
Abstract
Administering Likert-type questionnaires to online samples risks contamination of the data by malicious computer-generated random responses, also known as bots. Although nonresponsivity indices (NRIs) such as person-total correlations or Mahalanobis distance have shown great promise to detect bots, universal cutoff values are elusive. An initial calibration sample constructed via stratified sampling of bots and humans—real or simulated under a measurement model—has been used to empirically choose cutoffs with a high nominal specificity. However, a high-specificity cutoff is less accurate when the target sample has a high contamination rate. In the present article, we propose the supervised classes, unsupervised mixing proportions (SCUMP) algorithm that chooses a cutoff to maximize accuracy. SCUMP uses a Gaussian mixture model to estimate, unsupervised, the contamination rate in the sample of interest. A simulation study found that, in the absence of model misspecification on the bots, our cutoffs maintained accuracy across varying contamination rates.
In the social sciences, it is common to collect Likert-type self-report data online via crowdsourcing platforms such as Amazon Mechanical Turk (Buhrmester et al., 2011) or Prolific Academic (Peer et al., 2017). Because participants are given monetary compensation, online data collection risks the data being contaminated by survey bots—malicious software submitting invalid data while posing as legitimate human participants. Bot attacks range from crude web-browser-based form fillers to sophisticated server farms (Buchanan & Scofield, 2018; Dennis et al., 2020; Teitcher et al., 2015). As bots are known to inflate Type I and Type II errors as well as bias parameter estimates (Credé, 2010; Huang et al., 2015; Osborne & Blanchard, 2011), it is imperative that researchers detect them in the data.
Bot detection shares common ground with detecting aberrant-responding humans. The common denominator is content nonresponsivity, which is that responses are produced irrespective of the item prompt (Meade & Craig, 2012). For humans, content nonresponsivity occurs because they are in a hurry, disinterested, or distracted (DeSimone & Harms, 2018; Meade & Craig, 2012), but for bots, it is because they indiscriminately produce random numbers from some programmed distribution (Buchanan & Scofield, 2018). Although much of the content-nonresponsivity literature is not about bots per se, we regard the methods therein as relevant for “bot detection” insofar as they act on responses being indiscriminately “random” (e.g., Credé, 2010; Hong et al., 2020). To be more precise, a respondent’s severity is the proportion of items she answered in a content-nonresponsive manner (Hong et al., 2020) and a bot is presumed to have 100% severity. A focus on bots facilitates plausible statistical assumptions on the nature of “random” responding (Buchanan & Scofield, 2018) that may only sometimes be plausible for human respondents (Niessen et al., 2016).
Human or bot, detection of such aberrant responding is often via nonresponsivity indices (NRIs)—person statistics that, roughly speaking, quantify deviance from the factor or correlational structure of well-behaved participants (Curran, 2016; Meade & Craig, 2012). To name a few, NRIs include classic outlier detection indices (Mahalanobis distance), the similarity of responses to a prototype (person-total correlations), response consistency indices that require multi-item scales or reverse-worded items (even-odd consistency or psychometric antonyms), and model-based statistics (person fit statistics; for example, Dupuis et al., 2019; Meade & Craig, 2012; Niessen et al., 2016).
The premise underlying use of NRIs is that in NRI space, aberrant responders form a different cluster from nonabberant ones (Dupuis et al., 2019, 2020). To illustrate, Figure 1 is a plot of Mahalanobis distance and person-total correlation for a sample of humans and bots,
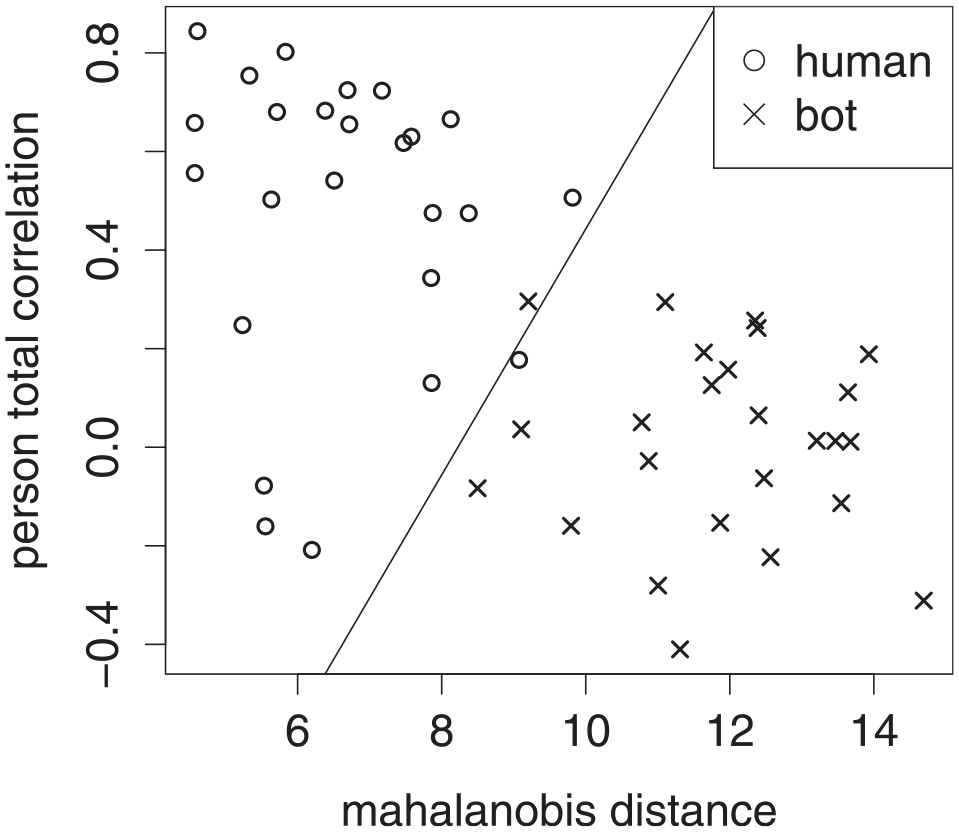
Scatter plot of Mahalanobis Distance Versus Person-Total Correlation for a Sample of 50 Humans and 50 Bots, Where the Bots’ Responses Were From a Uniform Distribution. A Straight Line Approximates the Boundary Between the Two Classes.
Toward detection of content nonresponsivity, the literature on NRIs has typically followed a common program (Dupuis et al., 2019, 2020; Hong et al., 2020; Meade & Craig, 2012; Niessen et al., 2016), which is to compute NRIs on a calibration sample—a sample for which the true classes are known. The calibration sample could be a mix of real and simulated data: Well-behaved responses may be actual human responses under interventions to ensure data quality or simulated from some item response model (Dupuis et al., 2019; Hong et al., 2020; Huang et al., 2012; Meade & Craig, 2012; Niessen et al., 2016); aberrant responders may be human participants instructed to respond in a “random” fashion or simulated as such (Huang et al., 2012; Meade & Craig, 2012; Niessen et al., 2016).
The utility of an NRI cutoff is quantified in terms of specificity and sensitivity. In the bot detection context, specificity (i.e., the true-negative rate) is the proportion of humans correctly predicted to be human, whereas sensitivity (i.e., the true-positive rate) is the proportion of bots correctly predicted to be bots (Hong et al., 2020; Huang et al., 2012; Niessen et al., 2016). The cutoff is then analogous to a critical value in null hypothesis testing—there is a trade-off between specificity and sensitivity, and it is desirable to attain a healthy amount of both.
Although studies on the use of NRIs have shown promise, they fall short of addressing the end goal of NRIs in the first place—the researcher endeavors to, provided her calibration sample, choose an optimal cutoff to predict classes on her target sample. Anecdotally, researchers may choose arbitrary cutoff values based on experience; if done post hoc, this could constitute use of a researcher degree of freedom (Simmons et al., 2011). Some studies go only as far as to show that their chosen NRIs discriminate well between the two classes, not how to find optimal cutoffs (Dupuis et al., 2019, 2020; Meade & Craig, 2012). In Meade and Craig (2012), Mahalanobis distance was shown to be a significant predictor of class in the calibration sample. But significance can be computed only if the class labels were already known, which is not true of the target sample. Other studies (Hong et al., 2020; Niessen et al., 2016) provide recommendations on where to set cutoffs but do so without adequately accounting for base rates – the contamination rate and its complement. In Hong et al. (2020), a parametric bootstrap method was proposed to find cutoffs with 99% nominal specificity, irrespective of the unknown contamination rate. But depending on the contamination rate, a high-specificity cutoff may still end up inaccurate.
To understand the connection between contamination rates and accurate cutoffs, Figure 2 shows a hypothetical NRI where the two classes have the same pair of normal distributions, under two contamination rates. Shifting the cutoff to the left sacrifices specificity in favor of sensitivity, and shifting to the right does the opposite. The most accurate cutoff is where the two density curves cross (James et al., 2013). Clearly, when the contamination rate is low, specificity is more valuable, but when the contamination rate is high, sensitivity is more valuable. For the same pair of normal distributions, Table 1 shows the accuracy of several specificity cutoffs, at different contamination rates. Unfortunately, bots being the majority of the sample is not unheard of (Perkel, 2020), and there is concern over their growing prevalence (Storozuk et al., 2020). We draw attention to the fact that without foreknowledge of the true classes, the density curve in Figure 2B may appear to be a single hump. In that case, an unsuspecting researcher may end up with the false impression that there are few bots in her data, and subsequent use of a cutoff value based on only specificity will prove to be unwise—the result is very low classification accuracy and the sample that remains is mostly bots.
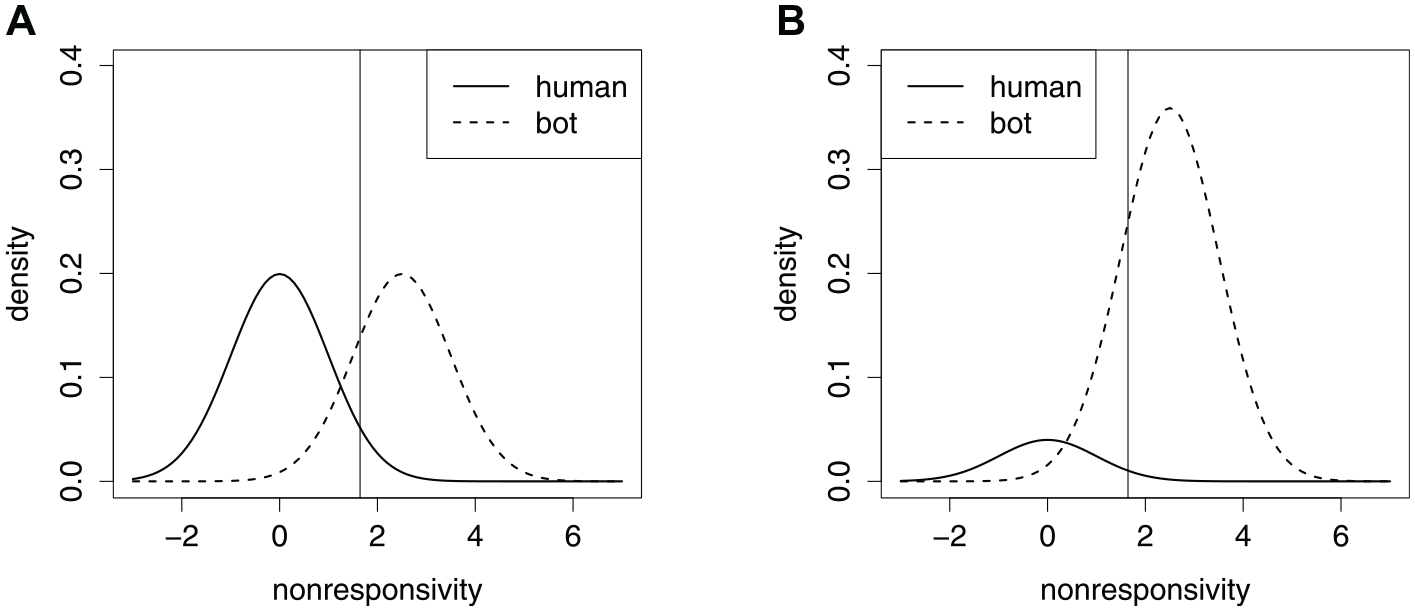
Density Curves for a Hypothetical Nonresponsivity Index, Varying the Contamination Rate. A Vertical Line Locates the Cutoff With 95% Specificity. (A) 50% Contamination. (B) 90% Contamination.
Accuracy Rates (in Percent) of Specificity (in Percent) Cutoffs Under Different Contamination Rates (in Percent), for the Hypothetical NRI in Figure 2.
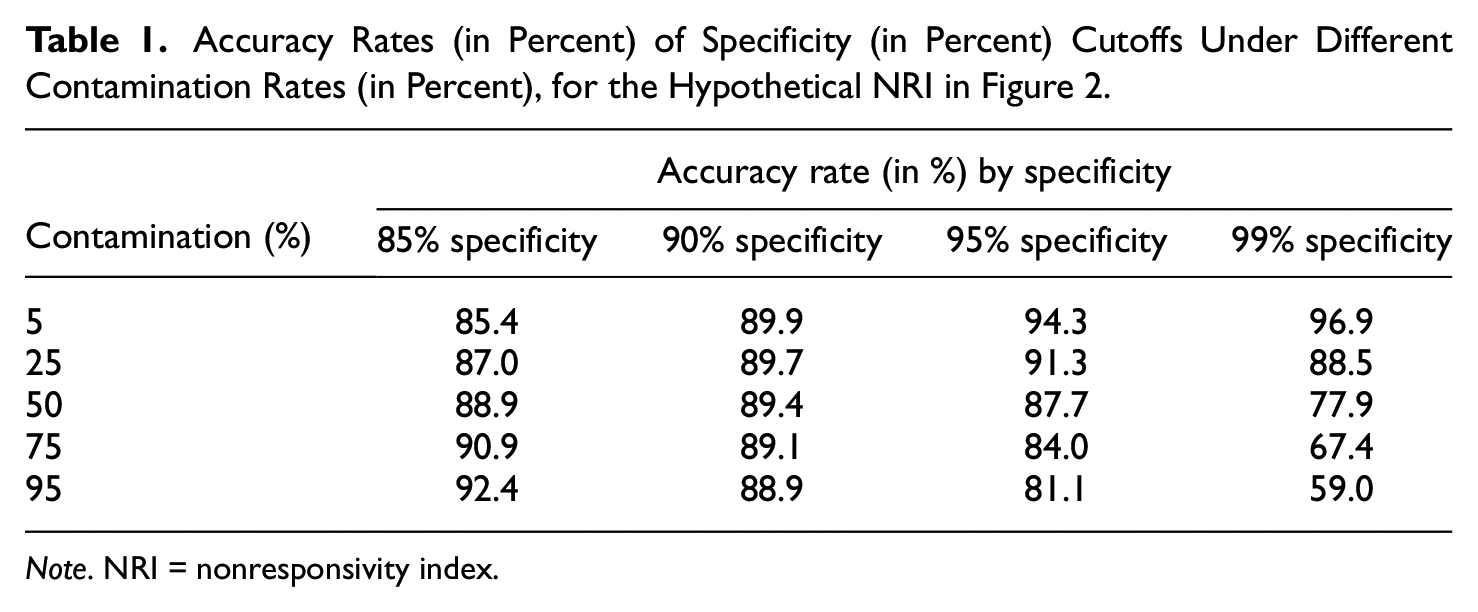
Note. NRI = nonresponsivity index.
The trade-off between specificity and sensitivity is visualized in the receiver operating characteristic (ROC) curve in Figure 3. Every chosen specificity rate (or its complement, false-positive rate) implies a sensitivity rate (i.e., true-positive rate). A larger area under the curve (AUC) is a more favorable trade-off overall, but it shows only the mere fact that it is worth seeking a cutoff, not how to find an accurate one (Unal, 2017). Accuracy is not a property of the NRI as a whole—it is instead a property of a cutoff, provided base rates.
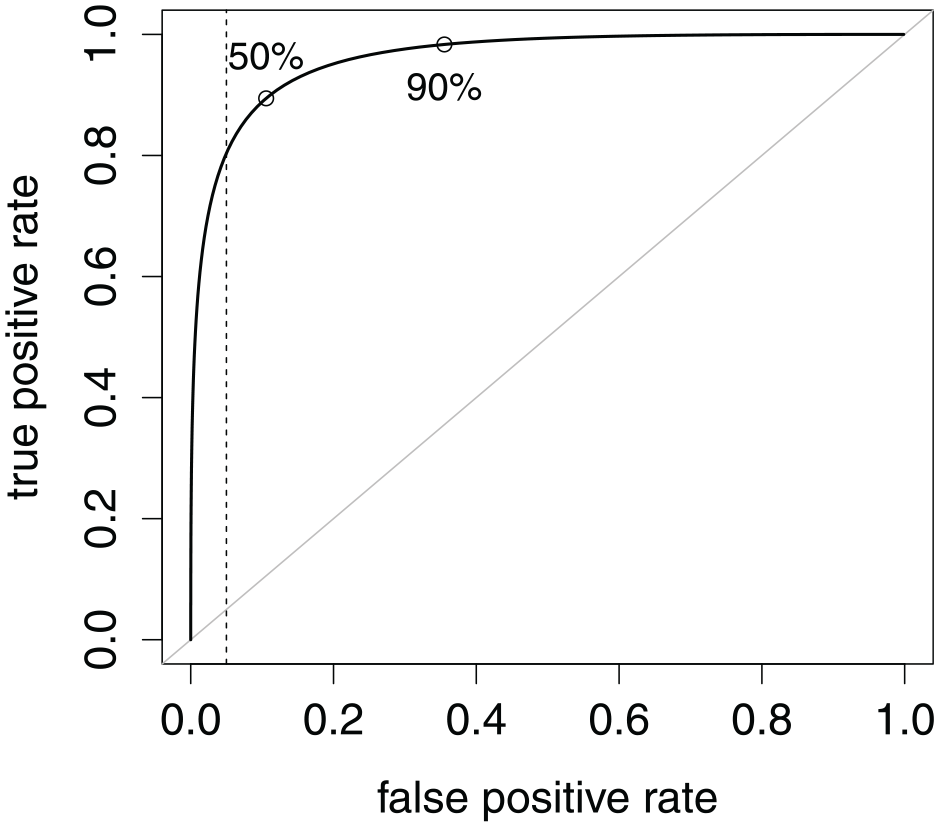
Receiver Operating Characteristic Curve Common to Both Scenarios in Figure 2. Points Locate the Maximum Accuracy Cutoffs Under the Two Contamination Rates. A Vertical Line Locates the Cutoff With 95% Specificity. Area Under the Curve Is 96.1%.
An underappreciated nuance in the NRI literature is that the target sample’s contamination rate cannot be estimated from the calibration sample. For an analogy, suppose a kitchen drawer contained only spoons and forks. Spoon and fork are the classes in the population. If one were to take a simple random sample, the proportion of spoons in that sample would estimate the prevalence of the spoon class. But if one were to take two simple random samples—one sample for spoon and another for fork—the total sample is said to be stratified by class (Lohr, 2010). Because the relative sample sizes of spoon and fork are arbitrary in the stratified sample, they cannot estimate the respective prevalences in the drawer population (or any simple random sample thereof). In the bot detection context, calibration samples are stratified by class, so base rates are likewise not available. For example, in Dupuis et al. (2019), a human sample was produced by a pen-and-paper administration of a questionnaire, whereas a bot sample was produced by simulation.
Besides stratified samples, another issue is the incorporation of multiple NRIs into the prediction. The literature typically finds univariate cutoffs, so that each NRI has its own cutoff value (DeSimone & Harms, 2018; Hong & Cheng, 2018; Huang et al., 2012; Niessen et al., 2016). However, doing so ignores the dependence structure between the NRIs. To illustrate, instead of the linear boundary in Figure 1, univariate cutoffs would result in two lines perpendicular to the axes. Furthermore, simultaneous univariate cutoffs amount to multiple testing, which, as in null hypothesis testing, is known to attenuate specificity rate from its nominal level (Bajorski, 2012; Hong et al., 2020).
It is desirable to find accurate multivariate cutoffs empirically, with a stratified calibration sample but without prior knowledge of the contamination rate in the target sample. In the present article, we propose such a method within the machine learning paradigm of supervised learning (James et al., 2013). We build mainly upon Dupuis et al. (2019) and Hong et al. (2020) to highlight underappreciated nuances of the bot detection problem. To be clear, we seek the most accurate cutoff for the data at hand. The remainder of the present article is organized as follows. In the second section, we lay out preliminaries. In the third section, we propose our novel solution, called Supervised Classes, Unsupervised Mixing Proportions (SCUMP). In the fourth section, we present a simulation study evaluating the performance of SCUMP under a variety of scenarios. The final section is a discussion.
Preliminaries
The Supervised Binary Classification Problem
We start with a
In the target sample, each observation
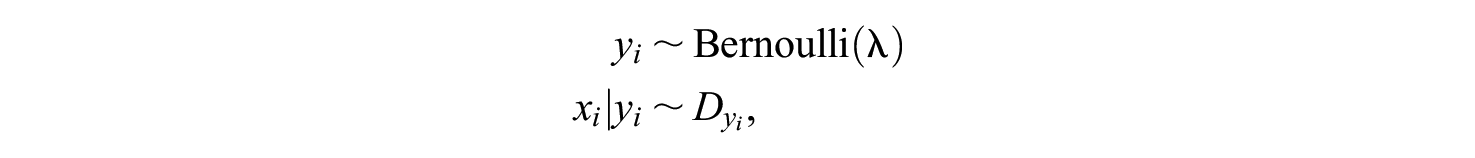
where
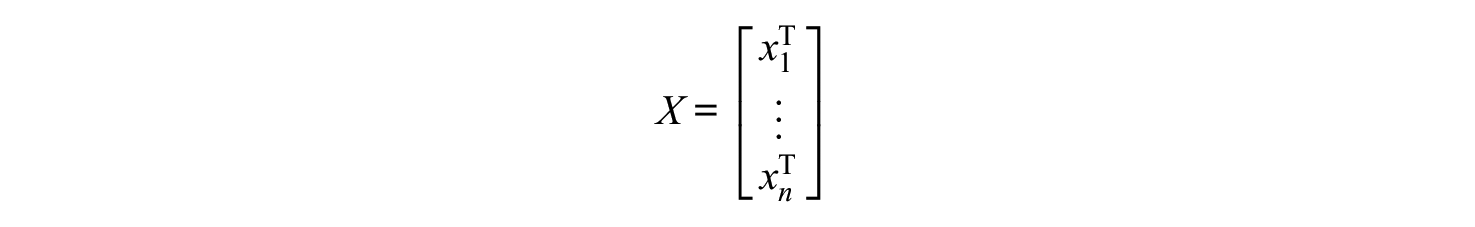
and
To make predictions on the unknown
In the bot detection context, we have the vector of class labels
If calibration sample bots are generated by the researcher, then the researcher must assume
Nonresponsivity Indices
Common to various NRIs is what we call the monotone suspicion property: The NRI may be suspicion-increasing, meaning that greater values are more suspicious, or the NRI may be suspicion-decreasing, meaning that greater values are less suspicious. In Figure 2, the hypothetical NRI is suspicion-increasing. It is straightforward to recode a suspicion-decreasing NRI into a suspicion-increasing form.
We consider four NRIs whose ROC curves had impressive (e.g., upward of 95%) AUC in Dupuis et al. (2019). Of the four considered NRIs, Mahalanobis distance and person-total correlation are widely used in the literature (Curran, 2016; DeSimone & Harms, 2018; Dupuis et al., 2019, 2020; Meade & Craig, 2012; Niessen et al., 2016). Let
Mahalanobis Distance
The Mahalanobis distance of
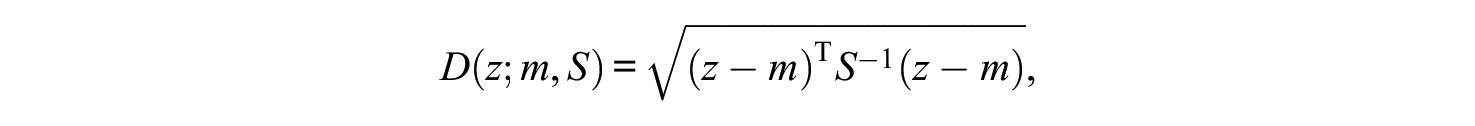
where
Person-Total Correlation
The person-total correlation of
Two more NRIs were taken from functional method theory (FMT), response coherence and response reliability (Dupuis et al., 2015, 2019, 2020). FMT is a testing framework competing with classical test theory and item response theory (Dupuis et al., 2015). Response coherence is suspicion-decreasing, ranging from 0 to
The four NRIs are outlier statistics, meaning that observations become suspicious by virtue of being outliers relative to some reference sample. In the supervised setting, it makes sense to set the reference sample as the human rows of
The set of NRIs considered is illustrative rather than exhaustive. There are more NRIs in the literature (e.g., Meade & Craig, 2012). The present article focuses on arriving at an accurate classifier given the features—the features themselves must be chosen beforehand. It is up to the researcher to determine which features they trust to discriminate between human and bot.
Thresholds and Trade-Offs
For observation
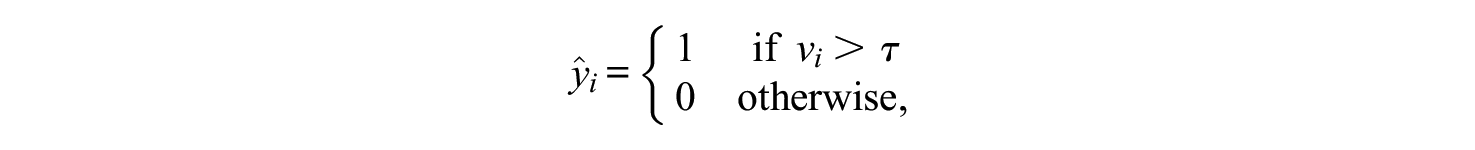
where the threshold
For observation
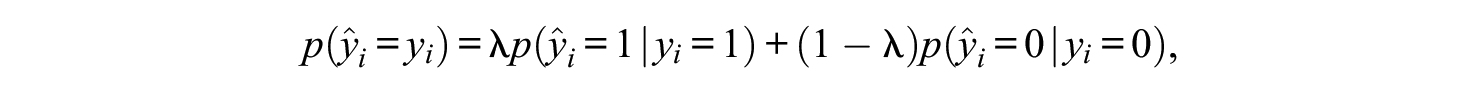
a weighted mean of specificity and sensitivity, where
In machine learning, the weighted-mean equation above is typically not directly used. Rather than choosing
Machine Learning Classifiers in the Absence of Stratification
To motivate SCUMP, consider a counterfactual where the calibration sample were taken from the hierarchy or mixture rather than stratified. If ground truth were readily available without doing stratified sampling, bot detection would be straightforward, as sample proportions would estimate class prevalences. In particular, consider prediction with logistic regression and Gaussian mixture models, both standard machine learning techniques in supervised classification (James et al., 2013).
In logistic regression, the parameter vector
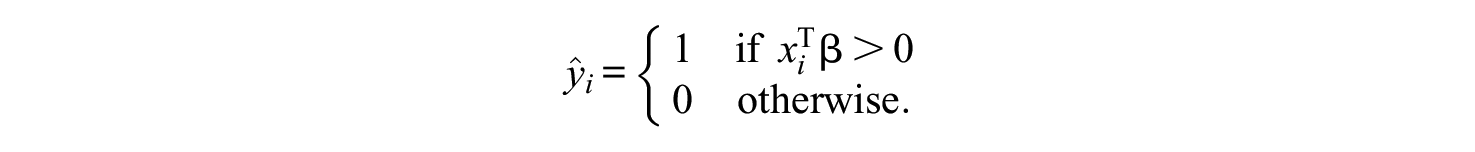
Considering multiple features (e.g., NRIs) simultaneously, the composite is
More relevant to SCUMP is Gaussian mixture models. Under the assumption that each class’s feature distribution is (multivariate) Gaussian, then the hierarchy can be modeled as (Boos & Stefanski, 2013; James et al., 2013)
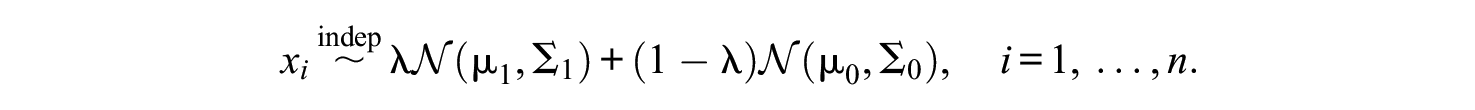
Under such a model, there are two kinds of parameters, estimated separately: the class feature distribution parameters and the mixing proportions.
Class Feature Distribution Parameters
For the parameters of
Mixture Proportions
For
Given the parameters, the Bayes classifier (James et al., 2013) is, for
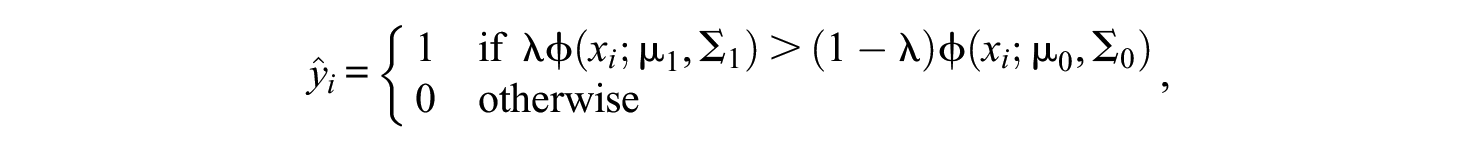
where
Note that in both logistic regression and Gaussian mixtures, once parameters are estimated from the training set, the classifier is determined. The prediction on each test set observation depends only on the training set, not on the other test set observations. Also note that in both techniques, the cutoff is multivariate; multiple testing is avoided.
Classifiers in the Nonresponsivity Literature
With calibration samples stratified, the standard machine learning techniques are not viable. Predictions depend on maximum likelihood estimates, which depend on an arbitrary number of bots,
In a simulation study, Hong et al. (2020) used a human calibration sample of
For the
Flag a respondent if and only if she exceeds the 99th percentile for any (as opposed to all) NRIs. Formally, the classifier is given by, for
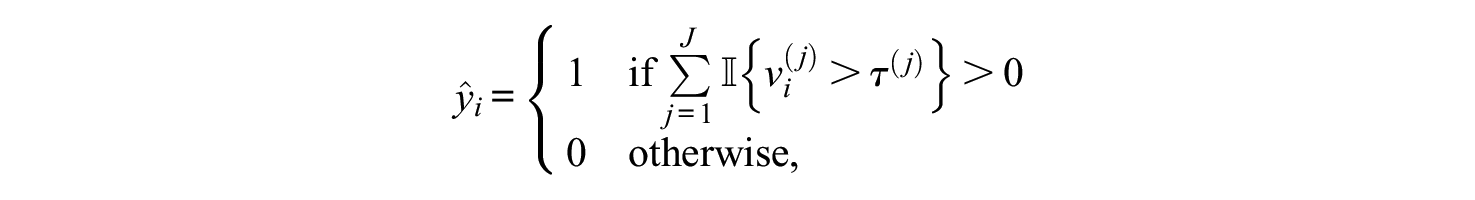
where
In the simulation study (Hong et al., 2020), scenarios had contamination rates up to 30%. A multidimensional graded response model was used to simulate human responders in the calibration and target samples. Random uniform responses were simulated for bots in the target sample. Because specificity was the criterion for choosing univariate cutoffs, the calibration sample did not need bots, so
Calibration sample size is an important consideration. Besides the issue of multiple testing, some discrepancy in specificity between calibration and target samples is expected due to sampling error. However, this threat is obscured by the large human calibration size in Hong et al. (2020). Furthermore, having
There is reason to suspect that test length is relevant to the trade-off that a specificity-calibrated classifier would neglect. Intuitively, more items are expected to induce a better AUC: When the inventory has many items, there is a lot of information to distinguish the classes, but for shorter inventories, the gains in specificity translate to dramatic losses in sensitivity. In Hong et al. (2020), both the 27-item test and the 54-item test retained a level of specificity at around 96%, but the sensitivity was around 99% for the longer test versus around 80% for the shorter test. By weighted-mean calculations, such a classifier would have 91.2% accuracy at 30% contamination but 84.8% accuracy at 70% contamination. By the same line of reasoning, the ROCs in Dupuis et al. (2019) may not have been as impressive if they had used a shorter inventory.
Because cutoffs were univariate, besides calibrating for each NRI’s threshold value
It is possible to have a specificity-calibrated classifier with multivariate cutoffs, without the need to make strong assumptions about the psychometric model for humans as in Hong et al. (2020). One way to do so is to use Mahalanobis distance on the feature space, relative to the human class. Such a classifier is given by, for
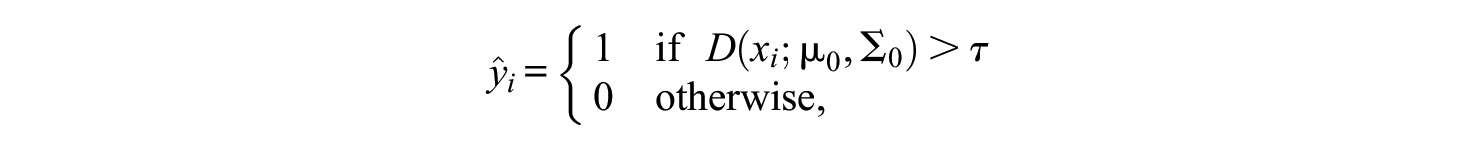
where
Proposed Solution
Our proposal assumes that the calibration sample has been obtained in a manner similar to Dupuis et al. (2019)—by policing a sample to ensure that it is human and by generating an arbitrarily large sample of bots from a model assumption. This strategy allows development of cutoff values for the Likert-type questionnaire of interest that may be used in separate samples (future or past) from a similar population. That is, our approach allows predictions about respondent class membership without prior knowledge of contamination rate
As logistic regression does not explicitly model
Our proposed solution, SCUMP, does estimation in two stages: supervised for the class feature distributions and unsupervised for the mixing proportions.
Supervised Classes
Estimate class feature distribution parameters
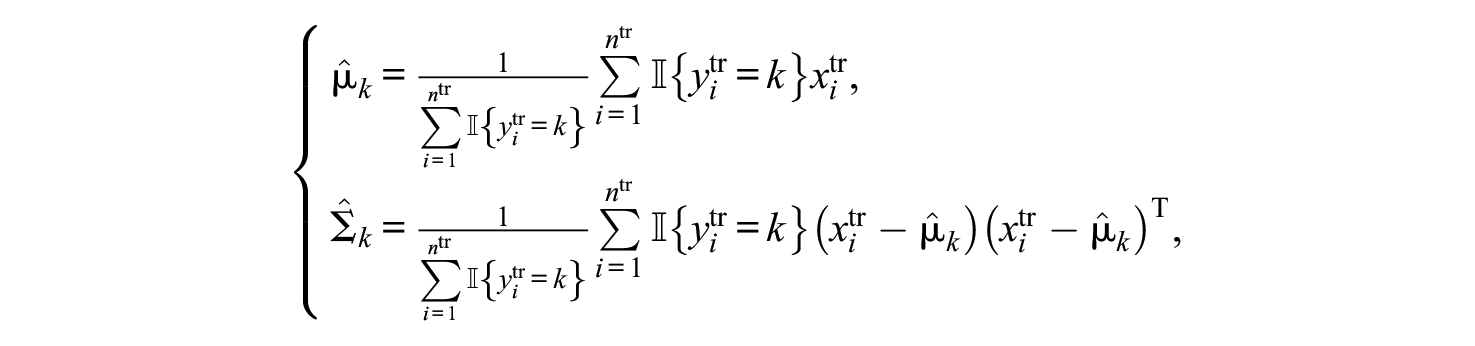
which are just the Gaussian maximum likelihood estimates within each class.
Unsupervised Mixing Proportions
Treat the mixture as if the class feature distribution parameters were known to be their supervised estimates. Thus, the model has only one free parameter remaining to estimate, the bot class prior
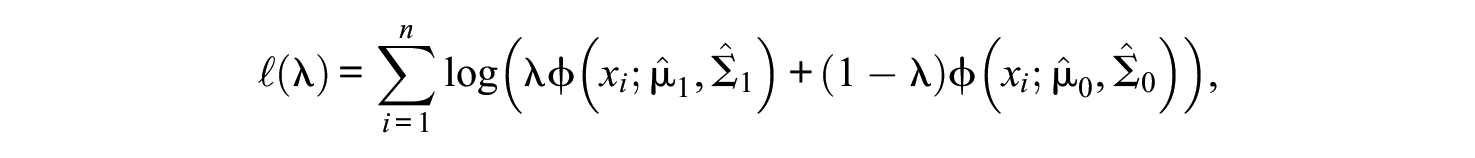
so the unsupervised estimator is given by
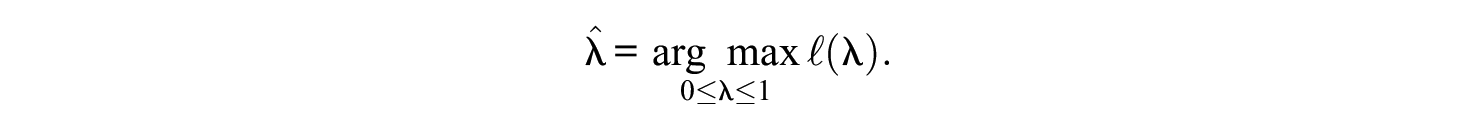
Computationally, we propose a bisection algorithm for finding
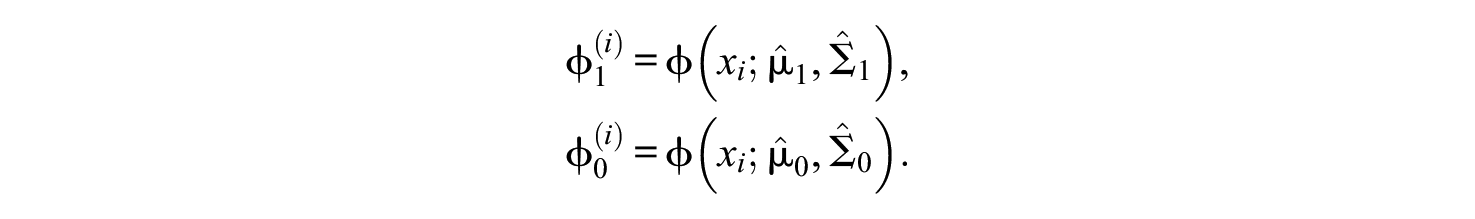
Taking the first derivative of the log-likelihood, the maximum likelihood estimator satisfies
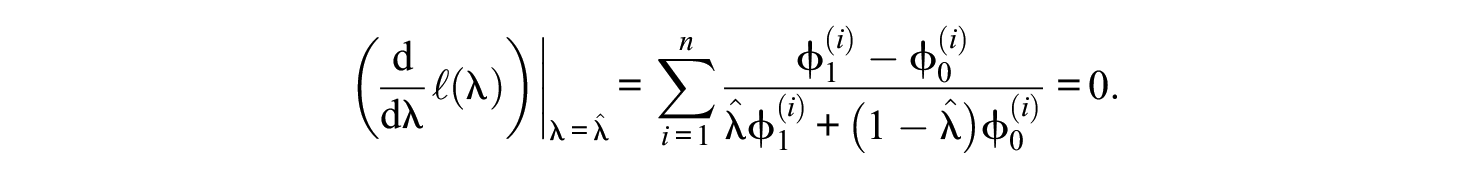
A global maximum exists, as guaranteed by the second derivative,
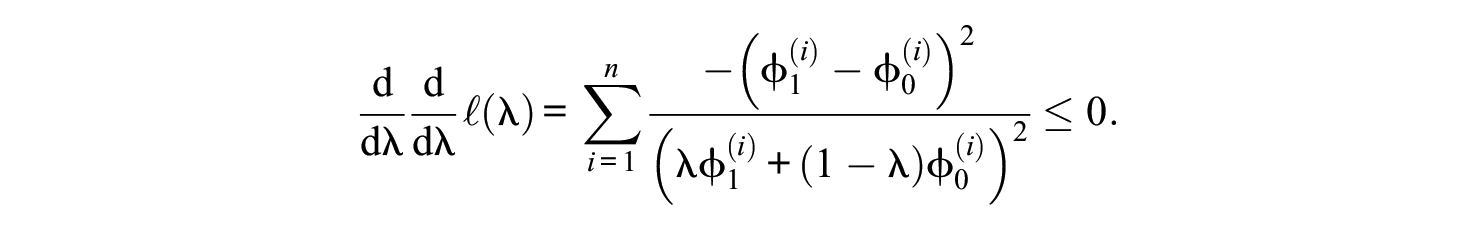
In R, we plug the derivative of the log-likelihood into the function stats::uniroot (R Core Team, 2021) if the endpoints of the search interval
Once all the Gaussian mixture parameters are estimated, we use the Bayes classifier (as defined in the “Preliminaries” section) to make predictions. Note that unlike in the nonstratified case, the parameters estimated supervised are not enough to determine the classifier. Instead, the prediction on each target sample respondent depends not only on the calibration sample but also on the other target sample respondents. In that sense, the classifier is self-adapted to the target sample, even if its contamination rate varies.
We demonstrate the SCUMP Bayes classifier in Figures 4 and 5. Figure 4A shows predictions from SCUMP, using the NRIs Mahalanobis distance and person-total correlation, on the HSQ where the calibration sample had

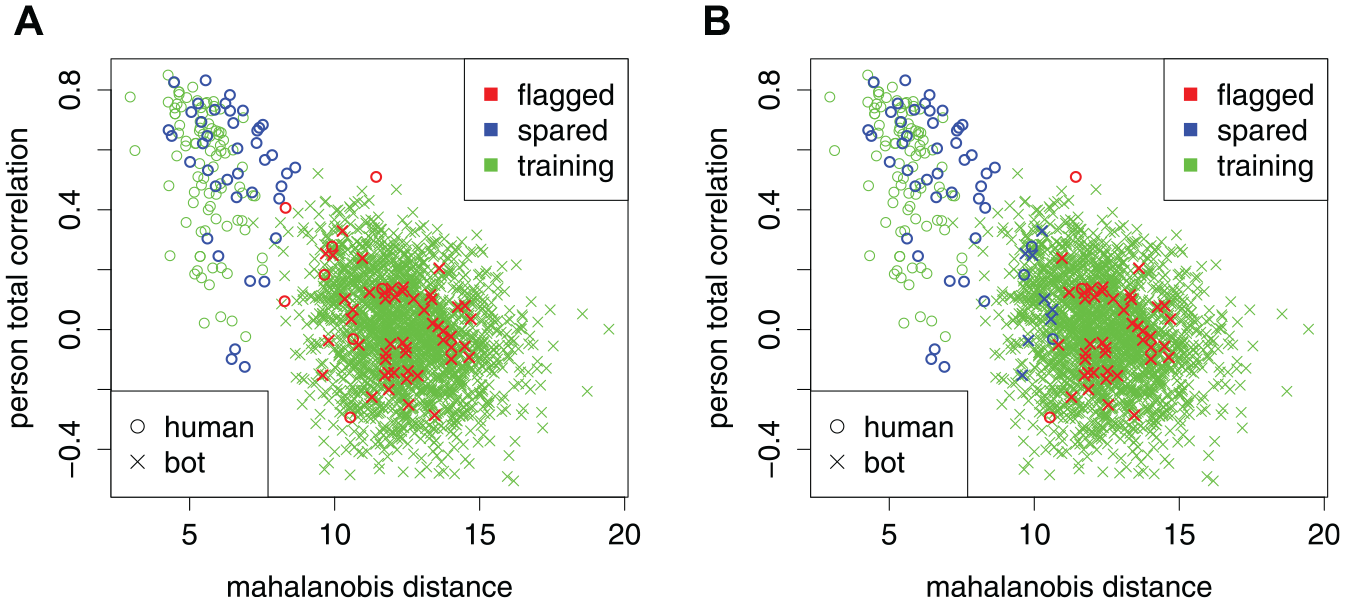
A Demonstration of the SCUMP Bayes Classifier and a Nominal 99% Specificity-Calibrated Classifier on the Same Pair of Calibration and Target Samples. Nonresponsivity Indices Used Were Mahalanobis Distance and Person-Total Correlation. (A) SCUMP Bayes. (B) Nominal 99% Specificity-Calibrated.
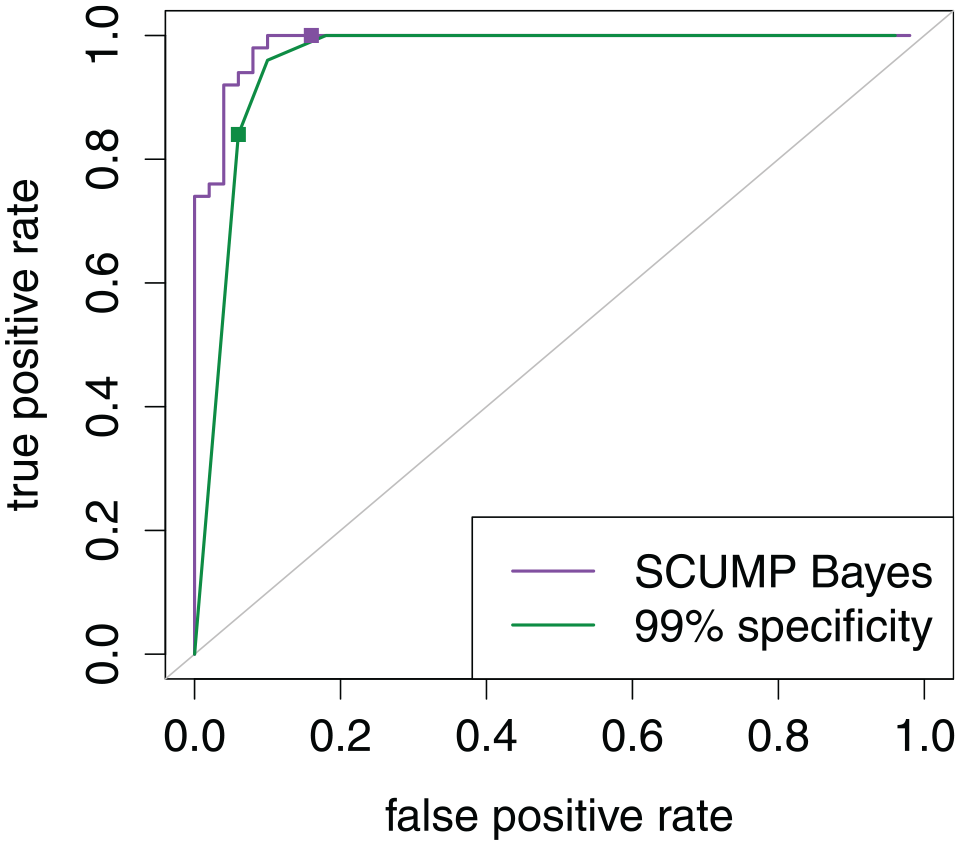
Receiver Operating Characteristic Curves on the Target Sample for the Classifiers Demonstrated in Figure 4. Points Locate the Chosen Cutoffs for the Two Classifiers. Area Under the Curve Was 96.7% for SCUMP Bayes Versus 92.0% for Specificity-Calibrated.
For comparison, Figure 4B shows a nominal 99% specificity-calibrated classifier on the same data. The confusion matrix is as follows.

In this target sample, specificity is 84% for the SCUMP Bayes classifier versus 94% for the specificity-calibrated classifier, but accuracy is 92% for SCUMP Bayes versus 89% for specificity-calibrated classifier. The two ROCs in Figure 5 show that SCUMP improved the predictions in two respects. First, incorporating
Although the researcher could “eyeball” a good-enough nominal specificity rate based on Figure 4, the apparent radius of the bot class depends on
Simulation Study
Study Design
To evaluate the performance of the SCUMP Bayes classifier, we conducted a simulation study. For comparison, we also included the specificity-calibrated classifier based on the Mahalanobis distance of the NRIs mentioned earlier in the article. We expected that the specificity-calibrated classifier would incur losses in accuracy at high contamination rates, whereas the SCUMP Bayes classifier would maintain accuracy.
To produce human observations for the simulation study, instead of simulating from a population model, we sampled with replacement from an actual data set. The data set was from a web administration of the HSQ, an inventory of
Generate the Target Sample
To do so, sample
Generate the Calibration Sample
To do so, sample
Compute NRIs
As a preprocessing step in line with Dupuis et al. (2019), impute all missing values with the middle category, in this case “3.” 2 Using the calibration sample as reference sample, convert all Likert-type observations to their NRI representations. Use four NRIs: Mahalanobis distance, person-total correlation, response coherence, and response reliability. For the FMT NRIs, assume that there are four factors, which is true of the HSQ (Kuiper, 2016); perform 30 iterations, in line with Dupuis et al. (2020).
Make Predictions
From the NRI representations, use the chosen classifier to yield
Compute Outcome Measures
Given the ground truth
In a
Conditions where the true bot response distribution was nonuniform represented the risks of model misspecification incurred by the uniform bot assumption. The nonuniform response distribution had the probability mass function
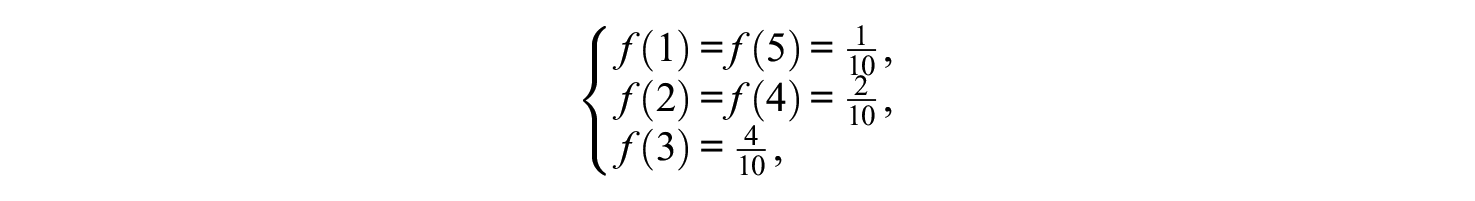
so that bots prefer the middle response category (Simone, 2019).
Each cell had 1,000 replicates. Each outcome measure was averaged over these replicates to yield a Monte Carlo estimate of its cell expected value. Larger values are desired for accuracy, sensitivity, specificity, and AUC. For flag rate, values closer to the contamination rate are desired.
The simulation study was carried out in R version 3.4.0 (R Core Team, 2021) on a desktop computer. The package mvtnorm (Genz et al., 2021) was used to compute multivariate Gaussian densities. FMT computations were our own implementation based on Dupuis et al. (2020). For parallel processing, packages furrr (Vaughan & Dancho, 2021) and future (Bengtsson, 2021) were used. R code to use SCUMP and reproduce this simulation study is publicly available at: https://osf.io/gjmsb/.
Results
Results were similar across the
Figure 6 presents the results in specificity versus accuracy plots (see also Supplementary Materials for exact values). Each colored trend line represents a contamination rate (e.g., red is for 5% contamination). Each point represents the number of training humans, increasing from
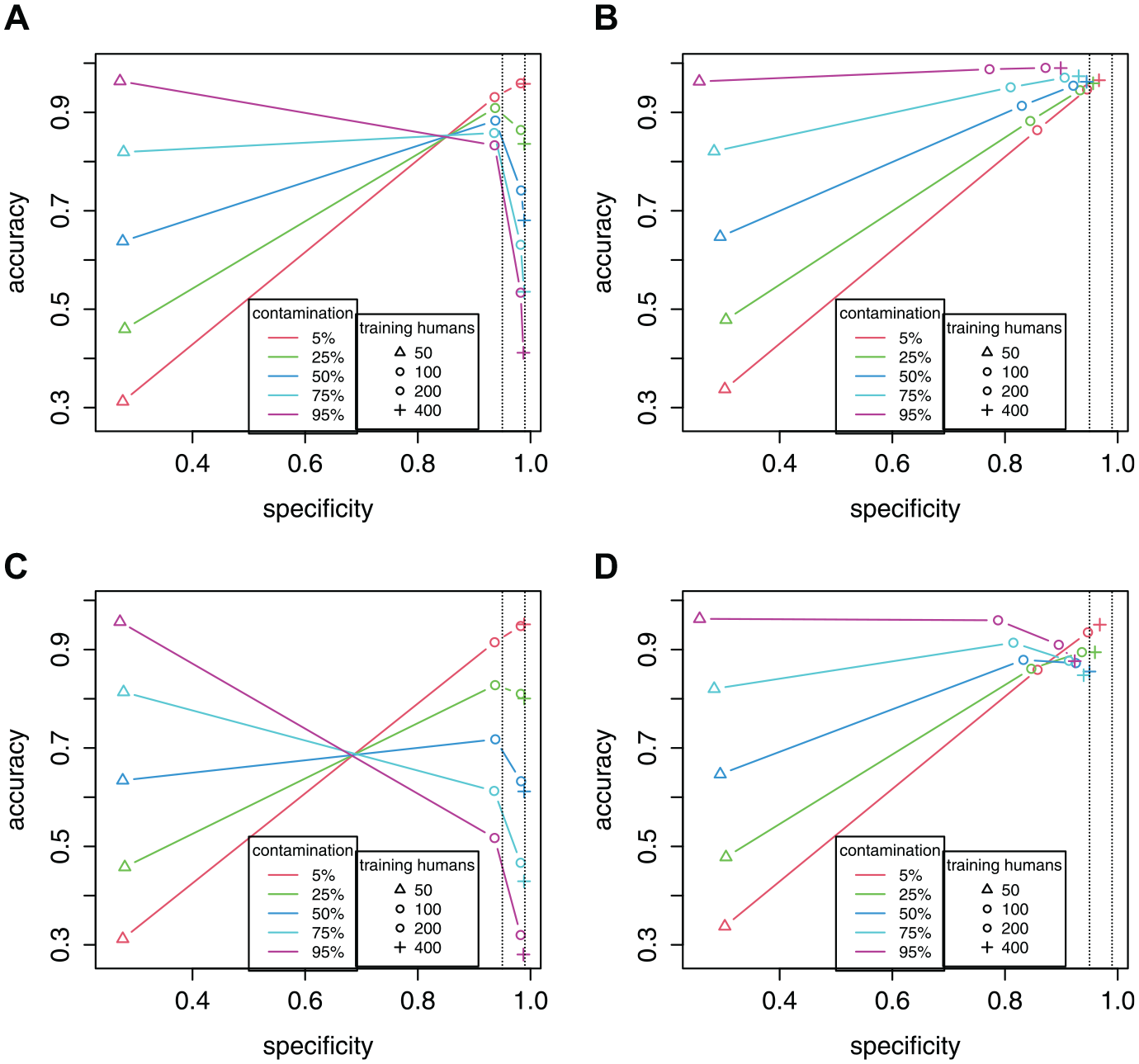
Specificity Versus Accuracy Plots From the Simulation Study. Each Panel Represents a Combination of Classifier and Response Distribution. See Text of Results Section for an Explanation of the Colored Trend Lines. Two Dotted Horizontal Lines Mark 95% and 99% Levels of Specificity. (A) Specificity-Calibrated, Uniform. (B) SCUMP Bayes, Uniform. (C) Specificity-Calibrated, Middle. (D) SCUMP Bayes, Middle.
Figure 6A shows the 99% specificity-calibrated classifier under the uniform response distribution. At the lowest
Figure 6B shows the SCUMP Bayes classifier under the uniform response distribution. At the lowest
In Figure 6C and D, we see the effects of nonuniform bots. For the specificity-calibrated classifier in Figure 6C, the trends are of similar form, but the drops in accuracy are sharper. For SCUMP in Figure 6D, the classifier performed well when
Discussion
Our simulation results affirm that contamination rate is key to the balancing act between specificity and sensitivity. At 5% contamination, sensitivity had little importance, so the specificity-calibrated classifier had similar accuracy rates to SCUMP Bayes. But at large contamination rates, calibrating for specificity was not the best strategy. In a real setting, the contamination rate is unknown, in which case the choice of nominal specificity (e.g., Hong et al., 2020) is uninformed. SCUMP offers a way out of this conundrum and it was successful relative to the specificity-calibrated classifier.
For specificity-calibrated classifiers, why does specificity end up systematically lower than the nominal? Because the training humans are the reference sample, their observed suspiciousness ends up artificially low. Then, choosing a cutoff with the nominal rate on these low-balled levels of suspicion ends up setting a low bar for suspicion. Consequently, the humans who did not have the privilege of appearing in the calibration sample are flagged at a rate higher than intended. As
Our results extend the 100% severity conditions in Hong et al. (2020) on two aspects. First, we considered contamination rates above the 30% in Hong et al. (2020). Doing so let the trade-off between specificity and sensitivity play out to its logical conclusion—that specificity-calibrated classifiers are unviable at large contamination rates. Second, we considered a smaller number of training humans than in Hong et al. (2020). Doing so demonstrated that in smaller calibration samples, specificity ends up lower than the nominal rate, which may unexpectedly end up benefiting accuracy. Both insights, in our view underappreciated in the literature, benefited from the prediction-oriented perspective of machine learning (Yarkoni & Westfall, 2017).
There are several limitations that we believe can be addressed in future research. Although SCUMP works to fully utilize a stratified calibration sample, it offers no remedy to issues around taking a stratified sample in the first place. SCUMP still relies on assumptions about the bot response distribution (Dupuis et al., 2019). While there is evidence for the existence of bots with uniform response distribution (Buchanan & Scofield, 2018), bots do not all have the same programming (Perkel, 2020). In addition, unlike Hong et al. (2020), we did not study content nonresponsivity in humans, which may have below 100% severity and follow a different process. Without knowing the correct fully-specified population model, detecting a broader spectrum of severity would require a calibration sample free of content nonresponsivity. It is unclear how such a sample could be produced, even with stratification interventions (Huang et al., 2012; Meade & Craig, 2012). We also assumed that human response behavior generalizes from calibration sample to target sample. Depending on how the calibration humans are policed (DeSimone & Harms, 2018; Huang et al., 2012; Meade & Craig, 2012), this generalizability may be questioned. For instance, university samples may be different from online-crowdsourced samples (DeSimone & Harms, 2018; Henrich et al., 2010).
As a future variant of SCUMP, the use of model-based person fit statistics as an NRI may allow portability to other samples that vary in the mean and/or variance of their latent trait distribution. However, the use of person fit usually requires a correctly specified item response model (Meijer & Tendeiro, 2012), that parameter invariance holds, a large human calibration sample (
Supplemental Material
sj-pdf-1-epm-10.1177_00131644221104220 – Supplemental material for Supervised Classes, Unsupervised Mixing Proportions: Detection of Bots in a Likert-Type Questionnaire
Supplemental material, sj-pdf-1-epm-10.1177_00131644221104220 for Supervised Classes, Unsupervised Mixing Proportions: Detection of Bots in a Likert-Type Questionnaire by Michael John Ilagan and Carl F. Falk in Educational and Psychological Measurement
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: We acknowledge the support of the Natural Science and Engineering Research Council of Canada (NSERC) (funding reference number RGPIN-2018-05357 and DGECR-2018-00083). Cette recherche a été financée par le Conseil de recherches en sciences naturelles et en génie du Canada (CRSNG) [numéro de reference RGPIN-2018-05357 et DGECR-2018-00083].
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.