
Abstract
Urban road travel time is an important parameter to reflect the traffic flow state. Besides, it is one of the important parameters for the traffic management department to formulate guidance measures, provide traffic information service, and improve the efficiency of the detectors group. Therefore, it is crucial to improve the forecast accuracy of travel time in traffic management practice. Based on the analysis of the change-point and the ARIMA model, this paper constructs a model for the massive data collected by loop detectors to forecast travel time parameters. Firstly, the preprocessing algorithm for the data of loop detectors is given, and the calculating model of the travel time is studied. Secondly, a change-point detection algorithm is designed to classify the sequence of large number of travel time data items into several patterns. Then, this paper establishes a forecast model to forecast travel time in different patterns using the improved ARIMA model. At last, the model is verified by simulation and the verification results of several groups of examples show that the model has high accuracy and practicality.
1. Introduction
The travel time (TT) refers to the average time of all vehicles to pass a section of a road, as is shown in Figure 1. If

Distribution of the loops on the road.
Urban road travel time is an important parameter to reflect the state of traffic flow of a road [1, 2]. Based on the forecast information of travel time, the traveler can choose their travel route reasonably [3], and the traffic management department can establish impeccable guiding measures [4]. Thus, the precise forecast of travel time plays important role in improving the quality of urban traffic information service and the efficiency of detector group on the road [5], which has drawn great attention from scholars all the time.
Mori et al. give a thorough classification of the methods for travel time forecasting and they divide the forecasting model into naive model, traffic flow model, data model, and hybrid model [6]. Vlahogianni et al. give a short-term traffic forecasting method of where we are and where we are going [7]. Shao et al. give the method of real-time travel time forecasting based on the improved Kalman filter [8]. Chilukuri et al. forecast the short travel time of the highway by using microsimulation technique [9]. Yao and Zhang give the short-term forecasting algorithm of interval travel time for urban freeway by analyzing the floating car data, which provides the basis for the subsection forecast of the travel time [10]. Zhao et al. propose a forecasting algorithm based on equal interval interpolation and Sage-Husa adaptive Kalman filtering, which effectively improve the forecast accuracy of travel time [11]. Gui and Yu come up with a new idea for travel time forecast by establishing a forecast model with the selective forgetting ability, which enables the algorithm to adapt to trip conditions changes well [12].
The literatures which have been mentioned above provide some idea for this paper to forecast the travel time based on massive data collected from loop detectors. First, travel time and the traffic state of the road have a certain correlation. Besides, most of the travel time forecast models are using historical data for analysis. And the characteristics of traffic flow tend to change with the seasons and the environment in certain regularity. Thus, if the traffic flow can be divided into several state intervals, this means that the different intervals in the same pattern have the similar statistical characteristics of the mean and variance. As a result, it is easier to get the more optimized forecast result than to obtain it by using the global search.
Therefore, this paper proposes a travel time forecasting model based on change-point detection, which uses the change-point detection to identify different patterns of travel time series and set up the forecasting model by ARIMA in each of the patterns.
The rest of the content of this paper is summarized as follows:
Preprocessing of the massive data collected by the loop detectors and calculation of travel time parameter. The pattern partition of travel time series based on change-point analysis and setting up the forecasting model based on ARIMA. Verification of the travel time forecasting model based on actual data.
2. Identification and Correction of the Loop Detector's Data
Because of the reasons such as the detector fault, the fault of communication system, and the environmental factor, the real-time detector data contain some unpredictable data missing or invalid data. Therefore, it is necessary to preprocess the data collected by the traffic detectors [13]. So this paper gives the basic rules to identify and correct loop detector's data based on practical experience.
Basic Rule 1. When the data of traffic volume, speed, and occupancy rate is negative or null, it is recorded as the error data. When the data of volume is significantly greater compared to the maximum volume of road (
Basic Rule 2. When the data of occupancy rate is greater than some reasonable threshold such as 95% and the data of speed is greater than the normal range such as 5 km/h, it is recorded as the error data. When the speed is zero and the volume is not zero, the data is the error data. When the volume is zero and the occupancy rate is not zero, the data is the error data. When the average effective vehicle length (
Basic Rule 3. Each data item should be recorded similarly by n piece of data in time t before it. And the data should be done in first-order difference. If the difference value of first-order does not belong to the reasonable change range made by n data before it, this data can be defined as the abruptly changing distortion data.
The data collected by the detectors can be expressed as four-tuple structure, that is
Algorithm 1.
Step 1. It is determining
Step 2. When the occupancy rate
Step 3. When
Step 4. When
Step 5. Calculate the average effective vehicle length (AEVL) according to the current detected data. If
Step 6. It is using the reasonable and nearest data to replace those error data which have been found in Steps 1–5.
Step 7. It is using the first-order differential operation to process data. If the difference value does not belong to the reasonable change range made by the differential mean value and variance of n piece of data before it (such as
3. Calculation of Travel Time Based on the Data from Loop Detector
Using the preprocessed data, the travel time parameter values can be calculated [14]. The calculation result of the travel time parameter is usually related to the speed of the vehicle on the road.
Assume the speed is conformed to liner change and the upstream and downstream of each section of the road have a detector and each trip chain has multiple parts, so that
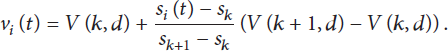
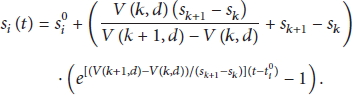

According to formulas (1), (2), and (3), the formula for time calculation of the road section based on the vehicle moving track can be divided into two situations:
When the speed is fast, consider the following:
The approximate result for the travel time of the road section is
When the speed is slow, consider the following: When

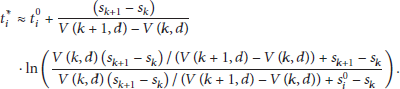

This algorithm based on the method mentioned above can be summarized as follows.
Algorithm 2.
Step 1. Launch vehicles, and select sections (
Step 2. For vehicle in
Step 3. If
Step 4. Set
This algorithm is firstly assuming the motion trajectory of the vehicle on the road and then through using the location-time curve gets the time at which a vehicle runs out of the detector area to obtain the travel time [15]. This method of travel time estimation through time space motion trajectory has high accuracy. The error between the results of the calculation in [13, 16] and the result of this algorithm is below 6%, which means that this algorithm's result is acceptable.
4. Forecast Model for Short-Term Travel Time Based on ARIMA
4.1. Change-Point Searching
Because the traffic data has different numerical characteristics in different time periods, it can be divided into numbers of similar small states by conditional change-point searching, which can effectively improve the fitting degree of the model. In [17, 18], a new algorithm for state division based on the demand variation of the observation function is introduced. The mean and the variance of the sequence can be expressed by statistical formula.
Whole sequence is
Convex (concave) wave is

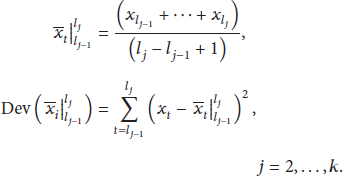
The observation function decides whether to retain the possible change-point. Before that, the control parameter and observation function values of the minimum state variable are required.
Observation function is
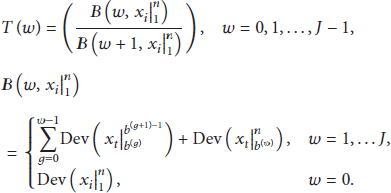
The algorithm is as follows.
Algorithm 3.
Step 1. Make the travel time series into carve, u represents the time of cycles, w represents the number of change-points, and
Step 2. Select two convex waves along the axis of time from

Step 3. Change-point estimation is
If If If If Make effective judgments for

Step 4. If you have
The paper [18] has provided a complete method on how to improve this kind of algorithm. However, there has been a crucial control parameter
4.2. ARIMA Forecasting Model
The preprocessing of the time series short-term forecasting model includes stationary test and random test. If the time series is nonstationary, it needs to be transformed into stationary series by differential operation. In this circumstance, the ARIMA model is converted to ARMA model. The sequence of d order differences is expressed as

ARIMA

The order number p, q of ARIMA
For random inspection, the data collected by the detector is a large density data point, so the calculation result of travel time is also a large sample of high density, which needs to test the hypothesis by using Q statistics:
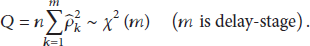
When Q is less than the quintile of

Because there is only a short-term significant correlation in the sequence, the test for the hypothesis is only for Q and
After differential operation, the ARIMA model is degraded to the standard ARMA model; its standard form is

In the formula,

There are
Calculate the expectation and variance of formula (16) on each side and get

The parameters of the equation are reduced to the number of
In the case of ARMA

Thus, overall observed sum of squared residuals of the sample is

Set the objective function for parameter estimation as
The essence of the weighted least square method is to transform the original data to obtain the new explanatory variables and explained variable. Assume that
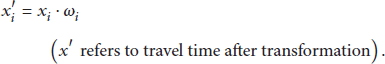


5. Application Example
5.1. Preprocessing of the Massive Data from Loop Detectors
This paper takes the actual data of 2nd ring road in a big city as an example (detector number is

Data distribution of Lan 1's volume-speed-occupancy rate in 24 hours.
In Figure 2, mutation points can be observed in the data series of all the three parameters. In fact, the data of traffic conditions cannot change more than 500% times within two minutes. So it can be concluded that there are abnormal or distorted data in the actual data and it is necessary to filter those data.
According to Algorithm 1, we can finish the data cleaning. Firstly, according to the definition, the control parameters based on the basic traffic flow principle and the actual physical meaning are set up in Table 1.
Selection of filtering model's parameters.

Under the control of parameters listed in Table 1, we can finish the data cleaning to find out the data beyond the maximum control range or contrary to the theory of traffic flow. The result is shown in Figure 3.

Fault data points of filtering intermediate state search.
Use a one-dimensional matrix to record the effectiveness of each record. All the initial value of the matrix is 1. When the abnormal data is detected, the corresponding matrix value is changed into 0. From Figure 3, there is a series of error data points at the time 3:00–6:00, which is consistent with the original graph shown in Figure 4.

Comparison between the actual data and the results of the filter's intermediate state.
Because these error data points do not have actual physical meaning, they are replaced by the closest normal record. After the cleaning, the figure of volume-speed-occupancy rate is shown in Figure 5.

Result of filter's intermediate state.
Data quality has been improved to a certain extent, especially for the speed data. But there still has been mutation in the filtering results. Test the first-order differential of the data to determine the mutation data. The first-order difference graph of intermediate state is shown in Figure 6.

First-order difference graph of intermediate state.
Control parameter of differential operational is
When
Result of the filter by different parameters.


Distortion data distribution when
According to the results shown in the table,

Comparison of the source data and the filter result.
From Figure 3 it can be seen that the algorithm has a small correction for the traffic data and the data with the occupancy rate, but the algorithm has better effect on the speed data. In the process of predicting travel time, the speed of the detector is often used only, which means that the algorithm can be simplified so that it only needs to produce speed data.
Because only the speed data is processed, we need to set the upper and lower limit of speed and the limit of first-order differential change range to restrict data. As a result of using the detector data to calculate and predict travel time, we need three continuous detector's data points to simulate the travel time forecast in whole road network. The sketch map is shown in Figure 9.

Distribution of the three serial detectors on the road.
Under the condition that

Filter result of the speed data of Detector 1.

Filter result of the speed data of Detector 2.

Filter result of the speed data of Detector 3.
As shown in Figures 10~12, the red correction curve basically achieved a reasonable correction of the distortion data.
5.2. Calculation of Travel Time Parameters
Use the travel time conversion model given by formulas (5) and (6); we can do the travel time conversion according to the speed data. For example, when one calculates the travel time driving from east to west, the vehicles pass through sections

Travel time calculation result from
5.3. Pattern Partition of Travel Time Series Based on Change-Point Analysis
Because it is not clear how to choose
Result of change-point searching of each section.

According to the characteristics of the travel time series, we need to select the result that has 5 to 10 change-points. So

Result of the global state change-point searching.
According to the time sequence diagram, the results of the algorithm are basically completed, and the travel time series is decomposed into a series of time periods with practical meaning.
On the situation of
Then, if we assume that this moment is 17:00, we can predict the travel time of 17:02 and 17:04. The historical data of the forecast model is shown in Figure 15.

Historical data of the forecast model.
5.4. Travel Time Forecasting Based on ARIMA Model
To sum up, we choose ARIMA model to build up the forecast model and regress the parameter. Using the data of 221~330 collected by Detector 1 at the time 13:28~17:00 and testing the time sequence, we found it is a nonrandom stationary sequence. The fix order result of the ARIMA model for the time of 13:28~17:00 is
After the weighted least squares are transformed into ordinary least squares, we use four kinds of weight function to do the fitting experiment and also have the error analysis to the output results. The forecast results of different weight functions are as in Table 4.
ARIMA model and forecast result of different weight functions.

Actual value on 17:02: 0.20577.
Actual value on 17:04: 0.196385.
Error analysis result is shown in Table 5 and we can see that the crucial index MAPE has a certain degree of reduction at the proximal point.
Error matrix of different model fittings.
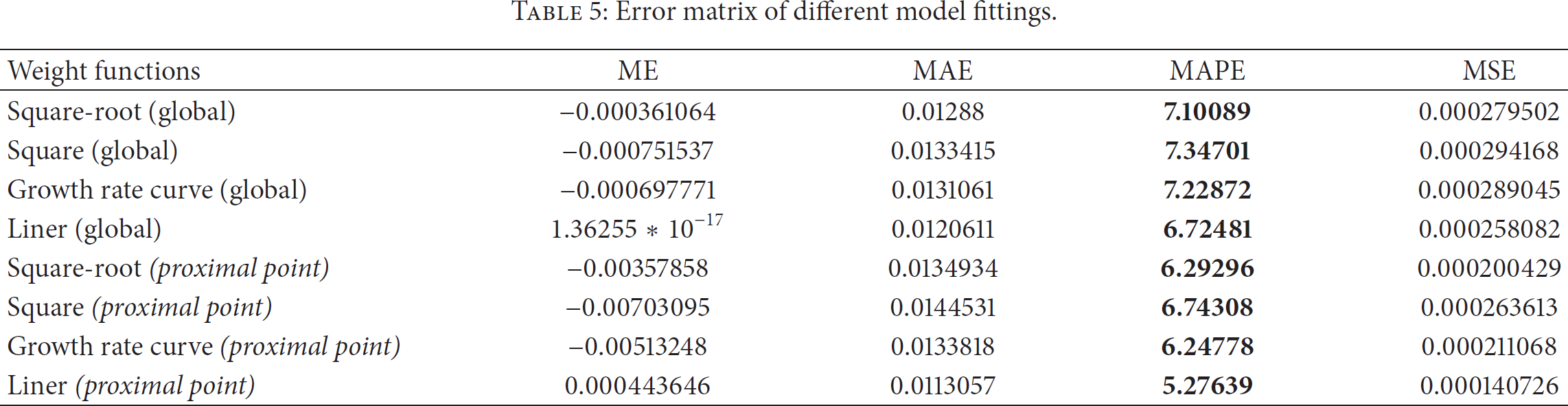
The forecast results of four different weighting functions can meet the basic requirements of the accuracy error of 10%. At the same time, we can know that the linear weight function has good fitting and forecasting effect on the experimental data. The linear weighting function is the optimal weight function for this forecast according to the statistics in Table 5.
6. Conclusion
This paper uses the change-point detection algorithm to divide travel time series into several patterns and set up forecasting model through ARIMA for different patterns based on massive data collected by the loop detectors on the roads. Different from traditional forecasting methods, it is easier to get the more optimized forecasting result than to obtain it by using the global search because the different intervals in same pattern have similar statistical characteristics of the mean and variance. In the process of dividing the travel time series, the calculation of algorithm is complicated and the derivation of control parameters is only obtained by experiments, which still needs research in the future.
Footnotes
Conflict of Interests
The authors declare no conflict of interests.
Authors' Contribution
Guangyu Zhu designed the forecasting model of travel time based on the change-point detection algorithm and wrote the paper; Li Wang designed the preprocessing algorithm and performed the data preprocess and revised the paper. Peng Zhang and Kang Song analyzed the data.
Acknowledgments
This work is supported by the National Science Foundation of China (nos. 61572069 and 61503022), the Fundamental Research Funds for the Central Universities (no. 2014JBM211), the Open Project Program of Key Laboratory of System Control and Information Processing, Ministry of Education, Shanghai Jiaotong University (no. Scip201507), Beijing Municipality Key Laboratory of Urban Traffic Operation Simulation and Decision Support, Beijing Transportation Research Center, the project of the Department of Traffic and Transportation of Hebei Province (no. A0201-150505), and The National Key Technology Support Program (no. 2014BAG01B02).