
Abstract
Employing user access patterns to develop a prefetching scheme can effectively improve system I/O performance and reduce user access latency. For massive spatiotemporal data, traditional pattern mining methods fail to directly reflect the spatiotemporal correlation and transition rules of user access, resulting in poor prefetching performance. This paper proposed a prefetching scheme based on spatial-temporal attribute prediction, named STAP. It maps the history of user access requests to the spatiotemporal attribute domain by analyzing the characteristics of spatiotemporal data in a smart city. According to the spatial locality and time stationarity of user access, correlation analysis is performed and variation rules are identified for the history of user access requests. Further, the STAP scheme mines the user access patterns and constructs a predictive function to predict the user's next access request. Experimental results show that the prefetching scheme is simple yet effective; it achieves a prediction accuracy of 84.3% for access requests and reduces the average data access response time by 44.71% compared with the nonprefetching scheme.
1. Introduction
The development of smart cities based on cloud computing and the Internet of Things has generated massive spatiotemporal data, including meteorological data, hydrological data, natural disaster data, and remote-sensing images, with three basic attributes, namely, location, time, and type. Such data are characterized by wide variety, large quantity, high redundancy, and dynamic growth over time. A smart city can quickly and conveniently provide users with rich predefined applications through a network platform based on the users' demands for spatiotemporal data services such as data visualization, spatiotemporal correlation analysis, temporal emergency aid, and massive information retrieval.
Low latency, high concurrency, and high aggregate bandwidth are the three important criteria for measuring the quality of spatiotemporal data services in a smart city. Under the same bandwidth and computing power, the key factor affecting the quality of a spatiotemporal data service is the system delay in the network environment. Prefetching schemes have been widely used because they can effectively improve the data transfer rate and reduce the user access latency [1]. Therefore, it is important to develop an efficient prefetching scheme for improving the quality of spatiotemporal data services in a smart city.
Compared with nonspatiotemporal data, spatiotemporal data not only have three basic spatiotemporal attributes but also have obvious spatiotemporal correlation of user access; moreover, the corresponding prefetching schemes are different. Based on the different types of data, data prefetching schemes can be divided into two categories in the network environment.
(1) Nonspatiotemporal Data Prefetching. Nonspatiotemporal data prefetching mainly concerns web prefetching and personalized recommendations. In general, user access information is obtained by clustering or correlation analysis of webpages or users in order to mine user access patterns and develop a prefetching scheme. Pallis et al. [2] employed the association rule to filter webpages visited by users in order to perform webpage clustering; then, they used the clustering result sets to develop a prefetching scheme for overcoming the problem of web access latency. Further, Wan et al. [3] used clustering to develop a method based on random indexing with various weight functions in order to track user access and cluster users with similar activity patterns. Khosravi and Tarokh [4] adopted a naive Bayesian approach for dynamic mining of user access patterns in order to predict the pages accessed by users. Bamshad et al. [5] developed a personalized webpage recommendation system by using the a priori algorithm to identify pagesets frequently accessed by users; then, they matched the users' currently accessed pages with the frequently accessed pagesets. Matthews et al. [6] proposed a genetic algorithm based on association rules and discovered extra rules that are complementary to existing algorithms, which can facilitate the development of more effective prefetching schemes. Similar studies have been described in the literature [7–13].
(2) Spatiotemporal Prefetching. Spatiotemporal data prefetching mainly concerns WebGIS. The corresponding prefetching schemes use not only the characteristics of the data but also the spatiotemporal correlation of user access. Typically, the characteristics of the data are used to mine user access patterns and develop a prefetching scheme by spatiotemporal correlation analysis, transition probability calculation, access frequency ranking, and other methods related to user access requests or data. In order to overcome the problem of a long delay when users browse large objects in WebGIS, Park and Kim [14] used the spatial clustering characteristic of the Hilbert curve. They divided the entire geographic space using Hilbert curves and gave them appropriate values; then, they proposed a prefetching method based on the spatial locality of user access. Dong et al. [15] exploited the spatial locality of user access and proposed two prefetching methods. The first method computes transition probabilities between tiles and prefetches the most probable tile; the second method uses a “Neighbor Selection Markov Chain” to compute the objects to be prefetched based on the data of the k tiles previously requested. Considering the previous action of a given user, Yeşilmurat and Işler [16] proposed a heuristic prefetching algorithm that analyzes and ranks the previous moves of a user to predict the user's next move; then, it identifies the locations of candidate tiles to be prefetched. Considering both long-term and short-term popularity features for tile access in a geographic space, Li et al. [17] presented a Markov prefetching model in a cluster-based caching system based on the Zipf distribution and verified that the method has a high prefetch hit rate and a short average response time.
From existing studies, it can be seen that, in the network environment, a typical data prefetching scheme is based on current/historical user access information. It analyzes and processes the information at the level of access requests or data by using user access continuity, spatial locality, popularity, association rules between objects, and other methods in order to mine the user access patterns. Then, it predicts user access requests according to these patterns in order to achieve data prefetching.
However, we note that user access to spatiotemporal data usually has obvious spatiotemporal features in a smart city. The general approach mines user access patterns at the level of access requests or data, the results can only reflect this feature indirectly, and they are not useful for developing a high-efficiency prefetching scheme for massive spatiotemporal data. But if we analyze and process user access information at the level of spatiotemporal attributes, then the hidden spatiotemporal correlation and transition rules can be found, and we can develop a more targeted prefetching scheme. Therefore, how to effectively mine the spatiotemporal features and patterns from the user access information is the focus of this paper.
In this paper, we propose a prefetching scheme, STAP, for massive spatiotemporal data in a smart city. The proposed method analyzes the characteristics of spatiotemporal data and the spatiotemporal correlation of user access, parameterizes the history of user access requests, and extracts the spatiotemporal attributes. Then, it uses regional meshing, association rules, and the autoregressive integrated moving average (ARIMA) model in the spatiotemporal attribute domain to perform correlation analysis and identify transition rules, mines user access patterns, and constructs a predictive function to predict the user's next access request, in order to achieve spatiotemporal data prefetching.
The remainder of this paper is organized as follows. Section 2 introduces the motivation and principle of our prefetching scheme. Section 3 describes the implementation of our prefetching scheme, which mainly involves two steps. The first step shows how to (i) mine the user access patterns from the history of user access requests and (ii) construct the predictive function for predicting requests. The second part explains how to (i) predict the user's next access request according to the current one by using the abovementioned predictive function and (ii) prefetch the corresponding data. Section 4 presents and discusses the performance evaluation results of our prefetching scheme. Finally, Section 5 briefly summarizes our findings and concludes the paper.
2. Principle of Prefetching Scheme
2.1. Motivation
Typical prefetching schemes involve two steps. The first step is to mine the user access patterns and construct the predictive function; the second step is to predict access requests and prefetch the data. The first step is usually based on historical user access information as well as the characteristics of the data. It uses clustering, association rules, Markov models, and other methods to mine associate items accessed by users. Then, it merges them to form associate itemsets or uses mathematical functions to describe the correlation between the associate items. Thus, the corresponding request predictive function is constructed. The second step is based on the current user access request, the predictive function is used to predict the next access request of the user, and then the corresponding data is loaded into the cache.
For instance, suppose that
It can be seen that the key aspect of the prefetching scheme is to mine user access patterns and construct the request predictive function. However, unlike ordinary user access features in the network environment, the users obtain spatiotemporal data services based on predefined applications in a smart city, which have obvious spatiotemporal correlation. For example, if a user checks the weather conditions by predefined applications, the access data are current time and location related meteorological data; when searching for the nearby living facilities, the access data, such as restaurants and parking lots, are closely related to the user's current location. Therefore, if we treat the access request as a whole for direct mining as in the case of traditional mining patterns, the spatiotemporal correlation of user access will not be reflected directly, and the corresponding prediction function will not predict user access requests accurately.
In order to overcome the inherent drawback of mining user access patterns directly at the level of access requests, we start with the characteristics of spatiotemporal data and the spatiotemporal correlation of user access. Then, we mine the user access patterns at the level of spatiotemporal attributes and construct the access request predictive function.
2.2. Principle
Suppose that the history of user access requests in a smart city can be expressed as the sequence

Because the spatiotemporal attribute sequences
Therefore, to simplify access pattern mining, we process spatiotemporal attribute sequences For access requests with self-correlation of spatiotemporal attributes, we analyze the self-correlation of the spatiotemporal attribute sequences to mine associate items For access requests with cross-correlation of spatiotemporal attributes, we carry out cross-correlation analysis of the spatiotemporal attribute sequences, and we mine associate items
3. Implementation
The method is implemented in two steps. The first step is the offline mining of user access patterns to construct the predictive function, and the second step is the online access request prediction and data prefetching.
3.1. Construction of Predictive Function
The predictive function consists of the independent attribute prediction function
3.1.1. Construction of Independent Attribute Predictive Function
(1) Construction of Location Attribute Predictive Function. The key aspect of the location attribute predictive function
(a) Regional Meshing. The location attribute of spatiotemporal data represents the geographical location of a data source in a smart city, usually expressed by latitude and longitude coordinates
Suppose that the geographic area is a two-dimensional Euclidean rectangular space

Figure 1(a) shows the geographic rectangular area divided into 4 × 5 cells and the meshing cell coding. Figure 1(b) shows all the neighbor cells of the cell
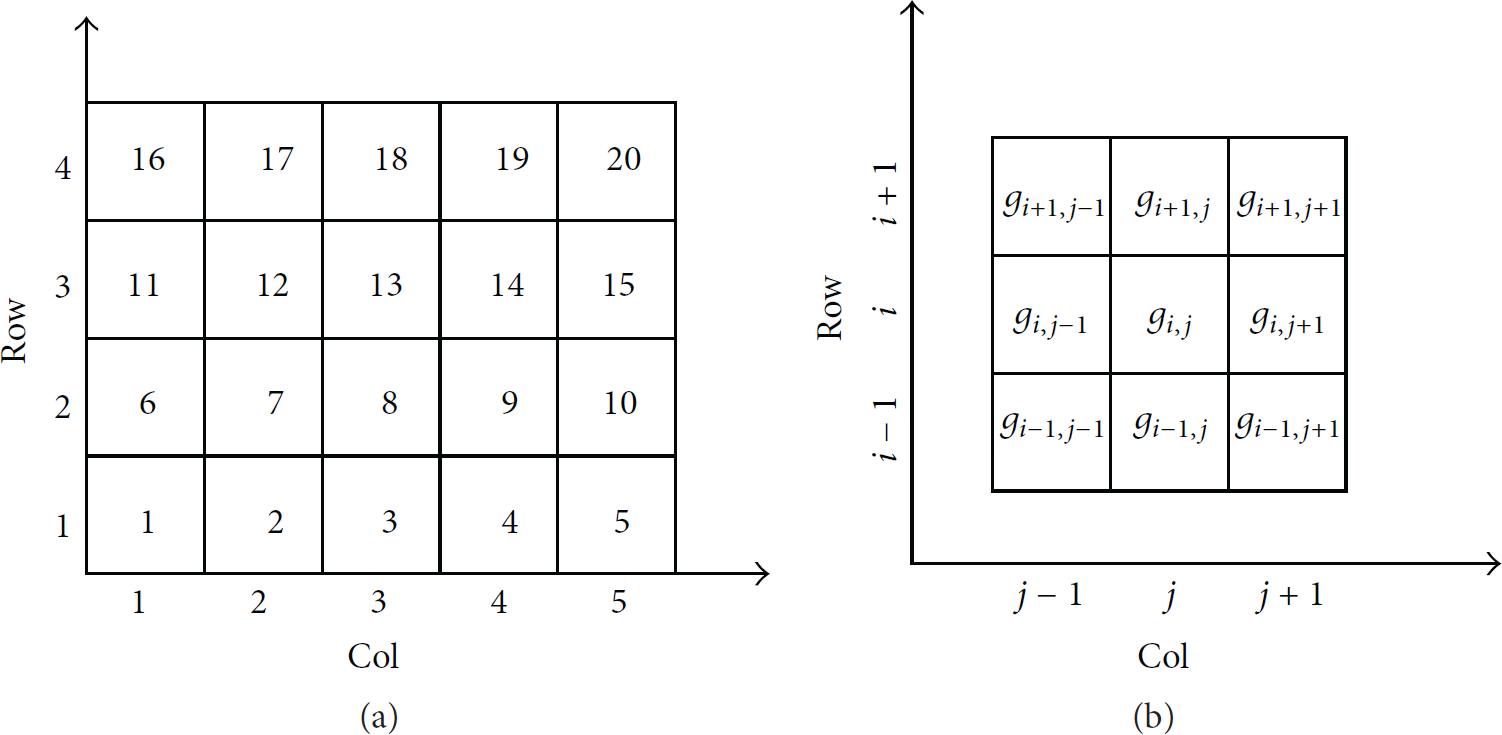
Regional meshing and coding: (a) meshing cell coding; (b) neighbor cells of
(b) Construction of Predictive Function. Through regional meshing, we can use an association rule algorithm to mine the associate items of each cell from the sequence of location attributes Calculate the location coordinate sets Count the number of times every coordinate point Calculate the confidence of each frequent m-itemsets and its subset frequent m-1-itemsets. Generate association rules Loop through each cell in the geographical area to calculate the location attribute association rulesets and merge them to form the associate rulesets where

(2) Construction of Type Attribute Predictive Function. The key aspect of the type attribute predictive function Count the number of times every Calculate the confidence of each frequent m-itemsets and its subset frequent m-1-itemsets. Generate association rules

(3) Construction of Time Attribute Predictive Function. The key aspect of the time attribute predictive function
The time attribute sequence of user access requests is a typical nonstationary sequence influenced by a predefined application, which has obvious trends in a local range. ARIMA is an important and widely used short-term time series prediction model. It can predict future values according to the current and historical values of the sequence, but it requires the sequence to be stationary [19–23]. To this end, we can piecewise represent the time attribute sequence and perform difference processing to achieve local stationarity. Then, we build the ARIMA model and construct the time attribute predictive function.
(a) Piecewise Representation of Time Attribute Sequence. We use extreme point detection based on the slope change and piecewise representation of the time attribute sequence according to local extreme values in the sequence (the beginning and end value of each curve). The method calculates the slope difference
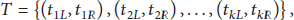
(b) Construction of Predictive Function. With the abovementioned piecewise representation and difference processing, we can realize local stationarity of the time attribute sequence and build ARIMA to construct the time attribute predictive function

Suppose that the right-and-left local extreme value of j,
Finally, we can build

3.1.2. Construction of Conjoint Attribute Predictive Function
Because the access requests with cross-correlation of spatiotemporal attributes account for a very small proportion of the total number of requests, it is difficult to jointly analyze the attributes. Therefore, we analyze only the access requests that have special cross-correlation of spatiotemporal attributes, that is, if the sequence of location attributes

Then, we assume that the location attribute and the type attribute remain unchanged in the next access request, and the time attribute can be predicted by
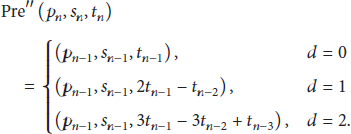
3.2. Prediction Method for Access Requests
The purpose of this section is to show how to use the predictive function to predict the user's next access request based on the current one.
Suppose that the current user access request can be expressed as the sequence
We define a sliding and adaptive observation window with initial size w, and we take the spatiotemporal attribute sequence

3.2.1. Independent Attribute Predictive Function
For the access requests that dissatisfy formula (8), we predict the spatiotemporal attribute according to independent attribute prediction
(1) Location Attribute Prediction. Because regional meshing is used for the entire geographic area, before prediction, we need to judge whether the coordinate points belong to the same cell or neighbor cells according to formula (2). If the points belong to the same cell, we trigger the prediction; otherwise, we forgo prediction. The pseudocode for prediction of the location attribute is shown in Pseudocode 1.
Here,
(2) Type Attribute Prediction. The type attribute prediction is similar to the location attribute prediction. Scan associate rulesets
(3) Time Attribute Prediction. The time attribute prediction is based on the predictive function
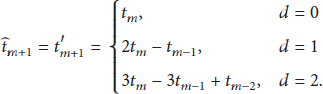
3.2.2. Conjoint Attribute Predictive Function
For the access requests that satisfy formula (9), we predict the next access request

3.3. Data Prefetching
Data prefetching is performed to load data into the cache in accordance with the predicted request. To avoid unnecessary consumption of memory and computing resources, we built two data structure queues of length λ. One is used to store the actual access requests and the other to store the predicted requests. By calculating the consistent rate of the two queues, we can judge the degree of credibility of the current predicted requests. If the consistent rate achieves the predefined threshold, we assume that the predicted request is credible, and accordingly we carry out the data prefetching.
Suppose that the actual access request stored in a queue of length λ is
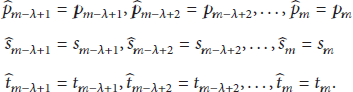
4. Experiment
This section consists of three parts. The first part introduces the performance evaluation metrics for our prefetching scheme. The second part describes the experimental data and methods. The last part presents and discusses the results of the experiments.
4.1. Evaluation Metrics
We propose five criteria for performance evaluation of the proposed prefetching scheme in terms of accuracy, efficiency, and effectiveness.
Prediction Accuracy. It is the correct number of predicted requests as a percentage of the total number of requests.
Prediction Coverage. It is the number of predicted requests as a percentage of the total number of requests.
Pattern Mining Time. It is the time consumed for mining user access patterns from the history of user access requests.
Request Prediction Time. It is the average time for predicting an access request.
Average Response Time. It is the average response time to obtain a single data item.
4.2. Experimental Data and Methods
The experimental data was obtained from Wuhan smart city network application demonstration platform, which includes 14 types of sensors in different regions; it has been generating sensor data since January 1, 2010, and provides 20 types of predefined applications to the public. We obtained the historical user access information from the user access log in the server for the period from September 1, 2014, to February 16, 2015. After processing, we generated 1,819,008 data access requests. The initial 1,628,183 requests formed the training set for mining user access patterns and constructing the predictive function. The remaining 190,825 requests formed the test set for testing the performance of the prefetching scheme.
The performance of the prefetching scheme is determined by the initial size of the observation window, regional meshing level, support threshold, and confidence threshold. Considering that the pattern mining is performed offline, the objective of the prediction is to choose the association rules with the maximum confidence. In order to choose the maximum number of rules and improve the trigger probability of prediction, we set the support threshold at 0.05% of the total number of access requests; that is,
4.3. Experimental Results
4.3.1. Prediction Accuracy and Coverage
(1) Spatiotemporal Attribute Prediction
(a) Location Attribute Prediction. The prediction accuracy and coverage of the location attribute with different regional meshing levels and observation window sizes are summarized in Table 1. As can be seen, for the same observation window size, when the meshing level increases (the area of the cell becomes smaller), the accuracy and coverage decrease. This is because the regional meshing results in the loss of the association rules between nonneighbor cells and leads to unsuccessful trigger prediction of some access requests. In contrast, for the same regional meshing level, as the observation window size increases, the accuracy gradually increases while the coverage remains unchanged. This can be explained as follows. On the one hand, the larger the window size, the greater the amount of available prediction information. On the other hand, the short rules form a subset of the long rules, and the current observation window cannot trigger prediction; the size of the window will adaptively decrease for further prediction until the minimum size is reached.
Location attribute prediction.

(b) Type Attribute Prediction. The prediction of the type attribute is related only to the observation window size. As can be seen from Table 2, as the observation window size increases, the prediction accuracy gradually increases from 94.38% to 96.05%, while the prediction coverage remains unchanged at 96.76%. This can be explained as follows. The larger the observation window size, the greater the amount of available prediction information, and the adaptive observation window size achieves exactly the same prediction coverage.
Type attribute prediction.

(c) Time Attribute Prediction. The time attributesare predicted by the ARIMA model, because the change trend of the time attribute sequences comprises only three situations (remaining unchanged, changing periodically, and changing in step length). Furthermore, the adaptive observation window size makes the ARIMA model available for all the time attribute sequences. Therefore, the prediction errors appear only in the case of inconsistent change trends of sequence, and all requests falling within the observation windows can be predicted. The experimental results show that the prediction accuracy of the time attribute with different observation windows sizes is 88.63%, while the prediction coverage is 100%.
(2) Access Request Prediction. The final prediction request must include three basic attributes: location, time, and type. Therefore, we should synthesize the spatiotemporal attributes predicted previously to form the access request.
The prediction accuracy and coverage of the user access requests with different regional meshing levels and observation window sizes are shown in Figures 2 and 3. We can see that, without meshing for the same observation window size, the prediction accuracy and coverage are the highest, and as the meshing level increases, the prediction accuracy gradually decreases. This is because the regional meshing can result in the loss of association rules between nonneighbor cells and reduce the probability of triggering prediction. In contrast, at the same regional meshing level, the prediction accuracy at different observation window sizes varies slightly, except for a window size of 2, where the prediction accuracy is significantly lower. And the curves for different window sizes overlap completely. These results can be explained as follows. First, the rules mined from user access are very similar when the rule length is greater than 2. Second, when the window size
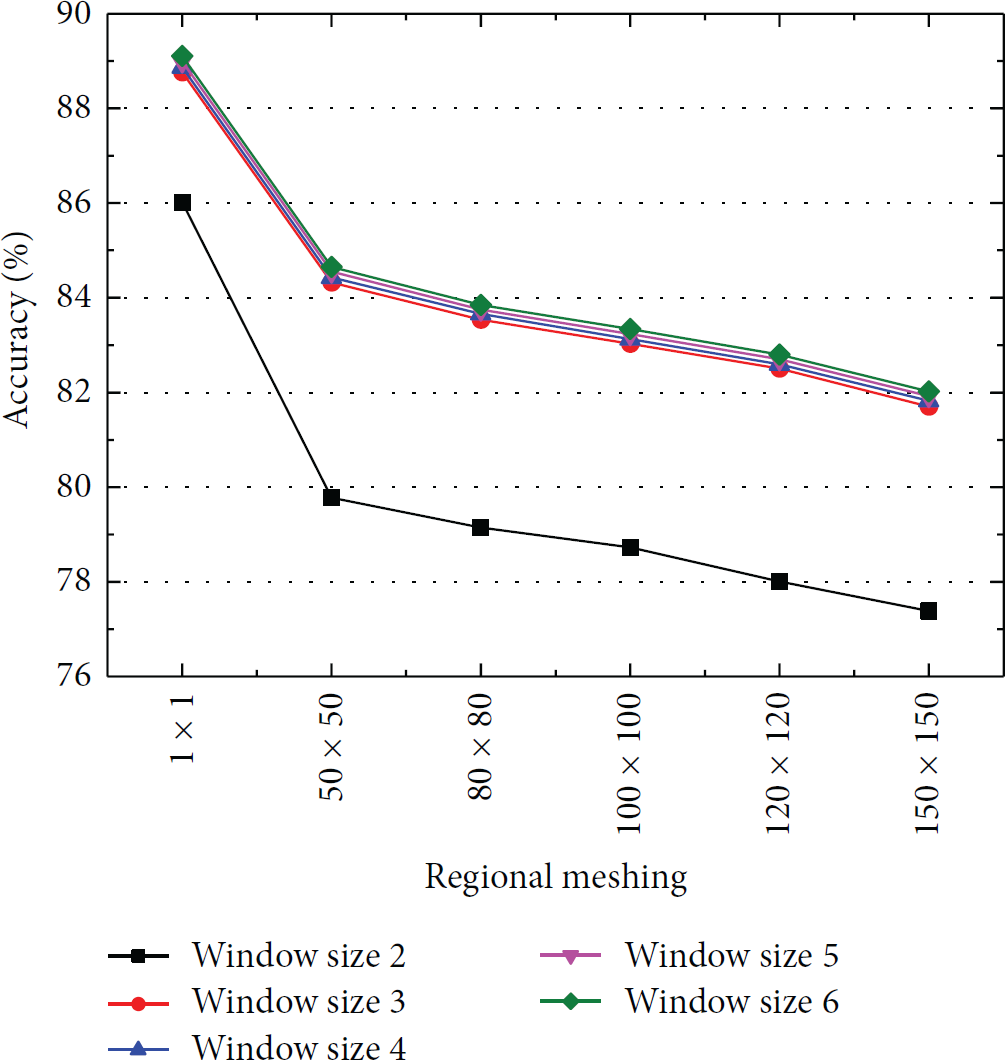
Request accuracy.

Request coverage.
Figures 4 and 5 show the prediction accuracy and coverage of the user access of the proposed prefetching scheme STAP and another two schemes, ARP [5] and MCP [15], with different observation window sizes. Regional meshing levels were set as
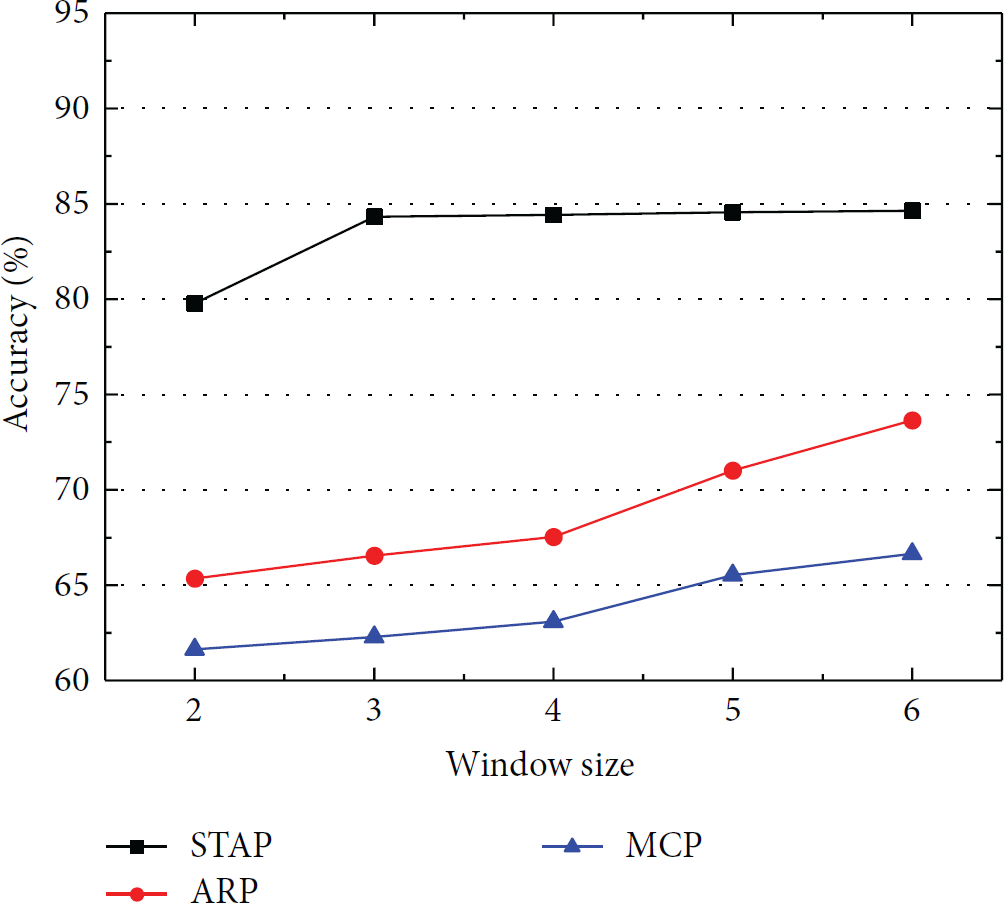
Request accuracy.
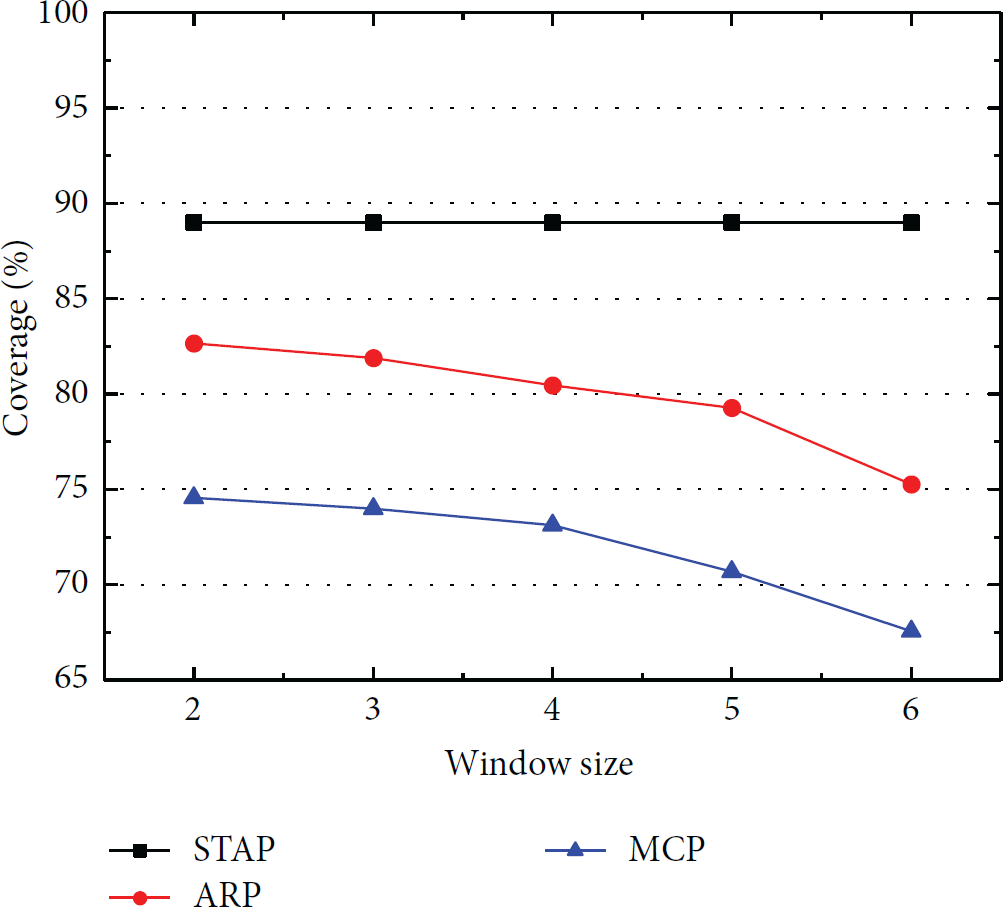
Request coverage.
4.3.2. Pattern Mining and Prediction Times
Figure 6 shows the time consumed for mining user access patterns from the history of user access requests. As can be seen, the time of construction decreases from 430,401 s to 21,237 s; it falls drastically as the regional meshing level increases. This is because the calculation of associate rules for the coordinate points of the entire geographic area is disaggregated to the calculation of cells and neighbor cells based on regional meshing, and partial and incremental solutions of the association rules of the location attribute are achieved.
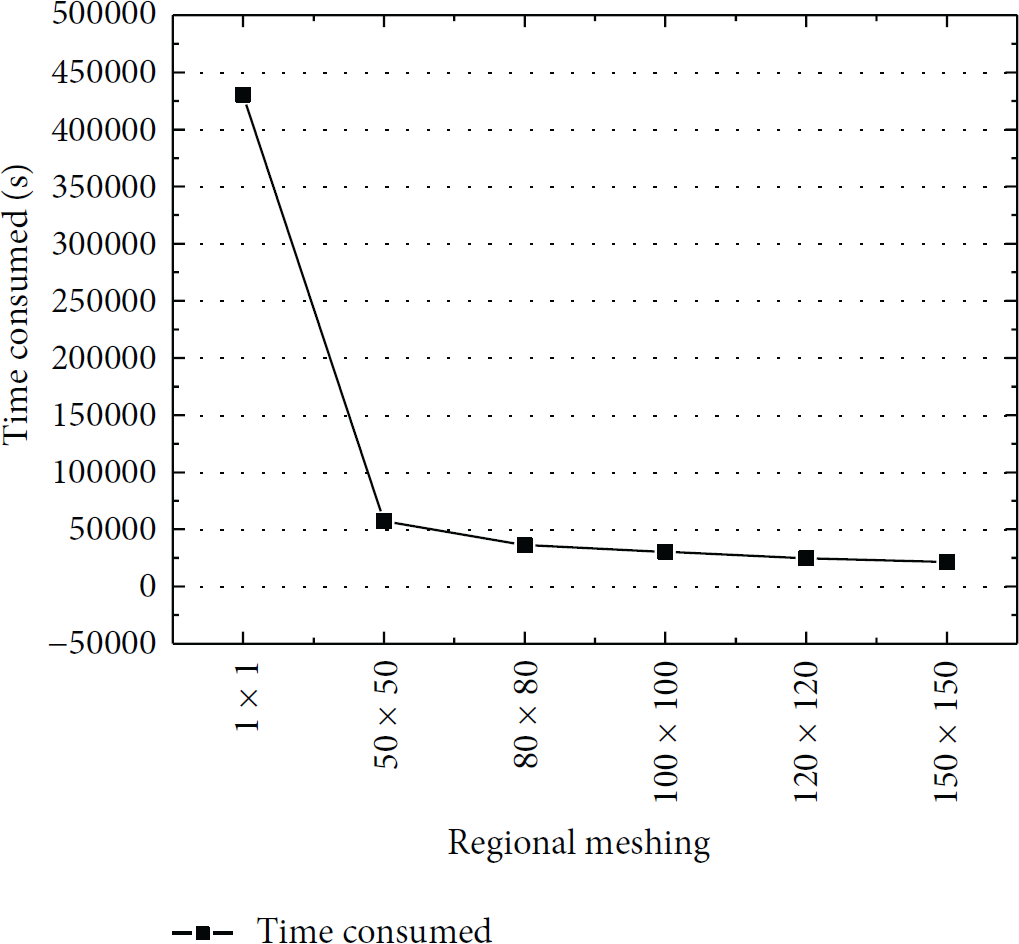
Patterns mining time.
Figure 7 shows the time for predicting 190,825 access requests with different regional meshing levels and observation window sizes. As can be seen, without meshing for the same observation window, maximum time is consumed. Then, as the meshing level increases, the time consumed decreases gradually and reaches a stable level. In contrast, for the same regional meshing level, the prediction time clearly varies with the size of the observation window. The smaller the window size, the short the prediction time. This is because, without regional meshing, the entire regional rulesets need to be scanned for matching to predict requests. However, with meshing, only the association rules belonging to the cell are to be scanned, and it is clear that the larger the window size, the longer the prediction time.

Request prediction time.
4.3.3. Average Response Time
From the abovementioned experimental results, we can see that, in the request prediction phase, although the prediction accuracy and coverage of requests decrease under the regional meshing, the time consumed for pattern mining is effectively reduced, and more importantly, regional meshing avoids the numerous calculations required for updating the location attribute. In the data prefetching phase, it is clear that the larger the length of the buffer queue, the more credible the request for the previous prediction, and the prefetching data is more accurate. However, it also means that some data of the predicted request fail to be prefetched.
Therefore, to compare the average response time, we set the regional meshing as
The average response time (ms).

5. Conclusion
In this study, we exploited the spatiotemporal features of user access for spatiotemporal data in a smart city. We mapped the history of user access requests to the spatiotemporal attribute domain to perform correlation analysis and identify variation rules, mined the user access patterns, and developed a simple and efficient prefetching scheme. Specifically, the regional meshing methods use the spatial locality of user access; thus, they not only achieve partial and incremental solutions of association rules but also reduce the computation considerably. Furthermore, the ARIMA model uses the time stationarity of user access and realizes accurate prediction of the time attribute. Experimental results showed that our prefetching scheme is simple yet effective, and it can reduce the user access latency significantly.
Finally, the proposed concept of access pattern mining in the spatiotemporal domain for spatiotemporal data not only has a significant effect on spatiotemporal data prefetching in a smart city but also can be widely used for user-personalized recommendation, active pushing of information, and other network applications based on location services.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was supported by the National Key Basic Research and Development Program of China (no. 2011CB302306), the National Natural Science Foundation of China (no. 61471162), and the Open-End Foundation of Hubei Collaborative Innovation Center for High-Efficiency Utilization of Solar Energy (no. HBSKFMS2014032).