
Abstract
The Dempster-Shafer (DS) theory of evidence has significant weaknesses when dealing with conflicting information sources, as demonstrated by preeminent mathematicians. This problem may invalidate its effectiveness when it is used to implement decision-making tools that monitor a great number of parameters and metrics. Indeed, in this case, very different estimations are likely to happen and can produce unfair and biased results. In order to solve these flaws, a number of amendments and extensions of the initial DS model have been proposed in literature. In this work, we present a Fraud Detection System that classifies transactions in a Mobile Money Transfer infrastructure by using the data fusion algorithms derived from these new models. We tested it in a simulated environment that closely mimics a real Mobile Money Transfer infrastructure and its actors. Results show substantial improvements of the performance in terms of true positive and false positive rates with respect to the classical DS theory.
1. Introduction
Nowadays, mobile communication networks represent a key enabling infrastructure for financial service provision since they offer significant opportunities for increasing the efficiency and pervasiveness of such services by expanding access and lowering transaction costs. Mobile financial services are currently applied to several banking products, such as deposit and transact products, over-the-counter bill payments, saving products, intracountry remittances, and international remittances. In this paper, we focus on Mobile Money Transfer (MMT) services which allow using virtual money in order to carry out payments, money transfers, and transactions through mobile devices.
Such services are an increasingly important and common payment means in many markets due to the pervasive use of mobile phones, the steady growth in remittances, and the need for an electronic person-to-person payment that may be an alternative and reliable option to paper-based mechanisms like cash and checks [1].
The growing coverage of cellular networks as well as the increasing availability of mobile communication services is enabling the widespread adoption of mobile-based financial services especially in developing countries, like Kenya, India, Uganda, and the Philippines, thus creating the opportunity for a significant proliferation of mobile commerce services as well as for an expanding financial inclusion. It is expected that in those countries most mobile financial transactions will concern MMT services in the near term since “unbanked” people, that is, people who do not have their own bank accounts, will be attracted by financial services allowing for performing payments and remittances by simply using a mobile phone. The same phenomenon is being observed in developed countries where citizens are becoming unbanked due to the widespread economic crisis, and financial service providers are beginning to investigate the potential for adopting these newer payment systems that are emerging in less developed countries in order to meet financial needs of customers.
However, as the mobile financial services market grows, the risks related to the use of mobile phone-based payments increase, since MMT services become the target of more skilled and motivated attackers, and the amazing volume of data impairs the ability of the control mechanisms to timely spot frauds. In one case, a supplier of Mobile Money services lost $3.5 million due to a single type of fraud. Like any other money transfer service, an MMT service is vulnerable to a number of misuses, including money laundering (i.e., disguising the proceeds of crime and illegal activities and transforming them into ostensibly legitimate money or other assets), fraudulent use of customer details, and money theft. More in general, MMT frauds consist in intentional deception performed to gain financial profit.
In this paper, we focus on account takeover in MMT services. There are two main reasons behind this choice. First, account takeover per se is possibly the most prominent fraud in MMT services. Second, it is often the precondition for more sophisticated frauds. We propose a Fraud Detection System (FDS) that uses some extensions of the Dempster-Shafer (DS) theory to spot evidence of ongoing account takeover attacks against MMT systems. The DS theory is a data fusion technique that allows correlating evidence provided by multiple information sources and computing a belief value. Basically, correlation of attack symptoms through the DS theory-based combination of multiple pieces of evidence significantly outperforms other approaches that use a single source of evidence, thus enabling the proposed FDS to achieve higher detection rates while experiencing a smaller number of false positives. However, in certain cases, the DS theory of evidence does not take into account the conflicting degree of belief, which means that the experience in conflict is completely discarded, thus generating counterintuitive results. In order to solve this issue, a number of methods and combination rules have been proposed. In this paper, we tested and compared these extensions of the DS theory by validating their application to fraud detection in MMT services. In our previous research work [2], we applied the Dempster-Shafer model to MMT services. In that paper, we considered an offline analysis based on the sole Dempster combination rule. In this work, we have taken into account other fusion models derived from the initial theoretical framework. In particular, the Dezert-Smarandache theory represents a framework subsuming the initial formulation of DS as a particular case. For what concerns the DS model, the two works, this and [2], show different performance because we performed an improved tuning in the parameters used for detection. The most significant improvement is obtained with the transaction delay monitor (see Section 3 for more details). In the experimental section, we provide a methodology (and a pseudocode) to assess the performance of those models. Finally, we provide an in-line version of the analyzer that can be used for stream-based processing of events. Due to the lack of real and publicly available MMT service data, the effectiveness of this FDS has been assessed by performing simulations, using synthetic data, containing both legitimate and fraudulent transactions generated by a simulator which closely mimics the behavior of a real system, from a major MMT service operator.
The paper is organized as follows. Section 2 provides an overview of the DS theory and presents some extensions of this theory. Section 3 describes the Mobile Money Transfer case study and the architecture of the Fraud Detection System based on the evidence theory. In Section 4, experimental tests and results are presented. Section 5 presents related work on the use of the DS theory and its extensions for fraud and intrusion detection. Finally, Section 6 concludes by remarking achieved results.
2. Extensions of the Dempster-Shafer Theory
The main objective of this work is to investigate the performance of different algorithms derived from Dempster-Shafer's theory of evidence and from subsequent extensions of the initial model. This theory is widely used to perform data fusion, that is, to obtain a reliable estimation of metrics and parameters representative of the (unknown) state of a system. Informally speaking, by reliable we mean very near to the real value. In our case, we want to evaluate its performance on a Fraud Detection System that uses “features” to classify attacks on transactions made through mobile devices. As we present in this work, the accuracy of a Fraud Detection System can be significantly improved by considering multiple features, where each of them can represent a different characteristic of the fraudster's behavior. Also, we show that the detection accuracy can be further increased by considering recent modifications to the original mathematical model. These modifications have been elaborated in order to solve problems that emerged with the initial mathematical framework which suffered from counterintuitive results under particular conditions. In order to present the advancements of the Dempster-Shafer (DS) theory, we recall the basic features of the initial model. The basic principle of the theory of evidence is that it does not require an a priori distribution of the states and knowledge on the system by observers. Indeed, the observer evolves and changes its uncertainty as more observations are realized and more evidence is available. Dempster-Shafer's theory (DST) has been introduced in the 1960s by Arthur Dempster [3] and then improved with the work of Glenn Shafer [4]. The theory can be considered as a framework, where it provides both a theoretical foundation to reason about uncertainty and a set of mathematical tools to work with it. In particular, propositions are subsets of a given set of hypotheses. For example, in a Fraud Detection System, the set of hypotheses is composed of the categories of frauds or not frauds. The events are evaluated based on their propositional set. The sets compose the frame of discernment Θ, and, as said, the propositions of interest are in a one-to-one correspondence with the subsets of Θ. In the original DS model, the sets of possible states of the system
In the DS theory, we assign probabilities to elements of the power set Θ, that is, to sets. This approach is very different from the Bayesian one, where we assign probabilities only to single events, that is, outcomes of the experiments. Again, the bba contains an elementary knowledge (via belief) about the propositions of the frame of discernment. The bba does not provide directly knowledge of individual propositions. This individual knowledge is bounded by the belief and the plausibility values. These can be calculated as follows:
The Belief function Bel, describing the belief in a hypothesis H, as The Plausibility function of H,
Therefore, the true belief in the hypothesis H lies in the interval
Finally, the DS theory provides a rule of combination that permits combining two independent pieces of evidence

This formula allows combining our observations to infer the system state based on the values of belief and plausibility functions. The numerator of this equation corresponds to the conjunctive consensus, known also as rule of conjunctive combination or Transferable Belief Model (TBM), on the H set. The denominator of this rule is a normalization factor that takes into account the mass of the agreement among the information sources. It is typically identified as

Note that the combination rule allows incorporating new evidence and updating our beliefs as new knowledge is acquired. Also, the model allows combining incomplete, uncertain, and also partially contradictory information. The rule does not consider full contradictory sources, because in that case the denominator is zero and no value is defined in the combination rule.
2.1. Counterintuitive Results in the Dempster-Shafer Model
The denominator in Dempster rule (
2.2. Combination Rules Based on Dempster-Shafer Model
In order to solve the problems pointed out in [5], a number of methods and combination procedures have been investigated in literature, mostly addressing the treatment of conflicting evidence and the definition of the frame of discernment. We will discuss some of these alternatives. Some rules are derived from the DS model and some from the extended version of the original theory. Important properties that differentiate the models below can be expressed in the following points: combination results must be coherent for any number of sources, any values of bpa, and any types of frames; the rule of combination should preserve the commutativity; that is, the order by which the sources are combined should not affect the results; the total ignorance should be neutral with respect to the combination rule; that is, combining information sources with a new full ignorant source should maintain the same belief: the associativity of the operator. The Dempster rule of combination has all the properties above. Here we recall the Dubois-Prade rule, which is a combination rule preserving associativity and commutativity. Other DS-based rules not discussed here are Yager's rule, which assigns the conflict to the ignorance, that is, to the union of all exhaustive and exclusive elements in the frame, and Smet's rule, which redistributes the conflict to the empty set (i.e.,
2.2.1. Dubois-Prade Model and Rule
The disjunctive combination rule has been introduced by Dubois and Prade and has been initially defined on the power set of the DS model. This rule has been conceived for the case of sources that may be mistaken indifferently. It provides more knowledge when all the sources are conflicting. For two sources, it defines

The rule of combination by Dubois and Prade [9] supposes that in case of conflicts one source is right and one is wrong, while in case of agreement they are both reliable. Thus, in case of agreement, the estimation of the mass is in the intersection of the sets (

2.3. Dezert-Smarandache's Theory of Plausibility
Dezert and Smarandache point out two main problems in the Dempster-Shafer theory: it is implicitly defined on a finite set of exhaustive and exclusive elements (the power-set), that is, it is based on the excluded third principle. Limits in the applicability of the Dempster's rule of combination exist, as explained above. As for the second problem, several fixing formulas have been proposed in literature, each one with its pros and cons in terms of mathematical properties and applicability. As for the first problem, the principle of the excluded third does not allow hypotheses that can be only vague and imprecise; that is, it does not take into account situations where precise refinement is impossible to be obtained because exclusive elements cannot be properly identified and precisely separated. But actually this is what happens for a wide class of fusion problems (e.g., in natural language analysis for sets as tallness/smallness, pleasure/pain, cold/hot, and sorites paradoxes). Many problems of this kind typically identify fuzzy sets. The real nature of the hypothesis reflects on the type of frame of discernment used. In the DS theory, the frame is provided by the power set. In order to address other cases, two additional sets may be considered: the hyper power set and the super power set. The power set of Dempster-Shafer is composed of the exhaustive elements θ and the elements given by their union; that is,
2.3.1. PCR5, PCR5-Approximate, and PCR6
The Proportional Conflict Redistribution (PCR) [10] rule transfers conflicting masses to nonempty sets involved in the conflicts proportionally to the masses assigned to them by sources. The rule works in three steps: calculate the conjunctive rule of the belief masses (see the beginning of this section); calculate the conflicting masses; redistribute the (total or partial) conflicting masses to the nonempty sets involved in the conflicts proportionally with respect to their masses assigned by the sources. The way the conflicting masses are redistributed generated several versions of PCR rules [11]. The most sophisticated one is denoted as PCR5, which is actually the most efficient as claimed by the authors. PCR5 rule is quasiassociative and preserves the neutral impact of the vacuous belief assignment. The rule has been defined for two information sources and states that
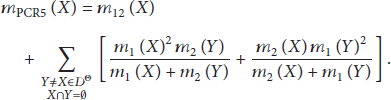
In the formula,
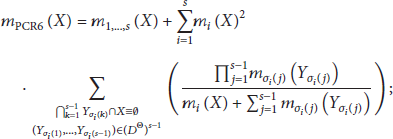
2.3.2. PCR#
In [13], Dambreville proposes a new approach to design the fusion rules based on the Referee functions. For the sake of brevity, we omit the formulas and the mathematical framework; more details are available in [13, 14]. The Referee function is a function that discriminates the characteristics of all the fusion rules, including those presented by other authors. Its core element is the conditional arbitrament quantity used into the generic fusion rule. The rejection rate generalizes the conflict mass. The general fusion rule proposed by Dambreville includes a sampling method and a summarization method. The two processes reduce adaptively the set of focal elements, that is, the set of elements in the frame with nonzero mass. This eventually avoids the combinatorics load by providing an approximation of the most significant bbas. In a first stage, the sources provide the values of beliefs on a specific proposition through a sampling process. Then, the Referee function provides a result conditionally to the entries; the final output might not be produced, based on the value of the initial beliefs. The principle is to limit the size of the set of focal elements by reducing this size during the summarization process. According to Dambreville, the PCR6 algorithm works just in case of full consensus or no consensus, but no intermediate cases are considered. The author proposes a new rule, named PCR#, which is able to address the above-mentioned case.
3. Use of the Dempster-Shafer Theory and Its Extensions for Fraud Detection: The Mobile Money Transfer Case Study
3.1. MMTS Infrastructure
A Mobile Money Transfer (MMT) service relies on the use of virtual money, called mMoney, to perform various types of money transfers and transactions. For example, a customer can use his/her mobile phone for purchasing goods, receiving his/her salary, paying bills, taking loans, paying taxes, or receiving social benefits. MMT services are becoming more and more appealing, especially in developing countries, where banking infrastructures are not as capillary as in developed ones, whereas the penetration of mobile phones is high (as compared to bank accounts), and the regulatory environment is weak. In these countries, the number of customers is increasing at a fast pace. According to the 2012 Global Mobile Money Adoption Survey on the status of the Mobile Money industry [15], 150 live Mobile Money services for unbanked people were active in 2012, 41 of which were launched in 2012. Almost 30 million active customers used Mobile Money services, who performed 224.2 million transactions totaling $4.6 billion during the month of June 2012. M-Pesa, which was launched in 2007 in Kenya, totaled in December 2011 about 19 million subscribers, that is, 70% of all mobile subscribers in Kenya [16].
Like any other money transfer service, an MMT service is vulnerable to a number of fraud schemes. Fraud is commonly understood as dishonesty calculated for advantage, that is, deception deliberately practiced in order to secure unfair or unlawful gain. In the context of Mobile Money fraud is the intentional and deliberate action undertaken by players in the mobile financial services ecosystem aimed at deriving gain (in cash or e-money) and/or denying other players revenue and/or damaging the reputation of the other stakeholders. Furthermore, as telecommunication operators support the provision of financial services across shared networks in cross-border jurisdictions, the large adoption of mobile payment services can result in a growing risk of money laundering in mobile transfer services. Since the success of any payment system is based on ubiquity, convenience, and trust, it is necessary to address emerging security risks in order to safeguard public confidence in MMT services. Fraud detection is particularly challenging in the MMT context due to the scarce willingness to disclose security information by mobile service providers as well as due to the confidentiality requirement that has to be met while dealing with user profiles and transaction data.
As depicted in Figure 1, an MMT infrastructure is normally composed of the following subsystems: the Front Office (FO) that authenticates the users, through the Operations Server, and forwards requests for performing financial transactions to the Account Management System (AMS); the AMS that authorizes and processes the transactions; the Security Database that contains the security information related to MMT service users (thresholds, blocked accounts, activated/deactivated accounts, and number of transactions within a certain time period); the Logs Server that stores logs related to the operations performed by the MMT system; the Data Warehouse that contains historical data about user's activities and accounts. Both the FO and the AMS query the Security Database to authenticate users and manage transactions.
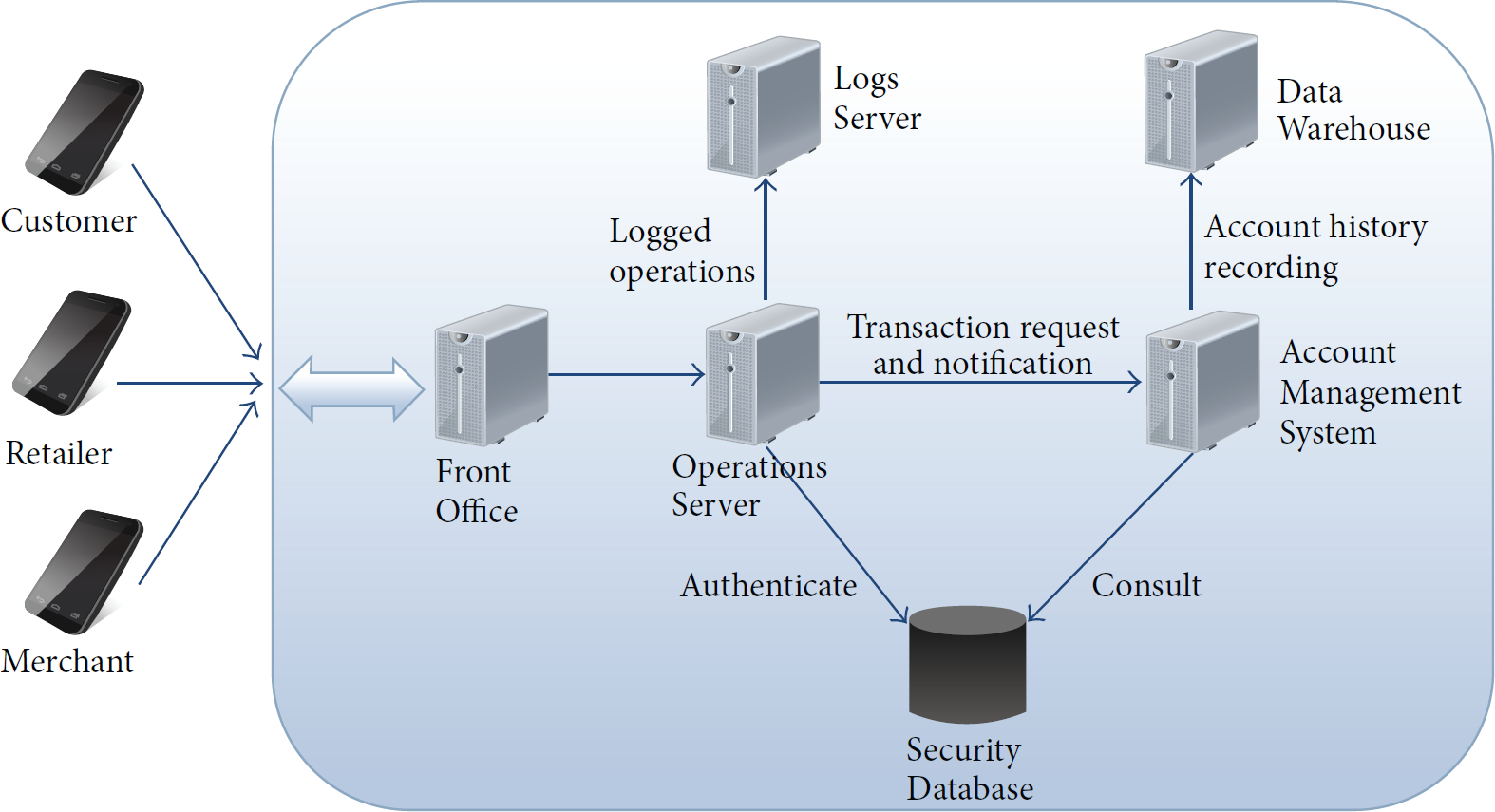
Architecture of a Mobile Money Transfer system.
In an MMT service scenario, each user of the system has some virtual money that he/she can use to perform various types of money transfers and transactions. Mobile Money service users comprise customers, retailers of mMoney, and merchants. These actors use their mobile phones to communicate with the FO that provides the interface towards the Operations Server. Each user is an mWallet holder. An mWallet is an account hosted in the system enabling the mWallet holder to carry out various actions by using mMoney. In order to access the system MMT service users are required to connect to the FO and authenticate to the Operations Server. This server is in charge of authenticating users, executing simple account management operations (e.g., PIN code update), and delivering notification messages. The Operations Server provides two main functions: view through a User Interface, that is, the Operations Server interacts with the users to collect operation requests and send notifications, and processing of an operation request, that is, the Operations Server analyzes the request coming from the user and implements the actions needed to fulfill that request. The server either performs the operation by itself (this is the case when, e.g., the requested action consists in modifying customer's password for the service or authenticating the user) or forwards the request to the Account Management System (this happens when the operation concerns account management or credit/debit control). The Account Management System is in charge of managing accounts. In particular, it controls user's credit/debit before a financial transaction is authorized and performed. Furthermore, it stores information about users' habits.
The Operations Server is also linked to the Logs Server that stores logs of any operation carried out in the system. Logs contain records of users' activities, such as requests for PIN modification, failed authentication, transaction requests, and notifications of successful transactions. The input to the MMT system is an operation request received from mWallet holders, while the output is the notification of success/failure of the required operation; that implies the registration of operation information. Data that are of interest to fraud detection activities are archived in the Logs Server and in the Data Warehouse. While the security-relevant information that can be gathered by accessing the Logs Server and parsing the stored logs can be used to detect simple fraud cases, historical data about accounts available in the Data Warehouse can be exploited to draw customer behavior and support the detection of complex frauds.
The MMT misuse case addressed in the paper is called account takeover. That misuse case is particularly challenging because the attacker uses stolen credentials to perform a violation, thus making it difficult to detect the anomaly at infrastructural level, like, for instance, analyzing network packets or the execution of suspicious applications. This misuse case relies on the following scenario: a fraudster steals the mobile phone of a legitimate MMT service customer and uses it to make illicit money transfers. It is very likely that the behavior of the fraudster differs from that of the legitimate user. In order to detect such fraudulent behavior we exploit data fusion techniques based on the theory of evidence. Specifically, we test several algorithms, introduced in the previous section, to combine the metrics of attack and design a detector of anomalous behavioral patterns. The detector compares the customer behavior with a normal user's profile.
3.2. A Fraud Detection System Based on Evidence Theories
In this section, we present a Fraud Detection System (FDS) based on the theories of evidence and plausibility introduced in the previous section. Our objective is to evaluate the performance of this detector by investigating how different algorithms behave under different assumptions by an expert system. We assess the performance of different algorithms with different bbas. Also, we investigate the performance as a function of several detection parameters, specifically the thresholds to discriminate the belief of attacks. In this section, we describe the general workflow of the detector and provide details on the monitors of single features, that is, how the bbas have been assigned by the experts. The detector uses a number of rules that analyze the deviation of each incoming transaction from the normal profile of the user. The rules assign beliefs to “features” of the transactions. The belief values are combined to obtain an overall belief by applying the Dempster-Shafer (DS) model, the Dubois and Prade models (DP), and the Dezert-Smarandache model with several versions of the PCR algorithms (PCR5a, PCR6, and PCR#). The overall belief is then compared with a “detection” threshold in order to understand if the user's behavior has to be considered fraudulent or genuine. The proposed FDS consists of the following three major components: Rule Based Filter, Evidence Combiner, and Analyzer. The flow of events in the FDS has been depicted in the flow diagram in Figure 2.

Flow diagram of the proposed FDS.
To evaluate the effectiveness of the proposed FDS, we generated, via accurate simulation of a real system, events representing an account takeover misuse case, where a fraudster steals the mobile phone of a legitimate user and uses it to make money transfers. Particularly, the fraudster chooses a victim and approaches him/her physically. Once in touch with the victim, he/she steals the phone. Then, he/she tries to guess the PIN related to the mobile payment application. Usually the fraudster makes several attempts to access the victim's account. After breaking in the system, he/she typically starts to purchase goods from various merchants.
3.2.1. Rule Based Filter (RBF)
The RBF is a rule based module that classifies the transactions executed by the users and assigns a certain rank of the fraud risk to them. The assigned value is a measure of the deviation of the observed behavior from the normal behavior profile. The rules used in our study are as follows:
Rule R1, number of authentication attempts: we analyzed the number of authentication attempts performed by the regular users of the system and by the fraudsters. The larger the number of attempts, the higher the probability that the transaction is fraudulent. Rule R2, delay of authentication attempts: we analyze the time interval between the first and the last authentication attempts being failed. If this time interval exceeds a given threshold (e.g., 15 seconds), then there is a high probability that the transaction is fraudulent. Rule R3, outlier detection: users usually carry out similar types of transactions in terms of amount. Supposing we build a cluster of regular transactions, fraudsters are likely to perform transactions out of this cluster. This process is known as outlier detection. An outlier detector must take into account the transaction amount, the date, and the identification code of the customer. As we describe later, in the experimental trials every user spends money following a Normal distribution
Normally, an FDS is subjected to a large number of transactions, mostly genuine. The role of the RBF is essential since it separates out most of the easily recognizable genuine transactions from the rest.
3.2.2. Evidence Combiner (EC)
The EC combines the bbas resulting from the application of rules R1, R2, and R3 and computes the overall belief of attack for each transaction. For the detection of frauds in the MMT system, the DS, DP, and PCRs allow introducing alternative sets and a rule for computing the confidence levels associated with them. In order to apply the rules of combination, we need to define a frame of discernment U which is a set of exhaustive possibilities. Note that we do not impose the exclusivity in our model; that is, we consider the general case that the possibilities compose a power set as used in the DST or a hyper power set as used in the DSmT. The refined elements in the frame are Mass probability Mass probability Mass probability As we can see, the values provided by the three features can produce high conflicts, which are not easy to be solved with the classic DST model.

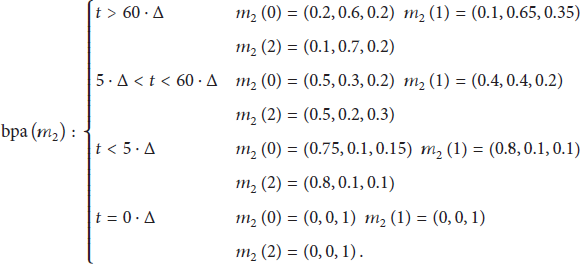

3.2.3. Analyzer
In this module, we perform the analysis of the fused bbas of the three features. The three bbas are combined using the formulas in the previous section and provide the value of Belief (Bel) of fraud (F) and not fraud (NF) for each authentication attempt as well as for each transaction made by the users. Particularly, we consider
4. Experimental Campaign
The objective of this experimental campaign is to evaluate the performance of our FDS with different data fusion rules. Also, we perform the tuning of bpas in order to obtain the best performance for each algorithm. Due to unavailability of real samples related to frauds, we used a simulator that closely mimics the behavior of the real system to create data related to several thousand transactions of the Mobile Money Transfer service (in the experiments, we focused on transactions executed in a delimited geographical area and in a relatively short time). The simulator [17] reproduces the operations of the real system in great detail, including virtual money exchange operations by m-vendors, log collection systems, authentication servers, and transaction authorization servers, and more. These entities generate a multitude of logs that contain authentication records, money transfer logs, real to virtual currency conversion operations, and so forth. The simulator creates events related to legitimate users and to fraudsters. The simulator can be configured in order to define the number of legitimate users, fraudsters, (virtual money) merchants, and m-vendors and to generate random lists of customers' preferred merchants. System activities are driven by random processes. User behavior is given in Table 1. Regular users and fraudsters enter the PIN in the system to perform transactions. Legitimate users rarely make wrong authentication attempts: PIN error distribution is Normal with 0 mean and 0.35 standard deviation. Fraudsters are more prone to PIN errors that have been modeled as Uniform distribution in the range 0–10. Legitimate users successfully entering the system perform transactions following a
Simulation parameters. N and U are Normal and Uniform distribution, respectively.

Before analyzing the performance of the combination rules, we shortly describe the pseudocode of the detector and of the performance evaluator. The code is provided in the algorithms shown in Algorithms 1 and 2. The core of the implementation is the application of the fusion rules discussed in Section 2. We implemented the fusion rules by adapting the library described in [18]. Also, the implementation of PCR5 and PCR5 approximated is new since it is not provided in this template library. The implementations are in Java programming language. It is worth noting that the current implementation of Dubois-Prade model in that library does not consider intermediate cases. During the experiments, the DP model exposed the worst performance, and we think this is a consequence of the current implementation in use.
(1) (2) Algorithms (3) ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( ( (
(1) (2) Algorithms (3) tokens (4) (5) features (6) (7) update_users_profile( (8) (9) (10) (11) (12) (13) (14) (15) ( ( ( ( ( ( ( ( ( ( (
In Algorithm 1, we provide the procedure used for the performance assessment. This code is similar to that used in our previous work [2], except that there we considered only the DS model for the fraud detection. Also we point out that performance in this work is better than in [2], because we performed more fine-grain tuning on the parameters used for the detectors. The most significant improvement is obtained from the transaction delay monitor, rule 2, which now has been parametrized on a scale factor Δ. All the tests are performed by considering the ground truth of the events; that is, the events contain information about the actual malicious state of the activity (fraud or not fraud) performed by the regular user/fraudster. Ground truth labeling can be easily done through a simulator, because for each activity we set the label during the logging process based on the real identity of the actor. In both algorithms, once a log is entered, it is parsed and tokenized in order to extract the information about the event. Specifically, we are interested in
For what concerns the in-line procedure in Algorithm 2, we consider the general case that the threshold θ is different for each user. Again, in a simulated scenario with similar users, we can consider the same θ for any actors. In lines 12–14, we apply the detection rules described in the previous section. Given the specific bba for that user and the current value of the feature, we obtain the mass of the attack state (
The approach to performance assessment in Algorithm 1 is similar, but the analysis has to be done on the whole set of events. In Algorithm 1, the performance is calculated by scanning linearly all the detection parameters indicated in the previous sections (lines 3–6), namely, (1) Δ of the delay feature detector; (2) the two bpa vectors, counter and delay, to be combined with the fusion algorithms; (3) the θ threshold. Also, for each combination of parameters, data fusion rules are applied to produce a vector of masses (
As shown in the algorithm in Algorithm 1, in order to evaluate the FDS, we tested the performance of the classifier with different values of the θ threshold. θ ranges between 0 and 1 and is used to decide whether a given transaction/authentication attempt is to be considered dangerous or not, based on the Bel value of the event. Bel is calculated by combining the bpa of the three features. If the authentication fails, we consider only the Bel calculated starting from rule R1 and rule R2; that is, the amounts have not been considered. Also, for each θ, we calculated four typical classification metrics: True Positives (TP), True Negatives (TN), False Positives (FP), and False Negatives (FN). From these metrics, two indexes have been calculated, namely, the true positive rate (TPR), that is, TP/(TP + FN), and the false positive rate (FPR), that is, FP/(FP + TN). Both have been plotted on ROC curves. The ROC curves have been plotted for all the combination rules in Figures 3–11. The curves are related to the Δ factor equal to 0.200, which is the one that provided the best values for the detectors. The ROC curves show that the DS combination rule changes smoothly with respect to the others when FPR has lower values. Instead, the best values are reached by other combination rules. In particular, the curves are obtained considering all the combinations of bpas for rule 1 and rule 2, namely, changing in turns
Best performance per algorithm. Criteria:

Best performance with
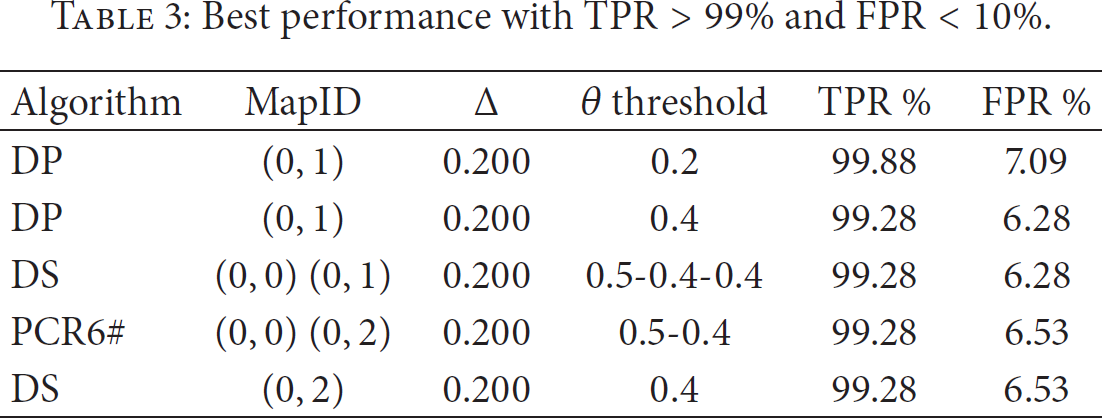

ROC curves for bpas
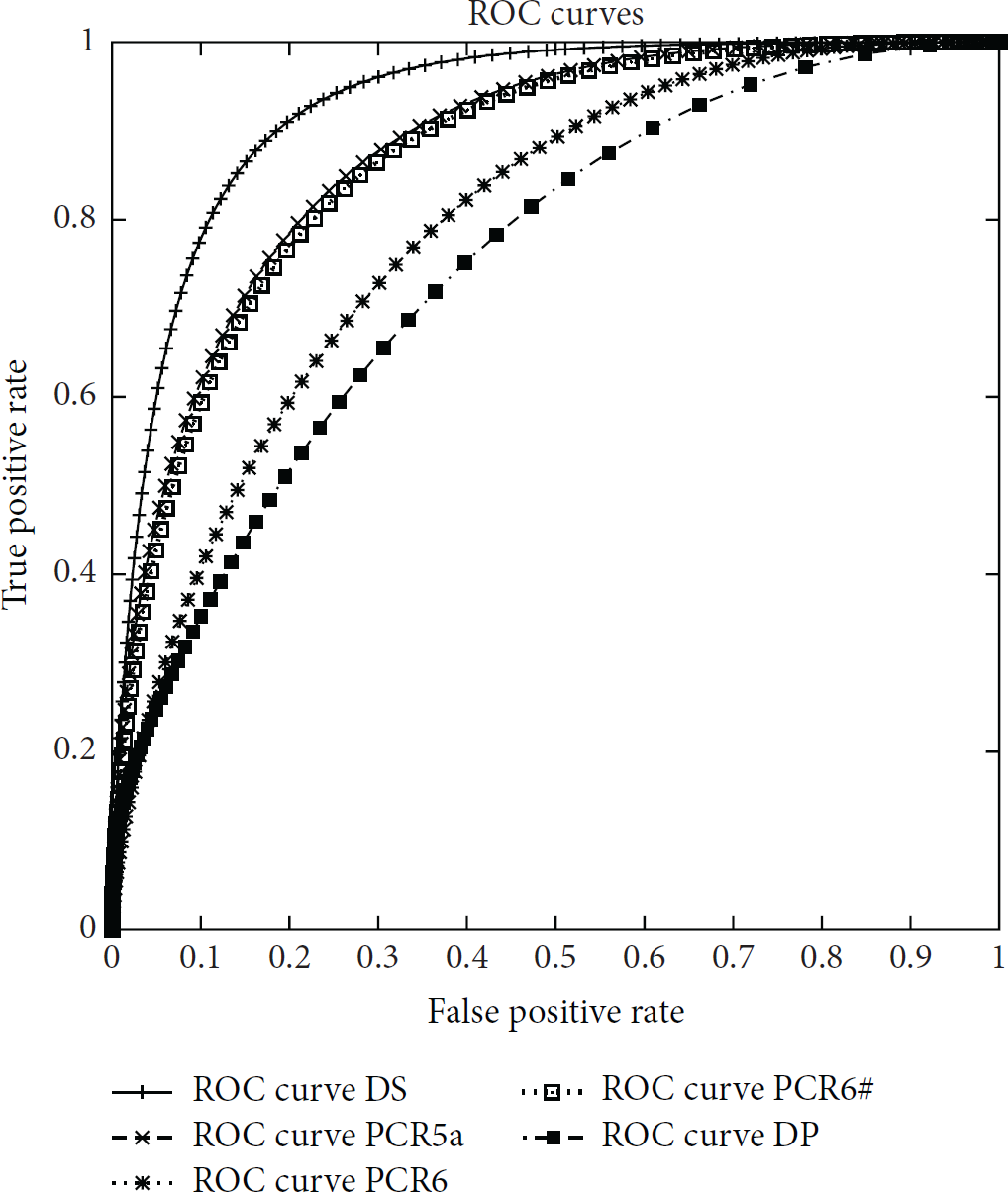
ROC curves for bpas

ROC curves for bpas

ROC curves for bpas

ROC curves for bpas
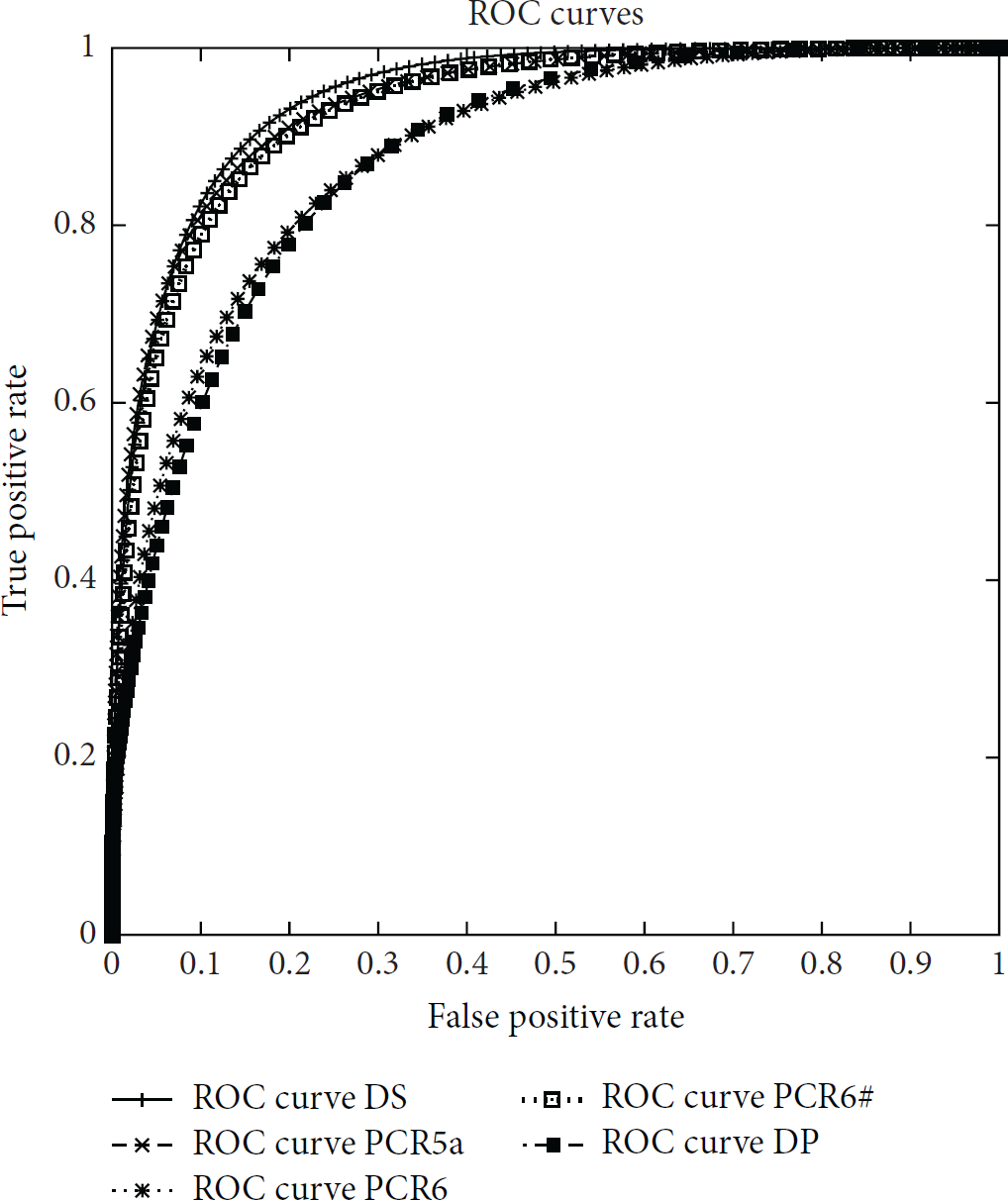
ROC curves for bpas

ROC curves for bpas
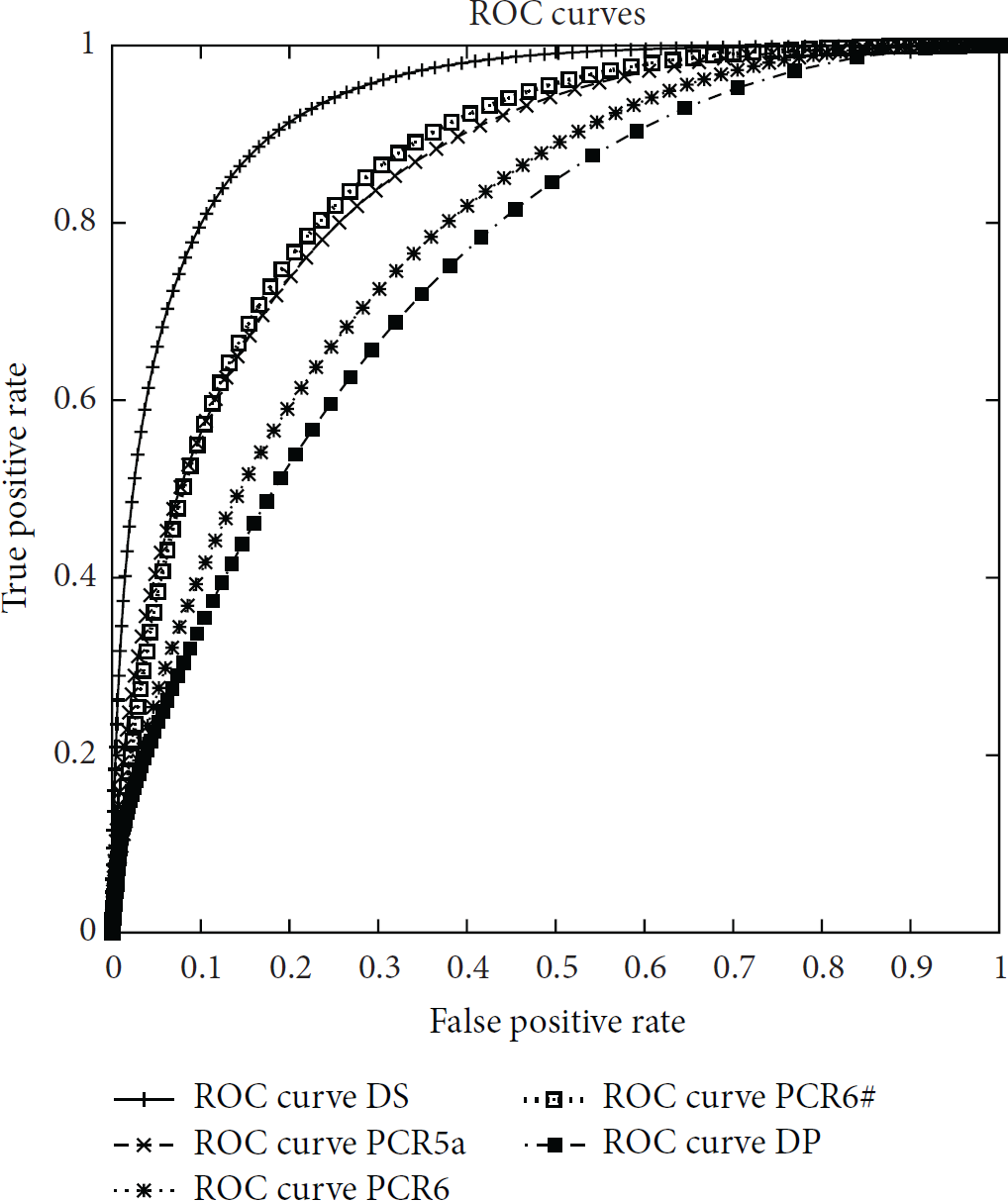
ROC curves for bpas

ROC curves for bpas
5. Related Work
Several research papers exist in literature that demonstrate the effectiveness of the Dempster-Shafer theory to combine multiple pieces of evidence and get an accurate picture of the context to be monitored and analyzed. In this section, we selected the most relevant papers showing how the Dempster-Shafer theory can help in network security to spot intrusions or to detect frauds.
In [19], the authors present an approach for credit card fraud detection that combines different types of evidence by using the DS theory. In the proposed FDS, a number of rules, like average daily/monthly spending of a customer, shipping address being different from billing address, and so forth, are used to analyze the deviation of each incoming transaction from the normal profile of the cardholder by assigning initial beliefs to it. The initial belief values are combined in order to obtain an overall belief by applying the DS theory. The overall belief is further strengthened or weakened according to its similarity with fraudulent or genuine transaction history using Bayesian learning. The authors demonstrate the effectiveness of the proposed FDS by testing it with large scale data. Due to unavailability of real life credit card data or benchmark data set for testing, they developed a simulator to generate synthetic transactions that represent the behavior of genuine cardholders as well as that of fraudsters.
In [20], authors propose the use of DS model to perform intrusion detection on the DARPA dataset of network related attacks. The work points out the limits of DS model in case of conflicting information sources and proposes using a context-dependent operator. That operator changes the combination rule (conjunctive, disjunctive, or average) based on the degree of conflict among the sources.
In [21], the authors investigate the use of Dempster-Shafer evidence theory for intrusion detection in ad hoc networks. A common problem in distributed intrusion detection is how to combine observational data from multiple nodes that can vary in their reliability or trustworthiness. Other approaches have used simplistic combination techniques such as averaging or majority voting. In this study, the authors demonstrate that the DS theory is well suited to this type of problem. First, it reflects uncertainty or a lack of complete information, and second, Dempster rule for combination gives a convenient numerical procedure for fusing together multiple pieces of data.
In [22], a two-step approach is proposed to accurately detect shilling behavior for online auction systems. In the first step, the authors adopt a model checking method to detect suspicious shilling behaviors in real time. To verify the detection results from the first step and to reduce the number of possible false positives, in the second step, knowledge obtained in the first step is combined and the combination is carried out using the Dempster-Shafer theory. This two-step process for shill inference produces a shilling score that can assist an auction house with trust judgment for each shill suspect. To demonstrate the feasibility of the proposed approach, the authors provide a case study using real eBay auction data. The results show that using the DS theory to combine multiple sources of evidence of shilling behavior the approach can reduce the number of false positives that would be generated from a single source of evidence.
In [23], the authors used the DS theory to develop an algorithm for protecting Wireless Sensor Networks (WSNs) from internal attacks. In the reference scenario, a number of sensors in the WSN are nodes, for which the observations are assumed independent of each other. The Dempster-Shafer evidence combination rule provides a means to combine these observations. The study conducted by the authors assumes that the neighbor nodes with one hop will observe the data of the suspected internal attacker. In these observations, without loss of generality, the physical parameter (temperature) and transmission behavior (packet dropping rate) for each sensor are considered as independent events. The proposed algorithm observes neighbor nodes in the WSN and uses the two parameters to make judgments for the behavior based on the DS theory. The DS theory considers the observed data as a hypothesis. If there is uncertainty about which hypothesis the data fits best, the DS theory makes it possible to model several single pieces of evidence within the relations of multiple hypotheses. Using this method, the system does not need any a priori knowledge of the preclassified training data of the nodes in a WSN.
In [24], a DS theory-based approach is proposed to handle the uncertainty due to the large rate of false positives in the sensors used by Intrusion Detection Systems. This approach relies on an algorithm that performs DS belief computation on an IDS alert correlation graph, thus allowing determining a belief score for a given hypothesis; for example, a specific machine is compromised. The belief strength can be used to sort incident-related hypotheses and prioritize further analysis of the hypotheses and the associated evidence by a human analyst. The authors have implemented the proposed approach for the open-source IDS Snort and evaluated its effectiveness on a number of datasets as well as on a production network.
In [25], two network probes collecting traffic data are used as sensors that feed an Intrusion Detection System based on the Dempster-Shafer theory. This IDS uses the combination rule to correlate the collected data in order to detect DDoS attacks.
In [26], the authors propose an algorithm based on the exponentially weighted Dempster-Shafer theory of evidence to improve and assess alert accuracy. In order to test the proposed approach, offline experiments have been performed by using two DARPA 2000 DDoS evaluation datasets. The experimental results demonstrated that the proposed alert fusion algorithm based on an extended version of the Dempster-Shafer theory provides better performance than an alert correlation engine relying on Hidden Colored Petri-Net (HCPN).
In [27], the theory of evidence by Dezert and Smarandache (DSmT) is used in the threat assessment domain. DSmT distinguishes two operations: combination and conditioning for fusion of uncertain information and integration of uncertain pieces of information with confirmed, that is, certain, evidence, respectively. However, each of these operations has its drawbacks and, therefore, another type of fusion rules, called relative conditioning, has been proposed. In this kind of rules, the predominance of the condition over the uncertain evidence is stated explicitly, while the trust in the conditioning hypothesis is not absolute by definition. In this paper, two of these rules are presented as possible solution of the multilevel conditioning in threat assessment problem.
6. Conclusions
The Mobile Money Transfer industry is rapidly expanding around the world and this growth is particularly fast in less developed countries, where people see the MMT service as a valid and appealing alternative to the traditional and poorly disseminated banking agencies. Unfortunately, as the number of people using this service grows, the MMT infrastructure is exposed to increasingly sophisticated frauds. This paper addressed a challenging security misuse case concerning MMT services. This misuse case is called account takeover and it takes place when a fraudster performs money transfers by using the mobile phone stolen to a legitimate service customer. The choice of that misuse case does not represent a limitation for our fraud detection approach. Different misuse cases would require other detectors or event probes in addition or in place to those used in this work. In order to spot these illicit financial transactions, the Fraud Detection System is required to collect, process, and correlate a massive amount of data regarding the operations performed by the service customers. Data fusion techniques can definitively help improve the performance and effectiveness of the correlation process supporting the detection task. In this paper, we presented a component-based Fraud Detection System that implements data fusion algorithms deriving from the Dempster-Shafer theory of evidence. These algorithms use combination rules and procedures facing the problem of conflicting degree of belief affecting the DS theory. An extensive experimental campaign has been conducted in order to test and validate these data fusion algorithms in the MMT account takeover detection scenario.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
The research leading to these results has received funding from the European Commission within the context of the Seventh Framework Programme (FP7/2007-2013) under Grant Agreement no. 313034 (Situation AWare Security Operation Center, SAWSOC Project). It has been also partially supported by the TENACE PRIN Project (no. 20103P34XC) funded by the Italian Ministry of Education, University and Research and the MELISSA (Microwave ELectronic Imaging Security & Safety Access) Project funded by the Italian Ministry of Economic Development (Grant MI01 00042).