
Abstract
Fingerprint positioning can take advantage of existing WLAN to achieve indoor locations, which has been widely studied. We analyzed the corresponding positions distribution of similar fingerprints, and then found that the fuzzy similarity between fingerprints is the root cause of the larger errors existing. According to clusters distribution feature of corresponding positions of the similar fingerprints, we proposed a K-Means+ clustering algorithm to achieve fine-grained fingerprint positioning. Due to the K-Means+ algorithm failing to locate the positions of outliers, we also designed a linear sequence matching algorithm to improve the outliers positioning, and reduce the impact of fuzzy similarity. Experimental results illustrate that our algorithm can get a maximum positioning error less than 5 m, which outperforms other algorithms. Meanwhile, all the positioning errors over 4 m in our algorithm are less than 2%. The positioning accuracy has been improved significantly.
1. Introduction
Indoor positioning is the foundation of indoor location services. GPS with indoor limitation and cellular positioning with rough accuracy makes indoor positioning need for fine-grained efficient positioning method. Fingerprint positioning algorithm does not rely on additional hardware overhead, which can utilize the existing infrastructure (e.g., WLAN) to complete the positioning tasks. First, through the acquisition of the received signal strength (RSS) at each sampling point of the object area, the offline fingerprint database will be constructed. Then, we are able to match the signal strength online measured with the fingerprint in the offline database and choose the corresponding position of the optimal matching fingerprint as the positioning result. Therefore, as long as the area can be covered by wireless WiFi networks, where it is easy to realize fingerprint positioning algorithm, the versatility of fingerprint positioning as a technology choice for indoor positioning will be improved.
The current researches on fingerprint algorithm mostly focus on two aspects. One is to reduce the cumbersome workload during offline acquisitions, and another is to improve the fingerprint positioning accuracy. Because the different orientation fingerprints need to be gathered at each sampling point of the target region, the fingerprint acquisition of a large-scale indoor space will be very time-consuming. The current study of this issue is mainly based on the signal model [1, 2] and crowdsourcing method [3, 4], which have achieved many better results. For the positioning accuracy, researchers have designed various online matching algorithms to reduce the positioning error [5, 6] and achieved the median error of around 2 m. But there always are some larger positioning errors with more than 6 m, which is one of the bottlenecks in improving the positioning accuracy. Liu et al. [7] considered the larger positioning errors problem in the practical application of fingerprint positioning. But they ignore the human blocking problem. In fact, the positioning equipment needs to be carried with users, where the human body will lead to the signal multipath and shadow so as to produce severe attenuation of signal strength [8]. In this paper, we analyze the impacts of different orientations and holding positions and find that body blocking will cause the positioning error over 8 m. This means that the multipath and shadow will further aggravate the larger positioning errors. As far as we know, there are few studies to reduce these large positioning errors caused by human blocking.
For the problem of larger positioning errors, we discuss the position distribution of some offline similar fingerprints and find there is fuzzy similarity between offline fingerprints. The corresponding positions of some similar fingerprints are far apart, called fuzzy similarity, which is the root cause of larger positioning errors. Meanwhile, the multipath and shadow will further aggravate the fuzzy similarity, which leads to more large positioning errors. Through further analyzing positions distribution of similar fingerprints, we also find that most of the corresponding positions had a cluster feature. Therefore, we design a method based on K-Means clustering to achieve fine-grained positioning accuracy, which is called K-Means+ (Algorithm 1). Due to the fact that the K-Means+ positioning algorithm is invalid to the outliers, we further designed a linear sequence matching algorithm to improve the accuracy of outliers positioning, thus eliminating the problem of fuzzy similarity in offline fingerprints. Experimental results demonstrate that our algorithm can improve the positioning accuracy significantly.
(1) /*Compute the number of clusters of k*/ (2) (3) /*X is all the fingerprint database*/ (4) (5) /* (6) (7) (8) (9) (10) (11) Center( (12) goto (4) (13) (14) return (15)
The remainder of the paper is organized as follows. The related work is shown in Section 2. We analyze the fingerprint feature in Section 3 while leaving the details of our algorithm design in Section 4. Then we show the experiment and evaluation results of our algorithm in Section 5. Finally, we conclude the paper in Section 6.
2. Related Work
Fingerprint positioning with no limit of extra deployment is widely studied. Various methods, such as deterministic kNN [9], Bayesian estimation [10], Sequential Monte Carlo [11], support vector machine [12], and neural network, are used for improving positioning accuracy. But most of fingerprint algorithms rarely reduce the larger errors caused by the body blocking in order to improve the positioning accuracy. Radar system is an earlier attempt of fingerprint positioning using wireless signal strength [8]; although the system finds that body blocking has a serious influence on the positioning accuracy, it does not provide an effective solution. Thereafter, some papers begin to consider body blocking problem during indoor positioning. Papapostolou and Chaouchi [13] build the different direction of signal attenuation model based on a lot of experiments and provide an orientation aware fingerprint positioning algorithm to reduce the influence of body blocking. COMPASS [14] algorithm introduces the device with a digital compass, measuring the personal orientation as a dimension of signal strength fingerprint vector to improve the positioning accuracy with body blocking. LoSF [15] algorithm provides a double node mechanism to avoid the nonline of sight effects from body blocking. These algorithms reduce the influence of body blocking to a certain extent, but they have not considered body blocking impact on fuzzy similarity fingerprint and are unable to avoid larger positioning errors.
Liu et al. [7] consider the fingerprint fuzzy similarity problem in the practical application of fingerprint positioning, which uses the existing mobile phone to provide a peer assisted algorithm. They adopt the sound ranging method to measure the distance between mobile users by the microphone and loudspeaker of mobile phone and use the acquired distance relationship between mobile users to constrain the fingerprint positioning results, which can prevent the emergence of larger errors. This method can avoid larger positioning errors, but it requires additional sound-based ranging method which will increase the energy consumption of positioning service. More importantly, the sound-based ranging method is hardly used in noisy public environments.
We analyze the distribution features of offline similar fingerprints and find similar fingerprints have a cluster position distribution feature besides the fuzzy similarity. Therefore, we design an efficient clustering method on offline fingerprints to eliminate fuzzy similarity and avoid the restrictions of sound ranging.
3. Fingerprint Fuzzy Similarity and Positioning Performance
3.1. Body Blocking Influence
To analyze the WiFi signal fingerprints positioning performance, we first conduct a study on the impact of various factors, such as orientation and holding position. Due to the development of smart phones, people use the mobile phone to obtain indoor positioning services increasingly. So we select a GALAXY Note 3 as the WiFi terminal device to acquire signal data. The test mainly studies the multipath and shadow influence on the WiFi signal fingerprint without considering the factor of device diversity.
The testbed is an open lab area of

The distribution of sampling points in the experiment.
Generally, wireless signal strength will change with time leading to some measurement errors [15]. Suppose that these measurement errors follow zero mean normal distribution with ϵ variance. Fingerprint matching often uses the Euclidean distance to measure the similarity of fingerprint vectors, and then the maximum measurement error

To analyze the influence on fingerprint granularity and positioning performance with different orientations and holding positions on mobile phone, we design four group tests using the
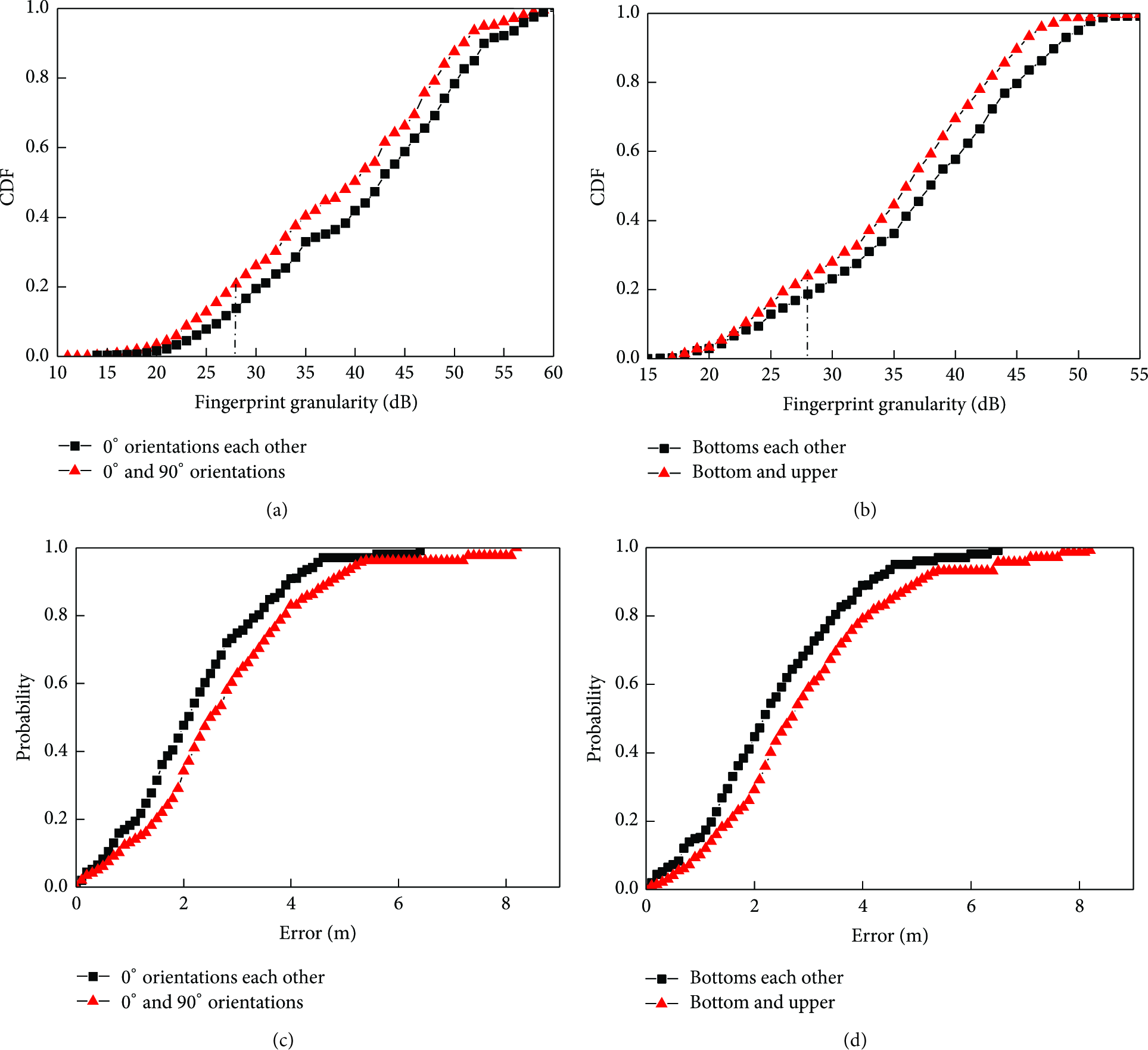
Influences of orientations and holding positions.
Figures 2(a) and 2(b) show the fingerprint granularity cumulative distribution with different orientations and holding positions. Suppose the mean error of WiFi signal strength measurement is 5 db [15]. We can compute that the maximum intrinsic fingerprint granularity error is
3.2. The Root Cause of Larger Errors
In order to analyze the cause of larger errors, we compared the position distribution of similar fingerprints with different orientations. Sampling positions of the similar fingerprints will be displayed in the indoor floor plan. We select the similar fingerprints from

The distribution of similar fingerprints at four sampling points.
4. Removing Fingerprint Fuzzy Similarity
At present, many researches focus on the design of online matching algorithm and filtering optimization algorithm to improve the fingerprint positioning accuracy. The filter can smoothly fit positioning results according to the previous results to avoid the larger deviation. But if there are larger positioning errors, the filtering and fitting will lose efficacy. Based on cluster features of similar fingerprints, we provide a K-Means+ method to cluster the offline similar fingerprints, and we also design a linear sequence matching algorithm to locate the outliers position so as to increase the positioning accuracy.
4.1. Clustering Offline Fingerprints
The traditional K-Means algorithm is a classic machine learning method based on samples similarity measurement. The criterion function is usually the least sum of squared error. Suppose an m-dimensional real vector
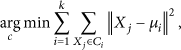
Step 1.
Divide the indoor corridors according to a fixed length l, and compute the segmentation number k. We can obtain k clusters, where the initial cluster center is the center position of each segmentation.
Step 2.
Compute the fingerprint granularity between each sampling point and the cluster center, and add the less than
Step 3.
Recompute the center of all sampling points in each cluster.
Step 4.
Set the cluster radius as
It is important to note that when repeating Step 2, we do not use
After clustering the offline fingerprint, we adopt a layered kNN matching algorithm for positioning. First, we match the sampling real-time fingerprint vector with the fingerprints of the cluster centers. Then we run the exact matching in clusters. The layered kNN matching algorithm can reduce the matching computational overhead and obtain more accurate positioning result. However, this clustering method cannot solve outliers positioning. When computing the outliers position, it will be false matching to other clusters due to the fact that the outliers do not belong to any cluster. Although the outliers are fewer, they also cause larger positioning error. We further propose a linear sequence matching method to replace the traditional point matching.
4.2. Linear Sequence Matching
Since the K-Means+ algorithm ignores the influence of outlier data, the outlier sampling points are difficult to obtain the accurate positioning result. We propose a linear sequence matching algorithm to replace the traditional point matching. In the process of positioning, we record matching position sequence and set the length of the sequence as s. Since the offline fingerprint cluster covers a larger area, two adjacent positioning intervals usually do not exceed the scope of the cluster. Sequence generating process is described in Algorithm 2.
(1) /*Initial position detection*/ (2) (3) /*Sequence increase or decrease*/ (4) (5) /* (6) (7) IndirectAdd( (8) (9) (10) DirectAdd( (11) (12) (13) return S
Step 1 (initial position detection).
When there are θ consecutive positioning results in the same cluster, we can determine the initial position in the current cluster. We use the kNN matching method to obtain the precise initial position and take the current position number as the linear sequence header. Otherwise, we continue to execute the positioning and detection. The θ is an experimental experience value.
Step 2 (sequence increase or decrease).
The initial length of the sequence is Compute the average length If If Otherwise, keep the sequence unchanged until next positioning is completed.

A diagram of generating linear sequence.
Step 3 (matching).
The end position of the sequence is the current positioning result.
The linear sequence matching method considers both physical distance and fingerprint distance to avoid the outlier failure problem of K-means+ matching algorithm. However, the accuracy of initial position will affect the correctness of the increasing sequence. We will verify the rationality of initial position selection by the experimental method.
5. Experiment Results and Evaluation
5.1. Experiment Design
In order to verify the performance of the linear sequence K-Means+ clustering matching algorithm, we still adopt the
5.2. Performance Evaluation
Before executing K-Means+ method, we need to select

Fingerprint granularity distribution under different numbers of clusters.
We select

Positioning errors under different numbers of clusters.
When analyzing the influence of different clusters k on fingerprint granularity and positioning accuracy, there are similar performances between
The initial position of the linear sequence is important to the matching performance. Generally, user cannot move out of the clustering range immediately. According to the above test results, the cluster diameter is about
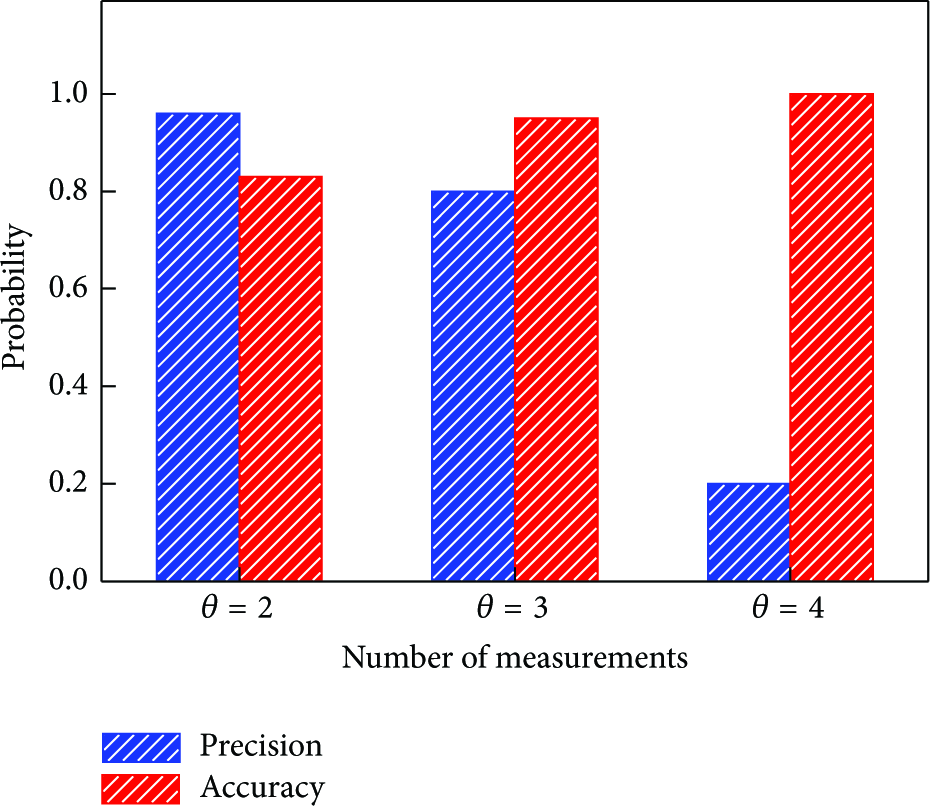
Influence of measurement times on initial sequence position accuracy.
Based on above clustering results, we further verify the influence of linear sequence length on outlier positioning. The sequence length will affect the average sequence segments
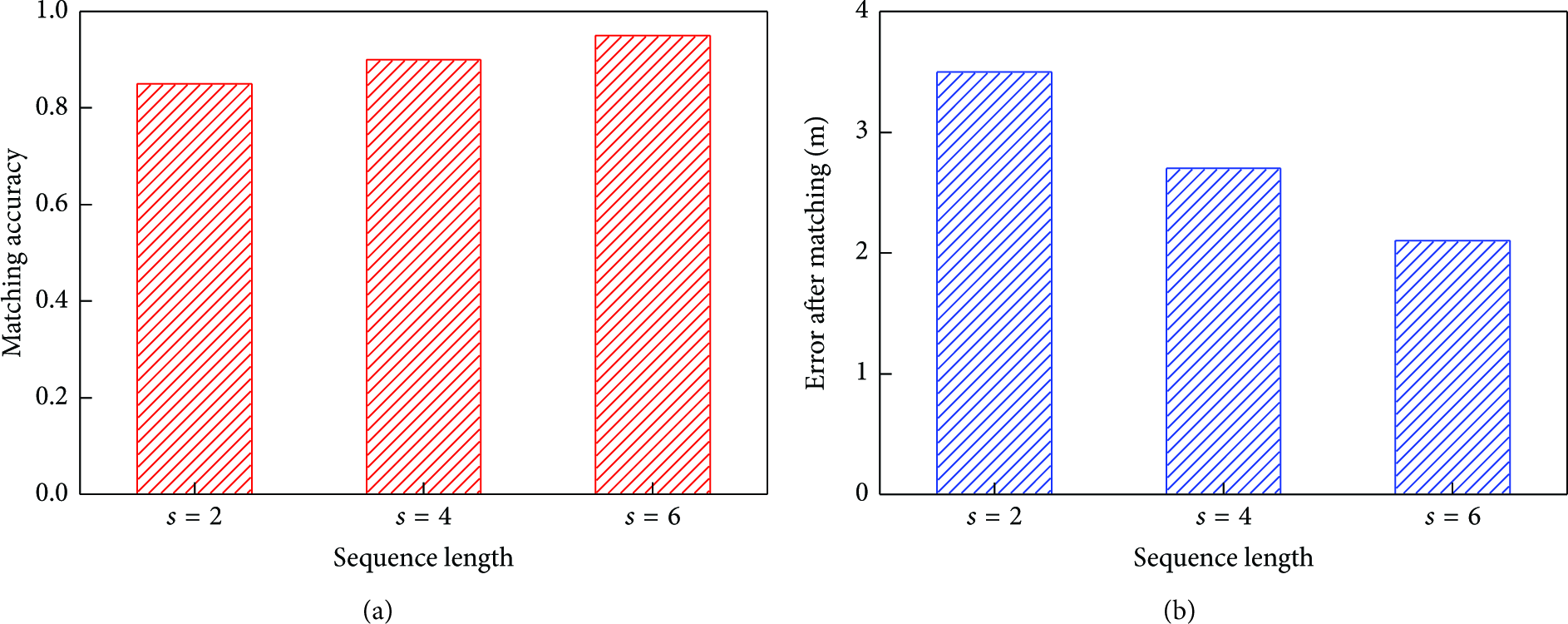
Influence of sequence length on outlier points positioning accuracy.
Figure 8(a) describes the matching accuracy of outliers. The sequence length has less impact on matching accuracy. With the increasing of sequence length, the matching performance has a little improvement. Figure 8(b) represents the average positioning error with wrong matching. The outlier positioning error will reduce while the sequence length increases. But the error falling is not distinct and ranges from around
To verify the performance of our fuzzy similarity fingerprint eliminating algorithm, we compare the classical Radar,

The performance of the fuzzy similarity fingerprint eliminating algorithm.
6. Conclusion
Fingerprint positioning is the foundation of indoor location services, which has been widely studied. We analyzed the corresponding position distribution of similar fingerprints and then found the larger errors problem. Through analyzing the corresponding positions distribution of the similar fingerprints, we also found fuzzy similarity is the root cause of larger errors. According to the cluster features of similar fingerprints, we proposed a K-Means+ clustering algorithm to achieve fine-grained fingerprint positioning. Due to the K-Means+ algorithm failing to locate the positions of outliers, we also designed a linear sequence matching algorithm to improve the outliers positioning. Experimental results show that our algorithm can get a maximum positioning error less than
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work is supported by National Natural Science Foundation of China (NSFC) under Grant no. 61401300, National High Technology Research and Development Program of China (863) under Grant no. 2012AA013104, the Innovation Program of Institute of Information Engineering Chinese Academy of Sciences (no. Y3Z0071E02), Scientific and Technological Innovation Programs of Higher Education Institutions in Shanxi (STIP) under Grant no. 2014124, and Youth Foundation of Taiyuan University of Technology (no. 2013Z060 and no. 2014TD054).