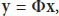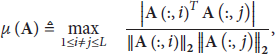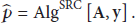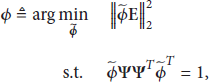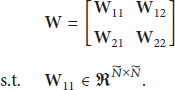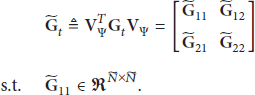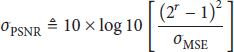Compressive sensing (CS), as a new theory of signal processing, has found many applications. This paper deals with a CS-based face recognition system design. A novel framework, called projection matrix optimization- (PMO-) based compressive classification, is proposed for distributed intelligent monitoring systems. Unlike the sparse preserving projection (SPP) approach, the projection matrix is designed such that the coherence between different classes of faces is reduced and hence a higher recognition rate is expected. The optimal projection matrix problem is formulated as identifying a matrix that minimizes the Frobenius norm of the difference between a given target Gram and that of the equivalent dictionary. A class of analytical solutions is derived. With the PMO-based CS system, two frameworks are proposed for compressive face recognition. Experiments are carried out with five popularly utilized face databases (i.e., ORL, Yale, Yale Extend, CMU PIE, and AR) and simulation results show that the proposed approaches outperform those existing compressive ones in terms of the recognition rate and reconstruction error.
1. Introduction
Face recognition (FR) has played a very important role in multimedia based applications. In spite of many years' research, it remains an interesting and challenging research area [1]. Figure 1 depicts the conventional face recognition process. As it involves storing and transmitting high dimensional images, image compression techniques such as JPEG and JPEG2000 are used to alleviate the problem [2, 3]. At the receiver end, users have to decompress (reconstruct) images and extract the image features for classification. Such a procedure usually requires a lot of computations and hence makes the systems expensive. It can be much simplified if the images can be acquired using compressive sensing, which outputs features of images extracted directly, and the classification and reconstruction are done with the extracted features. See Figure 2.
Block-diagram of the conventional FR Systems.
Block-diagram for compressive sensing-based FR Systems.
With the development of Internet of Things and information technology, the demand for the distributed intelligent image monitor systems, as shown in Figure 3, increases greatly, which need an intelligent Internet end with the capacity of sensing and classifying. The cameras are connected by wireless Internet. The main problems with such a system are the transmission and storage of the images and the cost, including the infrastructure and the communications. To implement this architecture, technically speaking, there are several factors to consider: data storage space, RAM space, the computation time, and the transmission bandwidth. The key to solve these issues is to develop a data compression algorithm which can integrate the signal reconstruction and the classification with an accepted performance.
Block-diagram of a distributed intelligent monitoring system.
Dimension reduction plays an extensively important role in high dimensional data analysis and studies. In recent years, many dimensionality reduction methods are successfully applied in pattern recognition [4, 5]. The principal component analysis (PCA) intends to represent faces by projecting the facial images to the directions of maximal covariance in the facial image data. One of the advantages of PCA is to reduce dimensionality of data but such an approach ignores the relationship between data in high dimensions. Linear discrimination analysis (LDA) explicitly attempts to model the difference between the classes of data. The Fisherface method combines PCA and the Fisher criterion to extract the information that discriminates the differences between the classes of a sample set. The projection matrix is chosen to maximize the ratio between the determinant of the between-class scatter matrix of the projected samples and that of the within-class scatter matrix. Nevertheless, Martinez et al. demonstrated that when the training data set is small, the eigenface method outperforms the Fisherface method. Some novel algorithms attempt to reduce the data dimensionality, while keeping the intrinsic characteristics. The local preserve project (LPP) aims to find embedding which can preserve local information and obtain a face subspace that best detects the essential face manifold structure. Because LPP has an excellent ability to find a better projection direction when the distances between classes are large, it can keep the local structure of the data very well. But when the distance between two classes is close or even partially overlapping, it can not process classification effectively due to the characteristics of keeping local information.
The recently developed compressed sensing (CS) is a signal processing technique that can acquire a signal efficiently and reconstruct it by finding the solution to an undetermined linear system [6, 7]. Its essence is to achieve analog signal discretization with sampling-compression integration, namely, the analog-to-discrete CS. The basic principle of such a CS framework is similar to that of discrete-to-discrete CS [8, 9], which can be explained below. In the standard CS framework, it is assumed that the high dimension signals can be represented as a linear combination of L vectors :
where is known as the dictionary (matrix), while s is -sparse vector with denoting the number of nonzero elements of s and corresponding x is said to be -sparse in the dictionary . The basic mathematical problem of CS is to study how to reconstruct the original high dimensional signal x from its low dimensional projection y which is mathematically of the form
where is called a projection matrix (it is also called measurement or sensing matrix, which will be used alternatively in this paper) with . Signal reconstruction means to find x from (2) with y and the pair given. There are two conditions under which recovery is possible. The first one is sparsity which requires the signals x to be sparse in some . The signal reconstruction problem is given as
where is called equivalent dictionary. The solution to (3) is unique for sparse signals if A satisfies the restricted isometric property (RIP). See [6, 7].
The second condition is related to the mutual coherence [10, 11] of the equivalent dictionary A, which is defined below:
where T denotes the transpose operator. represents the worst-case coherence between any two atoms of A. As shown in [10], the K-sparse signal can be exactly recovered from the measurement as long as
As seen, the smaller the value of is, the bigger the value of K is allowed. The latter implies a wider range of signals that can be recovered exactly using such a CS system. So, minimizing is of importance. Simulations showed that the signal reconstruction accuracy is more related to the number of columns that are strongly correlated compared with . Noting this fact, Elad in [11] proposed to minimize averaged mutual coherence with respect to for a given dictionary . Since then, many different approaches have appeared. Roughly speaking, these approaches are all based on the same framework: to design the sensing matrix such that the Gram matrix of A, defined as , is as close to a target Gram matrix as possible in the sense of
where denotes the Frobenius norm, is a class of Gram matrices possessing certain properties, and the dictionary is assumed to be given. See [12–15]. As the diagonal elements of are all assumed to be one, the Frobenius norm-based error above actually represents the averaged coherence except for a constant factor if all the diagonal entries of are equal to one. The properties of the CS systems designed using (6) are strongly related to the choice of the target Gram . A column normalized matrix is said to be equiangular tight frame (ETF) if , , where is the smallest mutual coherence that an matrix possibly has. Such a problem has been investigated for being the identity matrix and some analytical solutions are available [13]. In the ETF-based approach, the target Gram is taken as the one of a relaxed ETF matrix and the obtained sensing matrix shows an improved performance [13, 15]. Developing algorithms to solve (6) for arbitrary is still an interesting topic.
Sparse representation (SR), an important prerequisite for CS theory, has been applied in face classification [16]. Such an approach, usually referred to as SRC standing for sparse representation classification, can yield a higher recognition rate with varying illumination and expression. With SRC, the recognition is converted to the problem of classification among multiple linear regression models. The desired representation is sparse since the test sample should only be represented in terms of training samples belonging to the same class. The sparse representation can be computed with minimization [6]. However, this algorithm is very time-consuming for large scale databases with images of high resolution. The recognition rate degrades with the feature dimension reduction in general [16]. Sparse preserving projection (SPP), proposed in [17], builds the graphs based on the sparse reconstruction of data. Such a technique tries to preserve the sparsity without considering the coherence issue, which would affect the face recognition rate.
Sparse representation works well in applications where the original signal x needs to be reconstructed as accurately as possible, such as denoising, image inpainting, and coding. However, sometimes we just need to discriminate the signal from its representation rather than reconstructing it. The difference between reconstruction and discrimination has been widely investigated in the literature. It is known that typical reconstructive methods, such as PCA and independent component analysis (ICA), aim at obtaining a representation that enables sufficient reconstruction, and thus they are able to deal with signal corruption, that is, noise, missing data, and outliers. On the other hand, discriminative methods, such as LDA, generate a signal representation that maximizes the separation of distributions of signals from different classes. While both classes of methods have broad applications in classification, the discriminative methods, as expected, have often outperformed the reconstructive methods for the classification task.
The main objective of this paper is to develop an algorithm for face classification and reconstruction, which is intended to be used in distributed monitoring systems and to be implemented in a low-cost microprocessor (e.g., ARM Cortex-M3 and ARM Cortex-M4) platform. The algorithm to be proposed in this paper is projection matrix optimization- (PMO-) based compressive classification, which tries to design the projection matrix in such a way that the within-class coherence is enhanced while between-class one is reduced. The receiving end uses the sparse representation coefficients in the equivalent dictionary for image reconstruction and classification. Precisely speaking, the main contributions in this paper are given as follows:
A new distributed monitoring system oriented face recognition framework is proposed based on compressed sensing. Instead of the high dimension original images, their lower dimension counterparts obtained using projection are transmitted and used for reconstruction and recognition. A new target Gram, denoted by , is proposed for designing the projection matrix in order to improve the discrimination between classes.
The optimal projection matrix design problem is formulated in terms of identifying those sensing matrices that minimize the difference between the Gram of the equivalent dictionary and the proposed target Gram in Frobenius norm sense. A class of analytical solutions is derived for the proposed problem which is a generalization of that in [14].
With the PMO-based CS system, two frameworks are proposed for face recognition. Experiments are carried out and the results confirm that the proposed approaches can effectively improve the system performance in terms of face classification and reconstruction.
The paper is outlined as follows. Section 2 is devoted to providing some existing works on compressive classification and recognition, which are closely related to ours. Our main contribution is given in Section 3, in which the PMO for compressive classification problem is formulated and an algorithm is derived to solve this problem. With the obtained PMO-based CS systems, two FR frameworks are proposed for distributed intelligent monitoring systems. Experiments are carried out in Section 4 to examine the performance of the proposed approaches and to compare them with some of the prevailing ones. To end this paper, some concluding remarks are given in Section 5.
2. Related Works and Problem Formulation
This section intends to review the sparse representation classification and some projection-based SRC methods, which have been considered as successful applications of signal sparse representation and compressive sensing theory to face recognition and are closely related to our present work to be developed in this paper.
2.1. Sparse Representation Classification
In [18], the sparse representation is shown to achieve state-of-the-art performance in image denoising. Such a technique was also used as an inpainting method in [19] for recovering missing pixels in images. It was extended to face recognition in [16].
Suppose we have P class samples ; each class has a set of samples with the same size, from which we randomly select Q samples for training purpose. Each sample forms a vector of dimension and scaled to unit in -norm, yielding an atom of the dictionary :
where is the dictionary for the pth class.
In the standard SR framework, it is assumed that the original face image signals can be represented as a linear combination of vectors :
where and s is sparse.
The procedure for classifying given -normalized x contains the following steps [16].
Step 1.
Normalize x in :
Step 2.
Find the sparse vector s with
Such a problem can be solved efficiently using a linear programming technique as the constraint is also linear.
Step 3 (compute the residual energy).
Denote by the subvector of , corresponding to the pth dictionary . Calculate
Step 4 (classification).
x belongs to the th class, where is determined with
The input-output relationship of this algorithm is simply denoted by
where the dictionary is -normalized.
It should be pointed out that the SRC described above works on high dimensional signals x. See (10). In the remainder of this section, we will present some methods that carry out the SRC in lower dimensionality domain by working with the projection y of original x via (2); that is, . Such a class of classification techniques is referred to as compressive SRC. Therefore, a method in this class differs from another by the ways in which the projection matrix is designed.
2.2. PCA-Based SRC
The PCA provides a dimensionality reduction technique to represent the high dimensional signal x with a lower dimensional one y obtained using (2). The projection matrix is determined as follows.
Let be the mean of . Denote and
By singular value decomposition (SVD), R can be rewritten as
where with the principal components satisfying , .
Under the PCA, the optimal projection matrix with is given by the first M columns of the orthonormal matrix U:
The original signal x is projected into .
The PCA-based SRC approach, denoted by , is a classification based on y rather than x.
Step 1.
With obtained above, compute and .
Step 2.
Normalize the equivalent dictionary:
where with the denominator being the -norm of the kth column of for all .
The SPP proposed in [17] aims at carrying out the classification/recognition in a lower dimensional space. Precisely speaking, it works with signals y which are obtained using (2), where the projection matrix belongs to with .
In such a framework, the kth sample in the dictionary is featured by its sparse vector obtained with
where is the column vector whose entries are all equal to and is the vector space of dimension L, in which each of the vectors has its kth element equal to zero. Denote
where as the sparse representation error matrix in the sense specified by (19). The projection matrix is chosen such that each row vector of will minimize the sparse representation errors [17]:
where the constraint is for avoiding degenerate solutions. Using Lagrange multiplier approach, one can find the solution to (21) from the following generalized eigenvalue problem:
and the M row vectors of optimal are given the transposed eigenvectors, that is, , corresponding to the top M eigenvalues of the above equation. Equation (22) can be solved using MATLAB command eig.m:
where with assumed. Then, the optimal projection matrix for SPP is given by first M row vectors of :
As noted in [17], to avoid singularity of this problem, PCA-based preprocessing is usually used (let be the SVD of ; then, replace X with ).
As understood, the SPP-based SRC method, denoted by , is exactly the same as except that the projection matrix is given by (24).
2.4. Sparse Related Face Recognition
In [20], a class of structured sparsity-inducing norms was included into SRC framework which mainly concerns the misalignment, shadow, and occlusion scenarios. But the authors did not take dimensionality reduction into account which is crucial for the implementation of distributed systems. SRC assumes that the sparse representation residual follows Gaussian or Laplacian distribution, while robust sparse coding (RSC) considered in [21] models the sparse coding as a sparsity constrained robust regression problem and seeks the maximum likelihood estimation solution of the sparse coding. All these make it much more robust than SRC. However, the computational complexity of RSC is also much higher than SRC's which is not practical for the investigated distributed system.
2.5. Problem Formulation
In a distributed intelligent monitoring system, images acquired by the agents are usually of high dimension and have to be transmitted to the back-end server for recognition. In order to have an efficient transmission, it is desired to compress these high dimension signals with , where . One way to do so is through projection , where the projection/sensing matrix with compresses into a much lower dimension signal . Instead of , is transmitted.
Once is received by the back-end server, the recognition of (corresponding to image ) is done with the equivalent dictionary A:
where the dictionary , as formed in (7), is assumed to be given. The main problem to be investigated in the remainder of this paper is how to design the sensing matrix such that the image can be recognized with the measurement and the equivalent dictionary A.
3. The Proposed CS System for FR Distributed Monitoring Systems
As mentioned before, the key to solve the problems encountered in distributed intelligent monitoring systems is to compress the original (high dimensional) image signals and to carry out face recognition effectively with the low dimensional measurements.
This can be done using CS systems. In fact, both and , described in Section 2, can be viewed as two special CS systems in which the sensing matrix is designed to preserve principal components of the signal covariance matrix and the sparse representation of the samples in the dictionary , respectively.
As seen in the previous section, the optimal sensing matrix design problem is formulated by (6). Such a problem has been studied intensively for signal compression application, in which achieving high reconstruction accuracy is the ultimate goal of the design.
In the context of face recognition, what we are interested in the most is the recognition rate. Therefore, it is desired to design the projection matrix to enhance the recognition rate. This is strongly related to how to choose the target Gram . Another important issue is how to solve (6) with arbitrary .
3.1. How to Choose the Target Gram?
Optimizing projection matrix for CS systems has been an important research topic in CS theory, which was initiated by Elad's work reported in 2007 [11]. Since then, many theoretical achievements have been obtained [12–15]. Roughly speaking, all these results are based on the following formulation:
where is defined as the Frobenius norm, G is the Gram matrix of the equivalent dictionary , and is a target Gram matrix.
For a given dictionary, the performance of the projection matrix depends on the choice of . When a CS system is designed for signal compression, the reconstruction accuracy is the ultimate goal to achieve. In such a case, is chosen such that the resultant projection matrix makes the equivalent dictionary A have small coherence between its columns and the system robust against noises, say sparse representation errors of signals. Recently, Cleju showed in [14] that the images can be well reconstructed from the low dimensional measurements projected with the sensing matrix designed based on , the Gram of the dictionary.
Comment 1.
It should be pointed out that, in -image compression oriented CS systems, the images are divided into subimages, each of which forms a signal vector, say with (this is very different from what has been used in the SRC-based face recognition approaches, in which the signals are of dimension ), while the constructive dictionary is of dimension with . The K-SVD [18] has been considered as one of the most successful methods for designing such a dictionary. It was observed that the dictionaries obtained with different classes of images/samples are very similar. And our experiments showed that a direct application of such a CS system to face recognition based on reconstruction error does not yield a satisfactory performance in terms of recognition rate. Note that, for face recognition application, our ultimate objective is accurate recognition and to enhance recognition rate it would be better to design the sensing matrix by improving the discrimination between the classes at the price of sacrificing reconstruction accuracy. This is actually one of the main motivations for our proposed approach in this paper, which will be developed further.
Let with be the overall dictionary defined before for face recognition and its Gram is
with .
When choosing such that is minimized, one emphasizes the reconstruction accuracy as the fundamental assumption of the SRC-based face recognition approach is that a sample (image), belonging to a class, is close to a linear combination of a few atoms of the dictionary of the same class. This, however, can not ensure that such a sample can not be well represented sparsely in a linear combination of other (sub)dictionaries. In other words, the reconstruction error itself may not be a proper measure for recognition. As mentioned before, recognition rate is our primary goal and hence in the CS system design, it is desired to choose the projection matrix such that the coherence between the columns of and those of for all is reduced. By doing so, the discrimination between classes is improved. This can be achieved by choosing the sensing matrix such that the Gram of the corresponding equivalent dictionary is close to the following target Gram as much as possible:
where
with defined below:
where both and are used to adjust the coherence between different classes and that between the columns of the same class, called correction parameter. These parameters should be chosen such that the off-diagonal elements of are all within . Such a target Gram is called discriminative Gram.
Comment 2.
(i) In [12], sensing matrix optimization for block-sparse decoding was investigated. It is observed that our problem is the simplest block-sparse case, where the blocks are prefixed according to the classes of face images. is taken as the identity matrix in [12] and in our problem is assumed to be symmetric. Both encounter how to choose the weighting factors, which is application dependent and purely empirical. We will present some experimental results in the next section.
(ii) It should be pointed out that though, as to be seen, the recognition/classification is done based on the errors , which has a physical meaning close to the reconstruction error, these errors have taken the discrimination between classes into account via all or the sensing matrix which is designed based on the discriminative Gram defined in (28). So, such a measure can be considered as a mixture of reconstruction error and discriminative error. It is worth noting that, in [22], a dictionary learning-based classification scheme was investigated where the dictionary was trained by certain class of signals as the classifier, while, in this paper, we consider the classification task in compressive domain. The sensing matrix is designed according to the given dictionary and hence the equivalent dictionary (corresponding to the compressive domain) possesses good property so that the sparse coding can be implemented accurately.
In the next subsection, we will discuss how to solve the proposed optimal sensing matrix design problem.
3.2. An Algorithm for Optimizing Projection Matrix
With the target Gram defined in (28), one can now consider the optimal projection matrix design, which is formulated as follows:
Now, let us consider how to solve the above problem. First of all, assume that has the following SVD:
where . Then, we get
where . Let
Then,
where
Finally, the cost function can be rewritten as
We can see that the two right-hand sides have nothing to do with the projection matrix. Define
Let and be an SVD and eigen decomposition of and , respectively. Furthermore, assume that both and are in descending order. It then follows from [23] (see Corollary in page 468) that
and the lower bound (equality) is achieved if and only if
Noting that , one can see that the lower bound ϱ can be minimized with
Since , a class of solutions to (31) is obtained as
where and U is any orthogonal matrix with dimension of M.
Seen from the above discussion, the optimization of projection matrix is only related to the dictionary and the correction constants w and η, and, therefore, for given , w, and η, we can get , which is better than traditional feature selecting process. And (46) is an analytical solution. In addition, there are two degrees of freedom U and in the results, which provides the possibility to further improve system performance.
Comment 3.
Our proposed optimal sensing design problem shares the same form as that in [14]. It should be pointed out that, in [14], and the solutions are relatively easy to obtain, while our is a generalization of and the solutions are actually applicable to any symmetric . In terms of applications, ours is for face recognition, in which the degrees of freedom, brought by the parameters η and w, make our approach outperform that in [14].
3.3. The Proposed CS-Based Frameworks for FR
With the obtained optimal sensing matrix , any given high dimension face image x can be projected to a vector of much lower dimension, which will be transmitted to the server of the distributed monitoring system for classification/recognition. Two PMO-based classification methods are proposed here. The first one, denoted by , has exactly the same structure as and , except that the projection matrix is given by (46).
The second one, denoted by , is outlined as follows.
Step 1.
At a subsystem that captures a face image x, compress it using
and then encode and transmit y to the server of the distributed monitoring system.
Step 2.
At the server that receives y, compute
where is the equivalent dictionary for the pth class: .
Step 3 (classification).
x belongs to the th class, where is determined with
In the next section, we will examine the performance of the proposed algorithms and compare it with some existing ones.
4. Experiment Results
In this section, we examine the performance of various classification systems on five face databases: ORL [24], Yale [25], Yale Extend [26] (referred to as Yale-E), CMU PIE [27] (referred to as PIE), and AR [28]:
ORL database contains 400 images of 40 individuals (each provides 10 images); that is, . Some images are captured at different time, varying the lighting, facial expressions, and facial details. In our test, we randomly select images from each individual to form the dictionary set, while the remaining ones are for testing.
Yale database contains 165 images of 15 individuals (i.e., ; each provides 11 images) under various illumination conditions and facial expressions. A random subset with images per individual is taken to form the dictionary set, and the rest of the database is used for testing.
Yale-E database includes the Yale face database B and the extended Yale face database. A subset called Yale Extend face database is collected from these two databases, which contains 2414 face images of 38 subjects; that is, . In our test, we randomly select images from each individual to form the dictionary set, while keeping the remaining for testing.
PIE database is composed of 68 subjects (i.e., ) with 41368 face images which are captured by 13 synchronized cameras and 21 flashes, under varying pose, illumination, and expression. We generate a data set from it by selecting 184 images for each individual and totally 12512 samples are used in our experiments. images are sampled to form the dictionary set, while the remaining images are considered for testing.
AR database contains over 4000 color face images of 126 people (70 men and 56 women; i.e., ) taken during two distinct photo sessions (separated by two weeks), with different facial expression, lighting conditions, and occlusions. We choose 50 men and 50 women to generate a data set of 100 persons (each provides 26 images). Random selection of images per individual is taken to form the dictionary set, and the rest of the database is for testing.
For each of the five databases, we take all P classes (different persons) with each class containing Q different samples (images), leading to . All images are resized to resolution of and normalized in scale; hence, each face sample is represented as a column vector with . By doing so, the corresponding dictionary is then generated.
The systems consisted of different compression methods (PCA, SPP, RDM for random sampling matrix, and PMO) and various classifiers (SRC, RSC, Wlearning for [22], and ) are compared. For instance, denotes the system combining PCA and SRC with the subscript referring to compression method and the superscript the classifier.
4.1. The Effect of Q
Firstly, we briefly discuss the effect of the number of training samples with ORL database. Figure 4 shows the results of versus Q with different η values and , .
Recognition rate versus number of training samples Q with and η given in the legend.
As can be seen, an increasing trend is obtained when Q gets bigger in general with slight fluctuation. It is reasonable that more samples are used for representation, and higher accuracy is achieved. In the following, proper Q values will be chosen for different databases as introduced in the beginning of this section.
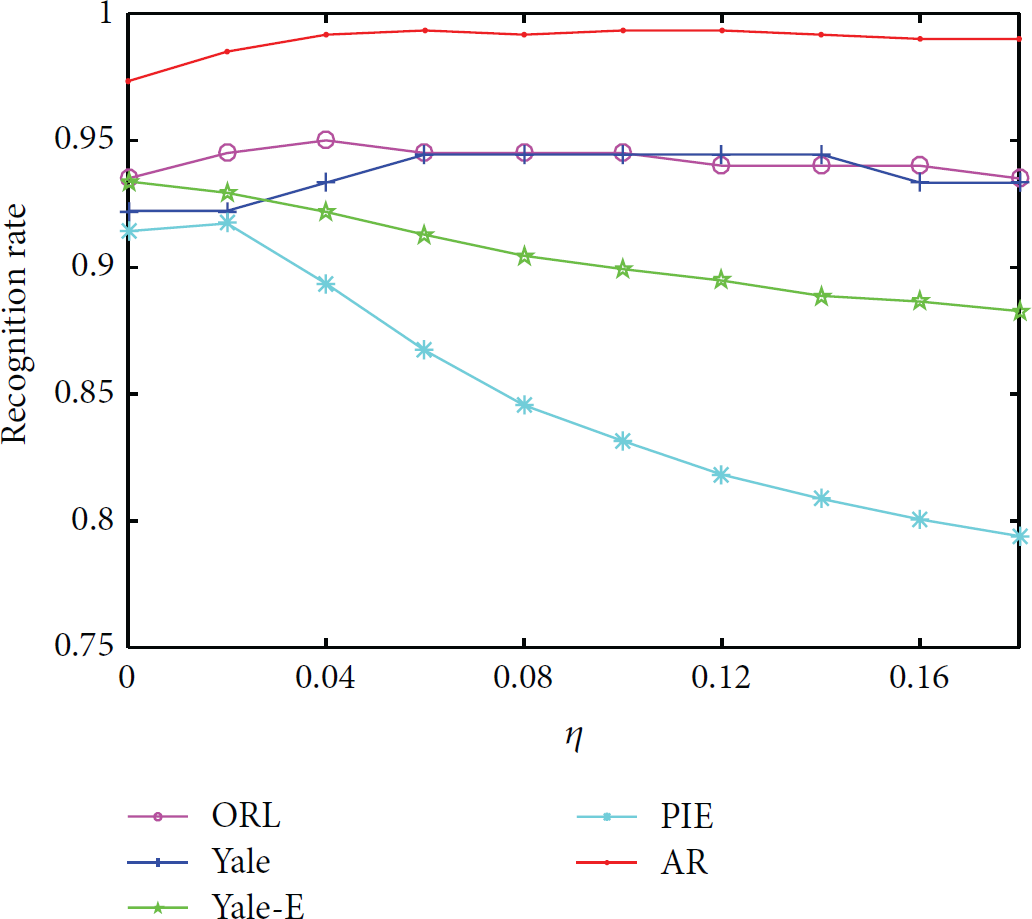
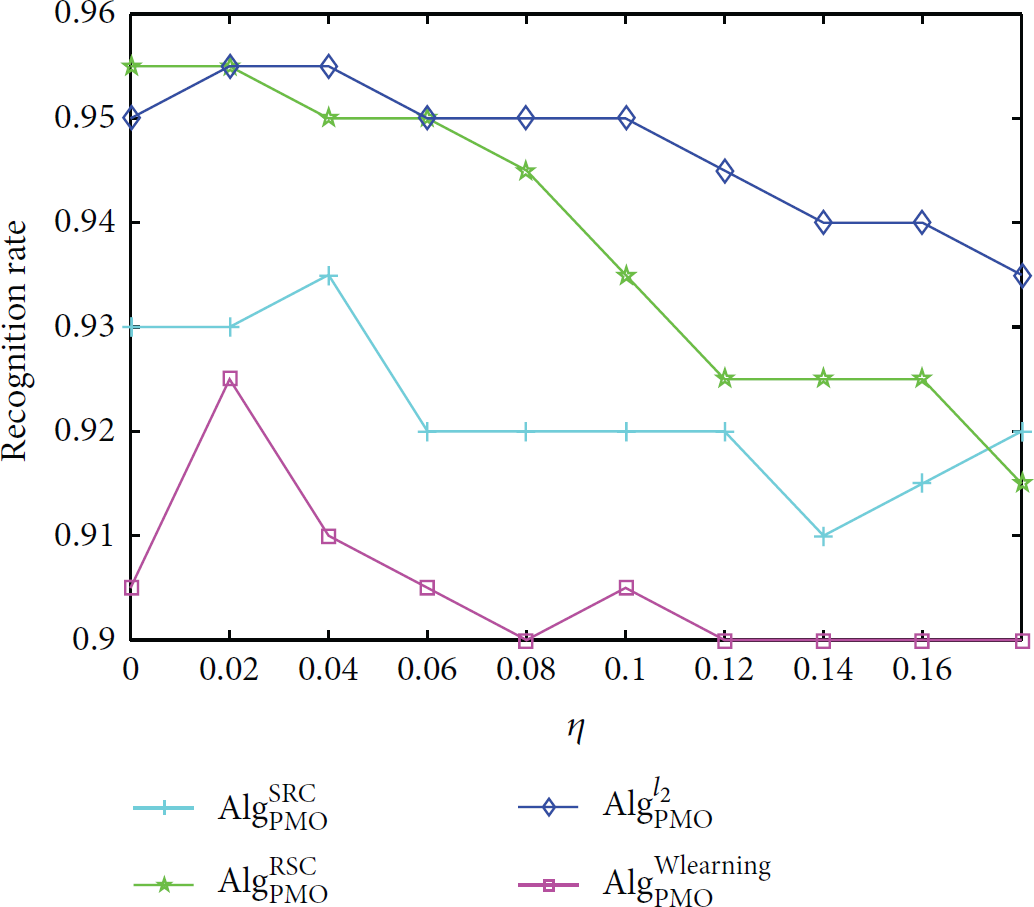
4.2. The Choice of the Correction Parameter η
One highlight of the proposed PMO method is the correction parameter η. Now, we set up experiment for testing the effect of η. Fixing and , the recognition rate versus the correction parameter η is depicted in Figure 5.
Recognition rate versus η with and .
It is clearly seen from the figure that the correction parameter η does affect the performance of classification systems though the value should be chosen as database adapted.
4.3. Comparison of Different Classifiers
In this part, we turn to examine the performance of classification methods (i.e., SRC, RSC, , and Wlearning) with PMO applied for compression. Figure 6 shows the recognition results with ORL database used.
Recognition rate versus η with various classifiers for and .
The computation times of different methods are given in Table 1.
Computation time of different classifiers.
Time (s)
4.39
29.80
1.96
1.87
For this case, the proposed classifier achieves the best results almost in every η. The recognition rates of RSC are comparable somewhere, but its computation complexity is much higher than the others as can be concluded from Table 1, and this is also why RSC is not suitable for large distributed system.
4.4. Comparison of Different Compression Methods
The scenarios where various compression methods are combined with the SRC are investigated and the statistical results are summarized in Table 2.
Comparison of different compression methods with , , and .
Database
ORL
Yale
Yale-E
PIE
AR
The computation time with ORL database considered is given in Table 3.
Computation time of different compression methods.
Time (s)
3.87
5.07
3.82
4.39
The data in Table 2 demonstrates the superiority of the proposed PMO methods. The computation times of various systems differ with each other in the projection matrix design methods, that is, dimensionality reduction procedure. PMO costs more time when compared with PCA. But the design process is an offline job, and it does not put any additional pressure on the front agents.
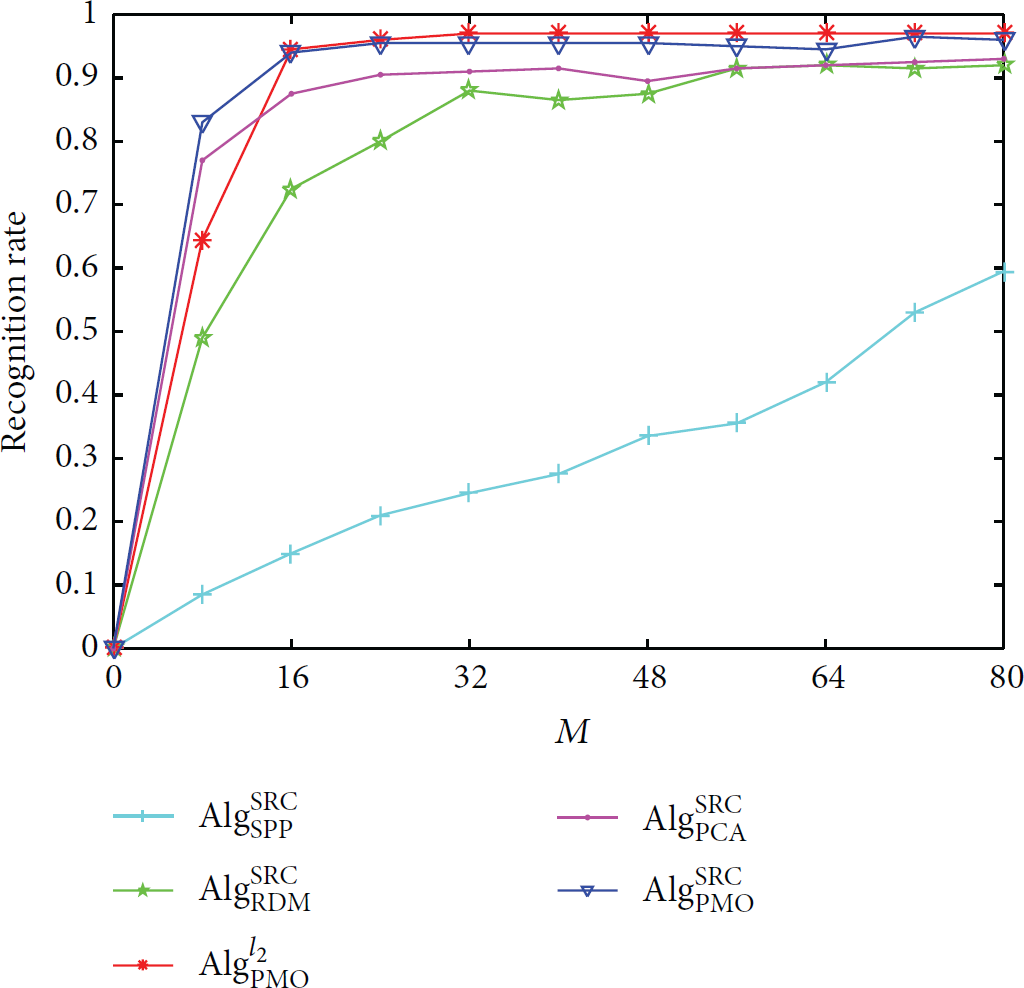
4.5. Recognition Rate versus Compression Dimension
In this part, we examine the performance of different systems with various compression rates on ORL database for , , and . Four compression methods are conducted with SRC. In addition, PMO combined with the proposed classifier is also carried out for comparison. Figure 7 displays the recognition accuracies versus measurement dimension M.
Recognition rates versus M.
As can be seen, higher recognition rates are obtained when bigger M values are set. The results in Figure 7 are coincident with the statistics of Table 2 that PMO achieves the best recognition rate, which is better than the results of PCA and RDM, and SPP once again performs the worst.
4.6. Effect of Occlusion
One of the most challenging problems in FR techniques is the robustness to face occlusion. In this subsection, we test the performance of our proposed method with different occlusion scenarios. The AR database consists of occlusion face images. Taking these samples for test, Figure 8 shows the recognition rates versus measurement dimension.
Recognition rate versus measurement dimension with AR database.
This figure indicates that even for occlusion scenarios, as the measurement dimension increases, better recognition rate results can be achieved and SPP is the worst of all.
Figure 9 depicts the recognition rates versus the occlusion percentage with ORL database used, and , , and for the proposed PMO.
Recognition rate versus occlusion percentage with ORL database tested.
The results of Figure 9 demonstrate that SPP and RDM are more sensitive to the occlusion, and PMO and PCA always perform better than the other two.
4.7. Image Reconstruction Experiment
The PMO algorithm is applied to distributed intelligent monitoring system, and image reconstruction can be performed on the server terminal. Denote the test sample and the reconstructed signal . The mean square error (MSE) is defined as
A popular used indicator to evaluate the image reconstruction accuracy is peak signal-to-noise ratio (PSNR) defined as
with bits/pixel. Figure 10 shows the evaluation of for varying measurement dimension M with and for the proposed PMO.
versus measurement dimension M.
Again, the results of PMO and PCA are similar and better than the others. Please note that as performs much worse than the others, we omit it in this figure. One example is given in Figure 11 to demonstrate the visual effect of the proposed system.
Visual effect of the reconstructed image. (a) Test image. (b) Reconstructed image.
5. Conclusion
This work presents a novel CS-based face recognition scheme for distributed intelligent monitoring systems. A new compression strategy has been proposed based on the projection matrix optimization. The analytical solution set of the corresponding optimization problem has also been derived. With this new compression method, two frameworks have been presented for compressive face recognition. Experimental results on face recognition tasks demonstrate the superiority of the proposed approaches.
The monitor system always encounters the problem that we need to register new face and update the whole system. The FR oriented online CS system learning is an interesting direction of research for distributed intelligent monitor system design. In our approach, the dictionary is formed directly with the samples. It is expected that more efficient FR oriented CS systems can be achieved if both the dictionary and the sensing matrix are optimized alternatively or simultaneously.
Footnotes
Competing Interests
The authors declare that they have no competing interests.
Acknowledgments
This work was supported by NSFC Grants 61273195, 61304124, 61473262, and 61503339 and ZJNSF Grants LY13F010009 and LQ14F030008.
References
1.
ZhaoW. Y.ChellappaR.PhillipsP. J.RosenfeldA.Face recognition: a literature surveyACM Computing Surveys200335439945810.1145/954339.9543422-s2.0-1842499650
2.
WallaceG. K.The JPEG still picture compression standardIEEE Transactions on Consumer Electronics19923812-s2.0-0026818192
3.
TaubmanD. S.MarcellinM. W.JPEG2000 Image Compression Fundamentals, Standards and Practice2002New York, NY, USAKluwer Academic
4.
ChenW.ErM. J.WuS.PCA and LDA in DCT domainPattern Recognition Letters200526152474248210.1016/j.patrec.2005.05.0042-s2.0-25844493811
5.
TurkM.PentlandA.Eigenfaces for recognitionJournal of Cognitive Neuroscience19913172862-s2.0-0026065565
6.
DonohoD. L.Compressed sensingTransactions on Information Theory20065241289130610.1109/tit.2006.871582MR22411892-s2.0-33645712892
7.
CandesE. J.WakinM. B.An introduction to compressive samplingIEEE Signal Processing Magazine2008252213010.1109/msp.2007.9147312-s2.0-41949092318
8.
LiuY.ZhuX.ZhangL.ChoS. H.Distributed compressed video sensing in camera sensor networksInternational Journal of Distributed Sensor Networks201220121035216710.1155/2012/3521672-s2.0-84872819007
9.
LiW.JiangT.WangN.Compressed sensing based on the characteristic correlation of ECG in hybrid wireless sensor networkInternational Journal of Distributed Sensor Networks20152015832510310.1155/2015/325103
10.
DonohoD. L.EladM.Optimally sparse representation in general (nonorthonormal) dictionaries via minimizationProceedings of the National Academy of Sciences200310052197220210.1073/pnas.0437847100
11.
EladM.Optimized projections for compressed sensingIEEE Transactions on Signal Processing200755125695570210.1109/TSP.2007.900760MR24402032-s2.0-36749022762
12.
Zelnik-ManorL.RosenblumK.EldarY. C.Sensing matrix optimization for block-sparse decodingIEEE Transactions on Signal Processing20115994300431210.1109/tsp.2011.2159211MR28659852-s2.0-80051751662
13.
LiG.ZhuZ. H.YangD. H.ChangL. P.BaiH.On projection matrix optimization for compressive sensing systemsIEEE Transactions on Signal Processing201361112887289810.1109/tsp.2013.2253776MR30641012-s2.0-84877903708
14.
ClejuN.Optimized projections for compressed sensing via rank-constrained nearest correlation matrixApplied and Computational Harmonic Analysis201436349550710.1016/j.acha.2013.08.005MR31750902-s2.0-84895927017
15.
BaiH.LiG.LiS.LiQ.JiangQ.ChangL.Alternating optimization of sensing matrix and sparsifying dictionary for compressed sensingIEEE Transactions on Signal Processing20156361581159410.1109/TSP.2015.2399864MR3316911
16.
WrightJ.YangA. Y.GaneshA.SastryS. S.MaY.Robust face recognition via sparse representationIEEE Transactions on Pattern Analysis and Machine Intelligence200931221022710.1109/TPAMI.2008.792-s2.0-61549128441
17.
QiaoL.ChenS.TanX.Sparsity preserving projections with applications to face recognitionPattern Recognition201043133134110.1016/j.patcog.2009.05.0052-s2.0-69049112203
18.
AharonM.EladM.BrucksteinA.K-SVD: an algorithm for designing overcomplete dictionaries for sparse representationIEEE Transactions on Signal Processing200654114311432210.1109/tsp.2006.8811992-s2.0-33750383209
19.
ChinT.-J.SuterD.Incremental kernel principal component analysisIEEE Transactions on Image Processing20071661662167410.1109/TIP.2007.896668MR24662872-s2.0-34249337437
20.
JiaK.ChanT.-H.MaY.Robust and practical face recognition via structured sparsityComputer Vision—ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, October 7–13, 2012, Proceedings, Part IV20127575Berlin, GermanySpringer331344Lecture Notes in Computer Science10.1007/978-3-642-33765-9_24
21.
YangM.ZhangL.YangJ.ZhangD.Robust sparse coding for face recognitionProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR '11)June 2011Providence, RI, USA62563210.1109/cvpr.2011.59953932-s2.0-80052913149
22.
MairalJ.BachF.PonceJ.Task-driven dictionary learningIEEE Transactions on Pattern Analysis and Machine Intelligence201234479180410.1109/TPAMI.2011.1562-s2.0-84857419890
23.
HornR. A.JohnsonC. R.Matrix Analysis20122ndCambridge, UKCambridge University Press
24.
SamariaF. S.HarterA. C.Parameterisation of a stochastic model for human face identificationProceedings of the 2nd IEEE Workshop on Applications of Computer VisionDecember 19941381422-s2.0-0028734063
25.
GeorghiadesF. S. A.BelhumeurP. N.KriegmanD. J.From few to many: illumination cone models for face recognition under variable lighting and poseIEEE Transactions on Pattern Analysis and Machine Intelligence200123664366010.1109/34.9274642-s2.0-0035363672
26.
LeeK.-C.HoJ.KriegmanD. J.Acquiring linear subspaces for face recognition under variable lightingIEEE Transactions on Pattern Analysis and Machine Intelligence200527568469810.1109/TPAMI.2005.922-s2.0-18144420071
27.
SimT.BakerS.BsatM.The CMU pose, illumination, and expression (PIE) databaseProceedings of the 5th IEEE International Conference on Automatic Face Gesture Recognition (FGR '02)May 2002Washington, DC, USA535810.1109/afgr.2002.10041302-s2.0-4544292940
28.
MartinezA. M.BenaventeR.The AR face databaseCVC Technical Report199824