
Abstract
Field-testing is an essential yet often resource-intensive step in the development of high-quality educational assessments. I introduce an innovative method for field-testing newly written exam items by substituting human examinees with artificially intelligent (AI) examinees. The proposed approach is demonstrated using 466 four-option multiple-choice English grammar questions. Pre-trained transformer language models are fine-tuned based on the 2-parameter logistic (2PL) item response model to respond like human test-takers. Each AI examinee is associated with a latent ability θ, and the item text is used to predict response selection probabilities for each of the four response options. For the best modeling approach identified, the overall correlation between the true and predicted 2PL correct response probabilities was .82 (bias = 0.00, root mean squared error = 0.18). The study results were promising, showing that item response data generated from AI can be used to calculate item proportion correct, item discrimination, conduct item calibration with anchors, distractor analysis, dimensionality analysis, and latent trait scoring. However, the proposed approach did not achieve the level of accuracy obtainable with human examinee response data. If further refined, potential resource savings in transitioning from human to AI field-testing could be enormous. AI could shorten the field-testing timeline, prevent examinees from seeing low-quality field-test items in real exams, shorten test lengths, eliminate test security, item exposure, and sample size concerns, reduce overall cost, and help expand the item bank. Example Python code from this study is available on Github: https://github.com/hotakamaeda/ai_field_testing1
Keywords
Introduction
Assessments are integral to education, providing valuable feedback on student learning progress and guiding enhancements in teaching and curriculum design. To develop and maintain high-quality educational assessments, field-testing, or pretesting, is necessary to evaluate the quality of test items before they are used for scoring. In many large-scale assessments, field-testing involves asking a sample of examinees from the target population to complete unscored field-test items, often embedded among operational scored items. The quality of the field-test items is evaluated using a variety of statistical techniques, and is calibrated for future scoring. However, traditional field-testing methods are often resource-intensive, time-consuming, and can raise item exposure concerns (AlKhuzaey et al., 2023; Hsu et al., 2018; Jiao & Lissitz, 2020). In many cases, thousands of examinee test data are needed to conduct sufficiently accurate analyses (Morizot et al., 2007).
The literature provides successful cases of using collateral information to improve item parameter calibration efficiency (Mislevy, 1988; Wang & Jiao, 2011). But some researchers took this idea further by attempting to bypass the field-testing process altogether. These studies present models that predict item difficulty from various item text features, such as semantic and syntactic complexity, word and sentence lengths and counts, word embeddings, and readability indices (see AlKhuzaey et al., 2023; Benedetto et al., 2023). While some methods relied on expert judgment (Beinborn et al., 2014; Choi & Moon, 2020; Loukina et al., 2016; Settles et al., 2020), these subjective approaches often suffered from poor inter-rater reliability (i.e., consistency between multiple judges) and limited reproducibility (AlKhuzaey et al., 2023; Conejo et al., 2014). Other approaches relied on machine-driven natural language processing (NLP) techniques to predict item difficulty and/or discrimination (Benedetto et al., 2020a, 2020b, 2021; Yaneva et al., 2019; Zhou & Tao, 2020). However, the accuracy of these prediction methods remains limited, and merely estimating item difficulty and discrimination fails to capture the full scope of traditional field-testing. In addition, these models often do not replicate the complete human test-taking experience, such as by excluding the distractor options in their predictions (e.g., Benedetto, 2023; Benedetto et al., 2021).
An alternative approach to estimating item difficulty has been developed by Lalor et al. (2019) using artificial intelligence (AI). The researchers corrupted (i.e., altered or damaged) a random percentage of sentiment analysis data to intentionally create 1,000 sets of training data with varying levels of quality. Training deep learning models on these data resulted in 1,000 models with varied levels of accuracy in completing sentiment analysis tasks. They then used these models to generate response data and fitted item response theory (IRT) models to estimate the difficulty of completing each NLP task (also see Rodriguez et al., 2021). Others have used this approach to estimate item discrimination parameters as well (Byrd & Srivastava, 2022).
Although originally developed in the area of computer science, Lalor et al.’s (2019) approach could be adapted and applied to field-testing educational assessment items. This adaptation could lead to the development of AI field-testing that replaces human examinees with AI examinees, while preserving the natural flow and structure of traditional human field-testing. Compared to past item difficulty and discrimination prediction methods (e.g., AlKhuzaey et al., 2023), there is one key major advantage. AI examinees have the potential to simulate the test-taking process and generate item response data that closely mimic patterns observed in human responses. If successful, these AI-generated data could be analyzed in the same ways as traditional field-test data, offering applications far beyond merely predicting item difficulty. Therefore, I propose a method of training transformer large-language models (LLMs) by integrating them with IRT (Lord, 1980) to generate human-like item responses, which could then be used for field-test analyses. I will briefly introduce some backgrounds on LLMs and IRT in the upcoming sections. Then, I will evaluate the methods using data from a large-scale English language assessment program. This article builds on the preliminary work by Maeda (2023).
Background on Transformer Language Models
Introduced by Vaswani et al. (2017), the transformer neural network revolutionized NLP. Unlike recurrent neural networks, transformers utilize attention mechanisms, allowing them to consider all positions in an input sequence simultaneously. This parallelization significantly accelerated training and made transformers highly scalable.
Transformer language models like Bidirectional Encoder Representations from Transformers (BERT; Devlin et al., 2018) are pre-trained on large amounts of corpora. Since they are available open-access, users can download pre-trained models and customize them on specific downstream tasks. Input text is first tokenized and converted into word embeddings, which results in a numeric vector for each word or part of a word. These numerical representations of text are passed through the encoder layers of the transformers neural network, where the final layer is often fine-tuned to complete a specific NLP task. These include language translation, text summarization, question answering, sentiment analysis, or regression.
Transformers have become the backbone of contemporary NLP models, facilitating nuanced understanding of context and semantic relationships within language data, and achieving state-of-the-art performance on benchmarks. They excel in capturing the contextual meaning of long texts and can differentiate between various definitions of the same word (see Devlin et al., 2018).
In this article, the pre-trained DeBERTa-v3-large transformer language model (He et al., 2021) was used. DeBERTa (He et al., 2020) is an enhanced variant of the BERT (Devlin et al., 2018) and RoBERTa models (Liu et al., 2019). Each word in DeBERTa is associated with two vectors that independently represent its content and positioning. The attention weights between words are also calculated separately for their content and positioning. This allows, for example, for DeBERTa to learn that word “artificial” is highly associated with “intelligence” when they occur next to each other, unlike when there are other words between them. More recently, the training efficiency of DeBERTa was enhanced by utilizing replaced token detection techniques rather than masked language modeling. The resulting model was named DeBERTa-v3, which has 304 million parameters (He et al., 2021).
Background on Psychometric Theories
IRT is widely used for measuring latent abilities in educational assessment (Lord, 1980). Let
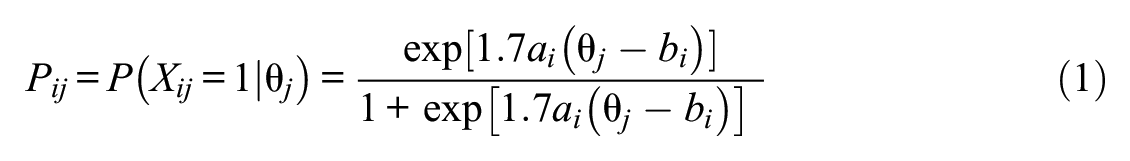
where
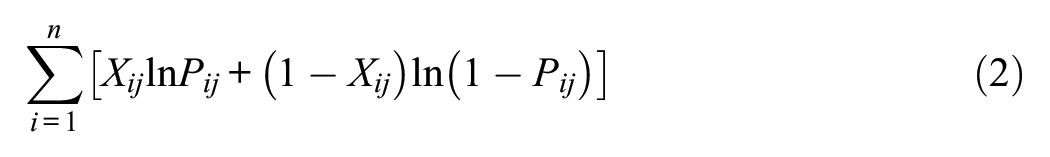
The
Proposed AI Field-Testing Methodology
The proposed method requires a scenario with (a) a substantial number of previously field-tested and calibrated items accompanied by their item text, (b) a new set of field-test items that currently lack data aside from their text, and (c) these two groups of items are consistent in overall design variations and measurement constructs. The overall flow of AI field-testing is shown in Figure 1.
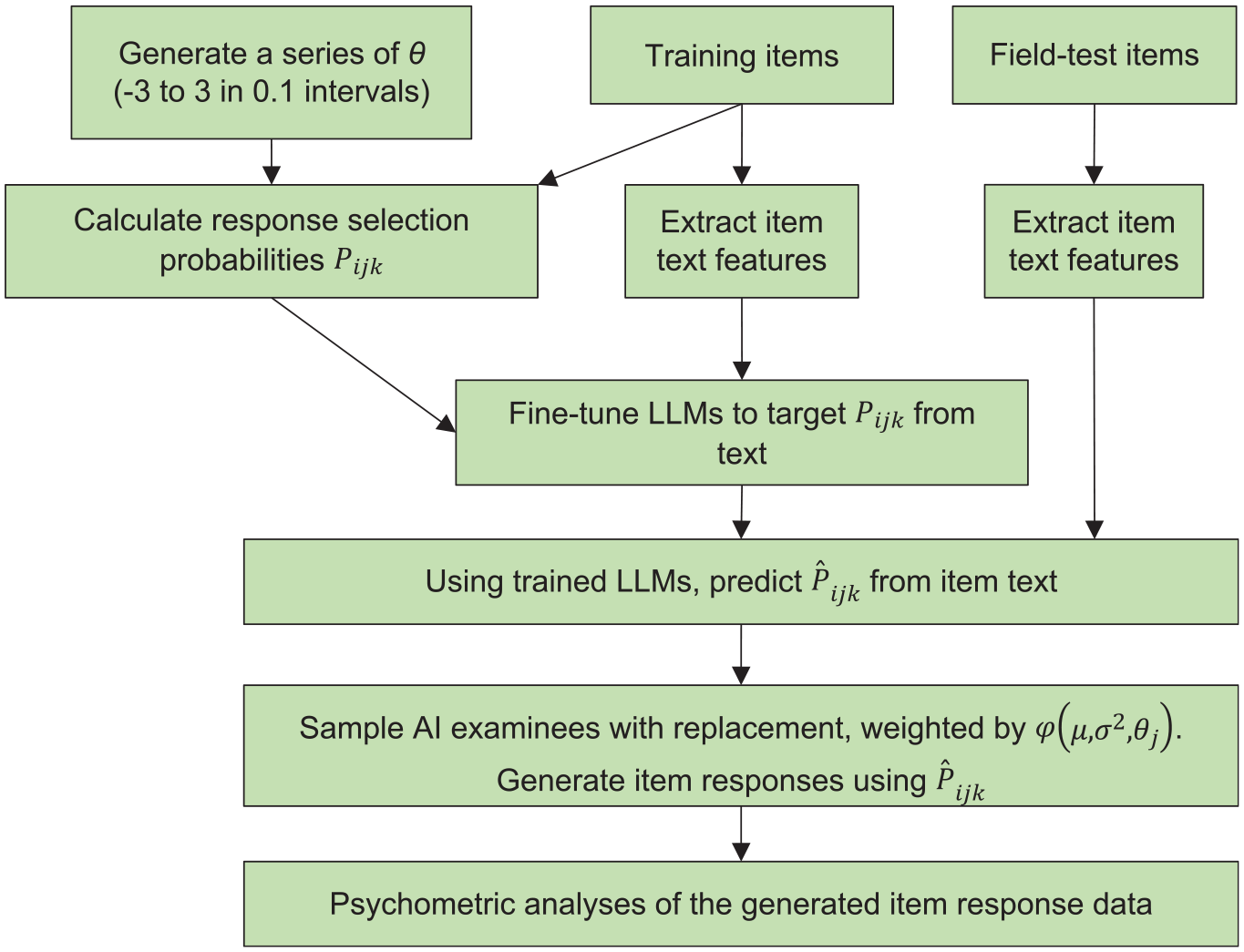
Flowchart of AI Field-Testing
Process Item Text Data
I use English grammar multiple-choice items from a real large-scale assessment to illustrate the proposed approach. These items assess skills to apply or edit English grammar usage, capitalization, punctuation, and spelling. The stems of these items can vary greatly. For example, they may state, “Choose the sentence that is punctuated correctly” or “Choose the correct word to replace the underlined word in the sentence.” The design inconsistencies in the stem may add unnecessary challenges for LLMs to understand the text. Therefore, the item text data are restructured. First, the item response option text is modified to be compatible with a stem that states “Choose the sentence(s) with correct grammar usage” (i.e., if not already compatible). The option text is reworded appropriately to one or more complete sentences with or without any grammatical errors (see Figure 2). Then, because now the stem is identical for all items, we can remove the stem from the input text data, and use the target label to guide the LLMs to find the sentences with correct grammar (see next section). Removing the stem also limits the data consumed by LLMs and speeds up the training. Note that to apply AI field-testing to other types of items, the item text processing procedure may need considerable adjustments.

Example Restructuring of Multiple-Choice Question Text for LLM Consumption
Calculate Conditional IRT Probabilities
A total of 61 AI examinee ability levels
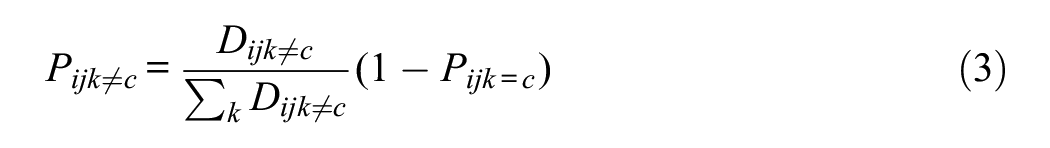
Therefore, the selection probabilities sum to
Fine-Tune Transformers With Item Options as “Separate_” Sequence Inputs
The item option text is tokenized and used to fine-tune the DeBERTa-v3-large transformer neural network (He et al., 2021) for a regression task, using
A softmax function
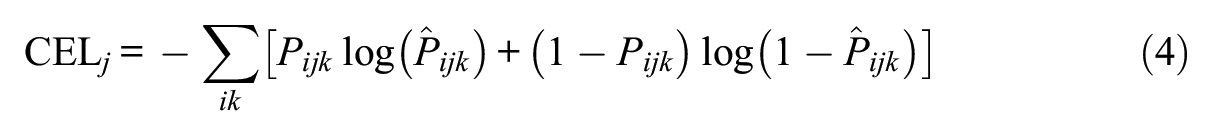
This modeling approach is named the “Separate_” method.
Alternative Method: “Concatenate_” the Item Options
Instead of inputting the four option texts for each item separately, an alternative is to concatenate them into a single input sequence using a separator special token “[SEP]” between each option. The advantage may be that this gives the model the entire context of the item text for each response option prediction. We can still predict four individual selection probabilities by outputting four values per text sequence (i.e., item). However, one issue is that there is no direct way for the model to know which output value is associated with each option. A solution to this could be to input items in the training data with multiple duplications, each time reordering item option text and target probabilities. This way, the model may learn the connection between the item option text and probabilities based on their locations. As short hand, the model with no duplication in the training data is named “Concatenate_1,” and models with items repeated in the training data 4 and 24 times are named “Concatenate_4” and “Concatenate_24,” respectively. Concatenate_4 option text is ordered like 1234, 3412, 2143, and 4321, so each option is positioned at all four locations exactly once. Repeating each item 24 times with Concatenate_24 is the maximum possible ways that four options can be ordered (4 × 3 × 2 × 1 = 24). Otherwise, the fine-tuning process is identical to the Separate_ method.
Generate Item Responses
For every training and field-test item i, use the fine-tuned LLM to obtain predicted probabilities
Methods
Using real data, I simulate a scenario where I have a large number of previously calibrated items that can be used as training data, and wish to field-test a smaller set of new items that do not yet have any data, other than their text. Statistics previously obtained from real field-testing were treated as true values. Results from multiple modeling approaches were compared. Example Python code from this study is available on Github: https://github.com/hotakamaeda/ai_field_testing1
Assessment Data
The study included 466 items from a large-scale English language arts and literacy exam item bank. All items were four-option multiple-choice items used to assess 3rd to 8th and 11th grade students’ skills to apply or edit English grammar usage, capitalization, punctuation, and spelling. These items have been previously field-tested among grade-appropriate students from the United States (mean student N per item = 3,161). Items have been calibrated on a vertical scale with the 2PL model.
The items were randomly divided into about 85% training (n = 396) and 15% field-test items (n = 70). The training items are analogous to scored operational items that are calibrated and available in the item bank. They were used to train the LLMs, and also served as anchor items for calibration. The field-test items take the role of new items that are not available for training the LLMs. They were used to evaluate the performance of the trained models. See Table 1 for the number of items in each grade level. This table also shows
Number of Items and True Ability Distribution for Each Examinee Grade
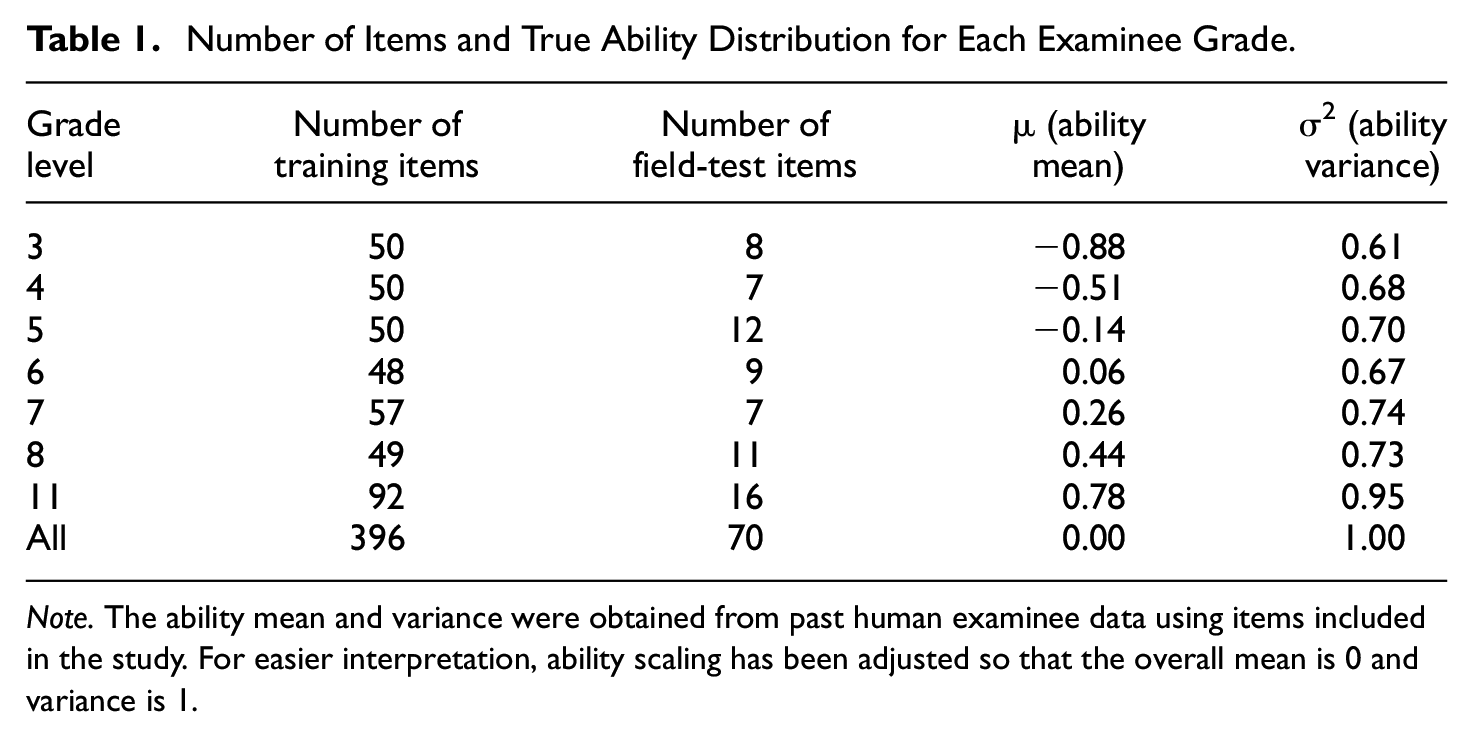
Note. The ability mean and variance were obtained from past human examinee data using items included in the study. For easier interpretation, ability scaling has been adjusted so that the overall mean is 0 and variance is 1.
Separate_ and Concatenate_ Modeling Approaches
The DeBERTa-v3-large LLMs (He et al., 2021) were fine-tuned for the Separate_, Concatenate_1, Concatenate_4, and Concatenate_24 modeling approaches, each for all 61 ability levels
Model Training Data Size and Hyperparameters

Note. The “Initial” training step is when the model is initially trained to have a
To create a representative item response data set for each grade level, LLMs were sampled with replacement 10,000 times weighted with probabilities
“Simulated_Human” Field-Testing Approach
Human field-testing was simulated as a point of comparison. Unlike AI, human examinees have a practical limit to the number of items they can respond to, which also limits the number of respondents per item.
Every field-test item was taken by 1,000 simulated human examinees with
IRT Calibration and CTT Analysis
For the Separate_, Concatenate_, and Simulated_Human approaches, field-test items were calibrated to the 2PL model one item at a time using the data set with the matching grade level. Mean and variance of
“Predicted_2PL”a and d Parameters Modeling Approach
As an additional baseline comparison, the 2PL a and d parameters were predicted directly from the item text using DeBERTa-v3-large (He et al., 2021). This method is an attempt to replicate common difficulty prediction approaches found in the recent literature (AlKhuzaey et al., 2023; Benedetto, 2023; Benedetto et al., 2023). For each item, the four options were concatenated with the “[SEP]” separator special token, with the correct option text always in the first position. The mean squared error loss was minimized when fine-tuning the model. The 2PL b parameter was calculated based on the 2PL a and d by
Latent Ability Estimation
To evaluate ability estimation accuracy, I generated a separate set of item response data to simulate a future scenario where field-test items have become operational scored items. A total of 10,000 simulated human examinees with ability sampled from
Evaluation
Statistics obtained from prior field-testing with real human examinees were treated as the true values. These were compared to the estimates obtained from Separate_, Concatenate_1, Concatenate_4, Concatenate_4, Predicted_2PL, and Simulated_Human approaches. Mean signed bias (i.e., mean of estimate minus true), root mean squared error (RMSE), and Pearson correlations (r) were calculated for every estimate.
Results
Figure 3 shows the CEL values for the modeling approaches using the field-test items (evaluation data). Concatenate_1 clearly performed poorly, as it nearly consistently had the highest loss. Concatenate_4 and Concatenate_24 were nearly indistinguishable, despite Concatenate_24 requiring six times the amount of training data and time. The Separate_ method had the lowest CEL for all
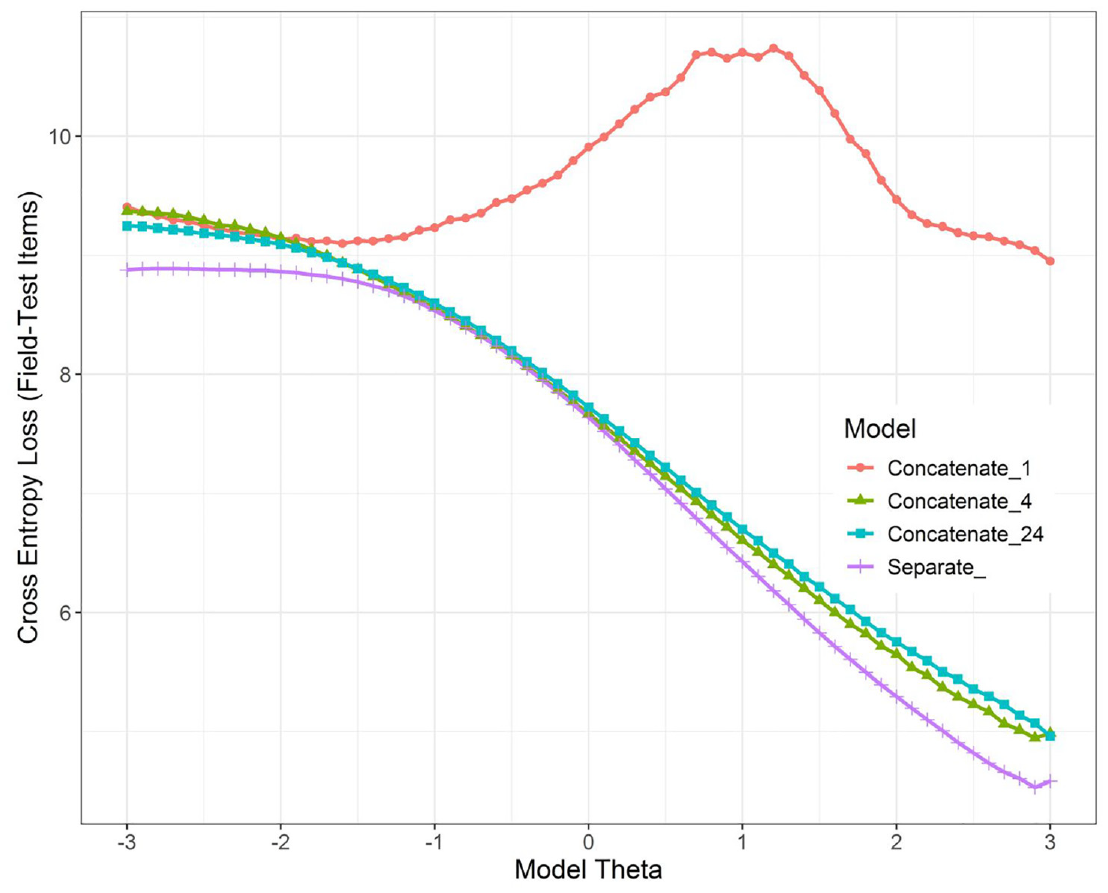
The Cross-Entropy Loss of the Field-Test Items, Based on the 61 Models for Each of the Four Modeling Approaches
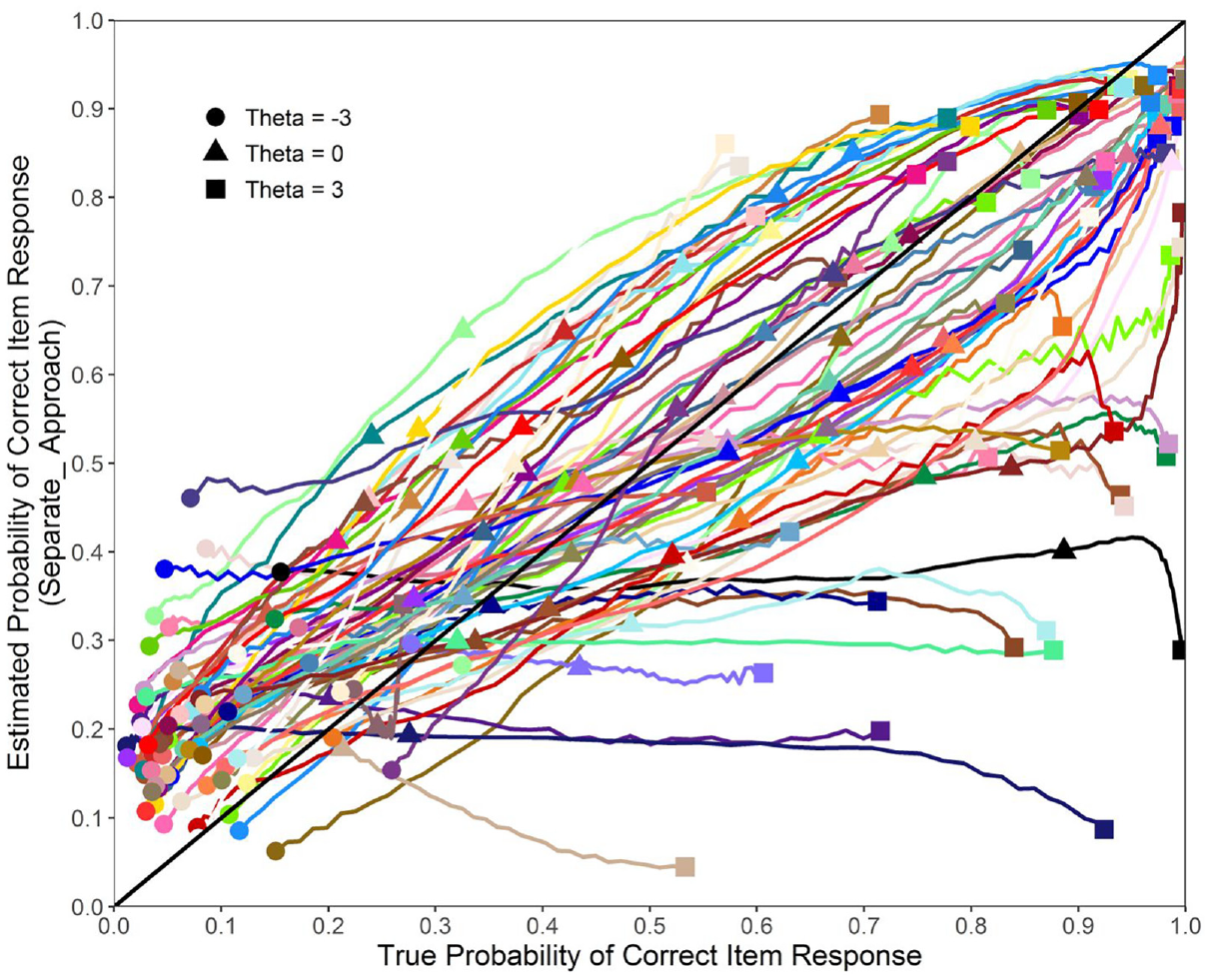
The positive slopes in Figure 4 confirm that AI examinee
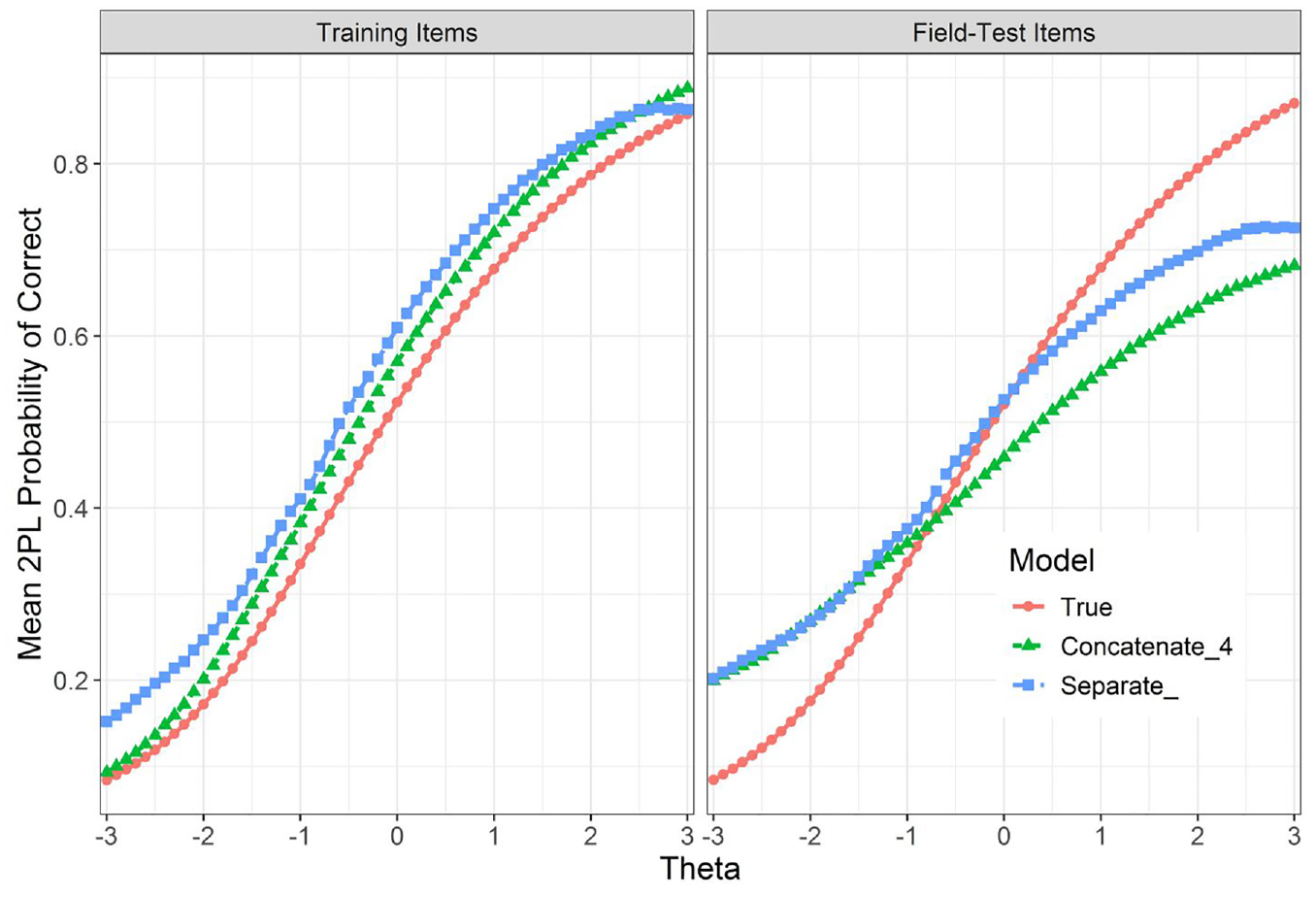
Difference in Slopes for Training and Field-Test Items for Concatenate_4 and Separate_ May Indicates the Limited Generalizability of the Trained Models
Table 3 presents the summary comparisons of all selection probabilities, IRT parameters, and CTT statistics calculated among field-test items for all approaches. For both Concatenate_4 and Separate_, mean of
Estimation of IRT and CTT Statistics

Note. The 2PL b parameter is bounded between [−3, 3] as some items had extreme values. 2PL = 2-parameter logistic model; RMSE = root mean squared error; IRT = item response theory; CTT = classical test theory.
Separate_ Approach Item-Level Results
Figures 5 and 6 show the item-level results of Separate_, which reveal more details about its performance. A key limitation of Separate_ was that in 11 of the 70 field-test items, the 2PL a estimation failed catastrophically, and resulted in estimates of near zero or negative, regardless of the true value (see Figure 5). This meant that, for example, two AI examinees with θ of 3 and −3 had similar probabilities of answering these items correctly. This resulted in an underestimated 2PL a and d and erratic 2PL b. For example, the 2PL b estimates bounded between [−3, 3] had bias = 0.06, RMSE = 1.76, and r = .08, but improved substantially without those 11 problematic items: bias = −0.23, RMSE = 0.92, and r = .59. Similarly, estimates of 2PL
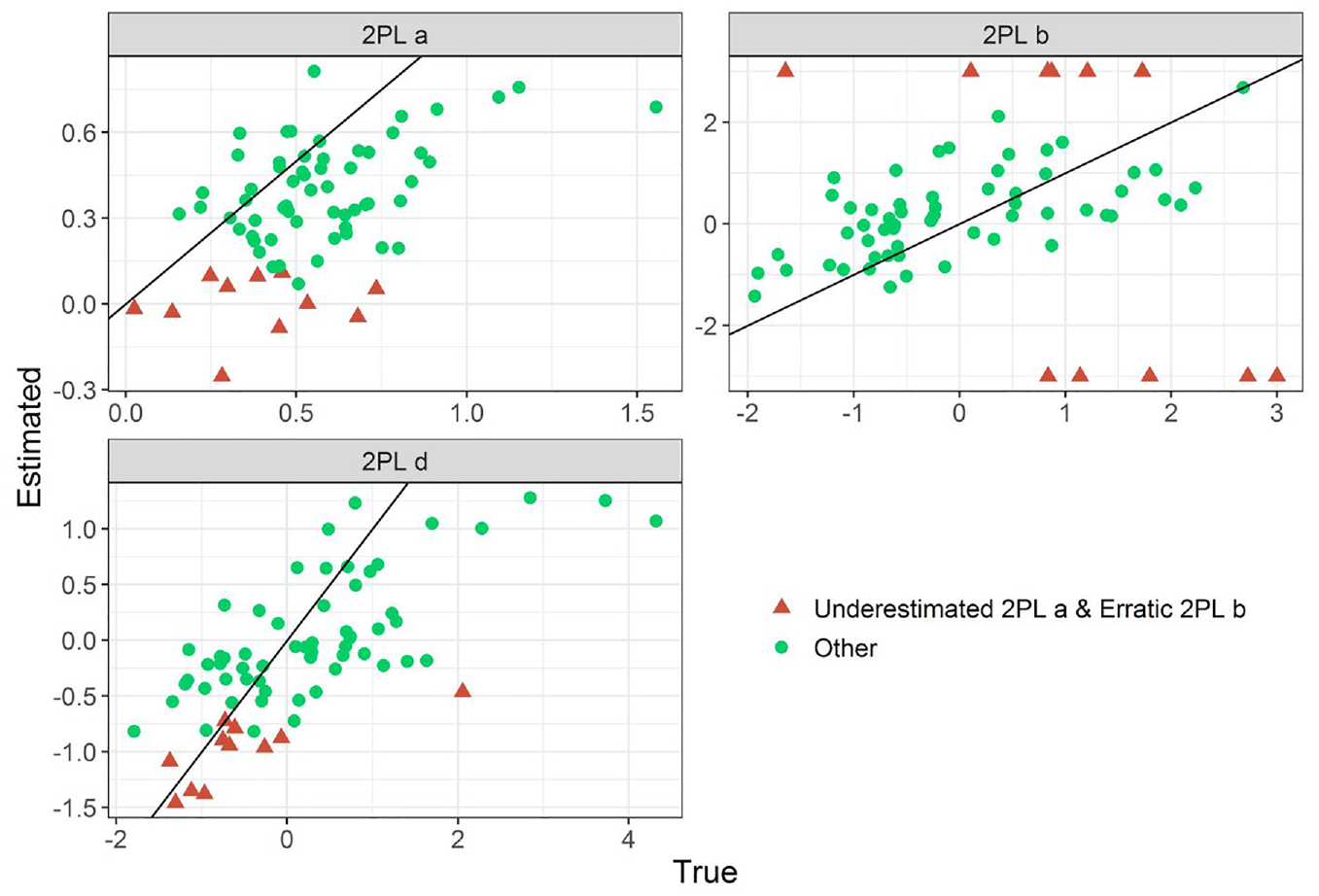
Separate_ Modeling Approach Can Fail Catastrophically for Some Items, Resulting in an Underestimated 2PL a and d, and Erratic b (2PL b Is Shown Bounded Within [−3, 3])
Separate_ Modeling Approach Used to Estimate Field-Test Item 2PL
Dimensionality
Unidimensionality is fundamental to test validity (Nunnally & Bernstein, 1994). Dimensionality of the AI examinee item response data was examined. Given that the target probabilities used to fine-tune the LLMs were generated from a unidimensional 2PL model, we can expect the generated responses to be unidimensional as well. Field-test item response data from a randomly generated 5,000 AI examinees from all grade levels were used. The first four eigenvalues for both the Separate_ (5.34, 0.28, 0.21, and 0.19) and Concatenate_4 (4.44, 0.23, 0.21, and 0.21) showed a sharp drop after the first value, which strongly indicated that these set of items were unidimensional (Cattell, 1966). Using the lavaan R package (Rosseel, 2012), confirmatory factor analysis (CFA) was conducted to confirm that the test was unidimensional (Bandalos & Finney, 2018). The estimator = “WLSMV” option was used as recommended for ordered categorical variables (Flora & Curran, 2004; Rhemtulla et al., 2012). Based on conventional standards (Hu & Bentler, 1999), fit statistics all indicated nearly perfect fit to the unidimensional CFA model for the Separate_ approach, χ2(2,345) = 2,301.2, p = .74, Tucker-Lewis index (TLI) = 1.001, CFI = 1.000, RMSE = .000, standardized root mean square residual (SRMR) = .021. Concatenate_4 had a marginally worse fit, but still very good, χ2(2,345) = 2,441.59, p = .080, TLI = .997, CFI = .997, RMSE = .003, SRMR = .023. Standardized factor loadings for Separate_ ranged from −0.16 to 0.59 (M = 0.31, SD = 0.18). Standardized factor loadings for Concatenate_4 ranged from −0.11 to 0.74 (M = 0.26, SD = 0.20).
Discussion
The ultimate goal of AI field-testing is to enhance the efficiency of field-testing by completely replacing human examinees with AI counterparts, and generate item response data that can be used for various statistical evaluations of item quality that are essential in traditional field-testing. The proposed approaches integrated LLMs and IRT to train AI to mimic human responses to English grammar multiple-choice items. The current study demonstrated that IRT- and CTT-based statistics calculated using AI item responses showed moderate resemblance of those obtained from human examinees. Latent ability estimation based on item parameter estimates from AI field-testing was similar to ability estimates based on the “true” item parameters that were originally used to fine-tune the AI models. AI-generated responses may also have the potential to be used for dimensionality analyses, which is typically plagued with data sparseness issues in computerized adaptive tests (Bulut & Kim, 2021).
Unlike AI, human examinees are limited in the number of items they can complete. This also lowers the sample size for each field-test item. These two factors limit the quality of human examinee item response data. Regardless, the study showed that human field-testing is still superior to AI field-testing for accurately calibrating items or calculating item statistics. One reason may be because the item text had to be reformatted for LLM consumption, including a complete elimination of the stem text. This was necessary as these items were not originally designed to be processed by LLMs. Past studies show that simple changes to the item text can change the item difficulty noticeably (Byrd & Srivastava, 2022). Especially considering AI examinees cannot think or feel like humans do, there may always be an inherent gap between how AI and humans respond to exam items.
Among the AI field-testing methods included in the article, the Separate_ method performed far more accurately than Concatenate_1, Concatenate_4, and Concatenate_24. Furthermore, Separate_ is more convenient than Concatenate_ approaches as it takes less training time, can handle longer input sequence text, and can elegantly accommodate items with varying numbers of response options.
Importantly, the proposed approaches preserved the core structure of traditional field-testing by replacing human examinees with AI counterparts, allowing most analyses and calibration procedures to proceed as usual. This seamless integration into existing workflows not only offers convenience and practicality but also makes the technology more accessible, which may help stakeholders better understand and accept it. Building this understanding and trust is crucial for the successful adoption of new technologies like AI in education (Aloisi, 2023; Nazaretsky et al., 2022; Qin et al., 2020).
Trust in AI may also be closely tied to the widespread concerns about AI bias and ethics (Bolukbasi et al., 2016; Caliskan et al., 2017; Hassija et al., 2023; Morales et al., 2023). Before AI field-testing can be confidently applied in high-stakes exams, it is essential to develop and implement robust methods to mitigate AI bias. In psychometrics, item bias against examinees based on their background is typically identified through differential item functioning (DIF) analysis (Holland & Wainer, 1993). As DIF was not addressed in the current article, research is needed to integrate it into the AI field-testing framework.
Another key issue was how AI examinees’ response behavior to the training items and field-test items was fundamentally different (see Figure 4). This mattered as training items were used as anchors during calibration. This likely had a negative effect on all 2PL parameter estimations. A solution could be to make an initial mutually exclusive distinction of three item groups: (a) calibrated training items, (b) calibrated anchors, and (c) new field-test items. This approach to avoid using training items as anchors may eliminate some issues. Another option may be to fix the AI θ to its true values, which eliminates the need for anchor items. Other alternatives could be to raise training item sample size, or adjust training hyperparameters so that the model is more generalizable to the field-test items.
While this article primarily presented a simulation study, simulated data were used sparingly. Simulated data were employed to create the Simulated_Human group and to assess the accuracy of latent ability estimation across all modeling approaches. However, the item parameters and statistics, the mean and standard deviation of
The current article used relatively simple English grammar multiple-choice items to illustrate and evaluate AI field-testing. Answering these items required only the knowledge of the English language, which made them exceptionally appropriate for testing English-based LLMs. In the literature, evidence shows that LLMs can be trained to answer mathematical problems (Xu et al., 2024) or medical items that require knowledge and reasoning (Singhal et al., 2023). Whether the proposed techniques can generalize to these other item types will need further context-specific investigation.
The literature provides examples of using NLP to handle varied item types. For instance, Settles et al. (2020) employed machine learning algorithms to generate an entire English language assessment. They first determined vocabulary difficulty using word frequency, word character lengths, and expert judgment. Next, they ranked passage difficulty based on average word and sentence length, word frequency, pre-labeled online passages, and expert evaluations. The predicted vocabulary and passage difficulty were then used to generate five item formats assessing listening, speaking, reading, and writing skills. Their use of multiple techniques highlights key considerations for predicting the difficulty of items with varied formats.
Benedetto (2023) may have reported the most comprehensive quantitative comparison of modern item difficulty prediction methods. The author compared BERT (Devlin et al., 2018) and DistilBERT (Sanh et al., 2019) transformers with random forest regression models that utilize linguistic features, readability indices, term frequency—inverse document frequency (Manning et al., 2008), and word2vec embeddings (Mikolov et al., 2013). Transformers were the most predictive of item difficulty. However, the accuracy depended heavily on the exam type, where R2 ranged from .19 to .62 with LLMs trained on 4,000 to over 100,000 items. Increasing the number of training items improved the R2. The best performing BERT models from Benedetto (2023) were partially replicated in the current study with the Predicted_2PL approach. Predicting the 2PL b parameter with Predicted_2PL had an R2 of .18. This relatively poor performance is likely due to the low item sample size and the particular type of items used in the current article. The results of the current study may improve drastically if models are trained on more data.
Limitations
The proposed method uses item text to predict IRT selection probabilities with regression. An alternative would be to predict the response selection categories instead, which was Lalor et al.’s (2019) approach. Predicting responses was substantially less convenient and less efficient than 2PL probabilities. However, if the ultimate goal is to mimic all aspects of human response behavior, training LLMs directly based on raw human examinee response data could be a necessary future direction, as many nuanced patterns are not captured by the 2PL model. This is evident in the extremely good fit of the unidimensional CFA to the AI examinee response data, suggesting that minor multidimensionality was lost in the process.
Similarly, I did not directly compare AI and human examinee item response patterns in this article. Rather, I compared item-level statistics obtained from such responses, such as proportion correct or the item parameters. Although these comparisons were sufficient in showing the model performance, comparing responses directly could be the ideal approach.
Furthermore, the parameters and statistics obtained from prior field-testing with real humans were treated as true values. In reality, these were estimates as well. This limitation likely inflated the accuracy of the Simulated_Human approach. The current article used English grammar multiple-choice questions to demonstrate the effectiveness of AI field-testing. However, English literacy exams are often not limited to these types of items or content. Research is necessary to develop LLMs that can respond to various types of items, or methods to integrate multiple LLMs that are designed to respond to specific item types. Incorporating additional text features in the LLM (e.g., item word count) may be another route to enhancing the approach, which may further close the distance between AI and human item response behavior.
Conclusion
This article presented an innovative approach of replacing human examinees with AI examinees for field-testing newly written exam items. The study demonstrated that AI item response data can be used to calculate item statistics and conduct item calibration, distractor analysis, dimensionality analysis, and latent trait scoring. Although AI field-testing still fell short of the accuracy of item calibration and analyses that were performed with human examinee response data, the potential resource savings in transitioning from human to AI field-testing cannot be understated. AI could shorten the field-testing timeline, prevent human examinees from seeing low-quality field-test items in real exams, shorten test lengths, eliminate item exposure, test security, and sample size concerns, and reduce the overall cost. In the era of generative AI, the research on automatic item generation may tend to far outpace the rate at which items can be field-tested, which could result in a bottleneck. A strategic combination of automatic item generation and AI field-testing may enable an extremely efficient expansion of the item bank. Researchers are encouraged to explore methods to enhance AI examinees to be more reflective of human examinee behavior, as well as generalize its capabilities to handle various types of items.
Footnotes
Acknowledgements
The author appreciates the support and feedback of Aren Simmons, Catherine Francis, Fang Peng, Rochelle Michel, Shumin Jing, and Yikai “EK” Lu.
Author’s Note
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.