
Abstract
Machine learning (ML), a branch of artificial intelligence, is rapidly transforming surgical complication and outcome prediction. Unlike traditional statistical approaches, ML can learn complex, nonlinear relationships across multiple variables, enabling more accurate and adaptable prognostication. Emerging ML-based tools have demonstrated strong performance across diverse surgical specialties, often surpassing conventional risk models. However, challenges remain, including opaque “black box” outputs, diminished performance during external validation, difficulty modeling rare events, and dependence on tabular data. These limitations can be mitigated but demand thoughtful design and rigorous validation. Importantly, ML introduces distinct methodological considerations unfamiliar to many surgeons. Successful clinical integration requires robust external validation and transparent sharing of trained models to ensure reproducibility and generalizability across diverse cohorts. By enhancing the precision of risk prediction, ML holds the potential to guide patient selection, optimize perioperative care, and strengthen shared decision-making between patients and surgeons.
Keywords
Introduction
Artificial intelligence (AI) is a rapidly advancing field that builds computer programs that are able to perform tasks which would normally require human intelligence. 1 AI research incorporates aspects of neuroscience, biology, statistics, linear algebra, and computer science.1,2 Over the past few years, AI applications in medicine have emerged and grown exponentially, integrating AI closely with the daily functioning of healthcare systems, teams, and personnel.2,3
Machine learning (ML) is a sub-discipline of AI that uses algorithms that autonomously learn from datasets. A wide range of ML algorithms have been developed, many of which are adaptations of traditional statistical methods designed to leverage modern computing power. 4 Recently, much of the focus in ML has been on applications of the neural network (NN) family of algorithms, which form the foundation of the deep learning (DL) field of ML. 3 The concept of NNs, first described in 1958 as a simplified model of neuronal connections in the human brain, was initially limited by computational constraints.5,6 However, the emergence of the “AlexNet” image classification architecture in 2012 demonstrated the transformative potential of DL when coupled with modern computing capabilities.6,7
The optimal integration of AI into medical decision-making is a complex and evolving challenge. The rapid advancement of DL has led to the commercial success of large language models (LLMs) such as ChatGPT (OpenAI, Inc, San Francisco, CA) and Grok (xAI Corp., Palo Alto, CA). While these models perform well on structured tasks such as United States Medical Licensing Exam (USMLE) questions, translating this success to the heterogenous and nuanced presentations of real-world clinical scenarios has proven far more difficult.1,8,9
ML vs Conventional Statistical Approaches
ML approaches to medical outcome prediction can be contrasted with conventional statistical approaches. In fact, many algorithms (such as linear and logistic regression) can be applied within either framework towards predicting outcomes.9-11
Shortcomings of Conventional Statistics
Compared with conventional statistics, modern ML algorithms can model subtle multifactorial effects that might be overlooked by simpler models or human users.9,11 Whereas a conventional statistician may opt for conservative selection of variables into a model, ML practitioners adopt a broader, relatively liberal approach during feature selection, thereby prioritizing predictive accuracy.9,11 This can lead to greater accuracy at outcome prediction by ML, compared with traditional techniques. 9 This contrast also exemplifies a few inherent shortcomings.
Conventional linear and logistic regression assume additive and either linear or log-linear relationships between predictors and outcomes.12-14 Additive models assume that each predictor is independent of the presence, absence, or magnitude of effect on the other predictors in the model. 14 Linearity assumes that a change in a predictor has a uniform effect regardless of baseline; for example, the effect of a decrease in hemoglobin concentration from 8 to 5 g/dL likely confers more mortality risk than a decrease from 15 to 12 g/dL, despite both reflecting a 3 g/dL decline.13,14 While simpler ML models may also utilize additive linear modeling techniques, many widely used algorithms are nonlinear and nonadditive.11-15
Example of a Conventional Statistical Approach
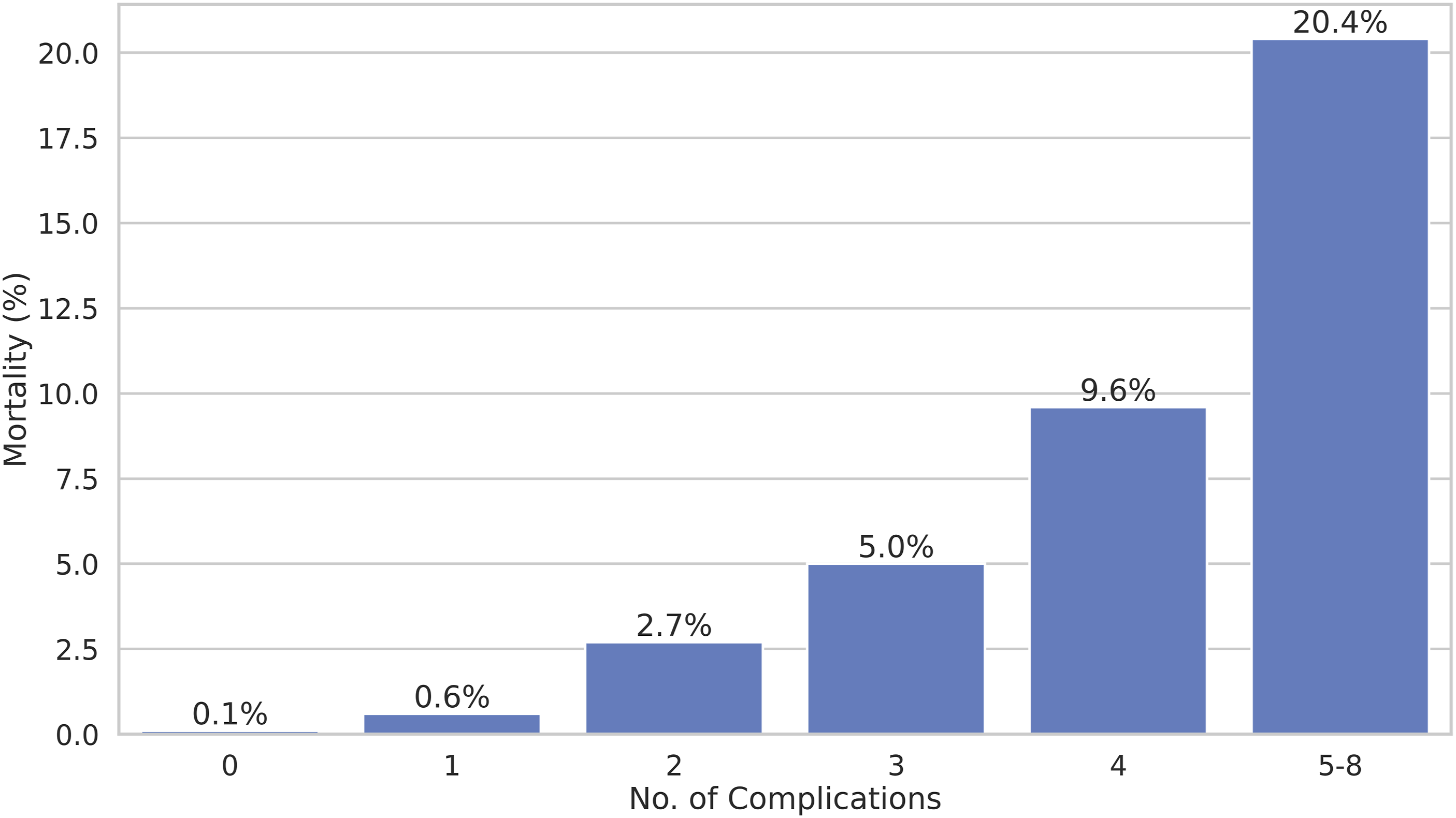
An illustrative example of the limitations of conventional statistics can be seen in a 2018 study by Merath et al that reported how multiple comorbid perioperative complications following hepatopancreatic surgery synergistically increase risk of 30-day mortality.
16
The authors found that while the presence of a single postoperative complication increased 30-day mortality by only 0.1% to 0.6%, subsequent complications increased mortality exponentially (Figure 1). Capturing such nonlinear effects in logistic regression would require the use of polynomial terms, which quickly complicates modeling even for a single predictor.
17
Additionally, the authors also analyzed the interactional effects between pairs of complications on mortality. Given 8 complications, a full exploration would require 28 separate regression models for bivariate interactions, with even greater complexity for higher-order combinations. Exponential Increase in Mortality Risk From Additional Postoperative Complications. This Nonlinear Effect can be Learned by Most Machine Learning Models, but can be Difficult to Model via Conventional Statistics. Created Based on Data From Merath et al (2018).
16
While conventional regression can be tuned to account for nonlinear and interactional effects, this requires prior knowledge of the functional form (eg, quadratic or square-root terms) or labor-intensive trial-and-error experimentation.17,18 Similarly, since the number of possible interactions increases following a power law as more predictors are considered, modeling these effects quickly becomes infeasible.17,19,20
Benefits of ML for Surgical Outcome Prediction
ML approaches address the aforementioned challenges by natively capturing nonlinear and interactional effects during model training. Nonparametric methods, such as decision trees (DTs) and neural networks (NNs), are particularly adept at identifying such relationships.12-14,21 Even in the case that a researcher presumes a relatively straightforward linear and additive relationship, models like NNs can also approximate regression functions; indeed, the universal approximation theorem in DL states that, given a sufficiently complex NN, any continuous mathematical function can be approximated to an arbitrary degree of accuracy.22-25 This inherent flexibility is a key advantage of ML over conventional techniques.
A unique benefit of ML is integrated validation testing. Typically, the datasets are randomly subdivided into a training and testing set in a 70:30 or 80:20 ratio. 26 Models are trained exclusively on the training dataset, and performance is then assessed on the testing dataset—referred to here as “internal validation.”26,27 Robust studies also evaluate external validation (generalizability), either temporally (new time period) or geographically (different sites or multicenter).26,28
Comparison Example of an ML Approach
Building on their prior work, Merath et al (2019) developed a DT model that predicted 30-day morbidity after hepatic, pancreatic, and colorectal surgery. 27 This model achieved predictive performance comparable to the regression-based American College of Surgeons (ACS) National Surgical Quality Improvement Project (NSQIP) Surgical Risk Calculator (NSQIP-SRC). Due to statistical reporting differences, the accuracy of the 2019 DT-based study could not be directly compared to the authors’ 2018 regression-based study, but this example underscores how even a relatively simple ML model can match the predictive power of numerous regression models.16,27
Limitations of ML
“Black Box” Predictions
A persistent limitation of ML is its agnosticism toward causality: while models identify associations, they do not establish whether predictors directly cause outcomes.11,29 To generalize, where statisticians are concerned with P-values, odds ratios, and other measures of statistical significance and effect size, ML scientists are more concerned with predictive performance metrics such as calibration (eg, Brier score) and discrimination (eg, area under the receiver operating characteristic curve (AUROC)).11,15 While ML models often outperform conventional statistics in predictive accuracy, 11 complex models can function as “black boxes,” obscuring relationships driving their predictions.11,29 By contrast, conventional regression models are relatively transparent: linear and logistic regression can be expressed as straightforward equations, while DT models resemble intuitive decision trees, albeit constructed mathematically.15,30
Overfitting
More advanced ML approaches may use more complex variants of regression algorithms, such as least absolute shrinkage and selection operator (LASSO) regression, ridge regression, or elastic net regression. These algorithms implement “regularization,” which aims to reduce “overfitting,” whereby a model learns to predict its training data too precisely that it no longer generalizes to new cases. Such overfitting manifests as a significant performance decline when predicting on external validation datasets. 31 While these methods may enhance performance, they can make interpretation less intuitive.
Tabular Data
Certain ML algorithms, including advanced DL techniques, are known to underperform on tabular data, a common data format in clinical research. 32 Thus, surgical ML research often uses other algorithms that perform particularly well on tabular data common in medical research include random forest (RF) and gradient boosting machines (GBM) variants, which combine multiple DT models in parallel or series configurations, respectively, to improve accuracy.33,34 Two notable GBM implementations that have gained traction are the eXtreme Gradient Boosting (XGBoost) and Categorical Boosting (CatBoost) algorithms, as further discussed in our work on emerging AI models.33,35
Despite the complexity, ML models are often more efficient and scalable for capturing nonlinearities and interactions. When conventional regression becomes so complicated that clinicians must treat it as a de facto “black box,” the advantages of ML algorithms including automated modeling, streamlined evaluation, and better handling of complex relationships, become particularly evident.
Conventional Perioperative Risk Assessment Tools
Accurate perioperative risk prediction is central to patient counseling, operative decision-making, and outcome prognostication. Formalized risk-assessment tools are well established; examples include the American Society of Anesthesiologists (ASA) physical status classification and the American College of Surgeons (ACS) National Surgical Quality Improvement Project Surgical Risk Calculator (NSQIP-SRC).36,37
Subjective Risk-Assessment Tools
Subjective tools rely on clinician judgment and can vary between assessors (ie, they are nondeterministic). The ASA classification for instance, grades risk based on comorbidity severity as assessed by the anesthesiologist. 36 While clinically intuitive, the subjective reliance contributes to modest intra- and inter-rater reliability.10,36,38
Scoring-Based Tools
Objective scoring systems are deterministic: identical inputs yield identical outputs. The Surgical Apgar Score (SAS) exemplifies this approach, using intraoperative variables translated into outcomes through univariate regression. 39 Although simple and reproducible, SAS has only moderate discriminative accuracy; a 2022 meta-analysis found a pooled AUROC (C-statistic) of only 0.63 for mortality. 40
Conventional Multivariable Regression Models
Multivariable regression models enhanced risk prediction by incorporating numerous preoperative variables. The original regression-based NSQIP-SRC achieved strong discrimination (AUROC 0.944 for mortality, 0.816 for morbidity) with subsequent studies reporting consistent values.37,41-43 Similarly, the Physiological and Operative Severity Score for the enUmeration of Mortality and morbidity (POSSUM) is a regression-based model and its Portsmouth-POSSUM (P-POSSUM) variant achieved respectable mortality prediction (AUROC 0.89 for mortality, 0.67-0.77 for morbidity).44,45 However, because these methods assume additive linear or log-linear relationships, they may miss subtle nonlinear or multifactorial effects, leading to underperformance relative to modern ML approaches, particularly in nonelective surgery.9,13,41,43
ML-Based Perioperative Risk Assessment Tools—Recent Advances
ML Predictive Models for Surgical Outcomes

Abbreviations: AUROC, area under the receiver operating characteristic curve; ML, machine learning; NSQIP-SRC, National Surgical Quality Improvement Project Surgical Risk Calculator; DT, decision tree; R-NSQIP-SRC, regression-based National Surgical Quality Improvement Project Surgical Risk Calculator; POTTER, Predictive OpTimal Trees in Emergency Surgery Risk; XGBoost, eXtreme Gradient Boosting; ML-NSQIP-SRC, machine learning-based National Surgical Quality Improvement Project Surgical Risk Calculator; CatBoost, Categorical Boosting; APE, absolute percentage error; DL, deep learning; CPT, Current Procedural Terminology; logit, logistic regression; SSO, surgical site occurrence; MARS, multivariate adaptive regression splines; NN, neural network; SVM, support vector machine; RF, random forest; KNN, k-nearest neighbors; SSI, surgical site infection; GBM, gradient boosting machine; LASSO, least absolute shrinkage and selection operator; LOS, length of stay; AdaBoost, Adaptive Boosting; STS, Society of Thoracic Surgeons risk score; CABG, coronary artery bypass graft; AVR, aortic valve replacement; MVRepair, mitral valve repair; MALE, major adverse limb events; ASA, American Society of Anesthesiologists Physical Status Classification System; BRF, balanced random forest; PJI, periprosthetic joint infection; GOS, Glasgow Outcome Scale; SSL, self-supervised learning; IGTD + CNN, Image Generator for Tabular Data + Convolutional Neural Network; FT-Transformer, Feature Tokenizer Transformer; PPC, postoperative pulmonary complication.
aExternal validation AUROC reported when available, unless otherwise specified;
bConventional statistical or other non-machine-learning prediction tool.
Pooled Surgical Cohort ML Models
Several ML models have emerged to address the above noted limitations. The Predictive OpTimal Trees in Emergency Surgery Risk (POTTER; Interpretable AI, Cambridge, MA) model, introduced in 2018, uses a decision tree requiring 4-11 binary responses to estimate morbidity and mortality. Trained on the NSQIP data, POTTER outperformed regression-based NSQIP-SRC (mortality AUROC 0.916 vs 0.898; morbidity 0.841 vs 0.806) and has since shown consistent performance (AUC >0.80 across outcomes). 14
In 2023, Liu et al created an XGBoost model that matched regression-based NSQIP-SRC performance (mortality AUROC 0.949 vs 0.944; morbidity 0.767 vs 0.763). 41 XGBoost was subsequently adopted as the official NSQIP-SRC model in June 2023.41,42 The same authors in 2025 assessed a newer CatBoost algorithm and noted better calibration of XGBoost for mortality and of CatBoost for all-cause morbidity. 42
Comparisons suggest that ML-based NSQIP-SRC generally surpasses POTTER in mortality discrimination, while POTTER performs slightly better for morbidity.14,41,42,46 POTTER’s strengths include simplicity (fewer inputs) and interpretability which may aid patient communication, as well as an exact transparent decision tree used for outcome prediction14,37 Importantly, unlike NSQIP-SRC, POTTER was designed specifically for emergency surgeries.14,46
Neural Network Models
While neural network (NN) models have generally underperformed DT-based models on tabular data, a DL model by Bonde et al performed similarly to POTTER for mortality (AUROC 0.912 vs 0.920, respectively), and demonstrated a modest improvement for morbidity prediction (AUROC 0.878 vs 0.851).21,32 This DL model also exceeded the performance of the original regression-based NSQIP-SRC.21,37 However, this model has not been made available publicly and has not been directly compared to ML-based NSQIP-SRC. The future implications of DL-based prediction models and their comparison to DT-based models are discussed further in our work on emerging AI models.
General Surgery
Hassan et al (2022) evaluated 9 ML algorithms for predicting postoperative complications after ventral hernia repair in a single-center cohort. 47 The best-performing models achieved AUROC values of 0.71 for hernia recurrence, 0.75 for surgical site occurrence (SSO), and 0.74 for 30-day readmission, all of which consistently outperformed regression models. 47 Notably, their models incorporated surgical technique variables (including rectus muscle violation, wound class, bridged repair, and component separation), whereas many prior approaches considered only preoperative factors. These models, however, were not publicly available. 47
Wu et al 48 (2024) similarly tested 5 ML models for predicting both surgical site infection (SSI) and SSO following elective open inguinal hernia repair. Their RF model performed best for both SSI and SSO, achieving AUROCs of 0.849 and 0.740, respectively. These models also considered procedural factors, notably operative time and use of antibiotic prophylaxis. Both models are publicly accessible online, though no external validation has been reported. Both the SSO and SSI prediction models are hosted online, though no external validation studies of these models were identified.49,50
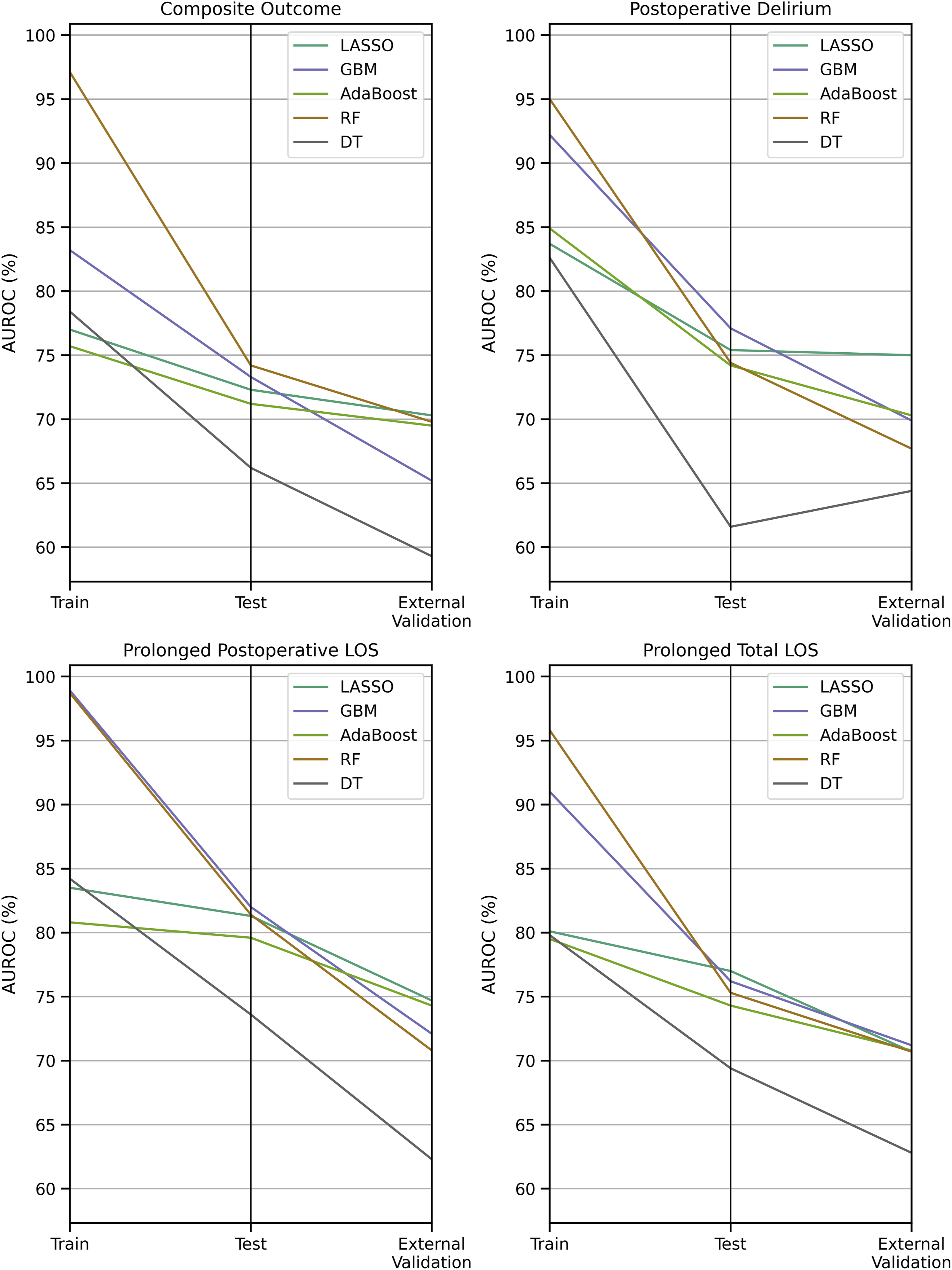
Choi et al (2023) tested 5 ML models in a ≥65-year-old general surgery population, with outcomes including a composite endpoint (90-day all-cause mortality or emergency department visit), prolonged postoperative stay, postoperative delirium, and prolonged total length of stay.
51
They included 21,766 patients in their model training datasets and internally validated on 5431 patients in their testing cohorts. The model was subsequently externally validated on a cohort of 32,857 patients from another hospital. While RF and gradient boosting (GBM) performed strongly in training and internal testing, they suffered a 4%-11% AUROC decline with external validation, suggesting overfitting (Figure 2).31,52 In contrast, LASSO regression was more stable and emerged as a top performer on external validation. This underscores the necessity of external validation before applying ML-based surgical risk models in clinical practice. Model Discrimination Degradation on Training vs Testing vs External Validation Datasets; Created Based on Data From Choi et al (2023).
51
Trauma Surgery
Du et al (2025) developed ML models to predict trauma-induced coagulopathy (TIC) in 2067 operative trauma patients across multiple centers. 53 Using perioperative demographics, injury features, labs, and intraoperative variables, random forest (RF) achieved the best performance (AUROC 0.820). External validation in 863 patients showed reduced accuracy (AUROC 0.73), likely reflecting inter-site heterogeneity and severe class imbalance (TIC incidence 25.4% vs 2.9%). This highlights a major challenge in medical ML: outcomes of interest often occur infrequently, impairing generalizability. 54
Xiong et al (2025) studied 10,023 trauma patients from the MIMIC-IV dataset for TIC prediction and validated their model on 3212 patients across 3 centers.55,56 RF again performed best, with stable discrimination across internal and external cohorts (AUROC 0.92 vs 0.91).53,55 This large-scale, multicenter design and code availability strengthen reproducibility, though models were not clinically deployed.55,57
TIC is associated with high mortality, massive transfusion, and multi-organ failure, making early recognition critical.53,55,58 While the above models remain research tools, they demonstrate how ML could enable earlier TIC identification and intervention.53,55,58
Cardiothoracic Surgery
Traditional risk models in cardiothoracic surgery, most notably the EuroSCORE II and Society of Thoracic Surgeons (STS) scores, estimate operative mortality using limited regression-based variables, with variable accuracy across populations.59-61
Weiss et al (2023) trained an XGBoost model using data from 6392 cardiac surgery patients, leveraging 4016 preoperative variables from their institutional electronic medical record (EMR). 62 Across 7 cardiac surgery types, the model achieved an AUROC of 0.978, outperforming STS risk scores. Although neither externally validated nor publicly shared, the study illustrates the potential of granular, institution-specific ML models that can utilize local EMR data beyond standardized registries.
Vascular Surgery
Li et al published 2 studies employing ML models for predicting postoperative outcomes following open vascular bypass procedures.63,64
In suprainguinal bypass (16,832 patients, Vascular Quality Initiative data), XGBoost predicted 1-year death or major adverse limb event (MALE) with AUROC 0.92 using preoperative data, improving to 0.98 when including postoperative data. Secondary outcomes such as revision, graft loss, and mortality were similarly predicted with AUROC >0.85 preoperatively and >0.95 postoperatively. 63
In infrainguinal bypass (24,309 NSQIP patients), XGBoost achieved AUROC >0.90 for most 30-day outcomes, including death, MALE, major cardiovascular events, MI, stroke, reintervention, amputation, and bleeding. In both studies, source code but not trained models were released. 64
While performance was strikingly high, the lack of external validation raises concerns of overfitting. These studies underscore the importance of external validation and open access to trained models to ensure reproducibility.31,52,61
Surgical Oncology
As discussed in the preceding section, Merath et al (2019) developed a DT model for postoperative complication rates in hepatic, pancreatic, and colorectal surgery. 27 Their model achieved AUROC 0.74 for 30-day morbidity, outperforming ASA classification (0.58) and regression-based NSQIP-SRC (0.71). AUROCs for individual complications ranged 0.76-0.98, demonstrating improved granularity compared with conventional tools.
Orthopedic Surgery
Most orthopedic ML models that were described in literature have remained limited to internal validation, with few undergoing external testing.
Chong et al (2025) predicted periprosthetic joint infection (PJI) after total knee arthroplasty using 3483 patients (81 infections).
65
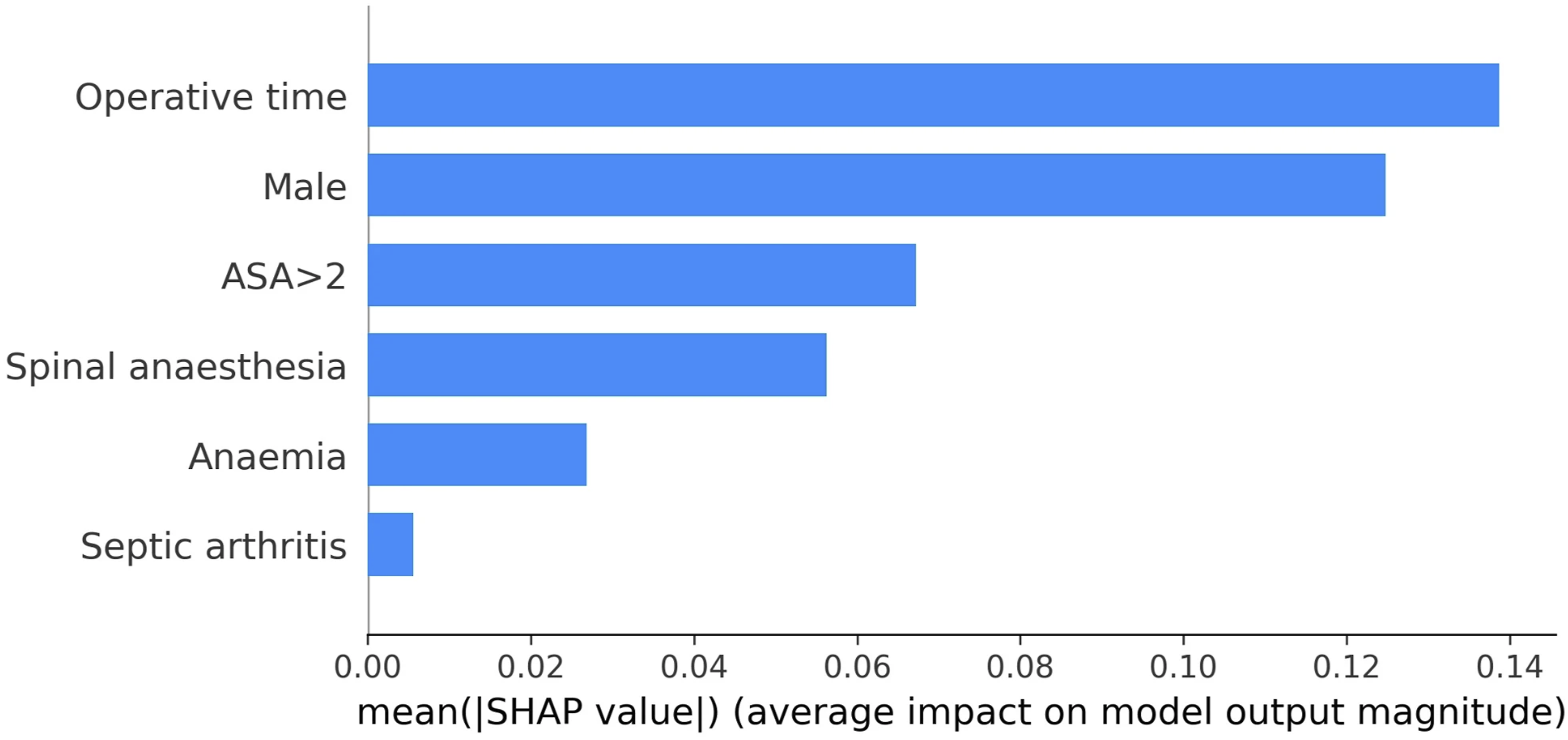
A balanced random forest (BRF) addressed class imbalance and achieved AUROC 0.963, outperforming prior regression and NN approaches.66,67 Chong et al also used Shapely Additive Explanations (SHAP) plots to visualize and explain individual predictors’ contributions to model predictions (Figure 3). Operative time, male sex, and ASA >2 were the strongest positive predictors of PJI, while spinal anesthesia was protective. No external validation was performed, nor was the model reproduced online. Shapely Additive Explanations (SHAP) Summary bar Plot Showing Relative Predictor Importance. Importance is Ranked by SHAP Value, which Measures the Average Effect a Predictor had on Determining the Model’s Overall Predictions. Reproduced With Permission From Springer Nature, Chong et al (2025), Figure 5.
65
While the Chong et al model performed well, methodological issues warrant caution. 65 Predictors were selected using regression on the full dataset, risking data leakage, where information from test patients influences feature selection. 28 By performing feature selection on the entire dataset, test set patients’ data can potentially inform which variables are selected for model inclusion. Per the taxonomy of data leakage defined by Kapoor et al (2023), “Feature selection on the entire dataset results in using information about which feature performs well on the test set to make a decision about which features should be included in the model.” 28
While we would not necessarily expect Chong et al’s regression results to differ drastically if applied to a 70%-80% training subsample of their cohort, it is worth noting that 5 of the 6 variables included into their models (Figure 3) had final regression P-values between 0.01 and 0.05. 65 The authors did not clearly disclose whether they utilized a completely separate test set (per explanation in Table 2 of original Chong et al), making it plausible that their reported AUROC does not come from internal evaluation on a completely unseen patient sample at all. 65 Such practices reduce reproducibility and highlight the need for rigorous validation and transparent ML methodology. 28
Neurosurgery
Yin et al (2024) tested 5 ML algorithms to predict discharge Glasgow Outcome Scale (GOS) after surgery for 416 moderate-to-severe TBI patients.
68
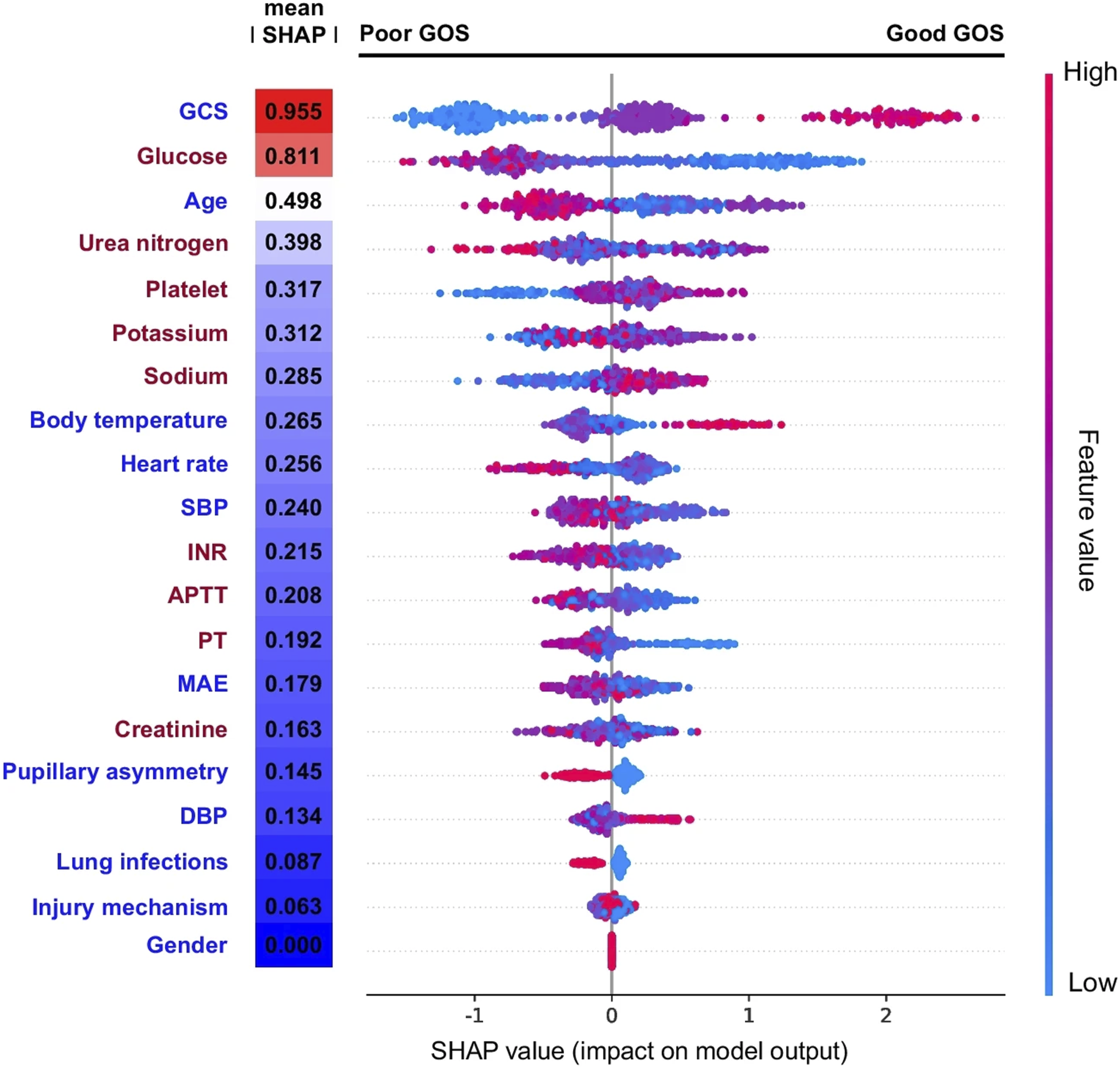
Temporal external validation 6 months later showed strong performance, with AUROCs of 0.861 (without labs) and 0.890 (with blood chemistry/coagulation values). SHAP visualization confirmed predictors such as high GCS consistently drove favorable outcome predictions (Figure 4). SHAP visualization to aid model comprehensibility is further explored in our work on emerging AI models. Shapely Additive Explanations (SHAP) Dotplot Showing Each Patient’s Predictor Values, With Red and Blue Dots Indicating Positive and Negative Predictor Values, Respectively (eg, Strong Red for Glasgow Coma Scale (GCS) Near 15). X-Axis Position Shows Positive or Negative Impact on GOS (Glasgow Outcome Scale) Prediction, Akin to a Forest Plot. Clustered Red/Blue Dots on Either Side of the Zero-Effect Line Indicate Consistent Predictor-Outcome Relationships. Strong Red Clustering (High GCS) on the Right Suggests High GCS Predicts Better GOS. Reproduced With Permission From Springer Nature, Yin et al (2024), Figure 4.
68
Xu et al (2025) developed models for predicting postoperative pulmonary complications (PPCs) in neurosurgical patients. 69 A DL neural network with 35 predictors performed best on external validation (AUROC 0.835), but a simplified LASSO-logistic regression model with 11 predictors achieved nearly identical accuracy (AUROC 0.831). Both models outperformed standard risk scores, including Assess respiratory RIsk in Surgical patients in CATalonia (ARISCAT; AUROC 0.672) and Laparoscopic Surgery Video Educational Guidelines (LAS VEGAS; AUROC 0.663). A nomogram derived from the regression model is hosted online and demonstrates how ML can translate into practical bedside tools. 70
The benefit of decompressive craniectomy for TBI remains debated, with prior work indicating lower mortality but greater rates of severe disability. 71 The findings by Yin et al (2025) may serve to guide the development of accurate predictive models, which can aid prognostication and targeted selection of the optimal operative candidates. 68 Similarly, the Xu et al work on predicting postoperative pulmonary complications in a broad neurosurgery cohort may facilitate early identification and management of at-risk patients. 69 Both studies provide examples of different yet effective approaches to understanding how ML models make predictions, which may aid understanding by both clinicians and patients.68,69
Plastic and Reconstructive Surgery
High-quality ML studies in plastic surgery are limited, though 2 recent investigations stand out.72,73
Braun et al (2023) developed an RF model to predict nipple-areolar complex (NAC) necrosis after nipple-sparing mastectomy in 181 patients. 72 Internal validation yielded AUROC 0.99, with temporal external validation on 62 patients showing AUROC 0.95. Meyer et al (2025) externally validated the same model in 388 patients from a different institution, and achieved an AUROC of 0.70 for predicting NAC necrosis. 73
These studies drive 2 important lessons on adopting ML in prediction of surgical complications and risk. First, exceptionally high AUROCs in small, internally validated datasets often reflect overfitting, with inevitable performance loss in new populations. 52 Secondly, this pair of studies demonstrate good methodology: the same model was subjected to temporal and multicenter external validation, showing that even imperfect but rigorously tested models can retain clinical value.72-74 Public release would further enable independent validation and refinement.
Call for Open Access to ML Models
A consistent theme across specialties is the need for open access to trained ML models. Source code alone is insufficient: finished models encode hundreds or thousands of tuned parameters derived from the training dataset. For the field to progress, models that demonstrate strong initial performance must be shared to allow replication, external validation, iterative improvement, and eventual clinical deployment. ML can only improve surgical practice if tested models move beyond proof-of-concept studies and into real-world clinical evaluation with external validation.
Conclusions
Machine learning has emerged as a transformative tool for predicting surgical complications, offering capabilities that extend beyond conventional statistical approaches. By capturing complex, nonlinear, and interactional effects inherent in surgical care, ML provides a more nuanced and reproducible framework for prognostication. As these models continue to mature, they hold the potential to enhance patient selection, refine risk-benefit discussions, and support truly informed shared decision-making. While ML carries both advantages and limitations, its thoughtful integration into practice can significantly elevate surgical precision, safety, and outcomes in the years to come.
Footnotes
Author Contributions
DL, VS – conceptualization, draft of preliminary manuscript, revision, approval of final version. MXM, NR, MM – conceptualization, critical review of manuscript with revision for incorporating intellectual content, approval of final version. AR – senior author, conceptualization, critical review of manuscript with revision for incorporating intellectual content, approval of final version
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.