
Abstract
Recognizing human action in wireless sensor networks (WSN) has raised a great interest owing to the requirements of real-world applications. Recently, the bag-of-features model (BOF) has proved effective in human action recognition. In this paper, we propose a novel method named local random sparse coding (LRSC) for human action recognition in WSN based on the BOF model. The contribution is twofold. First, we utilize random projection (RP) technique for each feature vector to alleviate the curse of dimensionality. Second, we consider the locality of codebook and correspondingly propose to reconstruct the features using similar codewords. Our method is verified on the KTH and UCF Sports databases, and the experimental results demonstrate that our method achieves better results than that of previous methods on human action recognition in WSN.
1. Introduction
The proliferation of wireless communications and electronics has created the opportunities for development of wireless sensor networks (WSN) [1, 2]. The WSN consists a variety of sensors, such as video cameras, microphones, infrared badges, and RFID tags, which drives the applications of WSN in the fields of surveillance systems, guiding systems, biological detection, habitat, agriculture, and health monitoring [3, 4]. Surveillance for abnormal event detection and monitoring elderly and sick people at home are examples of some applications that require the ability to automatically recognize human actions in WSN where each sensor node is a surveillance camera. Recognizing human action is also an essential issue in computer vision and pattern recognition. It mainly focuses on how to build a discriminative and compact representation for human actions in video.
Recently, some approaches are proposed to utilize local spatiotemporal descriptors together with bag-of-features model (BOF) [5–7] to represent the action, which have shown promising results. Since the BOF representation does not rely on preprocessing techniques, for example, trajectory tracking or motion detection, it is relatively robust to illumination variation, background changing, and noise. Nevertheless, there are three limitations for the BOF representation. The first limitation is the quantization error when generating a codebook. To solve this drawback, Wang et al. [8] proposed locality-constrained linear coding (LLC) which used several nearest codewords to linearly encode a descriptor in Euclidean domain. Yang et al. [9] proposed the ScSPM method where sparse coding was used instead of hard vector quantization to obtain kinds of nonlinear coding. The second limitation is the high dimensionality of local descriptors which results in the curse of dimensionality. A lot of approaches have been proposed to project high dimensional features into a lower dimensional subspace, including principal component analysis (PCA) and linear discriminant analysis (LDA). The last limitation is that the BOF representation neglects the local information because it counts the histogram of the whole action video.
In this paper, we propose a novel method named local random sparse coding (LRSC) for human action recognition in WSN to overcome the drawbacks of BOF representation. Since the proposed LRSC inherits the property of sparse coding, it can alleviate the quantization error. For all the features extracted from training action videos, we utilize random projection (RP) technique of projecting a set of descriptors from a high dimensional space to a randomly chosen low dimensional subspace. The theory of compressed sensing has demonstrated the effectiveness of RP technique for the information-preserving and dimensionality reduction power [10, 11]. Moreover, the RP technique is faster than the other dimensionality reduction technique, because the low dimensional features are directly obtained by multiplying a random projection matrix. When reconstructing the features, the codewords may be very heterogeneous, possibly leading to the loss of a large amount of information. Thus, we propose to consider the locality of codebook. Concretely, we utilize the similar feature vectors in the input space to construct the codebooks. The experimental results demonstrate the effectiveness of our LRSC.
The rest of this paper is organized as follows. We present our LRSC algorithm in Section 2. Section 3 shows the experimental results which outperform the state-of-the-art methods on the KTH and UCF Sports databases. Finally, in Section 4, we conclude the paper.
2. Approach
2.1. Method Overview
The proposed LRSC consists of six stages as shown in Figure 1: (a) detection of spatiotemporal interest points in action videos, (b) representation of each spatiotemporal interest point as a feature vector, (c) reduction of the dimensionality of feature vectors using RP technology, (d) consideration of the locality, (e) sparse coding, and (f) concatenation of all the sparse coefficient vectors for the final representation.
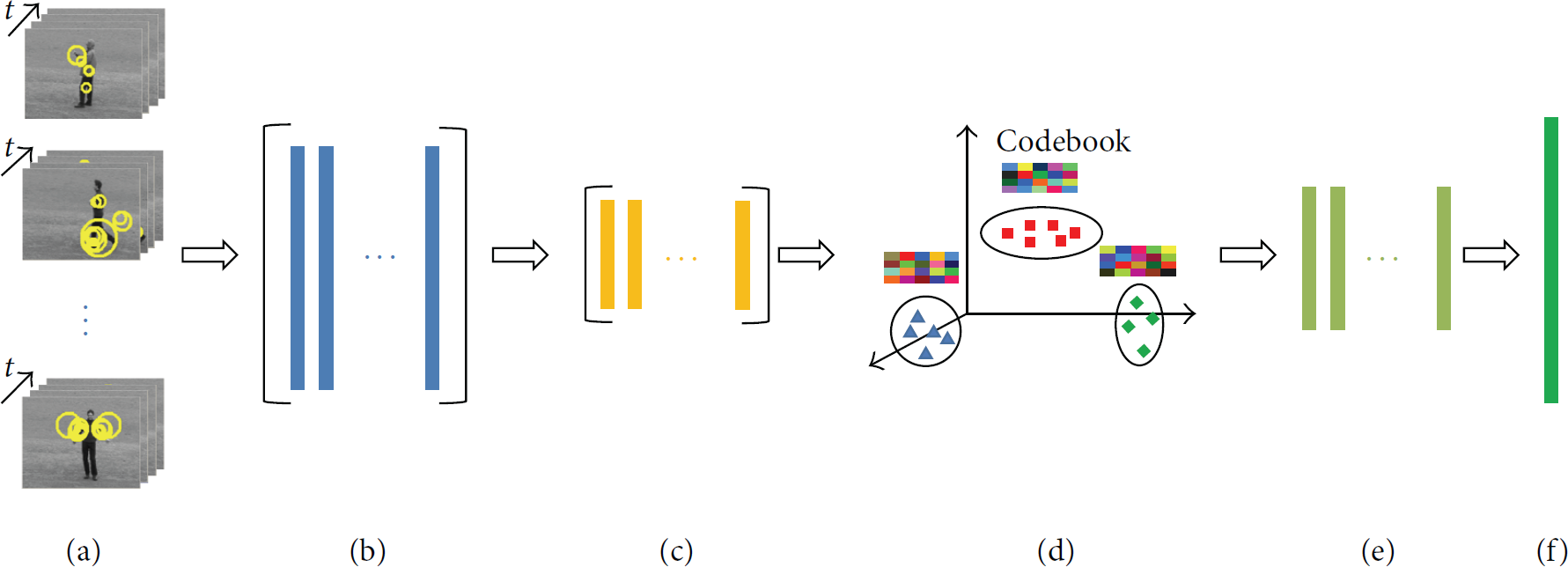
The flowchart of the proposed LRSC strategy.
2.2. Detection of Spatiotemporal Interest Points
To detect interest points in action videos, we employ the Harris 3D corner detector proposed in [12] as shown in Figure 1(a), which is an extension of the Harris 2D corner. The Harris 3D detects the location where the video intensities have significant local variations in both space and time. To this end, matrix F is defined as
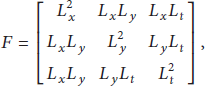
2.3. Representation of Spatiotemporal Interest Points
After detecting spatiotemporal interest points, we represent each interest point as a feature vector (see Figure 1(b)). For each interest point, the histogram of oriented gradients (HOG) and histogram of optical flow (HOF) are used as local appearance descriptors. Therefore, each interest point is represented as a 162-dimensional feature vector. Let
2.4. Random Projection
The dimensionality reduction is a key issue in processing high dimensional data because it alleviates the curse of dimensionality and other undesired properties of high dimensional spaces. Although there are an amount of methods for dimensionality reduction, such as PCA and variations, they are computationally expensive. Random projection is a kind of dimensionality reduction technology, which projects a set of points from a high dimensional space to a randomly chosen low dimensional subspace. The Johnson-Lindenstrauss lemma (JL lemma) [14] gave the theory of random projection, which provides the theoretical basis for dimensionality reduction. The JL lemma declares that a set of points in a high dimensional Euclidean space can be mapped into a low dimensional logarithmic space such that the distances between the points are approximately preserved. Based on this theorem, random projection has been used in a wide variety of applications, such as texture classification [15] and face recognition [16]. Hence, we employ RP in this paper as shown in Figure 1(c).
We choose a random projection matrix Φ to project the high dimensional vectors into a low dimensional subspace

2.5. Locality
When reconstructing the feature vectors, the codewords may be very heterogeneous, which may result in the loss of a large amount of information. We prefer to reconstruct the feature vector using the codewords which are similar to this feature vector. Thus, we propose to consider the locality of codebook. Concretely, we utilize k-means algorithm to cluster all the feature vectors
2.6. Sparse Coding
Based on the fact that natural signals are intrinsically sparse in some domain, sparse coding has achieved great success in many fields, such as face recognition [17], image classification [9], and nature texture classification [18]. Sparse coding reconstructs the input feature vector as a linear combination of few codewords over an overcomplete dictionary. For each cluster, we represent each feature vector using sparse coding algorithm:

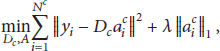
2.7. Final Representation
The final representation of each interest point is
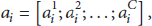
3. Experimental Results
We prove the effectiveness of our LRSC method on two publicly available databases: KTH dataset [20] and UCF Sports dataset [21]. We compare our algorithm with relevant baselines and other excellent algorithms on human action recognition. There are three algorithms as our relevant baselines: sparse coding (SC), sparse coding with random projection (R + SC), and sparse coding with local clustering (L + SC). The local clustering is controlled by the number of clustering centers, and the random projection is controlled by the dimension of random projection. Thus, the local clustering centers are set to 5 classes, and the dimension of random projection is set to 35. The number of codewords is set to 2000.
The KTH database is a widely used action database. It has 599 action videos, and the actions are in 6 classes including walking, jogging, running, boxing, waving, and clapping. They are performed by 25 subjects under four different scenarios. We adopt the leave-one-out cross validation strategy, specifically 24 videos of actors as training and the remaining one as test videos. The average accuracy values on the KTH database are listed in Table 1, and the confusion table of recognition results on the KTH database is shown in Figure 2. From Table 1, we can see that our LRSC method achieves the best accuracy value of 96.2% on the KTH database. Furthermore, the following four points can be drawn through analyzing the experimental results. First, comparing our LRSC method with L + SC method, we can see that the former is 2.8% higher than the latter one on the accuracy. It shows that the lower dimensional feature vector can capture the intrinsical structure of original space by using RP technology. Second, the accuracy value of LRSC method is 3.4% higher than that of R + SC, because we consider the locality of feature space. Third, our LRSC method gains 5.9% accuracy rate over SC method. It is because our LRSC not only inherits the positive properties of sparse coding but also considers the characteristic of feature space, that is, dimensionality and locality. Finally, from the confusion table, we can see that leg-related actions (running and jogging) are prone to be misclassified. We think the possible reason may be that they always exhibit similar context and appearance.
The comparison of our method with the state-of-the-art methods and the baseline methods on the KTH database.

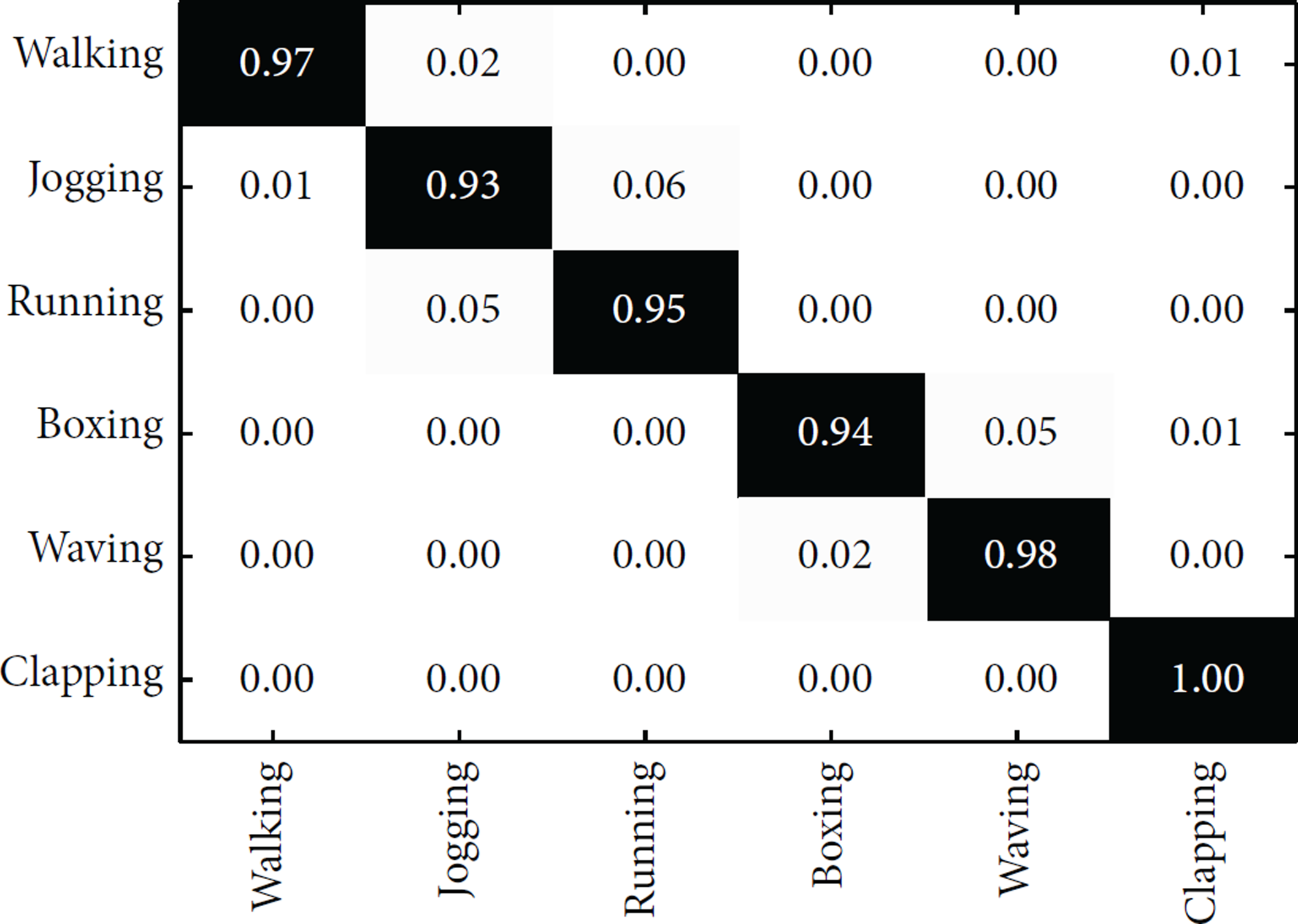
Confusion table of our method on the KTH database. The element of row i and column j in confusion table means the percentage of ith class action being recognized as jth class.
The UCF Sports database contains ten action categories resulting in 150 sports videos. This database represents a natural pooling of actions featured in a wide range of scenes and viewpoints, so the videos exhibit great intraclass variation. We take the leave-one-out cross validation, namely, cycling each sample as a test video one at a time. The performances of different methods are listed in Table 2 and the confusion table of recognition results on the UCF Sports dataset is shown in Figure 3. We can see that the proposed LRSC method outperforms the other three baselines and other state-of-the-art methods, reaching 89.3% on the UCF Sports database. The results prove the effectiveness of our LRSC on the realistic and complicated action database once again.
The comparison of our method with the state-of-the-art methods and the baseline methods on the UCF Sports database.


Confusion table of our method on the UCF Sports database.
4. Conclusions
In this paper, we propose a novel method named local random sparse coding (LRSC) for human action recognition in WSN. The proposed LRSC inherits the property of sparse coding; it can alleviate the quantization error. Moreover, the proposed LRSC considers the characteristic of feature space, that is, dimensionality and locality. Concretely, we reduce the dimensionality of feature vectors by using RP technology, such that we can capture the intrinsical structure of original space. To consider the locality, k-means clustering algorithm is employed to obtain similar feature vectors. The experimental results demonstrate that our method achieves better results than that of previous methods in human action recognition in WSN.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work is supported by National Natural Science Foundation of China under Grant no. 61401309 and Doctoral Fund of Tianjin Normal University under Grants no. 5RL134 and no. 52XB1405.