
Abstract
Recently, multiple systems estimation (MSE) has been applied to estimate the number of victims of human trafficking in different countries. The estimation procedure consists of a log-linear analysis of a contingency table of population registers and covariates. As the number of potential models increases exponentially with the number of registers and covariates, it is practically impossible to fit and compare all models. Therefore, the model search needs to be restricted to a small subset of all potential models. This paper addresses principles and criteria for model assessment and selection for MSE of human trafficking with special attention to sparsity which is typical to human trafficking data. The concepts are illustrated on data from Slovakia and Romania.
Introduction
In 2016 the United Nations adopted the Elimination of Human Trafficking/Forced Labor as Target 16.2 of its 2030 Agenda for Sustainable Development. In this context, the UN Statistical Commission’s Interagency and Expert Group on SDG Indicators (IAEG-SDGs) recommended to monitor the number of victims of human trafficking per 100,000 population, by sex, age, and form of exploitation. The institution responsible for collecting data on this indicator is the United Nations Office on Drugs and Crime (UNODC), and according to the UNODC, the indicator is composed of two parts: detected and undetected victims. The detected victims can be counted on a national level from activities of criminal justice systems, NGO’s and other service providing institutions, while the number of undetected victims has to be estimated. According to UNODC, the methodology for this should allow for estimating the victims’ sex, age, and form of exploitation.
The fact that these data are collected by a variety of institutions makes multiple systems estimation (MSE; e.g., Silverman, 2020) ideally suited for the estimation of the undetected number of victims. In its most simple form, the data for MSE consists of a cross-classification of two incomplete population registers A and B. This results in a two-by-two contingency table with the cells

Alternatively, the estimation can be performed with the log-linear model
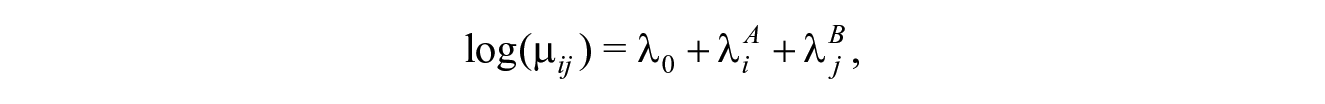
for
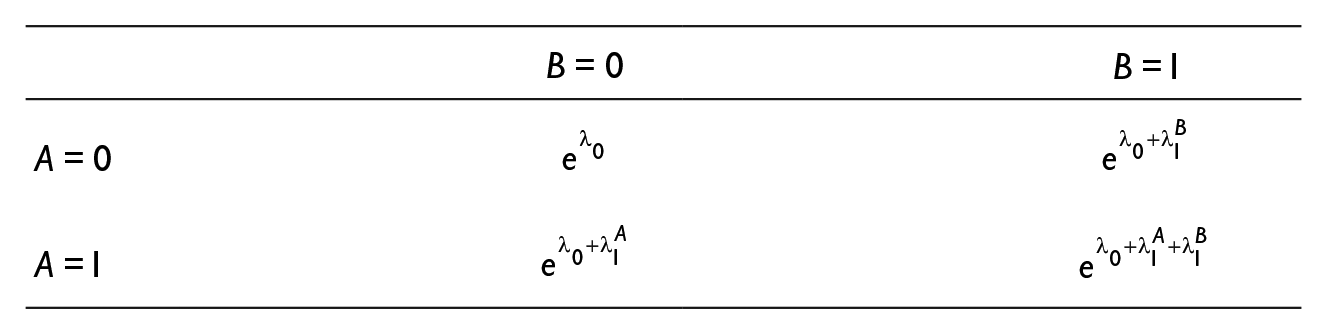
Given that in our example
If the inclusion odds of one register do not depend on the status on the other register, the registers are said to be mutually independent. The log-linear model that allows for dependence has an additional parameter
The mutual independence assumption of the lists can be relaxed when there are more than two lists. With a third list C it becomes possible to estimate pair-wise dependencies between the lists. This becomes possible because the number of persons not observed in two of the lists is observed for the persons observed in the third list. The notation for the log-linear model with three lists and all two-way interactions is
The assumption of homogeneous inclusion probabilities can also be relaxed by extending the model to include covariates. Covariates may play either a passive or an active role in the model (Van der Heijden et al., 2012). For example, suppose we have the two lists A and B, and that males have a different probability to be included in list A than females. The correct model would than be
Each unique combination of interactions is referred to as a model. Different models can provide very different estimates of the number of victims. For this reason, model selection is critical. This is essentially a balancing act between model fit (i.e., suitability to observed cell counts) and model complexity (measured by the number of interactions). As a model becomes more complex, the fit to observed counts improves, reducing bias in the population size estimate. However, at the same time, the chance of including spurious interactions increases which can lead to high variability in the estimates, observing large changes in the parameter estimates for small changes in the data set due to random fluctuations. Furthermore, including a large number of interactions in the model increases the likelihood of fitting models with non-estimable parameters, with very wide associated confidence intervals. This typically manifests itself in unrealistically large (exploding) estimates. Conversely, a too simple model does not fit the observed counts, providing estimates with low variability but with potentially high bias. The aim of model selection is to find parsimonious models that are neither too simple nor too complex, and thus trade-off between bias and variance (e.g., Hastie et al., 2009, Chapter 7).
Typically when performing model selection, associations are assessed using some measure of statistical significance, with only significant associations included in the model. One commonly used approach is to assess significance with an information criterion, such as the AIC and BIC, that penalize model complexity in order to prevent overfitting of the data (these criteria are discussed in more detail in section 2.2). Since different information criteria may result in different models (and hence different population estimates), the choice of a criterion is of crucial importance. Once the criterion is chosen, a strategy for model selection has to be defined. When the number of variables in the model is small, this procedure may simply consist of fitting all possible models, and choosing the one which performs best with respect to the chosen information criterion. For example, with two lists there is only one possible model, and with three lists there are seven possible models, and adding a single covariate increases this number to 28. However, when the number of variables further increases, it rapidly becomes impossible to fit all potential models. There are a large number of statistical methods for model selection including hypothesis testing; information criteria; and Bayesian methods, each aiming to balance model fit and parsimony. However estimating human-trafficking victims brings unique challenges to model selection for log-linear models (see Chan et al., 2019; Larsen & Durgana, 2017). Most notable of these challenges is data sparsity. The human trafficking data of the countries that have taken part in the UNODC monitoring project, the Netherlands (Cruyff et al., 2017; UNODC, 2017), Ireland (UNODC, 2018a), Serbia (UNODC, 2018b), Romania (UNODC, 2018c), and Slovakia (in press), are typically collected over a period of two or more years and include three or more lists, and three or more covariates. The numbers of observed victims are typically small in relation to the dimension of the contingency table, so the majority of the cells are sparsely filled or empty. In the case of the Netherlands, for example, the data were collected over a period of 6 years and included six lists and five dichotomous covariates (age, gender, form of exploitation, nationality, and year), yielding a contingency table with
Typically, the scope of models eligible for selection is restricted to models that only include pairwise associations between the variables. This means for example that with three lists A, B, and C and one covariate S, the model
The aim of this paper is to highlight the importance of model selection in estimating human-trafficking. The information criteria approach to model selection is adopted as an example, but the arguments also apply to other model selection methods. Information criteria provide a score for each model, balancing model fit and complexity, with the chosen model giving the smallest criterion. The datasets from Slovakia and Romania are considered, and it is shown how sparsity can affect model selection.
The remainder of the paper is organized as follows. Section 2 provides a technical description of log-linear models and model selection methods. In section 3, the results of applying information criteria to the Slovakia and Romania datasets are shown. The paper ends in section 4 with a discussion of future research directions.
Log-Linear Models and Model Selection for Estimating Human-Trafficking
Contingency tables and log-linear models
We provide a brief description of contingency tables and log-linear models (e.g., Fienberg, 1972) in the context of MSE. Suppose there are
The basic idea underlying MSE is to fit statistical models to the observed cell counts, to identify underlying patterns (associations or interactions between lists and/or covariates), and to use this information to estimate the total population size.
Let
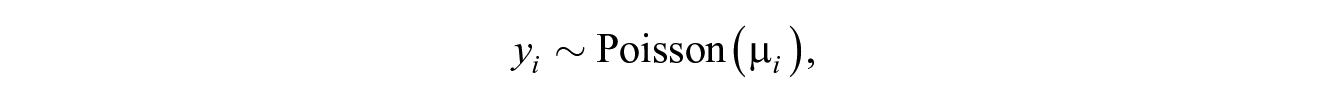
where the expected cell count is given by
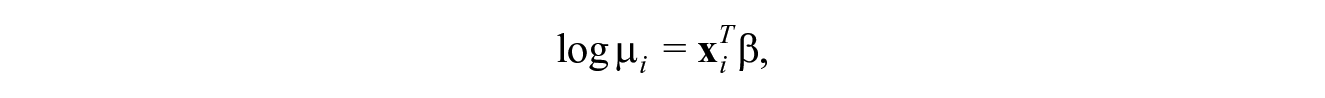
where
The total population size of victims of human trafficking can be estimated as follows. First, estimates, denoted by
However this approach assumes that the interactions present are known which is rarely the case in practice. Different models can provide significantly different estimates of the total population size and therefore model uncertainty should to be taken into account.
Model Selection
Initially, a set of models
One of the simplest approaches to model selection is hypothesis testing (e.g., Davison, 2003, section 4.5). Two nested models are compared: one with a given interaction and one without. If the inclusion of the interaction leads to a significant increase in likelihood then the model with the interaction is retained. The main disadvantage of hypothesis testing is that it can only compare two models. An alternative approach to model selection is that of information criteria (Burnham & Anderson, 2002). Information criteria assess models in terms of complexity (i.e., the number of parameters in the model) and how well they fit the observed cell counts. The likelihood provides a measure of the fit of a given model, with higher values indicating superior fit. Using the likelihood as the criterion for model selection, however, will result in the model including all potential interactions. This model will fit the data perfectly, but its predictions will be unreliable due to high variance; the parameter estimates may have large standard errors, and small changes in the data may produce large changes in the parameter estimates. By penalizing the number of parameters in the model the information criteria search for the most parsimonious model, that is, a model that fits the data adequately while keeping the variance of the model in check. Each model is given a score, and the model with the smallest score is then used to estimate the total population size. An information criterion (e.g., Davison, 2003, section 4.7) for a model can be written as follows
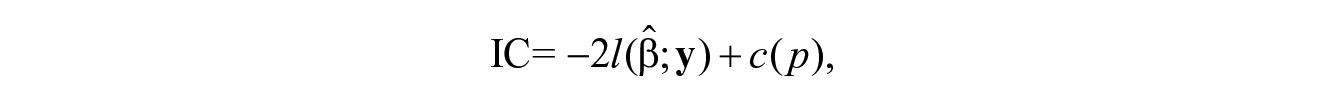
where
Estimation of the total population size is based on the model with the smallest information criterion. However even identifying this model can be problematic. The gold standard is to fit all models and select the model with the smallest criterion (e.g., Davison, 2003, section 8.7.3). However, even with the restricted set of models described above, there are typically a large number of models that can be fitted to a given contingency table. For example, suppose that attention is restricted to models with only pairwise interactions and that there are
Forward selection is given by completing the following steps.
0. Start by fitting the simplest model under consideration. This is the current model and calculate its IC.
1. Construct a proposal set of models by augmenting to the current model one interaction term at a time (while obeying effect hierarchy).
2. Calculate the IC of every model in the proposal set.
3. If the IC for the current model is less than the smallest IC from the proposal set, then stop, the current model is the final chosen model. Else, set the current model to be the model with the smallest IC from the proposal set and return to step 1.
The model chosen as the starting model in step 0 is usually the model with all main effects but no interactions.
Backward selection is similar but starts in step 0 with the most complex model under consideration and step 1 is replaced by the following step.
Construct a proposal set of models by removing from the current model one interaction term at a time (while obeying effect hierarchy).
Beyond the computational difficulties of finding the model that minimizes the chosen information criterion, there do exist other disadvantages. The theoretical basis of both AIC and BIC are based on a number of assumptions and approximations whose validity may be questionable for sparse data. Additionally, the estimate of the population size is based on the final chosen model. However there may be many models with near identical information criteria and these models may give significantly different estimates.
Alternatively, a fully Bayesian approach can be taken (King & Brooks, 2001; Madigan & York, 1997). This uses Bayes’ theorem to construct a posterior distribution over models, that is, each model is assigned a probability of being the true model. These posterior model probabilities are not available in closed form but can be approximated using trans-dimensional Markov chain Monte Carlo (MCMC) methods. The most common is the Reversible Jump MCMC approach, introduced by Green (1995). The Bayesian approach does not use one single model to estimate the total population size. Instead the estimate of the total population size is averaged over models with a model’s averaging weight equal to its posterior model probability. There do exist non-Bayesian model averaging techniques (Buckland et al., 1997) but we defer discussion until section 4.
Note that if the contingency table is sparse then there may be a large number of observed zero counts and the issue of parameter redundancy can arise. As described in section 1, this is a common occurrence in multiple systems estimation of human trafficking. In Chan et al. (2020), checks for parameter estimability based on a linear programming approach are used. Model selection is then conducted via a stepwise algorithm based on a predetermined threshold
Examples
In this section, we present an overview of model selection for Slovakia and Romania. To avoid confusion about the definitions of human trafficking that were used in these analyses, we start the overview for each with a brief description of the organizations that collected the data, and the definitions of human trafficking that were used by organizations. For a detailed discussion of the definitions of human trafficking, refer to Bales et al. (2020).
Slovakia
The data from Slovakia are collected by the Information Centre to Combat Trafficking in Human Beings and Crime Prevention of the Ministry of Justice, and cover the period 2016 to 2018. The data used for carrying out MSE were composed by linking the registers from the police, support organizations, the Programme for Support and Protection, and other organizations on a yearly basis. These registers are denoted by R1 to R3, respectively. Over this 3-year period a total number of 189 victims were identified. The original registers distinguish between the trafficking categories sexual exploitation, forced begging, forced labor, and forced marriage, which in turn are subdivided in the primary, secondary, and tertiary type of exploitation. For the analysis, the primary type of exploitation was recoded into sexual and non-sexual exploitation. Aside from Exploitation (E), the data also includes the covariates Sex (S), Age (A - minors vs. adults), and Year of observation (Y).
With three registers and the four covariates S, A, E, and Y, the contingency table has
Stepwise Model Selection Based on AIC and BIC for Slovakia.
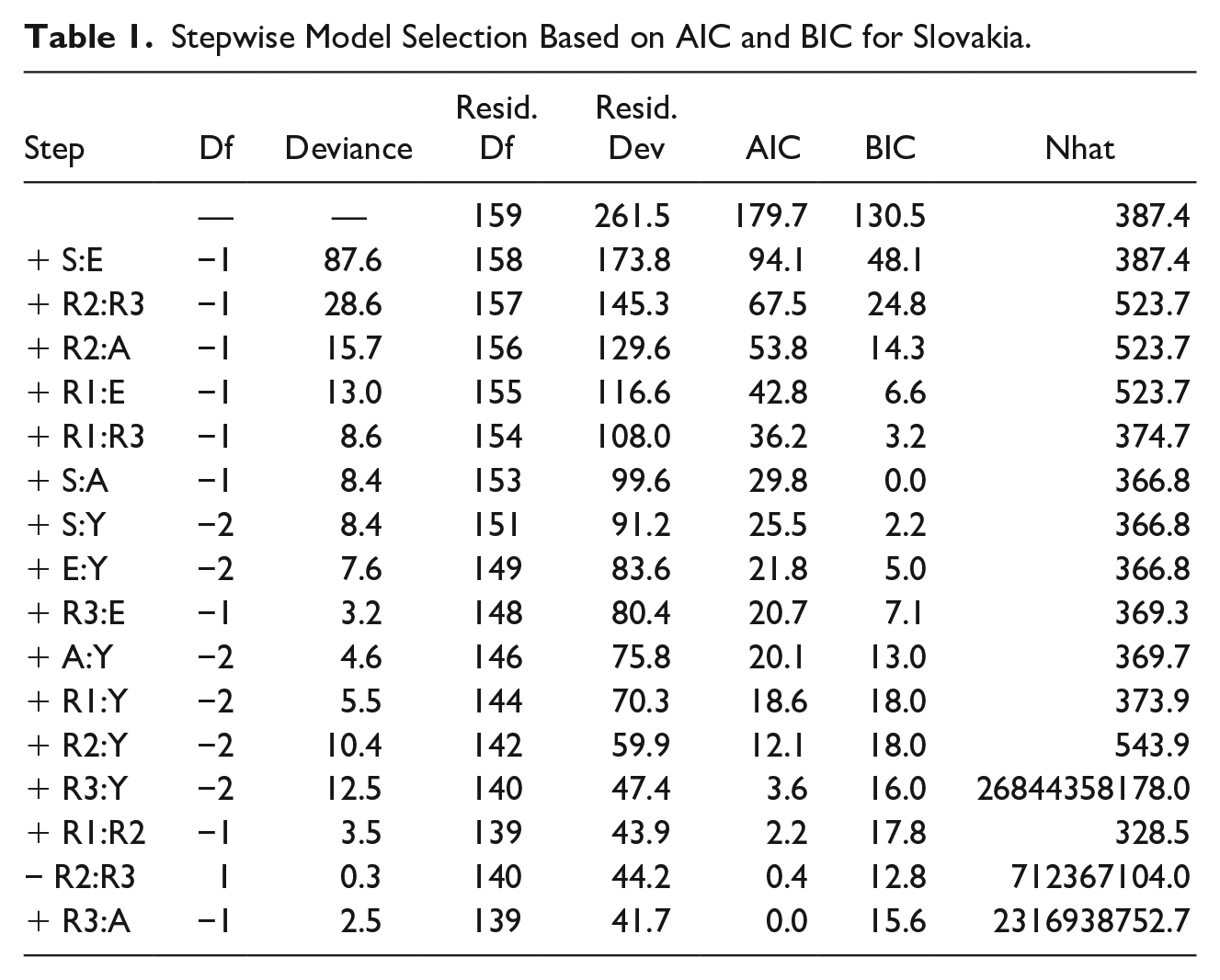
The best model as determined by BIC is
Romania
The data from Romania are maintained by the National Agency against Trafficking in Persons (ANITP) of the Ministry of the Interior, and include registers form the Police/NATP plus Border Police, IOM, NGOs, foreign authorities (mainly police forces) and other (mainly diplomatic missions). These are designated as R1 to R5. The data for the MSE were collected on a yearly basis over the years 2015 and 2016, and included a total of 1636 observations. The types of exploitation used for the MSE are sexual exploitation, beggary, and forced labor. Aside from type of Exploitation, the data included the covariates Sex, Age (minors vs. adults), Destination (D - transnational vs. domestic exploitation), and Year. With five registers and the five covariates S, A, D, E, and Y the contingency table consists of
Stepwise Model Selection Based on AIC and BIC for Romanian Data.
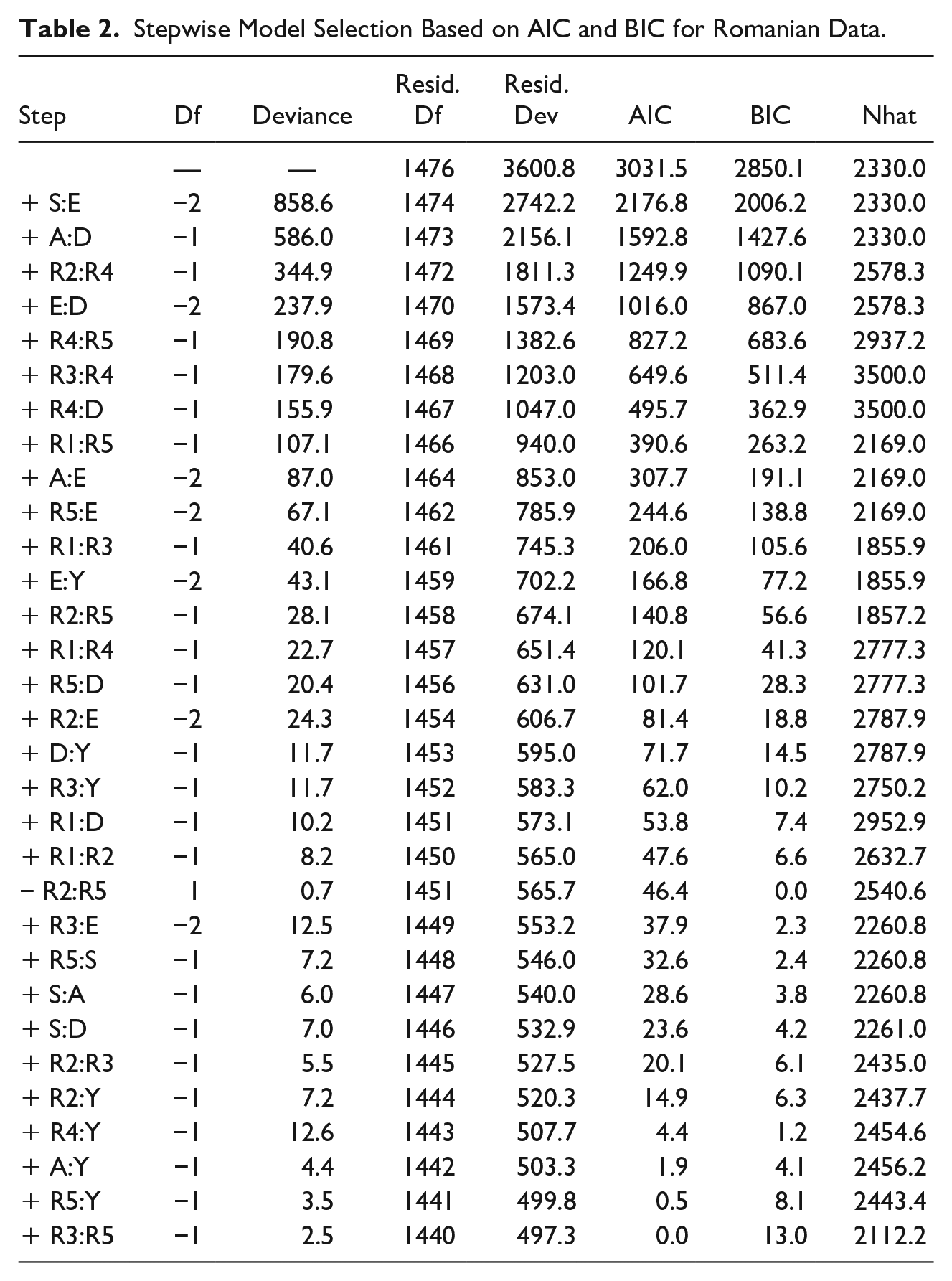
The model supported by BIC has
Discussion
This paper has investigated the issue of model selection for multiple systems estimation models using two commonly used information criteria. The motivation for such work is a result of different models resulting in substantially different estimates of population size, which is of course the primary parameter of interest. The paper has focused on the use of two information criteria; AIC and BIC. However there are many alternative methods of model selection which have not been considered in this paper, in addition to those discussed in the Introduction. For some applications it is possible to fit all models in a pre-specified model set, however it is sometimes necessary to take a practical exploration of model space, and one approach using information criteria has been described. Step-wise strategies using alternative test statistics have been considered in many fields. A step-up approach utilizing score tests has been applied in the related field of ecological capture-recapture models (McCrea & Morgan, 2011), and has the advantage that only the simpler model has to be fit to the data for the evaluation of the test statistic, thus avoiding the need to fit models which are not supported by the data. Disadvantages of such an approach however include the issue of multiple testing and the associated decision about significance levels and reliance on statistical significance has been heavily criticized in recent statistical articles (Wasserstein & Lazar, 2019). Further, the calculation of the expected information matrix, which is required for the evaluation of the score test statistic, is not always straightforward and approximations using the observed information matrix have been found to be flawed for some applications (Morgan et al., 2007).
An exploration of the model set in a classical paradigm has been proposed by Brooks et al., (2003), implementing a trans-dimensional simulated annealing approach. This is the classical counterpart to the Bayesian reversible jump MCMC approach (King et al., 2001) described in section 2.2. Generally however such approaches need tuning, and therefore do not offer a model selection solution which will work for all applications. Therefore this paper has focused on two approaches which can be easily implemented for all MSE applications. As mentioned earlier, it is possible to provide model-averaged estimates of the population size accounting for model-uncertainty. A decision on whether to model-average based on AIC or BIC is well-debated in the literature. Fletcher (2019) suggests that AIC weights should be better than BIC weights, as model averaging is about estimation and prediction and this is the goal of AIC. In contrast, BIC is focused on identifying the true model. For a fuller discussion of this, see Yang (2005). Some alternative criteria for model-averaging have been reviewed in Dormann et al. (2018) and a systematic review of the state of the art is given in Chapter 3 of Fletcher (2019).
This paper has shown that model assessment and selection play a crucial role in MSE of victims of human trafficking. It has also alluded to the alternative strategies that can be followed to arrive at a population size estimate. With the growing number of publications on MSE of human trafficking, —aside from the above mentioned UNODC studies there have also been studies in the UK (Bales et al., 2015), the US (Bales et al., 2020), and Australia (Lyneham et al., 2019)—our knowledge and understanding of the intricacies of human trafficking data will grow. From a methodological point of view, we envisage that future research will lead to a better understanding on how sparsity affects the estimability of model parameters for this type of data, and the prospect of modeling higher order interactions and more complex dependencies between the lists and covariates. All this will help us to optimize our strategies for model assessment and selection for MSE of human trafficking victims. This in turn will help national governments to formulate more substantiated policies on resource allocation for detection and prevention of human trafficking.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.