
Abstract
The Internet of Things (IoT) is involved in dealing with physical items, gadgets, vehicles, structures, and different things that are inserted into hardware, programming, sensors, and system availability, which empowers these items to gather and trade information. Improving extraction of sensor-based data for energy awareness and then annotating it and converting it into semantically enabled form for analyzing results with the use of improved tools and applications are the focus of this research. However, as the amount of real time data gets huge, it becomes difficult to track results when needed at once. Reconciliation of heterogeneous information sources into an interlinked data is a standout among the most pertinent difficulties for some learning based systems these days. This paper forms suitable elements by a methodology for adjustment of heterogeneous sensor-based Web assets, where different tools and applications like weather detection for self-observing and self-diagnostics use dispersed human specialists and learning. The proposed general model uses a capability of the Semantic Web innovation and concentrates on the part of a semantic adjustment of existing broadly utilized models of information representation to Resource Description Framework (RDF) based semantically rich arrangement. This work is valuable for sorting out and inquiry of the detecting information in the Internet of Things.
1. Introduction
The World Wide Web (WWW) permits general population to provide the data from vast database storehouses internationally. A measure of data develops plenty of databases. It is required to search deeper the data for accurate results, which are acquired with the usage of working devices. There is a hefty portion of Web indexes accessible today; recovering significant data is troublesome. However, to defeat this issue in the Web to recover significant data cleverly, Semantic Web advances are assuming a noteworthy part [1–4]. Enormous detecting information is produced persistently in the Internet of Things (IoT). The most effective method for sorting out and inquiry of the huge detecting information has enormous difficulties for clever applications. This paper considers the association of huge detecting information with sensor-based event-oriented system, where events are viewed as essential units for arranging information and connections are utilized to speak to the semantic relationship between events. A few distinct sorts of questions on such system are additionally investigated, which are not the same as inquiries on conventional social database [5]. We utilize an occurrence of weather-based dataset to demonstrate the adequacy and productivity of association of linked data based approaches taking into account the IoT-based system [6–8].
It is much less demanding to make information than to investigate information. The blast of information will unquestionably turn into a significant issue of IoT [9]. As of not long ago, various studies have endeavored to take care of the issue of inquisitive huge information on IoT [10, 11]. Without viable and proficient investigation, devices will be submerged by this exceptional measure of information. At the point when proposed model is connected to IoT, from the viewpoint of equipment, distributed computing and important appropriated innovations are the conceivable answers for huge information; similarly, from the point of view of software, most mining advances are planned and created to keep running on a self-contained framework. In the circumstances of huge information, it is verging on certainty that most Knowledge Discovery in Databases (KDD) [12] accessible today and most conventional mining calculations cannot be connected straightforwardly to prepare the expansive measure of information of IoT. As a rule, either the preprocessing monitoring based on KDD or the information mining advances should be updated for IoT that can deliver a lot of information. Semantic Web-based systems on top of agents can be taken into account to resolve huge information recovery for IoT [13–16].
Mechanical assets, for example, gadgets, specialists, and software segments, can be connected to the Semantic Web-based environment by means of connectors or interfaces, which incorporate sensors with advanced yield, information organizing (e.g., XML), and semantic connector parts, that is, XML, to Semantic Web. Specialists are thought to be doled out to every asset. They can screen semantically achieved information originating from the connector about conditions of the asset. They choose if even more profound diagnostics of the state are required and find different operators in the earth, which can covey to “leaders” and trade data, that is, specialists-to-operators correspondence with semantically enhanced substance dialect for analysis and choice. It is accepted that “choice making” Web-administration will be actualized in light of different machine learning calculations and will have the capacity to learn in light of tests of information taken from different administration shoppers and marked by specialists. Utilization of domain expert-like operators' innovations inside of multiagent-based communication permits versatility of the best parts between different stages, decentralized control disclosure, and FIPA (information concerning the term FIPA is available at http://www.fipa.org/) correspondence conventions usage of IoT-based systems.
Furthermore, the remaining part of the paper is structured as follows. In Section 2, reviews on concerning concepts are given looking in depth for a better understanding of the model. In Section 3, the model is given with its mathematical representation and algorithms to see its working. In Section 4, a case study is used to see this model support results given in Section 5. In Section 5, conclusion and future concern are given.
2. Literature Review
The Semantic Web (SW) is an expansion for presenting the Web that permits significance of data to be accurately portrayed as far as very much characterized words that are comprehended by individuals and PCs. On SW, data is portrayed utilizing another Web-based standard known as Resource Description Framework (RDF) (standard for RDF is available at http://www.w3.org/RDF/). Philosophy is a standout among essential ideas utilized as part of the SW base, and RDF(S) (Resource Description Framework/Schema) (standard for RDFS is available at http://www.w3.org/TR/rdf-schema/) and OWL (Web Ontology Languages) (standard for OWL is available at http://www.w3.org/2001/sw/wiki/OWL) are two W3C (see information about W3C at http://www.w3.org/) suggested material representations utilized to speak to ontologies. The SW will bolster extra proficient revelation, robotization, reconciliation, and reuse of information and give backing to interoperability issue, which cannot be determined with current Web advancements. As of now, research on Semantic Web indexes is before all other stages, as the conventional Web search tools, for example, Yahoo, Google, and Bing, still devastate the present markets of Web indexes [17].
The author of [18] has exhibited the study on the Web-based data transformation and the part of agent-based intelligence to extract closely linked data. At the present phase of semantical annotation advancement, there is an assorted quality of heterogeneous data models, applications, forms of information representation, and methods for linked data based communication [18]. Each one of those models was custom-made for specific undertakings and objectives. Different mechanical models, which have been made and executed by various consortia, seem, by all accounts, not to be adequate for developing fast analyses on IoT sensors [8].
2.1. Internet of Things (IoT)
Sensor gadgets, cell phones, online networking, and national detecting assets are a percentage of the key hotspots for creating and gathering physical-world information that can be conveyed, coordinated, and reached on the Web [19]. These assets can deliver extensive volumes of information in which the nature of the information can likewise shift after some time. The information can be spoken to as numerical estimation values or as typical depictions of events in the physical-world. Deciding the quality, legitimacy, and trust of information is among the key issues in big data [20] accumulations from the physical-world, particularly being used in case of situations where the information is made accessible by an expansive number of various (and here and there obscure) suppliers [21]. In the physical-world, information can be identified with the earth, individuals, and occasions, and protection and security are constantly key concerns. At the point when the size of the information and the quantity of various gatherings that can get to and process the information build, managing these issues turns out to be all the more difficult [6]. For instance, in a keen city environment where the tangible gadgets gather information identified with national exercises and numerous offices can get to this information, proprietorship, the length of time of capacity, and sorts of utilization can raise noteworthy protection and security concerns. Classification of sensors for multiagent is to collaborate information for enhanced data understanding and producing specific data analyzed [22].
2.2. Agent-Based Development
Specialists' mining is a rising interdisciplinary region that incorporates multioperators frameworks, information mining and learning revelation, machine learning, and other significant zones [23, 24]. It conveys new chances for handling issues in significant fields all the more proficiently by drawing together the individual advances. It will likewise realize beneficial interaction and symbionts that consolidate focal points from the comparing constituent frameworks [25]. The idea of operators mining is the principle territories for knowledge discovery and opportunities, which leads toward specialists mining in the system with the help of agents [26]. The connection and joining between specialists' innovation and information mining and machine taking in originate from the characteristic difficulties, needs, and opportunities faced by the constituent advancements both individually and commonly. New difficulties are showing up with the rise of new processing systems [27], for example, conduct figuring, distributed computing, and social registering [5]. Specialists' mining realizes multifold preferences to multioperators frameworks, information mining, and machine learning [24] and additionally new inferred speculations, instruments, and applications that passed any individual innovation [4]. A case in point is, in a multioperators' framework, specialists can team up with each other to work towards a common objective for every predefined strategy. With information mining and machine taking in, the examination of a partner's authentic practices and the discovery of current practices can successfully streamline operators coordinated effort execution and upgrade abilities for handling special cases and clashes [23, 25]. Similarly, cloud examination might be enormously improved by connecting with robotized participation between operators based processing segments. The flexibility of standards and conventions might be improved in a social framework [5] through taking in results from disseminated operators in authentic and continuous way through following of reasoning rules generated through ontologies [4, 26].
Ontologies can be spoken to by different dialects in Semantic Web going from Resource Description Framework Schema (RDFS), which is the weakest, to Web Ontology Language (OWL), which is the most grounded. Jena cosmology Application Programme Interface (API) gives a reliable programming interface to philosophy application advancement. Jena philosophy API is autonomous metaphysics dialect utilized amid programming. The Jena Ontology API dialects are with class names, which are implemented in Java, while the core Java packages does not provide the same. Reasoners take a shot at the metaphysics to determine extra truth on the demonstrated ideas. Jena reasoner makes another RDF model containing inferred tuples. This amplified model can be questioned similarly as a plain RDF model.
We cannot say yet that Semantic Web innovation, all things considered, is developed enough to be acknowledged by industry on an expansive scale. The explanations behind what we have divided and late findings express the same results. Some of the models still need alterations and, in addition, fitting instrument support. However, rising mechanical elements consider, for example, gears, forms, faculty, administration for conditional checking, unattended diagnostics, and upkeep to be a particular resource of Web assets. Such assets are actually progressive, besides the perspective of altering qualities for a few characteristics additionally from the perspective of evolving “status-marks” (state of the asset). Current RDF still needs transient and logical augmentations.
2.3. Semantic Annotation
Right now, two or three intelligent Web indexes are composed and actualized for various workplaces, and the components that understand these Web crawlers are particular. This exploration has joined portrayal rationale deduction framework and advanced library cosmology to finish clever Web search tool [3, 4, 14, 17]. By motor instrument, displaying requests and an equation assessing present related innovation of that can tackle and advance the productivity of Web crawler, as well as defining the requests of knowledge Web crawler.
The Semantic Web empowers PCs to comprehend the significance or semantics of the data accessible on the Web. The semantics have significantly benefited the examination of joining, pursuit, and investigation of information. The linked information is spoken to by organized or semiorganized ontologies and is portrayed by dialects, in particular Resource Description Framework (RDF) and Web philosophy dialect like OWL. Metaphysics is a formal particular of the conceptualization. The idea is spoken to utilizing classes, properties, and relations between them. The classes are of various sorts, specifically, subclass, superclass, convergence class, union class, and supplement class. The properties are principally of two sorts, in particular, information property and article property. Transforming data model from one form into semantic data model [28] in either RDF or OWL needs to support mapping between the two models.
2.4. Data Transformation
Over the previous decade, using relations and symmetries inside probabilistic models has turned out to be shockingly successful at taking care of extensive scale information mining issues. One of the key operations inside these lifted methodologies is numbering, be it for parameter/structure learning or for proficient deduction. Normally, nonetheless, they simply check misusing the coherent structure utilizing impromptu administrators. This paper researches whether accumulation to graph databases [1, 14] could be a viable procedure for scaling lifted probabilistic derivation and learning strategies [9, 26, 29]. We exhibit that chart database inquiry to get both correct and surmised numbers can make innovative derivation and learning systems requests of extent speedier, without yielding execution.
2.5. Data Extraction
Data recovery via looking at data on the Web is not a crisp thought but rather has distinctive difficulties when it is contrasted with general data recovery [17]. Diverse Web indexes return distinctive list items because of the variety in indexing and hunt process. Google, Yahoo, and Bing have been out there which handle the inquiries in the wake of preparing the catchphrases. They just make inquiry on data which are given on the webpages, some exploration gatherings begin conveying results from their semantics based on the Web search tools. However, the greater parts of them are in their introductory stages. Web crawlers do not index the whole Web content. Present World Wide Web is the longest worldwide database that does not have the presence of a semantic structure and henceforth it gets to be troublesome for the machine to comprehend the data given by the client as hunt strings. Recently, the Web indexes return vague or incomplete questionable result information set; SW is being produced in accompanying issues for the classical Web [3, 4, 14, 17].
3. Proposed Model: Multiagent Semantical Annotation Enhancement Model (MA-SAEM)
In the methodology of information change, we will present a technique that is utilized from information to noteworthy learning with two parts of adjustment: information model change and Application Programming Interface (API) (see information about Application Programming Interface at http://en.wikipedia.org/wiki/Application_programming_interface) adjustment as it was said in Introduction. The primary angle concentrates on a change of asset information put away in a particular information model (social database and a group of XML-based guidelines) to a brought-together semantically rich organization, for our situation to RDF, and the other way around. For this reason, we use a system for two-stage change, which accepts mapping of a particular information model to a relating sanctioned structure from the same group of information representation guidelines. In the event that, for example, we have to change an XML (standard for XML is available at http://www.w3.org/XML/) blueprint to RDF, as a matter of first importance we need to characterize the XML authoritative pattern and make a mapping to it. There is an assortment of assets expected for incorporation into a typical Smart-Resource environment [30]. For examination that is more effective, all assets were isolated into as many essential categories as needed. These assets speak to genuine articles, which ought to communicate in the certain path as indicated by fitting plans of action. The adjustment of such heterogeneous resources like sensing the data lies in a given situation, which would permit them to convey unified and a standard convention.
XSLT-based change is a decent illustration of grammatical change of XML records. For our situation, XSLT (standard for XSLT is available at http://www.w3.org/TR/xslt20/) is utilized for linguistic change between various XML-patterns; for example, XPATH (standard for XPATH is available at http://www.w3.org/TR/xpath20/) expressions are additionally a conceivable arrangement. Every report of a specific standard is changed into a comparing accepted structure amid the linguistic change stage. Amid the second stage, that is, sanctioned-to-authoritative semantic change, the accepted structure is changed into the brought-together semantic standard structure, which is RDF for our situation. The two-stage change accepts working in both bearings. That is, the CSV-XML-RDF (as shown in Figure 1) (for understanding CSV format check http://edoceo.com/utilitas/csv-file-format) is a way of the change which is similarly in the extent of the investigation. There are few tasks, which have expounded pilot strategies for change of CSV to XML. Subsequent to RDF is an improved subset of original RDF-based data; it is conceivable to embrace these routines moreover.

A model for IoT agent-based classification of data.
Obviously, since the issue of taking care of and dissecting vast scale information has been around for a considerable length of time, it is not shocking that few conventional but rather proficient techniques displayed in the past might be utilized to comprehend or alleviate the challenges of taking care of the huge information issue. These techniques can be found in some past information mining concentrates, for example, arbitrary examining, information buildup, isolation and vanquishing, and incremental learning.
Among them, a conceivable approach to take care of the huge information issue of IoT is to have sensors procure just the fascinating information rather than all the information. One of the agent research patterns has been on diminishing the many-sided quality of information. One instinctive system is to utilize the important segment examination or other measurement decrease strategies to reduce the quantity of elements of the information. As of late, there is another promising pattern called design decrease, which depends on an alternate thought. Contrastingly, this innovation has gone for decreasing the number of examples rather than the extent of measurements amid the union procedure. Therefore, it can likewise be utilized to diminish the multifaceted nature of information. Unique in relation to these strategies, some encouraging headings for taking care of the enormous information issue as of late have been highlight choice, dispersed figuring, and distributed computing.
3.1. Mathematical Modeling
Agents will be focusing on time-oriented classification of data by matching mechanism of ordering of each instant occurrence. Matching mechanism among agents is given in Definition 1 as follows.
Definition 1 (matching mechanism).
It is a matching representation between


Definition 2 (pattern recognition).
Given a resource r (could be any category of data) and its scoring functions
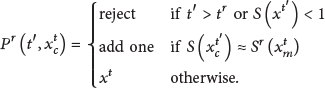
3.2. Algorithm
Three algorithms are built to cover data translation and annotation based on scoring mechanism devised in Section 3.1.
Algorithm 1 is taking value generated by sensors and running it through the process contained by agents based on (3) to see its fitness to be translated into a tag. Then, each tag based schema along with its value is generated and, according to the W3C standards for XML tags, each tag is closed accordingly in statements
recoded instant at time t ( ( ( ( ( ( ( ( (
Algorithm 2 further transforms XML tags into RDF triples. Statement
( ( //number of tags contained within an element ( //isElement() returns 1 when current tag is element ( ( ( ( ( (
Algorithm 3 is using both previous Algorithms 1 and 2 undertaken for updated list of triples at statement
( ( ( ( ( (
The following is the time complexity


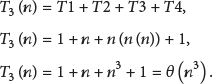

4. Case Study
Another issue for the Semantic Web standardization effort relates to the way that is paying little respect to various associations and consortiums have realized express delineation of semantics of data and region exhibiting is basic for application blend, they have still utilized for that reason their organization/consortia particular measures or XML dialect (for further information on XMLS dialect problem check http://broadcast.oreilly.com/2012/03/xmls-dialect-problem.html) that is wrong for worldwide incorporation. Notwithstanding understanding that Semantic Web is giving truly worldwide gauges, it is as of now past the point of no return, work and asset devouring to change physically immense measure of effectively displayed metadata from a neighborhood to the worldwide standard. One conceivable arrangement could be planning semantic connectors, which empower self-loader change from organization particular models to Semantic Web guidelines. This spurs the second goal of the Smart-Resource Adaptation Stage, which is an outline of general adaptation framework meant to give a technique to planning connectors from different information organizations to RSCDF [31] and back. With a specific end goal to recover the estimations, one can get to the connections underneath. One can compare region in the zone with dew point, moistness, temperature, and weight values all together for model testing (as shown in Figure 2), for example, to create encounters about air quality/meeting member comfort when the territory under study is impacted.
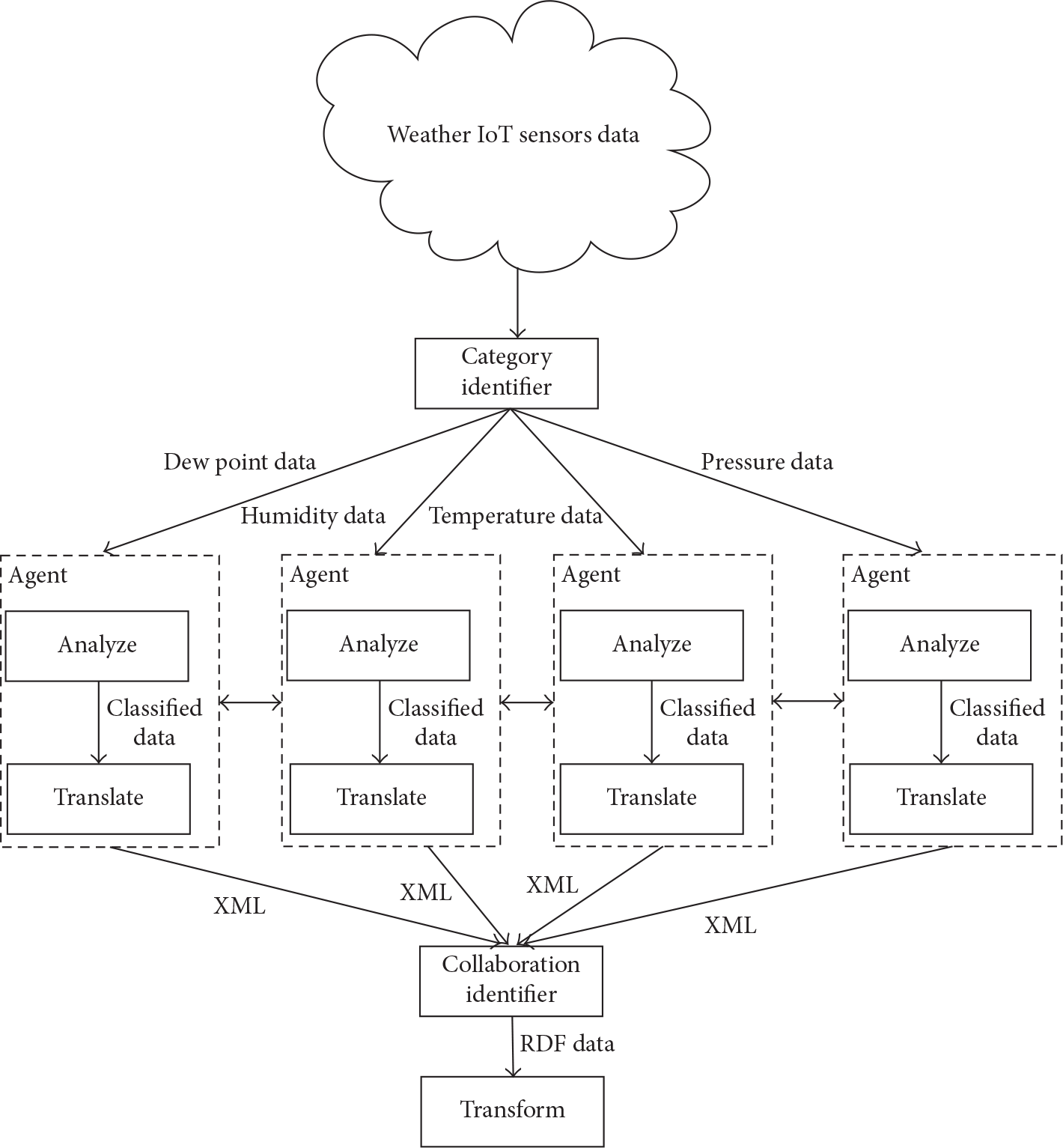
IoT agent-based classification of weather data.
The pilot variant of the errand and its answer are introduced as deliverables of the Smart-Resource venture alongside solid test usage of the methodology of general adaptation-connectors for three unique examples of heterogeneous assets, that is, gadget information, master interface, Web-service. To many, the gigantic information created or caught by IoT is considered to have exceptionally helpful and profitable data. Information mining will probably assume a basic part in making this sort of framework sufficiently keen to give more helpful administration and situations. At this point, a brief study of the components of information from IoT and information digging for IoT is given. Lastly, changes, possibilities, open issues, and future patterns of this field are tended to.
Weather attributes like dew point, humidity, temperature, and pressure dataset distribution are being represented in the charts as shown in Figures 3 and 4, whereas Figure 3 gives a clear picture of how each property/attribute of weather is dispersed over two days of the span. In addition, Figure 4 is correlation representation of the same data.

Weather-based sensors data distribution of dataset.
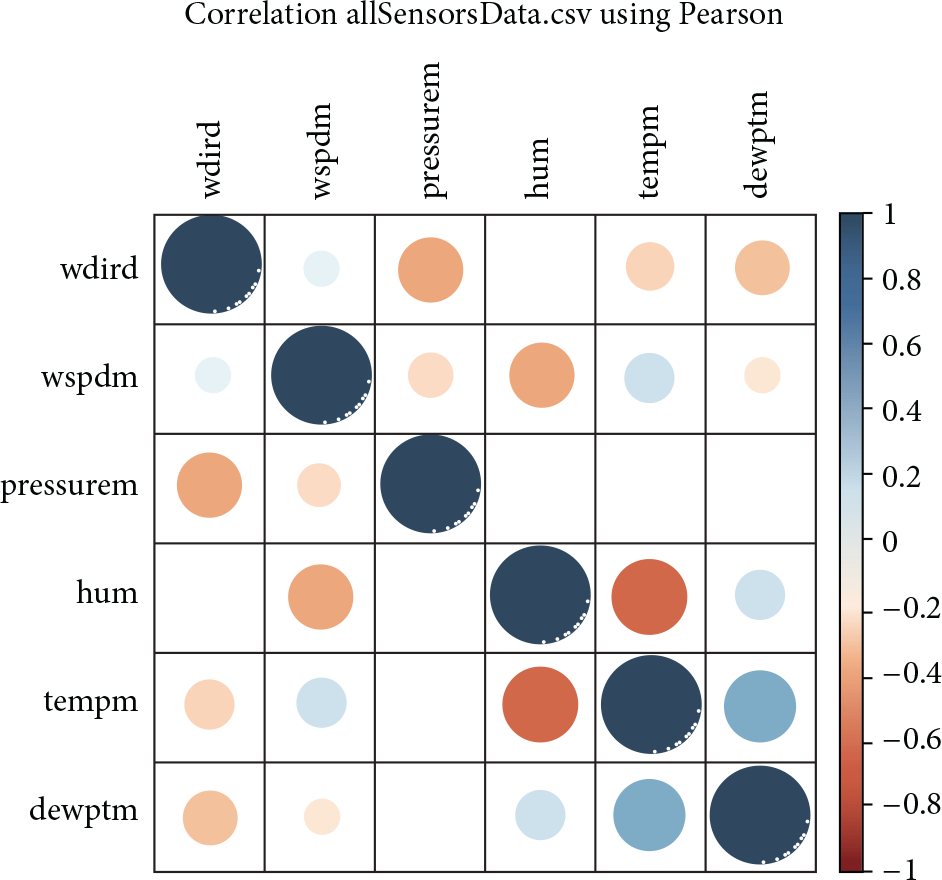
Correlation Pearson plot of weather sensors dataset.
After applying Algorithms 1, 2, and 3 to dataset, then outcome becomes concise enough to easily be classified into each attribute for weather analysis (as shown in Figure 5). Each of the bar graphs of Figure 5 represents the attributes impact based on time passage. These attributes are discussed before like dew point, humidity, temperature, and pressure being features of weather. Results from bar graph in the discussion show that increase in pressure and temperature at peak level leads to dew point increase, which further results in humidity increase, at the end.

Weather attributes wise training outcome by the use of decision stump.
After applying machine learning model called decision stump each attribute like pressure (as shown in Figure 6) and temperature can be visualized and predicted for weather future updates to increase and decrease on the basis of the prediction model.
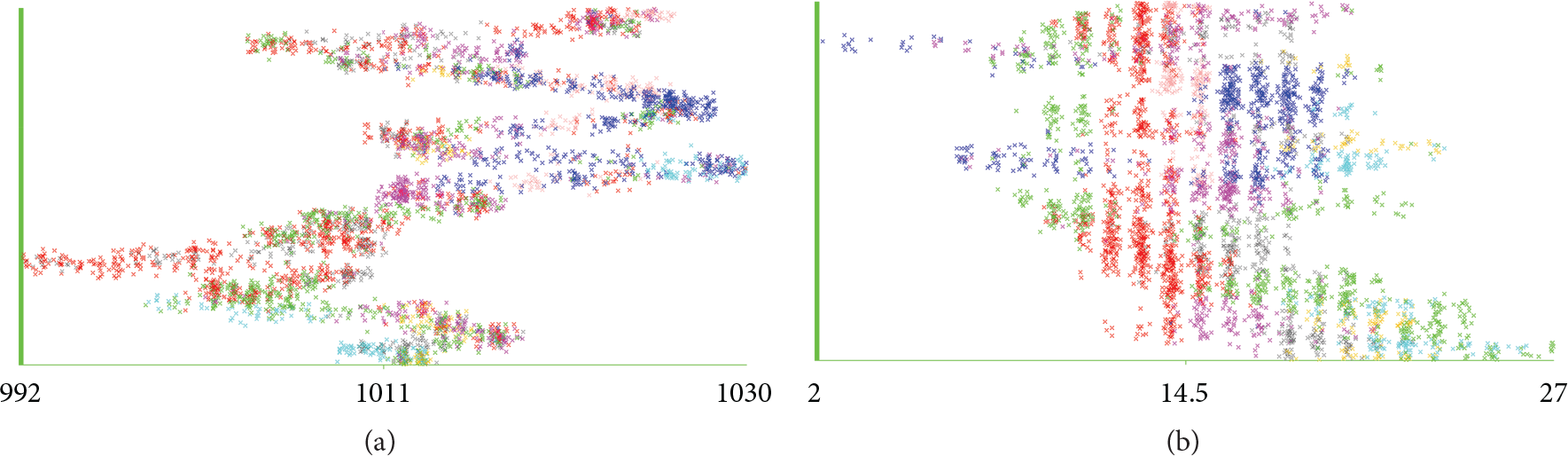
(a) Pressure data clustering for two days at different periods. (b) Temperature data clustered for two days at different periods.
Finally, plot matrix (as shown in Figure 7) represents one-to-one correspondence impact upon looking at periodic results of weather.

Weather attributes correlation with each other shown in plot matrix.
This proves to be a healthy resource when detecting key reasons of high updates in weather changes.
In Figure 8 XMLS defines the structure of the data capable of being used and understood by any machine compatible with XML language. In addition, RDFS provides the ability to be enhanced for reasoning to be done on machine easily.

Amid the semantic change process, changing item/module includes configuration's metadata (constructions) and change rules (as shown in Figure 9) in the form of RDF graph. Compositions, leads, and basic ontologies constitute a structure for semantic change. Semantic change characterizes usefulness in working with semantics of adapter usefulness (administration given by a connector); data representation gauges and models of connector frameworks; software interface models of adjusted frameworks; configuration properties of a connector runtime environment.

RDF graph for weather IoT sensors.
The research methodology is used to perform the semantic adjustment of mechanical assets; the methodology of change (semantic and grammatical) is expounded and executed for checking of a solid modern gadget with basic XML-based information representation model as utilization case. Detecting systems have extraordinarily provoked the rising and the improvement of the Internet of Things as can be seen in Figures 8 and 9. Huge detecting information is produced consistently that is firmly identified with our life. Step-by-step instructions on sorting out and how to inquire the enormous detecting information are huge difficulties for keen applications. We likewise propose a question instrument on occasion connected system which is not the same as the customary social database [5]. An occasion of the savvy home is created to demonstrate the adequacy and proficiency of association and question approach in view of the occasion connected system.
5. Conclusion and Future Work
A great part of the enormous information produced by IoT sensors, gadgets, frameworks, and administration is geolabeled or geofound; that is, area gives vital setting, in addition to being a fundamental bit of data to know when reacting to occasions/sending fitting activities. The significance of having powerful, smart geospatial examination frameworks set up to process and understand such information progressively cannot be overestimated. This applies to all parts of city life, including the strength of its natives. In reality, wellbeing is geospatial, and, in the event that we can see inclines spatially, we can screen and enhance populace and people's wellbeing. Yet, “huge information” strategies must be genuinely helpful on the off chance that they are combined with conventional types of data gathering, or what a few analysts call little information.
Presently SPARQL (standard for SPARQL is available at http://www.w3.org/TR/rdf-sparql-query/) is being reached out to with more expressive entailment administration. This permits an inquiry over derived, certain information. Nevertheless, for this situation the SPARQL endpoint supplier chooses which deduction principles are utilized for its entailment administration. Furthermore, it is required to propose model as an extension to the SPARQL query language to boost remote thinking, in which the information customer can characterize the derivation rules. In the meantime, this arrangement offers conceivable outcomes to understand interoperability issues while questioning remote SPARQL endpoints, which can bolster unified questioning systems. These systems can then be stretched out to give disseminated remote thinking. In future works, we might want to address storing plans, indexing component, and proficient answers to the question on the expansive scale for sensor oriented event based connected systems.
Footnotes
Competing Interests
The authors declare that they have no competing interests.