
Abstract
Nowadays, emergencies’ events have a great impact on people's daily life. Web is acting as an important platform for the diffusion and evolution of social events. With the popularization and development of web technology in the world, web is becoming an important platform to cover, transmit, and release the news. Information holders can use Internet as a medium to broadcast various news in real time. But it is difficult for people to excavate the events development trend from web information. In this paper, we introduce a method to measure the evolution process of the Web event based on the semantic outbreak power. Then, we propose an approach to distinguish the event type based on the fuzzy recognition. Finally, we give some instances validation of semantic outbreak power of web event and the correctness verification of the event type distinguish of Web event.
1. Introduction
With the popularization and development of web technology in the world, web is becoming an important platform to cover, transmit, and release the news. Information holders can use Internet as a medium to broadcast various news in real time. Web users can quickly and comprehensively grasp the dynamic events [1].
Web event refers to the web event which is sustainedly and extensively reported and discussed in short online media (such as BBS, news sites, and blogs) [2, 3]. It is likely to cause some harm to the social reality. The reported and discussed forms are various, such as a web page news commentary, the post and reply in BBS, and the records and message in blog. These reports and discussions have a major impact on the social stability and a large number of Internet users. It often accompanies the occurrence, development, and change of the hot topics and social events. Web event has some typical features: (a) it may have wide and speedy transmission; (b) it may have devastating effects on the society; (c) it is not easy to find and control the breaking point. So how to detect and compute the propagation speed, predict the direction of evolution, and effectively control web event is a major challenge. Therefore it is necessary to analyze the future of the web event and measure its evolution.
With the development of internet of things [4–6], big data [7–10], and cloud computing [11–14], evolution is a basic feature of the web events and important research content in the field of topic detection and tracking (TDT) [3]. The main research contents of the TDT [15, 16] involve topic detection and information collection, segmentation of event information and the first report event time detection, and topic tracking. Generally speaking, the TDT technologies try to detect unknown events and cluster news related to these events.
The TDT traces the development of the events. But it is not to measure the dynamic evolution process of the events and does not consider event semantic characteristics in the evolution process. So the TDT cannot offer us a global and clear understanding of the web event. Thus, in order to recover the insufficiency of the TDT, we have proposed a method to measure the evolution process of the web event based on semantic outbreak power. Then, we put forward an approach to distinguish the event type based on the fuzzy recognition.
The paper is organized as follows. Section 2 presents briefly the topic detection and topic tracking. Section 3 introduces a method to measure the evolution process of the web event based on semantic outbreak power. Section 4 puts forward an approach to distinguish the event type based on the fuzzy recognition. Section 5 gives some instances of validation of semantic outbreak power of web event and the correctness verification of the event type distinguish of web event.
2. Related Work
The TDT [17–19] was first initiated by the Defense Advanced Research Projects Agency (DARPA) and National Institute of Standards and Technology (NIST). It aims to develop a series of information organization technology based events and help people cope with information overload problem. Then, we mainly introduce the research of the two subtasks: topic detection and topic tracking.
2.1. Topic Detection
Topic detection puts data stream from the newswire and news sources reported into different topics. If it is necessary, topic detection will establish the new topic of technology. Topic detection can be thought of as an event cluster. Most of these clusters are incremental [20].
Most of current research topic detection using the traditional method of natural language processing: the center vector method [17],
More representative research includes the following: Yang et al. [24] used the strategy which combined the condensing type clustering algorithm and the average clustering algorithm; the researchers of CMU [25] mainly use the single pass clustering method with time Windows to detect the topic; literature [26] proposed a hierarchical community discovering algorithm based on event network, which exploits the semantic properties of event nodes and edge-weight information in the network, to discover fine granularity communities that are semantically meaningful.
In addition, establishing the model for the topic and report is another important study in the process of topic detection. Related models include space vector model, probabilistic model, lexical chain model, and graph model. The vector space model is the most commonly used model. There are many kinds of the formula to calculate the similarity based on this model, such as okap, Clarity, Hellinger, Tanimoto, Weightsumt, and cosine similarity formula.
2.2. Topic Tracking
Topic tracking is the technology used to identify the rest news associated with the topic from news flow according to the given small amounts of training reports associated with a topic. The essence of this task is a guided learning. Topic tracking uses few positive instances data (one or more samples) and a lot of negative instances (history data) to get a classifier. This classifier is used to distinguish whether the new report is associated with the topic. So the topic tracking can be regarded as a special kind of binary classification problem. Many of the technologies in text categorization are the foundation of topic tracking.
In the topic tracking study, the commonly used methods include k nearest neighbours (
Allan et al. used Rocchio algorithm to implement the topic tracking. The core idea of the algorithm is the structural strategy of the topic model. If the feature is conducive to the topic description, its weight will be strengthened. If the feature is tending to wrongly guide topic description, its weight will be weakened [33]. Leek and Sista used the probability model in their topic tracking and recognition system, mainly based on the simple Bayesian algorithm. The system combines multiple classifier system, organized to present the results of each classifier to the user [32].
In addition, another research about web events or topics includes this paper [34] which presents a novel hot event discovery framework to detect hot events online. It contained three stages: document preprocessing, threshold-resilient document classification, and adaptive splitting document clustering. Deng and Xu [35] propose a method to measure the influence and represent the event evolution graph. Lee et al. [36] proposed an incremental tracking framework for cluster evolution over highly dynamic networks. This paper considered the event evolution tracking task in social streams as an application, where a social stream and an event are modeled as a dynamic postnetwork and a postcluster, respectively.
Generally speaking, the traditional TDT technologies just detect unknown events and put related news reports into different topics based on text clustering and text classification. The TDT also traces the development of the events but does not analyze the event deeply. So it cannot provide us with a global and clear understanding of the web event.
3. The Semantic Outbreak Power
3.1. Semantic Features of the Web Event
Our goal is to measure the evolution process of the web event based on semantic outbreak power. So, first of all, we need to get the semantic features set of the web events in the evolution process (Table 2).
Definition 1 (the semantic features set of web event Fe).
The semantic features set of web event Fe consists of three parts including event seed set
Events seed set
The basic steps to get the semantic features set of web event Fe are as follows:
using events seed set extracting events keywords set
Then, we will discuss several basic semantic features of the web event set.
Definition 2 (the new increased web page set:
).
From time
It means that there are new increased n related web pages of event e during the time
Table 1 shows the event's time-series data of the new increased web page. The right of the table was the new increased number of Chinese web page of the specific source from the search engine on the day.
The new increased web page number of the events of “Libya unrest” every day.
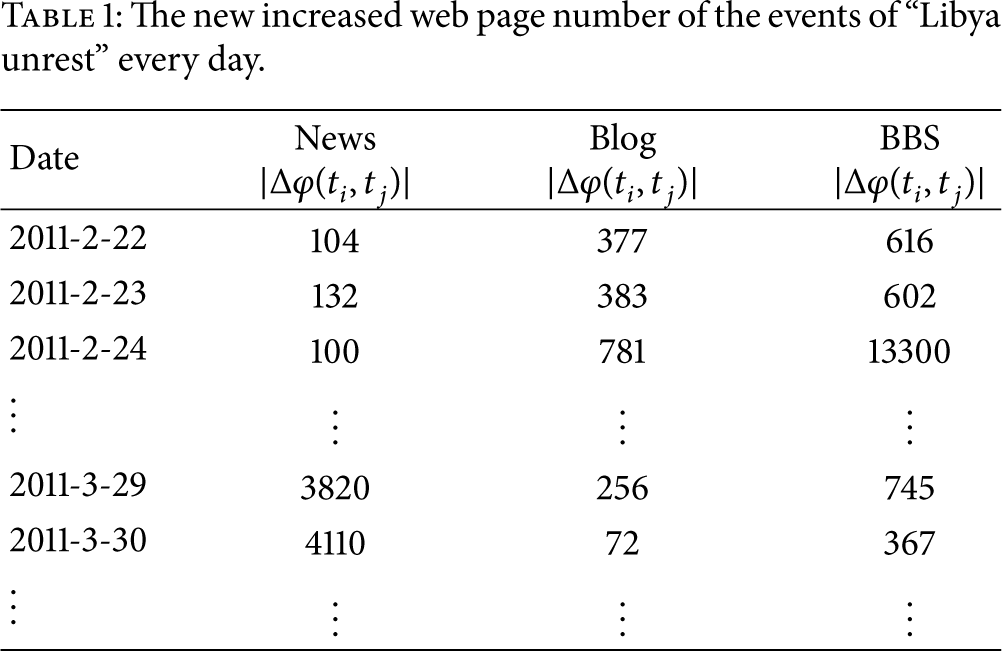
The semantic features original set of the web event evolution process.

Definition 3 (the new increased keywords set:
).
From time
Definition 4 (the distribution of event attributes in the new increased web page:
).
For a web event e, all the web pages of 
The new increased web page set
The details of dataset 1 (50 events).


The relationship of the events seed set
3.2. The Semantic Outbreak Power
Definition 5 (the outbreak power of web event:
).
From time
We understand the web event life process more comprehensively after discussing the semantic features set of web events. We will propose an iterative algorithm combining all of these characteristics of events, measuring the web event life process.
In the previous section, the semantic features set of web events have been defined and attained. Now, we will use these features to calculate the outbreak power. Before proposing the Calculation method, we introduce two important propositions: the representability of event keywords and the credibility of a web page.
Proposition 6 (the representability of event keywords:
).
It describes the ability of the event keywords to express the event.
Proposition 7 (the credibility of a web page:
).
It describes the believable event power of the keywords to express the event.
According to the observation of the actual data set and cognitive knowledge, we give the following few deductions to be the basis of calculating semantic outbreak power algorithm (Algorithm 1).
Repeat
Compute
Deduction 1.
The more web pages on event discussion, the higher semantic outbreak power during the time
Deduction 2.
The more keywords on event discussion, the higher semantic outbreak power during the time
Deduction 3.
When the disagreement is larger about the event discussion, the distribution of event keywords in the new increased web page
According to Deduction 3, on the condition that each event keyword is provided by one web page which only offers one keyword, the similarity power between each page will be 0. This means that all the webs are different. At this point, the disagreement is bigger and the event is likely to further deteriorate. In contrast, we can make Deduction 4.
Deduction 4.
If the web page number and keywords on the event discussion are decay during the time
According to Deduction 4, if the entire keywords exit in every web page, namely, the event keywords set and web page set constitute a complete graph, the similarity power between each page will be 1. This means that all web pages are reproduced from a web page. At this point, the web event is relatively uniform and is less likely to generate further threats.
From the previous discussion, we can know that the greatest influences on the semantic outbreak of web events are the new increased web page set
Considering the above discussion, we can use the representability of event keywords

The process of iterative calculating the credibility of web page and the represented ability of event keywords.
According to Figure 2, we get the following two deductions.
Deduction 5.
For a web page φ, if most of the event keywords have the strong representability
Deduction 6.
If a keyword k is provided by a higher
According to Deduction 4, for a web page φ, we can compute the average of the representability of event keywords to compute the credibility of a web page. Consider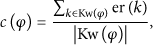
According to [38], we use the probability function to calculate the representability of event keywords: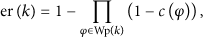
The semantic outbreak power 
Therefore, we put forward the detailed steps on semantic outbreak power algorithm as follows:
give each page the initial credibility; at the same time, all the initial credibility is a vector of a web page according to formula (4), compute the representability of each event keyword according to formula (3), compute the credibility of a web page: all types of the credibility calculated using (3) constitute a vector: computing will reach a stable state until cosine similarity of according to formula (4), calculate the semantic outbreak power.
4. Experiment
4.1. The Verification of the Semantics Outbreak Power
Experiments involve events derived from Baidu news sites. We chose 50 web events about 450000 web pages and 100 events about 900000 web pages as the experimental data set, which includes various areas such as political, accidents, and disasters, and terrorist attacks. Tables 3 and 4 show the statistical results of the experimental data set in detail in this paper. The determination of these web start events stamp according to the method in [26], and the end events stamp general settings for the experimental process in the time we crawl events related web pages; the average length of each event sampling time is 30~40 days. In addition, to determine the evolution process of event, we also obtain semantic futures of events, including event seed set, event web page set, and the event keywords set. We get the event seeds from Baidu. Baidu provides hot issues; at the same time, it also provides hot search words to help users search events.
The details of dataset 2 (100 events).

For example, about Japan's catastrophic earthquake and tsunami disaster in 2011, many web users want to search the related web page information. Baidu will provide a set of keywords about events such as “Japan, earthquake, tsunami.” We will be event seed as a search term and crawl events related web from the Internet, after getting the event seed from the search engines.
The detailed steps we collect from the web resources are
obtaining event seed set using the event seed set as the search keywords, crawl events related web pages from the Internet set, determining the event start time stamp obtaining timing source data of event every day from the web page set doing step (4) in the different sources of information (including news, blogs, and BBS).
We took “days” for the minimum time granularity, collected, from different sources on the web event, every day, the semantic characteristics of the source data, used the iterative algorithm to calculate the semantic outbreak powers every day based on the source data, and then got the events time-series data of the semantics outbreak over a period of time, as shown in Figures 3, 4, and 5.

The event “Japan nuclear leak” evolution based on semantic outbreak power.

The event “Maldives coup” evolution based on semantic outbreak power.
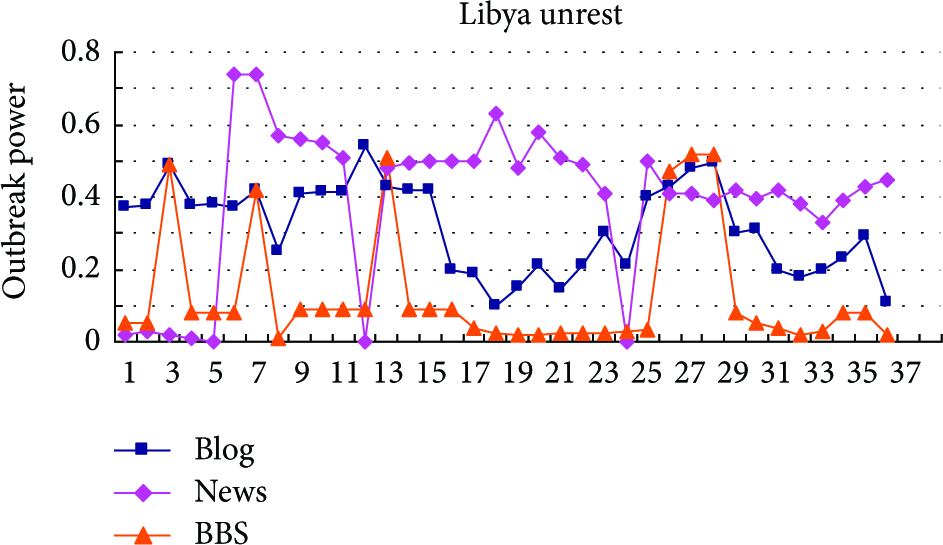
The event “Libya unrest” evolution based on semantic outbreak power.
5. Conclusions
Nowadays, emergencies events have a great impact on people's daily lives. And, with the popularization and development of web technology worldwide, web is acting as a platform for the diffusion and evolution of social events. However, faced with the huge disorder and continuous web resources, it is impossible for people to efficiently recognize, collect, and organize the events. Therefore, automatically collecting and organizing the information about events and then tracking the evolution process of events becomes a hot research field. Generally, the traditional topic detection and tracking (TDT) techniques have been attempting to detect or cluster news stories into these events, without discussing or interpreting the evolution process of events.
In this paper, we proposed the semantic outbreak power and events process measurement algorithm. For any one event, we can calculate the event time-series data of the semantic outbreak power and measure the evolution process of events by analysing the information from the web about the event. It can help people to understand clearly the evolution process of a web event. Then, we propose an approach to distinguish the event type based on the fuzzy recognition.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was supported in part by the National Science and Technology Major Project under Grant 2013ZX01033002-003, in part by the National High Technology Research and Development Program of China (863 Program) under Grants 2012AA011504, 2013AA014601, and 2013AA014603, in part by National Key Technology Support Program under Grant 2012BAH07B01, in part by the National Science Foundation of China under Grants 61300202 and 61300028, in part by the Science Foundation of Shanghai under Grant 13ZR1452900, in part by the Major Research Project of the Ministry of the Public Security under Grant 2014JSYJB009, in part by the China Postdoctoral Science Foundation under Grant 2014M560085, in part by the China National Social Science Fund 06BFX051, and in part by the Shanghai University Training and Selection of Outstanding Young Teachers in Special Research Fund hzf05046.