
Abstract
A Wireless Sensor Network (WSN), characterized as being self-organizing and multihop, consists of a large number of low-power and low-cost nodes. The cooperation among nodes is the foundation for WSNs to achieve the desired functionalities, such as the delivery or forwarding of packets. However, due to the limited resources such as energy, computational availability, and communication capabilities, there may exist some selfish nodes that refuse to cooperate with others. If the critical masses of nodes do not cooperate in the network, the network would not be able to operate to achieve its functional requirements. To resolve the problem above, we introduce a Win-Stay, Lose-Likely-Shift (WSLLS) approach into a Prisoner's Dilemma (PD) game framework, and it applies a utility-based function, which is a linear combination of one player's payoff and its neighbors' in a game, to evaluate a player's (i.e., node) performance for a game. Experimental results demonstrate that our approach performs well in stimulating cooperation in different settings under a certain condition with limited information, regardless of the static topologies types of WSNs, initial proportion of cooperation, and the average number of neighbors.
1. Introduction
Real-world Wireless Sensor Networks (WSNs) consist of a vast number of low-power and low-cost nodes. WSNs have been applied to resolve many real-world problems including military, traffic, and agriculture domains [1–4]. An issue that exists in these systems is that during operation some sensor nodes tend to choose selfish behavior given limited resources such as energy, computational power, and communication capacity. If, in order to maximize their payoffs and reduce their resource consumption at the same time, some nodes in the network begin to act this way instead of forwarding packets in the network [1, 2], the overall WSN will become paralyzed and unable to provide the normal service. Moreover, the cooperation among nodes is the foundation for WSNs to achieve the desirable functionalities, such as the delivery of packets [5, 6]. There are several literatures that investigate issues such as cooperation and task allocation in Wireless Sensor Network or other networks from a multiagent perspective [5, 7]. In this paper, the sensor nodes are autonomous and act as independent agents. Thus, a WSN can be viewed as a multiagent system.
In previous research, different mechanisms such as reputation system, trust management system, and payoff mechanism have been developed to stimulate cooperation and lessen nodes' selfish behaviors [3, 8–10]. In addition, incentive mechanisms based on the evolutionary game have been used to analyze the dynamics of the trust strategy selection, such as a trust strategy or a strategy that tends to cooperate [11, 12]. Moreover, there are many existing strategies or techniques for the evolution of cooperation in different situations, for example, agent societies [13] and networks [14]. These strategies mainly involve Tit-for-Tat (TFT) [15], which indicates that each player cooperates in the first round and then takes the opponent's strategy instead in the next round of a game. Once the two players have chosen the cooperate strategy, both sides get benefit from doing so. Both sides in this paper indicate that the focal player is as one side, and all its interacting neighbors are the other side. When one player changes its strategy, the TFT player will use the same strategy in the next round of a game and ignore its payoff; Imitate-Best-Neighbor (IBN) [16] is another strategy where a player selects the action with the maximum payoffs from its neighbors or itself in the former round of the game. In this case, once the player's neighbor who has many neighbors takes the defend strategy, it will make the neighbor receive maximum payoffs, and its action might be chosen and imitated by the player; Imitate-Best-Strategy (IBS) [13] is a strategy where the player sums up the payoffs of all cooperating neighbors and payoffs of all defending neighbors including itself, respectively, and then takes the action which brings a greater payoff from the former round of a game, in the current round; Win-Stay Lose-Shift (WSLS) [17] strategy makes a player hold the same action when the current payoff is equal or greater than the former one; otherwise, the player will shift its action. WSLS outperforms TFT in the iterated Prisoner's Dilemma (PD) game. Although the WSLS rule works well in a pairwise interaction model, it has not been investigated in multiplayer interaction model.
In the present work, each player in WSNs needs to interact with all its neighbors for the data transmission, in order for the WSN to operate as intended. In this paper, we propose and evaluate a Win-Stay, Lose-Likely-Shift (WSLLS) approach based on the utility-based function, which is a linear combination of a focal player's payoffs and its neighbors' in a game. The performance of a focal player in the current round of a game is evaluated in terms of the quality of the cooperation convergence in WSNs. Note that a focal player refers to one current player that is considered as the center to play with its neighbors. Thus, the utility-based function of a focal player binds the payoffs of neighbors with its own payoff, by making the focal player care about the payoffs of neighbors, not just the payoff of itself. The WSLLS approach works well in the PD game framework when the weight average value falls into a certain threshold. The WSLLS approach can also be viewed as an updating strategy or a rule that is used to adjust the current action for players. The updating strategy is different from the behavior strategies such as cooperate or defend, which are available for players to choose in the PD game.
The rest of the paper is organized as follows. In Section 2, the related work is presented and our contributions are outlined. In Section 3, a network is formalized as an undirected graph and a PD game is taken as the interaction model for nodes in WSNs. In Section 4, the proposed approach is introduced into the interaction model under the PD game framework, and the theoretical analysis is given about the proposed approach—WSLLS. In Section 5, the extensive experimental results are illustrated by comparing the proposed approach with the existing deterministic rules in different settings. Finally, the paper is concluded and some directions for future work are provided in Section 6.
2. Related Work and Our Contribution
2.1. Related Work
The previous work studies the dynamics of the trust strategy selection among nodes based on the evolutionary game theory in a WSN [11, 12], where the trust strategy signifies that players agree to cooperate. Specifically, if a player chooses the trust strategy, that is, the cooperate strategy, then it will forward packets for others. The authors apply the evolutionary game to analyze the evolution of the trust strategy among nodes in WSNs, based on the payoff model constructed. Chen et al. [9] adopt a dynamic incentive mechanism based on the evolutionary game; the mechanism emphasizes that the nodes adjust strategies forwardly and passively to maximize the fitness, making the population in WSNs converge to a cooperative state ultimately. Since the replicator dynamic model in the evolutionary game could not reflect the strategy adjustment of individuals, the model with the review mechanism proposed by Li et al. [18] could make up the shortcoming. This mechanism is used during the interaction process to make an individual adjust its strategy to other strategies with a probability. Due to the unreliable network, the lower the current payoff of individuals gets, the more frequently they will use the review mechanisms, while in our work the WSLLS approach is similar to a heuristic review mechanism, and it is used to adjust the behavior strategy for a focal player. We focus on the performance generated by the behavior strategy of a focal player, when it plays with its neighbors in the current round of the game. The performance is measured by both the payoff of itself and its neighbors', rather than its own payoff with a myopic attitude. Once the performance evaluation is lower than the desired one, the player shifts its strategy with a certain probability. Our idea is inspired by social and moral behavior in the community, where individuals do not benefit themselves at the expense of others.
Sen and Airiau [19] study the emergence of norms through social learning, where individual agents repeatedly interact with other agents in the society. They use the social dilemma game or the coordination game for modeling interaction process. However, in our work, we consider an interaction model of the PD game for the focal player and its neighbors in WSNs. Hofmann et al. [13] study the evolution of cooperation in self-interested agent societies. They use the repeated PD game for a player to interact with its neighbors and derive the evolution of cooperation in networked systems which depends on the combination of network types, update rules, and the initial fraction of cooperating agents. In our work, we propose a new strategy that performs well regardless of the network type and initial fraction of cooperating players.
Urpi et al. [20] develop a model based on the game theory, which is able to formally explain characteristics of ad hoc networks. They describe a simple strategy that enforces packets forwarding among nodes. The traditional iterated Prisoner's Dilemma game has been used widely to study the evolution of cooperation, and a theory of cooperation based on reciprocity is found in many existing literatures such as in [21]. Ye and Zhang [14] propose a self-adaptive strategy for evolution of cooperation in distributed networks. They study the phenomenon of the evolution of cooperation in distributed networks by using an iterated PD game.
The differences between their work and ours are as follows.
(1) In their work, a player gains its payoff by playing a game with its neighbors in each round and updates its action based on the actions and/or payoffs of its neighbors. In our work, a focal player updates its action depending on its evaluated performance.
(2) The self-adaptive strategy based on the existing strategies adopts the strengths and avoids the limitations of existing strategies. Our approach is innovative and may adapt any interaction situation including pairwise and multiplayer interaction models under a certain condition.
(3) Their strategy space is a set of updating strategies, and they use the proposed strategy to learn the probability of each updating strategy. However, we are not sure whether the updating strategies in the database are good enough.
Mihaylov et al. [22] propose an approach named Win-Stay, Lose-Probabilistic-Shift (WSLpS) for convention emergence in a pure coordination game, where if the focal agent receives the payoff “1” (i.e., it means “wins”), it stays with the former action. If the focal agent receives its payoff “0” (i.e., it means “loses”), it will shift its action with a certain probability due to the occurrence of conflict. For pairwise interaction model, it shifts with a certain probability to the other action or stay with the current action. For the multiple-player interaction model, the action also shifts with a certain probability. If it shifts in one case, it will either shift to the action most neighbors did or shift to any action randomly selected with a very small probability. Although the WSLpS approach literally looks similar to the WSLLS approach, they have different meanings for different game models.
(1) The WSLpS approach is used for the pure coordination game model; the WSLLS approach is proposed for the PD game model. The PD game model is different from the pure coordination game. The PD game model is typically used to solve the cooperation problem among players in competitive conditions, while the pure coordination game is applied to deal with the behavior expectation problem caused by the uncertainty strategies from participants.
(2) In the WSLpS approach, when the interacting players take the same action, it means “win”; when the players take different actions, it means “lose.” The focal player will keep its last action unchanged in the next iteration if it wins, that is, “Win-Stay.” On the other hand, it will adopt the action of its neighbor with a certain probability, that is, “Lose-Probabilistic-Shift.” In the WSLLS approach, when the focal player generates a higher utility value than the expected level, it means “win” and will stay with the current action in the next iteration; otherwise, it means “lose” and it may change its action with a certain probability.
(3) In the WSLpS approach, the action update in the multiplayer interaction model is different from ours. For the focal player, it either selects a major action following the choices from its neighbors and itself or selects an action randomly with a certain probability. In the WSLLS approach, the action update depends on the utility value. If it is not less than its expected value, the action will remain unchanged; otherwise, the action will change with a certain probability.
Therefore, the WSLpS approach does not fit the iterated Prisoner's Dilemma game, which is repeatedly played by the same players from PD game. Meanwhile, the players in iterated PD can learn about the strategy against their opponents from the game. The proposed approach will be described and applied into the iterated PD game in Section 4.
2.2. Contributions
The main contributions of this paper are summarized as follows:
(1) We have proposed an innovative and efficient approach for adjusting the behavior strategies of players and stimulating cooperation among nodes in WSNs. The utility-based function is applied to evaluate the performance of the behavior strategy of the focal player. The parameter in the function is defined by the relative weight of its own payoff and its neighbors' payoffs. It is also used to adjust the ratio of payoffs from two sides and to make the utility value of a behavior strategy reach the expected value.
(2) We have efficiently modified the WSLS updating strategy. WSLS only works well in the two-agent setting, and it has not been investigated in multiplayer settings. The WSLLS approach adds a shift in action update once a focal agent loses and redefines the concept of win and performs well for the interaction model of the PD game framework.
(3) We have performed an extensive empirical study analyzing the convergence of the cooperate strategy among nodes in different static topologies of WSNs. The experimental results show that the WSLLS strategy can stimulate the convergence of cooperation under certain conditions and that it outperforms the existing deterministic update strategies such as IBN, IBS, and WSLS, irrespective of the initial cooperator proportion. Furthermore, it converges faster than the WSLS rule regardless of the average number of neighbors.
3. Model
In this section, we firstly use an undirected graph to formalize the topology of a WSN. Then, we take the game model, that is, Prisoner's Dilemma (PD) game, for describing interactions among nodes in WSNs.
3.1. Formalize the Network
A WSN can be represented as an undirected graph
3.2. Prisoner's Dilemma (PD) Game
Prisoner's Dilemma is originally framed by Merrill Flood and Melvin Dresher working at RAND of America in 1950, and it is presented as follows [23, 24]. Two conspired prisoners are held separately and could not communicate with each other. If they do not betray each other, then each of them would be put in jail for one year due to the lack of evidence. If one of them exposes the other that keeps silent, then the former one would be set free due to the confession and the other one would be put in jail for five years due to incorporation. If they betray each other, both of them would be punished and put in jail for two years. The prisoners are selfish, and both tend to betray each other, and they are not willing to keep silent.
The PD game is a typical game model for the evolution of cooperation among selfish players and has already been used in many existing works [13, 14, 24, 25]. It is used here to model the interaction process among nodes in WSNs, where each node (a player) in the game has two available strategies, that is, cooperate and defend.
We are interested in investigating an efficient approach for the emergence of cooperation in WSNs. The WSLLS approach could be applied into the interaction model of the PD game. Algorithm 1 describes the interaction process for the model.
( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( (
In our case, we simply present the individual strategies with a Boolean value, where 0 means the defend strategy and 1 means the cooperate strategy. Thus, the individual behavior strategies are

4. Approach
To make WSNs operate normally, that is, the nodes in WSNs not only tend to get services from others but also provide their services regardless of the limited resources they own, we propose the WSLLS approach. The approach is suitable for the interaction model of the PD game and can apply to different topologies of the network, the initial proportion of cooperators, and the average number of neighbors.
Before describing the WSLLS approach, we firstly define a utility-based function for each focal player, which considers not only its own payoff, but also the payoffs from all its neighbors. Besides, we set a parameter μ characterizing the relative weight for payoffs from both sides. Thus, we can obtain the utility-based function for a focal player i as
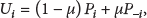
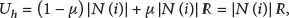
This interaction process occurs in an asymmetric way, similar to the method used in [22, 26]. We have similar reasons with [22], which discussed the application of the WSLpS approach in the coordination game for engineering application. The players in WSNs cannot always realize that an interaction is taking place, due to the interruption such as the unreliable networks. In this way, only the “initiator” of an interaction, for example, the one that sends the data, updates its action. Following the nature of radio communication, all other neighbors in range do not update their actions, because the neighbor nodes cannot always be aware that the interaction is happening, and they even do not know who the sender is.
In the following subsections, we outline the interaction process of players applying the WSLLS approach for the interaction model of the PD game framework. A classical game-theoretic assumption is that players select actions which could reach the maximum of their payoffs. In such a way, rational players would like to select an action based on their expectation of the playoff they will gain [27]. However, players usually are not able to observe actions of others before they interact, to obtain the expected outcome of a game; also they cannot observe the actions of others after interacting. In most cases, there is a common assumption that a player could observe the actions of others when interacting with them, that is to say, a player only can observe actions when others just did it. In this paper, we assume that both interacting players are aware of the game, and only the focal player can observe its neighbors' payoffs.
4.1. Algorithm for the Interaction Model of the PD Game
In this section, we present the interaction process among nodes in WSN under the PD game framework, as shown in Algorithm 1. At each step or each round, on average, each player will become the focal player at one time. Note that, at the first step, the focal player will randomly choose a strategy to play with all its neighbors. After playing with one of its neighbors, the focal player gets its own payoff and observes the payoff from its interacting neighbors to update its own strategy. After playing with all neighbors, the focal player computes its utility value and decides to update its strategy following the WSLLS approach, as shown in Algorithm 2. Once the focal player loses, a shift probability α is used to shift the current strategy with a certain probability. A random number is generated to compare with the given probability α. Once the random number is less than the value of α, it changes the current strategy. In other words, if the current strategy is the cooperate strategy, then it will be adjusted to defend; otherwise, it will be adjusted to cooperate. Once the random number is not less than the value of α, it will keep the current strategy even if it loses. On the other hand, if the focal player wins in the current round, it will keep the current strategy.
( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( (
4.2. Theoretical Analysis
In this subsection, the theoretical analysis for the WSLLS approach is presented. Firstly, we view each player and its neighbors in the network model as a focal player-centered cluster. In this way, the network model is viewed as a set of such clusters, represented as


In addition, the desirable heuristic utility is computed as in

Lemma 1.
Given the PD game framework and a network G, if each player in G cooperates with all its neighbors, then the system will converge to cooperate irrespective of μ.
Proof.
When all players cooperate with their neighbors in a round of a game in WSNs, this means that this situation is exactly the desirable one, and no player will change its current strategy when comparing with the desirable one. Using (4) and (6), we could derive that
Theorem 2.
One has a WSN G and a payoff matrix
Proof.
There are two situations to analyze the convergence of the cooperate strategy when Assume that the current strategy of a focal player is the defend strategy. Using the WSLLS approach, we compare If If If If If If If If If If If If Assume that a focal player selects the cooperate strategy. Following (4) and (6), we compute the difference between

From the derivation process mentioned above, we could see that when If If If If
Theorem 3.
One has a WSN G and a payoff matrix
Proof.
Following (4) and (6), we have known that
Assume the current strategy is the cooperate strategy. Then, we compare

In this case, if If If If
Thus, the focal player will stay with the current cooperate strategy when
Assume that the current strategy is the defend strategy, and
To sum up, each player stays with the cooperate strategy after the game, when
Corollary 4.
One has a WSN G and a payoff matrix
Proof.
Assume that the current strategy of a focal player is the cooperate strategy. Using (4) and (6), the difference between
Assume that the current strategy of a focal player is the defend strategy. Using (5) and (6), the difference between
Therefore, the current strategy for a focal player is unstable when
Example 5.
Based on Theorems 2 and 3, we present the typical payoff value used in the experiment, adopt If If If

Thus, according to Theorem 3, we could derive that when
Following Theorem 2, if the current strategy is the defend strategy, then If If
Thus, we derive that, according to Theorem 2, a focal player will stay with the current defend strategy, when
According to Corollary 4, when
5. Experiments
This section introduces the experimental settings and then presents experimental results and analyses by applying the WSLLS approach and comparing it with other existing deterministic rules such as IBN, IBS, and WSLS.
5.1. Experimental Settings
We adopt the typical payoff value for the matrix a ring-based WSN is a simple topology, which implies that each node has exactly two neighbors and thus forms a ring-like network; a scale-free-based WSN is generated by using the Barabási-Albert model with average degree 4 [28, 29]; we focus on the static scale-free network where nodes have fixed neighborhood, and the number of neighbors of each node follows a power-law distribution; a random-based WSN is a network in which an edge between two nodes is connected with a certain probability p; the probability that a node has k neighbors follows a binomial distribution a fully connected-based WSN, in which each node connects with all the others, means all nodes connect with each other; for any node, the left nodes in the network are all its neighbors; both the ring network and fully connected network are regular graphs; a small world-based WSN [30], which is a network between a regular network and a random network, shows high clustering coefficient and a short average path length.
In the experiments, each network consists of 1000 nodes; we perform 100 runs, and each run is composed of 100 rounds. The experimental results are obtained by averaging results over all the runs, which is viewed as our stopping stimulations. Note that each player is randomly assigned to one of the available behavior strategies, cooperate or defend, at first, as long as the initial proportion of cooperation equals the given one. Each player then changes or stays with its strategy following the different rules. Some of these networks have been tested with rules such as IBN, IBS, and WSLS [13, 14], while we are interested here in comparing our WSLLS approach with them under different static topologies types of WSNs.
Once the payoff values are set, we analyze the effects of the variable parameters μ and α in the WSLLS approach for the convergence of cooperation and the speed of convergence, respectively. As shown in Figure 1, we show the final proportion of cooperators, given different initial proportion of cooperators with different μ at interval between 0 and 1. We found that the cooperate strategy will converge when μ at least equals 0.6, irrespective of the initial proportion of cooperation, which is proved by Theorem 3. When μ is less than 0.6, the proportion of cooperation is around 50% given any initial proportion of cooperation except when all players cooperate initially, which is proved by Theorem 2. In addition, when all players cooperate with others at the beginning, the system converges to the cooperate strategy, irrespective of μ. Therefore, the value of μ greatly affects the convergence of cooperation. Also, the result is consistent with our theoretic analysis. Furthermore, we analyze the α probability, which is used to shift the current strategy with a certain probability, once a focal player loses. As shown in Figure 2, we found out that the smaller the value of α is, the more the number of rounds of a game will be. We can conclude that the value of α affects the speed of convergence, although it does not affect the convergence of cooperation.
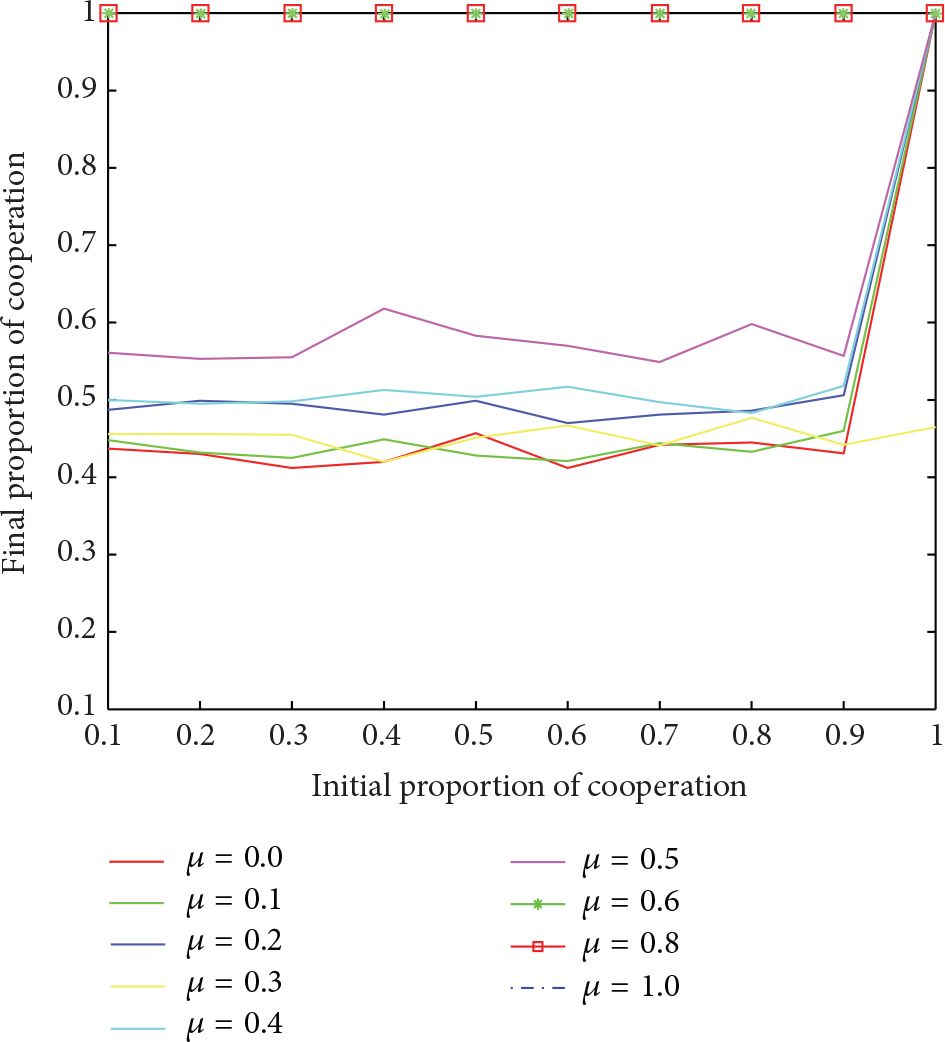
The final proportion of cooperators given different initial proportion of cooperators with different μ at interval

Rounds of a game due to the different values of α to cooperation convergence.
5.2. Results and Analysis
We test several initial proportions of cooperation as 0.2, 0.4, 0.6, and 0.8 for each type of a WSN as shown in Figure 3, where there are five subfigures. For each subfigure, x-axis denotes the initial proportion of cooperators and the y-axis indicates the final proportion of cooperators. These subfigures exhibit the evolution of cooperation in ring-based WSNs, scale-free-based WSNs, random-based WSNs, fully connected-based WSNs, and small world-based WSNs, respectively. Each subfigure uses the existing rules such as IBN, IBS, WSLS, and WSLLS in these networks. For the WSLLS approach, we set the value of μ as 0.6 and the shift probability α as 0.1 in these simulations.

The evolution of cooperation by using different updating strategies in the PD game framework, where the WSLLS approach uses
As for the IBN rule, no players will survive as long as at least one defender exists in all these networks except for the scale-free-based WSNs. In the ring-based WSNs, a IBN player randomly selects a neighbor with higher payoff, since the degree of each neighbor is two. Assume that a player i chooses the cooperate strategy, there are three cases as follows. If its two neighbors select the cooperate strategy, in such a way, i will not change its current strategy. If one of its neighbors j selects the cooperate strategy and the other one k chooses the defend strategy, we find out that the defend strategy dominates the cooperate strategy for the player i. Because the neighbor k selects the defend strategy, the payoff of k at least equals the payoff of j, no matter what the strategies j and k's neighbors would choose. Once the player i shifts its current strategy to defend, its payoff increases. If its two neighbors choose the defend strategy, the player i will not survive in this case, whatever the strategy their neighbors choose. Therefore, in the ring-based WSNs, it will change the cooperate strategy to the defend strategy if a player has a neighbor with the defend strategy. In the fully connected-based WSNs, a player will also change its cooperate strategy even when it is surrounded by only one defender in the network.
As for the small world-based and random-based WSNs, we found that there rarely exists the convergence of cooperation, according to the graph features. This is consistent with the statement in the literature of Hofmann et al. [13]. If a player with a high degree defects, it could gain a high payoff when all its neighbors choose the cooperate strategy. Applying the IBN rule, all its neighbors will imitate the player's strategy and turn their strategies to defect. However, when a player with a high degree chooses the cooperate strategy and most of its neighbors (i.e., the number of cooperators in its neighbors at least equals the number of defenders) choose the cooperate strategy, the player will stay with the current cooperate strategy, and the defenders among its neighbors will imitate the player's strategy to cooperate. IBN only works in scale-free-based WSNs, and its final proportion of cooperation increases as the initial proportion of cooperation rises.
Considering the IBS rule, it works in each type of WSN, where the final proportion of cooperation increases as the initial proportion of cooperation rises. We found that the IBS rule would lead to convergence of cooperation when the initial proportion at least equals 0.6 in all these networks except for ring-based and fully connected-based WSNs. For a ring-based WSN, it depends on the distribution of cooperators in the ring. If a cooperator is surrounded by two defenders, it would change its strategy in the next round of the game. Assume that the two strategies alternate permutation for each node around the network, then all nodes will tend to adopt the defend strategy. If a cooperator is surrounded by one cooperator and one defender, there is a high probability for the cooperator to change its strategy, due to the dominance of the defend strategy. A cooperator will only stay with its current strategy when it is surrounded by two cooperators. For a fully connected-based WSN, we found out that the convergence of the cooperate strategy needs a higher initial proportion of cooperation around 70%.
An interesting feature of the WSLS rule is that although the initial proportion of cooperation is different, the final proportion of cooperation is almost the same irrespective of the initial proportion of cooperation for each type of WSN. The WSLS rule always leads to the evolution of cooperation when
In contrast, in all these networks, the proposed WSLLS approach could reach the convergence of cooperation at 100% with
The specified rounds in each topology type of WSNs are set as the stopping criteria. If so, the WSLLS approach would need more time than that the other rules need in the specified rounds. As shown in Figure 4, the running time of using the WSLLS approach and that of the WSLS rule are both increased as the average number of neighbors grows in the random-based WSN with different densities. The average number of neighbors indicates that the number of neighbors of most nodes in the network is the same. In other words, the nodes with the average number of neighbors take up a high proportion in the random-based WSN. Furthermore, the running time of using the WSLLS approach is nearly twice as much as that of the WSLS rule. Because the WSLS rule is used to only consider a player's own payoff, the WSLLS approach depends on the utility-based function, which considers not only the payoff of a focal player, but also the payoff of its neighbors. We test a series of experiments to generate different numbers as the average number of neighbors in the random-based WSN. We found that the WSLLS approach converges much faster than the WSLS approach, irrespective of the average number of neighbors. As shown in Figure 5, as an example, it shows the convergence speed of WSLLS and WSLS, respectively, when the average number of neighbors is seventy.

Average number of neighbors in a random-based WSN with different densities.

Rounds in a game with average number of neighbors as 70 under a random-based WSN.
6. Conclusions
In this paper, we have proposed an innovative and efficient approach for stimulating cooperation among nodes in WSNs by modeling the interacting nodes with the PD game framework and applying a heuristic value to determine the action choice. The proposed approach modifies the WSLS strategy by adding a probability for shift and redefining the concept of winning. Specifically, a utility-based function has been defined to consider the payoffs of both a focal player and its neighbors, instead of only considering its own payoff. Once the utility value of a behavior strategy is less than the desirable one, the focal player will shift its strategy with a certain probability; otherwise, it stays with the current strategy for the next round of a game. By using the WSLLS approach in the PD game framework, the theoretical analysis proves that the final cooperator proportion tends to converge when
The experimental results are consistent with the theoretical analysis. Meanwhile, the experimental results have shown that when the weight average value is not less than a certain value, our approach performs well for stimulating cooperation in different settings with limited information, regardless of the static topologies types of WSNs and initial proportion of cooperation. Specifically, the WSLLS approach based on the utility-based function can stimulate the convergence of the final cooperator proportion, under different topologies of WSNs, irrespective of the initial cooperator proportion; it outperforms the existing deterministic rules like IBN and IBS and WSLS with
In the future work, we will explore our WSLLS approach in the dynamic networks for the evolution of cooperation. The WSLLS approach may be helpful in understanding the emergence of cooperation among selfish agents (or selfish population) in agent societies (or social system). Also, we assume that the interacting players are aware that the interaction is taking place; we are interested in finding out how to make the WSLLS approach work when relaxing this assumption in the future. Moreover, we mainly focus on the deterministic rules in the experiment; however, we would like to compare the WSLLS approach with the stochastic rules in the future as well.
Footnotes
Competing Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was supported in part by the National Natural Science Foundation of China under Grant no. 61272034.