
Abstract
As the technology of the Internet of Things (IoT) becomes more widely used in large-scale monitoring networks, this paper proposes an optimized obtaining strategy (OFS) for large-scale sensor monitoring networks. First, because of the large-scale features of sensor node network, this paper proposes a large-scale monitoring network area clustering optimization strategy. Second, based on the characteristics of regular changes in the sensed data in large-scale monitoring networks, this paper proposes a strategy for acquiring sensor data based on an adaptive frequency conversion. The OFS optimization strategy can prolong network lifetime, reduce the transmission bandwidth resources, and reduce average energy consumption of the cluster head and network energy consumption.
1. Introduction
In recent years, especially in the big data age [1], the technology of the Internet of Things and the prospects for building applications on this platform have become research hotspots for governments, academia, and industry. A wireless sensor network (WSN) [2], as an important technical aspect of the Internet of Things, can monitor, sense, and sample a wide range of information types from the environment or from monitored objects. A WSN can also process this information in real time [3]. Therefore, WSNs are widely used in large-scale network monitoring. With the development of wireless communication, sensor technology, and embedded computing technology [4], there is an urgent need for applications involving large-scale wireless sensor networks in various fields including the military, intelligent transportation, environmental monitoring, earthquake monitoring, weather disasters, and modern agriculture [1]. However, in these large-scale complex environments [5], wireless monitoring networks pose a series of new problems as follows: the areas that need to be monitored are too large, the number of sensors required is too great, the time overhead of the sensor nodes and the required bandwidth resources and energy consumption of signal transmission are too high. Because monitoring nodes are limited in computing power and storage space, obtaining high-quality sensor data samples and optimizing transmissions to ameliorate the problem of energy consumption [2] and improve the network life cycle have been the core research problems facing the field of large-scale monitoring networks [4, 6].
After analysing the existing research results, this paper proposes an optimized obtaining strategy (OFS) to address the issues facing large-scale monitoring sensor data in the Internet of Things. This strategy can effectively improve the overall operating efficiency of the monitoring network, balance energy consumption, and prolong the network life cycle.
The rest of this paper is organized as follows: Section 2 discusses an optimization strategy that is relevant for both current domestic and international wireless sensor monitoring networks. Section 3 deals with large-scale sensor networks. Because the number of nodes is large and their distribution is uneven, this paper proposes a type of large-scale wireless sensor network area clustering optimization strategy in which a large-scale monitoring network is divided into smaller areas to balance the distribution of cluster heads. It adopts uneven clustering in parallel to alleviate the problem of energy holes [7] in a given area. Section 4 discusses monitoring network data acquisition strategy based on adaptive frequency conversion. This strategy optimizes sensor data sampling using a linear regression model and offers a model compensation mechanism. Section 5 analyses the effectiveness of the proposed optimization strategy through experiments and data comparisons. Finally, the last section provides conclusions.
2. Related Work
Numerous domestic and foreign experts and scholars have carried out in-depth studies aimed at the existing problems of large-scale sensor monitoring networks for the Internet of Things. Younis and other experts proposed the hybrid clustering protocol HEED [8], which first selects preliminary cluster heads based on the residual energy of nodes and then selects a final cluster head based on the results of a competition to determine the clusters' internal communication costs. The communication overhead of this protocol is significant because it needs to carry out multiple message iterations within the cluster radius. A solution was proposed by [5, 9, 10] to resolve energy hole problems by using uneven clustering. However, this solution uses a heterogeneous network [2] in which the cluster head is the super node, and it calculates the deployment location of the node in advance, so there are no dynamically constructed clusters. Researchers in [9, 11] proposed the EECS clustering scheme, which constructs uneven clustering to balance the load by considering the distance between the candidate cluster head and the sink node, but, in this scheme, residual energy exists only in the local comparison node. It does not coordinate node energy consumption overall, and intercluster communication adopts single-hop communication, which limits the scalability of the algorithm and makes it unsuitable for large-scale networks. In [8, 12], the uneven clustering ant colony-based AC-EBUC routing algorithm inherits the advantages of the uneven clustering structure. On this basis, in combination with the ant colony algorithm, it introduces the link reliability parameter and can search multiple paths in real time, but this strategy can easily encounter local optimization problems. A hierarchy of chained network topology was proposed by [13, 14]. This strategy can add extra cluster head nodes to solve energy hole problems based on certain rules, and it significantly prolongs network survival time; however, because of cost, transmission distance time delays, and so on, this strategy is not feasible in large-scale sensor networks. In [15], a VA-DSC compression algorithm is proposed that adopts Slepian-Wolf [16] coding theory and achieves data independent encoding and joint decoding. The data error rate is small, but it needs to transmit all the data after compression. Consequently, the network energy consumption is still high. The TCDCP algorithm proposed in [17–28] can adaptively adjust the acquisition time based on the error between the data and the predicted value of a linear regression model. However, by enhancing the sampling time interval, the absolute value of the error will also increase. Therefore, this algorithm is not applicable in an actual monitoring environment. The linear regression strategy proposed in [18–31] can accurately measure data, adjust the sampling frequency, and reduce the transmission quantity. However, the algorithm is complex and its requirements are too difficult to achieve for sensor nodes. In addition, this algorithm spends too much time constructing the model. In this scheme, if the cluster head node does not receive data for a long period, the model updating process will result in data loss.
3. Area Clustering Optimization Strategy for Large-Scale Monitoring Networks
Most of the above optimization strategies are relatively complex, they cannot adapt well to large-scale sensor monitoring networks. In networks with large numbers of sensing nodes, the message volume of the entire network can increase abruptly, reducing efficiency. Therefore, OFS first adopts an area clustering optimization strategy for large-scale sensor monitoring networks; it then utilizes distributed processing to monitor network sensor data [22].
3.1. Network Energy Consumption Model
Assume that n sensors are arranged randomly in a monitored area. These sensors periodically monitor the environment to collect data. The sink node is located in the centre of the area, so the network covers the entire monitoring area. If

In formula (1),

3.2. Network Partition Strategy
As mentioned above, in the existing strategies, the cluster head selection requires all the nodes in the network to make a global judgement. When the number of nodes is large and they are unevenly distributed, all nodes are involved in the comparison, which reduces the efficiency of the whole system [23]. Therefore, this paper proposes a network partition strategy; Figure 1 shows the network partition topology schematic. Sensor nodes are randomly distributed in the monitoring area. The sink node is located in the centre of the area.
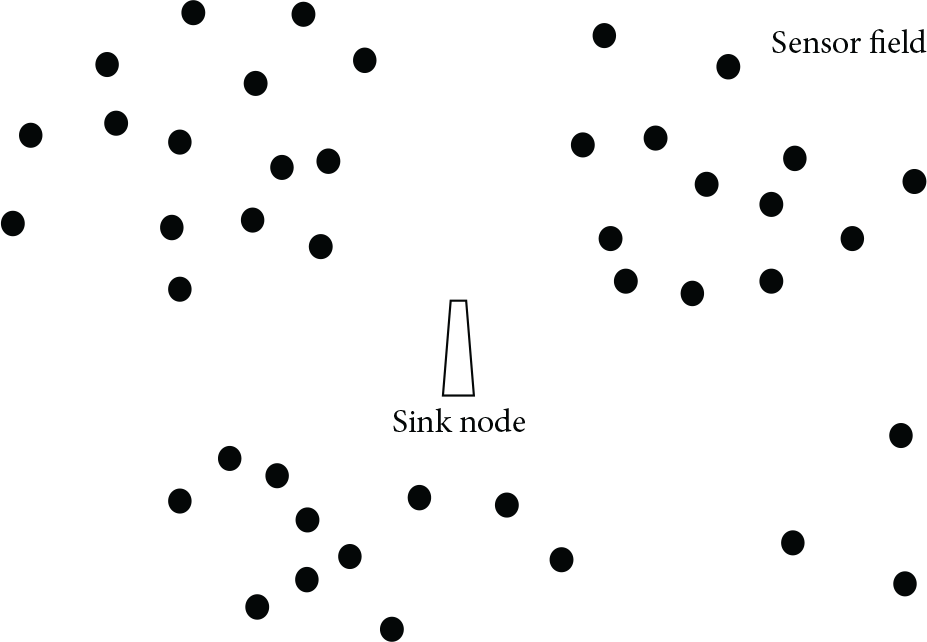
Network partition topology schematic.
As shown in Figure 1, sensor data in the monitoring area are transmitted to the sink node using multihop transmission [22]. This can easily lead to an energy hole around the sink node and then the sensor data cannot be transmitted to the sink node, which seriously affects the network lifetime. Therefore, the OFS strategy adopts the hierarchical clustering algorithm AGNES [19–27]. First, it divides the large-scale network into several subareas, selecting the cluster head and cluster in parallel in each area to boost efficiency. This scheme reduces the energy consumption requirements for all the nodes.
According to formula (1), the energy consumption of data transmission among nodes is closely related to the distance [25]. During network partition, the nodes send their location information to the sink node, which then divides the entire network into several subareas based on distance. Each node can belong to only one area. The distribution of nodes in each subarea is relatively uniform. When this division is complete, the sink node broadcasts relevant information concerning the subarea partitions. Using this broadcast information and its own location, each node can then find the subarea to which it belongs. The divided subarea is fixed over the entire network life cycle to reduce energy consumption from repeated clustering. Meanwhile, to prevent overfitting, the clustering operation needs to set the threshold M, where

Network partition schematic.
As shown in Figure 2, after clustering, the network in Figure 1 will be divided into 3 subareas of different densities. In the process of data transmission, the sensor nodes in the subarea will transfer their data to the selected cluster head nodes. However, the sensor nodes that are not in the subarea are called outliers. When transferring data, these outlier nodes will select the nearest cluster and either transfer their data to the nearest node in that cluster or transfer the data to the sink node directly. In each area, a distributed uneven clustering strategy is used to alleviate the problem of energy holes based on local competition rules that can improve election efficiency and extend the network life cycle.
3.3. Distributed Area Clustering Strategy
An area clustering strategy collects data periodically. The sink node broadcasts a message to perform network initialization, and each node calculates the distance between itself and the sink node according to the strength of the received messages. Candidate nodes participating in the election maintain a neighbour nodes table and elect a cluster head according to certain rules. The following lists the information available for a neighbour node: id, state, Eres, dtosk.
In the above, the
Rule 1.
During the election, if a candidate cluster head
The neighbour nodes set of the candidate cluster head


From formula (4),
After dividing the network, the clustering strategy divides the nodes in each area to control the distribution of cluster heads based on distance. At this point, the nodes in each subarea are relatively concentrated. Using a time broadcasting mechanism, a time threshold t is set up to control the proportion of candidate cluster heads based on the uneven clustering. Then, it is not necessary for each node to become a candidate cluster head. The average residual energy within each candidate cluster head competition radius and the average distance between the nodes and sink node are shown, respectively, in the following formulas:


The value of the time clock is calculated as

Within time t, if the candidate cluster head node
In summary, the OFS optimization strategy performs local uneven division in parallel when the number of sensor nodes is large and the distribution is uneven and dynamically sets the time threshold to control the proportions of cluster head competition, reduce the amount of communication transmission quantity, and balance cluster head energy consumption to effectively improve network efficiency and extend the network life cycle.
4. Adaptive Frequency Conversion Data Acquisition Strategy for Large-Scale Sensor Monitoring Networks
Based on the area clustering described in the previous section that optimizes sensor data acquisition and network transmission energy consumption, this paper proposes an adaptive frequency conversion based sensor network optimization strategy. By analysing the regression model, it can adjust the sampling frequency and update the model dynamically through a mechanism of sensed data compensation and reduced data redundancy.
4.1. Frequency Conversion Sampling Model
A clustered wireless sensor network [20–28] has a chain network topology. Figure 3 shows a schematic diagram of the structure of the sensor network.

Schematic diagram of the structure of the sensor network.
As shown in Figure 3, each sensor node SN can communicate with its next hop node, effectively forwarding data to the cluster head CHN [21] by following a path.
4.1.1. Establishment of Acquisition Model
Through time series analysis, it is found that the sensor message of a single sensor node is similar in continuous sampling; that is, the collected data at the same node over a given a period of time has a high temporal correlation [22–29]. So this study creates a linear regression model that approximately estimates the sensor data [23–30]. Figure 4 shows a schematic diagram of the regression model [30].
Schematic diagram of regression model.
4.1.2. Fitting a Regression Curve
Because of the wireless sensor network nodes' limited computing power and storage space, this paper uses a linear regression model to improve the accuracy of prediction and reduce the complexity of the algorithm [24–31]. Its form is

TS can be regarded as a linear function based on the sampling time t as the independent variable and the sampled data value a as the dependent variable [25–31]. The linear regression model is fitted according to the least squares method to acquire the least sampling data and minimize the square of the error of the fitting curve:

At the same time, to make the prediction closer to the true values, this paper computes the second-order partial derivative of D to a and b, as follows:
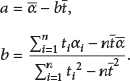
The values of a and b are the model parameters. The cluster head node utilizes parameters a and b to construct the regression model for a SN node. Then, it can calculate the measurement value of that SN using the model every time the SN would normally take a measurement. This reduces redundant transmissions and the overall energy consumption of the network.
4.2. Adaptive Frequency Conversion Acquisition and Optimization Strategy
Because of the temporal correlation of sensor data [22], sensor data are distributed along the time axis in the prediction model and the optimal strategy can adaptively adjust the acquisition frequency. Figure 5 shows a schematic diagram of adaptive frequency conversion. Set ε as the error range, α as the true value of the acquisition time t, and δ as the difference between the predicted value and the true value; that is,

Schematic diagram of adaptive frequency conversion.
As shown in Figure 5, the actual value of the sensor data will float within the error range, and the initial value of the threshold
Rule 2.
When
Rule 3.
When
The OFS optimization strategy adjusts the sampling frequency adaptively by using real-time monitoring data. The alternative changes of the threshold and the time axis are used to prevent the continuous emergence of a minimum or maximum measurement interval. Network energy consumption is reduced by avoiding data transmission as long as there is a guarantee of measuring accuracy.
4.3. Failure Data Compensation Mechanism
As mentioned earlier, when the regression model fails, the network needs to remeasure and fit a new model, but the inflection point at which the monitoring data causes the model to fail also generates a problem of data loss. Because the inflection point is not predicted and the time of that data inflection point is already in the past by the time the data deviation gets measured, the scheme needs to compensate for this loss of data around the inflection point. Figures 6 and 7 are schematic diagrams that show the failure data compensation mechanism: EA is Model 1 and CF is the updated Model 2. When the old and the new model are replaced, the data will be lost. According to the values of the model parameters, different estimation strategies are used in the compensation mechanism.
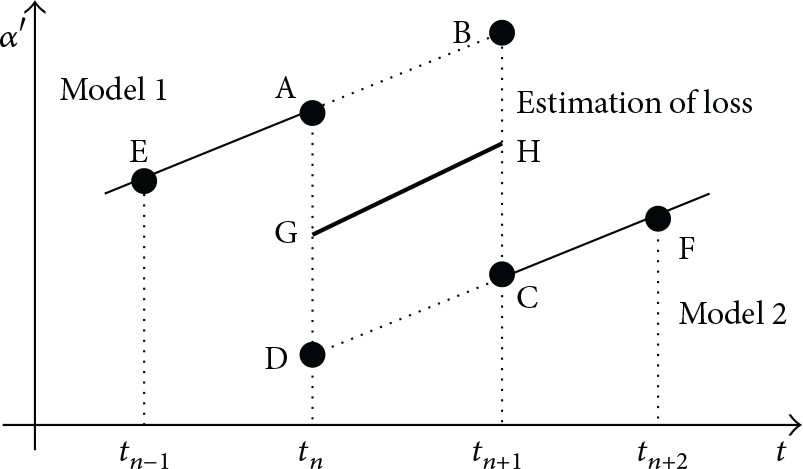
Schematic diagram of the failure data compensation mechanism.
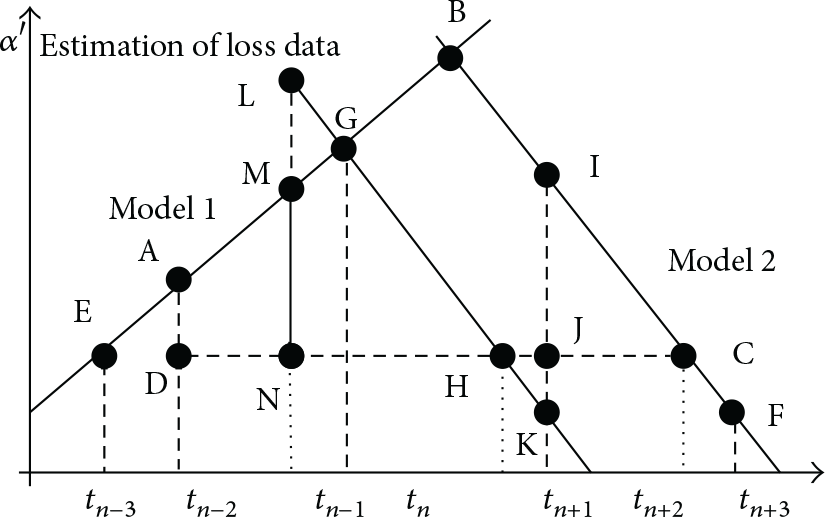
Schematic diagram of the failure data compensation mechanism.
As shown in Figure 6, if Model 1 and Model 2 have the same sign of parameter b, the extension line of Model 1 is AB, and the extension line of Model 2 is CD, then ABCD represents data estimated to be lost. At the same time, the two final measurement points E, A and C, F in Model 2 are the two new starting points selected. These 4 data points will be synthesized into a new linear regression model GH via the least squares principle. In this way, the measurement between Point A and Point C will be deduced at any given moment. At this point, the estimated value must fall in the range of estimation, so the linear regression model of GH is the compensation model for lost data in the time period within
As shown in Figure 7, if Model 1 and Model 2 do not have the same sign of parameter b, AB is the extension of Model 1, CB is the extension of Model 2, and the quadrangle ABCD is the estimated range of the missing data. The two final measurement points E, A in Model 1 and C, F in Model 2 are the two new starting points that are selected. These 4 data points are synthesized into a new linear regression model GH via the least squares principle. At this point, the lost data from
In summary, according to the trend of data in the model, the OFS optimization strategy adaptively adjusts frequency and dynamically updates the model in real time based on the error range. Each SN node will return the respective parameters to the corresponding CHN node. According to the least square method, the CHN node can use these parameters to calculate a regression model for each SN node in the cluster and then obtain the node's sensor data. Subsequently, unless the model fails, the SN node does not need to transmit sensor data to the CHN node, which effectively reduces the quantity of transmissions and reduce network energy consumption.
5. Experiments and Comparison
There are 400 sensor nodes distributed randomly over a 300 m × 200 m area. These sensor nodes monitor changes in temperature during four one-hour time slots distributed throughout a day as follows: 7:00-8:00, 12:00-13:00, 17:00-18:00, and 23:00-24:00. The initial sampling frequency of these sensor nodes is 0.0083 Hz. This experiment tests the feasibility of OFS and gauges its effectiveness using measures of network lifetime, total energy consumption, comparison of node energy balance, error analysis, data acquisition quantity, total quantity of network transmission, and so on. The simulation parameters are shown in Table 1.
Simulation parameters.

5.1. Network Lifetime
Figure 8 shows a comparison of different optimization strategies to maximize network lifetime. Network lifetime can be expressed by the relationship between the numbers of nodes that survive a given number of rounds. At this stage, a cluster head is chosen to join in a round. By capturing the number of rounds from the death of the first node to the death of all nodes, a round can show how well the network balances energy consumption. A greater number of rounds indicate a correspondingly greater efficiency in network energy utilization.

Network lifetime comparisons.
OFS optimizes the residual energy of nodes, the distribution density, and the transmission distance. The network lifetime can be prolonged because weaker nodes can continue to function longer. In Figure 8, compared to LEACH, HEED, and EEUC, OFS prolongs network lifetime by 38%, 15%, and 3.7%, respectively, while also balancing its energy consumption better.
5.2. Comparison of Total Network Energy Consumption
Figure 9 shows the comparison of total network energy consumption for different optimization strategies. To test precisely, when the number of survive nodes drops below 20, we consider the network DEA.

Comparison of total network energy consumption.
The OFS optimization strategy uses a clustering algorithm to divide the network into zones and generates the optimal cluster structure, which distributes cluster head nodes uniformly in the network and reduces energy loss to alleviate energy holes. In Figure 9, when the network has reached 800 rounds, the total network energy of OFS strategy remains 3.456 J, but other strategies have run out of network energy. This result shows that total network energy consumption using the OFS optimization strategy is lower than others.
5.3. Comparison in Consumption of Node Energy Balance
Figure 10 shows the curves of node residual energy variance for different optimization strategies. The energy balance performance can be tested for all these optimization strategies using 10 random rounds. The function of energy variance is shown as (note: the unit is 10−3 J)

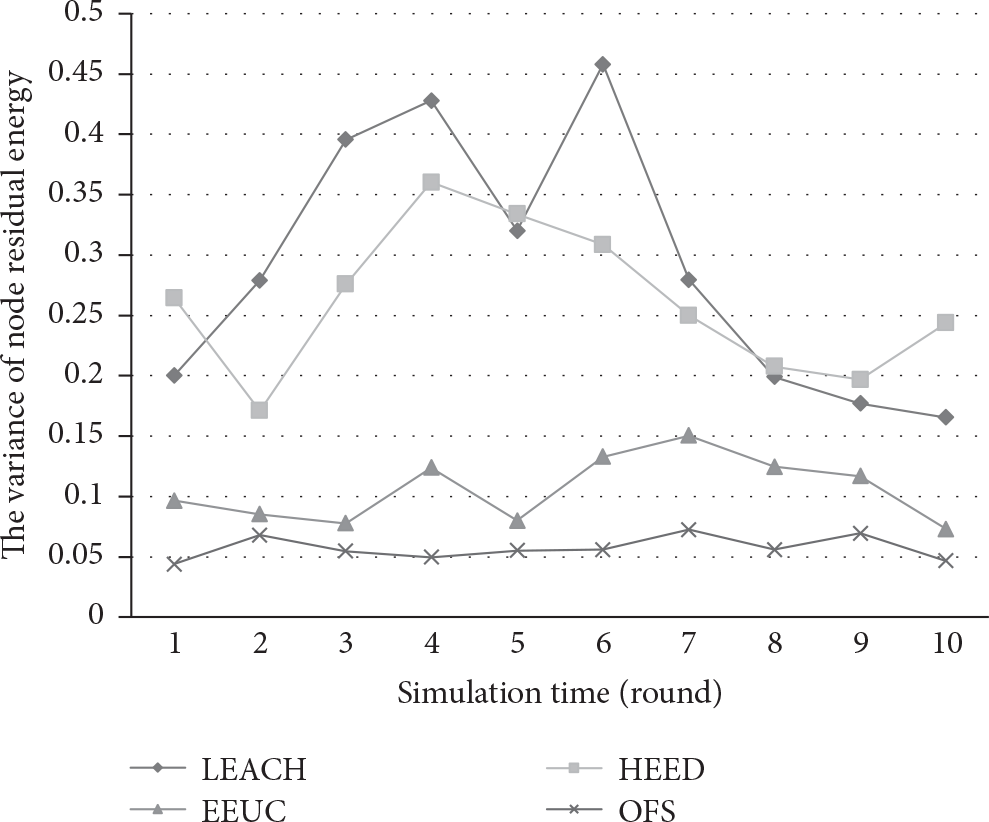
The curves of node residual energy variance.
Compared to other optimization strategies, Figure 10 indicates that the OFS optimization strategy has a more stable curve with fewer fluctuations from node energy variance; therefore, OFS performs better in node energy consumption and energy balance than the compared optimization strategies.
5.4. Error Analysis
Figure 11 shows comparisons of sensor data errors using different optimization strategies. In a fixed time slot, this test randomly selects the absolute value of sensor data from 400 sensors.

Comparisons of sensor data error.
In Figure 11, VA-DSC simply compresses and transfers sensor data. It has the minimum error; the value is 0.07°C. The maximum absolute errors using the OFS linear regression strategies are 0.39°C and 0.43°C, respectively. As the sample interval of TCDCP increases, the absolute error also increases. Absolute error increases to 0.89°C after one hour. The test indicates that OFS achieves slightly lower scores than VA-DSC for error control, meaning that it performs slightly better.
5.5. Data Acquisition Quantity
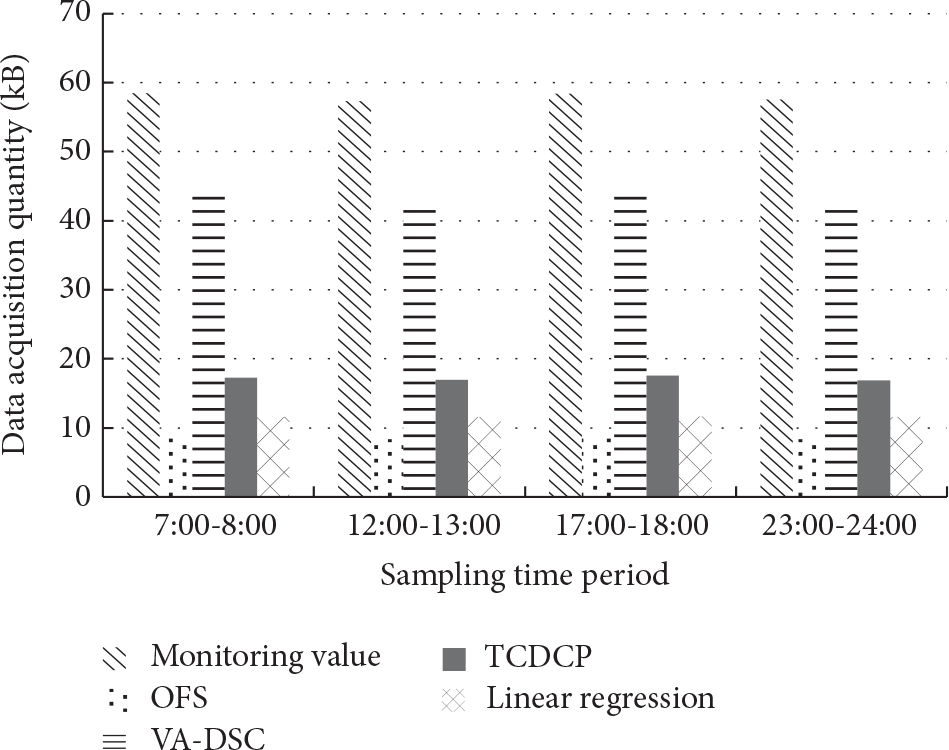
Figure 12 shows a comparison of data acquisition quantity for different optimization strategies. The experiment tested the average value of the data collected by the 400 monitoring nodes over 4 time periods.

Data acquisition quantity.
OFS utilizes the adaptive frequency conversion optimization strategy, which means it can constantly modify the threshold value β and the time interval T according to change trends of sensor data. By doing this, OFS substantially reduces the quantity of data acquisition required. Figure 12 shows that the average data acquisition quantity in OFS is 241.5 KB. The values in the linear regression, TCDCP, and VA-DSC methods are all higher: 264 KB, 283.25 KB, and 357.5 KB, respectively. This result indicates that OFS performs excellently in controlling the quantity of sensor data that must be transmitted.
5.6. Network Transmission Quantity
Figure 13 shows comparisons of network transmission quantity for different optimization strategies. In four time slots, this test selects the average network transmission quantity from 400 sensors.
Network transmission quantity.
Figure 13 shows that OFS needs only two regression parameters when building a model. Therefore, its network transmission quantity is minimum and the average is 8.4 MB. In comparison to the linear regression, TCDCP, and VA-DSC models, OFS reduces network transmission quantity by 27%, 80%, and 85%, respectively. These results show that OFS dramatically reduces the quantity of network transmissions required.
6. Conclusions
With the rapid development of Industry 4.0 and the Internet of Things, large monitoring networks have introduced new problems. The research hotspot for the Internet of Things is still wrestling with these problems. This paper proposes an optimized obtaining strategy (OFS) for acquiring sensor data in large monitored networks connected to the Internet of Things. OFS uses a hierarchical clustering algorithm to divide the network, generating a better clustering structure and reducing network communication overhead. OFS also builds a one-dimensional linear regression model for sensor data that serves to regulate acquisition frequency adaptively, reducing sensor data acquisition and transmission quantity requirements.
The experimental results indicate that OFS can effectively control the energy consumption of sensor nodes to prolong network lifetime. The results of this study provide an effective path for future development of Internet of Things and large-scale monitoring networks.
Footnotes
Competing Interests
The authors declare that they have no competing interests.
Acknowledgments
This work is supported by the National Natural Science Foundation of China (nos. 61502474, 61501105, and 61300233), the Foundation of Science Public Welfare of Liaoning Province in China (no. 2015003003), Major Industrial Project of Science & Technology of Liaoning Province (no. 2012216007), and Doctoral Scientific Research Foundation of Liaoning Province (no. 20141014). This work is also supported by Beilin District 2012 High-Tech Plan, Xi'an, China (no. GX1504) and supported by Xi'an Science and Technology Project (CXY1440