
Abstract
An important aspect of realizations of the Internet of Things containing sophisticated sensors and actuators is their integration with the Cloud, by the use of a middleware. This integration results in handling streams of data produced by sensors as well as streams sent back to actuators. In cases for which both large streams and a short reaction time are required, a special real-time oriented approach is necessary to design and build an interconnecting middleware. This paper proposes a hybrid low-cost, low-power middleware architecture for handling and processing of sensor related data streams. It is based on two microprocessor boards interconnected by high speed USB link. Variants including three embedded hardware implementations of the proposed architecture, two software realizations (single and multithread ones), and two process scheduling algorithms have been examined to evaluate their real-time performances. Series of experiments have been performed in order to measure closed loop control times and sensor data streams achievable in practice. An outcome is presented and discussed in detail. Obtained results confirm that the proposed architecture can be applied as middleware to integrate such elements of Internet of Things as robots and similarly time-constrained systems with the Cloud. The results can serve as reference point in research and development of real-time middleware solutions.
1. Introduction
Specialized, small sized, low powered interconnecting devices known as middleware are being used for the development of Internet of Things (IoT) projects. The latter are, generally speaking, focused on joining elements of the real physical world with the people, in other words of joining embedded systems containing sophisticated sensors and actuators with the Cloud.
Regardless of an application area, the integration problems are common. Acquisition of sensor data and sending the data back to the actuators are the most important tasks. Sensors and actuators can be of various types, with different interfaces requiring different sampling frequencies resulting in capability of handling of different data streams.
The design and development of middleware usable for Internet of Things (IoT) applications are even more complicated when real-time constraints are to be taken into account, so this research problem has motivated our work.
Processing of a large amount of data from sensors is constrained by the required short reaction time and by the necessity of providing of simultaneous reliable communication with the Cloud. The data has to be acquired from sensors at a relatively high sampling frequency; for example, in case of mechatronic constructions it is a must, because in these systems the acquired data is then used by the control algorithms to prepare commands for actuators, which has to be performed in real-time. The data should be logged locally as continuous data stream (in case of disconnection from the Cloud, for further off-line analysis and to document the course of the experiments, etc.). It can be then forwarded to the Cloud. To summarize, middleware interconnecting real-time constrained devices require an approach based on high speed communication link.
Recently available on the market System on Chip (SoC) processors containing high speed Universal Serial Bus (HS-USB) and single board computers (SBC) with ARM/Cortex core provide new opportunities and encourage researchers to look for new solutions in the domain of hardware interconnection.
In this paper we propose a novel middleware solution, based on hybrid architecture and on high speed USB link fulfilling the real-time constraints that have been presented earlier. The aim has been to develop a hardware architecture which can serve as a middleware for integration of sensors and actuators with the Cloud on one hand and on the other hand usage of which can ease and speed up the development process of Internet of Things (IoT) applications, especially its prototyping phase.
Our solution combines advantages of System on Chip with advantages of general purpose single board computers. A SoC and a SBC are interconnected via HS-USB link with converter-less configuration in order to achieve both the high data bandwidth and the short latency. Performance of the proposed middleware architecture has been examined. Several trials, in which we have investigated the quality of the hi-speed USB communication, have been performed.
The contributions of the paper are
proposition of a hybrid architecture which combines COTS components and SoC microprocessor and high-speed USB communication link between them, to be used as a middleware for joining sensors and actuators to the Cloud, development of three hardware variants of this architecture: two 32-bit SoC platforms, based on ARM/Cortex architecture and i64 PC-based reference platform, implementation of single and multithread communication and data logging applications, experimental evaluation of performances of communication link, involving closed loop control latency (timing) and sensor data stream with simultaneous logging to SDHC disc as well as their statistics, comparison of experimentally obtained results for each variant of hybrid architecture and software application, presentation of design advices based on an analysis of the obtained results and experiences gained.
The paper is organized as follows. Section 2 discusses shortly related work. Section 3 contains description of proposed hybrid hardware architecture. Data streams in acquisition-control-logging system are described in Section 4. Results of the performed experiments are presented and discussed in Section 5. Conclusions are presented in Section 6.
2. Related Work
Many simple peripheral devices containing sensors and actuators, with low rate of input and output, are connected with desktop computers and laptops via the USB link. The data from these devices can be exported to the Cloud, so it is worth noticing that the USB link participates in this process of information exchange. The older, full-speed variant of the USB link is commonly used for microprocessors and computer boards interconnection. The full-speed USB becomes a successor of the RS-232 because of the simplicity of its hardware. Many microprocessors and microcontrollers are equipped with built-in full-speed USB controllers, so this solution is frequently used in embedded real-time applications [1, 2]. However, the maximal bitrate is limited to 12 Mbit per second.
Newer version of the USB link, called hi-speed USB, offers 40 times higher transfer rate. Availability of hi-speed USB (HS-USB) to parallel bus converters has encouraged researchers to experiment with it, and, therefore, several prototype applications of the high-speed USB in the area of embedded systems have been reported. The one in the area of power electronic is reported in [3]. The system consists of (analogue to digital converter) ADC, quadrature encoders, digital signal processor (DSP), and field programmable gate array (FPGA). It handles HS-USB converter with 16-bit parallel bus and processes three-phase-motor signals. Acquisition and control tasks are performed locally in DSP. However, no information on experimental results concerning transfer timing between the system and the PC was given.
System for acquisition of magnetic resonance images is proposed in [4]. Specialized hardware devices are interconnected via FPGA with CY7C68013A 16-bit parallel FIFO to HS-USB converter. Application concentrates on one-way image transmission. The authors claim that they have achieved user data transfer rate of 288 Mb/s (36 MB/s), but no detailed information was given.
Yet another example of acquisition system for conductive flow level measurements using FPGA and HS-USB converter is described in [5]. As still one more example can serve a general purpose acquisition node is based on multichannel AD converter, CPLD chip, and FT232H HS-USB converter [6]. Here, a LabVIEW application transfers the data from the node to the PC at 8 MB/s rate.
The idea of usage of 16-bit parallel port to interconnect microprocessor via high-speed USB converter (CY7C68013A) was presented by authors of [7]. In their experiment, the researches achieved transmission rate of nearly 11 Mb/s. Another solution involving a CPLD and similar converter is presented in [8]. Application for vision CCD matrices utilising HS-USB converter and FPGA chip is depicted in [9], and another one for missile-borne systems is presented in [10]. The authors of the mentioned papers focused their attention on presentation of hardware solutions only. However, no information on software aspects or obtained results concerning timings and data transfer rate were given, either.
A hybrid acquisition-control system that constituted of a master board and some slave nodes based on microcontrollers is given in [11]. Here, the HS-USB link is used for interconnecting of PC104 standard COTS board and USB nodes. The PC104 runs under control of Linux. The experimentally achieved control latency of 3 ms and data stream of 10 Mb/s were reported. However, these results were obtained without saving of sensor data into SDHC disc.
The need of usage of the HS-USB link between PC computers and field programmable analogue array (FPAA) chips for the system for online simulations of analogue devices is presented in [12]. Since fulfillment of timing constraints is crucial, therefore, the HS-USB is suggested for setting values of simulation parameters and for receiving of simulation results. Some theoretical foundations of the presented idea were given by the authors.
To summarize, the authors of all of the mentioned papers are focusing their attention on description of solutions based on FPGA and high-speed USB converters. Papers describing applications of microprocessors with built-in high-speed USB ports with converter-less configuration appear sporadically, so there is a lack of detailed experimental results, especially those concerning timings of bidirectional communication.
3. Data Streams Typically Serviced by Middleware
An abstraction of data streams can be useful in analysis and description of data flows inside of a middleware system. For example, the functionality of pure acquisition systems is based on buffering of information forming a unidirectional information stream. On the contrary, control systems are based on a feedback loop principle, coupling together values describing the state of the controlled object and the necessary reactions to its change. Indeed, control systems require bidirectional flow of information to operate. So, we can speak of data streams in this case.
During our work on middleware architecture we have identified five critical data streams, (depicted with UML <<flow>> phrase). They are shown together with main data-processing threads (depicted as blue rectangles) in Figure 1(a). The workload is physically distributed between two components of the proposed middleware architecture called Direct Controller and Master Controller. From the point of view of data acquisition, the gray path is critical. However, when control is also to be taken into account, PSDS and CDS data streams have to be considered together. Main, typical requirements concerning functionality of middleware architecture are timing, criticality, continuity of data, basic processing, and destination. They form the necessary context for a more detailed study of static and dynamic properties of these streams. Short description of these critical data streams is given below.
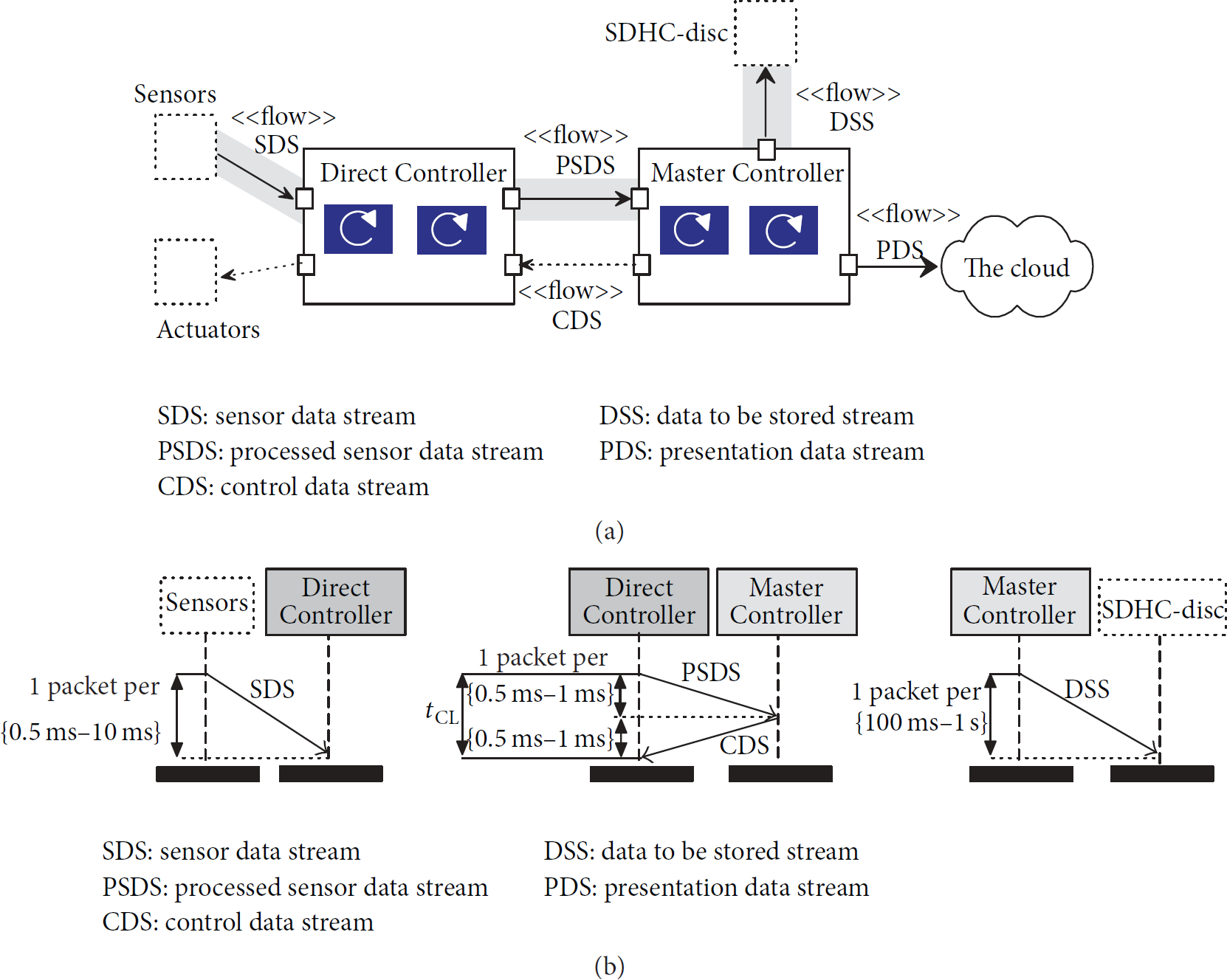
Critical data streams in hybrid acquisition-control-logging system. (a) Flow diagram. (b) Required timing for single packet (sequence diagram).
(i) Sensor Data Stream (SDS). Multichannel analogue to digital converters can produce samples at periods of range even to from 0.5 ms to 10 ms (it depends on requirements), resulting in data stream of value up to 10 MB/s. Sampling period limits the time available for basic handling of sensor data and, therefore, the stream is time critical. Continuity of data stream is critical too—no data can be lost. Basic processing is simple or it could even be no processing at all: data destinations—Direct Controller, Master Controller.
(ii) Processed Sensor Data Stream (PSDS). Data obtained from sensors is processed by Direct Controller resulting in computation of new values of state variables and new actuators settings. Both raw and processed data are grouped together forming a packet to be sent. Depending on requirements, the size of this packet can vary from 48 B to 7 kB. Both timing and continuity of data stream are critical. Basic processing is intensive: data destination—Master Controller.
(iii) Control Data Stream (CDS). This stream consists of packets containing commands prepared by Master Controller. These packets can optionally contain settings for actuators. Direct Controller interprets received packet which may influence behaviour of its algorithms. Generally, the size of CDS packet is short, tens of bytes typically. Required time period for consecutive packets sending operations is in range from 100 ms to 1 ms. Time of an operation is critical; continuity of data stream is required. Basic processing covers unpacking of the content of packet and then sending the extracted commands to actuators or algorithms: data destination—Direct Controller.
(iv) Data to Be Stored Stream (DSS). It consists of data, for which the design decisions concerning the necessity of its storage were made. Due to requirements, a SDHC disc has been chosen as a mass storage. There were two reasons for this decision: its shock resistance and a small size. DSS contents are a subset of PSDS; however, byte layout can differ from PSDS because of data regrouping and buffering. The size of the data buffer strongly influences the time of writing to physical media. This time is in range between 100 ms and 1 sec. The data buffer size, on the other hand, is limited by the amount of system memory. The importance assigned to data of this stream and the complexity of writing contents of large buffers in one operation impose criticality of writing of each chunk of data. However, duration of the writing operation is not critical: data destination—SDHC disc.
(v) Presentation Data Stream (PDS). This stream contains the data to be sent to the Cloud. Time of preparation of single packet for the Cloud can be in range between 50 ms and 100 ms. It is sufficient to take into account possible delays which may be caused by communication infrastructure of the Cloud. Keeping in mind possible delays which may be caused by communication infrastructure of the Cloud, this time is sufficient. Therefore, the priority of the data presentation thread can be low: data destination—the Cloud.
Some data like requests or commands can be occasionally sent by the Cloud, but since their influence on performance is low, it may be neglected.
4. Proposed Middleware Architecture
The hybrid architecture proposed in this paper is composed of a System on Chip (SoC) board and a single board computer interconnected by hi-speed USB. The idea originated from our practical experiences in the area of real-time systems. Table 1 summarizes our observations concerning hardware and software components of the mentioned subsystems.
Comparison of two subsystems of the proposed hybrid architecture.

The first subsystem is well-suited for performing real-time operations. In order to meet our needs focused in interaction with the physical world, and to fulfil the real-time requirements, we propose building this subsystem using dedicated hardware and software. It directly interacts with real-world objects via sensors, converters, and actuators. This interaction includes both measurement of physical quantities of the object and sending set points for actuators. This subsystem is also responsible for interfacing with the second subsystem. The mentioned real-time operations require both short sampling time (in the order of single microseconds) and high stability of sampling frequency (low jitter), ensuring communication data stream in the order of 10 MB/s, basic signal processing and computation of new values of control variables (e.g., PID controller). All of these requirements have to be fulfilled in order to ensure reliability of the whole system.
Basic operations of the second subsystem are gathering, supervisory control, and SDHC disc data logging of the data obtained from the first subsystem. Then, after necessary reorganization this data can be sent to the Cloud. Additionally, user interaction can be implemented. Communication with the Cloud is less demanding, so its execution can take more time, but the reliability and continuity of data stream must be retained. We propose implementing functionality of this subsystem using single computer board and a large variety of software libraries and tools provided by the Linux operating system.
Advantages of both subsystems forming the hybrid architecture became obvious in the area of acquisition-control systems. The first subsystem is equipped with functional blocks, necessary to interface controlled objects directly. These blocks contain hardware timers, interrupt controller and DMA channels, and so forth. Functionality of each block can be implemented by writing a small piece of code, directly operating on hardware registers. Then, it can be tested independently. The bare-metal programming technique is very effective for real-time programming, because its application enables reaching of stable sampling frequencies in the order of microseconds with negligible jitter, large data streams in the order of 10 MB/s and perfect real-time characteristics. The second subsystem involves internal and external communication, disc recording, and human interaction. Implementation of these elements can be simplified by the usage of procedural or object oriented programming styles as well as by the solutions and software tools provided by the Linux libraries. However, communication between these subsystems of hybrid architecture is the most important factor determining performance of the entire system. As user data stream of 10 MB/s is required, traditional SPI or UART links cannot be used because they are too slow. Full-speed USB link is quite simple, but since it works at 12 Mbit/s bitrate, it is also too slow for our needs.
The hi-speed USB link possesses bitrate of almost 0.5 Gbit per second. Thanks to this high bitrate and, moreover, thanks to the design of its protocol and a more straightforward software interface, this solution meets our needs. Therefore, we propose its usage in hybrid architecture considered in this paper. However, a solution based on an external USB-parallel converter cannot be controlled programmatically, so it represents the black box approach. Since further modification or adaptation is practically impossible, it cannot be used for our purpose. In our approach, this problem can be overcome by using SoC chip equipped with universal, programmable hi-speed USB controller. The built-in hi-speed USB hardware interface is available in some SoC processors. It can cooperate with SoC's core clocked with frequencies lower than 480 MHz. To be operational, it needs only an external physical layer (PHY) transceiver. This device is of type ULPI, which stands for UTMI Low Pin Interface, and UTMI is an acronym of USB 2.0 Transceiver Macrocell Interface [13]. The PHY converts voltage levels to the ones required by USB hi-speed standard and generates the 480 MHz clock signal. The 8-bit parallel bus interconnects the SoC microprocessor. It is clocked with frequency much lower than 480 MHz that simplifies printed circuit.
For the proof-of-concept, implementation of the first subsystem is based on the STM32F407 chip [14]. It has been selected among many chips equipped with hi-speed USB controller available on the market. They have been two crucial reasons for our choice. First of all, the internal USB port of this chip is particularly well suited for high throughput. The port contains separate DMA engine for user data handling. This DMA engine is especially important, as the need for bandwidth grows momentarily to 60 MB/s during USB packet transmissions. Each DMA channel can be regarded as a parallel processing core which operates independently of CPU; moreover, it relieves CPU core from time consuming transportation tasks. And, for this reason, our main goal, which is shortening of the reaction time of a proposed hybrid system, can be achieved.
As hi-speed USB host hardware is available in many single board computers and PC computers, we have chosen three different boards:
typical PC, as the reference board possessing richest resources, PandaBoard 4430, as an example of an industry standard board, Tiny6140, a cheap and popular board.
The first one, shown in Figure 2, serves as a reference point for the comparison of the performance. Moreover, program prototyping can be performed effectively using convenient software tools provided for this platform.

Our proposition of middleware-implementation with the PC board.
The second one, depicted in Figure 3, represents industry level standard. It can be characterized by small dimensions and low consuming power, so it is suitable for embedded applications. The third one represents low-end line of embedded boards, and it is shown in Figure 4.
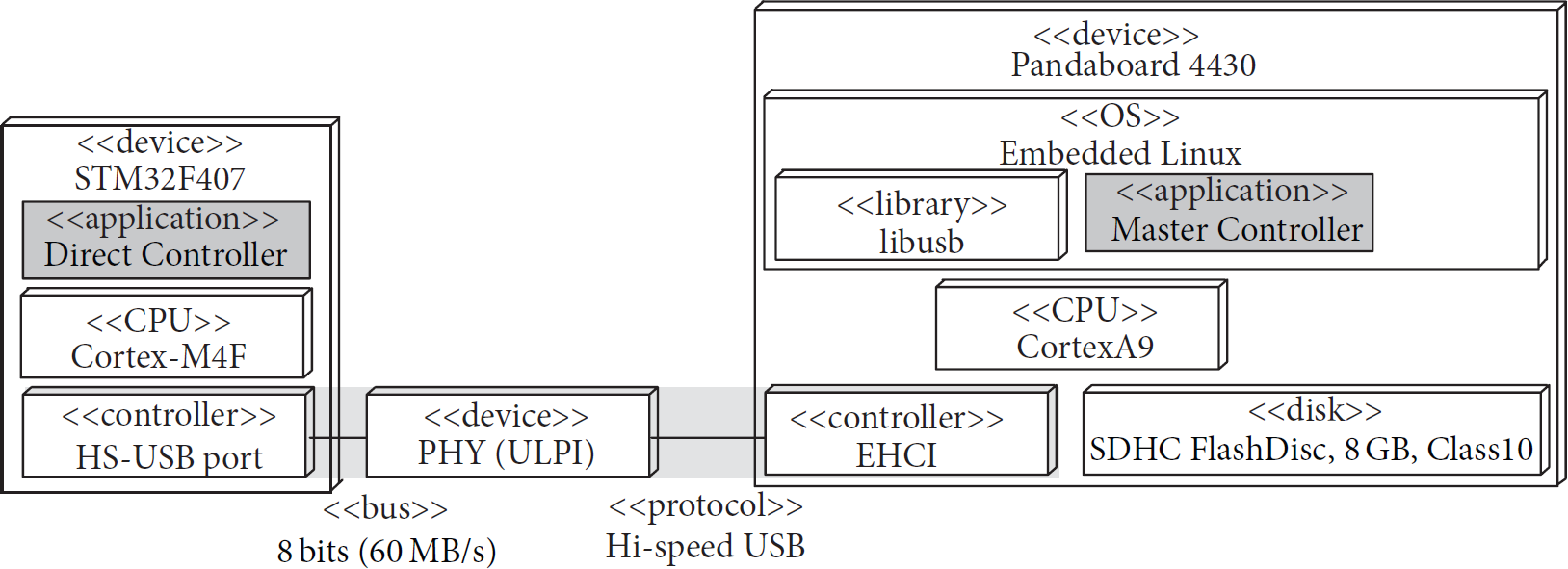
Our proposition of middleware-implementation with the Pandaboard.

Our proposition of middleware-implementation with the Tiny6410 board.
Portability on the source code level was our objective, too, so we have chosen the Linux operating system for this purpose. Thanks to its open architecture, many distributions for variety of produced boards have already been developed, and—what is more—one could expect Linux distributions for the boards that will be designed and produced in the future. Possessing the same operating system and the same libusb library (allowing access to the USB host port from the user space) enables the usage of the same source code [15]. Certainly, it has to be recompiled on each of the target platform. This also opens an option for further experimentation on other hardware platforms for which the Linux distribution exists.
5. Experimental Evaluation
Some properties of HS-USB link layer can be estimated from its standard [16]. However, the context of its usage must be taken into account in measuring and ranking of its time performance and other parameters. Software components as well as COTS hardware strongly influence the timing parameters of the real-time application. Moreover, the software execution itself is further influenced by COTS operating system. These factors and their interdependency require experimental investigation of performance of the entire system. The fundamental questions to be answered are what its performances in terms of reaction time for external events are and what the capabilities of continuous sensor stream transfer as well as logging on SDHC disc are. It is also of special interest to check whether is it possible to obtain the reaction time below 1 ms and the data stream in the order of 10 MB/s with simultaneous logging to SDHC disc.
As it was already mentioned, answers to these questions can be obtained only experimentally. The mentioned results will determine the area of applicability of the proposed middleware architecture.
In general, operation of a control system is based on a closed control loop principle, in which three main phases can be distinguished: gathering of input data from sensors, calculation of a control law, and sending output data back to actuators. So, there are two directions of information flow. When intensive data processing is to be taken into account, an interleaving of processing of sensor and control data packets is to be taken into account. Packets of CDS are interleaved with PSDS packets. Knowledge of timings of such interleaved data streams is of the most importance and, therefore, it was the main goal of our experiments.
We are also interested in comparison of performances achieved on three hardware platforms and, especially, in examination of direct impact of hardware. We think that the results will be useful for designers and developers of IoT applications, since typically the software is implemented and tested using PC platform and then just ported to the target embedded hardware platform.
Sequence beginning with receiving of PSDS packet, followed by computation of control law and finally by sending CDS control packet, is called a cycle. Its time is denoted as
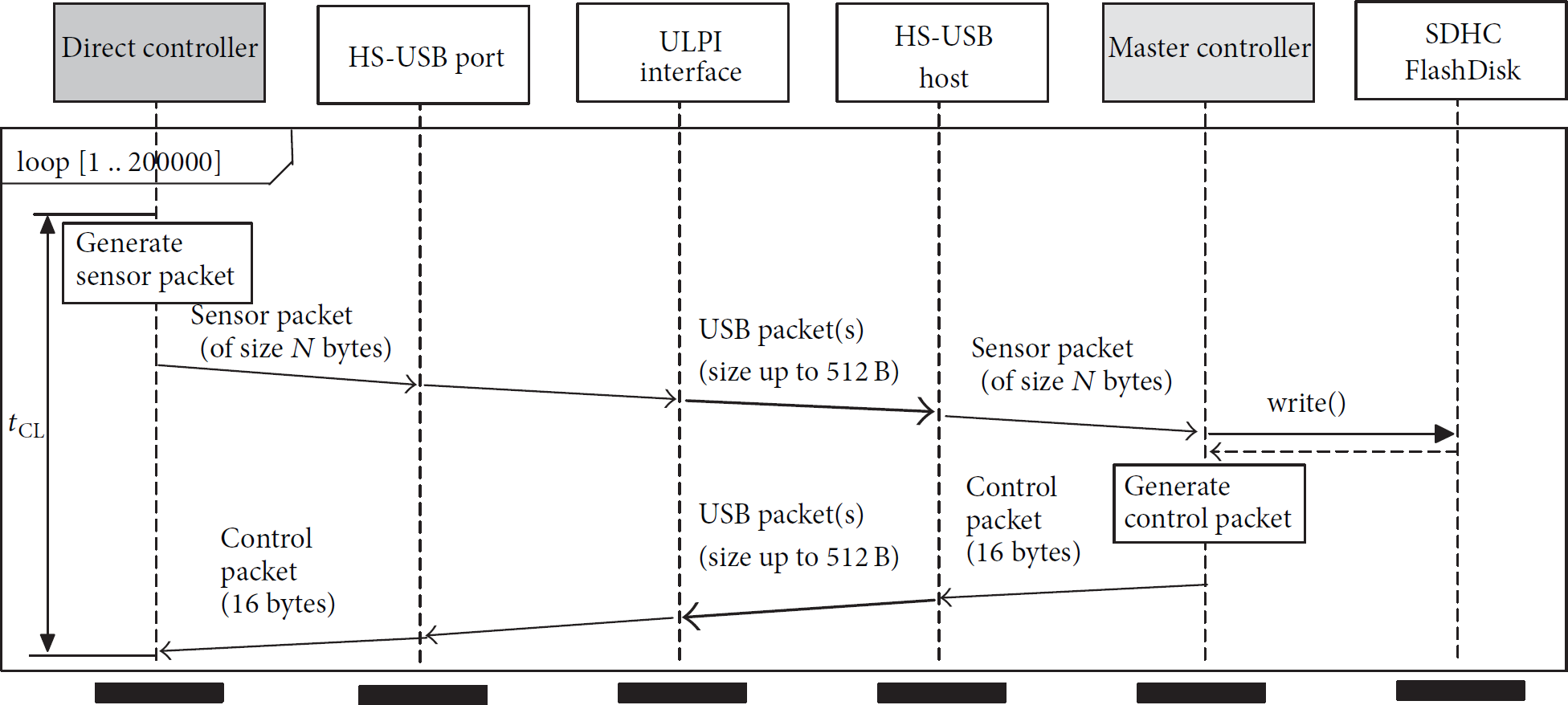
Single-thread application.
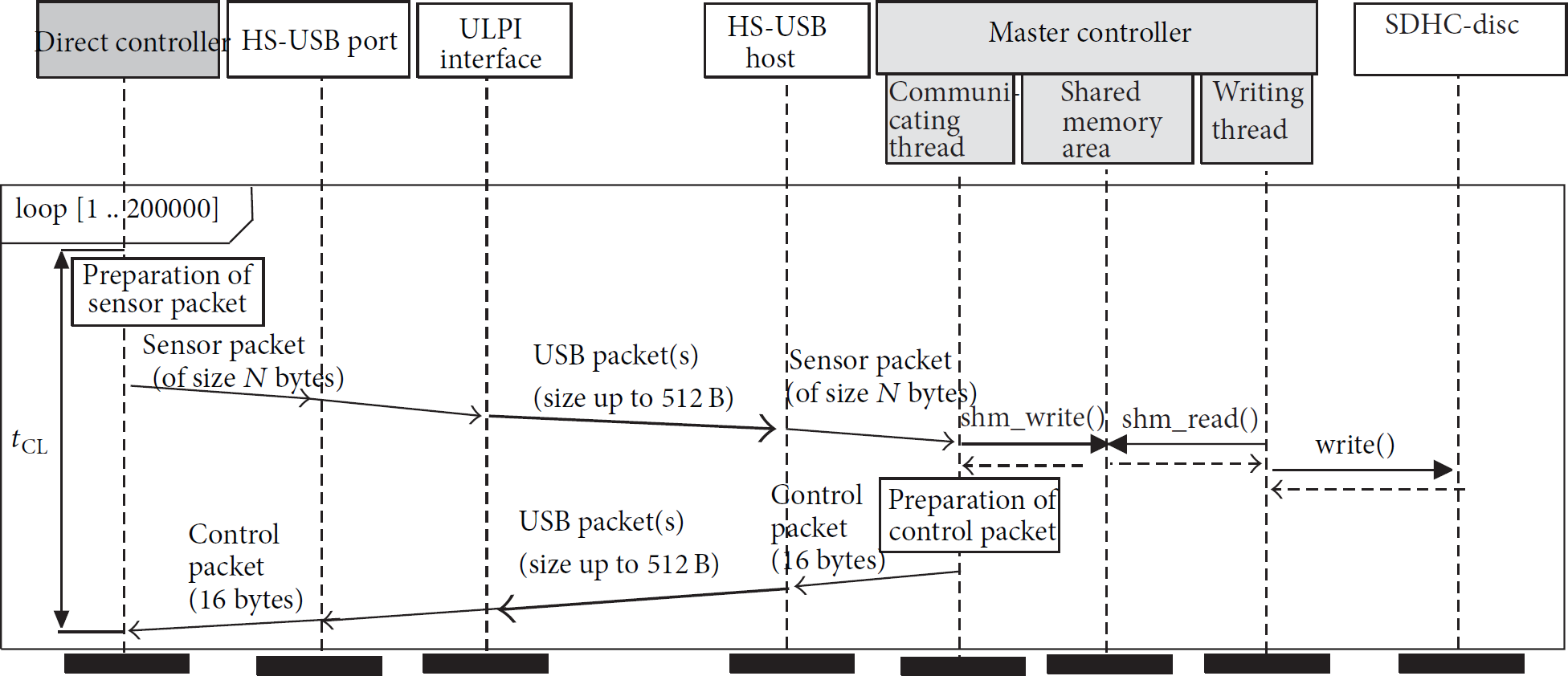
Multithread application.
The control and logging application of the Master Controller can process data streams in single-thread or multithread manner. In case of the former, communication and SDHC disc data logging operations are consecutively repeated. Multithreading represents another approach, in which the two mentioned operations can be concurrently executed by the two cooperating threads. The first of them communicates with Direct Controller via hi-speed USB link; it buffers received data; it can also compute control law. The control data is always being sent back. The second thread reads buffered data and stores it on SDHC disc.
We intended to examine and compare single-thread and multithread approaches in context of the whole system. We also wanted to check the impact of the various hardware platforms on What the What the Whether the effort put into programming pays off in significantly better performance.
Moreover, we would like to examine their impact, too, because different scheduling algorithms can be used for an application. In our measurements, we take into account two quantities describing behavior of an application, namely,
6. Summary of Experiments
We wanted to base the experiments on representative samples of the hardware boards available on the market and, therefore, we have chosen three quite different hardware platforms:
Typical PC-laptop with Intel x64 processor working under control of 64-bit Linux, equipped with xHCI USB host controller. Hardware specification: Intel® Core™ i5 Processor 3230 M (2 × 2.6 GHz, 3 MB L3 cache), memory 8 GB DDR3 at 1600 MHz. PandaBoard 4430 with OMAP4430 processor with dual-core Cortex-A9 core running at 1 GHz, and with 1 GB of DDR2 RAM, equipped with EHCI USB host controller, working under control of 32-bit Embedded Linux supplied by a producer [17]. Tiny6140 board, with S3C6410A processor with ARM1176JZF-S core running at 533 MHz, and with 256 kB of DDR RAM, equipped with OHCI USB host controller, working under control of 32-bit Embedded Linux supplied by a producer [18].
The same source codes of the Master Controller have been recompiled on each of them. Libusb library has been recompiled, as well. The libusb offers two modes of interaction with the USB hardware. In synchronous mode, an application is blocked until the transfer is finished. In asynchronous mode an application submits the transfer and is later informed about its completion by a callback. So, the application is not blocked between submission and completion of transfer. And, therefore, we have selected this mode of operation. Direct Controller subsystem is identical in each case.
As it was mentioned above, the size of PSDS packet is treated as a parameter. In our experiments the following PSDS packet sizes were used: 48, 100, 500, 2000, 4000, and 7000 B. CDS packet was of fixed size of 16 B. Sequence of transaction, called a cycle, consisting of receiving a PSDS packet and sending a CDS packet was repeated 200,000 times for each trial. Content of each of the PSDS packet was stored on a SDHC disc; this means that the DSS stream was equal to the PSDS one. The SDHC disc was formatted with 4 kB cluster size. Preliminary tests had shown that changes of cluster size up to 32 kB did not influence time performances. The same concerned preallocation of disk space.
Durations of cycles (
The Completely Fair Scheduler (CFS) is the default scheduling algorithm used in current versions of Linux. Another scheduling algorithm is First-In-First-Out (FIFO). It is used for real-time applications. We intended to examine performances of two versions of application, employing both scheduling algorithms.
On the basis of gathered information, the influence of the target platform and of the application type on the performance has been examined. These results can be especially useful in design of real-time middleware systems as well as for their prototyping and validation. Our main observations and conclusions have been summarized below:
Outcome of conducted experiments confirmed expected high performance of the proposed solution based on hi-speed USB interconnection. For the PC platform and short packet sizes of 48–500 B, the mean For the PC platform and large packets (2000, 4000, and 7000 B) with simultaneous logging of data on SDHC disc, the mean values of data streams, about 9500 kB/s, were comparable. However, by taking into account the minimum of mean For the PandaBoard and packet sizes between 48 and 2000 B mean Multithread application was more effective than single-thread one for the PandaBoard. Speedup ratio was about 1.5 and, therefore, this approach is advised. The FIFO scheduling algorithm for the PandaBoard was more effective than the CFS one, and speedup ratio was about 1.5, so application of the former one is suggested. For the PandaBoard, continuous data stream up to 9500 kB/s was simultaneously received and logged on SDHC disc (multithread application, packet size 7000 B). It is interesting that the value of achieved data stream was similar to the one achieved on PC platform. And, for this reason, this packet size is suggested for the PandaBoard to keep the compatibility with PC when porting the middleware software to this platform is considered. For the PandaBoard and packet size of 4 kB, standard deviation of For the Tiny6140 platform, the value of the mean
On the basis of observations and conclusions presented above, we formulated the general advice for middleware designers: PC based cross-platform prototyping should be focused on the target platform. And, during the design process, all of the experimental data concerning the time performance presented in this paper should also be taken into account. In our opinion, performances of other Soc boards equipped with hi-speed USB port are comparable with the ones discussed in this work. So, the Direct Controller can be implemented on variety of hardware platforms according to the needs.
7. Conclusions
In this paper the novel hybrid architecture for acquisition, control, logging, and interconnection with the Cloud is proposed. Here, it can be used as the middleware. The architecture is focused on application about integrating high bandwidth sensors and actuators. It is composed of direct acquisition-control subsystem (Direct Controller) based on SoC processor and master control-logging subsystem (Master Controller) based on single board computer. The communication based on the hi-speed USB link gives, to the system, achievable high data streams with simultaneous SDHC disc logging and short response time of closed control loop. Two principal approaches, namely, single and multithread ones, to the implementation of communication and data logging tasks have been proposed. Two scheduling algorithms (Completely Fair Scheduler (CFS) and FIFO) have been taken into account as well. Finally, the systems have been built, programmed, and tested.
The Direct Controller has been implemented on STM32F407 processor with hi-speed USB port and PHY interface. The three variants of the Master Controller have been implemented on three different hardware platforms. Two of these platforms belong to a class of embedded single board solutions: the low cost Tiny6140 and the PandaBoard; the last one is the PC based reference platform.
Throughout this paper, the series of experiments involving all possible variants of hardware and software have been performed. Outcome of our experiments have confirmed usability of the proposed solution. The data stream about 10 MB/s and 0.5 ms of response time have been achieved on PandaBoard. So, low cost and low power middleware systems for creation of Internet of Things and for their further connection with the Cloud can be built this way. Furthermore, our approach, which is usage of the off-the-shelf boards and the Linux based tools and libraries, shortens both the design and the development time.
The proposed hybrid architecture can be used in many fields. It covers the area of low power embedded acquisition, control, and logging systems with no mechanical hard disks. It is especially useful for real-time middleware, applied to robots and similarly constrained systems, for which the short reaction time and capturing of large amount of data is required.
The authors are planning to extend their experiments to the hi-speed USB based network composed of many SoC based Direct Controllers.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
This work was partially funded by National Centre for Research and Development (NCBiR, Krakow, Poland), Grant no. PBS2/A3/16/2013.