
Abstract
We provide a distributed method to partition a large set of data in clusters, characterized by small in-group and large out-group distances. We assume a wireless sensors network in which each sensor is given a large set of data and the objective is to provide a way to group the sensors in homogeneous clusters by information type. In previous literature, the desired number of clusters must be specified a priori by the user. In our approach, the clusters are constrained to have centroids with a distance at least ε between them and the number of desired clusters is not specified. Although traditional algorithms fail to solve the problem with this constraint, it can help obtain a better clustering. In this paper, a solution based on the Hegselmann-Krause opinion dynamics model is proposed to find an admissible, although suboptimal, solution. The Hegselmann-Krause model is a centralized algorithm; here we provide a distributed implementation, based on a combination of distributed consensus algorithms. A comparison with k-means algorithm concludes the paper.
1. Introduction
The problem of grouping large amounts of data into a small number of subsets with some common features among the elements (often referred to as the data clustering problem) has attracted the work of several researchers in different fields, ranging from statistics to imagine analysis and bioinformatics [1–3].
Data clustering techniques are developed to partition an initial set of observation data into collections with small in-group distances and big out-group distances.
Among the existing techniques, one of the most used is the k-means algorithm or its successive extensions (e.g., fuzzy c-means [4], mixture of Gaussians algorithms [5]). Given a set of initial observation data and a number k of desired clusters, the k-means algorithm computes a suboptimal placement of k cluster centroids and assigns the observations to such centroids, alternating between an assignment phase, where each observation point is assigned to its nearest centroid, and refinement phase, where each centroid position is updated as the center of mass of all observations belonging to that centroid.
A well-known limitation of data clustering algorithms, such as the k-means algorithm, is that the number of clusters has to be specified beforehand, based for example, on subjective evaluations or a priori analysis. Since this assumption is typically not feasible in practice, a typical solution consists of running several times the algorithm with a different number of clusters and then deciding the best obtained solution based on a posteriori evaluation [6]. Another issue of traditional algorithms is that there is no guarantee that the clusters are sufficiently far from each other. To this respect, distance-constrained data clustering approaches have been devised in the literature: in [7, 8] the considered constraints are the so-called must-links (i.e., an observation i must belong to a cluster j) and cannot-link (i.e., an observation i can not belong to a cluster j); in [9] the feasibility of a constrained problem involving the so-called δ-constraints (i.e., any two observations must have a distance greater than δ) and the ε-constraints (i.e., for any observation i in cluster j there must be at least another observation h in cluster j such that the distance between i and j is less than ε) is given. To the best of our knowledge, nowadays, there is no methodology to specify a constraint on the distance between cluster centroids, while this class of constraints might help finding a choice for the number k when such value is a priori unknown.
This problem has a particular relevance in a distributed setting, where a network of sensors has to classify information provided by several sensors without a central authority but using only local data exchange among neighbors in the network. Differently from community clustering in wireless networks (e.g., see [10]), here the nodes are clustered depending on the data they sense, with no particular dependency on the network topology.
In this paper, based on the preliminary results in [11], a novel approach to solve the data clustering problem with a distance constraint among cluster centroids is provided that does not require the specification of the initial number k of clusters and that is based on an extension of the Hegselmann-Krause (HK) opinion dynamics model [12, 13], which handles scalar data, in order to handle data in
Within the proposed approach, rather than striving for a complete agreement among the agents, we exploit the peculiarity of HK model to generate several clusters, with the aim to map a large set of measurement data into few values (i.e, the opinion clusters). In this view, as it will be discussed in the following, HK models can be seen as a powerful methodology to determine the number of clusters while respecting the constraints on the distance among cluster centroids. The HK model, in its original setting, is a centralized algorithm [13]; hence we devise a distributed implementation based on a combination of consensus algorithms, which are an effective way to distribute complex operations, for example, time synchronization [16].
The outline of the paper is as follows: after some preliminaries, in Section 2, we provide a formulation of the problem at hand and in Section 3 we analyze the formulation of the standard data clustering problem and the k-means algorithm; then in Section 4 the HK opinion dynamics model is reviewed, while in Section 5 the distributed consensus algorithms are examined; Section 6 is devoted to outline the proposed approach to solve the distance-constrained clustering problem, while Section 7 addresses the distributed implementation of the HK opinion dynamics model; Section 8 contains some numeric examples to show the potentialities of this method, while Section 9 contains some conclusive remarks.
Preliminaries. Let
A graph is said to be undirected if
2. Problem Statement
Consider a collection of n sensors, each equipped with a d-dimensional measurement or piece of information
Problem 1 (distance-constrained data clustering).
We want to find the number of clusters k, the cluster centroids,

subject to the constraints

The first set of constraints (I) along with the third one implies that each observation is assigned exactly to one cluster; the constraints (II) imply that ε is a lower bound for the distance between any pair of centroids; finally constraints (III) imply that
This problem is novel, since in the literature, the set of constraints (II) is typically not considered. Including such constraints, however, is quite useful, since it may improve the algorithm's ability to detect homogeneous clusters. The problem is very hard to solve exactly and traditional methods as the k-means algorithm [17] may fail even at finding an admissible solution, as it will be shown in the next section.
On the other side, the proposed algorithm uses an algorithm based on the Hegselmann-Krause model to choose an admissible, although suboptimal, solution, and it has a modest increase in computational complexity with respect to the k-means algorithm, while allowing several advantages (further discussed later in the paper):
the algorithm provided in this paper always finds an admissible, although suboptimal, solution to the problem by means of the HK model, while the k-means algorithm may fail;
the proposed approach does not require the user to define a priori the number of clusters, but it finds automatically a suitable number of clusters based on the parameter ε;
outliers can be automatically isolated, without any a priori data processing; this feature can be obtained by dropping out the clusters whose cardinality is significantly less than the others;
the solution provided in this paper is deterministic, that is, for fixed ε and fixed observations, the result is always the same, while the k-means algorithm depends on the initial random choice of the centroids;
while traditional approaches are very computationally expensive when applied in a decentralized and distributed setting [18] (i.e., for a sensors network), this method can be distributed with a modest increase in computational complexity [19].
2.1. Distributed Setting
In this paper we want to provide a solution to Problem 1, where a set of n agents solves the above problem in a distributed fashion, that is, by means of local information exchange among the agents instead of resorting to a centralized processing unit. Let
has an associated observation
knows
has a unique identifier;
can exchange directly information only with neighbors over G;
can act synchronously.
In the next section we briefly review the traditional data clustering problem and the k-means algorithm.
3. Data Clustering
Let us discuss the following problem.
Problem 2 (standard data clustering problem).
Given

Problem (3) is hard to solve, and in the literature, several iterative algorithms have been devised. Among the others, the k-means algorithm [17] proved its effectiveness.
Specifically, starting with a random set of k centroids
During the assignment phase, each observation

Within the refinement phase each centroid

The two steps are iterated until convergence or up to a maximum of M iterations.
Figure 1 reports a simulation run of the algorithm for a set of

Example of execution of k-means algorithm (source: Wikimedia Commons available under GNU Free Documentation License v. 1.2).
The k-means algorithm is granted to converge to a local optimum value, while there is no guarantee to converge to the global optimum [17, 20].
Since there is a strong dependency on the initial choice of the centroids, a common practice is to execute the algorithm several times and select the best solution. The algorithm, moreover, is extremely sensitive to outliers, which can significantly alter the results; to cope with this issue, the outliers have to be identified and excluded prior to the execution of the algorithm.
Note that, for each step, each of the n observations and for each of the d components of the observations, the algorithm calculates the difference with each of the k centers; hence the computational complexity is
Note further that, unfortunately, the k-means algorithm is not able to solve Problem 1; hence we need to seek for other solutions.
In the following we discuss an alternative method based on the HK opinion dynamics model, which is granted to provide an admissible solution to Problem 1. One of the peculiar characteristics of this algorithm is that the number of clusters k has not to be imposed a priori but becomes an output of the algorithm. The HK opinion dynamics model is reviewed in the next section, while the proposed approach is outlined in Section 6.
4. Hegselmann-Krause Opinion Dynamics Model
In this section we recall the so-called HK opinion dynamics model and revise some of the main theoretical results. Consider a group of n agents, each characterized by a discrete time dynamic equation. The opinions, represented by the state associated with each agent.
Specifically, each agent is provided with a scalar initial opinion
The key idea of the HK model is that agents with completely different opinions do not influence each other, while some sort of mediation occurs among agents whose opinions are close enough.
Let

Note that, at each step t,
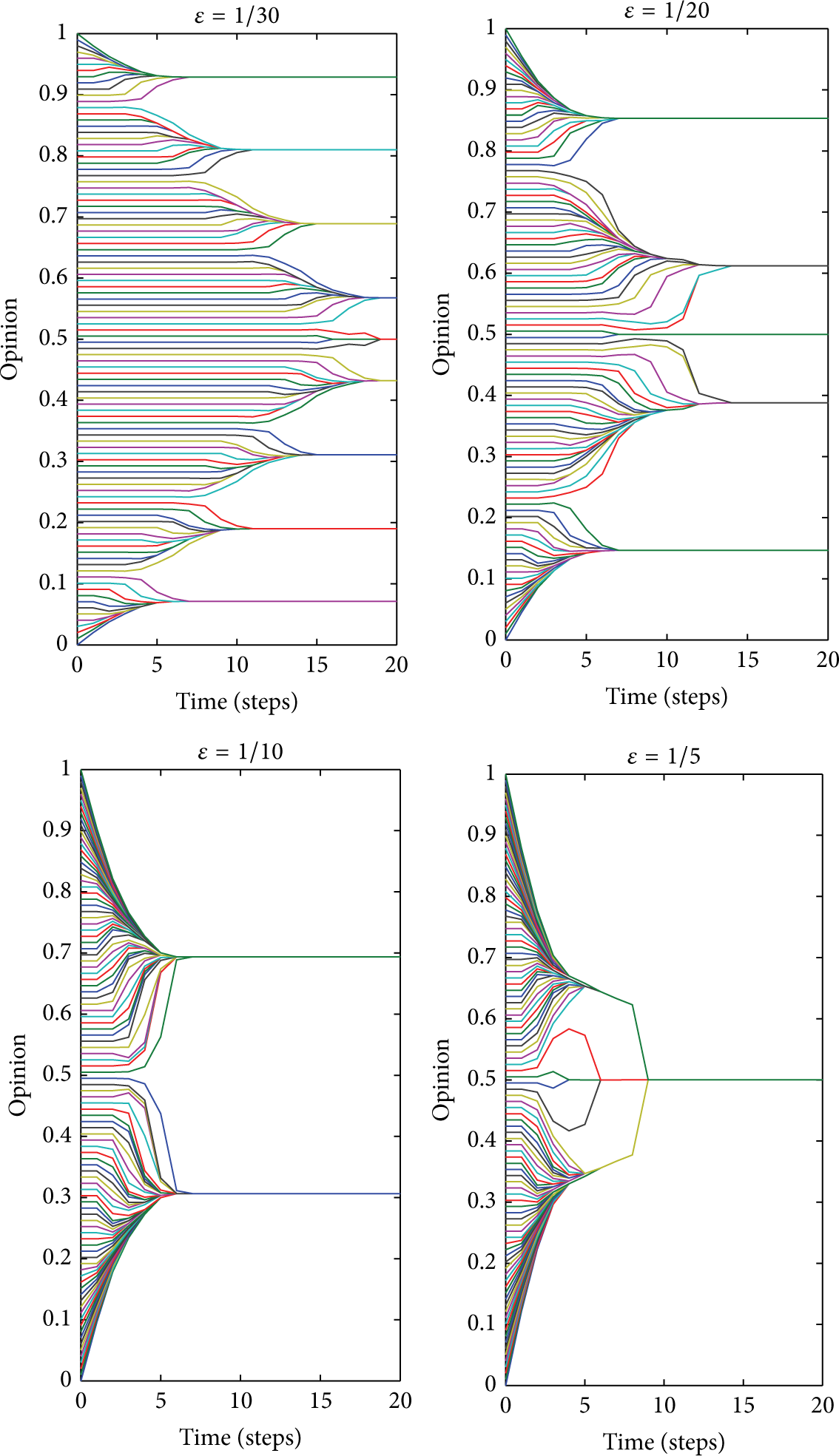
The HK dynamic model is in the form
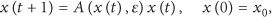
where

where
Several works can be found in the literature which attempt to characterize the properties of the HK model. Given the complexity of the above model, most of the studies consider simple initial opinion profiles (i.e., the initial condition
the equidistant profile, where
the random profile, where the opinions are uniformly distributed within
In [13] it is conjectured that for every confidence level ε there must be a number of agents n subject to the equidistant profile for which a consensus is obtained (i.e., a single shared opinion for all the agents), while in [21] it is conjectured that, for any initial opinion profile, there exists a finite time after which the topology underlying the matrix

Moreover it is proved that, if the initial opinion profile is sorted, the evolutions of the smallest opinion
Simulation of opinion dynamics for
Let us discuss the following property that will be used to solve the clustering problem with distance constraints.
Property 1.
ε is a lower bound for the intercluster distance; in fact, when a steady state is reached, any two clusters have a distance which is necessarily greater than or equal to ε, otherwise they would have merged during the evolution of the model.
The above property justifies the adoption of the HK model to solve the data clustering problem with distance constraints.
Regarding the computational complexity, at each step of the algorithm the distance among the opinion of all agents is calculated. Thus the computational complexity is
5. Consensus Algorithms
In order to provide a distributed implementation of the HK model, let us discuss distributed consensus algorithms with reference to connected, fixed, and undirected graphs.
Suppose each node in a graph G represents an agent with an initial condition

where
Let

Let us now discuss the
5.1. Max-Consensus
Assuming the graph is connected and undirected, the problem is known to have a solution in finite time [15] (and specifically in no more than n steps) choosing

In the following we will denote by

the execution of
5.2. Average-Consensus
In the average-consensus problem the nodes are required to converge to the average of their initial conditions, that is,
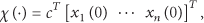
where
Let each node choose

where

where the
According to [26], this choice of
The above condition implies that, if the underlying graph is undirected, it needs to be connected.
A possible choice for W, assuming that each node knows n (or an upper bound for n), is that each node i chooses independently the terms

resulting in a matrix W that satisfies the conditions in [26]. Several other choices that yield to asymptotic consensus are possible (e.g., see [27]).
As for the complexity, note that at each time step t each agent i calculates the contribution of each neighbor to the next state; hence we have
In the following we will denote by

the execution of
5.3. Network Size Calculation
Combining the max-consensus and the average-consensus algorithms, it is possible to calculate the number of agents n in the network in a distributed way [29].
Specifically, suppose a leader is elected via max-consensus over G (e.g., the nodes, each, have a unique identifier and the node with maximum identifier is elected as leader via max-consensus). Now, let the nodes execute an average-consensus algorithm with

hence n can be calculated in a distributed way.
6. Data Clustering with Distance Constraints via Opinion Dynamics and k-Means
In this section we propose an algorithm for data clustering with measurement distance constraints, based on a generalization of the HK model.
Specifically, measurement data is processed by an HK-like opinion dynamics “filter,” which eventually segments the data into κ clusters. Moreover, based on the weight of each cluster (namely, represented by the amount of measurement data that has converged to that cluster), data outliers can be filtered out from the original set. More precisely, we assume that each agent i is provided with an initial measurement represented by a vector

for
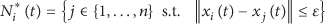
where
In [22] the HK model with vectorial opinions (i.e.,
In order to give an idea of the actual time required for convergence, we provide the simulation results of Figure 3, where the average instant in which a steady state is reached and the number of clusters obtained are reported in the case

Average instant in which a steady state is reached and the number of clusters obtained is reported for several choices of
The proposed approach, as discussed before, does not require the user to specify a value for the parameter k, but it finds a suitable number of clusters based on the parameter ε.
A high value of ε means very large and sparse clusters (eventually also very few of them) while a small value of ε means very compact and small clusters (eventually, many of them).
Note that, as said before, one of the biggest problems of the k-means-like algorithms is that the outliers have to be preprocessed and excluded; otherwise they would influence considerably the quality of the clustering. In the proposed approach, depending on the choice of ε, very far observation is not influenced by the others and is assigned to a singleton (or more in general to a cluster composed of very few elements).
Notice that it is always possible to execute a k-means algorithm with k equal to the number of clusters obtained via HK, in order to attempt to refine the solution found, but this can be done only if the solution of the k-means algorithm does not violate the constraints on the distance among cluster centroids.
The proposed algorithm, appears as a good candidate to allow the clustering of a set of sensors or mobile robots, based on perceived information such as position or other sensorial information (temperature, humidity, etc.).
As for the computational complexity of the extension of the HK model to opinions in
7. Distributed HK Opinion Dynamics
As shown in the previous section, the HK opinion dynamics model can be used to provide an admissible, although suboptimal, solution to the distance-constrained data clustering problem. However, since the topology underlying the HK model is indeed a state-dependent topology, theoretically each agent may exchange information with another agent, depending just on the difference in their opinions.
In order to adopt the HK model in a distributed perspective, we need to provide a different implementation, as provided in Algorithm 1.
/*Transmit the state of agent h to each other*/ /*Calculate
Since the agents have a unique identifier
Using average-consensus, multiplied by n, in order to obtain

the value

As for the computational complexity of the distributed version, note that, for each step
8. Numeric Examples
As discussed above, the k-means algorithm is generally unable to solve the data clustering problem with distance constraints. In this section, some examples are reported in order to show the effectiveness of the proposed approach. A comparative simulation between the HK model and k-means algorithm is first addressed. Afterwards the potentiality of the proposed mixed approach is showed; then the distributed implementation is discussed.
Figure 4 shows an example in

Clustering for
Figure 5 shows a case where

Clustering for
Figure 6 shows the ability of the proposed methodology to isolate the outliers. For

Clustering for
Figure 7, eventually, shows an example of application of the distributed HK model provided in Algorithm 1, in a case where
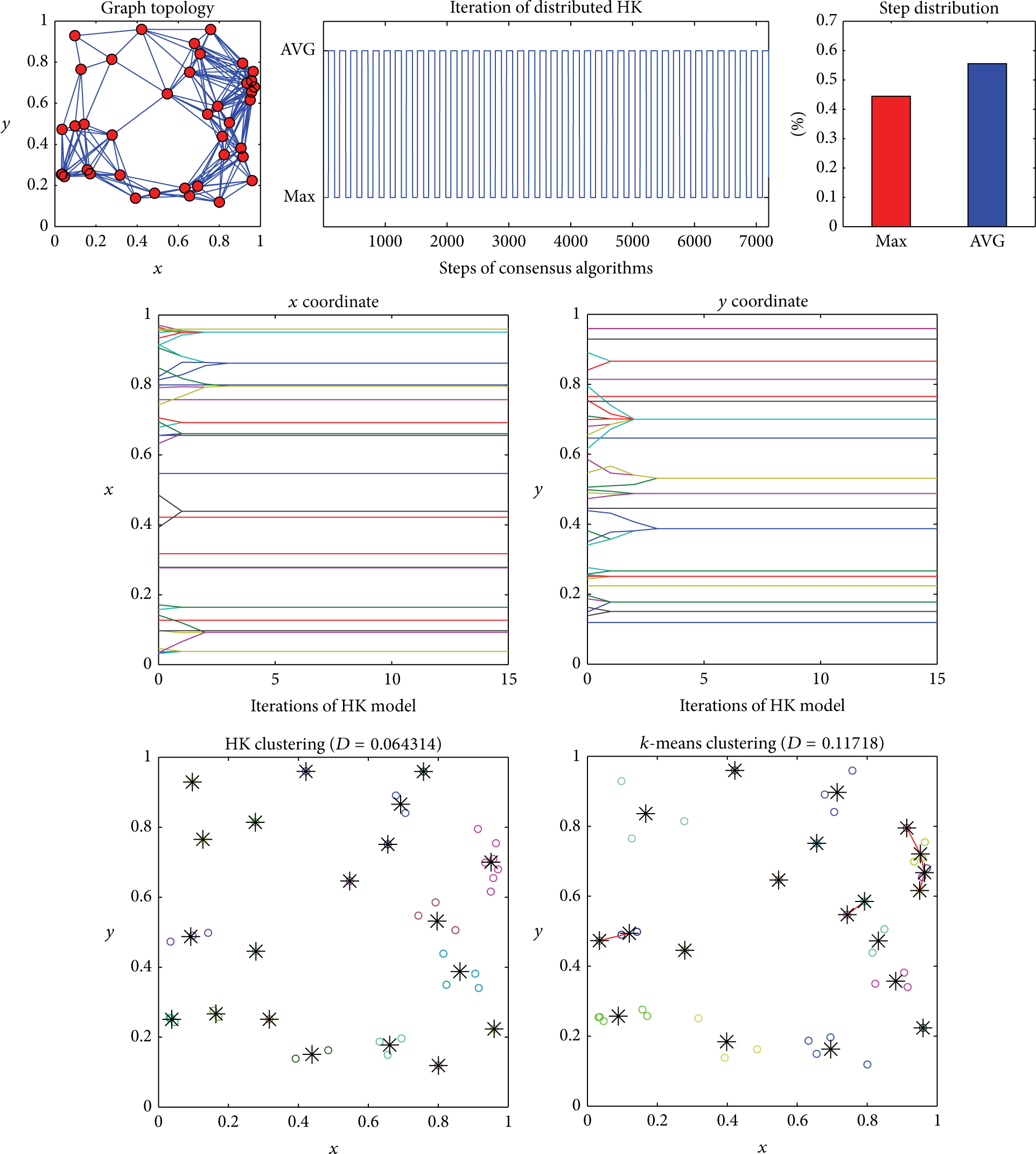
Distributed clustering on the positions of
9. Conclusions and Future Work
In this paper a distributed algorithm for a sensors network to solve a data clustering problem is provided, with the constraint that the centroids of the clusters must be within ε.
The proposed approach is based on the HK opinion dynamics model, which finds admissible, although suboptimal, solutions without requiring a user-specified number of desired clusters and applies the k-means algorithm to find a better solution.
In its original application, the HK opinion dynamics model is a centralized algorithm. In this paper, a distributed implementation is provided instead, based on a combination of consensus algorithms.
Future work will focus on providing a bound for convergence time in high-dimensional spaces and testing the algorithm in a real world scenario, including noise and packet loss.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.