
Abstract
The diffusion of behaviors and ideas is a core concern in many fields and highly relevant to collective action and innovation adoption. A common assumption is that well-connected individuals within social networks are especially influential and so are good targets to initiate behavioral interventions. Here, we argue that the effectiveness of network-based targeting depends on how social ties are organized within a network. We theorize that there is a structural “network paradox”: when social ties are concentrated around a small number of well-connected individuals, a focus on targeting those individuals becomes less effective at generating broad diffusion. We further argue that this paradox is especially pronounced for behaviors that require high levels of social reinforcement to spread. We conducted a three-part study including theoretical analysis, empirical analysis based on a randomized field trial of health practices in Honduras, and simulations. Across all three studies, the results highlight the critical role of network structure in shaping diffusion dynamics under targeting protocols that privilege individuals with more ties. Such protocols may fail when those individuals are clustered together. Our findings have implications for understanding leadership and influence, innovation, public health and developmental economic interventions, and marketing.
Introduction
Well-connected individuals, sometimes called “influentials” or “opinion leaders,” have long been central to theories of social influence and diffusion. Identifying and understanding how such well-connected individuals promote information diffusion and social change is relevant to a wide range of social settings, such as influencing public opinion (Katz and Lazarsfeld 1955), spurring technological innovation (Rogers 2003), promoting public health behaviors (Kim et al. 2015; Valente and Pumpuang 2007), initiating new religions (Becker et al. 2020), marketing new products (Iyengar, Van Den Bulte, and Valente 2011), and understanding online influence (Aral 2021). Randomized controlled field trials have targeted well-connected individuals as initial adopters to facilitate the spread of desirable behavior or information, such as health-promoting practices or knowledge (Airoldi and Christakis 2024; Alexander et al. 2022; Campbell et al. 2008; Kim et al. 2015; Li et al. 2013).
Intuitively, well-connected individuals should promote diffusion because they connect to many people and can generate more influence. However, empirical research provides inconsistent results on whether targeting well-connected individuals improves diffusion (Campbell et al. 2008; Kim et al. 2015; Li et al. 2013; Majumdar, Tsuyuki, and McAlister 2007; NIMH Collaborative HIV/STD Prevention Trial Group 2010), highlighting a puzzle—why do strategies targeting well-connected actors sometimes fail to deliver substantial diffusion outcomes?
Such mixed findings raise questions about when and how people can be structurally influential, and for which outcomes, and in particular about the relationship between network structure and influence. Here, we explore a “network paradox”: the concentration of network ties around well-connected actors in some naturally occurring social networks can undermine these actors’ special ability to drive large-scale diffusion. Our core proposition is that the effectiveness of targeting well-connected individuals declines as social ties become more concentrated around them, particularly for behaviors requiring high-threshold adoption (i.e., adoption that requires reinforcement from many, rather than just a few, neighbors). In such settings, targeting central actors can yield worse diffusion outcomes, even though those actors are individually influential.
First, we conduct a theoretical analysis to illustrate how network structures can alter the effectiveness of targeting well-connected actors. Second, we analyze empirical data from a large-scale intervention (involving 5,773 people in 32 villages in Honduras [Kim et al. 2015]) to assess how diffusion outcomes vary with network concentration around well-connected actors (i.e., the extent to which a network is “hubby” as measured by the Barabasi-Albert parameter) and behavioral thresholds. Finally, we perform simulation experiments to test the relationship between network structure, adoption thresholds, and targeting strategies. Our results indicate that the details of network structure are essential when assessing the effectiveness of using well-connected individuals as targets of interventions to promote change.
Opinion Leadership and its Structural Network Characteristics
The literature on opinion leadership is one of the most relevant to understanding how well-connected actors in a network can propel change. In the 1950s, the two-step flow theory of communication argued that mass media does not directly influence public opinion. Instead, critical actors in society, or “opinion leaders,” actively consume media knowledge and spread this information to others (Katz and Lazarsfeld 1955). Expanding on the idea of opinion leadership, in his model of how innovation diffuses in society, Rogers (2003) identified opinion leaders as critical change actors. These opinion leaders often possess distinct characteristics, such as credibility, knowledge, or socioeconomic status, leading them to have disproportionate influence (Hsiao and Pfaff 2022).
Our work focuses on the structural properties of potential opinion leaders. While such actors are structurally positioned to exert broad influence through their disproportionate number of ties, this does not necessarily mean they are also personally inclined to adopt new behaviors early or to champion change (Aral and Walker 2012; Battilana and Casciaro 2012; Beaman et al. 2021; Christakis and Fowler 2009; Shakya, Christakis, and Fowler 2015). A person can be influential by virtue of their network position even if they are cautious, resistant, or slow to innovate themselves. This distinction highlights the difference between individuals’ personal willingness to adopt innovations and their structural capacity to promote diffusion once adoption occurs, which is our main focus here.
The structural network perspective posits that the way social ties are organized (the network structure) can shape both collective dynamics and individual behavior (Christakis and Fowler 2009; Martin 2009; Wasserman and Faust 1994). A prominent example is how “long ties,” or ties beyond one’s more intimate social circle, can provide unique informational access that enables the flow of novel information and opportunities (Granovetter 1973). Furthermore, structural network characteristics (including antagonistic ties) and other characteristics (e.g., credibility) may be related, as structural network positions may provide the basis of interpersonal influence (Brass 1984; Becker et al. 2026; Ghasemian and Christakis 2024).
Opinion leaders may possess certain structural positions in a network that enable them to exert social influence. Different scholars propose different structural network characteristics to identify such people (Burt 1999; Kitsak et al. 2010; Valente and Davis 1999), but the predominant way of characterizing the network position of opinion leaders is the number of ties, also known as degree centrality (Katz and Lazarsfeld 1955; Kwak et al. 2010; Rogers 2003; Valente and Pumpuang 2007). Early work by Katz and Lazarsfeld (1955) suggested that individuals with many social ties are often opinion leaders. Rogers (2003) also shows that the number of ties is a common indicator of leadership in agricultural networks. Valente and Pumpuang (2007) argue that using the number of ties to indicate opinion leadership yields valid and reliable results. Campbell and colleagues (2008) used the number of ties to select opinion leaders to initiate the intervention of an anti-smoking program. Iyengar, Van Den Bulte, and Valente (2011) also used the number of ties to indicate opinion leadership in a product diffusion setting. Risselada, Verhoef, and Bijmolt (2016) found that degree centrality is a good indicator of identifying opinion leaders in marketing campaigns. In social media studies, Kwak and colleagues (2010) found online influencers by calculating the number of followers and retweets. Keuchenius and Mügge (2021) defined opinion leaders in a scholarly community as authors who are well-connected in a citation network. And an appealing approach that can identify high-degree individuals without having to map network sociocentrically exploits the friendship paradox, which is the observation that “your friends have more friends than you do” (on average) (Airoldi and Christakis 2024; Christakis and Fowler 2010; Feld 1991; Kim et al. 2015).
Focusing on the number of ties has several appealing features. First, it is simple, as it is intuitive to conceive individuals with more ties as being more influential; moreover, other centrality measures, such as closeness centrality or betweenness centrality, are more complicated to calculate (Freeman 1977). Second, prior work has shown that using more complex centrality measures to identify opinion leaders does not outperform the simple measure of the number of ties (Van Woudenberg et al. 2019). Third, the number of ties is a building block for more complicated algorithms for identifying opinion leaders, such as combining different network measures (Khan, Ata, and Rajput 2015). Finally, and most important, number of ties is by far the most utilized method to identify opinion leadership via structural network positions (Katz and Lazarsfeld 1955; Kwak et al. 2010; Rogers 2003; Valente and Pumpuang 2007), especially in intervention settings (Campbell et al. 2008; Kelly 2004; Kim et al. 2015).
The Role of Well-Connected Actors in Network Diffusion
Social diffusion studies propose that adopting new ideas or behavior happens incrementally (Coleman, Katz, and Menzel 1966; Rogers 2003; Strang and Soule 1998). Diffusion can occur through many pathways, such as via mass media or over geographic distance (Myers 2000; Strang and Tuma 1993; Tolnay 1995), but relevant to this study is the process of diffusion through social networks (Burt 1987; Centola and Macy 2007; Christakis and Fowler 2007; Valente 1996; Watts and Strogatz 1998). Social ties between actors can serve as the conduit for diffusion through many mechanisms, including peer pressure and social influence, information transmission, high trust and credibility in people one has ties with (Coleman et al. 1966), repeated exposure within clusters (Burt 1987), and emotional contagion (Fowler and Christakis 2008). Mostly regardless of the mechanism, individuals with more ties are generally expected to exert greater influence in diffusion processes. A person with one tie can only put peer pressure or foster social contagion on one person, whereas a person with two ties can influence two people. Thus, high-degree actors should be more influential in network diffusion processes.
Existing research advances two related but distinct arguments about the role of highly connected actors in diffusion. The simpler version is that high-degree actors will be critical in facilitating diffusion because they have more ties. However, such an argument has received mixed support. Iyengar, Van Den Bulte, Eichert, and West (2011) found that high-degree actors are more influential in adopting new products in a pharmaceutical setting (see also Christakis and Fowler 2011). On the other hand, Watts and Dodds (2007) argue that highly connected individuals play a limited role in generating large-scale diffusion cascades. Instead, widespread diffusion depends on the participation of many actors who are not necessarily high-degree actors but are willing to adopt early. In a study of media preferences, Friemel (2015) found that opinion leaders are not more influential than other actors, after accounting for network selection.
A more nuanced perspective specifies that if high-degree actors are early adopters, they can be powerful proponents of the diffusion of new behavior. Work by Valente and colleagues (Valente and Davis 1999; Valente and Pumpuang 2007; Valente and Vega Yon 2020) shows that the spread of new behavior significantly increases if high-degree nodes are the first to adopt. Multiple intervention programs have adopted this approach of targeting high-degree actors in networks (Campbell et al. 2008; Kim et al. 2015; Li et al. 2013). Empirically-grounded simulation approaches (Lakon et al. 2025; McMillan and Schaefer 2021) use estimates from longitudinal network data to simulate diffusion outcomes of health behaviors, such as smoking or drinking, and find that targeting well-connected individuals lowers the prevalence of such behaviors, in keeping with empirical estimates (Christakis and Fowler 2008; Rosenquist et al. 2010). A focus on connectedness and high degree is also a major rationale for the more widely used but cheaper “popular opinion leader” (POL) intervention model, which aims to identify well-connected people by asking participants to nominate popular people as a proxy of connectedness, instead of going through the formal process of collecting network data and calculating degree distributions (Banerjee et al. 2013; Kelly et al. 1991; Quinn 2020). 1 As Quinn (2020:3291) states, “the POL model identifies socially influential members of a population who have sufficient large social networks. These individuals are then trained in how to effectively communicate risk reduction strategies to their peers during everyday conversations and are able to establish momentum as a community social movement.”
Despite the popularity of targeting high-degree actors for innovation diffusion, evidence regarding its effectiveness is inconsistent at best. Some studies find that targeting high-degree actors in a social network can achieve desirable diffusion outcomes (Campbell et al. 2008; Li et al. 2013; Majumdar et al. 2007). Other studies, however, find that intervention efforts targeting opinion leaders are not significantly better, and sometimes even worse, than targeting random people in a network depending on the outcome (Kim et al. 2015; NIMH Collaborative HIV/STD Prevention Trial Group 2010). Results from simulation work also vary. For example, Valente and Davis (1999) show that targeting high-degree actors boosts diffusion, but Watts and Dodds (2007) find that targeting high-degree actors has limited influence compared to targeting other actors. Similar to the empirical studies, these simulation studies have limited considerations of network structure.
Valente and Vega Yon’s (2020) simulations are closer to this article’s goals, as they provided a broad mapping of diffusion outcomes across different network structures, seeding strategies, influence processes, and threshold distribution. We extend prior simulation studies by theorizing and testing a specific mechanism of the structural paradox of targeting high-degree actors. As we will argue, hubs/opinion leaders often have more influence compared to those who are more socially isolated, but network structures where ties are concentrated toward such hubs are less conducive to diffusion and offer less benefit from targeting hubs. Thus, the advantage of targeting hubs decreases with degree inequality and adoption thresholds. 2 By “adoption threshold,” we follow the framework of complex contagion and conceptualize the adoption threshold as the minimum proportion of an individual’s network contacts whose prior adoption is required to trigger their own adoption (Centola 2018; Centola and Macy 2007).
Understanding whether targeting high-degree actors indeed facilitates diffusion has significant consequences. As Holliday and colleagues (2016) argue, collecting network data is costly. If the intervention effects of targeting high-degree actors are not significantly better than those of other methods, such as randomly targeting nodes, resources may be better spent elsewhere—although efficient alternatives to collecting network data do exist (Airoldi and Christakis 2024; Alexander et al. 2022). Furthermore, actors central in a network are often more resistant to change and slow to adopt innovations (Aral and Walker 2012; Battilana and Casciaro 2012; Beaman et al. 2021; Shakya et al. 2015), and it may be more costly to persuade such actors to become initial adopters of an innovation.
Main Proposition and Hypotheses: The Diffusion Paradox of Targeting Well-Connected Individuals
We contend that instead of the simple question of whether targeting high-degree actors facilitates diffusion, we should ask under which structural network conditions does targeting high-degree actors facilitate diffusion. A longstanding literature contends that the structure of social networks determines the extent to which diffusion is successful (Barabási 2009; Burt 1987; Centola and Macy 2007; Christakis and Fowler 2009; Moody and White 2003; Rand et al. 2014; Watts and Strogatz 1998).
Network structures differ in how unevenly social ties are distributed, ranging from relatively egalitarian networks to those dominated by a few highly connected actors. Consider a scale-free network (Barabási 2009; Barabási and Bonabeau 2003), in which social ties are highly unequal. A critical structural network property of the scale-free network is a tendency for degree concentration (i.e., formally the “preferential attachment” mechanism), whereby new nodes are more likely to connect to existing nodes with higher degrees, leading to a power-law distribution of degree. As a result, a small number of actors accumulate many ties, while most actors remain less connected. The scale-free network structure has been widely used to describe situations where a few opinion leaders receive disproportionate ties (Barabási and Bonabeau 2003; Hsiao 2021; Katz and Heere 2013; Siegel 2009). In fact, Siegel (2009) explicitly labels the scale-free network structure as an “opinion leader network” structure.
However, a critical insight regarding scale-free networks is that, while network ties can concentrate around a few actors (opinion leaders), the degree of such concentration of ties can vary across populations according to a scaling parameter. More formally, if a degree distribution follows a power law distribution, then P(X = x) is proportional to Main Proposition: The diffusion outcome of targeting high-degree actors becomes worse as network ties become more concentrated around high-degree actors.
At first sight, such a proposition is counterintuitive: the logic of targeting high-degree actors is that they are opinion leaders with many ties to others in a network. If so, the more ties such actors have in a network, the more successful diffusion should be. For instance, say an intervention program targets five people as initial adopters. If these five actors can reach 40 people, the intervention program should fare better than another scenario where these five actors can reach only 10 people.
However, we contend that diffusion might become suboptimal when network ties are concentrated around a few other actors for several reasons. First, when the network structure is one where ties are more concentrated around high-degree actors, clusters of multiple overlapping ties are less likely. If most network ties are connected to one or two opinion leaders, it reduces the probability that clustered circles of small groups form, as the “followers” have fewer ties among each other. Such clusters can be critical to facilitate certain kinds of diffusion, because clusters generate multiple social reinforcements required to overcome the barrier of adopting new behavior, especially in high-threshold behavior (Centola and Macy 2007; Christakis and Fowler 2009; Valente 1996). The theory of “complex contagions” (Centola 2018; Centola and Macy 2007) illustrates this logic well, as it posits that diffusion outcomes depend on two factors: threshold and clustering. Threshold indicates how much exposure an individual needs before adopting a behavior. High-threshold behavior requires multiple social reinforcement. Clustering, or tightly-knit groups in a network, facilitates diffusion by providing the necessary local reinforcement to overcome high thresholds, thus fostering the spread of high-threshold behavior.
As such, this prediction stands in contrast to a large literature that contends scale-free networks with high degree concentration are beneficial to diffusion (Barabási and Bonabeau 2003; Esquivel-Gómez and Barajas-Ramírez 2024; Lin and Li 2010; Pastor-Satorras and Vespignani 2001). These empirical cases, which examine the spread of phenomena such as diseases, computer viruses, and knowledge, fit the pattern of low-threshold dynamics, where as few as one contact can substantially increase diffusion. If degree concentration is high, the high-degree actors (hubs) with many connections can shorten paths, increase exposure, and facilitate diffusion. However, for other outcomes with high thresholds, such as new health practices or innovations, what may matter is not simply whether people are exposed, but whether exposure comes from multiple sources. When ties are disproportionately concentrated in a few high-degree actors, these high-degree actors may lack the supporting network ties among the non-hub actors to generate social reinforcement to further propel diffusion. Such concentration creates bottlenecks of diffusion, because, if adoption does not occur in the hub’s immediately connected neighbors, there will be few alternative pathways of diffusion to generate the clustered network structure essential to high-threshold/complex contagion diffusion. Scale-free networks that maximize reach via degree concentration may suppress the clustered small group structure that benefits high-threshold diffusion. As such, for high-threshold behavior, we may anticipate a much worse diffusion outcome in scale-free networks compared to the literature on the spread of low-threshold diffusion phenomena such as viruses or information.
Second, high-degree actors may tend to cluster together, generating redundancy and limiting the scope of diffusion (Aral and Walker 2012). Kim and colleagues (2015) suggest that when there is more degree concentration of ties, targeting high-degree actors might only reach clusters centered around opinion leaders, failing to reach more peripheral actors. In contrast, sprinkling network targeting throughout a network, for instance via the “friendship paradox” method, might be more effective (as this randomized trial showed). However, Kim and colleagues did not formally test this argument. This is a high degree assortativity (i.e., the tendency for nodes with a similar number of ties to interconnect) argument as it relies on the fact that high-degree actors might connect to other high-degree actors.
A third possible mechanism hinders diffusion but for reasons opposite to the second possibility. If ties tend to be concentrated around high-degree actors, this might be associated with a reduction in degree assortativity; and this could generate stronger “rich-get-richer” dynamics that create many core-peripheral connections. New nodes could overwhelmingly attach to already high-degree hubs, which lowers the likelihood that hubs connect to other hubs, and thus reduces degree assortativity. Such low degree assortativity can be detrimental to diffusion if one targets high-degree nodes, as it may create a “wide but shallow spread” where many peripheral nodes are reached but without strong reinforcement from their neighbors. In contrast, in high degree assortativity networks, targeting high-degree actors in this context triggers cascades among not just isolated spokes but a densely interconnected “core,” where adoption can reinforce and sustain itself and then spread to the periphery. Note that the second and third mechanisms are in contrast, and which one occurs needs to be tested, which we address in Part Three.
To clarify, we do not argue that degree concentration is itself a diffusion “mechanism,” as degree concentration is merely a description of the degree distribution of a network. Instead, because network characteristics tend to be structurally interdependent, we contend that when a network tends to have a high/low level of degree concentration, the network may also exhibit corresponding changes in other structural characteristics, including clustering and degree assortativity. In other words, when one changes the level of degree concentration in a network (as we show in the simulations in Part Three), one also, as a byproduct, typically alters the level of clustering and degree assortativity, which researchers have found to be positively or negatively related to diffusion outcomes (Centola and Macy 2007; Gallos, Song, and Makse 2008; Wu et al. 2018).
Valente and Vega Yon (2020) run simulations on how the effectiveness of targeting high-degree actors depends on the network structure. They find that a scale-free network slows down diffusion compared to a random network. However, they do not elaborate on structural network reasons but instead cite algorithm possibilities of how the scale-free network is generated. As such, we propose our core hypothesis on a negative relationship between the level of degree concentration in a network structure and the diffusion outcome when targeting high-degree actors:
Hypothesis 1 (Core Hypothesis): The more ties are concentrated around high-degree actors in a network structure, the worse the diffusion outcome when targeting high-degree actors.
We expect our main argument to be especially present for high-threshold diffusion. As mentioned, the concentration of ties to a few actors will decrease network clusters, which especially hampers the diffusion of high-threshold behavior. As such, we hypothesize the following:
Hypothesis 2: The negative relationship in Hypothesis 1 will be stronger for high-threshold diffusion.
Based on the arguments above, we can derive hypotheses about the difference in diffusion outcomes between high-degree targeting and random targeting (randomly selecting nodes as initial targets of adoption):
Hypothesis 3: As ties are more concentrated around high-degree actors in a network structure, the difference in diffusion outcomes between high-degree targeting and random targeting in a set of populations (e.g., distinct villages, firms, classrooms) will decrease.
Hypothesis 4: As thresholds of adoption increase, larger tie concentration around high-degree actors will be associated with a larger disadvantage of targeting high-degree actors compared to random seeding.
Research Design
First, we provide a theoretical illustration of our primary argument on the network paradox of high-degree influence. By reanalyzing Valente and Davis’s (1999) key work on opinion leadership, we show the theoretical value of how our central argument changes results from existing studies.
Second, we analyze rare empirical data with suitable measures from a key network-based randomized field trial (Kim et al. 2015). Such an empirical analysis allows us to gauge the external validity of our hypotheses, although it has statistical power limitations due to the infeasibility of collecting data on many networks (here, we use 18 village-level networks).
Third, we conduct a simulation study. Simulation experiments allow us to test how network structure, adoption thresholds, and targeting methods might affect diffusion outcomes. However, while simulations can estimate direct effects that do not suffer from confounding issues, they often face questions of external validity. Our analyses focus on degree centrality, but we conducted robustness checks on betweenness centrality and eigenvector centrality in our simulation exercise, as some research uses these measures (Burt 1999; Valente and Vega Yon 2020). The results are essentially the same (see Parts C and D of the online supplement).
Part One: A Theoretical Reanalysis of Valente and Davis (1999)
Overview
Much intervention research (e.g., Holliday et al. 2016; Rice et al. 2012) references Valente and Davis’s (1999) work on accelerating diffusion through opinion leaders, which provides theoretical grounding for targeting high-degree actors. As Valente and Davis show, targeting high-degree actors achieves better diffusion outcomes than does targeting random actors in a network.
A critical setup of the Valente and Davis (1999) model is that the network is random. However, in other network structures, such as a scale-free network (Barabási 2009; Barabási and Bonabeau 2003), ties preferentially attach to actors with more ties, and so the results may not hold.
Results
Mirroring Valente and Davis’s (1999) setup, we conducted a simulation using a random network with 100 nodes with an average degree of 7. We follow Valente and Davis (1999) and specify that adoption is simulated with a threshold of 15 percent, meaning that if 15 percent or more neighbors adopt, the actor also adopts. High-degree targeting is simulated by activating the top 10 percent of high-degree actors as initial adopters, and random targeting means 10 percent of the actors are randomly assigned as initial adopters.
We show that changing the network structure from a random to a scale-free network can significantly affect the diffusion outcome. Figure 1 compares diffusion outcomes when targeting high-degree actors as initial adopters. The x-axis is the iteration; the y-axis is the proportion of actors that adopt the behavior, averaged across 1,000 simulations. The red (circles) line represents the diffusion outcome under a random network. Consistent with Valente and Davis (1999), diffusion occurs quickly from the baseline level, and the proportion of adoption increases to 100 percent.
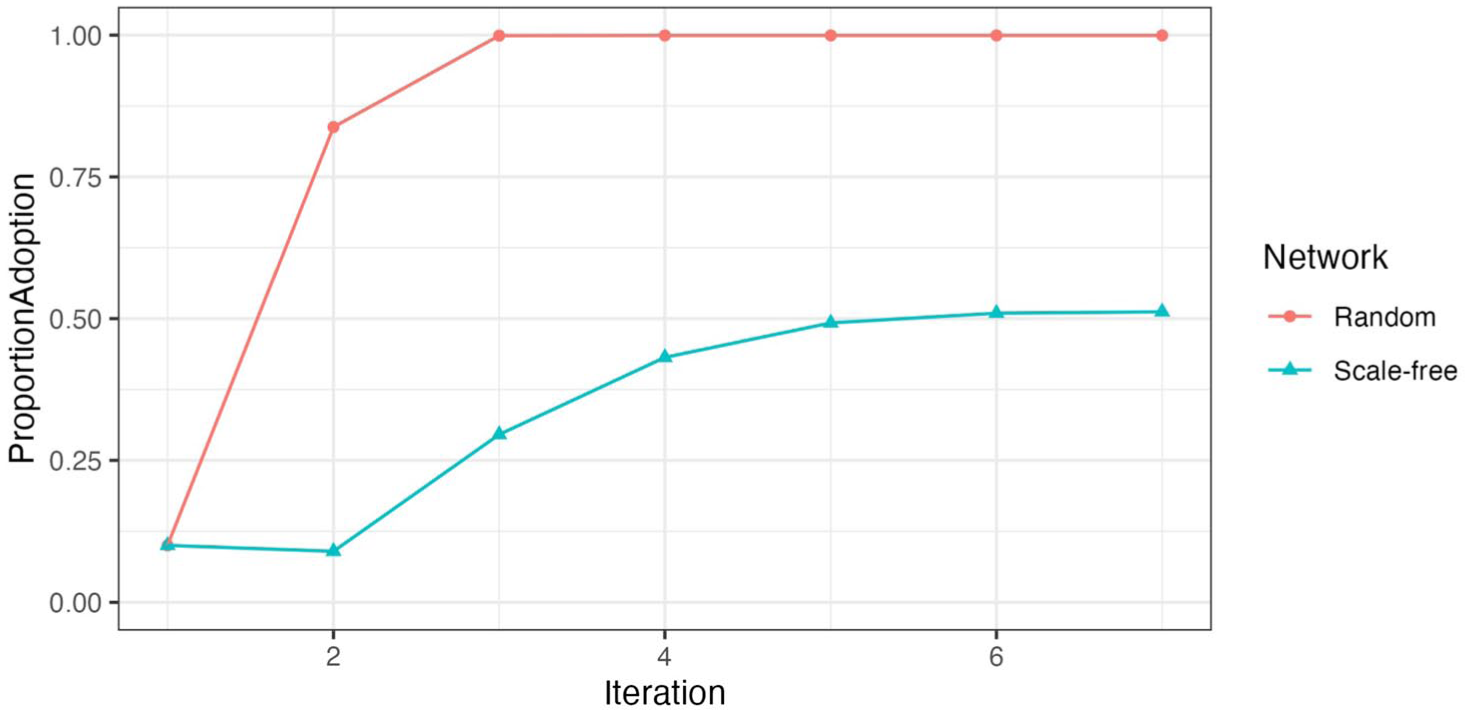
Diffusion Outcomes of High-Degree Targeting under Random and Scale-Free Networks.
However, the results change drastically when we change to a scale-free network with a scaling parameter of 2, in the base case. 4 Note that the random network is a special case of a scale-free network with the scaling parameter of 0. The blue (triangles) line represents results with all conditions the same except the network is a scale-free network. Diffusion is much slower here: the slope is lesser, and the proportion of adoption is only slightly larger than 50 percent, resulting in a drastic reduction from the 100 percent adoption rate.
In contrast, Figure 2 shows results when the initial adopters are randomly selected. The difference in results under different network structures is smaller, as one can see that the gap between the blue and red lines is much smaller.
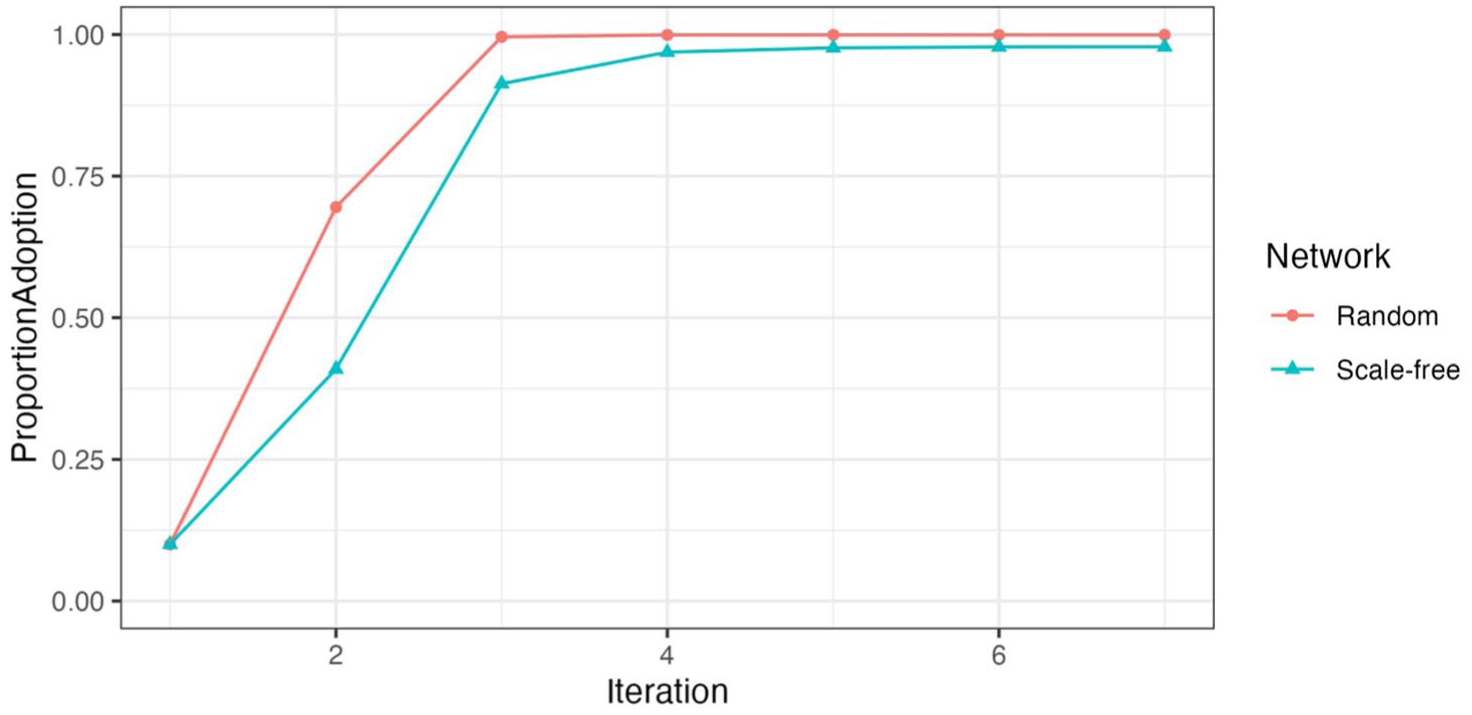
Diffusion Outcomes of Random-Targeting under Random and Scale-Free Networks.
This brief exercise illustrates our core argument regarding the network paradox of targeting well-connected individuals: the more network ties are concentrated around a few actors, the worse the diffusion outcome, as seen in the comparison between the red and blue lines in Figure 1.
Part Two: An Empirical Examination of Intervention Data
Overview
The data requirements to test our arguments are stringent. One would first need data on many networks to assess network structure effects. Compared to many single-network studies (e.g., Coleman et al. 1966; Fowler and Christakis 2008), one would need multiple networks to compare how different network structures affect diffusion outcomes. Second, to determine the diffusion effect of high-degree actors being initial adopters, one would need data on network-based experiments that target high-degree actors. Observational data that trace naturally occurring diffusion (e.g., Myers 2000; Strang and Soule 1998) do not satisfy such requirements, because high-degree actors may not be initial adopters. Only intervention studies achieve such a design. Third, one would need measures of different diffusion outcomes to compare different thresholds. Data on a single diffusion outcome (e.g., Campbell et al. 2008; Iyengar, Van Den Bulte, and Valente 2011) do not allow the variation to assess threshold effects.
Fortunately, Kim and colleagues’ (2015) intervention study satisfies these requirements. Kim and colleagues (2015) conducted interventions in 32 villages (5,773 participants) in Honduras to enhance the diffusion of two public health outcomes: chlorine for water purification and multivitamins for micronutrient deficiencies. Adoption of these outcomes was measured by whether (and when) village members redeemed tickets for chlorine or multivitamins. Network ties were constructed based on nominations of spouses, siblings, and friends from a photographic census, representing a directed network. Kim and colleagues used three methods of targeting initial adopters in each village, but two are relevant to this study: targeting high-indegree actors and random targeting.
The data satisfy all three requirements. The 32 villages each represent a network. The two interventions had very different adoption percentages, suggesting different adoption thresholds. The chlorine adoption percentages were lower (around 55 percent across intervention arms), and the multivitamin adoption percentages were higher (ranging from 61 to 74.3 percent, depending on the intervention arm). 5 Finally, one intervention arm intentionally targeted the top 5 percent of actors with the highest indegree, allowing us to assess how the effectiveness of such a strategy depends on network structure. Additionally, the random targeting intervention arm can serve as another source of comparison to test Hypotheses 3 and 4.
The dataset still has limitations, however. First, despite the data having measures on multiple networks (villages), the number of villages is still small. Nine villages conducted the high-degree targeting intervention for chlorine and nine villages for multivitamins. Although such data are still better than single-network studies, we cannot fully control for other confounding variables. This is a common issue for network studies, as data on many networks are rare, even rarer in intervention studies (for exceptions, see, e.g., Airoldi and Christakis 2024; Campbell et al. 2008). On the other hand, the number of observations at the individual level is quite large, with more than 1,200 individuals, ensuring enough statistical power to detect intervention effects.
To analyze the data, we first estimate the level of degree concentration for each village. 6 Note that this estimated parameter is equivalent to the degree concentration (preferential attachment) parameter in a scale-free network. However, we name it “degree concentration parameter” to reflect the fact that we refer to the degree distribution rather than the network-generating process. Then, we conduct a correlation analysis at the village level, supplemented by a logistic regression at the individual level as a robustness check (see the online supplement). 7 For the logistic regression, the binary outcome is whether the individual adopted the public health behavior of chlorine or, separately, multivitamins. In short, we examine whether variation in the level of degree concentration is associated with differences in diffusion outcomes. For instance, we will find support for our argument if we find that diffusion outcomes are worse in villages with more degree concentration (i.e., ties are more concentrated around a few people).
Results
We start with the high-threshold outcome, that is, the chlorine intervention. Figure 3 shows the adoption percentage (i.e., the ticket redemption rates) for the chlorine intervention at the village level and the estimated degree concentration parameter of each village’s network. Supporting Hypothesis 1, we see a negative relationship (as reflected in the downward slope in the plot), showing that the more degree concentration in a village’s network, the worse the diffusion outcome. A logistic regression at the individual level shows the same results, with a statistically significant negative coefficient for the village’s level of degree concentration (for tables, see Part A of the online supplement).
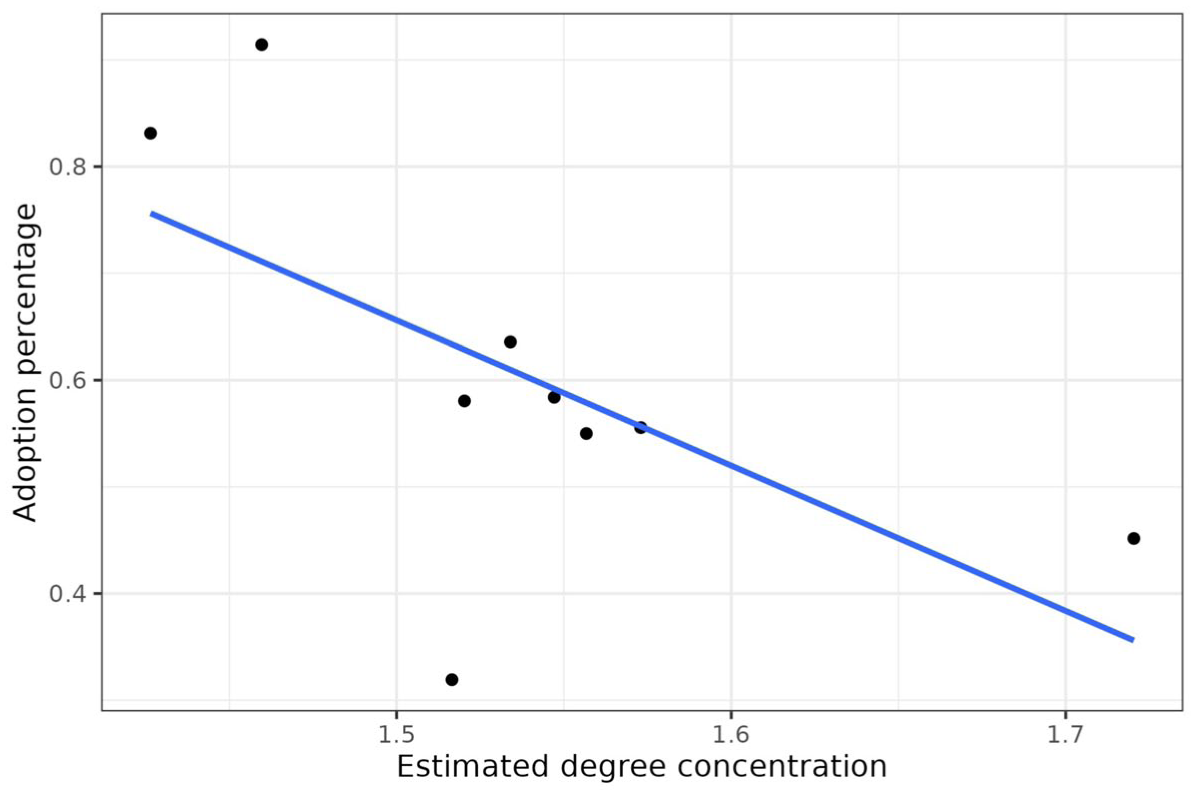
Relation between Estimated Degree Concentration of Each Village’s Network and the Adoption Proportion (Chlorine).
Figure 4 shows results for the low-threshold outcome, that is, the multivitamin intervention. We see a slight positive relationship between degree concentration and redemption percentage (and a logistic regression shows a similar pattern at the individual level). Individual-level logistic regressions confirm such patterns. However, we note that this positive relationship is mainly driven by the one village on the right of the plot. Nonetheless, the contrast with the results from the chlorine intervention is stark. The negative relationship was apparent in the chlorine intervention, a high-threshold outcome. In contrast, for the multivitamin intervention, a low-threshold outcome, the relationship is slightly positive or close to zero. Taken together, these results provide support for Hypothesis 2.
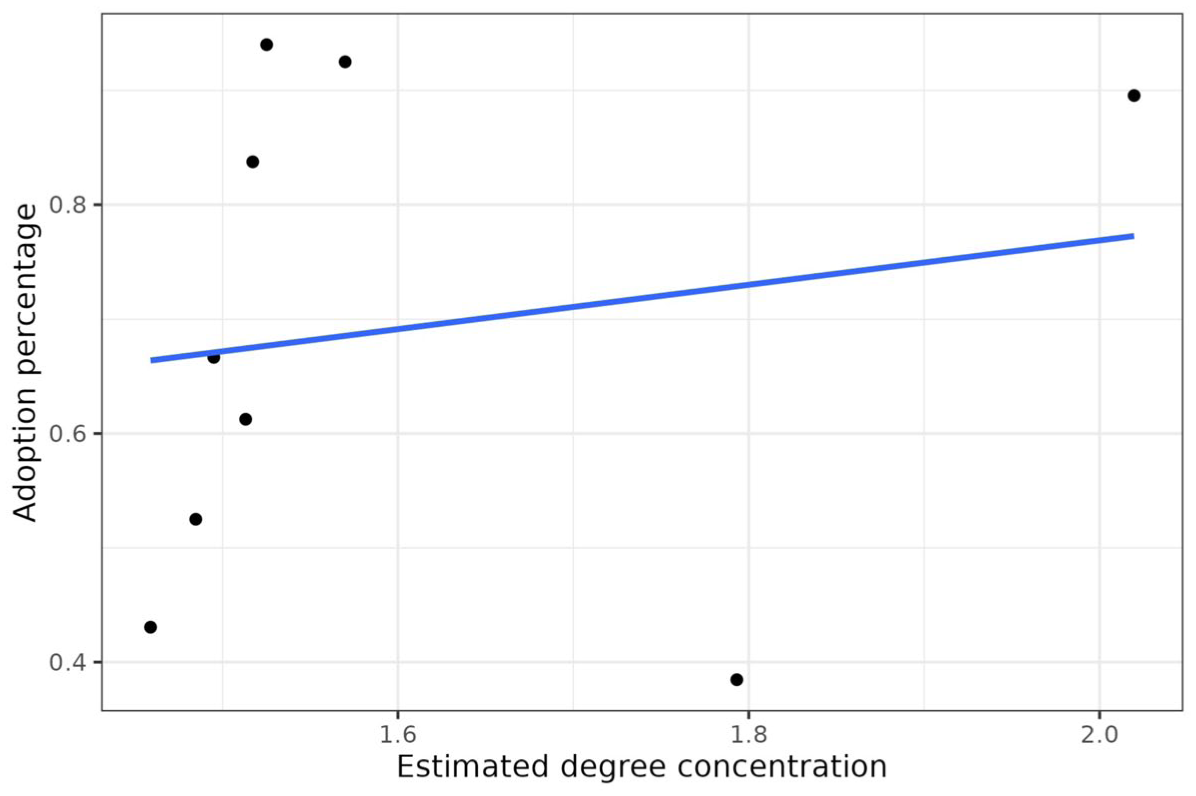
Relation between Estimated Degree Concentration of Each Village’s Network and the Mean Adoption Proportion (Multivitamins).
Hypotheses 3 and 4 concern whether the difference in intervention effectiveness between high-degree and random-targeting decreases as degree concentration increases. To address this question, we pool the data from the high-degree and random-targeting arms, estimate a logistic regression, 8 and then show the difference in model-predicted probabilities of adoption.
Figure 5 shows the difference in predicted adoption probabilities between high-degree targeting and random targeting for the chlorine intervention (for the model that generated the plot, CI’s generated using bootstrapping, see Part A of the online supplement). The x-axis shows the village’s estimated degree concentration, and the y-axis shows the difference in the predicted probability of redemption. Supporting Hypothesis 3, we observe a negative relationship, showing that the difference between high-degree targeting and random targeting decreases as ties become more concentrated around high-degree actors.
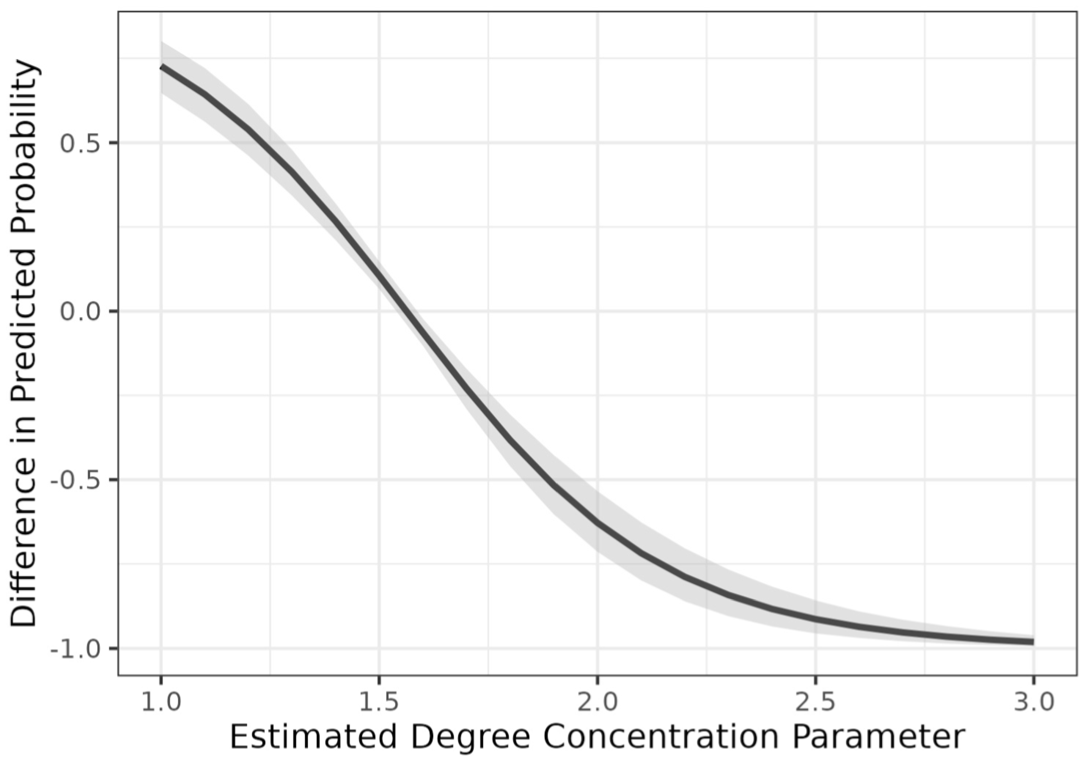
Difference in Predicted Probabilities of Chlorine Redemption by Estimated Degree Concentration Parameter.
Figure 6 shows the difference in predicted probabilities for the multivitamin intervention (for the model that generated the plot, see Part A of the online supplement). According to Hypothesis 4, we expect a more negative slope in the chlorine intervention (Figure 5) than in the multivitamin intervention (Figure 6). We not only see a steeper negative slope in Figure 5, but the slope in Figure 6 is positive (a difference test using bootstrapping is statistically significant at the 0.05 level). Together, Figures 5 and 6 show support for Hypothesis 4.
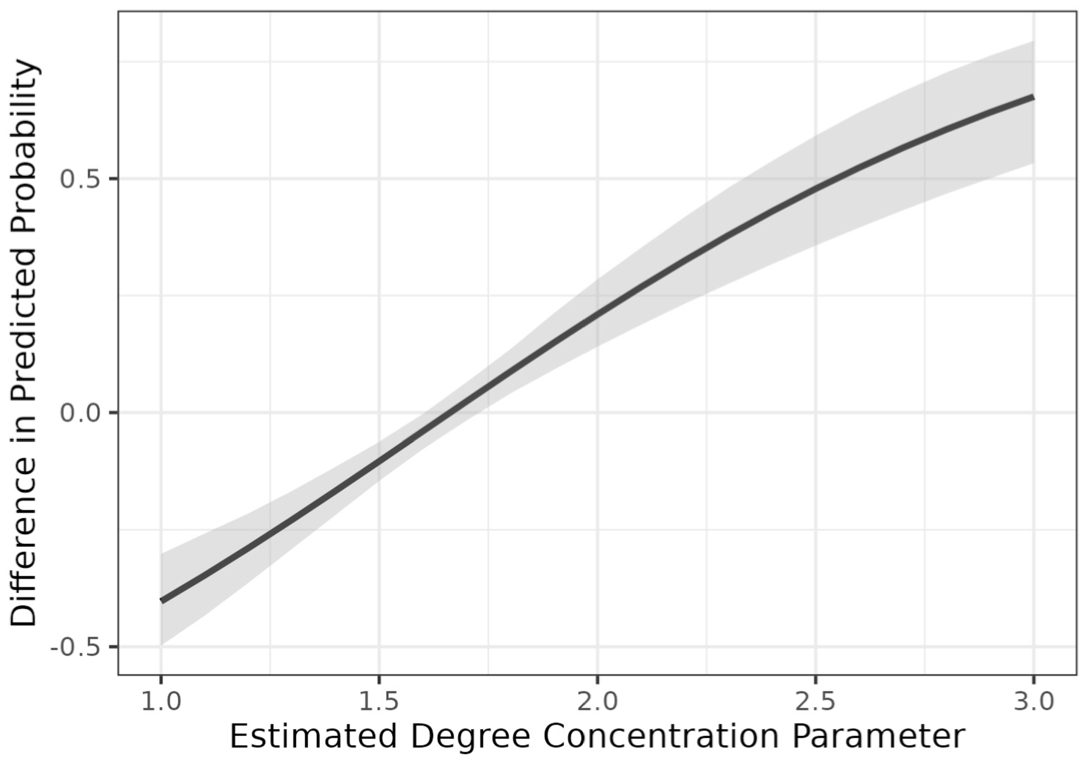
Difference in Predicted Probabilities of Multivitamin Redemption by Estimated Degree Concentration Parameter.
Robustness Check with Respect to Network Degree Assortativity
Although we have limited statistical power to test many different confounding network structures, we conducted a robustness check with respect to a key metric: degree assortativity. Degree assortativity is a measure of the tendency of nodes in a network to connect with other nodes that have similar degrees (Newman 2002). This measure quantifies the correlation between the degrees of connected nodes, where a positive value indicates a preference for high-degree nodes to connect with other high-degree nodes (assortative mixing), a negative value indicates a preference for high-degree nodes to connect with low-degree nodes (disassortative mixing), and a value near zero suggests no particular correlation.
Kim and colleagues (2015), when analyzing the data of this study, discussed the potential role of degree assortativity in influencing the effectiveness of targeting well-connected nodes. They speculated that the lack of success in such targeting strategies might arise from the tendency of high-degree nodes to connect with other high-degree nodes (i.e., positive degree assortativity), which amplifies network redundancy and limits the spread of influence or information across the network. In brief, it could be that high-degree actors tend to connect to each other (i.e., degree assortativity), resulting in clustering differences between networks and, in turn, targeting effectiveness differences. The question of whether it is degree concentration or degree assortativity thus arises. That said, we note there is some tension between degree concentration and degree assortativity, as a network where hubs mainly connect with other hubs reduces its scale-freeness. This is because the fewer the hubs, the fewer the neighbors of a node that mainly connects with hubs, hence a node reduces its “hubiness.” We explore this relationship between degree assortativity and degree concentration in more detail in Part Three. This situation does not rule out the possibility that degree concentration and degree assortativity are correlated if hubs prefer to be interconnected.
To address this concern, we estimated degree assortativity of each village, then plotted them against the adoption percentages in Figure 7 (for chlorine) and Figure 8 (for multivitamins). The results are clear: for chlorine, the slope is almost zero, and for multivitamins the slope is negative. Such patterns are substantially different from the slopes in Figures 5 and 6, where the slopes were negative and slightly positive, respectively. Logistic regression results, shown in Part B of the online supplement, show that the degree concentration effect is statistically significant even after controlling for degree assortativity. The coefficients are also largely similar to the ones in Part A of the online supplement. In short, degree concentration appears to have a separate effect on adoption from degree assortativity.
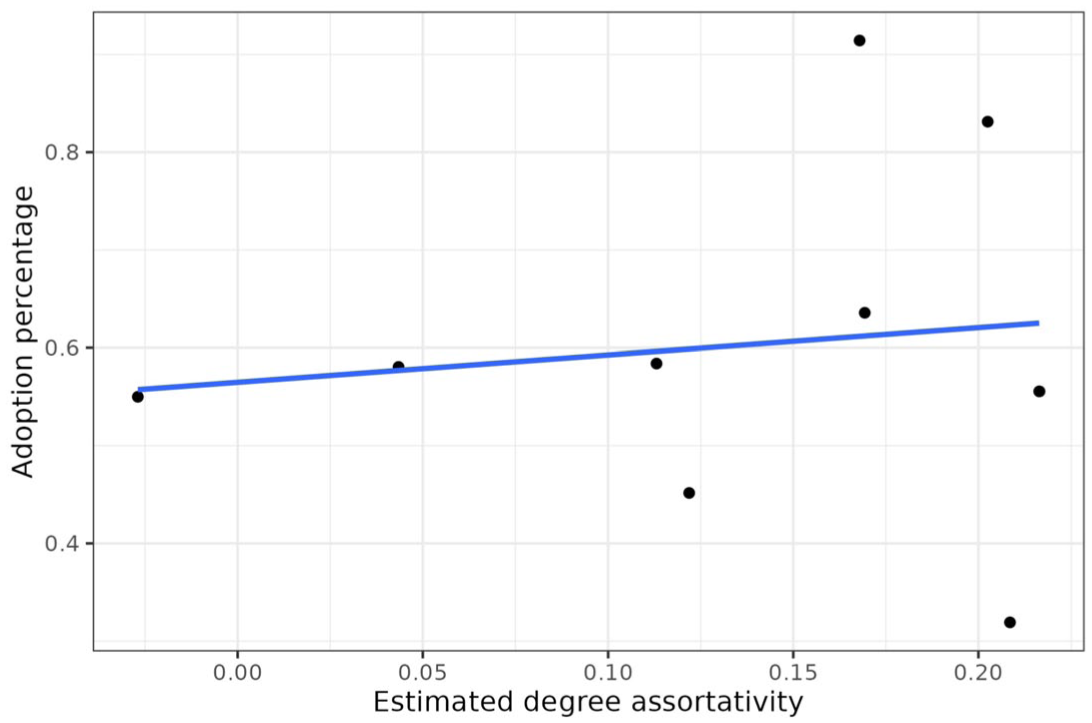
Relation between Degree Assortativity of Each Village’s Network and the Adoption Proportion (Chlorine).
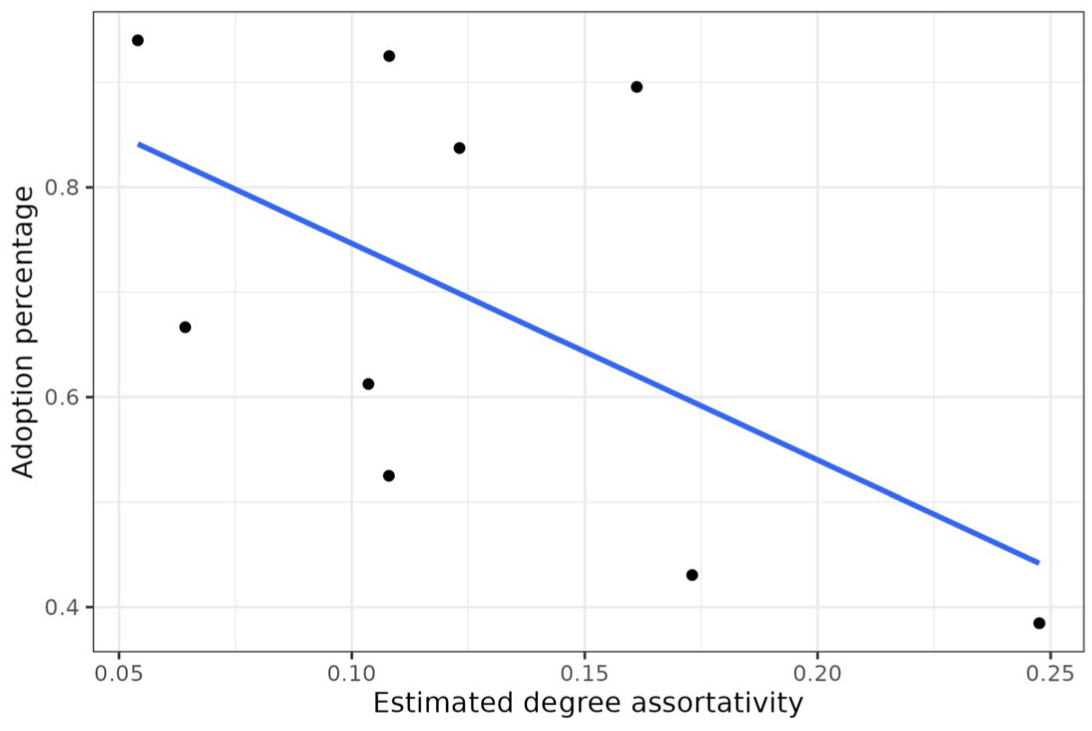
Relation between Degree Assortativity of Each Village’s Network and the Adoption Proportion (Multivitamins).
As a brief note, we also conducted a robustness check controlling for network size instead of degree assortativity. Results are similar as there is still a negative significant (p < 0.001) relationship between estimated degree concentration and diffusion outcome (results not shown). To further assess the possibility of confounding, we conducted additional analyses by re-analyzing data from Airoldi and Christakis (2024) (see Part G of the online supplement). We computed correlations between a large number of village-level characteristics and the degree concentration of each village network. If such correlations are low, then the potential impact of confounding is correspondingly reduced. In addition, Airoldi and Christakis include 33 intervention outcomes that have been shown to be related to network diffusion, allowing us to examine how village characteristics relate to diffusion outcomes. If the correlations between village characteristics and these outcomes are low, then confounding is less likely. We find that both the correlations with degree concentration and the correlations with diffusion outcomes are quite low (see the online supplement for these supplementary robustness analyses).
Part Three: A Simulation Study on Network Structures, Threshold, and High-Degree Targeting
Overview
Given the sample size of 18 villages in the foregoing analysis, there is the threat of confounding by pertinent unobserved traits of the villages. For instance, the villages could have different network sizes and densities, and it is not possible to fully and adequately control for such network-level confounders. To address this, we conduct a simulation study. As such, Part Three uses simulations to complement the empirical analysis by evaluating the associations without confounding. Whereas the field experiment documents associations between network structure and diffusion outcomes, simulations allow us to systematically vary network structure, adoption thresholds, and targeting strategies while holding all other factors constant. This enables us to disentangle the effects of degree concentration from correlated network features and to identify how and why certain network structures might amplify or dampen the effectiveness of targeting well-connected actors. The simulations also allow us to systematically assess the mechanisms of clustering and degree assortativity, which we were unable to disentangle in Part Two.
The setup of the simulation study is similar to the setup in Part One. However, we make two additions. First, we vary the degree concentration parameter of the scale-free network, which reflects the level of degree concentration. If the degree concentration is zero, nodes make random ties to other nodes, corresponding to a random network. In contrast to Part Two, this degree concentration parameter is not estimated but determined, thus addressing potential confounding. Also, the network size and number of ties are fixed, eliminating any confounding with the structural effect of degree concentration. Second, in Part One, we set the adoption threshold to 0.15. To test threshold effects, here we vary threshold levels from 0.1 to 0.5.
The other parts of the setup are the same. We generate a network of 100 nodes with a mean degree of 7; activate 10 percent of the initial adopters; and then simulate the diffusion process according to the threshold. Again, we recorded and averaged the final adoption percentage across 1,000 simulations. We also vary these parameters as robustness checks.
Results
Figure 9 shows the results of testing Hypothesis 1. The x-axis is the degree concentration parameter (not the iteration), and the y-axis is the final adoption percentage (averaged across 1,000 simulations). Each panel represents a different diffusion threshold. For instance, the top-left panel indicates results when the adoption threshold is 0.10.
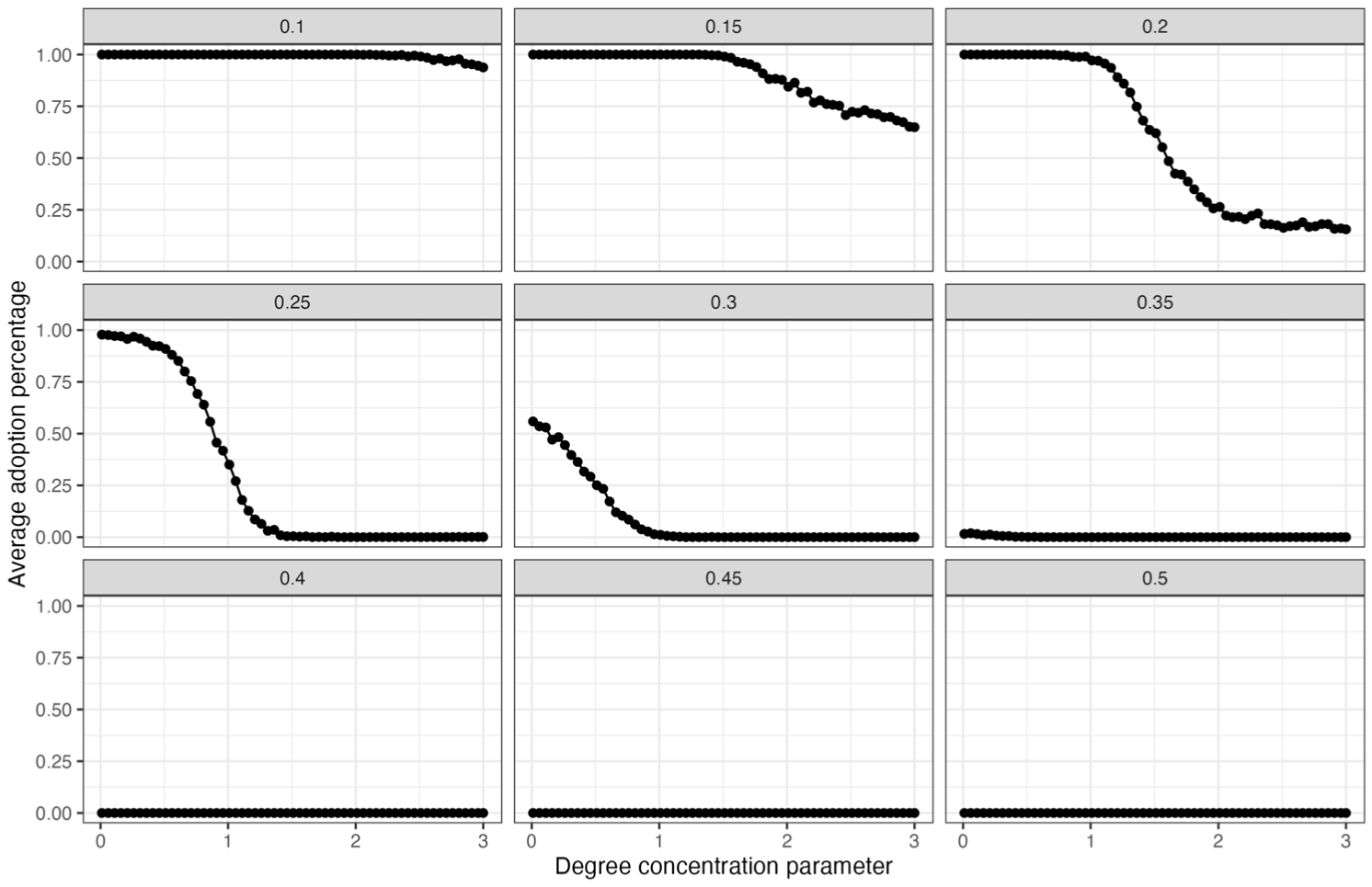
Relation between Degree Concentration of Each Network and the Mean Adoption Percentage under Different Thresholds of Diffusion (Each Panel Represents a Different Threshold).
When the threshold is 0.3 or above, diffusion does not occur at all, so we focus on the results when the threshold is from 0.1 to 0.3. Supporting Hypothesis 1, the more degree concentration in a network structure, the worse the diffusion outcome, as seen in the negative slopes in each panel. The slope becomes steeper as the threshold increases, supporting Hypothesis 2, where the negative relationship between degree concentration and diffusion outcome will be stronger for high-threshold diffusion. Such results echo the empirical results from Part Two, where we saw a stronger negative relationship in the high-threshold outcome of chlorine intervention.
Table 1 uses a linear regression model to confirm the visual patterns. The coefficient for the degree concentration parameter is negative and becomes even more negative as the threshold increases (reflected in the negative interaction term between threshold and degree concentration; ignore the main coefficient of degree concentration parameter because that coefficient is when threshold is zero, an impossible case).
Linear Regression with Mean Adoption Percentage as Outcome and Degree Concentration Parameter and Threshold as the Covariates.
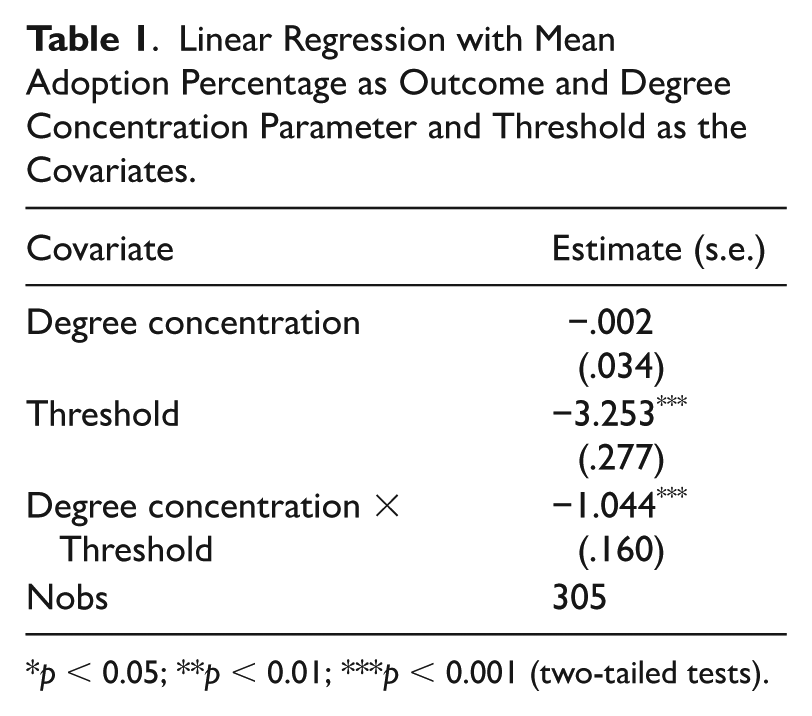
p < 0.05; **p < 0.01; ***p < 0.001 (two-tailed tests).
To analyze Hypotheses 3 and 4, we specify a linear regression with the outcome as the difference in average adoption percentage between high-degree targeting and random targeting. 9 Table 2 shows the results. The negative interaction term between degree concentration and threshold shows that as threshold increases, the slope of the relationship between the difference in adoption percentage and degree concentration becomes more negative, supporting Hypothesis 4. This echoes the empirical contrast between the chlorine and multivitamin interventions in Part Two. We also note that Hypothesis 3 is only partially supported (only for high-threshold scenarios), as the slope can be positive when the threshold is very low because the coefficient for degree concentration is positive when the threshold is zero.
Linear Regression with Difference in Adoption Percentage between High-Degree Targeting and Random Targeting as Outcome and Degree Concentration and Threshold as the Covariates.
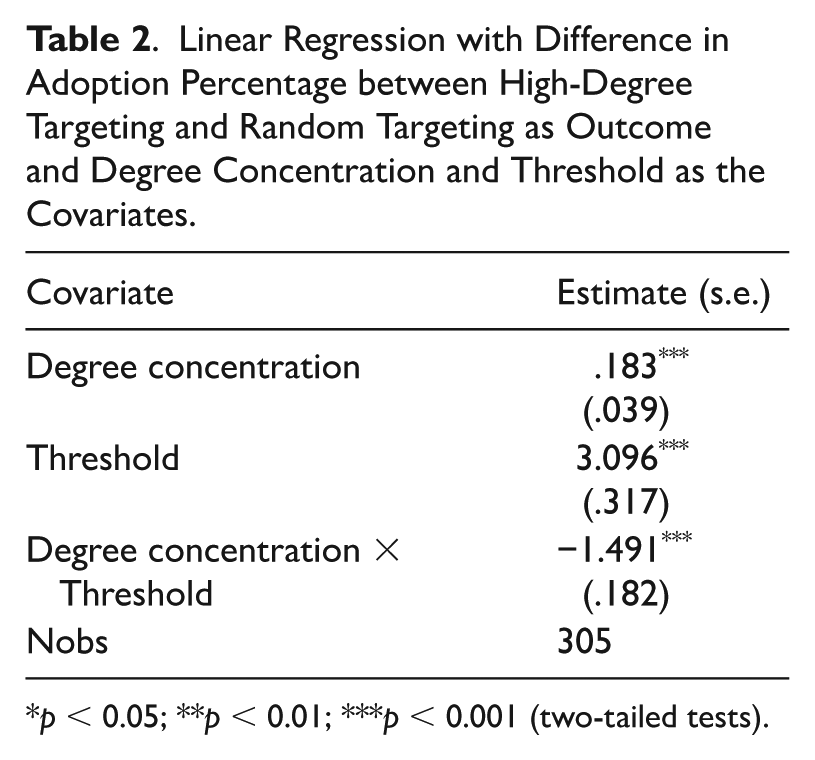
p < 0.05; **p < 0.01; ***p < 0.001 (two-tailed tests).
We also did robustness checks on network size and the proportion of initial adopters (i.e., seeding proportion). The results support the findings (see Part E of the online supplement). Part F of the online supplement explores additional network structures other than scale-free networks.
Exploring Mechanisms: Global Clustering and Degree Assortativity
When setting up our core proposition, we noted three possibilities, related to clustering and degree assortativity, regarding why degree concentration might hinder the effectiveness of targeting high-degree actors. One advantage of simulations is that we can explore mechanisms in depth. We ran further analyses of how increasing the degree concentration parameter changes the network structure of (global) clustering and degree assortativity of each network, and how such changes affect adoption percentages. Note that because of the simulation setup, we can ensure that the order of effect is degree concentration → clustering/degree assortativity → adoption percentage of targeting high-degree actors. This is because we explicitly manipulate degree concentration (so it is exogenous), which changes the network structure and in turn clustering/degree assortativity. These structures then affect the diffusion outcome.
In brief, we find that degree concentration affects both clustering and degree assortativity, which then affects adoption percentages. We first examine the degree concentration → clustering → adoption percentage link. As seen in the loess curve in Figure 10, there is a curvilinear relationship between degree concentration (x-axis) and clustering (y-axis). As degree concentration increases a little, clustering also increases, but then the association turns sharply negative as degree concentration increases more. This pattern supports the argument that too much concentration around high-degree actors decreases ties among the non-hubs. Figure 11 further shows that the relationship between clustering and adoption is also curvilinear: some clustering improves diffusion, but too much clustering decreases it. 10
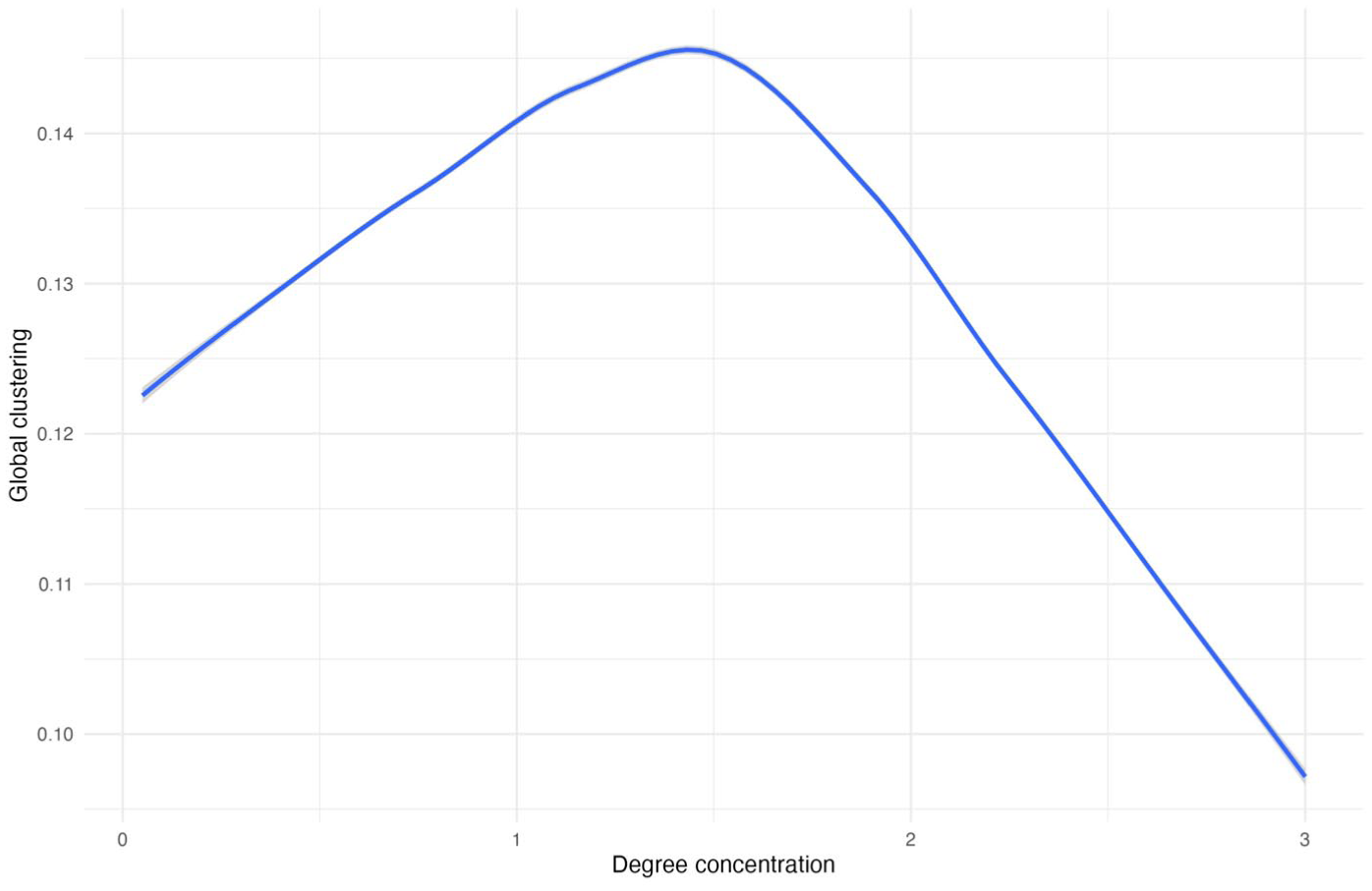
Relationship between Global Clustering (y-axis) and Degree Concentration (x-axis).
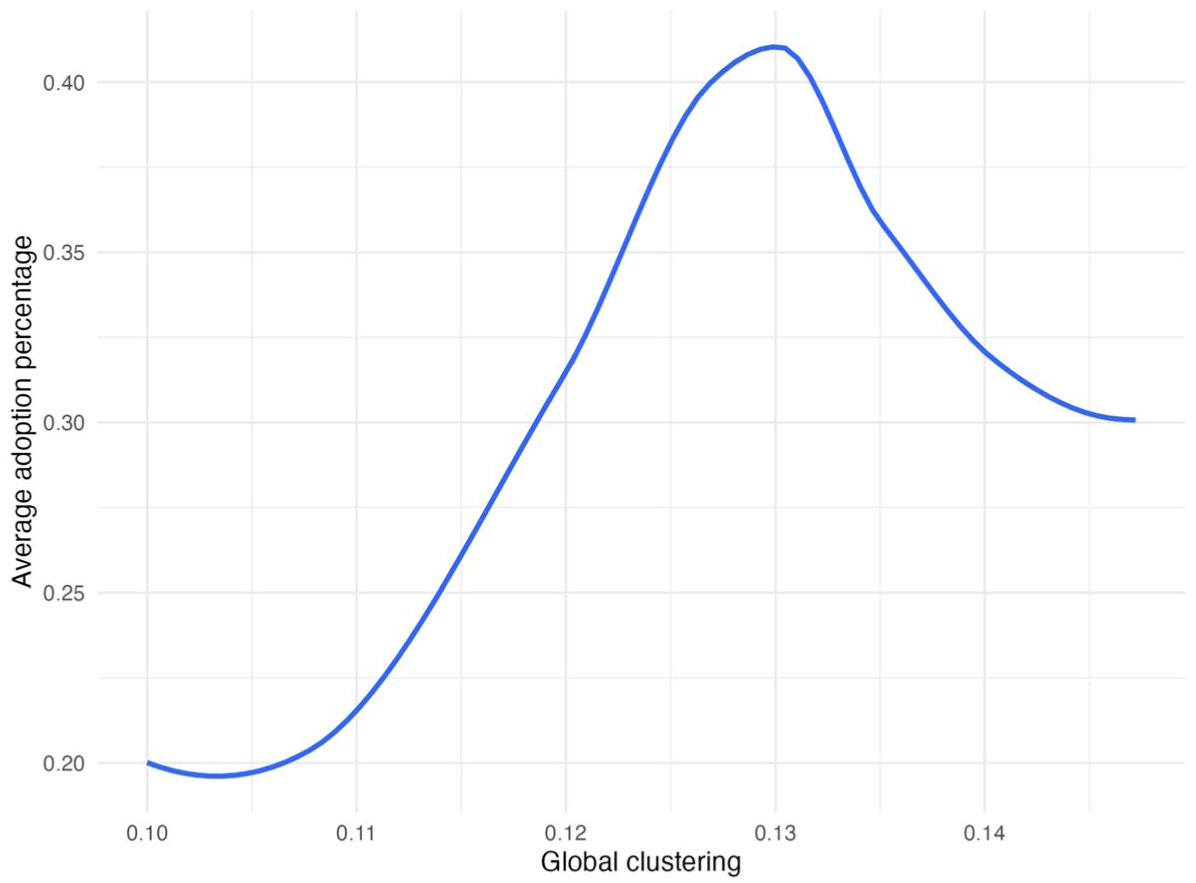
Relationship between Average Adoption Percentage (y-axis) and Global Clustering (x-axis).
We then examine the degree concentration → degree assortativity → adoption percentage link. Here we find support for the argument that degree concentration decreases degree assortativity rather than increases it. Figure 12 shows that as degree concentration increases, degree assortativity decreases. Figure 13 shows a positive relationship between degree assortativity and adoption. 11 Overall, these results point to the third mechanism of explaining the network paradox, where if degree concentration lowers degree assortativity, targeting high-degree actors may create a “wide but shallow spread,” where many peripheral nodes are reached but adoption stalls without reinforcement.
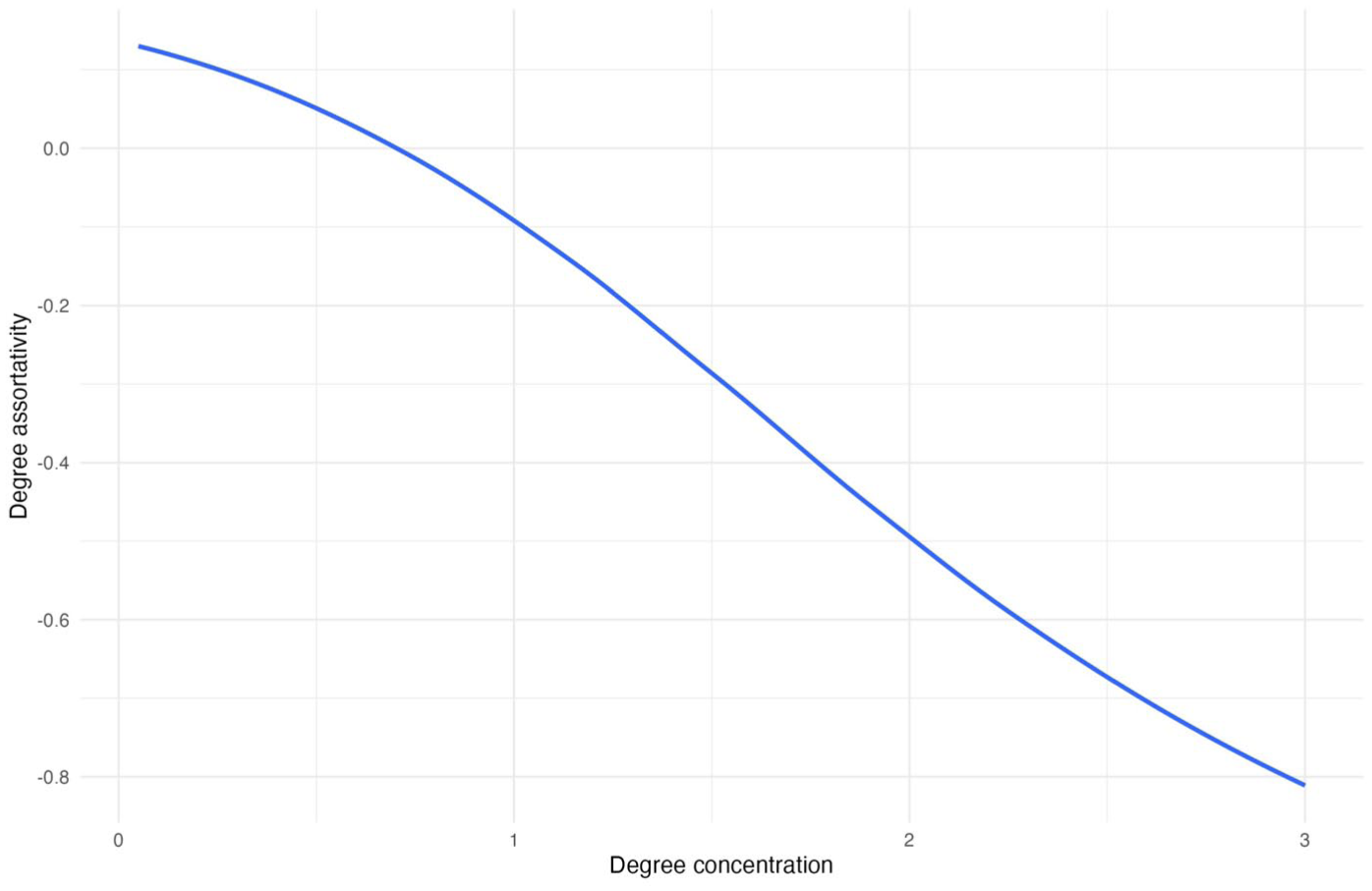
Relationship between Degree Assortativity (y-axis) and Degree Concentration (x-axis).
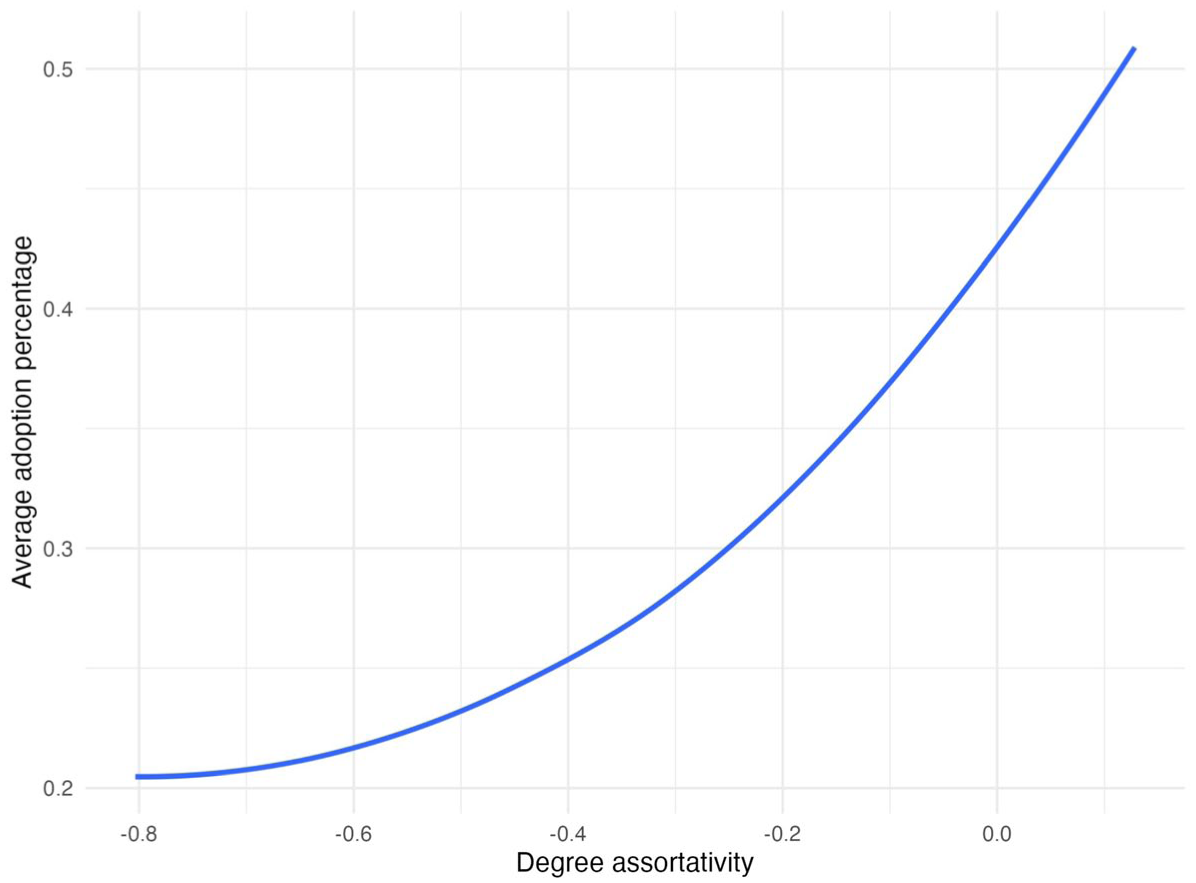
Relationship between Average Adoption Percentage (y-axis) and Degree Assortativity (x-axis).
Discussion and Conclusions
We explored a network diffusion “paradox” of targeting well-connected actors: the diffusion outcome of targeting high-degree actors worsens as network ties become more concentrated around high-degree actors. We argued that this phenomenon is especially pronounced for high-threshold diffusion. Both simulations and field experiments support these conclusions. For high-threshold diffusion, the effectiveness of high-degree targeting is negatively associated with the extent to which networks have more degree concentration in a sample of Honduran villages. For low-threshold diffusion, the results are less clear, however. Finally, while the effectiveness of high-degree targeting decreases as networks become more concentrated around opinion leaders, such a pattern is more pronounced for high-threshold diffusion. For high-threshold diffusion, the difference in effectiveness in high-degree targeting and random targeting decreases as the degree concentration increases.
Our results help shed light on a fundamental question: what is influence in the first place? Conventional research on opinion leadership conceptualizes influence as the capacity to shape the opinions or behaviors of those connected to an individual (Burt 1999; Cho, Hwang, and Lee 2012; Katz and Lazarsfeld 1955; Rogers 2003). In other words, it is the ability to influence directly connected individuals. However, from a structural network perspective, influence can be thought of as the ability to initiate large-scale change or “cascades” (Fowler and Christakis 2010; González-Bailón et al. 2011; Hsiao 2021; Watts and Dodds 2007). From the latter perspective, as our argument shows, the influence of high-degree individuals diminishes as they dominate more ties in a network. Even if the people who are connected to the high-degree leaders are influenced by such leaders, collectively, the leaders cannot generate much change beyond their immediate social circle compared with alternative targeting approaches.
Our results contribute to the debate on whether the strategy of targeting high-degree actors, a widely used approach in network-based intervention, is optimal. Studies have shown inconsistent results in the effectiveness of targeting high-degree actors as initial adopters (Campbell et al. 2008; Kim et al. 2015; Li et al. 2013; Majumdar et al. 2007; NIMH Collaborative HIV/STD Prevention Trial Group 2010). Our results suggest the question may not be whether targeting high-degree actors works but the structural network conditions under which targeting high-degree actors works. Perhaps one source of such inconsistencies in results is that the network structures are very different. As we have shown, diffusion outcomes are much worse when the network structure exhibits a deep power law for such a strategy of targeting high-degree actors. In contrast, diffusion spreads better if ties in the network structure are less concentrated around high-degree actors.
Hence, we may need to revisit the network structures of past intervention efforts to evaluate further their effectiveness, which is feasible for some studies (as has been done in investigations of the circumstances under which static network structure can stabilize cooperation; see Rand et al. 2014). For instance, the ASSIST program (Campbell et al. 2008; Holliday et al. 2016) conducts anti-smoking interventions in multiple schools and classrooms. If one considers each classroom as a separate network, then one could evaluate whether such programs work better when ties are less concentrated around a few popular students.
Our results also bear relevance to questions of innovation diffusion and marketing. If the influence of high-degree leaders diminishes in networks with concentrated ties around leaders, one should spend fewer resources to persuade such leaders, who often are hard-to-influence individuals (Aral and Walker 2012; Battilana and Casciaro 2012; Beaman et al. 2021). These actors may be hard to influence because of where they are topologically located (e.g., because they are less able to change their behavior given social pressure from their more numerous social contacts [see Shakya et al. 2015]) or because of personal attributes (e.g., a self-confidence—and related aversion to innovation—that may have attracted many ties to begin with).
Siegel (2009) shows that without detailed network data, one can still identify the general network structure through intuitive heuristics. If one suspects a network follows a strong scale-free structure, one should use alternative strategies for targeting initial adopters, rather than mapping out the whole network and identifying high-degree individuals (such an approach could be cost-efficient, as collecting network data is often very costly) (Siegel 2009). Aral (2021) discusses marketing settings where, rather than targeting high-degree actors such as super-influencers, targeting moderately connected individuals may better promote products. Kim and colleagues (2015) and Airoldi and Christakis (2024) report that one can achieve desirable diffusion results without mapping out full networks with a simple method of random targeting and friendship nomination. In some settings, targeting is not needed at all, as universal, low-cost interventions that cover everyone may still achieve desirable outcomes (Greenberg and Abenavoli 2017). All these strategies should be weighed against the costs and benefits of implementing high-degree targeting, which depends on the structure of the network.
Our results also speak to diffusion studies about scale-free networks (Lloyd and May 2001; Pastor-Satorras and Vespignani 2001). Prior work notes that some types of diffusion, such as computer viruses, can spread very quickly in scale-free networks, mainly because hubs connect widely. Our results align with work involving threshold models (Centola and Macy 2007; Valente 1996; Watts and Dodds 2007), and we contend that one should exercise caution in overgeneralizing such results, as the interplay between initial adopters, network structure, and threshold levels affects the extent to which diffusion occurs rapidly or slowly. Scale-free networks can spread low-threshold outcomes, such as diseases, very rapidly because once the well-connected hub is “infected,” all the connections to the hubs are also infected. However, such a dynamic often does not apply to high-threshold outcomes, such as the perceived risky adoption of some new health practice (e.g., adding chlorine to water). A hub adopting such a practice does not generate enough social reinforcement to persuade others to follow suit. Thus, a sort of network paradox appears where targeting hubs with more connections leads to lower diffusion rates.
Methodologically, our study combines field experimental data with simulations to triangulate evidence. Other studies can extend our approach of combining empirical and simulated results. One fruitful avenue would be to use empirically grounded SAOMs (Stochastic Actor Oriented Models) and conduct simulations to test our findings. Past research has already used empirically-derived estimates to simulate diffusion (Lakon et al. 2025; McMillan and Schaefer 2021), and it would be straightforward to incorporate network structure as covariates to see how diffusion occurs differently. We note that field experimental data, pure simulations, and empirically-grounded simulations each have their strengths. Simulations explore more scenarios but do not have the external validity of empirical data. Empirically-grounded simulations are in the middle ground, with more scenarios but fewer than in pure simulations. For instance, past studies (Lakon et al. 2025; McMillan and Schaefer 2021) did not vary the level of threshold, as the “influence parameter” was empirically estimated rather than simulated.
This study has limitations that set up future research. First, we focus on the structural network aspect of the influence of high-degree actors. We do not consider other characteristics of such high-degree actors, such as social status or persuasiveness. Separating out the effects of network versus non-network characteristics can be a future direction. Second, the number of networks in our empirical analysis is still small. Although costly, research that implements interventions on hundreds of networks exists (e.g., Airoldi and Christakis 2024), which would allow for a more comprehensive empirical test of our arguments. Third, we only evaluated two strategies of intervention—high-degree targeting and random targeting. We did not evaluate other strategies such as targeting moderately-connected individuals, targeting friends of random people, or universal interventions. Finally, we specified that the way influence spreads through a social network is through direct contact, yet alternative mechanisms of diffusion may exist. For example, diffusion can occur between structurally equivalent actors (Burt 1987; Fujimoto and Valente 2012; Valente and Vega Yon 2020). This is an underexplored area where one could extend this study’s framework to examine how targeting strategies and network structure co-influence adoption outcomes under structurally equivalent pathways of diffusion.
In a network paradox, population-wide structural network properties may undercut the effect of targeting well-connected actors. Global and not just local properties of networks matter substantially to the efficacy of using network targeting to enhance collective well-being.
Supplemental Material
sj-pdf-1-asr-10.1177_00031224261438845 – Supplemental material for The Influence “Paradox”: When More Network Ties Lead to Less Change
Supplemental material, sj-pdf-1-asr-10.1177_00031224261438845 for The Influence “Paradox”: When More Network Ties Lead to Less Change by Yuan Hsiao and Nicholas A. Christakis in American Sociological Review
Footnotes
Acknowledgements
We thank David J. Knight and Keitaro Okura for their feedback on previous versions of the manuscript. We also thank the editors for their insightful oversight and the reviewers for the detailed comments.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The collection of the Honduras data used here was originally supported by the National Institute on Aging and the Bill and Melinda Gates Foundation.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.