
Abstract
Artificial intelligence (AI) and machine learning (ML) are rapidly transforming surgery, moving beyond traditional risk prediction to real-time clinical support and intraoperative assistance. However, successful integration requires clinicians to understand key methodological challenges, including overfitting, data bias, and the “black box” nature of many models, which can obscure interpretability and limit generalizability. Recent advances demonstrate AI’s growing ability to process text and audiovisual data to streamline documentation, enhance intraoperative decision-making, and even perform basic operative tasks through robotic automation. This review outlines core ML principles relevant to surgical applications, discusses data modalities and evaluation metrics, and highlights emerging models that exemplify the evolving role of AI in the operating room. As these systems progress from experimental to practical use, understanding both their potential and limitations will be essential to ensure safe, effective, and ethically sound adoption in surgical practice.
Introduction
Artificial Intelligence (AI) is a multidisciplinary field focused on building computer programs that perform tasks requiring human-like cognition. 1 Current implementations are almost exclusively artificial narrow intelligence (ANI), which is designed for specific tasks. 2 In contrast, human intellect is remarkably general-purpose, in that our innate “programming” can apply our intelligence to a diverse set of cognitive tasks. 3 The theoretical general-purpose AI is termed artificial general intelligence (AGI). 2
Machine learning (ML) is an approach to AI that employs algorithms which autonomously learn from data to perform AI tasks, and makes up the preponderance of common AI implementations.4,5 ML algorithms, as elaborated upon in this review, are numerous and diverse. Neural networks (NNs) are a large class of ML algorithms that are modeled after the synaptic wiring of human neuronal circuits.6,7 Many current NN implementations qualify as deep learning (DL), where multiple hidden layers allow hierarchical processing of data, akin to how the human brain processes visual information. 7
Computer vision (CV) and natural language processing (NLP) describe certain AI objectives: understanding, recognition, classification, and/or reproduction of visual-medium or human language data, respectively; CV and NLP do not necessarily strictly prescribe implementation.7,8 Large language models (LLMs), including ChatGPT (OpenAI, Inc, San Francisco, CA), Claude (Anthropic PBC, San Francisco, CA), Grok (xAI Corp., Palo Alto, CA) et al, are NLP systems built on massive DL architectures containing billions of parameters, enabling them to generate contextually relevant text at scale. 9
Relevance to Surgical Practice
Fundamentally, ML models are predictive engines that differ in how they learn, generalize, and handle diverse data types. Many aspects of surgical care can be framed as predictive tasks, making ML relevant across the continuum of clinical practice. For example, documentation support with LLMs can be modeled as complex “auto-complete” tasks, incorporating patient context, structured data, and even audio from surgeon–patient encounters. 9
Predictive ML models can improve clinical efficiency by automating the burden of certain administrative tasks. 10 A 1-year retrospective study by The Permanente Medical Group (TPMG; Oakland, CA) following implementation of AI scribes (so-called “ambient AI,” see discussion of audio-based ML models) found that the heaviest users of AI tools saved time in note writing relative to infrequent and non-users. 10 However, actual time saved by even heavy users was quite modest: less than 1 minute per note. 11 As models advance, their adoption will likely depend on whether they deliver efficiency gains or accuracy improvements substantial enough to outweigh familiarity with current workflows.
This review aims to contextualize the opportunities and limitations of AI for surgeons, highlighting tasks these tools are already impacting and areas where further evolution is needed. Specifically, we address the technical aspects of algorithm and AI utilization to guide a surgeon in clinical practice.
Fundamentals of ML Model Development
Data Preprocessing and Model Selection
ML model development begins with a defined clinical question: patient population, timeframe, intervention(s), and outcome(s). These decisions guide data requirements, algorithm selection, and evaluation strategies. High-quality data are essential, typically sourced from surgical registries or electronic health records (EHRs). Preprocessing includes handling missing/errant values and formatting raw variables into meaningful features.
The data set is then split into development and evaluation subsets. Typically, 70-80% of data are allocated for training and 20-30% for testing, without overlap to prevent information leakage. Feature selection may also be applied to prevent overfitting, wherein a model becomes too finely tuned to training data, learning to predict meaningful patterns but also random noise, reducing performance on new, unseen cases. Next, an algorithm is selected and undergoes hyperparameter tuning: adjusting settings controlling how a model learns, such as number of trees in a random forest model, boundary complexity in support vector machines (used to separate outcomes), or layer and connection complexity in NNs. Hyperparameters determine model complexity and flexibility, in turn dictating underfitting and overfitting tendencies during cross-validation. 12
If only one data set is available, before model training, a “hold-out split” randomly sequesters 20-30% of data for testing, approximating a truly novel data set. However, testing completely independent data sets is preferable, whenever possible. Cross-validation provides more reliable estimates by repeatedly splitting the training data, training on some, and validating on the rest in rotation. Averaging results across folds gives more stable performance estimates. Careful preprocessing and validation design minimizes overfitting, and optimizes models for training and evaluation. 13
Example Model Creation
An example random forest (RF) classifier model was built using open-source University of California, Irvine (UCI) ML Repository Thoracic Surgery Data for illustrative purposes of understanding the working of an ML model.
14
Mortality among primary lung cancer following “major lung resections” was predicted from preoperative features. This model serves as the basis for further discussion of graphical ML model evaluation and interpretation throughout this section (Figures 1–3). Example Calibration Curve Showing Observed Proportion of Survivors (Positives) as a Function of Model’s Predicted Survival Probability. Constant-Slope (Blue) Line Represents Perfect Calibration: For Each Given Survival Probability Prediction, the Observed Proportion of Survivors Would Match Exactly. Variable (Orange) Line Indicates Observed Calibration; for Most Predicted Probabilities, Observed Proportion of Survivors Matched Acceptably, Except Around Predicted Survival Probability of 50%. Model Created Using Open-Source University of California, Irvine Machine Learning Repository Thoracic Surgery Data.
14
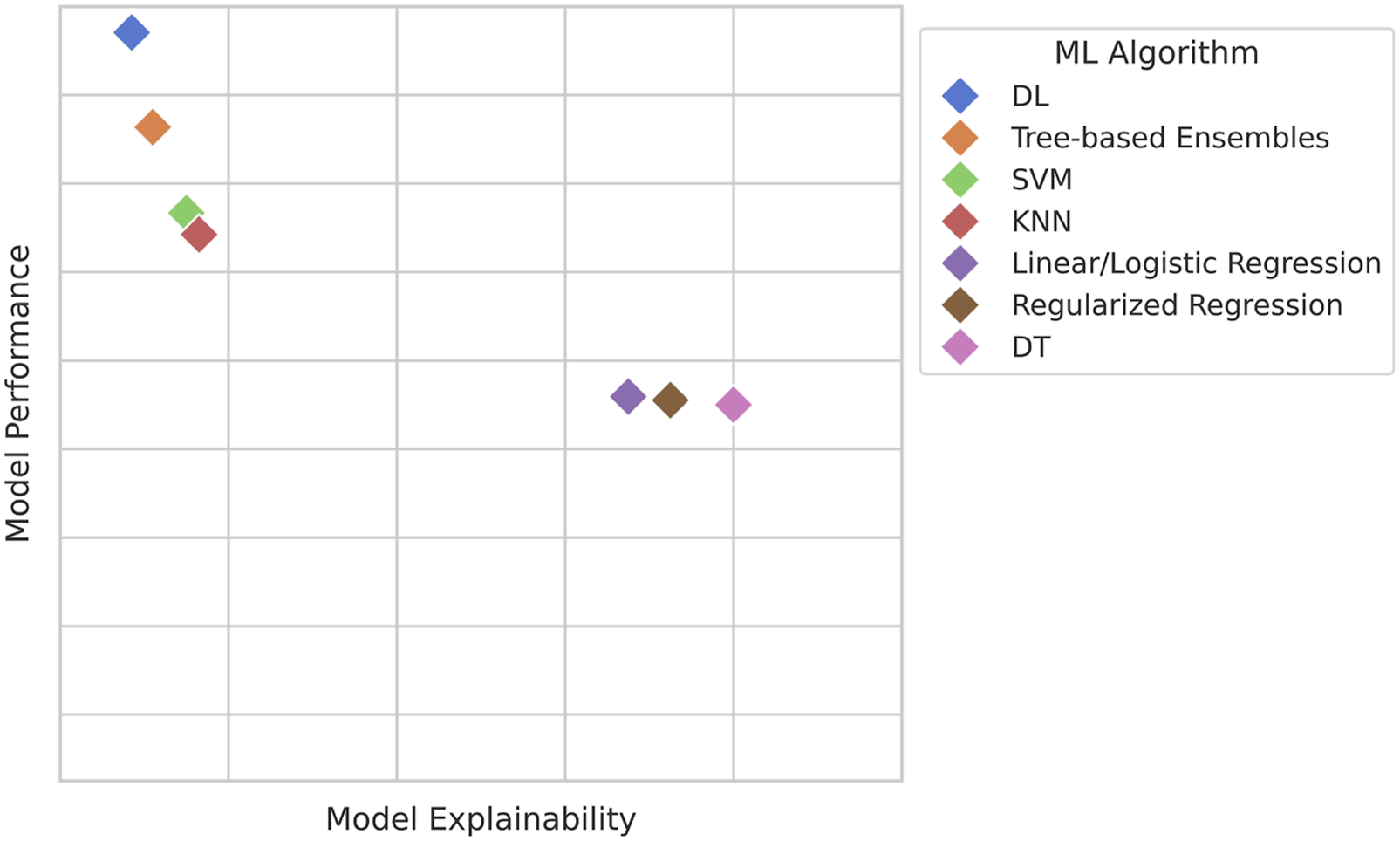
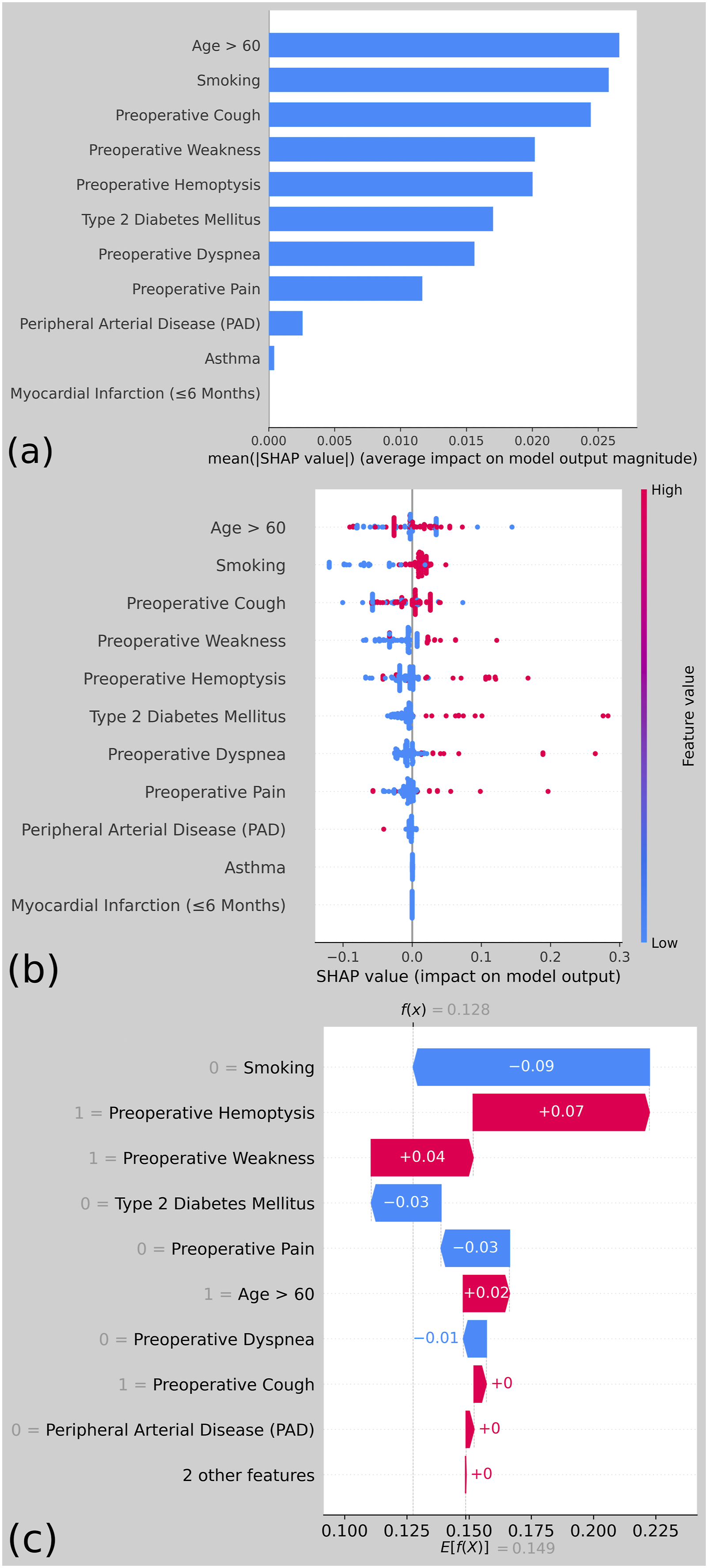
Notional Representation of Algorithms’ Approximate Explainability-Performance Tradeoff. In Practice, Relative Performance Depends on Data Format and Modality, Linearity, Class Imbalance, Sample Size, etc. (DL, Deep Learning; SVM, Support Vector Machines; KNN, K-Nearest Neighbors; DT, Decision Trees) Common Types of Shapely Additive Explanations (SHAP) Plots, Created From an example Random Forest Model Using Preoperative Factors to Predict One-Year Mortality Following Pulmonary Resection for Lung Cancer, From the Open-Source University of California, Irvine Machine Learning Repository Thoracic Surgery Data.
14
(A) SHAP bar Plot Showing Predictors’ Average Impacts on Predicted Mortality Probability. (B) SHAP Beeswarm Plot Showing Each Predictors’ per-Patient Impact on Predicted Probability of Mortality; Red and Blue Dots Indicate High and Low Predictor Values, Respectively. Color Clustering to Either Side of the Zero-effect Line Implies a Consistent Effect of the Predictor on Mortality Probability Prediction. (C) SHAP Waterfall for a Single Patient, Showing How Each Feature Affected the Model’s Mortality Probability Prediction for This Patient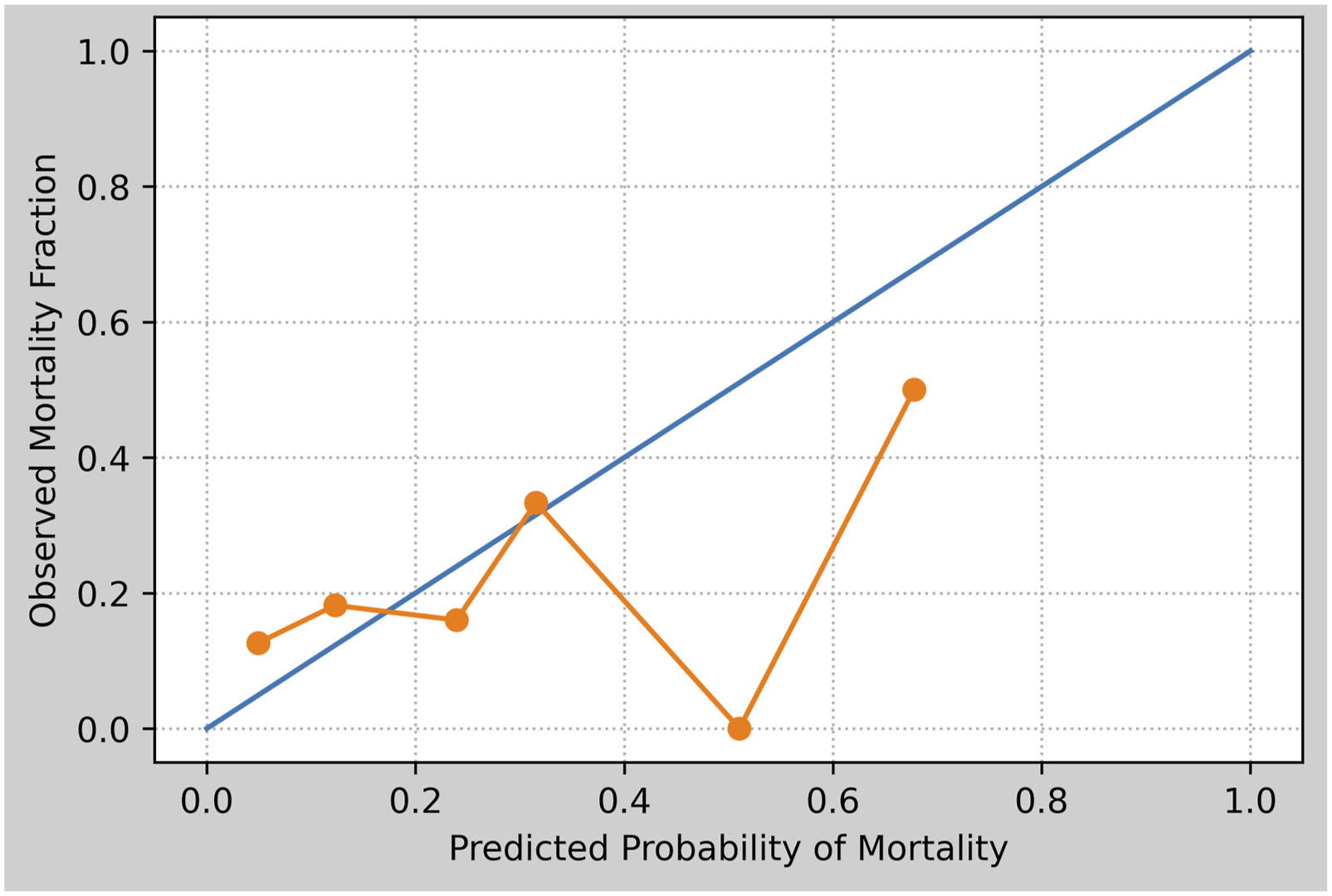
Evaluation Parameters
Common Discrimination and Calibration Metrics

PPV, positive predictive value; NPV, negative predictive value; AUROC, area under the receiver operating characteristic curve; AUPRC, area under the precision-recall curve; AP, average precision; CV, computer vision; IoU, intersection-over-union score; MSE, mean squared error; MAE, mean absolute error; ECE, expected calibration error; MCE, maximum calibration error.
ML models can be benchmarked using many different measures, but classification metrics are broadly grouped into measures of “discrimination” or “calibration.” Whereas discrimination relates to a model’s ability to correctly classify outcomes (eg, whether or not a patient will experience a given complication), calibration describes the error between the model’s predicted vs observed probability of an outcome within the study population (Figure 1). For example, if a group of patients all have an estimated 30% chance of a given complication, 30% of this group should experience the complication in a well-calibrated model. While discrimination metrics are important, many studies often overlook reporting calibration plots. 16 Over-reliance on discrimination metrics can lead to overprediction or underprediction of events, which can be mitigated by the inclusion of calibration. 17
Model Validation
Arshi et al 18 (2025) concluded that only one in six clinical prediction models are externally validated, and impact assessments are completed for even fewer. The disparity between the number of clinical models being created vs validated is indeed concerning, and reflects important missing steps in the eventual path to model deployment and use. Lack of impact assessment studies make it difficult to ascertain if a model outperforms standard clinician practices, further impeding model deployment and adoption into regular clinical use. 19 Clinicians critically appraising models should consider the use of temporal (collected at a separate time) or geographic (collected at a different institution) validation cohorts, and look for externally validated models when considering clinical implementation. For example, our illustrative RF model created from UCI Thoracic Surgery Data underwent internal validation only, which risks performance degradation in practice if applied to broader populations. 14 Validating models across disparate cohorts promotes generalizability. This topic is further explored in our accompanying work on ML prediction models for surgical complications and outcomes. 20
Interpreting ML Models
While ML models are often trained to achieve maximum accuracy, clinicians may hesitate to adopt them if the reasoning behind their predictions is unclear. “Interpretability” in AI refers to the degree to which a human can understand and trust the decisions made by AI systems. 21 Importantly, interpretability and performance often exist in tension: complex models such as DL-NNs may achieve higher accuracy but are frequently viewed as “black boxes.” Thus, selecting an appropriate model for surgical applications often requires balancing predictive performance with the ability to explain and justify predictions (Figure 2). 22
Shapley additive explanations (SHAP) techniques are often used to explain how much a particular feature contributes to a model’s predictions by calculating the difference between each of a model’s predictions and the mean prediction. SHAP assigns a contribution value to each feature in a data set by comparing predictions made with and without that feature. In practical terms, it helps clinicians understand why the model reached its decision for a specific patient. As an example, SHAP may determine that high intraoperative blood loss or advanced age most strongly influenced a predicted risk of postoperative complication. SHAP plots are intuitive, visually ranking variables by their contribution to an outcome, making them particularly helpful for clinical interpretation (Figure 3).
A complementary approach is Local Interpretable Model-agnostic Explanations (LIME). LIME works by locally perturbing features in a data set and observing how predictions change. This allows users to approximate how a “black box” model is behaving in a specific case, effectively providing a simplified, more interpretable local model. In the clinical context, LIME can illustrate how small changes in patient characteristics (eg, comorbidity profile or operative time) influence outcome predictions, thereby clarifying the decision-making logic of otherwise opaque algorithms. 23
AI Applications in the Surgical Workflow
The following discussion of surgical AI applications is organized according to surgeons’ routine clinical workflows and responsibilities: (1) nonoperative clinical decision-making, (2) administrative tasks, including documentation, and (3) intraoperative patient care.
I. AI for Clinical Decision Support
In surgical data analysis, an important question is whether DL truly surpasses traditional ML approaches on structured clinical data. Tree-based ensembles such as decision trees, random forests (RFs), and gradient boosting machines (GBMs; eg, XGBoost, LightGBM, and CatBoost) remain highly effective for tabular data sets. Recent comparisons across medical diagnosis data sets show GBMs often rank highest in accuracy, ahead of both older techniques and state of the art tabular DL. 24 Strengths include robustness to heterogeneous inputs, lower computational cost, and easier optimization, whereas NNs struggle with sparse categorical variables and weak feature correlations.
DL is nonetheless competitive when adapted carefully. Bonde et al 25 (2024) developed a multilabel DL-NN for surgical outcome prediction, utilizing entity embeddings for high-dimensional categorical variables such as Current Procedural Terminology (CPT) codes. By mapping similar procedures close together in vector space, the model captures latent clinical relationships ignored by one-hot encoding. CPT embedding enabled their DL-NN to outperform both the American College of Surgeons (ACS) National Surgical Quality Improvement Project (ACS-NSQIP) Surgical Risk Calculator (NSQIP-SRC), and RF baselines across multiple prediction tasks.
Data volume is critical to DL model performance. 25 DL-NNs often need very large data sets to generalize. This is challenging in surgery; individual hospitals may only have hundreds or thousands of cases for a given outcome. 25 Tree-based models handle smaller data sets better via built-in regularization. Large-scale efforts such as ACS-NSQIP provide detailed data across many procedures, enabling NN training. Bonde et al 25 used pooled general surgery surgical data to train a broad model, then applied transfer learning to a low-volume subset, improving prediction for pancreaticoduodenal surgery compared with training from scratch. This approach illustrates how pooled surgical data sets can be adapted for specialized tasks. With expanding national registries like ACS-NSQIP and Trauma Quality Improvement Project (ACS-TQIP), DL limitations are being overcome, making them increasingly viable options for surgical risk prediction.
Our accompanying article on machine learning for predicting complications and outcomes compares specific ML models for prognostic prediction tasks in further detail. 20
II. AI for Administrative Tasks
Most surgical ML research leverages clinical data to predict outcomes such as complications, morbidity, or mortality. These data sets are typically tabular (rows: patients/encounters; columns: variables). 24 Text, audio, video, and image data are gaining relevance in surgical ML. 7
Text-Based ML in Surgery
Text-based surgical ML primarily includes natural language processing (NLP) models. 26 NLP excels at tasks such as summarizing large volumes of text, potentially aiding clinical documentation, such as for complex patients with extensive existing documentation. 26 These models can also adapt tone, audience, or linguistic complexity (style transfer), simplifying patient communications. 27 Beyond summarization, clinical applications for text data in surgery appear somewhat limited. While research has shown reasonable accuracy in diagnosis tasks, diagnosis based on existing clinical documentation including progress notes and radiology or procedure reports is not a practice-changing function; physicians still fundamentally performed most of the diagnostic work. 26 However, in surgical research, the ability to summarize and glean meaning can be transformative. NLP-based chart review can ease data collection burdens in retrospective studies. Prior literature has found both LLMs and non-DL NLP models to extract target data from medical records with comparable accuracy to human evaluators.28,29 Importantly, NLP-assisted chart review still allows for human-in-the-loop (HITL) approaches for questionable classifications, and commercial LLMs (eg, Ollama models; ollama.org LLC, Fort Lauderdale, FL) can run on protected servers to ensure protected health information (PHI) compliance.28,29
Audio-Based ML in Surgery
In surgical applications, audio-based ML largely consists of voice recognition and transcription technologies. Scribing and documentation software often utilize audio-based ML to assist clinical documentation. Older systems like Dragon® Medical (Nuance Communications, Inc, Burlington, MA) use ML for simple speech-to-text transcription. 30 Newer “ambient AI” systems listen to clinical interactions and read clinical documentation, using NLP models to draft clinical documentation in real time. 30 Examples include DAX™ Copilot (Nuance Communications, Inc, Burlington, MA) and models implemented by The Permanente Medical Group (TPMG; Oakland, CA). 10 While these tools can reduce documentation burden, they carry risks: beyond transcription errors, models may introduce fabricated details (“hallucinations”), even documenting procedures that were never performed. 10 In an example by Mess et al 10 (2025), an ambient AI wrote “Capsules removed during surgery will be sent to pathology for examination,” in an email to a patient, though no capsulectomy during implant removal was performed. Beyond documentation, specific surgical implementations of audio-based ML have included detection of intraoperative phase and events based on audio signature (eg, table movement or electrocautery tones), and verification of preoperative time-out information.31,32
III. Intraoperative Applications of AI
Image- and Video-Based ML in Surgery
Computer vision (CV) is the AI discipline focusing on detection and classification of image and video data.
33
Operationally, CV takes the form of DL techniques such as convolutional neural networks (CNNs) and vision transformers.33-35 CV is of particular interest in minimally invasive surgery (MIS), where existing video-based operative techniques make CV integration a natural adjunct.33-35 Initial CV applications included operative phase recognition, such as recognizing the critical view of safety (CVS) in cholecystectomy, but recent efforts have sought real-time integration, such as detailed on-screen overlays (Figure 4) that assess operative difficulty and technique, aiding communication with surgical trainees and operative team members.33,36 CV is also a critical element of research into autonomous surgical robotics, such as the Hierarchical Surgical Robot Transformer (SRT-H) model from Kim et al
37
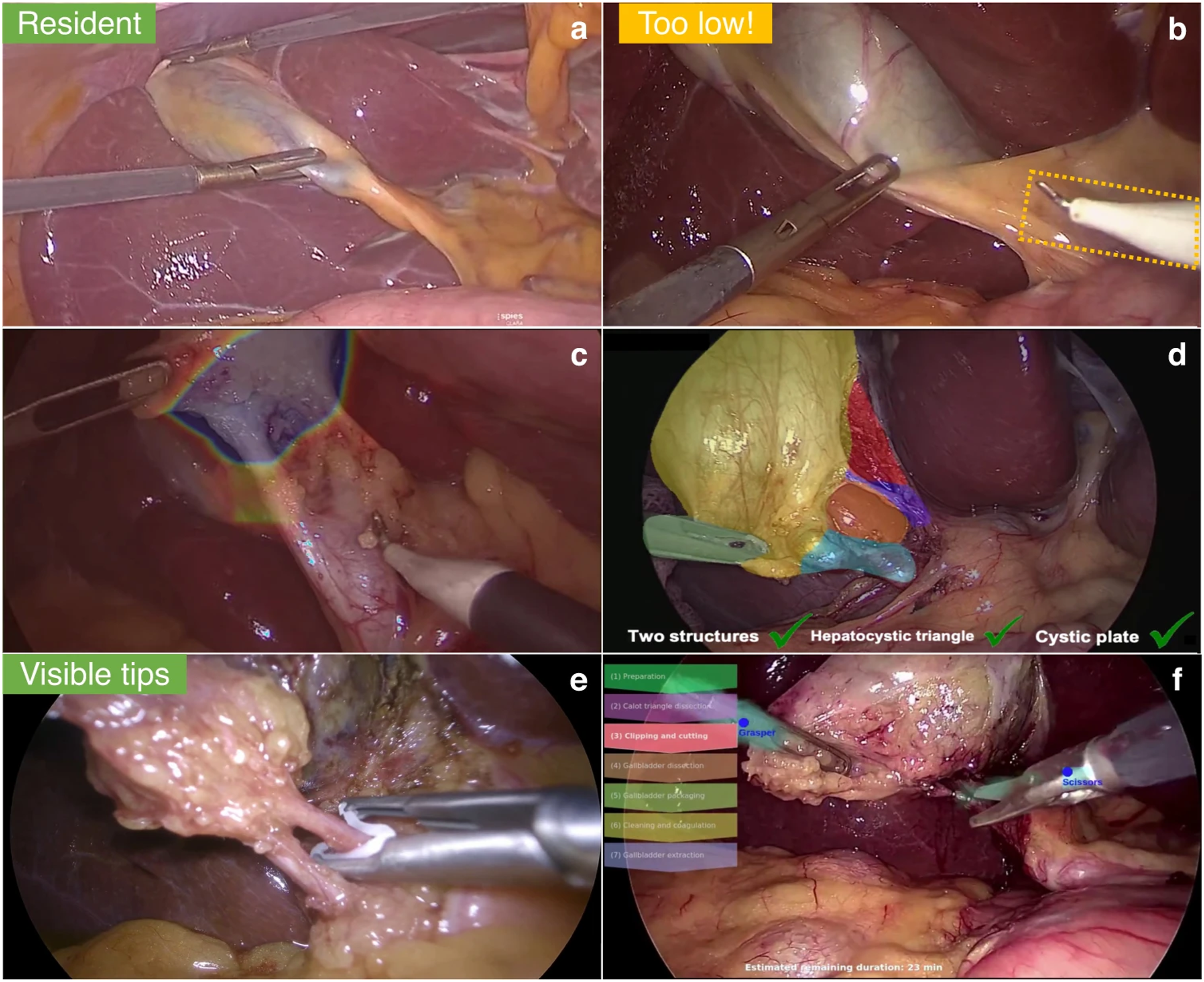
(2025), which autonomously performed certain steps of a simulated robotic-assisted laparoscopic cholecystectomy. Examples of Potential Computer Vision (CV) Based Overlays, as They Might be Integrated Into Laparoscopic Surgical Visualization Systems in the Future, Using Robotic-Assisted Laparoscopic Cholecystectomy in This example. Potential Applications Include (A) Rating of Expected Procedure Difficulty Based on Local Anatomy, in This Case Rated “Resident” Difficulty; (B) Issuing Warnings for Dissection Into Potentially Unsafe Areas; (C) a Heatmap-Style Overlay of Safe Area to Begin Dissection; (D) a Color-Coded CV-Based Identification of Elements of the Critical View of Safety, With On-Screen Checklist; (E) On-Screen Reminders for Proper Clip Application, as Might be Used in a Teaching Context; (F) an On-Screen Indicator of Procedure Steps, which May Help Assist Surgical Technologists, Anesthesia, Circulator Nursing, etc. Image Reproduced Under Creative Commons 4.0 CC-BY Open License From Mascagni et Al (2022), Figure 2.
33
Emerging Surgical AI Models
Much of the recent intraoperative ML literature focuses on laparoscopic cholecystectomy (LC). As one of the most common surgeries in the United States, LC is particularly well-suited to ML given its standardized workflow, relatively straightforward anatomy, and clear procedural endpoints: achieving the critical view of safety (CVS), clipping, and dividing the cystic duct and artery. Robotic-assisted LC (r-LC) further expands available data sets and provides a platform for ML integration. Per Mascagni et al, 33 laparoscopic procedures are natural choices for CV models given their consistent steps and visual structure, making LC a recurring testbed for surgical AI.
Autonomous Robotic Cholecystectomy
In testing, SRT-H completed grasping, clipping, and dividing the cystic duct and artery in eight ex-vivo porcine specimens (10% excluded for variant anatomy) with 100% accuracy. 37 Average task time was 5 minutes 17 seconds, which was slower than expert-operated dVRK, but with smoother and more efficient instrument paths. Notably, SRT-H did not perform dissection or skeletonization of the hepatocystic triangle, dissection of the gallbladder off the cystic plate, or specimen removal. SRT-H completed all procedure steps with 100% accuracy across all eight specimens. 37
SRT-H demonstrates an effective pathway toward task-specific automation of operative tasks in surgery. 37 However, SRT-H has not addressed common intraoperative challenges such as bleeding, adhesiolysis, obscured visualization, or variant anatomy. These limitations underscore the considerable gap between controlled ex-vivo tasks and safe in-vivo autonomous surgery; overcoming such challenges is a prerequisite for the futuristic concept of AI-driven autonomous surgery.
Safe Zones for Laparoscopic Dissection
Protserov et al 34 (2024) sought to create and deploy a DL semantic segmentation model to identify safe (“go”) and unsafe (“no-go”) zones for dissection in LC video feeds. Semantic segmentation assigns each pixel to an anatomical class (eg, liver, gallbladder, cystic duct), here reframed as safe (go zone), unsafe (no-go zone), or background (neither). 39 The Protserov et al 34 models label pixels with a probability of belonging to each of three classes; the highest-probability class becomes the prediction for the pixel.
The authors previously created “GoNoGoNet” for similar LC segmentation tasks, which was validated by an external panel-of-experts, and showed potential efficacy in avoiding bile duct injury.40-42 However, the new architectures developed in Protserov et al 34 (2024) offer several notable advancements. Their overall focus was to create LC segmentation models that were useful in broader contexts, including real-time use, resource-limited or remote settings, and on more diverse or underpowered hardware. The authors compared two segmentation architectures: U-Net, a biomedical CNN-based image segmentation architecture, and SegFormer, a transformer-based segmentation architecture.43,44 Both models included image processing techniques to facilitate prediction on wider arrays of video formats, for example, different laparoscope models, which vary by aspect ratio or other image features. Implementing data processing optimizations, including image downscaling and bandwidth throttling, ensuring accurate, low-latency, real-time image overlays could be obtained when communicating with the models hosted on university cloud servers, even with limited internet speeds.
The models utilized two separate data sets. Training and internal validation occurred on 289 open-source LC videos from 37 countries. External validation included 25 expert-annotated cases from the Society of American Gastrointestinal and Endoscopic Surgeons (SAGES) Safe Cholecystectomy Task Force. In external validation, U-Net achieved PPV of 82% and 92% for predicting go and no-go zones, respectively, and incorrectly labeled dangerous zones as go zones in 4% of pixels. SegFormer achieved PPV of 75% (go) and 92% (no-go), with 1% mislabeling of unsafe zones. Their flow-control bandwidth calibration allowed both models to achieve >60 frames per second (fps) and <100 millisecond image latency, via a 32 megabits per second (Mbps) internet connection, without image downscaling (United States median home broadband speeds were 285 Mbps and 48 Mbps for download and upload, respectively, as of July 2025). 45 For internet speeds as slow as 2 Mbps, as might be encountered in remote or resource-limited settings, image downscaling still allowed frame rates >60 fps and latency <150 milliseconds for both models, while only reducing various accuracy metrics by approximately 2-5%. Thus, both U-Net and SegFormer achieved usable predictive accuracy and sufficient speeds for real-time image overlay, even in places with slow internet access.
Both U-Net and SegFormer, as well as the PSPNet architecture from the authors’ prior GoNoGoNet model, are available online.41,46 The models allow real-time synchronous image overlay, streamed from laptops, laparoscopic video towers, or other internet-connected devices, as well as upload and prediction from pre-recorded operative video. The models also integrate a go zone threshold slider, allowing users to tune the minimum threshold to display go zones. Online, open-access model hosting facilitates validation studies in more diverse clinical populations.
Intraoperative Diagnosis
Chen et al 47 (2025) created a semantic segmentation model called AI laparoscopic exploration system (AiLES) to intraoperatively detect intra-abdominal metastases (IAMs) during diagnostic staging laparoscopy (DSL) for gastric cancer. The authors focused on small, occult IAM detection in a cohort of 100 gastric cancer patients. An expert surgeon gold standard was used, and AiLES was compared to both novice surgeons and five generalized image segmentation models.
AiLES was the most discriminative (Dice 0.76) and fastest-predicting (11 fps) ML model and was non-inferior to novice surgeon detection across IAM types, though instances of novice-missed but AiLES-detected IAMs were reported. AiLES achieved excellent detection (Dice ≥0.80) for uterine (Dice 0.93), mesenteric (Dice 0.80), single peritoneal (Dice 0.90), and “tiny” (≤5 mm; Dice 0.87) IAMs.
In gastric cancer, DSL is a definitive diagnostic step for peritoneal carcinomatosis, which portends treatment failure and up to 60% of gastric cancer mortality.48,49 DSL is prone to missing small, solitary, and peritoneal lesions, leading to under-staging and inappropriate treatment; AiLES excelled in detection of such lesions, and was non-inferior to surgical trainees.47-49 Current performance may have surgical education applications, and modest performance improvements may justify evaluation as an intraoperative diagnostic adjunct. AiLES architecture could also be suitable for training on surgical anatomy relevant to other procedures and tumor types. Image prediction latency was slower than that reported by Protserov et al, but the authors noted that 11 fps aligns with most surgical image segmentation models; the supplementary video qualitatively exhibits sufficient responsiveness for real-time intraoperative use.34,50 The authors’ model code is available by request.
Other Surgical AI Frontiers
The above examples highlight two objectives of surgical AI development: CV-driven safety tools (Protserov et al and Chen et al) and more “agentic” models capable of real-world action (SRT-H).34,37,47 Other CV applications include ML-based laparoscopic video-feed smoke removal, robotic instrument recognition, surgical phase, task, and workflow recognition, and segmentation of operative anatomy.39,51-55 Agentic models include the STAR model by Saeidi et al (2022), which demonstrated autonomous robotic hand-sewn porcine intestinal anastomosis, while the micro-STAR model by Haworth et al (2024) similarly performed ex-vivo vascular anastomosis.56,57 Gruijthuijsen et al (2022) autonomously targeted a rigid endoscope in a lab setting, while Ma et al (2019) demonstrated an autonomously tracked flexible laparoscope on the dVRK system.58,59 These AI principles have been expanded to improve surgical education and trainee assessment—as an example, Kawaharazuka et al 60 (2024) reported autonomous performance on the peg transfer task of the Fundamentals of Laparoscopic Surgery® course (SAGES, Los Angeles, CA; ACS, Chicago, IL). A detailed discussion of AI in contemporary surgical education is reviewed in an accompanying article as part of this symposium. 61 Together, these advances suggest a trajectory toward increasingly autonomous performance, though clinical translation is still in evolution.
Ethical Considerations for Implementing Surgical AI
Clinical benefits offered by surgical AI entail novel ethical risks, warranting additional ethical considerations and protections. AI can “learn” human sociocultural biases to which models are exposed during training, contributing to disparate or inequitable health outcomes. 62
AI use in surgical research also raises questions regarding authorship; likewise, unique methodological aspects of ML research require new transparency standards for reporting results; to this end, ML-specific reporting guidelines have been promulgated. AI use as clinical adjuncts have led to codification of new regulatory frameworks, which may regulate Software as a Medical Device (SaMD). 63 Finally, use of surgical AI may carry novel medicolegal implications, particularly as AI models gain agentic functionalities. Ethical aspects of surgical AI are addressed in detail in our upcoming work on evolving ethical challenges of AI in surgical research.
Conclusion
Although most agentic surgical AI systems remain confined to the laboratory, progress is advancing rapidly. Surgical machine learning has expanded far beyond prognostic modeling, with deep learning now enabling real-time intraoperative tools that enhance safety, efficiency, and training, particularly in laparoscopic and robotic-assisted surgery. Early work in laparoscopic cholecystectomy, a standardized and well-defined operation, illustrates how common procedures can serve as testbeds for broader applications. Many emerging models rely on convergent architectures, suggesting that once validated, proven designs could be rapidly adapted across diverse operations. These advances highlight that surgical ML is not only a computer science challenge but a clinical one, and as capabilities move closer to real-world integration, a working knowledge of surgical AI is becoming essential to modern surgical practice.
Footnotes
Author Contributions
DL, VS – conceptualization, draft of preliminary manuscript, revision, approval of final version, NR, PN – conceptualization, critical review of manuscript with revision for incorporating intellectual content, approval of final version, AR – senior author, conceptualization, critical review of manuscript with revision for incorporating intellectual content, approval of final version.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.