
Abstract
Neural network is easy to fall into the minimum and overfitting in the application. The paper proposes a novel dynamic weight neural network ensemble model (DW-NNE). The Bagging algorithm generates certain neural network individuals which then are selected by the K-means clustering algorithm. In order to solve the problem that K-value cannot be selected automatically in the K-means clustering algorithm when conducting the selection of individuals, the K-value optimization algorithm based on distance cost function is put forward to find the optimal K-values. In addition, for the integrated output problems, the paper proposes a dynamic weight model which is based on fuzzy neural network with accordance to the ideas of dynamic weight. The experimental results show that the integrated approach can achieve better prediction accuracy compared to the traditional single model and neural network ensemble model.
1. Introduction
With the continuous development of artificial intelligence technology, neural network, as an important method in the machine learning field, has advantages which make it a new and favorable choice in many fields. The advantages mentioned above are the function of self-learning and adaptation which enables people to obtain a more efficient model only if sufficient training data is available, showing great advantages over the traditional models. Any single model, however, is often veiled with the characteristic of not being robust. Therefore, in some cases, a single model can not adapt itself to subtle changes in projects, thus making the prediction error increase sharply. Shortcomings like overfitting create many problems in using a single model. However, in the current society, the increasing demand urges a model with generality and high accuracy. On the basis of guarantying the model accuracy, the problem of how to improve the generalization ability of the models has been put forward to people as a main research topic.
Neural network ensemble was officially put forward by Hansen and Salamon [1] in 1990. Hansen and Salamon conducted an experiment in which multiple neural networks were used to study the same issue and the prediction results were synthesized, thus effectively improving the generalization ability of neural networks. Sollich and Krogh [2] presented similar neural network ensemble definitions in 1996. Because of its convenience and ideal effect, this method won wide approval from experts. This method was referred to as the first of the four current most important machine learning research directions [3] by the international authoritative TG Dietterich. Currently, neural network ensemble has been widely used in various fields, such as medical diagnosis [4], the exchange rate prediction [5], image classification [6], and software reliability prediction [7].
The research on neural network ensemble is mainly concentrated on the following two aspects: individual network generation and integrated output. Neural network generalization error is mainly affected by the network individual accuracy and the degree of difference. Generally, it is, to some extent, difficult to improve the network individual “accuracy.” Therefore, the research mainly focuses on how to increase the neural network individual differences. Currently, the research on how to obtain greater individual difference in general can be divided into three categories: data transformation, changing of the network characteristics, and individual neural network optimization. As for the regression problems of “integrated output,” a simple average or weighted average method is usually adopted.
In this paper, the research on the software reliability prediction based on neural network ensemble also concentrates on two aspects: the individual neural network optimization and the integration output. Meanwhile, the optimization algorithm of K-value based on the distance cost function is put forward to solve the problem that clustering number needs to be manually set in clustering algorithm. This paper also proposes the method to solve the problem of the integrated output of neural network ensemble through the establishment of dynamic weighting model based on fuzzy neural network.
2. Related Work
2.1. Individual Generation Method
Neural network generalization error is mainly affected by the network individual accuracy and the degree of difference. Generally, it is, to some extent, difficult to improve the network individual “accuracy” because if there were some effective method, the integration algorithm is of no necessity. Therefore, only by increasing the individual differences of the neural network method can the goal of generalization error reduction be realized. However, currently, there is no unified solution to obtain greater individual difference and this question has also become a hot research topic. According to the characteristics of neural network, in order to obtain different network individuals, the most simple and practical method in the construction of the neural network and training process is to conduct this process independently and separately. In general, the methods can be divided into three categories: data transformation, changing the network characteristics, and individual neural network optimization.
2.1.1. Transform Training Data
For the same set of training data, using different methods to extract samples for training, or removing the redundant attributes in the data, is a common method for generating the neural network integrated individuals and is also the kind of method being most commonly studied. This kind of method can be divided into the following two cases.
(a) Resembling the Sample Set. Due to the fact that the training set of this method is a subset of the original sample data extracted, the commonly used methods are as follows: Boosting method [8] proposed by Schapire and Bagging method [9] proposed by Breiman.
The Boosting method was first put forward by Schapire [8] and then improved by Freund [10]. This method can be described as giving the same weights to each training sample, obtaining a learning machine by training samples, and testing the learning effect of these training samples and then improving the weight of samples with poor learning effect. With this method, the appearance probability of the samples in this part will be increased in the next training set, thus enhancing the learning dynamics of the samples in this part to ensure a better performance in dealing with the samples with poor learning effect in the new period. By repeating the above process, an ideal learning machine will eventually be got.
“Bagging,” as an ensemble learning technique, was first put forward by Breiman. Its main idea is to generate multiple training samples through the Bootstrap resampling, thus training multiple classifiers or predictors. In this method, the integrating differences between members are mainly obtained through the “Bootstrap resampling.” In other words, they are obtained through the random sampling technique. Its main idea is giving a learning machine and a training sample set and setting a “maximum iteration time” as T; several samples were randomly selected from the training samples to form a new training set when an iteration is conducted every time, and then a prediction function is got as
(b) Changing the Input Variables Set. The input variable set can be changed by choosing different attributes. Due to the differences of the attributes of the training set, the emphasis of the models is different, which leads to the differences between models. For example, when predicating software quality, many descriptions can be made from many different attributes. Therefore, different attributes help produce different training samples used for model training. In comparison with Bagging algorithm, this method tends to reduce the input dimensions, thus simplifying the structure of the network model. This method, to some extent, accelerates the individual training speed. In addition, this method can also remove some redundant attributes to avoid the influence on the individual precision.
2.1.2. Changing of the Network Characteristics
Except for changing the neural network training data, another method commonly used to produce neural network individuals is to generate different individuals by changing the internal characteristics of neural network. The internal characteristics here mainly refer to initial weights of neural network, topology structure [11], learning algorithm, and target function.
Changing the initial weights of individual neural network training: because the weights of neural network use the gradient descent method for correction, different initializing weight will lead to different final convergent extreme value, causing differences of individuals. Changing the individual neural network topology structure: to generate individuals and train these network individuals mainly by changing the number of hidden layer nodes [12, 13]. The differences of the network topology structure lead to comparatively huge differences of the whole training model, thus generating individuals with differences. Changing the objective function of network training: the most representative method to produce individuals by changing the objective function is the negative correlation learning method. By adding a penalty term based on the traditional error function, it produced individual differences and guaranteed the individual accuracy [14].
2.1.3. Neural Networks Individual Optimization
After a certain number of neural network individuals are generated comes another question of equal importance: which network individual should be chosen and how many network individuals should be selected as more appropriate? This question has gradually evolved into an individual selection problem in neural network ensemble and has drawn increasing attention from many experts.
Neural network individual selective problem is defined as generating a certain number of individual neural networks by a certain method, and then, according to the analysis of the neural network ensemble generalization ability in this paper, selecting the individuals with huge difference and high precision for the final integration.
A global search algorithm is a kind of method which can be viewed as a method choosing a number of individuals from multiple candidate individuals to achieve the optimal effect, which essentially is about global optimization. Meanwhile, the global optimal problems can be solved by method such as intelligent algorithm. Take the GASEN algorithm put forward by Zhou et al. [15] as an example. It adopted the neural network integration error as the objective function and used the genetic algorithm to find the differences of individuals from the trained neural network individuals, thus helping the construction of neural network ensemble to achieve ideal results.
The neural network ensemble of individual selection is based on clustering algorithm. Selective algorithm can be interpreted as selecting large individual differences in network to integrate. By analyzing the degree of similarity between individuals and making classification according to the difference degree between the individual candidates, the clustering algorithm produces differences between individuals of different categories. Li and Huang put forward a new neural network integration method based on the choice of clustering named CLU_ENN which classifies the individual candidates through the clustering algorithm to produce differences between individuals in similar category and then selected individual with differences to integrate [16]; Giacinto and Roli also used a similar algorithm for selection of neural networks individuals and chose an individual for integration from each category [17].
2.2. Integrated Output Method
After the above generation and selection of individuals, the final step is network individual integration. In the process of neural network ensemble, the problem of combination of individual output is also a very important research direction, which, to a certain extent, determines the quality of integration. Assuming that all the independent outputs of the neural network individuals are available, then the next necessity is to proceed from relevant information of network individuals to comprehensively utilize the predicted information provided by each individual network and then to integrate these individuals with appropriate weighting method; thus the accuracy of prediction will be improved.
Integration output method for regression problems is unlike what it is for the classification problems for it is usually being carried out by simple average or weighted average method. Perrone and Cooper [18] and others thought that choosing the appropriate weighting with the weighted average could achieve better generalization ability than the simple average method does. However there are also some experts [19] who believed that simple average method is suitable when the number of the individuals is large, while when the number of individuals is relatively small, it is better to adopt weighted average method.
In recent years, many researchers are using different optimization methods to determine the weights of the network during the process of integrating output. After obtaining a certain number of neural network individuals, Pan and Wu dynamically solved the weight coefficient of the integrated individuals with genetic algorithm, researched integrated modeling, and then achieved good results [20]. Shen and Kong proposed a neural network ensemble construction method based on dynamic weight [21]. After the selection of the network individuals by genetic algorithms, the training sample is established according to the fitting error of the selected network individuals and then the generalized regression neural network is trained to predict the future time in order to calculate the weight of network individuals during different periods.
3. Selective Neural Network Ensemble Algorithm Based on the Dynamic Weight
3.1. Individual Neural Networks Optimization Based on K-Means Clustering
As discussed above, the main principle of Bagging is based on a kind of technology called “Put back the random sampling technique” (Bootstrapping sampling) to generate multiple predictors. The main idea of Bagging is to choose different training samples by random sampling technique to get the differences of training model, which actually means a reinforcement of the difference between individual neural networks, whereby the generalization ability has been improved. Here Elman neural network is adopted as individual neural networks.
Software reliability prediction is adopted as example for the DW-NNE model. The problem can be described as follows.
Initialization: the given original training set is To training the neural network individuals putting the neural network Returning to the neural network ensemble Predicting
Clustering algorithm is an important method in the field of data mining. It is mainly used to solve classification problems and has been widely adopted in many fields for its superior performance. Its main idea is to partition data objects into several classes to make the data objects with high similarity flock in the same class, while the data objects in different classes differentiate with each other obviously.
In the neural network ensemble, clustering algorithms are mainly used for individual choice. After a certain number of neural network individuals have been produced, this clustering algorithm divides these individual candidates into several classes based on their differences and then, respectively, selects one individual from each class as a representative of the whole category to participate in the integration. Generally, the individual with the lowest fitting error of each class would be chosen to participate in the integration.
3.1.1. K-Value Optimization Problem in K-Means Clustering Algorithm
With very high efficiency, the traditional k-means clustering algorithm is simple and easy to operate. Particularly for large data set with comparatively complex structures, the algorithm has strong scalability and higher execution efficiency. But in the process of using this algorithm, a critical problem is exposed which is the selection of k value. The fact that the k value in the k-means clustering algorithm needs to be given in advance will have certain impact and restriction on its rationality of applicability. Particularly as to the selection of individual neural networks in this paper, the exact number of the individuals supposed to be selected from the neural network individual candidates is hard to be determined.
Based on this problem, in order to realize the optimization algorithm of K-value, this paper puts forward the concept of distance cost function. Suppose that n spatial objects are divided into K clusters; respectively, define the distance between classes as L and the distance inside a class as D. Consider that

Herein, L represents the sums of the distances from all the clustering centers to the global center, D represents the sums of the total internal clustering distances, K represents clustering number, m represents the mean of all samples,
Then the distance cost function

The comparison of the
However, currently there are still no theoretical approaches to solve the problem of the range of K. Reference [22] is an example to derive by assuming that the sample space is distributed with sets, as follows:

In the formula,
When
The K-value optimization algorithm can be described as follows.
Set the limit of iterations (T) as To to realize the spatial clustering under K numbers by using K-means algorithm; calculate the current Search the minimum
3.1.2. Individual Selection Method Based on K-Means Clustering Algorithm
After a plurality of neural network individuals have been produced with Bagging algorithm, each neural network will produce a set of predictions on the training data
The k-means clustering algorithm and the K optimization method are mainly for the model clustering; the main sector is as follows.
Generate n neural network individuals with Bagging algorithm. The outputs of every individual neural network on the training set To divide matrix Y into k groups with K-means clustering algorithm; calculate the current Search for the minimum of the distance cost Clustering for matrix Y by using K-values and selecting individual with the highest fitting accuracy from each cluster as the candidate individual meet both the two requirements for individual neural network of its high precision and large differences.
The flow chart of individual neural networks optimization algorithm based on K-means clustering is as shown in Figure 1.

The flow chart of individual neural networks optimization algorithm based on K-clustering.
3.2. Neural Network Ensemble Method Based on Dynamic Weighting
After a certain number of neural network individuals being generated, how to comprehensively utilize the prediction offered by each individual network as well as to achieve neural network ensemble predictive model with appropriate weighted average form has become another important research direction. For regression problems, the integrated approach such as the arithmetic average method and the simple weighted average method is commonly used. These methods, to different extent, can effectively solve the problem about the neural network ensemble output.
However, the weights calculated by this kind of algorithm are fixed, which leads to limited reflection of overall prediction accuracy of model and the prediction accuracy of the single model is not immutable and frozen. Thus, the prediction accuracy will inevitably decline if the fixed weights method is adopted directly. In this section, the dynamic integrated output method based on fuzzy neural network is adopted to solve the dynamic weight problems under the time-varying condition.
3.2.1. T-S Fuzzy Neural Network
T-S fuzzy neural network structure, as shown in Figure 2, mainly includes four layers: input layer, fuzzification layer, calculation of fuzzy rules layer, and output layer.

The structure of T-S fuzzy neural network.
The first layer is the input layer, in which each node is directly connected with the input vector
The second layer is the fuzzy layer for transforming information from the input layer into the fuzzy quantity. It works mainly by the calculation of the membership function μ, which is about the input vector belonging to each node (the linguistic variables) of fuzzy set. Here Gauss function is usually used.
The third layer is fuzzy rules calculation layer. Each node of the layer represents a fuzzy rule. The fitness of each rule is calculated with the fuzzy multiplication formula.
The fourth layer is output layer. The weighted average method is used in this layer to realize normalized calculation, namely, to calculate the neural network output by using the fitness ω.
The main learning parameters of the fuzzy neural network are the coefficient of neural network Error cost function:
α represents neural network learning rate;
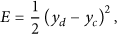


3.2.2. Dynamic Weight Model Based on Fuzzy Neural Network
For the dynamic weight model based on neural network, the solution of weights still mainly depends on the computation of the error. As to the error solution, in reference to the previous method and combined with fuzzy neural network, this paper designs a dynamic weight model with three inputs and a single output. Therefore, the error variation can be reflected more objectively from both overall and partial perspectives.
Here is a hypothesis. For a prediction problem, if the actual value is

While the overall neural network structure can be represented as a model with three inputs and a single output, of which the three inputs are, respectively,
The main process of this algorithm is as follows.
Producing m neural individuals after the optimal individual selection to form a set. Predicting the training sample by using the trained N neural networks and then calculating Establishing the dynamic weight model based on fuzzy neural network with three inputs which are Using the test data as input dynamic weight to predict the absolute value of relative error Predicting the test data by using m trained models with the weights obtained from (3) and the predicted results used for weighted integration. The final prediction result of the prediction model of neural network ensemble is generated as

Dynamic weight integration is based on fuzzy neural network, as shown in Figure 3.

The flow chart of dynamic weight integration based on fuzzy neural network.
3.2.3. Selective Neural Network Ensemble Based on the Dynamic Weight
Selective neural network ensemble algorithm based on the dynamic weights improves the traditional neural network ensemble algorithm by combining the two improvements mentioned in this paper.
The thought of this algorithm can be described as follows. By using Bagging algorithm a number of the individual neural networks can be generated; then cluster individuals by K-clustering algorithm and select optimal K-value by the K-value optimization algorithm, finally integrate the selected individuals using dynamic weight model based on fuzzy neural network, and then get the final solution.
The main processes of this algorithm are as follows.
Generate n neural network individuals by Bagging algorithm. Make a matrix Divide matrix Y into k groups through the K-means clustering algorithm. Search for the minimum of the distance cost Cluster matrix Y by using K-values, and select individual which has the highest fitting accuracy in each cluster as the candidate individual; then k neural network individuals were generated. Predict the training sample by using the trained N neural networks, and then, respectively, calculate Establish the dynamic weight model based on fuzzy neural network; then input Use the test data as input dynamic weight, and predict the absolute value of relative error Predict the test data by using m trained models. Make the weights obtained from (g) and the predicted results into weighted integration. The forecast result of final prediction model of neural network ensemble is

Selective neural network ensemble algorithm is based on the dynamic weight flow chart as shown in Figure 4.

The flow chart of selective dynamic weight neural network ensemble algorithm.
4. Simulation Experiment and Analysis
This paper chooses Data11 and Data12 from [1]. Data11 contains 118 groups of sampled data, and Data12 consists of 180 groups of sampled data. Sampling points in each group include the cumulative number of defects and the cumulative execution time. Firstly, normalize data

For the Elman individual neural network, its network structure has three layers: an input layer, a hidden layer, and an output layer. The number of the input nodes is 3, the number of the output nodes is 1, and the number of the hidden layer nodes is 7. The training frequency is 2000 times with 0 error, during which the network learning algorithm adopted is LM algorithm.
To quantitatively compare the performance of different methods, the MAE (Mean Absolute Error), MSE (Mean Squared Error), and MAPE (Mean Absolute Percent Error) are used in our simulation as the evaluation criterion of network prediction:

4.1. Experimental Verification of the Individual Optimization Based on Clustering
4.1.1. Experiment 1 (Data11 Set)
According to the method (optimization algorithm of K-value) described in the paper, limit the maximum value of K to 5 in the K-means clustering algorithm, then cluster, respectively, when
Thus it proves that the optimal value of K is 3.
Here the individual optimization method based on the optimization algorithm of K-value was defined as KF-NNE. In addition, to verify the performance of KF-NNE algorithm, this paper chooses K as 1, 5, 7, and 9, which are, respectively, called K1-NNE, K5-NNE, K7-NNE, and K9-NNE, and they are, respectively, compared with KF-NNE. In order to verify the effectiveness of individual optimization method, this paper also compares it with traditional integration method (NNE). According to previous introduction, by the arithmetic average method, integrate the individual which has minimum fitting errors in each class (the number in each class may be different).
4.1.2. Experiment 2 (Data12 Set)
According to the method of experiment 1, the results can be calculated as follows:
Select 2, 6, 8, and 10 as the value of k; meanwhile, name them as K2-NNE, K6-NNE, K8-NNE, and K10-NNE. Then compare them with KF-NNE and NNE; the performance is shown in Table 2.
Performance comparison of each model in Tables 1 and 2 shows that, in the case that the number of integration of experiment 1 is 1 and that experiment 2 is 2 or 10, the performance of neural network ensemble algorithm based on clustering is inferior to the traditional integrated approach, but it cannot completely negate the validity of clustering algorithm. The goal of this paper is to achieve the best clustering effect by selecting the appropriate k value. Tables 1 and 2 also show that after using the KF-NNE algorithm proposed in this paper, the prediction accuracy is obviously higher than that of traditional integration method and the other k value clustering method, and the integrated prediction effect also has a significant improvement.
The performance comparison of different individual optimization models in Data11.

The performance comparison of different individual optimization models in Data12.

In addition, the contrast of the relative error in Figures 5 and 6 proves that by using KF-NNE method put forward in this paper, except that individual point error is slightly lower than other clustering methods, the relative error of most points is lower than other methods. It also shows the application effectiveness of KF-NNE algorithm proposed in this paper in the field of software reliability prediction, which is a kind of effective method to improve the prediction performance compared with the NNE algorithm.

The relative error comparison of different individual optimization models in Data11.
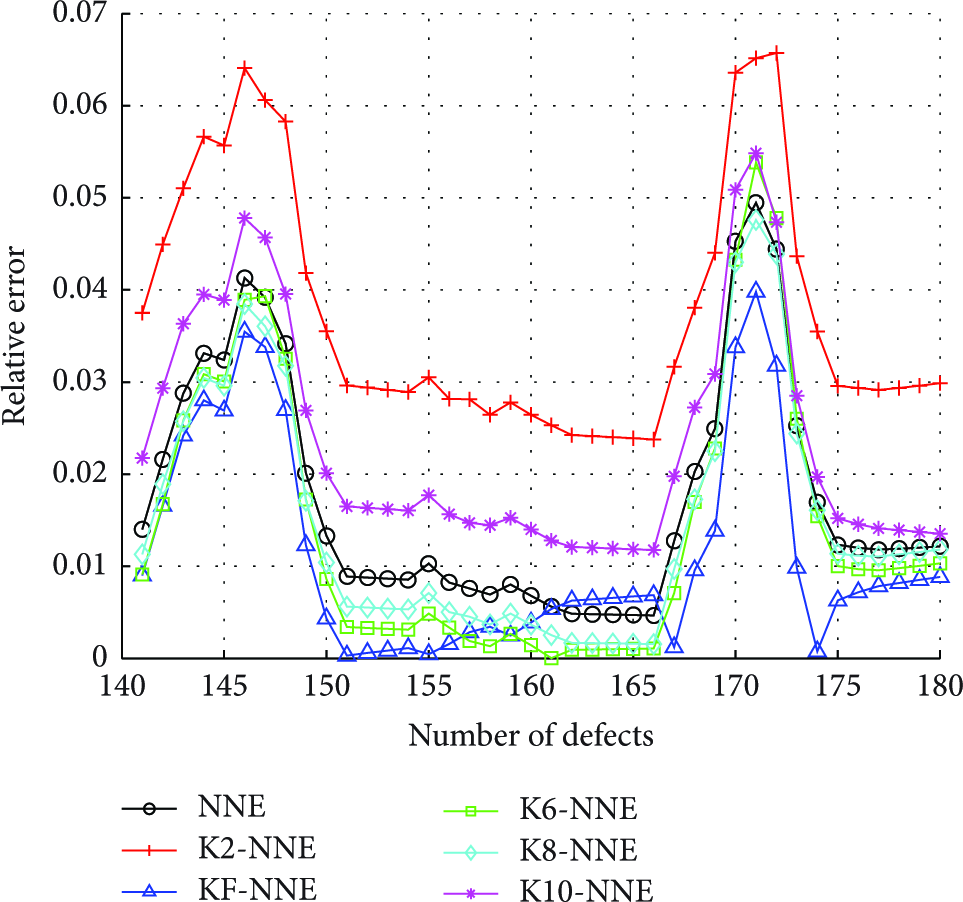
The relative error comparison of different individual optimization models in Data12.
4.2. Verification of Integrated Output Method Based on Dynamic Weighting
4.2.1. Experiment 1 (Data11 Set)
In the previous section, the experiment proved that K takes effect best when its value is 3 in Data11 Set. Here four individuals under k value of 3 were chosen to calculate the weight values of square error method, inverse method, and the simple weighted square sum method and then compared with the dynamic weight method.
The weight values of each model of square error method and inverse method were
The weight values of each model of simple weighted square sum method were
We also use the MAE (Mean Absolute Error), the MSE (Mean Squared Error), and the MAPE (Mean Absolute Percent Error) as the evaluation criterion of network prediction in our simulation experiment. The performance comparison of different integration methods is shown in Table 3.
The performance comparison of different integration models in Data11.

4.2.2. Experiment 2 (Data12 Set)
For Data12, data in the previous section, the best results have been obtained when
The weight values of each model of square error method and inverse method were
The weight values of each model of simple weighted square sum method were
The comparison of the error performance in Tables 3 and 4 proves that the dynamic weight method proposed in this paper shows high performance under different performance indexes. In addition, expect the dynamic weighting method, other methods are not stable in performance. For instance, the predictive performance of square error method and inverse method in experiment 1 is the best; however, in the second experiment, the predictive performance of arithmetic average method is the best. In other words, using the method of fixed weight will make integrated output model exhibit great instability; thus the user may blindly choose the number of neural networks ensemble individuals. The cause of this situation, in the final analysis, is the difference between the fitting performance and prediction performance of single model. In other words, although the results of traditional method of fixed weights are different, the results can only reflect the fitting data error. For future data, it is obvious that the method of fixed weight has a lot of disadvantages because the predictive effect of single model may change at every moment.
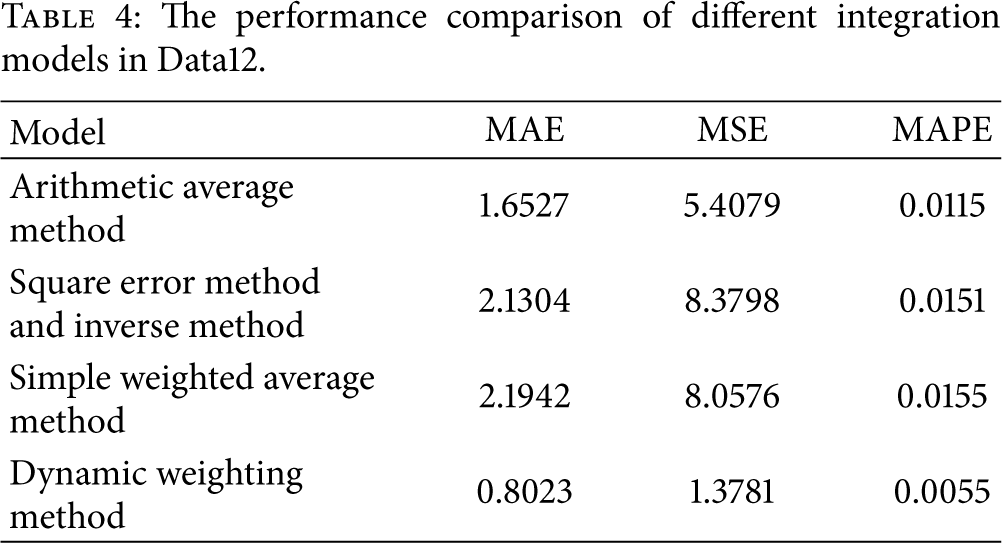
The performance comparison of different integration models in Data12.
In addition, the error comparison in Figures 7 and 8 shows that after using dynamic weight, the fluctuation of error is significantly decreased. Particularly when the traditional method shows drastic change, the dynamic weight method still has a relatively stable effect. In other words, the dynamic weight method proposed in this paper is an effective neural network ensemble output method.
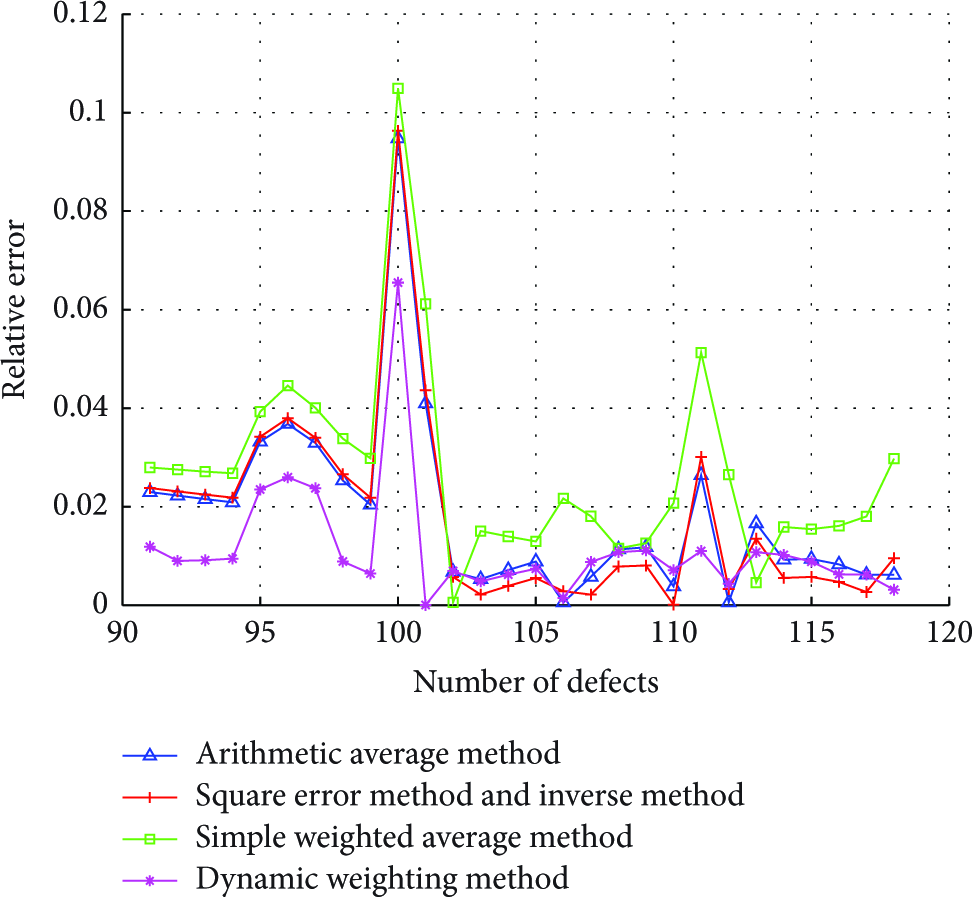
The relative error comparison of different integration models in Data11.
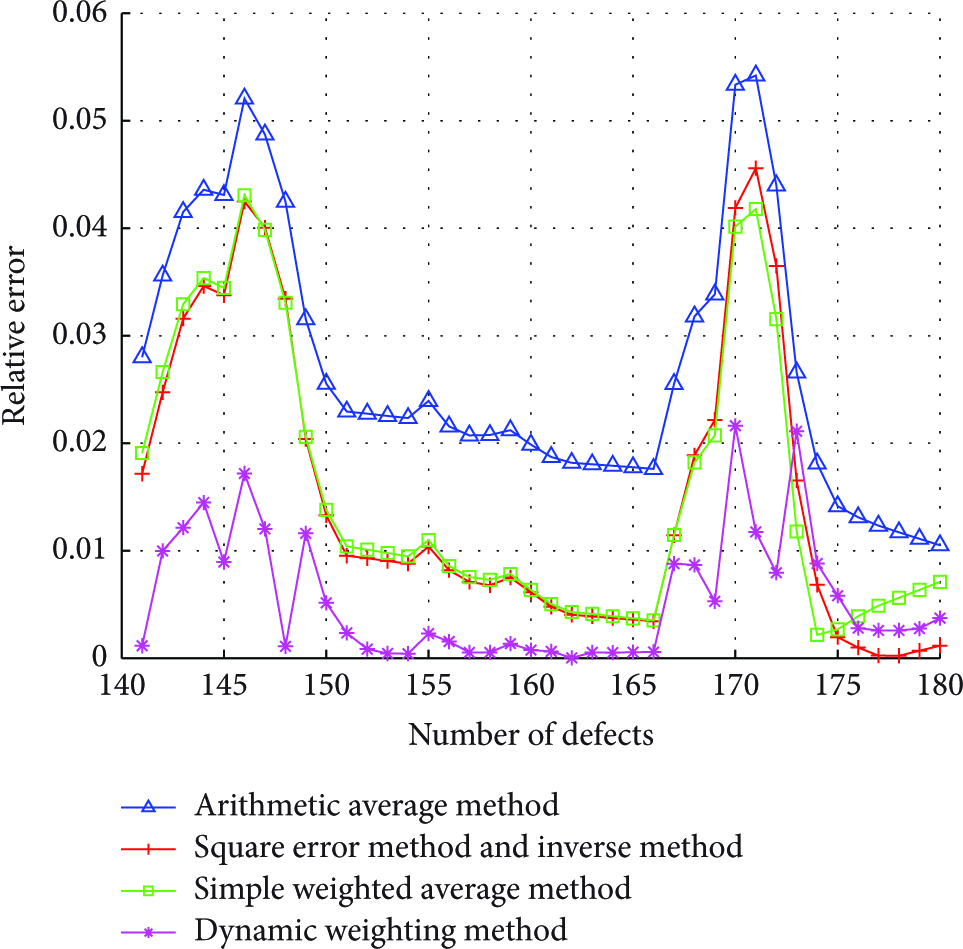
The relative error comparison of different integration models in Data12.
4.3. Verification of the Selective Dynamic Weights of Neural Network Ensemble
In this section, the improved points of the two parts mentioned above are combined and then compared with BP, Elman, and the traditional NNE algorithm, and the selective dynamic weights of neural network ensemble algorithm proposed in this paper are supposed to be DW-NNE.
The performance comparison of each model in Data11 and Data12 is shown in Tables 5 and 6.
The performance comparison of different neural network ensemble models in Data11.

The performance comparison of different neural network ensemble models in Data12.

The comparison of relative error in Figures 9 and 10 shows that BP is relatively stable. Except that the individual points show relatively large deviation, the vast majority of points’ error in Elman neural network is relatively small. In addition, from the overall trend of neural network integrated model, the whole prediction accuracy tends to be steady and its error fluctuation is small, except that the rate of prediction error in very few points is higher than that of single model. However, the fluctuation of the error has been significantly reduced after being further optimized by using the method proposed in this paper.

The relative error comparison of different neural network ensemble models in Data11.
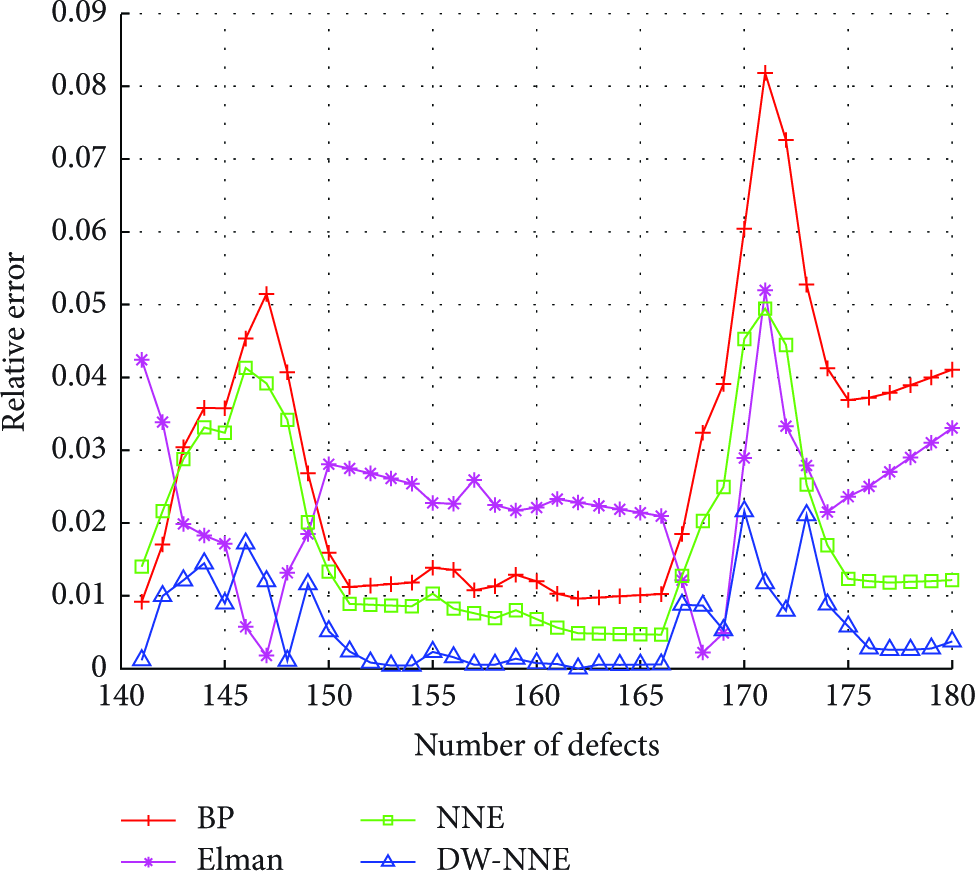
The relative error comparison of different neural network ensemble models in Data12.
Besides, the comparison with each predictive index of each model in Table 2 proves that after using the integrated method, the performance under MAE, MSE, and MAPE, three indicators, was significantly improved compared with any other single models. In addition, due to the fact that the DW-NNE algorithm proposed in this paper combines two kinds of improvement methods based on the traditional integration methods, the integration effect has been further improved; meanwhile its generalization ability also has been enhanced.
The above analysis shows that DW-NNE algorithm proposed in this paper can achieve better prediction effect than other methods.
5. Conclusion
The paper proposed a novel dynamic weight neural network ensemble model (DW-NNE), which solves the problem that the clustering number of clustering algorithm cannot be automatically selected in individual optimization of neural network set. Besides that, the integration output model based on dynamic weight was set up in the paper, and two improved points proposed in the paper have been proved through experiment that they can improve the prediction effect of neural network integration in the software reliability which has the relatively obvious improvements compared with the prediction performance of the traditional models.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
The authors acknowledge the support of the Natural Science Foundation of Shandong Province, China (no. ZR2013FL034).