
Abstract
Genetic algorithm is easy to fall into local optimal solution. Simulated annealing algorithm may accept nonoptimal solution at a certain probability to jump out of local optimal solution. On the other hand, lack of communication among genes in MapReduce platform based genetic algorithm, the high-performance distributed computing technologies or platforms can further increase the execution efficiency of these traditional genetic algorithms. To this end, we propose a novel Phoenix++ based new genetic algorithm involving mechanism of simulated annealing. Simulated annealing genetic algorithm has two distinctive characteristics. First, it is the synthesis of the conventional genetic algorithm and the simulated annealing algorithm. This characteristic guarantees our proposed algorithm has a higher probability of getting the global optimal solution than traditional genetic algorithms. The other is that our algorithm is a parallel algorithm running on the high-performance parallel platform Phoenix++ instead of a conventional serial genetic algorithm. Phoenix++ implements the MapReduce programming model that processes and generates large data sets with our parallel, distributed algorithm on a cluster. The experiments indicate that the convergence speed of GA algorithm is significantly faster after adding the simulated annealing algorithm on Phoenix++ platform.
1. Introduction
Genetic algorithms (GA) are a subclass of evolutionary algorithms that use the principle of evolution in order to search for solutions to optimization problems. Evolutionary algorithms are by their nature very good candidates for parallelization, and genetic algorithms do not make an exception [1]. Moreover, researchers have stated that genetic algorithms with larger populations tend to obtain better solutions with faster convergence [2]. These are the main reasons why they can benefit from a MapReduce implementation.
The high-performance distributed computing technologies or platforms can further increase the execution efficiency of these traditional genetic algorithms [3]. As we know, there are at least two ways to improve the performance of genetic algorithms. One way to enhance genetic algorithms is to reconstruct the original genetic algorithm by synthesizing itself with another algorithm to get global optimal solutions. The traditional genetic algorithms are easy to achieve local optimal solution because they tend to fall into the early constringency and low efficient search in the late stage of evolutionary [4]. A simulated annealing algorithm achieves nonoptimal solution at a certain probability to jump out of local optimal solution [5]. The combination of the genetic algorithm and the simulated annealing algorithm can overcome the harsh selection of parameters and improve the performance of algorithm. The other way to further increase the performance of a traditional serial genetic algorithm is to transform this algorithm into a parallel algorithm running on a high-performance distributed computing platform [6]. Based on the parallel characteristic of genetic algorithms, the parallelized genetic algorithms can generally be categorized into 3 types: the master-slave type, the single population fine-grain type, and the multiple population coarse-grain type [7]. The difficulties for common programmers to parallelize a genetic algorithm include the lack of knowledge in computer architecture and details in computer network communication. Moreover, when the scale of problem grows, the proportion of the communicating time for procedure execution also grows rapidly.
Following this thought, this paper proposes a novel Phoenix++ based simulated annealing genetic algorithm that has two corresponding characteristics. The first is that the proposed algorithm is the synthesis of the conventional genetic algorithm and the simulated annealing algorithm. While most traditional genetic algorithms are easy to fall into local optimal solution, the simulated annealing algorithm accepts nonoptimal solution at a certain probability to jump out of local optimum and achieve the global optimal solution. This characteristic guarantees our proposed algorithm has a higher probability of getting the global optimal solution than traditional genetic algorithms. The second characteristic is that our algorithm is a parallel algorithm running on the high-performance parallel platform Phoenix++ other than a conventional serial genetic algorithm [8, 9]. Phoenix++ is a parallel platform that was developed by Stanford University to paralyze traditional serial genetic algorithms. Phoenix++ implements the MapReduce parallel model based on shared memory. So Phoenix++ can process and generate large data sets with our parallel algorithm on distributed clusters. By doing so, Phoenix++ makes up for the lack of communication between the genes in traditional Hadoop platform and improves the platform performance. Before our work, Jin et al. proposed an adapted model of MapReduce with an additional reduce step, in order to deal with iterative algorithms like evolutionary algorithms [10]. With two reduce processes, MRPGA enables MapReduce computing framework applying the iterative process of genetic algorithm [10, 11].
To summarize, we mainly make the following contributions.
We increase the probability of obtaining the global optimal solution of the generic algorithm by synthesizing the generic algorithm with the simulated annealing genetic algorithm. We take advantage of the characteristic of the simulated annealing algorithm in jumping out of local optimal. We parallelize the traditional generic algorithm with the platform Phoenix++ to overcome the deficiency of communication among two genes. Phoenix++ implements a parallel MapReduce model that can further enhance the performance of our proposed algorithm.
The remainder of the paper is organized as follows. Section 2 presents necessary background of our work. Section 3 explains the main work about implementation of the simulated annealing genetic algorithm on Phoenix++. Section 4 illustrates the experiment of the proposed algorithm. Section 5 concludes this paper.
2. Background
2.1. MapReduce Model
Google engineers pioneered the implementation of the MapReduce model [12]. They applied hundreds of dedicated calculation algorithms to handle massive raw data, for document capture (similar to the Web crawler procedures), Web request log, and so forth. To handle these complex computing issues, Google engineers designed the new abstract MapReduce model to isolate data analysts from technical computing operations such as the parallel computing, fault tolerance, data distribution, and load balancing. By doing so, analysts can focus on handling data processing tasks. MapReduce provides users service of the parallel computation and the large scale distributed computing with a set of exposed interfaces.
Hadoop as open source computing platform is the implementation of MapReduce model. Computing nodes in Hadoop work independently and reduce time cost by depositing data locally to save time of data transmission. So Hadoop is weak in communication among computing nodes. One salient characteristic of genetic algorithms is that individuals can communicate with each other randomly in each generation. Obviously, it is hard for Hadoop to support this characteristic naturally. Accordingly, although Hadoop is of high performance to speedup ratio, it can also result in decreasing the probability of getting optimum solution. For this reason, we turn to study the parallelization of genetic algorithms on Phoenix++ platform.
2.2. Phoenix++ Parallel Computing Platform
With the rapid development of computer hardware, the applications of multicore and multi-CPU machine become the trend of current computing techniques. Many parallel platforms have developed to increase the system resource utilization and reduce programming complexity, for example, OpenMP and Phoenix/Phoenix++ [13]. A platform takes care of the internal thread management, provides operators a set of unified application programming interfaces (API), and improves execution performance of parallel programs. Phoenix++ is this sort of platform that was developed by Stanford University. As an updated parallel computing platform of Phoenix system, Phoenix++ implements both the MapReduce model and a shared memory model [14]. With multiple-thread technique, Phoenix++ can produce a large number of parallel Map tasks and reduce tasks to enhance the performance of parallel algorithms. Phoenix++ also applies a shared memory buffer to promote the exchange of data between two threads but avoid frequent data copy operation. Phoenix++ not only automatically manages threads but also executes dynamic task scheduling, data segmentation, and fault tolerance between two processor nodes. By doing so, Phoenix++ can provide efficient parallel support for multicore systems.
3. Implementation of the Simulated Annealing Genetic Algorithm on Phoenix++
3.1. Implementation of the Simulated Annealing Genetic Algorithm
The typical process on genetic algorithm includes selection, crossover, mutation, and screening the best gene. We insert the simulated annealing algorithm into the genetic algorithm in stages of crossover and mutation. The whole process of simulated annealing genetic algorithm is shown as Figure 1.

The whole process of simulated annealing genetic algorithm.
3.1.1. Crossover
The individuals of population can pairwise couple using a random method. If the result of a two-two cross operation on any gene segments of two individuals is below the crossover probability (we usually take the empirical crossover probability as 0.8 in experiments), the fitness of two individual genes after crossover will be reappraised. We compare the fitness of new individual with its father individual. In this way, we can accept individuals of poor fitness as the next generation's new individual at a certain probability according to the simulated annealing model. This work is beneficial to reducing the possibility of falling into a local adaptive optimal.
3.1.2. Mutation
We usually make genes in chromosome to mutate with a certain probability (we usually take the empirical mutation probability as 0.2 in experiments). We use Guotao operator to reverse the mutation procedure. For the new individual
3.1.3. Retain Elites
To guarantee that the best genes in each generation can continue the population reproduction, we need to screen the whole population of genes after each crossover. That is to make the next generation inherits the highest fitness in this generation. For a serial genetic algorithm in the following experiments, we take a traverse of the whole individuals of the population to find the best gene. However, when there are a large number of individuals in population, this operation may become a bottleneck to improve the performance of the serial program. So the proposed parallel algorithm will solve this problem with the parallel technique.
3.2. Design of Simulated Annealing Genetic Algorithm on Phoenix++
A genetic algorithm abstracts the problem space as a population that consists of a large number of individuals. The loop function of the genetic algorithm enables the population evolution and constantly searches for the best individual. Each generation of evolution involves the operations as chromosome crossover, gene mutation, evaluation of the individual genetic quality, and selection of the best individual. Chromosome crossover means banning arbitrary choice of two ancestral individuals and swapping gene segments of these two ancestral individuals. Genic mutation means randomly transforming any gene fragments of an ancestral individual. Evaluation of the individual genetic quality uses the evaluation scheme for individual. Selection of the best individual means selecting the individual that passes the best gene to the next generation from the ancestral individuals according to the evaluation parameters.
Since the probability of the gene mutation is relatively small, it persists for a short period of time. However, since the chromosome crossover's operation involves multiple individuals, the level of parallel is not high. If we insert a plurality of individuals into the input queue of Map phase and randomly take out two individuals to crossover in the map function, we have to solve two problems in the implementation of a genetic algorithm on Phoenix++. The first is that Phoenix++ provides the user with interface that gets an individual from the input queue as parameters to the map function at a time. Unfortunately, the map function can only operate on this individual. But we must operate on these two individuals at the same time to realize the crossover. So it is difficult to realize this implementation if we cannot revise the API interface of the Phoenix++. The second problem is that Phoenix++ for all of the user's API interface functions is the constant function. So the API interface function is not able to change the class of any member variables. While the crossover needs to change the order of individual gene, it is difficult to do this task if we cannot revise the API interface of the Phoenix++.
In this paper, we put chromosome crossover and genic mutation out of the MapReduce framework. For a larger population, compared with the time of evaluation of individual genetic quality and selection of optimal individual, the time of chromosome crossover and genic mutation is a correspondingly smaller proportion. Consequently, the parallelization of the genetic algorithm mainly reflects the individual genetic quality's evaluation of the operation and the selection of optimal individual operation.
3.2.1. Genetic Algorithm Framework on MapReduce
Using MapReduce for running genetic algorithms has been a subject of research in the last few years. Verma et al. proposed the system framework of MRPGA in 2009 [15]. This system consisted of a master, a number of mappers, and multilevel reducers. The master is mainly responsible for the distribution of tasks and scheduling work. User enables the Mapper according to the map rules. Each reducer is responsible for the execution of reduce task. Di Geronimo et al. presented a parallel genetic algorithm for the automatic generation of test suites. The solution is based on Hadoop MapReduce since it is well supported to work also in the cloud and on graphic cards, thus being an ideal candidate for high scalable parallelization of genetic algorithms [16]. Narayanan and Krishnakumar proposed a simple genetic algorithm with optimum population size, mutation rate, and selection strategy which is parallelized with MapReduce architecture for finding the optimal conformation of a protein using the two-dimensional square HP model [17].
In our work, we introduce the mechanism of simulated annealing based on the system framework of MRPGA and implement simulated annealing genetic algorithm on Phoenix++. To meet the evolving of population, our prototype system introduces a coordination mechanism to manage the system operations as a whole.
3.2.2. The Key Value Pairs of Simulated Annealing Genetic Algorithms on Phoenix++
The execution process of our proposed parallel genetic algorithm is divided into three phases: “map,” the first phase of “reduce” and the second phase of “reduce.” Table 1 exhibits the output key value pairs in the three phases.
The output key value pairs in the three execution phases of the proposed parallel genetic algorithm.

First, every individual is distinguished by its unique ID number. After the map phase, all individuals get together by the same ID number. But these results of the map phase are deposited in the current thread's processor cache. So these results are identified as a “local” data. For the standard MapReduce implementation, all individuals with the same ID number gather together as the reduce phase of the input. And the implementation of the generic algorithm on Phoenix++ is that Phoenix++ provides three optional intermediate key values of storage mode for the application: the variable length hash table implementation, the fixed length hash table implementation, and the fixed length array implementation. The combiner container is attached behind to the hash table or the array.
In the first phase of “reduce,” the implementation of the content is to select the best individual from its input queue and put it into the output queue through the evaluation function. In the second phase of “reduce,” Phoenix++ merges the output queue of the first “reduce” into a queue and finds the global optimal individual by sorting the value in the queue and gets the global optimal individual as the final result.
3.2.3. The Map Phase
Each individual of the Map operation in each generation cycle will call a map function. As the input of map function, datatype int &p represents an individual and map container &out represents the container object of the storage map output. And the output of the map function includes the ID number of the individuals in the population and the individual evaluation value. The Pseudo-code of the map function is represented as in Algorithm 1.
Function mapper(p, / x = Evaluation(p) / id = find_id(p) / Emit(
Algorithm 1
When there is a big population size, the time of paired chromatids and genetic mutation is substantially less than the time on estimating individual genes and selecting optimal individual genes. To compensate the cost of communication and computation on the execution of genetic algorithm, Map component in MapReduce optimizes the operations on estimating individual genes and selecting optimal individual genes, that is, the estimation function evaluation(int k) and the select function find_id(int Sumgen), as shown in Algorithm 2.
double Evaluation(int k) { double fit; fit = 1.0/group_dist return fit; } void dist() { int for ( group_dist for ( group_dist } group_dist } //The total distance Pop_Num populations are stored in group_dist } String find_id(int Sumgen) { int double tmpfit; for ( tmpfit = (double)(rand()%1000000 + 1)/1000000.0; //1000000 if ((tmpfit − Sumgen[1].refit) < eps) { tmpgen } else { for ( if ((tmpfit − Sumgen tmpgen for (int tmpgen tmpgen break; } } } } //Using a random function to re-select a population for ( Sumgen Return tmpgen }
Algorithm 2
We insert all the outputs of the “map” phase into the local output queue and take all results that are in accordance with ID as an index into a fixed length hash container. The operation find_id() can record the ID by adding a ID domain in a structure definition of individual body. By doing so, we can avoid re-putting individual p back into the population search and time waste.
3.2.4. The First Reduce Phase
The output results of “map” phase can be integrated and redistributed into each queue as the input of the first phase of “reduce” phase through the container and combiner. The first phase of “reduce” aims to find out the optimal individual from the input queue and insert the ID number and the assessment value of optimal individual as the output of this phase into the output queue. The first phase of “reduce” also aims to find out the local optimal individual. The corresponding Pseudo-code of this procedure can be described as a function “reduce,” as shown in Algorithm 3.
function reducer(key, values, out) eval = INF foreach value in value_list eval = / Emit(key, eval)
Algorithm 3
3.2.5. The Second Phase of “Reduce”
The second phase of “reduce” is to complete the selection of a global optimal individual to make the output of the second phase of “reduce” for each reduce queue as the input of second “reduce” queue input. For the second phase of “reduce,” the Phoenix++ provides a merge mechanism that can rank all the outputs of the first phase of “reduce” in global according to a certain value. Consequently, this algorithm can easily achieve the global optimal individual search by using this merge mechanism. The corresponding Pseudo-code can be presented as function “final_reducer,” as shown in Algorithm 4.
function final_reducer(key, value) sort() / Emit(id, val); /
Algorithm 4
4. Algorithm Experiment
4.1. Experimental Setup
We setup an experiment that applies the proposed parallel distributed algorithm to the classical TSP problem that solves combinatorial optimization issues. The experiment runs the serial simulated annealing genetic algorithm and the simulated annealing genetic algorithms on Phoenix++, respectively. The experiment takes the CPU as Intel (R) Xeon (R) E5630 @ 2.53 GHz, 16 Cores; the cache size 12288 KB/core Memory, 16 GB; and the population size as 3001; the genetic Algebra as 10000. The experiment uses TSP data set at http://www.tsp.gatech.edu/index.html, beta site test data. The number of test of the city is 38. Data are deposited as text that can be exported in the city number/horizontal/vertical coordinate with information, as described in Table 2.
Details information of experimental data set.

4.2. Experimental Result
After several round experiments, the final path is obtained as follows: 0→9→13→20→28→ 29→31→34→36→37→32→33→35→30→26→27→23→21→24→25→22→19→14→12→15→16→17→18→10→11→8→7→6→5→4→2→3→1→0. The length of the path is 6659.431533 that is only 3.431533 times length than the optimal beta results 6656 in TSP data set as http://www.tsp.gatech.edu/index.html and is the same as the optimal results of the serial programs. Besides the optimal global results, the proposed algorithm also aims at improving the execution performance of parallel algorithm. Therefore, we compare our parallel algorithm with its serial correspondence at the same computing environment.
Table 3 exhibits the results of the algorithm executions after 5 rounds, respectively.
The results of the algorithm executions after 5 rounds, respectively.
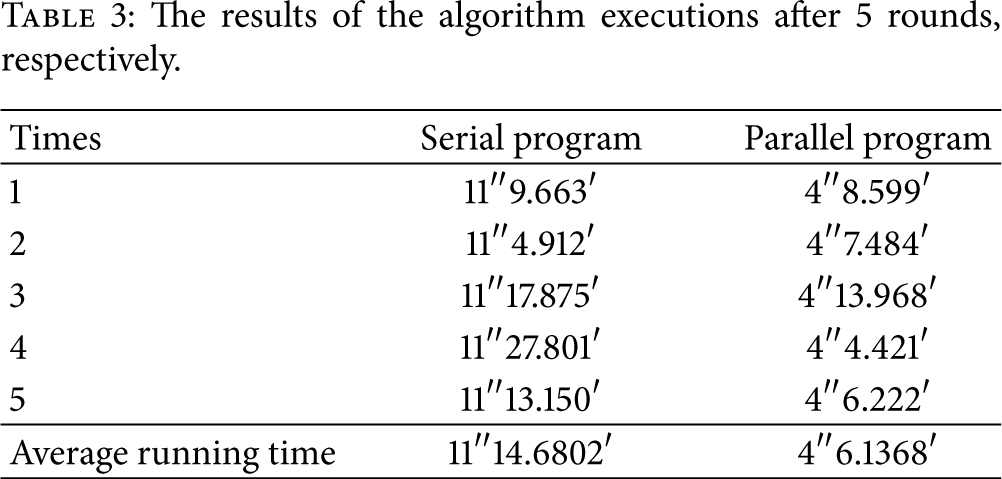
According to Table 3, the speed-up ratio of the serial program to the parallel program is
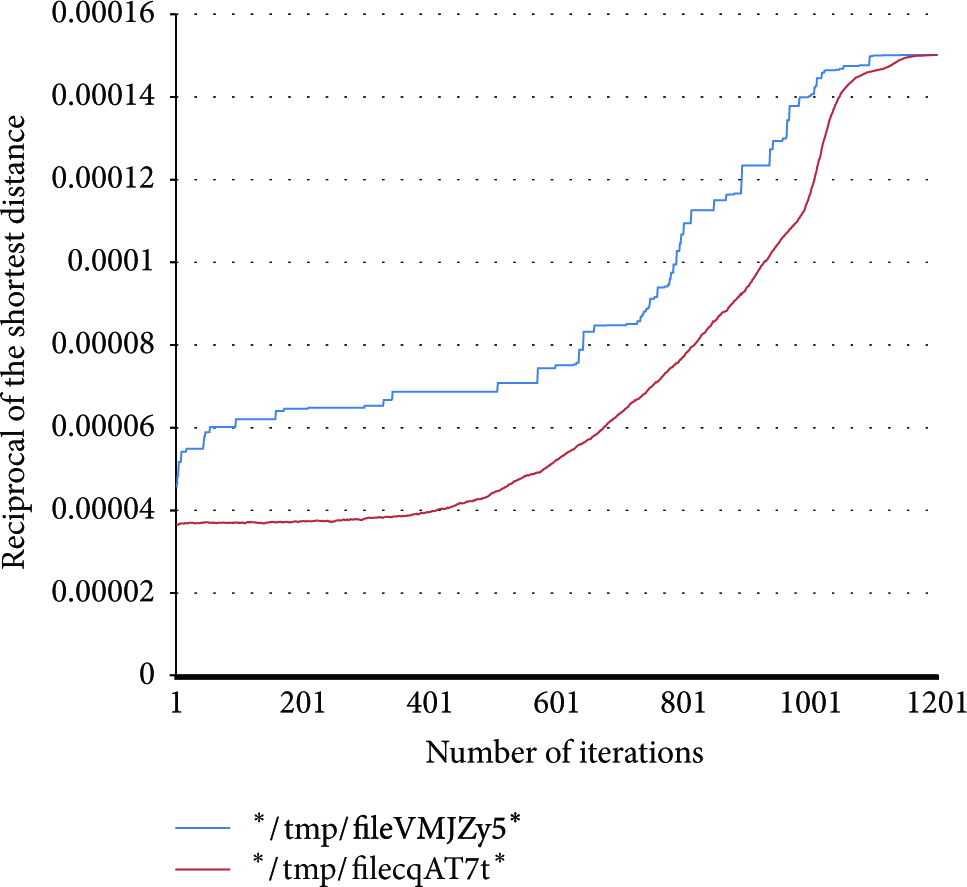
Renderings in the case without emerging of the simulated annealing algorithm.

Renderings in the case of emerging of simulated annealing algorithm.
We further deploy the same program on the Hadoop platform that consists of 10 PCs and get the optimal result as 6549.43. Compared with traditional parallel computing frameworks such as MPI OPMAP, MapReduce simplifies the design of communication within a parallel genetic algorithm and enhances the robustness. Thus it cannot interrupt executing computing tasks due to the computing equipment failure. This characteristic is very important in the execution of complex tasks. So compared with Hadoop, the Phoenix++ is more efficient in the parallel communication because it adopts the way of shared memory to implement MapReduce.
5. Conclusion
This paper proposes a simulated annealing genetic algorithm based on Phoenix++ and the shared memory, which synthesizes the advantages of both the simulated annealing algorithm and the genetic algorithm. Phoenix++ provides a unified programming interface (API) for users. Users only need to call its API without taking consideration of the management of its internal thread. It can easily achieve the program parallelization which greatly improves the efficiency of programming. The proposed algorithm also takes advantage of the parallel distributed computing architecture and meets the natural parallel characteristic of swarm intelligence algorithm. So this proposed algorithm is suitable for handling the issue with the large scale data optimization and modeling. The proposed algorithm also keeps the best individual in each subgroup. By keeping the excellent individual evolutionary stability, our algorithm accelerates the evolution and avoids the phenomenon of premature convergence during the single species evolutionary process. Our algorithm exhibits its excellent performance in dealing with the classical combinatorial optimization problem TSP.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was partially supported by grant from the Hubei Provincial Department of Education scientific research programs for youth project (no. Q20133003), the Natural Science Foundation of Hubei Province (no. 2014CFB568), the grants of the National Natural Science Foundation of China (61070013 and U1135005), and Guangxi Key Laboratory of Trusted Software (no. kx201421).