
Abstract
This article provides a meta-analysis of experimental research findings on the existence of bias in subjective grading of student work such as essay writing. Twenty-three analyses, from 20 studies, with a total of 1935 graders, met the inclusion criteria for the meta-analysis. All studies involved graders being exposed to a specific type of information about a student other than the student’s performance on a task. The hypothesized biasing characteristics included different race/ethnic backgrounds, education-related deficiencies, physical unattractiveness and poor quality of prior performance. The statistically significant overall between-groups effect size was g = 0.36. Moderator analyses showed no significant difference in effect size related to whether the work graded was from a primary school student or a university student. No one type of biasing characteristic showed a significantly higher effect size than other types. The results suggest that bias can occur in subjective grading when graders are aware of irrelevant information about the students.
Bias in grading can be either conscious (Malouff, 2008) or unconscious (Malouff, Stein, Bothma, Coulter, & Emmerton, 2014). The focus of the bias could be prior experience with a student (e.g. a halo effect), some physical characteristic such as sex, race, or physical attractiveness or some assigned status, such as being classified as gifted or learning disabled.
Because of the perceived possibility of bias in grading, Brennan (2008) and Warren Piper, McNulty, and O’Grady (1996), as well as a student union in the United Kingdom (Middlesex Students’ Union, n.d.), called for keeping students anonymous when possible during grading. Nobel Prize winner Daniel Kahneman (2011) made the same recommendation, based on his findings of bias in decision making.
In line with this recommendation, some universities require instructors to keep students anonymous when possible during grading, for instance, La Trobe University (2008) and the University of Melbourne (Brennan, 2008). Anonymity may be important during subjective grading, where the grader uses judgment, as in evaluating essays. It usually will not matter much during objective grading, for instance grading responses to multiple-choice and true-false items.
Academics who want to keep students anonymous during subjective grading have used various methods, including asking students to submit work with a student number, code number, or bar code rather than their name (Haeran & Cowling, 2010; Malouff, Emmerton, Schutte, & 2013) or just covering the students’ names during grading.
Some studies a few decades ago looked for evidence of apparent bias in actual grading undertaken in schools and universities. The usual non-experimental research method involved comparing scores assigned before and after blinding graders to some potentially biasing student characteristic, such as sex (e.g. Bradley, 1984; Dennis & Newstead, 1994). These findings are important because they involve grading by real teachers or assessors in the course of their work. Hence, the findings have good external validity. However, the lack of experimental control limits the internal validity of the findings. Factors other than bias could have affected the results. For instance, if women received higher scores in a year where students were kept anonymous, cohort differences could explain the results. Studies of actual grading have produced mixed evidence regarding the existence of bias (Belsey, 1988; Perry-Langdon, 1990).
Many studies have examined grading bias using an experimental method that typically involves giving randomly selected graders possibly biasing information about students, while other graders do not receive the information. For instance, Sprietsma (2013) randomly assigned participants to grade work labeled as completed by someone with a name typical of immigrants or typical of natives. These studies have value in their high internal validity, allowing one to rule out interpretations of the results other than unfair bias. An experimental research design is the gold-standard method of determining causation (Shadish & Ragsdale, 1996); other methods are seriously limited when it comes to determining causation (Pirog, Buffardi, Chrisinger, Singh, & Briney, 2009). The experimental method has a limitation in that the graders typically do not evaluate assigned work of their own students.
One way to quantify the effect size of possibly biasing information is to aggregate the different findings using meta-analysis, while looking for moderators relevant to the question of generalization and to other characteristics of the research sample and method. The present article provides such a meta-analysis of experimental studies of bias in grading. The research hypothesis was that, overall, studies would show evidence that information about student characteristics can unfairly affect the grading of their work. In addition, it was examined statistically whether specific characteristics of the studies, such as whether the grader used a rubric, were associated with effect size as this has been shown to affect results (Gerritson, 2013; Kayapınar, 2014).
Method
To be included in this meta-analysis studies had to (1) use the experimental method, (2) examine whether bias occurred in grading student academic work, and (3) provide adequate statistical information for meta-analysis, including number of participants for each of two conditions and outcome statistics that could be converted into a between-group effect size. Studies that reported using an “experimental” method were considered to have had done so even when the report did not explicitly state that graders were randomly assigned to conditions. Then explicit mention of random assignment as a moderator was evaluated.
The following databases were searched on 25 September 2015: PsychINFO, Google Scholar, ERIC, Informit A+ Education, Taylor and Francis, and Proquest Education using key terms bias with grading, marking, or assessment, as far back in each database as possible. Terms were searched for in the abstract or in the article itself.
When a title was relevant to the meta-analysis, one member of the research team read the abstract. If the abstract was relevant, that researcher read the article. In addition, the introduction of each relevant article was read to look for references to other relevant articles. For articles published in the past five years that fit the three aforementioned inclusion criteria, the lead author was contacted to ask for any unpublished findings relevant to the meta-analysis. Articles that were included were checked in Google Scholar to see if they had been cited. Any articles citing the included articles were then checked to see if they fitted the inclusion criteria. Where possible, searches included published articles, book chapters, dissertations, and unpublished studies. The aim was to include all relevant studies, published or not, to avoid the file-drawer effect (Rosenthal, 1979), in which published studies by themselves point to an unrealistically high effect size.
Figure 1 shows the search flowchart of most of the exclusion criteria used in this meta-analysis. In addition, several relevant studies were excluded because they lacked sufficient effect-size information for meta-analysis. Included in this group are studies by Seraydarian and Busse (1981) showing no biasing effect on essay grading depending on the popularity of the first name of the child. In very similar studies, Erwin and Calev (1984) found a significant effect and Harari and McDavid (1973) found mixed evidence of an effect. In a study with only 15 graders, Batten, Batey, Shafe, Gubby, and Birch (2013) found no significant evidence of information about university students’ prior performance biasing grading of their essays. Likewise, Chase (1986) found no evidence of knowledge of prior performance affecting grading of the essays of primary school students. In a study with real graders of the work of high school students, Baird (1998) found no significant evidence of bias related to student sex.
Flowchart of search for relevant studies.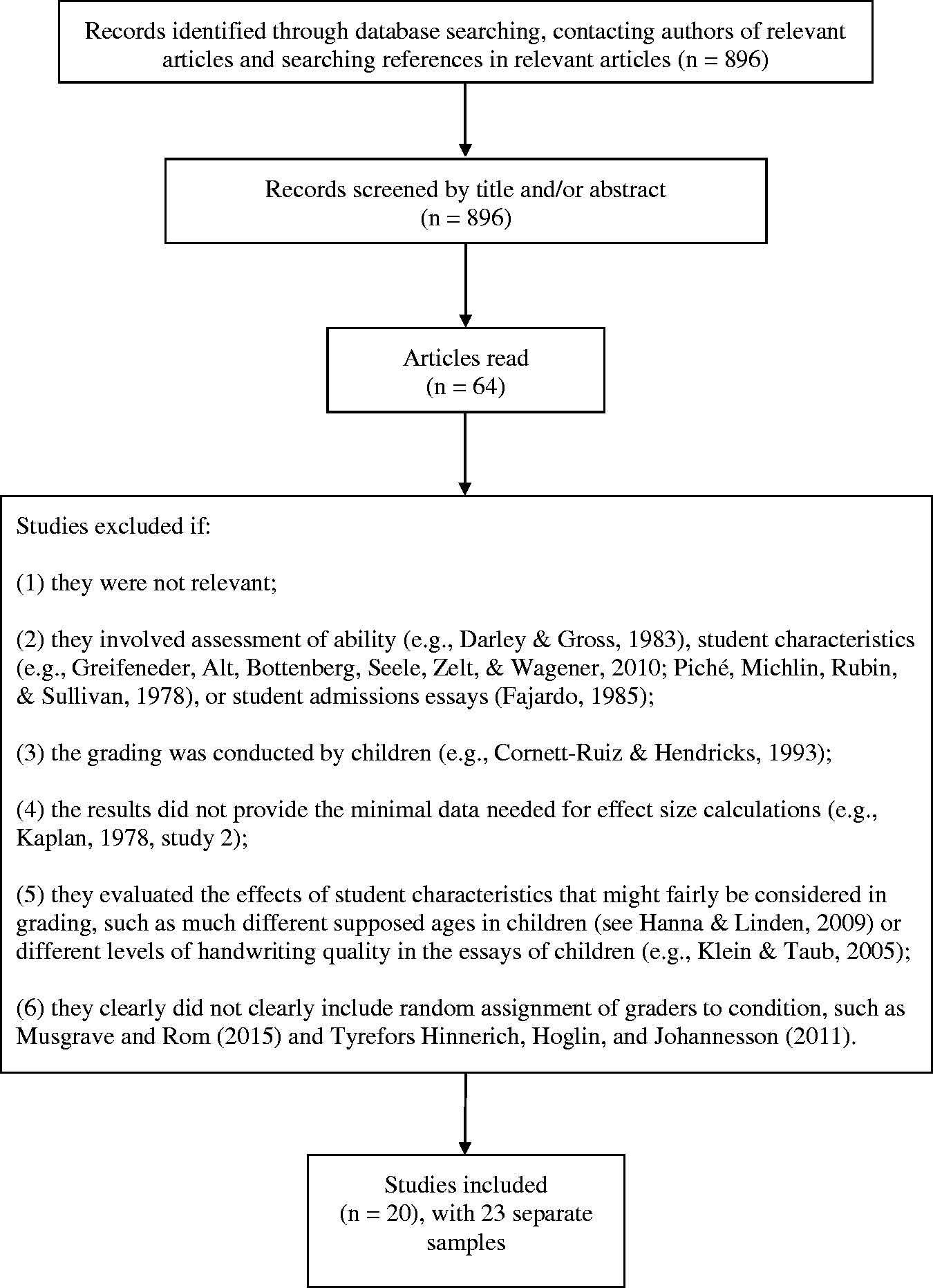
These exclusions reduced the original pool of 896 retrieved records to 20 articles and 23 separate analyses that were included in the meta-analysis. Three of the 20 articles had multiple samples, each with an experimental group and control group, and no overlapping participants. All 23 samples were used in the meta-analysis.
Several moderators were examined by coding the data on (1) whether the study article explicitly stated use of random assignment or merely described the between-group research design as experimental, (2) whether the grader was experienced in grading (e.g. an actual teacher), (3) the type of students (primary school or university), (4) whether the grader used a grading rubric or not, and (5) specific type of bias (e.g. sex). These moderators were selected because they might influence outcome or generalizability of results and because they could be coded as they were reported in many of the included studies. Two of these moderators might reasonably be expected to reduce bias: experienced graders and using a grading rubric. The other three moderators pertained to generalizability of the studies.
Bias was coded as positive if the results were in the direction hypothesized by the researchers. One researcher coded effect-size data and moderator data, and the other checked the coding. Inter-coder agreement was assessed by setting aside nine studies with a total of 10 samples for independent coding. Each analysis included eight coding decisions involving N, outcome results and status on six moderators. Three of the studies had multiple outcomes that required the coding of a total of an additional seven outcome results. For the 87 total independent coding decisions, there was agreement on 78 of 87 (90%). In cases of disagreement on any of the studies included in the meta-analysis, final decisions were made by consensus.
The current meta-analysis followed Lipsey and Wilson (2001) and employed the Comprehensive Meta-Analysis Program Version 2 (Borenstein, Hedges, Higgins, & Rothstein, 2005) to calculate the overall weighted effect size (Hedges’ g unbiased). This statistic enables a statistical comparison of different groups. The Q statistic assessed the significance of differences in effect-size between different subsets of studies. This statistic is similar to ANOVA. The homogeneity Q was used to assess to what extent effects sizes within a set of studies varied more than one would expect by chance.
Results
Characteristics of each study included in the meta-analysis.

Ed: educational; PPP: poor prior performance; SES: low socio-economic status; MR: mentally retarded; primary: supposed work of school children assessed; university: supposed work of university students assessed.
Stated: random assignments explicitly stated in article; unstated: study set up as an experiment, but no explicit statement of random assignment.
A random-numbers table was used to assign an n of 9 to one condition in this study and 10 to the other three conditions.
Classic fail-safe N, Orwin’s fail-safe analysis, and the trim and fill method assessed the impact on the overall effect size of possibly missing studies. The classic fail-safe N was 461, indicating that 461 studies would be needed with 0 effect size to reduce the overall effect size to nonsignificant. Orwin’s fail-safe analysis showed that 26 additional studies with a zero effect size would bring the combined effect size down to 0.15, which one might consider a trivial between-groups difference in that it represents a mean difference of only 15% of the pooled standard deviation. A trim-and-fill analysis, which aims to identify funnel plot asymmetry resulting from publication bias, indicated no evidence of publication bias, leaving the original effect size unchanged.
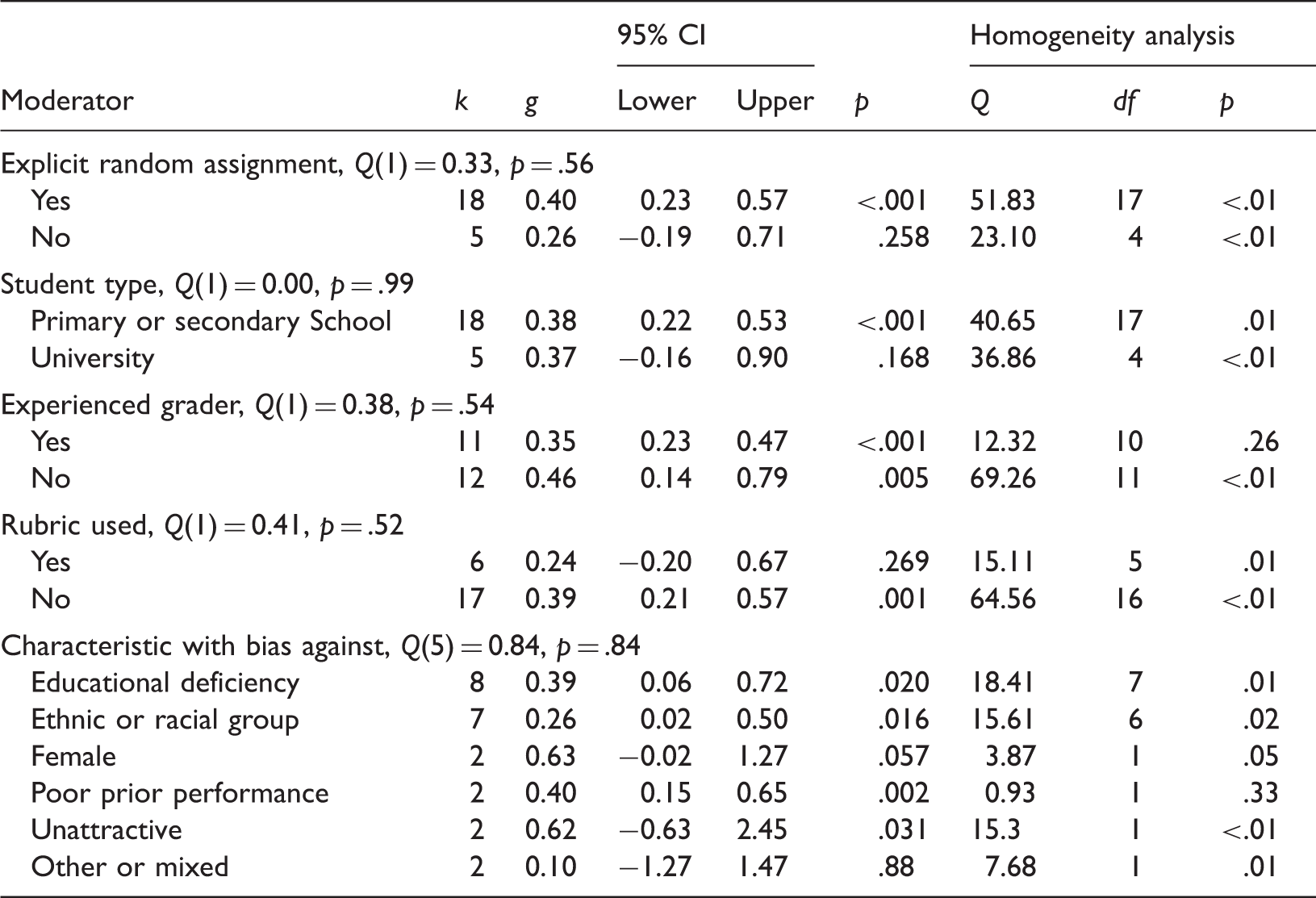
Moderator analysis.
Discussion
The overall meta-analytic effect of 0.36 indicated that there was 36% of a standard deviation in score differences between students in the hypothesized-bias condition and students not in that condition. This finding suggests that students who are members of a group against which there is a bias will tend to receive lower grades than students outside this group. However, the results were heterogeneous, with some studies showing trends in a direction opposite to that hypothesized, suggesting that “reverse” bias may take place. The overall results indicated that bias can occur and can have a substantial effect.
The types of bias with significant meta-analytic findings included bias against students who have negative educational labels, students who are members of specific ethnic or racial groups, students who have previously performed poorly, and less attractive students.
The findings do not offer evidence of why the biased grading occurs, but one could hypothesize that all the types of bias examined involve implicit expectancies about the quality of student performance on the present task. When the grading has subjective elements involving opinions as to quality based on characteristics external to the assessment piece, these expectancies may color the work of the student enough to affect assigned scores.
The findings reported in this article are stronger than the mixed findings of experimental studies that provided insufficient data to be included in this meta-analysis (Baird, 1998; Batten et al., 2013; Chase, 1986; Erwin & Calev, 1984; Harari & McDavid, 1973; Graham & Dwyer, 1987 [untrained graders]; Kehle, 1976 [physical attractiveness analyses]; Seraydarian & Busse, 1981). The meta-analytic findings reported here are also clearer than the results of non-experimental field studies (see e.g. Bradley, 1984; Dennis & Newstead, 1994).
The present findings are consistent with findings of unintended, implicit, or unconscious bias in various other realms of evaluating others outside academic work of students, such as with regard to halo effects in rating others (Cooper, 1981), and with regard to implicit prejudicial orientations toward members of various groups that historically have been the subject of discrimination (Greenwald & Banaji, 1995).
The main limitation of the present findings is that the studies did not examine grading of student work by the actual teachers of the students. Hence, it might be safest to view the results as suggestive of bias in actual grading.
The present results suggest that, when feasible, it may be worthwhile for graders of student work to keep themselves unaware of potentially biasing information about students, as recommended by a student union in the United Kingdom (Middlesex Students’ Union, n.d.) and some experts (see, e.g. Brennan, 2008; Kahneman, 2011, p. 83).
The heterogeneity of the study findings seems to indicate an occasional boomerang effect in the studies when the graders see through the experimental instructions, guess that the study is about grading bias, and consciously or unconsciously avoid bias or even exercise bias in the direction opposite of the bias that was hypothesized. However, it is unknown whether any of the graders did in fact see through the experimental design, and various factors such as sample differences could have produced the heterogeneity.
The moderator analyses showed no significant effects and only a few trends. Thus, a lower effect size seemed to be more related to grading with than without rubrics. Similarly, a higher effect size seemed to be more associated with inexperienced graders than with experienced graders while a higher effect size also tended to emerge in studies which explicitly stated that the experiment used a random assignment to conditions. Whether the students were in primary school or in university seemed unrelated to effect size, as did the specific type of bias studied. However, the moderator results are best regarded as suggestive only as the analyses had low power due to the limited number of relevant studies.
A potentially fruitful idea for further research might be the examination of trends in favor of less bias where graders use rubrics and are experienced in grading. Across studies where the graders used a rubric, the weighted effect size (0.24) was statistically significant but was also much lower than the effect size when graders did not use a rubric (0.39). The direct comparison of effect size with and without rubrics by Gerritson showed only a trivial level of bias for graders using a rubric (g = 0.05), compared to a substantial effect for graders not using a rubric (g = 0.36). It makes sense that using rubrics might decrease bias effects because using rubrics tends to remove some of the subjective elements in grading, resulting in increased reliability (Jonsson & Svingby, 2007).
Across all studies that used experienced graders, the weighted effect size (0.35) was notably lower than the effect size for inexperienced graders (0.46). In a study involving the training of graders, Graham and Dwyer (1987), reported significant bias for untrained graders. This study, which found “no significant” bias for trained graders, was reviewed as part of the meta-analysis. However, the nonsignificant result could not be included in the meta-analysis because the article lacked minimal information about effect size and direction.
Future research on bias might most profitably examine to what extent bias occurs in various circumstances with actual graders and to what extent use of rubrics or training reduces bias. These studies could help determine in what circumstances the present findings of bias generalize to actual grading.
The best research methods for future research would probably include using experimental research designs where the researcher refrains from making the research hypothesis too obvious, and, at the end of a study, asking the graders to guess the research hypothesis. Their responses might provide useful information regarding the effects of the experimental manipulation. The best reporting methods probably would include describing in the study report details of the randomization process, and providing an effect size, such as Hedges’ g, regardless of whether the result was statistically significant.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.