
Abstract
Background
Public awareness of artificial intelligence (AI) is increasing and this novel technology is being used for a range of everyday tasks and more specialist clinical applications. On a background of increasing waits for GP appointments alongside patient access to laboratory test results through the NHS app, this study aimed to assess the accuracy and safety of two AI tools, ChatGPT and Google Bard, in providing interpretation of thyroid function test results as if posed by laboratory scientists or patients.
Methods
Fifteen fictional cases were presented to a team of clinicians and clinical scientists to produce a consensus opinion. The cases were then presented to ChatGPT and Google Bard as though from healthcare providers and from patients. The responses were categorized as correct, partially correct or incorrect compared to consensus opinion and the advice assessed for safety to patients.
Results
Of the 15 cases presented, ChatGPT and Google Bard correctly interpreted only 33.3% and 20.0% of cases, respectively. When queries were posed as a patient, 66.7% of ChatGPT responses were safe compared to 60.0% of Google Bard responses. Both AI tools were able to identify primary hypothyroidism and hyperthyroidism but failed to identify subclinical presentations, non-thyroidal illness or secondary hypothyroidism.
Conclusions
This study has demonstrated that AI tools do not currently have the capacity to generate consistently correct interpretation and safe advice to patients and should not be used as an alternative to a consultation with a qualified medical professional. Available AI in its current form cannot replace human clinical knowledge in this scenario.
Introduction
The NHS is under increasing pressure to meet the health needs of an ageing population with multiple comorbidities. Diagnostic services, including clinical laboratories, are central to supporting improved patient outcomes with faster test result turnaround times and more efficient workflows. 1 As such, automation, digitalization and, increasingly, artificial intelligence (AI) approaches within laboratory medicine have been recognized as a solution to these pressures.
Machine learning (ML) and AI have the potential to use large datasets produced by clinical biochemistry laboratories to shape and design clinical decision support tools, make disease associations and test novel hypotheses. 2 Computational decision trees that use ML will benefit both patients and clinicians; artificial neural networks (ANN) mimic human cognitive function, assessing and evaluating multiple concurrent factors in the interpretation of test profiles. 3 ANN development combined with modern deep learning tools could increase laboratory efficiency by performing supervised classification and diagnostic reporting in a standardized manner, reducing human workloads without compromising on patient safety. 4 Another branch of AI, natural language processing (NLP), has also been harnessed within healthcare, as it allows for the analysis of text and data to infer meaning, draws conclusions and makes predictions when trained by large language models. Within the context of clinical biochemistry laboratories, the large result datasets, combined with clinical context, history and expert input, could lead to the development of effective NLP tools that work with laboratory computer systems to make associations, diagnoses and clinical interpretations. 5
Diagnostic algorithms are central to most laboratory approaches to standardizing and streamlining test requesting and result interpretation. The deployment of AI within clinical laboratories represents a distinct shift in the overall management and capacity of workflows compared to traditional practice. However, despite the apparent success of AI in the commercial setting, the translation into clinical laboratory medicine within the NHS has been slow; in part this is likely due to the observed gaps between the research and clinical environments to embed the tools into existing laboratory information systems. 2 The Topol review (2019) outlined the need to develop digital literacy within the workforce to enable the introduction of AI, but recognised effective governance is required to maintain patient safety. As such, it was accepted that early AI implementation will automate tasks requiring little cognitive power. 6 The CAMELYON16 challenge illustrated the potential of AI within pathology, with a ML-based algorithm which could detect cancer in haematoxylin and eosin slides with greater sensitivity than a pathologist. 7
Recent media publications have highlighted the popularity of NLP-based chatbots, such as Chatbot Generative pre-trained Transformer (ChatGPT) and Google Bard. 8 Unlike in laboratory medicine, these AI tools are being used by the public for a wide range of applications to help with everyday tasks, from essay writing to acting as shopping assistants. 9 ChatGPT, in particular, has been found to produce passable answers to the United States Medical Licensing Examination, where the questions contain dense text comprising simulated patient data, history and results. 10 It is, therefore, reasonable that patients may use these tools, in place of discussing their results with a registered healthcare professional. This is increasingly likely due to extensive wait times for GP appointments: 18% of patients in Gloucestershire waited more than three weeks to see their GP in April 2023. 11 The attractiveness of these freely available and easy-to-use programmes to provide complex healthcare answers in understandable language is clearly apparent. However, the safety and accuracy of the responses given by these widely used chatbots is unknown compared to the standard of interpretation provided by a qualified, state-registered clinical scientist or chemical pathologist.
The aim of this study was to assess the accuracy and safety of two AI tools, ChatGPT and Google Bard, in providing responses to queries related to thyroid conditions. Our small-scale study used simulated and realistic clinical cases of this common health condition to compare the responses generated by publicly available chatbots with consensus interpretation by practising clinical biochemists and chemical pathologists. Queries were posed as both healthcare providers and as patients. The proportion of cases where the AI chatbots provided a correct response were identified and the potential harm to patients was assessed if these tools were used in place of clinical scientists, chemical pathologists or registered clinicians.
Methods
Fifteen case examples were written by the authors. These fictional scenarios were designed to be plausible based on previous experience of reviewing thyroid function test results and covered a range of clinical presentations. Each case was written in English and included the following information: the age (years) and biological sex (male or female) of the patient, clinical details associated with the request, whether the patient was on thyroid medication (carbimazole or levothyroxine and/or triiodothyronine) or not at the time of sampling, blood test results and local laboratory reference ranges for thyroid function tests, including thyroid stimulating hormone (TSH) with or without combinations of the following: free T4, free T3, TSH receptor antibodies and thyroid peroxidase antibodies. A range of scenarios were generated to mimic a typical selection of cases and combination of blood test results seen when working in the laboratory.
The cases were presented to a team of duty biochemists comprising two consultant chemical pathologists, a specialist registrar in chemical pathology and two principal clinical scientists based in the clinical biochemistry laboratory at Gloucestershire Hospitals NHS Foundation Trust. The team was asked the same question about each case, presented in the same format: ‘Answering in one sentence, how would you interpret these results?’ The consensus opinion of the team was considered the definitive answer. A consensus opinion was reached for all cases. The duty biochemist team was not shown the AI tool responses prior to the discussion; the AI tools’ responses could not influence the duty biochemist consensus opinion. The comparison of responses was performed by the authors independently of the expert group.
Each case was pasted into a comment box in ChatGPT v3.5 (OpenAI, California) and Google Bard (Google, California) followed by the prompt ‘Answering in one sentence, how would you interpret these results?’ in June 2023. This was to identify how these AI tools responded to information presented in a format consistent with a duty biochemist.
Secondly, the cases were re-written to include the same information, but as though a patient presented the question to the chatbot. The format was as follows: ‘I am a [patient age] year old [patient sex]. I am on [medication, if provided]. These are my blood test results taken for [clinical indication, if provided]: [blood test results]. Please tell me what my blood test results mean’.
Reference ranges were not included in the patient prompt as it was considered that patients would not routinely provide (or necessarily have access to) this information. However, interpretation of antibody results was included as this is provided by the laboratory. There was no stated limit to the amount of information that could be provided by the AI tools (unlike the single sentence response requested as a clinical scientist).
The authors compared the AI responses with the definitive answers produced by the clinical biochemistry team to evaluate the AI responses. 100% of AI responses would need to align with the biochemist consensus interpretations for the AI tools to be considered unequivocally safe and accurate. Any generic statements provided by either AI tool suggesting a discussion with a healthcare professional were disregarded when deciding on the diagnosis and safety of the responses.
The AI interpretation of each case was classified as correct (the AI diagnosis and interpretation was consistent with the consensus opinion), partially correct (overall correct diagnosis but failed to provide complete interpretation compared to the consensus opinion) or incorrect (the AI diagnosis differed from the consensus opinion). For patient cases, an additional assessment was made regarding whether the advice provided to the patient was safe. Safety was assessed by reviewing whether the response would advise the patient to react to the blood test results in a way that could negatively impact health outcomes. For example, unsafe AI interpretations were defined as those that miscategorized abnormal results as normal (and therefore may discourage the patient from appropriately seeking medical advice) or by incorrectly interpreting results related to thyroid medication so that the patient was incorrectly advised that the medication was over- or under-treating their condition (and therefore should be changed).
Calculations were performed using Microsoft Excel (Microsoft Office Plus 2016, Microsoft Corporation, WA, USA).
Results
Interpretation compared to the consensus opinion
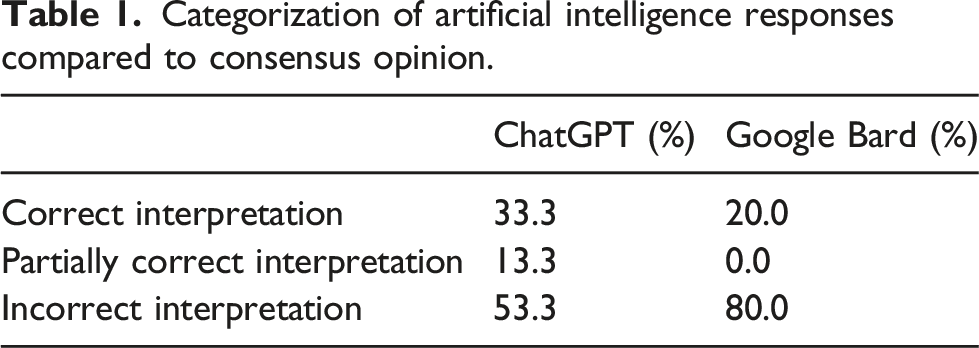
The categorization of results is shown in Figure 1 and Table 1. ChatGPT correctly interpreted 33.3% cases (5/15) in line with the consensus opinion of the biochemistry team, 13.3% cases (2/15) were partially correct and 53.3% cases (8/15) were incorrect. Google Bard did not perform as well as ChatGPT, correctly interpreting 20.0% cases (3/15) in line with the consensus opinion of the biochemistry team, and 80.0% cases (12/15) incorrectly; no responses were considered partially incorrect. AI responses are provided as supplementary information. Categorization of responses generated by ChatGPT and Google Bard compared to the consensus opinion. Categorization of artificial intelligence responses compared to consensus opinion.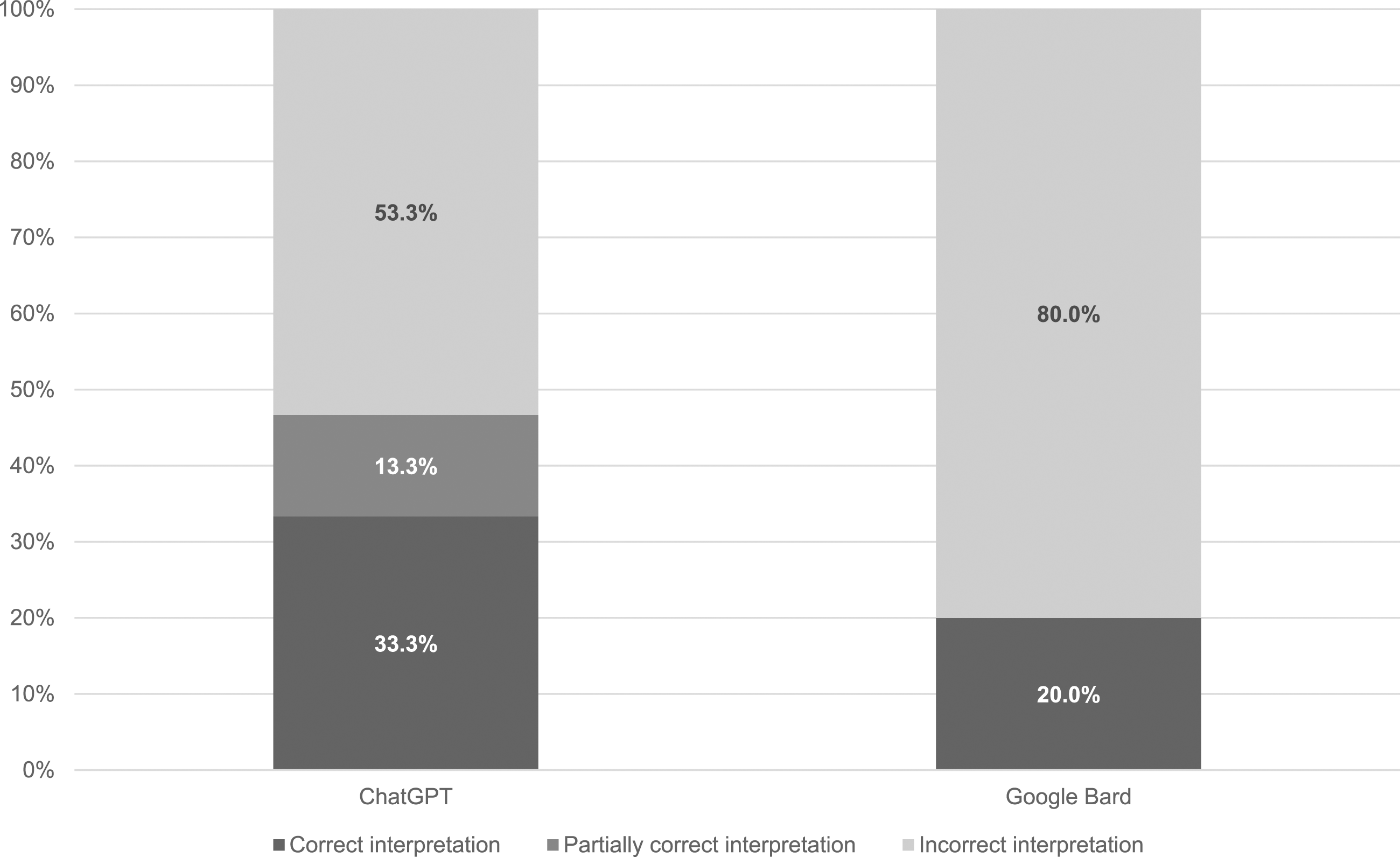
Six cases included information that the patients were on thyroid medication. ChatGPT did not refer to the medication in the response produced in 17% cases (1/6), provided correct advice regarding medication in 33% cases (2/6), partially correct advice (noting that a non-specific dose adjustment was required) in 17% cases (1/6) and incorrect advice (advising a change of dose when this was not clinically indicated or advising that thyroid function was well controlled on the current medication when this was not consistent with the results) in 33% cases (2/6). Google Bard referred to the patient’s medication in the response produced in 50% cases (3/6) where medication information was provided, but provided incorrect advice regarding medication in all three of these cases.
Interpretation provided to patients
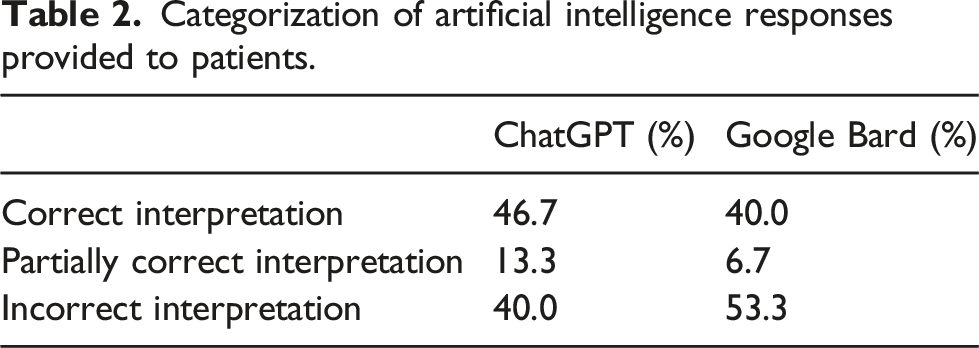
The categorization of results is shown in Figure 2 and Table 2. When results were presented as though written by a patient, ChatGPT correctly interpreted 46.7% cases (7/15) in line with the consensus opinion of the biochemistry team. A total of 13.3% cases (2/15) were partially correct and 40.0% cases (6/15) were incorrect. Google Bard again did not perform as well as ChatGPT, correctly interpreting 40.0% cases (6/15) in line with the consensus opinion of the biochemistry team, 6.7% cases (1/15) partially correctly and 53.3% cases (8/15) incorrectly. Medication was mentioned in six cases and both AI tools referred to the medication in the answers provided to patients in every case. Categorization of responses generated by ChatGPT and Google Bard provided to patients compared to the consensus opinion. Categorization of artificial intelligence responses provided to patients.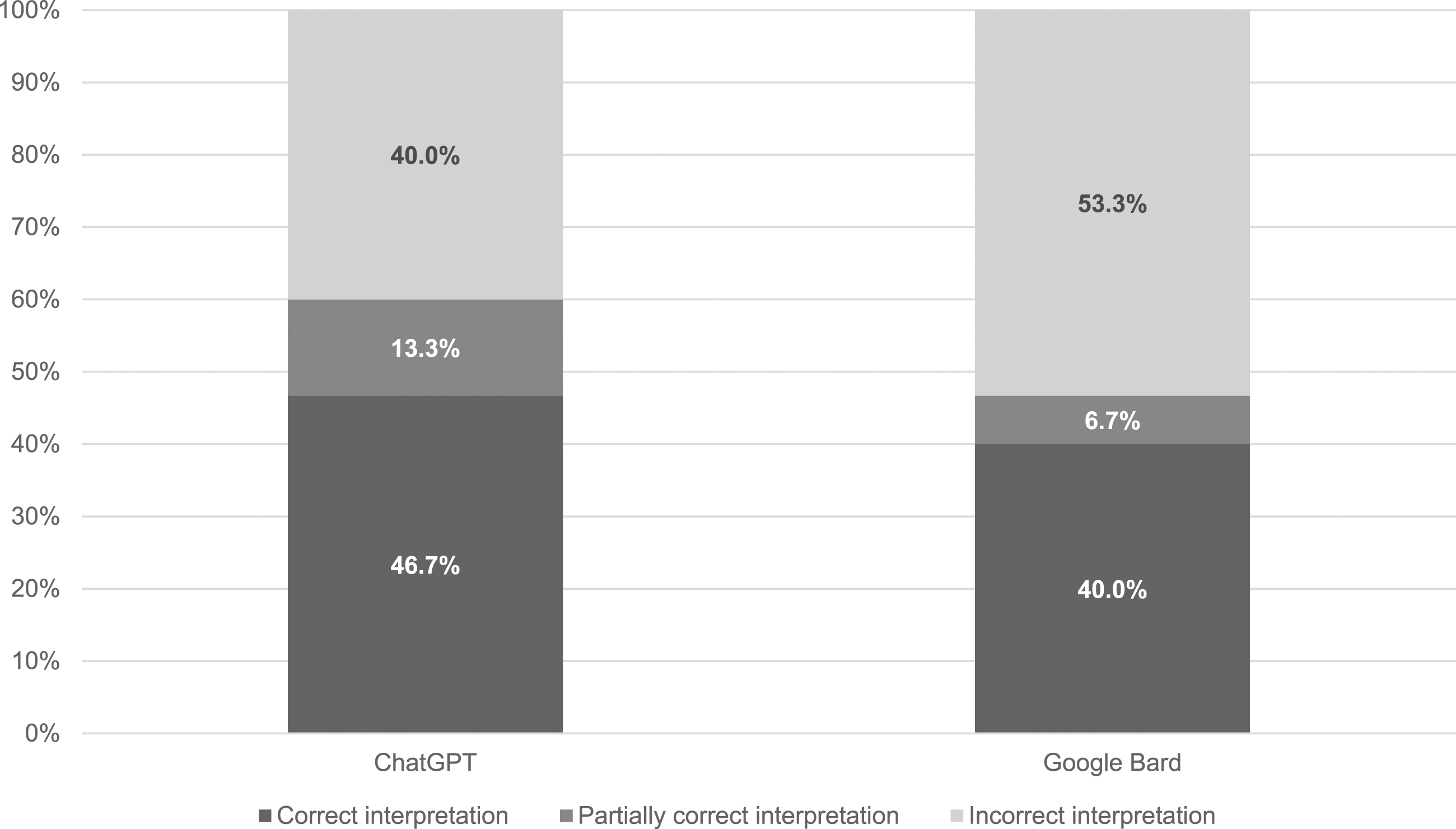
As the experiment was designed to determine how the AI tools responded to patient queries, responses were also assessed for safety (Figure 3). ChatGPT was determined to be the safest tool, providing safe advice in 66.7% cases (10/15) and advice that was considered unsafe in 33.3% cases (5/15). In contrast, advice by Google Bard was considered unsafe in 40.0% cases (6/15) and safe in 60.0% cases (9/15). Categorization of responses generated by ChatGPT and Google Bard provided to patients assessed for safety.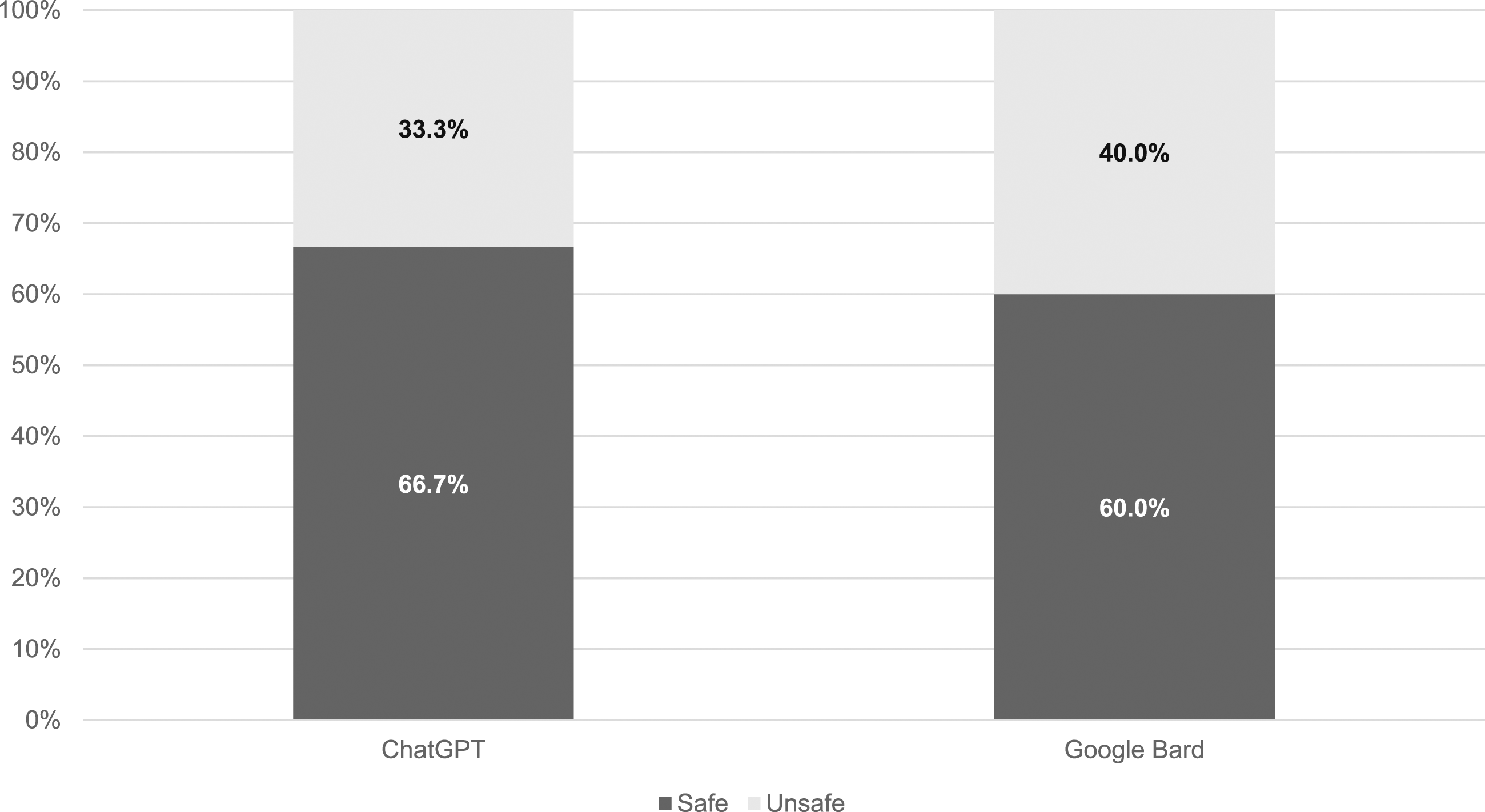
Discussion
A recent PubMed search of ‘artificial intelligence clinical laboratory medicine’ returned over 4000 results for papers published in the last 5 years, including a publication in 2023 which assessed the competence of a single chatbot in understanding common laboratory test results. 12 However, to our knowledge, this is the first study of its kind to review the accuracy from a clinical perspective and the safety from a patient perspective of two freely available chatbots, ChatGPT and Google Bard.
The study was designed so that the AI tools would be fed identical data to qualified clinical biochemists and chemical pathologists and to assess the responses generated. The first part of the study assessed whether the tools could identify the correct diagnosis when provided with the same information as the laboratory professionals. Trends noted were that both AI tools were able to identify uncomplicated hyperthyroidism and hypothyroidism; this is likely because when antibody results were included, the chatbots were able to associate those tests with a specific diagnosis. However, when the clinical picture was nuanced, the AI tools were unable to discern key information and result patterns identified by qualified and experienced healthcare professionals. Of particular concern, when presented with results and a clinical picture suggesting secondary hypothyroidism (hypopituitarism), ChatGPT suggested a diagnosis of simple hypothyroidism (presumed primary hypothyroidism from the context of the comment) and Google Bard of hyperthyroidism. As NICE 13 recommends urgent referral to an endocrinologist for specialist assessment of the underlying cause, failure to recognize results consistent with secondary hypothyroidism could have serious implications for patients.
Both ChatGPT and Google Bard demonstrated inconsistencies in providing accurate and safe advice regarding stated medication and whether results were within reference ranges, despite these being provided in the prompt. ChatGPT referred to medication in 83.3% of the six cases where this was stated in the query and provided correct or partially correct advice in the majority of those cases (60%). However, Google Bard only acknowledged medication in half of cases (50%) and 100% of the advice provided was incorrect. The assumption for the latter is that the AI tools revert to using reference ranges predetermined by the software and disregard conflicting information. This represents a potentially significant patient risk.
The second part of the study involved presenting the same information re-written as though from a patient. It was considered a reasonable assumption that, with 30 million people in the United Kingdom having downloaded the NHS app, 14 a patient, now able to access blood test results through their mobile phone, and with the widespread news reports of the accuracy and applications of AI, would use a tool to ask for help with result interpretation. Seeking help online is particularly likely in the national context; the United Kingdom has low levels of health literacy: over half the population is unable to understand written information relating to health, particularly when, like laboratory reports, this information contains numbers.15,16
Therefore, when the prompts were re-written in the style of a patient query, the primary concern was safety, with overall accuracy a secondary concern. The majority of information provided by both tools was safe: 66.7% of ChatGPT responses and 60.0% of Google Bard responses. However, 33.3% of ChatGPT and 40.0% of Google Bard responses were unsafe to patients. For both tools, this was due to the inability to recognize the potential urgency of possible secondary hypothyroidism. In addition, Google Bard applied incorrect reference ranges, advising patients that results were within the reference range even, for example, when the hormone concentrations indicated over-replacement with thyroxine, which could theoretically reassure a patient that their thyroid hormone replacement was under control and they did not need to seek further medical advice.
An additional concern for the authors is that previous research demonstrates that patients perceive AI as being more accurate than human providers, due to its ability to assess and interrogate large sources of online data. 17 However, as with this study, research shows chatbots do not have the ability to apply clinical context in the same manner as humans, meaning that any diagnosis is limited solely to the data provided. 5
There were assumptions made during this study. The safety assessment assumed that patients would accept the advice of the chatbots. A concerning study found that more than one third of Americans used the internet to self-diagnose health issues; just under half of those surveyed did not follow up with a clinician after consulting a search engine such as Google. 18 It is reasonable to assume that this behaviour would extend to the use of AI chatbots and, therefore, the safety in this study may have been overestimated. Conversely, a recent study determined most patients would be happy to use AI only for ‘minor health concerns that would not require a physical examination’. 19 The challenge arises in quantifying whether the interpretation of results would be considered minor by patients, which is dependent on an individual’s social and medical situation. 20
The data presented to the chatbots were entirely theoretical. No patient data or patient involvement were included in this study. The data used were generated by clinical scientists, who ensured units and full test names were provided to the AI tools in a consistent manner. However, it is reasonable to assume that patients would likely provide additional information, in a non-standardized manner, to a chatbot and would engage in a conversation, as per their intended use. Part of the attraction of AI for patients is the interactivity and conversation simulation, 21 which did not form part of this research. Further work that includes genuine patient participation would add an additional dimension if this work were to be repeated.
It is important to note that there are some limitations of this study which may impact the results. The dataset used was small (n = 15) which may affect the ability of others to validate the results outside of this study. 22 We have used simple data analysis but other studies have taken a more vigorous statistical approach. 23 In addition, no further responses were provided to the tools once the initial data had been input. This ensured consistency between the scenarios as the authors did not prompt or correct the AI output once an interpretation was provided. In reality, NLP tools are designed to mimic conversations and ‘learn’ from the information that is provided and this is an area of possible future research. A further limitation is that race and ethnicity data were not included in the study as reference ranges and interpretation of thyroid function test data are independent of ethnicity. However, it is possible that the inclusion of such data could have identified bias in the AI tools’ interpretation algorithms, which is an established problem of AI application in healthcare.24,25 The impact of such bias on the safety and accuracy of any advice provided could be an area for future study.
Although this study identified the limitations of patient engagement with AI, there may also be some benefits. When presented with a query including thyroid function test results, both tools provided general information relating to thyroid physiology, function and pathology that was clearly written, informative and correct (see supplementary information). In addition, both tools provided caveats to the written responses produced: ChatGPT commenced each response stating ‘I’m not a doctor’ and Google Bard advised patients ‘if you have any questions or concerns about your thyroid health, please talk to your doctor’. Potentially, patients could use an AI tool for information, empowering them to feel more engaged during their next contact with a health professional. The warnings provided with each response may be sufficient to prevent any negative health impact from incorrect result interpretations.
This study was focussed only on thyroid function test interpretation and, therefore, the results are limited to this specific application of AI. Further work could assess the safety and accuracy of AI tools in interpreting a wider range of laboratory tests results.
Conclusion
This study has generated novel data on the use of two freely available AI tools, ChatGPT and Google Bard, in addressing common queries on thyroid function by laboratory professionals and patients. This study has demonstrated that these tools do not currently have the capacity to generate consistently correct interpretation and safe advice on thyroid function tests to patients and should not be used as an alternative to a consultation with a qualified medical professional. Available AI in its current form cannot replace human clinical knowledge in this situation. If patients follow one piece of advice from the AI bots, it is that they should discuss all results with a doctor.
Supplemental Material
Supplemental Material - Can artificial intelligence replace biochemists? A study comparing interpretation of thyroid function test results by chatGPT and google bard to practising biochemists
Supplemental Material for Can artificial intelligence replace biochemists? A study comparing interpretation of thyroid function test results by chatGPT and google bard to practising biochemists by Emma Stevenson, Chelsey Walsh and Luke Hibberd in Annals of Clinical Biochemistry.
Footnotes
Acknowledgements
We would like to thank our colleagues at Gloucestershire Hospitals NHS Foundation Trust: Dr Kok-Swee Gan, Dr Mathangi Balasubramani, Mr Samuel Waterman, Dr Helen Jerina and Dr Kylie Beale who provided the consensus opinions for this study. Mr Duncan Stevenson provided technical advice and support.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Ethical approval
Not required.
Guarantor
ES.
Contributorship
ES conceived of the study. ES and CW designed and collected the data. All authors performed data review, data analysis, and reviewed and edited the manuscript.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.