
Abstract
Radio Frequency Identification (RFID) technology is widely used in object tracking and tracing, especially in real-time locating system (RTLS). Due to the external and internal influence of RFID systems, a lot of redundant and uncertain location streams could be generated in RFID-based RTLS applications, which could seriously affect the accuracy of estimation for RFID mobile object position and cause great difficulties in RFID-based RTLS applications. In this paper, we systematically analyzed the characteristics of RFID location streams. We then derived the optimal weight for the attributes of RFID location streams by applying information entropy based methods and used probability matrix to optimize weight attributes in location streams. We also proposed an optimal estimation particle filter algorithm (OEPF) based on traditional particle filter, which greatly reduced the data redundancy and realized online measurement for the uncertainty of RFID location streams. Finally, the experimental results showed that, compared to the existing algorithms, our algorithm effectively improved the accuracy of location estimation in ensuring the premise of real-time.
1. Introduction
RFID (Radio Frequency Identification) technology now is widely used in real-time location-based applications, due to the impact of the sensor itself and the surrounding environment, resulting in a large number of uncertain RFID location streams in these applications [1–3]. It is urgently needed to resolve the uncertainty estimation for RFID location streams, since effectively dealing with uncertainty of RFID data is important for improving the accuracy of positioning.
The current studies [4–6] in uncertainty measure of RFID data streams are still in their infancy. Due to the large data streams characteristics of the RFID data, the existing probability estimation methods are not suitable for RFID and other sensor data streams. Previous studies did not mention probability measure for raw sensor data, particularly the multiple sensor data streams probability measurement problems. Those studies have focused on using particle filter to measure the uncertainty of RFID data streams shown in Figure 1. Zheng et al. [7] proposed a novel statistical method which could dynamically adapt the size of the particle filter sample set, using evolutionary theory to solve particle degradation problem and improved Particle Swarm Optimization (PSO) to optimize resampling performance. They solved the conflicts between effectiveness and diversity in resampling which is caused by relying solely on the KL-divergence [8] to determine the number of particles. They also improved particle depleted and proposed the uncertainty measurement for the raw data. The core of evolutionary theory is using the weighted sum of a series of random samples to represent the needed posterior probability density, which required the increase of particles number. While along with an increase of particles number, it is difficult to converge to the true state after a few iterations that cannot guarantee accuracy. The efficiency of the algorithm will be significantly reduced and cannot meet the requirements of real-time RFID data streams. Therefore, we propose that an RFID data streams uncertainty measurement algorithm, which uses tuple dependence on properties of RFID location streams to weight sum, uses the maximum weight particle to efficiently capture the current state from the uncertain RFID data streams, while reducing the required number of resampling particles, which is very suitable for online processing of real-time RFID data streams.

Uncertain RFID location streams in real-time locating system.
2. Uncertain RFID Location Streams
The background of this study is RTLS based on RFID technology [9]. While in the RFID moving objects positioning and tracking applications, at a time t, the location of a tag
Definition 1 (uncertain RFID moving object).
An uncertain RFID moving object can be seen as a point x, which is located at the readable range of the RFID reader R; the location of the moving object is the probability density

Definition 2 (uncertain RFID data streams).
The mobile object carried RFID tags sensed by readers and generated data streams tuples, in the form of
Definition 3 (uncertain RFID location streams).
It consists of multiple data streams
Conclusion can be made from Definitions 2 and 3: the essence of the estimation of RFID moving object location is the problem of probability calculation for uncertain RFID location streams tuple data, which is adding probability dimension for original RFID data streams tuples.
In order to specifically measure the uncertainty of RFID location streams, which usually is within a targeted area, we used two indicators to measure the uncertainty of RFID location streams, namely, the Read Rate and the Missing Read Rate.
Definition 4 (Read Rate).
The probability of a moving object in some area
Definition 5 (Missing Read Rate).
The Missing Read Rate is the probability that a tag
Considering the limitlessness of RFID data streams, in order to determine the amount of the appropriate RFID data streams collected, a sliding windows mechanism is generally adopted. In this paper, we use an adaptive sliding window mechanism [10].
Definition 6 (sliding window).
Let
Definition 7 (particle filter for RFID data streams).
Measure values use a weight point set

3. Models and Definitions
In the RFID-based RTLS applications, the tags in the same location may be sensed by multiple readers at the same time, which need correlation calculation on location tuple data and readers, called dependent metric measurement [12]. The readers' location data were regarded as the properties of tuples that can be optimally selected by using the attribute weights optimization algorithm.
The uncertainty of RFID location data streams is usually divided into tuple-level uncertainty and attribute-level uncertainty [13]. The tuple-level uncertainty merely describes whether the tuple data exists or not, while the attribute-level uncertainty is not directly related to tuple-level uncertainty, so as to avoid the search results which have the same data but different probability. We increase different weights to attributes of tuple to generate weight matrix with different properties and then do the merit-based selection for tuples after optimizing the matrix.
For the RFID data streams
Definition 8 (probability degree).
There are two uncertain variables,

Definition 9 (distance).
The distance between
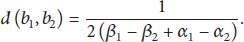
Due to the uncertainty of RFID data streams, the attribute weights of RFID location streams are unknown or uncertain, which should be determined in advance.
Definition 10 (probability degree matrix).
The uncertain tuples
Due to the data uncertainty of RFID data streams, it is often difficult to assign query plan for definite attribute weights. Some attribute weights are even completely unknown so that the weights of attributes need to be determined in advance.
For the sample tuples which have different probability values but the same data, the smaller the difference of the attribute values under attribute
For attribute

Therefore, for attribute

And for attribute

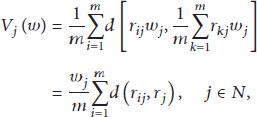
Entropy measure can be used as a measurement for the uncertainty of weight optimization matrix; larger entropy represents larger uncertainty [14]. So value corresponding to the maximum return probability can be used as the value of the uncertain variable. If

The number of possible values for uncertain variables B may be a great influence on the entropy value. The more the possible values, the greater the entropy value and the greater the uncertainty. In order to reduce impacts, we use entropy normalization method. If there are n possible values for the uncertain variable, the entropy normalization process is as follows:

Here we introduce the weight optimization problem, and its solution is defined by comparing the upper and lower values weight objective function through the weight vector. By considering the selection of attribute weight vector w, the sum of the total tuples portfolio deviation under each attribute should reach a maximum value. The objective function can be constructed as
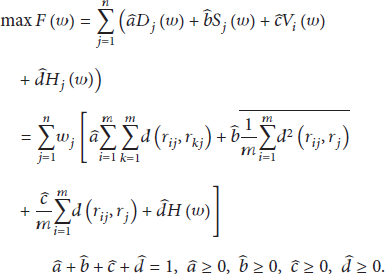
If

Thus, solving w is equivalent to solving the single objective optimization problem as follows:

Solution to the problem is

The weight vector normalization is

After the optimal weight vector
4. Algorithm Description
In order to address the online measurement of RFID data uncertainty, in this paper, we improve the particle filter algorithm and propose a novel uncertain data optimal algorithm for RFID location streams. The algorithm is named optimal estimation particle filter (OEPF) and described as follows.
Algorithm 1.
Optimal estimation particle filter-based measuring uncertainty algorithm for RFID location streams (OEPF) is as follows.
Input.
Output.
Step 1 (Initialization)
Step 2 (Generated samples)
FOR the particles in W at time k DO Select N particles represented by Update the particle weights:

Step 3 (Update particles)
FOR each particle Using PSOPF algorithm [7] to update each particle; WHILE

Step 4 (Resampling)
WHILE Resampling the original particles
Step 5 (Optimal Estimation)



Step 6 (Continue). If t is the last moment for object, then end the algorithm. Otherwise, set
The particles in the algorithm are the tuples of RFID location streams. The OEPF algorithm uses the self-information, local extreme information, and global extreme information of particles to guide the next iteration location of particles. The improved weight optimization estimation could make the particles set towards high likelihood region before the weights get updated so as to solve the problem of particles of depleted and by using the sliding windows to adjust the number of particles to improve the particle degradation. The algorithm uses the complementary judgment matrix to preferentially select the best tuple without increasing the number of particles at the same time, to improve the efficiency and meet the requirements of real-time RFID location streams.
5. Experiments
In order to test the OEPF algorithm performance, we set the experimental environment in a nonelectromagnetic interference laboratory, which is divided into 14 subregions of uniform size position (8 m2), as shown in Figure 2. We deploy one reader (R1–R14) in each subregion, and let the laboratory person (a total of 20 people) carrying RFID tags make random uniform motion in the identifiable range of readers. The RFID data samples with location information are regarded as particles. The readings on the same tag at the same time of each reader are the properties of the reader, which formed a tuple at that time. The tuples forming RFID location data streams are sent to a workstation for further processing. The workstation is equipped with CPU Intel Core TIM2 Duo (2.9 GHz) with 4G RAM. To verify the effectiveness of the proposed algorithm, we compared the SIRPF algorithm [15], the PSOPF algorithm [7], and PPMU algorithm [5] with our algorithm.
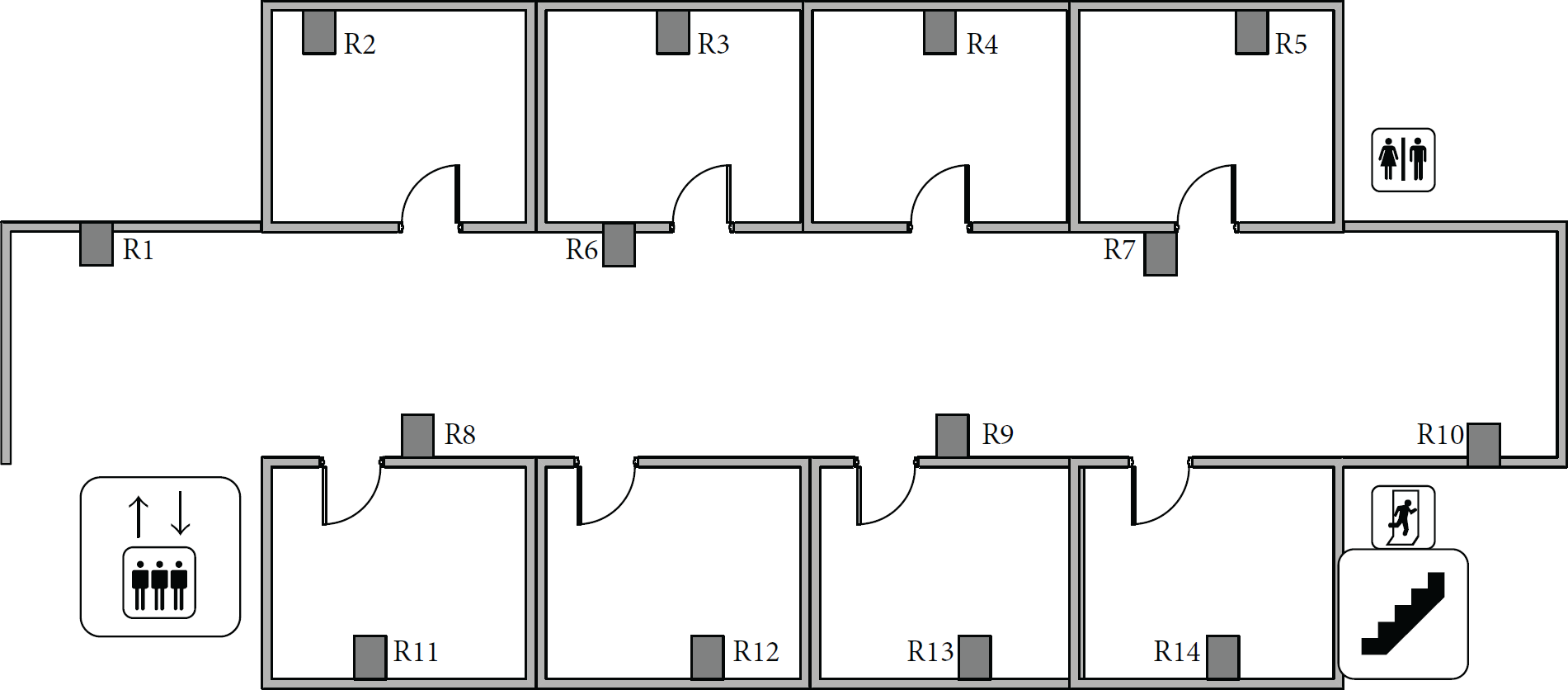
Experimental scene.
The experimental parameters are shown in Table 1.
Experimental parameters.
5.1. Performance Test for Different Size of Samples
RFID positioning applications will produce large amounts of RFID location data samples in short time, forming a huge flow of RFID data streams, which demands higher performance for the algorithm.
The comparison of convergence rate for four methods (SIRPF, PSOPF, PPMU, and OEPF) with the same number of particles is shown in Table 2. For RFID real-time location applications, SIRPF and PSOPF did not converge in the cases of very few particles (less than 50), which cannot achieve correct positioning. While the PPMU and OEPF algorithm both can rapidly converge in the cases of very few particles (less than 50) and large amount particles (more than 5000), they can meet the requirements of RFID real-time positioning.
Comparison of convergence rate.
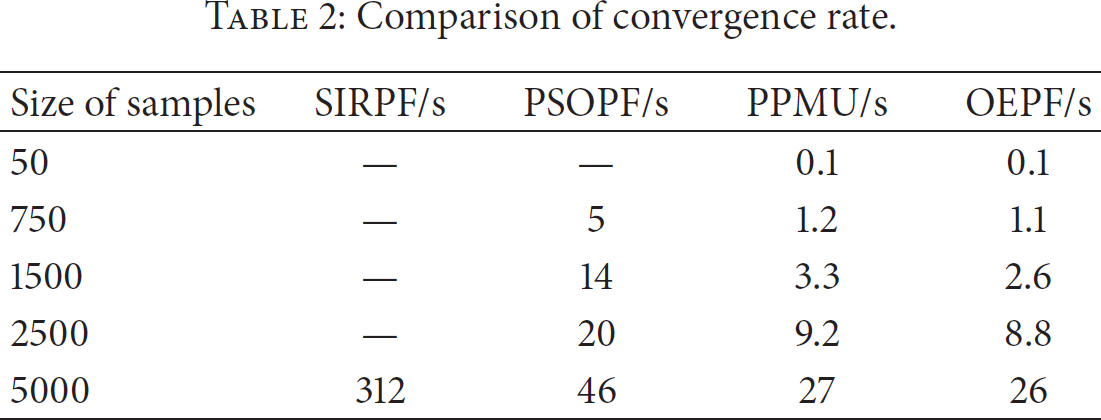
Table 2 is the running time comparison of our proposed OEPF algorithm with other algorithms proposed with different numbers of average samples. As can be seen from Table 2, the number of average samples and the run time is linearly correlated, and the OEPF algorithm is faster than other algorithms.
5.2. Performance Test for Different Reading Rates
The proposed algorithm can take advantage of the recent observation value within the period of time of a sliding window. Accurate information of the particles could even be obtained at a low reading rate. Since the low reading rate would affect the attributes relation effective confirmation for tuples and also result in loss of the same position information between the adjacent tuples, the derivation accuracy of the dependencies relation between the tuples and the attributes decrease significantly with the decrease of the reading rate, as shown in Figure 3.
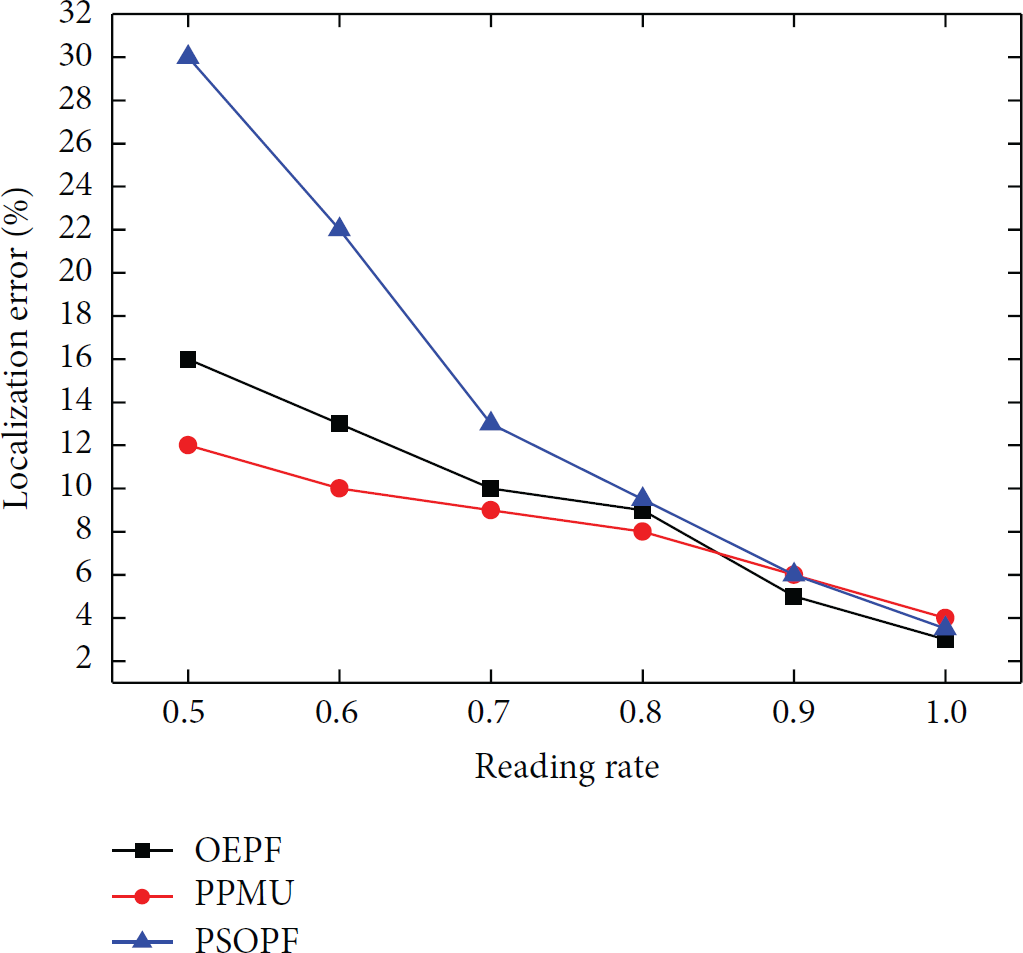
The reading rates changing testing.
The error rates of three algorithms are lower than 10% when the reading rates are no less than 0.8. Compared to the PSOPF algorithm, our OEPF method increases accuracy of particles confirmation by 9% while the reading rate is 50%. Compared to the PPMU algorithm, OEPF has relatively lower accuracy, but the PPMU and OEPF algorithm are very close when the reading rate is greater than 70%. Since the OEPF method adopts the amendment weights confirmation method with the probability of entropy, in a certain extent, the probability degree matrix is enhanced for the recognition of particle information.
5.3. Online Processing Performance Test
The processing of uncertain data streams is a major feature of RFID data uncertainty evolution. Since the data streams arrive fast, the algorithm needs to meet one-shot online processing requirements. The test results of three algorithms are shown in Figure 4. It can be seen that there is a balance between the selection cost of samples number and online processing constraints. The lack of sample selection will lead to higher leakage reading rate. Thereby the real information of particles is often unable to be confirmed; on the other hand, if too many samples are chosen, the algorithm needs several seconds in each update, which can also cause higher leakage reading rate. In comparison, the OEPF is still able to get better particle truthful information even in two extreme cases. The performance indicators leakage reading rate is very close to PPMU, and much better than PSOPF.
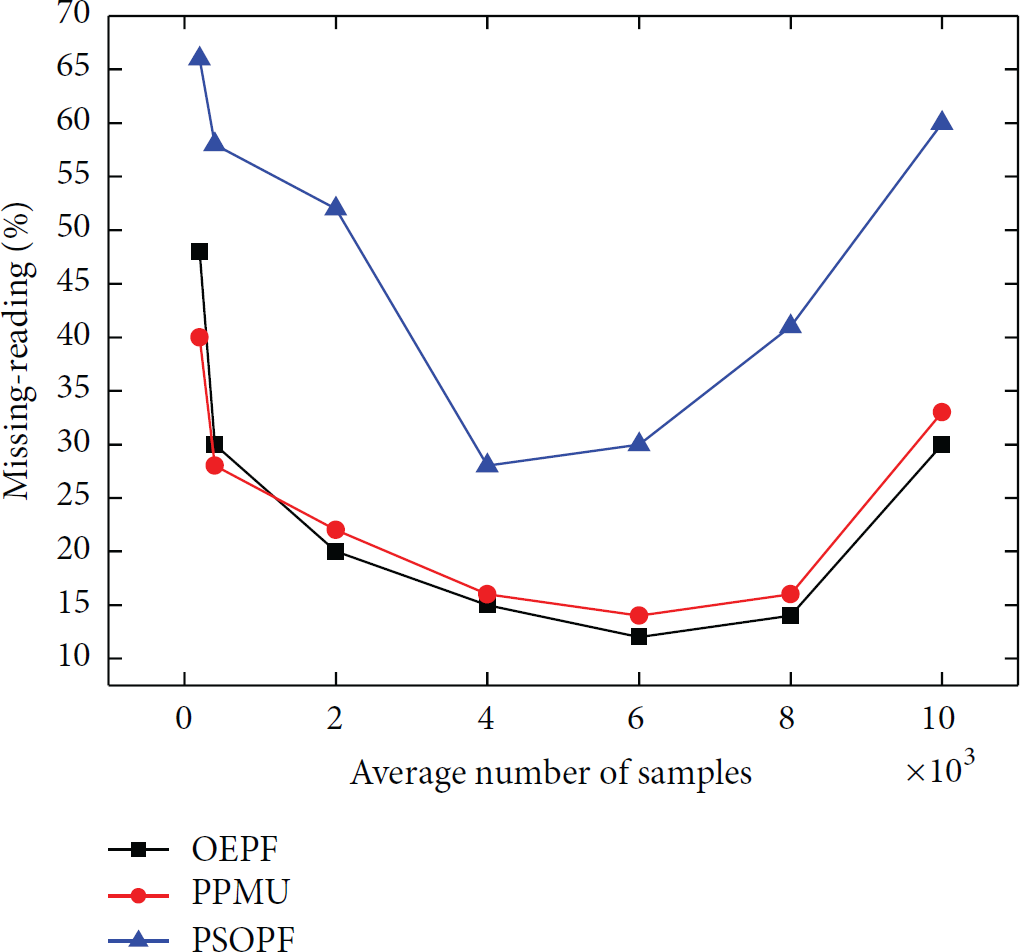
The missing-reading rates change with a different average number of samples.
The definitions in (1) and (2) give the white noise with variance of Q and R to represent its filtering performance, and the filtering performance comparison of three algorithms (PSOPF, PPMU, and OPEF) is shown in Tables 3 and 4. Experimental data deduced from Tables 3 and 4 showed that, in the same noise environment, the proposed algorithm (OEPF) has the most effective samples and has the high efficiency in terms of suppressing particle degradation and increasing particle diversity. With the same precision, the proposed algorithm improves the efficiency of the filter and maintains high filter estimation accuracy when the noise is increasing.
Comparison filtering performance of three algorithms with
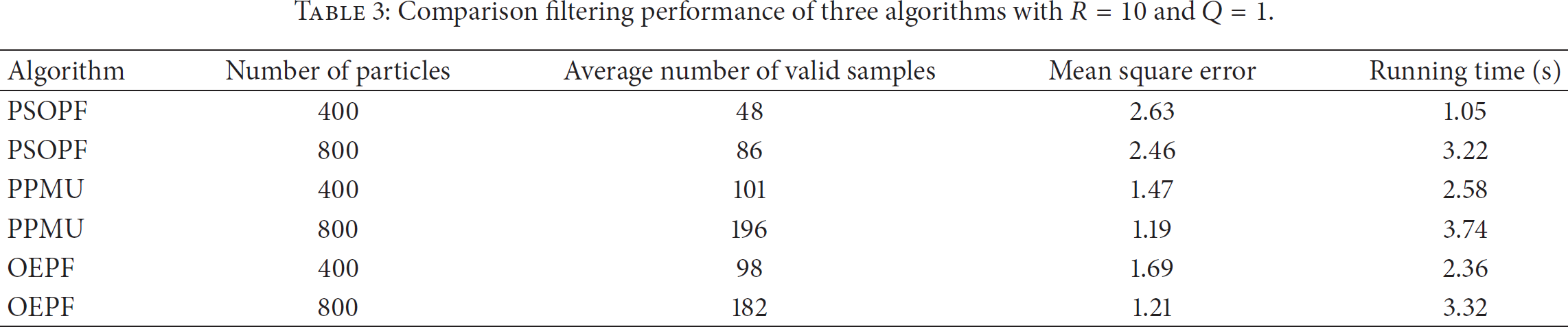
Comparison filtering performance of three algorithms with

6. Conclusions
The RFID positioning applications could generate a lot of redundant and uncertain location streams, which would greatly affect the accuracy of RFID positioning. The traditional particle filter algorithm needs to use the maximum weight particle to indicate the system state and increase the number of particles to prevent the particle depleted phenomenon. In this paper, we improved and optimized the particle filter algorithm and proposed a particle filter algorithm based on attributes optimization estimation. By using an entropy based method, we derived most likely reader location in the redundant location streams and chose the best particles with probability matrix method and excluded the low weight particles which could not fall into reader location, which not only ensured the diversity of particles without increasing the number of particles, but also improved the computational efficiency of the algorithm. Experimental results showed that the proposed method resulted in accurate data and high efficiency, which is suitable for RFID mobile object position estimation. Our future research will focus on applying this algorithm to a distributed RFID location tracking system.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
This work was supported by the Fundamental Research Funds for the Central Universities, Nanjing Forest Police College (no. LGYB201505).