
Abstract
Range-free localization algorithms have caused widespread attention due to their low cost and low power consumption. However, such schemes heavily depend on the assumption that the hop count distance between two nodes correlates well with their Euclidean distance, which will be satisfied only in isotropic networks. When the network is anisotropic, holes or obstacles will lead to the estimated distance between nodes deviating from their Euclidean distance, causing a serious decline in localization accuracy. This paper develops HCD-DV-Hop for node localization in anisotropic sensor networks. HCD-DV-Hop consists of two steps. Firstly, an anisotropic network is decomposed into several different isotropic subnetworks, by using the proposed Hop Count Based Decomposition (HCD) scheme. Secondly, DV-Hop algorithm is carried out in each subnetwork for node localization. HCD first uses concave/convex node recognition algorithm and cleansing criterion to obtain the optimal concave and convex nodes based on boundary recognition, followed by segmentation of the network's boundary. Finally, the neighboring boundary nodes of the optimal concave nodes flood the network with decomposition messages; thus, an anisotropic network is decomposed. Extensive simulations demonstrated that, compared with range-free DV-Hop algorithm, HCD-DV-Hop can effectively reduce localization error in anisotropic networks without increasing the complexity of the algorithm.
1. Introduction
Node localization is one of the most fundamental technologies in wireless sensor networks (WSNs). For most applications of WSNs [1–3], only when nodes know their locations can they tell the system “what is happening in what position.” For instance, in a fire monitoring system, a sensor node detects that a fire breaks out. The system is able to notify people where the fire is only when it knows the node's location. This allows fireman to reach the correct location and take effective measures immediately in order to prevent the spread of the fire. In addition, accurate localization is the foundation of many other WSNs technologies, such as position-aware data processing [4–6] and geographic routing [7, 8].
Among existing localization algorithms, range-free schemes [9–12] have been widely used due to their low cost and low power consumption. However, these schemes assume that the hop count distance between two nodes correlates well with their Euclidean distance, which will be satisfied only in isotropic networks [9, 13] (the definition of isotropic and anisotropic networks can be found in [14]). In practical applications, such as large-scale heritage protection [15] and military reconnaissance [16], sensor nodes are often randomly deployed in complex environments, which makes their network topologies highly irregular, with the possibility of holes or obstacles. Such network is called anisotropic network.
For example, Figure 1 shows an application of WSNs. In this scenario, sensors are distributed in the region to be monitored, and Figure 2 shows the corresponding node deployment. It is obvious in Figure 2 that the hop count distances between some pairs of nodes heavily deviate from their Euclidean distances (Take A and B in Figure 2, e.g., the black solid line represents the hop count distance between A and B, and the orange dotted line represents the Euclidean distance between them). Using the deviated shortest path distance instead of Euclidean distance to take part in localization will cause a serious decline in localization accuracy.

Application example of WSNs.

Node deployment.
(1) Related Work. In order to improve the node localization accuracy in anisotropic networks, scholars have put forward many schemes in recent years, which can be divided into three categories.
The first scheme is mainly dedicated to amending the estimated distance between nodes. Li and Liu [17] proposed REP (Rendered Path) for localization in anisotropic sensor networks. REP assumes that the boundary nodes around obstacles have been obtained by a boundary recognition algorithm. The shortest path between nodes is divided into many different subsections according to the location of the obstacles. The angle between two subsections is calculated by constructing a unit circle in the intersection point of the shortest path and network holes; then, the Euclidean distance can be obtained by using the cosine law. REP is able to amend the estimated distance that is affected by obstacles. The main drawback is that REP suffers heavy computation and communication overhead, requiring high density and computation power of nodes. PDM (Proximity-Distance Map) [18] first uses a matrix to record the estimated distance and the Euclidean distance between anchor nodes. Then, it calculates the linear transformation matrix between the estimated distance and the Euclidean distance using the least square method. By using the linear transformation matrix, the estimated distance can be transformed into an amended distance, which is used to participate in localization. The disadvantage is that PDM requires the uniform deployment of anchor nodes, which is difficult in real applications.
The second solution aims at reducing the localization error by avoiding serious bent path participating in localization. Reference [19] proposed an improvement scheme for DV-Hop. It uses the cubic polynomial interpolation to obtain paths that are not heavily bent. By using these “good” paths in the calculations, the performance of DV-Hop in an anisotropic network can be improved. Reference [20] estimates the shortest paths affected by obstacles or network boundaries between unknown nodes and anchor nodes. By grading the estimating result, [20] chooses the anchor nodes corresponding to those less affected paths to participate in calculation, thus reducing the localization error. Reference [21] chooses some suitable anchor nodes in the networks and calculates the locations of unknown nodes through iterative multilateration. The localization error is controlled by avoiding the use of serious bent paths. Since iterative multilateration is employed, there is cumulative effect in localization error. Reference [22] proposed an improved multihop localization algorithm which is called i-multihop. It can automatically identify and eliminate severely miscalculated distances. In the localization process, these “bad” distances will not be used in calculation. Thus, the localization error can be controlled.
The third method achieves localization of unknown nodes by means of building landmark network. Reference [23] first locates a landmark network, which is composed of nodes that are uniformly sampled from the original network. The density of the landmark network is preset by the system. Each nonlandmark node uses trilateration to calculate its own location according to the distances to its closest three landmarks. References [24, 25] first select some landmark nodes using particular rules. Then, they calculate the Voronoi diagram and its dual Delaunay diagram according to the landmark nodes. The location of an unknown node is computed in each subdiagram. Finally, the original network can be restored through all the Delaunay diagrams. The difference between [24] and [25] is the method of selecting landmarks. Since both of the algorithms require Delaunay division for anisotropic networks, they are much more complicated to implement, which limits the application of the algorithms.
As can be seen from the above analysis, the similarity among the methods in [17–22] is that they all use various mechanisms to avoid or amend serious bent paths, which does not fundamentally solve the impact of anisotropic networks characteristics on localization. Although the schemes in [24, 25] proposed new ideas, their implementation processes are complex, which is not suitable for large-scale sensor networks.
(2) The HCD-DV-Hop Scheme. In this paper, a new method for localization is proposed based on decomposition. Our scheme is composed of two steps. First, it decomposes an anisotropic network into several isotropic subnetworks by using the proposed Hop Count Based Decomposition (HCD) algorithm. Second, it uses the typical range-free DV-Hop algorithm to achieve node localization in each subnetwork. For simplicity, we call the proposed method HCD-DV-Hop algorithm. The contributions of this paper are summarized as follows:
We analyze the reason why range-free DV-Hop algorithm is suitable for localization in isotropic networks but causes serious localization error in anisotropic networks. Then, we give an improved solution. We introduce a distributed localization algorithm for anisotropic networks, which is called HCD-DV-Hop algorithm. HCD-DV-Hop first decomposes an anisotropic network into several different isotropic networks, so that the influence of holes or obstacles on the shortest communication path between far-away nodes is avoided. Since there is no longer serious bent path in each isotropic subnetwork, DV-Hop can be carried out for node localization in such subnetwork. A Hop Count Based Decomposition (HCD) algorithm for anisotropic networks is proposed. HCD includes four steps: boundary recognition, concave/convex node recognition and cleansing, boundary segmentation, and region decomposition. All of these steps are distributed and only require connectivity information. Simulation results demonstrate the superior performance of HCD-DV-Hop under different ratios of anchor node and communication radius in anisotropic networks.
The rest of this paper is organized as follows. In Section 2, we present the motivation of our scheme. Section 3 is an overview of HCD-DV-Hop. Section 4 is devoted to a description of the proposed HCD algorithm for anisotropic networks. The performance of HCD-DV-Hop is evaluated in Section 5. Finally, Section 6 concludes this paper.
2. Motivation
2.1. DV-Hop Algorithm
DV-Hop [9, 26] is one of the most widely used range-free schemes and it consists of three steps.
Step 1 (obtain the minimum hop count).
Each anchor node broadcasts its location information and hop count value with a packet
Step 2 (calculate the estimated distance).
Once an anchor node gets distances to other anchors, it estimates an average size for one hop, that is,
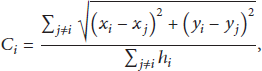
Step 3 (each unknown node estimates its location by using the maximum likelihood estimation).
Let the coordinate of unknown node M be

By using the maximum likelihood estimation, we get the location of unknown node M by


2.2. The Limitation of DV-Hop in Anisotropic Networks
As can be seen from DV-Hop, the estimated location accuracy of an unknown node depends on the accuracy of its estimated distances to the anchor nodes. That is, if the estimated distance between two nodes is closer to their Euclidean distance, the localization result will be more accurate. If the estimated distance heavily deviates from the Euclidean distance, the localization accuracy will be seriously declined.
In Figure 3, we use


The shortest communication path between nodes in different networks.
The estimated distance between M and N in Figure 3(b) is

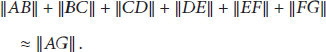
Then,

That is to say, the estimated distance between A and G is approximately equal to their Euclidean distance. Therefore, in such isotropic networks, when the estimated distance takes the place of the Euclidean distance in localization, it will not cause serious error. That is why DV-Hop is suitable for localization in isotropic networks.
However, in an anisotropic network like Figure 3(b), it is obvious that

Taking formula (6) into consideration, then we have

Formula (10) means that the estimated distance between M and N is much larger than their Euclidean distance. When we use the estimated distance to replace the Euclidean distance to participate in localization, it will cause serious localization error.
From the above analysis, we observe that the shortest communication path between nodes is crucial to localization result. Only when the shortest estimated distance between nodes is approximately equal to their Euclidean distance can the estimated location of node obtained by localization algorithm be approximate to its real location. In an anisotropic network, because of the barrier and irregularity of the network topology, the shortest estimated distance between far-away nodes will heavily deviate from the Euclidean distance, which will cause serious localization error.
A straightforward way is decomposing an anisotropic network into many different isotropic subnetworks and then carrying out DV-Hop for node localization in each subnetwork. Since there is no longer serious bent path between nodes in each subnetwork, the estimated distance can be approximately equal to the Euclidean distance. Therefore, in theory, this scheme can reduce localization error to a certain extent in anisotropic networks.
3. HCD-DV-Hop Overview
In this paper, we assume that the network is fully connected. Our proposed decomposition based localization scheme, that is, HCD-DV-Hop, mainly consists of the following two steps, as is shown in Figure 4.
The anisotropic network is decomposed into several different isotropic subnetworks by using the Hop Count Based Decomposition (HCD) algorithm. HCD goes through four steps: boundary recognition, concave/convex node recognition and cleansing, boundary segmentation, and region decomposition, which will be shown in Section 4. For each isotropic subnetwork, the typical range-free DV-Hop algorithm will be carried out for node localization.

HCD-DV-Hop overview.
4. Hop Count Based Decomposition (HCD) Algorithm for Anisotropic Networks
In large-scale wireless sensor networks, there may be thousands of sensor nodes, which makes it almost impossible to decompose the network by artificial means. So this paper will design an algorithm to achieve decomposition by using connectivity information of the network. The proposed Hop Count Based Decomposition (HCD) algorithm consists of four steps.
Step 1 (boundary recognition).
This step aims at recognizing the boundary nodes in the network.
Step 2 (concave/convex node recognition and cleansing).
Based on boundary recognition, the concave/convex node recognition algorithm and cleansing criterion is proposed to obtain the optimal concave and convex nodes.
Step 3 (boundary segmentation).
The optimal concave and convex nodes are used to flood the boundary nodes to segment the boundary into different branches.
Step 4 (region decomposition).
The neighboring boundary nodes of optimal concave nodes flood the network to decompose an anisotropic network into different subnetworks.
4.1. Boundary Recognition
The existing boundary recognition algorithms can be divided into two categories: statistical methods [27] and geometrical methods [28]. After years of researches and developments, scholars have proposed many boundary recognition algorithms with good performance, such as [29–31]. Since this paper mainly focuses on region decomposition and node localization, we directly use [31] in our simulations for boundary recognition.
4.2. Concave/Convex Node Recognition and Cleansing
4.2.1. Definition of Concave/Convex Node Based on Cyclotomy
The cyclotomy [32] refers to increasing the number of sides of the regular polygon inside a circle to estimate the circumference by summing them (see Figure 5), based on which the concavity and convexity function of O point is given as


Schematic diagram of the cyclotomy.
In practical application, since the sensor network is discrete, there may be deviations in the calculation results due to the boundary noise. Considering this factor, the definitions of the concave nodes and the convex nodes based on the boundaries of

Therefore, the concavity/convexity of point O can be determined by calculating the value of φ.
4.2.2. Concave/Convex Node Recognition Algorithm Based on Minimum Hop Count
Given an anisotropic network (see C-shape network in Figure 6 for an example), the boundary nodes can be recognized through [31]. Define ω as the set of boundary nodes (the black nodes in Figure 6). For an arbitrary node

Boundary nodes are filled with black. (a) For
For each boundary node
Because of the discreteness of the network,
Next, we give the detail derivation process of concave/convex node recognition criterion. Take

Taking account of the deployment efficiency of sensor nodes, it is reasonable to assume that
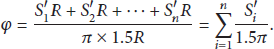
Note that each
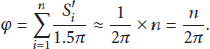
Let

Thus,
Initial concave/convex node recognition criterion in different values of k.

In order to make the results more accurate, the values of
As shown in Figure 7, α and β, respectively, are the intersection points of
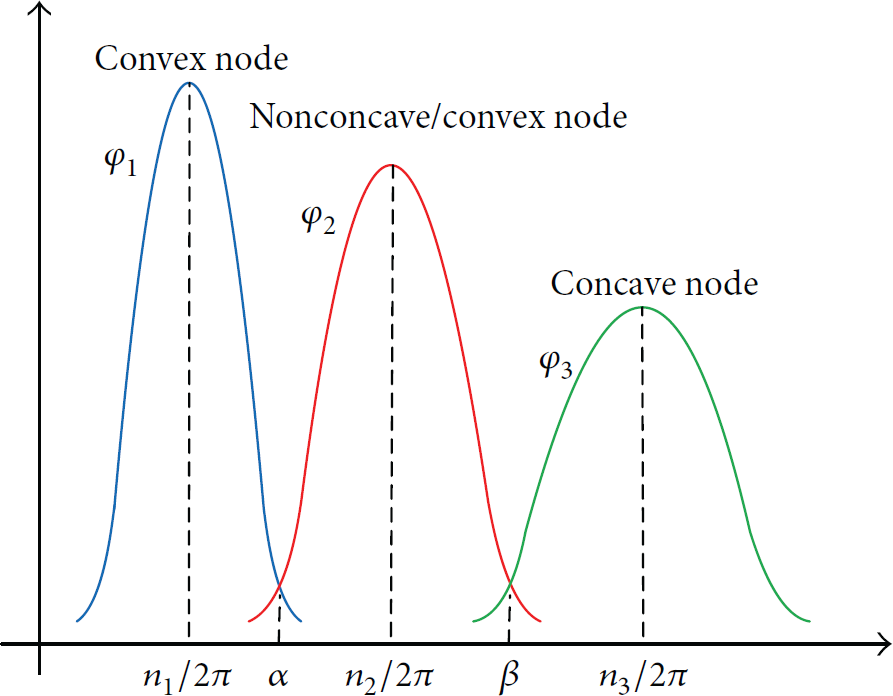
Distribution curve when k is 2.
The normal probability density function is

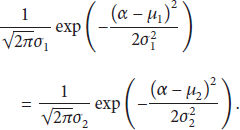
Thus,

The corresponding minimum hop count of α is
Let k, respectively, be 3, 4, and 5, and calculate the corresponding values of α and β. Then, the corrected value of the minimum hop count n is determined and the concavity or convexity of
Final concave/convex node recognition criterion in different values of k.

Assume that there are M boundary nodes in the network, represented by
Step 1.
For each boundary node
Step 2.
If there are
Step 3.
Step 4.
4.2.3. Concave/Convex Node Cleansing
After concave/convex node recognition algorithm, the concavity or convexity of each boundary node has been identified. Since the sensor network is discrete, it is possible that a nonconcave node which is in the nonconcave region is identified as a concave node by mistake. These mistaken concave nodes often appear in an isolate way. In contrast, there always are several concave nodes in a concave area; that is, real concave nodes always gather together (seen in Figures 8(c), 9(c), and 10(c), e.g.; the black nodes are ordinary nodes, and the red nodes are boundary nodes. The nodes with peach circles are concave nodes, and those with cyan circles are convex nodes. Other red nodes without any circles are nonconcave/convex nodes). Therefore, the isolate concave node can be directly eliminated from the recognition result (to simplify our algorithm, we define isolate concave node as the concave node which has no concave node within its two hops; similarly, isolate convex node is the convex node which has no convex node within its two hops), as well as the isolate convex node.

Region decomposition of L-shape network. 763 nodes are uniformly distributed, and average degree of the network is 9.13. (a) Original map. (b) Boundary recognition result. The red nodes are boundary nodes. (c) Concave/convex node recognition result,

Region decomposition of C-shape network. 1295 nodes are uniformly distributed, and average degree of the network is 9.04. (a) Original map. (b) Boundary recognition result. The red nodes are boundary nodes. (c) Concave/convex node recognition result,

Region decomposition of single-window-shape network. 1505 nodes are uniformly distributed, and average degree of the network is 9.01. (a) Original map. (b) Boundary recognition result. The red nodes are boundary nodes. (c) Concave/convex node recognition result,
For the concave nodes that gather together in one concave area, since larger concavity of the concave node will lead to larger deviation between hop count distance and the Euclidean distance, we choose the concave node with the maximum concavity as the optimal concave node in this area. In our algorithm, the node with maximum concavity corresponds to the node which is with the biggest minimum hop count between its two k-hop neighboring boundary nodes. It is possible that in some concave area there may be more than one concave node with the same biggest minimum hop count. For this case, we randomly choose one of them as the optimal concave node. The above process is called cleansing process.
Similarly, we use the cleansing criterion to cleanse the convex node in the network. The difference is that the convex node with the smallest minimum hop count should be taken as the optimal convex node. If there is more than one convex nodes with the same smallest minimum hop count in a convex area, we randomly choose one of them as the optimal convex node.
Through the cleansing criterion, the optimal concave/convex node is obtained. For example, the cleansing results of Figures 8(c), 9(c), and 10(c), respectively, are Figures 8(d), 9(d), and 10(d), where the optimal concave nodes are marked with peach and the optimal convex nodes are marked with cyan.
4.3. Boundary Segmentation
Assume that the boundary of the network is fully connected. For simplicity, the optimal concave and convex nodes are called the optimal nodes in this section. In order to segment the boundary, we use the optimal nodes to flood Boundary Segmentation PacKeT (BS-PKT) among the boundary nodes. Each BS-PKT concludes the ID number of the node which generates the BS-PKT. When a boundary node A receives a BS-PKT, A deals the current BS-PKT with the following ways:
If A is not a boundary node, A discards BS-PKT. If A is a boundary node but not an optimal node, A records the ID number in BS-PKT and sends BD-PKT to its neighbor nodes. If A is both a boundary node and an optimal node, but A has not recorded any ID number of other optimal nodes, then A records the ID number in BS-PKT and does not send BS-PKT anymore. If A is both a boundary node and an optimal node, and A has recorded an ID number of another optimal node, A discards the BS-PKT.
After flooding, each boundary node will record two different ID numbers of the optimal nodes. Assume the ID numbers, respectively, are I and J. Let
4.4. Region Decomposition
For a fully connected anisotropic network, define U as the set of the optimal concave nodes. For an arbitrary optimal concave node
To decompose the network, all neighboring boundary nodes of the optimal concave nodes flood Region Decomposition PacKeT (RD-PKT) in the network. Each RD-PKT concludes the ID number of the node which generates this RD-PKT and the boundary number
By this means, each node in the network will record only one RD-PKT, in which the ID and
In summary, after boundary recognition, concave/convex node recognition and cleansing, boundary segmentation, and region decomposition, an anisotropic network finally is decomposed into several different isotropic subnetworks. During the process of HCD, we only need to use the connectivity information of the network, without any additional hardware on sensor nodes. As a range-free localization algorithm, the complexity of communication cost of DV-Hop is
5. Performance Evaluation
To evaluate the proposed algorithm, we simulate on three typical anisotropic network topologies: L-shape, C-shape, and single-window-shape network topologies. In simulations, nodes are uniformly distributed. All nodes have the same communication range. Two nodes are connected if and only if the Euclidean distance between them is smaller than a given communication radius R.
We compare our algorithm with DV-Hop. For comparison, two metrics are used in this section: LE (localization error) and ALE (average localization error). The LE of an unknown node i is calculated by
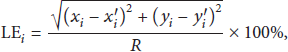

5.1. Region Decomposition
Given three typical anisotropic networks, L-shape network, C-shape network, and single-window-shape network, as shown in Figures 8(a), 9(a), and 10(a), respectively, nodes are uniformly distributed in each network. The communication radius is 40 m. First we use HCD (Hop Count Based Decomposition algorithm) to decompose the networks. Simulation results are shown in Figures 8–10.
5.2. Performance Evaluation of Algorithms under Certain Communication Radius and Ratio of Anchor Node
Here the communication radius is 40 m and the ratio of anchor node is 10%. Anchors are randomly distributed in the networks.
For each anisotropic network, after decomposing, DV-Hop is carried out in each subnetwork. Thus, the LE (localization error) of each unknown node is obtained through HCD-DV-Hop algorithm, as shown in Figures 11(a), 11(c), and 11(e). The LE obtained by DV-Hop is shown in Figures 11(b), 11(d), and 11(f), respectively. Table 3 gives the corresponding ALE (average localization error) of each network by HCD-DV-Hop and DV-Hop.
ALE of each network by HCD-DV-Hop and DV-Hop algorithm.

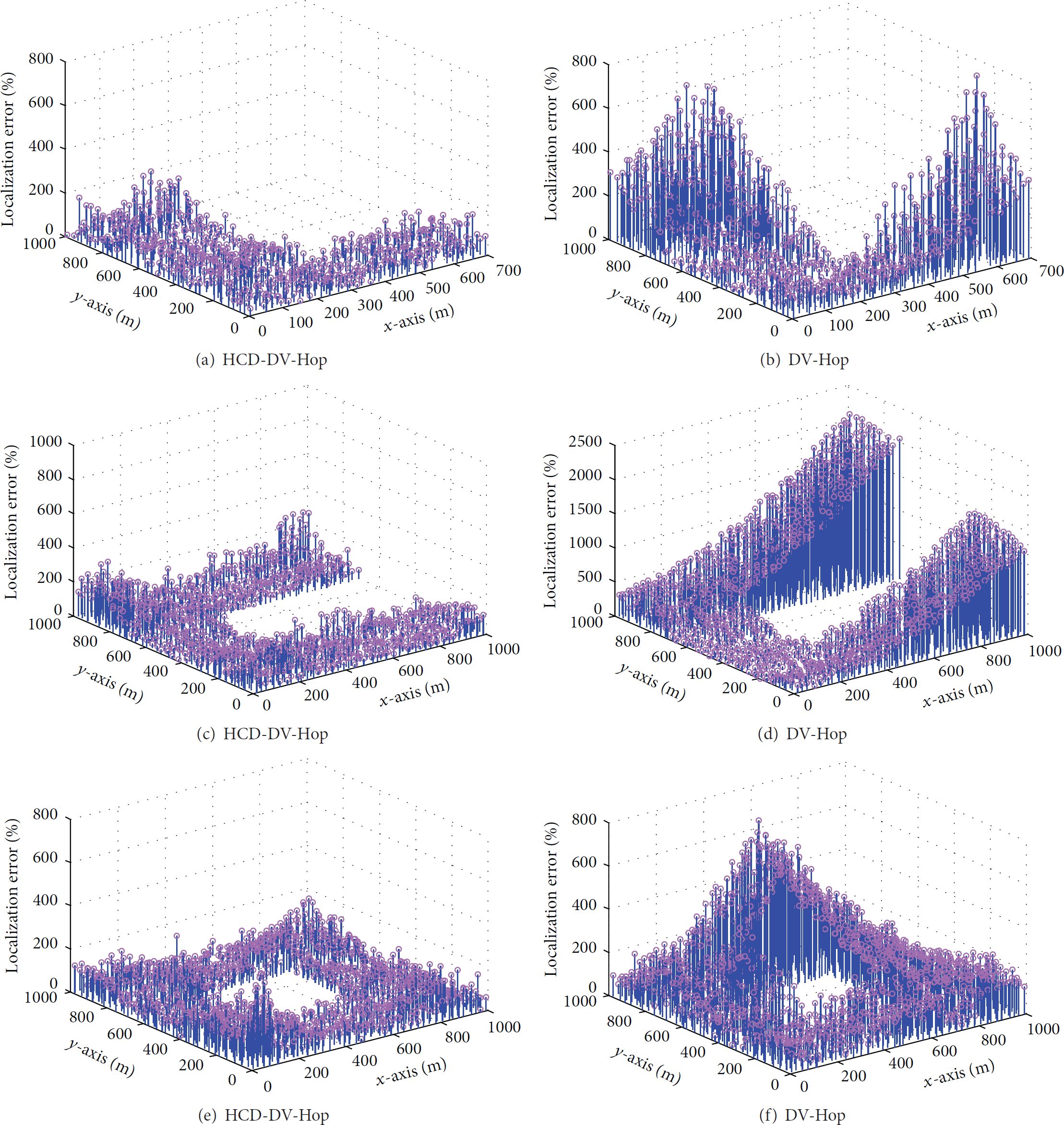
LE (localization error) of each network by different algorithms. (a) LE of L-shape network by HCD-DV-Hop. (b) LE of L-shape network by DV-Hop. (c) LE of C-shape network by HCD-DV-Hop. (d) LE of C-shape network by DV-Hop. (e) LE of single-window-shape network by HCD-DV-Hop. (f) LE of single-window-shape network by DV-Hop.
As shown in Figure 11 and Table 3, we found that whatever the network topology is, HCD-DV-Hop can effectively reduce the LE of most unknown nodes compared with DV-Hop, and the ALE obtained by HCD-DV-Hop is much smaller than that by DV-Hop. Obviously, the reason is that HCD-DV-Hop uses decomposition scheme to avoid serious bent path between far-away nodes participating in localization.
5.3. Performance Evaluation of Algorithms under Different Ratios of Anchor Node
Given a certain communication radius (take 40 m as the communication radius in the simulations), we examine the performance of HCD-DV-Hop and DV-Hop under different ratios of anchor node. In simulations, we randomly generated 200 networks and computed the ALE of each network. Finally, we take the average value of the 200 ALE as the average error under each ratio of anchor node. Simulation results of L-shape, C-shape, and single-window-shape network are shown in Figures 12(a), 12(b), and 12(c), respectively.

Average error under different ratios of anchor node.
Figure 12 shows that, for different communication radius in Lshape, C-shape, and Single-window-shape networks, compared with DV-Hop, the average error of HCD-DV-Hop is significantly decreased. That is, HCD-DV-Hop performs much better in localization than DV-Hop.
5.4. Performance Evaluation of Algorithms under Different Communication Radius
Given a certain ratio of anchor node (take 10% as the ratio of anchor node in the simulations), we examine the performance of HCD-DV-Hop and DV-Hop under different communication radius. In simulations, we randomly generated 200 networks and computed the ALE of each network. Finally, we take the average value of the 200 ALE as the average error under each communication radius. Simulation results of L-shape, C-shape, and single-window-shape network are shown in Figures 13(a), 13(b), and 13(c), respectively.
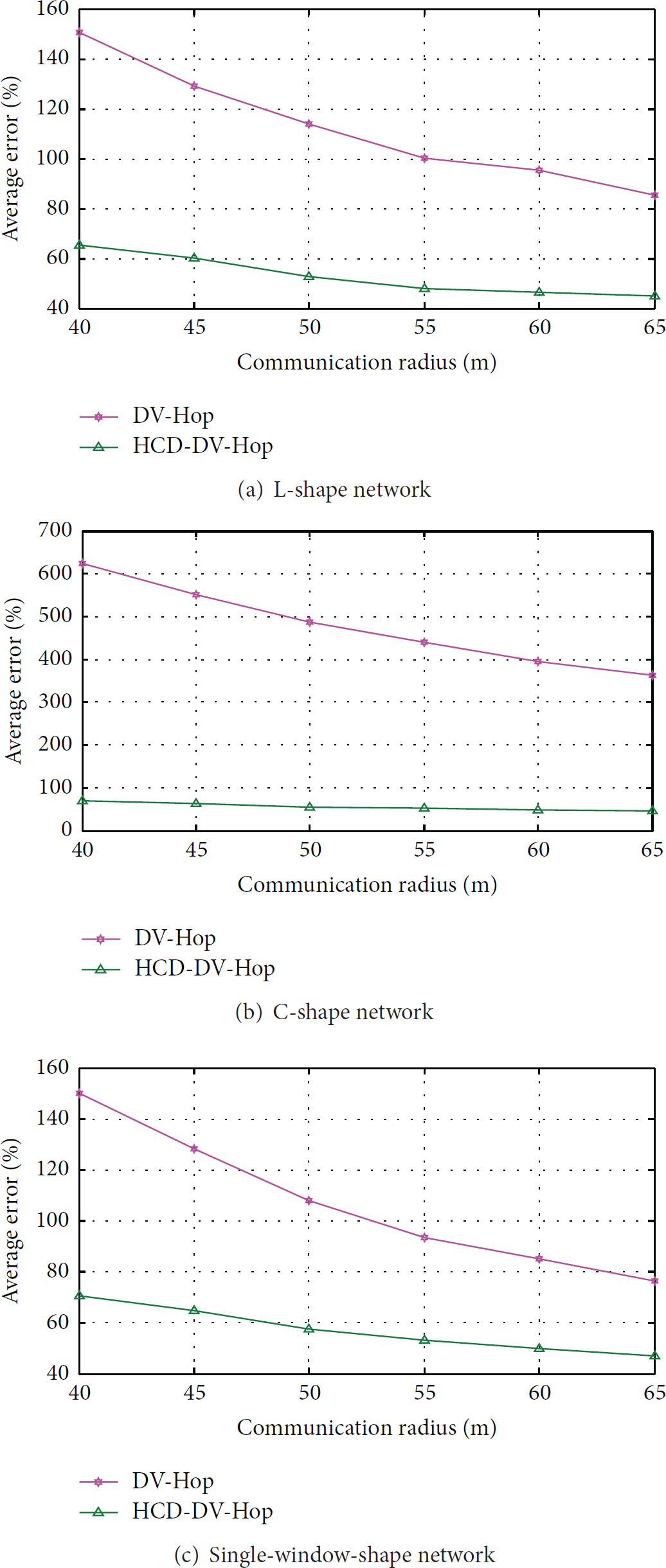
Average error under different communication radius.
From Figure 13, we observe that the average error of our proposed HCD-DV-Hop is much smaller than that of DV-Hop, which obviously proves the localization advantage of HCD-DV-Hop in anisotropic networks.
6. Conclusion and Future Work
In this paper, we have proposed a novel decomposition based localization (HCD-DV-Hop) scheme for anisotropic sensor networks. The main idea of HCD-DV-Hop is first decomposing an anisotropic network into several different isotropic subnetworks in order to avoid the influence of holes or obstacles on the shortest communication path between far-away nodes; then, the typical range-free DV-Hop algorithm is used for node localization in each subnetwork. The HCD algorithm is the core of HCD-DV-Hop. It includes boundary recognition, concave/convex node recognition and cleansing, boundary segmentation, and region decomposition. All of these steps are distributed and only require network connectivity information. Simulation results show that no matter how node communication radius or the ratio of anchor node changes, compared with DV-Hop algorithm, the proposed HCD-DV-Hop scheme can effectively reduce localization error in anisotropic networks without increasing the complexity of the algorithm.
In HCD-DV-Hop, we use the typical range-free DV-Hop algorithm to achieve node localization in each isotropic subnetwork. As HCD scheme is able to decompose an anisotropic network into different isotropic subnetworks, it can be used to investigate the localization performance on the combination of HCD with other range-free algorithms. Additionally, the proposed HCD-DV-Hop scheme is designed for 2D networks. In our future research, we will explore the possible improvements on HCD-DV-Hop in order to adapt to 3D networks.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was supported by the Project NSFC (61170218, 61272461, 61373177, 61070176, 61202198, and 61202393), by the National Key Technology R&D Program (2013BAK01B02), and by the Key Project of Chinese Ministry of Education 211181.