarios, such as smaller sample size and/or shorter test length, the cutoff threshold approach outperformed the PP-PPMC method, yielding a significant increase in the true-positive rates with only a small to moderate increase in the false-positive rates. The cutoff threshold approach also performed well under high levels of data missingness common in a large-scale assessment context. However, in cases where researchers cannot afford a high false-positive rate, the PP-PPMC approach offers a more conservative alternative that strictly controls the Type I error rate, even in data-limited scenarios. These tools effectively complement the existing visualization techniques by enhancing the efficiency and accuracy of item fit evaluation. While the findings demonstrate a strong performance of these methods within the scope of the simulation studies, caution should be exercised when applying them beyond the simulated conditions.
Supplemental Material
sj-pdf-1-epm-10.1177_00131644251369532 – Supplemental material for Evaluation of Item Fit With Output From the EM Algorithm: RMSD Index Based on Posterior Expectations
Supplemental material, sj-pdf-1-epm-10.1177_00131644251369532 for Evaluation of Item Fit With Output From the EM Algorithm: RMSD Index Based on Posterior Expectations by Yun-Kyung Kim, Li Cai and YoungKoung Kim in Educational and Psychological Measurement
Footnotes
Author Note
A part of this work was originally presented at the 2023 annual meeting of the National Council of Measurement in Education (NCME) held in Chicago, IL, United States.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.