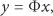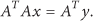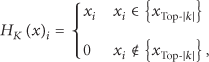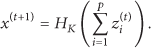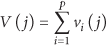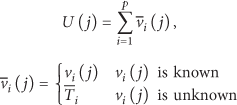We propose a three-phase top- query based distributed data collection scheme which is designed for clustered or multisink wireless sensor networks. The proposed scheme consists of a distributed iterative hard thresholding algorithm and a three-phase top- query algorithm. In the distributed iterative hard thresholding algorithm, the cluster heads or sink nodes reconstruct the compressed data in a distributed and cooperative manner. Meanwhile, the top- query operation in the above algorithm is realized by pruning unnecessary elements among cluster heads or sink nodes in the three-phase top- query algorithm. Simulation results show that there is no obvious difference in the performance of data reconstruction between our proposed scheme and existing compressive sensing theory based data collection schemes. However, both the number of interactions and the amount of transmitted data among cluster heads or sink nodes can be effectively reduced in the proposed scheme. The performance of the proposed scheme is analyzed in detail in this paper to support the claims.
1. Introduction
A wireless sensor network (WSN) is a cooperative network consisting of small, battery operated, and energy constrained wireless sensor nodes. Main applications of WSNs include the monitoring of the areas covered by sensor nodes through the collection of local surveillance data and the transmission of the collected data to one or more sink nodes in multihop communication for processing and analysis [1]. WSNs can be deployed to support a series of new and exciting applications such as wildlife monitoring, disaster response, military surveillance, smart building, and industrial quality control [2].
However, limited resources in wireless sensor nodes in terms of computation, storage, communication bandwidth, and energy make data collection a very challenging issue. Two representative types of data collection schemes that have been proposed for WSNs are spatial-temporal correlation based data prediction schemes [3–5] and distributed source coding schemes [6, 7]. In the first types of schemes, the sensed data are derived using a data prediction model based on preconstructed spatial and/or temporal correlation in the server without being transmitted to the sink node through one or more hops. In the second types of schemes, a coding algorithm based on distributed Slepian-Wolf theory can be designed to reduce the number of transmitted messages among sensor nodes. However, both types of schemes still suffer from the shortcomings of high computational cost in the sensor nodes as well as high communication cost. For example, revised model parameters and coded sensed data need to be transmitted within the network from time to time.
Recently, some new ideas based on the compressive sampling theory have been introduced into solving the data collection problem in WSNs. In the classical Shannon sampling theory, a limited bandwidth of the signal is utilized, resulting in a high degree of redundancy in the sampled data. The compressive sampling theory aims to lift the limitation of the Shannon sampling theory by suggesting that a few random linear projections of a sparse or compressible signal would contain enough information to reconstruct the original signal [8]. The characteristics of the compressive sampling theory, such as compressibility, asymmetry, versatility, and robustness, make it feasible to design sampling algorithms for WSNs [9]. The compressive sampling theory has started to be applied to deal with the problems of data collection [10], localization [11], channel estimation [12], video streaming [13], and coding [14] in WSNs only recently.
In the area of research in data collection based on the compressive sampling theory, Luo et al. proposed the compressive data gathering (CDG) scheme [15] in which through adopting a chain-type topology and a distributed random coefficient projection method the sensed data are compressed among wireless sensor nodes and reconstructed in the sink node. Wang et al. proposed a data collection scheme based on the adaptive compressive sampling theory [16] by taking advantage of characteristics of the spatial-temporal inconsistency of the sparsity in the sensed data and by introducing an autoregressive model into the data reconstruction process. Xu et al. proposed a group of compressive sparse functions by utilizing the symmetric and orthogonal properties of the discrete cosine transform (DCT) functions so that sensed data can be reconstructed after the coefficients of the compressive sparse functions are recovered from the partial sensed data [17]. Motivated by the chaos technology and compressive sampling theory, Lu et al. proposed a distributed secure and efficient data collection scheme by designing a chaotic sequence based sensing matrix generation algorithm and active node matrix algorithm [18]. Wu et al. proposed a sparsest random scheduling scheme for compressive data gathering in wireless sensor networks based on a specially designed sparsest measurement matrix [19]. Although the above data collection schemes can perform energy efficient data collection in WSNs, the compressed projections in each sensor node must be transmitted to the sink node in a multihop fashion and the sensed data can be reconstructed only in the server in a centralized manner. In a clustered or multisink WSN, the cluster heads or sink nodes are not able to obtain the sensed data unless the server retransmits the reconstructed results to them. However, such a compression-reconstruction-retransmission process is time consuming and less energy efficient.
In this paper, we propose a three-phase top- query based distributed data collection scheme for clustered or multisink WSNs. A key characteristic of our scheme is that, by collecting the local set of sensed data and exchanging the compressed projections of these data, the cluster heads or sink nodes are able to obtain the sensed data of the whole network without the need of retransmission from the server. Our proposed data collection scheme consists of a distributed iterative hard thresholding algorithm and a three-phase top- query algorithm. With the distributed iterative hard thresholding algorithm, the cluster heads or sink nodes can reconstruct the compressed data in a distributed and cooperative manner. With the three-phase top- query algorithm, the top- query operation in the above algorithm is realized in a distributed manner among cluster heads or sink nodes through pruning unnecessary elements in the data set. We show through experiment results that the proposed data collection scheme requires a few numbers of interactions and a smaller amount of data transmission among cluster heads or sink nodes than existing compressive sensing theory based data collection schemes while achieving the same performance for data reconstruction.
The main contributions of this paper are summarized as follows.
We propose a distributed compressive sensing theory based data collection scheme in WSNs by utilizing the spatial sparsity of the sensed data. By decomposing the tasks of the iterative hard thresholding algorithm into several correlated parts, the cluster heads or sink nodes can reconstruct the original sensed data in a distributed, energy efficient manner.
We propose a three-phase top- query algorithm to implement the hard thresholding operation in the iterative hard thresholding algorithm in a distributed manner. Differing from the traditional top-k query algorithm which is only suitable to monotonic aggregation functions, such as the sum of nonnegative numbers, the proposed three-phase top- query algorithm can be applied to nonmonotonic aggregation functions. In particular, we use the sum of all numbers as the nonmonotonic aggregation function in this paper.
We compare the performance of the proposed data collection scheme with some current compressive sampling theory based data collection schemes. We also perform a thorough analysis on the overall performance of the proposed scheme, including data reconstruction performance, the amount of transmitted data, and that of computed data.
The remainder of this paper is organized as follows. In Section 2, we briefly introduce the compressive sampling theory and the iterative hard thresholding algorithm. In Section 3, we introduce the system model. In Section 4, we describe the three-phase top- query based distributed data collection scheme. In Section 5, we evaluate the performance of the proposed scheme. Finally, in Section 6, we conclude this paper in which we also discuss our future research directions.
2. Compressive Sampling
2.1. The Basics
In the compressive sampling theory, the signal measurement process can be described as
where is the original signal, is the measurement signal, and () is the measurement matrix. The underdetermined system (1) has an infinite number of solutions for the reason of . In other words, the measurement signal y cannot be accurately reconstructed through the original signal x.
However, the natural signals are usually sparse in a set of appropriate transform bases although they are not sparse in the time domain. Therefore, the original signal x can be expressed as
where is an orthonormal basis matrix and is a k sparse vector. In other words, and indicates the number of nonzeros in s.
By plugging (2) into (1), the signal measurement process can be described as
where matrix is usually referred to as a sensing matrix. Although the underdetermined system (1) is ill-posed, its sparsest solution can be obtained by solving the following optimization problem:
However, the optimization problem (4) is a NP-Hard problem [20]. In practice, it is usually relaxed as the following optimization problem:
A key result in the compressive sampling theory states that if the sensing matrix A satisfies the restricted isometry property (RIP) of order and the restricted isometry constant (RIC) , then, for all k sparse signals, the solutions of (4) and (5) are equal as long as the number of measurements satisfies
where stands for the mutual coherence between matrixes and [21]. The commonly used algorithms for solving the compressive sampling problem include the optimization algorithms, the greedy algorithms, and the iterative thresholding algorithms. In the optimization algorithms, a series of convex optimization methods are adopted to search the global optimal solution of the optimization problem (5). The representative optimization algorithms include the basis pursuit algorithm [22], the gradient projection algorithm [23], and the interior point algorithm [24]. In the greedy algorithms, the support set of the signals is selected based on some kind of greedy selection criteria. This category includes the matching pursuit algorithm [25], the orthogonal matching pursuit algorithm [26], the regularized orthogonal matching pursuit algorithm [27], the compressive sampling matching pursuit algorithm [28], and the subspace matching pursuit algorithm [29]. In the iterative thresholding algorithms, the optimal sparse solution is obtained through hard or soft thresholding operations in a number of iterations. The typical iterative thresholding algorithms include the iterative hard thresholding algorithm [30], the hard thresholding pursuit algorithm [31], and the soft thresholding algorithm [32].
2.2. The Iterative Hard Thresholding Algorithm
The iterative hard thresholding algorithm belongs to the set of iterative algorithms. Its core idea is to approximate the inverse of the sensing matrix A using the transverse of that matrix; that is, let .
By multiplying on the two sides of the constraint condition of the optimization problem (5), we can get
Then we can obtain
by transposition and thus the following iterative equation:
In each round of the above iteration, we choose the largest (in magnitude) k elements of the current iterative vector x and set other elements to zero because the original signal x is k sparse in the orthonormal basis . The aforementioned selection operation is executed using the following hard thresholding operator:
where represents the set of the largest k elements of x in magnitude. Therefore, the iterative equation (9) becomes
After a number of iterations, the results of the iterative hard thresholding algorithm will converge to the optimized solution of optimization problem (5).
3. The System Model
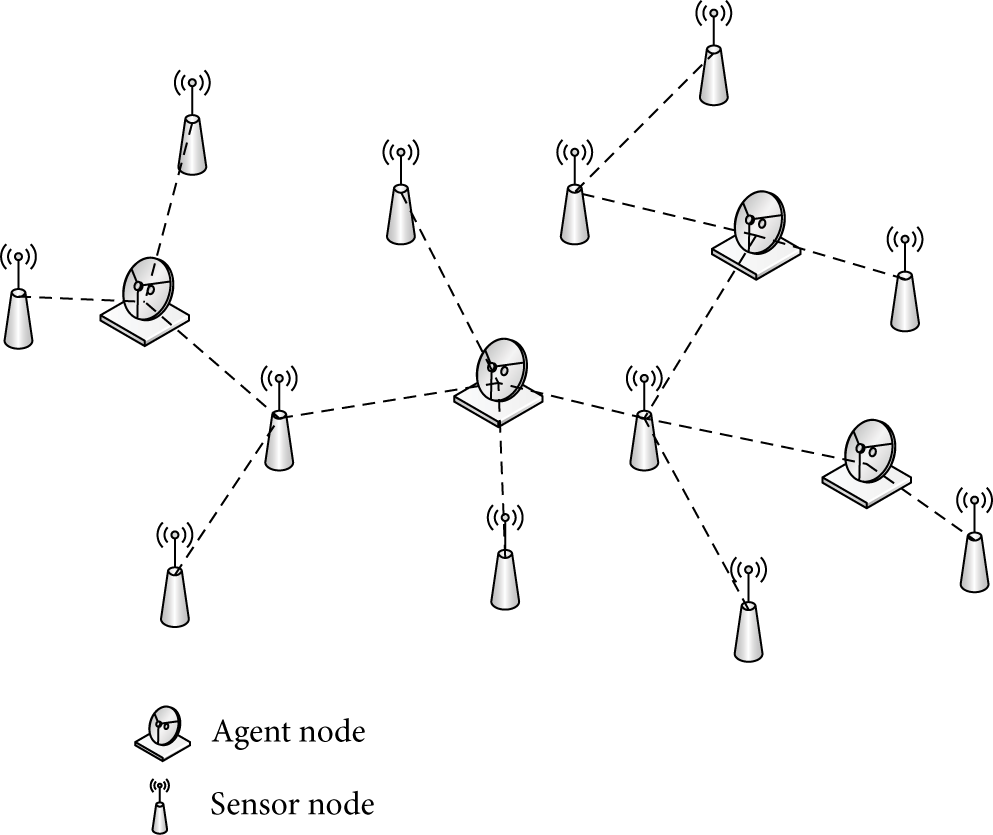
Considering a static WSN in a two-dimensional space as shown in Figure 1 where a number of wireless sensor nodes are distributed uniformly and randomly in the surveillance area, the agent node in the figure can be either a cluster head or a sink node.
The system model.
We assume that there are p agent nodes and m sensor nodes that have been deployed in the WSN and all agent nodes know their own locations. The agent node which is located closest to the center of the network is appointed as the administrator agent and other agent nodes are appointed as the member agent nodes.
The sensed data in a WSN at a certain point of time constitute a k sparse vector because there is spatial correlation among the surveillance data in the monitored area. Each agent node takes linear measurements of x using its subsensing matrix . Thus, the set of all agent nodes will equivalently obtain linear measurements using global sensing matrix , where
Therefore, the problem of sensed data collection in the set of all agent nodes can be ascribed to the optimization problem (5). By reconstructing the original sensed data vector in a distributed manner, all agent nodes can obtain the sensed data of whole sensor network completely.
4. The Distributed Data Collection Scheme
The three-phase top- query based distributed data collection scheme consists of two correlated algorithms: the distributed iterative hard thresholding algorithm and the three-phase top- query algorithm. The first algorithm implements the iterative hard thresholding algorithm in a distributed and cooperative manner while the second algorithm provides the distributed version of the top- operator in (10) for the first algorithm.
4.1. The Distributed Iterative Hard Thresholding Algorithm
Firstly, the initial value of the original sensed data vector and the iteration time t at each agent node are set to zero vector 0 and 0, respectively. Then, each agent node would calculate the intermediate result using its own subsensing matrix and measurement projection by executing
in each iteration t. In particular, the administrator agent node and every member agent node would calculate and , respectively. Then, all the agent nodes would execute the three-phase top- query algorithm to be described in the next subsection and the administrator agent node would get
Finally, the administrator agent node would send the recovered vector to each member agent node and all the agent nodes will continue to the next round of iteration.
We will show through Theorem 1 that the iterative results (14) in the distributed iterative hard thresholding algorithm are equal to the iterative results (11) in the centralized iterative hard thresholding algorithm. Therefore, after a number of iterations, the intermediate result will converge to the optimized solution of the optimization problem (5).
Theorem 1.
The intermediate result in the centralized iterative hard thresholding algorithm is the same as that in the distributed iterative hard thresholding algorithm.
Proof.
According to (13) and (14), the intermediate result in the distributed iterative hard thresholding algorithm is
Therefore, the iterative results in the distributed iterative hard thresholding algorithm are equal to that in the centralized iterative hard thresholding algorithm.
The pseudocode of the distributed iterative hard thresholding algorithm is presented in Algorithm 1.
Algorithm 1: The distributed iterative hard thresholding algorithm.
() All agent nodes run the three-phase top- query algorithm;
() The administrator agent node sends to other member agent nodes;
() ;
() While
4.2. Three-Phase Top- Query Algorithm
The three-phase top- query algorithm is proposed to realize the hard thresholding operator in a distributed manner. Unlike the classical top-k query algorithm which is only suitable to monotonic aggregation functions, our proposed algorithm can perform the largest k absolute elements selection operation which is a nonmonotonic aggregation function in a distributed way. The basic idea of this algorithm is to prune unnecessary elements in the distributed system by only exchanging partial elements among administrator agent node and member agent nodes in three phases.
The three-phase top- query algorithm includes the following three phases.
The initial data set selection phase: in this phase, the initial data set L is selected and distributed among the agent nodes.
The candidate data set selection phase: in this phase, the candidate set S is built by computing the upper bounds and lower bounds of sums for the top- elements.
The top- elements selection phase: in this phase, the precise sums for the top- element are finally determined based on the candidate data set S.
In each round of iteration in the distributed iterative hard thresholding algorithm, every agent node i can obtain its own intermediate result through (13). Before executing the three-phase top- query algorithm, every agent node i should sort by value in a descending order and would get , where j is the element index, is the corresponding element value, and is the number of elements in agent node i.
In the three-phase top- query algorithm, the whole sum , the partial sum , the upper bound of the whole sum , and the lower bound of the whole sum for each element are computed according to the following formulas:
where and are the smallest positive local value and the largest negative local value in among all elements in the initial data set L, respectively. If an element in L does not appear in , just set it to 0.
The partial sum is used to represent the sum of top- elements roughly. The upper bound of the whole sum and the lower bound of the whole sum are used to estimate the range of the sum of the top- elements. By comparing the partial sum with the upper bound and the lower bound of the whole sum, we can filter out unnecessary elements and construct the candidate set S. Thus, the amount of transmitted data among agent nodes can be effectively reduced. Finally, the whole sum is used to compute the sums of each top- element in the aforementioned candidate set S.
The three-phase top- query algorithm is presented in Algorithm 2 where it is worth noting that the administrator agent node and the member agent nodes all follow the same element selection rules.
Algorithm 2: The three-phase top- query algorithm.
Input: the descending list , .
Output: the sums of each top- elements.
The initial data set selection phase
() If node is a member agent node Then
() Sends first k positive and last k negative elements in to administrator agent node;
() Else
() Computes partial sums for received elements according to (17);
() the largest k positive sums and the smallest k negative sums};
() Sends L to all member agent nodes;
The candidate data set selection phase
() If node is a member agent node Then
() Finds and in among all elements in the initial data set L;
() Sends unsent elements in whose values ≥ or ≤ combined with and to the administrator agent node;
() Else
() Computes the partial sum for received elements according to (17);
() the kth highest positive element;
() the kth lowest negative element;
() Computes upper bounds of whole sum for received elements according to (18);
() Computes lower bounds of whole sum for received elements according to (19);
() or ;
() Sends S to all member agent nodes;
The top-elements selection phase
() If node is a member agent node Then
() Sends unsent elements in S to administrator agent node;
() Else
() Computes whole sums for received elements according to (16);
() the largest k elements in magnitude};
The interactive process between administrator agent node and member agent nodes in one iteration of the proposed scheme is shown in Figure 2. Although the three-phase top- query algorithm includes three phases, the computation complexity of the algorithm is trivial. By analyzing the algorithm thoroughly, we can see that sorting and summation are the two nontrivial parts in the proposed algorithm. If the number of involved elements in each agent is n, then the computational complexities of sorting and summation are and , respectively. Therefore, the computational complexity of the three-phase top- query algorithm is . The communicational complexity of the three-phase top- query algorithm will be analyzed through simulations in Section 5.
The process of interaction.
4.3. An Example of the Three-Phase Top- Query Algorithm
We now describe the three-phase top- query algorithm through an example in which the elements in the administrator agent node and in the member agent nodes are shown in Table 1. These elements are sorted by value in a descending order. In this case, the number of agent nodes and the number of selected elements . In other words, we query top- elements in a distributed manner.
An explanation of the example follows. In the initial data set selection phase, member agent nodes 1 and 2 send and to the administrator agent node, respectively. After receiving the elements, the administrator agent node begins to compute the partial sums according to (17). For element 1, because , , and are all known. For element 3, because and are known, but is located in neither the first 2 elements nor the last 2 elements in the administrator agent node. Following the similar computing process, we can get , , , and . Therefore, the initial data set is selected and transmitted to all the member agent nodes.
In the candidate data set selection phase, the smallest positive local value and the largest negative local value in among all elements in L are , , and and , , and , respectively. Therefore, member agent nodes 1 and 2 transmit unsent elements and to the administrator agent node. After receiving the elements, the administrator agent node begins to compute the partial sums as well as the upper and the lower bounds of the whole sum according to (17)–(19). The positive threshold and the negative threshold are the second highest positive element and the lowest negative element. Therefore, candidate data set is selected and transmitted to all the member agent nodes.
In the top- elements selection phase, there are no unsent elements in S. The administrator agent node computes the whole sum according to (16) and selects . Finally, it sends to all the member agent nodes.
5. Experiment and Analysis
We perform the experiment through simulation to investigate the performance of the proposed three-phase top- query based distributed data collection scheme under various conditions. The performance matrices that we have evaluated include data reconstruction accuracy, communication complexity, and computational complexity. The simulation is carried out using Matlab R2011b on a Dell desktop computer with dual core E7500 CPU and 3.0 G memory and involves 50~200 wireless sensor nodes randomly distributed in a 400 × 400 m2 area. Multiple uncorrelated two-dimensional Gaussian distribution has been assumed to simulate the spatial correlated data source. The number of agent nodes is 4~6 and the Gaussian random matrix is selected as the sensing matrix. Finally, the simulation repeats 500 times and the final results are the averages of the 500 results.
5.1. Performance Analysis
We now analyze the performance of the three-phase top- query based distributed data collection scheme. Included in our performance analysis are data reconstruction, the amount of transmitted data, and that of computed data. The amount of transmitted data and that of computed data are the basis for measuring the communication and computational complexity of the scheme in which we count the accumulated amount of transmitted and computed data in all the three phases of the proposed scheme.
Figures 3, 4, and 5 show the signal noise ratio (SNR) of the reconstructed data, the amount of transmitted data, and the amount of computed data of the proposed scheme, respectively, at different data sampling rates. The SNR is computed using the following formula:
to measure the data reconstruction error, where is the original data and is the reconstructed data. We can draw the conclusion from the figures that the performance on data reconstruction improves along with the increase on the data sampling rate. At the same time, the amount of transmitted data and that of computed data would also increase. The reason is obvious since any increase on the data sampling rate would cause more data to be transmitted and computed while leading to better performance on data reconstruction.
The performance on data reconstruction at different data sampling rates.
The amount of transmitted data at different data sampling rates.
The amount of computed data at different data sampling rates.
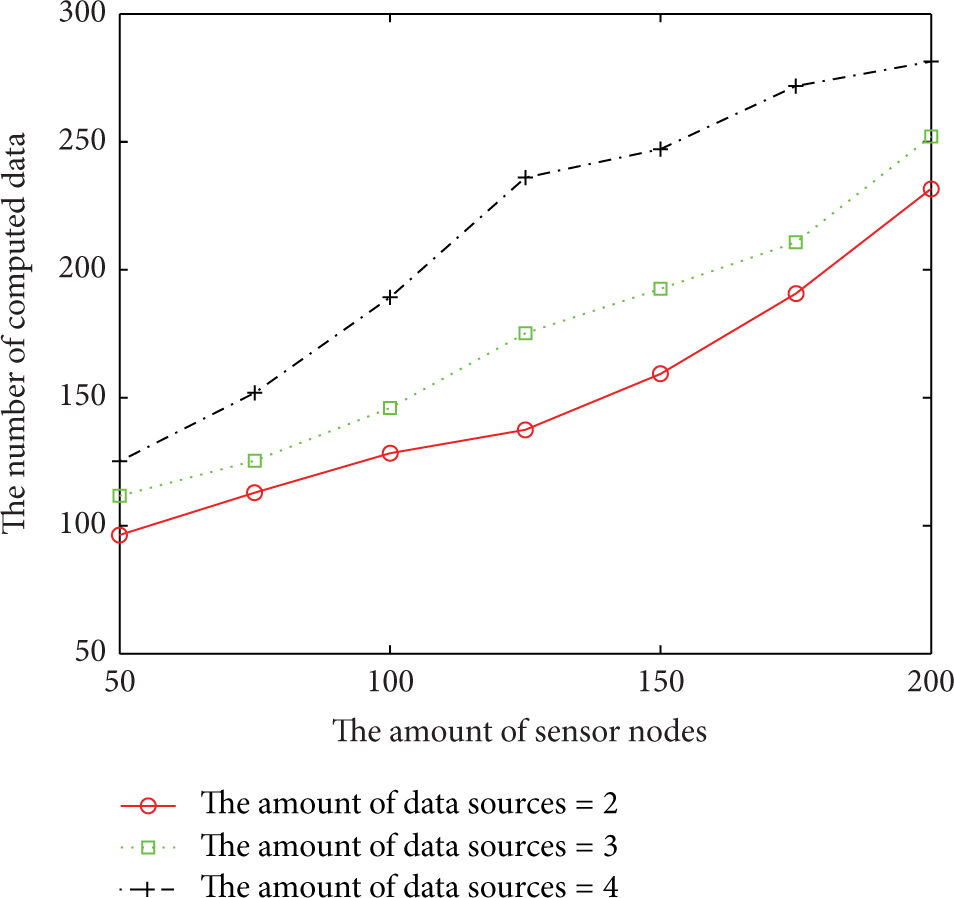
Figures 6, 7, and 8 show the SNR of the reconstructed data, the amount of transmitted data, and the amount of computed data of the proposed scheme, respectively, in different surveillance environments. In the experiment, the number of random data sources varies between 2 and 4. We can draw the conclusion from the figures that the performance on data reconstruction of the proposed scheme would degrade when the number of data sources increases. At the same time, the amount of transmitted data and that of computed data would still increase. The reason is that any increase in the number of data sources will cause an increase in the sparsity of the sensed data set in the network, which would degrade the performance on data reconstruction and cause more data to be transmitted and computed in the agent nodes.
The performance on data reconstruction with different numbers of data sources.
The amount of transmitted data with different numbers of data sources.
The amount of computed data with different numbers of data sources.
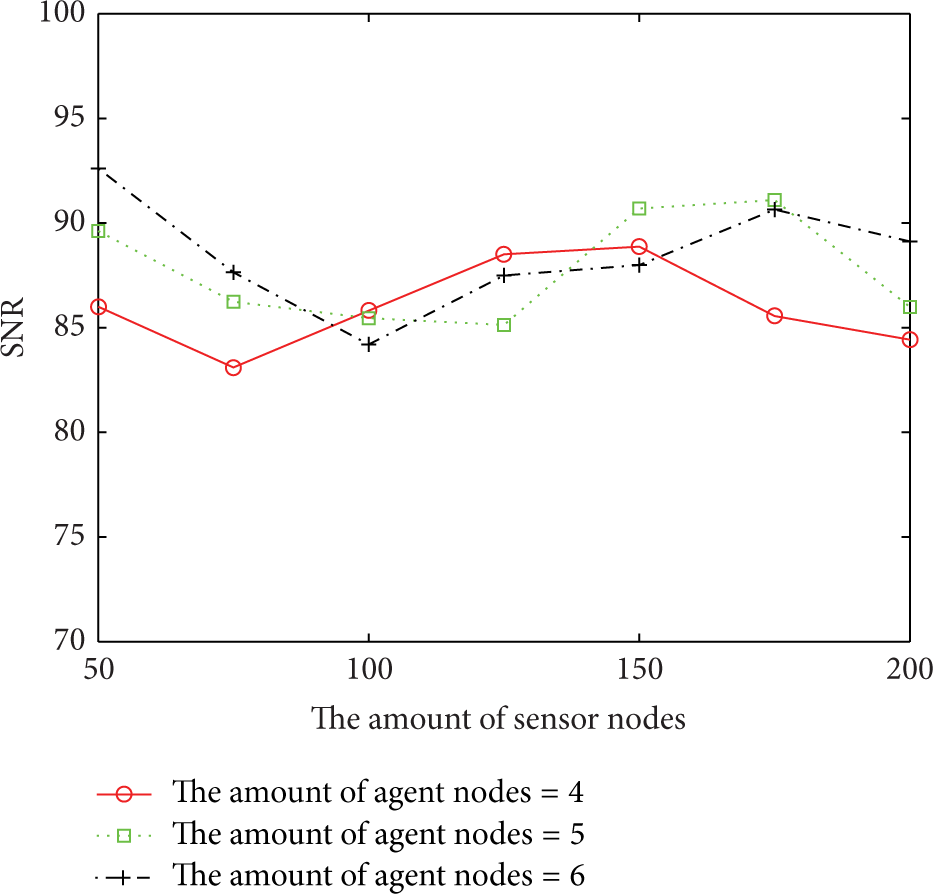
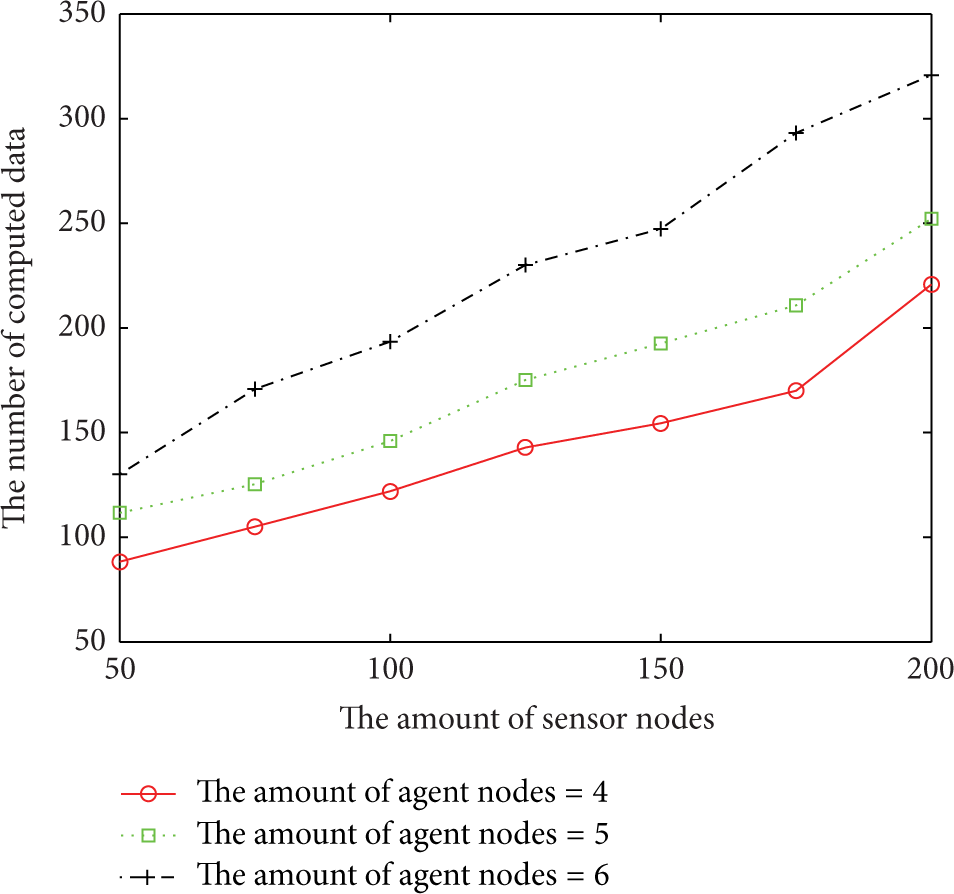
Figures 9, 10, and 11 show the SNR of the reconstructed data, the amount of transmitted data, and that of computed data of the proposed scheme, respectively, with different numbers of agent nodes. In the experiment, the number of agent nodes varies between 4 and 6. We can see from the figures that the performance on data reconstruction has no obvious difference when the number of agent nodes changes. However, the amount of transmitted data and that of computed data would increase along with the increase in the number of agent nodes. The reason is that the number of agent nodes has little influence on the performance of data reconstruction. However, more data should be transmitted and computed when more agent nodes are involved in the scheme.
The performance on data reconstruction with different numbers of agent nodes.
The amount of transmitted data with different numbers of agent nodes.
The amount of computed data with different numbers of agent nodes.
5.2. Performance Comparison
We compare the performance on data reconstruction between our proposed algorithm and two similar schemes, that is, the iterative hard thresholding (IHT) algorithm [30] and the absolute threshold algorithm (ATA) based distributed data recovery algorithm [33], in this subsection.
In the ATA based distributed data recovery algorithm, the top- elements are selected based on computing the absolute thresholds for each element in the list in a distributed manner. The algorithm processes the sorted lists from both the top and the bottom in one single instance. In each direction, the administrator agent node requests an (index, value) pair from each member agent node i and updates the corresponding top- sums it has received so far for agent node i. Meanwhile, the administrator agent node also records the largest value for each agent node i. As long as the administrator agent node has received k values which are larger than , the algorithm terminates. However, multiple interactions among agent nodes are needed while the exact number of interactions cannot be determined in advance. In addition, interactions among agent nodes are not very efficient because only the values that correspond to the same index are transmitted in an interaction.
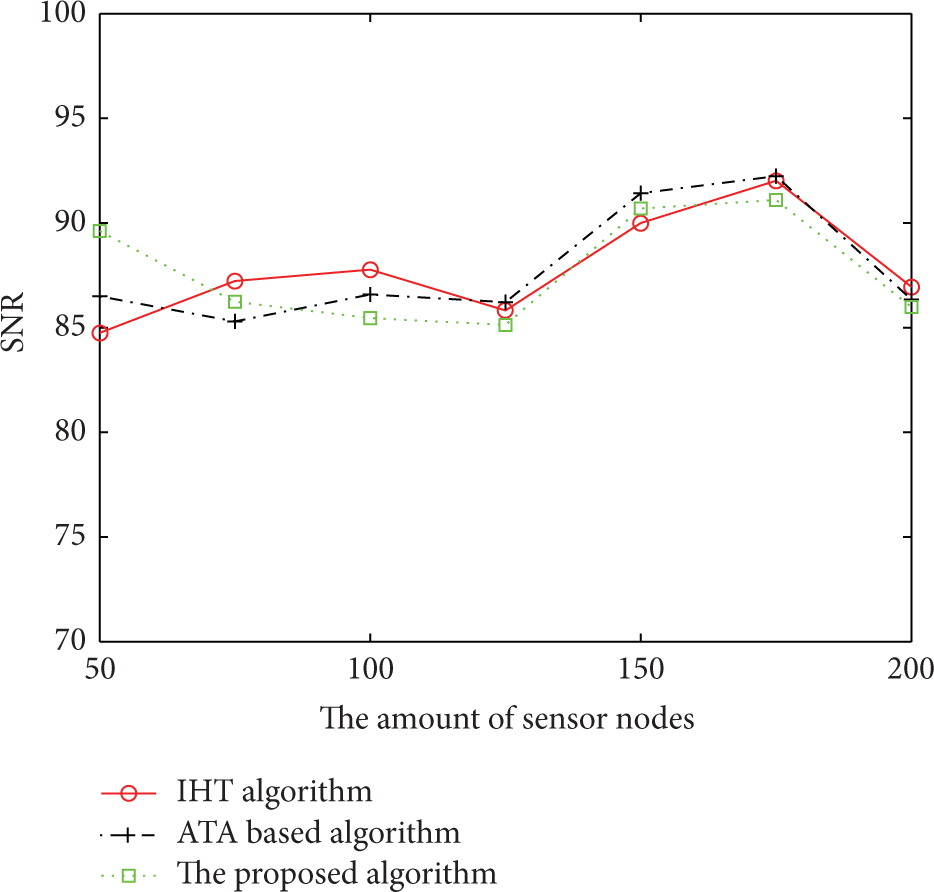
Figure 12 shows the performances on data reconstruction of the three algorithms in which the number of agent nodes is 5, the number of data sources is 3, and the data sampling rate is 50%. We can see from the figure that the three algorithms exhibit little difference in the performance of data reconstruction.
The comparison of data reconstruction performance.
Figures 13 and 14 show the number of interactions and the amount of transmitted data of the three algorithms, respectively. Since IHT is not a distributed algorithm, all the data in the member agent nodes need to be transmitted to the administrator agent node for processing. Thus, the number of iterations is 1. However, since no data pruning is performed before data are transmitted to the administrator agent node, the amount of transmitted data is significantly more than the other two algorithms. Conversely, since ATA and our proposed algorithm are distributed, multiple interactions are needed. We can see clearly from Figure 13 that the number of interactions in ATA increases with the number of sensor nodes. However, the number of interactions in our proposed algorithm always stays at 3, making it a fixed number which is generally far smaller than that in ATA. Therefore, the time delay of executing our proposed algorithm is less than that of ATA. Meanwhile, we can see from Figure 14 that the total amount of transmitted data of our proposed algorithm is the smallest among three algorithms, thus consuming the least amount of energy among the three algorithms.
Number of interactions of the three algorithms.
The amount of transmitted data of the three algorithms.
In summary, the above experiment and performance analysis show that our proposed three-phase top- query based distributed data collection scheme can effectively reduce the amount of transmitted data through limiting the number of interactions while maintaining a similar performance on data reconstruction compared to some comparable schemes.
6. Conclusion
In this paper, we proposed the three-phase top- query based distributed data collection scheme designed for clustered or multisink WSNs. In the scheme, the cluster heads or sink nodes can reconstruct the sensed data of the whole network by collecting local information and exchanging intermediate results among them. The distributed hard thresholding operator is realized by pruning unnecessary elements between the administrator agent node and the member agent nodes in three phases.
The performance on data reconstruction as well as the overhead incurred by the proposed scheme was analyzed through experiment and compared to some existing compressive sampling theory based data collection schemes to demonstrate its clear advantages. The computation and communication overheads of the proposed scheme were also analyzed in detail. Our future research includes the design of the compressive sampling theory based data collection schemes through utilizing the inherited spatial and temporal correlations in the sensed data.
Footnotes
Conflict of Interests
The authors declare that they have no competing interests.
Acknowledgments
The work in this paper has been supported by the National Natural Science Foundation of China (Grant nos. 61402094, 61272500, and 61300195), the Research Fund for the Doctoral Program of Higher Education of China (Grant no. 20120042120009), the Fundamental Research Funds for the Central Universities of China (Program no. N120423005), the Natural Science Foundation of Hebei Province, China (Grant nos. F2012501014 and F2014501078), Beijing Natural Science Foundation (Grant no. 4142008), the General Project of Liaoning Province Department of Education Science Research (Grant no. L2013099), and the Science and Technology Support Program of Northeastern University at Qinhuangdao (Grant no. XNK201401).
References
1.
KulkarniR. V.FörsterA.VenayagamoorthyG. K.Computational intelligence in wireless sensor networks: a surveyIEEE Communications Surveys & Tutorials2011131689610.1109/surv.2011.040310.000022-s2.0-79951581342
JiangH.JinS.WangC.Prediction or not? An energy-efficient framework for clustering-based data collection in wireless sensor networksIEEE Transactions on Parallel and Distributed Systems20112261064107110.1109/tpds.2010.1742-s2.0-79955521337
4.
VillasL. A.BoukercheA.GuidoniD. L.de OliveiraH. A. B. F.de AraujoR. B.LoureiroA. A. F.An energy-aware spatio-temporal correlation mechanism to perform efficient data collection in wireless sensor networksComputer Communications20133691054106610.1016/j.comcom.2012.04.0072-s2.0-84877711091
5.
LiG.WangY.Automatic ARIMA modeling-based data aggregation scheme in wireless sensor networksEurasip Journal on Wireless Communications and Networking201320131, article 8510.1186/1687-1499-2013-852-s2.0-84878035274
6.
ChengS.-T.ShihJ.-S.ChouC.-L.HorngG.-J.WangC.-H.Hierarchical distributed source coding scheme and optimal transmission scheduling for wireless sensor networksWireless Personal Communications201370284786810.1007/s11277-012-0725-02-s2.0-84879688850
7.
WangW.PengD.WangH.SharifH.ChenH.-H.Cross-layer multirate interaction with distributed source coding in wireless sensor networksIEEE Transactions on Wireless Communications20098278779510.1109/twc.2009.0710092-s2.0-61349170742
8.
DonohoD. L.Compressed sensingIEEE Transactions on Information Theory20065241289130610.1109/tit.2006.871582MR22411892-s2.0-33645712892
9.
QaisarS.BilalR. M.IqbalW.NaureenM.LeeS.Compressive sensing: from theory to applications, a surveyJournal of Communications and Networks201315544345610.1109/jcn.2013.0000832-s2.0-84889657929
10.
XiangL.LuoJ.RosenbergC.Compressed data aggregation: energy-efficient and high-fidelity data collectionIEEE/ACM Transactions on Networking20132161722173510.1109/tnet.2012.22297162-s2.0-84882961435
11.
ZhaoC.XuY.HuangH.Weighted centroid localization based on compressive sensingWireless Networks20142061527154010.1007/s11276-014-0686-12-s2.0-84892741104
12.
BajwaW. U.HauptJ. D.SayeedA. M.NowakR. D.Joint source-channel communication for distributed estimation in sensor networksIEEE Transactions on Information Theory200753103629365310.1109/tit.2007.904835MR24198062-s2.0-35148822623
13.
PudlewskiS.PrasannaA.MelodiaT.Compressed-sensing-enabled video streaming for wireless multimedia sensor networksIEEE Transactions on Mobile Computing20121161060107210.1109/tmc.2011.1752-s2.0-84860380810
14.
XuL.LiangQ.ChengX.ChenD.Compressive sensing in distributed radar sensor networks using pulse compression waveformsEURASIP Journal on Wireless Communications and Networking201320131, article 3610.1186/1687-1499-2013-362-s2.0-84878034032
15.
LuoC.WuF.SunJ.ChenC. W.Efficient measurement generation and pervasive sparsity for compressive data gatheringIEEE Transactions on Wireless Communications20109123728373810.1109/TWC.2010.092810.1000632-s2.0-78650203708
16.
WangJ.TangS.YinB.LiX.-Y.Data gathering in wireless sensor networks through intelligent compressive sensingProceedings of the IEEE Conference on Computer Communications (INFOCOM '12)March 2012Orlando, Fla, USAIEEE Press60361110.1109/infcom.2012.61958032-s2.0-84861600807
17.
XuL.QiX.WangY.MoscibrodaT.MarsanM.Efficient data gathering using compressed sparse functionsProceedings of the IEEE International Conference on Computer Communications (INFOCOM ’13)2013Turin, ItalyIEEE Press310314
18.
LuW.LiuY.WangD.A distributed secure data collection scheme via chaotic compressed sensing in wireless sensor networksCircuits, Systems, and Signal Processing20133231363138710.1007/s00034-012-9516-9MR30693442-s2.0-84878873117
19.
WuX.XiongY.YangP.WanS.HuangW.Sparsest random scheduling for compressive data gathering in wireless sensor networksIEEE Transactions on Wireless Communications201413105867587710.1109/twc.2014.2332344
20.
BaraniukR. G.Compressive sensingIEEE Signal Processing Magazine200724411812410.1109/MSP.2007.42865712-s2.0-34548253373
21.
DuarteM. F.EldarY. C.Structured compressed sensing: from theory to applicationsIEEE Transactions on Signal Processing20115994053408510.1109/TSP.2011.2161982MR28659692-s2.0-80051736221
22.
ChenS. S.DonohoD. L.SaundersM. A.Atomic decomposition by basis pursuitSIAM Journal on Scientific Computing19982013361MR16390942-s2.0-003213129210.1137/S1064827596304010
23.
FigueiredoM. A. T.NowakR. D.WrightS. J.Gradient projection for sparse reconstruction: application to compressed sensing and other inverse problemsIEEE Journal on Selected Topics in Signal Processing20071458659710.1109/jstsp.2007.9102812-s2.0-39449126969
24.
KimS.-J.KohK.LustigM.BoydS.GorinevskyD.An interior-point method for large-scale ℓ1-regularized least squaresIEEE Journal on Selected Topics in Signal Processing20071460661710.1109/JSTSP.2007.9109712-s2.0-39449109476
25.
MallatS. G.ZhangZ.Matching pursuits with time-frequency dictionariesIEEE Transactions on Signal Processing199341123397341510.1109/78.2580822-s2.0-0027842081
26.
TroppJ. A.GilbertA. C.Signal recovery from random measurements via orthogonal matching pursuitIEEE Transactions on Information Theory200753124655466610.1109/tit.2007.9091082-s2.0-64649083745MR2446929
27.
NeedellD.VershyninR.Signal recovery from incomplete and inaccurate measurements via regularized orthogonal matching pursuitIEEE Journal on Selected Topics in Signal Processing20104231031610.1109/jstsp.2010.20424122-s2.0-77949732443
28.
NeedellD.TroppJ. A.CoSaMP: iterative signal recovery from incomplete and inaccurate samplesApplied and Computational Harmonic Analysis: Time-Frequency and Time-Scale Analysis, Wavelets, Numerical Algorithms, and Applications200926330132110.1016/j.acha.2008.07.002MR25023662-s2.0-62749175137
29.
DaiW.MilenkovicO.Subspace pursuit for compressive sensing signal reconstructionIEEE Transactions on Information Theory20095552230224910.1109/tit.2009.2016006MR27298762-s2.0-65749110333
30.
BlumensathT.DaviesM. E.Iterative hard thresholding for compressed sensingApplied and Computational Harmonic Analysis200927326527410.1016/j.acha.2009.04.002MR25597262-s2.0-69949164527
31.
FoucartS.Hard thresholding pursuit: an algorithm for compressive sensingSIAM Journal on Numerical Analysis2011496254325632-s2.0-8485603447410.1137/100806278MR2873246
32.
DaubechiesI.DefriseM.de MolC.An iterative thresholding algorithm for linear inverse problems with a sparsity constraintCommunications on Pure and Applied Mathematics200457111413145710.1002/cpa.20042MR20777042-s2.0-7044231546
33.
PattersonS.EldarY. C.KeidarI.Distributed sparse signal recovery for sensor networksProceedings of the 38th IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP '13)May 2013Vancouver, BC, CanadaIEEE Press4494449810.1109/icassp.2013.66385102-s2.0-84890459643