
Abstract
In spite of the increasing demand for all kinds of sensing services and applications, there still lacks a clear understanding of collaborative techniques to design collaborative protocols for wireless sensor networks. This paper proposes collaborative data gathering mechanism based on fuzzy decision for wireless sensor networks. The proposed algorithm integrates some key parameters, for example, nodes’ residual energy level, the number of neighbors, centrality degree, and distance to the sink, into fuzzy decision. Numerical and simulation results validate the proposed algorithm for the networks in finding the optimum cluster heads and realizing better performances in clusters distribution and energy efficiency improvement.
1. Introduction
In recent years, wireless sensor networks (WSNs) have seen rapid development in many applications, such as in environmental monitoring, target tracking, outer space exploring, and industrial automation [1]. In spite of the increasing demand for all kinds of sensing services and applications, there still lacks a clear understanding of collaborative techniques to design collaborative protocols for WSNs. Notably, through collaboration WSNs can organize efficiently, prolong system lifetime, and handle dynamics, all with the final goal of eventually executing reliably multiple user applications. Since sensor nodes are expected to be remotely deployed and usually equipped with limited power, it is always inconvenient or even impossible to replenish the power. It is clear that energy conservation and collaborative processing have become the most important challenge in the design of wireless sensor networks. The design should take into consideration the power limitation and incorporate some techniques to maximize the network's lifetime [2, 3].
The main task of a sensor node in the monitoring field is to detect events, perform quick local data processing, and transmit the data to the sink node. Among these processes, routing and data gathering are the major considerations in designing the pattern and operation modes of the WSNs. A routing algorithm achieving significant energy efficiency is cluster routing [4]. At present, the cluster organization is widely used in wireless sensor networks. The advantages of using clustering techniques for data collection are as follows: (1) cluster head (CH) node is responsible for long-distance transmission and forwarding of data to ensure the original data communications coverage area; (2) the cluster members can close the communication unit whenever it is necessary, so that the network's energy consumption can be effectively saved; (3) clustering topology is simple and easy to manage and is conducive to the application of distributed algorithms; (4) the protocol for communication between nodes is adaptive and just relies totally on the neighbor node information to decide whether to join or become a cluster head, so that network routing control information can be reduced; (5) the data from all members gathered in the cluster should be aggregated by cluster head, and it can greatly reduce the amount of network traffic.
This paper considered the remaining energy level of sensor nodes, centrality degree, and the number of neighbor nodes and consequently determined the weight of each attribute for cluster head selection by the fuzzy decision, which can effectively increase the high level of residual energy of sensor nodes become cluster head node probabilities and ensure that the distribution of cluster heads is more uniform and reasonable.
For reducing the communication overhead, data aggregation method was presented in wireless sensor networks. For the sensor network with high nodes density, there may be a large amount of redundant data from those who detect the objects in the same domain [5]. According to the relevance of sensing data, error function and fuzzy correlation function can be designed to acquire a comprehensive support degree among the nodes, and then it is possible to determine the reliability of each sensor and improve precision of the data fusion result. As far as the accuracy of cluster head data gathering was concerned, it can effectively reduce the amount of intracluster data and improve the energy efficiency [6].
This paper specifically focuses on exploring energy-efficient data gathering mechanism for collaborative WSNs to make WSN-based applications more reliable and effective in industry-related scenarios. In this paper, a collaborative data gathering mechanism based on fuzzy decision (DGM-FD) is proposed, aiming at distributing the load among all sensor nodes evenly. In order to reach this objective, some critical parameters, such as nodes’ residual energy level, the number of neighbors, centrality degree, and distance to the sink, are taken into account during the cluster head competition. Numerical and simulation results validate that the proposed algorithm can effectively find the optimum cluster heads and realize performances both in proper distribution of clusters and in improving the energy efficiency of the networks.
The specific contributions of this paper include the following:
a literature survey about various existing data gathering algorithms and analysis of their advantages and disadvantages, an effective collaborative data gathering mechanism based on fuzzy decision for wireless sensor networks is proposed, an algorithm (DGM-FD) for collaborative data gathering in wireless sensor networks is proposed, performance analysis of the proposed algorithm and an evaluation of the algorithm with respect to other existing algorithms.
The rest of the paper is organized as follows. We present the related works in Section 2. The energy-efficient data gathering mechanism is formally discussed in Section 3. The proposed DGM-FD model is introduced in detail in Section 4. In Section 5 the proposed mechanism is evaluated and finally we conclude in Section 6.
2. Related Works
In this section, we present a review of the recent developments of collaborative wireless sensor networks. The focus of attention varies from application specific detection to enhancement of middleware. In order to gather information more efficiently in energy consumption, clustering algorithm is introduced into the applications of wireless sensor networks. In WSNs, nodes can be partitioned into a number of small groups called clusters. Each cluster has a coordinator, referred to as a cluster head, and a number of member nodes. The cluster heads are responsible for aggregating the collected data and forwarding it to the base station (BS) through other cluster heads in the network. By rotating cluster heads periodically, the energy consumption of the sensor nodes over the network can be balanced.
Several WSNs applications require only an aggregate value be reported to the observer. In this case, sensors in different regions of the field can collaborate to aggregate their data and provide more accurate reports about their local regions [7]. Data aggregation reduces the communication overhead in the network, leading to significant energy savings.
Meghanathan proposed two distributed algorithms to construct (i) stable predicted link expiration time-based data gathering (LET-DG) trees that also incur lower delay per round as well as larger throughput per tree and (ii) energy-efficient minimum-distance spanning tree based data gathering (MST-DG) trees that incur larger node and network lifetimes and inflict lower coverage loss on the underlying network at any time instant [8]. Bober and Bleakley proposed BailighPulse, an energy efficient data gathering protocol for mostly-off WSN applications [9]. BailighPulse incorporates a novel multihop wake-up scheme that allows for energy efficient recovery of network synchronization after long off periods. Ebrahimi and Assi proposed MSTP [10], a new method for data aggregation in large-scale WSN using compressive sensing and random projection. The proposed method selects random projection nodes to generate routing trees with each projection node gathering a weighted sum from all the nodes in the network. Gupta et al. presented the problem of static itinerary based Agent migration protocol in WSN [11]. ETMAM (energy and trust aware mobile agent migration) presented an integrated solution for reliable agent migration within network. In ETMAM, energy and trust are both considered for deciding the next node for the agent migration.
EECS algorithm had improved LEACH (low-energy adaptive clustering hierarchy) method by changing probability. In probability function [12], energy parameter has been considered to choose cluster heads. Also reduction in search space has increased clustering speed. Li et al. proposed an unequal clustering algorithm (EEUC), where the clusters close to the base station have smaller sizes than clusters far from the base station [13]. However, it may produce lone nodes since the cluster head election is probabilistic.
Fuzzy logic showed its ability to cope with information with a high degree of uncertainty in heterogeneous engineering fields [14]. For some problems, it is usually assumed that there is fuzziness in each objective due to the imprecise nature of judgment as a decision maker [15]. The fuzzy mechanism can be used to find a compromised solution, which looks at the way the solutions are contributing to each objective and assigns a fuzzy variable [16]. The fuzzy mechanism supplies a possible way of finding a compromised solution in case solutions are very close to each other. In this paper, the problem of choosing the optimal cluster heads in wireless sensor networks is solved by a fuzzy based mechanism.
Some of the clustering algorithms employ fuzzy logic to handle uncertainties in WSNs. FCAs use fuzzy logic for blending different clustering parameters in selecting cluster heads [17]. They assign chances to tentative cluster heads according to the defuzzified output of fuzzy if-then rules. The tentative cluster head becomes a cluster head if it has the greatest chance in its vicinity. There are distributed and centralized fuzzy logic clustering approaches. A fuzzy energy-aware unequal clustering algorithm (EAUCF) was proposed to address the hot spots problem [18]. EAUCF aimed to decrease the intracluster work of the cluster heads that either are close to the base station or have low remaining battery power. A fuzzy logic approach was adopted in order to handle uncertainties in cluster head radius estimation. The Gupta fuzzy protocol using the fuzzy logic approach to select CHs utilizes three parameters: energy level, concentration, and centrality [19]. The protocol is used to collect energy level and location information for each node in the setup stage.
The CHEFL (cluster head election mechanism using fuzzy logic) protocol used a fuzzy logic approach to maximize the lifetime of WSNs [20]. It was similar to the Gupta protocol but it does not need the BS to collect information from all nodes. Instead, the CHEF protocol uses a localized CH selection mechanism with fuzzy logic. The LEACH-FL (LEACH protocol using fuzzy logic) protocol was proposed in [21]. This protocol used fuzzy logic to improve the LEACH protocol by considering three different parameters: energy level, node density, and distance between the CH and the BS. This model was the same as the Gupta protocol in the sense of a setup stage and a steady-state stage. In order to choose cluster heads, a two-level fuzzy method that included local level and global level was used [22]. In local level, node's capability of being cluster head can be evaluated based on two parameters: energy and the number of neighbors. In global level, three parameters had been considered: centrality degree, closeness to base station, and the distance between cluster heads.
3. Collaborative Data Gathering Mechanism
3.1. Collaborative Data Gathering
At present, in most of the existing clustering algorithms, a certain probability of nodes is chosen to become cluster heads that is usually based on the residual energy of nodes, the average energy, neighbors, and other factors [23]. In case of an uneven distribution of network, the energy consumption of nodes is likely to cause uneven and rapid death and is resulting in the coverage holes problem. Therefore, while designing clustering data collection protocol for WSNs, we should consider the following aspects: firstly, clustering algorithm uses fully distributed control mechanisms and overcomes the shortcomings of inadaptability in centralized way. Secondly, compared to the direct routing, clustering algorithm can uniformly manage the distributed nodes in the network so as to achieve the load balancing of the whole network. Thirdly, for avoiding excessive energy consumption of certain nodes with high burden, the distribution of cluster heads should be chosen as evenly as possible.
The collaborative strategy ensures the efficiency and the robustness of the data gathering, while limiting the required communication bandwidth. Data aggregation has emerged as a useful paradigm in sensor networks. The key idea is to combine data from different sensors to eliminate redundant transmissions and provide a rich, multiperspective view of the environment being monitored. However, most of the research works focus on reducing the energy consumed by the sensors during the process of data gathering, such as finding routes between pairs of end nodes. On the other hand, some researches focus on the intrinsic characteristics of the collected data. In some scenarios, sensors are deployed to monitor continuous environmental conditions such as temperature, humidity, or seismic activity and periodically produce relevant information by sensing an extended geographic area that is eventually transmitted to the sink for processing. Since different sensors partially monitor the same spatial region result in the correlated data, the data aggregation can reduce the energy consumption in transmission. For the organization model of clustering, due to the members distributed in an immediate area, there is a strong correlation of the data collected in the cluster.
In the following sections, we will analyze and define the critical elements for cluster head selection, and a correlation function in fuzzy theory is adopted for the intracluster data aggregation.
3.2. Centrality Degree
Due to the uneven distribution of nodes in wireless sensor network, the centrality degree of cluster head will influence the whole intracluster energy dissipation. The more the cluster head deviated from the geometric centre of the cluster, the more energy the member node will consume for transmitting the message. Assume that node i is the candidate cluster head with a coordinate which is
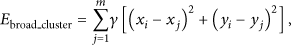
The centrality degree of cluster head i is defined as follows:
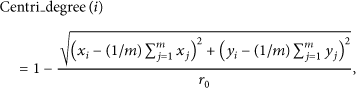

Cluster head with high centrality degree can help reduce intracluster communication energy. Therefore, the centrality degree of candidate cluster head can contribute to the rational distribution of cluster heads.
3.3. The Number of Neighbor Nodes
In this paper, the network coverage ratio

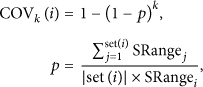

The optimum number of clusters
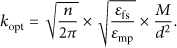
Hence, the average number of neighbors is
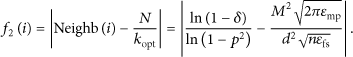
3.4. Energy Level
In the cluster head election, the remaining energy of nodes is a very important factor. The selected nodes which are with plenitudinous residual energy and are relatively close to the sink can well extend the lifetime of network. In order to optimize the energy consumption, this paper adopts the concept of residual energy level.
Assume that initial energy of nodes is

With the energy dissipation of the sensors, the level of the residual energy will vary from 1 to ρ. When the remaining energy is reduced, the energy differential is smaller. This indicates that the gap of energy level is getting smaller while the node declines. During the selection of cluster heads, the nodes with high energy level have an advantage. Thus, the energy level of nodes should reasonably reflect the nodes’ residual energy:

3.5. Distance
According to the radio energy dissipate model, the node closer to the sink is elected as a cluster head which consumes the lower power than the one far away. Therefore, the distance function is defined as follows:

The four indicators described above for the reasonable selection of cluster head have a very important impact. In the next section, we propose the method based on the correlation functions and fuzzy nearness to analyze the proportion of these critical indicators in the cluster heads selection. It will effectively avoid the situation where the lower residual energy node becomes a cluster head node or the distribution of cluster head is uneven.
4. The Proposed DGM-FD Mechanism
The most important thing is to select appropriate cluster heads according to the above indicators for balancing energy expenditure and improving the network lifecycle. Fuzzy decision can be an effective method to sort the complex objectives in the domain of decision theory or select the optimal target resolution with respect to the restriction of fuzzy logic.
The most important factors for the nodes competing for being cluster head (i.e., the remaining energy level of sensor nodes, centrality degree, and the number of neighbor nodes) are fully considered. It would be simplistic and subjective if it is to just use the weighted sum of the evaluation results. Therefore, we adopt the method of fuzzy mathematics to obtain the comprehensive evaluation, and the objective weights of attributes are determined through the entropies according to the positive relationship between the values of the samples. According to the sampled index value of all nodes in the cluster, the ideal solution and the negative ideal solution are calculated. Next, the distance between the object attributes and the ideal solutions can be obtained by the method of weighted Euclidean distance. Finally, the nodes with the
(1)
After measuring the various attributes for all nodes, the observing matrix Z can be constructed. The structure of the matrix can be expressed as follows:

(2) In order to reflect the differentiation among the raw data of each attribute and reduce the computational overhead of nodes, normalization scheme is adopted and degree of the deviation from the mean value can be given as follows:

(3) To solve the problem of cluster head selection, the objective function and the constraints of this model can be described as follows:

(4) Calculating the separation of each alternative from the ideal solution and negative ideal solutions in 14,

According to the information theory [25], the relative entropy of systems α and β is defined as follows:
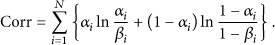
In terms of the definition of the relative entropy,
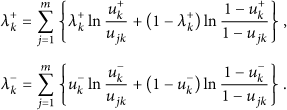
The relative closeness to the ideal solution is calculated by the following equation:

Finally,
In densely distributed network, there is an abundance of information that can be collected by sensors. For the nodes especially in one cluster, they usually locate in an adjacent region and monitor same objects. In order to minimize the volume of the transmitted data, we can design an aggregation scheme to exploit spatiotemporal correlations in the readings, which is obtained by the nodes in the network. When the target object is detected, the readings from different sensing nodes often exhibit certain correlation. Obviously, it is possible that there is a lot of redundant data which has a strong correlation in the process of perception. With some nodes being scheduled into the sleep state to avoid the production of these redundant data, it will undoubtedly reduce network energy consumption and prolong the network lifetime.
Therefore, the correlation function in fuzzy theory is presented to calculate the mutual support degree between the nodes during the process of the data aggregation in a single cluster. Then the redundant nodes, which should be changed into sleeping mode, can be chosen in order to save the energy. After receiving the sensed data of all members, the cluster heads will start analyzing perceptual characteristics of these readings. Moreover, as far as cluster density distribution was concerned, the more the nodes with equal or approximate coverage area in the network, the faster the running speed and the more the residual energy. Generally speaking, the nodes’ sensibility of data has a positive correlation with the comprehensive support degree.
Assume that

According to confidence distance measurement, confidence distance matrix sensor data
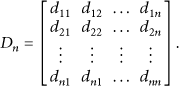
Next, we can obtain the supported degree of the data by the other nodes based on the method of fuzzy logic. In general, the threshold ξ is given, and a random

If

The threshold
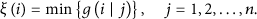
And the correlation matrix

The comprehensive level of support can be finally obtained as
In order to minimize the energy consumption, the nodes with low supported degree can be filtered as the redundant nodes, which will be in sleep mode in the next rounds. The rounds of sleep
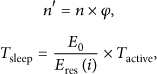
The number of rounds that the redundant nodes are scheduled to be in sleep mode is associated with the node residual energy.
5. Simulation Experiment
In this section, the experiments are implemented to evaluate DGM-FD. DGM-FD is compared with two different data gathering algorithms, namely, EECS [12] and FSC [26]. EECS and FSC are known as the classical methods for collaborative data gathering in wireless sensor networks. Several experiments are conducted on NS2 simulator to evaluate these algorithms. In order to evaluate the proposed algorithm, three different scenarios are developed. In the first scenario, the base station is located at the center of the WSNs. In the other two scenarios, the base station is outside the WSNs. In
In order to extend the lifetime of sensor nodes, FSC makes use of fuzzy logic for cluster head selection. In this section, we firstly utilized FSC to examine the distribution of nodes in the WSNs. Figures 1(a) and 1(b) show the snapshots of proposed algorithm and FSC, respectively. When the sink node locates at the center of the network, there are 65 clusters in DGM-FD and the number of isolated nodes is 6. The average number of nodes in the cluster is 6.15, and the cluster size variance is 4.07. FCS produced 41 cluster heads and 5 isolated clusters. The average cluster size is 9.75 with its variance 7.31. This means that DGM-FD controls the size of each cluster better and obtains less fluctuation in the number of nodes in all clusters. In other words, there is not much difference in the number of members for most clusters, and these cluster heads will not undertake excessive communication burden. In FCS, the scale of the clusters is much larger, and the cluster head will have to bear a heavier traffic load and sometimes may lead to premature death.
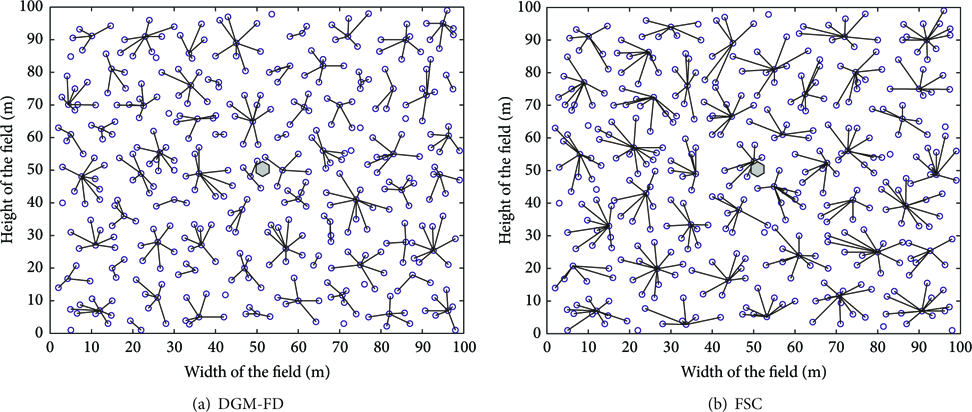
Sink locates at the center of the WSNs.
In the next scenario, the base station is located at the edge area of the wireless sensor network. The sink coordinates on this scenario are (100,100), and the topology of cluster formation is shown in Figure 2. DGM-FD produced 66 cluster heads and 5 isolated clusters, in comparison to 39 cluster heads and 5 isolated nodes. Nevertheless, the cluster size variance of FCS is 8.37, which is still much larger than 3.68 in DGM-FD.

Sink (100,100) is located at the edge area of the WSNs.
In the third scenario, the base station locates at the edge area of the wireless sensor network and the position of sink is (100, 50), and the topology of cluster formation is shown in Figure 3. It is observed that there are 66 clusters in DGM-FD. Meanwhile, there are 7 isolated nodes with a cluster size variance 3.98. Comparatively, 41 clusters come into being in FCS, and the cluster size variance is 5.37. Due to the factors of centrality of cluster head taken into account, most cluster heads generally located in the center of the cluster, which can significantly reduce energy expenditure. Since the average size of the cluster in DGM-FD is smaller than that in FCS, the former can afford relative low burden.
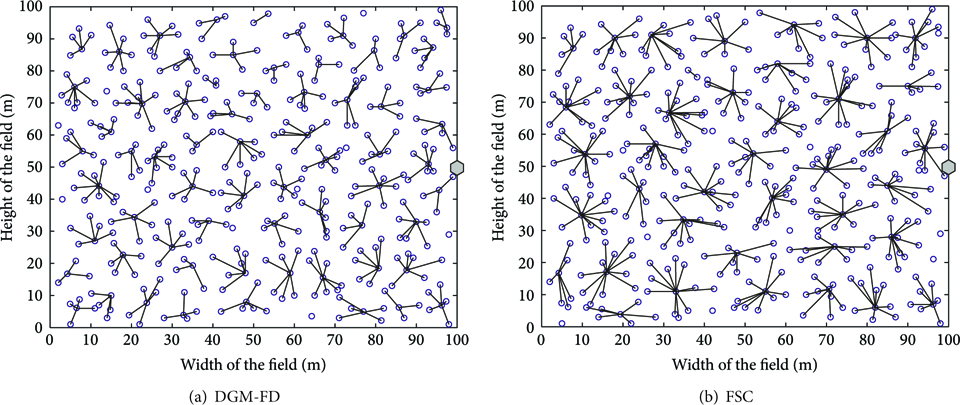
Sink (100, 50) is located at the edge area of the WSNs.
Figure 4 shows the distribution of the alive sensor nodes with respect to the number of rounds for each simulated algorithm. As shown in this figure, DGM-FD is apparently the most energy-efficient algorithm. The sensor nodes of EECS and FSC start to die in the earlier rounds. The death time of the first node of DGM-FD is much smaller than that of nodes of all the other algorithms. DGM-FD provides at least 1970 stable rounds for these particular WSNs, whereas EECS provided 1080 rounds and FSC 1490 rounds. Furthermore, the energy of the network exhausts gradually about 2250 rounds at EECS and 2440 rounds at FSC. But DGM-FD cannot undertake 2700 rounds even when all nodes die. This figure clearly shows that the proposed algorithm is more stable than the other algorithms, in which sensor node deaths begin later for DGM-FD and continue linearly until all sensor nodes die.

The distribution of alive sensor nodes with different rounds.
The distribution of the average energy consumption of all nodes with respect to the number of rounds for each algorithm is depicted on a fast line chart in Figure 5. The simulation results show that the average energy consumption of all nodes varies comparative stably during the most of the rounds in DGM-FD. The average energy consumption of other algorithms fluctuates in wide range, especially in EECS. On the other hand, the average energy consumption of DGM-FD can keep in the low level, which benefits from the optimization of the selection of cluster heads.

The distribution of the average energy consumption of all nodes with different rounds.
During the formation of clusters in DGM-FD, the residual energy of nodes is paid full consideration, and the node with high energy level is selected as cluster head. The factors about the number of adjacent nodes and centrality degree are introduced, which makes the cluster size even and the cluster head locates near the centrality of its cluster as much as possible, while in EECS, due to the random selection of the cluster head, low residual energy nodes may also be selected as cluster head and in this case the death of nodes of low energy level would be accelerated.
The energy dissipation of all nodes in the three algorithms, as well as the variation tendency, is illustrated in Figure 6. As shown in the figure, DGM-FD consumes much less energy than FSC and EECS. As explained earlier, the optimal cluster heads selection is adopted at every round, and the reasonable intracluster data aggregation mechanism is added in DGM-FD, resulting in a significant energy-saving effect.

The total energy consumption per round.
6. Conclusions
To improve the energy-efficiency and achieve the network load balancing, a DGM-FD mechanism is proposed in this paper. DGM-FD aims to distribute the workload among all sensor nodes evenly. Moreover, a correlation function in fuzzy theory is adopted for the intracluster data aggregation. The experimental results show that the proposed algorithm can effectively optimize the selection of cluster heads and obtain better performances both in proper distributing of cluster heads and in improving the energy efficiency of the networks. In the future, we will explore energy-efficient data gathering mechanism for collaborative WSNs to make WSN-based applications more reliable and effective in industry-related scenarios.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This research work was supported by Shanghai Natural Science Fund (no. 14ZR1429800), Teachers Training Plan of Shanghai Municipality under Grant (nos. SXY12003 and ZZSD13008), and National Natural Science Foundation of China (nos. 61170044 and 61073050). And the authors wish to thank the anonymous reviewers who helped to improve the quality of the paper.