
Abstract
Large-scale assessments often use a computer adaptive test (CAT) for selection of items and for scoring respondents. Such tests often assume a parametric form for the relationship between item responses and the underlying construct. Although semi- and nonparametric response functions could be used, there is scant research on their performance in a CAT. In this work, we compare parametric response functions versus those estimated using kernel smoothing and a logistic function of a monotonic polynomial. Monotonic polynomial items can be used with traditional CAT item selection algorithms that use analytical derivatives. We compared these approaches in CAT simulations with a variety of item selection algorithms. Our simulations also varied the features of the calibration and item pool: sample size, the presence of missing data, and the percentage of nonstandard items. In general, the results support the use of semi- and nonparametric item response functions in a CAT.
Introduction
Despite Stout (2001) declaring that nonparametric item response theory (IRT) is viable for the scaling of educational and psychological tests, significant barriers remain to the use of these approaches. For example, large-scale assessments are more likely to use models such as the two-parameter logistic (2PL), three-parameter logistic (3PL; Birnbaum, 1968), or generalized partial credit model (Muraki, 1992) when modeling the relationship between a latent trait and item responses. These parametric models are often used despite the fact that nonparametric and flexible IRT approaches typically make fewer restrictive assumptions. One challenge to the use of more flexible modeling approaches is the desire to use estimated item response functions (IRFs) in a computer adaptive test (CAT).
The performance of flexibly estimated response functions when used in a CAT is largely unknown as many techniques are not easily tractable with existing testing programs. Classical CAT item selection algorithms, such as maximum Fisher information (MFI; Lord, 1980) or maximum weighted posterior information (MPWI; van der Linden, 1998) are still heavily used in operational CAT settings. These techniques typically require derivatives of the IRF with respect to the latent trait, which are not always readily available for flexibly estimated IRFs. Thus previous applications of CATs to nonparametric IRFs have used alternative item selection algorithms, as otherwise numerical derivatives may be unstable (Y.-P. Chang et al., 2019; Xu & Douglas, 2006).
A novel monotonic polynomial (MP) approach to IRF estimation could be more easily used with traditional item selection algorithms but has not yet been evaluated with a CAT. In brief, the MP approach consists of replacing the linear predictor of parametric IRT models with an MP (Falk & Cai, 2016a, 2016b; Feuerstahler, 2016; Liang, 2007; Liang & Browne, 2015). Although the approach technically has additional parameters and results in more flexibly estimated IRFs like those from nonparametric approaches, these parameters are not easily interpretable. Thus, the MP approach has been called “semiparametric” or “quasi-parametric” (Liang, 2007; Liang & Browne, 2015). In addition, the MP approach has some distinct practical advantages that we believe permit its further study. In particular, the MP approach can allow calibration of IRFs by maximizing the marginal likelihood or posterior using the expectation-maximization algorithm (EM-MML; Bock & Aitkin, 1981; Mislevy, 1986). This feature is distinct from kernel smoothing (KS; Ramsay, 1991) and smoothed isotonic regression (Lee, 2002, 2007), in which estimation was developed by relying on a proxy of the latent trait that is computed from observed scores. The MP approach is therefore more readily usable in settings where a planned missing data design is used for field testing (i.e., there are missing item responses; Falk, 2019, 2020), in multiple group settings (Falk & Cai, 2016a), and for linking (Feuerstahler, 2019). The MP approach can also be used in conjunction with parametrically modeled items on the same test, which may facilitate a more seamless integration into operational settings. However, simulations studies have also shown that the MP approach is most suitable for large-scale testing as good estimation typically requires larger sample sizes and many items.
Little prior research has studied the performance of flexible or nonparametric IRFs with a CAT. Xu and Douglas (2006) developed two item selection algorithms for the KS approach based on Kullback–Leibler (K-L; H.-H. Chang & Ying, 1996) information and Shannon entropy (Shannon, 1948). These item selection algorithms avoid the need to compute derivatives of the IRF in order to perform item selection. These authors evaluated the item selection algorithms with a fixed 50-item CAT. Other details of simulations included a 500-item test bank (with true IRFs from a 2PL) calibrated using KS with 1,000 subjects’ complete responses. Although the item selection algorithms with KS were found to perform well, the scope of simulations was limited. In particular, KS with both item selection algorithms was compared only with a “random” item selection algorithm and comparisons of this approach with traditional IRT models (2PL, 3PL, etc.) was not made. Furthermore, it is unlikely that calibration sample students would be able to complete 500 items each. In later research, Y.-P. Chang et al. (2019) used similar item selection algorithms to evaluate the performance of a nonparametric technique with a cognitive diagnosis model. They found that a nonparametric approach performed better than parametrically estimated IRFs, yet the focus of their study was on smaller sample educational testing contexts.
We therefore have little knowledge of the performance of nonparametric or flexible IRF estimation techniques versus parametric techniques in a CAT under conditions that may be typical of a large-scale test, and no prior research evaluating MP-based models in a CAT. On the one hand, simulations do suggest that flexible IRF estimation techniques such as the MP can improve recovery of the true IRFs, which in turn often leads to better recovery of latent traits (e.g., Falk & Cai, 2016a; Feuerstahler, 2016). However, these previous studies have typically only studied the case where calibration and latent trait estimation is performed on the same sample, and all items on the test are used for all respondents. Use of one calibration sample followed by a CAT using a separate sample is perhaps more similar to cross-validation of the estimated IRFs, and we may not be able to easily extrapolate based on the results of limited previous simulations.
In this article, we present a simulation study that compares the performance of the MP approach, KS, and 2PL in a CAT. We begin by describing each IRF estimation technique, followed by item selection algorithms. Then, we present the method and results of a Monte Carlo simulation study. We finally make concluding remarks.
Method
Studied Item Response Function Estimation Techniques
For the purpose of notation for calibration, consider
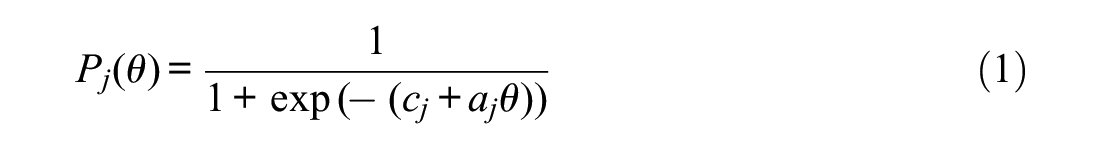
where
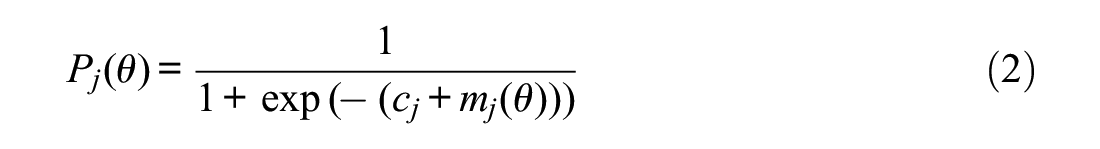
Here, the MP is a function of
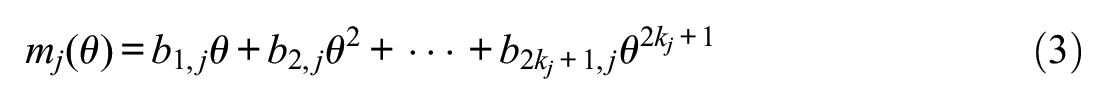
where
KS (Ramsay, 1991) is one of the most popular nonparametric techniques for IRF estimation, possibly due to its availability in programs such as TESTGRAF (Ramsay, 2000) and now in KernSmoothIRT (Mazza et al., 2014). In the context of dichotomously scored items, KS estimated IRFs at any given point along

where
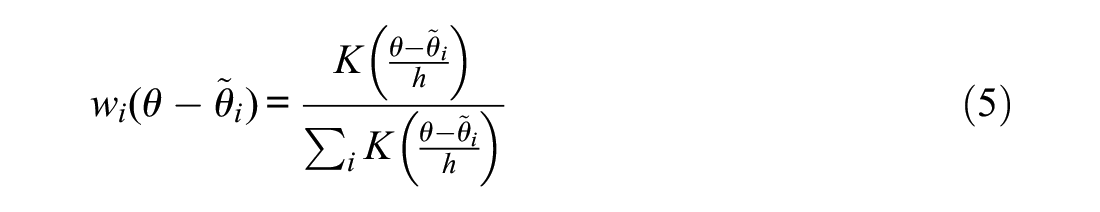
where
Studied Item Selection Algorithms
In the present article, we consider a fixed-length, item-by-item CAT with
To briefly cover the logic behind MFI (Lord, 1980) and MPWI (van der Linden, 1998), suppose that the true latent trait score for examinee

where
Due in part to instability in
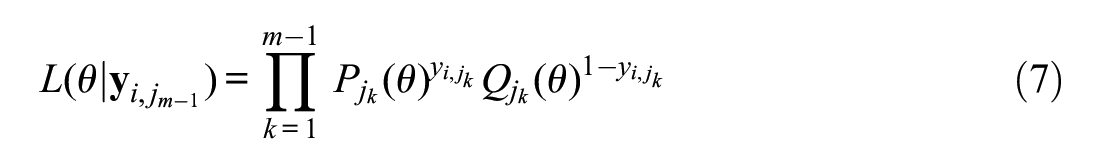
be the likelihood for examinee
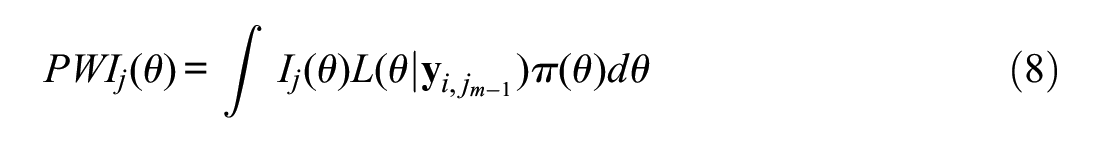
where the integral may be computed using numerical methods (e.g., rectangular quadrature). MPWI then proceeds at any given iteration by computing
Finally, K-L information (H.-H. Chang & Ying, 1996) resembles the likelihood ratio between the unknown but true value
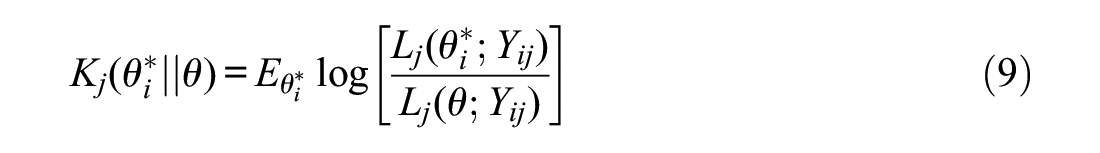
with the expectation over possible responses for the item (values for the random variable
While MFI and MPWI computations for each item rely on some estimate or posterior for
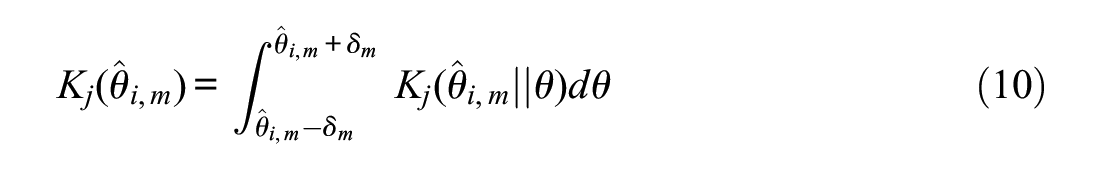
with a typical choice for
Note that computation of Equation (10) does not require any derivative computations, only the ability to evaluate
Study Design and Simulation Details
For clarity, we separate the study design details into two sections. First, we describe how calibration data were simulated and how models were estimated. On the basis of IRF estimation from calibration data, we describe how CAT simulations were then conducted.
Calibration and Data Generating Models
To attempt to construct realistic field testing conditions, we generated calibration sample data under two broad conditions: Complete data and missing data. Within each of these two conditions, we also varied sample size and the percentage of items that had an IRF that departed drastically from the traditional 2PL model (nonstandard items). This resulted in a total of eight different data generating conditions for the calibration samples.
For the complete data conditions, all respondents completed all items. The number of items was fixed at
For the missing data conditions, each respondent completed only a random subset of 40 items, which is similar to some recent large-scale educational tests (e.g., Smarter Balanced Assessment Consortium, 2017). Since the number of items under this condition was fixed at
All items were dichotomous, and standard items were generated using a normal cumulative distribution function (CDF) as the IRF,
For each data generating condition, a single calibration sample was generated, with a standard normal
To each calibration sample, several models were fit to obtain IRF estimates for later use in CAT simulations. The exact models depended on the data generating conditions. The KS approach using KernSmoothIRT (Mazza et al., 2014) with default settings was utilized for all complete data generating conditions. As noted, this method is possible but not ideal when there are missing item responses and so was used with only complete data conditions. To obtain
In addition, a 2PL model was fit to all data sets. Finally, an MP-based model was fit to each data set. For the MP models, the order of the polynomial was determined through use of simulated annealing as described by Falk (2019) with up to
Computer Adaptive Test Simulations
We first describe simulation conditions that were fixed across all CAT simulations, followed by manipulated factors. First,
Manipulated factors for CAT simulations involved (1) the source of IRF estimation, and (2) the item selection algorithm. The IRFs used in the CAT involved up to four conditions: those from the calibration samples (2PL, KS for complete data only, and the MP approach), as well as use of the true IRF. Use of the 2PL allowed us to gauge whether KS or MP have much of an advantage over a parametric model and use of the true IRF allows a benchmark for the best possible IRF that could be used. Three possible item selection algorithms were crossed with the available IRF estimation techniques (where possible): MFI and MPWI (for the 2PL and MP only) and K-L information. 2
Results
In what follows, we first briefly present results pertaining to the IRF recovery for the eight calibration samples. These results are presented to frame understanding of how different IRF estimation techniques may recover true IRFs, which may indirectly affect CAT performance. Following such results, we will turn to the primary results of interest regarding performance of each type of IRF and item selection method in CAT simulations. As the amount of data collected for the study is vast, this represents our best attempt at understanding the pattern of results.
Calibration Results
Recovery of IRFs was assessed using root integrated mean square error (RIMSE), which is computed as a squared discrepancy between the true,
where
Mean RIMSE for Item Banks Under Complete Data Collection Design.
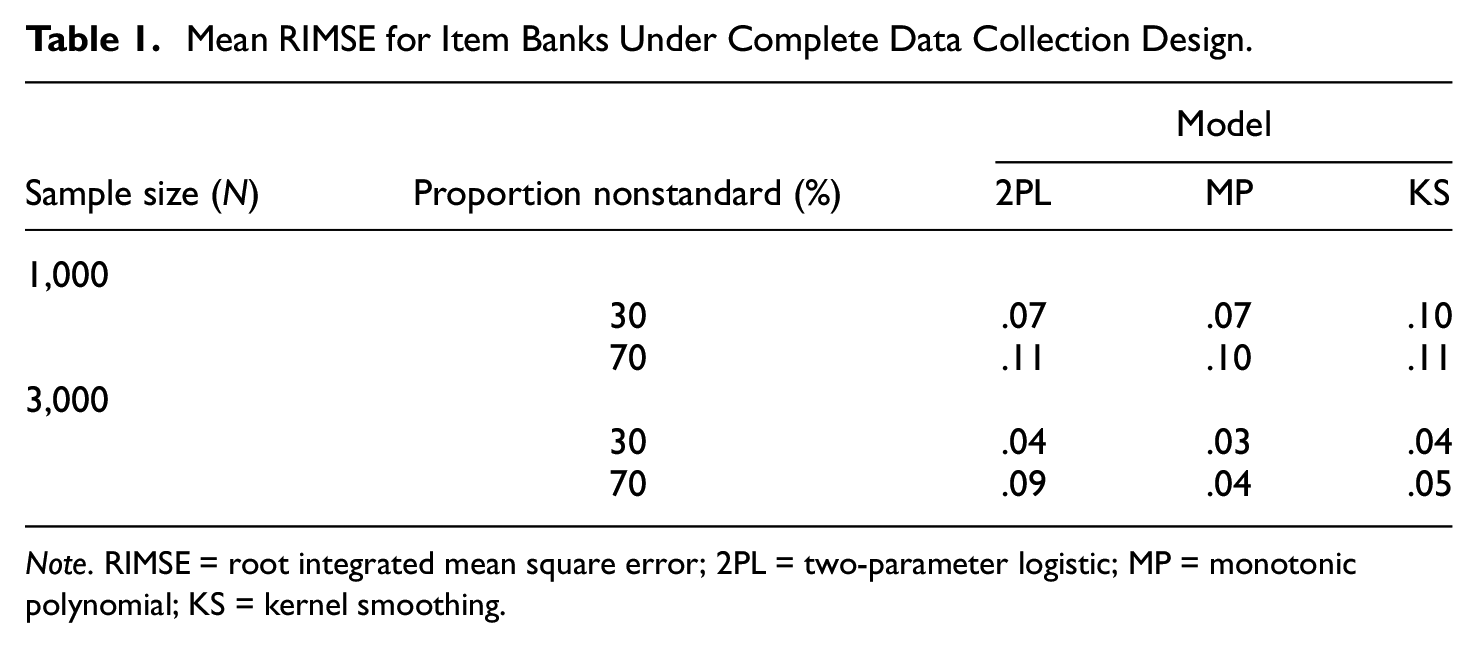
Note. RIMSE = root integrated mean square error; 2PL = two-parameter logistic; MP = monotonic polynomial; KS = kernel smoothing.
Mean RIMSE for Item Banks Under Missing Data Collection Design.
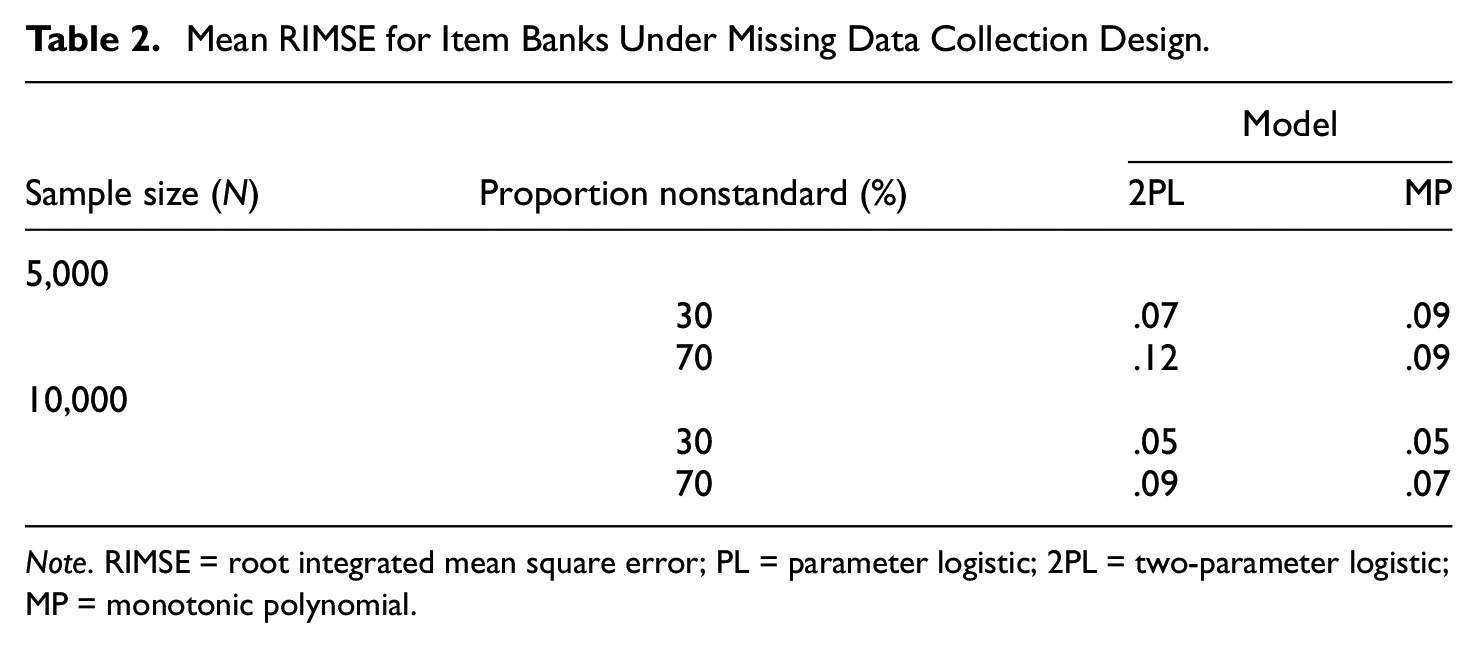
Note. RIMSE = root integrated mean square error; PL = parameter logistic; 2PL = two-parameter logistic; MP = monotonic polynomial.
Examining the distribution for RIMSE for standard and nonstandard items separately, it was apparent that gains with the MP were due mainly to better estimation for nonstandard items (Figure 1). The MP did not perform better than the 2PL for standard items, and sometimes performed slightly worse. The KS approach performed on par with MP for nonstandard items but clearly worse than the 2PL and MP approaches for standard items.
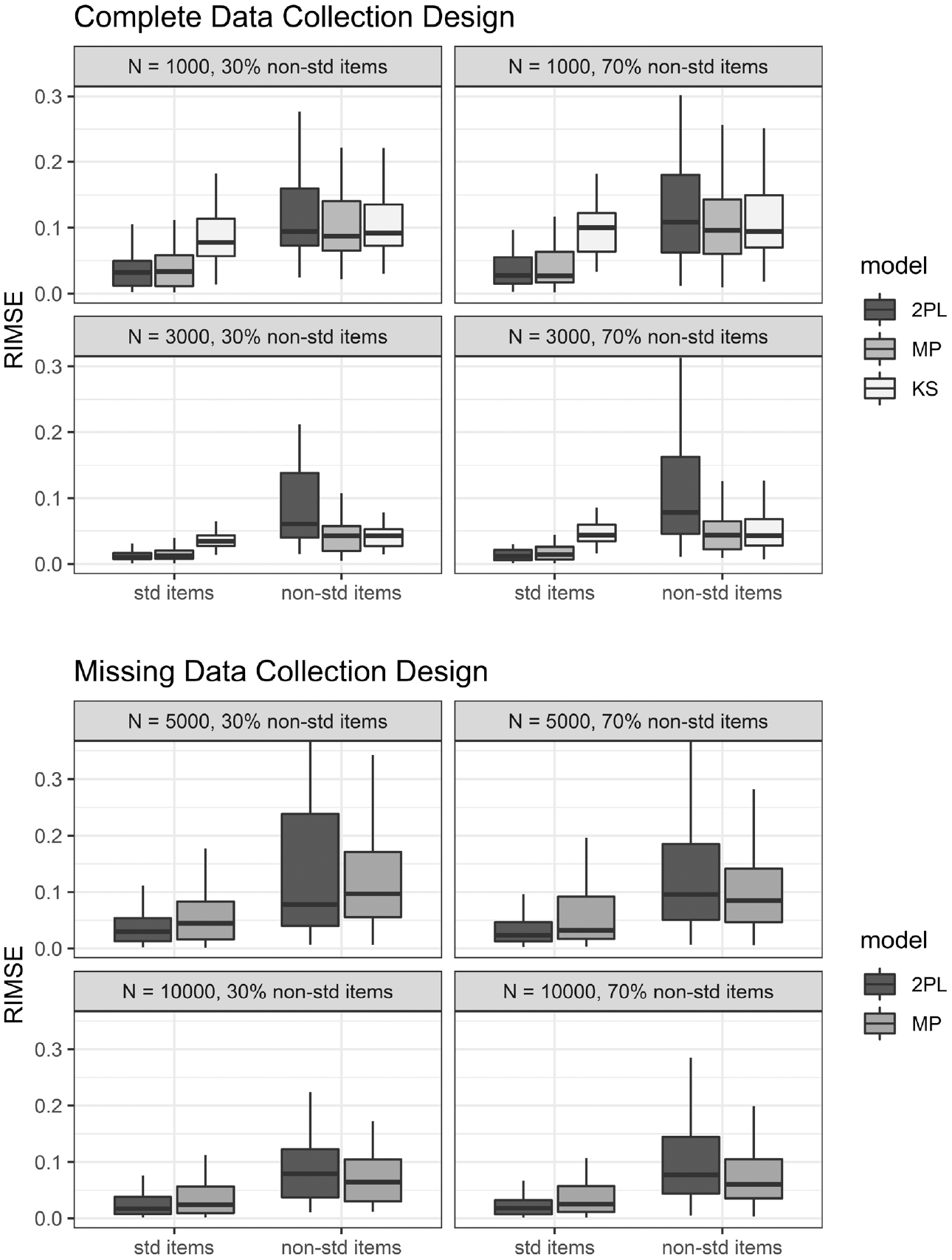
Recovery of response functions for standard (std) and nonstandard (nonstd) items for each calibration.
We also compared the recovery of item-level information among the estimated 2PL and MP items. As shown in the Supplemental Material, available online, MP and 2PL items provided equally accurate information, although nonstandard items tended to have worse information accuracy than standard items when fit to both models.
Computer Adaptive Test Simulations
The primary outcome of interest from CAT simulations was recovery of true latent trait scores. For this purpose, we examined root mean square error:
Average RMSE of Latent Trait Scores for CAT Simulations Under Complete Data Calibration, Standard Normal Latent Traits.
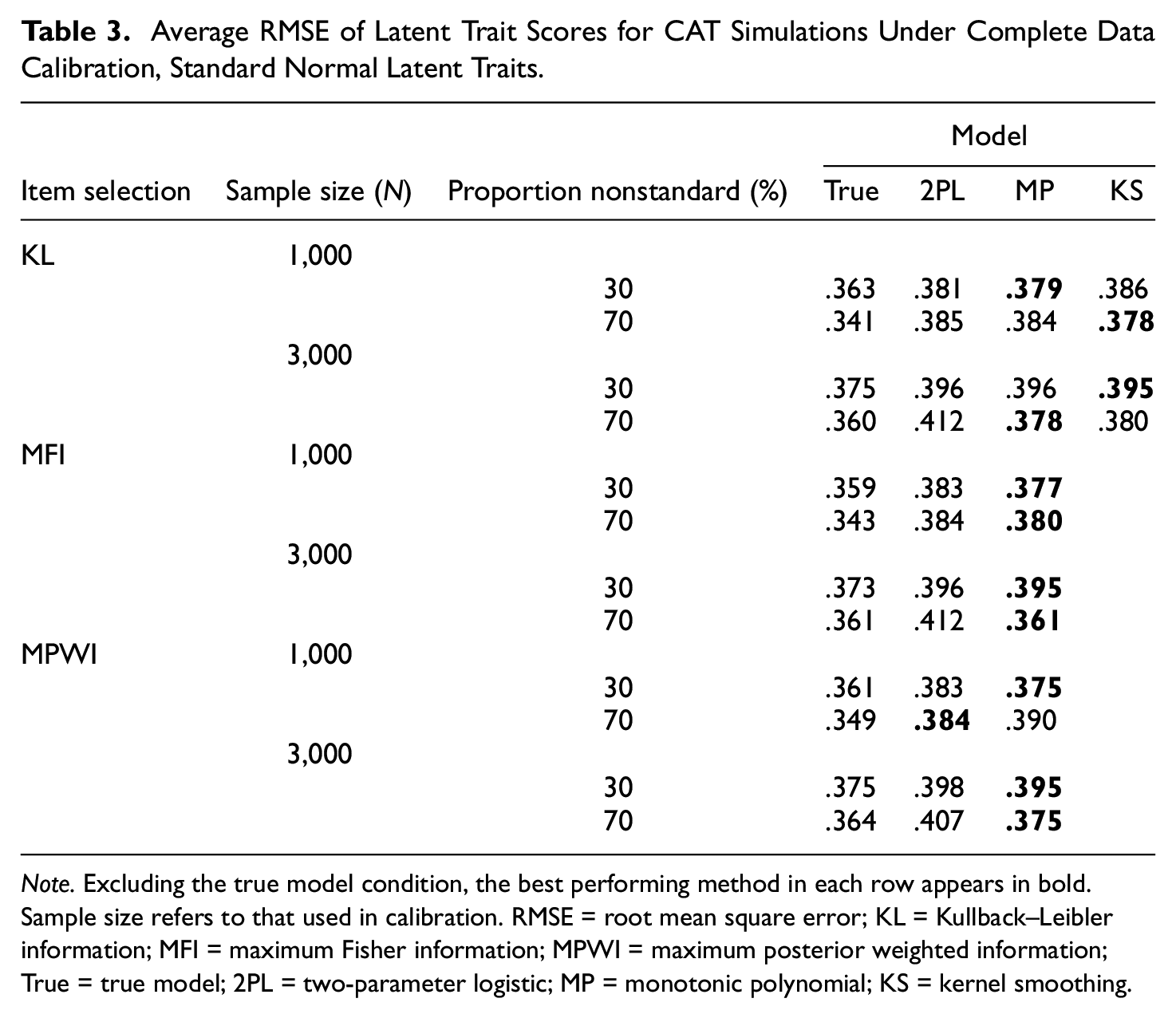
Note. Excluding the true model condition, the best performing method in each row appears in bold. Sample size refers to that used in calibration. RMSE = root mean square error; KL = Kullback–Leibler information; MFI = maximum Fisher information; MPWI = maximum posterior weighted information; True = true model; 2PL = two-parameter logistic; MP = monotonic polynomial; KS = kernel smoothing.
When the data calibration had missing data, the MP and 2PL often led to similar average RMSEs as each other (Table 4). MP always led to equal or lower average RMSEs with MFI item selection, but these patterns were more mixed with KL and MPWI item selection. As an example with KL and MPWI, with 70% nonstandard items and
Average RMSE of Latent Trait Scores for CAT Simulations Under Missing Data Calibration andStandard Normal Latent Traits.
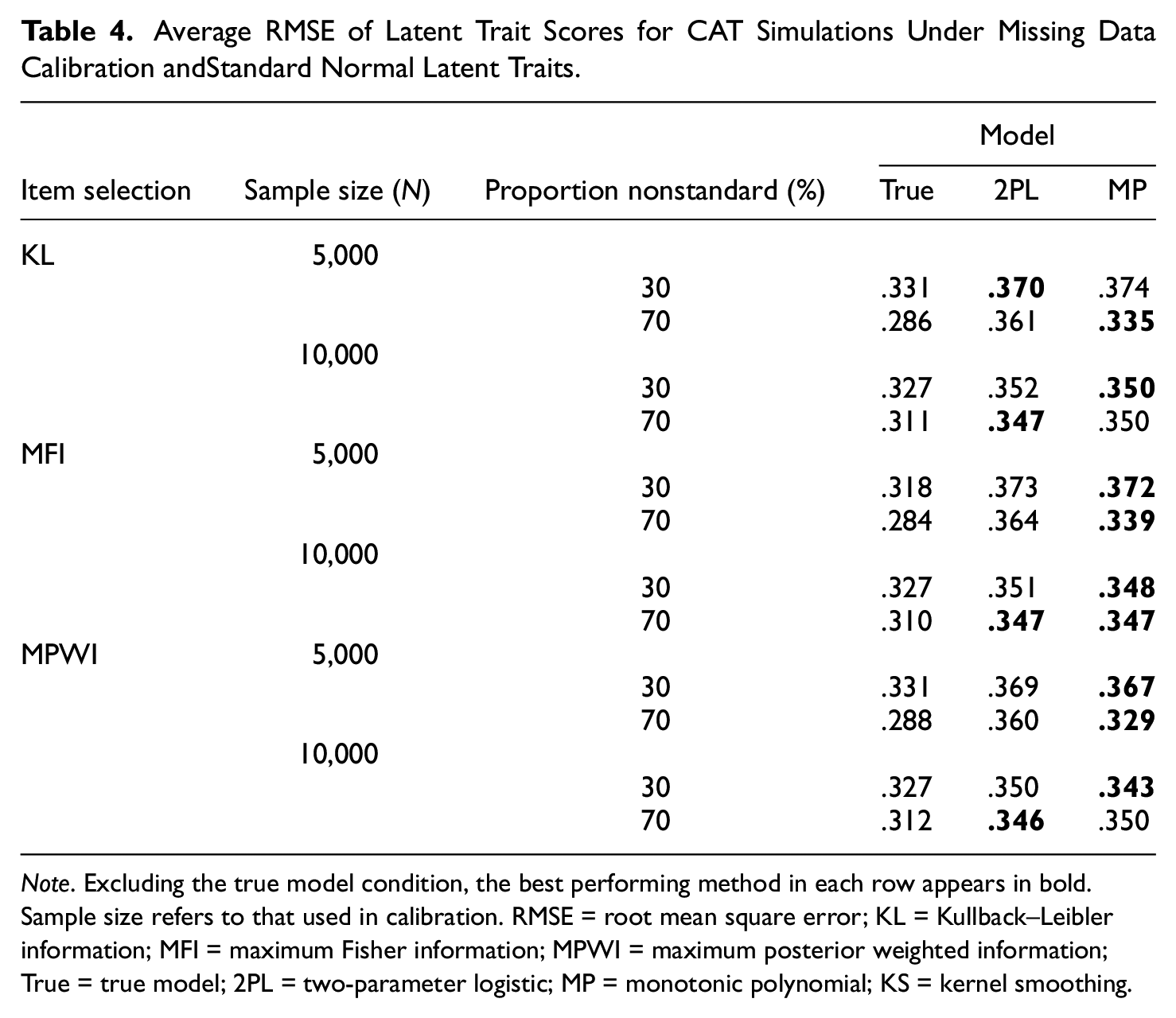
Note. Excluding the true model condition, the best performing method in each row appears in bold. Sample size refers to that used in calibration. RMSE = root mean square error; KL = Kullback–Leibler information; MFI = maximum Fisher information; MPWI = maximum posterior weighted information; True = true model; 2PL = two-parameter logistic; MP = monotonic polynomial; KS = kernel smoothing.
Turning to RMSE at discrete points along
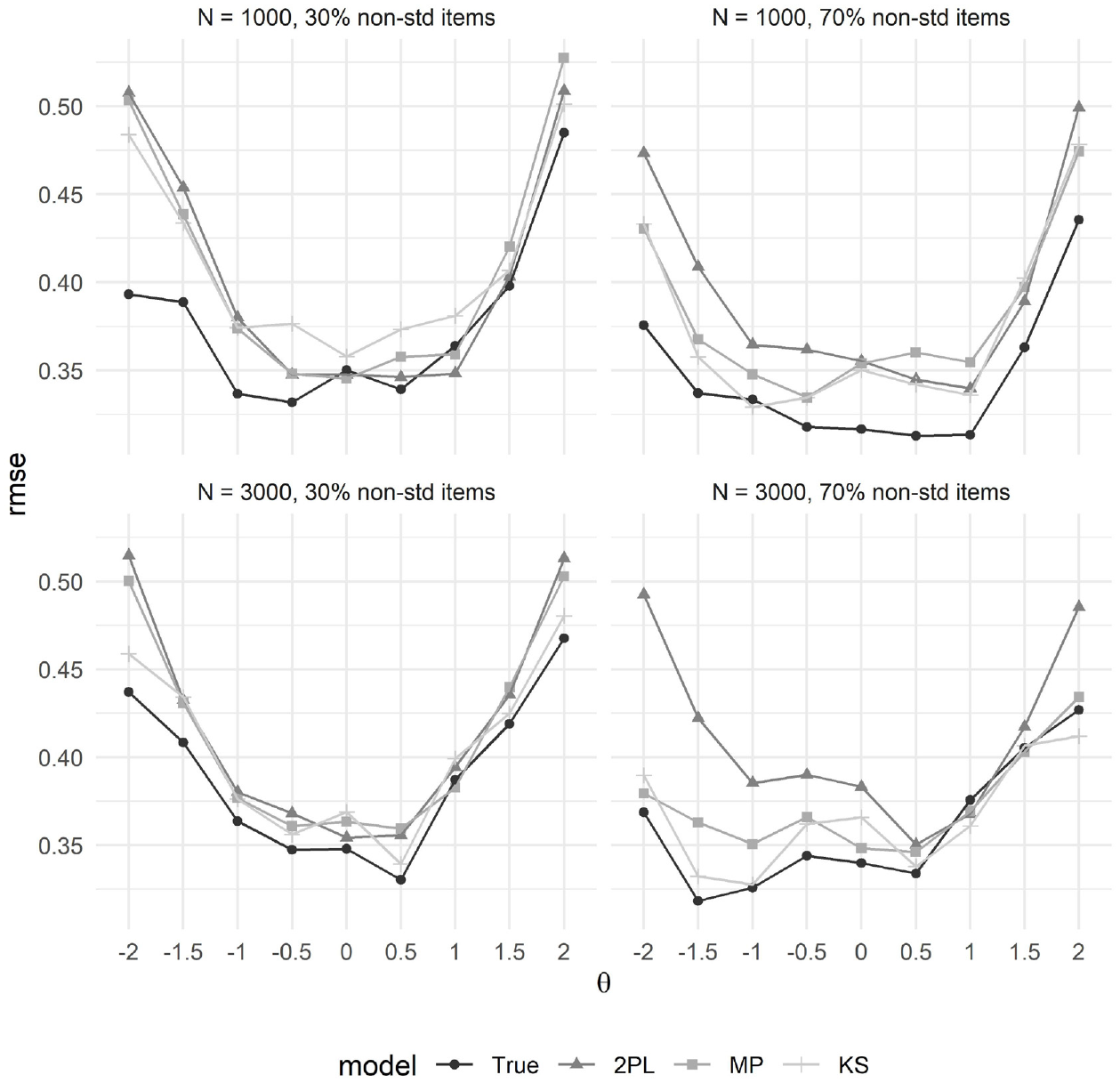
RMSE of latent trait scores at discrete points along
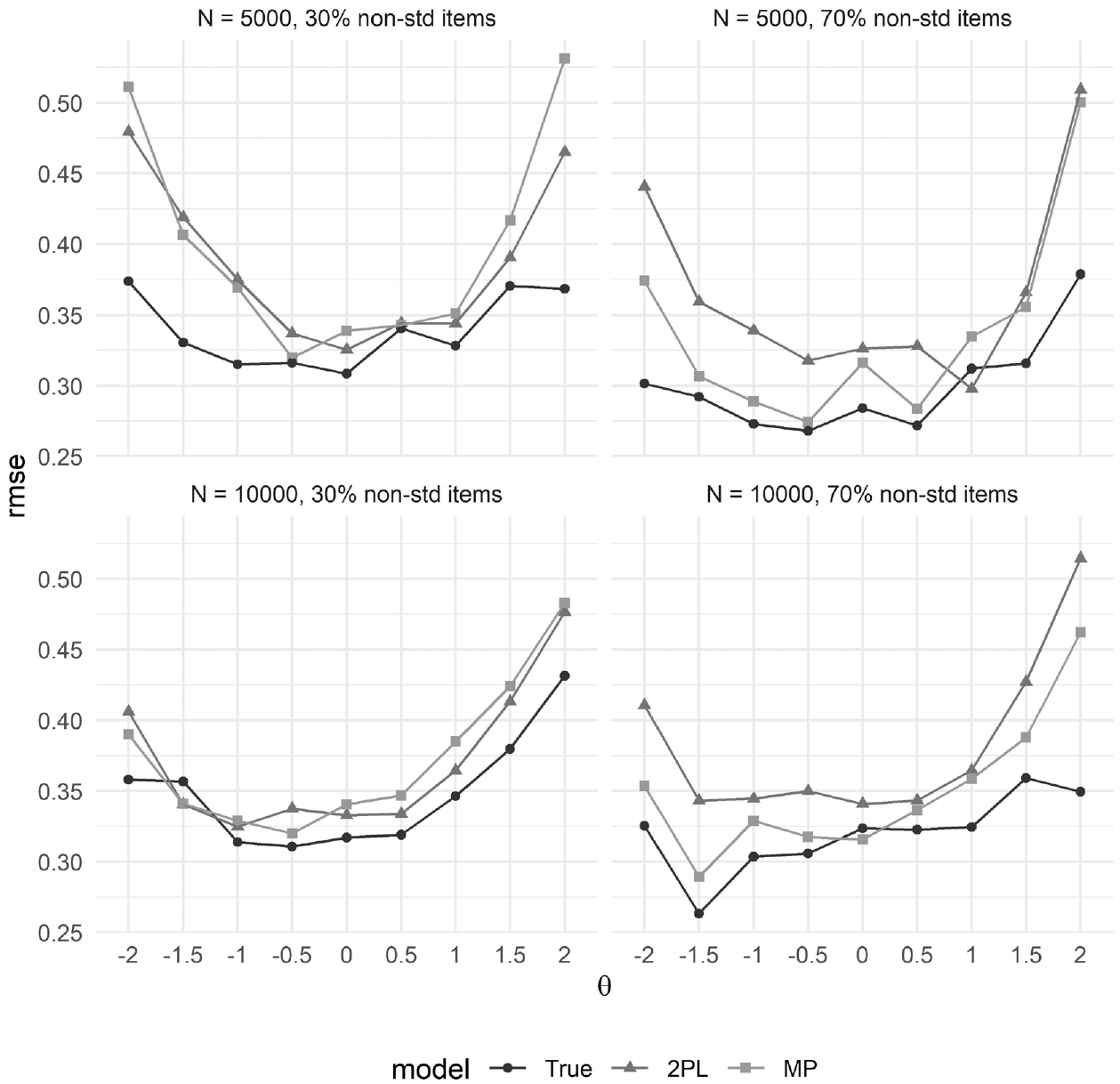
RMSE of latent trait scores at discrete points along
Discussion
The presented simulation study examined the performance of MP and KS IRF estimation techniques for use with a CAT, and compared them with a standard 2PL approach using item selection techniques based on KL information, MFI, and MPWI. Our results demonstrate that MP and KS approaches lead to comparable or better latent trait recovery than the 2PL.
Despite the promise of the MP and KS approaches, it is difficult to pinpoint exact conditions under which such an approach is universally preferable to standard approaches such as the 2PL. In retrospect, different IRFs can still result in very similar latent trait estimates (e.g., Yen, 1981). More substantial departures from the 2PL in the form of more extreme IRFs (including nonmonotonic) may need to be present in the item bank for the various methods to perform much more differently than one another. Our manipulated conditions mainly varied features of the calibration sample to mimic conditions that might be used for a large test (item banks of 100 or 200, and complete or planned missing data collection). While prior simulation studies have found that MP and KS can on average recover IRFs better than the 2PL when nonstandard items are in an item bank (e.g., Falk & Cai, 2016a; Feuerstahler, 2016), in any given calibration sample it may be that such gains do not always clearly materialize or do not then lead to subsequent gains in scoring or CAT performance. With some exceptions, the MP tended to perform better with larger calibration samples and with a larger proportion of nonstandard items. It is suggested that future research may focus on features of the CAT itself (test length, stopping criteria) that may affect performance, as well as on identifying the conditions for which flexible IRF estimation provides a clear advantage over the standard approaches. Our study utilized a realistic calibration phase prior to conducting CAT simulations. We thought this necessary for studying the relative performance of IRF estimation techniques in a CAT. However, this approach also makes it slightly difficult to know whether the relative performance observed in any given cell of the CAT simulation design was due in part to random sampling fluctuation from doing only a single calibration per cell. Although this issue could be addressed by doing multiple calibrations per cell and then multiple CAT simulations, such analyses demand a large amount of computational time and space. In addition, given the size of the item banks (100 and 200 items, depending on the condition) relative to the length of the CAT (25 items), we expected that doing only a single calibration would still be informative.
This study was also apparently the first to utilize a flexible IRF estimation technique (the MP) in conjunction with item selection algorithms that require analytical derivatives and are often used in operational settings (MFI and MPWI). We found little difference among item selection algorithms, 4 though we did not present any prior theory to favor any particular technique. This result holds promise for operational programs that may consider a nonparametric or semiparametric approach to IRF estimation but may prefer to use familiar, derivative-based item selection algorithms or would prefer to implement changes in stages to better ensure quality control.
In closing, we believe that the MP approach may be particularly well-suited to applications in CAT because it allows for both flexibly estimated IRFs and analytic derivatives. The initial results presented in this article indicate that the MP approach estimates latent traits as well or better than a standard approach when a significant proportion of nonstandard items exist and in the context of a planned missing data field test design.
Supplemental Material
sj-pdf-1-epm-10.1177_00131644211014261 – Supplemental material for On the Performance of Semi- and Nonparametric Item Response Functions in Computer Adaptive Tests
Supplemental material, sj-pdf-1-epm-10.1177_00131644211014261 for On the Performance of Semi- and Nonparametric Item Response Functions in Computer Adaptive Tests by Carl F. Falk and Leah M. Feuerstahler in Educational and Psychological Measurement
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for research, authorship, and/or publication of this article: We acknowledge the support of the Natural Science and Engineering Research Council of Canada (Funding Reference Number RGPIN-2018-05357 and DGECR-2018-00083).
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.