
Abstract
Data streams, which can be considered as one of the primary sources of what is called big data, arrive continuously with high speed. The biggest challenge in data streams mining is to deal with concept drifts, during which ensemble methods are widely employed. The ensembles for handling concept drift can be categorized into two different approaches: online and block-based approaches. The primary disadvantage of the block-based ensembles lies in the difficulty of tuning the block size to provide a tradeoff between fast reactions to drifts. Motivated by this challenge, we put forward an online ensemble paradigm, which aims to combine the best elements of block-based weighting and online processing. The algorithm uses the adaptive windowing as a change detector. Once a change is detected, a new classifier is built replacing the worst one in the ensemble. By experimental evaluations on both synthetic and real-world datasets, our method performs significantly better than other ensemble approaches.
1. Introduction
In recent years, some promising computing paradigms have emerged to meet the needs of big data. The only thing that the parallel batch process model copes with is the stationary massive data. However, there are a lot of applications in practice, such as sensor networks [1], spam filtering [2], intrusion detection [3], and credit card fraud detection [4], which generate continuously arriving data, known as data streams [5]. Most big data can be regarded as data streams, in which data are produced continuously [6]. In fact, model in the data stream is coping with the problem of three features of big data: big volume, big velocity, and big variety.
In general, most of the existing solutions constructing stream data mining are under the hypothesis that data are stationary. However, in the real-world, the generation of data streams is usually in the nonstationary environment, which means that the underlying distribution of the data can change arbitrarily over time. This phenomenon is known as concept drift [7, 8], which exists commonly in the scenarios of big data mining. For example, weather prediction models change according to the seasons, and in recommend systems, user consumption patterns may change over time due to fashion, economy, and so forth. The occurrence of such change leads to a drastic drop in classification accuracy. Therefore, the learning models should be able to adapt to the changes quickly and accordingly.
According to their speed, concepts drifts have been divided into two types: sudden drifts and gradual drifts [7]. Sudden concept drift is characterized by large amounts of change between the underlying class distribution and the incoming instances in a relatively short amount of time, while gradual concept drift is featured by large amount of time to witness a significant change in differences between the underlying class distribution and the incoming instances. Most of the existing methods just deal with one of the two types. However, in the real-world, data stream probably contains more than one type of concept drift. Thus, being able to track and adapt to various kinds of concept drift instantly is highly expected from a better classifier.
Concept drift has become a popular research topic over the last decade and many algorithms have been developed [9, 10]. The methodologies proposed for tackling concept drifts can be organized into three main groups: window-based approaches, weight-based approaches, and ensemble classifiers [7]. Ensemble methods are widely used in concept drift learning. The techniques for using ensemble to handle concept drift fall into two categories: block-based ensembles and online ensembles [11].
For block-based ensembles [4, 11–14], the streams are segmented into a series of successive fixed-size blocks. Every time when a new block appears, a new classifier, which is learned from the block, will be added to the ensemble, and the weakest classifier will be eliminated in line with the result of the evaluation. Consequently, the component classifiers of ensemble will be evaluated and later updated. Such approach ensures accurate reactions to gradual concept drifts. The main drawback of block-based ensembles is their delay in reacting to the sudden concept drifts. Another disadvantage is the difficulty of defining an appropriate size of the block [4]. Online ensembles update component weights after each instance without the need for storage and reprocessing [15]. So this method can adapt to sudden changes as quickly as possible. However, some of these algorithms are usually characterized by higher computational costs compared with block-based methods.
In order to meet the above challenges, we have come up with a novel ensemble paradigm, called Adaptive Windowing based Online Ensemble (AWOE), which combines the best elements of block-based weighting and online processing. The main contributions can be summarized as follows. The proposed algorithm is designed to assign different size of block to each ensemble member using adaptive windowing as a change detector. Therefore, it can capture sudden drifts immediately. The proposed approach synthesizes the essential features of the two groups of ensembles to handle various types of concept drifts.
The performance of the proposed algorithms was evaluated on both synthetic and real-world datasets, and a comprehensive comparison study of online and block-based ensemble algorithms was presented. The results show that our method achieves better performance than previous methods, especially when concept drift occurs.
The remainder of this paper is organized as follows. Section 2 presents the related work. In Section 3, we describe the approach in detail. In Section 4, we evaluate the method on both artificial and real-world datasets. Finally, some conclusions are drawn and future researches are discussed in Section 5.
2. Related Work
In this section, some relevant concepts of this study are to be introduced first, and then some previous work will be summarized.
2.1. Basic Concepts and Notation
Definition 1.
A data stream is an infinite sequence of training records:

Definition 2.
One considers that the term concept refers to the whole distribution of the problem in a certain point in time, being characterized by the joint probability
Definition 3.
Concept drift, that is, the underlying distribution of the data, is evolving over time [7]. It can be formally defined as any scenario where the posterior probability changes over time; that is,
Definition 4.
A change detector is an algorithm that takes a stream of instances as input and outputs an alarm if it detects a change in the distribution of the data.
2.2. Ensemble Classifiers for Data Streams with Concept Drift
Block-based approaches have been designed to work in the environments where instances arrive in portions, called chunks or blocks. Most block-based ensembles periodically evaluate their components and substitute the weakest ensemble member with a new (candidate) classifier after each block of instances. Such an approach ensures accurate reactions to gradual concept drifts.
The first of such block-based ensembles was the Streaming Ensemble Algorithm (SEA) [12], which used a heuristic replacement strategy based on accuracy and diversity. Accuracy Weighted Ensemble (AWE) is a generic framework for dealing with concept drifts in data streams [4]. The idea is to train a group of classifiers from sequential blocks of the data streams. Each classifier is weighted and only the top K-classifiers are kept. And the final output is based on the decision made by the weighted votes of the classifiers. The Accuracy Updated Ensemble (AUE1) [13], which incrementally trains its component classifiers after every processed block of instances. Results obtained by AUE2 [11] suggested that by incremental learning of periodically weighted ensemble members one could preserve good reactions to gradual changes, while reducing the block size problem and, therefore, improving accuracy on suddenly changing streams.
It is significant to notice that the performance of the block-based ensembles primarily depends on the size of the blocks. A small block does not supply adequate data for building a new classifier, while a too large block may include data coming from various concepts, causing delay of the adaptation to new concepts.
Oza and Russell [16] developed online versions of bagging and boosting for data streams. They show how the process of sampling bootstrap replicates from training data can be simulated in a data stream context. They observe that the probability that any individual instance will be chosen for a replicate tends to a Poisson (1) distribution. Kolter and Maloof [17] proposed an algorithm called Dynamic Weighted Majority (DWM), which is one of the most cited online learning approaches to handle drifts. In DWM, weighted experts are dynamically created and removed according to their accuracy after each incoming instance. Bifet et al. [18] introduced an algorithm named Leveraging Bagging (Lev), which intends to add more randomization to the base classifiers.
In terms of the sudden drifts, the online ensembles can respond faster with both of their components evolving over time. However, online ensembles do not take advantage of periodical component evaluations and do not weight or introduce new components periodically. As a result, on data streams with gradual changes, online ensembles are often less accurate than block-based approaches.
To address the above problems, a hybrid ensemble, which combines the strength of the above two, was proposed in this study.
3. Our Algorithm
In this section, an adaptive windowing change detector based on entropy will be introduced first, and then an online ensemble with internal change detector is demonstrated in detail. The complexity of the algorithm will be analyzed lastly.
3.1. Adaptive Windowing Change Detector Based on Entropy
This study proposed a two-window paradigm for change detection, which is inspired by Adaptive Window (ADWIN) [19]. The ADWIN algorithm increases the window size until two subwindows are found that are “distinct enough.” Distinct enough means the average of the two subwindows is larger than a threshold defined by the Hoeffding bound [20]. The window will be dynamically magnified when no obvious change is detected and will be compressed when a change occurs.
Theorem 5 (Hoeffding bound).
The Hoeffding bound is stated as follows: with probability

Theorem 6.
Let
Proof.
Assume the true mean of W is μ. According to the Hoeffding bound,
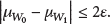
According to Theorem 5, (3) can be converted into

Since the entropy can be viewed as an average value. This study adopts the relative entropy (Kullback-Leibler distance) [21] as a measure to compare the difference between two subwindows with the Hoeffding bound to determine if the target concept is drifted. Different from ADWIN, the change detector was used to obtain the entropy from window dynamically. The sliding window W was partitioned into two equal length subwindows: a left subwindow

(01) Initialize Window W; (02) (03) (04) repeat (05) Drop elements from the tail of (06) (07) end for (08) Output ChangeAlarme; (09) end
3.2. Online Ensemble Using Adaptive Windowing
The primary disadvantage of the block-based ensembles lies in their delay in responding to the sudden concepts drifts, and this resulted from analyzing real labels only after every full block of instances. Another disadvantage is the difficulty of tuning the block size to offer a compromise between fast reactions to concept drifts and high accuracy in periods of concept stability.
In order to solve the above problems, an online ensemble with internal change detector was proposed, which retains a pool of weighted classifiers by obtaining the final output of components based on the weighted majority voting rule. The sliding window is chosen to monitor the classification error of the most recent data. Furthermore, a long-term buffer mechanism is selected to store the recent training instances, on which a new classifier is built when a change is detected. In this way, it can assign different size of block to each ensemble member.
Furthermore, the addition of an online learner and drift detector offers quicker reactions to sudden concept changes compared to most block-based ensembles. The online learner, which is incrementally trained with each incoming instance, is taken into account during component voting. Such strategy ensures that the most recent data is included in the final prediction. In the following experiments, we adopt an incremental algorithm for constructing decision trees, which is called Hoeffding Tree [20]. It builds a decision tree from data streams incrementally, without storing instances after they have been employed to renew the tree. The proposed Adaptive Window algorithm was selected as a change detector by monitoring the classification error. We consider a correct prediction to be 1 and an incorrect one to be 0. The full pseudocode of AWOE is listed in Algorithm 2.
buffer of size d; k: number of ensemble members, B: long-term (01) (02) incrementally train (03) (04) (05) build and weight new classifier (06) weight all classifiers (07) (08) (09) reinitialize (10) reinitialize D; (11) (12) end if (13) end for
Let S be a data stream; E represents the ensemble. When an instance arrives, online classifier is incrementally trained with internal change detector D. Instead of evaluating component classifiers after each block of instances, the ensemble members
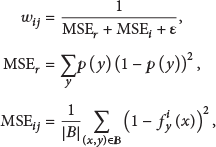
3.3. Complexity
It is important to analyze the time and space complexity of the algorithms. At this point, now the AWOE algorithm has been described and a detailed analysis of this complexity is presented. It should be noted that the ensemble algorithm can be configured with different base classifiers, so the final details about complexity will depend on the final base classifier used. In our experiments, the Hoeffding Tree [20] was chosen as the base classifier, but one could use any online learning algorithm as a base learner.
Temporal Complexity. Therefore, the analysis can be done according to two situations: building new base classifiers or weighting them. As the Hoeffding Tree is learned in constant time per instance [20], the training of an ensemble of k Hoeffding Trees has a complexity of
Spatial Complexity. It is basically determined by the maximum number of base classifiers stored in the ensemble (max) and their maximum size. The memory requirements of an ensemble of Hoeffding Trees depend on the concept being learned and can be denoted as
4. Experimental Results
In this section, we demonstrate all the used datasets, describe experimental setup, and discuss experiment results.
4.1. Datasets
The experiments are implemented in Java with the help of Massive Online Analysis (MOA) [23]. MOA is a software environment for implementing algorithms and running experiments for online learning. In our experiments, we adopt four synthetic and three real-world datasets.
4.1.1. Synthetic Datasets
Synthetic datasets have several advantages: they are easier to reproduce and bear low cost of storage and transmission, and, most importantly, synthetic datasets provide an advantage of knowing the ground truth. For instance, we can know where exactly concept drift happens, what the type of drift is, and the best classification accuracies achievable on each concept. The synthetic datasets contain three types of concept drift: sudden, gradual, and mixture.
HyperPlane is a two-class dataset that models a rotating hyperplane in a d-dimensional space. It is represented by the set of points x that satisfy
The SEA dataset was first described in [12]. It consists of three attributes, where only two are relevant. All the attributes have values between 0 and 10. The points of the dataset are divided into four blocks with different concepts. In each block, the classification is done using
The goal of LED dataset is to predict the digit displayed on a seven-segment LED display. The particular configuration of the generator used for the experiment produces 24 binary attributes, 17 of which are irrelevant. Concept drift is simulated by interchanging relevant attributes. We generated a stream of 1,000,000 instances with sudden and gradual concept drifts and 10% of noise.
Waveform is composed of a stream with three decision classes, in which the instances are depicted by 40 attributes. The aim of the task is to distinguish between three diverse classes of waveform, and each of them is produced by a synthesis of two or three base waves. We produce a stream consisting of 1,000,000 instances with no drift. It has been applied before, such as in [15].
4.1.2. Real-World Datasets
When working with real-world datasets, it is not possible to know exactly when a drift starts to occur, which type of drift is present, or even if there really is a drift. Therefore, it is not possible to perform a detailed analysis of the behavior of algorithms in the presence of concept drift using only pure real-world datasets. The real-world datasets employed in the experiments can be obtained at http://moa.cms.waikato.ac.nz/datasets/, and they can be simulated into data streams by the MOA generators.
The Covertype dataset comes from UCI archive [24] including the forest cover type for cells of 30 × 30 meters procured from US Forest Service (USFS) Region 2 Resource Information System (RIS) data. It contains 581,012 instances, which are defined by 53 cartographic variables that depict one of seven possible forest cover types. The aim is to predict the forest cover type based on cartographic variables. It has been used in [16, 25].
The Poker Hand dataset represents the problem of identifying the hand in a Poker game. It consists of 1,000,000 instances representing all possible poker hands. Each instance represents a hand comprising five cards drawn from a standard deck of 52. Each card is described using two attributes (suit and rank), for a total of 10 predictive attributes. There is one class attribute that describes the “Poker Hand.”
The Electricity dataset which consists of 45,312 instances, each described by 7 attributes, presents the problem of predicting whether the price in the Australian New South Wales Electricity Market will increase or decrease. The dataset is a collection of successive measurements at every 30 minutes, spanning the period from May 1996 to December 1998. The class label of each point is either UP or DOWN, referring to whether the electricity price at the specified time is higher or lower than the average price of the preceding 24 hours. It has been used in [17, 25, 26].
4.2. Experimental Setup
To evaluate the effectiveness of the methods, we use the prequential evaluation method [27]. This way the classifier is tested against all instances before seeing them. All the algorithms were implemented in Java as part of the MOA framework. The experiments were performed on 3.0 GHz Pentium PC machines with 8 GB of memory, running Microsoft Windows 7.
All the tested ensembles used
4.3. Results and Discussion
4.3.1. Drift Detection
The proposed entropy-based change detection was compared against the following change detections: Drift Detection Method (DDM) [25], Early Drift Detection Method (EDDM) [26], and Adaptive Window (ADWIN) [19] on the performance measures such as the false positive rate and false negative rate.
False Positive Rate. The false positive rate is the probability of falsely rejecting the null hypothesis for a given test.
False Negative Rate. The false negative rate is the probability of falsely accepting the null hypothesis when it is in fact true.
All of the change detections have freely available implementations in the MOA framework. The results are shown in Tables 1 and 2. The lower values indicated a better performance. It is clearly revealed that DDM is the method with the best performance on the dataset with sudden changes (SEA). However, its detection speed is very slow. EDDM is more suitable for detecting gradual changes, while most misdetection appeared under static environments because of their sensitivity to errors and noise. The relatively higher false positive rate for ADWIN is due to the use of compression to reduce storage size of its buffer. Our method achieves better false positive rates than ADWIN in the presence of the dataset with mixture concept drift (LED). The results showed that our method ensures certain superiority over others comparing change detections especially on datasets containing different types of drifts.
The false positive rate of change detections.

The false negative rate of change detections.

4.3.2. Comparative Performance Study
The AWOE was evaluated against the following methods: Accuracy Weighted Ensemble (AWE), Accuracy Updated Ensemble (AUE2), Dynamic Weighted Majority (DWM), Lev Bagging (Lev), and Online Accuracy Updated Ensemble (OAUE). They all have freely available implementations in the MOA framework, except for DWM, which was implemented and is available at (http://sites.google.com/site/moaextensions/) as MOA extensions.
The performance can be evaluated in terms of accuracy, time, and memory in Tables 3–5 (the best results for each dataset are indicated in bold).
Classification accuracies of different algorithms (%).

Times of different algorithms (seconds).
Memory usage of different algorithms (MB).

Classification Accuracy. As Table 3 shows, in terms of accuracy, Lev and our method outperform all the other algorithms. On the dataset with no drift (Waveform), Lev, AWE, and DWM performed almost identically, with OAUE being slightly less accurate. For the dataset with gradual concept drift (HyperPlane), AWE is the best, followed by AUE. However, our method seems to be the most accurate in the case of sudden changes (SEA). This is partly because the addition of drift detector offers quicker reactions to sudden concept changes compared to most block-based ensembles. For the dataset with mixed concept drift (LED), our proposed method largely outperformed other algorithms. On the real-world datasets, in terms of accuracy, there is no single best performing algorithm. On the Covertype, our method clearly outperformed all the other algorithms. On the Poker, OAUE is the most accurate followed by Lev, while on the Electricity all the algorithms perform almost identically.
Time Analysis. In terms of the running time, as shown in Table 4, through the comparative analysis, we found that DWM consumed the least, followed by our algorithm, and Lev is the longest time-consuming. Although Lev achieves the highest classification accuracy rate, it consumes more time. We have observed that the online ensemble is the best strategy in terms of accuracy, but it also had a poor performance in terms of the processing time.
Memory Usage. According to Table 5, in most cases, AUE2 achieved minimal memory consumption, followed by our algorithm, while the Lev consumed the most memory. It is clear that the memory usage of the AUE2 is lower than others because of the pruning strategy. This is partly because our algorithm not only uses an adaptive sliding window algorithm based on classification error rate to track changes in data streams but also just stores classification error rate instead of all the instances so that it consumes less memory compared with other algorithms.
In conclusion, the results proved that the proposed algorithm achieves better performance with regard to accuracy and costs less time and memory. The Lev enjoys the slight advantage over other algorithms in terms of accuracy. Unfortunately, it is also the costliest strategy in terms of processing time, as it requires estimating each component's predictive performance after each instance.
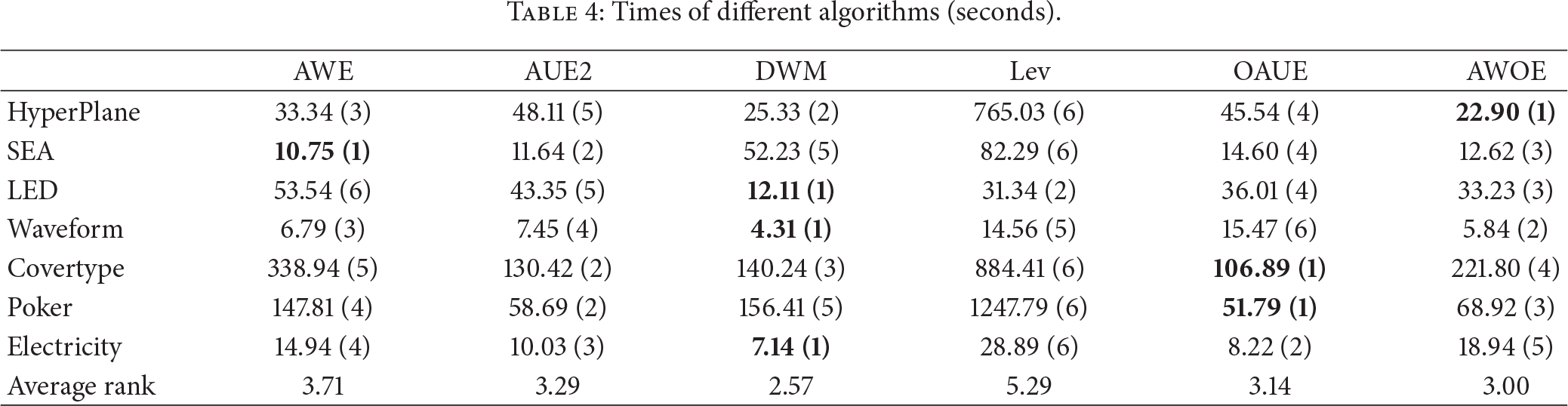
Figure 1 shows the classification accuracy on the SEA dataset, which was designed to evaluate the ability to handle sudden concept drifts. Whenever a concept drift occurred, the accurate rates of all the algorithms will undergo instantaneous fluctuations except for our algorithm, which maintains a high, stable accuracy and suffered the smallest accuracy drops. This might be attributed to the addition of drift detector which could capture sudden concept drifts promptly, according to changes in the concept and in a timely manner to build a classifier to deal with this type of drift.
Accuracy on the SEA dataset.
Figure 2 presents the classification accuracy on the LED dataset, which intended to verify the algorithms’ response to mixed drifts. This dataset included a complex change by combining two gradually drifting streams. After 500K instances, the target concept was instantly switched from a concept to another. We observed that all the algorithms maintain a high and stable accuracy when the data was relatively stable. When the concept drift occurred at 500K, accuracy of all the algorithms declined sharply, except in our method. Since our method can track the various kinds of changes immediately, it reestablished a new classifier in real-time. Since the dataset contained 10% of the noise, it illustrated that the proposed method was more suitable for the noise environment.
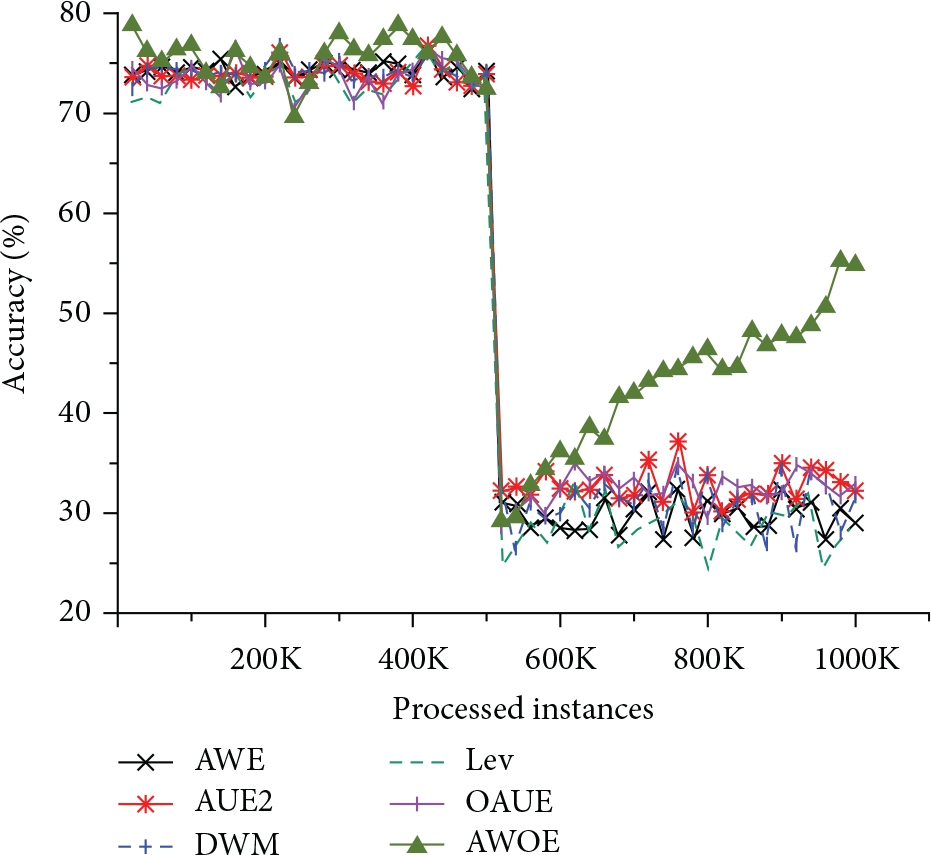
Accuracy on the LED dataset.
Real-world stream environment conceptual changes have unpredictability and uncertainty which can better verify the performance of the algorithm. Figure 3 depicts the accuracy changes on the Covertype. We observed the accuracy curves of all algorithms with varying degrees of volatility, which indicates that concept drift may exist in the dataset. Our method is the most accurate one, followed by the OAUE. The accuracy curve of the proposed algorithm is relatively stable, as it is robust to concept drift, which also shows that our algorithm has better adaptability for real environment.
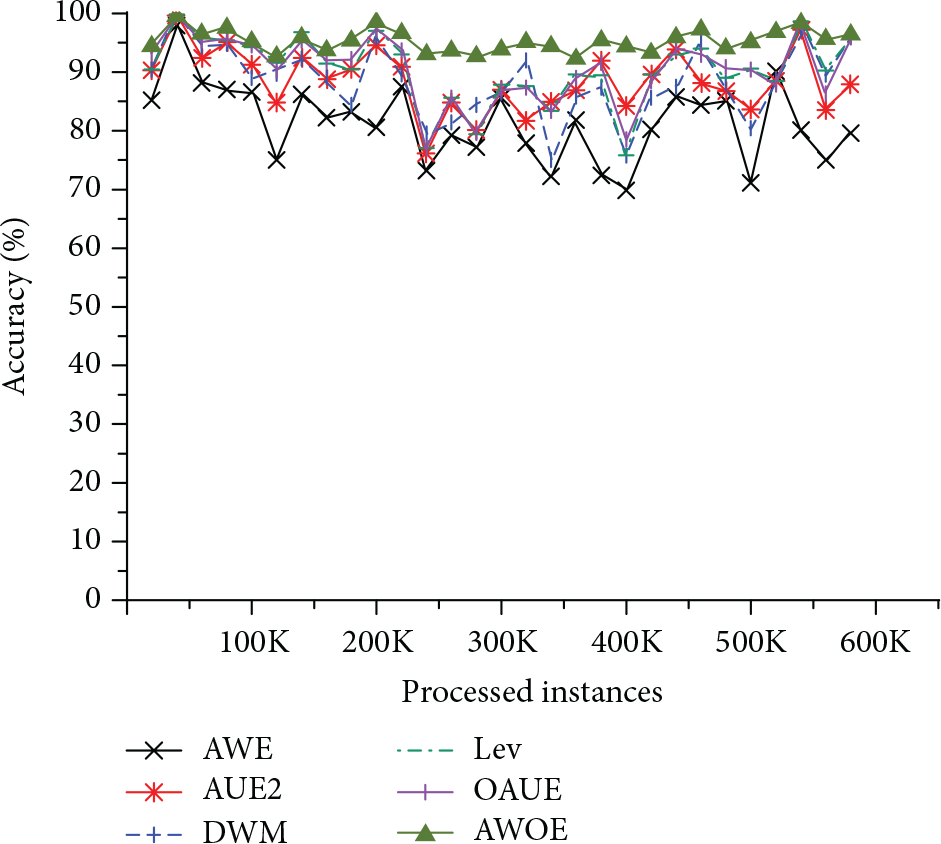
Accuracy on the Covertype dataset.
In conclusion, our approach has better performance than other ensembles in the following three aspects: (1) it better resolves the problem of setting an appropriate size of block; (2) it is more suitable for the scenarios with different types of drift; and (3) our algorithm is more efficient than other ensemble approaches in terms of accuracy and memory consumption.
5. Conclusion and Future Work
This study, through studying the influence of the size of data block on performance of the ensemble classifier, proposed an online ensemble with internal change detector to capture concept drifts in timely manner by determining block size dynamically. The experimental results prove that our approach performs better than other ensembles and gains the best tradeoff between accuracy and resources.
Most existing data stream algorithms assume that true labels are immediately and entirely available. Unfortunately, such assumption is often violated in real-world applications because it is expensive to obtain all true labels. As the future work, we intend to investigate the potentiality of adapting the proposed algorithm to the streams with unlabeled data.
Footnotes
Competing Interests
The authors declare that they have no competing interests.
Acknowledgments
This work was supported by the National Natural Science Foundation of China (no. 61572417, no. 61563001, and no. 61572005), the Natural Science Foundation of Beijing (no. 4142042), and the Fundamental Research Funds for the Central Universities (no. 2015YJS049).