
Abstract
Worker selection for many crowd-sensing tasks must consider various complex contexts to ensure high quality of data. Existing platforms and frameworks take only specific contexts into account to demonstrate motivating scenarios but do not provide general context models or frameworks in support of crowd-sensing at large. This paper proposes a novel worker selection framework, named WSelector, to more precisely select appropriate workers by taking various contexts into account. To achieve this goal, it first provides programming time support to help task creator define constraints. Then its runtime system adopts a two-phase process to select workers who are not only qualified but also more likely to undertake a crowd-sensing task. In the first phase, it selects workers who satisfy predefined constraints. In the second phase, by leveraging the worker's past participation history, it further selects those who are more likely to undertake a crowd-sensing task based on a case-based reasoning algorithm. We demonstrate the expressiveness of the framework by implementing multiple crowd-sensing tasks and evaluate the effectiveness of the case-based reasoning algorithm for willingness-based selection by using a questionnaire-generated dataset. Results show that our case-based reasoning algorithm outperforms the currently practiced baseline method.
1. Introduction
Recent years have seen rapid improvements in the capabilities of mobile phones, such as processing power, embedded sensors, storage capacities, and network data rates. These technology advances coupled with the sheer number of user-companioned mobile phones enable a new and fast-growing sensing paradigm, which is referred to as crowd-sensing. Crowd-sensing is a capability by which application developers can create tasks and recruit smartphone users to provide sensor data to be used towards a specific goal. In this paper, developers who create the crowd-sensing task are referred to as task creators, while mobile users who fulfill the task by contributing data are referred to as workers.
To support crowd-sensing at large, many mediation platforms and frameworks have been proposed recently to connect the task and worker, which can be divided into two modes. The first is pull mode. For many existing mediation platforms, it is the worker's responsibility to search for the task he/she wants to undertake. In these platforms, the task creators post tasks on the platform by describing what should be done, defining the layout of the user interface, and specifying the reward. Then workers actively login to the platform and search for tasks that they are qualified for and interested in by providing some keywords. Then a worker will get a list of tasks and decides which one to complete. Typical systems adopting the pull mode include Amazon Mechanical Turk [1], Medusa [2], CrowdDB [3], CrowdSearch [4], and TurKit [5]. The second is push mode, in which the mediation platform or framework must be able to select appropriate workers automatically based on certain constraints. Typical systems or frameworks using the push mode include [6], PRISM [7], and Anonysense [8]. With the popularity of crowd-sensing paradigm, the number of both tasks and workers has been increasing rapidly. As a result, both the pull mode and push mode connection between task and worker are important, since they either help workers find their preferred tasks or deliver a certain task to the most appropriate workers. The pull/push modes are analogous to the search-based and recommendation-based approaches, respectively, utilized for dealing with the information overload problem on the Web.
There are several research works focusing on the worker selecting for crowd-sensing. However, they have the following limitations.
First, many platforms do not provide general support for managing various and complex contexts. This is a significant deficit given that one of the biggest challenges for worker selection is the ability to utilize complex and generalized contexts in many cases. In this paper, factors that need to be considered in identifying appropriate workers are supported by a variety of contexts to be utilized by the crowd-sensing worker selection process. Existing mediation platforms or frameworks also take contexts into account to some extent. However, they only consider specific or sample contexts to support their own motivating scenarios but do not provide general context models or frameworks in support of crowd-sensing at large. For example, [6] points out that people's availability in terms of space and time, transportation mode, and the coverage must meet certain requirements in the selection phase. PRISM [7] takes the device's sensing capabilities and worker's location as the contexts. Anonysense [8] takes time, worker's location, and privacy setup into account. The authors in [9] regard the location, battery level, and coverage as contexts. In [10, 11], the budget and coverage are the contexts for selection.
Second, the selection is not precise enough, because existing platforms exploit contexts only in terms of the requirements defined by the task creator without considering other worker-required contexts that could highly decide whether the worker would accept the task or not. The task creator is either a skilled software developer or people with very basic programming language skills. According to their programming capabilities, different levels of language support are provided to help them define the contexts for worker selection. For example, [2] provides XML-based language for nonprofessional programmers, while PRISM [7] provides higher level programming support for professional programmers. No matter what level of programming support is provided, existing systems select the workers based on the constraints predefined merely by the task creator. However, this is not precise enough if too many workers meet the constraints. With the increasing popularity of crowd-sensing, such imprecise task pushing may overwhelm the workers given the large number of recommended tasks. In fact, workers decide whether to accept and actually undertake a recommended task based on many other contexts, for example, whether the reward is attractive enough, whether the worker is interested in the task domain, and if accomplishing the task may not cause too much privacy violation. These contexts are not well exploited in existing systems.
To overcome abovementioned limitations, this paper proposes a novel worker selection framework, named WSelector, to select appropriate workers by taking various contexts into account. To achieve this goal, WSelector first provides programming time support, which is based on context modeling technique, to help task creators define all constraints for worker selection. Then a two-phase selection process is adopted at runtime to identify workers who not only are qualified but also would be more willing to undertake a crowd-sensing task. In the first phase, it selects workers satisfying predefined constraints. In the second phase, by leveraging the worker's past participation history, it uses a case-based algorithm to further select workers who are more likely to accept to undertake the task. WSelector is not a mediation platform and does not handle many of the complex issues found in many of the existing platforms. However, it is intended to be integrated into existing or future mediation platforms to better support their worker selection features.
The main contributions of this paper are as follows:
We propose a core context model to semantically express the general context for worker selection in crowd-sensing systems and to provide a mechanism for task creators to utilize context modeling in their applications. We propose a two-phase worker selection framework to identify workers who not only are qualified but are more likely to be willing to undertake a crowd-sensing task by taking various worker-side contexts into account. We demonstrate the expressiveness of the framework based on various crowd-sensing tasks and evaluate the effectiveness of a case-based reasoning algorithm based on a dataset collected from an online questionnaire.
2. Related Work
In this section, we review the related literature from two perspectives. The first is the worker selection capabilities of related platforms/frameworks for crowd-sensing, which is the main problem we are addressing in this paper. The second is the ontology-based context modeling, which is related to a key technique we use as a solution to the problem in our framework.
2.1. Worker Selection Framework
Many crowd-sensing mediation platforms, including Amazon Mechanical Turk [1], Medusa [2], CrowdDB [3], CrowdSearch [4], TurKit [5], and mCrowd [12], adopt the pull mode to connect task and worker. In these platforms, workers search the task and the platform does not need to select workers. Compared with these frameworks, ours can identify appropriate workers based on various contexts information and push tasks to them.
There are many other frameworks that are based on the push mode. In this mode, the mediation platform must be able to identify appropriate workers automatically based on certain factors. References [11, 13] develop a selection framework to enable organizers to identify well-suited participants for data collections based on geographic and temporal availability, transportation mode, and the coverage. PRISM [7] takes the device's sensing capabilities and worker's location as the constraints to select appropriate workers. Anonysense [8] takes time, worker's location, and privacy setup into account when identifying workers. Reference [9] proposes an assignment policy to identify suitable workers based on their device's location, battery level, and the overall spatial coverage. CrowdRecruiter [10] aims at minimizing incentive payments by selecting a small number of participants while still satisfying probabilistic coverage constraint. Crowdlab [14] schedules the task based on location and battery resource budget. Reference [15] takes location as the only context for worker selection. A QoI-Aware energy-efficient worker selection framework has recently been proposed [16], which considers the QoI requirements, the energy consumption index, and the estimation of the collected amount of data. The literature [17] selects workers based on the data quality requirements, location, and budget constraints. Although these works also take many contexts into account for worker selection, they only consider demonstrative contexts to support their motivating scenarios but do not provide general context models in support of crowd-sensing at large. Our paper proposes a core context model for worker selection, in which the general concepts for crowd-sensing are defined and characterized. All the demonstrative contexts in above frameworks can be modeled by extending our core context model. Besides, worker selection in the most of existing frameworks is merely based on the constraint defined by the task creator, while WSelector takes the worker-side contexts into account.
A comparison of the platforms or frameworks in terms of worker selection is summarized in Table 1.
Worker selection of typical mediation platforms or framework: a comparison.

2.2. Ontology-Based Context Modeling
Ontology-based context modeling techniques are widely used in pervasive computing systems, especially for modeling heterogeneous contexts in smart pervasive spaces. One of the first approaches of modeling the context with ontologies has been proposed by [18], which analyzed psychological studies on the difference between recall and recognition of several issues in combination with contextual information. Another approach has been proposed as the Aspect-Scale-Context Information (ASC) model [19]. Ontologies provide a uniform way for specifying the model's core concepts as well as an arbitrary amount of subconcepts and facts, altogether enabling contextual knowledge sharing and reuse [20]. The model has been implemented by applying selected ontology languages. These implementations build up the core of a nonmonolithic Context Ontology Language (CoOL), which is supplemented by integration elements such as scheme extensions for Web Services and others [21, 22]. The CONON context modeling approach [23, 24] created an upper ontology which captures general features of basic contextual entities and a collection of domain-specific ontologies and their features in each subdomain. Above works inspire our work to some extent, especially the idea of building domain-specific ontology based on an upper-level ontology proposed by [23, 24]. However, to the best of our knowledge, our paper is a first work using ontology-based context modeling in crowd-sensing.
There are also other literatures inspiring our work, in that they also use the crowd-sourced way for ontology-based knowledge modeling. Reference [25] presented a hybrid metamodel that combines features from key-value, markup, object oriented, and ontology-based context modeling approaches. The architecture is also introduced to allow the dynamic collaborative extension and crowd-sourced convergence of context models. In [26], the authors presented different concepts to create context models, including a collaborative one. In [27], the authors proposed consensus-building mechanisms for collaborative ontology building, which is based on offline discussions. Reference [28] presented an entirely online-based process for ontology building and convergence that is implemented on an extended Wiki.
3. Framework Design Overview
3.1. Challenges
The goal of our framework is to perform a precise worker selection for crowd-sensing. It should be able to identify workers who not only are qualified but also willing to undertake a specific task. In order to achieve the goals, at least the following challenges exist.
First, it is difficult to model various contexts for worker selection. A key challenge for worker selection is that in many cases complex and various contexts must be considered, and they are all factors that need to be considered for selecting appropriate workers. To the best of our knowledge, though context modeling is a widely used technique in mobile and pervasive systems, there are no existing context models for characterizing the concepts and their relationships in crowd-sensing applications.
Second, it is difficult for the task creator to define all contexts reasonably or properly. A naive idea for enabling the worker selection is to require the task creator to define all the contexts which can be realized by task specification languages such as two-level predicate in [7], AnonyTL [8], and Medscript [2]. Although these languages are useful in defining the contexts to some extent, there are limitations in many scenarios. It is not at all clear if certain combinations of contexts may be unnecessarily too restrictive, or to the contrary, adequate to achieve successful selection. Task creator may not be thoughtful enough to define all needed contexts that some workers are likely to be missed and the task is likely to be pushed to inappropriate workers. Sometimes they may define a context that is unnecessarily too restrictive, thus excluding many appropriate workers.
Third, selecting workers who are willing to undertake a task is not easy. On the one hand, different contexts could have different influence in deciding whether the worker is willing to undertake a task. It is very difficult for task creator to predict or learn these differences. On the other hand, even the same context may have different impact on different workers, which is subjective and varies from one worker to another. For example, privacy preserving is more important than earning money for some workers, but it may be the opposite case for others.
3.2. Insights
The design of our framework is based on the following insights.
3.2.1. Insight 1: Context Classification
Context is an abstract concept. According to the abovementioned definition, it can be any factor that needs to be considered in the crowd-sensing worker selection. However, these contexts are not semantically at the same level and can be divided into the following categories.
Constraints. Constraints are the minimum and basic requirements that can be set on the workers (e.g., spatial constraint, temporal constraint, and sensing capability constraint). They are the objective requirements from the task itself.
Worker-Side Factors. They are subjective factors considered when the worker decides whether to undertake a recommended task, for example, whether the reward (incentive) is attractive, whether the task falls into his interested domain, whether his privacy is well protected, and whether the workload is too heavy.
Task Properties. Task properties characterize basic information of a crowd-sensing task (e.g., title, description, reward, keywords, and assignment). They are commonly key-value pairs whose value can be assigned in the mediation platform by either the form-like user interface or the task specification language.
3.2.2. Insight 2: The Opportunity of Leveraging Worker's Participation History
When a crowd-sensing task is pushed to a worker, it may be undertaken or declined, which is referred to as the outcome in this paper. Over a period of time, the outcome, together with the corresponding worker-side factors and task properties, constitutes a worker's participation history.
Workers' participation history contains knowledge about how the worker-side factors and task properties affect the workers' decisions. Therefore, one basic idea in this paper is to leverage the participation history to improve the precision of future worker selection, making the task recommend to those who are more likely to accept it. Since WSelector must be integrated into an existing mediation platform (e.g., Amazon Mechanical Turk) in practical usage, we assume that our framework can access the participation history from the mediation platform.
3.3. Design Overview
With abovementioned challenges and insights, we design a novel worker selection framework, named WSelector. The basic idea for the design of WSelector is as follows: (1) since it is difficult for the task creator to define all contexts reasonably or properly, WSelector first provides a programming framework to help task creators define constraints for the worker selection; (2) WSelector adopts a two-phase process at runtime to select workers who are not only qualified but also more likely to undertake a crowd-sensing task. We demonstrate the system design in terms of programming time and runtime support as follows.
3.3.1. Programming Time Support
A context-driven programming framework (see Figure 1) is used to assist the task creator define task properties and constraints.

Programming time support.
First, this programming framework is based on a core context model and crowd-sourced context modeling mechanism. (1) We propose an ontology-based context model, named CCMCS (core context model for crowd-sensing), to define the most fundamental concepts for crowd-sensing. The objectives of the CCMCS include modeling a set of upper-level concepts and providing flexible extensibility to add specific concepts for different crowd-sensing tasks. In realistic crowd-sensing tasks, there are other task-dependent concepts needed to be characterized, which share common concepts that are modeled in CCMCS and differ significantly in detailed features. Our framework enables the task creators to build their task-specific ontologies by extending CCMCS. (2) To enable the reuse of context models, we also provide a crowd-sourced mechanism. When a task creator wants to create a context model, he can either extend the CCMCS or import existing models that are established and saved in the context model repository by other task creators. Since the creation and management of ontologies are a mature technology and there are many existing tools, our framework directly exploits the Protégé (http://protege.stanford.edu/), a free open-source Java tool, to support the creation and management of ontologies.
Second, the framework provides interfaces for task creators to define constraints for worker selection. (1) Our framework provides an abstract interface WorkerFilter(), and the task creator can create task-specific filters by extending this interface. To make the filter creation more efficient, the framework generates some JAVA components automatically, which can be directly imported to realizing task-specific filters. Task-specific ontology classes and their data properties defined by the task creator are automatically transformed into corresponding Java components including classes and interfaces. Our framework adopts the approach in [29] to implement the transformation from ontologies to Java components. (2) We propose QualifyScript, an XML-based language, to define the references of all the worker filters. The worker selection reference is defined between the <filter> and </filter> tags and refers to an executable filter implemented by the task creator. QualifyScript also provides other predefined tags, including title, description, reward, and assignment, to define task properties. It also allows task creator to define new tags.
Box 1 shows a QualifyScript program for the air quality report application.
report PM 2.5 measurement in the scenic spot.
The advantage of our design is that it better supports software reuse and maintenance. First, existing filters created by others can be imported into a QualifyScript program very easily when defining a new task. Second, when a new constraint emerges for a predefined task, the task creator only has to implement a new filter and configure it in the QualifyScript without modifying and recompiling others.
3.3.2. Runtime Support
WSelector adopts a two-phase process at runtime for worker selection by taking both the predefined constraints and worker-side factors into account (see Figure 2).

Runtime support.
Phase 1—Qualification-Based Selection. In this first phase, we propose a pipe filtering model to select workers who satisfy the predefined constraints. This is done through executing a flow of predefined filters one by one through a virtual pipeline at runtime.
The input for this stage is all registered users in the crowd-sensing mediation platform, which is denoted as a worker set
The qualification-based selection mainly consists of two steps: (1) QualifyScript interpreter parses the QualifyScript program into several references of worker filters and passes them to the filter executer. (2) The worker filters are then executed one by one by the executer (the filters are JARs (JAVA executable packet), while the executor is a component to invoke each JAR). The execution of the worker filters needs the current contexts of workers. For example, a worker filter
Ultimately, at the end of the pipeline, we get the selected workers who are qualified for all predefined constraints, which is denoted as the worker set
In the crowd-sensing paradigm, energy consumption and privacy violation are two key concerns for workers. It is more satisfactory if the mediation platform updates worker's dynamic or private-sensitive contexts in a lower frequency. For example, updating location information uses more smartphone battery and could lead to violation of privacy, thus workers may not want it to be collected too frequently. The optimized execution orders of filters can make the crowd-sensing mediation platform update the contexts in a more energy-saving and privacy-preserving way. We preestablish an execution order knowledge base (see Figure 2), in which the execution orders of some predefined contexts are specified. At runtime, worker filters will be executed one by one in the filter executer based on the predefined orders in the knowledge base. Filters relevant to contexts that are more static (e.g., those determined when the worker registered to the mediation platform or those which change very slowly) will be executed in front of those filters relevant to contexts that are more dynamic or privacy-sensitive. Take the air quality report task in Box 1 as an example. If the LocationFilter is executed at first, then the location information of all workers in
Phase 2—Willingness-Based Selection. After the qualification-based selection phase, if the number of candidates (i.e.,
In this phase, WSelector further selects workers who are more likely to undertake the task. The input of this stage is the worker set
We achieve such a goal based on our second insight, which is leveraging the candidate worker's participation history over time to perform a more precise selection. To implement this idea, we propose a case-based reasoning approach to select those k workers, which will be introduced in great detail in Section 5. We assume that the mediation platform has been recording participation history and storing them in the case database, to which our framework can get access (see Figure 2).
4. Context Modeling for Crowd-Sensing
4.1. Core Context Model and Extensibility
We propose an ontology-based context model, named CCMCS (Core Context Model for Crowd-Sensing), to define basic concepts and their relationships in crowd-sensing worker selection (see Figure 3). Each entity in the context model is associated with its attributes (represented in owl:DatatypeProperty) and relations with other entities (represented in owl:ObjectProperty).

CCMCS: Core Context Model for Crowd-Sensing.
Due to space limitation, Figure 3 only shows owl:ObjectProperty. Task, task creator, and worker are the most basic concepts, to which other concepts are related. Generally speaking, each task has its filters defining constraints, task property including name, description, reward, and assignments. Each worker also has his/her profile, location, and carried device. In the CCMCS, we establish reputation, interest, and privacy setup as part of predefined profiles and sensing capability as predefined object property of carried device.
WSelector also provides extension ability for adding task-specific concepts based on the CCMCS. First, the built-in OWL property (such as owl:subClassOf and owl:partOf) allows for most of the extensions. Second, the task creator can define its own OWL property (both the owl:ObjectProperty and owl:dataTypeproperty).
4.2. Crowd-Sourced Context Modeling
Our framework supports crowd-sourced context modeling. It allows a collaborative creation of context models and provides automated mechanisms for validation.
As Figure 1 shows, the context model repository is open to the public, into which everyone can contribute new context models. The repository automatically validates new models for using a unique name and in terms of the OWL (Web Ontology Language) grammar requirements. The automatic validity check ensures the integrity of all models that are published. After acceptance, all context models in the repository can directly be used by other task creators.
Even though they provide better support for context models reuse and for accelerating the task creation, crowd-sourced context modeling mechanisms come at a cost and overhead. Allowing everyone to submit models might lead to the fast growth in the size of repository, because each task creator creates the model that best fits his/her purpose. As an example it can be expected that there are many different models for “smartphone.” When searching a specific model (e.g., smartphone), the task creator might be overwhelmed by getting numerous alternatives. Therefore, this paper proposes a mechanism to rank the context models based on their popularity. WSelector collects two types of different data as the metric to rate the popularity of context models. One is the number of downloads of a context model, and the other is the task creator's manual scoring for the model (from 0~10). When a task creator wants to search a model, the framework can sort the alternatives by either the number of downloads or the average scoring.
5. Willingness-Based Selection
In the willingness-based selection phase, we aim to select workers who are more likely to accept to undertake a certain task by leveraging worker's participation history over a period of time.
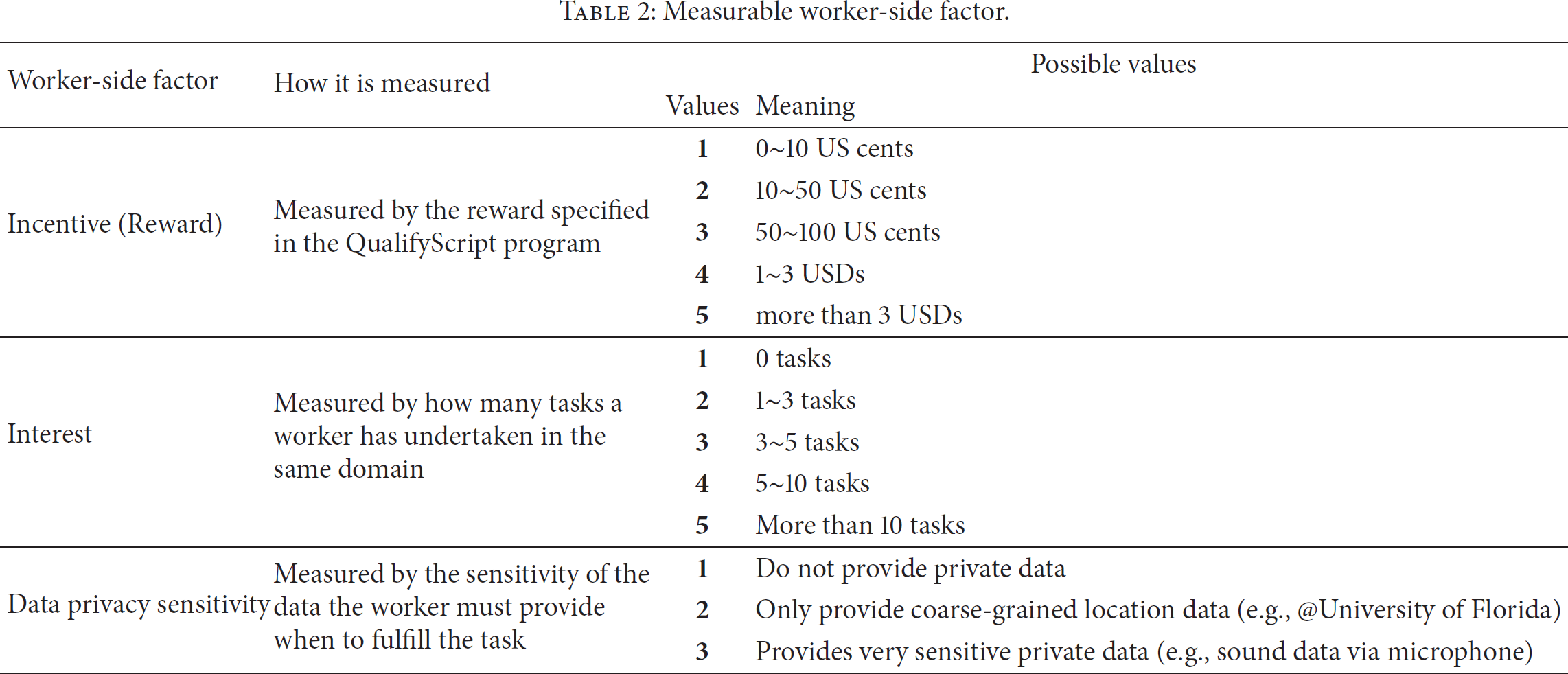
5.1. Measurable Worker-Side Factors
There are many worker-side factors that may affect a worker's decision to undertake or decline a certain task. However, the current implementation of WSelector takes only those measurable worker-side factors (in Table 2) into consideration. Here the term “measurable” means these factors can be measured by either the task property in the QualifyScript program or the worker behavior learned over time from the mediation platform.
Measurable worker-side factor.
5.2. Case-Based Reasoning Algorithm
We propose a case-based reasoning algorithm to fulfill the willingness-based selection. Although current implementation of the algorithm takes only those worker-side factors in Table 2 into account, the algorithm itself is not limited to these three factors and can be extended easily if additional measurable factors are used in the future.
5.2.1. Problem Formulation
The problem is formulated as follows.
Consider that
The goal is to find
5.2.2. The Algorithm
We first define the concept of historical case.
Consider that
Our case-based reasoning algorithm consists of the following two steps.
Step 1 (case selection).
Since the influence of different worker-side factors varies from one worker to another, the algorithm first selects historical cases of worker i to compute the likelihood of a worker i to undertake the task 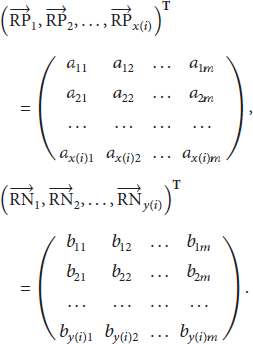
Step 2 (likelihood measurement and worker selection).
We use 
Note that different worker-side factors could have different impact on deciding the outcome; the weights of different factors have to be considered (see (3)) when calculating the distance, where Determine the variables and target to be analyzed according to the problem. Vary only one variable, observing and measuring the change of target. Repeat the analysis in (b) for each variable repetitively for calculating the corresponding effect on the target. The variables are worker-side factors, and the target is the outcome (accept/decline). Matrix Lines 3~19 calculate the weight of a certain worker-side factor In lines 11~12, We adjust the weight to make sure that their sum is equal to 1 (in line 20).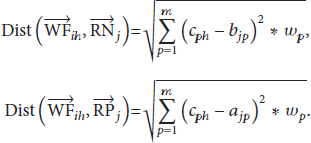
Based on the above sensitivity analysis principle, we propose a personalized weight calculation algorithm according to our problem. Some key points of this algorithm are explained as follows.
5.2.3. Strategy for Cold-Start Problem
We may encounter the cold-start problem when a worker just registered in a crowd-sensing mediation platform. In this situation, the number of one's historical cases is zero and our framework knows nothing about the new worker.
We deal with the cold-start problem by leveraging the cases of other workers, because users tend to make similar decisions under similar contexts. The approach is almost similar to Algorithm 1, but is different in the following two aspects.
reference matrix of the worker i, and vector corresponding feedbacks ( (1) (2) float total = 0, effect = 0; (3) (4) / (5) (6) (7) (8) other components of (9) total ++; (10) (11) (12) (13) effect = effect + (14) (15) (16) (17) / (18) total = 0, effect = 0. (19) (20) (21) //Adjust the weight to make their sum to be 1 (22)
(1) Case Selection. In the case selection step, we select historical cases of other workers whose worker-side factor vector is identical to the current context vector
(2) General Weight Calculation. The weight calculation algorithm is almost the same as the personalized weight calculation algorithm, but the input is changed to the entire datasets (all cases from all workers). The calculated weights are referred to as the general weight, which will be used in the likelihood measurement and worker selection.
5.3. Iterative Selection Strategy
5.3.1. Problem Statement
After the execution of willingness-based worker selection algorithm, K workers will be selected and the task is pushed to them. However, in real-world circumstances, the selected workers may not be able to accomplish the task due to some unexpected reasons.
For example, a candidate worker, named Tom, has a very high probability of accepting a certain crowd-sensing task according to his historical participation records and the attributes of the task. Thus, our willingness-based worker selection algorithm selects him, and the platform pushes the task to him. Nevertheless, Tom has something urgent to do all of a sudden, so he declines the pushed task.
Therefore, sometimes the number of workers who actually accept and accomplish the task may be less than K, which does not satisfy the requirement of the task creator.
5.3.2. Strategy Description
To deal with above-stated problem, this paper proposes an iterative worker selection strategy. The main idea of the strategy is to divide the willingness-based selection phase into the iterative execution of several substeps, by which it can achieve a high probability that there are K workers actually accepting the task.
Figure 4 shows the workflow of the strategy. Before the execution of workflow, willingness-based worker selection algorithm will calculate the all qualified candidate workers' probability of accepting a task named tsk. Then the workflow is executed as follows:
Select K workers who are more likely to accept the task. Observe the result after a short period of time (denoted as Reselect certain number of workers (supplementary selection) and then go to (2). Here, the reselected workers are those who have not been selected in previous iterations and with highest likelihood of accepting the task.
Now the key problem is how many workers should be selected in each of the iterations.

Iterative selection process.
We denote the number of selected workers in each of the iterations as
For the ith iteration, the number of reselected workers 


Thus after
As
6. Evaluation
In this section, we evaluate the qualification-based and willingness-based selection of WSelector. The goals of our evaluation are as follows. (1) For the qualification-based selection, we first demonstrate the extensibility of the core context model and the expressiveness of the programming interfaces. Then we evaluate the correctness of the runtime selection. (2) For the willingness-based selection, we evaluate the validity of our case-based reasoning algorithm.
Our experiments are conducted on a prototype of WSelector. The core context model is created using the Protégé [38], a free and open-source ontology editor. The management of the crowd-sourced context modeling process is implemented with the help of OWL API [39]. The programming interfaces and the runtime environments (including the QualifyScript interpreter, filter executor, and case-based reasoning module) are implemented using Java. The context database and case database are established and managed by the MySQL system, and Java SDK is imported for accessing the MySQL database.
6.1. Qualification-Based Selection
We have implemented worker selection module of 10 crowd-sensing tasks, among which 7 tasks are from literature review and other three are borrowed from the examples we mentioned in the introduction section. The constraints for worker selection of these tasks are listed in Table 3.
Constraint for worker selection.

In Table 3, we assume that all mobile devices are all embedded with modules for localization, so that we do not include it in the sensing capability. Since this paper does not focus on the context collection from mobile nodes and assumes this to be the crowd-sensing mediation platform's duty, the client side of these crowd-sensing tasks ranges from mobile phone to wearable devices.
By implementing the worker selection of all these tasks, we can report the results as follows.
(1) All these constraints can be modeled by our framework successfully, by either directly importing the classes and properties in the core context model or extending by the user-defined ones.
(2) Our programming interfaces are expressive enough for supporting the task creator to define relevant worker filters. The ontology classes and properties in the task-specific ontology model are transformed into Java classes and interfaces, which are used to develop relevant worker filters. Finally, we define the reference of worker filters in the QualifyScript program. Then we randomly generated 100 testing cases for each task to evaluate the result of qualification-based selection at runtime. Each testing case corresponds to one candidate worker and contains the values for different constraints. We manually label each worker as “selected” or “not selected” based on the constraints in Table 3, which are taken as the ground truth. By running the implemented worker selection module in the runtime environments of WSelector, we demonstrate that all the
6.2. Willingness-Based Selection
6.2.1. Data Collection
We post a questionnaire on an online platform to generate the dataset [40]. First, we assume that there is a crowd-sensing task with basic description. Then we design 15 questions, each of which ask for the outcome under different combination of worker-side factors. Second, we invite 26 volunteers (including the undergraduate, graduate students, and faculties in our institute) to respond to this questionnaire. Third, we collect all these questionnaires and generated the dataset. The generated dataset consists of
6.2.2. Experimental Methodology
After the dataset has been generated, we design a 6-round experiment to evaluate the case-based reasoning algorithm for willingness-based worker selection. The generated datasets are used to establish both the case database, which is the input of our algorithm, and testing cases containing the ground truth. Our 6-round experiment is summarized in Table 4.
Summary of 6-round experiment.

(1) The First Round Is for the Baseline Method. It is assumed that none of the cases have been preacquired, so that we can only randomly select k workers from 26 candidates. This round of experiment consists of the following steps: (a) randomly assign value to the components of worker-side factor vector
(2) The 2nd~6th Round of the Experiments Is to Test Our Case-Based Reasoning Algorithm When the Number of Cases in the Case Database Changes. (1) The 2nd~4th round of experiments assumes that each of 26 candidate workers has preacquired cases, and the difference among these three rounds is the number of cases. In these three rounds, we calculate the personalized weight based on the approach in Section 5.2.2. (2) The 5th~6th round assumes that some workers do not have preacquired cases (3 and 5 workers, resp.). In these two rounds, we will use our mechanism in Section 5.2.3 for workers without historical cases. In both 2nd~6th rounds, we first randomly generated 100 worker-side factor vectors as testing cases. Then for each vector, we changed the second component (i.e., interest) randomly since each candidate worker's interest for the same task may be different and kept the other two components (i.e., reward and data privacy sensitivity) unchanged since they are the same among workers for a specific task.
6.2.3. Experimental Results
The willingness-based selection accuracy of each round is measured by
Since the number of selected workers (i.e., k) has impact on the selection accuracy, we conduct our 6-round experiments for 3 times by changing k from 10 and 15 to 20, respectively. Hence we have completed
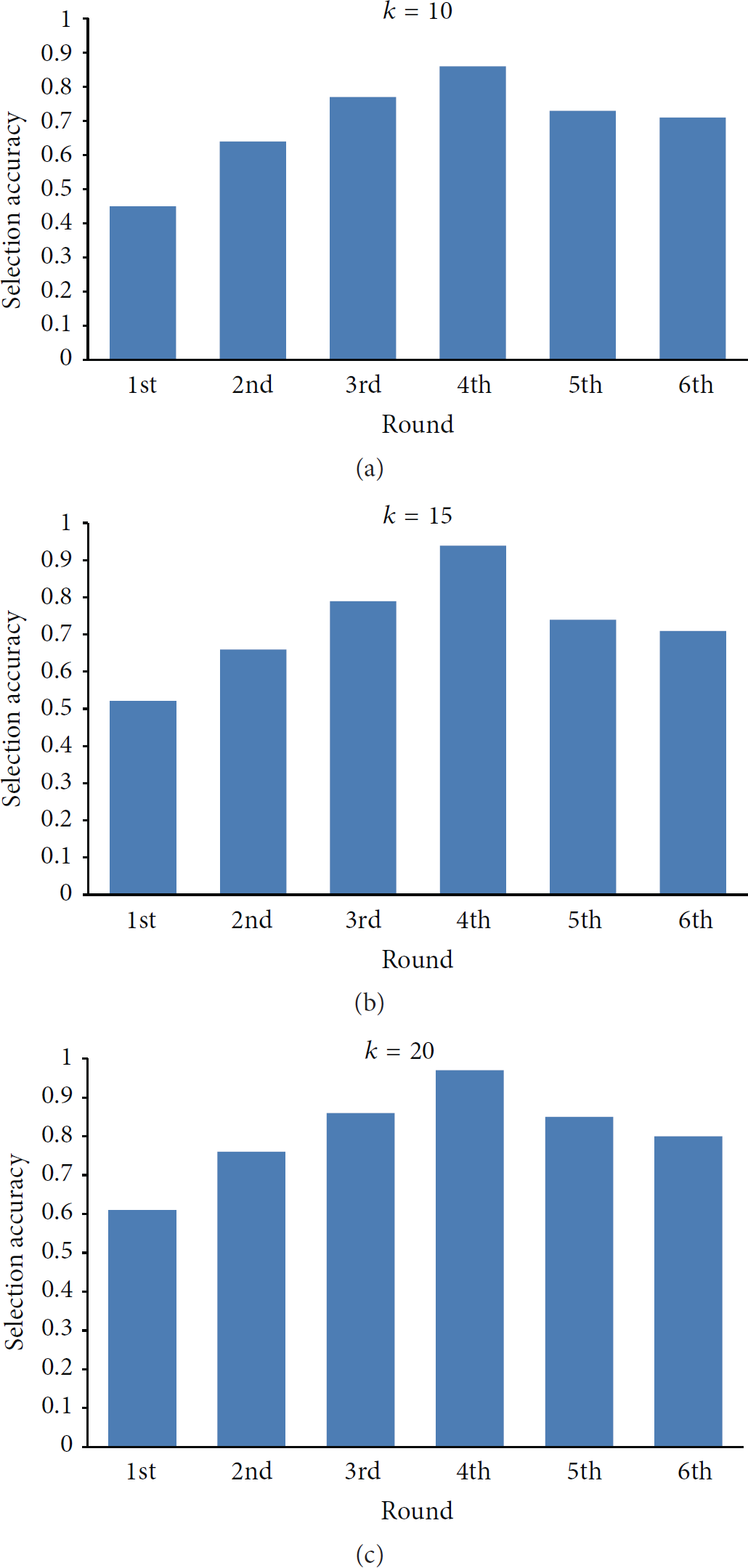
Selection accuracy of different rounds.
According to the observation of the results, we can draw the following conclusions:
Our case-based reasoning algorithm outperforms the baseline method no matter The smaller k is, the bigger the increase in selection accuracy of our algorithm is compared to the baseline method. Compared to the 2nd, 3rd, and 4th rounds, we can see that the selection accuracy of our algorithm is improved with the increasing of the number of historical cases. The experimental result of 5th and 6th round shows that our mechanism in Section 5.2.3 is effective to solve the cold-start problem to some extent. Although the accuracy of 5th and 6th round is lower than the 3rd round, it still significantly outperforms the baseline method.
7. Discussion
In this section, we discuss some limitations of WSelector and additional important issues, some of which will be the subject of our future work.
7.1. Access to Mediation Platforms
A fundamental assumption in this paper is that WSelector can get access to the participation history in the mediation platform. In practical usage, WSelector is to be integrated into an existing crowd-sensing mediation platform. If our framework is effective enough in selecting appropriate workers, it is reasonable to assume that mediation platforms will provide participation history APIs, to enable a loose and inexpensive integration. At the same time, in our future work, we plan to propose a simple API of the same, which could guide and encourage existing mediation platforms to implement it. Besides, device's functionalities/sensing capabilities are determined when the worker registers to a certain crowd-sensing platform. When integrated to the platform, our framework can get the device's functionalities of each worker.
7.2. The Number of Worker-Side Factors
Although current implementation and evaluation of the case-based reasoning algorithm only take three worker-side factors into account, the algorithm itself is not limited to these factors only. It can be extended easily if we find new measurable ones in future work. For example, if a mediation platform requires task creator to assign value for a new task property (e.g., the approximate workload) when specifying the task, we can easily add it as the fourth factor for willingness-based selection. In our future work, we will analyze and propose a broader set of worker-side factors. We will also include additional factors that we may learn about from the literature. However, when more factors can be added, there is a new challenge, that is, how to determine which subset of factors is more significant in selecting workers? We plan to exploit feature selection mechanisms in the future work.
7.3. Dynamic Adjustment of the Number of Selected Workers
This paper assumes that all workers are selected before they start to undertake the task. However, not all crowd-sensing tasks obey this assumption. For example, a crowd-sensing task may require that selected workers must meet certain geographical coverage rather than reaching certain number in total. In this case, it is a better strategy to dynamically adjust the number of selected workers online according to the current distribution of workers who have already fulfilled the task. Therefore, we plan to propose a dynamic worker selection mechanism in the future work to make WSelector able to handle more crowd-sensing tasks.
7.4. Fine-Grained Privacy Measurement
In the current implementation of WSelector, we consider privacy as one of three contexts in the willingness-based selection. However, since our main contribution mainly lies in the case-based reasoning algorithm, we only measure privacy factor in a very simple way by giving them three possible values. However, the measurement of the privacy factor is much more complex in reality. We plan to leverage the model proposed in [41] to measure the privacy factor in a more fine-grained manner.
8. Conclusion
In this paper, we proposed a novel worker selection framework, named WSelector, to select appropriate workers for crowd-sensing more precisely by taking various contexts into account. It first provides programming time support to help task creator define all constraints. Then a two-phase process was adopted at runtime to select workers who not only are qualified but also have higher possibility to undertake a crowd-sensing task. Evaluations with 11 crowd-sensing tasks indicate the expressiveness of our core ontology model and programming interface. Besides, evaluations with a questionnaire-generated dataset show that our case-based reasoning algorithm outperforms the baseline method.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work is funded by the National High Technology Research and Development Program of China (863) under Grant no. 2013AA01A605. Besides, this research is supported by NSFC Grant (no. 61572048) and Microsoft Collaboration Research Grant.