
Abstract
Objective:
The objective of this paper is to describe two methods of qualitative analysis – thematic analysis and content analysis – and to examine their use in a mental health context.
Method:
A description of the processes of thematic analysis and content analysis is provided. These processes are then illustrated by conducting two analyses of the same qualitative data. Transcripts of qualitative interviews are analysed using each method to illustrate these processes.
Results:
The illustration of the processes highlights the different outcomes from the same set of data.
Conclusion:
Thematic and content analyses are qualitative methods that serve different research purposes. Thematic analysis provides an interpretation of participants’ meanings, while content analysis is a direct representation of participants’ responses. These methods provide two ways of understanding meanings and experiences and provide important knowledge in a mental health context.
Keywords
Introduction
Qualitative research methods are oriented towards understanding meanings and experiences. They are therefore potentially very useful in the mental health context because they can provide new insights and knowledge in poorly understood and complex areas, such as understanding subjective experiences of mental disorders and their treatments (Fossey et al., 2002). While quantitative and statistical research methods enable deduction and prediction irrespective of context, qualitative research enables contextualised understandings of subjective experiences. This research involves the use and collection of a variety of empirical materials that describe routine and problematic moments and meanings in individuals’ lives. Qualitative researchers study things in their natural setting, attempting to make sense of or interpret phenomena in terms of the meanings people bring to them (Denzin and Lincoln, 2003: 5).
Thematic analysis (TA) and content analysis (CA) are methods that enable the researcher to capture the meanings within the data. They provide a strategy for organising and interpreting qualitative data to create a narrative understanding that brings together the commonalities and differences in participants’ descriptions of their subjective experiences. This narrative is developed from the identification of categories and themes within the data. As techniques of analysis, TA and CA draw on the skills that mental health clinicians utilise in their everyday practice in attempting to understand the complexities of what is happening for patients and translating the various components into a coherent description. As a research technique, this process is extended across multiple patients’ descriptions of their experiences in order to develop a broader understanding of the experience itself. Qualitative methods allow for the in-depth study of the dynamic and subtle interplay of factors at the individual level (Davidson et al., 2008).
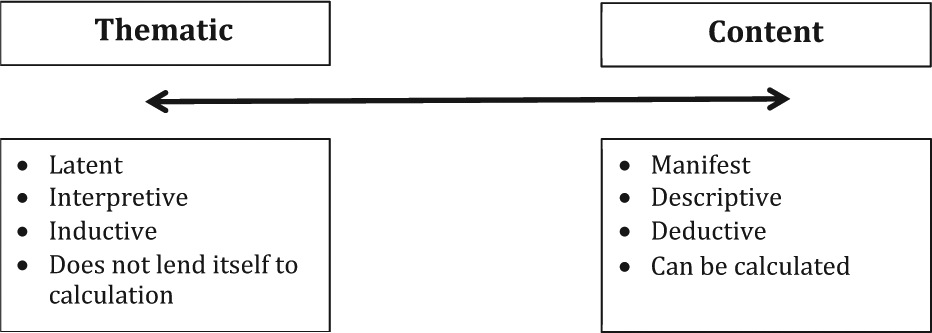
TA can be defined as a process of interpretation of qualitative data in order to find patterns of meaning across the data. TA methods are essentially independent of theory and epistemology and can be applied across a range of theoretical and epistemological approaches (Braun and Clarke, 2006). CA traverses quantitative and qualitative methodologies, but as a qualitative process it can be defined as a process of description of qualitative data in order to represent clusters of responses. CA involves establishing categories and identifying the frequency by which they occur (Joffe and Yardley, 2004). Category refers to the manifest content and theme moves from this to an understanding of the latent meaning.
This paper focuses on the process of using TA and CA as methods of analysis for qualitative data and applies this to a set of data. It describes the method of qualitative data collection common to both TA and CA, and then the differences between the two approaches will be highlighted by an illustration of their use with the same set of data. These previously unpublished data are drawn from transcribed interviews with participants who were asked on entry to a randomised controlled trial of a Bipolar Disorder Clinic study about their current self-management strategies. Ethical approval had been obtained for the collection and use of both qualitative and quantitative data, andall patients had provided signed consent for this. The intervention for the Bipolar Disorder Clinic study wasan 18-month combination of Interpersonal and Social Rhythm Therapy and medication management, and the control was treatment as usual. The interviews were conducted by a Research Nurse prior to randomisation into either arm of the study. In order to present an illustration of the processes of TA and CA, we focused specifically on how the participants described medication adherence in the context of self-management.
Qualitative data collection
Both TA and CA may use similar approaches for collecting data. While TA usually involves interviews withboth individual and focus group, CA can also utilise questionnaires.
The research question
The research question needs to reflect the principles of qualitative research with an emphasis on subjective experiences and the meanings participants attach to that experience. It needs to be an open question that does not pre-empt any findings or reflect the researcher’s beliefs about the object of inquiry. Both TA and CA can be used to answer the same research question (Vaismoradi et al., 2013). For example, the research objective in the data presented below was to understand what self-management strategies were currently used by participants. The question that informed the interview – what strategies do participants currently use for managing their Bipolar Disorder? – provides participants the opportunity to talk about the aspects of self-management useful for them. When the data (the transcripts from the first six interviews) were examined, it was evident that many participants wanted to talk about their use of medication. For this methodological paper, we focused our illustration on the following: what are the participants’ experiences and feelings about taking medication?
The selection of participants
The selection of participants is determined by the research question, and because the research does not value representativeness in the same way as quantitative research, it may take a purposive approach to sampling (people admitted to mental health services) or a more open sampling approach (invitations to participate sent to everyone on a support network database). While representativeness is not sought, it does add to the understanding of the object of inquiry if people from different groups are recruited, e.g., age, gender. The sample size can vary – it may not be practical to interview more than 40 participants, but it will be possible to send more than 40 participants’ questionnaires. In this illustration, we chose a convenience sample of the first six transcribed interviews from the 100 participants who were recruited into the Bipolar Disorder Clinic study. The participants whose interviews were selected for this methodological illustration were five female and one male; all had Bipolar Disorder I diagnosis and were aged from 38 to 58 years (mean age: 46.5 years).
The interview process
Data can be collected via a range of means, e.g., observation, textual constructions, open-ended questionnaires, but the most commonly used process is the interview. The interview needs to be conducted according to ethical approval policies in a private and quiet space. It needs to be semi-structured around a series of prompt points to ensure all interviews cover similar material. The prompt points are designed to elicit an in-depth description of the object of inquiry from the participant. These prompts should not be used to constrain the interview process but rather to provide a direction for the interview. An example of prompt points for gathering data for the research question ‘What strategies do participants currently use to manage their Bipolar Disorder?’:
Can you tell me about your treatment for Bipolar Disorder – when it was diagnosed; what you were told; what treatment you received over time?
How have you managed the symptoms of Bipolar Disorder?
A one-hour interview can generate approximately 30 pages of transcription, so the researcher needs to consider the practical and ethical issues related to managing that amount of data. There are a number of electronic qualitative data management systems, e.g., NVivo (QSR International, 2007), but many qualitative researchers have developed manual management systems that are equally effective.
The quality and depth of the data collected during interviews will frequently determine whether that data will be analysed using TA or CA. TA requires in-depth exploration of the research question and active exploration by the interviewer in order to identify themes; however, CA can be used across all levels of interview and written responses from questionnaires.
Qualitative data analysis
While the process of data collection is similar for both TA and CA, it is in the process of analysis that they differ.
TA
The process of TA has been described by Braun and Clarke (2006) as a theoretically flexible method that organises, describes and interprets qualitative data. The first step in TA involves becoming closely familiar with the data by reading and re-reading the interview transcripts. Following this close reading, initial codes are generated. This involves examining the data keeping the research question (not the interview prompts) at the forefront. For example, while reading the transcripts the researcher needs to focus on what is this participant saying in relation to what they think about medication? This involves noting down additional material that might not be directly related to the question but may provide a context to understanding the participant’s experiences.
The next step involves searching for themes. After generating codes, the researcher clusters them into ideas that are related. All the data relevant to each theme need to be extracted and a system developed to ensure all the relevant data are associated first with individual codes and then with the themes. Once themes have been identified, the next step involves defining and naming themes. The themes need to be refined in relation to the overall meaning that is captured, and definitions for each theme need to be generated. Once each theme is clearly defined and described, it needs to be illustrated with reference to the transcripts. This involves using extracts or quotes that capture the essence of the theme. While all transcript data are required in order to arrive at the themes, it is not necessary to use all the data to illustrate the theme. The quotes used need to be those that capture discrete aspects of the themes. Because a narrative of the meaning of the experience under investigation is being constructed in the presentation of findings, it is not necessary to use multiple quotes to illustrate single facets or aspects of the theme.
The presentation of each theme requires a process of writing and re-writing; it is through this process that the themes become developed to an in-depth level to enable to examine the relationships between themes and to draw together a narrative. The descriptive narrative supersedes extracts from the transcripts at this point in the analysis with the quotes used as illustrations. Because this is the beginning of the interpretative process, it is useful to remember that potentially any set of data can have multiple interpretations. It is up to the researcher to provide sufficient evidence to support their interpretation.
The final phase can be described as the process of synthesis. This involves exploring the relationship of the themes to each other and to the socio-cultural context within which they emerged. It is at this point that the presentation of findings shifts from description of the data to the meanings that have emerged and what Braun and Clarke (2006) describe as making an argument in relation to the research question. This analytic argument then needs to be taken further and situated within the existing literature on the topic. Examples of the types of questions that could drive the synthesis are as follows:
What do these findings mean (in relation to the research question)?
What contextual factors (health status, social, cultural, historical) have impacted the findings and their meaning?
Examples of TA conducted in a mental health context include an examination of nurses’ experiences of restraint (Bigwood and Crowe, 2008), patients’ experiences of receiving a diagnosis of Bipolar Disorder (Inder et al., 2010), the concept of job satisfaction in community mental health nursing (Wilson and Crowe, 2008) and mental health nurses’ understandings of clinical responsibility (Manuel and Crowe, 2014).
CA
CA is a process consisting of a number of steps. Some authors, e.g., Elo and Kyngas (2008), use a simple three-phase process of Preparation, Organising and Reporting. Preparation deals with the design, identifying units of analysis and representative sampling. The organisation phase deals with the analytic process of coding and identification of categories. The final phase is the reporting phase which is the presentation of the results with linking to the findings to previous knowledge.
Krippendorf (2013) has expanded the three-step framework to six steps which provides a useful, more detailed description of the process of CA. The first step is the design which identifies the context and clarifies the research question and potential sources of data. This is followed by unitising where the units of analysis are defined and identified. Sampling addresses the selection of the sample ensuring representativeness of the wider group. Coding entails coding and classifying the data using a systematic process. Analysis of data occurs in the context of the coding framework. Drawing inferences relates to the application of the research findings to the current body of knowledge. The final step is validation which entails identifying validating evidence to support the research findings.
The core features of the analytic process are coding and classifying. A code is a descriptive label of a meaning unit, while a category is a description of the phenomenon under investigation (Graneheim and Lundman, 2004). Categories can be grouped under higher order headings with those similar. These categories are named using content-relevant wording. The process entails a circular rather than linear process with movement between the whole and parts of the text. These units are then condensed ensuring the core of the content is preserved. Examples of CA in a mental health context include descriptions of discrimination experiences (Hamilton et al., 2014), mental health help-seeking in rural communities (Boyd et al., 2011), parental perspectives of their child’s bipolar disorder (Crowe et al., 2011) and loneliness among mental health patients (Lindgren et al., 2014).
At a basic level, the main difference between the methods is that CA reduces the data into categories and TA takes this a step further by examining the relationships and meanings in the categories to identify themes. TA and CA can be considered to be on a continuum rather than as dichotomous with TA tending more towards inductive approaches to uncover latent meanings and CA tending more towards deductive approaches to identify manifest meanings. However, CA lends itself to calculation, while TA does not (See Figure 1). These calculations can include those described by Bauer et al. (2000: 6):
Purely descriptive study that counts the frequency of all the coded features of the text;
Normative analyses that make comparisons with standards, e.g., of objective or unbiased reporting;
Cross-sectional analysis – empirical comparison may involve data derived from different contexts;
Longitudinal analysis – comparisons that span the same context over a longer period of time.
The analysis continuum.
Using TA and CA to analyse data
A useful framework for conceptualising the relationship between TA and CA is on a continuum between an interest in latent and manifest content, an interpretative or descriptive approach and inductive and deductive reasoning (see Figure 1). In order to illustrate the use of both TA and CA, excerpts from interviews with patients with a diagnosis of Bipolar Disorder were used to illustrate how each type of analysis can be applied to the same data with different results. For this illustration, we examined an unpublished subset of the data on self-management generally to examine in particular how participants experienced their use of medication. The quotes in Table 1 were the first six interviews from an on-going larger sample (see Table 1).
Transcribed data.

TA
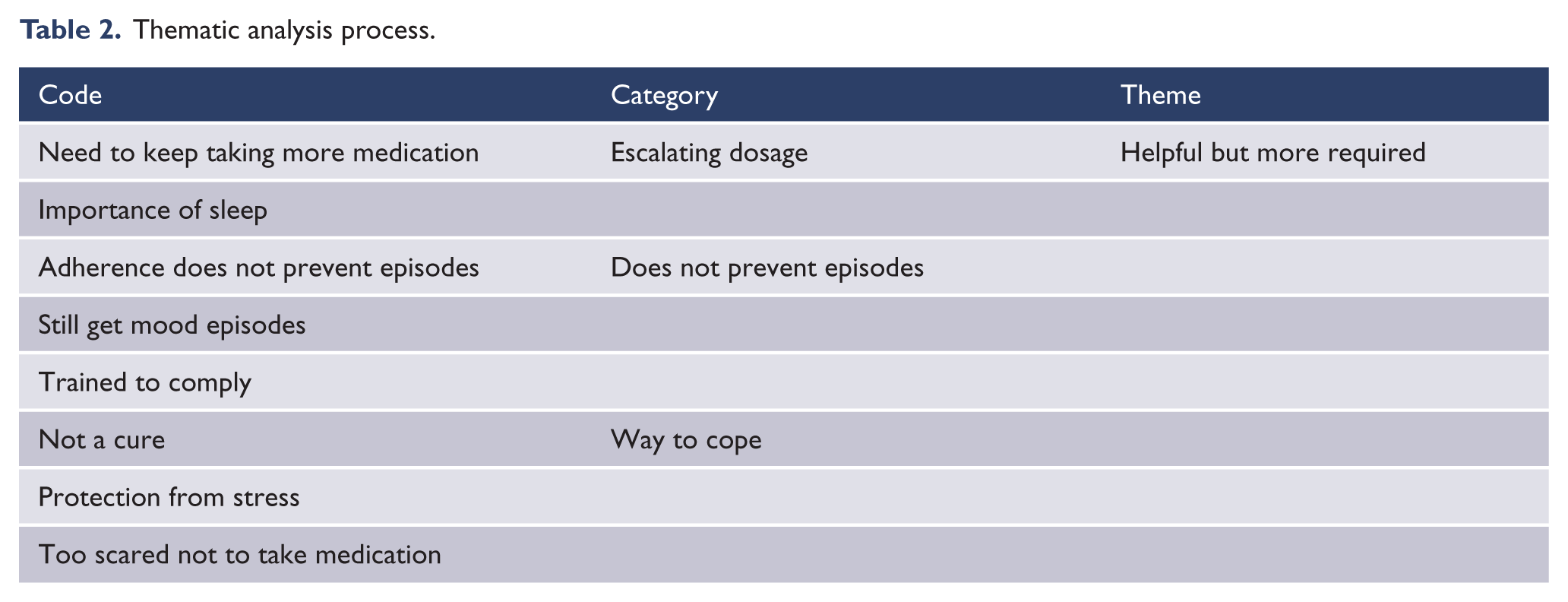
An interpretative TA was conducted on these transcribed interviews following the process described in Table 2. The analysis focused on the selected data as a whole and examined the meanings embedded within it. The theme that was interpreted from the data was that participants found it helpful but more was required. It evolved from coding the data for what taking medication meant for the participants. This was then grouped into three categories: the dosage keeps escalating, taking medication does not prevent episodes and medication is a way to cope. The three categories were interpreted as meaning that while medication was helpful it was not all that was required to keep them well.
Thematic analysis process.
CA
A deductive CA focused on the manifest content of the interviews – what did participants think about taking medication. The transcribed interviews became the raw data and unit of analysis. These were read and information related to the use of medication was identified (meaning units). The coding process entailed the identification of descriptive terms for the relevant areas identified in the transcripts. Categories are then identified from the codes. The participants thought that medication helped them maintain an equilibrium. This category evolved from the codes: reducing mood episode frequency; stabilising; balancing and normalising (see Table 3). The process of analysis does not involve interpretation but rather a description of the manifest statements made by the participants.
Process of content analysis.

Both TA and CA provide different information for the researcher. CA is a direct representation of what was said in answer to the research question, and TA provides an interpretation of the broader meaning embedded in their responses. Both approaches provide useful understandings of what the participants think about their medication in the context of an interview about self-management. Because it occurs at a manifest level, the CA appears to suggest what the participants have been told about their medication. More in-depth interpretative TA provides insights into the participants’ experiences of using medication.
Establishing rigour
The hallmarks of qualitative rigour have been described by Koch (2006): credibility, transferability and dependability. Credibility relates to the way in which data were interpreted. Although qualitative research is an interpretive process, the interpretations may need to be substantiated or supported in some way. This may involve providing a theoretical rationale for the interpretation, having the interpretation validated by participants or adopting a consensus among the research team. Two of the authors (M.C. and M.I.) independently conducted each analysis of the data and developed a consensus that was validated by the third author (R.P.).
Transferability involves providing the reader with sufficient information in order for them to assess similarities or differences between the context in which the study was conducted and their own clinical practice setting. Qualitative research needs to provide sufficient contextual information for this to be ascertained. It is acknowledged that context has a strong influence on findings. In these interviews, the participants were taking part in an 18-month randomised controlled trial involving Interpersonal and Social Rhythm Therapy in combination with medication. They were recruited into the study immediately following discharge from community mental health services. It could be anticipated that these participants were active in attempting to identify new self-management strategies and were willing to engage in that process over an 18-month period. It can also be assumed that because they had recently been discharged from services that they were likely to be euthymic or not in full episode at the time of interview. This context to the data collection provides the reader with a context that would have influenced these particular findings. Dependability involves providing sufficient information on both the data collection and data analysis processes to enable the decision-making trail to be followed. The illustration of the process of each analysis should provide readers with sufficient information to follow how the findings were developed. In this case, one of the authors (R.P.) who was reasonably naïve to qualitative research processes was involved in checking dependability by questioning each step of the process in order to identify how these led to the identification of categories and themes.
Limitations of TA and CA
Qualitative research has a strong emphasis on written and spoken word as the mode by which a ‘reality’ can be captured; however, as noted by Crowe (1998), words do not operate as external signs of internal meaning for the individual but rather as a pre-determined system for the allocation of meaning. An awareness of this limitation is important for both TA and CA. The same questions may elicit different responses at different points in time and when asked by different people, so the dynamic nature of participants’ perceptions of their experiences needs to be central to the interpretation of those responses.
Some qualitative researchers, acolytes of strictly structured methodologies, are sceptical that TA and CA can provide sufficient analytic depth because they are methods not underpinned by prescribed philosophies and methodologies, e.g., phenomenology. As Vaismoradi et al. (2013) have noted, there is a stereotype among qualitative researchers that portrays TA and CA as the easiest approaches within qualitative methodologies, but this does not mean they produce low-quality results. While this might be considered a limitation of TA and CA, these methods do provide the researcher with the opportunity to take an analytic position that is broader and more open to a range of theoretical interpretations.
An obvious limitation of CA is that it occurs at the manifest level and maybe regarded as fairly superficial; however, this limitation does produce categories that can be quantified. TA is concerned more with latent meaning, and as such it is difficult to quantify in discrete codes. Despite the limitations of both methods, they do provide an efficient and effective method for interpreting the large amount of data produced in qualitative research.
Conclusion
The qualitative methods of TA and CA provide insights into patients’ experiences and perceptions that may elude quantitative approaches. While there are similarities in the data collection processes of both these methods, there are differences in the processes of analysis. TA provides an interpretation of the broader meaning embedded in participants’ responses, while CA provides a representation of what was said in answer to the prompt. Each method has a role in qualitative research, and it is important to understand the capabilities of each method along with the limitations.
Footnotes
Declaration of interest
The authors declare no conflicts of interest. The authors alone are responsible for the content and writing of the paper.
Funding
This methodological paper used data collected as part of a New Zealand Health Research Council–funded randomised controlled trial of a Bipolar Disorder Clinic.