
Abstract
The main focus of this paper is the resilience of communication protocols for data gathering in distributed, large scale, and dense networks. In our previous work, we have proposed the resilient methods based on random behavior and data replications to improve route diversification, thus to take advantage of redundant network structure. Following these previous methods, we propose in this paper a new resilient method based on network coding techniques to improve resilience in Wireless Sensor Networks (WSNs) for smart metering applications. More precisely, using our resilience metric based on a performance surface, we compare several variants of a well-known gradient based routing protocol with the previous methods (random routing and packet replications) and the new proposed methods (two network coding techniques). The proposed methods outperformed the previous methods in terms of data delivery success even in the presence of high attack intensity.
1. Introduction
Recent advances in wireless communications and electronics have developed a next generation of distributed, large scale, and dense networks. In particular, Wireless Sensor Networks (WSNs) have become popular for smart metering to gather data from multifunctional sensor nodes communicating at short distance to collect and transmit data to one or more data collectors. WSNs have well-known features such as low-power consumption, changing topology awareness, open noisy environment, and unreliable radio links. This leads to possible collisions and interferences which makes data gathering a real challenge. In addition, the nature of wireless communication medium of the smart devices combined with their deployment in an open environment makes them vulnerable to malicious attacks.
An outsider attacker could eavesdrop on communications and alter transmitted messages. Smart electronic devices deployed in an unattended and possibly hostile environment for resource monitoring enable physical attacks and their resource limitations (computation, energy, and communication) could ease node tampering. Due to node compromise, numerous malicious insider attacks are possible such as injecting bad data to the network to manipulate control actions and provide multiple Denial-of-Service (DoS) attacks to disrupt data gathering process for monitoring.
The main focus of this paper is the resilience of such constrained networks for data gathering. Resilience study encompasses a wide range of multidisciplinary research topics and is still a relatively new concept in networking. Recently, in works on the resilience of Internet, several concomitant domains (fault tolerance, security, survivability, etc.) were jointly considered in [1–4], where the lack of a metric and a valid definition of the resilience in networking is underlined. Resilience of routing protocols has been defined as their ability to absorb the performance degradation under some failure pattern (random or intentional) and to continue delivering messages with an increasing number of k compromised nodes in [5]. This definition introduces an analogy related to the original definition of resilience in mechanics which characterizes the properties of the materials to resist a shock.
In our previous work, a quantitative metric was proposed in [5] and several resilient routing techniques such as Random Gradient Based Routing (RS-GBR) and Random Gradient Based Routing with Replication (RM-GBR) were studied in [6]. They consist of three main features: (i) introduction of random behavior, (ii) limitation of route length, and (iii) data replication. Random behaviors increase uncertainty for an adversary, making the protocols unpredictable. Limiting the route length is necessary to reduce the probability of a data packet meeting a malicious insider along the route. Data replication allows route diversification between the smart devices and the data collector, thus improving the delivery success rate and the fairness of the network. Such techniques are particularly interesting for smart metering to take advantage of the redundant topology created through wireless medium.
The originality and novelty of this paper is introducing a new resilient routing technique based on network coding mechanisms to exploit data redundancy, thus to take advantage of the route diversity inherently present in wireless networks. Network coding [7] provides an interlaced multiple packets generation process, where each packet possesses a part of the data information a source node wants to route to the data collector. The network coding techniques are well investigated [7]; however, to our knowledge, this is the first study applying those techniques to resilience context to improve routing protocols against insider attacks. The objective is thus to compare the proposed network coding techniques with the data replication mechanisms studied previously [8] in terms of our resilience metric [5].
The rest of the paper is organized as follows. Section 2 gives an overview of the attack categories in smart metering. In Section 3, the previous resilient methods are presented including random behavior and packet replications. In Section 4, we propose new resilient methods based on network coding techniques. Section 5 defines the resilience metric, assumptions, and simulation parameters followed by the results and comparative analysis. Finally, Section 6 concludes this paper and outlines future work directions.
2. Attack Categories
This section introduces the main attack categories in smart metering communication network according to the ontology introduced in [9].
According to its capabilities an attacker can be characterized as laptop-class and mote-class. A laptop-class attacker may have access to powerful devices with more computational resources. A single laptop-class attacker might be able to eavesdrop on and/or jam the entire network. In smart metering infrastructure, mote-class attacker with no resource advantages over legitimate nodes is also possible because an ordinary smart device can be captured and compromised.
According to its intent an attacker can be characterized as passive and active. A passive attacker attempts to learn or make use of information from a system but does not affect system resources. For example, passive eavesdropping that simply gathers information can compromise privacy and confidentiality. An active attacker attempts to alter system resources or affect system operations. Compared to the passive attacker, here the goal is to produce DoS attacks to disrupt communication by destroying links or exhaust available resources such as bandwidth or energy. Such attacks are challenging for smart metering, which relies on reliable data gathering from smart devices for resource monitoring.
According to point of initiation an attacker can be characterized as outsider and insider. An outsider attack is initiated from the outside of the security perimeter by an unauthorized or illegitimate user of the system. For instance, jamming, eavesdropping, and injecting replayed or fabricated messages are examples of such attacks. An insider attack is one that is initiated by an entity inside the security perimeter, that is, an entity that is authorized to access system resources but uses them in a way not approved by the party that granted the authorization. This is possible for smart metering because an attacker could tamper low cost network devices like smart meters deployed in an open and unattended environment. Such attacks are particularly critical for smart metering because an insider attacker could inject false data to manipulate control actions and/or provide numerous DoS attacks such as selective forwarding, Sinkhole, Sybil, node replication, and Wormhole to disrupt data gathering process [10].
In this paper, we deal with an attacker that has no resource advantages over legitimate devices because ordinary network nodes could be captured and compromised by an adversary. We deal with an insider attacker (physical attacks on electronic devices deployed in an open environment), who is authorized to access network resources but uses them in an inappropriate way. An adversary is active: he/she attempts to alter network resources and/or affect network operations especially at routing layer.
3. Previous Resilient Methods
Most of the routing protocols for data gathering in smart metering are deterministic, based on the “best” route selection criterion to be efficient. For instance, the RPL routing protocol standard adopted by IETF in March 2012 favors the most “stable” routes [11]. As a result, the same route is used to deliver all data packets of a source to a destination. Its sensitivity to faults and attacks has been shown in [12, 13]. Note that the packet delivery success and failure are not fairly distributed among the network nodes; some nodes will have good delivery ratio and others will be completely disconnected. This is a limitation of the protocol, since the redundant topology created by wireless communications is not exploited to benefit from physically existing alternative routes.
In previous work, we have shown through simulations in [6] and analytically in [14] that the random behavior improves the resilience of communication protocols in the presence of insider attacks. It increases uncertainty for an adversary, making the protocols unpredictable. In addition, it allows route diversity, as each data packet takes potentially different routes thanks to the random selection of the next hop. This enhances the connectivity between a source and a destination.
When the random route selection is combined with data replication, the delivery success of each data packet is improved thanks to the route diversity and data redundancy. Based on these observations, to take advantage of data redundancy and path diversity, thus to improve resilience, we introduce a new resilient technique based on network coding mechanisms. The main goal of this paper is to study both data replication and network coding based techniques and to compare them in terms of resilience against insider attacks.
3.1. Random Behavior
We have proposed a theoretical framework of the resilience based on the biased random walks [14]. The theory of random walks is widely used in various fields such as mathematics, physics, and telecommunications. In networking, random walk is related mostly to a data packet generated at a node, traveling randomly across the network to reach a destination. Given a graph and a starting node, a neighbor node is selected at random and a data packet is sent to this neighbor; then again a neighbor of the current node is selected at random, and the data packet is sent to it, and so forth. The random sequence of nodes selected in this way to route a data packet from a source to a destination is a random walk on a graph [15].
In the context of networking, the traditional unbiased random walks are not relevant due to their low performance in average number of hops required to reach a destination [16]. In unbiased random walk, no state information on the direction is available and the probability of selecting the next hop is uniform. Thus, a data packet could travel a long time across the network before reaching a destination. A bias could be introduced to random walks to reduce the route length. Biased random walks study the influence of bias on the stochastic process (random behavior) to determine its influence on the performance of random walks. The most biased random walk is based on the shortest path principle allowing reaching the destination faster, while keeping a random behavior.
Previously, we have introduced the random behavior to the well-known gradient based routing (GBR) protocol [6] considering different parameters for the route length. Simulation results showed that introducing random selection of the next hop to the GBR routing protocol based on shortest paths improved the resilience against insider attacks without bringing about a significant extra cost. However, despite this improvement, the general shape of the average delivery success curve was still concave down, reflecting a sensitivity to insider attacks. Therefore, data replication mechanisms are necessary to provide data redundancy, thus, to increase the delivery success of each data packet.
3.2. Data Replication
To improve the delivery success of each message, the packet replication is introduced and combined with random selection of the next hop. If the original packet is lost, some replicated copies could reach the destination successfully. The classical deterministic protocols cannot take advantage of data replication as a source uses the same route for all messages, whereas the randomized variants may increase the delivery success thanks to multiple routes.
In a previous study, we have studied several replication methods such as replicating packets at the sources only, both at the source and at each intermediate node along the route [6], depending on the distance of a source to the destination (distant nodes replicate more than closest nodes) [8], and so forth. The best method that allows a good trade-off between the data delivery success and the overhead was the replication at the sources only [8].
Even though the data replication combined with random routing improves the resilience, it brings about an overhead. Note that providing redundant data has an important cost in terms of energy consumption. Now, the main goal is to study other mechanisms to provide data redundancy and take advantage of route diversity in the network. It seems to us that the most intuitive method to provide data redundancy is to introduce network coding mechanisms to improve the resilience of routing protocols and compare this method to the data replication methods studied previously.
4. The Proposed Resilient Methods
Still aiming at a delivery success improvement, we introduce a new resilient method based on network coding instead of packets replication. This version is still combined with random next hop selection. The main idea is to generate multiple coded packets from the data a node wants to send. Each coded packet will contain a part of information from the original one. Due to the random next hop selection, each coded packet will take a different route, increasing the overall delivery success rate. As soon as the data collector receives enough coded packets, it decodes them in order to retrieve the original data.
In order to understand how this version works, it is important to give several definitions of network coding [7]. Basically, we can say that coding at a node in a network is network coding, where coding means a causal mapping from inputs to outputs. This definition has the inconvenience of not distinguishing the network coding we are going to speak about from the channel coding used in noisy networks.
We will then define the network coding as coding at a node in a network with error-free links. Moreover, this definition helps us to make a difference between network coding and source coding.
But this definition can be more specific, and if we are considering that we are in packets networks, we can define network coding as coding content of packets inside a node. If we had a little generalization by saying that we apply the coding above the physical layer, we can distinguish the network coding function from the information theory. Then we base our work on the previous definition of network coding.
There are two major versions of network coding: the interflow network coding and the intraflow network coding as shown in Figure 1. Interflow network coding consists in coding different packets from various origins together to create a packet containing information from all of them, while intraflow network coding consists in creating multiple coded packets from an original one. In this work, we focus on intraflow network coding. More precisely, we will use intraflow network coding based on random linear network coding.
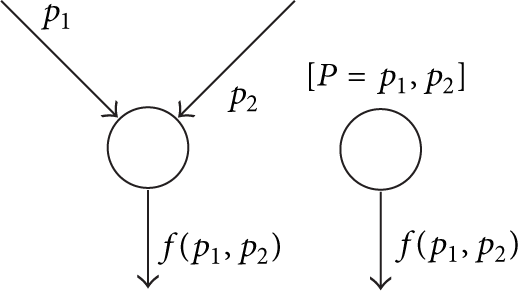
Network coding illustrations.
In packets networks, intraflow (intrasession) network coding consists in dividing a message (a data packet) into multiple submessages of the same size and then creating a linear dependency between them before transmitting [7]. When the data collector receives enough packets, it can recreate the initial message, by resolving the linear system created by the linearly independent subpackets. More precisely, random linear network coding works as follows [7].
Step 1 (the packet subdivision).
As we have seen before, intrasession network coding relies on the division of a data packet into a predefined number of the same sized packets. Here, we consider a message as a chain of bits.
The initial source node has to split a data packet p into k packets
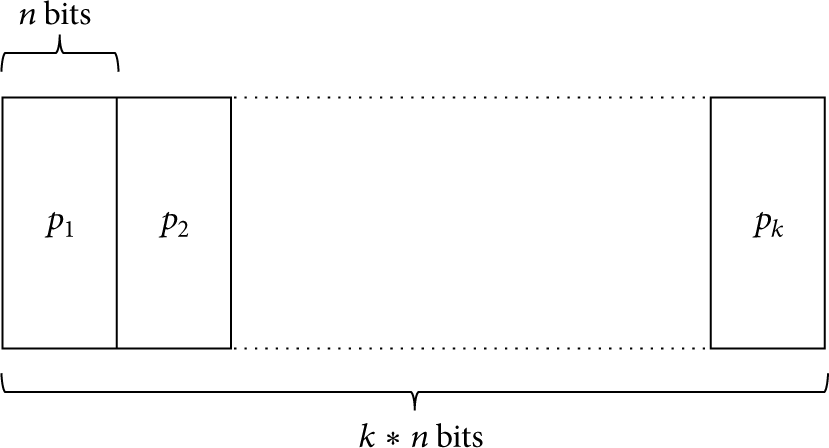
Subdivision illustration.
Step 2 (the coding coefficients choice).
For each packet
Step 3 (the coding).
We put the previous vectors in a

Then we create the encoded data

Step 4 (the dissemination).
Each encoded data
Moreover, because we are in a Galois Field, each intermediate node receiving b encoded packets

Encoded packet.
Step 5 (the decoding).
Whenever the data collector receives m packets, it puts the received coefficients vectors into a matrix. If these coefficients satisfy the full rank matrix condition [18], which means that they are all linearly independent, the data collector can retrieve the original subdivided messages and thus the original data packet p computing
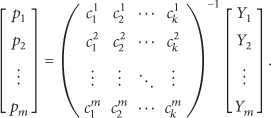
We have to notice that the vector
Thus, the idea is to use network coding in addition to random behavior to create resilient routing protocols as it will be detailed in Section 5.1.
5. Resilience Evaluation
Resilience evaluation of the proposed resilient methods based on network coding is presented in this section and compared to the previous resilient methods based on random behavior and packet replications. The focus of our simulations is comparing four GBR versions in terms of the resilience metric presented in Section 5.2. GBR has been preferred to other routing protocols as the classical version has obtained the best results in terms of resilience metric according to [8]. The four versions of the GBR routing protocol under study described in Section 5.1 are (i) random variant without data redundancy (RS-GBR), (ii) random behavior with data replication at the sources (RM-GBR), (iii) random variant with network coding without ACK mechanism (RS-GBR-NC), and (iv) random variant with network coding with ACK mechanism (RS-GBR-NC-ACK). The first two variants introduce the previous methods and the last two variants provide the new proposed methods.
5.1. Routing Protocols under Study
GBR [19] is a classical flooding based routing protocol well adapted for constraint environment such as WSNs and smart metering. It constructs the routes incrementally using gradient information. The data collector floods an INIT packet in order to set up a gradient. The INIT packet records the number of hops taken from the data collector. Then a node can discover its minimum number of hops from the data collector, called the node “height.” The height difference between a node and one of its neighbors is the gradient on that link. Then source nodes send their DATA packets to one of their minimum gradient neighbors and their neighbors do the same until the data collector is reached constructing a single route that guarantees the shortest path.
5.1.1. Previous Resilient Methods
Instead of fixed routes with minimal gradients, Random Gradient Based Routing (RS-GBR) avoids deterministic routing by introducing some random choices in the next hop selection. Before forwarding, a node randomly chooses a next hop among its neighbors with a certain probability depending on the distance to the data collector [8]. More precisely, a node divides its next hop node possibilities into two groups: the subset of neighbors closer to the data collector, that is, the set of nodes with next hop gradient = node’s gradient − 1, and the subset of neighbors with the same height as itself, that is, the set of nodes with next hop gradient = node’s gradient. The node will randomly choose a next hop in the first group with a probability
The classical shortest path routing protocols cannot take advantage of data replication as each source uses the same route for all messages, while the randomized versions combined with data replication may increase the delivery success thanks to multiple paths. Random Gradient Based Routing with Replication (RM-GBR) replicates a packet a chosen number of times and sends it this number of times over different randomly chosen paths using the RS-GBR random mechanism. For our simulation, RM-GBR replicates two times each DATA packet at the source. Thus, if the original packet is lost, some replicated copies could reach the data collector successfully increasing the probability of the transmission success for each message.
5.1.2. The Proposed Resilient Methods
To show the benefits of network coding in terms of resilience, we designed an Intrasession Network Coding Random Gradient Based Routing (RS-GBR-NC) protocol. In this alternative, the DATA packets are coded at the source. The number of generated encoded submessages is fixed and is equal to 16. The original message size is equal to 32 bits and is divided into four 8-bit sub-messages to use coefficients from
We also propose Random Gradient Based Routing with Network Coding and Acknowledgment (RS-GBR-NC-ACK) which is a slight improvement of RS-GBR-NC. In this version, the number of coded packets is not fixed. Instead, an acknowledgment mechanism is introduced to dynamically generate coded packets. As soon as the data collector achieves a successful decoding, it sends back to the node an acknowledgment message to stop the coded packets generation. To ensure that each coded packet possesses enough time to reach the data collector and to avoid useless packets generation, a delay between each coded packet generation is introduced.
Moreover, the introduction of an ACK mechanism with unlimited retransmission (i.e., the sender continues to generate new coded packets while it has not retrieved any ACK from the data collector) highlights the fact that some nodes will never be able to communicate with the data collector. Indeed, some devices could be completely disconnected from the network due to a massive presence of malicious nodes in their neighborhood. In this case, these nodes unnecessarily create and send an unlimited amount of messages leading to consumption of a lot of energy in the network for nothing.
This possibility leads to bounding the number of coded packets generated while the node is waiting for the data collector ACK to limit the energy exhaustion of disconnected nodes. Figure 4 shows the results of the increase of the maximum number of generated packets in terms of energy consumption and average delivery ratio while being in an environment with 50% of malicious nodes. As a reference, the values of energy consumption and average delivery ratio of the RS-GBR-NC in the same attacker context are also added to Figure 4. As shown in Figure 4, a good compromise between the average delivery ratio and the energy consumption seems to be for 32 generated coded packets. Indeed, having a number of retransmissions greater than 64 does not improve the average delivery ratio while increasing the energy consumption; and choosing a number of retransmissions equal to 16 leads to lowering the average delivery ratio when compared with RS-GBR-NC even if it greatly decreases the energy consumption. Thus, if the number of generated coded packets is equal to 32, the average delivery ratio is increased by 20% with a slightly lower energy consumption when compared with RS-GBR-NC.

Average delivery ratio and energy consumption depending on the maximum number of generated coded packets while waiting for an ACK with 50% malicious nodes.
Thus, in the rest of this paper, we choose a number of generated coded packets equal to 32 in the case of RS-GBR-NC-ACK.
5.2. Resilience Metric
A new metric to measure and thus quantify resilience has been proposed in [5]. This metric introduces a new method to aggregate meaningfully several performance metrics using a two-dimensional graphical representation, because of the numerous manifestations of resilient behavior with respect to various performance metrics. The average packet delivery alone is not enough to represent the resilience and we should consider it in combination with several other performance parameters such as fairness, protocol overhead, delay, and average throughput. To obtain a comprehensive measure of resilience, all these metrics need to be somehow meaningfully aggregated. The new resilience metric provides an equiangular polygon surface for each protocol to represent its resilience, where each performance metric is presented by an axis (see Figure 5). Not only does this method allow discerning visually various trade-offs, but also a quantitative value is obtained by computing the polygon surface.

Resilience surface
For more comprehensive description, let us consider n routing protocols to compare according to m performance metrics. A routing protocol i (

Following the work of [5], the resilience could also be directly computed as the area of the polygon using the following formula:

A routing protocol is considered as resilient if this computation stays constant when the percentage k of attackers increases.
5.3. Resilience Parameters
In the context of smart metering, data gathering should be firstly successful, secondly efficient, and finally fairly distributed among all network nodes. The following five performance parameters were selected for the resilience metric evaluation: Average Delivery Ratio (ADR). It is defined as the fraction of the number of received packets by a data collector and the number of sent packets by all sources. It represents the main goal of a WSN in terms of data delivery. Energy Efficiency (EE). It is defined as the efficiency of the overall energy expenditure for all routing generated and forwarded (CONTROL and DATA) packets by all network nodes; this is the protocol overhead in terms of power consumption. Delay Efficiency (DE). It is defined as the efficiency of average time delay (including queuing, retransmissions, and propagation delays) required for a packet to go from the source to the data collector; this is a function of the average path length (hop count). It characterizes the network efficiency in terms of speed. Average Throughput (AT). It is defined as the average of the maximum amount of data flows received by a data collector per source per unit of time; this in a sense represents the network capacity (the overall throughput when the traffic is saturated). Delivery Fairness (DF). It is defined as the standard deviation of the delivery ratio of each source from the average. It characterizes both the fact that sources eventually reach the data collector and the data delivery success distribution among the sources which should be as uniform as possible for good geographic coverage required in smart metering.
5.4. Assumptions and Simulation Parameters
Simulations have been performed using the WSNet simulator [20] and averaged over
Summary of the simulation parameters.

Selective forwarding attack [6, 10] is considered, where forwarding malicious nodes (
5.5. Results and Analysis
The focus of our simulations in this subsection is the comparison of the four variants of GBR routing protocol with the previous methods (RS-GB and RM-GBR) and the new proposed methods (RS-GBR-NC and RS-GBR-NC-ACK) as described in Section 5.1 in terms of resilience polygon diagram and of resilience surface.
The resilience quantitative evaluation of the four protocols along the 5 axes (ADR, DE, EE, AT, and DF) defined in Section 5.3 is shown in Figure 6. The different protocols exhibit different behaviors. Firstly, as shown in Figure 7, there is a gap between RS-GBR on the one hand and RM-GBR, RS-GBR-NC, and RS-GBR-NC-ACK on the other hand in terms of energy efficiency (EE). Indeed, RM-GBR, RS-GBR-NC, and RS-GBR-NC-ACK transmit more packets than RS-GBR to achieve a successful delivery. As the normalization is computed according to the best result (here RS-GBR), their energy efficiencies become close to zero. However, RS-GBR-NC-ACK has a better energy behavior than RS-GBR-NC when few malicious nodes are present in the network.

Resilience area depending on the percentage of malicious nodes according to the 5 metrics defined in Section 5.3.

Evolution of energy efficiency in the presence of malicious nodes.
Secondly and as shown in Figure 8, we observe the same behavior with the average throughput (AT) metric. As RS-GBR-NC generates

Evolution of average throughput in the presence of malicious nodes.
Finally and as shown in Figure 9, we observe quite the same thing concerning the delay efficiency (DE), but the result is not as sharply contrasted as the previous ones. RS-GBR-NC is less efficient due to the fact that the decoding to the data collector is time consuming and that it has to wait until there are enough packets in order to decode. Due to the delay introduction in RS-GBR-NC-ACK to mitigate the number of generated coded packets, this version is slightly below RS-GBR-NC in terms of delay efficiency.
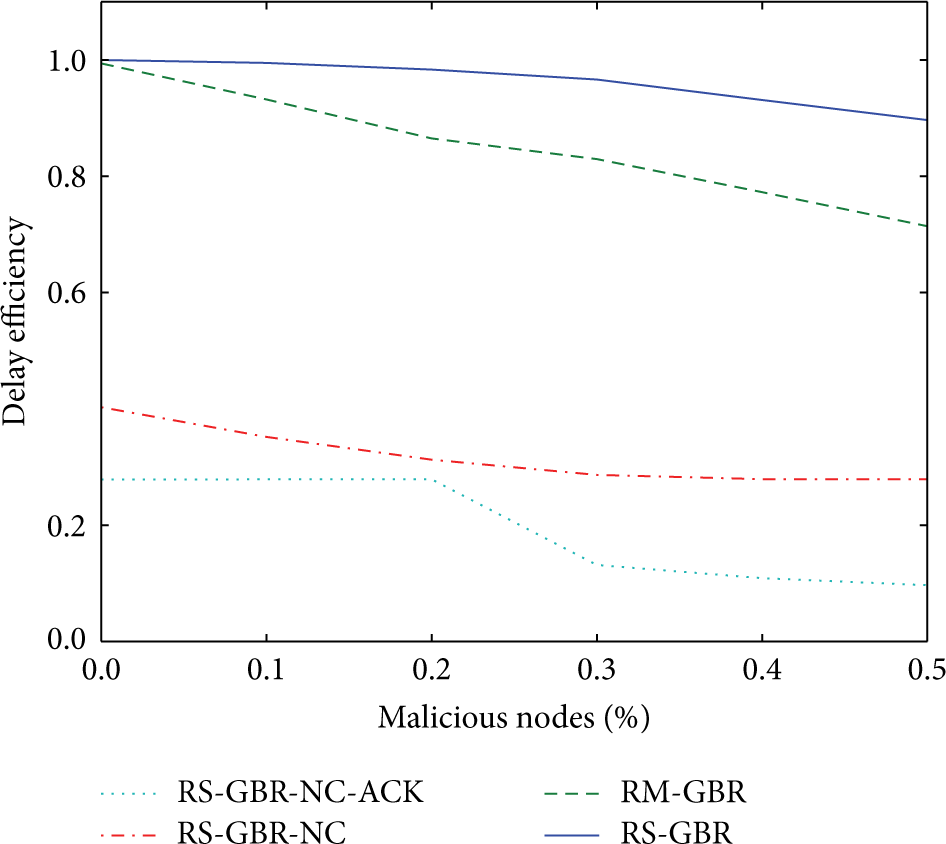
Evolution of average throughput in the presence of malicious nodes.
The resilience surface evolution over the percentage of malicious nodes is presented in Figure 10.

Resilience surface evaluation in the presence of malicious nodes.
As shown in Figure 10, RS-GBR has the best resilience surface over the other protocols. This is mostly due to the fact that RS-GBR has greater energy efficiency than the others. But the resilience surface evolution of RS-GBR is not as good as the others. More precisely, the RS-GBR resilience falls quicker than the others when the malicious nodes increase from
Oppositely, RM-GBR resilience falls less quicker during the same malicious nodes increase, which means that it is more resilient to the first increases. The introduction of redundancy when RM-GBR is in use means that even if there is a malicious node on one path, a duplicated packet takes another path which could be malicious-nodes-free. So, redundancy introduction could be seen as a good compromise when the number of malicious nodes present in the network does not exceed 30%.
Concerning RS-GBR-NC-ACK, when the percentage of malicious nodes is below 20%, we could see that RS-GBR-NC-ACK has very low variations and that its resilience surface stays constant. This flat curve means that RS-GBR-NC-ACK is very resilient when the number of malicious nodes begins to increase. However, this protocol has a low resilience value because the flat evolution has a strong cost in terms of delay efficiency and energy efficiency.
Finally, considering only the good delivery of information, regardless of the delay and the energy consumption, Figure 11 presents the results obtained for average delivery ratio alone. The first noticeable thing is that there is a clear gap in terms of delivery ratio between solutions with multiple packets generation (RM-GBR, RS-GBR-NC, and RS-GBR-NC-ACK) and the other (RS-GBR). For solutions with multiple packets, clearly and as shown in Figure 11, the overall network keeps a good average delivery ratio longer before the fall than RS-GBR whereas RS-GBR sees its average delivery ratio falls as soon as there are some malicious nodes in the network. Among the solutions with multiple packets generation the best one is clearly RS-GBR-NC-ACK which has a graceful degradation and thus allows a large number of malicious nodes before having an average delivery ratio below 90% even if this good behavior has a cost as seen before.
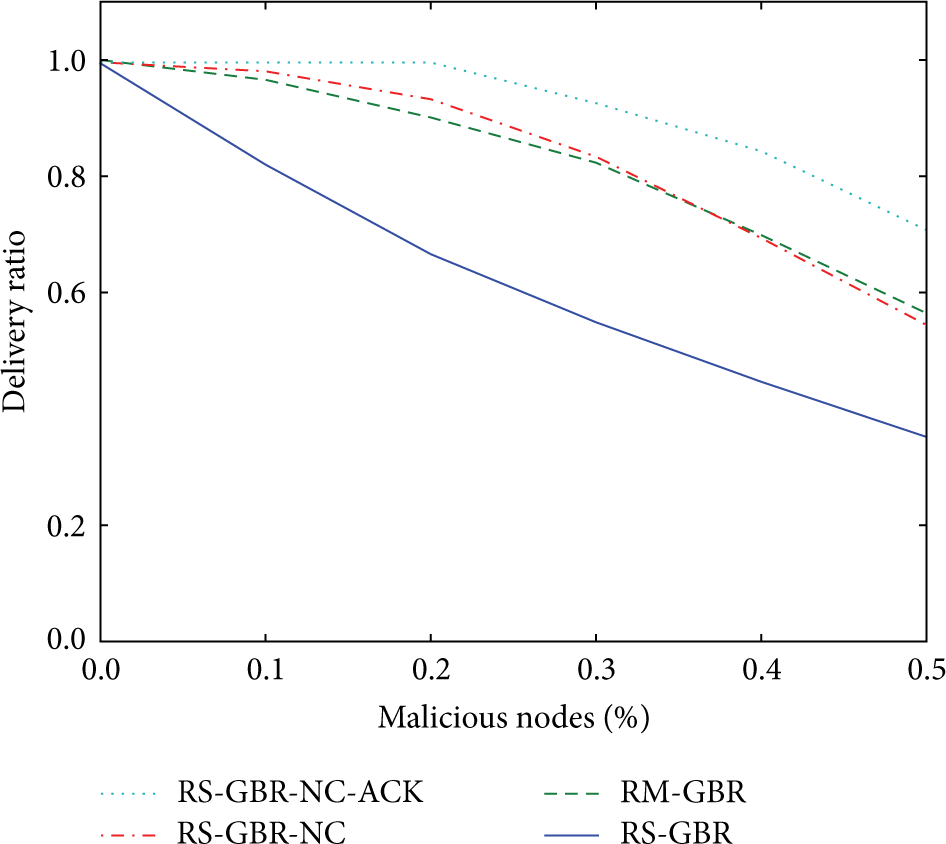
Evolution of average delivery ratio in the presence of malicious nodes.
We also should notice that because of the nature of the resilience computation, the order of the parameters matters as noticed in [8]. They are acting as a weighting of each other. Using the same experimental protocol as in [21], delay efficiency weights the average delivery ratio, and energy efficiency weights both delay efficiency and average throughput. Even if the importance of the axes position was clearly justified in [21], as we deal here with protocols based on redundancy to achieve good deliveries and because of the sharp contrasts between delay efficiency, energy consumption, and average throughput, maybe another parameters order could be more relevant in this particular case.
6. Conclusion
In this paper, we have compared using the metric introduced in [5] the resilience of several routing protocols that exploit redundancy under maliciously packet dropping attacks. We essentially compared redundant methods which are data replication and network coding. Simulation results show that even if RS-GBR has the best resilience surface, the versions that include network coding especially RS-GBR-NC-ACK keep the same resilience surface when the number of attackers increases leading us to think that there is no performance degradation. Moreover, we show that, in terms of average delivery ratio, the routing protocols with multiple packets strategies clearly behave better than RS-GBR.
So, in summary, we proposed some methods that are able to maintain a high average delivery ratio even in the presence of many attackers and even if they have of course an energy cost to pay.
In near future, we plan to modify the resilience metric itself to better take into account, in the context of multiple packet protocols, the gain in terms of average delivery ratio. In the same research direction, the average throughput metric may introduce a bias because, in all cases, we do not achieve the network capacity. We think of using a better parameter like “Goodput” to characterize the quantity of useful data received by time unit.
Footnotes
Disclaimer
The statements made herein are solely the responsibility of the authors.
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
This research was made possible by NPRP Grant no. 6-149-02-058 from the Qatar National Research Fund (a member of Qatar Foundation).