
Abstract
With the development of mobile communication networks and intelligent terminals, recent years have witnessed a rapid popularization of location-based service (LBS). While obtaining convenient services, the exploitation of mass location data is inevitably leading to a serious concern about location privacy security. Obviously, high quality of service (QoS) will result in poor location privacy protection, so that a trade-off is needed to fulfill users' individual demands for both sides. Although existing methods perform well in certain scenarios, few have considered the abovementioned balance problem. Therefore, by combining k-anonymity-based cloaking technique and obfuscation method, a new distributed user-demand-driven (DUDD) location privacy protection scheme is put forward in this paper. The basic idea is still to select a subcloaking area within the cloaking area generated by Location Anonymization Server. Moreover, by using the improved LBS system model, this paper constructs a distributed framework, in which location privacy protection is wholly occupied in server side and LBS provider is only dedicated to QoS-guarantee. In addition, normalized privacy demand and QoS metrics are given and a user-defined weight parameter is introduced to ensure location privacy security without decreasing QoS. The feasibility of the proposed method is proved through simulation.
1. Introduction
Recently, the popularization of intelligent terminals such as smart phones and the growing of mobile network coverage have provided location-based service (LBS) with various fields of applications. LBS employs mobile communication networks or Global Positioning System (GPS) to obtain the location information of mobile users. With the help of Geographic Information System (GIS) platform, it offers users many value-added services, including navigation services, life assisted services, social services, and commercial push services [1].
In order to get access to all these convenient services, it is a prerequisite for users to furnish their own location information to service providers. The acquisition as well as exploitation of mass location data inevitably leads to location privacy issues because sensitive data like location information can easily expose users' work places, places of residence, travel destinations, and even their precise locations at a certain moment. Associated with some available background information, it is enough for an adversary to infer more important information about users, which may constitute a threat for their lives and security of properties [2–4].
In particular, when users arrive at some sensitive places such as hospitals and banks, they would like to preserve their location privacy and obtain services simultaneously. However, location privacy protection and QoS are checks and balances, which means that the improvement of location privacy protection must be at the expense of dropping QoS. And conversely, the accurate location service is bound to bring several location privacy threats. Therefore, for mobile wireless communication networks, the QoS-guaranteed location privacy protection has become a big challenge. Also, it is a key factor affecting the future prospects of mobile wireless communication networks and LBS service [5].
During the past few years, for the purpose of handling the aforementioned problem, numerous approaches regarding location privacy protection have been proposed and are gradually showing a personalized trend with the increase of user demands [6]. Although those existing methods have performed very well, there exist some unavoidable limitations. The anonymity-based method is commonly used in LBS, but it is vulnerable to the background information attack (edge information attack) and, moreover, it has a limited protection degree while being applied alone [7]. Nevertheless, the computational complexity of obfuscation-based method is considerably high. What is more, to the best of our knowledge, few approaches take users' individual demands for location privacy and QoS into consideration.
Hence, in order to improve the effectiveness of location privacy protection and to reduce the computational complexity, this paper proposes a new algorithm of location privacy protection to meet users' individual demands and to seek the balance between location privacy protection and QoS, which is in combination with k-anonymity-based cloaking technique and obfuscation method. First, users initialize and send their LBS queries to Location Anonymization Server and, at the same time, forward a parameter called type of service (ToS) to LBS provider to declare the types of services. Then, the server and LBS provider will return to users, respectively, their restrictions on the distance between the real user location and the subcloaking area. Meanwhile, in the first step, Location Anonymization Server generates a large cloaking area according to users' desired privacy protection degree and returns it to users. Second, users select a subcloaking area a(c) within this large cloaking area by applying a selection algorithm and then send it back to LBS provider. Finally, LBS provider returns service responses back to users, and then the entire LBS process is completed. Since the subcloaking area selection method has randomness, the real user location might be contained in the subcloaking area or not. Hence, even if an adversary manages to know about the cloaking area reported to LBS provider, it is still quite difficult to find out the real user location. In this way, an effective location privacy protection will be achieved. The main contributions of this paper can be summarized as follows:
By using an improved LBS system model, this paper constructs a distributed framework in order to isolate Location Anonymization Sever and LBS provider, which will prevent user information disclosure through untrusted server or LBS provider and realize a function separation of QoS-guarantee and location privacy protection to improve the system efficiency. This paper designs a subcloaking area selection algorithm, which enables users to seek a specific cloaking area within a large cloaking area on the condition of satisfying their individual demands, making it truly user-demand-driven. This paper proposes new quantitative and normalized representations of QoS as well as location privacy demand and introduces two boundary parameters, namely, location privacy security distance The entire cloaking area computation process in this paper does not need to assume that the server has known users' next locations, which is more realistic.
The remainder of this paper is organized as follows: The second section summarizes related works on location privacy protection. The third section defines problems and introduces the traditional system model. The fourth section presents the improved system model and three core algorithms of location privacy protection. The simulation analysis of feasibility is detailed in the fifth section, and section six concludes this paper and puts forward some future research directions.
2. Related Works
As shown in Figure 1, existing location privacy protection methods can be roughly divided into four categories: regulatory method, privacy policy-based method, anonymity-based method, and obfuscation-based method [8]. Among them, the development of anonymity-based and obfuscation-based methods is more thorough, making them two major directions of research on location privacy protection.
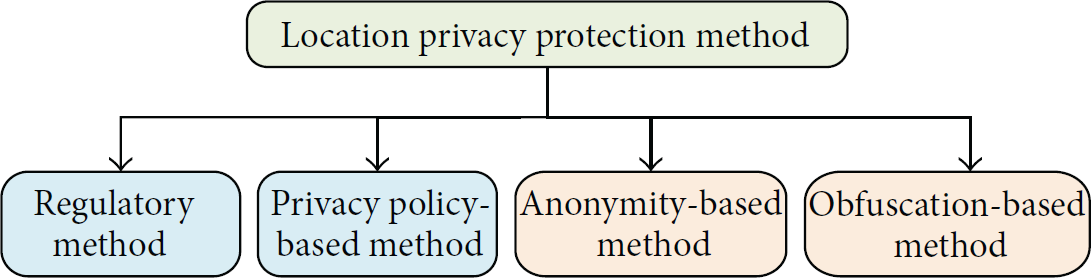
Categories of location privacy protection methods.
Anonymity-based method is also named time-space cloaking technology, among which k-anonymity method is the most well-known and is applied in location privacy protection by Gruteser and Grunwald for the first time [9]. By employing the quadtree data structure, k-anonymity method is able to guarantee that a cloaking area of one user contains at least
Obfuscation-based method protects location privacy by producing a virtual user location or by separating locations from identities. Duckham and Kulik pointed out that the obfuscation-based method was one of the most important methods in location privacy protection and proposed a new obfuscation approach, in which users could balance privacy demands and QoS through the negotiation with the LBS provider [16]. Reference [17] proposed a dummy method, in which the server produced virtual location information according to real user locations and mixed them to protect location privacy. However, attackers were able to distinguish real users from virtual users through long-term tracking. The algorithm improved by You et al. [18] increased the continuity of virtual location generation, making those virtual locations more authentic. Ghinita et al. came up with a new Private Information Retrieval based framework [19] to divide the whole space into different modules. In this way, users could extract the necessary information without leaking concrete locations because users could only get access to the information stored in their own modules. The two algorithms mentioned above have achieved remarkable results in privacy protection. However, the calculation complexity and communication cost of their works were just high. To handle the source-consuming issue, [20] put forward a distributed obfuscation method, which was able to reduce one half computation expense, but it was still high-cost compared with k-anonymity method.
3. System Model and Problem Definition
3.1. Problem Definition
3.1.1. Edge Information Attack
Edge information attack frequently occurs while applying k-anonymity method [12]. Considering the scenario shown in Figure 2 and supposing that user

Edge information attack illustration (revised from [12]).
The concept of edge information attack is that, by comparing the user information in two different cloaking areas, such as users' location coordinates and LBS query traces, those who are not in the common user set (here
3.1.2. Limitations of Existing Approaches
To counter the edge information attack, literature [8] proposed a cloaking area algorithm based on the common user set. In this algorithm, a cloaking area should meet not only the individual demand for k, but also the demand of all the users in the common user set for k. Although the algorithm is thoughtful, on the one hand, the calculation cost will dramatically increase due to the consideration of all the users in a set; on the other hand, since each user's location in the next moment will affect the calculation of the coverage area, the premise of using this algorithm is to know users' future locations, which is obviously unrealistic.
In summary, although existing approaches such as the method proposed in [8] have acquired good results, limitations still cannot be ignored:
Calculating the public privacy value k in unit of user-set, instead of considering the different privacy levels demanded by different users, cannot meet individual demands for privacy security. Assumption that next-moment location of each user is known by Location Anonymization Server is not feasible. The purpose of this algorithm is to find the smallest coverage area, namely, maximizing the QoS, which neglects the trade-off between QoS and the degree of privacy protection. While applying this algorithm at high population density places (e.g., classrooms or meeting rooms), it is still likely to expose users' locations, because, in this kind of scenario, the value of k is easily fulfilled. Excessive calculation may be caused, especially while considering that some users may have continuous privacy demands.
3.2. Traditional LBS System Model
The traditional LBS system is composed of three parts [8], including user, Location Anonymization Server, and LBS provider, as shown in Figure 3.
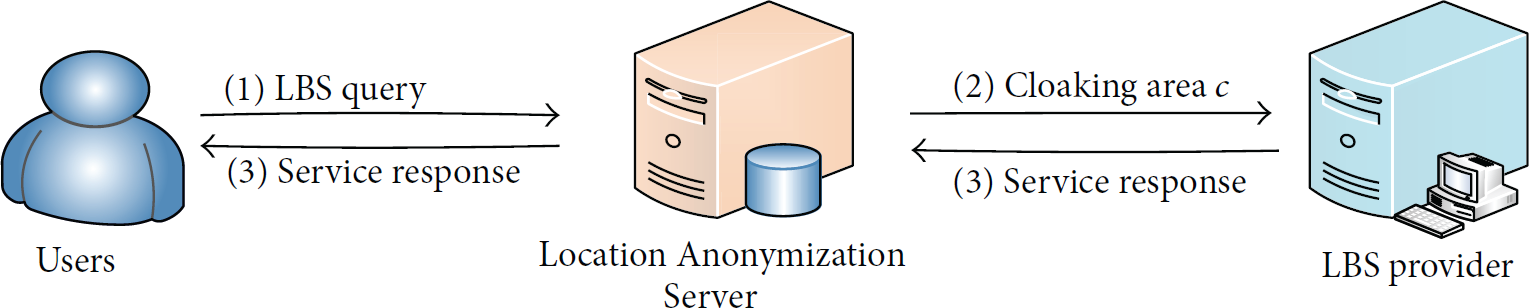
Traditional LBS system model.
In this model, Location Anonymization Server acts as a bridge, which is responsible for cloaking area generation and link connection between users and LBS provider. LBS query is represented in the form of
However, several drawbacks exist in this model. On the one hand, the model assumes by default that Location Anonymization Server is trusted. But in reality, the trustworthiness cannot always be assured. LBS queries containing users' location information might be divulged to LBS provider easily via malicious servers. On the other hand, because of the central position of Location Anonymization Server, service responses cannot be returned to users directly, which will lead to a longer service delay. Furthermore, Location Anonymization Server has to allocate some extra resources to deal with the information transit, causing a waste of resource.
4. Proposed Location Privacy Protection Scheme
4.1. Improved LBS System Model
Hence, in order to make up for those defects present in the traditional system model, this paper draws on the experience of [12] and introduces an improved LBS system model as shown in Figure 4(a).

Improved LBS system model.
The improved model transforms from Location Anonymization Server-centric into user-centric, which highlights the dominant position of users. In this model, the LBS query is expressed in the form of
There are two differences from the conventional form.
First, Second, an extra parameter type of service (ToS) is added to inform LBS provider that the service required by the user, and then LBS provider will generate the QoS-guaranteed distance
In this new system model, Location Anonymization Server provides independent service for each user. Firstly, when the server records a user's LBS query, at this moment, it will produce a cloaking area c and return it to the user. Further, the user selects a smaller area called subcloaking area a(c) within c by using a selection algorithm and then sends it to LBS provider. Finally, LBS provider directly returns the query response to the user. Thus, based on the system mentioned above, the bridge between users and LBS provider is no longer necessary. It is the user who solely screens the cloaking area and directly gets access to the service returned from LBS provider, isolating Location Anonymization Server and LBS provider and avoiding user information disclosure. According to the selection algorithm, a(c) may or may not contain the real user location.
Compared to the conventional LBS system model, there are several advantages of the improved one.
First, Location Anonymization Server provides independent service for each user and users can completely express their individual demands through the selection of subcloaking area. Second, realizing the isolation of Location Anonymization Server and LBS provider can strongly reduce the probability of user information disclosure caused by malicious servers or providers. Third, by applying the improved model, a function separation between Location Anonymization Server and LBS provider is realized, and a distributed system framework is formed, as shown in Figure 4(b). Location Anonymization Server is specifically responsible for location privacy protection, and LBS provider is dedicated to QoS-guarantee. Moreover, the balance between the two sides is determined by users, which will significantly reduce the service delay and save system resources.
4.2. Data Structure
Similar to the approach presented in [8], a quadtree T is used to recursively partition the whole spatial domain into squares, as shown in Figure 5.

Spatial domain partitioning method using a quadtree (revised from [8]).
The whole spatial domain is partitioned into L levels (L is predefined by Location Anonymization Server, without further change). Every layer is partitioned into
For each user location
4.3. Definition of Parameters
Here again, in order to be clear, the definitions of several parameters are given. First of all, two practical scenarios are necessary to be introduced to facilitate the comprehension.
Scenario 1.
When a user asks for the nearest supermarket location, even the cloaking area sent to LBS provider that is only a few meters away from his/her real location, the service result may be far from the reality, which means the probability of generating errors of LBS response is high.
Scenario 2.
When a user asks about the weather, even the cloaking area reported to LBS provider that is several kilometers away, the feedback might be right.
Seen from the two different scenarios above, it is evident that, for different types of service, the requirements for QoS and location privacy protection are also different. For example, service like navigation requires for a small cloaking area to achieve a certain precision, and, therefore, leading to a higher location privacy protection degree; service like weather query requires for a relative large cloaking area, therefore resulting in a lower location privacy degree.
Hence, we define a parameter called type of service (ToS) to indicate which type of service is being asked for by the user. By allocating different values to ToS, the service type is declared.
And when Location Anonymization Server receives ToS, it will generate a parameter called the location privacy security distance
Similarly, when LBS provider receives ToS, it will generate another parameter called the QoS-guaranteed distance
It is worth mentioning that, in this paper,
4.4. Quantification and Normalization of Privacy Demand Value and QoS
The design of cloaking-area-based location privacy protection algorithm must take into consideration the three factors below: privacy demand value (denoted by P), QoS demand (denoted by Q), and the attack ability of adversaries [21]. From the point of view of users, the larger and farther the cloaking area obtained by LBS provider is and the greater the number of users in it is, the higher degree of privacy protection is, but oppositely the quality of service is lower. In a word, the privacy protection demand value increases with the number of users in the cloaking area; however the QoS descends instead. In addition, the higher the adversary ability is, the worse the reliability of location privacy protection is. In this paper, in order to simplify the analysis of the relation between location privacy protection and QoS, it is assumed that the attack ability of every adversary is equal.
(i) The Quantitative Representation of Privacy Demand Value
P. The quantitative representation form of privacy demand value is given as below:
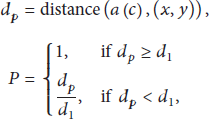
(ii) The Quantitative Representation of QoS Demand
Q. In this paper, the QoS demand value is calculated using the distance between the real user location and the farthest point in the subcloaking area

(iii) The Quantitative Representation of LBS Demands
R. In order to balance the privacy demand and the QoS demand, a parameter When When

4.5. Algorithm Design and Analysis
In this section, the three core algorithms applied in DUDD location privacy protection scheme will be presented in detail, namely, parameters generation algorithm (composed of Algorithms 1 and 2), subcloaking area selection algorithm (composed of Algorithms 3 and 4), and user side process algorithm.
(1) Receive the parameter ToS from user side. (2) LBS provider generates (3)
The privacy demand value and the minimum area required (k, (1) Initialize a LBS request ( (2) According to ToS, Location Anonymizatiton Server generates (3) Find the leaf area represents the current level in the quadtree T. At the beginning, n is supposed to be L, that is the bottom level of T. (4) (5) Let (6) (7) (8) Let (9) (10) Let (11)
User location (1) Let the user choose a value from [0, 1] for parameter α according to his/her individual demand for location privacy protection. (2) Let (3) (4) (5) Let (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) (16)
4.5.1. Algorithm of Parameters Generation
Employing the k-anonymity method, Location Anonymization Server generates and returns a cloaking area c for every user. Beginning with the smallest square which contains the user location, Location Anonymization Sever will move upwards one level every time until the value of k is satisfied. The server will then check if
4.5.2. Algorithm of Subcloaking Area Selection and User Side Process
After receiving the cloaking area c returned from Location Anonymization Server, users will select a subcloaking area a(c) within c and send
The algorithms of subcloaking area selection and user side process are detailed in Algorithms 3 and 5.
(1) Initialize current location PM and let t = current time. (2) Send a LBS query ( where r represents the anonymity level which contains the couple (k, (3) Wait for a moment until get the cloaking area c from Location Anonymization server. (5) (6) Make a circle of area (7) (8) Let (9) (10) (11)
Since there are four candidates in the set of subcloaking area
By Algorithms 3 and 4, users can balance the privacy demand and QoS by adjusting α when there is a conflict between privacy protection and QoS-guarantee. The subcloaking area
After the execution of Algorithms 3 and 4, the most optimal subcloaking area a(c) will be picked out. In general, the user's next move is to send a(c) to LBS provider and to get the service response in return. However, sometimes, in order to guarantee QoS, LBS provider will have its own restriction on the size of a(c), and generally it demands a smaller area than a(c). Therefore, in line 5 of Algorithm 5, considering that LBS provider might have restriction on the subcloaking area size, it is necessary to select a smaller region
In lines 6 to 9 of Algorithm 5, it is considered that sometimes users might send the same LBS query for several times during a short time interval but they are not leaving the cloaking area c. Therefore, in order to not waste the computation time of the server, a location tracker PM is set to verify if the user location is out of boundaries of the cloaking area c. If the user location is no longer within the range of the cloaking area c, it is allowed to send the same query again. If not, the response of the last query will be returned to the user.
5. Feasibility Simulation Results and Analysis
The feasibility simulation results of the proposed DUDD location privacy protection scheme are given in this section. The software MATLAB is used to conduct the simulation. Here, the value of the parameter ToS is predefined in order to simplify the simulation. The simulation parameters are shown in Table 1.
Simulation parameters designed for LBS query.

5.1. Location Anonymization Server Side
On Location Anonymization Server side, a 5-level quadtree model is constructed within a square region, and the whole square region is partitioned using the method presented in Section 4.1, as shown in Figure 6.
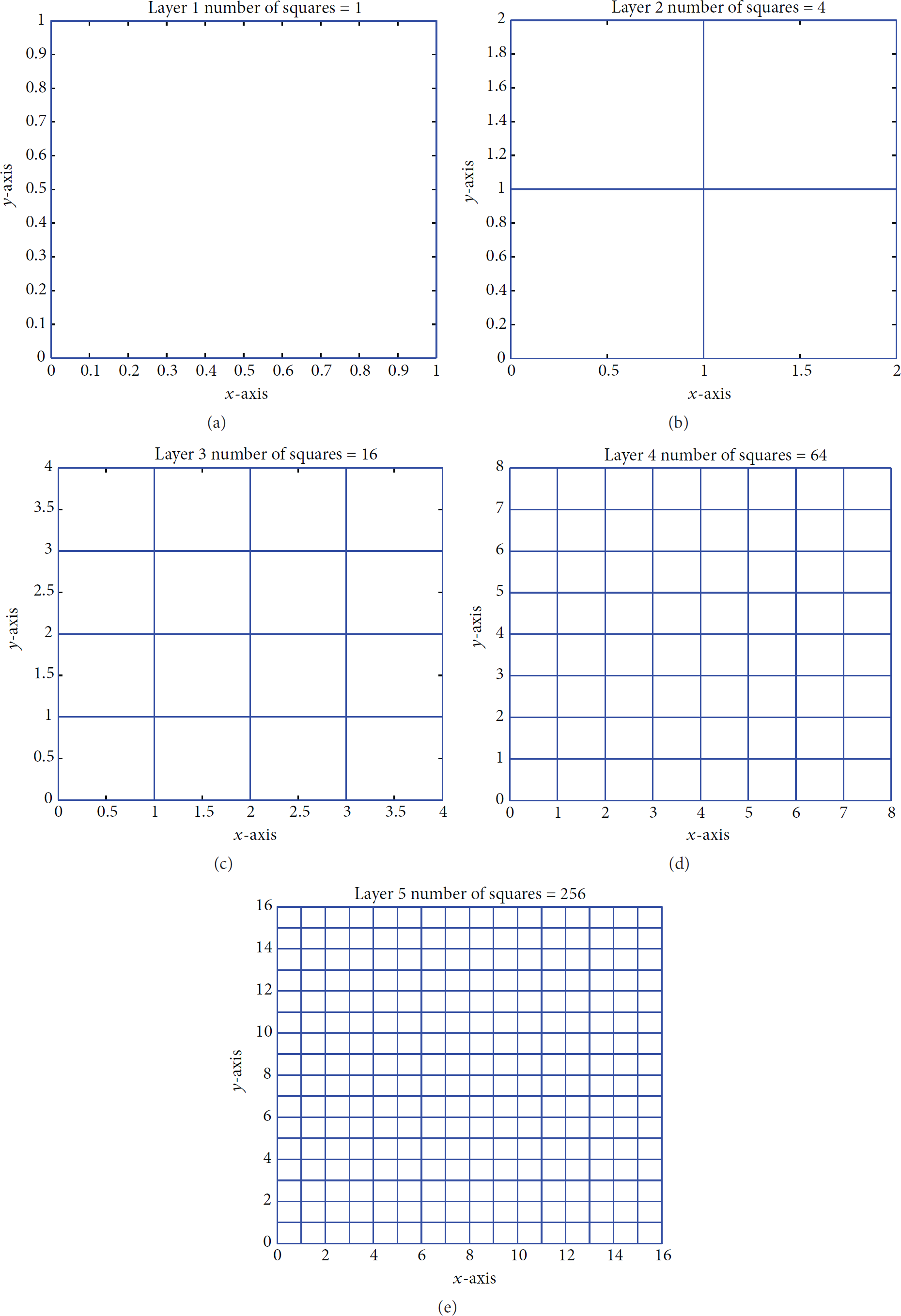
A quadtree with 5 levels. Pictures (a) to (e) contain, respectively, 1/4/16/64/256 squares corresponding to level 1 till level 5 in a quadtree.
Then, 53 points are generated at random to represent 53 different user locations and they are distributed randomly within a square whose vertex coordinates are

Cloaking area c returned to user (4.5,8.6) and its 4 subcloaking areas. (b) is the zoom-in of the shadow area in (a).
5.2. User Side
On user side, according to the value of α, a specific subcloaking area
(i) LBS Provider Has No Restriction on the Subcloaking Area Size Selected by the User. Suppose that user A is still at point (4.5,8.6); α is set as 0.5; that is, the privacy protection demand and the QoS demand are equal. By comparing the value of R in every subcloaking area, that is,

Subcloaking area selection result for user (4.5,8.6) without any size restriction from LBS provider. After selection, the subcloaking area
(ii) LBS Provider Has Restriction on the Subcloaking Area Size Selected by the User. Suppose that LBS provider requires that the subcloaking area offered by the user should be no more than 0.8. Then, a circle area of 0.8 will be selected within

Subcloaking area selection result for user
5.3. Validation of Edge Information Attack Prevention
5.3.1. Two-User Situation
Take 15 uneven distributed values between 0 and 1 as α and select two points (4.5,8.6) and (4.8,8.9) to repeat the aforementioned simulation operation. The simulation results are presented in Tables 2(a) and 2(b).
(a) Subcloaking area selection results for user position (4.5, 8.6) under different values of α. (b) Subcloaking area selection results for user position (4.8, 8.9) under different values of α.

Through data analysis, several conclusions can be made:
The randomness of algorithms:
for point (4.5,8.6), when α gets different values in for the same value of α, the result is different based on user's location. And, for two points in the same area (e.g., the two points selected here are both in area
Because of this kind of randomness, it becomes more difficult for LBS provider to find out the real user location, making location privacy protection more effective.
The assignment of α:
for a single user, when α is assigned a small value, it tends to get the subcloaking area nearer to the real user position; however, when α is assigned a large value, it tends to get the subcloaking area farther from the real user position.
Therefore, if the user chooses location privacy protection over QoS, a larger α value should be selected (usually greater than 0.5) and if the user needs a better QoS, a smaller α value should be selected (usually less than 0.5).
5.3.2. Multiuser Situation
In Section 5.3.1, only two users located in

Subcloaking area selection result comparison under multiuser situation.
Several conclusions can be made:
When α gets identical values, for users in different areas, the subcloaking area selection results are unevenly distributed; when α gets different values, for users in identical areas, the subcloaking area selection results are still unevenly distributed. In reality, α is defined all by users according to their own actual situations, which will bring a great randomness to the subcloaking area selection. Therefore, even if the adversary can manage to know the subcloaking area reported to LBS provider, it is extremely difficult to find out the real user location, which will prevent the edge attack effectively and realize the location privacy protection.
5.4. Subcloaking Area Selection Rule
Firstly, several definitions are given below.
(i) Initial Subcloaking Area. It is the subcloaking area where users are when they launch their LBS queries.
(ii) Diagonal Subcloaking Area. It is the subcloaking area which is in the diagonal direction of the initial subcloaking area.
(iii) Clockwise Neighbor Subcloaking Area. It is the adjacent subcloaking area of the initial subcloaking area, in the clockwise direction.
(iv) Counterclockwise Neighbor Subcloaking Area. It is the adjacent subcloaking area of the initial subcloaking area, in the counterclockwise direction.
For example, as shown in Figure 7(b), if
Then, upon analyzing the simulation results of all the 53 users, a broken line graph illustrating the probability that the subcloaking area falls into initial and diagonal subcloaking areas at different α values is given in Figure 11.
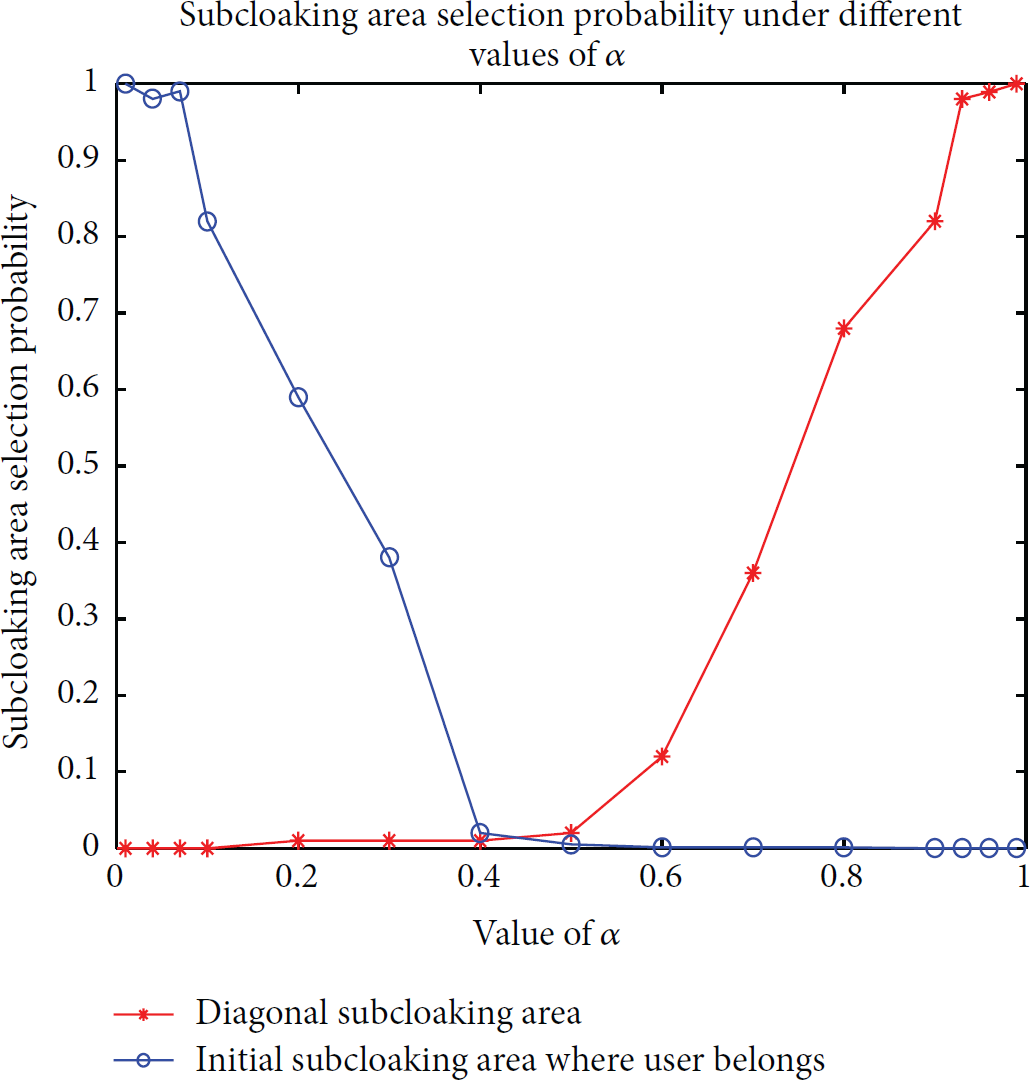
Probability distribution of initial and diagonal subcloaking areas selection under different values of α.
Similarly, the probability that the subcloaking area falls into clockwise and counterclockwise subcloaking areas at different α values is described in Figure 12.

Probability distribution of clockwise and counterclockwise subcloaking areas selection under different values of α.
With the analysis of Figures 11 and 12, a few conclusions can be conducted:
In the interval When α approaches to 1, it is more likely to select the diagonal subcloaking area. When With the increase of α, the probability of falling into the clockwise and counterclockwise subcloaking areas shows the same tendency of a first increase then decrease, reaching the maximum when α fluctuates around 0.5.
Those abovementioned conclusions fit well with the actual situation. In reality, when α is small, it means that users pay more attention to QoS rather than to location privacy protection. Therefore, in order to gain a high QoS, the initial subcloaking area should be returned because it is closer to the real user location. Otherwise, when α augments, it means that now users attach more importance to location privacy protection. As a consequence, the diagonal subcloaking area will be returned because it is farther from the real user location. When α fluctuates around 0.5, users hope to preserve their location privacy and obtain a high QoS at the same time. Hence, adjacent subcloaking areas will be returned.
5.5. Simulation Result When k Increases
When k gets bigger, the cloaking area c generated via Algorithm 2 at the same user location (4.5,8.6) might be the same as before or not. If it is not the same, the level of the new cloaking area c must become higher, which means that the subcloaking area corresponding will also change.
Here, it is assumed that k equals 100, and the level of cloaking area c moves upwards only one to level 3. Then, according to Algorithm 2, the new cloaking area c becomes the square whose vertex coordinates are (4,8), (8,8), (8,12), (4,12), as shown in Figure 13(a). Four subcloaking areas are, respectively, named as

Cloaking area returned to user (4.5,8.6) and its 4 subcloaking areas when
Take all the different user locations in

(a) Subcloaking area selection results comparison of users located in
Seen from Figure 14, several conclusions can be made:
When k increases, the subcloaking area selection result after the anonymization process is still unevenly distributed; that is, the randomness of algorithm remains unchanged no matter the size of k. However, it is obvious that the probability of choosing diagonal subcloaking area significantly increases with the augmentation of k. It is because the augmentation of k means that a higher degree of location privacy protection is in need, so the subcloaking area will be farther from the real user location in order to realize a higher location privacy protection degree.
6. Conclusion and Future Works
With the increasing importance of location privacy protection, various methods have been proposed over the past few years to preserve the location privacy. However, it is observed that few approaches take individual demands into consideration and seek a balance between the privacy protection and QoS, which matters a lot in real scenarios. Hence, in this paper, a new distributed user-demand-driven location privacy protection scheme is proposed, an improved LBS system model is introduced, and a user-defined weight parameter is used to realize a balance between location privacy protection and QoS. A subcloaking area will be found under the premise of protecting location privacy and guaranteeing QoS. The feasibility simulation results prove the effectiveness and feasibility of the proposed method. Nevertheless, there are still lots of future work to do. First, which value should be allocated to ToS in accordance with the type of service requires further consideration. Second, the accuracy of the two quantitative models should be improved in the future research. Third, some integrated metrics are needed to evaluate if user demands are really fulfilled.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This paper is supported by New Century Excellent Talents in University (no. NCET-13-0657) and State Key Laboratory of Rail Traffic Control and Safety (no. RCS2014ZT31) and is also partially supported by NSFC (no. U1261109).