
Abstract
A distributed parallel clustering method MCR-ACA is proposed by integrating the ant colony algorithm with the computing framework Map-Combine-Reduce for mining groups with the same or similar features from big data on vehicle trajectories stored in Wide Area Network. The heaviest computing burden of clustering is conducted in parallel at local nodes, of which the results are merged to small size intermediates. The intermediates are sent to the central node and clusters are generated adaptively. The great overhead of transferring big volume data is avoided by MCR-ACA, which improves the computing efficiency and guarantees the correctness of clustering. MCR-ACA is compared with an existing parallel clustering algorithm on practical big data collected by the traffic monitoring system of Jiangsu province in China. Experimental results demonstrate that the proposed method is effective for group mining by clustering.
1. Introduction
Recently, big data on vehicle trajectories collected by traffic monitoring systems are more and more important in practice, which are based on license plate identification and the RFID techniques. For example, there are more than 100 subsystems in a traffic monitoring system of Jiangsu province in China, which includes more than
The biggest challenge in big data clustering is designing effective algorithms for clustering and distributed parallel computation [3]. For these issues, some distributed parallel computing frameworks based on Cloud Computing [4] and MapReduce [5] have been proposed in recent years, such as the batch computing framework [6, 7], the stream parallel computing framework [8], the customized parallel computing framework [9], and the mixed parallel computing framework [10]. Based on such computing frameworks, some distributed parallel clustering algorithms have been proposed. A new density-based clustering algorithm DBCURE-MR [11] was introduced, which is robust to find clusters with various densities and suitable for parallelizing the algorithm with MapReduce. A nonparametric accuracy estimation method and system [12] were proposed for speeding up big data analysis. Sampling with replacement was adopted to obtain the sampling points according to the sampling distribution. The amount of data input to MapReduce can be decreased considerably. Taking into account the distributed nature of portioned data and model, three clustering algorithms [13], k-mean, canopy, and Fuzzy k-mean, were implemented in parallel on MapReduce. The efficiency of distributed clustering was improved significantly. For detecting in large community networks, a parallel structural clustering algorithm was introduced [14], which is based on the similarity of edge structures and MapReduce. The interfaces and implementations for user-defined aggregation in several states of the distributed computing systems were evaluated in [15], where communication overhead of data-intensive applications could be decreased largely by local clustering, which clusters the intermediate results generated by Map tasks and then transmits the clustered results to Reduce tasks.
The existing methods improve clustering efficiency either by parallel computing on physically centralized big data or by reducing data scale using sampling. However, the communication overhead of data centralization and the impact on sparse data for clustering accuracy have not been considered yet. In this paper, by integrating the ACA (ant colony algorithm) with the computing framework Map-Combine-Reduce (MCR), a MapReduce based distributed parallel clustering method MCR-ACA is proposed for group mining on big data of vehicle trajectories in WAN. Some parallel ACA methods based on MapReduce have been proposed [16, 17] (defined as MR-ACA). However, since these methods work on physically centralized big data in LAN, the communication overhead of data centralization is ignored. The MCR-ACA method contains three stages: Map operation, Combine operation, and Reduce operation. Both the computation tasks with the heaviest burden are conducted and their results are combined in parallel on data source nodes. The combined result is transmitted to the central node and new cluster centers are generated adaptively. The presented method avoids the communication overhead of big data migration, improves the clustering efficiency, and guarantees the accuracy of the global cluster among distributed nodes.
The rest of this paper is organized as follows. The problem of group mining for vehicle trajectories is described in Section 2. A distributed parallel clustering method MCR-ACA is proposed in Section 3. Section 4 shows the computational experiments, followed by the conclusion and future work in Section 5.
2. Group Mining for Vehicle Trajectories
Distributed frameworks in WAN are always adopted by traffic monitoring systems. Hierarchical ones are even utilized by some complex systems. For the traffic monitoring system of Jiangsu examined in this paper, a 3-layer framework is applied. There are 13 independent branch centers in 13 cities, respectively, which are responsible for the integration of independent data branches within each city. A head center is in charge of all the branch ones. Therefore, the main characteristics of big data of vehicle trajectories in WAN are multiple data sources and hard to be physically centralized. In this paper, the data branches are called source nodes, city branch centers are city nodes, and the head center is the central node. The topological network is shown in Figure 1.

Topological network of traffic monitoring system.
Traffic monitoring systems which contain multiple independent subsystems are being developed in the cities. They form distributed data sources which increase rapidly. There are more than one hundred subsystems in the system of the Jiangsu province. The amount of data in the subsystems is quite huge and growing rapidly (data increment in one city of Jiangsu is over 12 million records every day). Multimedia data in various formats (such as photos and videos) increase several TBs each day, which is very difficult to be physically centralized in the central node. The trajectory data of the cars collected by a subsystem is listed in Table 1.
Data collected by a subsystem.

Group mining for vehicle trajectories (GMVT for short) is critical for data clustering on big data of distributed traffic monitoring systems in WAN. The main idea of mining groups on big data of vehicle trajectories is to implement the automatic partition of vehicle trajectories with the same or similar features by clustering on attributes, which consist of the metadata (e.g., time and location) of the vehicle trajectories. The information (the number of license plates) of the vehicle trajectories in the same clusters can be drawn from the partition result. A complete vehicle trajectory record includes those metadata: the number of the license plates, passing time, location, direction, speed, and car color. These attributes are set as metadata. Records collected by different sensors in various subsystems are normalized as a 6-tuple (the number of license plates, passing time, location, direction, speed, and car color). The first record in Table 1 is normalized as S032V0, 20130521073907, checkpoint at the crossroad of Suyuan road and west Qingshuiting road, 1, 41, and A. Every element is assigned to a weight. Features of vehicle trajectories with the same or similar elements are clustered on the data records.
Suppose there are
3. Group Mining Methods for Vehicle Trajectory in WAN
In WAN, GMVT is critical for clustering data of vehicle trajectories by attribute features such as time or location to construct various classes with the same or similar attributes, according to which drivers with the same or similar features are identified as a group. Because of the two characteristics mentioned in Section 2, traditional parallel clustering methods are no longer efficient, which motivates us to present the following method.
3.1. Clustering Framework for Distributed Big Data in WAN
Data clustering is very difficult for big data that is stored distributively in WAN. The reason lies in two aspects: (i) huge amount of data makes clustering computing more time-consuming, which leads to existing methods being infeasible. (ii) Communication overhead on data migration is generally more than the computing cost. It is better to migrate computation rather than migrate data. Therefore, a distributed parallel computing framework (MCR), which is based on MapReduce, is proposed in this paper. The framework of MCR is depicted in Figure 2.
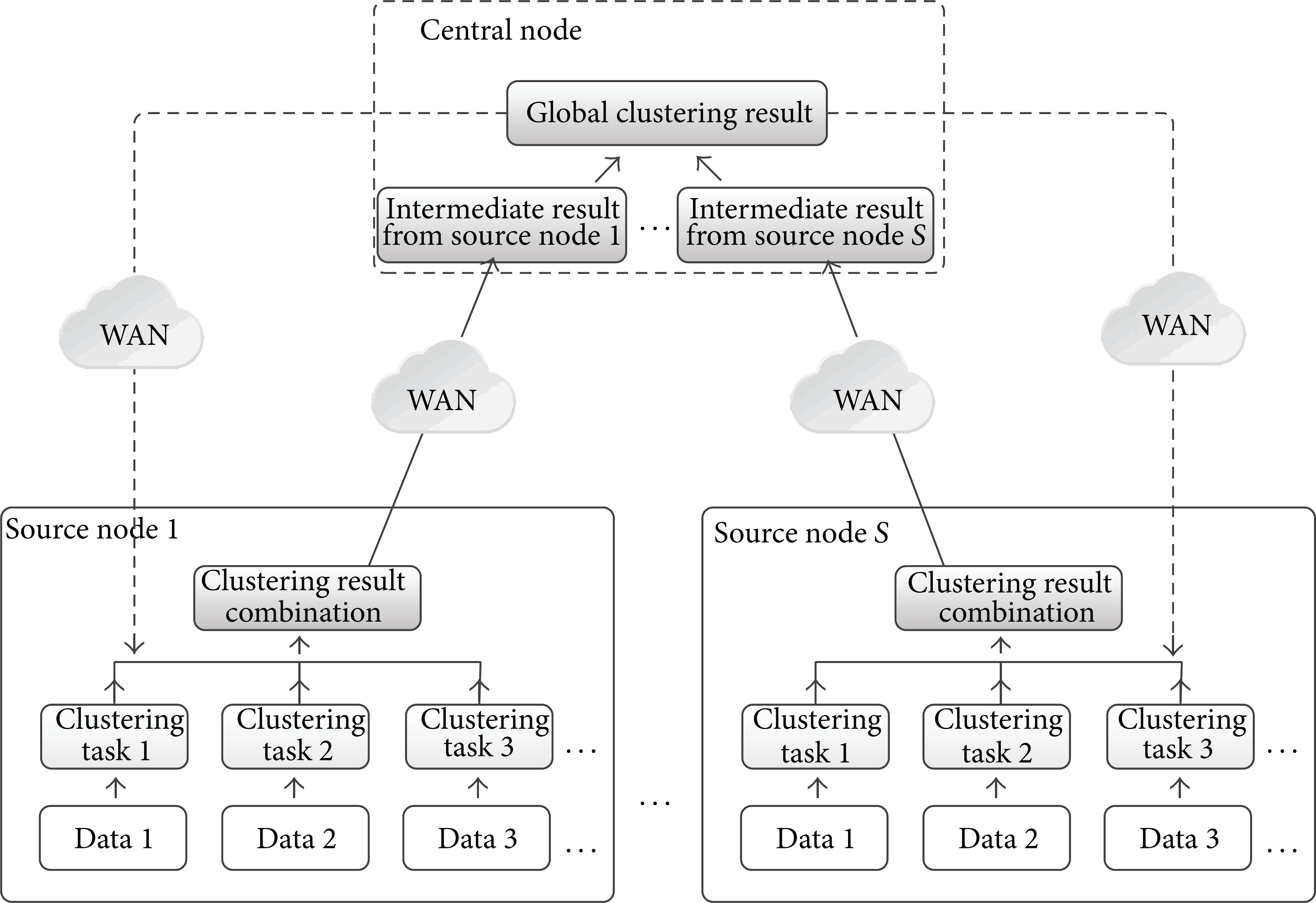
MCR distributed parallel computing framework.
Based on MCR, the traditional ACA is adapted to MCR-ACA for group mining for big data. The procedure of MCR is described as follows.
Divide the data source Map operations are carried out on each data chunk The clustered results are merged into intermediate ones by Combine. For example, The intermediate results are sent to the central node, where Reduce is conducted for global clustering. The method terminates if the global clustering converges to or reaches the maximal iterations
Computing operations with the heaviest burden are conducted in parallel at source nodes. Data in each source node is divided into data chunks. All chunks are clustered in parallel which leads to good efficiency. Communication overhead is significantly reduced by transmitting intermediate results combined at local source nodes rather than the source data. The global clustering is conducted on the intermediate results at the central node.
3.2. MCR-ACA Method for Group Mining
ACA was inspired from the phenomenon that ant individuals gather at a location with food by pheromone interaction among them [18, 19]. By integrating ACA with the computing framework MCR, the group mining method MCR-ACA is proposed. The number of classes and the trajectory records in a class are determined adaptively, and clustering centers are generated in iterations without predefinition, which is desirable for the considered problem.
3.2.1. Map Function of MCR-ACA
A vector of m elements (attributes) is developed for each record of vehicle trajectories; that is, a data record 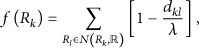


The decision of putting down or moving
The Map function takes
(1) (2) (3) Calculate the weight distance (4) Calculate the comprehensive similarity (5) Read the pheromone value (6) (7) Cluster (8) Go to Step 17. (9) (10) Abandon (11) Go to Step 17. (12) Select the node with largest (13) (14) Abandon (15) Go to Step 17. (16) (17) Randomly assign the ant a new record which has not been clustered or abandoned. (18) Output the clustering result (19)
3.2.2. Combine Function of MCR-ACA
The results obtained by the Map function 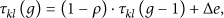
For the records with the clustering probability less than the given threshold
Multiple Combine functions can be conducted in parallel for one data source
(1) (2) (3) Output (4) Combine records with the same (5) Calculate (6) Update pheromone (7)
There are only two possible outputs from the Combine function, either
3.2.3. Reduce Function of MCR-ACA
At the gth iteration, two parts obtained from the Combine phase on data chunks, that is, intermediate results
(1) Calculate the weighted distance cluster centers (2) (3) Combine (4) Calculate the global cluster center (5) (6) output the global clustering result. (7) Go to Step 9. (8) Output the minimal (9)
3.2.4. MCR-ACA Method Description
MCR-ACA is constructed by integrating MCR with the Map function conducted on various data chunks in different source nodes, the Combine one on the local clustering results, and the Reduce one on global cluster centers. Assume the maximum iteration is
(1) (2) (3) Conduct Map function in parallel, output the clustering result (4) Perform Combine functions in parallel, output intermediate results (5) Reduce functions are carried out in parallel to develop the global cluster (6) (7) (8) Output (9) Output the global classes. (10)
4. Experimental Results on Practical Big Data
In the experiment, the MCR-ACA method is compared with the existing MR-ACA method on the traffic monitoring system of Jiangsu province in China. The two cities Nantong and Changzhou are selected; two subsystems are chosen from each of them, respectively. Nanjing is the central city. Subsystems are linked by fiber with 1000 Mbps within each city. The distance between Nantong and the central city is 270 kilometers. There are 140 kilometers from Changzhou and the center Nanjing. The cities are connected by the Internet with network width of 200 Mbps. We adopt Hadoop, Mahout, and IK as software tools. Two PCs are used in the two cities, respectively, while four PCs work in the central node. All of them are configured with Intel 5620CPU, 2.4 GHZ, 6-core, 4 G memory, and 300 G disk. In the MCR-ACA experiment, Map and Combine operations are conducted parallel in four PCs in two cities, and the Reduce function is conducted in the central node. In the MR-ACA experiment, all data is transmitted to the central node and processed by the four PCs in the central node, where Map, Combine, and Reduce functions are performed.
The records on vehicle trajectories are represented by a set of 6 elements (HPHM, JGSJ, JGDD, XSFX, XSSD, and CSYS) with the weight
The clustering time (H)/the accuracy (%) of MCR-ACA with different neighborhood radius

The clustering time (H)/the accuracy (%) of MCR-ACA with different threshold probability
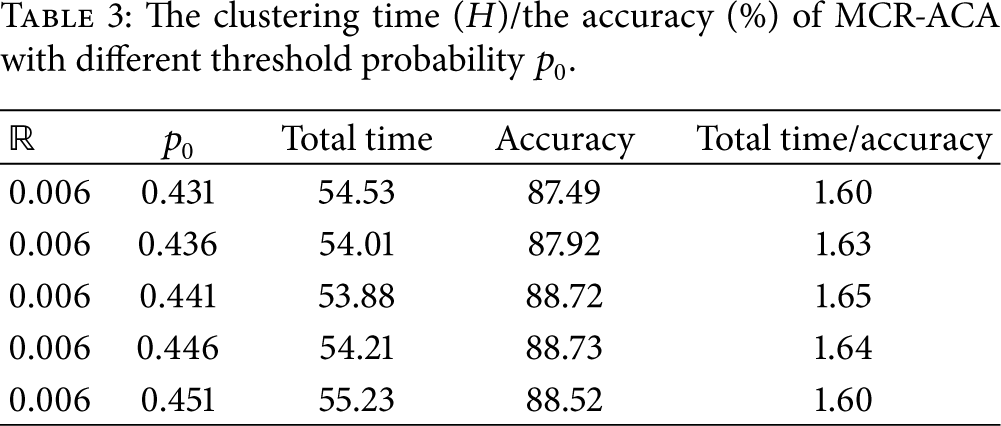
It can be seen from Table 2 that as
Therefore, the experimental parameters are set as below: 56 Map functions, 4 Combine functions, 4 Reduce functions, the maximal iteration being 5, 3 ants for each Map function, the neighbourhood radius
Comparison experiments of MCR-ACA and MR-ACA.

Table 4 implies that the accuracy of the two methods is similar and rising as the data amount becomes larger. The data amount is key to the clustering accuracy. Reducing data scale by sampling also reduces the accuracy. The increasing rate of clustering accuracy for MCR-ACA is greater than MR-ACA, as depicted in Figure 3.
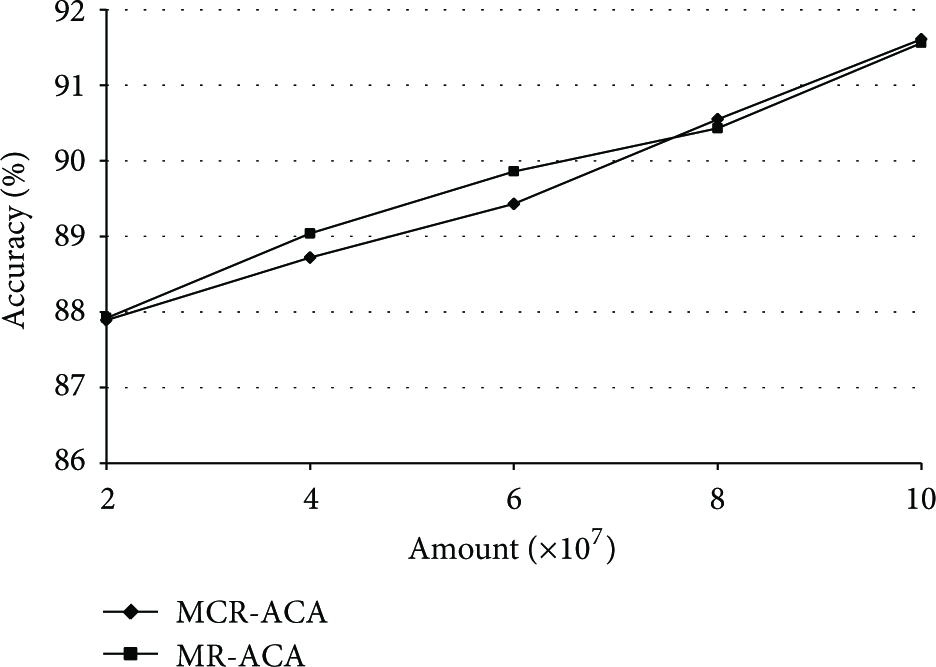
Comparison on group mining accuracy.
Furthermore, the computing time for Map function of MR-ACA is longer than MCR-ACA, and the difference becomes bigger as data amount increases. The reason lies in that all records are mixed up in hard disk after extraction, which makes the Map function more complicated in the central node than that in the data source nodes. The Map function of MR-ACA works on the data chunks that are divided from the data mixed stored on the central node, and these data chunks are more complex in elements as the data amount grows. Therefore, the Map function of MR-ACA costs more computing time. The comparison is indicated in Figure 4.

Comparison on Map function time consumed.
For Reduce function, the time consumed in MR-ACA is about twice as much as that in MCR-ACA, but less than the sum of computing time in both the Reduce function and the Combine function in MCR-ACA. Actually, the processing time in the Combine function in MCR-ACA is included in the Reduce function in MR-ACA.
As shown in Table 4, the total time in MR-ACA is 50% longer than that in MCR-ACA due to the data extracting time on average, which indicates that the data extraction is the most essential influential factor for big data cluster.
Table 4 also demonstrates that as the data amount increases, the computation time of both of the two methods increases rapidly while the accuracy improvement is quite limited. The reason is that as the number of Map functions, Combine functions, and Reduce functions keeps the same, the amount of data in the data blocks among Map functions, Combine functions, and Reduce functions grows proportionally, which finally causes the computation time to grow rapidly. The clustering accuracy is a relative value, mainly determined by data amount (the ratio of the clustered records of one car to the total records which this car is involved in). As the data amount grows, the clustering accuracy increases gradually. However, there is no relationship between the clustering accuracy and the computation time, which leads to the inconsistency of the computation time increasing and the accuracy increasing. According to the experiment, the number of obtained classes is listed in Table 5.
The number of classes.

The results show that 4 cars in a research group illustrate the obvious similar trajectories, which is listed in Table 6.
Trajectories of the cars in a group.
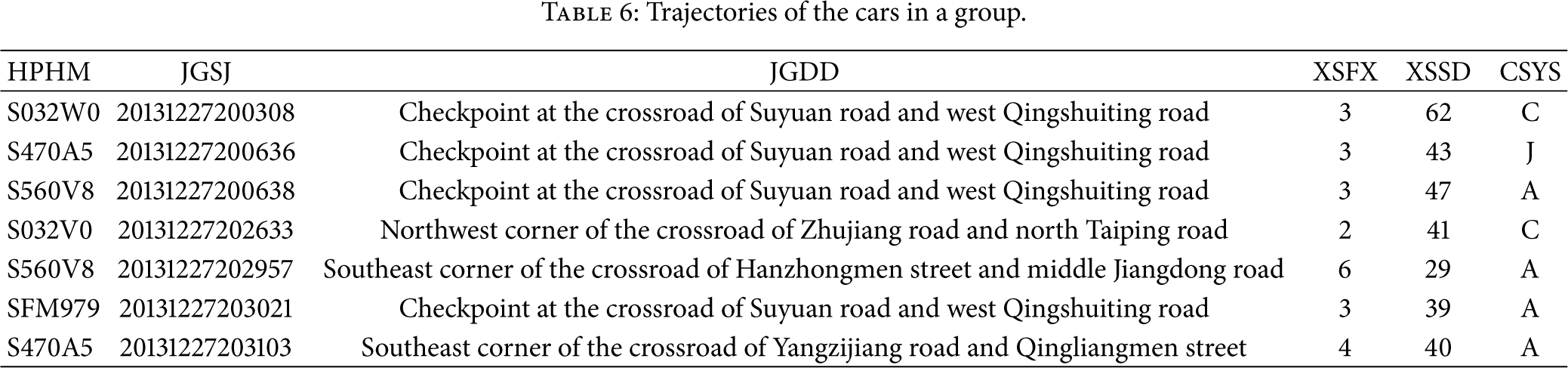
Table 6 indicates that the 4 cars were caught by the same camera in half an hour. The car number “S032V0” was misidentified as “S032W0” by the camera capture. Through clustering, the trajectories of these 4 cars have plenty of traces with the same or similar features which construct a cluster. The time feature is on every Friday evening; the location feature is overlapped along the way to the university, as shown in Figure 5.

Trajectories of the cars in a group.
5. Conclusion and Future Work
Critical issues for group mining on big data of vehicle trajectories are centralization and source distribution. In this paper, a distributed parallel clustering method MCR-ACA is proposed for group mining on distributed vehicle trajectories. Parallel clustering is realized while communication overhead of big data is avoided. The method is tested on traffic monitoring systems of three cities (including the center city Nanjing) of Jiangsu province in China. Experimental results demonstrate that the proposed method achieves better performance on group mining.
Group mining can be used in many scenarios. According to the experiment results in this paper, two aspects are promising for further work: (i) the forecast of group behavior based on specific features; for example, if the time feature of a group is in midnight and the location feature is somewhere with high crime incidence, the group can be regarded as a possible crime group with high possibility; (ii) outlier analysis for vehicle trajectory. Some vehicle trajectory outliers are formed in the clustering process (e.g., the abandoned vehicle trajectories defined in the paper); the reason that these vehicle trajectories are abandoned as outliers is useful for behavior forecast.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work is supported by the National Natural Science Foundation of China (Grant 61272377) and the Key Technology R&D Program of Jiangsu Province (BE2014733).